

خلاصه
چندین کاربرد در دنیای واقعی شامل تجمیع ویژگی های فیزیکی مربوط به پدیده های مختلف جغرافیایی و توپوگرافی است. این اطلاعات نقش مهمی در تحلیل و پیشبینی چندین رویداد دارد. مناطق کاربردی، که اغلب به تجزیه و تحلیل بلادرنگ نیاز دارند، شامل جریان ترافیک، پوشش جنگلی، پایش بیماری و غیره است. بنابراین، اکثر سیستم های موجود محدودیت هایی را در سطوح مختلف پردازش و پیاده سازی به تصویر می کشند. برخی از متداول ترین عوامل مشاهده شده شامل فقدان قابلیت اطمینان، مقیاس پذیری و بیش از حد هزینه های محاسباتی است. در این مقاله، ما به چارچوبهای مختلف بدون سرور مقیاسپذیر معروف، مانند خدمات وب آمازون (AWS) Lambda، Google Cloud Functions و Microsoft Azure Functions برای مدیریت دادههای بزرگ جغرافیایی میپردازیم. ما برخی از رویکردهای موجود را که به طور رایج در تجزیه و تحلیل دادههای بزرگ جغرافیایی استفاده میشوند مورد بحث قرار میدهیم و محدودیتهای آنها را نشان میدهیم. ما کاربرد چارچوب پیشنهادی خود را در بستر سیستم اطلاعات جغرافیایی ابری (GIS) گزارش میکنیم. گزارشی از برخی فناوریها و ابزارهای پیشرفته مرتبط با حوزه مشکل ما مورد بحث قرار میگیرد. ما همچنین عملکرد چارچوب پیشنهادی را از نظر قابلیت اطمینان، مقیاسپذیری، سرعت و پارامترهای امنیتی تجسم میکنیم. علاوه بر این، ما تحلیل همپوشانی نقشه، تجزیه و تحلیل نقطه-خوشه، نقشه حرارتی تولید شده و تجزیه و تحلیل خوشهبندی را ارائه میکنیم. برخی از نمودارهای آماری مربوطه نیز تجسم می شوند. در این مقاله، دو مطالعه موردی کاربردی را در نظر می گیریم. اولین مطالعه موردی با استفاده از مجموعه داده سیستم داده منابع معدنی (MRDS) مورد بررسی قرار گرفت. که به تراکم جهانی منابع معدنی به صورت کشوری اشاره دارد. مطالعه موردی دوم با استفاده از مجموعه داده Fairfax Forecast Households انجام شد که نشاندهنده پیشبینی خانواده در سطح بسته برای 30 سال متوالی است. مدل پیشنهادی یک چارچوب بدون سرور را برای کاهش محدودیتهای زمانی ادغام میکند و همچنین عملکرد مرتبط با پردازش دادههای مکانی را برای دادههای ابرطیفی با ابعاد بالا بهبود میبخشد.
کلید واژه ها:
رایانش ابری ؛ چارچوب بدون سرور Cloud GIS ; ژئوپورتال ; مقیاس پذیری ؛ تاخیر
1. معرفی
سالهای اخیر شاهد رشد عظیمی در تولید دادههای دیجیتال عظیم بودهایم که درک و شناخت چندین ویژگی از دنیای فیزیکی را تسهیل کرده است. تلاقی هوش مکانی با این ویژگیهای فیزیکی منجر به درک و مدیریت فعالیتهای ارجاعشده جغرافیایی شده است [ 1 , 2 ]]. با تکامل فنی پلتفرمها و ابزارهای مدرن، ادراک و نمایش دادهها به طور قابل توجهی تغییر کرده است. استخراج اطلاعات مکانی کمک زیادی به بخش های اجتماعی، صنعتی و بهداشتی کرده است. اطلاعات بهدستآمده با کمک این مدلها معمولا نیازمند محاسبات و ذخیرهسازی فشرده است. بنابراین، فناوریهای امیدوارکنندهتری مانند محاسبات ابری، محاسبات لبه، محاسبات مه و غیره به سرعت برای مدیریت و نظارت بر چنین اطلاعات عظیمی در حال ظهور هستند. زیرساخت محاسبات ابری قابلیتهای شهودی بیشتری را ارائه کرده است و شیوه نمایش دادههای مکانی-زمانی را بهطور قابلتوجهی تغییر داده است. در این راستا، ژئوپورتالها نقش مرتبطی در ساخت پلتفرمهای سیستم اطلاعات جغرافیایی ابری (GIS) دارند.3 ، 4 ، 5 ]. پیادهسازی ژئوپورتالها بستری مبتنی بر وب را برای کانالگذاری دادههای جغرافیایی فراهم میکند. پورتال های جغرافیایی در همگرایی با چارچوب Cloud GIS به عنوان یک ویژگی کلیدی برای تسهیل تبادل داده های مکانی به دست آمده از بسیاری از مکان ها از طریق اینترنت عمل می کنند.
الگوی محاسبات ابری چندین برنامه پیچیده را ارائه می دهد و هزینه های ذخیره سازی و محاسباتی را تا حد زیادی کاهش داده است. مفهوم محاسبات بدون سرور به عنوان پیشبینی برای مدیریت جمعآوری دادهها در مقیاس فزاینده به وجود آمد. رشد فناورانه در قابلیتهای رویکردهای بدون سرور، آنها را در رسیدگی به مسائل تأخیر و ارائه خدمات بدون وقفه به کاربران تطبیقپذیرتر کرده است [ 6 ، 7 ]]. بنابراین، نیاز به رسیدگی به نیازهای متنوع سیستم را می توان به طور موثر و قابل اعتماد مدیریت کرد. پلت فرم بدون سرور به طور قابل ملاحظه ای قابلیت های مبتنی بر ابر را گسترش می دهد و زیرساخت های برون سپاری را که برای انجام چندین محاسبات پیچیده حیاتی هستند، فراهم می کند. بر اساس مفاهیم تکاملی ارائه شده توسط پلت فرم بدون سرور، دو دسته بندی اساسی را می توان انجام داد:
-
Back-end-as-a-Service (BaaS): از نظر مفهومی مشابه نرم افزار به عنوان سرویس (SaaS) است. این شامل قرار دادن راه حل های خارج از قفسه در سمت سرور با افزودن ماژولاریت بیشتر به سیستم است [ 8 ]. سرویسهای BaaS مؤلفههای عمومی دامنه را نشان میدهند که میتوانند در چندین برنامه کاربردی خارجی تعریفشده توسط کاربر گنجانده شوند. Firebase یکی از پلت فرم های تحلیلی مبتنی بر وب گوگل است که از چارچوب BaaS برای مدیریت اجزای داده کاربران استفاده می کند.
-
Functions-as-a-service (FaaS): یک دامنه جامع برای توسعه و پیاده سازی برنامه های کاربردی سمت سرور فراهم می کند [ 8 ، 9 ]. FaaS بیشتر بر عملیات درگیر در توسعه یک برنامه کاربردی، به جای نمونه های میزبان و برنامه به عنوان یک کل، تأکید می کند. بنابراین، FaaS آن را به یک چارچوب مبتنی بر رویداد برای تجزیه و تحلیل داده های پیشرفته تبدیل می کند. یک مثال محبوب از این چارچوب، خدمات وب آمازون (AWS) Lambda است که قادر است میلیاردها رویداد را در بازههای زمانی کوتاهتر پردازش کند.
شکل 1 تصویری از مبادله بین رویکرد سنتی و مبتنی بر FaaS برای استقرار نرم افزار است. FaaS را می توان از استقرار سمت سرور سنتی متمایز کرد زیرا عملیات های مختلفی را برای توسعه برنامه ها بدون دخالت نمونه های میزبان در نظر می گیرد.
در این مقاله، به کاربرد چارچوب بدون سرور برای استفاده از مدلهای Cloud GIS روی یک پلت فرم توزیعشده میپردازیم. پلتفرمهایی مانند Amazon AWS Lambda، Microsoft Azure Functions، Google Cloud Functions و سایرین، یک رابط برنامهنویسی کاربردی (API) برای اجرای نرمتر قطعههای کد که در بسیاری از زبانهای برنامهنویسی مختلف پشتیبانی میشوند، ارائه میکنند. زبان برنامه نویسی پایتون در میان حداکثر چارچوب های بدون سرور رایج است. بنابراین، تکههای کد پایتون که برای پیادهسازی GIS روی نوتبوکهای Jupyter نوشته شدهاند، میتوانند به عنوان پایه چارچوب پیشنهادی ما عمل کنند. کتابخانه های زیادی وجود دارد، اما API های مناسب بر روی الگوی محاسباتی بدون سرور نیاز به تحقیق و توسعه بیشتری دارد. مدل ما چنین راهی را برای اعمال پیادهسازی GIS در چارچوب بدون سرور پیشنهاد میکند. مجموعه داده ها به طور کلی روز به روز بزرگتر می شوند و به همین دلیل، نیاز به فناوری GIS افزایش می یابد. پردازش مجموعه دادههای با ابعاد بالا در موتورهای پردازش محلی دشوار است و چنین دادههایی را دادههای بزرگ فضایی (SBD) مینامند.10]. چارچوب های بدون سرور می توانند به پردازش چنین SBD به روشی کارآمد و قابل اعتماد کمک کنند. وجود محدودیتهای متمایز در مدلهای موجود برای مدیریت دادههای مکانی در مقیاس بزرگ، ما را بر آن داشت تا یک چارچوب نسبتاً جدید ایجاد کنیم. این چارچوب برای خدمت به جمع آوری، پردازش و نمایش داده های عظیم جغرافیایی توسعه داده شد. مدل پیشنهادی شامل تمام قابلیتهای سرویسهای ابری به همراه راهحلهای BaaS و FaaS میشود. برخی از مهمترین مسائل مرتبط با مدیریت دادههای مکانی مانند جمعآوری، ذخیرهسازی و انتشار در پلتفرمهای متعدد مورد بررسی قرار گرفت. سیستم پیشنهادی تا حد زیادی زمان انتظار را در مقایسه با مدل ابری سنتی کاهش میدهد. زمان اجرا یکی از اشکالات بیشتر پلتفرم های مبتنی بر سرور برای انجام تجزیه و تحلیل داده های جغرافیایی عظیم با ارائه یک پلت فرم مقیاس پذیر و خودکار برای پردازش آنها است. یافتههای این مقاله سهولت توسعه برنامههای کاربر محور بیشتر برای مدیریت و نقشهبرداری ویژگیهای مرجع جغرافیایی با قابلیت حمل و استفاده بالا را نشان میدهد.
اهداف
اهداف این مقاله به شرح زیر است:
-
در مورد مبادله بین رویکرد مبتنی بر سرور و رویکرد بدون سرور پیشنهادی برای دادههای مکانی توضیح دهید.
-
برخی از مسائل مهم مانند تأخیر، مقیاس پذیری، مسائل مبتنی بر هزینه و امنیت برای پلتفرم های محاسباتی در همگرایی با چارچوب پیشنهادی مورد بحث قرار می گیرند.
-
برخی از چارچوب های برجسته ای که اجرای رویکردهای بدون سرور را تسهیل کرده اند ارائه شده است.
-
طبقهبندی برخی از فنآوریهای پیشرفته و برخی از کارهای مرتبط مرتبط با پیادهسازی مدلهای Cloud GIS مورد بحث قرار میگیرد.
-
چارچوب پیشنهادی و انطباق آن با برخی ابزارهای موجود برای انتزاع و شبیهسازی دادههای مکانی مورد بررسی قرار میگیرد.
-
تجزیه و تحلیل همپوشانی همراه با تولید نقشه حرارتی و تجزیه و تحلیل خوشهای برای نشان دادن پیچیدگی پردازش دادههای مکانی با استفاده از دو مطالعه موردی کاربردی، یعنی مجموعه دادههای سیستم داده منابع معدنی (MRDS) و مجموعه دادههای خانواده پیشبینی Fairfax مشاهده شد.
-
محدودیتهای معماری و سطح خدمات، دامنه آینده و نکات پایانی ارائه شده است.
2. روش تحقیق
شکل 2جریان کار پشت کار تحقیقاتی انجام شده را ارائه می دهد. مرحله اول مطالعه پارادایم محاسباتی بدون سرور از منابع مختلف اینترنتی برای ایجاد یک پایگاه دانش را نشان می دهد. مرحله دوم نشاندهنده بررسی ادبیات انجام شده بر روی مقالات است که در واقع چارچوبهای بدون سرور و کاربرد آنها را در حوزههای مختلف مهم نشان میدهد. مرحله سوم جدول بندی نظرسنجی انجام شده به منظور ارائه آثار اجرا شده به خواننده است. علاوه بر این، مراحل چهارم و پنجم، فرآیند ساخت چارچوب پیشنهادی را با ادغام کتابخانههای پایتون با GIS برای استقرار راحتتر قطعه کدهای Python GIS تجسم میکنند. در نهایت، مرحله ششم کاوش چالشهای آینده و جهتگیریهای تحقیقاتی را در زمینه اجرای وظایف GIS در یک محیط بدون سرور ارائه میکند.
3. کارهای مرتبط
بالدینی و همکاران [ 7 ] یک نظرسنجی بر روی پلتفرمهای مربوطه به منظور انجام محاسبات بدون سرور انجام داد. این مطالعه بر روی مشکلات آینده نگرانه ای متمرکز بود که باید در حوزه محاسبات بدون سرور مورد توجه قرار گیرند. نویسندگان یک “سکوی بدون سرور” ارائه کردند. معماری پیشنهاد میکند که سرورها اجباری هستند، اما توسعهدهنده اصلاً نگران مدیریت سرورها نیست. این مقاله بیان کرد که معماری یک فرآیند خودکار است که برای تعیین تعداد سرورها و ظرفیت مورد نیاز برای محاسبه استفاده می شود. جهتهای تحقیقاتی آینده برای محاسبات بدون سرور با ارائه مشکلات تحقیق باز به عنوان یک پرسشنامه مورد بررسی قرار گرفت.
کرسپو و همکاران [ 11] چالشهایی را که در هنگام اجرای برنامههای بیو انفورماتیک با استفاده از یک پلتفرم بدون سرور با آن مواجه میشوند، ارائه کرد. آنها مفهوم CloudDmetMiner را بررسی کردند، که چارچوبی است که با استفاده از الگوریتم متابولیسم دارو و آنزیمها و انتقالدهندهها (Dmet)-Miner طراحی شده است. علاوه بر این، پلت فرم آمازون AWS Lambda برای اجرا بر روی مجموعه دادههای پلیمورفیسم تک نوکلئوتیدی (SNP) استفاده شد، که بسیار مرتبط با برنامههای بیو انفورماتیک هستند. کار پیشنهادی از طریق نمونههایی که با موفقیت روی مجموعه دادههای SNP در نظر گرفته شده برای آزمایشهای اولیه اجرا میشوند، تأیید و اعتبارسنجی شد. مقایسه مزایای ارائه شده توسط چارچوب CloudDmetMiner نسبت به یک اکوسیستم بدون سرور و یک محیط ابری خالص ارائه شد. مشاهده شد که زیرساخت در مورد محاسبات بدون سرور موضوعی نگران کننده نیست.
نیو و همکاران [ 12 ] یک مطالعه موردی اثبات مفهوم برای تحقیقات زیست پزشکی ارائه کرد. این مقاله بر روی هم ترازی حدود 20000 توالی پروتئین با استفاده از الگوی محاسباتی بدون سرور متمرکز شده است. محدودیتهای منبعی که واقعاً در هنگام استفاده از یک الگوی بدون سرور وجود داشت شامل فضای دیسک، مدت زمان اجرا، فضای حافظه اولیه و تعداد واحدهای پردازش مجازی است. آنها از یک رویکرد توزیع شده برای مقابله با محدودیت های منابع به روشی هوشمندانه استفاده کردند. ابزارهای مقایسه شده برای پردازش داده های بیو-انفورماتیک عظیم با زمان اجرای کمتر در پلت فرم بدون سرور، AWS Lambda و Google Cloud Functions بودند. مشاهده شد که AWS Lambda در مقایسه با توابع ابری گوگل کارایی بسیار بالاتری دارد.
کیم و همکاران [ 13 ] چارچوبی به نام Flint برای تجسم مفهوم تجزیه و تحلیل داده های بزرگ با استفاده از محاسبات بدون سرور پیشنهاد کرد. از نقطه نظر توسعه دهنده، استفاده از PySpark با Flint ارائه شد. پیاده سازی کامل، چالش های مرتبط و تجزیه و تحلیل عملکرد مورد بررسی قرار گرفت. استنباط شد که تجزیه و تحلیل داده های بزرگ در یک پلت فرم بدون سرور کاملاً امکان پذیر است و پرس و جوهای تحلیلی را می توان به خوبی مدیریت کرد. استنباط شد که معماری فلینت یک انتخاب عالی برای تجزیه و تحلیل داده های بزرگ، غلبه بر چالش های پیش فرض های Spark برای تجزیه و تحلیل ad-hoc و بسیاری از وظایف تجزیه و تحلیل داده های دیگر است.
اساکیان و همکاران [ 14] نشان می دهد که تامین کنندگان ابر و شرکت های سازمانی در حال پیاده سازی هوش مصنوعی (AI) هستند تا خود را منزوی کنند یا خدمات ارزشمندی را به مشتریان ارائه دهند. نویسندگان کمال یک محیط محاسباتی بدون سرور را با حدس و گمان بر روی نمونه های اولیه شبکه عصبی عظیم ارزیابی کردند. محاسبات تجربی بر روی یک محیط AWS Lambda با استفاده از چارچوب یادگیری عمیق MxNet اجرا شد که تأخیر حدسزنی را در محدوده رضایتبخشی نشان داد. نتایج تأخیر درخواستهای گرم را در یک محدوده عملی در مقایسه با تأخیر درخواستهای سرد، که در محدوده بسیار بالایی هستند، برجسته کرد. از این رو، نویسندگان اعلام کردند که در صورت ادغام برنامههای هوش مصنوعی و قراردادهای سطح خدمات سفارشی، این مشکل باید حل شود.
آناند و همکاران [ 15] جنبه های کلیدی ساخت مکانیزم ردیابی GPS برای وسایل نقلیه با استفاده از الگوی محاسباتی بدون سرور را مورد بحث قرار داد. این شامل سیستم کم مصرف، ردیابی بلادرنگ، اعلان سرقت خودکار توسط شیوههای geofences برای افزایش مهارت در ذخیرهسازی و تجزیه و تحلیل دادهها بود. این ویژگی ها را افزایش داد و خدمات ایمن و بهبود یافته را در زمینه سیستم های ردیابی خودرو تضمین کرد. نویسندگان یک ردیاب GPS فعال را پیشنهاد کردند که مجهز به یک برنامه کاربردی موبایل/وب مناسب برای مشاهده نتایج بلادرنگ بود که آن را کاربرپسندتر کرد. می توان آن را در وب سایتی مشاهده کرد که به طور انحصاری برای راه حل ردیابی خودرو مربوطه ساخته شده است. برای غلبه بر جنبههای امنیتی، اگر کاربری خارج از مرز جغرافیایی شناسایی میشد، اعلانها برای کاربر پست میشد.
هلرستین و همکاران [ 9] بر شکاف های قابل توجه بین محاسبات بدون سرور نسل اول و محاسبات مدرن متمرکز شده است. در این مقاله آمده است که AWS، یک ابر عمومی، یک پلت فرم محاسباتی اساسی و جدید ارائه می دهد: بزرگترین مجموعه توانایی داده و محاسبات توزیع شده، با توانی که دائماً در دسترس عموم مردم است و به عنوان یک سرویس مدیریت می شود. این مقاله همچنین توضیح داد که محاسبات بدون سرور مفهوم چشمگیر یک پلتفرم در فضای ابری را ارائه می دهد که در آن توسعه دهندگان صرفاً کد خود را آپلود می کنند و پلت فرم کدها را از طرف آنها در صورت لزوم اجرا می کند. مشاهده شد که توسعه دهندگان نباید خود را نگران سرورهای عملیاتی کنند و فقط برای منابعی که استفاده می کنند هزینه می پردازند. این مقاله بدون سرور را بهعنوان FaaS که توسط یک کتابخانه استاندارد پشتیبانی میشود، خدمات مختلف مقیاسبندی خودکار چند مستاجر ارائه شده توسط فروشنده ارائه میکند. محدودیتهای ارائهشده این بود که فروشندگان به اهمیت پردازش دادههای کارآمد توجهی نمیکنند و مانع از گسترش سیستمهای توزیعشده میشوند، که مرکز بیشتر نوآوریهای محاسبات مدرن است. این مقاله بر روی کاستیهای زیر در FaaS تمرکز دارد: طول عمر محدود، ارتباط از طریق ذخیرهسازی کند و موارد دیگر.
مالاوسکی و همکاران [ 16 ] مطالعه ای بر روی زیرساخت های بدون سرور به منظور پردازش پس زمینه مورد نیاز در برنامه های کاربردی وب و اینترنت اشیا (IoT) انجام داد. این ویژگی های اصلی زیرساخت محاسباتی بدون سرور را ارائه کرد و با مدل ابری Infrastructure-as-a-Service (IaaS) مقایسه شد. نمونه اولیه ای که شامل سه پلتفرم مجزا بود: AWS Lambda، موتور گردش کار Hyperflow و Google Cloud Functions در زمینه گردش کار علمی ارائه شد. نویسندگان رویکرد پیشنهادی را با استفاده از گردش کار مونتاژ تأیید کردند، که به معنای یک برنامه نجومی در یک محیط بلادرنگ است. این کار راههای مؤثری برای مدیریت منابع ارائه میکند، زیرا منابع برای گردشهای کاری علمی مورد توجه است.
Varghese et al. [ 17 ] پیشرفتهای زیرساختهای رایانش ابری را به سمت رویکرد غیرمتمرکز محاسباتی که مراکز داده در مرکز قرار ندارند، مورد بحث قرار داد. به منظور پیادهسازی زیرساختهای نسل بعدی برای محاسبات ابری، بر چالشهایی تمرکز کرد که باید با آن مقابله کرد. تمرکز اصلی این مقاله روی بحث در مورد مدلهای رایانش ابری بود که به علاقه همتایان برای شکلدهی به نسل آینده رایانش ابری نیاز داشتند.
لی و همکاران [ 18]، مدعی رفتار پویا محاسبات بدون سرور برای اجرای موازی وظایف پارتیشن بندی شده بر روی نمونه های عملکرد کوچک است. نتایج مربوط به عملکرد CPU، حافظه و استفاده از دیسک برای انجام وظایف محاسباتی فشرده در محیطهای بدون سرور ارائه شد. چهار محیط محاسباتی بدون سرور قابل توجه ارزیابی شدند: توابع بدون سرور Google Cloud، آمازون AWS Lambda، Apache OpenWhisk و توابع بدون سرور Microsoft Azure. مجموعهای از توابع برای پردازش همزمان دادهها به کار گرفته شد تا مبادلات عملکرد بین ماشینهای مجازی و محیطهای محاسباتی بدون سرور را نشان دهد. از آزمایش استنباط شد که پلتفرمهای بدون سرور پردازش صریح دادهها را ارائه میدهند. ویژگیهای مقیاسپذیری بالقوه پلتفرمهای بدون سرور در زمینه استفاده از منابع و اثربخشی هزینه مورد تجزیه و تحلیل قرار گرفت. می توان استنباط کرد که پلتفرم های محاسباتی بدون سرور در شکل فعلی خود معمولاً با کار بر روی بارهای کاری زودگذر همراه هستند که در آینده ممکن است فضای بیشتری با تنظیمات پیشرفته برای مدیریت بارهای کاری پیچیده پیدا کنند.
جدول 1 مطالعه جامعی را برای کارهای مختلف مورد بحث همراه با سهم قابل توجهی که در هر کدام در جهت ارزیابی قابلیت های پلتفرم های بدون سرور ارائه شده است، ارائه می دهد.
4. پس زمینه
4.1. محاسبات توزیع شده برای به اشتراک گذاری اطلاعات مکانی
پیشرفتها در سیستمهای مدرن GIS و چارچوبهای متنوع جمعآوری دادهها به طور قابلتوجهی به تولید دادههای جغرافیایی انبوه منجر شده است. منابع محاسباتی و جمع آوری داده های مرتبط با این سیستم ها معمولاً در یک منطقه جغرافیایی بزرگ توزیع می شوند. 19 ]]. پردازش دادههای جغرافیایی انبوه تولید شده از دستگاههای ناهمگن، چالشهایی را بر پایگاههای داده مرسوم و منابع محاسباتی برای انجام پرس و جوی پیشرفته و پردازش دادههای مکانی پیچیده تحمیل میکند. از این رو، نیاز به یک پلت فرم محاسباتی توزیع شده برای مدیریت نیازهای مشتریان مختلف از راه دور برای پردازش داده های مکانی اجتناب ناپذیر می شود. یک پلت فرم محاسباتی توزیع شده به اشتراک گذاری اطلاعات مکانی را روی چندین مشتری و پلت فرم های محاسباتی متنوع تسهیل می کند. چندین مطالعه بر کارایی به دست آمده از طریق پیاده سازی پلتفرم های محاسباتی توزیع شده برای پرس و جو، پردازش و به اشتراک گذاری اطلاعات مکانی تمرکز کرده اند [ 20 ، 21 ، 22]. این چارچوب برای غلبه بر بیشتر چالشهای مرتبط با منابع محاسباتی محلی و پایگاههای داده با تسهیل جمعآوری و توزیع دادههای مکانی ناهمگن مشاهده شد. چارچوب محاسباتی توزیع شده از زیرساخت ابری برای ادغام منابع محاسباتی توزیع شده محلی استفاده می کند. این می تواند به ارائه یک چارچوب محاسباتی پویا برای به اشتراک گذاری منطقی منابع محاسباتی در مقیاس جهانی کمک کند. این اساسا چالش های پیچیده پردازش داده های مکانی را حل می کند. پلتفرمهای محاسباتی توزیعشده سنتی با افزایش تقاضاهای محاسباتی به شدت تکامل یافتهاند. به منظور تسهیل در ارائه خدمات بهبود یافته، کلاسهای متمایز متفاوتی از جمله، محاسبات سیار، محاسبات مه و چارچوبهای محاسبات لبه به وجود آمدند.22 ، 23 ، 24 ، 25 ].
4.2. محاسبات لبه برای تجزیه و تحلیل جغرافیایی
محاسبات لبه اقتباس نسبتاً جدیدتری از پارادایم محاسباتی توزیع شده برای ارائه استفاده کارآمد از توان محاسباتی با تسهیل خدمات محاسباتی در لبه است. این منابع محاسباتی را برای دستگاههای ناهمگن مرتبط با شبکه در مجاورت منابع دادههای مکانی، یا دستگاههای محاسباتی فراهم میکند [ 22 ، 23 ، 24 ]]. محاسبات لبه بر برخی از چالشهای مهم مرتبط با پارادایمهای محاسبات توزیعشده مرسوم غلبه میکند. مدیریت مشکلات تاخیر در شبکه های بزرگ، تامین امنیت حریم خصوصی کاربران و به اشتراک گذاری ایمن داده ها، ایجاد ارتباط بهبود یافته، مصرف انرژی پایین و غیره از جمله مواردی است که می توان با محاسبات لبه به طور موثر مدیریت کرد. این قابلیتها برای سیستمهای فضایی توزیعشده در مقیاس بزرگ برای دستیابی به یک چارچوب امن، قابل اعتماد و کارآمد انرژی بسیار مفید هستند. مزیت اصلی استفاده از محاسبات لبه برای به اشتراک گذاری و پردازش اطلاعات مکانی این است که با ارائه خدمات محاسباتی در لبه، قابلیت کشف و در دسترس بودن خدمات را تسهیل می کند. از این رو، دستگاه های محاسباتی متصل برای بهره مندی از خدمات نیازی به مدت طولانی تری ندارند.25 ].
4.3. رویکرد مبتنی بر سرور
پردازش اطلاعات مکانی غنی بر روی سرورهای مبتنی بر ابر برای استخراج و ارائه الگوهای مفید مکانی-زمانی، پردازش مبتنی بر سرور نامیده میشود [ 7 ]. در یک رویکرد مبتنی بر سرور، سرور اغلب از راه دور از مشتری قرار دارد و مسئول مدیریت و اجرای برنامه های کاربردی در سمت مشتری است. محاسبات Thin Client یک نمونه محبوب از پردازش مبتنی بر سرور است که شامل دستگاههای محاسباتی سبک وزن (که به تین کلاینتها گفته میشود) که قادر به نمایش برنامههای از راه دور هستند، میباشد. این کلاینتها معمولاً با سرور ارتباط برقرار میکنند و میتوانند حسابی از برنامههای مختلف در حال اجرا روی سرور ارائه دهند. برخی از برنامه های کاربردی برجسته دنیای واقعی که از SBA استفاده می کنند عبارتند از Citrix، Tarantella، GraphOn و بسیاری دیگر.
4.4. رویکرد بدون سرور
رویکرد بدون سرور (SLA) پردازش داده ها را در غیاب سرور نشان نمی دهد، اما از قابلیت های عملیاتی بیشتری بهره می برد. مقیاس پذیری، نگهداری، تحمل خطا و مدیریت منابع مواردی هستند که باید به آنها اشاره کرد [ 6 ، 16 ]. SLA راحتی بسیار بیشتری را از نظر هزینه برای مدیریت دستگاههای محاسباتی فیزیکی بالا ارائه میدهد. به طور خودکار منابع مناسب را با افزایش تقاضاهای محاسباتی فراهم می کند و از این رو قابلیت های یکپارچه را برای مشتریان میزبان ارائه می کند. از این رو، SLA یک جایگزین برتر برای SBA خواهد بود. برخی از نمونه های محبوب SLA عبارتند از AWS lambda، OpenLambda، عملکرد Google Cloud و بسیاری از این قبیل.
شکل 3 مقایسه دادههای Google Trends را برای کلیدواژههای محاسباتی «مبتنی بر سرور» و «بدون سرور» بر اساس کارهای تحقیقاتی انجامشده طی پنج سال گذشته به صورت جهانی نشان میدهد. خط آبی نشان دهنده رشد دامنه محاسباتی بدون سرور است در حالی که خط قرمز نشان دهنده سقوط رویکرد مبتنی بر سرور است.
4.5. املاک مبتنی بر دولت
مدیریت حالت ها در یک پلت فرم بدون سرور به دلیل عدم تداوم در بین توابع بسیار چالش برانگیز است. بنابراین، در زمینه SLA، ما بیشتر نگران مقیاس پذیری منابع هستیم، بنابراین ویژگی های ویژگی بی تابعیتی در ارائه همزمانی اجرا [ 6 ]. این ویژگی کمک زیادی به گسترش قابلیت های سیستم برای پردازش داده های مکانی می کند. با این حال، به منظور حفظ هر گونه اطلاعات فراتر از یک دوره زمانی خاص، برنامه های کاربردی باید اطلاعات را به برخی از اجزای حالت دار هدایت کنند. تابع AWS Lambda یکی از این نمونهها از یک پلت فرم بدون حالت است که اجرای همزمان نمونههای هر مؤلفه را بدون نیاز به تأمین منابع بیشتر برای هر نمونه تسهیل میکند ( شکل 4).).
4.6. مدیریت تاخیر
همانطور که منابع در محیط های بدون سرور به شدت افزایش می یابند، تعامل بین اجزای موجود در سیستم افزایش می یابد و تاخیر بیشتری ایجاد می کند. این امر پیچیدگی کلی سیستم را افزایش می دهد. در یک برنامه SBA، تأخیر ایجاد شده در بین مؤلفه ها را می توان با مکان یابی مشترک مؤلفه ها، یا با وارد کردن آنها به همان فرآیند کاهش داد. در اینجا هممکانی مؤلفهها شامل قرار دادن مؤلفهها در همان نمونههای میزبان است. این تکنیکها به بهینهسازی عملکرد سیستم کمک میکنند و میتوانند به صورت همزمان یا جداگانه برای اجزای آن اعمال شوند. علاوه بر این، بهینه سازی را می توان با افزایش عملکرد کانال ارتباطی، با استفاده از برخی پروتکل های تخصصی و فرمت های داده مناسب به دست آورد.
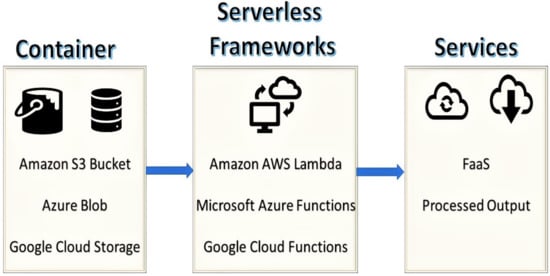
4.7. آمازون AWS Lambda
این پلتفرم محاسبات بدون سرور در بین تمامی پلتفرم های موجود محبوب ترین است. دلیل آن تطبیق پذیری این پلتفرم در پشتیبانی از کدهای Node.js، Python، Java و C# است. این یک مفهوم کانتینری است که در آن هر نمونه به عنوان یک محفظه تولید شده توسط آمازون لینوکس AMI با مقدار مورد نیاز مشخصات سرور اختصاص داده شده برای قطعه کد برای اجرا در محیط عمل می کند. کد خام را نمی توان مستقیماً در بستر بدون سرور اجرا کرد و بنابراین از یک سطل S3 برای بسته بندی تمام محتویات مورد نیاز برای اجرای قطعه کد استفاده می شود. این چارچوب کاملاً بدون دولت است. کارایی این چارچوب قابل ستایش است. حداکثر زمان اجرا برای هر درخواست 900 ثانیه در این پلتفرم است [ 26]. در زمینه ما، اجرای برنامههای جغرافیایی کدگذاری شده در پایتون با استفاده از GeoPandas یا ArcPy یک راه دشوار و در عین حال کارآمد با اهمیت آیندهنگر برای تجسم نقشهها در بازه زمانی کوتاهتر است. بهینه سازی هزینه در زمینه محاسبات بدون سرور جغرافیایی یک مسئله حیاتی است و به تحقیقات بیشتری نیاز دارد.
4.8. پلتفرم بدون سرور Google Cloud
این پلتفرم بدون سرور به دلیل اعتماد گوگل به آن بسیار مورد استفاده قرار می گیرد. علاوه بر این، با رفتن عمیق به جنبههای فنی، این پلتفرم از قطعههای کد نوشته شده با استفاده از Python و Node.js در حال حاضر پشتیبانی میکند. محیط اجرا که Knative با کمک Kubernetes ساخته شده است، امکان استفاده از این چارچوب بدون سرور را برای اهداف متعدد فراهم می کند. این پارادایم با سهولت کدنویسی ارائه می شود و نسبتاً برای این قابلیت های بدون سرور جدید است. حداکثر زمان اجرا برای هر درخواست به طور پیشفرض 60 ثانیه است و میتوان آن را تا 540 ثانیه افزایش داد که نسبتاً بسیار کم است و کارایی آن را ثابت میکند [ 26 ]. نقطه ضعف این است که حداکثر تعداد توابع مجاز در هر پروژه به طور پیش فرض 1000 است.
4.9. پلتفرم بدون سرور Microsoft Azure
پلتفرم Azure Serverless از قطعه کدهای نوشته شده در C#، Python، Java، F#، PHP و Node.js پشتیبانی می کند. ویژگی منحصر به فرد آن این است که اجرای همزمان آن کاملاً به محرک ها و اتصالات بدون محدودیت خاصی وابسته است. مقیاس بندی از نوع متری یا دستی است. این پلتفرم می تواند یک قطعه کد با حافظه بالا را در عرض چند دقیقه اجرا کند. علاوه بر این، مقیاس بندی به قدری عالی است که کاربر مجبور نیست روی حجم کار تمرکز کند. این پلتفرم دارای یک ویرایشگر کد جذاب است که پایگاه کاربری آن را بهبود می بخشد. دو ویژگی اصلی آن عبارتند از یکپارچگی مداوم (CI) و تحویل مداوم (CD). نظارت بر قطعه کد ارسالی به خوبی واسط است. حداکثر زمان اجرای هر درخواست به طور پیش فرض 300 ثانیه است که در این پلتفرم تا 600 ثانیه قابل ارتقا است [ 26 ]]. این چارچوب در زمینه برنامههای کاربردی بدون سرور جغرافیایی میتواند خود را به بهترین شکل ثابت کند، زیرا در برخورد با مشکلات پیچیده ارکستراسیون کمک میکند و بر اساس محرکها و اتصالات است. فرآیند ساخت و به دنبال آن اشکال زدایی و سپس استقرار و در نهایت نظارت در این پلتفرم ساده و آسان شده است.
4.10. اصطلاحات استفاده شده
4.10.1. تحلیل پوششی
اصطلاح آنالیز همپوشانی در GIS برای نشان دادن روی هم قرار گرفتن ویژگی های چندگانه به عنوان نقشه های برداری استفاده می شود [ 27 ]. در زمینه ما، تحلیل همپوشانی به نقاط داده ای اشاره دارد که روی نقشه خیابان باز همپوشانی دارند. تحلیل همپوشانی وزنی شامل طبقهبندی مجدد لایههای فضایی بسته به تأثیر هر لایه تعریفشده توسط وزنها است. این تجزیه و تحلیل برای انجام تجسم های بیشتر بسیار مهم است. نمادهای مختلفی را می توان برای رسم نقاط داده بر روی نقشه بر اساس مقادیر طول و عرض جغرافیایی استفاده کرد. عملیات همپوشانی می تواند برای سیستم های محاسباتی سنتی برای مدیریت SBD [ 27 ] محاسباتی فشرده باشد. از این رو، چارچوب بدون سرور می تواند انتخاب خوبی برای رسیدگی به نیازهای بلادرنگ اکثر برنامه های GIS باشد.
4.10.2. تجزیه و تحلیل نقطه ای-خوشه ای
تحلیل خوشهای نقطهای یک نمایش نمادین است که برای کاهش و دقت تعداد زیادی از نقاط داده استفاده میشود. تجزیه و تحلیل الگوهای جغرافیایی یک کار ضروری است و می توان آن را از طریق تجزیه و تحلیل نقطه-خوشه انجام داد. یافتن مناطق با غلظت کم یا زیاد از طریق تجزیه و تحلیل نقطه-خوشه امکان پذیر است. یک الگوی نقطه ای ممکن است به عنوان مجموعه ای از مختصات جغرافیایی در یک منطقه تعریف شده در نظر گرفته شود که در آن رویدادهای مورد علاقه ثبت می شوند [ 28 ]. در مورد SBD، نقاط داده به طور متراکم بسته بندی شده اند و تجزیه و تحلیل الگوهای جغرافیایی و مسیرها یک کار پیچیده است. بنابراین، تجزیه و تحلیل نقطه-خوشه فرآیند شناسایی الگوها را با خوشه بندی نقاط متراکم در خوشه های منفرد آسان تر می کند.
4.10.3. تجزیه و تحلیل نقشه حرارتی
برای یافتن مناطق بسیار متراکم روی نقشه، در برخی موارد لازم است تحلیل خود را به یک منطقه خاص که در آن تراکم نقاط بسیار زیاد است محدود کنیم. نقشه حرارتی نقش مهمی در تعیین مناطق بر اساس تراکم و تمایز بر اساس عمق رنگ ایفا می کند. نقشه حرارتی باید به درستی تجزیه و تحلیل شود و پارامتر برای توزیع وزن باید مشخص شود.
4.10.4. آنالیز خوشه ای
پارتیشن بندی فضایی اصطلاحی است که برای تقسیم بندی نقاط داده های مکانی بر اساس مجاورت استفاده می شود که اغلب به آن خوشه بندی فضایی می گویند [ 29 ]. خوشهبندی فضایی روشی برای خوشهبندی نقاط داده مشابه است که در آن شباهت بر اساس ویژگیها است و نقاط یک خوشه با نقاط دیگر خوشهها متفاوت هستند [ 30 ].]. تجزیه و تحلیل خوشه ای را می توان با استفاده از دو تکنیک خوشه بندی شناخته شده مورد استفاده در یادگیری ماشین انجام داد، یعنی خوشه بندی فضایی مبتنی بر چگالی برنامه های کاربردی با نویز (DBSCAN) و خوشه بندی K-means. هر دوی این تکنیکها را میتوان روی نقشه حرارتی یا روکش برای تخصیص شناسههای خوشهای خاص به نقاط داده مختلف بر اساس ویژگیها استفاده کرد. علاوه بر این، ما باید تعداد خوشههایی را که میخواهیم تجسم کنیم مشخص کنیم تا بتوانیم تعداد زیادی شناسه خوشه و همچنین نقاط خوشهبندی را تولید کنیم. در DBSCAN، باید نقاط مرزی را مشخص کنیم که به عنوان نویز در نظر گرفته شوند. چگالی خوشه توسط دو پارامتر eps تعیین می شود که نشان دهنده شعاع دایره و minpts است که حداقل تعداد نقاط را در آن دایره مشخص می کند [ 31 ]].
4.11. پردازش داده های بزرگ جغرافیایی
داده های مکانی را می توان به عنوان سه مدل اولیه نشان داد، یعنی داده های شطرنجی که نشان دهنده شبکه های پیکسل، داده های برداری نشان دهنده خطوط یا چند ضلعی پیکسل ها و داده های نموداری است که شبکه های فضایی را نشان می دهد [ 32 ]. دادههای مکانی در سناریوی امروزی در جنبههایی مانند حجم، تنوع و پیچیدگی پردازش در حال افزایش است، که باعث میشود ابزارهای پردازش فضایی موجود قادر به پردازش و تجزیه و تحلیل دادهها نباشند که منجر به SBD میشود [ 10 ]. داده کاوی مکانی نقش محوری در فرآیند تجزیه و تحلیل SBD ایفا می کند. برخی از الگوریتمهایی که میتوانند به پردازش چنین دادههایی کمک کنند عبارتند از: مدل خودکار رگرسیون فضایی (SAR)، طبقهبندیکنندههای میدان تصادفی مارکوف، یادگیری فرآیند گاوسی یا هیبریداسیون این الگوریتمها. 33 ].]. عصر محاسبات بلادرنگ نیازمند پردازش دادههای مکانی برای محیطهای بلادرنگ است و بنابراین نیازمند روشهایی برای مدیریت SBD است. Spatial Hadoop، GIS on Hadoop، Declustering و Space Partitioning برخی از پارادایمهای محاسباتی برای مدیریت SBD هستند [ 34 ].
5. چارچوب پیشنهادی
انگیزه های اساسی در پشت ادغام پلت فرم بدون سرور برای تجزیه و تحلیل جغرافیایی در دستیابی به قابلیت های عملیاتی بالا و پردازش تقریباً بلادرنگ داده های بزرگ جغرافیایی نهفته است. همانطور که در بخش قبل بحث شد که SLA مقیاس پذیری و نگهداری بیشتری را در یک محیط محاسباتی بسیار ناهمگن اضافه می کند، در نتیجه یک جایگزین کم هزینه برای پردازش داده های عظیم مکانی فراهم می کند. همچنین به کاربران یا مشتریان امکان می دهد تا با مجازی سازی منابع محاسباتی، داده های خود را بر روی پلتفرم های محاسباتی پیشرفته پردازش کنند. این معماری نیاز به استقرار فیزیکی دستگاهها را حذف میکند و با پیادهسازی مدل پرداخت بهموقع به برآورده کردن نیازهای پویای مشتریان کمک میکند. از این رو در راستای این هدف، ما کاربرد چارچوب بدون سرور را برای تجزیه و تحلیل داده های بزرگ جغرافیایی پیشنهاد می کنیم. شکل زیر چارچوب پیشنهادی بدون سرور برای تجزیه و تحلیل داده های مکانی را نشان می دهد. در اینجا ژئوپورتالهای مبتنی بر وب مسئول کشف و دسترسی به دادههای مکانی هستند که میتوانند از دستگاههای محاسباتی پراکنده ناهمگن مختلف گرفته شوند. دادههای مکانی بهدستآمده از منابع ناهمگن مختلف ممکن است از طریق دروازههای اینترنتی به مشتری/سرور مربوطه برای پردازش دادهها هدایت شوند. پورتال های جغرافیایی ممکن است با استفاده بهینه از پلت فرم های GIS به ایجاد و تجسم اطلاعات مکانی برای داده های جغرافیایی به دست آمده از راه دور کمک کنند. اطلاعات به دست آمده از این چارچوب نقش مهمی در توسعه زیرساخت های داده های مکانی (SDI) ایفا می کند. سرورهای برنامه، مشتریان را با یک سرور تسهیل می کنند تا درخواست های خود را در یک محیط چند مشتری اجرا کنند. کلاینت های مرتبط با این چارچوب از تین کلاینت ها، کلاینت های ضخیم و کلاینت های موبایل تشکیل شده اند. تین کلاینت ها ممکن است کاربران مرتبط با سرورهای وب برای دسترسی به شی مکانی باشند (یعنی مجموعه ای از ویژگی ها و نمونه هایی که یک پایگاه داده جغرافیایی را تشکیل می دهند.19 ]). این مشتریان ممکن است بخواهند اشیاء مکانی را مطابق با نیاز خود با استفاده از برخی ابزارهای GIS یا نرم افزارهای کاربردی که به عنوان کلاینت های ضخیم نامیده می شوند، نمایش داده و دستکاری کنند. مشتریان تلفن همراه قادر به انجام عملیات بر روی داده های مکانی به صورت محلی از طریق دستگاه های محاسباتی سیار مانند تبلت ها، رایانه های شخصی (PC)، تلفن های همراه و غیره هستند.
به منظور ذخیره سازی اشیاء مکانی به دست آمده از سرویس ذخیره سازی ساده آمازون (S3)، می توان از سطل ها به طور موثر استفاده کرد. در رابطه با پلت فرم به اشتراک گذاری اطلاعات مکانی، سطل S3 می تواند قابلیت کشف بالایی از منابع را فراهم کند. بارگذاریها از سطل S3، دروازههای اینترنتی، سرورهای برنامه و پورتالهای جغرافیایی، عملکرد AWS lambda (یا، به سادگی به نام تابع lambda شناخته میشود) را فعال میکند تا کارها را برای پردازش به ارائهدهندگان خدمات ابری ارسال کند. این امر با استفاده از چارچوب بدون سرور، مفهوم FaaS را به وجود می آورد. توابع لامبدا را میتوان توسط کلاینتها یا کاربران فراخوانی کرد، بسته به الزامات برنامهای که به نظر میرسد در خدمت آن است. پلت فرم بدون سرور از میکروسرویس ها برای پردازش نیازمندی های برنامه کاربردی پیچیده تولید شده توسط ماژول سرور برنامه استفاده می کند. معماری میکروسرویس ماژول های کاربردی پیچیده بزرگ را به ماژول های فرعی ساده تر تجزیه می کند که می توانند به سرعت اجرا شوند. علاوه بر این، این به مشتریان انعطافپذیری بیشتری را برای افزودن ماژولهای جدید یا ایجاد اصلاحات در ماژولهای موجود بر اساس الزامات برنامههای مکانی خاص ارائه میدهد. چارچوب بدون سرور یک راه کارآمد و راحت برای پردازش اطلاعات مکانی به دست آمده از دستگاه های محاسباتی ناهمگن و همچنین برای رسیدگی به نیازهای محاسباتی فزاینده در یک محیط چند مشتری فراهم می کند. علاوه بر این، این به مشتریان انعطافپذیری بیشتری را برای افزودن ماژولهای جدید یا ایجاد اصلاحات در ماژولهای موجود بر اساس الزامات برنامههای مکانی خاص ارائه میدهد. چارچوب بدون سرور یک راه کارآمد و راحت برای پردازش اطلاعات مکانی به دست آمده از دستگاه های محاسباتی ناهمگن و همچنین برای رسیدگی به نیازهای محاسباتی فزاینده در یک محیط چند مشتری فراهم می کند. علاوه بر این، این به مشتریان انعطافپذیری بیشتری را برای افزودن ماژولهای جدید یا ایجاد اصلاحات در ماژولهای موجود بر اساس الزامات برنامههای مکانی خاص ارائه میدهد. چارچوب بدون سرور یک راه کارآمد و راحت برای پردازش اطلاعات مکانی به دست آمده از دستگاه های محاسباتی ناهمگن و همچنین برای رسیدگی به نیازهای محاسباتی فزاینده در یک محیط چند مشتری فراهم می کند.
چارچوب پیشنهادی مبتنی بر استراتژی پیادهسازی مورد نیاز برای ادغام سرویسهای مکانی با الگوی محاسباتی بدون سرور است. چارچوب های موجود برای محاسبات بدون سرور از ورودی ها به عنوان قطعه کد نوشته شده در Node.js، C#، Java و Python پشتیبانی می کند. بنابراین، به منظور پیاده سازی خدمات مکانی در یک اکوسیستم بدون سرور، به یک معماری جدید و قابل اجرا نیاز داریم. همانطور که می دانیم، فرمت های داده های جغرافیایی شامل فرمت شطرنجی و فرمت برداری است که می تواند با استفاده از ابزارهایی مانند QGIS، ArcGIS و بسیاری دیگر پردازش شود. کاربردهای جغرافیایی نیاز به پردازش سطح بالایی دارند اما یک مفهوم کاملا متمرکز است. تازگی ما در این حوزه انجام پردازش در یک پلت فرم غیرمتمرکز و توزیع شده است. بسیاری از پلتفرمها و کتابخانههای پایتون در پردازش دادههای مکانی مهم هستند. بدین ترتیب، هدف معماری پیشنهادی ما استفاده از کدهای پایتون است که برای پیاده سازی GIS نوشته شده است تا در یک چارچوب محاسباتی بدون سرور استفاده شود. معماری پیشنهادی میتواند منجر به استفاده گسترده از فناوری GIS در یک پلتفرم بدون سرور شود که توسعهدهندگان را از سطح بالای پیشپردازش که در حال حاضر در همه برنامههای مکانی مورد نیاز است، معاف میکند.
شکل 5 یک معماری سه لایه سطح بالا از چارچوب پیشنهادی را نشان می دهد که نشان دهنده پردازش داده ها در لایه اول است. لایه دوم با تبدیل خروجی پردازش شده به قطعه کد پایتون می پردازد، که عملاً امکان پذیر است زیرا بسیاری از ابزارهای GIS که در حال حاضر کار می کنند از پایتون در انتهای خود استفاده می کنند. لایه سوم نشان دهنده استفاده از چارچوب های بدون سرور است که از کدهای پایتون برای کار روی چارچوب پشتیبانی می کند.شکل 6نشان دهنده یک مدل تعمیم یافته برای ارائه تعامل محاسباتی مشتری و بدون سرور است. می توان آن را از طریق مکانیسم های مختلف دسترسی به داده های مکانی و تولید تحقق بخشید. این شامل ژئوپورتال ها، دروازه های اینترنتی، سرورهای برنامه و سطل آمازون S3 مربوط به مدل های مختلف کلاینت است که بر روی پلتفرم های مختلف کار می کنند و جوهر پارادایم محاسباتی بدون سرور است.
6. ارزیابی عملکرد
در جدول 2 ، مقایسه برخی از معیارهای عملکرد برای فناوریهای نوظهور مختلف که معمولاً برای مدلسازی دادههای مکانی استفاده میشوند، ارائه شده است. در اینجا، ما چهار پارادایم محاسباتی یعنی رویکرد مبتنی بر سرور (SBA)، محاسبات لبه، محاسبات توزیع شده و SLA را مقایسه کردیم [ 35 ، 36 ، 37]. یک SBA سنتی معمولا مقیاس پذیری و قابلیت اطمینان بسیار کم را به دلیل ماهیت ایستا سیستم به تصویر می کشد. اگر فرد مجبور باشد به طور مداوم با سیستم موجود و افزایش مقیاس منابع داده کار کند، هزینه های زیادی برای پیاده سازی و نگهداری وجود دارد و در نتیجه بار بیشتری بر مراکز داده وارد می شود. معماری بسیار توزیع شده پلت فرم محاسبات لبه، شانس تهدیدات امنیتی را بیشتر افزایش می دهد، زیرا از یک پلت فرم مبتنی بر وب استفاده می شود. رویکرد محاسباتی توزیع شده ممکن است همیشه داده های عظیم مکانی را در زمان واقعی پردازش نکند [ 38 ، 39 ، 40]. این به دلیل پیچیدگی در معماری پلتفرم های توزیع شده است که شامل تعداد بیشتری از سرورها و سایت های عملیاتی می شود که اغلب منجر به مدیریت پیچیده و هزینه های بالای نگهداری می شود.22 ، 41 ]. در مقابل این محدودیتها، SLA چارچوبی بسیار مقیاسپذیر، قابل اعتماد و نسبتاً کم هزینه با حداقل نیازها برای مدیریت سرورها ارائه میکند. همچنین حداقل تأخیر را برای پردازش داده های مکانی در مقیاس بزرگ فراهم می کند. بنابراین، میتوان استنباط کرد که SLA پیشنهادی از نظر قابلیت اطمینان، مقیاسپذیری، سرعت پردازش و هزینه عملکرد بهتری از بیشتر پارادایمهای محاسباتی دارد ( شکل 7 ).
معیارهای عملکرد مربوط به هر یک از فناوریهای مورد بحث را میتوان با اختصاص مقادیر عددی از 1 تا 3 برای معیارهایی که بر اساس آن عملکرد هر فناوری ارزیابی شد، ارزیابی کرد. در اینجا، مقدار 1 نشان دهنده عملکرد کم یا ناکافی، 2 نشان دهنده سطح عملکرد متوسط یا متوسط و 3 نشان دهنده سطح عملکرد بالا است. همه این معیارها با تجزیه و تحلیل کیفی مستندات بخش استانداردسازی مخابرات مربوطه اتحادیه بینالمللی ارتباطات از راه دور (ITU-T) و از مطالعات بالا [ 22 ، 35 ، 36 ، 37 ، 38 ، 39 ، 40 ، 41 ] استنباط شدند.
7. راه اندازی آزمایشی
تجسم داده های بزرگ جغرافیایی یک کار پیچیده بود و پیاده سازی با استفاده از موتورهای محلی زمان زیادی می برد. بنابراین، ما یک چارچوب بدون سرور برای تجسم داده های بزرگ در یک زمینه جغرافیایی پیشنهاد کردیم. بسته ها و کتابخانه های فعلی به اندازه کافی برای انجام تجسم کافی نبودند. پایتون یک زبان مشترک برای اکثر معماری های بدون سرور است. انتظار می رود معماری بدون سرور، قطعه کدهای پایتون را اجرا کند. ما تجسمها را بر روی یک موتور محلی ارائه کردیم تا ضرورت پارادایم محاسباتی بدون سرور را با فناوری GIS ادغام کنیم. از آنجایی که مجموعه داده های در نظر گرفته شده پیچیده و از نظر اندازه بزرگ بودند، برچسب گذاری نقاط داده روی نقشه با استفاده از موتورهای محلی از نظر محاسباتی سخت است. کتابخانه ها و بسته های پایتون که می توانند برای پارادایم محاسباتی بدون سرور استفاده شوند به شرح زیر هستند:
کتابخانه GeoPandas در پایتون از بسته های زیر تشکیل شده است:
-
CartoPy: این بسته به تجسم نقشه ها کمک می کند و یک ابزار نقشه کش است. این یک رویکرد شی گرا به سمت تجزیه و تحلیل مکانی است و برای پردازش فرمت های شطرنجی و برداری شناخته شده است [ 42 ].
-
Shapely: گاهی اوقات ما با داده های دو بعدی برای برخی کاربردهای مکانی سروکار داریم و این بسته برای دستکاری چنین داده های هندسی در یک صفحه دکارتی کاملاً عمل می کند [ 43 ].
-
فیونا: این بسته دارای یک API واضح است که کاربران را به خواندن و همچنین نوشتن داده های مکانی مختلف و همچنین محتویات فشرده جذب می کند. داده های مکانی را می توان به صورت تک لایه در قالب فایل های چند لایه جمع آوری کرد [ 44 ].
-
PyProj: همانطور که از نام آن پیداست PROJ به پیش بینی ها و تغییرات مربوط به داده های مکانی اشاره دارد. این بسته فقط برای تبدیل مختصات و به خوبی طرح ریزی آن استفاده می شود [ 45 ].
-
RTree: برای نمایه سازی داده های مکانی، از این بسته استفاده می شود و بسیاری از ویژگی های نمایه سازی فضایی مانند بارگذاری چند بعدی، بارگذاری انبوه، سریال سازی دیسک، جستجوی نزدیکترین همسایه و بسیاری موارد دیگر را پشتیبانی می کند [ 46 ].
-
دکارت: مانند کتابخانه رسم پرطرفدار matplotlib عمل می کند و بر روی داده های هندسی برای ترسیم مسیرهای ضروری مختلف که برای توسعه برنامه های مکانی مورد علاقه هستند [ 47 ] کار می کند.
-
Rasterio: برای استفاده از داده ها در فرمت های شطرنجی جغرافیایی، وارد کردن فرمت های فایل از نوع GeoTIFF و موارد دیگر ضروری است. این بسته چنین دادههای شطرنجی را میخواند و مینویسد و یک API بر اساس آرایههای N بعدی [ 48 ] تولید میکند.
از ماژول های زیر نیز می توان برای تولید قطعه کد پایتون استفاده کرد:
ArcPy : این ماژول برای دستکاری ابزار ArcGIS به منظور دستیابی مستقیم به کارایی پایتون در وظایف GIS استفاده می شود.
PyGRASS : این بسته پایتون بر روی GRASS GIS 7 که معروف است برای کار با دادههای مکانی کار میکند. بنابراین، کتابخانه PyGRASS کارایی ابزار GRASS را در محیط پایتون نشان می دهد. همانطور که مطالعه کردیم، ماژول های پایتون مختلفی برای کار بر روی داده های مکانی وجود دارد. بنابراین، معماری پیشنهادی ما با هدف استفاده از کدهای پایتون نوشته شده برای پیاده سازی GIS برای استفاده در یک چارچوب محاسباتی بدون سرور است. چارچوب پیشنهادی میتواند منجر به استفاده گسترده از فناوری GIS در یک پلتفرم بدون سرور شود، که توسعهدهندگان را از سطح بالای پیشپردازش که در حال حاضر در همه برنامههای مکانی مورد نیاز است، معاف میکند.
ابزارهای کمکی
ابزار مورد استفاده برای مصورسازی بسته نرم افزاری QGIS بود که در آن از ما می خواست مجموعه داده ها را با مقادیر طول و عرض جغرافیایی وارد کنیم تا آن را بر روی نقشه خیابان باز ترسیم کنیم. تجزیه و تحلیل همپوشانی برای تجسم نقاط داده عاقلانه مکان برای هر دو مجموعه داده انجام شد. تجزیه و تحلیل همپوشانی توسط نسل نقطه-خوشه دنبال شد که در آن نقاط را بر اساس فاصله نشان دادیم، که با مثلث های قرمز نشان داده شد. تجزیه و تحلیل نقشه حرارتی در کنار نشان دادن نقاط داده پرجمعیت که به مناطق مورد نظر اشاره دارد، انجام شد. سپس تجزیه و تحلیل نقشه حرارتی توسط خوشهبندی DBSCAN و خوشهبندی K-means، یکی در هر مجموعه داده با 50 شناسه خوشه دنبال شد. نمودارهای آماری مربوطه با استفاده از جعبه ابزار پردازش QGIS برای اعتبارسنجی نتایج تجسم تولید شد.
8. نتایج و بحث
در این بخش، دادههای بزرگ جغرافیایی پس از پردازش با قابلیتهای متعدد به تصویر کشیده شد. مجموعه داده در نظر گرفته شده ممکن است به عنوان یک داده بزرگ مکانی عمل کند. چارچوب پیشنهادی استفاده از الگوی محاسباتی بدون سرور را پیشنهاد میکند. در حال حاضر، پردازش داده های مکانی از طریق معماری بدون سرور یک کار دشوار است. ما خروجیها را روی بسته نرمافزاری QGIS، که از Python در انتهای خود استفاده میکند، تجسم کردیم. ابزار در نظر گرفته شده برای پیاده سازی بر روی یک چارچوب بدون سرور مناسب بود.
8.1. مطالعه موردی 1: نقشه برداری و تجزیه و تحلیل منابع معدنی جهان
8.1.1. مشخصات مجموعه داده
مجموعه داده سیستم داده منابع معدنی (MRDS) اطلاعاتی را در مورد منابع معدنی در سراسر جهان ارائه می دهد که شامل منابع فلزی و غیرفلزی می شود. ویژگی های مختلفی مانند موقعیت جغرافیایی، انواع کانی ها و نام آنها و سایر ویژگی های فیزیکی و جغرافیایی را تشکیل می دهد. در این مطالعه، پتانسیل منابع معدنی در سراسر جهان در مناطق مختلف مورد تجزیه و تحلیل قرار گرفت و نقشههای جغرافیایی مربوطه ارائه شد. پتانسیل کالاهای معدنی مربوط به یک منطقه جغرافیایی خاص نشان دهنده احتمال وقوع برای منابع معدنی در سراسر یک منطقه خاص است [ 49 ، 50 ]]. اطلاعات مربوط به ذخایر معدنی را می توان در یک حوزه فضایی عظیم به دست آورد و می تواند در توسعه پایگاه داده های جغرافیایی برای انجام برخی وظایف تخصصی استفاده شود. اینها عبارتند از پرس و جو، تجسم، تجزیه و تحلیل و به روز رسانی اطلاعات مکانی. نقشه های همپوشانی سفارشی برای کالاهای معدنی مختلف با استفاده از ابزار QGIS برای مجموعه داده MRDS تولید شد. این امر مطالعه توزیع منابع معدنی مختلف در حوزه فضایی گسترده را تسهیل کرد. شناسایی مرزهای جغرافیایی مختلف بر اساس در دسترس بودن منابع معدنی قابل انجام است. در این مقاله، DBSCAN [ 51] الگوریتم، یک تکنیک خوشهبندی مبتنی بر چگالی که به طور رایج برای شناسایی اطلاعات متراکم از یک فضای ویژگی مشخص استفاده میشود، پیادهسازی شد. در اینجا، تکنیک DBSCAN برای شناسایی مناطق جغرافیایی با منابع معدنی متراکم در مقایسه با مناطق با تراکم وقوع کمتر استفاده شد. این تکنیک برای کشف ویژگی های پراکنده متراکم در حوزه های فضایی بزرگ بسیار محبوب است [ 52 , 53 ]] زیرا می تواند به صورت تطبیقی نویزهای مرتبط با داده ها را بدون تأثیر بر عملکرد الگوریتم کنترل کند. این چارچوب میتواند منجر به پیشبینی تولیدات معدنی آینده و تجزیه و تحلیل فضایی آنها با ادغام دادههای مکانی در دسترس محلی با مجموعه دادههای جغرافیایی از راه دور شود. ادغام این خدمات با پلتفرم بدون سرور میتواند منجر به پیچیدگیهای محاسباتی کمتر و همچنین کاهش زمان انتظار شود که معمولاً برای پردازش دادههای مکانی عظیم در برنامههای تقریباً بلادرنگ مطلوب است. کل دادههای موجود در مجموعه داده 304633 ردیف است که نشان میدهد دادهای با ابعاد بالا است.
8.1.2. تجسم مجموعه داده MRDS
همپوشانی وزنی که نقاط داده تولید شده برای نمونه های مجموعه داده MRDS روی نقشه خیابان باز را مشخص می کند در شکل 8 نشان داده شده است. تولید همپوشانی وزنی وظیفه اصلی برای تجسم بیشتر نقاط داده با استراتژی های تجسم متعدد است. شکل 9 تجزیه و تحلیل خوشه نقطه ای را برای مجموعه داده MRDS نشان می دهد. دایره های کوچک قهوه ای و مثلث های قرمز به ترتیب نشان دهنده نقاط و خوشه ها هستند. تجزیه و تحلیل نقطه-خوشه با تولید نقشه حرارتی دنبال شد که در شکل 10 نشان داده شده است.. نقشه حرارتی مناطق بسیار متراکم را شناسایی می کند که حداکثر نقاط داده در آن قرار دارند. نقشه حرارتی به ما این امکان را می دهد که مناطق مورد نظر را که می توانند بر اساس شدت رنگ متمایز شوند، مشخص کنیم. مکانیسم خوشهبندی مورد استفاده روی این مجموعه داده، خوشهبندی DBSCAN بود که با استفاده از سه پارامتر eps ، minpts و تعداد خوشهها پیادهسازی شد. در اینجا، تعداد خوشه ها روی 50 تنظیم شد. نتایج برای خوشه بندی DBSCAN در شکل 11 نشان داده شده است و منطقه بسیار متراکم مربوطه با شناسه خوشه اختصاص داده شده 1 در شکل 12 نشان داده شده است . برای اعتبار سنجی مکانیسم خوشه بندی، نمودار نوار آماری برای ویژگی های Country و Cluster ID برای تجسم 50 خوشه مربوط به کشورهای نشان داده شده در تولید شد.شکل 13 . نمودار میانگین و انحراف استاندارد در شکل 14، که بین ویژگی های Region و MRDS-ID رسم می شود. این نشان دهنده منابع معدنی موجود در مناطق مختلف در سراسر جهان است. حداکثر مقدار متناظر، مقدار میانگین و مقدار حداقل مشاهده می شود. برچسب ها را نمی توان در نقشه ها ارائه کرد زیرا مجموعه داده ها به عنوان یک SBD عمل می کنند و تجزیه و تحلیل چنین داده هایی بر روی موتورهای محلی عملاً کار دشواری است.
8.2. مطالعه موردی 2: پیش بینی خانوار برای شهرستان فیرفکس
8.2.1. مشخصات مجموعه داده
ما مجموعه داده پیشبینی خانوار منتشر شده توسط GIS شهرستان فیرفکس را در نظر گرفتیم که پیشبینی 30 ساله خانوارها را در منطقه فیرفکس ارائه میدهد. مجموعه داده متشکل از مقادیر طول و عرض جغرافیایی به منظور پیش بینی مکانی [ 54 ] است. واحدهای مسکونی در سطح بسته ردیابی شدند. مجموعه داده شامل شناسههای بسته، تخمینهای حداکثر احتمال (MLE) خانوارهای اخیراً توسعهیافته، کد کاربری زمین (LUC)، نوع واحد مسکونی (یعنی تک خانواده، واحد چندگانه، واحد خانه شهری، واحد دوبلکس و غیره)، مساحت است. در هکتار و سالهای مربوط به تأسیس واحدهای مسکونی. کل داده های موجود در مجموعه داده 342308 ردیف است. که بیانگر این است که داده ای با ابعاد بالا است.
8.2.2. تجسم مجموعه داده های خانواده پیش بینی Fairfax
تحلیل همپوشانی وزنی برای پیشبینی خانوارهای 30 ساله شهرستان فیرفکس در نقشه خیابان باز ایجاد شد. نقاط داده روی نقشه در جایی که هر نقطه داده به هر ردیف یا به طور متناوب یک ویژگی از مجموعه داده اشاره دارد، تجسم شدند. پوشش وزنی در شکل 15 نشان داده شده است . تجزیه و تحلیل نقطه-خوشه برای مجموعه داده در نظر گرفته شده در شکل 16 نشان داده شده است که در آن دایره های قهوه ای کوچک و مربع های قرمز به ترتیب نشان دهنده نقاط و خوشه ها هستند. نقشه حرارتی تولید شده با شدت رنگ های مختلف برای تعیین منطقه بسیار متراکم در شکل 17 نشان داده شده است . روش خوشهبندی K-means که با 50 خوشه استفاده میشود، زودتر از مطالعه موردی 1 پردازش شد و میتوان آن را در شکل 18 قابل مشاهده است.. نمودار بین شناسه شی و خانوارهای پیشبینیشده برای سال 30 یک قطعه نوار بود که در شکل 19 مشاهده میشود . علاوه بر این، نمودار میانگین آماری و انحراف معیار برای شناسه خوشه در مقابل خانوارهای پیش بینی شده برای سال 30 که 50 شناسه خوشه را در رنگ های متنوع نشان می دهد در شکل 20 ارائه شده است . این مجموعه داده همچنین به عنوان SBD عمل می کند.
اجرای این تجسمها زمان زیادی را میطلبد و بنابراین چارچوب پیشنهادی راهحلی برای مقابله با محدودیت زمانی با استفاده از الگوی محاسباتی بدون سرور برای کاهش زمان مربوط به تجزیه و تحلیل چنین دادههای بزرگ و تولید همزمان نتایج سریعتر ارائه میدهد. ما دو مجموعه داده بزرگ جغرافیایی را با استفاده از بسته منبع باز QGIS با یک جهت تحقیقاتی آینده به سمت همگرایی ابزار تجسم با یک محیط محاسباتی بدون سرور تجزیه و تحلیل کردیم.
9. اجرا در سطح اجرای مطالعه تجربی
مشخصات سخت افزاری موتور محلی که آزمایش بر روی آن انجام شده است شامل یک CPU Intel Core i5-8265U، 8.00 گیگابایت رم، سیستم عامل 64 بیتی Windows 10 Home Single Language 2019، یک درایو حالت جامد 256 گیگابایتی و یک هارد دیسک 1 ترابایتی است. . در این بخش، عملکرد سطح اجرا را برای هر عملیات انجام شده با استفاده از ابزار QGIS مقایسه می کنیم. برای دو مطالعه موردی کاربردی، ما عملیات های مختلفی مانند تجزیه و تحلیل همپوشانی وزنی، تجزیه و تحلیل خوشه نقطه ای، تولید نقشه حرارتی و تجزیه و تحلیل خوشه فضایی را انجام دادیم. زمان اجرا برای انجام عملیات فوق مقایسه شد.شکل 21مقایسه بین زمان اجرا (در نظر گرفته شده بر حسب ثانیه) برای انجام تجزیه و تحلیل همپوشانی وزنی، تجزیه و تحلیل خوشه نقطه و تولید نقشه حرارتی مربوط به دو مطالعه موردی را فراهم می کند. با توجه به واریانس قابل توجه در مقیاس، زمان های اجرا برای انجام تجزیه و تحلیل خوشه ای به طور جداگانه در شکل 22 نشان داده شده است.. در اینجا، زمان اجرا مربوط به دو مطالعه موردی برای دو تکنیک مختلف خوشهبندی، یعنی خوشهبندی K-means و الگوریتم DBSCAN ارائه شده است. شایان ذکر است که دادههای MRDS در نظر گرفته شده در مطالعه موردی 1 از نظر محاسباتی برای انجام عملیات مکانی با استفاده از موتورهای محلی بسیار فشرده است زیرا زمان صرف شده برای تشکیل خوشههای فضایی با استفاده از تکنیک DBSCAN 23 دقیقه و 10 ثانیه (≈1390 ثانیه) است. از این رو، پلت فرم محاسباتی بدون سرور برای انجام چنین محاسبات پیچیده ای اجتناب ناپذیر است.
10. چالش های معماری و سطح خدمات
در این مقاله، ما بینشی نسبت به ادغام پلت فرم بدون سرور با چارچوب GIS برای پردازش پیشرفته دادههای بزرگ جغرافیایی ارائه کردیم. اگرچه شرکت های مختلف جهانی مانند آمازون، گوگل و مایکروسافت مدل کار بدون سرور را برای برآورده کردن نیازهای محاسباتی پیشرفته کاربران خود اتخاذ کرده اند. با این حال، هنوز چالشهای معماری و همچنین سطح خدمات متعددی وجود دارد که قبل از اتخاذ کامل این پلتفرمها نیاز به بررسی دارد [ 8 ]. در زیر برخی از مسائل و چالش های مهم برای ادغام پارادایم های محاسباتی بدون سرور در ارتباط با تجزیه و تحلیل داده های مکانی را مورد بحث قرار می دهیم:
-
پیچیدگی مرتبط با پردازش داده های عظیم مکانی برای ایجاد برنامه کاربردی خاص مشتری، چالش های معماری را در موتورهای محلی ایجاد می کند. ما به دنبال استفاده از پلتفرم های بدون سرور برای اجرای آنها هستیم. همانطور که در بخش 5 مورد بحث قرار گرفت ، معماری میکروسرویس می تواند به طور موثر در این سناریو برای پیاده سازی برنامه های کاربردی پیچیده با تقسیم آنها به زیر ماژول های ساده تر مورد استفاده قرار گیرد و در نتیجه انعطاف پذیری بیشتر و نتایج سریعتر برای کاربران فراهم شود. با این حال، این معماری در سناریوی بدون سرور هنوز یک موضوع بسیار مورد بحث است زیرا هیچ استاندارد خاصی برای یکپارچهسازی این نتایج برای دستیابی به برنامههای کاربردی مکانی کاملاً قابل استفاده ارائه نشده است.
-
ابزار GIS در حال حاضر برای ایجاد پایگاه های اطلاعاتی مکانی استفاده می شود. با این حال، تجسم آنها فاقد بسته های قطعی مناسب برای پشتیبانی از معماری بدون سرور است.
-
همانطور که نیازهای محاسباتی با افزایش داده های مکانی به دست آمده افزایش می یابد، توابع بیشتری برای انجام عملیات مورد نظر مورد نیاز است. اکثر پلتفرمهای محاسباتی بدون سرور موجود، فاقد تعداد کافی توابع برای اجرای تعداد فزاینده درخواستهای دریافتی هستند. به عنوان مثال، پلتفرم بدون سرور Google Cloud تنها 1000 عملکرد را در هر 297 پروژه ارائه می کند.
-
از آنجایی که دادههای مکانی لزوماً ممکن است شامل اطلاعات جغرافیایی باشد که ممکن است اطلاعات مکان واقعی را در بر بگیرد، بنابراین امنیت و حریم خصوصی این اطلاعات باید حفظ شود. معماری بدون سرور به دلیل ماهیت غیرمتمرکز خود، فاقد کنترل متمرکز بر فعالیتهای شبکه است. بنابراین داده ها در معرض نقض امنیت قرار می گیرند.
11. جهت گیری تحقیقات آینده
حوزه محاسبات بدون سرور ثابت کرده است که یک راه حل FaaS بسیار کارآمد است. مدیریت داده های پیچیده ممکن است یکی از محدودیت های یک الگوی محاسباتی بدون سرور باشد. محاسبات بدون سرور نشان دهنده یک مدل Pay-as-you-Go است. با این حال، پیچیدگی زمانی مرتبط با استقرار بلوکهای پیچیده کد به بهینهسازیهای بیشتری نیاز دارد تا نیازهای مشتری را برآورده کند. SBD به پردازش پیچیده نیاز دارد و برای اینکه توسعهدهنده را از پردازش قطعه کد معاف کنیم، به صلاحیت بیشتر چارچوبهای بدون سرور نیاز داریم. جهت گیری های تحقیقاتی آتی را می توان به صورت زیر خلاصه کرد:
-
بهینه سازی داده های مکانی یک نگرانی اصلی در زمینه استقرار داده های GIS در یک پلت فرم بدون سرور است. دلیل آن هزینه ای است که فرد برای پردازش و استقرار قطعه کد بهینه نشده روی هر چارچوب بدون سرور می پردازد.
-
تکنیکهای استفاده از منابع به تحقیقات بیشتری نیاز دارند تا اندازه کدهایی را که میتوان در یک شکاف زمانی واحد در یک پلتفرم بدون سرور اجرا کرد، بهبود بخشید.
-
برنامههای افزودنی کدهایی که در حال حاضر پشتیبانی میشوند باید برای پیادهسازی قطعههای کد حداقل آن دسته از برنامههای افزودنی که در جامعه محاسباتی امروزی محبوب هستند، ارتقا یابند.
-
کاربرد جغرافیایی در زمینههای کشاورزی، تجزیه و تحلیل جرم، تصاویر ماهوارهای و بسیاری از این قبیل نیازمند تحقیقات بیشتر برای ارائه یک پلتفرم انحصاری مبتنی بر پایتون برای پیادهسازی آسانتر در هر پارادایم محاسباتی بدون سرور است.
-
بهینهسازی کد یک چالش بزرگ است که باید به گونهای با آن برخورد شود که پیادهسازی برنامههای GIS در یک پلتفرم بدون سرور ارزشمند باشد.
12. نتیجه گیری
محاسبات بدون سرور در سال های آینده یک پلت فرم غالب خواهد بود. در این مقاله، ما چارچوبی را برای برنامههای فضایی برای اجرای یک الگوی محاسباتی بدون سرور پیشنهاد کردیم. محاسبات کاربردی جغرافیایی مورد نیاز پیچیده هستند. بسیاری از پلتفرمهای بدون سرور موجود میتوانند قطعههای کد نوشته شده در Node.js، جاوا، سی شارپ و پایتون را بسازند، اشکالزدایی کنند، مستقر کنند و اجرا کنند. مشکل برنامه های مکانی این است که از ابزارهای خاصی برای اجرا مانند QGIS، ArcGIS و غیره استفاده می کند. چارچوب پیشنهادی استفاده از کتابخانههای پایتون را برای پردازش دادههای مکانی پیشنهاد میکند. از آنجایی که قطعه کد در پایتون برای AWS Lambda، Google Cloud Functions و Microsoft Azure Functions قابل قبول است، چارچوب پیشنهادی یک جهت تحقیقاتی آینده را به سمت پیادهسازی قطعههای کد جغرافیایی کدگذاریشده در پایتون برای ساخت موفقیتآمیز در یک محیط بدون سرور ارائه میدهد. نتایج ارائهشده بر تجزیه و تحلیل دادههای مکانی با کمک ابزاری متمرکز است که پایتون در انتهای آن کار میکند. این ابزار را میتوان برای ادغام چارچوبهای محاسباتی بدون سرور برای کاهش محدودیتهای زمانبندی مرتبط، بداهه ساخت. شایستگی پلتفرمهای بدون سرور در نظر گرفته شده برای بسیاری از محققان شناخته شده است، ما سعی کردیم با تعبیه آن در یک الگوی محاسباتی بدون سرور، رویکرد جدیدی را برای کاهش پیچیدگی پردازش و محدودیتهای زمانبندی مرتبط با برنامههای مکانی ارائه کنیم. در این مقاله، چالش های معماری و سطح خدمات ارائه شده است تا خواننده را از محدودیت های ناشی از چارچوب پیشنهادی آگاه کند.
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| GIS | سیستم های اطلاعات جغرافیایی |
| MRDS | سیستم داده منابع معدنی |
| BaaS | Back-end به عنوان یک سرویس. |
| فاس | عملکرد به عنوان یک سرویس |
| DMET | آنزیم ها و ناقلین متابولیسم دارو |
| AWS | خدمات وب آمازون |
| SNP | پلی مورفیسم های تک نوکلئوتیدی |
| جی پی اس | سیستم موقعیت یاب جهانی. |
| IaaS | زیرساخت به عنوان یک سرویس |
| CPU | واحد پردازش مرکزی. |
| SBA | رویکرد مبتنی بر سرور |
| SLA | رویکرد بدون سرور |
| CI | یکپارچه سازی مداوم |
| سی دی | تحویل مستمر. |
| SDI | زیرساخت داده های مکانی |
| آمازون S3 | سرویس ذخیره سازی ساده آمازون. |
| DBSCAN | خوشه بندی فضایی مبتنی بر چگالی برنامه های کاربردی با نویز. |
| SBD | داده های بزرگ فضایی |
| SAR | مدل خودرگرسیون فضایی. |
| QGIS | سیستم های اطلاعات جغرافیایی کوانتومی |
| API | رابط برنامه نویسی کاربردی |
| ITU-T | بخش استانداردسازی مخابرات اتحادیه بین المللی مخابرات. |
| QoS | ارزش خدمات. |
| MLE | برآورد حداکثر احتمال. |
| LUC | کد کاربری زمین |
منابع
- دلد، جی. گروپمن، جی. آینده هوش مکانی. ژئو اسپات. Inf. علمی 2017 ، 20 ، 151-162. [ Google Scholar ] [ CrossRef ]
- سوئیل، پ. برگر، ا. دی مارکی، دی. کمپینرز، پی. رودریگز، دی. سیریس، وی. Vasilev, V. یک پلت فرم محاسباتی همه کاره با داده فشرده برای بازیابی اطلاعات از داده های بزرگ جغرافیایی. ژنرال آینده. محاسبه کنید. سیستم 2018 ، 81 ، 30-40. [ Google Scholar ] [ CrossRef ]
- Iosifescu-Enescu، I.; ماتیس، سی. گکونوس، سی. ایوسیفسکو-انسکو، سی. Hurni، L. معماریهای مبتنی بر ابر برای ژئوپورتالهای وب مقیاسپذیر خودکار به سمت Cloudification GeoVITe Geoportal دانشگاهی سوئیس. ISPRS Int. J. Geo-Inf. 2017 ، 6 ، 192. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- باریک، RK; کندپال، م. دوبی، اچ. کومار، وی. Das, H. Geocloud4GI: Cloud SDI Model for Geographical Indications Information Infrastructure Network. که در رایانش ابری برای تجزیه و تحلیل داده های بزرگ جغرافیایی ؛ Springer: برلین/هایدلبرگ، آلمان، 2019؛ صص 215-224. [ Google Scholar ]
- باریک، RK; دوبی، اچ. مانکودیا، ک. ساسان، SA; Misra, C. GeoFog4Health: یک چارچوب SDI مبتنی بر مه برای تجزیه و تحلیل داده های بزرگ سلامت جغرافیایی. J. هوش محیطی. اومانیز. محاسبه کنید. 2019 ، 10 ، 551-567. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رابرتز، ام. چاپین، جی. بدون سرور چیست؟ O’Reilly Media Incorporated: Sebastopol, CA, USA, 2017. [ Google Scholar ]
- بالدینی، آی. کاسترو، پی. چانگ، ک. چنگ، پی. فینک، اس. اساکیان، وی. میچل، ن. موثامی، وی. رباح، ر. اسلومینسکی، آ. و همکاران محاسبات بدون سرور: روندهای فعلی و مشکلات باز که در پیشرفت های تحقیقاتی در رایانش ابری ؛ Springer: برلین/هایدلبرگ، آلمان، 2017; ص 1-20. [ Google Scholar ]
- طیبی، د. ال یوینی، ن. پهل، سی. Niederkofler، JRS Patterns for Serverless Functions (Function-as-a-Service): A Multivocal Literature Review. در مجموعه مقالات دهمین کنفرانس بینالمللی علوم رایانش ابری و خدمات، CLOSER 2020، پراگ، جمهوری چک، 7 تا 9 مه 2020. [ Google Scholar ]
- Hellerstein, JM; فالیرو، جی. گونزالس، جی. شلایر اسمیت، جی. سریکانتی، وی. تومانوف، آ. Wu, C. محاسبات بدون سرور: یک قدم به جلو، دو قدم به عقب. arXiv 2018 , arXiv:1812.03651. [ Google Scholar ]
- شکر، س. گونتوری، وی. ایوانز، ام آر. یانگ، ک. چالشهای دادههای بزرگ فضایی متقاطع تحرک و محاسبات ابری. در مجموعه مقالات یازدهمین کارگاه بین المللی ACM در مورد مهندسی داده برای دسترسی بی سیم و موبایل، اسکاتسدیل، AZ، ایالات متحده آمریکا، 20 مه 2012. صص 1-6. [ Google Scholar ]
- Crespo-Cepeda، R. آگاپیتو، جی. وازکز پولتی، جی.ال. Cannataro، M. چالش ها و فرصت های خدمات لامبدا بدون سرور آمازون در بیوانفورماتیک. در مجموعه مقالات دهمین کنفرانس بین المللی ACM در بیوانفورماتیک، زیست شناسی محاسباتی و انفورماتیک سلامت، آبشار نیاگارا، نیویورک، ایالات متحده آمریکا، 7 تا 10 سپتامبر 2019؛ صص 663-668. [ Google Scholar ]
- نیو، ایکس. کومانوف، دی. آویزان، LH; لوید، دبلیو. Yeung، KY استفاده از محاسبات بدون سرور برای بهبود عملکرد برای مقایسه توالی. در مجموعه مقالات دهمین کنفرانس بین المللی ACM در بیوانفورماتیک، زیست شناسی محاسباتی و انفورماتیک سلامت، آبشار نیاگارا، نیویورک، ایالات متحده آمریکا، 7 تا 10 سپتامبر 2019؛ صص 683-687. [ Google Scholar ]
- کیم، ی. Lin, J. تجزیه و تحلیل داده های بدون سرور با سنگ چخماق. در مجموعه مقالات یازدهمین کنفرانس بین المللی IEEE 2018 در محاسبات ابری (CLOUD)، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 2 تا 7 ژوئیه 2018؛ ص 451-455. [ Google Scholar ]
- اساکیان، وی. موثامی، وی. Slominski، A. ارائه مدل های یادگیری عمیق در یک پلت فرم بدون سرور. در مجموعه مقالات کنفرانس بین المللی IEEE 2018 در مهندسی ابر (IC2E)، اورلاندو، FL، ایالات متحده آمریکا، 17 تا 20 آوریل 2018؛ صص 257-262. [ Google Scholar ]
- آناند، اس. جانسون، ا. ماتیکشارا، پ. Karthik, R. ردیابی GPS بلادرنگ با استفاده از معماری بدون سرور و پردازنده ARM. در مجموعه مقالات یازدهمین کنفرانس بینالمللی سیستمها و شبکههای ارتباطی 2019 (COMSNETS)، بنگلور، هند، 7 تا 11 ژانویه 2019؛ صص 541-543. [ Google Scholar ]
- مالاوسکی، م. گاجک، ع. زیما، ع. بالیس، بی. Figiela، K. اجرای بدون سرور جریانهای کاری علمی: آزمایشهایی با hyperflow، AWS lambda و توابع ابری Google. ژنرال آینده. محاسبه کنید. سیستم 2017 . [ Google Scholar ] [ CrossRef ]
- Varghese, B. Buyya, R. محاسبات ابری نسل بعدی: روندهای جدید و جهت گیری های تحقیقاتی. ژنرال آینده. محاسبه کنید. سیستم 2018 ، 79 ، 849-861. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، اچ. ساتیام، ک. فاکس، جی. ارزیابی محیطهای محاسباتی بدون سرور تولید. در مجموعه مقالات یازدهمین کنفرانس بین المللی IEEE 2018 در محاسبات ابری (CLOUD)، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 2 تا 7 ژوئیه 2018؛ صص 442-450. [ Google Scholar ]
- Goodchild، MF; فو، پی. Rich, P. به اشتراک گذاری اطلاعات جغرافیایی: ارزیابی یک مرحله ای جغرافیایی. ان دانشیار صبح. Geogr. 2007 ، 97 ، 250-266. [ Google Scholar ] [ CrossRef ]
- ششی، س. پایگاه داده های فضایی ; آموزش پیرسون: بنگالورو، هند، 2007. [ Google Scholar ]
- یانگ، سی. لی، دبلیو. زی، جی. Zhou، B. پردازش اطلاعات مکانی توزیع شده: به اشتراک گذاری منابع جغرافیایی توزیع شده برای پشتیبانی از زمین دیجیتال. بین المللی جی دیجیت. زمین 2008 ، 1 ، 259-278. [ Google Scholar ] [ CrossRef ]
- اسکامیلا-آمبروسیو، پی. رودریگز-موتا، آ. آگویر-آنایا، ای. آکوستا برمجو، آر. Salinas-Rosales، M. توزیع محاسبات در اینترنت اشیا: مروری بر محاسبات ابر، مه و لبه. در NEO 2016 ؛ Springer: برلین/هایدلبرگ، آلمان، 2018; صص 87-115. [ Google Scholar ]
- باریک، RK; دوبی، اچ. Mankodiya، K. SOA-FOG: معماری محاسبات لبه ای خدمات محور برای تجزیه و تحلیل داده های بزرگ سلامت هوشمند. در مجموعه مقالات کنفرانس جهانی IEEE 2017 در مورد پردازش سیگنال و اطلاعات (GlobalSIP)، مونترال، QC، کانادا، 14 تا 16 نوامبر 2017؛ ص 477-481. [ Google Scholar ]
- محاسبات هیگاشینو، تی. اج برای کنترلهای همزمان مشارکتی با استفاده از دادههای بزرگ جغرافیایی. در سنسورها و سیستم های هوشمند ؛ Springer: برلین/هایدلبرگ، آلمان، 2017; صص 441-466. [ Google Scholar ]
- کائو، ایکس. Madria، S. جمع آوری داده های مکانی کارآمد در شبکه های IoT برای محاسبات لبه موبایل. در مجموعه مقالات 2019 IEEE هجدهمین سمپوزیوم بین المللی محاسبات شبکه و برنامه های کاربردی (NCA)، کمبریج، MA، ایالات متحده آمریکا، 26-28 سپتامبر 2019؛ صص 1-10. [ Google Scholar ]
- سیمفرم. توابع AWS Lambda در مقابل Azure Functions در مقابل Google Cloud Functions: مقایسه ارائه دهندگان بدون سرور. 2018. در دسترس آنلاین: www.simform.com/aws-lambda-vs-azure-functions-vs-google-functions (در 1 مه 2020 قابل دسترسی است).
- وانگ، ی. لیو، ز. لیائو، اچ. لی، سی. بهبود عملکرد محاسبات همپوشانی چند ضلعی GIS با MapReduce برای پردازش داده های بزرگ فضایی. خوشه. محاسبه کنید. 2015 ، 18 ، 507-516. [ Google Scholar ] [ CrossRef ]
- گترل، AC؛ بیلی، تی سی؛ دیگل، پی جی؛ رولینگسون، BS تحلیل الگوی نقطهای فضایی و کاربرد آن در اپیدمیولوژی جغرافیایی. ترانس. Inst. برادر Geogr. 1996 ، 21 ، 256-274. [ Google Scholar ] [ CrossRef ]
- جیانگ، ز. Shekhar, S. علم داده های بزرگ فضایی و مکانی-زمانی. در علم داده های بزرگ فضایی ; Springer: برلین/هایدلبرگ، آلمان، 2017; صص 15-44. [ Google Scholar ]
- شکر، س. ایوانز، ام آر. کانگ، جی.ام. Mohan, P. شناسایی الگوها در اطلاعات مکانی: بررسی روشها. در بررسی های میان رشته ای وایلی: داده کاوی و کشف دانش ; وایلی: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2011; جلد 1، ص 193-214. [ Google Scholar ]
- ژو، سی. فرانکوفسکی، دی. لودفورد، پی. شکر، س. تروین، ال. کشف مکانهای معنادار شخصی: رویکرد خوشهبندی تعاملی. ACM Trans. Inf. سیستم (TOIS) 2007 ، 25 ، 12-es. [ Google Scholar ] [ CrossRef ]
- کاگلر، دی سی; الیور، دی. ایوانز، ام آر. شکر، س. Medeiros، CB Spatial Big Data: Platforms، Analytics و Science. در دسترس آنلاین: https://pdfs.semanticscholar.org/c64e/b7f733cf78573e962c6b5df24860eed3aabe.pdf (دسترسی در 1 مه 2020).
- وتساوایی، ر.ر. گانگولی، ا. چاندولا، وی. استفانیدیس، ا. کلاسکی، اس. Shekhar, S. داده کاوی فضایی و زمانی در عصر داده های مکانی بزرگ: الگوریتم ها و کاربردها. در مجموعه مقالات اولین کارگاه بین المللی ACM SIGSPATIAL در مورد تجزیه و تحلیل برای داده های مکانی بزرگ، ردوندو بیچ، کالیفرنیا، ایالات متحده آمریکا، 6 نوامبر 2012. صص 1-10. [ Google Scholar ]
- ایوانز، ام آر. الیور، دی. یانگ، ک. ژو، ایکس. علی، RY; Shekhar, S. فعال کردن داده های بزرگ فضایی از طریق CyberGIS: چالش ها و فرصت ها. در CyberGIS برای کشف و نوآوری جغرافیایی ؛ Springer: برلین/هایدلبرگ، آلمان، 2019؛ صص 143-170. [ Google Scholar ]
- باریک، RK; دوبی، اچ. صمددار، ع.ب. گوپتا، RD; Ray, PK FogGIS: محاسبات مه برای تجزیه و تحلیل داده های بزرگ جغرافیایی. در مجموعه مقالات کنفرانس بین المللی IEEE Uttar Pradesh Section 2016 در مورد مهندسی برق، کامپیوتر و الکترونیک (UPCON)، بنارس، هند، 9 تا 11 دسامبر 2016؛ صص 613-618. [ Google Scholar ]
- باریک، RK; تریپاتی، ا. دوبی، اچ. لنکا، RK; پراتیک، تی. شارما، اس. مانکودیا، ک. کومار، وی. Das، H. Mistgis: بهینه سازی تجزیه و تحلیل داده های مکانی با استفاده از محاسبات مه. در حال پیشرفت در محاسبات، تجزیه و تحلیل و شبکه ؛ Springer: برلین/هایدلبرگ، آلمان، 2018; صص 733-742. [ Google Scholar ]
- Blower، JD GIS در ابر: پیادهسازی یک سرویس نقشه وب در موتور برنامه Google. در مجموعه مقالات اولین کنفرانس بین المللی و نمایشگاه محاسبات برای تحقیقات و کاربردهای زمین فضایی، واشنگتن، دی سی، ایالات متحده آمریکا، 21 تا 23 ژوئن 2010. پ. 34. [ Google Scholar ]
- آپوستو، ا. پویکان، اف. اولارو، جی. سوسیو، جی. تودوران، جی. مطالعه مزایا و معایب رایانش ابری – مزایای کاربردهای تله متری در فضای ابری. Recent Adv. Appl. محاسبه کنید. علمی رقم. خدمت 2013 ، 2103 ، 118-123. [ Google Scholar ]
- یانگ، سی. Huang، Q. محاسبات ابری فضایی: یک رویکرد عملی . CRC Press: Boca Raton، FL، USA، 2013. [ Google Scholar ]
- سیکورا، پ. اشنابل، او. Enescu، II; Hurni، L. رابط های نقشه برداری توسعه یافته برای پردازش باز توزیع شده. کارتوگر. بین المللی جی. جئوگر. Inf. جئوویس. 2007 ، 42 ، 209-218. [ Google Scholar ] [ CrossRef ]
- کاظمی تبار، SJ; بنایی کاشانی، ف. McLeod, D. Geostreaming در ابر. در مجموعه مقالات دومین کارگاه بین المللی ACM SIGSPATIAL درباره ژئواستریمینگ، شیکاگو، IL، ایالات متحده آمریکا، 1 نوامبر 2011. صص 3-9. [ Google Scholar ]
- PyPI. کتابخانه نقشه نگاری پایتون با پشتیبانی از Matplotlib برای تجسم. 2018. موجود آنلاین: pypi.org/project/Cartopy (در 1 مه 2020 قابل دسترسی است).
- PyPI. اجسام هندسی، محمولات و عملیات. 2018. در دسترس آنلاین: pypi.org/project/Shapely (در 1 مه 2020 قابل دسترسی است).
- PyPI. فیونا فایل های داده های مکانی را می خواند و می نویسد. 2019. در دسترس آنلاین: pypi.org/project/Fiona (در 1 مه 2020 قابل دسترسی است).
- PyPI. رابط پایتون به PROJ (کتابخانه پیش بینی های نقشه برداری و تبدیل مختصات). 2019. در دسترس آنلاین: pypi.org/project/pyproj (در 1 مه 2020 قابل دسترسی است).
- PyPI. R-Tree Spatial Index برای Python GIS. 2016. در دسترس آنلاین: pypi.org/project/Rtree (در 1 مه 2020 قابل دسترسی است).
- PyPI. از اشیاء هندسی به عنوان مسیرها و وصله های Matplotlib استفاده کنید. 2017. در دسترس آنلاین: pypi.org/project/descartes (در 1 مه 2020 قابل دسترسی است).
- PyPI. I/O سریع و مستقیم Raster برای استفاده با Numpy و SciPy. 2019. در دسترس آنلاین: pypi.org/project/rasterio (در 1 مه 2020 قابل دسترسی است).
- مک لمور، پتانسیل منابع معدنی VT منطقه وحشی سابینوسو و بنای یادبود ملی ریو گراند دل نورته در شمال شرقی نیومکزیکو. 2018. در دسترس آنلاین: https://geoinfo.nmt.edu/publications/openfile/details.cfml?Volume=599 (در 1 مه 2020 قابل دسترسی است).
- ژو، دبلیو. چن، جی. لی، اچ. لو، اچ. هوانگ، کاربرد SL GIS در تجزیه و تحلیل منابع معدنی – مطالعه موردی طلای پلاسر دریایی دریایی در نوم، آلاسکا. محاسبه کنید. Geosci. 2007 ، 33 ، 773-788. [ Google Scholar ] [ CrossRef ]
- استر، ام. کریگل، اچ پی؛ ساندر، جی. Xu, X. یک الگوریتم مبتنی بر چگالی برای کشف خوشه ها در پایگاه داده های فضایی بزرگ با نویز. Kdd 1996 ، 96 ، 226-231. [ Google Scholar ]
- برایانت، آ. Cios، K. RNN-DBSCAN: یک الگوریتم خوشه بندی مبتنی بر چگالی با استفاده از تخمین تراکم نزدیکترین همسایه معکوس. IEEE Trans. بدانید. مهندسی داده 2018 ، 30 ، 1109–1121. [ Google Scholar ] [ CrossRef ]
- زنگ، ی. ژانگ، اچ. نیش، ز. لیو، ایکس. کروچیانی، ال. Vizzari، G. تشکیل خط در جریان مخالف بر اساس DBSCAN. در مجموعه مقالات چهارمین کارگاه بین المللی ACM SIGSPATIAL در مورد ایمنی و انعطاف پذیری، سیاتل، WA، ایالات متحده آمریکا، 6 نوامبر 2018؛ صص 1-6. [ Google Scholar ]
- GIS، FC پیش بینی خانوارها. 2017. در دسترس آنلاین: https://catalog.data.gov/dataset/forecast-households-371f2 (در تاریخ 1 مه 2020 قابل دسترسی است).
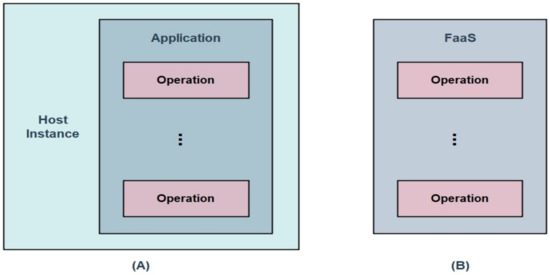
شکل 1. ( A ) رویکرد سنتی برای استقرار نرم افزار در سمت سرور را نشان می دهد. ( B ) رویکرد مبتنی بر توابع به عنوان یک سرویس (FaaS) را برای استقرار نرم افزار مربوط به عملیات های مختلف نشان می دهد.
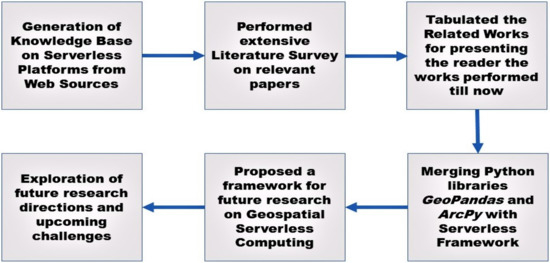
شکل 2. نمایش بصری روش تحقیق در پشت کار تحقیقاتی ما.
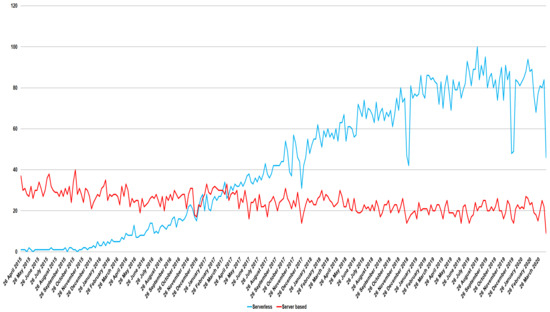
شکل 3. مبادله بین رویکرد بدون سرور و مبتنی بر سرور به دست آمده از Google Trends.
شکل 4. معماری تعمیم یافته برای چارچوب های محاسباتی بدون سرور موجود.
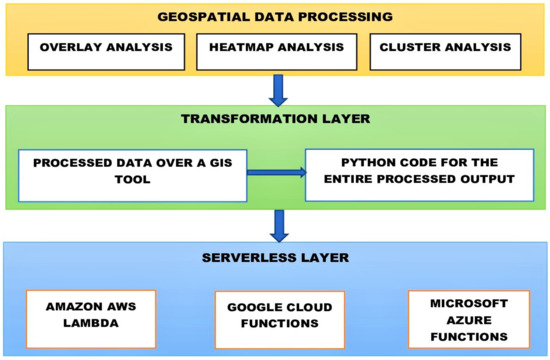
شکل 5. چارچوب پیشنهادی برای استقرار محاسبات بدون سرور جغرافیایی.
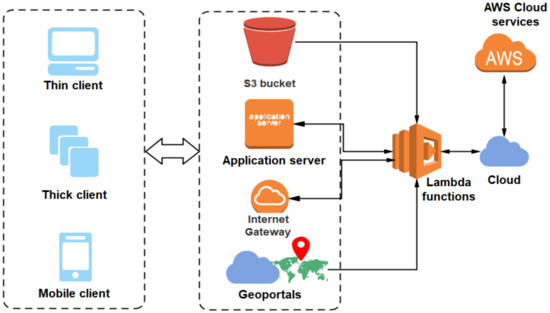
شکل 6. چارچوب بدون سرور برای تجزیه و تحلیل داده های مکانی با خدمات وب آمازون (AWS) Lambda تعبیه شده برای انجام عملکردهای فعال سازی تجزیه و تحلیل داده های مکانی خاص.
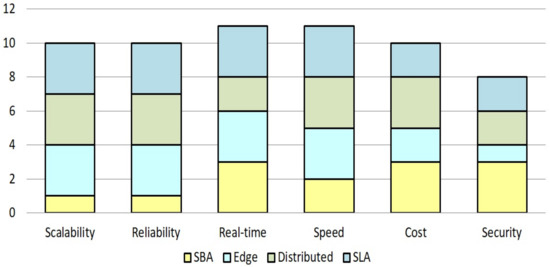
شکل 7. تجزیه و تحلیل کیفی پارامترهای مختلف Ouality of Service (QoS) برای فناوری های مورد مطالعه با چارچوب پیشنهادی رویکرد بدون سرور (SLA).
شکل 8. تحلیل همپوشانی وزنی مجموعه داده سیستم داده منابع معدنی (MRDS) روی نقشه خیابان باز بدون برچسب.
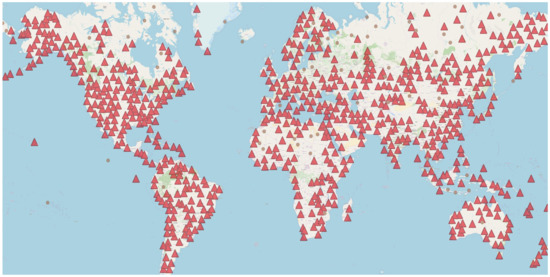
شکل 9. تجزیه و تحلیل خوشه نقطه با خوشه در مثلث قرمز و نقاط در دایره های کوچک قهوه ای.
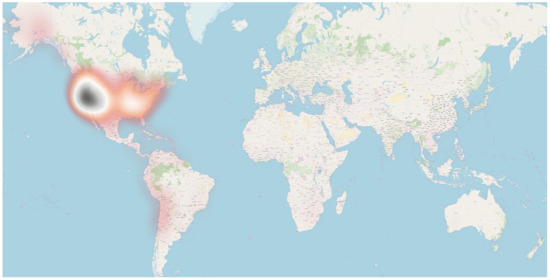
شکل 10. تجزیه و تحلیل نقشه حرارتی برای تعیین منطقه بسیار متراکم با استفاده از رنگ های مختلف بر اساس ویژگی ها.
شکل 11. تجزیه و تحلیل خوشه ای با کمک خوشه بندی فضایی برنامه های کاربردی با نویز مبتنی بر چگالی (DBSCAN) روی نقشه تولید شده.

شکل 12. تجسم یک خوشه منفرد با شناسه خوشه 1، که منطقه بسیار متراکم ایالات متحده طبق مجموعه داده MRDS است.
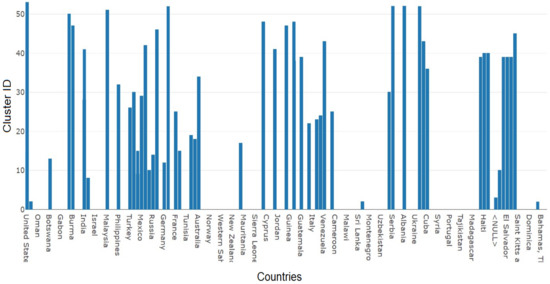
شکل 13. نمودار میله ای بین ویژگی های “country” و “Cluster ID” ایجاد می شود تا مشخص شود کدام کشور متعلق به خوشه DBSCAN است.
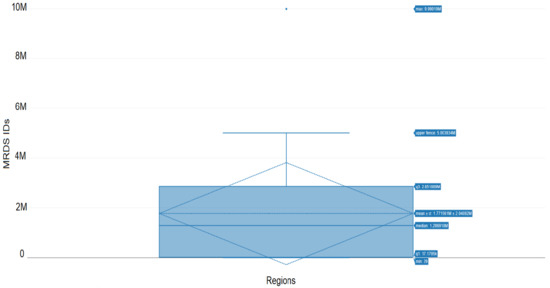
شکل 14. نمودار میانگین و انحراف استاندارد بین ویژگی های “region” و MRDS-ID.
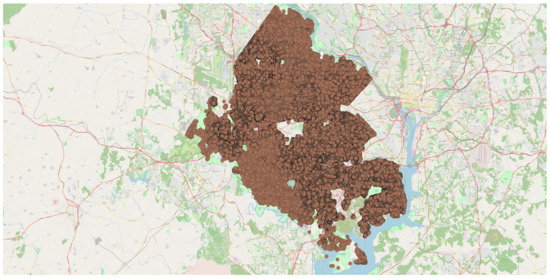
شکل 15. تجزیه و تحلیل همپوشانی وزنی برای نقاط داده ترسیم شده بر روی نقشه خیابان باز.
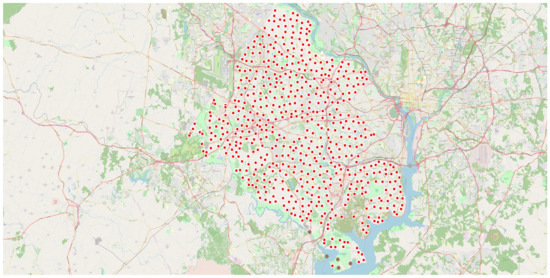
شکل 16. تجزیه و تحلیل نقطه ای-خوشه ای که در آن نقاط با دایره های قهوه ای و خوشه ها با مربع های قرمز نشان دهنده خانوارهای منطقه است.
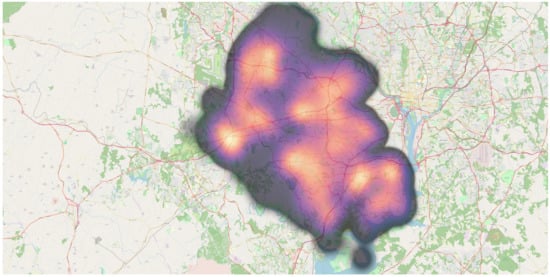
شکل 17. تجزیه و تحلیل نقشه حرارتی برای تعیین مناطق با تراکم بالای خانوارها انجام شد.
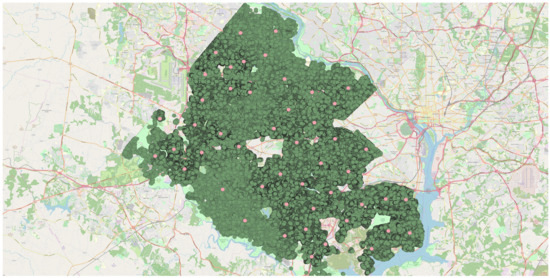
شکل 18. تجزیه و تحلیل خوشه ای با کمک K-means خوشه بندی بر روی نقشه تولید شده با 50 شناسه خوشه.
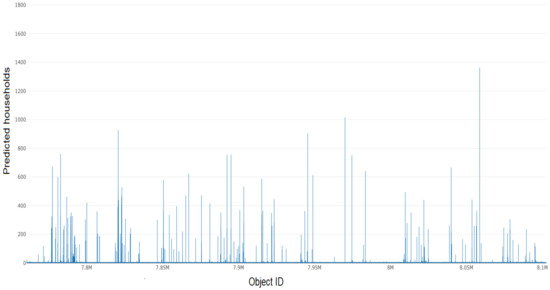
شکل 19. نمودار نواری برای نشان دادن خانوارهای پیش بینی شده برای سال 30 بر اساس شناسه شی.
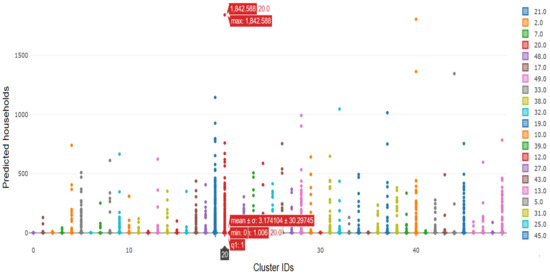
شکل 20. نمودار میانگین و انحراف معیار برای نشان دادن شناسه های خوشه ای K-means مرتبط با خانوارهای پیش بینی شده برای سال 30.
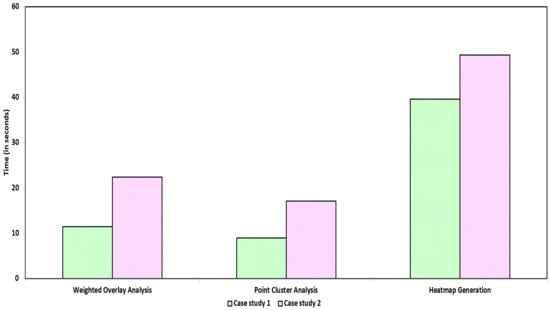
شکل 21. زمان اجرا برای عملیات مختلف انجام شده در مطالعات موردی 1 و 2.
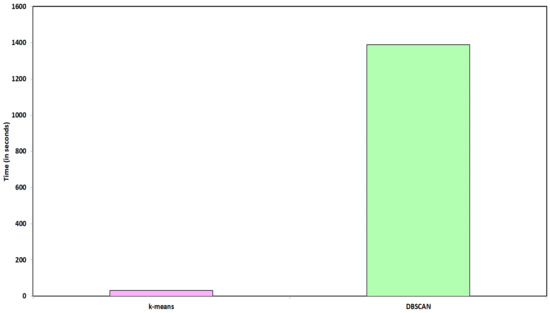
شکل 22. زمان اجرا برای خوشه بندی K-means و الگوریتم های DBSCAN.


بدون دیدگاه