

خلاصه
:
تهیه نقشه توزیع جمعیت با وضوح خوب با دقت بالا برای برنامه ریزی و مدیریت شهری بسیار مهم است. این مقاله شهر گوانگژو را به عنوان منطقه مورد مطالعه در نظر میگیرد، نقشه توزیع جمعیت شبکهای را با استفاده از روشهای یادگیری ماشین مبتنی بر استراتژی منطقهبندی با دادههای مکانی چندمنبعی مانند دادههای سنجش از راه دور نور شب، دادههای نقطه مورد نظر، دادههای کاربری زمین و غیره نشان میدهد. نتایج ارزیابی دقت در سطح خیابان نشان میدهد که رویکرد پیشنهادی به دقت کلی خوبی، با ضریب تعیینکننده ( R20.713 و ریشه میانگین مربعات خطا (RMSE) 5512.9 است. در همین حال، خوبی برازش برای مدل رگرسیون خطی تک (LR) و مدل رگرسیون جنگل تصادفی (RF) به ترتیب 0.0039 و 0.605 است. برای مساحت متراکم، دقت مدل جنگل تصادفی بهتر از مدل رگرسیون خطی است، در حالی که برای منطقه پراکنده، دقت مدل رگرسیون خطی بهتر از مدل جنگل تصادفی است. نتایج نشان داد که روش پیشنهادی پتانسیل بالایی در نقشه برداری جمعیت در مقیاس ریز دارد. بنابراین، توصیه میشود که استراتژی مدلسازی منطقهای باید انتخاب اولیه برای حل تفاوتهای منطقهای در تحقیقات نقشهبرداری توزیع جمعیت باشد.
کلید واژه ها:
نقشه برداری جمعیت ; نقطه مورد علاقه جنگل تصادفی ; مدل منطقه ای ; گوانگژو
1. معرفی
مردم بدنه اصلی محیط جغرافیایی و فعالیتهای اجتماعی هستند و الگوی توزیع آنها موضوع مهمی در بسیاری از زمینههای تحقیقاتی مانند جامعهشناسی، جغرافیا، مطالعات محیطی و غیره است [ 1 و 2 ]. داده های رایج جمعیت عمدتاً شامل دو شکل است: داده های جمعیت شناختی و داده های فضایی. در حال حاضر استفاده از داده های جمعیت شناختی بر اساس واحدهای اداری اصلی ترین راه برای به دست آوردن اطلاعات توزیع جمعیت است. اگرچه دادههای سرشماری دارای مزایای جامع، دقیق و معتبر هستند [ 3 ، 4]، دارای معایب وضوح مکانی پایین، دوره آماری بیش از حد طولانی و فرکانس به روز رسانی کم هستند. بنابراین، تفکیک مکانی و زمانی پایین دادههای سرشماری برای حکمرانی شهری مؤثر نیست. در مقایسه با دادههای جمعیتشناختی، دادههای جمعیتی فضایی میتوانند توزیع واقعی جمعیت را به صورت شهودی و در مقیاسهای چندگانه بیان کنند، در نتیجه به طور موثر بر کاستیهای دادههای جمعیتی غلبه کنند.
در سالهای اخیر، ظهور دادههای چندمنبعی مانند نقطه مورد علاقه (به اختصار POI)، دادههای بررسی موقعیت مکانی، مسیرهای اشتراکگذاری دوچرخهها، GPS شناور خودرو، و دادههای سنجش از راه دور نور شب، ارائهدهنده زمان کارآمد و خوب است. منبع داده دانه بندی شده و قابل اعتماد برای تخمین توزیع جمعیت شبکه ای، در حالی که فناوری های یادگیری ماشین روش های پیشرفته ای را برای شبیه سازی توزیع جمعیت شبکه ای ارائه می کنند. از این رو، با پیشرفت منابع داده ها و روش های تحقیق، می توان به طور دقیق توزیع جمعیت شهری را در مقیاس های چندگانه درک کرد و الگوهای مکانی-زمانی را شناخت [ 5 ، 6 ، 7] .]. گوانگژو یکی از شهرهای اصلی منطقه خلیج بزرگ گوانگدونگ-هنگ کنگ-ماکائو است. به دلیل روند سریع شهرنشینی، با تهدیدات متعددی از جمله جمعیت زیاد، تراکم بالای جمعیت، تراکم ترافیک و تخصیص غیرمنطقی منابع مواجه است. برای حل مشکلات فوق، اطلاعات دقیق توزیع جمعیت، اطلاعات اساسی ضروری است.
تحقیقات بر روی نقشه توزیع جمعیت را می توان به سال 1930 ردیابی کرد. جغرافیدان اجتماعی آمریکایی رایت JK روش داسیمتری را پیشنهاد کرد که توزیع جمعیت را با انواع کاربری اراضی ترکیب کرد تا نقشه توزیع جمعیت در کیپ کاد، ماساچوست [8] تولید شود . بر اساس بررسی ادبیات، رویکردهای مورد استفاده برای نقشهبرداری جمعیتها در تکنیکها (تجمع یا تجمیع)، واحد نقشهبرداری (به عنوان مثال، واحدهای اداری، واحدهای شمارش، واحدهای جغرافیایی، شبکه منظم)، دادههای جانبی مورد استفاده (مانند نقشههای توپوگرافی، کاربری اراضی/ مجموعه دادههای بردار پوشش زمین، دادههای کاداستر، تصاویر ماهوارهای، دادههای LIDAR، و غیره) و روشهای تجسم (به عنوان مثال، نقشه کروپلث، خطوط ایزوله، نقشه داسیمتری، تجسم سه بعدی) [ 9]. در این مقاله، ما بر روی تکنیک نگاشت تفکیک در واحد شبکه تمرکز می کنیم. با توجه به تحقیق دادههای توزیع جمعیت شبکهای، مطالعات موجود را میتوان به مقیاسهای مختلف از جمله جهانی، کشور، شهر و کمون تقسیم کرد. در دهه 1990، بسیاری از مجموعه داده های جمعیت جهانی مانند جمعیت شبکه ای جهان (GPW)، پروژه نقشه برداری شهری روستایی شبکه ای (GRUMP)، LandScan، Worldpop و غیره توسعه یافتند. این مجموعه دادههای جمعیت جهانی از مجموعه دادههای فرعی مختلف با رویکردهای مختلف استفاده میکنند. با وجود این، مجموعه داده ها برای مناطق فقیر از داده مهم هستند. دقت آنها در مقیاس شهر یا کمون هنوز قابل توجه است. نویسندگان یک روش خودکار و قدرتمند برای بهبود دقت نقشهبرداری مجموعه داده GPW ایجاد کردند.10 ]. کار آنها ارزش و سهم احتمالی دادههای سنجش از دور دقیق، بهروز شده و مستقل را برای تکمیل و بهبود منابع مرسوم آمار بنیادی جمعیت نشان میدهد. در کار آنها، گزارشدهی جهانی و منسجم از دادههای سنجش از دور در مورد حضور ساختهشده برای تجدیدنظر در واحدهای سرشماری که به عنوان «بدون جمعیت» در نظر گرفته میشوند و برای هماهنگ کردن توزیع جمعیت در امتداد خطوط ساحلی استفاده شد. نتایج نشان میدهد که ناهنجاریهای هدف بهطور قابلتوجهی کاهش یافته و پایگاهداده سرشماری پایه بهبود یافته است و بهطور بالقوه برای استفادههای دیگر از همان پایگاه آماری سود میبرد. همچنین برخی از محققان تلاش کردند تا تحقیقات جمعیتی با وضوح بالا را در سطح ملی انجام دهند [ 11 ، 12 ، 13]]. با این حال، به دلیل الگوهای مختلف بافت شهری و پیچیدگی شهر، مطالعات دقیق نسبتا کمی در مناطق کوچک مقیاس مانند شهرها وجود دارد. شهرها به عنوان واحد اصلی فعالیتهای اقتصادی و مدیریت اجتماعی چین، به اطلاعات دقیق و دقیق توزیع جمعیت برای بهبود سطح حکمرانی شهری نیاز فوری دارند.
به طور خلاصه، توزیع جمعیت شبکهای معمولاً به چهار روش مختلف شبیهسازی میشود، از جمله روش درونیابی فضایی، روش وارونگی کاربری اراضی، روش مدلسازی روشنایی شبانه و روش همجوشی دادههای چند منبعی. هر روشی مزایا و معایب خود را دارد. روش درونیابی فضایی از الگوریتم درونیابی برای به دست آوردن داده های توزیع جمعیت شبکه ای با در نظر گرفتن داده های سرشماری به عنوان ورودی مدل استفاده می کند [ 14 , 15 , 16 ] و به طور گسترده برای تجزیه مکانی داده های سرشماری [ 17 , 18 , 19] استفاده شده است.]. داده های جمعیت شبکه ای را می توان به طور مستقیم یا بر اساس اطلاعات ارائه شده توسط سایر داده های کمکی درون یابی کرد، بنابراین به درون یابی منطقه ای بدون داده های کمکی و درون یابی منطقه ای با داده های کمکی تقسیم می شود. روش های درون یابی فضایی رایج شامل درون یابی نقطه ای و درون یابی وزن منطقه است. مراحل اجرای روش درون یابی نقطه ای به شرح زیر است. ابتدا نقاط کنترل در منطقه مورد مطالعه انتخاب شده و از تراکم نقطه مرکزی برای نماد تراکم جمعیت هر ناحیه منبع استفاده می شود. سپس، یک الگوریتم درونیابی مناسب (مانند وزن معکوس فاصله (IDW)، کریجینگ، و غیره) برای تولید نقشه شطرنجی تراکم جمعیت انتخاب می شود. در نهایت، نقشه جمعیت شبکه بندی شده با همپوشانی نقشه شطرنجی تراکم جمعیت و مرز اداری به دست می آید. اجرای این روش نسبتاً آسان است، اما محدودیت های شدیدی دارد. اول، وضوح فضایی خروجیهای مدل عموماً درشت است، عمدتاً در دهها کیلومتر. دوم، کمیت کردن خطای مدل دشوار است. سوم، درون یابی منطقه ای تحت تأثیر خطای عملیات تجمیع یا تجزیه منطقه اصلی است و دقت آن تا حد زیادی به نحوه تعریف منطقه اصلی و منطقه هدف، درجه تعمیم در طول فرآیند درون یابی و ویژگی های پارتیشن بستگی دارد. سطح [20 ]. بنابراین، توانایی روش درونیابی فضایی برای توصیف توزیع واقعی جمعیت ضعیف است.
اصل روش وارونگی کاربری اراضی این است که با توجه به تفاوت تراکم جمعیت بین انواع کاربری های مختلف، وزن های متفاوتی به هر نوع کاربری اراضی داده شود [ 18 ، 21 ، 22 ، 23 ]. با این حال، روش وارونگی کاربری زمین نمی تواند تفاوت توزیع جمعیت را در همان نوع قطعات زمین منعکس کند و تصادفی بودن توزیع جمعیت را نادیده می گیرد. از زمان پرتاب ماهواره DMSP/OLS در دهه 1970، روش مدلسازی نور شب به یکی از روشهای اصلی برای شبیهسازی توزیع جمعیت شبکهای تبدیل شده است [ 24 ، 25 ، 26] .]. با این حال، استفاده از دادههای DMSP/OLS نسبتاً نادر است، زیرا سنسور در سال 2013 کار نمیکند و وضوح فضایی بسیار پایین است (1KM). ظهور دادههای مجموعه رادیومتر تصویربرداری مادون قرمز مرئی (NPP-VIIRS) با مشارکت ملی مداری قطبی Suomi به طور موثر بر کاستیهای دادههای DMSP-OLS در وضوح مکانی-زمانی [27] غلبه میکند، و چنین دادههایی برای مطالعه اجتماعی انسان مناسبتر هستند . و فعالیت های اقتصادی [ 28 و 29 ]. ساتون کی و همکاران از داده های نور شب DMSP/OLS برای تخمین جمعیت جهان بر اساس مقیاس جهانی استفاده کرد و دریافت که جمعیت جهان حدود 6.3 میلیارد نفر است [ 30] .]. با این حال، وضوح فضایی منابع داده نور شب DMSP/OLS و NPP/VIIRS هنوز برای مدلسازی جمعیت در مقیاس محلی درشت هستند. امروزه، اولین ماهواره سنجش از دور درخشان حرفه ای جهان که توسط دانشگاه ووهان (ووهان، چین)، Luojia 1-01 (LJ 1-01) طراحی شده است، با موفقیت در ژوئن 2018 پرتاب شد. در مقایسه با داده های NPP-VIIRS، داده های LJ 1-01 بهبود قابل توجهی در وضوح فضایی و سطح کمی دارند، که منبع داده های تصفیه شده تری را برای شبیه سازی های توزیع جمعیت در مقیاس کوچک فراهم می کند [ 31 ، 32 ، 33]. در اصل، روش مدلسازی نور شب، توزیع جمعیت شبکهای در منطقه مورد مطالعه را با ایجاد یک رابطه خطی بین شدت نور شب و تراکم جمعیت شبیهسازی میکند. با این حال، مشکلات موجود در داده های نور شب به طور جدی بر دقت خروجی های مدل تأثیر می گذارد، مانند اشباع پیکسل، سرریز، و دقت پایین بازیابی جمعیت در مناطق نور ضعیف. به منظور بهبود دقت شبیه سازی، برخی از محققان سعی کرده اند داده های روشنایی شب را با داده های کاربری زمین برای تحقیق ترکیب کنند [ 34 ، 35 ، 36]. با این حال، بهبود در دقت قابل توجه نبود. سپس، برخی از محققان تلاش کردند تا دقت شبیهسازی را با ترکیب دادههای چراغهای شب، دادههای کاربری زمین، دادههای نقطه مورد علاقه (POI) و انواع دیگر دادهها بهبود بخشند [37 ، 38 ، 39 ] . با غنیسازی مداوم دادههای سنجش اجتماعی، برخی از محققان تلاش میکنند تا پویایی توزیع جمعیت را با استفاده از این دادهها، مانند دادههای GPS تاکسی [40]، دادههای تلفن همراه [41] ، دادههای سرویس مکان tencent [ 42 ]، گرمای بایدو به تصویر بکشند. داده های نقشه [ 43] و غیره. روش ترکیب داده های چند منبعی به یکی از محبوب ترین روش ها تبدیل شده است. با توجه به محدودیتهای این دادهها، از جمله در دسترس بودن ضعیف دادهها، ناهمگونی دادهها و غیره، شرایط برای تولید مجموعه داده توزیع جمعیت شبکهای در مقیاس بزرگ هنوز بالغ نشده است.
اساساً، تجزیه مکانی دادههای سرشماری به واحد شبکه یک فرآیند رگرسیونی است. چندین مدل رگرسیون برای ایجاد لایه وزنی پیشنهاد شده است، مانند رگرسیون خطی (LR)، رگرسیون وزنی جغرافیایی (GWR)، رگرسیون تصادفی جنگل و غیره [23 ، 44 ] . به طور خاص، جنگل تصادفی (به اختصار RF)، یک روش یادگیری ماشینی که برای اولین بار به طور سیستماتیک توسط بریمن [ 45] ارائه شد.]، در مطالعه مدلهای تولید لایه وزنی دادههای جمعیت، روز به روز محبوبتر میشود، زیرا دارای مزایای متعددی از جمله مناسب بودن برای همخطی، اجتناب از برازش بیش از حد، سرعت محاسبه بالا و غیره است. ایده الگوریتم RF استفاده از روش نمونهگیری مجدد راهانداز برای استخراج چندین نمونه از نمونه اصلی، مدلسازی درخت تصمیم برای هر نمونه بوت استرپ، و سپس ترکیب نتایج درختهای تصمیم چندگانه برای به دست آوردن نتیجه رگرسیون نهایی با رایگیری است. برای اولین بار، محققان نتایج نقشه برداری جمعیت شبکه ای 100 متری را در سه کشور توسعه نیافته به دست آوردند [ 46 ]. به دلیل سهولت آموزش و تفسیر، روش جنگل تصادفی در تحقیقات نقشه برداری جمعیت مورد توجه فزاینده ای قرار گرفته است [ 42 ، 47] .، 48 ]. در فرآیند مدلسازی تصادفی جنگل، لازم است چندین پارامتر برای بهبود عملکرد و تأثیر یادگیری بهینه شود، مانند حداکثر تعداد ویژگیها و حداکثر عمق درختان و غیره [49 ، 50 ] . به طور کلی، برای جلوگیری از تأثیر پارتیشن داده های اولیه بر نتایج، اعتبار سنجی متقاطع (CV) و جستجوی شبکه ای معمولاً برای کاهش گاه و بیگاه و اطمینان از اعتبار و دقت آموزش مدل انجام می شد [51 ] .
عدم قطعیت مدلسازی نیز موضوع مهمی در مطالعه نقشهبرداری توزیع جمعیت است که شامل خطای اکولوژیکی، مشکل واحد منطقهای قابل اصلاح (MAUP) و غیره است. MAUP یک مشکل کلاسیک در علوم اطلاعات جغرافیایی است که مدتهاست مورد تایید و بررسی قرار گرفته است. برای هر تفکیک مکانی، مانند هر مجموعه ای از مرزها، MAUP ممکن است به طور جدی قدرت نتایج آماری را مختل کند [ 52]]. تحلیل حساسیت یک روش مفید برای کشف عدم قطعیت مدلسازی است. نویسندگان با استفاده از چندین مجموعه داده برای دو منطقه مورد مطالعه از جمله پرتغال قاره ای (مخلوط شهری و روستایی) و شهرداری لیسبون (شهری) تأثیر طرحوارههای مختلف تجمیع دادههای هندسی – مناطق اداری و لایههای سطحی شش ضلعی – را بر روی آمار همبستگی فضایی جهانی آزمایش کردند. و نکته مهمی را مطرح کرد، به عنوان مثال، استنتاج های مبتنی بر تحلیل فضایی داده های منطقه تا حد زیادی به روش مورد استفاده برای تعیین کمیت درجه مجاورت بین واحدهای فضایی بستگی دارد [ 52 ].
همانطور که می دانیم، رابطه بین توزیع جمعیت و عوامل موثر، یک رابطه غیرخطی بسیار پیچیده است. انواع الگوریتمهای یادگیری ماشین، از جمله جنگلهای تصادفی، شبکه عصبی و غیره، میتوانند برازش روابط غیرخطی را به خوبی مدیریت کنند، در حالی که یک مدل آشکارساز جغرافیایی میتواند ناهمگونی فضایی عوامل تأثیرگذار را مدیریت کند. با این حال، اکثر مطالعات موجود از یک مدل واحد برای کل منطقه استفاده می کنند. برای مناطقی با تفاوت تراکم جمعیت زیاد، یک مدل واحد یا جهانی نمی تواند مکانیسم توزیع فضایی جمعیت داخلی را به درستی توضیح دهد. استراتژی منطقه ای می تواند به طور موثر کاستی های مدل واحد را برطرف کند، زیرا می تواند مدل سازی پارتیشن ثانویه را در منطقه مورد مطالعه با توجه به ویژگی ها انجام دهد. به این منظور، این مقاله قصد دارد با استفاده از دادههای فضایی چندمنبعی مانند کاربری زمین، POI، چراغهای شبانه و غیره، نقشه جمعیت شهر گوانگجو را بر اساس ایده مدلسازی منطقهبندی و روشهای یادگیری ماشینی به تصویر بکشد. این مقاله سعی دارد مطالعه نقشه برداری توزیع جمعیت را بهبود بخشد و اطلاعات اساسی مهمی را برای مدیریت شهری ارائه دهد.
2. مواد و روشها
در این بخش ابتدا منطقه مورد مطالعه و منبع داده معرفی شده است (به بخش 2.1 و بخش 2.2 مراجعه کنید ). دوم، ما نیاز به انتخاب اندازه سلول شبکه مناسب برای شطرنجی کردن دادههای عامل تأثیر اولیه بر اساس فرمولهای محاسباتی مختلف داشتیم (به بخش 2.3.1 مراجعه کنید ). سوم، ما عوامل اصلی مؤثر بر توزیع جمعیت را بر اساس یک مدل آشکارساز جغرافیایی شناسایی کردیم (به بخش 2.3.2 مراجعه کنید ). در نهایت، اطلاعات توزیع جمعیت شبکهای منطقه مورد مطالعه را بر اساس الگوریتمهای یادگیری ماشین و استراتژی منطقهای شبیهسازی کردیم (به بخش 2.3.3 و بخش 2.3.4 مراجعه کنید ). علاوه بر این، ما دقت مدل را با استفاده از چندین متریک بیشتر ارزیابی کردیم.
2.1. منطقه مطالعه
گوانگژو، مرکز استان گوانگدونگ، بین 112 درجه و 57 دقیقه شرقی تا 114 درجه و 3 دقیقه طول شرقی و 22 درجه و 26 دقیقه تا 23 درجه و 56 دقیقه عرض شمالی واقع شده است و مساحتی در حدود 7434 کیلومتر مربع دارد .. مورد مطالعه در شش منطقه شهری مرکزی شهر گوانگژو، از جمله Yuexiu، Liwan، Tianhe، Haizhu، Huangpu و Baiyun انجام شد. به منظور اطمینان از سازگاری با کالیبر آمار جمعیت در سال 2013، منطقه Huangpu شامل واحدهای سطح خیابان منطقه سابق Luogang نیست. این مناطق دارای بالاترین تراکم جمعیت در شهر گوانگژو هستند و به عنوان مراکز سیاسی، فرهنگی و اقتصادی گوانگژو عمل می کنند. بر اساس داده های ارائه شده توسط اداره آمار گوانگژو، جمعیت ساکن گوانگژو در سال 2019 15.3059 میلیون نفر و تراکم جمعیت این شهر نزدیک به 2059 نفر در کیلومتر مربع بوده است .. با این حال، منطقه مورد مطالعه تقریباً 20.9٪ از کل مساحت شهر گوانگژو را پوشش می دهد، و جمعیت ساکن دائم ثبت شده شامل 63.18٪ از کل جمعیت ساکن گوانگژو است. نقشه تراکم جمعیت در مقیاس خیابان منطقه مورد مطالعه در سال 2013 در شکل 1 نشان داده شده است .
2.2. داده ها و پیش پردازش
وضوح مکانی داده های مدل رقومی ارتفاع (DEM) 30 متر و مرجع مکانی GCS_WGS_1984 است. دادههای کاربری اراضی شامل شش دسته عمده زمینهای زیر کشت، زمینهای جنگلی، علفزار، مساحت آبی، شهری و روستایی، صنعتی و معدنی، زمینهای مسکونی و اراضی بلااستفاده با تفکیک فضایی 30 متر است. با در نظر گرفتن نسبت ها و پتانسیل مشارکت در توزیع جمعیت، نوع کاربری ساخت و ساز شهری و مسکن روستایی به سه زیرگروه شامل اراضی شهری، اراضی روستایی و دیگر زمین های ساختمانی طبقه بندی شد. داده های جاده شامل بزرگراه ها، بزرگراه های ملی، بزرگراه های استانی، جاده های شهری و بزرگراه های شهرستانی است. سیزده نوع داده POI وجود دارد، از جمله امکانات پذیرایی، امکانات عمومی، شرکت ها و شرکت ها، امکانات خرید، تسهیلات حمل و نقل، مالی و بیمه، امکانات علمی، آموزشی و فرهنگی، مسکن تجاری، امکانات خدمات زندگی، امکانات ورزشی و تفریحی، امکانات خدمات پزشکی، سازمان های دولتی و گروه های اجتماعی و امکانات اقامتی. پس از به دست آوردن داده های POI، قبل از اینکه بتوان به طور معمول از آن استفاده کرد، لازم است کارهای پاکسازی داده ها مانند حذف مجدد و تصحیح انجام شود. در نهایت، تمام مجموعه داده ها با سیستم مختصات پروژه آلبرز متحد شدند. بیضی مرجع Krasovsky_1940 بیضی است. قبل از اینکه بتوان به طور معمول از آن استفاده کرد، لازم است کارهای تمیز کردن داده ها مانند حذف مجدد و تصحیح انجام شود. در نهایت، تمام مجموعه داده ها با سیستم مختصات پروژه آلبرز متحد شدند. بیضی مرجع Krasovsky_1940 بیضی است. قبل از اینکه بتوان به طور معمول از آن استفاده کرد، لازم است کارهای تمیز کردن داده ها مانند حذف مجدد و تصحیح انجام شود. در نهایت، تمام مجموعه داده ها با سیستم مختصات پروژه آلبرز متحد شدند. بیضی مرجع Krasovsky_1940 بیضی است.
2.3. مواد و روش ها
2.3.1. شطرنجی سازی داده های عامل تأثیر اولیه
اندازه سلول شبکه تأثیر مهمی بر کیفیت نتایج شبیهسازی توزیع جمعیت دارد. داده های جمعیت شبکه ای با اندازه سلول مناسب می تواند انواع فضایی الگوی توزیع جمعیت را با وضوح بیشتری نشان دهد. طبق تحقیقات قبلی [ 53 ]، مناسب ترین اندازه شبکه تقریباً 10٪ از کوچکترین مساحت خیابان است. خیابان شامیان کوچکترین خیابان مورد مطالعه ما است و مساحت آن 308348 متر مربع است. بنابراین، اندازه سلول در مورد مطالعه ما 150 متر تعیین شد. مجموعه داده های ضریب تاثیر اولیه به 150 متر شطرنجی شده اند. روش های محاسبه هر عامل در مقیاس شبکه در جدول 2 نشان داده شده است .
2.3.2. شناسایی عوامل اصلی بر اساس مدل آشکارساز جغرافیایی
آشکارساز جغرافیایی توسط وانگ جین فنگ و همکاران توسعه داده شد. [ 54]. این یک روش آماری برای تشخیص تمایز فضایی و آشکارسازی عوامل محرک پشت آن است. از آنجایی که این روش نیازی به مفروضات خطی ندارد و شکل ظریف و معنای فیزیکی واضحی دارد، به طور گسترده در مطالعه مکانیسم تأثیر عوامل اجتماعی اقتصادی و محیط طبیعی استفاده می شود. آشکارساز جغرافیایی عمدتاً شامل چهار آشکارساز فرعی است: آشکارساز عامل، تشخیص تعاملی، آشکارساز خطر و آشکارساز اکولوژیکی. این مقاله عمدتاً از آشکارساز عامل برای محاسبه توان توضیحی ضریب تأثیر بر توزیع جمعیت استفاده می کند که برای اندازه گیری به عنوان مقدار q نشان داده می شود. مقدار q از 0 تا 1 متغیر است. هر چه مقدار q بزرگتر باشد، قدرت توضیحی عامل قوی تر است. عوامل تأثیر اولیه (X) شامل X1 (سازمان های دولتی و سازمان های اجتماعی)،
ابتدا از ابزار Create Random Points در ArcGIS 10.2 (ESRI Inc., Redland, USA) برای ایجاد تصادفی 3000 نقطه نمونه در منطقه مورد مطالعه استفاده شد. سپس از ابزار استخراج چند مقدار به امتیاز برای استخراج مقادیر تراکم جمعیت نقاط نمونه مربوطه و مقادیر شاخص هر عامل استفاده شد. در نهایت، نرم افزار GeoDetector2015 (Wang Jinfeng و همکاران [ 54 ]، پکن، چین) برای محاسبه توان توضیحی (مقدار q) ضریب تأثیر (X) برای تراکم جمعیت (Y) استفاده شد.
نتایج تحلیل مدل آشکارساز جغرافیایی در شکل 2 نشان داده شده است. نتایج نشان می دهد که به جز شاخص سطح آبی و شاخص مرتع، سطح معنی داری عوامل باقی مانده 05/0 است. به عبارت دیگر، به جز شاخص مساحت آبی و شاخص مرتع، عوامل باقی مانده تأثیر آشکاری بر تراکم جمعیت دارند. از نتایج رتبهبندی توان توضیحی، عوامل اجتماعی-اقتصادی تأثیر بیشتری بر توزیع فضایی جمعیت در منطقه مورد مطالعه دارند تا عوامل طبیعی. در بین عوامل اجتماعی-اقتصادی، به جز متراژ ساختمان و تراکم شبکه راه، مقادیر توان توضیحی سایر ضرایب تاثیر همه بالاتر از 0.1 است که نشاندهنده تاثیر قابل توجهی بر تراکم جمعیت است. در بین عوامل طبیعی به جز شاخص کاربری اراضی شهری، توان توضیحی q سایر عوامل تأثیرگذار نسبتاً کم است. برای بهبود دقت مدل، پنج عامل شامل شاخص علفزار، شاخص مساحت آب، شاخص زمین شهری، شاخص زمین روستایی و سایر شاخص های زمین ساخت و ساز حذف می شوند. فاکتورهای تاثیر نهایی توزیع جمعیت شامل 20 شاخص شامل شاخص زمین زیر کشت، شاخص زمین جنگلی، شدت نور شبانه، ارتفاع، شاخص شدت تاثیر POI، مساحت ساختمان، شاخص راه و غیره است.
ویژگیهای نمونه به صورت عددی ارائه میشوند و محدودههای عددی بین برخی ویژگیهای مختلف کاملاً متفاوت است. علاوه بر این، ابعاد ویژگی های مختلف ناسازگار است. به منظور حذف تأثیر ابعاد غیر یکنواخت و مقدار شدید، داده ها نرمال می شوند. 106 رکورد در مجموعه داده نمونه خیابانی پس از نرمال سازی حداقل تا حداکثر وجود دارد و هر رکورد شامل 20 مقدار ویژگی است. مجموعه داده نمونه شبکه ای در مجموع 48648 رکورد دارد و هر رکورد حاوی 20 مقدار ویژگی است.
2.3.3. شبیه سازی توزیع جمعیت شبکه ای با استراتژی مدل سازی منفرد
مدل رگرسیون خطی
مدل رگرسیون خطی بر اساس دادههای کاربری اراضی و دادههای سنجش از دور نور شب در حال حاضر یک روش پرکاربرد برای فضاییسازی دادههای جمعیت است. به همین دلیل، بر اساس دادههای نور شب NPP/VIIRS و دادههای کاربری زمین، این مقاله یک مدل رگرسیون خطی از شبکه توزیع جمعیت در منطقه مورد مطالعه را برای تحقق فضاییسازی دادههای جمعیت ایجاد میکند.
مدل به صورت زیر ساخته شده است:
پمن=∑j = 1nآj×اسمن ج+ k ×مn l+ ب��=∑�=1���×���+�×���+�
جایی که پمن��نشان دهنده داده های جمعیتی خیابان i-ام (شهر) است. آj��نشان دهنده ضریب اولیه توزیع جمعیت برای نوع کاربری j ام است. اسمن ج���نشان دهنده j-مین شاخص نوع کاربری اراضی خیابان i (شهر) است. n�نشان دهنده نوع کاربری زمین انتخاب شده است. ک�نشان دهنده ضریب شدت نور شب است. مn l ���میانگین مقدار شدت نور شبانه هر خیابان را نشان می دهد. و ب�اصطلاح ثابت است
مدل رگرسیون جنگل تصادفی
در این تحقیق از مجموعه داده های مقیاس خیابانی به عنوان مجموعه آموزشی و از مجموعه داده های مقیاس شبکه ای به عنوان مجموعه توسعه استفاده شده است. کتابخانه یادگیری ماشینی که برای مدلسازی استفاده میشود، scikit-learn 0.21.3 است که مجموعهای از نرمافزار رایگان است که توسط جامعه بینالمللی scikit-learn منتشر و نگهداری میشود. ابتدا، این مدل با استفاده از الگوریتمهای انتخابشده در مقاله آموزش میدهد، تراکم جمعیت هر خیابان را بهعنوان متغیر وابسته و عوامل تأثیر شناساییشده توسط مدل آشکارساز جغرافیایی بهعنوان متغیر مستقل در نظر میگیرد. در طول فرآیند آموزش، بهترین پارامترهای مدل مانند حداکثر عمق و ویژگیهای درخت تصمیم توسط تابع GridSearchCV در scikit-learn به دست آمد که برای آزمایش هر امکانی از طریق پیمایش حلقه در تمام انتخابهای پارامتر کاندید انجام میشود.55 ، 56 ]، اعتبار سنجی متقاطع K-fold (CV) برای به دست آوردن پارامترهای مدل استفاده شد. بنابراین، CV 10 برابر انجام شد، و امتیاز ضریب تعیین کننده (R 2 ) برای تعیین دقت کلی مدل استفاده شد. سپس، مدل بهینه به مجموعه داده مقیاس شبکه برای پیشبینی مقدار تراکم جمعیت هر سلول شبکه اعمال میشود. سپس، تراکم جمعیت در مساحت سلول ضرب می شود تا جمعیت هر سلول به دست آید و جمعیت هر سلول در واحد اداری خیابان ادغام می شود. در نهایت، دقت نتیجه مدل از طریق شاخصهای خطا مانند میانگین خطای نسبی (MRE)، ریشه میانگین مربع خطا (RMSE)، R2 و غیره با در نظر گرفتن دادههای جمعیتی هر خیابان به عنوان مقدار واقعی ارزیابی میشود .
2.3.4. شبیه سازی توزیع جمعیت شبکه ای با استراتژی مدل سازی منطقه ای
با استفاده از روش تقسیم تمرکز جمعیت، منطقه مورد مطالعه برای بهبود دقت شبیهسازی تقسیمبندی میشود. روش محاسبه غلظت جمعیت در رابطه (2) نشان داده شده است:
جیDDمن=(پمن/پn) × 100 %(آمن/آn) × 100 %=پمن/آمنپn/آn����=(��/��)×100%(��/��)×100%=��/����/��
جایی که جیDDمن����نشان دهنده درجه تمرکز جمعیت یک خیابان خاص (شهر) است. پمن��و پn��به ترتیب جمعیت خیابان (شهر) و جمعیت کل منطقه را نشان می دهد. و آمن��و آn��مساحت خیابان (شهر) و مساحت کل منطقه را نشان می دهد.
منطقه مورد مطالعه بر اساس معیارهای طبقه بندی تمرکز جمعیت به دو بخش تقسیم می شود. به منظور اطمینان از اینکه هر منطقه دارای حجم نمونه کافی برای مدلسازی یادگیری ماشین است، با اشاره به استاندارد طبقهبندی تجمع جمعیت چین [ 57 ]، منطقه مورد مطالعه به دو زیر ناحیه تقسیم میشود: منطقه متراکم و ناحیه پراکنده. این منطقه متراکم شامل 54 خیابان و میانگین تراکم جمعیت 37647 نفر در کیلومتر مربع است . منطقه غیر جمعیتی شامل 52 خیابان و تراکم متوسط جمعیت 3594 نفر در کیلومتر مربع است . نتایج منطقه بندی خاص به شرح زیر است که در شکل 3 نشان داده شده است .
فاکتورهای مدل مختلف برای دو زیر حوزه انتخاب شدند. برای مساحت متراکم و ناحیه پراکنده، مدل رگرسیون خطی و مدل جنگل تصادفی هر دو اجرا میشوند. مدلهای مناسب برای هر زیرمنطقه با توجه به دقت شبیهسازی انتخاب شده و در نقشه توزیع جمعیت برای کل منطقه مورد مطالعه ادغام میشوند.
3. نتایج
3.1. نتایج شبیه سازی بر اساس مدل رگرسیون خطی جهانی
تراکم جمعیت هر خیابان (شهرک) در منطقه مورد مطالعه به عنوان متغیر وابسته و شاخص زمین شهری (X1)، شاخص زمین زراعی (X2)، شاخص زمین جنگلی (X3)، شاخص زمین روستایی (X4)، سایر شاخص زمین ساختمانی (X5)، شاخص علفزار (X6) و میانگین شدت نور شبانه (X7) به عنوان متغیرهای مستقل انتخاب شدند. مدل از طریق تحلیل رگرسیون خطی محاسبه شده و در رابطه (3) نشان داده شده است:
Y = 10250.41ایکس1− 17485.5ایکس2– 9795.53ایکس3+ 1131.15ایکس4– 3585.8ایکس5+ 858.03ایکس6 + 29487.86ایکس7Y=10250.41X1−17485.5X2−9795.53X3+1131.15X4−3585.8X5+858.03X6 +29487.86X7
مقدار ضریب تعیین (R 2 ) 0.59 است که به این معنی است که تراکم جمعیت در یک واحد خیابانی در 59 درصد با شاخص های کاربری اراضی و شاخص شدت نور شب توضیح داده می شود. نتایج تحلیل واریانس مدل در جدول 3 نشان داده شده است .
بر اساس رابطه رگرسیون خطی چندگانه (3)، از ماشین حساب شبکه در نرم افزار ARCGIS برای تولید داده های توزیع جمعیت منطقه مورد مطالعه استفاده شده است. نتیجه در شکل 4 نشان داده شده است .
از شکل 4 قابل مشاهده استکه جمعیت از مرکز شهر به اطراف به تدریج در حال کاهش است. از آنجایی که نتایج شبیهسازی بیش از حد تحتتاثیر الگوی فضایی زمین ساختوساز و شدت نورهای شبانه قرار میگیرد، جمعیت مساحت زمین ساختوساز بیش از حد برآورد شده است و تمایز فضایی توزیع جمعیت آشکار نیست. به طور خاص، بخش شمالی شهر رنه نزدیک به فرودگاه بینالمللی گوانگژو بایون (گوانگژو، چین) و منطقه صنعتی متمرکز است، که در نتیجه تخمینهای جمعیتی که با وضعیت واقعی ناسازگار است، پرت آشکار میشود. به منظور بررسی صحت نتایج شبیه سازی، برازش خطی بین جمعیت شبیه سازی شده خیابان (شهر) و داده های سرشماری انجام شد. مشخص شد که خوبی تناسب (R 2) فقط 0.0039 است و RMSE 1,007,871.35 است. نتایج شبیه سازی در بیشتر خیابان (شهر) دارای انحراف زیادی از مقدار واقعی بود. در یک کلام، دقت شبیه سازی بسیار ضعیف است. از طریق مقایسه مطالعات و تحلیل های قبلی، مشخص شد که دلایل انحراف زیاد تخمین مدل ممکن است تقریباً به شرح زیر باشد:
- (1)
-
منطقه تحقیقاتی منطقه مرکز شهر گوانگژو است که عوامل موثر بر توزیع جمعیت در منطقه بسیار پیچیده است. شبیه سازی دقیق ویژگی های توزیع جمعیت تنها با تکیه بر داده های کاربری زمین و نور شب غیرممکن است.
- (2)
-
وضوح مکانی داده های کاربری زمین کم است که تنها 30 متر است. در عین حال، تفکیک انواع کاربری اراضی در این پژوهش که تنها دارای پنج دسته است، به اندازه کافی دقیق نیست. از آنجایی که منطقه مورد مطالعه منطقه شهری مرکزی شهر گوانگژو است، زمین ساخت و ساز نوع کاربری غالب در منطقه است. بنابراین، در فرآیند نقشهبرداری توزیع جمعیت شبکهای، نتیجه شبیهسازی عمیقاً تحت تأثیر الگوی توزیع فضایی و مساحت زمین ساختمانی قرار میگیرد که به راحتی منجر به تخمین بیش از حد و انحراف زیاد از دادههای واقعی سرشماری میشود. همانطور که می دانیم، مطالعات قبلی نیز نشان می دهد که هرچه وضوح داده های کاربری زمین بالاتر باشد و انواع کاربری های زمین با جزئیات بیشتر می تواند دقت شبیه سازی جمعیت را بهبود بخشد.
- (3)
-
داده های زمان نور شب، داده های کاربری زمین و داده های آماری جمعیت متناقض هستند. دادههای سرشماری مورد استفاده در این مورد مطالعه مربوط به سال 1392 است، در حالی که دادههای کاربری اراضی و دادههای نور شب به ترتیب مربوط به سالهای 1394 و 1395 هستند. ناسازگاری بین داده های مدل سازی شده و داده های واقعی به ناچار منجر به کاهش دقت مدل می شود.
3.2. نتایج شبیه سازی بر اساس مدل جنگل تصادفی جهانی
به منظور کاهش خطای شبیهسازی و بهبود دقت شبیهسازی، انتخاب عوامل مؤثر بر توزیع فضایی جمعیت بهینه شده و از مدل جنگل تصادفی برای تحقق فضاییسازی دادههای جمعیت در منطقه مورد مطالعه استفاده میشود. با در نظر گرفتن ضرایب خطای مدل رگرسیون خطی جهانی، متغیرهای مستقل مدل جنگل تصادفی به 20 شاخص شامل شاخص زمین زیر کشت و شاخص جنگل، شدت نور شب، ارتفاع، شدت تأثیر POI، مساحت ساختمان، تراکم شبکه راه و میانگین به روز شد. قیمت خانه بر اساس مقیاس خیابان (شهر)، پایگاه داده ویژگی های آموزشی ساخته شد. با توجه به ابعاد ناسازگار عوامل تأثیرگذار، داده ها استانداردسازی شدند تا تأثیر ابعاد ناسازگار و مقادیر شدید حذف شوند.
از آنجایی که تعداد خیابانهای مورد استفاده برای تناسب با مدل تنها 106 است، CV 10 برابری انتخاب شد. به این معنی که نمونه های 9 برابری برای به دست آوردن پارامترهای مناسب در مدل پذیرفته شد و دقت با استفاده از نمونه های باقی مانده ارزیابی شد. اعتبارسنجی متقاطع 10 برابری و جستجوی شبکه برای یافتن پارامترهای مناسب در مدل RF انجام شد ( جدول 4 ). هنگامی که حداکثر عمق درخت تصمیم 9 و تعداد برآوردگرها 500 بود، ضریب تعیین کننده (R 2 ) امتیاز CV به حداکثر مقدار 0.7250 رسید. در نهایت، با تنظیم حداکثر عمق زیردرختها روی 9 و تعداد تخمینگرها روی 500، یک مدل جنگل تصادفی ساختیم.
بر اساس پارامترهای تنظیم شده در بالا، آموزش مدل با مجموعه داده های خیابان (شهر) به عنوان مجموعه آموزشی انجام شد. پس از آن، مدل رگرسیون جنگل تصادفی ایجاد شده برای هر سلول شبکه برای پیشبینی تراکم جمعیت اعمال میشود. در نهایت، نتیجه شبیه سازی با ضرب تراکم جمعیت و مساحت سلول به دست می آید. نتیجه شبیه سازی در شکل 5 نشان داده شده است .
همانطور که در شکل 5 نشان داده شده است، توزیع جمعیت در منطقه مورد مطالعه یک الگوی آشکار “هسته-لبه” را ارائه می دهد، به عنوان مثال، جمعیت به شدت در مرکز منطقه مورد مطالعه متمرکز است، در حالی که تراکم جمعیت در منطقه لبه کوچک است. در این میان، شمال شرقی ناحیه یوکسیو، ناحیه لیوان و ناحیه تیانهه دارای بیشترین جمعیت است و اثر تجمع آشکار است. شایان ذکر است که ضریب تعیین (R 2) از نتیجه مدل جنگل تصادفی 0.605 و RMSE 6497.02 است. در عین حال میانگین خطای نسبی تمامی خیابان ها (شهرک ها) در محدوده مورد مطالعه نزدیک به 16/32 درصد است. در مقایسه با مدل رگرسیون خطی جهانی، مشاهده می شود که دقت شبیه سازی با استفاده از مدل رگرسیون جنگل تصادفی به طور قابل توجهی بهبود یافته است. با این حال، برای مناطقی با تفاوت تراکم جمعیت زیاد، یک مدل جهانی نمی تواند مکانیسم توزیع فضایی جمعیت را به طور دقیق توضیح دهد.
3.3. نتایج شبیه سازی با استفاده از استراتژی منطقه ای
3.3.1. نتایج شبیه سازی برای منطقه متراکم
منطقه متراکم در مرکز شهر قرار دارد و توزیع جمعیت بیشتر از عوامل محیطی طبیعی متاثر از عوامل اجتماعی و اقتصادی است. برای این منظور، شانزده ضریب تاثیر برای مدلسازی توزیع جمعیت در منطقه متراکم انتخاب شدند که شامل تراکم شبکه راه (X1)، مساحت ساختمان (X2)، میانگین قیمت خانه (X3)، امکانات پذیرایی (X4)، امکانات عمومی (X5) میشود. ، شرکت ها (X6)، امکانات خرید (X7)، تسهیلات حمل و نقل (X8)، بیمه مالی (X9)، امکانات علمی، آموزشی و فرهنگی (X10)، ساختمان های مسکونی تجاری (X11)، امکانات خدمات زندگی (X12)، ورزشی و امکانات اوقات فراغت (X13)، امکانات خدمات پزشکی (X14)، سازمان های دولتی و گروه های اجتماعی (X15)، و امکانات اقامتی (X16).
از روش رگرسیون گام به گام برای ایجاد یک مدل رگرسیون خطی چندگانه برای مساحت متراکم استفاده شد. مدل به صورت زیر نشان داده شده است:
Y = 51753.187ایکس11+ 26819.234ایکس2− 20028.002ایکس6+ 19690.791ایکس5Y=51753.187�11+26819.234�2−20028.002�6+19690.791�5
مدل جنگل تصادفی به همان روش مدل سازی جهانی RF که در بالا ذکر شد انجام شد. اعتبارسنجی متقابل ده برابری و جستجوی شبکه برای یافتن پارامترهای مناسب در مدل RF برای منطقه متراکم انجام شد. مشخص شد که وقتی حداکثر عمق درخت تصمیم 10 و تعداد برآوردگرها 600 بود، ضریب تعیین کننده ( R2) امتیاز CV به حداکثر مقدار رسیده است. بنابراین، مدل جنگل تصادفی با تنظیم حداکثر عمق زیردرختها بر روی 10 و تعداد تخمینگرها بر روی 600 ساخته شد. پس از آن، مدل رگرسیون تصادفی جنگل ایجاد شده برای هر سلول شبکه برای پیشبینی تراکم جمعیت در مناطق متراکم اعمال میشود. در نهایت، نتیجه شبیه سازی با ضرب تراکم جمعیت و مساحت سلول به دست می آید. دو نتیجه شبیه سازی برای ناحیه متراکم در شکل 6 و دقت آنها در جدول 5 نشان داده شده است .
3.3.2. نتایج شبیه سازی برای منطقه پراکنده
در مقایسه با منطقه متراکم، عوامل مؤثر بر توزیع تراکم جمعیت در مناطق پراکنده پیچیدهتر است. از یک سو، از نقشه طبقه بندی کاربری اراضی می توان دریافت که با توجه به پراکندگی وسیع و وسعت زیاد زمین های زیر کشت و اراضی جنگلی در سطح کم، نباید در مدل سازی پراکندگی جمعیت از آنها غافل شد. از سوی دیگر، از مدل رقومی ارتفاع می توان دریافت که تفاوت های مکانی ارتفاعی در ناحیه پراکنده مشهود است. بنابراین در فرآیند انتخاب عوامل مؤثر بر توزیع فضایی جمعیت باید به محیط طبیعی و عوامل اقتصادی-اجتماعی توجه کامل داشت. 20 ضریب تأثیر به عنوان عوامل اصلی برای مدلسازی فضایی جمعیت در مناطق کم جمعیت مورد استفاده قرار میگیرد که شامل شاخص زمین زیر کشت (X1)، شاخص زمین جنگلی (X2) میشود.
از روش رگرسیون گام به گام برای ایجاد یک مدل رگرسیون خطی چندگانه برای مساحت متراکم استفاده شد. مدل به صورت زیر نشان داده شده است:
y = 3747.097ایکس19+ 2635.488ایکس14+ 5723.723ایکس4– 4189.312ایکس10+ 6198.014ایکس17 – 7990.993ایکس8+ 7751.247ایکس18+ 4081.011ایکس16– 4301.300ایکس12 + 2524.483ایکس9– 3200.836ایکس11y=3747.097�19+2635.488�14+5723.723�4−4189.312�10+6198.014�17 −7990.993�8+7751.247�18+4081.011�16−4301.300�12 +2524.483�9−3200.836�11
مدل جنگل تصادفی به همان روش مدل سازی جهانی RF که در بالا ذکر شد انجام شد. اعتبار سنجی متقابل ده برابری و جستجوی شبکه برای یافتن پارامترهای مناسب در مدل RF برای ناحیه پراکنده انجام شد. مشخص شد که وقتی حداکثر عمق درخت تصمیم 7 و تعداد تخمینگرها 600 بود، ضریب تعیینکننده ( R2) امتیاز CV به حداکثر مقدار رسیده است. بنابراین، مدل جنگل تصادفی با تنظیم حداکثر عمق زیردرختها بر روی 7 و تعداد تخمینگرها بر روی 600 ساخته شد. پس از آن، مدل رگرسیون جنگل تصادفی ایجاد شده برای هر سلول شبکه برای پیشبینی تراکم جمعیت در ناحیه پراکنده اعمال میشود. در نهایت، نتیجه شبیه سازی با ضرب تراکم جمعیت و مساحت سلول به دست می آید. دو نتیجه شبیه سازی برای ناحیه پراکنده در شکل 7 و دقت آنها در جدول 6 نشان داده شده است .
3.3.3. نتایج شبیه سازی برای کل منطقه
با ادغام نتایج شبیهسازی تصادفی جنگل منطقه متراکم و نتایج شبیهسازی رگرسیون خطی ناحیه پراکنده، نتیجه شبیهسازی نهایی برای کل منطقه مورد مطالعه به دست میآید ( شکل 8 را ببینید ).
با مقایسه نتایج شبیهسازی با استفاده از مدل ناحیهای ( شکل 8 ) با نتایج شبیهسازی با استفاده از مدل جهانی LR و مدل RF جهانی ( شکل 4 و شکل 5 )، میتوان دریافت که نتایج شبیهسازی مبتنی بر استراتژی مدل منطقهای میتواند منعکس شود. ویژگی های فضایی توزیع جمعیت “هسته-حومه” در منطقه مورد مطالعه واضح تر است. با در نظر گرفتن جمعیت واقعی خیابان به عنوان مقدار واقعی، دقت شبیهسازی مدل منطقهای و مدل جهانی با استفاده از خوبی برازش ارزیابی شد. نتایج در جدول 7 نشان داده شده است .
از جدول 7 می توان دریافت که دقت شبیه سازی مدل سازی ناحیه ای بهتر از مدل های غیر منطقه ای است. از آنجایی که دقت شبیه سازی مدل رگرسیون خطی منفرد بسیار پایین است، در اینجا به آن پرداخته نخواهد شد. سپس خطاهای نسبی مدل منطقه ای و مدل جنگل تصادفی تک مورد تجزیه و تحلیل قرار گرفت. نتایج در جدول 8 نشان داده شده است .
از جدول 8 قابل مشاهده استکه در نتایج مدل منطقهای، نسبت خیابانهای دارای خطای شبیهسازی در محدوده 30 درصد، 51.89 درصد است، در حالی که مدل جنگل تصادفی منفرد، 49.06 درصد است. تفاوت بین این دو مدل مشخص نیست. با این حال، در نتایج مدلسازی، نسبت خیابانهای با خطای نسبی بیش از 50 درصد بر اساس یک مدل جنگل تصادفی منفرد، 13/31 درصد است که آشکارا بیشتر از مدل منطقهای است. در مقایسه با مدل جنگل تصادفی جهانی، نسبت خیابانهای با درصد خطای نسبی بیش از 50 درصد در نتایج مدلسازی منطقهبندی از 13/31 درصد به 98/16 درصد کاهش یافته است. به طور خلاصه، نتایج نقشهبرداری بهدستآمده بر اساس استراتژی مدلسازی منطقهای بیشتر با وضعیت واقعی مطابقت دارد که میتواند دقت نقشهبرداری توزیع جمعیت را به طور قابل توجهی بهبود بخشد. نقشه های موضوعی برای مقادیر درصد خطای نسبی هر خیابان تولید شده توسط دو مدل ترسیم شده است. نقشه های موضوعی در نشان داده شده استشکل 9 .
از شکل 9 قابل مشاهده استکه دقت نتایج شبیهسازی در منطقه شامل منطقه بایون، شرق منطقه تیانه و منطقه هوانگپو کمتر از سایر مناطق است. درصد خطای نسبی خیابانهای این منطقه عمدتاً بیش از 50 درصد است. در میان آنها، خیابان Tonghe در منطقه Baiyun دارای بالاترین MRE در نتیجه مدل جنگل تصادفی جهانی است، در حالی که خیابان Sanyuanli در منطقه Baiyun دارای بالاترین MRE در نتیجه مدل منطقه ای است. اگرچه در این مقاله مدلهای متفاوتی برای زیرمنطقههای مختلف اعمال شد، اما به دلیل تفاوتهای آشکار در محیط طبیعی و سطح توسعه اجتماعی-اقتصادی بین دو زیرمنطقه. با این حال، در منطقه متراکم، چه جنگل تصادفی جهانی یا مدل منطقهای، دقت مدل نسبتاً پایین است. یک تخمین منطقی این است که از آنجایی که مناطق پرجمعیت معمولاً مناطقی با نرخ شهرنشینی سریع هستند، عدم تطابق وضوح زمانی و مکانی منابع داده های مختلف ممکن است باعث انحرافات زیادی بین نتایج مدل و داده های آماری شود. این نارسایی ممکن است دقت شبیه سازی مدل را کاهش دهد.
4. بحث و نتیجه گیری
4.1. بحث
در مورد دادههای سرشماری واحدهای اداری، این نشان میدهد که چند نفر در یک محدوده مکانی خاص (مثلاً یک شهرستان یا یک شهرستان) توزیع شدهاند و در کجا توزیع خاص قابل ارائه نیست. به این معنا که دادههای سرشماری با هدف فضاییسازی طراحی نشدهاند و نقشهبرداری بر اساس واحدهای شبکهای میتواند به نقشهبرداری دقیق توزیع جمعیت دست یابد [ 41] .]. بنابراین، نقشهبرداری جمعیتی شبکهای برای مدیریت شهری بسیار مهم است. با این حال، مطالعات قبلی در مورد نقشهبرداری جمعیت در مقیاس ریز اندک است و وضوح فضایی نتایج نقشهبرداری عمدتاً مبتنی بر شبکهای با وضوح فضایی 500 متر یا 1 کیلومتر است که برآورده کردن الزامات مدیریت دقیق دشوار است. این مطالعه دادههای جمعیت شبکهای 150 متری را در مرکز گوانگژو با استفاده از استراتژی مدلسازی منطقهبندی با دو روش یادگیری ماشینی یکپارچه تولید کرد. از پیشرفته ترین مدل جنگل تصادفی و مدل رگرسیون خطی برای ادغام داده های چندگانه و پیش بینی توزیع تراکم جمعیت استفاده شد که برای نگاشت جمعیت شبکه ای استفاده شد. نتایج اطلاعات به موقع و مهمی را در اختیار سیاستگذاران برای مدیریت و برنامه ریزی شهری قرار می دهد [ 51]. بدیهی است که نقشههای دارای واحدهای شبکه از نظر بصری درشت هستند و نمیتوانند اطلاعات متشکل از واحدهای جغرافیایی (یعنی سکونتگاههای مسکونی انسانی) را تولید کنند. در مقابل، نتیجه نگاشت ما میتواند با استفاده از چند ضلعیهای همگن با مرزهای نامنظم، اطلاعات دقیق جمعیت را ارائه دهد. بر اساس تجزیه و تحلیل تجربی فوق، لازم است در مورد مسائل زیر بیشتر بحث شود.
4.1.1. یافته های اصلی و دلالت معنادار
- (1)
-
مدل آشکارساز جغرافیایی ابزار بسیار مفیدی برای شناسایی ضریب تاثیر بر توزیع تراکم جمعیت است. همانطور که بسیاری از متغیرهای طبیعی و اجتماعی-اقتصادی مرتبط در مدلسازی ما وارد شدند، تحلیل مدل آشکارساز جغرافیایی تأثیر مثبت آشکاری بر درک مکانیسم تأثیرگذاری بر توزیع جمعیت در این منطقه مورد مطالعه دارد. نتایج تجربی نقشهبرداری توزیع جمعیت نشان میدهد که عوامل تأثیر انتخاب شده توسط مدل آشکارساز جغرافیایی معقول هستند. با این حال، ضریب تاثیر انتخاب شده توسط مدل آشکارساز جغرافیایی، فاکتورهای مدلسازی نهایی برای مدل رگرسیون خطی نیست. نتایج رتبهبندی توان توضیحی نشان داد که عوامل اجتماعی-اقتصادی تأثیر بیشتری بر توزیع فضایی جمعیت در منطقه مورد مطالعه نسبت به عوامل طبیعی دارند. این یافته با مطالعات قبلی مطابقت دارد.
- (2)
-
استراتژی مدلسازی منطقهبندی با استفاده از روشهای یادگیری ماشینی میتواند دقت نقشهبرداری جمعیت در مقیاس دقیق را در مناطق شهری بهبود بخشد. نتایج نشان میدهد که برازش مناسب برای نتیجه مدل پهنهبندی نزدیک به 0.713 است، در حالی که برازش برای مدل رگرسیون خطی تک و مدل رگرسیون جنگل تصادفی به ترتیب 0.0039 و 0.605 است. ما حدس می زنیم که دقت ضعیف مدل رگرسیون خطی منفرد عمدتاً به دلیل وضوح مکانی پایین داده های کاربری زمین و طبقه بندی ناکافی انواع است که منجر به انحرافات زیادی در نتایج شبیه سازی می شود. در مقایسه با مدل منطقه ای، دلیل دقت پایین تر مدل جنگل تصادفی جهانی ممکن است به دلیل بی توجهی به تفاوت های محیطی طبیعی و انسانی بین سطح متراکم و منطقه پراکنده باشد. برای منطقه متراکم، دقت مدل جنگل تصادفی بهتر از مدل رگرسیون خطی است. در حالی که برای منطقه پراکنده، دقت مدل رگرسیون خطی بهتر از مدل جنگل تصادفی است. در مقایسه با مدل رگرسیون خطی، اگرچه مدل جنگل تصادفی از نظر تئوری مزایای زیادی دارد، اما تضمین نمیکند که دارای مزیت دقت در نقشهبرداری توزیع جمعیت باشد. بنابراین، توصیه میشود که استراتژی مدلسازی منطقهای باید اولین انتخاب برای حل تفاوتهای منطقهای در تحقیقات نقشهبرداری توزیع جمعیت باشد. تضمین نمی کند که دارای مزیت دقت در نقشه برداری توزیع جمعیت باشد. بنابراین، توصیه میشود که استراتژی مدلسازی منطقهای باید اولین انتخاب برای حل تفاوتهای منطقهای در تحقیقات نقشهبرداری توزیع جمعیت باشد. تضمین نمی کند که دارای مزیت دقت در نقشه برداری توزیع جمعیت باشد. بنابراین، توصیه میشود که استراتژی مدلسازی منطقهای باید اولین انتخاب برای حل تفاوتهای منطقهای در تحقیقات نقشهبرداری توزیع جمعیت باشد.
- (3)
-
استفاده از رگرسیون تصادفی جنگل در نقشه برداری جمعیت در مقیاس ریز باید محتاطانه باشد. علیرغم اینکه مدل جنگل تصادفی به عنوان مزایای آن در بسیاری از رشته ها رایج است، برخی از پارامترهای اصلی و حیاتی می توانند بر نتایج به دست آمده توسط کاربران تأثیر بگذارند [ 58 ، 59]]، مانند حداکثر عمق درخت های تصمیم، حداکثر تعداد ویژگی ها و غیره. بنابراین، تنظیم پارامترها یک کار مهم در مدلسازی تصادفی جنگل است. جستجوی شبکهای همراه با اعتبارسنجی متقاطع K-fold یک روش مؤثر برای یافتن پارامترهای بهینه است، بهویژه زمانی که تعداد نمونهها کم باشد. از آنجایی که تعداد خیابانهای مورد استفاده برای تناسب مدل تنها 106 است، CV 10 برابری در مطالعه ما انتخاب شد. نتیجه پیشبینی با خوبی برازش 605/0 در مدل جنگل تصادفی جهانی تأثیر خوبی دارد.
4.1.2. توضیحاتی برای تحقیقات بیشتر
نقشه برداری توزیع جمعیت در مقیاس ریز یک مشکل بسیار پیچیده است. این مقاله ابتدا از مدل آشکارساز جغرافیایی برای انتخاب عوامل موثر بر توزیع فضایی جمعیت استفاده می کند و سپس با استفاده از مدل واحد و مدل پهنه بندی، نقشه برداری توزیع جمعیت را محقق می کند و در نهایت نتایج شبیه سازی را برای اثبات صحت روش منطقه ای پیاده سازی شده با هم مقایسه می کند. این مقاله به طور قابل توجهی بهبود یافته است. اما با توجه به محدودیت توانایی تحقیق علمی شخصی، زمان و سایر عوامل، همچنان نواقص زیر در روند تحقیق این مقاله وجود دارد که در آینده نیاز به بهبود تدریجی دارد.
- (1)
-
کیفیت منبع داده برای مدل سازی را می توان بهبود بخشید. وضوح فضایی داده های نور شب NPP/VIIRS نزدیک به 500 متر است که برای نقشه برداری جمعیت در مقیاس شهر یا کمون بسیار درشت است. در مقایسه با داده های NPP-VIIRS، وضوح مکانی و سطح کمی داده های LJ 1-01 از 500 متر به 150 متر افزایش یافته است. علیرغم بهترین وضوح دادههای LJ 1-01، الگوهای بافت شهری پیچیده و عدم قطعیت کالیبراسیون تابش Luojia1-01 استفاده از تصاویر را در انجام تخمینهای دقیق جمعیت در مقیاس خوب محدود میکند. علاوه بر این، تفکیک مکانی و نوع دادههای کاربری اراضی مورد استفاده در این مقاله نیز به اندازه کافی دقیق نیست، که ممکن است به وضوح بر دقت مدل تأثیر بگذارد. علاوه بر این، ویژگی های زمانی منبع داده مطابقت ندارد. دادههای جمعیتی خیابان (شهر) مورد استفاده در تحقیق مربوط به سال 2013 است، در حالی که کاربری زمین، روشنایی شبانه، POI و سایر دادههای مورد استفاده در مدلسازی مربوط به سال 2015 است. عدم تطابق ویژگیهای زمانی به طور اجتنابناپذیری بر دقت و صحت مدل. بنابراین، استفاده از مجموعه داده های دقیق تر و دقیق تر در نقشه برداری جمعیت باید در اسرع وقت مورد مطالعه بیشتر قرار گیرد.
- (2)
-
موضوع عدم قطعیت مدل باید در مطالعات بیشتر مورد توجه قرار گیرد. مشابه بسیاری از مطالعات، پارامترهای مدل مختلف نتایج مدل متفاوتی را بهویژه در زمینه علم جغرافیا تولید میکنند. برای مثال، اندازه شبکه ممکن است بر نتیجه مدل تأثیر بگذارد. داده های جمعیت شبکه ای با اندازه سلول مناسب می تواند انواع فضایی الگوی توزیع جمعیت را با وضوح بیشتری نشان دهد. با توجه به تجربه تحقیقاتی قبلی، برای جلوگیری از افتادن کوچکترین واحدهای مسکونی در یک شبکه، اندازه شبکه در مطالعه ما 150 متر تعیین شده است. با این حال، اینکه آیا اندازه شبکه مناسب تری برای مدل وجود دارد یا خیر، هنوز باید مورد مطالعه قرار گیرد. همانطور که می دانیم، تحلیل حساسیت یک روش مفید برای کشف عدم قطعیت مدل سازی است. در نتیجه،
- (3)
-
هنوز پتانسیل بهبود در انتخاب عوامل مدل سازی وجود دارد. در واقع، مکانیسم نفوذ توزیع جمعیت موضوع سختی است. اگرچه این مقاله با ادغام تجربیات قبلی با تجزیه و تحلیل مدل آشکارساز جغرافیایی، عوامل تأثیرگذار اصلی را شناسایی کرد، اما هنوز آشکار کردن مکانیسم ذاتی به طور کامل دشوار است. به عنوان مثال، مدل جنگل تصادفی نیز می تواند برای تشخیص اهمیت ویژگی های مختلف استفاده شود [ 60]. در میان عوامل تاثیر انتخاب شده در این مقاله، دادههای POI اکثریت قریب به اتفاق را تشکیل میدهند که تاثیر بسیار مهمی بر مدلسازی توزیع جمعیت دارد. در همین حال، هر دسته از POI ممکن است با یکدیگر مرتبط باشند، که ممکن است باعث سوگیری اهمیت ویژگی شود. مطالعات بیشتر باید به استقلال هر ویژگی یا برازش مدل با ادغام همه POIها در یک لایه بپردازد.
علاوه بر این، تنها از دو روش کلاسیک یادگیری ماشین مانند رگرسیون خطی و جنگل تصادفی در این مقاله استفاده شده است. کاربرد و ارزیابی دقت سایر روش های یادگیری ماشین مانند شبکه های عصبی، ماشین بردار پشتیبان و غیره باید بیشتر مورد مطالعه قرار گیرد. به عبارت دیگر، تلاش های بیشتری برای اعمال روش های جایگزین برای ساخت مدل های جدید با پارامترهای مناسب مورد نیاز است.
4.2. نتیجه گیری
این مطالعه یک روش منطقه ای برای کاهش مقیاس جمعیت سرشماری به مقیاس شبکه ای 30 متر در مرکز گوانگژو، چین ارائه کرد. ابتدا، مدل آشکارساز جغرافیایی برای انتخاب عوامل مؤثر بر توزیع فضایی جمعیت استفاده میشود. سپس نقشه توزیع جمعیت به ترتیب با مدل تک و مدل پهنه بندی محقق می شود. در نهایت، دقت نتایج مدل های مختلف مقایسه می شود. نتایج ارزیابی دقت در سطح خیابان نشان میدهد که رویکرد پیشنهادی به دقت کلی خوبی با R2 دست یافت .0.713 و RMSE 5512.9 است. این در حالی است که میزان برازش برای مدل رگرسیون خطی تک و مدل رگرسیون جنگل تصادفی به ترتیب 0039/0 و 605/0 است. مطالعه ما نشان داد که دقت نقشه برداری توزیع جمعیت را می توان به طور موثر در مقایسه با نقشه برداری که از استراتژی مدل سازی منطقه بندی استفاده نمی کند، بهبود بخشید. نتایج نشان داد که روش پیشنهادی پتانسیل بالایی در نقشه برداری جمعیت در مقیاس ریز دارد. برای مساحت متراکم، دقت مدل جنگل تصادفی بهتر از مدل رگرسیون خطی است. برای منطقه پراکنده، دقت مدل رگرسیون خطی بهتر از مدل جنگل تصادفی است. بنابراین، توصیه میشود که استراتژی مدلسازی منطقهای باید اولین انتخاب برای حل تفاوتهای منطقهای در تحقیقات نقشهبرداری توزیع جمعیت باشد.
مشارکت های نویسنده
مفهوم سازی، گوانوی ژائو و موژوانگ یانگ. روش شناسی، گوانوی ژائو و موژوانگ یانگ. نرم افزار، Guanwei Zhao; اعتبار سنجی، گوانوی ژائو؛ تحلیل رسمی، گوانوی ژائو؛ تحقیق، گوانوی ژائو؛ منابع، گوانوی ژائو و موژوانگ یانگ. مدیریت داده، گوانوی ژائو؛ نوشتن – آماده سازی پیش نویس اصلی، گوانوی ژائو و موژوانگ یانگ. نوشتن-بررسی و ویرایش، Guanwei Zhao و Muzhuang Yang. تجسم، گوانوی ژائو و موژوانگ یانگ. نظارت، موژوانگ یانگ. همه نویسندگان نسخه منتشر شده نسخه خطی را خوانده و با آن موافقت کرده اند.
منابع مالی
این تحقیق تا حدی توسط بنیاد علوم طبیعی استان گوانگدونگ، چین تامین مالی شده است: شماره کمک مالی 2017A030313240، برنامه تحقیقاتی فلسفه و علوم اجتماعی شهر گوانگژو، استان گوانگدونگ، چین: شماره گرنت 2020GZGJ183، و پروژه طرح سرمایه گذاری علمی و فناوری گوانگژو-Jo توسط شهر و دانشگاه (نام پروژه شبیه سازی دقیق توزیع جمعیت در شهر گوانگژو با در نظر گرفتن اثر مقیاس است، اما شماره پروژه هنوز اعلام نشده است).
قدردانی ها
نویسندگان از کار ویراستار و داوران قدردانی می کنند.
تضاد علاقه
نویسندگان هیچ تضاد منافع را اعلام نمی کنند. تامین کنندگان مالی هیچ نقشی در طراحی مطالعه نداشتند. در جمع آوری، تجزیه و تحلیل یا تفسیر داده ها؛ در نوشتن دستنوشته یا تصمیم به انتشار نتایج.
منابع
- یانگ، ایکس. یو، دبلیو. گائو، دی. بهبود فضایی توزیع جمعیت انسانی بر اساس داده های سنجش از راه دور چند حسگر: ورودی برای ارزیابی قرار گرفتن در معرض. بین المللی J. Remote Sens. 2013 ، 34 ، 5569-5583. [ Google Scholar ] [ CrossRef ]
- ژائو، ی. Ovando-Montejo، GA; Frazier، AE; ماتیوس، ای جی. فلین، کی سی; الیس، EA برآورد جمعیت کار و خانه با استفاده از حجم ساختمان مشتق شده از لیدار. بین المللی J. Remote Sens. 2017 , 38 , 1180-1196. [ Google Scholar ] [ CrossRef ]
- Maantay، JA; ماروکو، آر. Herrmann، C. نقشه برداری توزیع جمعیت در محیط شهری: سیستم داسیمتریک خبره مبتنی بر کاداستر (CEDS). کارتوگر. Geogr. Inf. علمی 2007 ، 34 ، 77-102. [ Google Scholar ] [ CrossRef ]
- مارتین، دی. لوید، سی. شاتل ورث، I. ارزیابی مدل های جمعیت شبکه ای با استفاده از داده های سرشماری ایرلند شمالی در سال 2001. محیط زیست طرح. 2011 ، 43 ، 1965-1980. [ Google Scholar ] [ CrossRef ]
- ریه، تی. لوبکر، تی. Ngochoch، JK; Schaab, G. مدلسازی توزیع جمعیت انسانی در سطح منطقه با استفاده از تصاویر ماهوارهای با وضوح بسیار بالا. Appl. Geogr. 2013 ، 41 ، 36-45. [ Google Scholar ] [ CrossRef ]
- اوبرشت، سی. Aubrecht، DO; اونگار، ج. فریره، اس. Steinnocher، K. VGDI-پیشبرد مفهوم: اطلاعات ژئودینامیک داوطلبانه و مزایای آن برای مدلسازی پویایی جمعیت. ترانس. Gis 2017 ، 21 ، 253-276. [ Google Scholar ] [ CrossRef ]
- جیا، پی. Gaughan، AE Dasymetric modeling: یک رویکرد ترکیبی با استفاده از داده های پوشش زمین و بسته مالیاتی برای نقشه برداری جمعیت در شهرستان آلاچوا، فلوریدا. Appl. Geogr. 2016 ، 66 ، 100-108. [ Google Scholar ] [ CrossRef ]
- لی، جی. Weng، Q. استفاده از تصاویر Landsat ETM+ برای اندازه گیری تراکم جمعیت در ایندیاناپولیس، ایندیانا، ایالات متحده. فتوگرام مهندس Remote Sens. 2005 ، 71 ، 947-958. [ Google Scholar ] [ CrossRef ]
- کالکا، بی. نواک دا کوستا، جی. Bielecka، E. داده های تراکم جمعیت در مقیاس خوب و کاربرد آن در ارزیابی ریسک. Geomat. نات. خطر خطرات 2017 ، 8 ، 1440-1455. [ Google Scholar ] [ CrossRef ]
- فریره، اس. شیاوینا، م. فلورچیک، ای جی؛ مک مانوس، ک. پسری، م. کوربن، سی. بورکوفسکا، او. میلز، جی. پیستولسی، ال. اسکوایرز، جی. و همکاران دادهها و روشهای پیشرفته برای بهبود شبکههای جمعیتی آزاد و باز جهانی: عملی کردن «هیچکس را پشت سر نگذارید». بین المللی جی دیجیت. زمین 2020 ، 13 ، 61-77. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آذر، د. انگستروم، آر. گریسر، جی. Comenetz, J. تولید لایههای جمعیتی در مقیاس ریز با استفاده از تصاویر ماهوارهای با وضوح چندگانه و دادههای مکانی. سنسور از راه دور محیط. 2013 ، 130 ، 219-232. [ Google Scholar ] [ CrossRef ]
- رید، FJ; Gaughan، AE; استیونز، FR; یتمن، جی. سوریچتا، ا. نقشههای جمعیت شبکهبندیشده Tatem، AJ که توسط محصولات سکونتگاههای ساختهشده مختلف اطلاعرسانی شدهاند. داده 2018 ، 3 ، 33. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- هنوز.؛ ژائو، ن. یانگ، ایکس. اویانگ، ز. لیو، ایکس. چن، کیو. هو، ک. یو، دبلیو. چی، جی. لی، ز. و همکاران بهبود نقشهبرداری جمعیت برای چین با استفاده از دادههای سنجش از راه دور و نقاط مورد علاقه در یک مدل جنگلهای تصادفی. علمی کل محیط. 2019 ، 658 ، 936–946. [ Google Scholar ] [ CrossRef ]
- فلاوردیو، ر. گرین، ام. تحولات در روش های درونیابی منطقه ای و GIS. ان Reg. علمی 1992 ، 26 ، 67-78. [ Google Scholar ] [ CrossRef ]
- Goodchild، MF; آنسلین، ال. دایچمن، چارچوب UA برای درونیابی منطقه ای داده های اجتماعی و اقتصادی. محیط زیست طرح. یک اقتصاد. فضا 1993 ، 25 ، 383-397. [ Google Scholar ] [ CrossRef ]
- منیس، جی. تولید مدل های سطحی جمعیت با استفاده از نقشه برداری داسیمتری. پروفسور Geogr. 2003 ، 55 ، 31-42. [ Google Scholar ]
- توبلر، دبلیو. دایچمن، یو. گوتسگن، جی. Maloy، K. جمعیت جهان در شبکه ای از چهارضلعی های کروی. بین المللی جی پوپول. Geogr. 1997 ، 3 ، 203-225. [ Google Scholar ] [ CrossRef ]
- لین، جی. کراملی، RG ارزیابی داده های توئیتر موقعیت جغرافیایی به عنوان یک لایه کنترل برای درونیابی منطقه ای جمعیت. Appl. Geogr. 2015 ، 58 ، 41-47. [ Google Scholar ] [ CrossRef ]
- شی، ایکس. لی، ام. هانتر، او. گوتی، بی. اندرو، ا. استومل، ای. بردلی، دبلیو. کاراگاس، MR برآورد قرار گرفتن در معرض محیطی: درون یابی، تخمین چگالی هسته یا عکس برداری فوری. ان GIS 2019 ، 25 ، 1-8. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لام، روشهای درونیابی فضایی NSN: مروری. صبح. کارتوگر. 1983 ، 10 ، 129-149. [ Google Scholar ] [ CrossRef ]
- وو، سی. موری، AT یک روش کوکریجینگ برای تخمین تراکم جمعیت در مناطق شهری. محاسبه کنید. محیط زیست شهری. سیستم 2005 ، 29 ، 558-579. [ Google Scholar ] [ CrossRef ]
- لنگفورد، ام. Unwin، DJ تولید و نقشه برداری از سطوح تراکم جمعیت در یک سیستم اطلاعات جغرافیایی. کارتوگر. J. 1994 , 31 , 21-26. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Gaughan، AE; استیونز، FR; لینارد، سی. جیا، پی. Tatem، AJ نقشه های توزیع جمعیت با وضوح بالا برای جنوب شرقی آسیا در سال 2010 و 2015. PLoS ONE 2013 ، 8 ، e55882. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- جیا، پی. کیو، ی. Gaughan، AE توزیع جمعیت فضایی در مقیاس خوب بر روی سطح جمعیت شبکهای با وضوح بالا و کاربرد در شهرستان آلاچوا، فلوریدا. Appl. Geogr. 2014 ، 50 ، 99-107. [ Google Scholar ] [ CrossRef ]
- تاونسند، ای سی؛ Bruce, DA استفاده از تصاویر ماهواره ای نورهای شبانه به عنوان معیاری برای مصرف برق منطقه ای استرالیا و توزیع جمعیت. بین المللی J. Remote Sens. 2010 , 31 , 4459-4480. [ Google Scholar ] [ CrossRef ]
- بریگز، دی جی; گالیور، جی. فچت، دی. مدلسازی داسیمتری Vienneau، DM توزیع جمعیت در مناطق کوچک با استفاده از داده های پوشش زمین و انتشار نور. سنسور از راه دور محیط. 2007 ، 108 ، 451-466. [ Google Scholar ] [ CrossRef ]
- چن، ی. ژنگ، ز. وو، زی. کیان، کیو. بررسی و چشم انداز کاربرد داده های سنجش از دور نور شبانه. Adv. علوم زمین 2019 ، 38 ، 205-223. [ Google Scholar ]
- چن، ز. یو، بی. هو، ی. هوانگ، سی. شی، ک. Wu, J. تخمین نرخ خالی خانه در مناطق شهری با استفاده از دادههای ترکیبی نور شبانه NPP-VIIRS. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2015 ، 8 ، 2188-2197. [ Google Scholar ] [ CrossRef ]
- ژو، Q. ژنگ، ی. شائو، جی. لین، ی. وانگ، اچ. یک روش بهبود یافته برای تعیین توزیع جمعیت انسانی بر اساس تصاویر نور شبانه 1-01 Luojia و داده های شبکه جاده – مطالعه موردی شهر شنژن. Sensors 2020 , 20 , 5032. [ Google Scholar ] [ CrossRef ]
- ساتن، ک. رابرتز، دی. الویدج، سی. سرشماری از بهشت: برآوردی از جمعیت جهانی انسان با استفاده از تصاویر ماهواره ای شبانه. بین المللی J. سنجش از دور 2001 ، 22 ، 3061-3076. [ Google Scholar ] [ CrossRef ]
- لی، ایکس. ژائو، ال. لی، دی. Xu, H. نقشه برداری وسعت شهری با استفاده از تصاویر نور شبانه Luojia 1-01. Sensors 2018 , 18 , 3665. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- جیانگ، دبلیو. او، جی. لانگ، تی. گوا، اچ. یین، آر. لنگ، دبلیو. لیو، اچ. Wang, G. پتانسیل استفاده از تصاویر نور شبانه Luojia 1-01 برای بررسی آلودگی نور مصنوعی. Sensors 2018 , 18 , 2900. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، اف. یان، س. بیان، ز. لیو، بی. Wu, Z. A POI و LST Adjusted NTL Urban Index برای استخراج منطقه ساخته شده شهری. Sensors 2020 , 20 , 2918. [ Google Scholar ] [ CrossRef ]
- وو، تی جی; لو، جی سی. دونگ، دبلیو. گائو، ال جی. هو، XD; وو، ZF; Sun، YW; لیو، JS تفکیک دادههای سرشماری در سطح شهرستان برای نقشهبرداری جمعیت با استفاده از اشیاء جغرافیایی مسکونی با دادههای جغرافیایی-مکانی چند منبعی. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2020 , 13 , 1189–1205. [ Google Scholar ] [ CrossRef ]
- Xiong، JN; لی، ک. چنگ، WM; بله، CC; ژانگ، اچ. یک روش فضایی سازی جمعیت با توجه به ایستایی فضایی پارامتریک: مطالعه موردی منطقه جنوب غربی چین. ISPRS Int. J. Geo Inf. 2019 ، 8 ، 495. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- وانگ، LT; وانگ، اس ایکس؛ ژو، ی. لیو، WL; Hou، YF; زو، جی اف. Wang، FT نقشه برداری تراکم جمعیت در چین بین سال های 1990 و 2010 با استفاده از سنجش از دور. سنسور از راه دور محیط. 2018 ، 210 ، 269-281. [ Google Scholar ] [ CrossRef ]
- باکیالله، م. لیانگ، اس. مبشری، ع. جوکار ارسنجانی، ج. Zipf، A. نگاشت جمعیت با وضوح خوب با استفاده از نقاط مورد علاقه OpenStreetMap. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 1940-1963. [ Google Scholar ] [ CrossRef ]
- ما، YJ; خو، دبلیو. ژائو، XJ; لی، ی. مدلسازی توزیع ساعتی جمعیت در وضوح فضایی و زمانی بالا با استفاده از دادههای کارت هوشمند مترو: مطالعه موردی در منطقه مرکزی پکن. ISPRS Int. J. Geo-Inf. 2017 ، 6 ، 128. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- آهنگ، JC; تانگ، XY; وانگ، LZ; ژائو، CL; پریشچپوف، AV نظارت بر تراکم جمعیت در مقیاس کوچکتر در مناطق عملکردی شهری: رویکرد ادغام داده های سنجش از دور. Landsc. شهری. طرح. 2019 ، 190 ، 103580. [ Google Scholar ] [ CrossRef ]
- یو، بی. لیان، تی. هوانگ، ی. یائو، اس. بله، X. چن، ز. یانگ، سی. Wu, J. ادغام تصاویر سنجش از راه دور نور شبانه و داده های ردیابی GPS تاکسی برای افزایش سطح جمعیت. بین المللی جی. جئوگر. Inf. علمی 2019 ، 33 ، 687–706. [ Google Scholar ] [ CrossRef ]
- شی، ی. یانگ، جی. Shen, P. آشکارسازی همبستگی بین تراکم جمعیت و توزیع فضایی تسهیلات خدمات عمومی شهری با دادههای تلفن همراه. ISPRS Int. J. Geo Inf. 2020 ، 9 ، 38. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- یائو، ی. لیو، ایکس. لی، ایکس. ژانگ، جی. لیانگ، ز. مای، ک. ژانگ، ی. نقشه برداری توزیع جمعیت در مقیاس خوب در سطح ساختمان با ادغام داده های بزرگ جغرافیایی چندمنبعی. بین المللی جی. جئوگر. Inf. علمی 2017 ، 31 ، 1220-1244. [ Google Scholar ] [ CrossRef ]
- لی، جی. لی، جی. یوان، ی. لی، جی. ویژگی های توزیع فضایی و زمانی و تجزیه و تحلیل مکانیسم تراکم جمعیت شهری: موردی از شیان، شانشی، چین. شهرها 2019 ، 86 ، 62–70. [ Google Scholar ] [ CrossRef ]
- آذر، د. گریسر، جی. انگستروم، آر. کومنتز، جی. لدی، آر.ام. Schechtman، NG; اندروز، T. پالایش فضایی توزیع جمعیت سرشماری با استفاده از برآوردهای سنجش از راه دور سطوح غیرقابل نفوذ در هائیتی. بین المللی J. Remote Sens. 2010 , 31 , 5635–5655. [ Google Scholar ] [ CrossRef ]
- بریمن، ال. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گائو، ن. لی، اف. زنگ، اچ. ون بیلسن، دی. دی جونگ، ام. آیا دادههای سنجش از دور دقیقتر در شب میتوانند توزیع دقیقتر جمعیت را شبیهسازی کنند؟ پایداری 2019 ، 11 ، 4488. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- دیویل، پی. لینارد، سی. مارتین، اس. گیلبرت، ام. استیونز، FR; Gaughan، AE; بلوندل، وی دی. Tatem، AJ نقشه برداری پویا جمعیت با استفاده از داده های تلفن همراه. Proc. Natl. آکادمی علمی ایالات متحده آمریکا 2014 ، 111 ، 15888-15893. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- استیونز، FR; Gaughan، AE; لینارد، سی. Tatem، AJ تفکیک دادههای سرشماری برای نقشهبرداری جمعیت با استفاده از جنگلهای تصادفی با دادههای سنجش از دور و فرعی. PLoS ONE 2015 ، 10 ، e0107042. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کریمیسی، ا. شاتون، جی. Konukoglu، E. جنگل های تصمیم: یک چارچوب یکپارچه برای طبقه بندی، رگرسیون، تخمین تراکم، یادگیری چندگانه و یادگیری نیمه نظارت شده. پیدا شد. محاسبه گرایش ها نمودار. Vis. 2011 ، 7 ، 81-227. [ Google Scholar ] [ CrossRef ]
- Boulesteix, A.-L.; جانیتزا، اس. کروپا، جی. König، IR مروری بر روش شناسی جنگل تصادفی و راهنمایی عملی با تاکید بر زیست شناسی محاسباتی و بیوانفورماتیک. وایلی اینتردیسیپ. Rev. Data Min. بدانید. کشف کنید. 2012 ، 2 ، 493-507. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژو، ی. ما، م. شی، ک. پنگ، زی. تخمین و تفسیر جمعیت شبکهبندی شده با مقیاس ریز با استفاده از رگرسیون جنگل تصادفی و دادههای چند منبعی. ISPRS Int. J. Geo Inf. 2020 ، 9 ، 369. [ Google Scholar ] [ CrossRef ]
- رودریگز، AM; Tenedório، JA تجزیه و تحلیل حساسیت خودهمبستگی فضایی با استفاده از تنظیمات هندسی متمایز: رهنمودهایی برای جغرافیدان کمی. بین المللی جی. آگریک. محیط زیست Inf. سیستم IJAEIS 2016 ، 7 ، 13. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- بای، ZQ; وانگ، جی ال. وانگ، MM; گائو، MX؛ Sun، JL دقت ارزیابی مجموعه داده های توزیع جمعیت شبکه بندی شده چند منبعی در چین. Sustainability 2018 , 10 , 1363. [ Google Scholar ] [ CrossRef ][ Green Version ]
- وانگ، جی اف. لی، XH; کریستاکوس، جی. لیائو، YL; ژانگ، تی. گو، ایکس. ژنگ، ارزیابی خطر سلامت مبتنی بر آشکارسازهای جغرافیایی XY و کاربرد آن در مطالعه نقص لوله عصبی منطقه هشون، چین. بین المللی جی. جئوگر. Inf. علمی 2010 ، 24 ، 107-127. [ Google Scholar ] [ CrossRef ]
- اوه، YJ; پارک، اچ اس. Min, Y. درک اتصال برنامه سرویس مبتنی بر مکان: توسعه مدل و اعتبارسنجی متقابل. محاسبه کنید. هوم رفتار 2019 ، 94 ، 82-91. [ Google Scholar ] [ CrossRef ]
- قلی نژاد، س. نائینی، ع.ا. امیری سیمکویی، بهینهسازی ازدحام ذرات قوی AR از RFM برای تصاویر ماهوارهای با وضوح بالا بر اساس اعتبارسنجی متقاطع K-Fold. IEEE J. Sel. بالا. Appl. زمین Obs. از راه دور. Sens. 2019 , 12 , 2594–2599. [ Google Scholar ] [ CrossRef ]
- لیو، آر. فنگ، ز. یانگ، ی. شما، Z. تحقیق در مورد الگوی فضایی تجمع و پراکندگی جمعیت در چین. Prog. Geogr. 2010 ، 29 ، 1171-1177. (به زبان چینی) [ Google Scholar ]
- بیاو، جی. Scornet, E. A Random Forest Guided Tour. تست 2016 ، 25 ، 197-227. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گرومپینگ، U. ارزیابی اهمیت متغیر در رگرسیون: رگرسیون خطی در مقابل جنگل تصادفی. صبح. آمار 2009 ، 63 ، 308-319. [ Google Scholar ] [ CrossRef ]
- گرگوروتی، بی. میشل، بی. سن پیر، پی. همبستگی و اهمیت متغیر در جنگل های تصادفی. آمار محاسبه کنید. 2017 ، 27 ، 659-678. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
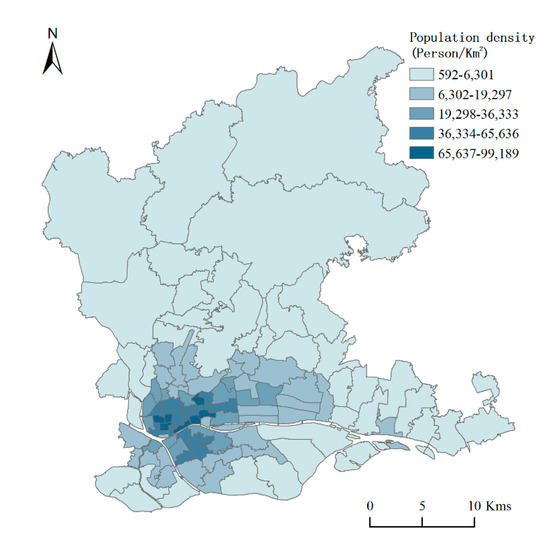
شکل 1. نقشه تراکم جمعیت منطقه مورد مطالعه در سال 1392.

شکل 2. قدرت توضیحی عوامل موثر بر تراکم جمعیت.

شکل 3. نقشه پهنه بندی منطقه تحقیقاتی بر اساس جماعت جمعیت.
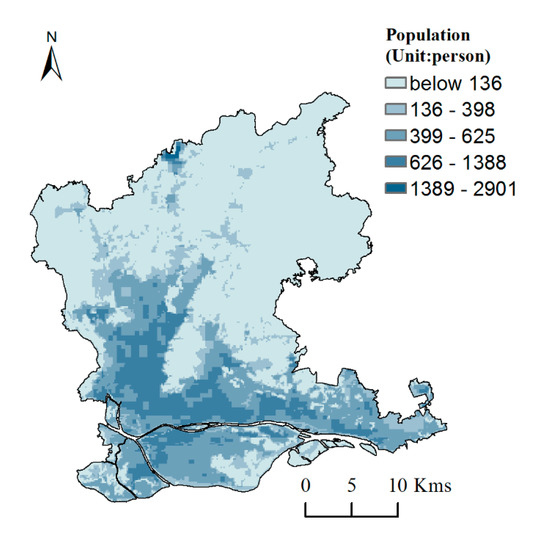
شکل 4. نتیجه شبیه سازی با استفاده از مدل رگرسیون خطی جهانی.

شکل 5. نتیجه شبیه سازی با استفاده از مدل رگرسیون تصادفی جنگل جهانی.

شکل 6. نقشه های پراکنش جمعیت در منطقه متراکم.

شکل 7. نقشه های پراکنش جمعیت در ناحیه پراکنده.
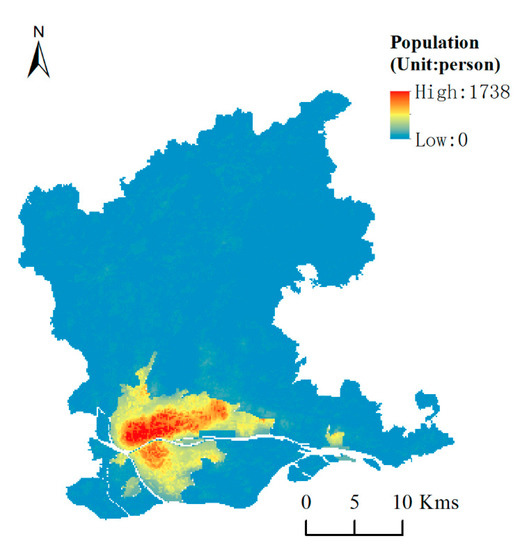
شکل 8. نقشه پراکنش جمعیت در منطقه مورد مطالعه.
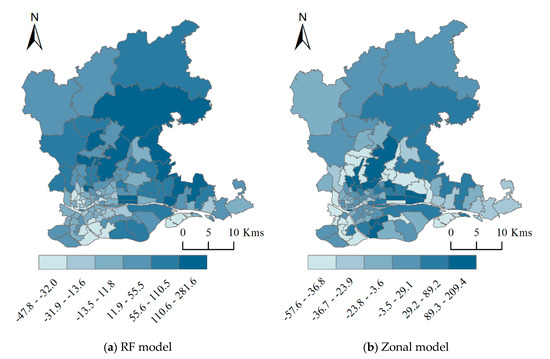
شکل 9. نقشه توزیع میانگین خطای نسبی (MRE) در دو مدل.


بدون دیدگاه