1. معرفی
داشتن یک زندگی شاد و لذت بخش احتمالاً هدف همه افراد در دنیای امروز است. محققان برای چندین دهه کیفیت زندگی را مورد بحث قرار داده اند. در مراحل اولیه تحقیقات کیفیت زندگی (اواسط قرن بیستم)، این موضوع عمدتاً با توسعه اقتصادی مرتبط بود – اصطلاح کیفیت زندگی برای اولین بار توسط سیسیل پیگو، اقتصاددان انگلیسی در دهه 1920 استفاده شد [ 1 ]. به دنبال دوره پیشگام در شکل گیری مفهوم کیفیت زندگی (نشریات جامع منتشر شده، به عنوان مثال، توسط اسمیت، کمپبل و همکاران یا اندروز [ 2 ، 3 ، 4 ]])، دانشمندان به دنبال تعریف بهتر کیفیت زندگی و استخراج روشهایی برای اندازهگیری آن بودهاند. با این حال، کیفیت زندگی یک موضوع پیچیده و چند رشتهای است و هیچ اتفاق نظری در مورد تعریف آن وجود ندارد [ 4 ، 5 ]. تنوع جهتگیریهایی که پژوهش در پیش گرفته است توسط لیو [ 6 ] نشان داده شده است: «به تعداد افراد تعاریف کیفیت زندگی وجود دارد». بسیاری از نویسندگان تعاریف خود را از کیفیت زندگی ارائه کرده اند [ 7 ، 8 ، 9 ، 10 ].
اگرچه کیفیت زندگی متنوع است، برخی توافقات گسترده در بین رشته ها و رویکردها را می توان با توجه به چندین ویژگی شناسایی کرد. یکی از مهم ترین ویژگی های کیفیت زندگی دوگانگی آن است که دو رویکرد اصلی تحقیق را توصیف می کند [ 11 ]. از آنجایی که امکان اندازه گیری مستقیم کیفیت زندگی وجود ندارد، ارزیابی معمولاً بر اساس خودارزیابی ذهنی یا شاخص های نمایان عینی است که حوزه های اصلی کیفیت زندگی را پوشش می دهد.
ارزیابی عینی از شاخصهایی مبتنی بر مقادیر عینی و کمی که در طی بررسیهای آماری جمعآوری شده یا از سایر دادههای اجتماعی-اقتصادی یا مکانی به دست آمده است استفاده میکند. بزرگترین نقطه قوت این گروه از شاخص ها در عینیت آنها نهفته است. آنها را می توان به راحتی و بدون نیاز به بررسی احساسات شخصی، کمیت و تعریف کرد. مقادیر اندازه گیری شده را می توان با اطمینان بیشتری با یکدیگر مقایسه کرد. به طور کلی، شاخص های عینی وضعیت محیط و جامعه را توصیف می کنند که می تواند پتانسیل افراد برای داشتن زندگی خوب را توضیح دهد. بنابراین بین شاخص های عینی و رضایت ذهنی از زندگی رابطه معناداری انتظار می رود.
رویکرد ارزیابی ذهنی بر این فرض استوار است که برای درک رضایت شخصی فردی، لازم است احساسات فرد در رابطه با بخشهای مختلف زندگیشان به طور مستقیم و در چارچوب استانداردهای زندگی مورد انتظار یک فرد بررسی شود. شاخص های ذهنی معمولاً از طریق یک پرسشنامه به دست می آیند – مقیاسی که میزان توافق با هر سؤال را توصیف می کند اغلب استفاده می شود (برای چگونگی بیان رضایت ذهنی از طریق استفاده از مقیاس، برای مثال به Cantril [ 12 ] مراجعه کنید). شاخص های ذهنی اغلب به دلیل غیرقابل مقایسه یا غیرقابل درک بودن [ 13 ] و به دلیل غیرممکن بودن تأیید مورد انتقاد قرار می گیرند . به گفته کانمن و کروگر [ 14]، رضایت ذهنی یک قضاوت گذشتهنگر جهانی است که در بیشتر موارد، تنها در صورت درخواست ساخته میشود و تا حدی با روحیه و حافظه فعلی پاسخدهنده و همچنین با زمینههای فوری تعیین میشود.
تحقیق در مورد شاخص های ذهنی به دلیل ادراکات و ترجیحات مختلف هر فرد و همچنین دشواری جمع آوری داده های ذهنی بسیار پیچیده است. در چارچوب رویکرد ذهنی به کیفیت زندگی، مفهوم بهزیستی نباید حذف شود. تعاریف زیادی از بهزیستی وجود دارد (مطالعه ای در مورد توسعه و تعریف بهزیستی توسط دوج و همکاران [ 15 ] انجام شد). فرهنگ لغت کمبریج به سادگی و به طور خلاصه بهزیستی را به عنوان “وضعیت احساس سلامت و شادی” توصیف می کند [ 16 ].
چه از اصطلاح کیفیت زندگی استفاده شود و چه از واژه بهزیستی ، وضعیت ذهنی رضایت نیز تحت تأثیر عوامل محیطی بسیاری است که میتوان آنها را از طریق شاخصهای عینی ارزیابی کرد (بحث بیشتر توسط برنگر و وردیه-چوشان [ 17 ] انجام شد.]). پیوند داده های ذهنی و عینی با هدف آشکارسازی روابط بین دو گروه اغلب در تحلیل های کیفیت زندگی گنجانده نمی شود. اگر اطلاعاتی در مورد رضایت واقعی ذهنی از زندگی جمعیت وجود داشته باشد، میتوان جزئیات آن اطلاعات را در رابطه با شاخصهای عینی که شرایطی را که فرد/جامعه در آن قرار دارد، تجزیه و تحلیل کرد و آن شاخصهایی را شناسایی کرد که رابطه قابل اثباتی با رضایت ذهنی دارند. چنین تحلیلی می تواند روابط شگفت انگیزی را آشکار کند که اغلب با قدیمی ترین فرضیات تحقیق کیفیت زندگی در تضاد است. معروف ترین آنها پارادوکس ایسترلین است که اشاره می کند که به نظر نمی رسد شادی در داخل کشور (مانند ایالات متحده) با افزایش تولید ناخالص داخلی سرانه افزایش یابد.18 ]. آگاهی از اهمیت شاخصهای عینی در مطالعه رضایت از زندگی میتواند در ساخت شاخصهای کیفیت زندگی – ابزارهایی که اغلب برای کمیسازی کیفیت زندگی استفاده میشوند، استفاده شود. شاخص یک شاخص بدون بعد، به راحتی قابل درک و مقایسه است که حاوی اطلاعات پیچیده ای است که از ترکیب داده های متعدد حاصل می شود. استفاده از شاخص های مربوط به کیفیت زندگی توسط بسیاری از نویسندگان، مانند سوماریبا و پنا، مورد توجه قرار گرفته است. دوج و همکاران. Mederly، Nováček و Topercer; مارتین و مندوزا یا گریلینگ و ترگنا [ 10 ، 17 ، 19 ، 20 ، 21]. شاخصهایی که در رابطه با رضایت از زندگی گزارششده بهعنوان معنیدار علامتگذاری شدهاند، میتوانند این شاخصها را اصلاح کنند و به آنها اجازه دهند از تعداد کمتری داده ساخته شوند، که مزایای غیرقابل انکاری مانند تفسیرپذیری بهتر، دسترسی آسانتر به دادهها و غیره دارد.
رحمان و همکاران [ 22 ] از شاخص های عینی برای ارزیابی پتانسیل رضایت از زندگی استفاده کنید. یک اصل مشابه در ابتکار زندگی بهتر OECD یافت می شود: اندازه گیری رفاه و پیشرفت ، که مجموعه ای از شاخص های مرتبط با کیفیت زندگی را ارائه می دهد [ 23 ]. تجزیه و تحلیل رگرسیون مقایسه رضایت از زندگی یک جمعیت و تعدادی از متغیرهای مستقل توصیف کننده محیط و ویژگی های جمعیت توسط اسوالد و وو [ 24 ] استفاده شده است. بوآرینی و همکاران [ 25] یک تحلیل رگرسیونی از رضایت از زندگی را انجام داد که با نردبان کانتریل اندازه گیری شد و آن را با لیستی از متغیرهای مستقل جمعیت شناختی و اجتماعی-اقتصادی که حوزه های مختلف زندگی در کشورهای OECD را نشان می داد مقایسه کرد. مدل آنها رابطه معناداری بین رضایت از زندگی گزارش شده ذهنی با درآمد، اشتغال و شاخص تحصیلی را نشان داد. هاسکینز و می [ 26 ] از داده های بررسی سلامت جامعه کانادا برای برآورد عوامل تعیین کننده رضایت ذهنی از زندگی در کانادا از طریق طراحی چندین مدل رگرسیون استفاده کردند. سلامت خود گزارشدهی، درآمد خانوار، شغل و وضعیت تأهل بهعنوان معنیدار شناسایی شدهاند، اما این بین مدلهای رگرسیون مختلف متفاوت است.
دولان و همکاران [ 27 ] یک بررسی مفصل ارائه می دهد که هفت حوزه اصلی را که بر رضایت از زندگی تأثیر می گذارند تعریف می کند: (1) درآمد. (2) خصوصیات شخصی؛ (3) ویژگی های توسعه یافته اجتماعی؛ (4) چگونه زمان خود را صرف می کنیم. (5) نگرش ها و باورها نسبت به خود/دیگران/زندگی. (6) روابط؛ و (7) محیط اقتصادی، اجتماعی و سیاسی گسترده تر [ 27 ]. اگرچه اینها حوزههای بسیار گستردهای هستند که تقریباً تمام بخشهای اساسی زندگی را پوشش میدهند، میتوانند در هنگام ایجاد اولین فرضیات در مورد نتایج تجزیه و تحلیل مفید باشند. برای شواهد بیشتر، به عنوان مثال، Kahneman و Krueger، Clark and Oswald، Layard، Poláčková، Kämpfer یا Haslauer و همکاران را ببینید. [ 14 ، 28 ، 29 ، 30، 31 ، 32 ]، که در آن سایر شاخص های اجتماعی-اقتصادی-دموگرافیک بر رضایت از زندگی فرد تأثیر می گذارد.
از آنجایی که رضایت از زندگی ذاتاً مفهومی مبهم است، غیرمنطقی است که انتظار داشته باشیم همه افراد رضایت از زندگی را به یک شکل درک کرده و قضاوت کنند. اطلاعات جمعآوریشده در نظرسنجیهای رضایتمحور منعکسکننده تفاوتهای فرهنگی، محیطی یا شخصی مختلف است که منجر به عدم اطمینان و تنوع قابلتوجهی در رابطه بین رضایت از زندگی و شاخصهای عینی میشود. به منظور ثبت این ابهام در دادهها و گنجاندن آن در تجزیه و تحلیل دادهها و تفسیر نتایج، مجموعههای فازی و منطق در دهه 1970 توسط لطفی زاده توسعه یافت (برای مثال، زاده [ 33 ] را ببینید). بر اساس تئوری فازی، مدل های رگرسیون خطی فازی توسط تاناکا و همکاران معرفی شدند. [ 34] در سیستم های مدل با نامعین بودن در ماهیت سیستم گنجانده شده است، به خصوص اگر تخمین انسانی در سیستم تأثیرگذار باشد. مدل های رگرسیون کلاسیک انتظار داشتند که تفاوت بین مقادیر مشاهده شده و پیش بینی شده به دلیل خطاهای مشاهده باشد که در مورد رضایت از زندگی، فرض معقولی نیست. در مدل های رگرسیون فازی انحراف بین مقادیر مشاهده شده و پیش بینی شده نتیجه ابهام سیستم فرض می شود. با توجه به این واقعیت ها، مدل رگرسیون فازی مدل مناسبی برای این کاربرد در نظر گرفته می شود.
ادبیات موجود تأیید میکند که کاوش در روابط بین رضایت ذهنی و سایر شاخصهای مستقل همیشه بخش ارزشمندی از تحقیقات کیفیت زندگی است و درک عمیقتری از این پدیده پیچیده را امکانپذیر میسازد. تجزیه و تحلیل کیفیت زندگی در سطح ملی موضوع مکرر تحقیق است – مطالعات بسیاری در زمینه اروپایی انجام شده است. برای مثال نگاه کنید به Glatzer، Somarriba and Pena، Rogge et al., Ivaldi et al., Pena and Somarriba یا Eurostat [ 1 , 10 , 35 , 36 , 37 , 38]. ارزیابی های سطح زیر ملی که فراتر از مرزهای ملی است چندان رایج نیست. ارزیابی زیرملی کیفیت زندگی با توجه به استانداردهای زندگی و بعد سلامت توسط آنونی و همکاران ارائه شده است. [ 39 ]؛ مثال دیگری را می توان در لاگاس و همکاران مشاهده کرد. [ 40 ] یا Petrucci et al. [ 41 ]. در زمینه فعالیتهای موجود اتحادیه اروپا (ابتکار کمیسیون اروپا فراتر از تولید ناخالص داخلی – اندازهگیری پیشرفت در جهان در حال تغییر ؛ برای اطلاعات بیشتر، به کمیسیون اروپا [ 42 ، 43 ) مراجعه کنید.])، این ایده مطرح می شود که ارزیابی را بر قلمرو کشورهای اتحادیه اروپا متمرکز کرده و آن را به سایر کشورها در سطح زیر ملی گسترش دهد. بر اساس این افکار، وظایف تحقیقاتی زیر پیشنهاد شد: (1) جمعآوری مجموعه دادهای مناسب که رضایت ذهنی را در ترکیب با شاخصهای کیفیت زندگی عینی مکمل در سطح زیر ملی، که بخش عمدهای از اروپا را پوشش میدهد، توصیف کند. (2) برای تجزیه و تحلیل روابط بین رضایت ذهنی از زندگی و شاخص های کیفیت عینی زندگی مکمل با روش رگرسیون فازی مناسب. و (3) برای شناسایی تعداد محدودی از آن شاخص هایی که رابطه آماری قابل اثباتی با رضایت ذهنی از زندگی دارند. این وظایف به سؤال تحقیق پاسخ خواهند داد:
2. مواد و روشها
2.1. داده ها
2.1.1. داده های ذهنی
تعداد محدودی از نظرسنجی ها داده های ذهنی را در مورد رضایت از زندگی/کیفیت زندگی انسان در سطح فراملی پاناروپایی ارائه می دهند. نتایج بررسیهای یوروبارومتر و رفاه منطقهای OECD و آمار اتحادیه اروپا در مورد درآمد و شرایط زندگی (EU-SILC) بهعنوان مجموعه دادههای کلیدی برای استفاده در تجزیه و تحلیل زیر ملی شناسایی شدند. با توجه به فقدان سایر داده های ذهنی در مقیاس جغرافیایی (فرعی) و پوشش (پاراروپایی) – و پس از ارزیابی پارامترهایی مانند تعداد پاسخ دهندگان، به موقع بودن و پوشش فضایی- مجموعه داده EU-SILC انتخاب شد. برای پردازش بیشتر در مطالعه انتخاب شده است.
EU-SILC توسط Eurostat انجام شد و منبع داده اولیه برای تجزیه و تحلیل مقایسه ای درآمد و شرایط زندگی در اتحادیه اروپا است. همچنین اطلاعاتی را ارائه می دهد که می تواند برای تجزیه و تحلیل جنبه های مختلف طرد اجتماعی [ 44 ] استفاده شود. انتظار می رود در آینده مجموعه داده EU-SILC ابزار اصلی در ارزیابی کیفیت زندگی باشد [ 45 ]]. یک ماژول موقت در مورد بهزیستی ذهنی در EU-SILC 2013 اجرا شد و شامل سؤالاتی در مورد رضایت از حوزه های مختلف زندگی بود. برای هدف این مطالعه، سؤال مربوط به رضایت کلی از زندگی بیشتر توضیح داده شد. رضایت کلی از زندگی نشان می دهد که چگونه یک پاسخ دهنده زندگی خود را به عنوان یک کل در نردبان کانتریل ارزیابی یا ارزیابی می کند (0 – اصلاً راضی نیست تا 10 – کاملاً راضی است). شکل 1 رضایت ذهنی از زندگی را همانطور که در مجموعه داده های EU-SILC 2013 گزارش شده است نشان می دهد و به عنوان یک بینش بصری در مجموعه داده عمل می کند. تفسیر مقادیر بعداً در مقاله در زمینه تحلیل رگرسیون فازی گنجانده شده است.
2.1.2. داده های هدف
تعریف مجموعه شاخص های عینی مرتبط با رضایت ذهنی از زندگی یک کار بسیار چالش برانگیز است. حجم وسیعی از ادبیات موجود ارزیابی های کیفیت زندگی را با داده های عینی ارائه می دهد. بسیاری از این مطالعات به دلیل فقدان دادههای کافی (به ویژه مجموعه حوزههای کیفیت زندگی و شاخصهای آنها که در طرح اروپایی فراتر از تولید ناخالص داخلی تعریف شدهاند، نمیتوانند هنگام پرداختن به سطح زیرملی تجزیه و تحلیل استفاده شوند [ 42 ].]). بنابراین چارچوب نظری جدیدی از حوزه های کیفیت زندگی طراحی شد. بررسی ادبیات برای انتخاب دامنهها حیاتی بود. در مجموع، 31 مطالعه موجود، که بیانگر مطالعات موردی حل شده عملی ارزیابی کیفیت زندگی هستند، برای تحلیل مفهومی مجموعه هدف انتخاب شاخصها مورد بررسی قرار گرفتند (همه مطالعات در پیوست C فهرست شدهاند.). این شناسایی با موضوع استفاده از نامگذاریهای مختلف دامنههایی مواجه بود که باید برای یک مرور کلی بعدی از فراوانی وقوع آنها یکپارچه یا تعمیم داده میشد. به عنوان مثال، حوزههایی با عنوان «آموزش»، «کیفیت آموزش»، «آموزش و آموزش» و «دانش» تعمیم داده شده و تحت دامنه «آموزش» ادغام شدند. شناسایی حوزههایی که مکرراً در این مطالعات گنجانده شدهاند، امکان تعریف مهمترین آنها (که در اینجا حوزههای اصلی نامیده میشوند) را میدهد که باید در تحلیل گنجانده شوند.
دامنهها متعاقباً با در دسترس بودن دادههای آماری در سطح زیر ملی در تضاد قرار گرفتند. در سطح زیر ملی، انتخاب دامنه ها باید با در دسترس بودن داده های آماری زیرملی به عنوان منبع شاخص های حوزه ها مطابقت داشته باشد. فقط Eurostat و پایگاه داده منطقه ای OECD داده های آماری زیرملی کافی را ارائه می دهند که بیشتر اروپا را پوشش می دهد. به دلیل ناسازگاری و در دسترس نبودن دادههای فردی، جمعآوری یک مجموعه داده با ترکیب دادهها از واحدهای آمار ملی منفرد مناسب نیست. ابتدا مجموعه ای از شاخص های اساسی (متعلق به حوزه های اصلی) تعریف شد. اینها به عنوان مثال، امید به زندگی، مرگ و میر نوزادان، درآمد، تولید ناخالص داخلی، نرخ جمعیت تحصیل کرده و غیره هستند. تمام داده های موجود در منابع داده (فقط با تمرکز بر سطح منطقه ای) در نظر گرفته شد و سایر شاخص های مناسب انتخاب شدند. معیارهای انتخاب شاخص های خاص (الف) گنجاندن شاخص در یکی از مطالعات از یک بررسی سیستماتیک و (ب) ارزیابی ذهنی نویسندگان از مناسب بودن شاخص ها بود. این رویکرد تا حدی مبتنی بر داده است، اما در حال حاضر، تنها راه برای گردآوری مجموعه داده کافی برای ارزیابی کیفیت زندگی در سطح زیر ملی است.
از آنجایی که این مقاله بخشی از یک مطالعه گسترده تر است که بر ارزیابی کیفیت زندگی در سطح ملی متمرکز شده است، داده های موجود در NUTS 2 در ابتدا جستجو شد. با این حال، برای ترکیب واحدهای NUTS 2 با نتایج EU-SILC، جزئیات مربوط به هر کشور تنظیم شده است تا منعکس کننده در دسترس بودن اطلاعات رضایت مندرج در EU-SILC باشد (طبقه بندی فضایی در هر کشور را در شکل 1 ببینید).
مجموعه داده نهایی شامل پنج حوزه اصلی و 22 شاخص متناظر است. جدول 1 خلاصه ای از داده های مورد استفاده را نشان می دهد (برای توصیف دقیق شاخص ها، به پیوست A مراجعه کنید ). دوره زمانی مطابق با نظرسنجی EU-SILC، یعنی سال 2013 است.
2.2. تحلیل داده ها
از یک همبستگی ساده می توان برای نظارت بر روابط بین رضایت ذهنی از زندگی و شاخص های عینی کیفیت زندگی استفاده کرد و این روابط زیربنایی را در داده های ارائه شده آشکار می کند. از آنجایی که اطلاعات رضایت ذهنی به عنوان یک متغیر اصلی بیان شده است، می توان از رگرسیون خطی چندگانه برای مدل سازی روابط بین رضایت ذهنی و مجموعه ای از شاخص های عینی کیفیت زندگی استفاده کرد. تحلیل رگرسیون خطی چندگانه قادر به ارزیابی اهمیت متغیرهای پیش بینی کننده در توضیح متغیر وابسته و ارزیابی کیفیت مدل محاسبه شده است. همانطور که در فصل مقدماتی ذکر شد، به دلیل مبهم بودن رضایت از زندگی، استفاده از اصلاح فازی رگرسیون خطی چندگانه منطقی تر است. که قادر به گرفتن عدم قطعیت مربوط به این نوع متغیر وابسته است. با توجه به استفاده از رگرسیون فازی خطی چندگانه، عدم قطعیت مرتبط با متغیر وابسته در تحلیل گنجانده شده است. در عین حال، امکان استفاده از روشهای محاسباتی کلاسیک را فراهم میکند که برای تحلیل روابط بین متغیر وابسته و پیشبینیکنندههای آن مناسب هستند.
یک شکل مناسب از رگرسیون فازی چندگانه برای دادههای موجود، تحلیل رگرسیون فازی چندگانه برای دادههای غیر فازی با ضرایب فازی نامتقارن است، همانطور که توسط Ishibuchi و Nii [ 46 ] تعریف شد. در این مورد خاص، هم مقادیر پیشبینیکننده و هم مقدار پیشبینیشده، مقادیر کلاسیک (غیر فازی) هستند. رگرسیون فازی چندگانه ضرایب رگرسیون را به عنوان اعداد فازی برآورد می کند [ 47 ]. از دیدگاه عملی، از اعداد فازی مثلثی [ 48 ] استفاده می شود. اعداد فازی مثلثی (به صورت گرافیکی در شکل 2 نشان داده شده است ) ساده ترین اعداد فازی هستند که با سه مقدار تعریف می شوند. [ خطای پردازش ریاضی ]آ˜=آ�، آسی، آ�. طبق گفته هانس [ 49 ] ، اعداد فازی مثلثی همچنین امکان اجرای ساده ترین محاسبات فازی را فراهم می کنند. یک عدد فازی شامل به اصطلاح [ خطای پردازش ریاضی ]�– برش ها [ خطای پردازش ریاضی ]�مقداری از بازه [0،1] است. یک [ خطای پردازش ریاضی ]�-cut بازهای با مقادیری است که حداقل مقدار عضویت دارند [ خطای پردازش ریاضی ]�[ 49 ]. برای یک عدد فازی مثلثی، [ خطای پردازش ریاضی ]�-برش با [ خطای پردازش ریاضی ]�مقدار 0 وسعت عدد فازی است [ خطای پردازش ریاضی ]آ�،آ�. را [ خطای پردازش ریاضی ]�-برش با [ خطای پردازش ریاضی ]�مقدار 1 یک بازه است [ خطای پردازش ریاضی ]آسی، آسی.
رگرسیون فازی چندگانه برای مجموعه ای از جفت متغیر وابسته به پیش بینی [ خطای پردازش ریاضی ]ایکسپ،�پ، پ=1، …، متر، جایی که [ خطای پردازش ریاضی ]ایکسپ=ایکسپ1، …، ایکسپ�، با ضرایب فازی [ خطای پردازش ریاضی ]آ˜0، آ˜1، …، آ˜�به صورت [ 46 ] محاسبه می شود:
برای هر داده شده [ خطای پردازش ریاضی ]پ.
تعیین ضریب فازی [ خطای پردازش ریاضی ]آ˜مندر دو مرحله انجام می شود [ 46 ]. را [ خطای پردازش ریاضی ]�سیایکسبرای تعیین مراکز ضرایب فازی با استفاده از رگرسیون حداقل مربعات تعیین می شود [ خطای پردازش ریاضی ]آمنسی. حد پایین و بالایی توسط یک مسئله برنامه ریزی خطی تعیین می شود:
به حداقل رساندن
موضوع به
جایی که [ خطای پردازش ریاضی ]ساعتهست یک [ خطای پردازش ریاضی ]�-برش. را [ خطای پردازش ریاضی ]ساعتپارامتر گسترش ضرایب فازی را مشخص می کند. هر چه بالاتر [ خطای پردازش ریاضی ]ساعتمقدار، پیش بینی ضرایب فازی گسترده تر است. برای تخمین عملی ضرایب فازی، مقدار h کمی بالاتر از 0 برای ساخت اعداد فازی مثلثی استفاده شد. این مقدار به این معنی است که ضرایب رگرسیون فازی باید به گونه ای تعریف شود که فقط مقادیر پیش بینی کننده ها را پوشش دهد. اجرای مسئله برنامه ریزی خطی با استفاده از نرم افزار GLPK [ 50 ] انجام شد. با [ خطای پردازش ریاضی ]آ˜0، آ˜1، …، آ˜�شناخته شده، برآورد [ خطای پردازش ریاضی ]�˜پمی توان با استفاده از محاسبات فازی [ 49 ] محاسبه کرد.
برای تحلیل دقیقتر لایههای حاصل (پیشبینی مدل فازی رضایت از زندگی و عدم قطعیت آن)، از همبستگی وزندار جغرافیایی پیشنهاد شده توسط Kalogirou [ 51 ] استفاده شد. این تغییر محلی ضریب همبستگی، همبستگی محلی وزنی را در هر مکان (در اینجا منطقه) فقط از k مکان مشاهده شده همسایه محاسبه می کند، که در آن k توسط کاربر به عنوان درصدی از تمام مشاهدات تعریف می شود، و وزن ها بر اساس فاصله اقلیدسی بین مکان مشاهده شده و هر مشاهده همسایه.
3. نتایج
ابتدا همبستگی بین رضایت از زندگی و شاخص های هدف انتخاب شده محاسبه شد. از آنجایی که آزمون Shapiro-Wilk نرمال بودن را ثابت نکرد، همبستگی رضایت ذهنی اسپیرمن با هر شاخص مستقل کیفیت زندگی از مجموعه داده ورودی محاسبه شد. این تحلیل اولیه روابط خطی بین برخی از شاخصها و رضایت ذهنی از زندگی را نشان داد (طبق گفته De Vaus [ 52]، ضریب همبستگی بالاتر از 0.5 را می توان به عنوان معنی دار نامگذاری کرد: بیکاری (0.65-)، تولید ناخالص داخلی (0.55)، درآمد (0.54)، خالص (0.52). همبستگی متوسط (ضریب همبستگی در محدوده 0.3-0.49) بین رضایت از زندگی و O3 (0.48-)، SUNSHINE (0.46-)، MIGRAT (0.4)، EDU_TER (0.38) و پیری (0.34-) مشاهده شد. تمام همبستگی های بین رضایت از زندگی و شاخص های انتخاب شده کیفیت زندگی در شکل 3 ارائه شده است. در همان زمان، همبستگی بین همه پیش بینی ها محاسبه شد. ماتریس همبستگی خروجی در پیوست B ارائه شده است.
گام بعدی انجام یک تحلیل رگرسیون فازی چندگانه به منظور دریافت روابط بین رضایت از زندگی و مجموعه شاخصهای کیفیت زندگی بود. در ابتدای مدلسازی رگرسیون فازی چندگانه، مدل خطی بهینه باید شناسایی شود که بعداً به عنوان یک مدل رگرسیون فازی چندگانه محاسبه میشود. ابتدا یک مدل پیچیده شامل تمام شاخص های ورودی طراحی و آزمایش شد (MODEL1). همبستگی بین متغیرهای مستقل می تواند باعث شود استنباط های آماری (فرض) بر اساس داده ها غیر قابل اعتماد باشد. بنابراین، داده ها برای حضور چند خطی مورد آزمایش قرار گرفتند. برای پیش بینی های فردی، چند خطی بودن با استفاده از عامل تورم واریانس (VIF) ارزیابی شد. امتیاز VIF بالاتر از پنج است که نشان دهنده چند خطی بودن قابل توجه است [ 53]، برای چندین پیش بینی گزارش شده است – مقادیر VIF در هر مدل در جدول 2 نشان داده شده است :
از آنجایی که در شاخص درآمد، مقادیر پرت قابل توجهی وجود دارد، به شکل 1/INCOME تبدیل شده است. پیشبینیکنندههای با VIF بالاتر از پنج، بهجز INCOME و EDU_TER از مدل حذف شدهاند. از آنجایی که این شاخص ها بر اساس نظری برای کیفیت زندگی بسیار معنادار در نظر گرفته می شوند، از مدل مستثنی نشده اند. پس از حذف شاخص های VIF بالا، MODEL2 طراحی شد که در آن همه نشانگرها شرایط VIF را برآورده می کنند. مدل حاصل، MODEL2، به عنوان یک مدل رگرسیون فازی چندگانه پردازش شد و در جدول 3 توضیح داده شده است :
جدول 3. ضرایب فازی مدل رگرسیون. پذیرش پیش بینی کننده در سطوح معنی داری 05/0 (**) و 1/0 (*).
که در آن L حداقل آن عدد فازی مثلثی، C مرکز آن، U حداکثر عدد فازی مثلثی، a C – a L تفاوت بین مرکز و حداقل عدد فازی و U- است . a C تفاوت بین حداکثر و مرکز عدد فازی است. وقفه (ثابت) مقدار میانگین مورد انتظار متغیر وابسته است، زمانی که همه پیش بینی ها برابر با صفر باشند. هفت مورد از چهارده پیش بینی کننده در سطح معنی داری 05/0 پذیرفته شدند. پیش بینی کننده PHYSICIAN در سطح 0.1 پذیرفته شد.
9 تا از ضرایب اعداد کلاسیک (غیر فازی) هستند. این اعداد به هیچ وجه فاقد قطعیت هستند. شش متغیر دیگر (INFANT، D_CANCER، PHYSICIAN، SUICIDE، MURDER و NEET) حداقل دارای عدم قطعیت هستند. شکل مقادیر فازی منفرد با روش برنامه ریزی خطی تعیین می شود، به این معنی که ممکن است بتوان بیش از یک راه حل عملی (مجموعه ای از ضرایب فازی) را پیدا کرد. با این حال، همه راهحلها نتایج بسیار مشابهی را ارائه میدهند، زیرا باید محدودیتهای یکسانی را در مورد دادهها برآورده کنند.
مقدار R 2 تعدیل شده 0.631 نشان می دهد که 63.1 درصد از واریانس رضایت ذهنی از زندگی را می توان با شاخص های انتخاب شده توضیح داد. اهمیت شاخص های فردی در این مدل در نهایت با نسبت واریانس توضیح داده شده (تحلیل تسلط بسته R ) ارزیابی شد. به گفته آزن و بودسکو [ 54 ]، اگر در سطح معینی از تحلیل، یک پیش بینی کننده بیشتر از دیگری در پیش بینی مشارکت داشته باشد، از دیگری مهم تر است. تابع مقادیر معناداری زیر را برای متغیرهای اندازه گیری شده توسط R2 برگرداند ( شکل 4 ) . تسلط پیش بینی کننده های INCOME و NEET به وضوح قابل مشاهده است.
هنگامی که رابطه بین رضایت ذهنی و پیشبینیکنندههای آن بررسی میشود، تفسیر و توضیح ضرایب محاسبهشده به جای کمی کردن آنها نیز مناسب است. از آنجایی که مدل کاملتر ایجاد شد، تفسیر مختصری از تنها پیشبینیکنندههای مهم معرفی میشود. از آنجایی که هر یک از پیشبینیکنندههای عینی معنای متفاوتی در زمینه کیفیت زندگی دارند، ضرایب آنها در مدل برای تفسیر بهتر به سه گروه تقسیم شدند:
-
تفسیر آسان (INCOME، INDEX_CS، NEET): رابطه این شاخص ها با رضایت از زندگی تعجب آور نیست و به راحتی قابل توضیح است. شاخص درآمد (مقدار ضریب منفی ناشی از تبدیل داده های ورودی) مهم ترین است. می توان پذیرفت که با وضعیت مالی بهتر خانوار، رضایت اعضای خانوار افزایش می یابد. بر اساس این مدل، به طور فرضی، رضایت از زندگی اندازهگیری شده با نردبان کانتریل یک امتیاز افزایش مییابد اگر درآمد خانوار تقریباً 17800 یورو PPS افزایش یابد. به طور مشابه، در مورد INDEX_CS، کیفیت منظره نیز به راحتی قابل درک و ارزش گذاری است. نتایج نشان می دهد که پاسخ دهندگان کیفیت چشم انداز بیان شده توسط شاخص INDEX_CS را به روشی مشابه و عمدتا مثبت درک می کنند. بیان ضمنی اینکه چگونه تغییر در کیفیت منظر بر رضایت ذهنی تأثیر میگذارد، چندان ساده نیست، زیرا کیفیت منظر یک شاخص پیچیده بدون واحد است. در نهایت، شاخص NEET، به عنوان معیاری برای بازار کار (در نهایت معیاری برای انتقال آموزش به بازار کار)، می تواند در رضایت از زندگی نیز درک شود. گروه مورد نظر از جوانان می توانند تحت تأثیر شرایط نامساعد رشد کنند که ممکن است منجر به نارضایتی طولانی مدت از زندگی شود. همچنین این شاخص با بیکاری بلندمدت کلی همبستگی دارد (ضریب همبستگی 0.77).
-
تفسیر دشوار (AGEING): علامت ضرایب این شاخص با معنای مورد انتظار در زمینه کیفیت زندگی یکسان است، اما درک آن برای رضایت از زندگی می تواند مغرضانه باشد. در این حالت، افرادی که در یک جامعه قدیمی زندگی میکنند ممکن است این واقعیت را منفی درک کنند، زیرا پیری جمعیت میتواند باعث وابستگیهای اجتماعی و اقتصادی و همچنین اختلافات در سطح شخصی (عدم درک بین نسلی) شود.
-
“کنتراندیکاتورها” (EDU_TER، HOSPITAL، PHYSICIAN، INFANT): از این گروه انتظار می رفت که رضایت ذهنی از زندگی را با مقادیر شاخص بالاتر افزایش دهند، زیرا سطوح بالاتر این معیارها به عنوان شاخص های کیفیت زندگی مثبت در نظر گرفته می شوند. با این حال، ضرایب رگرسیون در برابر مفروضات معنای مورد انتظار در زمینه کیفیت زندگی منفی بود. این شاخصها ممکن است برخی روابط پنهان یا غیرمستقیم با رضایت از زندگی داشته باشند که توضیح آنها ساده نیست.
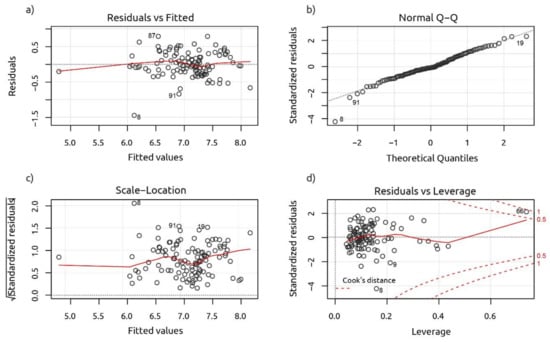
این مدل برای تأیید مفروضات مدلسازی رگرسیون و ارزیابی کیفیت مدل بهدستآمده، با بررسی خطی بودن، همسداستیک بودن، نرمال بودن چند متغیره و تأثیر عوامل پرت تشخیص داده شد. خطی بودن داده ها را می توان از طریق نمودار اصلی که داده های برازش شده را در مقابل باقیمانده ها نشان می دهد ارزیابی کرد ( شکل 5 a). مقداری تحریف در رابطه خطی وجود دارد، اما هیچ الگوی واضحی آشکار نیست. برای تست همسویی از آزمون بروش-پاگان استفاده شد. مقدار p خروجی آزمون 0.24 اجازه رد فرضیه صفر مبنی بر اینکه باقیمانده ها دارای واریانس ثابت هستند را نمی دهد، بنابراین ناهمسانی اثبات نشد. بازرسی بصری هموسداستیسیته را می توان در شکل 5 انجام دادج. نمودار QQ از توزیع باقیمانده های ارائه شده در شکل 5 ب نشان دهنده برخی نقض نرمال بودن توسط چندین رکورد است. این فرض توسط آزمون Shapiro-Wilk تأیید شده است. p-value 0.018 فرضیه توزیع طبیعی باقیمانده را رد می کند. در نهایت، حضور پرت مورد بررسی قرار گرفت. نقاط پرت ممکن است با افزایش مقدار خطای استاندارد باقیمانده (RSE) بر کیفیت مدل تأثیر بگذارد. با استفاده از فاصله کوک، ترکیب اهرم و اندازه باقیمانده، هیچ یک از رکوردها به عنوان پرت تأثیرگذار علامت گذاری نشدند ( شکل 5 د).
در نهایت، مدل رگرسیون فازی چندگانه امکان پیشبینی رضایت از زندگی را با توجه به عدم قطعیت رابطه بین رضایت از زندگی و پیشبینیکنندههای آن فراهم میکند. این نوع نتیجه برای کاربران سودمند است. پیش بینی در قالب اعداد فازی ابهام نتیجه را تأیید می کند. این رویکرد از بیان دقیق پیشبینی دوری میکند، که ممکن است در شرایط عدم قطعیت نامطلوب باشد. پیشبینی رضایت از زندگی برای دادههای مکانی دقیقتر، که اکثریت اروپا را در سطح NUTS 2 پوشش میدهد، اعمال شد. اگرچه هر دو مجموعه داده در وضوح فضایی متفاوت هستند و بنابراین مقایسه آنها دشوار است، توزیع فضایی مقادیر پیش بینی شده ( شکل 6)الف) رضایت از زندگی به طور قابل توجهی با داده های ورودی اصلی متفاوت است ( شکل 1 ). واضح ترین تفاوت ها در مناطق اتریش و سوئیس است، جایی که مقادیر پیش بینی شده به طور مشخص کمتر از مقادیر اصلی است. نمونه های دیگر از تفاوت بین مقادیر پیش بینی شده و اصلی در مناطقی از رومانی، فرانسه یا بریتانیا است. از سوی دیگر، در بلژیک و هلند، هر دو مقادیر اصلی و پیش بینی شده بالا هستند. این پیشبینی همچنین به نامناسب بودن دادهها در سطح ملی اشاره میکند – در مورد آلمان، رضایت گزارششده نسبتاً زیاد است، اما در سطح دقیق پیشبینی، تنوع فضایی قابلتوجهی قابل مشاهده است.
از آنجایی که پیش بینی فازی با اندازه گیری عدم قطعیت تکمیل می شود ( شکل 6 ب)، می توان آن را همراه با رضایت پیش بینی شده به وضوح مشاهده کرد، در حالی که تغییرات در سراسر منطقه مورد علاقه را می توان به طور مشترک مشاهده کرد. بالاترین مقدار ثبت شده 5.2 است. متأسفانه، عدم قطعیت پیشبینیشده را نمیتوان دقیقاً تفسیر کرد، زیرا نتیجه برنامهریزی خطی است، جایی که تعاملات بین روابط پیشبینیکنندهها با متغیر وابسته رخ میدهد. ارائه عدم قطعیت تأیید میکند که مدلهای خطی کلاسیک میتوانند تنوع و عدم قطعیت زیاد را که تنها با استفاده از رویکرد فازی آشکار میشوند، سرکوب کنند.
رابطه قوی منفی بین مقدار پیشبینیشده و عدم قطعیت با آزمون همبستگی آشکار شد (ضریب همبستگی اسپیرمن، 0.79-). برای بررسی تغییرپذیری فضایی همبستگی، همبستگی وزنی جغرافیایی با همسایگی تعریف شده به عنوان 3 درصد از همه مناطق محاسبه شد ( شکل 6).ج) که به طور متوسط با هشت همسایه برای هر منطقه مطابقت دارد. این تنظیم سطح مناسبی از جزئیات را فراهم می کند که ناهمگونی فضایی همبستگی محلی را آشکار می کند. مقادیر قابل توجه همبستگی وزنی جغرافیایی از همبستگی کامل (99/0-، متمرکز در آلمان، بلژیک، هلند، چک، یونان و بخشهایی از اسکاندیناوی) تا همبستگی قوی (75/0-، در فرانسه، ایتالیا و رومانیایی) متفاوت است. مرز بلغارستان). در بسیاری از موارد، مقادیر دیگر همبستگی محلی مشاهده شده در لهستان، رومانی، آلمان شرقی یا جنوب فرانسه از نظر آماری ناچیز بود. این مناطق غیر معمول هستند و تفسیر آنها دشوار است، با روندهای فضایی نوسانی در روابط بین مقدار پیش بینی شده و عدم قطعیت آن. از آنجایی که معیار محلی همبستگی هیچ اطلاعاتی در مورد اینکه آیا مقدار پیشبینی زیاد است و عدم قطعیت پایین (در مناطق با همبستگی منفی) و بالعکس، نمیدهد، نتیجه با گونهشناسی ساده مناطق تکمیل شد. تمام مناطق با توجه به مقدار پیش بینی شده و عدم قطعیت آن به انواع طبقه بندی شدند. آستانه توسط میانه تعیین شد. انواع حاصل به شرح زیر بود: HH – رضایت پیشبینیشده بالا با عدم قطعیت بالا، LL – رضایت پیشبینیشده کم با عدم قطعیت کم، HL – رضایت پیشبینیشده بالا با عدم قطعیت کم و LH – رضایت پیشبینیشده پایین با عدم قطعیت بالا. توزیع فضایی انواع نشان داده شده است تمام مناطق با توجه به مقدار پیش بینی شده و عدم قطعیت آن به انواع طبقه بندی شدند. آستانه توسط میانه تعیین شد. انواع حاصل به شرح زیر بود: HH – رضایت پیشبینیشده بالا با عدم قطعیت بالا، LL – رضایت پیشبینیشده کم با عدم قطعیت کم، HL – رضایت پیشبینیشده بالا با عدم قطعیت کم و LH – رضایت پیشبینیشده پایین با عدم قطعیت بالا. توزیع فضایی انواع نشان داده شده است تمام مناطق با توجه به مقدار پیش بینی شده و عدم قطعیت آن به انواع طبقه بندی شدند. آستانه توسط میانه تعیین شد. انواع حاصل به شرح زیر بود: HH – رضایت پیشبینیشده بالا با عدم قطعیت بالا، LL – رضایت پیشبینیشده کم با عدم قطعیت کم، HL – رضایت پیشبینیشده بالا با عدم قطعیت کم و LH – رضایت پیشبینیشده پایین با عدم قطعیت بالا. توزیع فضایی انواع نشان داده شده استشکل 6 د. تجسم گونهشناسی مناطق بالقوه راضی در اروپا، عمدتاً در بخش شمال غربی قاره، جزایر بریتانیا، اسکاندیناوی و لهستان را محدود میکند. در مقابل، پیشبینی پایین رضایت در کمربندی است که از شبه جزیره ایبری از طریق مناطق جنوب اروپا امتداد دارد و متعاقباً به بخشی از اروپای شرقی و همچنین به اتریش و آلمان گسترش مییابد.
4. بحث
بسیاری از مطالعات مربوط به رابطه بین رضایت ذهنی و مجموعهای از شاخصها معرفی شدند. تا آنجایی که نویسندگان میدانند، هیچ مطالعه دیگری در سطح منطقهای وجود ندارد که پیوندهای بین رضایت ذهنی از زندگی و مجموعه شاخصهای عینی را بررسی کند، بخش وسیعی از اروپا را پوشش دهد و تحلیل را با استفاده از اصول تئوری فازی انجام دهد. .
بخش مهمی از پژوهش ارائه شده، انتخاب شاخص های مستقل مناسب بود. از آنجایی که این مقاله در درجه اول یک مطالعه تجربی را نشان می دهد، هدف اصلی بحث در مورد مناسب بودن شاخص های هدف نظارت شده نیست، بلکه روش های پردازش آنها بود. نویسندگان مجموعه داده شاخص ورودی کافی (براساس بررسی ادبیات) را گردآوری کردهاند که مهمترین جنبههای کیفیت زندگی را پوشش میدهد، با در نظر گرفتن مسئله مهم عدم دسترسی به دادههای آماری زیرملی دقیق در سراسر اروپا.
تمام دادههای مورد بحث وارد فرآیند مدلسازی رگرسیون شدند، جایی که برخی از شاخصهای هدف به دلیل چند خطی بودن بالا حذف شدند. اگرچه برخی منابع بیان می کنند که مقدار VIF ده نیز قابل قبول است [ 53]، مقدار 5 به منظور کاهش چند خطی تا حد امکان استفاده شد. مدل اتخاذ شده از 14 پیش بینی تشکیل شده است. هشت مورد از آنها در سطح 0.05 یا 0.1 از نظر آماری معنی دار هستند. یک راه حل جایگزین در قالب رگرسیون گام به گام وجود دارد که می تواند مناسب ترین مدل فرعی را با مهم ترین پیش بینی کننده ها شناسایی کند. از آنجایی که رگرسیون گام به گام اغلب به دلیل حساسیت آن به چند خطی یا توزیع داده مورد انتقاد قرار می گیرد، تنها به طور مختصر مورد آزمایش قرار گرفت و با مدل کامل مقایسه شد. یک تطابق بین پیشبینیکنندههای معنیدار مدل کامل و مدل گام به گام – درآمد، NEET، AGEING، EDU_TER، INDEX_CS، PHYSICIAN و HOSPITAL پیدا شد. بنابراین، این شاخص ها ممکن است به عنوان “شاخص های اصلی” برچسب گذاری شوند که در هر دو رویکرد مهم هستند. از آنجایی که هدف مدلسازی رگرسیون توصیف رضایت از زندگی با تعداد کمی از شاخصها است، تفسیر بعدی با این انتخاب هسته کاهش یافته سادهتر است. روابط سایر پیش بینی کننده ها با رضایت از زندگی را می توان در آن مشاهده کردجدول 3 .
عدم قطعیت مقادیر پیشبینیشده از رگرسیون فازی ممکن است با معرفی یک پیشبینیکننده جدید بهطور قابلتوجهی تغییر کند. دلیل آن این است که پیش بینی کننده جدید ممکن است به طور قابل توجهی مسئله برنامه ریزی خطی مورد استفاده برای تخمین ضرایب فازی رگرسیون فازی را تغییر دهد. به همین دلیل، هر پیشبینیکننده جدید نیز میتواند پراکندگی عدم قطعیت را در مدل تغییر دهد. با وجود این مسائل، مدلهای رگرسیون فازی با توجه به دادههایی که برای تخمین مدل رگرسیون خطی استفاده شد، نتایج ارزشمندی را در قالب پیشبینیهایی با ارزیابی عدم قطعیت ارائه میدهند.
اهمیت پیشبینیهای فازی در صورتی برجستهتر است که از نتایج برای حمایت از برنامهریزی و تصمیمگیری استفاده شود. مقادیر پیشبینیشده در قالب اعداد فازی به طور طبیعی عدم قطعیتی را که ذاتاً در هر مدل پیشبینی وجود دارد، نشان میدهد. این امر تصمیمگیری بهتر را ارتقا میدهد، زیرا تصمیمگیرنده مجموعهای از پیشبینیهای ممکن را به جای یک مقدار واضح به دست میآورد، که ممکن است تصور نادرستی از دقیق و دقیق بودن مدل ایجاد کند. همین موضوع برای سایر مدل های پیش بینی [ 55 ] نیز قابل اجرا است. همانطور که در [ 56 ] نشان داده شده است، پیشبینیهای نامشخص میتوانند در چارچوب روشهای محاسباتی نرم برای حمایت از تصمیمگیری با اطلاعات بیشتر و ارائه نتایج غنیتر مورد استفاده قرار گیرند .
کیفیت مدل، که با R2 با مقدار 0.631 نشان داده شده است، مشکوک است اما ممکن است در زمینه موضوع رضایت ذهنی کافی باشد. به گفته لوکاس و دانلان [ 57]، تقریباً یک سوم واریانس کلی در رضایت ذهنی تحت تأثیر تغییرات تصادفی در ادراکات و حالات ذهنی افراد است. دو سوم باقی مانده را می توان با شرایط محیطی خارجی توضیح داد. از آنجایی که لوکاس و دانلان با عوامل تعیین کننده ثبات زمانی (عمدتا ژنتیک) و تنوع (بیشتر شرایط خارجی و خطای اندازه گیری) در سطح افراد کار کردند، مقایسه یافته های آنها با نتایج این مطالعه دشوار است. با این حال، این مرجع می تواند حداقل اطلاعات تقریبی را برای ارزیابی کیفیت مدل ارائه دهد.
در تشخیص مدل، برخی از مفروضات کلی مدلسازی رگرسیون (خطی بودن روابط و نرمال بودن باقیمانده) نقض شد. اگرچه هیچ یک از سوابق به عنوان موارد پرت توسط مدل شناسایی نشد، تجزیه و تحلیل عمیق تر از تشخیص، تأثیر قوی در داده های ورودی، به ویژه (از لحاظ جغرافیایی) در مناطق شمالی و شرقی بلغارستان را نشان داد. بررسی شاخص های ورودی در این منطقه نشان داد که کمترین مقدار در شاخص INCOME و در متغیر وابسته رضایت ذهنی، سومین مقدار در شاخص NEET بوده است. در سایر شاخص های پایش شده، منطقه رفتار متوسطی دارد. این ترکیب احتمالاً به تأثیر منفی بر کیفیت مدل کمک کرده است. مشکل تا حدی با تغییر شاخص درآمد حل شد.
پیش از این، مجموعهای از شاخصهای حاصل که از نظر آماری مرتبط با رضایت ذهنی برچسبگذاری شده بودند، فرض نمیشد. بنابراین، این شاخص های “غیرمنتظره” در معرض توصیف بیشتر قرار گرفتند. سه مورد از شاخص ها به راحتی قابل تفسیر بودند و برخی با مفروضات مورد انتظار متناقض بودند. بسیاری از شاخصهای ورودی عملاً در مدل منعکس نشدند، اگرچه رابطه آنها با رضایت ذهنی قابل انتظار بود – برای مثال، نرخ خودکشی ناچیز بود. علاوه بر این، تنها مرگ و میر نوزادان در رابطه با رضایت از زندگی از سلامت معنادار بودشاخص های دامنه از آنجایی که تفسیر آن مشخص نیست، این شاخص در دسته «معارضه ها» طبقه بندی شد. شاخص های سلامت مانند امید به زندگی و میزان مرگ و میر، شاخص هایی هستند که بیشتر وضعیتی از جامعه را توصیف می کنند که در سطح شخصی درک نمی شود. در مورد روابط ذکر شده در مطالعات دیگر، تنها تأثیر مثبت رفاه مادی که توسط دولان و همکاران ذکر شده است. و Boarinii و همکاران [ 25 ، 27 ] و رابطه منفی با سن [ 27 ] که در اینجا با شاخص پیری نشان داده شده است را می توان تأیید کرد. برخلاف انتظارات، رابطه با مدت زمان تابش خورشید همانطور که توسط شوارتز و کلور یا کامپفر و موتز مشاهده شد [ 31 ، 58] در تحقیقات ما ثابت نشده است، زیرا این اندیکاتور به دلیل چند خطی بودن آن حذف شده است. ممکن است توسط پیشبینیکننده دیگری در مدل پیشبینی شود، اما ارتباط آن آشکار نشده است. با این حال، یافتههای مطالعه ما نیازی به سؤال ندارد، زیرا به هر حال مقایسه مطالعات بسیار دشوار است (از نظر تعداد پاسخدهندگان، نمونههای نماینده، و وضوح مکانی و زمانی). نتایج نشاندادهشده در مقاله ما نشان میدهد که تعدادی از شاخصها کیفیت محیط یا کیفیت وضعیت جامعه را به جای سنجش آن توصیف میکنند، که در سطح شخصی منعکس میشود. شاخصهای «شخصی» بیشتر مانند سلامت خود گزارشدهی، رضایت شغلی، شدت فعالیتهای اجتماعی و موارد مشابه برای تحلیل رگرسیون مناسبتر هستند، اما این نوع شاخصها، متاسفانه،
به طور کلی، بررسی روابط بین رضایت ذهنی از زندگی و مجموعهای از شاخصهای مرتبط میتواند برای هر سیاست یا فرآیندی با هدف بهبود استانداردهای زندگی یا کیفیت زندگی مفید باشد. چنین تحلیلی ممکن است نشان دهد که آیا نظارت بر شاخص های انتخاب شده واقعاً به سیاست مربوط است یا خیر. در نظارت بلندمدت توسعه اجتماعی، تأثیر واقعی مداخلات سیاستی خاص و ادراک آنها توسط جامعه (یا افراد) قابل مشاهده است. برای محققانی که با موضوع کیفیت زندگی یا رضایت از زندگی سر و کار دارند، رویکرد مشابهی بینش مفیدی را در مورد ماهیت پدیده مورد بررسی ارائه می دهد که می تواند بیشتر مورد استفاده قرار گیرد، به عنوان مثال، در قالب انتخاب خاص تری از داده ها برای مدل سازی. از وظایف دنیای واقعی
در این مورد خاص، می توان استنباط کرد که سیاست ها باید در درجه اول رفاه مادی جمعیت را برای بهبود کیفیت زندگی هدف قرار دهند. این ممکن است صرفاً با درآمد خانوار نشان داده نشود، اما ممکن است اهداف کلی تری مانند کاهش خطر فقر، محرومیت مادی یا طرد اجتماعی داشته باشد. این اهداف همچنین اجزای اصلی سیاست استراتژی اروپا 2020 هستند.
5. نتیجه گیری ها
نمی توان انکار کرد که رویکرد ذهنی به ارزیابی کیفیت زندگی بخش مهمی از روش شناسی ارزیابی است. دادههای بهدستآمده از نظرسنجی ذهنی ممکن است به عنوان منبع مرجع برای اعتبارسنجی نتایج عینی مرتبط باشند. کاوش در روابط بین شاخصهای عینی و دادههایی که کیفیت زندگی درک شده را توصیف میکنند میتواند هنگام انتخاب دادههای ورودی برای طراحی شاخص کیفیت زندگی مفید باشد.
سه وظیفه فرعی برای پاسخ به سؤالات تحقیق در مورد چگونگی ارتباط معیارهای عینی با رضایت ذهنی از زندگی در سطح زیر ملی در اروپا انجام شد. مجموعه داده ای متشکل از 22 شاخص عینی که مهمترین حوزه های کیفیت زندگی بر اساس ادبیات جهان را پوشش می دهد، در سطح NUTS 2 گردآوری شد. در دسترس بودن دادههای ذهنی زیرملی قابل اعتماد به طور قابل توجهی کمتر از دادههای عینی است. مجموعه داده ذهنی با بهترین کیفیت (EU-SILC) فقط دارای جزئیات مکانی است که در مطالعه ما استفاده می شود ( شکل 1)) که بدتر از NUTS 2 برای یک مجموعه داده هدف در شاخص های کیفیت زندگی است. با در نظر گرفتن ابهام دادههای ذهنی، نظریه فازی برای مدلهای رگرسیون اعمال شد. رابطه بین داده های ذهنی و عینی با رگرسیون خطی فازی تحلیل شد. رگرسیون فازی می تواند عدم قطعیت ضرایب رگرسیون و همچنین عدم قطعیت مقادیر بالقوه پیش بینی شده را کنترل کند. هنگامی که با تجسم فضایی تکمیل شود، تنوع فضایی و الگوهای آن، که در این مورد بسیار متمایز هستند، قابل مشاهده است. نتایج حاصل از آخرین کار پژوهشی تنها هفت شاخص را با یک رابطه آماری ثابت شده با رضایت ذهنی نشان می دهد. علاوه بر این، تفسیر واضح رابطه بین پنج شاخص از هفت شاخص دشوار بود.
نتایج، یافتههای بررسی ادبیات را تأیید میکند که مناسب بودن شاخص برای مدلسازی رضایت ذهنی بسیار متغیر است و امکان صدور عبارات معتبر کلی در این زمینه وجود ندارد. اگرچه تعدادی از مطالعات استحکام اطلاعات بهدستآمده از نظرسنجیهای فردی را آزمایش کردهاند، نتایج همیشه تحتتاثیر وضعیت پاسخدهندگان، تفکیک مکانی نمونه، و زمانی که نظرسنجی انجام شده است، میباشد. در تحقیق خود، ما ثابت کردیم که عدم قطعیت داده های ذاتی می تواند توسط مدل رگرسیون خطی فازی پردازش شود. در واقع، ما توانستیم روابط بین ادراک ذهنی رضایت از زندگی و معیارهای عینی را که معمولاً برای تحقیق در مورد کیفیت زندگی مورد استفاده قرار میگیرند، کشف و بررسی کنیم. تحقیق ما نشاندهنده کمک کمی به بحثهای موجود در مورد رضایت از زندگی است و تلاش میکند راههای جدیدی برای مقابله با این موضوع پیچیده داشته باشد. در آینده، آزمایش سازگاری نتایج بر روی سایر دادههای ذهنی موجود در سطح منطقه (Eurobarometer، Eurofound یا OECD Regional Well-Being) و مقایسه نتایج بهدستآمده با روشهای مختلف، مانند رگرسیون، جالب خواهد بود. مدل در مقابل رویکرد یادگیری ماشین، و مانند درختان رگرسیون.











بدون دیدگاه