1. معرفی
تقسیم بندی معنایی یک جنبه اساسی از تحقیقات بینایی کامپیوتری است. هدف آن اختصاص یک برچسب دسته به هر پیکسل در یک تصویر است. همراه با انواع دیگر تحقیقات یادگیری عمیق، نقش مهمی در تشخیص انواع مختلف پوشش زمین در تصاویر سنجش از دور دارد [ 1 ، 2 ، 3 ]. شناخت اطلاعاتی که یک تصویر حاوی آن است، بخش کلیدی تفسیر تصویر سنجش از دور است. تقسیم بندی معنایی به طور گسترده در نقشه برداری و
پایش پوشش زمین، تحلیل طبقه بندی شهری، شناسایی گونه های درختی در مدیریت جنگل و غیره استفاده می شود. 4 ، 5 ، 6 ، 7 ، 8 ، 910 410 ، 11 ، 12 ]. برای انجام آن، انواع پوشش زمین باید از نظر “شیء مشابه، طیف متفاوت” یا “طیف یکسان، شی متفاوت” متمایز شوند. به عنوان مثال، “دریاچه” و “رودخانه” دو نوع مختلف پوشش زمین هستند، اما در سنجش از دور، می توانند ظاهری مشابه داشته باشند. مکان هایی با تراکم ساختمان های بالا یا تراکم ساختمان های کم ممکن است همچنان هر دو به عنوان مناطق مسکونی شهری طبقه بندی شوند. علاوه بر این، مرزهای بین انواع مختلف پوشش زمین پیچیده و نامنظم است، که کار تقسیمبندی سنجش از دور را دشوارتر میکند. بنابراین، تمایز بین ویژگیها در سطح پیکسل ضروری است.
در سالهای اخیر، پیشرفتهای روز در شبکههای تقسیمبندی معنایی بهشدت پیشرفت کرده است [ 13 ، 14 ، 15 ]. یکی از راههای حل مسائل فوق، استفاده از یک شبکه عصبی تکراری برای گرفتن اطلاعات زمینهای دوربرد است. این نوع شبکه می تواند به نتایج قابل توجهی دست یابد. به عنوان مثال، یک شبکه عصبی بازگشتی گراف غیر چرخه ای جهت دار [ 16 ] می تواند اطلاعات متنی غنی موجود در ویژگی های محلی را ضبط کند. با این حال، اگرچه این روش بسیار مؤثر است، اما تا حد زیادی به نتایج یادگیری طولانی مدت بستگی دارد. به دست آوردن چنین تعداد زیادی از برچسب های تقسیم بندی تصویر سنجش از دور بسیار دشوار است، بنابراین کاربرد عملی محدودی برای تقسیم بندی تصاویر سنجش از دور دارد.
یکی دیگر از راههای مؤثر برای مقابله با مسائلی که در بالا توضیح داده شد، استفاده از مکانیسمهای توجه به خود است. اینها به دلیل ساختار متنوع و انعطافپذیرشان برای انطباق با وظایف تقسیمبندی معنایی، محبوب و ساده هستند [ 17 ، 18 ، 19 ، 20 ، 21 ، 22]. مکانیسم های توجه به خود با تولید نقشه های ویژگی وزن و ترکیب نقشه های ویژگی پایین دست بر ویژگی های محلی تمرکز می کنند. این ممکن است مستلزم داشتن یک یا چند ماژول بر اساس ستون فقرات اساسی باشد که هر ماژول روی چیزهایی مانند کانال یا اطلاعات مکانی تمرکز دارد. با این حال، نقشههای ویژگی پایین دستی میتوانند اطلاعات مکانی زیادی را از دست بدهند، و گرفتن اطلاعات مکانی اصلی به طور مستقیم در حال حاضر امکانپذیر نیست. با این حال، داشتن اطلاعات مکانی بسیار دقیق برای تقسیم بندی موثر تصاویر سنجش از دور بسیار مهم است.
برای پرداختن به مسائل فوق، ما در اینجا یک مدل مکانیزم خودتوجهی جدید به نام شبکه توجه مسیر دوگانه (DPA-Net) پیشنهاد میکنیم که برای تقسیمبندی معنایی سنجش از دور طراحی شده است. این ماژول از دو ماژول توجه استفاده می کند: یک ماژول توجه فضایی کل برای گرفتن اطلاعات مکانی و یک ماژول توجه کانال برای گرفتن اطلاعات کانال به طور جداگانه. این دو ماژول را میتوان به راحتی به مدلهای تقسیمبندی دیگر مانند PSP-Net اضافه کرد [ 23]. در حال حاضر روش های زیادی برای استخراج کارآمد انواع مختلف اطلاعات ویژگی وجود دارد. با این حال، ورودی تقریباً تمام روشهای توجه فضایی، نقشه ویژگی پس از نمونهبرداری است. همانطور که در بالا ذکر شد، در مقایسه با تصویر اصلی، نقشه ویژگی پاییننمونهشده حاوی اطلاعات مکانی بسیار کمتری است. بنابراین، این نوع توجه فضایی به طور اجتناب ناپذیری ناکارآمد است، زیرا قادر به استفاده کامل از اطلاعات مکانی در داده ها نیست. بنابراین، به جای تصویر نمونه برداری شده، ورودی روش توجه فضایی را به تصویر اصلی تغییر دادیم. در ماژول توجه فضایی کل، اطلاعات مکانی از تصویر اصلی بر اساس مکانیسم توجه به خود که در بالا ذکر شد، گرفته می شود. خروجی TSAM یک ماتریس وزنی تک کانالی است. هر پیکسل از خروجی را می توان با ترکیب کردن با توجه به وزن مربوطه دوباره به روز کرد و وزن خود توسط ماژول تولید می شود. پس از ادغام با نقشه ویژگی نهایی DPA-Net، TSAM وزنی برای هر پیکسل ارائه می دهد. در طول آموزش، شبکه توجه بیشتری به نواحی با وزنه های بزرگتر دارد. این بدان معناست که هر پیکسل تمرکز خاص خود را در شبکه دارد. برای ماژول توجه کانال، مکانیسم خودتوجهی اطلاعات کانال را مطابق نقشه کانال می گیرد. همانند ماژول کل توجه فضایی، یک فاکتور وزن ایجاد می کند. نقشه های ویژگی با ادغام این فاکتور وزن به روز می شوند. هنگامی که دو ماژول عملیات خود را کامل کردند، دو نقشه ویژگی به دست می آید که به ترتیب حاوی اطلاعات مکانی و اطلاعات کانال هستند. سپس،
شایان ذکر است که اگرچه روش پیشنهادی موثرتر از روش اصلی خود توجهی است، اما تغییر قابل توجهی در ردپای حافظه ایجاد نمی کند. به طور کلی، مشکلات مرسوم مرتبط با مکانیسم های توجه به خود را به روشی ساده حل می کند. اول از همه، TSAM محاسبات خود را بر اساس تصویر اصلی انجام می دهد. در مقایسه با نقشه های ویژگی پایین دست، تصاویر سنجش از راه دور اصلی حاوی اطلاعات مکانی بیشتری هستند. ثانیاً خروجی دو ماژول بر روی آخرین نقشه ویژگی در مدل عمل می کند. بنابراین، دو ماژول می توانند انتشار پشت کل مدل را کنترل کنند. علاوه بر این، سادگی ساختار ماژول، استفاده از آن را با هر مدل تقسیم بندی آسان می کند. برای تأیید اثربخشی روش خود، آزمایشهایی را با U-Net، PSP-Net،24 ، 25 ] در مجموعه داده تصویر Gaofen (GID) [ 26 ]. میانگین IoU برای هر ماژول را به ترتیب 0.84٪، 2.54٪ و 1.32٪ بهبود بخشید.
مشارکت های اصلی مقاله را می توان به شرح زیر خلاصه کرد:
-
ما یک شبکه توجه دو مسیره (DPA-Net) را پیشنهاد میکنیم که از مکانیزم خودتوجهی برای افزایش توانایی شبکه برای گرفتن ویژگیهای محلی کلیدی در تقسیمبندی معنایی تصاویر سنجش از راه دور استفاده میکند.
-
یک ماژول توجه فضایی کل برای استخراج اطلاعات فضایی در سطح پیکسل استفاده می شود و یک ماژول توجه کانال برای تمرکز بر ویژگی های مختلف پیشنهاد شده است. پس از استخراج ویژگی مسیر دوگانه، عملکرد بخش بندی معنایی به طور قابل توجهی بهبود می یابد.
-
از آنجایی که تعداد تصاویر در مجموعه داده آزمایشی، GID، نسبتاً کم بود، استراتژیهای پردازش برای بهبود کیفیت تستهای ما توسعه داده شد. با گسترش، این استراتژی ها می توانند به طور کلی برای بهبود بخش بندی مجموعه داده های کوچک مورد استفاده قرار گیرند.

2. کارهای مرتبط
سنجش از دور. تصاویر سنجش از دور با وضوح بالا، داده های اساسی برای فناوری اطلاعات مکانی در سیستم های اطلاعات جغرافیایی را تشکیل می دهند. آنها همچنین یک منبع اطلاعات استراتژیک ملی و بین المللی مهم هستند [ 1 , 26 , 27 , 28 , 29 , 30]. تصاویر جمعآوریشده توسط حسگرهای راه دور نصبشده بر روی هواپیما یا ماهوارهها، زیربنای تکنیکهای تشخیص از راه دور هستند که هدف آن شناسایی پوشش زمین، مانند ساختمانها، زمینهای کشاورزی، پوشش گیاهی، خاک برهنه، رودخانهها و غیره است. پس از شناسایی پوشش زمین، اغلب نقشههای موضوعی تهیه میشوند. برای نمایش بصری توزیع آن. هنگامی که با الگوریتمهای بینایی کامپیوتری ترکیب میشوند، تکنیکهای تشخیص از راه دور مزایای قابلتوجهی در مورد عکسبرداری بلادرنگ و هزینه در مقایسه با بررسیهای میدانی سنتی دارند. بنابراین، آنها به طور فزاینده ای در زمینه های برنامه ریزی کاربری اراضی، جنگلداری و نظارت بر تلفات خاک استفاده می شوند [ 31 ، 32 ، 33 ، 34 ].
تقسیم بندی معنایی هدف تقسیم بندی معنایی تقسیم و تجزیه یک تصویر صحنه به مناطق مختلف مرتبط با مقوله های معنایی است. در سال های اخیر، روش های مختلف مبتنی بر FCNs [ 35 ] به پیشرفت های مهمی در بخش بندی معنایی منجر شده است. یکی از راههای بهبود عملکرد یک مدل تقسیمبندی، افزایش تجمیع متنی آن است. چندین مدل مانند U-Net از ساختار رمزگذار-رمزگشا استفاده می کنند [ 24 ، 36 ، 37] برای ادغام ویژگی های میان جریان و ویژگی های پایین دست. ماژول رمزگذار به تدریج اندازه نقشه های ویژگی ها را کاهش می دهد و اطلاعات معنایی سطح بالاتری را ضبط می کند. اطلاعات مکانی توسط ماژول رمزگشا بازیابی می شود. مدلهایی مانند DeepLab V3+ از ادغام هرم فضایی آتروس برای فیوز کردن ویژگیها در چندین مقیاس مختلف و در مناطق مختلف فرعی مختلف استفاده میکنند [ 25 ، 38 ، 39 ، 40 ]. خارج از این، پیچش های متسع موازی با نرخ های اتساع متفاوت می توانند میدان گیرنده را بزرگ کنند. یکی دیگر از رویکردهای موثر، گرفتن وابستگی های زمینه غنی است. به عنوان مثال، پنگ [ 41] مفهوم موضوعات هسته بزرگ را برای یادگیری وابستگی های متنی با استفاده از یک شبکه کانولوشنال جهانی (GCN) توسعه داد. منیه و همکاران [ 42 ] یک مکانیسم توجه را به یک شبکه عصبی بازگشتی (RNN) اضافه کرد تا پیچیدگی آن را کاهش دهد. وانگ و همکاران [ 43 ] اولین کسانی بودند که ساختار توجه مکرر را برای تصاویر سنجش از دور پیشنهاد کردند. در اینجا، یک ماتریس ماسک برای وزنهای توجه استفاده میشود، که سپس نقشه ویژگی را ضرب میکند تا یک نمایش مبتنی بر توجه از ویژگیهای سطح بالا به دست آید.
مکانیسم های توجه به خود مکانیسمهای خودتوجهی روشی مؤثر برای افزایش توانایی شبکه عصبی برای گرفتن ویژگیهای مهم محلی ارائه میکنند. رویکرد [ 44 ] ابتدا برای ترجمه ماشینی پیشنهاد شد، اما اکنون به طور گسترده در طبقه بندی تصویر [ 1 ]، تقسیم بندی تصویر [ 22 ] و زمینه های دیگر [ 45 ، 46 ، 47 ] استفاده می شود. بسیاری از مطالعات نشان دادهاند که مکانیسمهای توجه میتوانند شناسایی نورونهای دارای ویژگیهای کلیدی را افزایش داده و عملکرد شبکه را بهبود بخشند. برای مثال، ماژولهای توجه بلوک پیچشی (CBAM) [ 19] از اطلاعات سطح بالا استفاده کنید تا با به هم پیوستن کانال ها و ماژول های توجه فضایی، وزن ها را از نظر کانال یا فعالیت های فضایی دریافت کنید. در رویکردی متفاوت، DA-Net [ 22 ] یک ماژول توجه کانال و ماژول توجه فضایی را به صورت موازی در یک ماتریس خودهمبستگی غیرمحلی اجرا میکند که نتایج خوبی ارائه کرده است.
3. روش ها
در این بخش ابتدا چارچوب کلی شبکه خود را ارائه می کنیم. سپس، دو ماژول توجه را معرفی میکنیم که اطلاعات زمینهای فضایی و مرتبط با کانال را میگیرند. این بخش با توضیح چگونگی تجمیع خروجی از دو ماژول برای ارائه خروجی نهایی به پایان می رسد.
3.1. بررسی اجمالی
برای تقسیمبندی معنایی منظم، صحنه تقسیمبندی شامل انواع مختلفی از اشیاء در مقیاسهای متنوع با نورهای مختلف است که از دیدگاههای مختلف قابل مشاهده هستند. با این حال، به دلیل یکسان بودن زاویه عکسبرداری و فاصله نمونه ها در تصاویر سنجش از دور مختلف، مسئله مرزی را می توان چیزی فراتر از یک مسئله چند مقیاسی و چند زاویه ای در نظر گرفت. در یک تصویر سنجش از دور، انواع مختلفی از
پوشش زمین وجود خواهد داشت. به طور کلی انواع مختلف پوشش زمین ویژگی های طیفی و ساختاری خاص خود را دارند که در مقادیر مختلف روشنایی، مقادیر پیکسل یا تغییرات فضایی در تصاویر سنجش از دور قابل مشاهده است. با توجه به پیچیدگی ترکیب، ماهیت، توزیع و شرایط تصویربرداری از ویژگی های سطح، تصاویر سنجش از دور را می توان در قالب «شیء مشابه، طیف مختلف» و «طیف یکسان، شی متفاوت» در نظر گرفت. همچنین دو یا چند نوع “پیکسل مختلط” وجود دارد که می تواند در یک پیکسل یا میدان دید آنی رخ دهد و کار تشخیص را در تصاویر سنجش از دور پیچیده تر می کند. همه این عوامل می تواند بر دقت نتیجه تاثیر بگذارد. برای مقابله با این، روش پیشنهادی ما به دنبال بهبود مجزای کانال و ویژگیهای فضایی است، بنابراین نمایش ویژگی برای تقسیمبندی سنجش از راه دور را بهبود میبخشد. همه این عوامل می تواند بر دقت نتیجه تاثیر بگذارد. برای مقابله با این، روش پیشنهادی ما به دنبال بهبود مجزای کانال و ویژگیهای فضایی است، بنابراین نمایش ویژگی برای تقسیمبندی سنجش از راه دور را بهبود میبخشد. همه این عوامل می تواند بر دقت نتیجه تاثیر بگذارد. برای مقابله با این، روش پیشنهادی ما به دنبال بهبود مجزای کانال و ویژگیهای فضایی است، بنابراین نمایش ویژگی برای تقسیمبندی سنجش از راه دور را بهبود میبخشد.
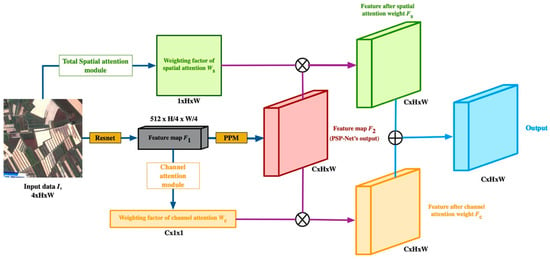
روش ما را می توان با هر مدل تقسیم بندی معنایی، مانند U-Net، PSP-Net، و غیره استفاده کرد. با در نظر گرفتن PSP-Net به عنوان مثال، ساختار اصلی آن در شکل 1 نشان داده شده است [ 22 ] . تصویر ورودی (a) به یک شبکه عصبی کانولوشن (CNN) تغذیه می شود تا نقشه ویژگی آخرین لایه کانولوشن (b) به دست آید. سپس، یک ماژول تجزیه هرمی (c) برای به دست آوردن نمایشهای زیر ناحیههای مختلف، و به دنبال آن لایههای upsampling و الحاق برای تشکیل نمایش ویژگی نهایی استفاده میشود. این شامل اطلاعات زمینه محلی و جهانی است. در نهایت، یک لایه کانولوشن برای به دست آوردن پیشبینی هر پیکسل (d) با توجه به نمایش مورد نیاز استفاده میشود.
ساختار کلی DPA-PSP-Net در شکل 2 نشان داده شده است . ما از ResNet50 از پیش آموزش دیده استفاده کردیم [ 48 ] و از یک استراتژی گشاد شده [ 38 ] برای ستون فقرات استفاده کردیم. با توجه به ساختار ResNet50، چارچوب پیشنهادی دارای چهار بلوک باقیمانده، یک ماژول ادغام هرمی (PPM)، یک ماژول توجه کانال و یک ماژول توجه فضایی است. ما عملیات نمونه برداری پایین را حذف کردیم و به جای آن از پیچش های گشاد شده در دو بلوک باقیمانده آخر استفاده کردیم، که مشابه فرآیند مورد استفاده در PSP-Net است. بنابراین، اندازه نقشه ویژگی نهایی در 1/8 مقیاس تصویر ورودی بود. با توجه به یک تصویر ورودی با اندازه 256 پیکسل × 256 پیکسل، ما از ResNet50 برای دریافت نقشه ویژگی، F 1 استفاده کردیم.در حالی که فاکتور وزن برای توجه فضایی، Ws، توسط ماژول توجه فضایی به دست آمد. F 1 به ترتیب به PPM و ماژول توجه کانال وارد شد تا نقشه ویژگی F 2 را پس از نمونه برداری بالا و اعمال ضریب وزنی برای توجه کانال Wc بدست آورد . در نهایت، F 2 در Wc و Ws ضرب شد تا ویژگیها برای به دست آوردن نقشه ویژگی وزندار کانال، F C ، و نقشه ویژگی وزندار توجه فضایی، F S به دست آید . سپس، F C و FS برای به دست آوردن خروجی نهایی تجمیع شدند.
3.2. ماژول توجه فضایی کل
اثربخشی استخراج ویژگی مستقیماً با دقت نتایج در تقسیمبندی تصویر سنجش از دور مرتبط است. ویژگی ها را می توان با استفاده از اطلاعات زمینه ای به دست آورد. با این حال، بسیاری از مطالعات [ 23 ، 41] نشان داده اند که ویژگی های محلی تولید شده توسط FCN های سنتی می تواند منجر به طبقه بندی اشتباه اشیا و پیش بینی نادرست اشکال اشیا شود. مکانیسم توجه نقش مهمی در سیستم بینایی انسان دارد. در مواجهه با صحنه های پیچیده، انسان می تواند به سرعت توجه خود را بر روی جنبه های مهم متمرکز کند و آنها را اولویت بندی کند. همانند سیستم بینایی انسان، مکانیزم توجه مبتنی بر کامپیوتر میتواند قدرت محاسباتی شبکه را بر روی ویژگیهای کلیدی متمرکز کند، به طوری که میتوان ویژگیهای مهم را از تصاویر سنجش از دور به طور موثرتری استخراج کرد و اطلاعات اضافی را کنار گذاشت. برای افزایش توانایی استخراج ویژگی محلی برای تصاویر سنجش از راه دور دشوار، ما یک ماژول توجه فضایی کامل (TSAM) ایجاد کردهایم. این ماژول می تواند اطلاعات مرزی فضایی تصاویر سنجش از دور را ضبط کند. که استخراج ویژگیهای مرزی و اصلاح سایر ویژگیهای تطبیقی را آسانتر میکند، در حالی که اطلاعات کمتر مهم را سرکوب میکند. ساختار ماژول بسیار ساده است و می توان آن را در هر شبکه ای تعبیه کرد تا توانایی یادگیری ویژگی های شبکه را بهبود بخشد. روش های متعددی برای رسیدگی به توجه فضایی در حال حاضر وجود دارد [20 ، 22 ]. با این حال، در ماژول توجه فضایی ما، ورودی به جای نقشه ویژگی، F 1، داده است . با توجه به ویژگی وضوح بالای تصاویر سنجش از دور و اطلاعات مکانی پیچیده ای که در آنها وجود دارد، دقت اطلاعات مرزی از اهمیت حیاتی برخوردار است. با عمیق شدن یک شبکه، میدان دریافتی به تدریج گسترش می یابد، اطلاعات معنایی به طور فزاینده ای پیشرفته می شود، نقشه ویژگی کوچکتر و کوچکتر می شود و اطلاعات مکانی دائما کاهش می یابد. اندازه نقشه ویژگی، F 1، تنها 1/8 از داده های ورودی است، بنابراین بسیاری از اطلاعات مکانی از بین رفته است. بنابراین، تصویر اصلی منبع بهتری برای ثبت اطلاعات مکانی مهم در یک تصویر سنجش از دور است.
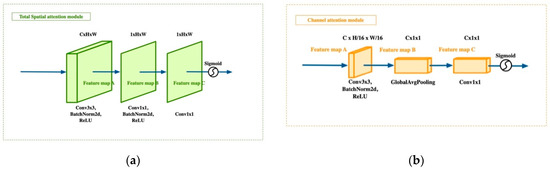
ساختار ماژول توجه فضایی کل در شکل 3 الف نشان داده شده است. داده های ورودی، تصویر سنجش از راه دور، I ∊ R 4×H×W هستند ، که همان داده های ورودی در ResNet است. ورودی I ابتدا از لایه های conv3×3، BN [ 49 ]، و ReLU با شماره کانال C عبور می کند تا نقشه ویژگی، A ∊ R C×H×W را ایجاد کند . سپس، A وارد لایههای conv1×1، BN، و ReLU میشود تا نقشه ویژگی بعدی، B∊ R 1×H×W به دست آید . نقشه ویژگی B از لایه conv1×1 دیگری عبور می کند تا نقشه ویژگی را ایجاد کند، C∊ R1×H×W. در نهایت، یک تابع سیگموئید برای بدست آوردن ضریب وزنی توجه فضایی، W s ∊ R H×W استفاده می شود . این فرایند به شرح زیر است:
که در آن I o تصویر سنجش از راه دور اصلی را نشان می دهد و A ، B و C نقشه های ویژگی مربوطه در شکل 3 a هستند. به این ترتیب، هر مقدار، w در W s است، بین 0 و 1 است. این می تواند به عنوان وزن هر پیکسل مربوطه در تصویر اصلی در نظر گرفته شود که نشان دهنده اهمیت نسبی پیکسل است. این روش ساده امکان تولید وزن موقعیت با عرض و ارتفاع برابر با تصویر اصلی را فراهم میکند و شبکه توانایی استخراج ویژگی محلی سطح پیکسل را بدون افزایش محاسباتی تقریباً افزایش میدهد. بنابراین، میتوان ویژگیهای صحنه سنجش از دور مؤثرتری را استخراج کرد و در نتیجه عملکرد طبقهبندی را بهبود بخشید.
3.3. ماژول توجه کانال
برخی از مشکلات رایج در مجموعه داده های تصویر سنجش از دور وجود دارد. اینها شامل توزیع نابرابر نمونه ها و پیچیدگی متفاوت انواع مختلف پوشش زمین است. هنگامی که یک مدل آموزش داده می شود، با عمیق شدن شبکه، اطلاعات معنایی به طور فزاینده ای پیچیده می شود. هر کانال در ویژگی های معنایی پیشرفته نهایی را می توان به عنوان خلاصه ای از انواع مختلف پوشش زمین مشاهده کرد. ما یک ماژول توجه کانال (CAM) را معرفی کردیم تا کانالهای ویژگی را با مقادیر مشابهی که در یک مکان تصویر اتفاق میافتند، تقویت کنیم. اگر موقعیت یکسانی در یک تصویر مقادیر مشابهی برای کانالهای مختلف داشته باشد، به این معنی است که ممکن است حداقل دو نوع ویژگی وجود داشته باشد، با تفاوت کم یا بدون تفاوت بین آنها. هدف خروجی CAM این است که ارتباط بین کانال های مشابه را آشکارتر کند. CAM می تواند انواع مختلفی از اطلاعات مهم را در یک تصویر سنجش از راه دور مربوط به کانال های مختلف در نقشه ویژگی معنایی سطح بالا ثبت کند. این امر استخراج ویژگی های کلیدی را تسهیل می کند و تعادل در استخراج ویژگی تطبیقی را اصلاح می کند. ورودی CAM نقشه ویژگی است،F 1 . این شامل ویژگی های معنایی بالاترین سطح در کل مدل است.
ساختار CAM در شکل 3 ب نشان داده شده است. داده های ورودی نقشه ویژگی، F 1 ∊ R 512×H/4×W/4 هستند . ورودی، F 1 ، ابتدا از یک لایه 3 × 3 کانولوشن، یک لایه BN، و یک لایه ReLU با شماره کانال، C عبور می کند تا نقشه ویژگی A ∊ R C ×H×W را ایجاد کند . سپس، جمعبندی میانگین جهانی برای به دست آوردن نقشه ویژگی، B∊ R C×1×1 استفاده میشود . سپس، B به یک لایه کانولوشن 1 × 1 وارد می شود تا نقشه ویژگی، C ∊ R C × 1 × 1 را دریافت کند . در نهایت از یک تابع سیگموئید برای بدست آوردن فاکتور وزن دهی توجه کانال استفاده می کنیم.W c ∊ R C×1×1 . فرآیند را می توان به صورت زیر خلاصه کرد:
که در آن F 1 نقشه ویژگی مربوطه در شکل 2 است . و A ، B، و C نقشه های ویژگی مربوطه در شکل 3 a هستند. مانند Ws ، هر مقدار در Wc بین 0 و 1 است. این می تواند به عنوان وزن هر دسته در نظر گرفته شود، که نشان دهنده دشواری استخراج ویژگی است . با استفاده از این روش ساده برای تولید وزن کانال، شبکه میتواند بر انواع پیچیدهتر استخراج ویژگی تمرکز کند، اطلاعات اضافی را کاهش دهد و طبقهبندی نوع پوشش زمین را بهبود بخشد.
3.4. تجمیع ویژگی ها
با استفاده از ماژول های فوق می توان اطلاعات مهم موجود در تصاویر سنجش از دور با وضوح بالا را به طور موثرتری استخراج کرد. برای استفاده کامل از اطلاعات زمینهای، ویژگیها پس از اعمال وزنهای توجه جمعآوری میشوند. این شامل ضرب خروجی دو ماژول ( Ws و W c ) و نقشه ویژگی، F 2 ( خروجی PSP-Net در مثال ما)، در عناصر مربوطه برای به دست آوردن دو نقشه ویژگی با اندازه یکسان، C × است. H × W. یکی نقشه ویژگی پس از اعمال وزن توجه کانال، F c است . دیگری نقشه ویژگی پس از اعمال وزن توجه فضایی، F s است. تجمیع ویژگی با جمع عناصر مربوطه در Fc و Fs تکمیل می شود . لازم به ذکر است که دو ماژول توجه بسیار ساده هستند و می توانند به طور مستقیم در هر مدل تقسیم بندی مورد استفاده قرار گیرند. آنها بار محاسباتی را به طور قابل توجهی افزایش نمی دهند، اما می توانند عملکرد شبکه را به طور قابل توجهی بهبود بخشند.
4. آزمایشات
در این بخش ابتدا مجموعه داده تصویر
Gaofen (GID) را معرفی کرده و نحوه پیاده سازی مدل را توضیح می دهیم. سپس، نحوه انجام یک آزمایش جامع بر روی مجموعه داده GID برای ارزیابی روش پیشنهادی ما و مقایسه عملکرد تقسیمبندی معنایی آن با سایر الگوریتمهای پیشرفته ارائه میکنیم.
4.1. مجموعه داده
4.1.1. توضیحات مجموعه داده
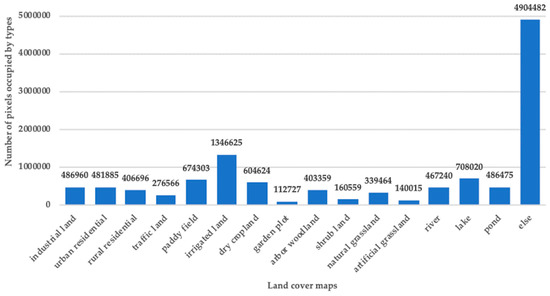
مجموعه داده تصویر با وضوح بالا، GID [ 26]، یک مجموعه داده پوشش زمین در مقیاس بزرگ است. این از تصاویر ماهواره ای GF-2 ساخته شده است. در نتیجه پوشش وسیع، توزیع گسترده و وضوح فضایی بالا، دارای تعدادی مزیت نسبت به مجموعه داده های پوشش زمین موجود است. GF-2 بالاترین وضوح ماهواره رصد زمینی در چین در حال حاضر است، بنابراین وضوح تصویر مجموعه داده استثنایی است. دسته بندی های تحت پوشش مجموعه داده نیز متنوع و معمولی هستند، بنابراین خصوصیات انواع پوشش زمین نشان دهنده توزیع پوشش زمین در اکثر نقاط چین است. در عین حال، پیچیدگی انواع پوشش زمین، مجموعه داده را به ویژه برای تحقیق ارزشمند می کند. مجموعه داده GID از دو بخش تشکیل شده است: یک مجموعه طبقه بندی در مقیاس بزرگ و یک مجموعه طبقه بندی پوشش زمین ریز دانه. مجموعه طبقه بندی در مقیاس بزرگ شامل 150 تصویر GF-2 است که در سطح پیکسل حاشیه نویسی شده اند. مجموعه طبقه بندی ریزدانه شامل 30000 بلوک تصویر چند مقیاسی و تصاویر GF-2 حاشیه نویسی شده در سطح 10 پیکسل است. ما عمداً استفاده از مجموعه داده های GID را با 16 نوع پوشش زمین انتخاب کردیم که آموزش آنها دشوارتر است. هر تصویر 6800 پیکسل × 7200 پیکسل، دارای 4 کانال NirRGB و برچسب های سطح پیکسل با کیفیت بالا برای 16 نوع پوشش زمین است. 16 نوع پوشش زمین به شرح زیر است: زمین صنعتی; مسکونی شهری; مسکونی روستایی; زمین ترافیکی؛ مزرعه شالیکاری؛ زمین آبی؛ زمین زراعی خشک؛ قطعه باغ؛ جنگل درختکاری; زمین بوته ای؛ علفزار طبیعی؛ مرتع مصنوعی؛ رودخانه؛ دریاچه حوضچه؛ و دسته های دیگر 000 بلوک تصویر چند مقیاسی و تصاویر GF-2 با حاشیه 10 پیکسلی. ما عمداً استفاده از مجموعه داده های GID را با 16 نوع پوشش زمین انتخاب کردیم که آموزش آنها دشوارتر است. هر تصویر 6800 پیکسل × 7200 پیکسل، دارای 4 کانال NirRGB و برچسب های سطح پیکسل با کیفیت بالا برای 16 نوع پوشش زمین است. 16 نوع پوشش زمین به شرح زیر است: زمین صنعتی; مسکونی شهری; مسکونی روستایی; زمین ترافیکی؛ مزرعه شالیکاری؛ زمین آبی؛ زمین زراعی خشک؛ قطعه باغ؛ جنگل درختکاری; زمین بوته ای؛ علفزار طبیعی؛ مرتع مصنوعی؛ رودخانه؛ دریاچه حوضچه؛ و دسته های دیگر 000 بلوک تصویر چند مقیاسی و تصاویر GF-2 با حاشیه 10 پیکسلی. ما عمداً استفاده از مجموعه داده های GID را با 16 نوع پوشش زمین انتخاب کردیم که آموزش آنها دشوارتر است. هر تصویر 6800 پیکسل × 7200 پیکسل، دارای 4 کانال
NirRGB و برچسب های سطح پیکسل با کیفیت بالا برای 16 نوع پوشش زمین است. 16 نوع پوشش زمین به شرح زیر است: زمین صنعتی; مسکونی شهری; مسکونی روستایی; زمین ترافیکی؛ مزرعه شالیکاری؛ زمین آبی؛ زمین زراعی خشک؛ قطعه باغ؛ جنگل درختکاری; زمین بوته ای؛ علفزار طبیعی؛ مرتع مصنوعی؛ رودخانه؛ دریاچه حوضچه؛ و دسته های دیگر 16 نوع پوشش زمین به شرح زیر است: زمین صنعتی; مسکونی شهری; مسکونی روستایی; زمین ترافیکی؛ مزرعه شالیکاری؛ زمین آبی؛ زمین زراعی خشک؛ قطعه باغ؛ جنگل درختکاری; زمین بوته ای؛ علفزار طبیعی؛ مرتع مصنوعی؛ رودخانه؛ دریاچه حوضچه؛ و دسته های دیگر 16 نوع پوشش زمین به شرح زیر است: زمین صنعتی; مسکونی شهری; مسکونی روستایی; زمین ترافیکی؛ مزرعه شالیکاری؛ زمین آبی؛ زمین زراعی خشک؛ قطعه باغ؛ جنگل درختکاری; زمین بوته ای؛ علفزار طبیعی؛ مرتع مصنوعی؛ رودخانه؛ دریاچه حوضچه؛ و دسته های دیگرشکل 4 توزیع انواع پوشش زمین را نشان می دهد.
4.1.2. پیش پردازش مجموعه داده
با توجه به توزیع نابرابر انواع مختلف پوشش زمین در مجموعه داده های GID و این واقعیت که تصاویر بسیار بزرگ هستند، مجموعه داده ها نیاز به پیش پردازش داشت تا آموزش بتواند موثرتر باشد. اول از همه، ما به صورت دستی 10 تصویر را به 1000 پیکسل × 1000 پیکسل برش دادیم تا به عنوان یک مجموعه اعتبار سنجی عمل کنند و تغییر در توزیع را تا حد امکان کوچک نگه داریم. دلیل انتخاب مجموعه اعتبارسنجی این بود که روش ما یک شبکه کانولوشن کامل (FCN) بود، بنابراین به اندازه تصویر ورودی حساس نبود. علاوه بر این، اندازه تصاویر سنجش از دور اغلب بسیار بزرگ است، بنابراین ما یک تصویر با اندازه بزرگتر را برای تأیید انتخاب کردیم. انتخاب دستی همچنین می تواند توزیع متعادل را تضمین کند. توزیع انواع پوشش زمین در مجموعه اعتبارسنجی در شکل 5 نشان داده شده است.
پس از حذف مجموعه اعتبارسنجی از مجموعه داده GID، 15000 تصویر به طور تصادفی از تصاویر اصلی به 256 پیکسل × 256 پیکسل برش داده شد تا یک مجموعه آموزشی ایجاد شود. از آنجایی که توزیع نابرابر انواع مختلف پوشش زمین وجود داشت، تصاویری را با کمترین توزیع پوشش زمین GID مانند زمین های باغ و چمنزار مصنوعی از تصاویر اصلی برش دادیم و حدود 9 تصویر با اندازه های مختلف ارائه کردیم. سپس 1000 تصویر 256 پیکسل × 256 پیکسل به طور تصادفی از این نه تصویر برش داده شد و برای بهبود توزیع به مجموعه آموزشی اضافه شد. بنابراین، مجموعه آموزشی نهایی از 16000 تصویر با اندازه 256 پیکسل × 256 پیکسل، همانطور که در شکل 6 نشان داده شده است، تشکیل شده است . شکل 7توزیع مجموعه آموزشی را نشان می دهد. ما از مجموعه آزمایشی استفاده نکردیم، زیرا اندازه مجموعه داده بسیار کوچک بود. اگرچه 16000 تصویر در مجموعه داده آموزشی وجود دارد، آنها به طور تصادفی از بقیه مجموعه داده های GID برش داده می شوند. بنابراین بین تصاویر مجموعه آموزشی همپوشانی وجود دارد. این عملیات به خودی خود یک فرآیند افزایش داده است و آموزش آن دشوار است زیرا حافظه زیادی را اشغال می کند.
4.1.3. افزایش داده ها
تصاویر سنجش از راه دور با وضوح بالا می توانند به راحتی باعث افزایش بیش از حد شبکه شوند زیرا به سختی می توان تعداد کافی از تصاویر برچسب گذاری شده را بدست آورد. تعداد محدود انواع در مجموعه داده کوچک GID نیز آموزش شبکه را دشوارتر کرده است. بنابراین، یک استراتژی افزایش داده برای افزایش قابلیت تعمیم شبکه به کار گرفته شد. ما از Albumentations (
https://github.com/albumentations-team/albumentations) برای تقویت مجموعه داده و اعمال توابع horizontalflip، verticalflip، randomrotate90 و تبدیل برای غنی سازی مجموعه داده آموزشی. این همچنین ویژگی های استخراج شده از تغییر ناپذیری چرخش شبکه را به دست می دهد. Elastictransform، blur، و cutout نیز برای هر تصویر در طول آموزش استفاده شد تا احتمال ثبت ویژگیهای ناچیز شبکه را کاهش دهد. احتمال تمام عملیات فوق 0.5 بود.
4.2. جزئیات پیاده سازی
ما از دقت پیکسل (Acc)، میانگین IoU و امتیاز F1 به عنوان معیارهای ارزیابی عملکرد برای نتایج تقسیمبندی معنایی استفاده کردیم. دقت پیکسل تعداد پیکسل های طبقه بندی شده صحیح بر تعداد کل پیکسل های تصویر است. می توان آن را به صورت زیر محاسبه کرد:
که در آن k تعداد دسته های پیش زمینه است. p ii تعداد پیکسل هایی است که به درستی پیش بینی شده است. و p ij نشان دهنده پیکسلی است که متعلق به کلاس i است اما پیش بینی می شود که متعلق به کلاس j باشد.
با توجه به تقسیمبندی معنایی، میانگین IoU میانگین تقاطع بیش از اتحاد دو مجموعه را با همان دستهبندی محاسبه میکند: حقیقت زمینی و تقسیمبندی پیشبینیشده. این یک معیار ارزشمند برای ایجاد عملکرد بخشبندی است. نتایج در محدوده 0 تا 1 قرار می گیرند و مقدار بالاتر نشان دهنده عملکرد بخش بندی بهتر است. میانگین IoU را می توان به صورت زیر محاسبه کرد:
که در آن k تعداد دسته های پیش زمینه است. p ii تعداد پیکسل هایی است که به درستی پیش بینی شده است. و p ij و p ji تعابیر مثبت کاذب و منفی کاذب هستند.
شاخص دیگری که استفاده می شود، امتیاز F1 است. امتیاز F1 میانگین وزنی هارمونیک دقت و یادآوری است. امتیاز F1 و فراخوان را می توان به صورت زیر بدست آورد:
که در آن Acc دقت پیکسلی است که در بالا ذکر شد. p ii تعداد پیکسل هایی است که به درستی پیش بینی شده است. و p ji تفسیرهای منفی نادرست را نشان می دهد.
پس از افزایش مجموعه آموزشی با استفاده از روش فوق، دوره آموزشی را برای همه آزمایشها روی 100 دوره تنظیم کردیم و برای به دست آوردن آموزش نیمه دقیق از یک آپکس استفاده کردیم. ما از کاهش وزن 0.00001 و تکانه 0.9 استفاده کردیم. تمام ستون فقرات مدل روی Resnet50 تنظیم شد که در ImageNet برای تسهیل آزمایشهای فرسایش از قبل آموزش داده شده بود. از دست دادن متقاطع آنتروپی در انتهای مدل برای نظارت بر نتایج نهایی استفاده شد. این را می توان به صورت زیر محاسبه کرد:
که در آن n تعداد کل پیکسل ها است. p gt حقیقت پایه پیکسل p i است . و p pre پیش بینی پیکسل p i است . نرخ یادگیری پایه بر روی 0.15 تنظیم شد و تا پایان آموزش از طریق آنیل کسینوس به 0.00001 کاهش یافت. ما از سیستم اوبونتو 18.04 برای آزمایش استفاده کردیم و GPU یک NVIDIA RTX2080TI بود. این آزمایش با استفاده از Pytorch اجرا شد و با اتخاذ یک رویکرد شیب نزولی تصادفی (SGD) بهینه شد.
4.3. نتایج
4.3.1. مطالعه فرسایشی بهبودهای مرتبط با ماژول توجه فضایی کل
رویکردهای متعددی در سالهای اخیر از کانالها و ماژولهای توجه فضایی استفاده کردهاند [ 20 ، 22 ، 26 ]. بیشتر از نقشه ویژگی، F 1 ، به عنوان ورودی استفاده می کنند ( شکل 2 را ببینید ). در ماژول توجه فضایی ما (TSAM)، ایده اصلی یک ماژول توجه فضایی با جابجایی مکان آن و سادهسازی ساختار اصلاح میشود تا از سادگی کلی روش اطمینان حاصل شود. نقشی که باید توسط CAM ایفا شود به خوبی تثبیت شده است، بنابراین نیازی به تکرار مطالعات CAM در اینجا نیست. بنابراین، آزمایشهای ما در درجه اول بر روی پیشرفتهای بالقوه ناشی از استفاده از TSAM متمرکز شدند.
از آنجایی که TSAM ویژگیهایی را از تصویر اصلی استخراج میکند، ممکن است فقدان اطلاعات معنایی پیشرفته بر اثربخشی آن تأثیر بگذارد. برای ارزیابی این احتمال، ما یک ماتریس عامل وزن فضایی را از ستون فقرات استخراج کردیم و آن را با خروجی TSAM ترکیب کردیم تا اطلاعات معنایی سطح بالا را افزایش دهیم. سپس، روشی بدون توجه فضایی سطح بالا (HLSA) با روش هایی که از توجه فضایی سطح بالا به روش های مختلف استفاده می کنند، مقایسه شد. ما از PSP-Net برای آزمایش (DPA-PSP-Net) استفاده کردیم زیرا DPA-Net را می توان به هر شبکه ای اضافه کرد. آزمایش نشان داد که استفاده از TSAM بدون HLSA برای تصویر اصلی به اندازه کافی موثر بود. نتایج 82.75٪ برای Acc و 67.92٪ برای میانگین IoU ارائه شد. HLSA عملکرد شبکه را بهبود نداد، بنابراین ما از آن استفاده نکردیم.جدول 1 .
با عمیق شدن شبکه، نقشه ویژگی کوچکتر می شود و اطلاعات مکانی کاهش می یابد. این مبنای استدلال ما بود که گرفتن اطلاعات مکانی از تصویر اصلی موثرتر است. برای تأیید این فرض، ما TSAM را برای سه مکان مختلف در مدل محاسبه کردیم: در ابتدا، در وسط و در انتهای ستون فقرات. ResNet از پنج بلوک به صورت سری تشکیل شده است. ما تصویر اصلی، خروجی ResNet بلوک سوم و خروجی ResNet بلوک پنجم را به عنوان ورودی TSAM انتخاب کردیم. نقشه های ویژگی مربوط به بلوک ها در ResNet 1، 1/4 و 1/8 برابر اندازه تصویر اصلی بود. همانطور که در جدول 2 نشان داده شده است، عملکرد TSAM مطابق با افزایش اندازه ورودی بهبود یافت و تأیید کرد که حدس اولیه ما درست بود.
برای ارزیابی تأثیر عمق TSAM، ما تعداد پارامترهای مختلفی را برای یافتن کارآمدترین ساختار آزمایش کردیم. ما فقط تعداد لایهها را قبل از لایهای که کانال 1 نقشه ویژگی را تشکیل میدهد تغییر دادیم. به عبارت دیگر، دو کانولوشن 1 × 1 آخر را نگه داشتیم و تعداد 3×3 پیچیدگی را کم یا زیاد کردیم. نتایج تجربی نشان میدهد که عملکرد زمانی مؤثرتر بود که سه لایه در TSAM وجود داشت. جدول 3 نتایج را برای مدل هایی با استفاده از تعداد لایه های مختلف نشان می دهد.
4.3.2. مطالعه فرسایشی برای هر دو ماژول توجه
به منظور ارزیابی هرگونه تفاوت بالقوه بین تأثیر دو ماژول بر بهبود عملکرد بخشبندی معنایی سنجش از دور، آزمایشهایی را با ترکیبهای مختلف انجام دادیم. نتایج در جدول 4 نشان داده شده است .
جدول 4بهبود عملکرد ناشی از استفاده از CAM و TSAM را آشکار می کند. در مقایسه با یک PSP-Net پایه، استفاده از CAM میانگین نتیجه IoU 66.90٪ و امتیاز F1 71.45٪ را ارائه می دهد که به ترتیب 1.52٪ و 7.48٪ بهبود می یابد. استفاده از فقط یک TSAM میانگین IoU را به 67.37٪ و امتیاز F1 را به 6.07٪ افزایش داد. با این حال، بزرگترین بهبود عملکرد ناشی از استفاده از هر دو ماژول با هم بود. هنگامی که ما CAM و TSAM را ادغام کردیم، میانگین نتیجه IoU 67.92٪ بود که 2.54٪ بیشتر از خط پایه بود. نتیجه امتیاز F1 72.56 درصد بود که 8.59 درصد بیشتر از پایه بود. این نتایج تجربی تأیید میکنند که رویکرد توجه به مسیر دوگانه با دو ماژول، استراتژی مؤثرتری برای بهبود عملکرد مدلهای تقسیمبندی معنایی بر روی تصاویر سنجش از دور است.
ما همچنین امکانپذیری یک عملیات Squeeze-and-Excitation (SE) را در نظر گرفتیم، بنابراین برای آزمایشهای مقایسهای، عملیات SE را به CAM و TSAM اضافه کردیم. ساختار در شکل 8 نشان داده شده است . برای TSAM، یک لایه کانولوشن اضافه می کنیم تا اندازه آن را به H/2 × W/2 کاهش دهیم. سپس، از یک عملیات upsampling برای بازگرداندن آن به اندازه اصلی استفاده کردیم. برای CAM، ما از یک لایه کاملا متصل استفاده کردیم تا اندازه آن را به C/2 × 1 تغییر دهیم و آن را بازیابی کنیم. خروجی TSAM نیز به 16 کانال تغییر یافت، یعنی تعداد کانال ها و تعداد انواع پوشش زمین یکسان بود. نتایج تجربی در جدول 5 نشان داده شده است .
ما متوجه شدیم که عملکرد TSAM با استفاده از عملیات فشار و برانگیختگی همیشه به خوبی مورد انتظار نبوده است. ساختار ماژول توجه نیز پیچیده تر شد، اگرچه عملکرد آن بهتر نبود. میانگین نتایج IoU برای عملیات SE نیز به ترتیب 0.59٪، 1.21٪ و 0.44٪ برای U-Net، PSP-Net و Deeplab V3+ کمتر از نتایج استفاده از روش ما بود. نتایج امتیاز F1 برای عملیات SE کمتر از نتایج حاصل از روش پیشنهادی ما به ترتیب 1.30٪، 6.81٪ و 0.21٪ بود. این ممکن است به این دلیل باشد که عملکرد عمل فشار و تحریک حذف اطلاعات اضافی است. با این حال، CAM ما روی ویژگیهای دستهها تمرکز میکند و دیگر قادر به حذف افزونگی نیست. هدف از تنظیم ورودی TSAM به عنوان تصویر اصلی، داشتن وضوح بهتر است. ویژگی های حالت بهتر را حفظ می کند و عملکرد موقعیت یابی بهتری را ارائه می دهد. بنابراین، عمل فشرده سازی و برانگیختگی ممکن است به بهترین وجه برای یک TSAM اعمال نشود.
4.3.3. مقایسه با مدل های مختلف
با توجه به حجم کمی از داده های GID، ما از تقویت برای جبران مشکل بالقوه اضافه کردن شبکه استفاده کردیم. برای تأیید اعتبار روش افزایش انتخابی خود، آزمایشهایی را انجام دادیم که در آن DPA-Net را بر روی مدلهای تقسیمبندی معنایی U-Net، PSP-Net و DeepLab V3+ با استفاده از مجموعه داده اصلی و مجموعه دادههای تقویتشده آموزش دادیم. نتایج در جدول 6 نشان داده شده است .
نتایج نشان میدهد که استراتژی افزایشی که ما بکار گرفتهایم مؤثر بوده است. میانگین تقسیم بندی معنایی IoU به ترتیب برای U-Net، PSP-Net و DeepLab V3+ به 67.07٪، 67.92٪ و 67.37٪ افزایش یافت. امتیاز F1 برای تکنیک های فوق به ترتیب به 65.75%، 72.56% و 67.31% افزایش یافت. این نشان میدهد که استراتژیهای تقویت میتوانند دامنه تعمیم شبکه را با غنیسازی دادهها افزایش دهند.
برای تأیید اثربخشی روش ما در رابطه با وظایف تقسیمبندی تصویر سنجش از دور واقعی، ما آن را با روشهای رایجتر مبتنی بر مکانیسمهای توجه به خود مقایسه کردیم. این روش ها NN غیر محلی، SE-Net، CBAM و DA-Net بودند. نتایج آزمایش در جدول 7 و جدول 8 نشان داده شده است .
نتایج تجربی نشان میدهد که DPA-PSP-Net مؤثرترین بخشبندی معنایی را ارائه میکند. SE-Net مؤثرترین بعدی بود. میانگین IoU برای CBAM و DA-Net ظاهراً قویتر به ترتیب تنها 65.45% و 64.67% بود. NN غیر محلی و SE-Net نمرات F1 بهتری داشتند. با این حال، آنها هنوز هم کمتر از DPA-PSP-Net بودند. این تایید می کند که تقسیم بندی تصاویر سنجش از دور با تقسیم بندی صحنه معمولی متفاوت است، بنابراین، DPA-PSP-Net ممکن است نسبت به روش های موجود برتری داشته باشد.
برای ارزیابی بیشتر اثربخشی روش پیشنهادی، میانگین امتیاز IoU و F1 را برای هر نوع پوشش زمین هنگام استفاده از سه مدل مختلف U-Net، PSP-Net و DeepLab V3+، با یا بدون DPA-Net مقایسه کردیم.
همانطور که در جدول 9 و جدول 10 نشان داده شده است ، هر مدل با DPA-Net بهتر از مدل خود عمل کرد. به ویژه توجه داشته باشید که اگرچه PSP-Net نتایج IoU کمتری نسبت به U-Net و DeepLab V3+ داشت، DPA-PSP-Net از هر رویکرد دیگری بهتر عمل کرد. همین امر در مورد امتیازات F1 نیز صادق است. نکته دیگری که باید به آن توجه داشت این است که از آنجایی که پراکندگی جنگل های بوته ای بسیار کم بود، هیچ شبکه ای راه خوبی برای ثبت ویژگی های کلیدی آن نداشت، بنابراین هر رویکردی نتایج ضعیفی داشت. با این حال، این واقعیت را تغییر نداد که DPA-Net همچنان مدل تقسیمبندی را بهبود بخشید. چندین مقایسه بصری با استفاده از PSP-Net به عنوان مثال در شکل 9 نشان داده شده است .
خروجی TSAM در سمت راست ترین ستون در شکل 9 نشان داده شده است . اگرچه ورودی TSAM تصویر اصلی است، اما به نظر می رسد خروجی شامل نویز زیادی نیست. برای برخی از ماژول های توجه موقعیت، مانند “دریاچه” در ردیف دوم و “زمین زراعی خشک” در ردیف آخر، جزئیات و مرزها حتی واضح تر هستند. این نتایج اثربخشی عوامل وزندهی تجسمی TSAM را نشان میدهد.
برای ارزیابی بیشتر کمک TSAM به DPA-Net، ما تفاوتها در خروجی DPA-Net را با اشکال مختلف توجه تجسم کردیم. ما به طور تصادفی یک تصویر آزمایشی را همانطور که در شکل 10 نشان داده شده است انتخاب کردیم . ما ابتدا خروجی DPA-Net را فقط با CAM مقایسه کردیم، سپس با هر دو TSAM و CAM، در حالی که نقشههای ویژگی خروجی را که تابع softmax را پشت سر گذاشتند، ذخیره کردیم. اندازه این دو نقشه مشخصه (C، H، W) بود. سپس، یک عملیات هنجار L1 را روی این دو نقشه ویژگی برای بعد C انجام دادیم و یک نقشه حرارتی با اندازه (1000، 1000) به دست دادیم. این در ستون سمت راست شکل 10 نشان داده شده است .
این نقشه حرارتی تفاوت خروجی بین DPA-Net با TSAM و بدون TSAM را نشان می دهد. هر چه برجسته تر باشد، سهم TSAM بیشتر است. در تصاویر مشاهده می شود که نواحی رودخانه و دریاچه نسبتاً مشخص است. این بدان معنی است که سهم TSAM به ویژه در این مناطق قابل توجه بود. این نقشه حرارتی سهم TSAM را در پیشبینی کلی آشکار میکند.
ما همچنین نتایج ضرب و انباشت (MAC) را برای DPA-Net و تعداد پارامترهای مورد نیاز شمارش کردیم و سپس، آنها را با مدلهای اصلی U-Net، PSP-Net و DeepLab V3+ مقایسه کردیم. همانطور که در جدول 11 مشاهده می شود ، نتایج MAC تنها به ترتیب 0.07G، 0.223G و 0.069G در سه مدل افزایش یافته است و تعداد پارامترها تنها به ترتیب 0.075M، 0.077M و 0.075M افزایش یافته است. . این نشان می دهد که در مقایسه با روش اصلی، DPA-Net فقط مقدار کمی ردپای حافظه را افزایش می دهد.
5. نتیجه گیری ها
در این مقاله، ما یک شبکه توجه مسیر دوگانه (DPA-Net) را برای تقسیمبندی معنایی تصاویر سنجش از دور پیشنهاد کردهایم. می توان آن را با هر مدل تقسیم بندی بدون تأثیر قابل توجهی بر روی ردپای حافظه یا تعداد پارامترها استفاده کرد. یک تصویر سنجش از دور ابتدا از طریق ستون فقرات و یک ماژول توجه فضایی کل پردازش می شود تا یک نقشه ویژگی و ضریب وزن فضایی به دست آید. سپس، یک CAM از نقشه ویژگی محاسبه می شود تا فاکتور وزن کانال را بدست آورید. در نهایت، خروجی مدل تقسیمبندی در ضریب وزن فضایی و ضریب وزن کانال به طور جداگانه ضرب میشود تا دو نقشه ویژگی به دست آید که جنبههای مختلف ویژگیها را به تصویر میکشد. سپس، این دو نقشه ویژگی برای به دست آوردن خروجی نهایی DPA-Net ترکیب می شوند. شبکه پیشنهادی آزمایش شد و برای بهبود عملکرد مدلهای تقسیمبندی پیشرفته در مجموعه دادههای GID یافت شد. ما معتقدیم که عملکرد را می توان با اصلاح ساختار دو ماژول توجه مسیر، بیشتر بهبود بخشید، بنابراین تمرکز کار آینده ما خواهد بود.











بدون دیدگاه