

خلاصه
کلید واژه ها:
یادگیری عمیق ؛ شبکه های عصبی کانولوشنال سیامی ; نقشه برداری اشیاء شهری
1. معرفی
2. کارهای مرتبط
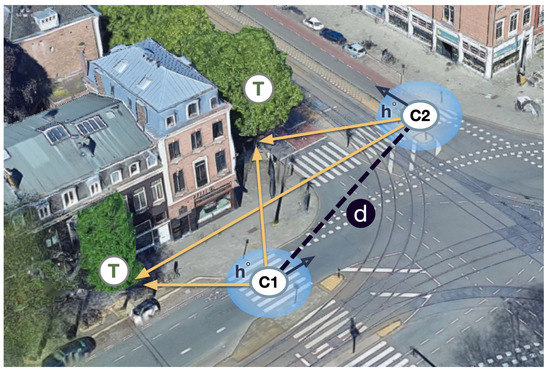
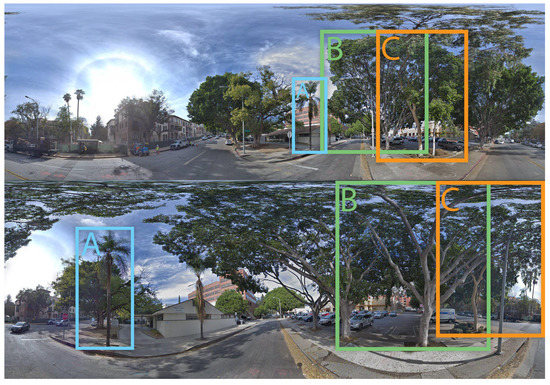
3. تطبیق نمونه با محدودیت های هندسی نرم
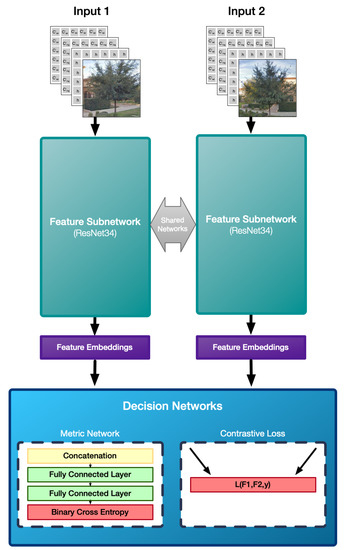
3.1. معماری مدل
3.2. توابع از دست دادن
Contrastive : اولین رویکرد ما یک CNN سیامی است که از دو زیرشبکه یکسان تشکیل شده است که با یک تابع تضاد متضاد آموزش داده شده اند [ 45 ]. یک ضرر کنتراست (معادله ( 1 )) یک جفت ویژگی ایجاد شده از دو شاخه شبکه را به عنوان ورودی می گیرد، بر خلاف سایر توابع از دست دادن که شبکه را در مجموعه داده آموزشی ارزیابی می کنند. هدف تابع از دست دادن این است که جاسازی های منطبق یا مثبت را نزدیک تر کند و جاسازی های غیر منطبق را در فضای ویژگی دور کند. بنابراین، تابع از دست دادن شبکه را تشویق میکند تا ویژگیهایی را که در فضای ویژگیها نزدیک هستند، اگر نمونهها مشابه هستند، یا ویژگیهای متفاوتی را اگر مشابه نیستند، خروجی دهد. این با جریمه کردن مدل بسته به نمونه ها به دست می آید. تابع از دست دادن کنتراست به صورت تعریف شده است
که در آن y برچسب حقیقت پایه است، m یک حاشیه است، و دnهر تابع فاصله بین دو ویژگی خروجی است.
متریک : این یکی دیگر از رویکردهای سی ان ان سیامی است که از زیرشبکه های مشابهی تشکیل شده است که شبکه متریک را با ویژگی های به هم پیوسته ارائه می کند. شبکه متریک از سه لایه کاملاً متصل با فعال سازی ReLU تشکیل شده است، به جز آخرین لایه که تابع آنتروپی متقاطع باینری را کد می کند (معادله ( 2 )). خروجی های لایه آخر دو مقدار غیر منفی در [0,1] است که مجموع آنها 1 است. هر مقدار مربوط به احتمال طبقه بندی نمونه ها به عنوان مشابه یا غیر مشابه است. آنتروپی متقاطع باینری به صورت تعریف می شود
جایی که ما فقط دو کلاس داریم. y1برچسب حقیقت زمینی است و س1امتیاز احتمال برای است سی1. در نتیجه، y2=1-y1و س2=1-س1امتیاز حقیقت و احتمال زمین برای سی2.
TripleNet : این یک معماری شبکه سه گانه است [ 46 ] که از سه زیرشبکه یکسان به جای دو تشکیل شده است. هر زیرشبکه ویژگی یک تصویر متفاوت برای ایجاد یک جاسازی دریافت می کند. ورودی ها یک تصویر لنگر (تصویر اصلی یا تصویر مورد نظر ما)، یک تصویر مثبت (تصویر مشابه تصویر لنگر) و یک ورودی منفی (که تصویری غیر مشابه با تصویر لنگر است) هستند. مشابه از دست دادن کنتراست، شبکه آموزش داده می شود تا لنگر و تعبیه های مثبت را به حداقل برساند در حالی که فاصله بین لنگر و تعبیه منفی را با افت سه گانه به حداکثر می رساند (معادله (3) ) . از دست دادن سه گانه به صورت زیر تعریف می شود:
که در آن m حاشیه، f خروجی ویژگی، A ویژگی لنگر، P ویژگی مثبت، و N ویژگی منفی است. توجه داشته باشید که هر سه معماری را می توان با زیرشبکه های ویژگی های مختلف مانند AlexNet، MatchNet، ResNet34 و غیره ترکیب کرد.
4. آزمایشات
4.1. مجموعه داده ها
4.1.1. پاسادنا
4.1.2. نقشه کشی
4.2. استراتژی ارزیابی
4.3. آیا هندسه کمک می کند؟
4.4. نتایج
5. نتیجه گیری ها
منابع
- وو، جی. یائو، دبلیو. Polewski، P. نقشه برداری از گونه های درختی و سرزندگی در امتداد راهروهای جاده شهری با LiDAR و سنسورهای تصویربرداری: تراکم نقطه در مقابل دیدگاه دید. Remote Sens. 2018 ، 10 ، 1403. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- وان، آر. هوانگ، ی. زی، آر. Ma, P. نقشه برداری خطوط ترکیبی با استفاده از یک سیستم نقشه برداری موبایل. Remote Sens. 2019 , 11 , 305. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- خرمشاهی، ا. کامپوس، ام. توماسلی، آ. ویلیجانن، ن. میلونن، تی. کارتینن، اچ. کوکو، ا. Honkavaara, E. طرح کالیبراسیون دقیق برای یک سیستم نقشه برداری موبایل با چند دوربین. Remote Sens. 2019 , 11 , 2778. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هیلمن، ام. واینمن، ام. مولر، ام. جوتزی، ب. کالیبراسیون خودکار بیرونی سیستم های نقشه برداری موبایل بر اساس ویژگی های هندسی سه بعدی. Remote Sens. 2019 ، 11 ، 1955. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- بالادو، ج. گونزالس، ای. آریاس، پ. کاسترو، دی. رویکرد جدید به فهرست خودکار علائم ترافیکی بر اساس داده های سیستم نقشه برداری موبایل و یادگیری عمیق. Remote Sens. 2020 , 12 , 442. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- جوگلکار، ج. Gedam, SS; Mohan، BK تطبیق تصویر با استفاده از ویژگیهای SIFT و تکنیک برچسبگذاری آرامش – یک روش مقداردهی اولیه برای تطبیق متراکم استریو. IEEE Trans. Geosci. Remote Sens. 2014 , 52 , 5643–5652. [ Google Scholar ] [ CrossRef ]
- Lowe، DG تشخیص شیء از ویژگیهای تغییرناپذیر مقیاس محلی. در مجموعه مقالات هفتمین کنفرانس بین المللی IEEE، کرکیرا، یونان، 20 تا 27 سپتامبر 1999. جلد 2، ص 1150–1157. [ Google Scholar ]
- لی، دبلیو. ژائو، آر. شیائو، تی. Wang, X. Deepreid: شبکه عصبی جفت شدن فیلتر عمیق برای شناسایی مجدد افراد. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، کلمبوس، OH، ایالات متحده، 23-28 ژوئن 2014. صص 152-159. [ Google Scholar ]
- بروملی، جی. گیون، آی. LeCun، Y.; ساکینگر، ای. شاه، آر. تأیید امضا با استفاده از شبکه عصبی تأخیر زمانی «سیامی». بین المللی ج. تشخیص الگو. آرتیف. هوشمند 1993 ، 7 ، 669-688. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چوپرا، اس. هادسل، آر. LeCun، Y. یادگیری معیار تشابه به صورت متمایز، با تأیید صحت کاربرد به چهره. در مجموعه مقالات CVPR، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 20-26 ژوئن 2005. صص 539-546. [ Google Scholar ]
- تایگمن، ی. یانگ، م. رانزاتو، م. Wolf، L. Deepface: بستن شکاف به عملکرد سطح انسانی در تأیید چهره. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو، کلمبوس، OH، ایالات متحده آمریکا، 23 تا 28 ژوئن 2014. صفحات 1701-1708. [ Google Scholar ]
- کوچ، جی. زمل، آر. سالخوتدینوف، R. شبکه های عصبی سیامی برای تشخیص تصویر تک شات. در مجموعه مقالات کارگاه آموزشی عمیق ICML، لیل، فرانسه، 6 تا 11 ژوئیه 2015. جلد 2. [ Google Scholar ]
- لفور، اس. تویا، دی. Wegner، JD; پرودویت، تی. Nassar, AS به سمت تجزیه و تحلیل صحنه چند نمای یکپارچه از ماهواره به سطح خیابان. Proc. IEEE 2017 ، 105 ، 1884-1899. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لین، TY; کوی، ی. بلنگی، اس. هیز، جی. یادگیری بازنمایی های عمیق برای زمین شناسی زمین به هوایی. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. صفحات 5007–5015. [ Google Scholar ]
- برتینتو، ال. والمادر، جی. هنریکس، جی اف. ودالدی، ع. Torr, PH شبکههای سیامی کاملاً پیچیده برای ردیابی شی. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر، مونیخ، آلمان، 8 تا 14 سپتامبر 2016. صص 850-865. [ Google Scholar ]
- گوا، کیو. فنگ، دبلیو. ژو، سی. هوانگ، آر. وان، ال. Wang, S. یادگیری شبکه سیامی پویا برای ردیابی اشیاء بصری. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، ونیز، ایتالیا، 22 تا 29 اکتبر 2017؛ صفحات 1763-1771. [ Google Scholar ]
- زبونتر، ج. تطبیق LeCun، Y. Stereo با آموزش یک شبکه عصبی کانولوشن برای مقایسه وصلههای تصویر. جی. ماخ. فرا گرفتن. Res. 2016 ، 17 ، 2. [ Google Scholar ]
- هان، ایکس. لئونگ، تی. جیا، ی. سوکتانکار، آر. برگ، AC Matchnet: یکپارچهسازی ویژگی و یادگیری متریک برای تطبیق مبتنی بر پچ. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. صص 3279-3286. [ Google Scholar ]
- تیان، ی. فن، بی. Wu, F. L2-net: یادگیری عمیق توصیفگر وصله متمایز در فضای اقلیدسی. در مجموعه مقالات کنفرانس IEEE در مورد دید رایانه و تشخیص الگو، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ صص 661-669. [ Google Scholar ]
- کومار، بی. کارنیرو، جی. Reid, I. یادگیری توصیفگرهای تصویر محلی با شبکه های پیچیده سیامی عمیق و سه گانه با به حداقل رساندن توابع از دست دادن جهانی. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو، لاس وگاس، NV، ایالات متحده، 27-30 ژوئن 2016. صص 5385–5394. [ Google Scholar ]
- Leal-Taixé، L. کانتون-فرر، سی. شیندلر، کی. یادگیری با ردیابی: سی ان ان سیام برای ارتباط هدف قوی. در مجموعه مقالات کنفرانس IEEE در کارگاه های آموزشی بینایی کامپیوتری و تشخیص الگو، لاس وگاس، NV، ایالات متحده، 26 ژوئن تا 1 ژوئیه 2016. صص 33-40. [ Google Scholar ]
- وانگ، بی. وانگ، ال. شوایی، بی. زو، ز. لیو، تی. لوک چان، ک. وانگ، جی. یادگیری مشترک شبکههای عصبی کانولوشنال و معیارهای محدود زمانی برای ارتباط مسیر. در مجموعه مقالات کنفرانس IEEE در کارگاه های آموزشی بینایی کامپیوتری و تشخیص الگو، لاس وگاس، NV، ایالات متحده، 26 ژوئن تا 1 ژوئیه 2016. صص 1-8. [ Google Scholar ]
- صادقیان، ع. الهی، ع. Savarese, S. Tracking the untrackable: یادگیری ردیابی نشانه های متعدد با وابستگی های طولانی مدت. در مجموعه مقالات کنفرانس IEEE در مورد دید رایانه و تشخیص الگو، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ صص 300-311. [ Google Scholar ]
- Wegner، JD; برانسون، اس. هال، دی. شیندلر، ک. پرونا، پ. فهرست نویسی اشیاء عمومی با استفاده از تصاویر هوایی و سطح خیابان – درختان شهری. در مجموعه مقالات کنفرانس IEEE در کارگاه های آموزشی بینایی کامپیوتری و تشخیص الگو، لاس وگاس، NV، ایالات متحده، 26 ژوئن تا 1 ژوئیه 2016. صفحات 6014–6023. [ Google Scholar ]
- برانسون، اس. Wegner، JD; هال، دی. لانگ، ن. شیندلر، ک. Perona, P. از Google Maps تا کاتالوگ ریزدانه از درختان خیابان. ISPRS J. Photogramm. Remote Sens. 2018 ، 135 ، 13-30. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، دبلیو. ویتارانا، سی. لی، دبلیو. ژانگ، سی. لی، ایکس. والدین، جی. استفاده از یادگیری عمیق برای شناسایی قطب های کاربردی با Crossarms و تخمین مکان آنها از تصاویر نمای خیابان Google. Sensors 2018 , 18 , 2484. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کریلوف، ویرجینیا؛ Dahyot, R. موقعیت جغرافیایی شی با استفاده از همجوشی چند سنسوری مبتنی بر MRF. در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی IEEE در مورد پردازش تصویر (ICIP) 2018، آتن، یونان، 7 تا 10 اکتبر 2018؛ صص 2745-2749. [ Google Scholar ]
- ژانگ، سی. فن، اچ. لی، دبلیو. مائو، بی. Ding, X. تشخیص و قرار دادن خودکار اشیاء جاده از تصاویر سطح خیابان. arXiv 2019 ، arXiv:1909.05621. [ Google Scholar ]
- لین، ی. ژنگ، ال. ژنگ، ز. وو، ی. هو، ز. یان، سی. یانگ، ی. بهبود شناسایی مجدد فرد توسط ویژگی و یادگیری هویت. تشخیص الگو 2019 ، 95 ، 151-161. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، ایکس. بی، س. ما، ایکس. وانگ، جی. شبکه عصبی کانولوشن چند نمونه ای برای شناسایی مجدد افراد چند شات. محاسبات عصبی 2019 ، 337 ، 303-314. [ Google Scholar ] [ CrossRef ]
- منگ، جی. وو، اس. ژنگ، شناسایی مجدد شخص تحت نظارت ضعیف WS. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 16 تا 20 ژوئن 2019؛ صص 760-769. [ Google Scholar ]
- بای، ایکس. یانگ، م. هوانگ، تی. دو، ز. یو، آر. Xu, Y. Deep-person: یادگیری ویژگی های عمیق تمایزآمیز برای شناسایی مجدد شخص. تشخیص الگو 2020 ، 98 ، 107036. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- شیائو، جی. زی، ی. تیلو، تی. هوانگ، ک. وی، ی. Feng, J. IAN: شبکه تجمیع فردی برای جستجوی افراد. تشخیص الگو 2019 ، 87 ، 332-340. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شیائو، تی. لی، اس. وانگ، بی. لین، ال. Wang, X. یادگیری ویژگی های تشخیص و شناسایی مشترک برای جستجوی افراد. در مجموعه مقالات کنفرانس IEEE در مورد دید رایانه و تشخیص الگو، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ صص 3415–3424. [ Google Scholar ]
- هوانگ، TW; کای، جی. یانگ، اچ. Hsu، HM; هوانگ، JN شناسایی مجدد خودرو با دید چندگانه با استفاده از مدل توجه زمانی و رتبهبندی مجدد فراداده. در مجموعه مقالات کارگاه چالش شهر هوش مصنوعی، کنفرانس بینایی و تشخیص الگوی رایانه ای IEEE/CVF (CVPR)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 16 تا 20 ژوئن 2019. [ Google Scholar ]
- لیو، ایکس. لیو، دبلیو. می، تی. Ma، H. یک رویکرد مبتنی بر یادگیری عمیق برای شناسایی مجدد پیشرونده وسیله نقلیه برای نظارت شهری. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر، آمستردام، هلند، 11 تا 14 اکتبر 2016؛ صص 869-884. [ Google Scholar ]
- آلتواجری، اچ. Belongie، SJ تطبیق تصاویر هوایی با خط پایه فوقالعاده در محیطهای شهری. در مجموعه مقالات BMVC، بریستول، انگلستان، 9 تا 13 سپتامبر 2013. [ Google Scholar ]
- دیتون، دی. مالیزیویچ، تی. Rabinovich، A. Superpoint: تشخیص و توصیف نقطه علاقه خود نظارت شده. در مجموعه مقالات کنفرانس IEEE در کارگاه های آموزشی بینایی کامپیوتری و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ صص 224-236. [ Google Scholar ]
- پارک، ای. هان، ایکس. برگ، TL; برگ، AC ترکیب چندین منبع دانش در cnn های عمیق برای تشخیص عمل. در مجموعه مقالات کنفرانس زمستانی IEEE در مورد کاربردهای بینایی کامپیوتری، لیک پلاسید، نیویورک، ایالات متحده آمریکا، 7 تا 10 مارس 2016. صص 1-8. [ Google Scholar ]
- نصار، ع. لانگ، ن. لفور، اس. Wegner، JD یادگیری محدودیتهای نرم هندسی برای تطبیق نمونههای چند نمای در سراسر پانورامای سطح خیابان. در مجموعه مقالات رویداد مشترک سنجش از دور شهری 2019 (JURSE)، وان، فرانسه، 22 تا 24 مه 2019؛ صص 1-4. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کریژفسکی، آ. سوتسکور، آی. هینتون، GE Imagenet طبقه بندی با شبکه های عصبی کانولوشن عمیق. در پیشرفت در سیستم های پردازش اطلاعات عصبی ; MIT Press: Wayne, PA, USA, 2012; صص 1097–1105. [ Google Scholar ]
- او، ک. ژانگ، ایکس. رن، اس. Sun, J. یادگیری باقیمانده عمیق برای تشخیص تصویر. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، لاس وگاس، NV، ایالات متحده، 26 ژوئن تا 1 ژوئیه 2016. صص 770-778. [ Google Scholar ]
- لین، TY; گویال، پ. گیرشیک، آر. او، ک. Dollár, P. از دست دادن کانونی برای تشخیص اجسام متراکم. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، ونیز، ایتالیا، 22 تا 29 اکتبر 2017؛ صفحات 2980-2988. [ Google Scholar ]
- او، ک. گیوکسری، جی. دلار، پی. Girshick, R. Mask r-cnn. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، ونیز، ایتالیا، 22 تا 29 اکتبر 2017؛ صفحات 2961-2969. [ Google Scholar ]
- هادسل، آر. چوپرا، اس. LeCun، Y. کاهش ابعاد با یادگیری یک نقشهبرداری ثابت. در مجموعه مقالات کنفرانس IEEE Computer Society در سال 2006 در مورد دید رایانه و تشخیص الگو (CVPR’06)، نیویورک، نیویورک، ایالات متحده آمریکا، 17 تا 22 ژوئن 2006. جلد 2، ص 1735–1742. [ Google Scholar ]
- هافر، ای. Ailon، N. یادگیری متریک عمیق با استفاده از شبکه سه گانه. در مجموعه مقالات کارگاه بین المللی تشخیص الگوی مبتنی بر شباهت، کپنهاگ، دانمارک، 12 تا 14 اکتبر 2015؛ صص 84-92. [ Google Scholar ]
- گلوروت، ایکس. Bengio، Y. درک دشواری آموزش شبکه های عصبی پیشخور عمیق. در مجموعه مقالات کنفرانس بین المللی هوش مصنوعی و آمار، ساردینیا، ایتالیا، 13-15 مه 2010; ص 249-256. [ Google Scholar ]
- Kingma، DP; Ba, J. Adam: روشی برای بهینه سازی تصادفی. arXiv 2014 ، arXiv:1412.6980. [ Google Scholar ]
- نوهولد، جی. اولمان، تی. روتا بولو، اس. Kontschieder، P. مجموعه داده چشم اندازهای نقشه برای درک معنایی صحنه های خیابان. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، ونیز، ایتالیا، 22 تا 29 اکتبر 2017؛ صفحات 4990-4999. [ Google Scholar ]
- نصار، ع. لفور، اس. Wegner, JD تشخیص نمونه چند نمایشی همزمان با محدودیتهای نرم هندسی آموخته شده. در مجموعه مقالات کنفرانس بین المللی بینایی کامپیوتر (ICCV)، سئول، کره، 27 اکتبر تا 2 نوامبر 2019؛ صص 6559–6568. [ Google Scholar ]
- گویچیچ، ز. ژو، سی. Wegner، JD; Wieser, A. تطبیق کامل: تطبیق ابر نقطه سه بعدی با چگالی صاف. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 15 تا 20 ژوئن 2019؛ صص 5545–5554. [ Google Scholar ]
- گویچیچ، ز. ژو، سی. Wegner، JD; Guibas، LJ; Birdal, T. آموزش ثبت نام ابر نقطه سه بعدی چند وجهی. arXiv 2020 ، arXiv:2001.05119. [ Google Scholar ]








بدون دیدگاه