1. معرفی
آدرس مشخصاتی است که به یک مکان منحصر به فرد در زمین اشاره دارد [ 1 ]. معمولاً در قالب یک سیستم آدرس دهی (یعنی ترکیبی از اجزای خاص مانند ویژگی های فضایی و روابط آنها، کدهای پستی و غیره) بیان می شود. سیستم های آدرس دهی را می توان بسته به ساختار آنها و همچنین انواع اجزای مورد استفاده، که اغلب با جنبه های اجتماعی و فرهنگی مطابقت دارند، متمایز کرد [ 2 ، 3 ].]. به عنوان مثال، در اروپا، جاده ها و شماره ساختمان های متوالی جزو اجزای آدرس دهی استاندارد هستند. با این حال، مکانهای دیگری مانند استانبول در ترکیه، ماسیو و سالوادور در برزیل و همچنین ایران وجود دارند که نامی که به یک ساختمان اختصاص داده میشود نیز میتواند ارزش آدرس دهی داشته باشد. سیستم های آدرس دهی ژاپنی و کره ای کاملاً متفاوت هستند، جایی که (بیشتر) خیابان ها نامی ندارند، در عوض، بلوک ها کدگذاری شده اند. علاوه بر این، شماره ساختمان ها در امتداد یک جاده سفارش داده نمی شوند، بلکه از نظر بلوک و بر اساس تاریخ ساخت ساختمان ها [ 4 ]. در ایران، نام خیابانها منحصربهفرد نیستند، بنابراین ترکیبی از نامهای خیابانی متعدد و روابط فضایی که به مقصد ختم میشوند، در قالب یک توصیف فرآیند راهیابی به منظور ایجاد یک مرجع منحصربهفرد استفاده میشود.
از سوی دیگر، ژئوکدینگ (یا تطبیق آدرس) به فرآیند مرتبط کردن یک آدرس به مکان مربوطه آن بر روی نقشه اشاره دارد [ 1 ]. این یک فرآیند مستقیم و به خوبی اجرا شده برای بسیاری از سیستم های آدرس دهی مورد استفاده در کشورهای مختلف است. امروزه اکثر سیستم های اطلاعات مکانی مجهز به موتورهای geocoding خودکار هستند که یکی از پیش نیازهای ارائه خدمات مبتنی بر مکان معنادار است [ 5 ، 6 ، 7 ]. تحقیق در مورد ارزیابی [ 2 , 3 , 8 , 9 , 10 , 11 , 12 , 13 , 14 ,15 ] و بهبود [ 16 ، 17 ، 18 ] دقت کدگذاری جغرافیایی به طور کلی موافق است که یک آدرس می تواند به طور خودکار جغرافیایی کدگذاری شود، در صورتی که بتوان آن را به اجزای آن تجزیه کرد، به طوری که آدرس را می توان به طور خودکار بر روی نقشه تفسیر و مطابقت داد. این فرآیند عمدتاً به ساختار نحوی سیستم آدرس دهی مربوطه و همچنین غنای پایگاه داده (ر.ک. gazetteers) مورد استفاده بستگی دارد [ 2 ، 3 ].
در حالی که هدف علم GIS مدلسازی رسمی تعامل انسانها با محیطشان است [ 19 ]، تعامل انسانها با آدرسها (به عنوان توصیف شفاهی مکانها در محیط) کمتر مورد بررسی قرار گرفته است. افراد یک گروه کاربری اصلی (اگر نه بزرگترین) آدرس ها هستند. آنها اغلب از آدرسها برای یافتن مکانهایی در محیط بدون هیچ ابزار کمکی استفاده میکنند. همانطور که در [ 2]، آدرسهای پستی «یک منبع متداول راهیابی است که در شهرها در همه جای دنیا استفاده میشود». با این حال، تحقیقات قابل توجهی در مورد اینکه چگونه یک آدرس توسط انسان قابل تفسیر است و چقدر می تواند با بازنمایی ذهنی فرد مرتبط باشد، انجام نشده است. علاوه بر این، انسان ها ممکن است با یک آدرس بیشتر از استفاده از آن به عنوان «مشخصاتی که به یک مکان منحصر به فرد در زمین اشاره دارد» تعامل داشته باشند. در واقع، اطلاعات ارائه شده توسط یک آدرس ممکن است بر دانش و فعالیت های فضایی افراد مانند راهیابی تأثیر بگذارد. برای مثال، آدرسی که حاوی ویژگیهای مکانی است، باید اطلاعات مکانی متفاوتی را در مقایسه با آدرسی که هم ویژگیهای مکانی و هم روابط آنها را شامل میشود، ارائه دهد. چنین تفاوت هایی ممکن است به عنوان یکی از عوامل درون فرهنگی در نظر گرفته شود که منجر به تفاوت های فرهنگی ظاهری می شود که ناشی از فرهنگ نیست [ 20 ]].
سیستم های آدرس دهی رسمی مدرن برای انتقال مکان ها با دقت بسیار طراحی شده اند. با این حال، توصیفهای فضایی روزمره مورد استفاده مردم، که از روابط فضایی ساده (مثلاً «کنار»، «بین»، «سمت چپ»، «جلو» و غیره) بین ویژگیهای فضایی تشکیل شدهاند، عبارتند از. خیلی دقیق نیستند، اما اغلب تولید می شوند و به آسانی درک می شوند [ 21]. به نظر می رسد ارزش چنین توصیفات فضایی برای ارتباطات فضایی در طراحی سیستم های آدرس دهی رسمی مدرن کمتر مورد توجه قرار گرفته است. یکی از دلایل ممکن است اجتناب از ساختار پیچیده زبان های طبیعی برای بیان چنین توصیف های فضایی باشد. به عبارت دیگر، به نظر میرسد که سیستمهای آدرسدهی مدرن «کاربران را مجبور میکنند تا زبان [فضایی] خود را بیاموزند و اطلاعات خود را به این قالب ترجمه کنند…، که این پتانسیل را دارد که توانایی [فضایی] کاربر را محدود کند» [ 22 ].
این مقاله به عنوان یک ایده نوظهور برای مطالعه مسائل شناختی فضایی سیستمهای آدرسدهی، این فرضیه را بررسی میکند که سیستمهای آدرسدهی رسمی (از نظر نوع، تعداد و ترتیب اجزا) میتوانند بر سرعت اکتساب دانش فضایی تأثیر بگذارند. به عنوان اولین گام، این فرضیه منجر به گزارههای زیر میشود که در این مقاله مورد بررسی قرار خواهند گرفت: (1) با فرض جدا شدن از سایر منابع اطلاعات مکانی، میتوان دانش مکانی را از آدرسها کسب کرد. و (2) سیستم آدرس دهی ممکن است بر سرعت اکتساب دانش فضایی و ساخت مدل ذهنی فرد تأثیر بگذارد. نتایج این مطالعه مقدماتی را می توان با ابزارهای علوم شناختی و زبانی (فضایی) از یک سو و منطق بازنمایی دانش از سوی دیگر مورد بررسی و ارزیابی قرار داد.
برای پاسخ به این پرسشهای پژوهش، سه شکل از آدرسها (مثلا ساختار یافته در اتریش، نیمه رسمی مانند ژاپن و توصیفی مانند ایران) تحت اصول نشانهشناسی مورد بررسی قرار گرفت.(یعنی از طریق سطوح نحو، معناشناسی و عمل شناسی). نحو از طریق تعاریف رسمی از سیستم های آدرس دهی مورد بحث قرار می گیرد، در حالی که معناشناسی و عمل شناسی با توجه به سطح اطلاعات مکانی که برای انسان و رایانه ارائه می کنند، چه به طور مستقیم و چه با استدلال فضایی، ارزیابی می شوند. برای این منظور، مفاهیم سیستم های آدرس دهی و همچنین اجزایی که مردم اغلب برای آدرس دهی استفاده می کنند، مورد بررسی قرار گرفت. سپس، سیستمهای آدرسدهی اتریش، ژاپن و ایران از طریق شبیهسازی مبتنی بر عامل معرفی و ارزیابی شدند تا چگونگی تأثیر آنها بر کسب دانش و رشد فضایی بررسی شود.
ساختار باقی مانده این مقاله به شرح زیر است. بخش 2 این ایده را مورد بحث قرار می دهد که سیستم های آدرس دهی بر شناخت فضایی ما و نحوه تعامل افراد با محیط تأثیر می گذارد. در بخش 3 ، ما یک طبقه بندی از سیستم های آدرس دهی مختلف را بر اساس ساختار آنها و انواع عناصر مورد استفاده ارائه می دهیم. سپس سه سیستم آدرس دهی اتریش، ژاپن و ایران معرفی می شوند. بخش 4 شبیه سازی مبتنی بر عامل کسب دانش فضایی از طریق سیستم های آدرس دهی موردی را معرفی می کند. بخش 5 و بخش 6 یافته ها را از نظر معنایی و عمل شناسی تحلیل و مورد بحث قرار می دهند. در نهایت، بخش 7مقاله را به پایان می رساند و ایده هایی برای تحقیقات آتی ارائه می دهد.
2. سیستم های آدرس دهی بر بازنمایی ذهنی فضایی ما تأثیر می گذارد
تورسکی اصطلاح «بازنمایی ذهنی فضایی» را برای روابط طبقهبندی فضایی بین عناصر ابداع کرد که به راحتی از زبان یا تجربه مستقیم قابل درک است. بازنماییهای ذهنی فضایی را میتوان از توصیفهای فضایی متشکل از روابط فضایی ساده بین ویژگیهای فضایی القا کرد و در میان اشکال دیگر، میتواند به صورت حقایق نوشتاری شفاهی باشد [ 21 ]. علاوه بر این، در میان چندین جنبه، توانایی فضایی به توانایی تصور آرایش فضایی از بازپست یا نوشتههای شفاهی اشاره دارد، که به پاسخ به سؤالات شناسایی و توصیف (“چه؟” و “کجا؟”) کمک میکند [ 23 ]. به این ترتیب، خطاب ها – به عنوان توصیف های شفاهی از محیط – به دانش فضایی و توانایی های ذهنی انسان کمک می کند.
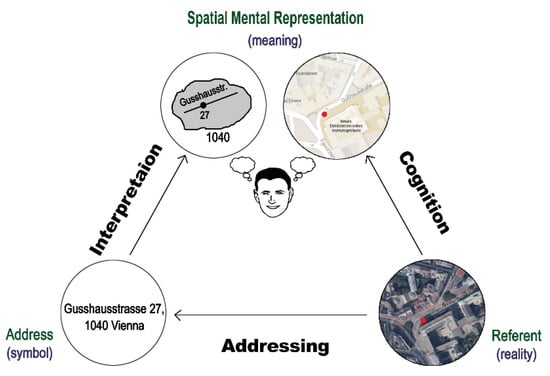
همانطور که شکل 1 نشان می دهد، یک آدرس به مردم تفسیری از محیط اطرافشان ارائه می کند، که در مقایسه با آنچه که ناشی از “دستکاری و عمل در محیط خارجی است، که یک قطعه ساختمانی اساسی برای فضا است، یک بازنمایی ذهنی متفاوت و کم اطلاعات از فضا است. کسب دانش فضایی» ([ 24]، ص161). تفاوت به اجزای آدرس دهی بستگی دارد: یک آدرس ژاپنی (که از کدهای غیر مکانی مرتب شده زمانی تشکیل شده است) باید نمایش متفاوتی از محیط را در مقایسه با آدرس اتریشی (که حاوی ویژگی های مکانی و شماره ساختمان های مرتب شده مکانی است) ارائه دهد. و به یک آدرس ایرانی (که روابط فضایی بین انواع مختلف ویژگی های فضایی را توصیف می کند). واضحتر، آدرسی که فقط حاوی ویژگیهای فضایی باشد به دستیابی به مؤلفههای اعلامی دانش مکانی کمک میکند (که شامل دانش اشیاء و/یا مکانها همراه با معانی و اهمیتهای متصل به آنها میشود)، در حالی که آدرسهایی با مؤلفههای رابطه فضایی نیز به کسب ارتباط یا ارتباط کمک میکنند. پیکربندیاجزای دانش فضایی (یعنی اطلاعات در مورد روابط فضایی بین اشیاء یا مکان ها) [ 24 ]. رابطه فضایی یک بعد کمتر تعریف شده از توانایی فضایی است که جزء مهمی از رفتار فضایی روزمره است [ 23 ]: «شناخت محیطی بسیار بیشتر از شناسایی عناصر یک محیط و/یا بازنمایی آن است. فراتر از درک روابط مستلزم یا نهفته در بازنمایی است» ([ 25 ]، ص 267). از جمله، این جنبه از توانایی فضایی مربوط به تصور فضا از یک توصیف شفاهی است، که شامل مورد یک آدرس است.
برای نشان دادن بهتر دیدگاه مقاله، دو آدرس مثال زیر را در نظر بگیرید: «Gusshausstrasse 27, 1040 Vienna» به آدرس دانشگاه فناوری وین که در سیستم آدرس دهی اتریش بیان شده است اشاره دارد (یعنی با استفاده از ساختار « streetName buildingNo , منطقه بدون شهر“. این را با «تهران، خیابان کارگر شمالی، 100 متر بالاتر از بلوار جلال، بعد از پست، پلاک 63» مقایسه کنید که به صورت توصیفی بدون ساختار به آدرس دانشگاه تهران اشاره دارد. آدرس بدون ساختار است، زیرا در ایران، نام خیابانها منحصر به فرد نیستند و یک آدرس به شرح مفصلی نیاز دارد که به اندازه کافی دقیق باشد تا آن را منحصر به فرد کند. علاوه بر این، شامل روابط فضایی بین ویژگیهای فضایی به منظور هدایت کاربر در فضا است. یعنی ایرانیها از توصیف فرآیند راهیابی استفاده میکنند که باید به صورت پویا ساخته شود تا به مقصدی خاص مراجعه کنند.
رایانه ای که ساختار آدرس اول را می داند می تواند به راحتی آن را به اجزای خود تجزیه (تجزیه) کند، در نتیجه به طور خودکار اجزای یک نقشه را تفسیر و مطابقت می دهد. با این حال، آدرس دوم به دلیل کمبود اطلاعات در مورد اجزای آن برای تجزیه و تفسیر کامل، تطبیق خودکار (اگر نه غیرممکن) دشوار است (اگر غیرممکن است).
در مورد کسی که می خواهد هر دو آدرس را پیدا کند و آنها را معنا کند، مثلاً با تلاش برای رسیدن به مقاصد و/یا ادغام این اطلاعات آدرس در بازنمایی ذهنی فضایی خود، چطور؟ عاملی که با ساختار سیستم آدرس دهی اتریشی ناآشنا است ممکن است نتواند برخی از مؤلفه ها را تفسیر کند (مثلاً 1040 که به منطقه چهارم وین اشاره می کند)، و بنابراین ممکن است فرآیند در مرحله اولیه مرحله تفسیر شکست بخورد. در مقابل، عاملی که این ساختار آدرسدهی را میشناسد، اما هرگز نام «Gusshausstrasse» را نشنیده است، فقط میتواند این آدرس را تا سطح منطقه درک کند. با این حال، تفسیر آدرس دوم به انواع دیگری از دانش نیاز دارد زیرا اجزا به عنوان ویژگی هایی بیان می شوند که با محیط واقعی مطابقت دارند. علاوه بر این، عاملی که با محیطی که به نقطه شروع آدرس اشاره می کند آشنا است، می تواند توضیحات ارائه شده توسط آدرس را دنبال کند (یعنی برای آنها آدرس نوعی دستورالعمل راهیابی است). از سوی دیگر، انسانها از آدرس اول متوجه میشوند که “Gusshausstrasse” در منطقه چهارم وین واقع شده است، که ایدهای کلی در مورد اینکه این خیابان تقریباً در کجای شهر وین قرار دارد را در اختیار نماینده قرار میدهد، اما هیچ سرنخی در مورد نحوه قرارگیری این خیابان وجود ندارد. برای رسیدن به آنجا آدرس دوم اما نشان میدهد که برای رسیدن به دانشگاه تهران باید از خیابان کارگر شمالی رفته و از بلوار جلال 100 متر عبور کرد. برای تأیید، حتی حاوی اطلاعات کمکی است که او از اداره پست عبور خواهد کرد. آدرس دوم نیز به طور ضمنی روابط فضایی بین خیابان کارگر شمالی، بلوار جلال را در اختیار انسان قرار می دهد. اداره پست و “دانشگاه تهران”، دانش فضایی خود را با اطلاعات بیشتر غنی می کنند. ما در نظر داریم که آدرس دوم حاوی اطلاعات بیشتری برای راهیابی و برای کسب و بهبود دانش فضایی است.
مثالهای بالا نشان میدهند که سیستمهای آدرسدهی مختلف سطوح مختلفی از جزئیات را ارائه میدهند و برای درک مفاهیم قبلی، نیاز به سطوح مختلف دانش قبلی در مورد معنای اجزا دارند. از سوی دیگر، بسته به شکل آدرس و همچنین نوع اجزای آنها، آدرس ها به شکل متفاوتی درک، تفسیر و در بازنمایی های ذهنی فضایی انسان ادغام می شوند. برای ادغام یک آدرس با بازنمایی ذهنی فضایی خود، انسان ها ابتدا باید اجزای آدرس را درک کنند و تفسیر آنها را درک کنند. برای این، ساختار آدرس دهی و معنای اجزای آن باید یا خود توضیحی باشد یا شناخته شده باشد. سپس، فردی که محیط را می شناسد، اجزاء را با عناصر بازنمایی ذهنی فضایی آنها مرتبط می کند. این فرآیند برای یک انسان ناآشنا شکست خواهد خورد، زیرا آنها هیچ بازنمایی ذهنی فضایی از محیط ندارند. از سوی دیگر، سطح اطلاعات مکانی ارائه شده توسط یک آدرس ممکن است بر نحوه استفاده بیشتر توسط افراد در فعالیت های فضایی خود تأثیر بگذارد.
3. سیستم های آدرس دهی: یک طبقه بندی
در میان بسیاری از مطالعاتی که تعاریف و جنبه های مختلف آدرس دهی را مستند می کنند، برخی آدرس ها را بر اساس عناصری که استفاده می کنند طبقه بندی می کنند. دیویس و فونسکا [ 2 ] آدرس ها را به عنوان ارجاع مستقیم یا غیرمستقیم به مکان ها طبقه بندی کردند و ارجاعات مستقیم را به عنوان توصیف های ساختارمند متشکل از عناصر فضایی و غیرمستقیم به عنوان اعداد یا کدهایی معرفی کردند که به یک مکان اشاره می کنند. یک خطاب مستقیم، فی نفسه، می تواند مطلق (یعنی اشاره به مکان معین) یا نسبی باشد(یعنی ارجاع مطلق به نشانه موقعیت نسبی، مثلاً “100 متر بالاتر از بلوار جلال.”). علاوه بر این، آنها مجموعه ای از مفاهیم را برمی شمرند که ممکن است دارای ارزش آدرس دهی مانند نام خیابان، تقاطع، شماره ساختمان، بخش شهر، محله، شهر، ایالت، نقطه عطف و کد پستی باشند.
از آنجایی که بسیاری از محققین تمایل به پرداختن به سیستم های آدرس دهی برای کدگذاری جغرافیایی مبتنی بر ماشین دارند [ 2 ، 11 ، 15 ، 27 ، 28 ، 29 ، 30 ]، دامنه خود را برای مدل سازی نحو سیستم های آدرس دهی ساختاریافته، که عمدتا مستقیم هستند، محدود کرده اند. سیستم های آدرس دهی مطلق و شامل مفاهیم آدرس دهی هستند که می توانند به شیوه ای ساختاریافته بیان شوند. با این حال، سایر کلاسهای آدرسدهی (مثلاً آدرسهای نسبی مستقیم)، همراه با سایر مفاهیم آدرسدهی (به عنوان مثال، گذرگاهها و نشانهها) ممکن است جنبههای کلیدی شناخت فضایی انسان باشند. به عنوان مثال، شناسایی نقطه عطف یکی از اولین مراحل کسب دانش فضایی است [ 31 ]]، که مقادیر آدرس دهی آن در اکثر تحقیقات فعلی در مورد سیستم های آدرس دهی تمرکز زیادی نداشته است.
در ادامه سیستم آدرس دهی اتریشی، ژاپنی و ایرانی را سه کلاس آدرس دهی با ساختارها و انواع اجزای مختلف در نظر گرفتیم. پس از توصیف هر سیستم آدرس دهی، نحو آن از طریق توصیف رسمی آن در فرم Backus Naur (BNF) مورد بحث قرار می گیرد. و معنای شناسی و عمل شناسی آن از طریق یک مدل مبتنی بر عامل ارزیابی می شود تا چگونگی تأثیر آنها بر کسب دانش و رشد فضایی بررسی شود. نتایج این ارزیابی نحوی، معنایی و عملی در مورد مطالعات موردی در جدول 7 در انتهای مقاله خلاصه شده است.
3.1. اتریش: آدرس دهی مطلق مستقیم ساختاریافته
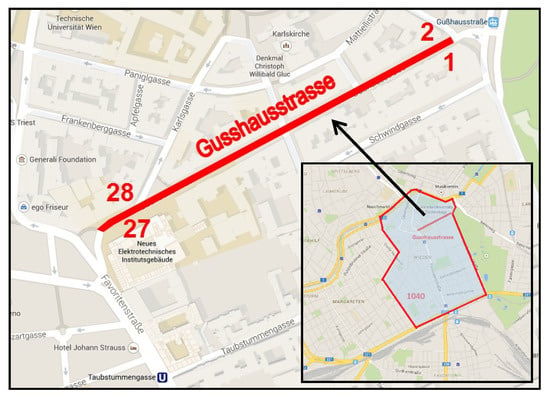
مانند بسیاری از کشورهای غربی و اروپایی، سیستم آدرس دهی رسمی اتریش از یک ساختار دقیق پیروی می کند (یعنی ترتیب عناصر و همچنین سبک نوشتاری آنها، به عنوان مثال، علائم نگارشی) کاملاً استاندارد شده است: آدرس های اتریشی با نام خیابان در کنار شماره خانه جدا شده شروع می شود. توسط یک فضای خالی، که می تواند یک عدد واحد (مثلاً 27 ) یا دو عدد جدا شده با یک خط تیره (مثلاً 27-29 ) باشد، که به چندین خانه اشاره می کند (همانطور که شکل 2 نشان می دهد، اعداد ساختمان در امتداد خیابان مرتب شده اند. با اعداد زوج و فرد در اضلاع مختلف). اگر واحدهای مختلفی در خانه وجود داشته باشد، شماره واحد (در) بعد از شماره خانه که با یک اسلش از هم جدا شده است (مثلاً 27/12) می آید .). در مورد داشتن یک بلوک، یک عدد اضافی بین خانه و شماره واحد قرار می گیرد که دوباره با یک اسلش از هم جدا می شوند (مثلاً 27/8/12 ) . سپس یک کاما و شماره منطقه به همراه نام شهر نوشته می شود که با یک فضای خالی از هم جدا می شوند:
سیستم اتریشی یک سیستم آدرس دهی مطلق مستقیم است که از نام خیابان های مشخص استفاده می کند. هیچ چیز توصیفی یا خارج از ساختار از پیش تعریف شده مجاز نیست. چنین سیستم ساختاری یک آدرس منحصر به فرد برای هر مکان ارائه می دهد (تنها استثنا ساختمان هایی با بیش از یک ورودی از خیابان های مختلف است).
توجه داشته باشید که کنوانسیون های آدرس دهی دیگری در اتریش و سایر کشورها وجود دارد که دارای سیستم های آدرس دهی ساختاری هستند که ممکن است برای اهداف خاصی مورد استفاده قرار گیرند. علاوه بر این، آدرس ها در معرض تغییرات کوچکی در ارتباطات شفاهی و نوشتاری هستند. به عنوان مثال، ترتیب اجزا ممکن است تغییر کند، که با انعطاف انسان یا ماشین جبران می شود. با این حال، مگر اینکه ذکر شود، در اینجا به سیستم های آدرس دهی رسمی (یعنی آدرس های پستی) اشاره می کنیم.
3.2. ژاپن: آدرس دهی غیر مستقیم نیمه ساختاریافته
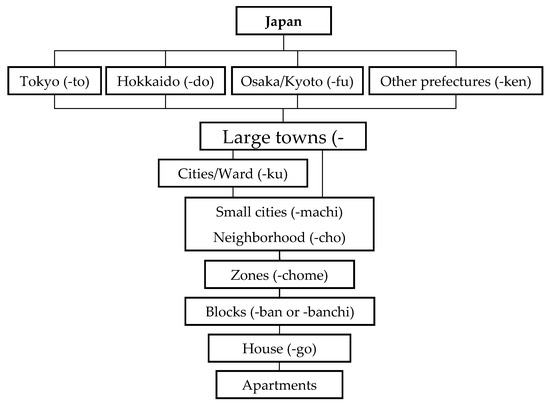
آدرس های ژاپنی بر اساس یک زیربخش سلسله مراتبی است که با کدهای الفبایی یا عددی نامگذاری شده است ( شکل 3 ). یک آدرس با بزرگترین شروع می شود و با کوچکترین سطح زیربخش پایان می یابد. این کشور به عنوان بزرگترین سطح زیربخش جغرافیایی به 47 « بخش » تقسیم شده است. همه استان ها دارای پسوند «-ken» هستند، به جز «توکیو-تو»، «کیوتو فو»، «اوزاکا-فو» و «هوکایدو-دو» که پسوندهای خاص خود را دارند. پسوند استان ممکن است در آدرس دهی حذف شود.
استانها به شهرهای بزرگ تقسیم میشوند که با پسوند «-shi» پسوند میشوند، که ممکن است در آدرسدهی نیز حذف شود. این شهرهای بزرگ خود به شهرهای کوچک تقسیم میشوند که با پسوند «-machi» یا محله با پسوند «-cho» به آنها اضافه میشود. در شهرهای بسیار بزرگ، ممکن است یک تقسیم بندی اضافی به نام “بخش” با پسوند “-ku” بین شهرهای بزرگ و شهرهای کوچک / محله ها وجود داشته باشد. شهرهای کوچک (ماچی) و محلهها (چو) به مناطق شمارهدار تقسیم میشوند که با پسوند «-chome» اضافه میشوند.
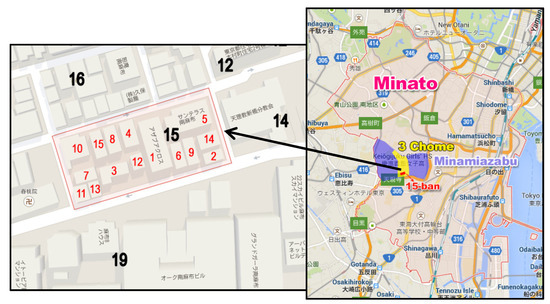
جالب است که (بیشتر) خیابان ها در ژاپن نام ندارند. مانند شکل 4نشان می دهد، آنها فقط فضاهای خالی بین بلوک ها هستند! بلوک ها در هر منطقه (chome) شماره گذاری می شوند که در قسمت های جدید با “-ban” و در قسمت های قدیمی شهرها با “-banchi” پسوند می شوند. ممکن است پسوند “-ban” در آدرس دهی حذف شود، برخلاف پسوند “-banchi” که ذکر آن الزامی است. در پایین ترین سطح، خانه های روی یک بلوک با پسوند “-go” شماره گذاری می شوند که می تواند در آدرس دهی حذف شود. ترتیب شمارهگذاری خانهها بر اساس تاریخی است که خانهها ساخته میشوند، که منجر به خانههایی میشود که از نظر مکانی به صورت متوالی در یک بلوک مشخص شمارهگذاری نشدهاند. شماره آپارتمان (در صورت وجود) اغلب بعد از شماره ساختمان با یا بدون پسوند “-go” (به عنوان مثال، 5-103 یا 5-103-go)، یا به ندرت به عنوان یک شماره در انتهای آدرس آمده است (مثلاً ، 5-go، 103).
سیستم آدرس دهی ژاپنی نیمه ساختاریافته است: بسته به انواع تقسیمبندی، قوانین قالببندی خاصی وجود دارد (یعنی یک مکان خاص با یک نوع آدرسدهی منطبق است، اما انواع مختلف تقسیمبندی بهطور متفاوتی نشان داده میشوند)، و سبکهای نوشتاری (یعنی پسوندها) شماره گذاری بلوک-خانه-آپارتمان و غیره) انعطاف پذیر هستند. علاوه بر این، آدرس دهی غیرمستقیم است، زیرا کدها و اعداد مختلف عناصر اصلی این سیستم آدرس دهی هستند.
3.3. ایران: آدرس دهی مستقیم مطلق/نسبی غیرساختار یافته
برخلاف مثال های بالا، گاهی اوقات هیچ ساختار آدرس دهی وجود ندارد و در عوض، آدرس ها متفاوت بیان می شوند. یک مثال جالب ایران است، که در آن نام خیابان ها در یک شهر خاص منحصر به فرد نیست و بنابراین اطلاعات رویه ای اضافی برای ایجاد یک مرجع منحصر به فرد مورد نیاز است. در ایران، مردم آدرسها را به صورت دنبالهای از ویژگیهای فضایی (مثلاً خیابانها، میدانها، مکانهای دیدنی و غیره) و روابط فضایی خود (مثلاً 100 متر بعد ، چند قدم قبل ، جلو و غیره) با شروع از یک عنصر شناخته شده به عنوان مثال، در شکل 5 ، آدرس نقطه A بر اساس مسیر شماره 1 است.خیابان شریعتی، قلهک، خیابان پابرجا، بلوار آیینه، نبش غربی کوچه گل یخ، پلاک 2، واحد 9 . « خیابان شریعتی » در صورتی که گیرنده قلهک را از قبل بداند ممکن است حذف شود . یا « بعد از خیابان ظفر » ممکن است بعد از « خیابان شریعتی » اضافه شود تا یک گیرنده کمتر آشنا با تخمینی از « خیابان شریعتی » طولانی مورد بحث ما باشد. حتی بدتر از آن، میتوان به همان مکان به روشهای کاملاً متفاوت اشاره کرد، زیرا ممکن است از نقاط شروع یا عناصر فضایی متفاوت استفاده شود [ 32 ]. برای مثال، بر اساس مسیر شماره 2 در شکل 5 ، نقطه A به عنوان «دروس، بلوار شهرزاد، خیابان پابرجا، بلوار آیینه، نبش غربی کوچه گل یخ، پلاک 2، واحد 9 . این به نوعی شبیه به شرح مسیر است، اما به شیوه ای رسمی تر، زیرا هیچ جمله کاملی استفاده نمی شود. در عوض بیشتر از نام ها و روابط فضایی گسسته تشکیل شده است. همچنین قابل مقایسه با توصیف مقصد معرفی شده توسط Tomko به عنوان قراردادی است که توسط افرادی با دانش مشترک از یک محیط برای برقراری ارتباط با مقصد از طریق روابط آن با ویژگی های اطراف استفاده می شود، که به کاربر اجازه می دهد تا به طور انعطاف پذیر از مرتبط ترین ویژگی ها استفاده کند (به عنوان مثال، نشانهها، مسیر، منطقه) در توضیحات تولید شده [ 33 ].
آدرس ایرانی ترکیبی از آدرس دهی مستقیم با ارجاعات مطلق یا نسبی است: هر مفهوم آدرس دهی (خیابان، تقاطع ها، نشانه ها و غیره) ممکن است دارای ارزش آدرس دهی در نظر گرفته شود و در آدرس به صورت مطلق یا نسبی استفاده شود. علاوه بر این، عنصر آدرس دهی و سطح جزئیات مورد استفاده ممکن است از یک کاربر به کاربر دیگر بر اساس دانش قبلی او در مورد محیط، هدف آدرس دهی، نقطه شروع و غیره متفاوت باشد.
4. کسب دانش فضایی از طریق آدرس ها: یک شبیه سازی مبتنی بر عامل
بررسیهای نظری فوق نشان میدهد که ساختار رسمی از پیش تعریفشده برخی از آدرسها، در حین بیان آدرس یک مکان، محدودیتهایی را بر زبان فضایی طبیعی افراد وارد میکند. به عبارت دیگر، با در نظر گرفتن اینکه یک آدرس قرار است قطعه ای از اطلاعات مکانی برای انجام وظیفه یافتن مسیر/مقصد روزمره باشد، تعریف یک ساختار دقیق برای آدرس دهی منجر به محدودیت در افزودن اطلاعات مکانی مرتبط و ضروری برای چنین کاربر خاص می شود. وظایف به منظور بررسی تأثیری که سیستمهای آدرسدهی مختلف ممکن است بر دانش فضایی افراد داشته باشند، یک مدل مبتنی بر عامل ساده برای شبیهسازی کسب دانش فضایی از طریق آدرسها پیشنهاد شد. ما یک روش دو مرحله ای را برای مدل سازی هر سیستم آدرس دهی دنبال کردیم: ابتدا با تعریف یک دستور زبان برای هر سیستم آدرس دهی به منظور تجزیه شدن آن توسط کامپیوتر. و دوم، با طراحی یک طرح یادگیری برای عوامل به دست آوردن دانش ممکن از آدرس ها.
4.1. تجزیه آدرس ها
تجزیه آدرس فرآیند تجزیه یک آدرس به عنوان رشته ای از اطلاعات مکانی، خواه به زبان رسمی یا طبیعی، به اجزای آن است. خروجی این فرآیند مجموعه گسسته ای از اجزای مکانی و/یا مبتنی بر کد است که از آدرس استخراج می شود. این فرآیند مستقیماً با جنبههای نحوی سیستمهای آدرسدهی مرتبط است و بنابراین معمولاً توسط ماشینهای کدگذاری جغرافیایی انجام میشود تا اجزای منطبق را از آدرسها بیرون بکشند و آنها را به عناصر مربوطه در پایگاههای داده یا نقشههای دیجیتال مرتبط کنند. اجزای استخراج شده توسط تجزیه کننده های آدرس بعداً توسط عامل برای فرآیند یادگیری استفاده می شود. در واقع، بلوک های دانش پایگاه دانش عامل از اجزای ارائه شده توسط فاز تجزیه ساخته می شوند.
جزئیات مربوط به فاز تجزیه عامل در زیر بخش نحو زیر هر سیستم آدرس دهی ذکر شده است و در فرم Backus Naur (BNF) توضیح داده شده است.
4.1.1. تجزیه کننده آدرس های اتریش
یک آدرس اتریشی از عناصر زیر تشکیل شده است که نشانه های زبان رسمی سیستم آدرس دهی اتریشی هستند:
که به ترتیب مخفف Strasse (=خیابان)، Haus (=خانه)، Block، Tür (=در)، Bezirk (=منطقه)، و Ort (=شهر) هستند. قوانین ترکیبی برای تولید/تجزیه یک آدرس اتریشی عبارتند از:
| آدرس AUS |
:= |
(strasse "" gebaude "," bezirk " " ort) |
|
|
|
| خیابان |
:= |
:= نام → [STR] |
| گباود |
:= |
(haus "/" block "/" tur) | (haus "/" tur) | خانه |
| خانه |
:= |
(شماره "-" شماره) | شماره → [HAUS] |
| مسدود کردن |
:= |
شماره → [BLK] |
| تور |
:= |
شماره → [TUR] |
| بزیرک |
:= |
شماره → [BZR] |
| ort |
:= |
نام → [ORT] |
قانون ” addressAUS ” نماد شروع زبان است. قاعده ” gebaude ” (=ساختمان) و ” haus” (=خانه) تنها نمادهای غیر پایانی زبان هستند (یعنی دارای چندین شکل از تنوع هستند). بقیه نمادهای پایانی هستند که به صورت ” x → y ” نشان داده می شوند، به این معنی که x یک نماد پایانی از نوع نشانه y است. به عنوان مثال، عبارت “name → [ORT]” به این معنی است که نام خروجی نام یک شهر است (یعنی ort). جدول 1 نتایج اعمال تجزیه کننده فوق را در دو آدرس اتریشی نشان می دهد.
زبان تعریف شده برای سیستم آدرس دهی اتریشی تأیید می کند که این سیستم آدرس دهی کاملاً رسمی است: همه نشانه ها در هر آدرس ظاهر می شوند. تنها یک نماد شروع وجود دارد، و قوانین ترکیب عمدتاً مستقیماً به نمادهای پایانی منتهی میشوند (یعنی مستقیماً منجر به نشانهها میشوند). حتی علائم نقطه گذاری ثابت است، و بنابراین می تواند به طور مستقیم در نماد شروع ذکر شود. تنها استثناها نشانههای “block” و “tur” و نماد غیر پایانی “gebaude” هستند که به دلیل انواع مختلف ساختمانها (یعنی ساختمانهای با یا بدون بلوک/واحد) رخ میدهد، بنابراین این موضوع مربوط به آدرس دهی استاندارد، اما نوع ساختمان. با این وجود، چنین استثناهایی تأثیر حداقلی بر ساختار آدرس دهی دارند:
4.1.2. تجزیه کننده آدرس های ژاپنی
یک آدرس ژاپنی از زیر مجموعه ای از نشانه های زیر تشکیل شده است:
قوانین ترکیبی برای تولید/تجزیه آدرس ژاپنی عبارتند از:
| آدرسJPN |
:= |
استان سپ تاون شهر سپ منطقه سپ بلوک سپ ساختمان) |
|
|
|
| استان |
:= |
(نام "-" prfپسوند) | نام → [PRF] |
| پسوند prf |
:= |
"به" | "do" |"fu" |"کن" |
|
|
|
| شهر |
:= |
(شی سپ ورد) | شی |
| شی |
:= |
(نام "-shi") → [SHI] | نام → [SHI] |
| بخش |
:= |
(نام "-ku") → [WARD] |
| منطقه |
:= |
(منطقه sep zone) | حوزه |
| حوزه |
:= |
(نام "-machi") → [MACHI] | (نام "-cho"؛) → [CHO] |
| منطقه |
:= |
(شماره "-chome") → [CHOME] |
| مسدود کردن |
:= |
(شماره «-بانچی») | (شماره "-ban") | شماره → [BLK] |
| ساختمان |
:= |
(خانه سپ اپارتمان) | خانه |
| خانه |
:= |
(شماره "-go") | شماره → [HOS] |
| اپارتمان |
:= |
(شماره "-go") | شماره → [APT] |
|
|
|
| سپتامبر |
:= |
"-" | "" | ";" |
قانون ” addressJPN ” نماد شروع زبان است. به دلیل تنوع بسیاری که در اجزای آدرس های ژاپنی وجود دارد، چندین نماد غیر پایانی در تجزیه کننده ظاهر می شوند. با این حال، تغییرات به سادگی با تعریف قوانین متعدد به عنوان آنها از طریق یک سلسله مراتب واضح توصیف می شوند ( شکل 3 را ببینید ). نتایج اعمال تجزیه کننده فوق برای دو آدرس ژاپنی در جدول 2 نشان داده شده است.
سیستم آدرس دهی ژاپنی را می توان به طور رسمی تعریف کرد، که تأیید می کند که از یک ساختار پیروی می کند و تنها با یک نماد شروع قابل تعریف است. با این حال، تنها زیر مجموعه ای از نشانه ها در یک آدرس خاص ظاهر می شوند و در مقایسه با سیستم اتریشی، نمادهای غیر پایانی بیشتری وجود دارد. تفاوت دیگر در قوانین ترکیبی نهفته است که به دلیل انواع مختلف اجزای آدرس دهی بر اساس نوع تقسیم بندی مکان مورد ارجاع است. به عبارت دیگر، ترتیب عناصر آدرسها تغییر نمیکند (و بنابراین یک نماد شروع میتواند همه موارد را به تصویر بکشد)، اما تعاریف عناصر ممکن است از موردی به مورد دیگر متفاوت باشد (به عنوان مثال، یک شهر میتواند از نوع شی باشد. -بخش یا شی). علاوه بر این، پیشوندهای مورد استفاده اختیاری، انواع مختلف علائم نگارشی و به ویژه،
4.1.3. تجزیه کننده آدرس های ایرانی
یک آدرس ایرانی ممکن است از هر تعداد گروه فضایی (SG) تشکیل شده باشد که از [ 32 ] تشکیل شده است:
-
نامهای جغرافیایی ( GN )
- 1.1.
-
نامهای جغرافیایی ثابت (CGN): خیابان، خیابان، کوچه و غیره.
- 1.2.
-
نامهای جغرافیایی متغیر (VGN): نامهای جغرافیایی ثابت (مثلاً نام خیابان).
-
روابط:
- 2.1.
-
روابط فضایی (SPR): بعد، قبل، جلو، سمت راست، چپ و غیره.
- 2.2.
-
روابط متریک (MTR): ترکیب یک مقدار عددی (مثلاً 100)، یک واحد (مثلاً متر، مراحل، دقیقه)، و یک رابطه فضایی (مثلاً بعد). توجه داشته باشید که تنها زیر مجموعه ای از روابط فضایی در اینجا مرتبط است. به عنوان مثال، “100 متر جلو” یک ترکیب منطقی نیست!
بنابراین، نشانه های یک آدرس ایرانی عبارتند از:
و قوانین ترکیبی برای تولید/تجزیه یک آدرس ایرانی به شرح زیر است:
| آدرسIRN |
:= |
{spGrp سپتامبر} |
|
|
|
| spGrp |
:= |
gn | (rel gn) |
|
|
|
| gn |
:= |
(cgn vgn) | (vgn cgn)| vgn |
| cgn |
:= |
"ave." | "خیابان" | "خیابان"| "خیابان" | "بلورود." | "کوچه" | "تعداد" | "واحد" → [CGN] |
|
|
|
| vgn |
:= |
نام → [VGN] |
|
|
|
| رابطه |
:= |
spRel | (mtRel spRelType1) |
| mtRel |
:= |
(واحد شماره) → [MTR] |
| spRel |
:= |
spRelType1 | spRelType2 |
| واحد |
:= |
"متر" | "m" | "گام ها" |
| spRelType1 |
:= |
"بعد" | "قبل" → [SPR] |
| spRelType2 |
:= |
"در مقابل" | "مقابل" | "سمت چپ" | "حق" → [SPR] |
| سپتامبر |
:= |
"-" | "" | ";"| ""| "." |
در اینجا فقط تعداد کمی از نام های جغرافیایی ثابت، روابط فضایی و واحدهای فاصله ذکر شده است. جدول 3 نتایج اعمال تجزیه کننده فوق را در دو آدرس ایرانی نشان می دهد.
سیستم آدرس دهی ایرانی کمترین ساختار را در بین آدرس های مورد بررسی در مطالعه موردی ما داشت. علامت شروع آدرس IRN نشان میدهد که آدرس مجموعهای از گروههای فضایی است که با نمادهای مختلف از هم جدا شدهاند، اما هیچ اطلاعاتی درباره ترتیب یا حتی تعداد آنها ندارند. علاوه بر این، یک گروه فضایی میتواند یک عنصر فضایی ” gn ” (آدرسیابی مطلق) یا یک رابطه ” (rel gn) ” (نشانیدهی نسبی) باشد، بنابراین فهرست مربوطه از نشانهها تنها تعداد محدودی از مفاهیم انتزاعی است (یعنی فضایی). رابطه ” spRel “، رابطه متریک ” mtRel ” و غیره). مشکلسازترین مسئله در اینجا برای کدگذاری جغرافیایی مبتنی بر ماشین، اصطلاحات است: نامهای جغرافیایی ثابت ( خیابان.، خیابان ، خ . ، خیابان ، و غیره)، روابط فضایی ( بعد ، قبل ، جلو ، و غیره)، و واحدها ( متر ، پله ها، و غیره) لیست های بی نهایت در واقعیت هستند. اصطلاحات نامحدودی وجود دارد که افراد ممکن است برای عناصر و روابط فضایی استفاده کنند. به طور کلی، در غیاب هیچ استانداردی، افراد ممکن است آدرسها را از نظر اصطلاحات، ترتیب ، ترکیبها و غیره متفاوت بیان کنند .]. بنابراین، نه تنها تطبیق، بلکه فرآیند تجزیه برای برخی از مؤلفه ها نیز ممکن است با شکست مواجه شود. به نظر می رسد این دلیلی است که این دسته از سیستم آدرس دهی به دلیل مدل سازی پیچیده نحوی آن برای رایانه ها بیشتر توسط محققان نادیده گرفته شده است.
توجه داشته باشید که ابزارهای سیستمهای استخراج اطلاعات [ 35 ، 36 ] (که به طور خودکار اطلاعات ساختاریافته را از اسناد بدون ساختار و نیمه ساختار یافته استخراج میکنند) ممکن است راهحلهایی برای سهولت تجزیه آدرسدهی توصیفی ایرانی ارائه دهند. همچنین رویکردهای مبتنی بر دانش مانند تجزیه کننده های سطحی [ 37 ] (همچنین به آنها تجزیه تکه ای یا تجزیه نور نیز گفته می شود ) وجود دارد که ممکن است در این زمینه مفید باشد. از سوی دیگر، الگوهای واژگانی- نحوی [ 38 ، 39] ممکن است بتواند انواع مختلفی از عبارات را در یک آدرس توصیفی بدون نیاز به فهرست کردن همه احتمالات مدیریت کند. با این حال، حتی اگر چنین رویکردهایی برای این هدف موفقیت آمیز باشد، این نشان می دهد که تجزیه آدرس های توصیفی در مقایسه با آدرس های ساختاریافته و نیمه ساختاریافته به تلاش گسترده نیاز دارد.
4.2. فرآیند یادگیری فضایی
این بخش یک ماژول برای شبیه سازی کسب دانش فضایی از آدرس ها توسط یک عامل پیاده سازی می کند. مشابه موتور تطبیق آدرس در اولین برخورد با آدرس، مغز انسان با تجزیه آدرس و استخراج اجزای آن شروع به کار می کند. سپس سعی در تفسیر اجزاء و ارتباط آنها با عناصر متناظر موجود در بازنمایی ذهنی فضایی آن دارد. اگر این فرآیند در مرحله تفسیر خاتمه یابد، آنگاه فرد احتمالاً باید به دنبال منابع خارجی کمک و اطلاعات باشد (مثلاً از افرادی که با محیط اطراف آشنا هستند یا استفاده از نقشه ها یا خدمات دیجیتال با قابلیت تطبیق آدرس مانند سیستم های ناوبری) بپرسد. از جهات دیگر، اگر فرد مرحله تفسیر را با موفقیت پشت سر بگذارد اما نتواند اجزاء را با عناصر متناظر در بازنمایی ذهنی فضایی خود مطابقت دهد، یک فرآیند استدلالی را در دانش فضایی که قبلاً در نقشه شناختی خود کدگذاری شده است، تشریح می کند تا آدرس را دریابد. اگر این کار انجام نشود، ممکن است دوباره به کمک منابع خارجی اطلاعات نیاز داشته باشند. در هر صورت، این تکههای اطلاعات مکانی یا بهعنوان یک بلوک دانش جدید ذخیره میشوند و به بازنمایی ذهنی فضایی اضافه میشوند، یا فقط بلوکهای دانش از قبل شناخته شده را تحریک میکنند و آنها را پایدارتر میکنند. آنها ممکن است دوباره به کمک منابع خارجی اطلاعات نیاز داشته باشند. در هر صورت، این تکههای اطلاعات مکانی یا بهعنوان یک بلوک دانش جدید ذخیره میشوند و به بازنمایی ذهنی فضایی اضافه میشوند، یا فقط بلوکهای دانش از قبل شناخته شده را تحریک میکنند و آنها را پایدارتر میکنند. آنها ممکن است دوباره به کمک منابع خارجی اطلاعات نیاز داشته باشند. در هر صورت، این تکههای اطلاعات مکانی یا بهعنوان یک بلوک دانش جدید ذخیره میشوند و به بازنمایی ذهنی فضایی اضافه میشوند، یا فقط بلوکهای دانش از قبل شناخته شده را تحریک میکنند و آنها را پایدارتر میکنند.
دقیقاً همان استراتژی برای طراحی و اجرای دانش فضایی یک عامل از آدرسها اتخاذ میشود. یک پایگاه دانش شکل جدولی ساده (KB) بلوک های دانش فضایی عامل را ذخیره می کند. فیلدهای این جدول شامل اجزای آدرس دهی ممکن (مثلاً نام خیابان، شماره ساختمان، ناحیه، شهر و غیره) و دو فیلد دیگر، ضریب برداشت (IF) و امتیاز یادگیری (LS) است که به زودی توضیح داده خواهد شد. به تفصیل برای هر آدرس، عامل ابتدا آن را به اجزای خود تجزیه میکند و سپس آن را به KB اضافه میکند (اگر اطلاعات جدیدی باشد)، یا رکوردهای موجود را با یک ضریب نمایش تعریف شده تقویت میکند تا عناصر متداول آدرسها را مشخص کند.
ضریب تأثیر ( IF ) عاملی است که توسط عامل برای تشخیص سطوح مختلف آشنایی با آدرس مورد استفاده قرار می گیرد و مشخص می کند که یک آدرس تا چه اندازه در کسب یا تکمیل دانش فضایی عامل کمک می کند. با توجه به یک آدرس خاص، هر یک از اجزای آن در KB عامل موجود جستجو می شود. به هر مؤلفه جدید IF e = 0 اختصاص داده می شود و به مؤلفه هایی که قبلاً در KB وجود دارند، IF e = 0.01 اختصاص داده می شود. سپس، IF آدرس، مجموع IF e تمام اجزای آن است. به عبارت دیگر، هر مؤلفه ای که از قبل در KB وجود داشته باشد، IF را افزایش می دهدآدرس توسط 0.01. به عنوان مثال، اگر یک آدرس اتریشی برای نماینده کاملاً ناشناخته باشد (یعنی هیچ یک از شماره های ناحیه، خیابان و ساختمان در KB آن وجود ندارد)، آنگاه IF = 0. با این حال، اگر نماینده از قبل منطقه را می شناسد، آنگاه IF = 0.01. توجه داشته باشید که یک مقدار عددی مانند شماره ساختمان (که در کل شهر منحصر به فرد نیست) نمی تواند به عنوان اطلاعات شناخته شده در نظر گرفته شود (و در نتیجه IF را افزایش می دهد ) مگر اینکه ترکیب آن با مقدار غیر عددی سطح بالای آن یک مرجع منحصر به فرد ایجاد کند (یعنی در KB وجود دارد).
نمره یادگیری معیار تجمعی برای عوامل تأثیر است (یعنی مجموع عوامل تأثیر برای همه رکوردها (معادله (1)).
این اندازه گیری می تواند میزان دانش فضایی به دست آمده توسط آدرس ها را منتقل کند و بنابراین می تواند به عنوان یک پایه کمی برای تجزیه و تحلیل منحنی یادگیری در بخش 4.3 در نظر گرفته شود .
4.2.1. یادگیری فضایی برای یک نماینده اتریشی
همانطور که قبلا ذکر شد، مرحله اولیه برای فرآیند یادگیری یک عامل، تجزیه آدرس است. به عنوان مثال، آدرس ورودی را “Mayerhofgasse 7, 1040 Vienna” در نظر بگیرید. تجزیه کننده لیست را به صورت زیر برمی گرداند:
در مرحله دوم، عامل بر اساس ساختار تعریف شده، پایگاه دانش را می سازد:
| خیر |
STR |
HAUS |
BZR |
ORT |
اگر |
LS |
| 1 |
Mayerhofgasse |
7 |
1040 |
وین |
0.0 |
0.0 |
در حال حاضر، عامل اجزای هر آدرس را به KB موجود اضافه می کند. با این حال، بخش مهم، جستجویی است که باید در KB برای یافتن IF صحیح برای آدرسهای تازه وارد شده انجام شود. تابع جستجوی مورد استفاده در اینجا یک عملگر جستجوی رشته ای ساده است که بر روی هر ستون به ترتیب ناحیه، خیابان و شماره خانه اعمال می شود. به عبارت دیگر، با ارائه آدرس های جدید به عامل، ابتدا ستون ناحیه را بررسی می کند تا IF صحیح را تعیین کند. اگر شماره منطقه منطبقی در KB وجود نداشته باشد، نماینده به ستون خیابان و سپس به شماره خانه ادامه می دهد. اگرچه ممکن است به نظر برسد که به دلیل منحصر به فرد بودن نام خیابان ها در وین، جستجو را می توان به راحتی فقط در این زمینه انجام داد، اما استثناهایی مانند خیابان طولانی Mariahilferstrasse وجود دارد که در دو منطقه (1060 و 1070) قرار دارد.
به عنوان مثال، در مورد واردات “Gusshausstrasse 27, 1040 Vienna” و سپس “Gusshausstrasse 36, 1040 Vienna” KB به صورت زیر تکمیل می شود:
| خیر |
STR |
HAUS |
BZR |
ORT |
اگر |
LS |
| 1 |
Mayerhofgasse |
7 |
1040 |
وین |
0.0 |
0.0 |
| 2 |
خیابان گوشاوس |
27 |
1040 |
وین |
0.01 |
0.01 |
| 3 |
خیابان گوشاوس |
36 |
1040 |
وین |
0.02 |
0.03 |
4.2.2. یادگیری فضایی برای نماینده ژاپنی
تقریباً همان فرآیند فرآیند یادگیری عامل اتریشی برای سیستم آدرس دهی ژاپنی انجام شد. تفاوت اصلی این است که فیلدهای Chome ، Block ، House و Apartment عددی هستند. بنابراین، همانطور که قبلا ذکر شد، آنها IF را تنها در صورتی افزایش می دهند که ترکیب آنها با تمام فیلدهای سطح بالا تا زمانی که اولین فیلد غیر عددی در KB وجود داشته باشد. برای مثال، اگر «Machi Maeda، Chome 10، Block 2 » در KB وجود داشته باشد، «Machi Minamiazabu، Chome 10، Block 2 »” دانش جدید محسوب می شود. تجزیه کننده آدرس های ژاپنی، اجزا را در قالب جدول برمی گرداند، درست مانند مورد اتریشی:
| خیر |
بخشداری |
شی |
بخش |
ماچی |
چوم |
مسدود کردن |
خانه |
اپارتمان |
اگر |
LS |
| 1 |
هوکایدو |
ساپورو |
تین |
مائده |
10 |
2 |
5 |
25 |
0.0 |
0.0 |
| 2 |
توکیو |
میناتو |
– |
مینامیازابو |
3 |
15 |
9 |
– |
0.0 |
0.0 |
| 3 |
هوکایدو |
ساپورو |
تین |
مائده |
5 |
7 |
6 |
12 |
0.04 |
0.04 |
4.2.3. فرآیند یادگیری فضایی برای یک نماینده ایرانی
همان روش تجزیه بر روی آدرس های ایرانی همانطور که در بخش 4.1.3 توضیح داده شد، انجام شد . خروجی این فاز مولفه های آدرس دهی است که سه نوع دارد: نام های جغرافیایی متغیر و ثابت و روابط فضایی. از آنجایی که آدرسهای ایرانی به زبان طبیعی بیان میشوند، کل فرآیند یادگیری و همچنین بخش استدلال فضایی پیچیدهتر و البته دشوارتر میشود. به منظور کاهش این عارضه، به ویژه در فرآیند استدلال فضایی، یک ساختار رابطه باینری برای اجزای آدرس دهی تعریف شده است. به عبارت دیگر، فرآیند استدلال مبتنی بر استخراج تمام روابط زوجی ممکن بین اجزا است. اجازه دهید n را در نظر بگیریمتعداد عناصر در یک آدرس باشد. با توجه به معادله (2)، وجود دارد n(n-1)2روابط بین جفت اجزا
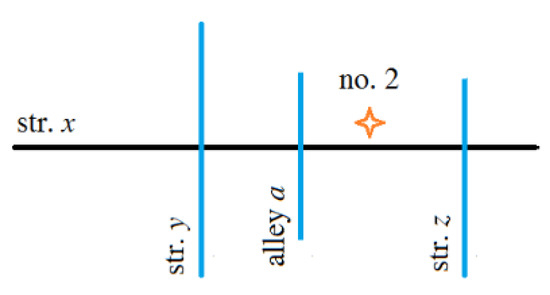
به عنوان مثال، «خیابان x ، پس از عبور از خیابان y ، شماره» را در نظر بگیرید. 2″ و طرح شماتیک آن ( شکل 6 ).
هم از لحاظ نظری و هم به طور قابل تشخیص، سه رابطه زوجی بین سه عنصر آدرس وجود دارد: < str. x ، خ. y >، <str. y ، نه 2>، و <str. x ، نه 2>. این روابط نشاندهنده « اتصال » (یعنی خیابانهای x و y به هم متصل هستند)، « توالی » (یعنی ساختمان شماره 2 بعد از خیابان y قرار دارد ) و « حفاظت » (یعنی خیابان x شامل ساختمان شماره 2 است)، به ترتیب. با این حال، این روابط زوجی همیشه از نظر منطقی معنادار نیستند. به عنوان مثال، آدرس قبلی را به عنوان “خیابان x ، خیابان ” در نظر بگیریدy ، نه 2” ( شکل 7 ). با حذف رابطه فضایی بین x و y از آدرس قبلی، رابطه باینری <str. x ، نه 2> دیگر درست نیست.
بر این اساس، ما باید محدودیتهایی را برای فیلتر کردن لیست روابط زوجی اجزای آدرسدهی تعریف کنیم تا به فهرستی از روابط مشروع هم از نظر منطقی و هم از نظر فضایی برسیم. پس از بررسی بیش از صد آدرس ایرانی، مجموعه ای از چهار قانون ساده برای فیلتر کردن لیست اولیه روابط باینری تعریف شد. قابل ذکر است که اگرچه این قوانین بر اساس آدرسهای معمولی در ایران در نظر گرفته شده است، اما از آنجایی که نشانیهای ایرانی به زبان طبیعی بیان میشوند، هرگز نمیتوان پوشش تمامی نمونههای آدرسی که توسط افراد مختلف داده میشود را تضمین کرد.
این قوانین در دستهبندی آدرسهای زیر توضیح داده میشوند:
-
دستورالعمل های خطی : آدرس های این دسته مشابه دستورالعمل های مسیر ساده ای است که با دنبال کردن یک مسیر خطی شرح داده شده شما را از مبدا به مقصد هدایت می کند. یک مثال می تواند «خیابان x ، پس از عبور از خیابان y ، مقابل ساختمان b ، شماره. 2″ که طرح شماتیک آن در شکل 8 نشان داده شده است .
-
دستورالعملهای خطی که با عنصر فضایی «کوچه» ختم میشود: از آنجایی که در ایران و بهویژه در تهران (مطالعه موردی در این مقاله)، مکانهای مسکونی به جای خیابانها به کوچهها ختم میشوند، اکثر آدرسهای ایرانی که به خانهها اشاره میکنند. و آپارتمان ها به شماره ساختمان در یک کوچه ختم می شوند. این عنصر فضایی رابطه پیوسته بین جفت ها را قطع می کند. به عبارت دیگر، عناصری که قبل از کلمه کلیدی «کوچه» قرار می گیرند، دیگر هیچ ارتباطی با عناصری که بعد از آن می آیند، ندارند. نمونه ای از این دسته عبارت است از «خیابان x ، پس از عبور از خیابان y ، قبل از رسیدن به خیابان z ، کوچه a ، پ. 2” ( شکل 9 ).
-
دستورالعملهای خطی با تغییر جهت صریح : گاهی اوقات پیش میآید که آدرسهای ایرانی (حتی آنهایی که برای خدمات تحویل پستی داده میشوند) دارای عباراتی مانند «چرخش به چپ/راست به خیابان x » باشد. این تغییر صریح در جهت دستور خطی را دقیقاً مانند دسته قبلی قطع می کند (یعنی روابط بین عناصری که قبل و بعد از این عبارت می آیند را قطع می کند). برای روشن شدن بیشتر، «خیابان x را در نظر بگیرید ، پس از عبور از خیابان y ، به سمت چپ به خیابان z ، کوچه a ، شماره بپیچید. 2” به عنوان مثال ( شکل 10 ).
-
دستورالعمل های خطی با تغییر جهت ضمنی: برخلاف دسته قبلی، آدرس های ایرانی در اکثر مواقع یک یا چند تغییر جهت دارند که به طور ضمنی به آنها اشاره می شود. رایجترین مثال زمانی است که آدرس دارای مولفه «تقاطع» است یا دو خیابان/خیابان به دنبال یکدیگر بدون هیچ رابطهای دیگر. خیابان x ، تقاطع c ، خیابان z ، کوچه a ، شماره را در نظر بگیرید. 2» یا «خیابان x ، خیابان z ، کوچه a ، پ. 2” ( شکل 11 ). بدیهی است که با چرخش به خیابان z ، تمام روابطی که x یا y را به آن متصل می کندیک یا نه 2 بریده شده اند.
بر اساس این چهار دسته، لیست روابط ممکن فیلتر می شود. فهرست اصلاح شده روابط، بلوک های دانش فضایی را برای پایگاه دانش عامل ایجاد می کند. با تغذیه نماینده با آدرس های جدید، نماینده چندین مرحله را برای هر آدرس انجام می دهد:
ایجاد روابط:
اعمال فیلترها:
و سپس با روابط خروجی پایه دانش را به صورت زیر می سازد:
| خیر |
VGN1 |
SR_ID |
VGN2 |
اگر |
LS |
| 1 |
کیهان |
1 |
کیهان چهارم |
0.0 |
0.01 |
| 2 |
کیهان چهارم |
2 |
5 |
0.01 |
ضریب برداشت در اینجا 0.01 برای هر رکورد جدیدی از رابطه فضایی در نظر گرفته شد. به عنوان مثال، اگر خیابان x قبلاً در پایگاه دانش موجود بود و یک آدرس جدید حاوی y است که به نحوی به x متصل است ، این قطعه اطلاعات < x, y > 0.01 به عنوان ضریب برداشت و 0 برای دانش تکراری دریافت میکند. بلوک ها
در آدرسهای توصیفی و به طور کلی توصیف مسیر، اصطلاحات زیادی برای روابط فضایی مانند “نزدیک” ، “چپ/راست” ، “در گوشه” و غیره، فرآیند استدلال فضایی را ارتقا میدهند. به منظور سهولت این فرآیند برای عامل ما، ستونی با عنوان “SR_ID” که مخفف Spatial Relation ID است، به پایگاه دانش اضافه شد. این فیلد حاوی کدهایی از 1 تا 6 است که هر کدام انواع مختلفی از رابطه فضایی بین نام های جغرافیایی متغیرها را مطابق جدول 4 نشان می دهد.
برای ترسیم هر رابطه فضایی کیفی با یک کد، مجموعه U SE = {خیابان، خیابان، خیابان، خیابان، تقاطع، مربع، مربع، کوچه} را به عنوان مجموعه عناصر فضایی ارائه دهنده مسیرها و U SR را به عنوان مجموعه ای از روابط فضایی (مثلاً در گوشه، جلو، چپ، راست، به جز دو رابطه «قبل» و «بعد» که در آدرس دهی استفاده می شود). دلیل حذف آنها از مجموعه روابط فضایی اهمیت آنها در استدلال فضایی است: اگر در یک استقرار خطی، A بعد از B و B بعد از C قرار گیرد، می توان استنباط کرد که A بعد از آن قرار دارد.سی . این رشته فکری از طریق چنین تحلیل توصیف فضایی به ساخت یک شبکه خیابانی ذهنی در نقشه شناختی فرد کمک می کند. بر این اساس، ردیف اول جدول 4 نشان می دهد که اگر هر دو نام جغرافیایی متغیر (VGN1 و VGN2) عناصر فضایی مسیر باشند و هیچ رابطه فضایی به صراحت بین آنها در آدرس ذکر نشده باشد، آنگاه ساده ترین رابطه برای استنتاج، اتصال خواهد بود (یعنی این دو مسیر به هم متصل می شوند.این اتصال با کد “1” مستند می شود. ردیف دوم وضعیتی را توصیف می کند که در آن یک شماره ساختمان یا یک نقطه عطف (هر ساختمان برجسته ای که به راحتی قابل تشخیص باشد و دارای ارزش آدرس دهی باشد) در یک خیابان یا انواع دیگر عناصر فضایی مسیر، سپس یک گنجاندنرابطه قابل استنباط است. اگر آدرس شامل دو عنصر/نقطه مکانی باشد که هر کدام دارای روابط متوالی «قبل» و «بعد» هستند (مثلاً « پس از عبور از خیابان x ، قبل از رسیدن به ساختمان b »)، یک رابطه توالی ساده نه تنها برای هدف این مقاله مناسب است. ، اما پیچیدگی ها را نیز از بین می برد. این رابطه توالی با شناسه “3” در پایگاه دانش عامل گزارش می شود. مورد مشابه دیگر، اما خاصتر، با این دو رابطه متوالی (“قبل” و “پس از”) زمانی اتفاق میافتد که فقط یک نام جغرافیایی متغیر با روابط قبل یا بعد از آن بیان شود (مثلاً ” خیابان xپس از عبور از ساختمان b ”). برخلاف وضعیت قبلی، این ترکیب به صراحت دنباله قبل یا بعد را مشخص می کند. در یک صورت فلکی خطی از ویژگیهای فضایی مانند شبکههای خیابانی شهری، دانستن رابطه ترتیبی خاص بین عناصر، بستر استدلال عملی را فراهم میکند. بنابراین، چنین روابطی با شناسه های “4” و “5” به ترتیب برای بعد و قبل از آن مشخص می شوند. هر نوع رابطه فضایی دیگری که یک نقطه عطف یا یک ساختمان می تواند با عناصر فضایی دیگر داشته باشد (به عنوان مثال، “در گوشه کافه قدیمی، شماره 5”) به سادگی یک رابطه را منتقل می کند.(مثلا بین کافه قدیمی و ساختمان شماره 5) که در پایگاه دانش با شماره 6 کد گذاری شده است.
به طور طبیعی، ممکن است ترکیبات دیگری از عناصر فضایی و روابط مورد استفاده در آدرسها وجود داشته باشد که منجر به سهگانههای مختلف <VGN، SR، VGN> میشود و در اینجا در این مقاله مورد توجه قرار نگرفتهاند. در واقع، آنچه در اینجا برای مدلسازی آدرسهای توصیفی معرفی میشود، نمونهای ساده از آنچه عملاً میتوان از پردازش زبان طبیعی آدرسهای توصیفی به دست آورد، است. برای این مقاله که ثابت میکرد آدرسدهی توصیفی میتواند حجم قابلتوجهی از اطلاعات و دانش را به مردم منتقل کند، این مجموعه کوچک از نمونهها به درستی کار میکند.
این کدها به هر سه گانه که به پایگاه دانش عامل اضافه شده بود اختصاص داده شد تا فرآیند استدلال فضایی را اجرا کند. وجود روابط فضایی در آدرس های توصیفی یا هر نوع توصیف فضایی، قابلیت قابل توجه رویه های استدلال فضایی را فراهم می کند. به عبارت دیگر، این قابلیت برجسته فقط به تعداد عناصری که یک آدرس توصیفی می تواند حمل کند وابسته نیست. در واقع با استفاده ساده از روابط فضایی در این گونه آدرس ها و توصیف ها به دست می آید. روابط نقش مهمی در فرآیند استدلال فضایی دارند و همچنین بخشهای مختلف بازنمایی ذهنی فضایی را به یکدیگر متصل میکنند.
با بهرهگیری از این منبع اطلاعات در آدرسهای توصیفی، در اینجا، یک فرآیند استدلال بر اساس شناسههای رابطه فضایی اختصاص داده شده به هر ردیف انجام دادیم. هر بار، با افزودن یک آدرس جدید به پایگاه دانش، یک فرآیند جستجو از طریق کل ردیفها توسط عامل مقداردهی اولیه میشود تا مقدار IF صحیح را تخصیص دهد، بلکه اطلاعات ممکن جدید را نیز از طریق فرآیند استدلال استخراج کند. این امر دوم منجر به کسب دانش بیشتر از آنچه در آدرس ذکر شده است می شود. مجموعهای از قوانین if-ther-else بدون نیاز به SR_ID برای کسب دانش جدید به شرح زیر اعمال میشود:
| مقدار SR_ID |
بیانیه |
بیانیه پایانی |
| اسآر_منD<ایکس، y>=5 |
x قبل از y قرار دارد |
اسآر_منD<ایکس، z>=5 |
x قبل از z قرار دارد |
| اسآر_منD<y،z>=1 |
y به z متصل است |
بر این اساس، نه تنها دو ردیف < x, 5, y > و < y, 1, z > به پایگاه دانش اضافه می شوند، بلکه ردیف استنباط شده < x, 5, z > نیز اضافه می شود. همین فرآیند باعث رشد قابل توجهی در پایگاه دانش عامل می شود که بعداً با منحنی های یادگیری در بخش های بعدی تحلیل می شود.
4.3. میزان یادگیری فضایی
به منظور مقایسه دانش فضایی به دست آمده از کلاسهای مختلف آدرسها، نرخ یادگیری به کار گرفته شد که یک معیار کمی است که برای نشان دادن سرعت یک فرآیند یادگیری استفاده میشود و تعیین میکند که حجم اطلاعات در ذهن یک عامل تا چه اندازه در حال افزایش است [ 40 ]. ]. فرآیندهای یادگیری معمولاً از طریق یادگیری به دست آمده توسط زمان، تجربه، هزینه، تعداد تکرارها، تلاش و غیره تجزیه و تحلیل میشوند. همانطور که هدف این مقاله بیان میکند، ما در صدد بررسی یادگیری فضایی بهدستآمده از تعداد آدرسهای ارائهشده به یک عامل هستیم.
راه های زیادی برای محاسبه نرخ یادگیری وجود دارد، با این حال، یک راه آسان، محاسبه آن از روی منحنی یادگیری مربوطه است. منحنی یادگیری یک نمایش گرافیکی از افزایش یادگیری (محور عمودی) با توجه به تجربه، زمان، یا هر عامل مورد علاقه دیگر (محور افقی) است [ 41 ، 42 ]. برای ترسیم یک منحنی یادگیری، ابتدا باید عامل یادگیری و همچنین عاملی که یادگیری بر اساس آن در نظر گرفته می شود، مشخص شود. در مورد ما، نمرات یادگیری (LS) که توسط عامل برای هر آدرس جمع میشد، عامل یادگیری در نظر گرفته شد. و تعداد آدرس های ارائه شده به عامل نقش محور افقی را بازی می کرد.
مسئله مهم در اینجا این است که برای داشتن یک مقایسه منصفانه، توزیع آدرس ها باید در هر شهر موردی نسبتاً برابر باشد. برای مثال، مقایسه تأثیر 100 آدرس توزیع شده در تهران با مساحت 950 کمتر2با همان تعداد آدرس توزیع شده در وین با 414 کمتر2قطعا معقول نیست ( شکل 12 ).
در این شرایط می توان از دو رویکرد استفاده کرد: یا انتخاب تعداد آدرس ها در مکاتبات با منطقه مورد مطالعه، یا محدود کردن مساحت مناطق مختلف مطالعه به نسبت مساوی و انتخاب تعداد آدرس های یکسان. مورد دوم در این مطالعه به کار گرفته شد. مساحت کل 9 منطقه اداری (شماره 1،2،3،4،6،7،8،11،12) تهران برابر با 419 است. کمتر2، که آن را در یک تقریب قابل قبول با وین قابل مقایسه می کند که در مورد توکیو نیز صدق می کند. بنابراین، 100 آدرس در این منطقه محدود از تهران، توکیو و شهر وین توزیع شد تا نرخ یادگیری نماینده را در هر مورد تجزیه و تحلیل کند.
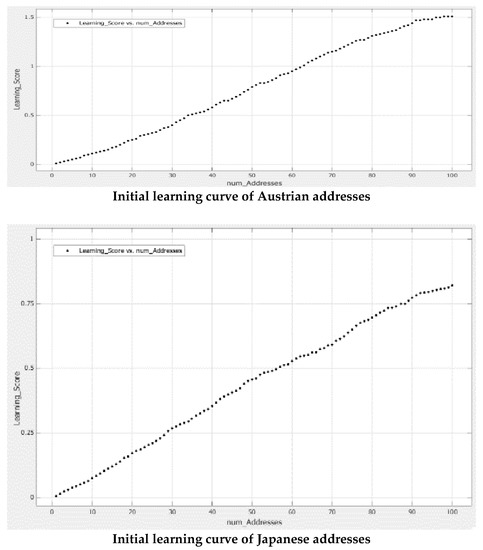
همانطور که قبلا ذکر شد، در اینجا ما LS را به عنوان معیار یادگیری و تعداد آدرس ها (که در همه موارد 100 بود) به عنوان عامل تجربه برای رسم منحنی یادگیری مربوط به هر سیستم آدرس دهی در نظر گرفتیم. پس از ترسیم این مقادیر در برابر یکدیگر، یک تابع هموارسازی به منحنی یادگیری خام اعمال شد تا محاسبات مشتق آن کمتر نیاز داشته باشد. میانگین مقدار مشتق هر منحنی یادگیری به عنوان نرخ یادگیری مربوط به آن سیستم آدرس دهی در نظر گرفته شد. شکل 13 نمودارهای اولیه LS تا 100 را برای سه مورد آدرس نشان می دهد.
توابع برازش برای همه موارد در اینجا با تابع لجستیک مطابقت دارد (معادله (3)).
که در آن e پایه لگاریتم طبیعی است (همچنین به عنوان عدد اویلر شناخته می شود). x 0 مقدار x نقطه وسط سیگموئید است. L حداکثر مقدار منحنی است. و k شیب منحنی است. جدول 5 پارامترهای توابع لجستیک متناسب با هر مورد را گزارش می کند.
در نهایت، نرخ یادگیری برای هر سیستم آدرس دهی موردی مطابق جدول 6 محاسبه شد .
نتایج پیاده سازی تأثیری را که مقدار و نوع اطلاعات مکانی کدگذاری شده در آدرس می تواند بر دانش فضایی افراد و همچنین بازنمایی ذهنی فضایی آنها داشته باشد، تأکید می کند. علاوه بر این، انواع و مجموعه اطلاعات مکانی ذکر شده در آدرس ها، سطوح مختلفی از دانش فضایی را فراهم می کند. مشاهده شد که آدرسهای ساختاریافته، که انعطافپذیری کمتری در افزودن اطلاعات مکانی مناسب دارند، اطلاعات کمتری را برای انجام وظایف مقصد یا برای به دست آوردن دانش فضایی ارائه میدهند. به طور خاص، ساختار مبتنی بر کد سلسله مراتبی سیستم آدرس دهی ژاپنی و همچنین قرارداد ترتیب زمانی آن در یک بلوک به شدت بر سرعت کسب دانش فضایی تأثیر می گذارد.
مهمترین بخش در فرآیند یادگیری توسط استدلال انجام می شود. فرآیند استدلال در یک مسئله فضایی بر اساس تعداد روابطی است که می توان از صورت فلکی اجرام استنباط کرد. هرچه روابط بیشتر به صورت صریح یا ضمنی ذکر شود، روابط و اطلاعات جدید بیشتری استنباط می شود. نحوه دقیق، دلیل این است که نرخ یادگیری از طریق آدرسهای توصیفی ایرانی هفت برابر بیشتر از آن چیزی است که از طریق ساخت یافته اتریشی و 10 برابر بیشتر از آدرسهای مبتنی بر کد نیمه ساختاریافته ژاپنی به دست میآید. به عبارت دیگر، به نظر میرسد روابط ذکر شده بین عناصر در آدرسهای ایرانی، بازنمایی ذهنی فضایی را از نظر اطلاعات غنیتر میکند و یادگیری مکانی را بهویژه در مناطق شهری تسریع میکند.
5. تحلیل معنایی و عملی سیستم های آدرس دهی مورد
این بخش برگرفته از شبیهسازی مبتنی بر عامل و ریشه در نتایج پیادهسازی، سیستمهای آدرسدهی موردی را تحت اصول تحلیل معنایی و عملگرایانه با نگاهی به جنبههای زبانی مرور میکند. زبان فضایی انسان را میتوان نشانهای در نظر گرفت که ابزار ارتباط افراد با محیط را فراهم میکند و از این رو میتوان آن را از طریق سطوح نحوی، معناشناسی و عملشناسی بررسی کرد. در اینجا، ما یک آدرس را به عنوان یک گزاره فضایی-زبانی حاوی اطلاعات لازم برای ایجاد یک مکان منحصر به فرد در نظر می گیریم. بخش های فرعی زیر به تحلیل معنایی و عملی برای سیستم های آدرس دهی اتریشی، ژاپنی و ایرانی می پردازد.
5.1. معناشناسی و عمل شناسی سیستم آدرس دهی اتریش
یک آدرس اتریشی از یک رابطه “محدودیت” بین خیابان و منطقه تشکیل شده است (خیابان S در ناحیه D موجود است ). علاوه بر این، شماره ساختمان ذکر شده در آدرس دارای ارزش آدرس دهی است زیرا ساختمان ها به صورت مکانی در امتداد خیابان مرتب شده اند و اعداد زوج و فرد متعلق به اضلاع مختلف است. بنابراین، آدرس اتریشی به این معنی است:
-
مهار: رابطه بین خیابان و منطقه.
-
نظم مکانی: رابطه بین شماره ساختمان و خیابان.
-
جهت: رابطه بین شماره ساختمان و طرفین خیابان.
با کنار هم قرار دادن اطلاعات فوق، کاربران منطقه و خیابان محل را می شناسند و می توانند موقعیت و جهت مکان مورد نظر را نسبت به خیابان تخمین بزنند.
از دیدگاه عملگرایانه، برای تفسیر یک آدرس اتریشی، دانش قبلی عامل در مورد ساختار آدرس دهی ضروری است. عامل باید ترتیب اجزا و تفسیر مربوط به آنها را بداند. آنها نمی توانند اجزایی مانند 27-29/8/12 یا 1040 را درک کنند مگر اینکه ساختار را بدانند (به بخش 3.1 مراجعه کنید ). با این وجود، یادگیری ساختار سیستم آدرس دهی اتریشی آسان است زیرا هیچ استثنا یا تغییری وجود ندارد. هنگامی که یک نماینده این ساختار را یاد می گیرد، می تواند هر آدرس اتریشی را تفسیر کند.
یک آدرس اتریشی اطلاعاتی در مورد روابط <منطقه–خیابان>، <خیابان–ساختمان> و <خیابان فرعی> ارائه می دهد. آدرس فقط شهر، ناحیه و خیابان را مشخص می کند. اما به عنوان خطاب مطلق، هیچ سرنخی از روابط بین آنها ارائه نمی کند (مثلاً، اگر کسی در منطقه باشد، به او آموزش داده نشده است که چگونه به خیابان برسد). بنابراین، آدرس یک تخمین منصفانه از مکان و همچنین نحوه پیمایش در آنجا بسته به دانش قبلی نماینده است. به عنوان مثال، اگر کسی فقط منطقه را بشناسد، اما خیابان را نه، برآورد آنها تا سطح منطقه است، که تا حدی برای پیمایش مفید است.
در نهایت، سیستم آدرس دهی اتریشی شامل ویژگی های فضایی “خیابان” و “منطقه” (یعنی آدرس دهی مستقیم) است. همانطور که در بالا ذکر شد، شماره ساختمان نیز یک مفهوم فضایی محسوب می شود. بنابراین، سیستم آدرس دهی اتریشی می تواند به بهبود بازنمایی ذهنی فضایی از نظر رابطه خیابان – ناحیه کمک کند. با این وجود، یک انسان باید از قبل خیابان یا حداقل منطقه را بشناسد تا مکان را تا حدی تصور کند. به عبارت دیگر، نمی توان تصویری از مکانی که یک آدرس به آن اشاره دارد، داشت، مگر اینکه برخی از عناصر فضایی آدرس قبلاً در بازنمایی ذهنی فضایی آنها وجود داشته باشد.
جدول 7 ارزیابی نحوی، معنایی و عملی را در مورد مطالعات موردی خلاصه می کند.
5.2. معناشناسی و عمل شناسی سیستم آدرس دهی ژاپنی
یک آدرس ژاپنی روابط مهاری بین استانها، شهرهای بزرگ (shi)، شهرها (بخش) و شهرها/محلههای کوچک (machi/cho) را نشان میدهد. با این حال، این مورد برای مناطق (chome)، بلوک ها (باند یا بنچی)، و شماره ساختمان (go) صدق نمی کند، زیرا آنها از 1 در هر زیربخش بالایی دوباره شروع می شوند (به عنوان مثال، هر منطقه دارای بلوک های #1، #2 است، شماره 3، …)، و بنابراین از نظر فضایی اطلاعات کمتری دارند. به طور خاص، شماره ساختمان ها به صورت زمانی مرتب شده اند و هیچ اطلاعاتی در مورد رابطه فضایی بین ساختمان ها ارائه نمی دهند. بنابراین، آدرس ژاپنی به این معنی است:
اطلاعات فوق استان، شهر بزرگ، شهر و شهر کوچک/محله محل را در اختیار کاربران قرار می دهد. با این حال، منطقه، بلوک، و به خصوص شماره خانه های مرتب شده زمانی، از نظر مکانی کمتر معنادار هستند.
از نظر عمل شناسی، مشابه اتریش، سیستم آدرس دهی ژاپنی برای درک نیاز به دانش قبلی دارد: چندین ساختار با انواع مختلف اجزاء برای انواع مختلف واحدهای اداری وجود دارد. وضعیت حتی دشوارتر است زیرا ممکن است بیشتر پسوندها حذف شوند و می توانند در قالب های مختلف نوشته شوند، بنابراین، تمرین قابل توجهی لازم است تا یاد بگیریم که در ” Osaka-fu, Yokohama, Hommachi-cho, 4-7-203 “، « یوکوهاما » و « 4 » «یک شهر» و «یک بلوک در بخش جدید هوماچی» هستند.محله، به ترتیب. به نظر میرسد مشکل اصلی این است که اجزاء بیشتر به واحدهای اداری مبتنی بر کد (یعنی آدرسدهی غیرمستقیم) مرتبط هستند که لزوماً با عناصر فضایی شناخت انسانی سازگار نیست.
از سوی دیگر، سیستم آدرس دهی ژاپنی از سطوح مختلف عناصر فضایی تا شهرهای کوچک/محله (به عنوان مثال، استان، شی، بخش، و ماچی/چو) تشکیل شده است. با این حال، مناطق، بلوکها و اعداد ساختمان در هر زیربخش بالایی تکرار میشوند و بنابراین امکان استنتاج فضایی کمتری را فراهم میکنند. هنگامی که در سطح زیربخش n هستید ، باید سطح زیربخش را جستجو کنید n را جستجو کنید+ 1، به خودی خود به عنوان آدرس هیچ اطلاعاتی در مورد روابط فضایی بین بخش های فرعی است. به عبارت دیگر، اگر کسی در بلوک 14 بوده است، ممکن است لزوماً محل بلوک 15 را تصور نکند. حتی اگر بلوک را بداند، نمی تواند تصور کند که شماره ساختمان به کجا اشاره دارد، مگر اینکه قبلاً آنجا بوده باشد و پیدا کرده باشد. آن را روی نقشه یا اشکال دیگر (به عنوان مثال، اطلاعات مکانی شفاهی). در هر صورت، این اطلاعات به شماره گذاری ارائه شده توسط آدرس بستگی ندارد، اما ارتباط بیشتری با ویژگی های فضایی محیط دارد. به عبارت دیگر، اطلاعات ارائه شده توسط آدرس کمک قابل توجهی به ارتباط آن با بازنمایی ذهنی فضایی یا راهیابی نمی کند.
در نهایت، این آدرس دهی عاری از روابط بین عناصر فضایی است. به نظر می رسد این آدرس دهی مبتنی بر کد غیرمستقیم فضایی-غیر متوالی چندان با تفکر فضایی انسان سازگار نیست. هنگامی که یک بلوک را بشناسید، می توانید به یاد بیاورید که کجاست، اما رابطه آن با سایر بلوک ها و روابط بین ساختمان های بلوک به دلیل شماره گذاری نامتوسط لزوماً به دانش فضایی اضافه نمی شود. شواهدی وجود دارد که بسیاری از سرویسهای پست ژاپنی نیز به آن اشاره میکنند و به وضوح به این واقعیت اشاره میکنند که در برخی از بخشهای کشور (به عنوان مثال، کیوتو، جایی که اغلب بیش از یک محله با همان نام در یک بخش وجود دارد، سیستم را ایجاد میکند. بسیار گیج کننده است)، مردم تمایل دارند از عناصر فضایی مانند نشانه ها یا نامگذاری تقاطع دو خیابان استفاده کنند و سپس نشان دهند که آیا آدرس شمالی است یا خیر.
5.3. معناشناسی و عمل شناسی نظام آدرس دهی ایران
سیستم آدرس دهی ایرانی یک آدرس را در قالب فرآیند توصیف مسیر از یک مکان شناخته شده برای گیرنده بیان می کند. روابط فضایی (به عنوان مثال، قبل، بعد، جلو، مقابل، تقاطع، بعدی، و غیره) بین مجموعه ای از ویژگی های فضایی را توصیف می کند. روابط می تواند کمی باشد (مثلاً 100 متر) یا کیفی (مثلاً چند قدمی، چند دقیقه پیاده روی، در میانه)، و ویژگی های فضایی می تواند هر چیزی با ارزش آدرس دهی باشد، از خیابان ها و گذرگاه ها گرفته تا شهر. بخشها، محلهها، نشانهها، ساختمانها و غیره. علاوه بر این، مانند اتریش، شمارههای ساختمان به صورت مکانی در امتداد خیابان، با یک قانون زوج و فرد مرتب میشوند. بنابراین آدرس ایرانی یعنی:
-
فرآیند: روابط فضایی کمی و کیفی بین مجموعهای از ویژگیهای فضایی متوالی در قالب فرآیند توصیف چرخشی.
-
نظم مکانی: رابطه بین شماره ساختمان و خیابان.
-
جهت: رابطه بین شماره ساختمان و طرفین خیابان.
ترکیب فوق فرآیندی است که موقعیت مکان هدف را در اختیار کاربران قرار می دهد.
از منظر پراگماتیک، آدرسهای ایرانی خود توضیحی هستند و برای تفسیر به حداقل دانش قبلی نیاز دارند، زیرا اجزا و ترکیبها عمدتاً به طور طبیعی بیان میشوند. مجموعه ای از گروه های فضایی است که هر یک اطلاعاتی در مورد ویژگی های فضایی ( CGN و VGN ) یا روابط ( SPR و MTR ) ارائه میکنند.). این قبلاً یک توصیف مسیر است که از یک مکان شناخته شده به یک آشنا شروع می شود، یا به اندازه کافی شناخته شده برای یک عامل ناآشنا به راحتی قابل دسترسی است، سپس به طور مداوم در مقصد با اشاره به ویژگی های فضایی محیط حرکت می کند. اگر عاملی نقطه شروع و ویژگی های فضایی را بداند، می تواند مقصد را تصور و تخمین بزند. با این وجود، مستلزم آن است که عامل نقطه شروع را بداند و بتواند دستورالعمل را با ویژگیهای فضایی که در طول مسیر با آن مواجه میشود تفسیر و تطبیق دهد.
این سیستم آدرس دهی مطلق/نسبی مستقیم اغلب عامل را در معرض ویژگی های فضایی محیط و همچنین روابط فضایی آنها قرار می دهد. چنین آدرس های توصیفی نه تنها مقصد را مشخص می کنند، بلکه گام به گام مکان را نیز هدایت می کنند. بنابراین سهم قابل توجهی در کسب دانش فضایی دارند.
ویژگی بارز سیستم آدرس دهی ایرانی انعطاف پذیری آن است: یک آدرس می تواند هر تعداد و ترتیبی از عبارات باشد تا زمانی که از قاعده گروه های فضایی تبعیت کنند. نقطه شروع و سطح جزئیات ارائه شده در آدرس انعطاف پذیر است و به مکان فعلی و همچنین دانش فضایی عامل بستگی دارد. آدرس را می توان به گونه ای تغییر داد که دو طرف بتوانند به سطحی از جزئیات بروند که برای هر دو طرف قابل درک باشد (بر اساس دانش آنها در مورد محیط، توانایی های فضایی و غیره). این ارتباط عملی به دانش فضایی طرفین ارتباط و همچنین انتظار آنها از دانش فضایی طرف ارتباط دیگر بستگی دارد. با این حال، مدل های ذهنی آنها لزوماً یکسان نیستند. از این رو،43 ، 44 ].
این انعطاف پذیری فرصتی برای یادگیری بهتر در مکان نیز فراهم می کند. همانطور که گولج و استیمسون [ 24 ] استدلال کردند، یادگیری مکان “یک فرآیند شناختی است که توسط روابط فضایی به جای توالی حرکت تقویت شده هدایت می شود… مفاهیم واضحی وجود دارد که مکان ها آموخته می شوند، ارتباطات احتمالی بین آنها در طول زمان ایجاد می شود، و افراد با ارجاع به یک طرح کلی فضایی که مفاهیم [روابط فضایی] را در بر می گیرد، ظرفیتی را برای پیوند دادن [مکان های] ناشناخته قبلی ایجاد کنید. یک آدرس ایرانی بهجای یک توالی حرکت ثابت، حرکات مختلفی را برای رسیدن به یک مکان خاص ارائه میکند.
6. بحث
انسان ها حافظه فضایی را به دو روش مختلف سازماندهی می کنند: مسیر خطی و تقسیمات منطقه ای سلسله مراتبی [ 31 ]]. بررسی سیستمهای آدرسدهی موردی نشان میدهد که سیستمهای اتریشی و ایرانی از این سازمان پیروی میکنند: آنها شامل یک زیربخش سلسله مراتبی برای اشاره تقریباً به یک مکان هستند و سپس یک بخش دوم خطی آن را همراهی میکند تا مقصد را دقیقاً مشخص کند. بخش اول یک توصیف شناختی LoD ارائه می دهد که تا حدی ممکن است کاربران مختلف آن را تفسیر کنند و از آن بیاموزند، و بخش دوم به صورت محلی تطبیق داده می شود. با این حال، سطح موفقیت بسته به مفاهیم آدرس دهی مورد استفاده متفاوت است. با این حال، در سیستم آدرس دهی ژاپنی، تقسیم سلسله مراتبی تا سطح بلوک ادامه می یابد و سپس یک نظم زمانی برای سطح شماره آپارتمان با یک بلوک به کار می رود.
از سوی دیگر، به عنوان یک تصویر ادراکی از مکانها در واقعیت، مردم انتظار دارند آدرسها دانش رویهای را ارائه دهند، «که شامل شناسایی مکانها در یک مسیر یا نشانهها در یا نزدیک یک بخش مسیر انتخابی است» ([ 24 ]]، ص163). با این حال، رایانهها انتظار دارند آدرسها به ترتیبی اعلام شوند که بتوان آنها را تجزیه کرد، تفسیر کرد و روی نقشه مطابقت داد، که این مسئله مربوط به نحو است و کمتر به مسائل شناختی مربوط میشود. همانطور که بررسی شد، باعث میشود که اکثر سیستمهای آدرسدهی ساختیافته کنونی فقط مفاهیم آدرسدهی مطلق را در بر گیرند (که میتوان از نظر نوع و ترتیب آنها رسمیت داد)، و مفاهیم نسبی و توصیفی (که میتوانند به روشهای مختلف و بدون هرگونه بیان شوند) را نادیده بگیرند. به صورت رسمی، و بنابراین با چنین دیدگاه های نحوی کاملاً سازگار نیستند). جالب است که ببینیم این موضوع چگونه جای تفکر فضایی ما را گرفته است [ 45] و اینکه چگونه بر پتانسیل آدرس ها برای کمک به کسب دانش فضایی پیکربندی و همچنین توسعه توانایی فضایی تأثیر گذاشته است. به عبارت دیگر، از آنجایی که سیستمهای آدرسدهی کنونی برای اهداف تطبیق مبتنی بر ماشین توسعه داده شدهاند، به نظر میرسد که آنها تمایل دارند به سؤال «شما اینجا هستید» پاسخ دهند، و بنابراین برای یک انسان، بیشتر شبیه «یادگیری از نقشه» است. نسبت به “یادگیری از سفر” محیطی را تجربه می کند که توسط روابط فضایی ارائه می شود [ 46 ].
با فرض نقشه شناختی به عنوان یک GIS درونی شده (سیستم اطلاعات جغرافیایی) که در آن داده ها نماد و کدگذاری می شوند [ 24 ]، مطابق با یک آدرس به بازنمایی های ذهنی فضایی، پردازش اطلاعات انسانی موازی با تطبیق آدرس مبتنی بر ماشین است. یک تفاوت عمده این است که در GIS تطبیق آدرس یک روش دستکاری است که به شیوه ای سریع و دقیق انجام می شود. با این حال، GIS درونی شده انسان اساساً همان فعالیت دستکاری را انجام میدهد، اما به دلیل کمبود اطلاعات منتقلشده توسط آدرس و همچنین وابستگیهای شخصی و اجتماعی ، مستعد نادرستی و ناکارآمدی است [ 21 ] .]. با توجه به اینکه آدرس ها ممکن است بر جنبه های شناخت فضایی تأثیر بگذارند، یک آدرس ممکن است بر سایر عملکردهای GIS درونی شده یک انسان نیز تأثیر بگذارد (مثلاً راهیابی و کسب دانش فضایی). با فرض اینکه مردم به طور فزاینده ای تفکر (فضایی) را به فناوری تخلیه می کنند [ 45 ]، ضروری است که تجربه و شناخت فضایی انسان به اندازه کافی در سیستم های شناختی توسعه یافته مشخص شود . یک سیستم شناختی توسعه یافته به عنوان “یک شی خارجی که در خدمت انجام عملکردی است که در غیر این صورت از طریق عمل فرآیندهای شناختی درونی به دست می آید” تعریف می شود [ 35 ].]. به طور خاص، جالب است که مطالعه کنیم که چگونه سیستمهای آدرسدهی ایدهآل، نیازهای اطلاعاتی کامپیوتری و انسانی را در نظر میگیرند تا به طور مساوی کدهای جغرافیایی خارجی و داخلی را توسعه دهند.
7. نتیجه گیری و تحقیقات آتی
این مقاله ایده نحو، معناشناسی و عملشناسی سیستمهای آدرسدهی را معرفی میکند: نحو یک آدرس بر دقت کدگذاری جغرافیایی خودکار آن تأثیر میگذارد، در حالی که معناشناسی و عملشناسی آن به میزان قابل تفسیر توسط انسان و میزان مطابقت آن مربوط میشود. عناصر بازنمایی ذهنی فضایی آنها. علاوه بر این، اطلاعات ارائه شده توسط یک آدرس ممکن است بر رشد دانش فضایی انسان ها و فعالیت های فضایی آنها تأثیر بگذارد.
به عنوان اولین گام، این مقاله سه دسته از سیستم های آدرس دهی را بر اساس تعاریف رسمی آنها و همچنین انواع و روابط اجزای آنها بررسی می کند. آزمایشات تجربی برای تأیید نتایج این تحقیق آزمایشی مورد نیاز است. علاوه بر این، نتایج باید از دیدگاه زبانی، فرهنگی و شناختی بیشتر مورد بررسی قرار گیرد، که ممکن است به طور قابل توجهی بر یافته ها تأثیر بگذارد. با این حال، هنوز مشخص نیست که چگونه می توان تفاوت در شناخت فضایی ناشی از عوامل بیرونی را ایجاد کرد.
مطالعه سیستم های آدرس دهی مختلف می تواند به درک بهتری از طرز فکر افراد مختلف در سراسر جهان در مورد فضای خود منجر شود. یک فرد ژاپنی که در معرض یک سیستم آدرس دهی بدون نام برای خیابان ها، اما کدهای (به طور موقت) برای بلوک ها و ساختمان ها قرار گرفته است، ممکن است فضا را متفاوت از یک ایرانی که با یک سیستم آدرس دهی مبتنی بر توصیف مسیر پر از فضای مکانی تعامل داشته است، درک کند. عناصر و همچنین روابط متریک و توپولوژیکی. ما معتقدیم که این امر بر جنبه های مختلف مربوط به تفکر فضایی مانند برنامه ریزی مسیر، ارتباطات فضایی کلامی و غیرکلامی و غیره تأثیر بسزایی دارد.
در نهایت، مطالعه این که چگونه یک فرد، مثلا ژاپنی، به یک سیستم آدرس دهی جدید، مثلا ایرانی، واکنش نشان می دهد و چگونه با سیستم جدید سازگار می شود، جالب خواهد بود. در میان عوامل دیگر، به نظر میرسد که این امر به معنایی و عملشناسی سیستمهای آدرسدهی مبدا و هدف و همچنین زمینههای کاربر بستگی دارد، که سوال دیگری را ایجاد میکند که یک سیستم آدرسدهی تا چه اندازه برای کاربران تازه واردی که به سایر موارد عادت دارند، کاربرپسند است. سیستم های آدرس دهی








بدون دیدگاه