1. مقدمه
همهگیری کووید-19 از اواخر سال 2019 از چین آغاز شد و هنگامی که پیامدهای انتشار آن مشخص شد، دولت چین بلافاصله قبل از روی آوردن به قرنطینه کامل برای منطقه ووهان، که به عنوان آسیب دیده ترین منطقه در منطقه هوبی شناسایی شده بود. بسیاری از دولتها و نهادهای محلی دیگر (مناطق و شهرداریها) در سراسر جهان اقدامات قرنطینه شدیدی را اعمال کردهاند، اما همیشه تصمیمهای پسینی اتخاذ کردهاند: سطوح فزاینده قرنطینه بر اساس تعداد مبتلایان، بستریها و فوتشدگان فعال شده است. قرنطینه عمومی، مانند آنچه در ایتالیا از ابتدای مارس تا تقریباً پایان ژوئن اعمال شد، و همچنین در بسیاری از کشورهای دیگر در سراسر جهان. این اقدامات قرنطینه عمومی با تقلید از آنچه در منطقه ووهان برای مهار گسترش کووید-19 تصمیم گرفته شد، اتخاذ شد، زیرا ثابت شده بود که تأثیر مثبتی از نظر تعداد عفونت ها داشته است.1 ، 2 ].
با این حال، ثابت شده است که اقدامات قرنطینه در کشورهای مختلف نتایج متفاوتی را به دنبال دارد، زیرا عوامل متعددی بر کارایی سطوح قرنطینه تأثیر میگذارند. ارزیابی این تفاوت ها و درک اینکه چرا پویایی ها برای هر کشور خاص است، مهم است. عادات و شیوه های تعامل جمعیت، همراه با توانایی آنها برای احترام به قوانین فاصله گذاری اجتماعی، بر شیوع COVID-19 تأثیر می گذارد. با این ویژگی ها، عوامل دیگری مانند تراکم جمعیت برای توصیف واکنش به اقدامات قرنطینه و کاهش تعداد مبتلایان جدید باید در نظر گرفته شوند. تحلیل جالبی در [ 3 ] ارائه شده است]، که در آن یک ابزار تعاملی برای نظارت بر روند کووید-19 ارائه شده است که بر حسب مبتلایان جدید برای 187 کشور تجزیه و تحلیل شده است. بسیاری از کشورهای اروپایی مسیر صعود و سقوط دو هفتهای را نشان دادهاند که ایتالیا و فرانسه با سریعترین کاهش در آخرین دوره قرنطینه در حدود پایان ماه می و روزهای اول ژوئن مشخص میشوند. در [ 3 ] میزان مرگ و میر نیز ترسیم و مورد بحث قرار گرفته است که به عنوان تعداد مرگ و میر بر تعداد مبتلایان شناسایی شده تعریف شده است. کشورهایی مانند آلمان و اتریش کمترین ارزش را نسبت به سایر کشورها نشان داده اند. به نظر می رسد میزان مرگ و میر در بین کشورها بسیار متفاوت است و این بیشتر به عوامل مختلف مؤثر بر این تعداد مربوط می شود: شرایط اجتماعی-اقتصادی، استعداد ژنتیکی، جنسیت، سن [ 4 ].]، وضعیت سلامت گذشته [ 5 ]، شدت ویروس [ 6 ]، کارایی خدمات بیمارستانی و در دسترس بودن مکان های مراقبت های ویژه [ 7 ]. واضح است که نرخ مرگ و میر عددی است که تحت تأثیر مقادیر مرگ و میر و مبتلایان است، همانطور که در پایگاه های داده عمومی موجود گزارش شده است. بنابراین، برخی از جنبهها بر ارزشها تأثیر میگذارند، مانند افرادی که به دلیل کووید-19 جان خود را از دست دادهاند اما گزارش نشدهاند، و افراد آلوده به دلیل بدون علامت بودن یا به دلیل عدم استفاده از سواب تشخیص داده نمیشوند. یک چیز واضح به نظر می رسد: فاصله گذاری اجتماعی جمعیت عامل اصلی افزایش یا کاهش شیوع بیماری بود. مطالعات زیادی برای تجزیه و تحلیل این پدیده انجام شده و مدلهایی ایجاد شده است [ 8 ، 9 ، 10, 11 , 12 ]. با این حال، اگر اقدامات قرنطینه، همانطور که بحث شد، از یک سو منجر به کاهش مبتلایان به دلیل افزایش فاصله گذاری و انزوای اجتماعی شود، از سوی دیگر، این روشهای مداخله به دلیل پیامدهای منفی برای اقتصادی مناسب نبودند [ 13 ]. ] و جنبه های اجتماعی [ 14 ، 15 ]. در حالی که تأثیر منفی اقدامات محدودیت ها بر اقتصاد آشکار به نظر می رسد، تحلیل عمیق تری در مورد دوم ضروری است. به طور خاص، در [ 14 ] تأثیر قرنطینه بر افزایش چاقی در جوانان نشان داده شده است، و در [ 15 ]] خطر بیشتری برای آسیب به سلامت جسمی و روحی افراد ارائه می شود که همگی به دلیل عدم تحرک و ماندن طولانی مدت در خانه است.
با توجه به همه ملاحظات فوق، قرنطینه های عمومی نمی تواند راه حل باشد و مداخلات آتی باید از گذشته درس بگیرد تا تصمیمات پیشینی اتخاذ شود، که تأثیر حداقلی بر فعالیت های تجاری و جنبه های اجتماعی دارد، اما به همان اندازه در محدود کردن گسترش ویروس مؤثر است. .
از آنجایی که حجم عظیمی از داده ها در فرآیند انتشار کووید-19 دخیل هستند و تعاملات آنها به سختی از طریق روش های سنتی ثبت می شود، الگوریتم های هوش مصنوعی ابزار مناسبی هستند که با آن می توان تعاملات پنهان بین داده ها را ثبت کرد و امکان یک میکرو را فراهم کرد. و تحلیل کلان پدیده، با اجازه دادن به مداخلات موضعی.
در این مقاله قصد داریم تا مفهوم چنین ابزاری را بر اساس الگوریتمهای هوش مصنوعی ارائه کنیم تا به موسسات و تصمیمگیرندگان در اتخاذ اقدامات هدفمند پیشینی کمک کنیم. علاوه بر این، چنین ابزاری باید بتواند به نظارت بر وضعیت در زمان واقعی کمک کند تا از آنچه متأسفانه در بسیاری از نقاط جهان و همچنین در ایتالیا رخ داد، زمانی که قرنطینه ها انجام شد، جلوگیری کرد: پس از چند هفته، وضعیت شروع شد. از نظر مبتلایان و بستری شدن مجددا بدتر شد و اقدامات قرنطینه اتخاذ شده قبلی از سر گرفته شد.
اگرچه مقاله ما یک مقاله مفهومی است، برخی از تحلیل های اولیه نیز نشان داده شده است و دو مطالعه موردی مختلف ارائه شده است که نتایج آنها همبستگی بین NO را برجسته کرده است. نوع گره ناشناخته: فونتUnknown node type: font، تحرک و داده های COVID-19، اما با توجه به پیچیدگی مکانیسم انتشار ویروس، مرتبط با آلاینده های هوا و همچنین بسیاری از عوامل دیگر، از یک سو نیاز به انجام تجزیه و تحلیل های عمیق تر و از سوی دیگر تایید شد. برای استفاده از الگوریتم های هوش مصنوعی برای ثبت روابط پنهان بین مقادیر عظیمی از داده های مرتبط. همانطور که در این مقاله به تفصیل توضیح داده شد، شایان ذکر است که یک تحلیل اولیه از برخی پارامترها نیز برای شناسایی آن شاخصها کارآمدتر از سایرین در آموزش شبکه عصبی انتخاب شده برای مدل پیشنهادی انجام شده است.
تا جایی که ما می دانیم، این پیشنهاد پیشرفت قابل توجهی را در مقایسه با وضعیت فعلی نشان می دهد. تنها مطالعات مرتبط با موضوعات مشابه مربوط به ایجاد داشبورد ESA RACE [ 16 ] است که در 5 ژوئن 2020 منتشر شده است که امکان استفاده از داده های ماهواره ای را برای پشتیبانی از نظارت بر فعالیت های تجاری و تولیدی فراهم می کند و از سوی دیگر، توسعه پروژه های ملی و بین المللی، مانند PULVIRUS [ 17 ]، EpiCovAir و RESCOP [ 18 ]]، برای مطالعه همبستگی بین غلظت ذرات معلق اتمسفر و COVID-19. پیشنهاد ما موارد فوق را ادغام می کند و فراتر از اهداف آنها است، با پیشنهاد یک سیستم پشتیبانی تصمیم (DSS) که قادر به تولید سطح ریسک است، اما همچنین برای شبیه سازی، تنظیم مقادیر ورودی برای تعیین اینکه کدام ورودی ها باید تغییر کنند و نیز مفید است. چگونه می توان سطح ریسک پایین تری را به دست آورد. علاوه بر این، یک یادداشت خاص به کار ارائه شده در [ 19 ] می رود، جایی که یک چارچوب نظری برای سیستم هشدار اولیه و واکنش تطبیقی (EWARS) مفهوم سازی شد. سیستم پیشنهادی مبتنی بر منطق فازی برای پردازش دادهها از منابع مختلف بود و هدف آن حمایت از تصمیمگیرندگان در پیشگیری و مبارزه با همهگیریها بود. نسخه جدیدی از این مدل در [ 20 ] ارائه شد] ده سال بعد توسط همان نویسندگان، جایی که استفاده از برنامه های کاربردی مبتنی بر گوشی های هوشمند مورد بحث قرار گرفت و یک شاخص ادراک پشه (MPI) به منظور مدیریت عفونت دنگی، که بسیاری از کشورهای آفریقایی و آسیایی را تحت تاثیر قرار می دهد، معرفی شد. با توجه به [ 19 ، 20 ]، مدل توصیف شده در مقاله ما متفاوت است زیرا بر استفاده روزانه از داده های ماهواره ای Sentinel-5P به صورت رایگان متکی است، علاوه بر سایر داده ها، بازیابی شده توسط پایگاه های داده عمومی یا جمع آوری شده توسط زمین. شبکه های حسگر مبتنی بر علاوه بر این، در مدل ما به جای الگوریتمهای مبتنی بر منطق فازی، یک شبکه عصبی حافظه کوتاهمدت (LSTM) را برای پردازش دادهها گنجاندهایم.
به طور خلاصه، سهم اصلی کار ما به شرح زیر است:
-
شرح یک ابزار جدید مبتنی بر الگوریتمهای هوش مصنوعی برای حمایت از موسسات در اجرای اقدامات متقابل هدفمند در برابر شرایط اضطراری، مانند همهگیری فعلی COVID-19.
-
برخی از تحلیلهای اولیه که همبستگی بین NO را نشان میدهد نوع گره ناشناخته: فونتUnknown node type: font، تحرک و داده های COVID-19.
-
تایید در مورد نیاز به استفاده از ابزارهای مبتنی بر هوش مصنوعی برای گرفتن روابط پنهان بین دادهها که از طریق روشهای سنتی قابل تشخیص نیستند.
این دست نوشته به شرح زیر سازماندهی شده است: در بخش 2 ، DSS، که قادر به پیشنهاد مداخلات پیشینی است، به طور خلاصه معرفی شده است، و عوامل اصلی دخیل در طراحی DSS شرح داده شده است. بخش 3 معماری پیشنهادی را با جزئیات بیشتری ارائه می کند. تجزیه و تحلیل اولیه داده های مورد استفاده برای تغذیه مدل در بخش 4 معرفی شده است . بخش 5 مطالعات موردی انتخاب شده را ارائه می کند که در آن همبستگی بین NO وجود دارد نوع گره ناشناخته: فونتUnknown node type: fontو موارد جدید COVID-19 نیز با استفاده از داده های تحرک تجزیه و تحلیل می شود. بخش 6 با تلاش برای برجسته کردن مشارکت های اصلی به بحث در مورد یافته های فوق اختصاص یافته است. نتیجه گیری در بخش 6 همراه با کارهای آینده برجسته شده است.
2. یک سیستم پشتیبانی تصمیم برای مقابله با COVID-19
در این مقاله مفهومی، هدف ما تمرکز بر چالشهای ناشی از همهگیری COVID-19 و ارائه یک رویکرد چند رشتهای و کمی برای پاسخ به بحران بهداشتی و اقتصادی است. مدل پیشنهادی AIRSENSE-TO-ACT نام دارد و شرح پروژه ای است که به فراخوان MIUR (وزارت دانشگاه و تحقیقات ایتالیا) FISR 2020 ارسال شده است که برای جمع آوری راه حل های مرتبط با انتشار صادر شده است. از همه گیر COVID-19، می تواند اثرات آن را مهار کند و راهی جدید برای مدیریت سازماندهی مجدد فعالیت ها و فرآیندها ارائه دهد.
این مدل مبتنی بر ادغام دادههای ناهمگن است که از حسگرهای مختلف به دست میآید: ماهوارههای روی برد و/یا روی سکوهای زمینی، هم متحرک و هم ثابت، به اضافه سایر دادههای عمومی استخراجشده از پایگاههای داده [ 16 ، 21 ، 22 ، 23 ] ، همه به طور مشترک از طریق استفاده از الگوریتم های یادگیری ماشینی (ML) [ 24 ، 25 ، 26 ، 27 ، 28 ] و استفاده و مقایسه کلان و میکروسیستم های تحلیل پردازش شده اند.
در مورد الگوریتمهای ML، کارهای قبلی اهمیت آنها را برای کاربردهای مرتبط با COVID-19 برجسته کردهاند. به طور خاص، 25 ، 26 ] از ترکیبی از الگوریتمهای مبتنی بر ML برای بهبود تشخیص COVID-19 و کمک به پزشکان برای شناسایی حضور آن در تصاویر موجود استفاده کردند، و [ 27 ]] یک مدل پیشبینی از انتشار COVID-19 بر اساس شبکههای LSTM ارائه کرد. از شبکه های LSTM برای پیش بینی، بر اساس اعداد گذشته بیماری های عفونی استفاده می کند و نرخ انتقال بین کانادا و ایتالیا و کشورهای ایالات متحده را مقایسه می کند. این تحقیق نشاندهنده این است که چگونه یک شبکه LSTM میتواند در یادگیری از گذشته کار کند تا بعداً خروجی مورد نظر را تولید کند، و از تصمیم برای انتخاب یک شبکه LSTM برای ابزار پیشنهادی در دستنوشته ما پشتیبانی میکند.
در مورد دادهها، لازم است تاکید شود که میتوان آنها را واقعاً از پایگاههای اطلاعاتی عمومی (یعنی اطلاعات اپیدمیولوژیک، تعداد مبتلایان، اطلاعات حرکتی، دادههای ماهوارهای و غیره) استخراج کرد که اخیراً در نتیجه گسترش بیشتری یافته است. آگاهی عمومی به دلیل شرایط اضطراری COVID-19، اما برای بهبود مدل و تجزیه و تحلیل هایی که باید اجرا شود، در کار ما امکان انجام کمپین های جمع آوری داده ها از طریق حسگرهای شبکه مبتنی بر زمین، به عنوان مثال، برای اعتبار سنجی توسعه یافته پیش بینی شده است. مدل، به ویژه، در مناطق ایتالیایی که در آن وضعیت اضطراری مسائل مهم تری را نشان داده است، مانند دره پو، و به طور خاص در منطقه لومباردی.اقدامات محلی و وقتشناسی با وضوح مکانی و زمانی بهتر، اثربخشی مبارزه با گسترش سرایت را افزایش میدهد و به ما امکان میدهد تا تجزیه و تحلیل را از مناطق ماکرو تحت پوشش ماهوارهها به مناطق کوچکی که از طریق شبکههای حسگر محلی (موبایل یا ثابت) نظارت میشوند، متمرکز کنیم. به منظور افزایش “دانه بودن” داده ها و کاهش زمان واکنش تصمیمات اتخاذ شده.
لازم به تاکید است که یک جنبه حیاتی مربوط به ایجاد مجموعه داده هایی است که شبکه مصنوعی زیربنای DSS باید با آنها آموزش داده شود، زیرا بر اساس تجربه قبلی، این فعالیت ممکن است تا 3/4 ماه طول بکشد. این موضوع در قسمت 3.1 به تفصیل در نسخه خطی مورد بحث قرار خواهد گرفت .
این پیشنهاد عمدتاً در حوزه پیشگیری از خطرات، ایجاد راهحلهایی برای مقابله و مهار اثرات COVID-19 و هر بیماری همهگیر آینده است. با این حال، به لطف تطبیق پذیری ابزار پیشنهادی، از آن برای پاسخ به سایر شرایط اضطراری، توسعه راه حل های متناسب و مدیریت سازماندهی فعالیت ها و فرآیندها، مربوط به مرحله غلبه بر پدیده در ایمنی، استفاده فوری می شود. شرایط علاوه بر این، همچنین شایان ذکر است که اگرچه برای مبارزه با همهگیری COVID-19 در ایتالیا توسعه یافته است، این مدل میتواند برای سایر شرایط اضطراری که کیفیت هوا پیامدهای سلامتی دارد، به ویژه در کشورهای دیگر با ویژگیهای اقتصادی و زیرساختی مشابه اعمال شود.
2.1. داده های ورودی و ابزار تحلیلی
با پرداختن به جزئیات، مدل پیشنهادی، همانطور که قبلاً در بالا ذکر شد، با هدف ترکیب دادههای ماهوارهای و دادههای بهدستآمده از طریق سکوهای زمینی، متحرک و ثابت، مرتبط با انواع مختلفی از اطلاعات، مانند غلظت برخی از آلایندهها مانند NOx، PM10 است. و PM2.5; داده های هواشناسی؛ جابجایی توده هوا؛ پارامترهای شیمیایی-فیزیکی مانند دما و رطوبت؛ و سایر دادههای مرجع، مانند تحرک جمعیت، دادههای اپیدمیولوژیک (تعداد مبتلایان)، تعداد مکانهایی که هنوز در مراقبتهای ویژه در دسترس هستند (مقادیر جهانی یا نقاط بستری در هر بیمارستان، توزیع شده در سراسر مناطق، ملی و غیره)، تمرکز ساکنان در هر کیلومتر نوع گره ناشناخته: فونتUnknown node type: font، میزان قفل اجرا شده و غیره. چندین مطالعه قبلاً تأثیرات و همبستگی عوامل ذکر شده بر COVID-19 را تجزیه و تحلیل کرده اند [ 13 ، 29 ، 30 ، 31 ، 32 ، 33 ، 34 ، 35 ]. علاوه بر این، تجربه گذشته در مورد آنچه اتفاق افتاده است نشان داده است که عوامل ذکر شده هر کدام تأثیر متفاوتی بر COVID-19 دارند و تعاملات آنها میتواند به شرایط بدتری منجر شود.
DSS ارائه شده در این دستنوشته نشان دهنده ابزاری است که می تواند به عنوان خروجی سطح ریسک را در سطوح خرد و کلان بر اساس همبستگی بین داده های انتخاب شده تولید کند. انتخاب مبناي مدل پيشنهادي بر اساس الگوريتمهاي هوش مصنوعي، همانطور كه قبلاً اشاره شد، ناشي از حجم عظيمي از دادههايي است كه بايد در نظر گرفته شوند، و مهمتر از همه از نياز به گرفتن همبستگيها، گاهي پنهان، بين اين اطلاعات ناشي ميشود. در واقع، ساختارهای علیت کاملاً متفاوتی از ادبیات زمانی پدیدار میشوند که عوامل مختلف به صورت ترکیبی در نظر گرفته شوند. به عنوان مثال، به نظر می رسد افزایش دما منجر به کاهش انتشار COVID-19 می شود، اما به مقادیر رطوبت نیز بستگی دارد، زیرا مشخص شده است که مقادیر دمای بالا با مقادیر رطوبت بالا مانع از انتشار COVID-19 نمی شود. ، بلکه برعکس آن را تسهیل می کند. به عنوان مثال، در [36 ] شاخصی برای ارزیابی خطر نسبی COVID-19 ناشی از آب و هوا و آلودگی هوا، پارامتر خطر آب و هوای کووید (CRW) معرفی شده است. CRW را می توان برای مقایسه تغییرات نسبی در تعداد تولید مثل برای بیماری به دلیل عوامل آب و هوایی (متوسط و دمای روزانه، شاخص اشعه ماوراء بنفش (UV)، رطوبت، فشار، بارش) و آلاینده های هوا (SO) استفاده کرد. نوع گره ناشناخته: فونتUnknown node type: fontو ازن). در [ 36 ] نویسندگان تاکید کردند که دمای گرمتر و قرار گرفتن در معرض متوسط UV در فضای باز ممکن است کاهش متوسطی در تعداد تولید مثل ایجاد کند. با این حال، قرار گرفتن در معرض اشعه ماوراء بنفش نمی تواند به طور کامل انتقال COVID-19 را مهار کند. اگر از یک سو دمای بالا و تابش خورشیدی قادر به افزایش سرعت غیرفعال شدن باشند، از سوی دیگر رطوبت نسبی بالا ممکن است سرعت انتشار را افزایش دهد [ 36 ، 37 ]. با این حال، در ادبیات انتشار بیماری های تنفسی، فعل و انفعالات بین عناصر متعدد – آلودگی، تراکم جمعیت بالا و ازدحام بیش از حد – مورد تجزیه و تحلیل قرار گرفته است و مطالعات اخیر همبستگی بین غلظت بالای ذرات ریز و انتشار COVID-19 را نشان داده است. 38 ، 39]. با این حال، این موضوع هنوز بسیار مورد بحث است و تحقیقات چند رشته ای بیشتر در حال انجام است.
2.2. عوامل کلیدی در طراحی DSS
هر کشور و دولت آن دارای یک بخش حفاظت مدنی است که در صورت وقوع حوادث خطرناک، موقعیت ها را مدیریت می کند. به عنوان مثال، در ایتالیا، وزارت حفاظت مدنی [ 40 ] مداخلات خاصی را زمانی فعال می کند که چندین خطر مانند لرزه، آتشفشان، سلامت، محیط زیست، آتش سوزی و غیره رخ دهد. در مورد خاص همهگیری COVID-19، مشکل و راهحلهای آن سه عامل اصلی را شامل میشوند:
-
آلودگی و جمعیت : آلودگی، افزایش جمعیت و ناهنجاری در شرایط آب و هوایی می تواند منجر به این بیماری شود.
-
گسترش بیماری ها : شیوع بیماری ها شامل مسائل مربوط به جمعیت و برخی تغییرات ژئوفیزیکی است، اما با تصمیم گیری صحیح می توان از آن جلوگیری کرد.
-
تصمیمات اتخاذ شده : تصمیمات توسط انسان بر اساس تجربه قبلی گرفته می شود، اما برای تصمیم گیری صحیح به اطلاعات صحیح و DSS های قوی نیاز است.
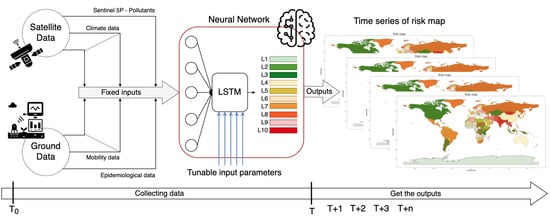
برای حرکت از یک مدل پسینی به یک مدل پیشینی، ابزار پیشنهادی به گونهای طراحی شده است که پارامترهای متعددی را از منابع متعدد در نظر بگیرد تا درجه ریسک را به عنوان خروجی تولید کند. طرح کلی آن در شکل 1 نشان داده شده است، که در آن سهم فعالیت های انسانی و فعالیت های اقتصادی برجسته شده است، اما تعامل با عواملی مانند شرایط آب و هوایی، تراکم آلودگی، داده های تحرک و غیره، منجر به تعداد مبتلایان و سایر اثرات می شود، که برهمکنش متقابل آنها منجر می شود. می توان از طریق پارادایم های مبتنی بر هوش مصنوعی گرفت.
بدیهی است که چنین سیستمی برای مؤثر بودن باید به در دسترس بودن داده ها تقریباً در زمان واقعی یا با زمان بازبینی کم (یعنی Sentinel-5P و سایرین) تکیه کند تا بتواند به تحقق یک سیستم نظارت مستمر کمک کند. برای ایجاد هشدار مناسب برای مدیریت مشترک خطرات چندگانه، مانند خطرات بهداشتی، زیست محیطی و اقتصادی در مورد مورد بحث.
بر اساس رویدادهای اخیر و مطالعات محققانی که روی انتشار COVID-19 کار می کنند، مشخص شد که بین لحظه سرایت و بروز علائم COVID-19 در فرد مبتلا (و نتایج آزمایش مثبت آن) فاصله زمانی وجود دارد. دوره ای که در ایتالیا بین 14 تا 21 روز ارزیابی می شود، اما در کشورهای دیگر می تواند بسیار متفاوت باشد، همانطور که در [ 3 گزارش شده است.] و قبلاً در بخش مقدمه بحث شده است. به همین ترتیب، بسته شدن ترافیک جادهها و محدودیتهای قرنطینه COVID-19 ممکن است در کاهش آلودگی تأثیر داشته باشد، اما این تنها پس از چند روز اتفاق میافتد و زمان سپری شده در مناطق مختلف متفاوت است. وضعیت حتی بدتر است به ویژه در برخی از مناطق ایتالیا، مانند دره پو، که از شرایط آب و هوایی و کوهنگاری رنج میبرد که جابجایی تودههای هوا را بسیار مشکلساز میکند.
با توجه به ملاحظات فوق، بدیهی به نظر می رسد که تعامل تاخیری بین علت و معلول باید در مدل گنجانده شود.
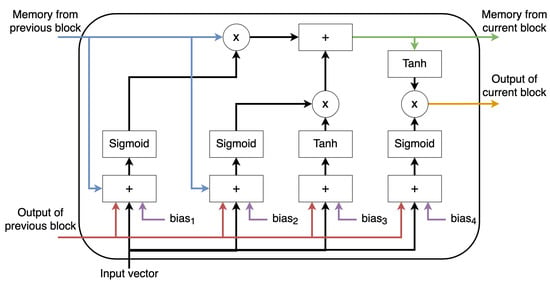
بنابراین، یک معماری شبکه خاص به نام LSTM برای ایجاد DSS انتخاب شد تا سری داده های تاریخی را پردازش کند و نه تنها سطح ریسک را در زمان عمومی T، بلکه در سایر لحظات بعدی نیز پیش بینی کند، به طوری که شبکه پس از آموزش دیده، می تواند به عنوان یک تابع انتقال برای محاسبه خروجی (سطح ریسک مورد انتظار) با استفاده از داده های ورودی جدید استفاده شود. معماری پیشنهادی و شبکه LSTM در شکل 2 و شکل 3 نشان داده شده است و در بخش بعدی توضیح داده شده است.
3. مواد و روشها
پارادایم پیشنهادی، همانطور که در شکل 2 نشان داده شده است، مبتنی بر یک شبکه LSTM است که برای حل مشکلات شیب های ناپدید شدن و انفجار، که شبکه های عصبی مکرر (RNNs) از آن رنج می برند، اختراع شده است [ 41 ]، و ممکن است به مدل اجازه دهد. برای یادگیری ویژگی های زمانی از داده های آموزشی. انتخاب این نوع شبکه همچنین با تحقیقات انجام شده در مورد گسترش بیماری ها انجام شد، همانطور که در چندین کار مرتبط توضیح داده شد [ 24 ، 27 ، 42 ، 43 ].
معماری کلی نشان میدهد که چگونه چندین ورودی (و ویژگیهای زمانی آنها نیز) در نظر گرفته میشوند تا ابتدا روابط بین دادهها را بیاموزیم و بعداً سطح ریسک را به عنوان خروجی تولید کنیم.
بلوک ساختمان اولیه شبکه LSTM در شکل 3 نشان داده شده است ، جایی که می توان دید که ورودی عمومی را در مرحله زمانی فعلی، خروجی واحد قبلی و حافظه واحد قبلی را دریافت می کند. هر بلوک ساختمانی شبکه LSTM با دانستن ورودی فعلی و خروجی و حافظه قبلی تصمیم می گیرد و یک خروجی جدید تولید می کند و حافظه خود را به روز می کند.
عملکرد مدل پیشنهادی به دو مرحله اصلی تقسیم میشود: آموزش و پیشبینی. در طول مرحله آموزش، تحت یک رویکرد یادگیری نظارت شده، مدل با داده های خروجی شناخته شده تغذیه می شود و مقادیر پارامترها همانطور که در بالا مشخص شده است. مجموعه آموزشی داده ها وضعیت واقعی را در این ماه ها، در طول همه گیری COVID-19، به تصویر می کشد.
تعریف کردن ایکس∈آرn�∈��، با m بردار مقادیر پارامتر و Y∈آرپ�∈��، با q بردار پیامدها. سپس مدل آموزش داده می شود تا همبستگی بین X و Y را پیدا کند، همانطور که در معادله ( 1 ) نشان داده شده است.
برای مدل مورد تجزیه و تحلیل، فرض می کنیم که ورودی یک ماتریس است ایکس∈آرn ، m�∈��,�، که در آن n تعداد منابع داده های مختلف و m نشان دهنده اندازه اکتساب ها در بعد زمان است. همین ملاحظات را می توان برای خروجی نیز در نظر گرفت. در واقع، Y∈آرp , q�∈��,�که در آن p ابعاد خروجی را در یک لحظه ثابت و q نشان دهنده بعد زمانی خروجی است. به عبارت دیگر، ورودی و خروجی هر دو ماتریس هستند. ورودی ها شامل داده های حس شده برای یک بازه زمانی ثابت و خروجی شامل پیش بینی مدل برای یک بازه زمانی ثابت خواهد بود.
فرآیند آموزش را می توان با تکنیک های معروف انتشار پشت و شیب نزول انجام داد [ 44 ، 45 ، 46 ، 47 ، 48 ، 49 ]. در چند کلمه، برای هر ورودی آموزشی، مدل با استفاده از خطا و مشتق آن به روز می شود. خطا از طریق یک تابع ضرر تعریف شده قبلی محاسبه می شود. مدل به منظور به حداقل رساندن این خطا آموزش داده خواهد شد. از این عبارت آخر، بهتر می توان فهمید که چرا در مرحله آموزش هم ورودی و هم خروجی مورد نیاز است. به عنوان مثال، با توجه به یک مدل F و مجموعه ای از داده ها (X, Y) با ایکس∈آرn ، m�∈��,�و Y∈آرp , q�∈��,�، در طول آموزش، برای سادگی، نمونه ای از مجموعه داده انتخاب می شود. تعریف کردن ایکسمن��و Yمن��به عنوان نمونه؛ مرحله آموزش را می توان تقریباً با معادلات نشان داد:
با استفاده از خطا و مشتق خطا که به ترتیب در معادلات ( 3 ) و ( 4 ) داده شده است، وزن مدل تا رسیدن به حداقل به روز می شود. پس از مرحله آموزش، مدل باید قادر به تعمیم باشد و با توجه به ورودی های جدید می تواند خروجی های جدید را با استفاده از حالت داخلی F تولید کند.
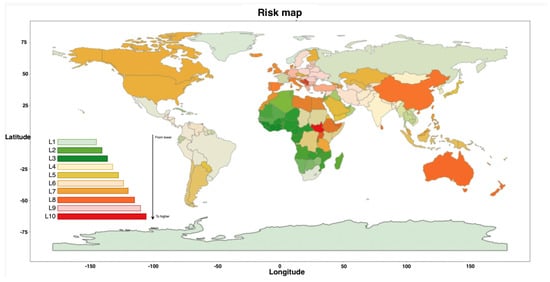
خروجی نهایی مدل یک سری زمانی از نقشه های ریسک خواهد بود، همانطور که در شکل 2 نشان داده شده است ، با وضوحی که می تواند از وضوح پایین به عنوان خطر برای یک کشور تا وضوح بالا در نظر گرفته شده به عنوان خطر برای یک شهر، یا کوچکتر متفاوت باشد. حوزه. نمونه ای از نقشه تک ریسک با وضوح پایین در شکل 4 پیشنهاد شده است .
3.1. مجموعه داده ها و پیش پردازش داده ها
مدیریت مجموعه داده را می توان به سه فرآیند اصلی تقسیم کرد:
این سه مرحله در شکل 5 نشان داده شده است، که در آن برخی از داده ها، که برای آموزش مدل استفاده خواهد شد، ارائه شده است.
اولین مرحله از زنجیره پردازش شامل تحقیق مجموعه داده های مناسب برای بازیابی داده ها است. نمونه های ارائه شده در شکل 5 مربوط به مجموعه داده های تحرک (ساخته شده توسط Google) [ 21 ]، مجموعه داده Covid-19 (ساخته شده توسط موسسه جانز هاپکینز) [ 22 ]) و مجموعه داده های آب و هوا و کیفیت هوا (ذخیره شده در Google) است. کاتالوگ های موتور زمین) [ 16 ، 23 ]. مرحله دوم عمدتاً به استخراج پارامترها از مجموعه داده ها اختصاص دارد. به عنوان مثال، همانطور که در شکل 5 مشاهده می کنیددادههای آب و هوا و آلاینده به ترتیب از مجموعه دادههای موتور Google Earth Era5 و Sentinel-5P استخراج شدند. موارد جدید روزانه Covid-19 از داشبورد جانز هاپکینز استخراج شد. و متغیرهای تحرک از مجموعه داده Google Mobility Reports استخراج شدند. مرحله سوم مربوط به پیش پردازش داده ها است. تمامی دادههای استخراجشده قبلاً بهمنظور داشتن متغیرهای قابل مقایسه، به همین روش پردازش شدند. ابتدا داده ها برای ناحیه مورد نظر (AOI) فیلتر شدند و سپس تنها داده های مربوط به بازه زمانی مورد علاقه ذخیره شدند. سپس، برخی از آمارها از داده ها استخراج شد، بیشتر به این دلیل که داده ها به صورت مکانی توزیع شده بودند (به عنوان مثال، داده های Sentinel-5P). برای این نوع داده ها، میانگین مکانی، حداکثر، حداقل، انحراف معیار و مقادیر میانه محاسبه شد. انواع دیگر داده ها (به عنوان مثال، دادههای آب و هوا از Era5) میتواند شامل چندین خرید در طول یک روز باشد. در چنین مواردی میانگین زمانی محاسبه شد. در این مورد، هر متغیر بردار مقادیر روزانه است، اما به طور کلی، همه متغیرها به منظور برازش کمترین وضوح زمانی از آنهایی که در مجموعه دادههای انتخاب شده هستند، پردازش میشوند. آخرین مرحله پیش پردازش، میانگین گیری زمانی است. از آنجایی که ممکن است در برخی از روزها داده ای وجود نداشته باشد، می توان با استفاده از میانگین زمانی (در مدل پیشنهادی ما 5 روز را انتخاب کردیم) بر این مشکل غلبه کرد و علاوه بر این مقادیر غیر عددی (NaN) حذف شدند. همه متغیرها به منظور تناسب با کمترین وضوح زمانی از متغیرهای موجود در مجموعه دادههای انتخابی پردازش میشوند. آخرین مرحله پیش پردازش، میانگین گیری زمانی است. از آنجایی که ممکن است در برخی از روزها داده ای وجود نداشته باشد، می توان با استفاده از میانگین زمانی (در مدل پیشنهادی ما 5 روز را انتخاب کردیم) بر این مشکل غلبه کرد و علاوه بر این مقادیر غیر عددی (NaN) حذف شدند. همه متغیرها به منظور تناسب با کمترین وضوح زمانی از متغیرهای موجود در مجموعه دادههای انتخابی پردازش میشوند. آخرین مرحله پیش پردازش، میانگین گیری زمانی است. از آنجایی که ممکن است در برخی از روزها داده ای وجود نداشته باشد، می توان با استفاده از میانگین زمانی (در مدل پیشنهادی ما 5 روز را انتخاب کردیم) بر این مشکل غلبه کرد و علاوه بر این مقادیر غیر عددی (NaN) حذف شدند.
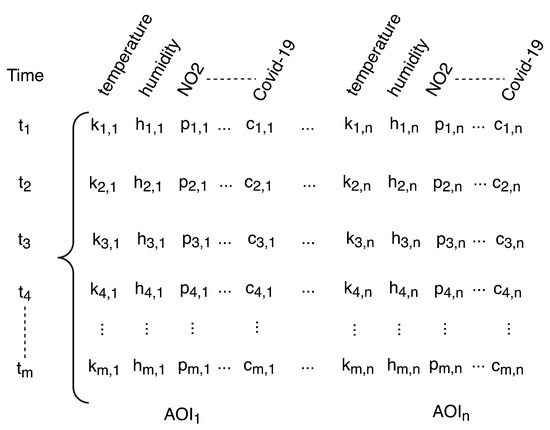
پس از این مراحل پیش پردازش، داده ها ساختار یافته و در فایل های CSV ذخیره می شوند. ساختار مجموعه داده را می توان در شکل 6 مشاهده کرد، که نشان می دهد چگونه مجموعه داده اساسا یک ماتریس دو بعدی است، جایی که ردیف ها زمان و ستون ها پارامترهای ورودی را تعیین می کنند. مجموعه پارامترها برای هر AOI تکرار می شود.
3.2. آموزش و پیش بینی
اولین نمونه اولیه از مدل در شکل 7 ارائه شده است . این مدل از 3 لایه LSTM، با چندین بلوک LSTM، همانطور که قبلا در شکل 3 ارائه شده است، تشکیل شده است.; یک شبکه متراکم یا کاملا متصل؛ و یک لایه پیش بینی لایه پیش بینی دارای 10 گره خروجی است، یکی برای هر سطح ریسک. این مدل با استفاده از مجموعه داده هایی که قبلا توضیح داده شد آموزش داده شد. ورودی ها که به صورت سری زمانی سازماندهی شده اند به لایه های LSTM فرستاده می شوند که اطلاعات زمانی را از داده ها استخراج می کنند. سپس با استفاده از یک لایه کاملاً متصل، این ویژگیها همبسته میشوند و در پایان لایه پیشبینی سطح ریسک را بر اساس نمایش داخلی ورودیها به عنوان خروجی میدهد. برای فرآیند آموزش، پیشبینی مدل با حقیقت اصلی، سطح واقعی خطر، که توسط یک اپراتور انسانی با استفاده از تمام اطلاعات (به عنوان مثال، درجه قرنطینه، تعداد مرگها و غیره) در مورد همهگیری تعریف شده است، مقایسه شد.
مهم است که برجسته شود که پس از فرآیند آموزش، این مدل می تواند برای پیش بینی سطح خطر منطقه ای که هرگز برای مرحله آموزش استفاده نشده است، استفاده شود. این یکی از مهمترین جنبه ها هنگام استفاده از هوش مصنوعی است. با توجه به ورودی های جدید از زمان تی1�1و زمان تیمتر��در یک منطقه جدید، مدل قادر است سطح ریسک را در بازه زمانی آینده پیش بینی کند.
مزایای اصلی مدل و روش پیشنهادی عبارتند از:
-
شبکه های LSTM، مانند RNN ها، می توانند ویژگی های زمانی را یاد بگیرند.
-
پس از مراحل تمرین، که ممکن است زمان زیادی طول بکشد (مثلاً چند روز)، مرحله پیشبینی سریعتر است (کسری از ثانیه).
-
LSTM بر خطاهای RNN غلبه می کند.
-
این مدل بسیار مقیاس پذیر است و می تواند در سناریوهای مختلف استفاده شود.
همچنین استفاده از هوش مصنوعی و LSTM دارای معایبی است:
-
LSTM محدودیتهایی در ثبت روابط دادهای بین سریهای مختلف داده در زمانی که تاخیر بسیار زیاد است، دارد، بنابراین ممکن است لازم باشد لایههای توجه معرفی شوند.
-
مدل هوش مصنوعی خروجی هایی را تولید می کند که قابل توضیح نیست – به همین دلیل، به اصطلاح “مدل های هوش مصنوعی قابل توضیح” در دست توسعه هستند.
-
اگر در زمینه بسیار متفاوتی نسبت به شرایطی که در آن آموزش داده شده است اعمال شود، ممکن است یک آموزش مجدد جزئی شبکه ضروری باشد.
از آنجایی که هر ملت، منطقه یا شهر با هر کشور دیگری متفاوت است و شرایط مرزی آن قطعاً متفاوت خواهد بود، ممکن است نیاز به آموزش مجدد شبکه، حتی اگر جزئی باشد، باشد. در واقع، در این مورد، امکان استفاده مجدد از یک شبکه آموزش دیده قبلی برای تخصصی کردن آن برای یک رژیم خاص، از طریق تکنیک معروف یادگیری انتقال وجود دارد [ 50 ، 51 ]. این تکنیک به فرد اجازه میدهد تا از وزنهای شبکهای که قبلاً آموزش داده شده استفاده کند، برخی از لایهها را قفل کند و لایههای دیگر را اصلاح یا اضافه کند تا شبکه را با سناریوی خاصی که در دست دارد تطبیق دهد. این بدان معنی است که روند آموزش برای یک سناریوی جدید بسیار سریعتر از کل آموزش است.
حتی اگر برای تجزیه و تحلیل تصویر اعمال شود، چندین کار در زمینه یادگیری انتقال برای تشخیص برخی ویژگیها در بیماران COVID-19 وجود دارد [ 28 ، 52 ، 53 ]، که باعث شد فکر کنیم این تکنیک را به طور مثبت در مدل خود اعمال کنیم.
4. تجزیه و تحلیل مقدماتی
همانطور که قبلاً بحث شد، پیشنهاد ما در پاسخ به یک فراخوان MIUR در مورد COVID-19 متولد شد و هدف آن ایجاد یک سیستم تجزیه و تحلیل چند مقیاسی بر اساس الگوریتمهای هوش مصنوعی، برای ارائه یک ابزار پیشینی برای تصمیمگیرندگان است. اطلاعات مورد نیاز مبتنی بر ترکیب دادههای چند منبعی با اندازهگیریهای بهدستآمده از حسگرهای شبکه ثابت و متحرک، از ماهوارهها و از طریق بررسیهای مجاورتی، در صورت لزوم است. چنین پیشنهادی مستلزم ادغام مهارتهای چند رشتهای، از توسعه شبکههای حسگر و پردازش دادههای ماهوارهای تا آشکارسازهای ذرات است. تجزیه و تحلیل بیوشیمیایی ذرات معلق؛ استراتژی های نوآورانه در زمینه محیط زیست؛ و فنآوریهای محاسباتی پیچیده برای درمان، تجزیه و تحلیل و تفسیر دادهها با استفاده از فناوریهای کلان داده.
ما می خواهیم مکمل بودن گروه کاری خود متشکل از سه تیم تحقیقاتی را برجسته کنیم که نظارت ماهواره ای و توسعه مدل های همجوشی داده ها و نظارت بر جمعیت (دانشگاه Sannio)، کوچک سازی و شبکه سازی حسگرهای با وضوح بالا در هواپیماهای بدون سرنشین را پوشش می دهد. Politecnico of Milano) و مسائل بیوشیمیایی، بهداشتی و زیست محیطی (دانشگاه بولونیا). این سطح بالای بین رشته ای به موفقیت پروژه کمک می کند. ایده پشت این کار ارائه یک “مقاله مفهومی” با هدف یافتن افراد علاقه مند برای همکاری در تحقیق و توسعه بیشتر پروژه، در صورت تامین مالی بود. بسیاری از کارها هنوز باید انجام شود، حداقل در مورد تحقق شبکه عصبی و ایجاد تمام مجموعه داده های لازم. با این حال، قبلاً پیشرفت هایی حاصل شده است،
4.1. اندازه گیری آلاینده ها، شرایط هوا و داده های همه گیر
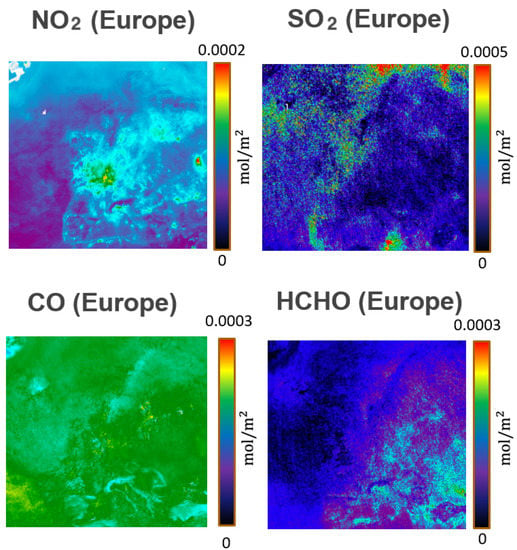
از آنجایی که هسته اصلی این ایده شامل استفاده از اندازهگیری آلایندهها و دادههای آلودگی است، فراتر از دخالت اطلاعات دیگر، همانطور که قبلاً مشخص شد، نویسندگان ابتدا فهرستی از آلایندههای احتمالی مانند دی اکسید نیتروژن (NO) را انتخاب کردند. 22دی اکسید گوگرد (SO 22فرمالدئید (HCHO) و ازن (O3)، که میتوانند با استفاده از Sentinel-5P بازیابی شوند، و سایر دادهها (به عنوان مثال، PM2.5، PM10، و غیره) که میتوانند با استفاده از منابع دیگر بازیابی شوند. سطوح مختلف چند مقیاسی
هدف از اندازه گیری آلاینده ها دو چیز است. همانطور که در ادامه صحبت خواهد شد، برخی از آلایندهها طرفدار انتقال بیماریهای تنفسی هستند و بنابراین با اندازهگیری آنها و تغذیه مدل با مقادیر آنها، سهمی در سطح خطر نهایی به دست میآید. عملاً، ما مجموعهای از پارامترها را برای انتخاب آنهایی که در آموزش شبکه عصبی کارآمدتر بودند، تجزیه و تحلیل کردیم، زیرا آنها قبلاً روابط متقابل واضحی را ارائه میدهند.
علاوه بر این، برخی از آلاینده ها اطلاعاتی در مورد میزان قرنطینه به ما می دهند. مجدداً، این مدل میتواند با استفاده از انواع خاصی از آلایندهها، خوبی قفل را ردیابی کند و روابط متقابل بین دادهها را به تصویر بکشد. آنچه مهم است درک این نکته است که تجزیه و تحلیل می خواهد دو سطح دید متفاوت را برجسته کند: دید ماکرو سطح بالا (به عنوان مثال، از طریق استفاده از ماهواره ها، به عنوان مثال، یا داده ها در سطح وسیع جغرافیایی، ملی، و غیره)، و دید سطح پایین میکرو که در آن درک محلی از پدیده انجام می شود. ابزار پیشنهادی مبتنی بر هوش مصنوعی و شبکه عصبی خاص، پس از آموزش میتواند در هر سطح مورد استفاده قرار گیرد و بینشهای مهمی را ارائه دهد. در این رابطه تحلیل جالبی در [ 54 ] انجام شده است]، که به این موضوع می پردازد که چگونه الگوریتم های ML می توانند در توصیف ذرات معلق در هوا برای کاربردهای مرتبط با سنجش از دور کمک کنند.
در مورد ما، ما شروع به تجزیه و تحلیل روند برخی از آلاینده ها در مناطق خاص مورد نظر کردیم. نمونه هایی از چنین داده هایی که هم از طریق سکوهای زمینی و هم از طریق سکوهای ماهواره ای بازیابی شده اند، به ترتیب در شکل 8 و شکل 9 نشان داده شده اند. شکل 8 یک نقشه کیفیت هوا در سطح اروپا را نشان می دهد که از طریق وب سایت آژانس محیط زیست اروپا [ 55 ] بازیابی شده است، و شکل 9 سطوح برخی از آلاینده های به دست آمده از پردازش داده های ماهواره Sentinel-5P را نشان می دهد.
در مورد کووید-19، ما از داشبورد عمومی جانز هاپکینز، نشان داده شده در شکل 10 استفاده کردیم ، که به فرد امکان میدهد دادههای سرایت سازماندهیشده در هر ایالت، منطقه و شهر را دانلود کند و حاوی اطلاعات بسیار بیشتری است، مانند موارد جدید روزانه، مرگ و میر جدید روزانه و غیره، در تمام جهان [ 22 ].
4.2. تأثیر کیفیت هوا بر انتشار COVID-19
درباره ارتباط بین آلودگی و انتشار COVID-19، چندین مطالعه اپیدمیولوژیک وجود دارد که با اجزای مختلف جو و ارتباط آنها با گسترش این بیماری سروکار دارد. مهمترین شاخصهای آلودگی هوا که همبستگی مثبت معنیداری را نشان دادند، ذرات ریز، اکسیدهای نیتروژن، مونوکسید کربن، ازن و ترکیبات آلی فرار هستند [ 32 ، 56 ، 57 ].
یک مطالعه دقیق، با در نظر گرفتن نقاط قوت و محدودیت های تجزیه و تحلیل آماری مشابه، با در نظر گرفتن بسیاری از پارامترهای مخدوش کننده، به ویژه ارتباط قوی بین قرار گرفتن در معرض PM2.5 و میزان مرگ و میر را نشان داد [ 58 ].
علاوه بر این، سایر شرایط محیطی و هواشناسی نیز در نظر گرفته شده است. اجماع گسترده در مورد همبستگی مثبت بین باد و عفونت COVID-19، و یک همبستگی منفی بین تابش خورشید و بیماری وجود دارد، و نقش رطوبت، دما و باران هنوز مورد بحث است [ 57 ].
در حال حاضر می توان نتیجه گرفت که بسیاری از این فرضیه ها می توانند معتبر باشند و بنابراین عوامل مختلفی می توانند عامل گسترش عفونت باشند. در هر صورت، تمرکز بر NOx و وجود ذرات ریز در هوا را بسیار مهم دانستیم. به همین دلیل، برخی کارها برای تجزیه و تحلیل ارتباط احتمالی بین ویروس و غلظت NOx و ذرات انجام شده است.
4.3. ذرات معلق (PM) – همبستگی ویروس
بیش از 240 دانشمند اخیراً تفسیری را امضا کردهاند که در آن جامعه پزشکی را مورد توجه قرار داده و نیاز به مقابله با انتقال SARS-CoV-2 از طریق هوا را برجسته کردهاند [ 59 ]. بسیاری از تحقیقات ثابت کرده اند که “فاصله ایمن” 6 فوتی که قبلاً نشان داده شده بود نمی تواند کافی در نظر گرفته شود، زیرا راه های مختلف انتشار می تواند در محیط های داخلی و خارجی رخ دهد [ 60 ]. از آغاز همهگیری کووید-19، مطالعات متعددی برای بررسی دلایل توزیع نابرابر عفونتها و مرگ و میرها در کشورهای مختلف انجام شده است و همبستگیهای مثبتی با آلودگی هوا، بهویژه با ذرات ریز معلق، پیدا شده است. 61 ، 62 ، 63 ،64 ، 65 ]. برخی از محققان این نتایج را با در نظر گرفتن اثرات حاد و مزمن بر روی سیستم تنفسی توضیح میدهند که میتواند آن را نسبت به عفونت پاتوژن حساستر کند، در حالی که برخی دیگر پیشنهاد میکنند که عوامل مختلف زیستی و غیرزیستی را میتوان با چسبیدن به ذرات ریز از قبل معلق استنشاق کرد [ 66 ].
حتی اگر روشهای انتقال COVID-19 هنوز مورد بحث است [ 67 ، 68 ، 69 ]، امکان در نظر گرفتن حضور RNA SARS-CoV-2 روی PM10 در محیطهای بیرونی نیز پیشنهاد شده است [ 70 ]. بسیاری از مطالعات قبلی قبلاً نشان دادهاند که انواع مختلفی از میکروارگانیسمها روی ذرات معلق وجود دارند [ 71 ]، و اخیراً هشدارهای اولیه در مورد احتمال اینکه آنها میتوانند نقش ناقلی برای کروناویروس ایفا کنند [ 72 ] داده شده است، که توسط یافتههای SARS پشتیبانی میشود. -CoV-2 یا اسید نوکلئیک ویروسی بر روی نمونه های ذرات در محیط های بیرونی [ 73 ، 74 ].
بر اساس تحقیقات ذکر شده، هر دو PM10 و PM2.5 می توانند برای بهبود عفونت ویروسی مرتبط باشند. با این حال، فرض شده است که اثر در همه شرایط خطی نیست، اما غلظت بالای طولانی مدت ذرات ریز (به عنوان مثال، بیش از حد روزانه 50 میکروگرم بر متر) 33PM10) می تواند یک اثر “تقویت کننده” در گسترش ویروس ایجاد کند [ 62 ].
5. مطالعات موردی: همبستگی بین NO 22و داده های COVID-19 در دو منطقه مورد علاقه
همانطور که قبلاً اشاره شد، تغییر سطح تجزیه و تحلیل، از سطح کلان به سطح خرد، برای درک بهتر و نظارت بر تکامل پدیده و به دست آوردن مقادیر ورودی مناسب برای DSS بسیار مهم است به گونه ای که انتشار اولیه ویروس را می توان با سطوح هدفمند قرنطینه یا اتخاذ تدابیر خاص دیگر شناسایی و متوقف کرد.
5.1. تجزیه و تحلیل کلان بر اساس داده های ماهواره ای
در بخش اول تحلیل ما، مطالعه ای برای ارزیابی همبستگی بین یکی از آلاینده ها، NO انجام شد. 22و COVID-19. این تحلیل اولیه نباید تعجب آور باشد. در واقع، حتی اگر درست باشد که شبکه عصبی وظیفه پیدا کردن روابط متقابل بین داده ها را دارد، پیش انتخابی از این داده ها برای بهبود مرحله آموزش شبکه عصبی کار می کند.
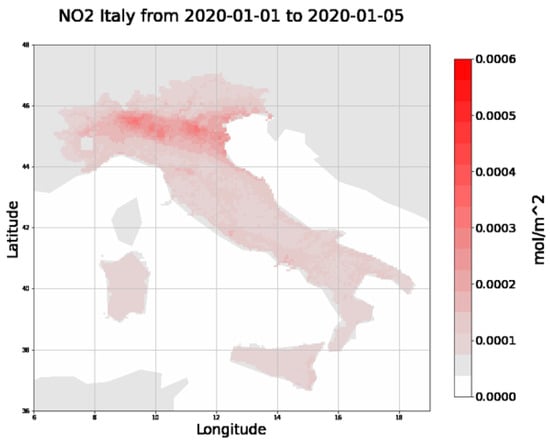
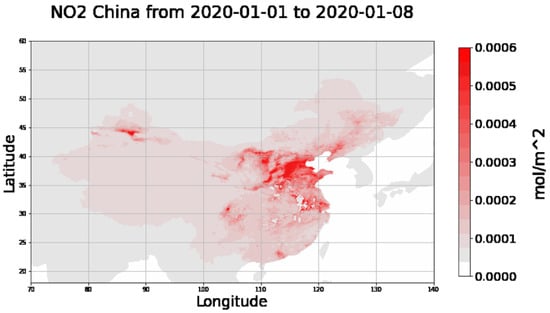
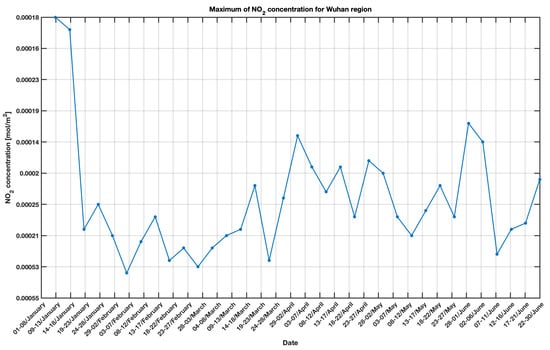
داده های ماهواره Sentinel-5P مربوط به NO 22غلظت ها با استفاده از اسکریپت های پایتون، از طریق موتور Google Earth (GEE) به دست آمده، پردازش، میانگین گیری و ترسیم شده اند. در شکل 11 و شکل 12 ، غلظت NO 22به ترتیب برای ایتالیا و چین در دو دوره مشابه نشان داده شده است. می توان مشاهده کرد که در بدترین دوره همه گیری برای هر دو کشور، بیشترین غلظت NO وجود دارد 22در مناطقی که COVID-19 بالاترین ارزش خود را داشت (منطقه لمباردی و ووهان) قرار گرفت.
به همین دلیل، به جای تجزیه و تحلیل دادههای مربوط به کل کشورها، ما تمرکز خود را بر مناطقی در ایتالیا و چین انتخاب کردهایم که در آنها شیوع ویروس در ماههای اول سال بسیار سریع و نمادین بوده است.
از آنجایی که Sentinel-5P مناطق وسیعی را پوشش می دهد، یک زیر مجموعه برای به دست آوردن NO ایجاد شده است 22غلظت های مربوط به مناطق انتخاب شده برخی از آمارهای زیر مجموعه شامل حداکثر، حداقل و انحراف معیار محاسبه شده است. حداکثر مقادیر آلاینده برای بحث بیشتر در شکل 13 و شکل 14 ترسیم شده است . در دو شکل، برای مدیریت عدم وجود برخی مقادیر در داده های Sentinel-5P، میانگین غلظت NO 22بیش از پنج روز محاسبه شده است که از اول ژانویه شروع شده و تا 30 ژوئن 2020 ادامه دارد.
همبستگی بین قله های میانگین NO 22تمرکز و تعداد افراد جدیدی که تست COVID-19 مثبت شده اند مورد تجزیه و تحلیل قرار گرفته است. برای تطبیق دادههای ماهوارهای و اپیدمیولوژیک، لازم بود برای تعداد عفونتهای جدید نیز میانگین 5 روز در نظر گرفته شود. چندین نمودار پراکندگی با استفاده از این داده ها ساخته شده است که تعداد افراد آلوده جدید را روی محور آبسیسا و NO قرار می دهد. 22تمرکز روی دستورات
علاوه بر این، برای در نظر گرفتن تاخیر بین لحظه ای که عفونت رخ می دهد و شواهد واقعی سرایت منتقل شده، یک تحلیل تاخیری انجام شده است: داده های COVID-19 در زمان به جلو منتقل شدند و در نتیجه نمودارهای پراکنده با تاخیرهای مختلف ایجاد کردند.
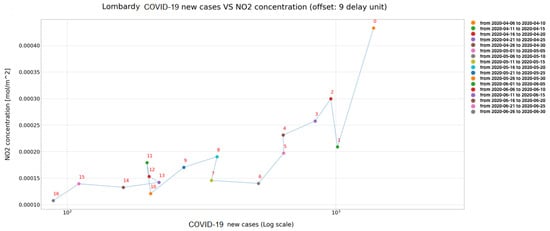
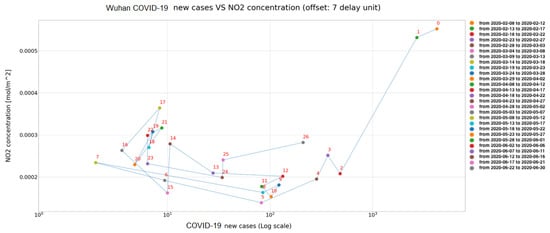
در شکل 15 و شکل 16 ، نمودارهای پراکنده هر کدام دنباله ای از داده ها را نشان می دهند، جایی که واحد تاخیر (مرتبط با 5 روز) با عدد نزدیک به نقطه تعریف می شود. در شکل اول یک افست نه واحد تاخیر بین دو سری داده اعمال شده است، در حالی که یک افست هفت واحد تاخیر در مورد دوم اعمال شده است. این نمایش به درک گرافیکی همبستگی بین NO کمک می کند 22و COVID-19 و همچنین شناسایی موارد نمادین مانند ووهان. در واقع، در این مورد اخیر، روند، در یک لحظه خاص، شروع به نوسان می کند.
این پدیده را می توان با تجزیه و تحلیل شکل 17 و شکل 18 بهتر توضیح داد ، جایی که مشهود است در حالی که برای منطقه لومباردی هر دو NO 22و COVID-19 در طول زمان روند کاهشی دارند (از تعداد زیاد آلوده و غلظت بالای آلاینده به تعداد کم آلوده و غلظت کم آلاینده)، برای منطقه ووهان وضعیت کاملاً متفاوت و غیرمنتظره است، زیرا پس از یک دوره مشخص، NO 22در حالی که عفونت های جدید پایدار و نزدیک به مقدار بسیار پایین هستند، دوباره شروع به افزایش می کند.
برای این نتیجه اخیر می توان چندین تفسیر ارائه کرد: (1) در ووهان اقدامات متقابل اتخاذ شده قادر به مهار ویروس بودند و برای رهایی از قرنطینه کافی بودند. (2) مردم میدانستند چگونه قوانین را رعایت کنند (مثلاً ماسک بپوشند) تا از افزایش تعداد عفونت جلوگیری کنند. (3) داده های COVID-19 ارسال شده در دوره دوم صحیح نبود. در واقع، ما نمی توانیم تصمیم بگیریم که کدام فرضیه درست است. به نظر ما دو مورد اول محتمل ترین هستند.
مقادیر افست استفاده شده برای طراحی نمودارهای پراکندگی شکل 15 و شکل 16 ، از طریق تجزیه و تحلیل همبستگی بین موارد جدید COVID-19 و NO تصمیم گیری شد. 22تمرکز. این همبستگی با استفاده از ضریب همبستگی پیرسون (PCC) و همانطور که قبلا مشخص شد، با استفاده از تحلیل تاخیری محاسبه شد.
از جدول 1 مشاهده می شود که حداکثر مقدار همبستگی (مثبت) با تاخیر 9 واحدی در مورد منطقه لمباردی و با تاخیر هفت واحد تاخیر در مورد ووهان ثبت شده است.
ملاحظات بیشتری را می توان در نظر گرفت. اول از همه، اگر واحدهای تاخیر به تعداد روز تبدیل شوند، حداکثر مقدار همبستگی بین NO 22و COVID-19 پس از 45 روز برای منطقه لمباردی و پس از 35 روز برای منطقه ووهان یافت می شود. به نوعی، به نظر می رسد که محدودیت های اتخاذ شده در ووهان نتایج بهتری از نظر کاهش COVID-19 نسبت به ایتالیا داشته است. علاوه بر این، واضح است که اقدامات پسینی قرنطینه نمیتواند ابزار مداخلهای کارآمد باشد، زیرا قبل از اینکه اثرات میزان آلودگی برای ناظران قابل توجه باشد، پس از گذشت بیش از یک ماه، یک ماه و نیم باید بگذرد. این بررسی اخیر در متقاعد کردن ما به این موضوع کار می کند که اقدامات پسینی دیرهنگام هستند و نمی توان آنها را کارآمد دانست.
5.2. تجزیه و تحلیل میکرو بر اساس حسگرهای شبکه ای
با توجه به تمام ملاحظات فوق و با در نظر گرفتن این که همه آلاینده ها را نمی توان از طریق تجزیه و تحلیل ماهواره ای بازیابی کرد، و اینکه سطوح مختلف تحقیقات ممکن است برای هدف قرار دادن این اقدام در سطح محلی ضروری باشد، بحث در مورد ویژگی هایی مهم است که شبکههای حسگر باید برای تضمین جمعآوری مقادیر آلاینده به گونهای نگه داشته شوند که برای اهداف مورد نظر مفید باشد.
با توجه به سنسورهای مورد استفاده در سطح زمین، چالش اصلی و یک عنصر مهم نوآوری، مربوط به شناسایی سنسورهای گرد و غبار، به ویژه برای PM2.5، با هزینه محدود، مصرف برق و ردپای برای نصب گسترده در هر دو است. شبکه های بی سیم ثابت و متحرک (به عنوان مثال با هواپیماهای بدون سرنشین)، برای بررسی مناطق جغرافیایی مورد علاقه خاص، در حالی که ویژگی های عجیب و غریب مانند انتخاب پذیری و حساسیت در اندازه گیری حفظ می شود.
به طور سنتی، PM با استفاده از تکنیک پراکندگی لیزری اندازهگیری میشود و ذرات به صورت هیدرودینامیکی متمرکز میشوند تا در یک جریان واحد که پرتو لیزر روی آن متمرکز است، جریان پیدا کند. حضور و اندازه هر ذره را می توان از شدت پالس نور پراکنده با فرض شکل کروی و خواص نوری متوسط تعیین کرد. بنابراین، توزیع گرانولومتری با دقت معقولی به دست میآید، و کوچکترین قطر قابل تشخیص محدود به پراش، به ترتیب طول موج نور، یعنی صدها نانومتر است. تکنیک پراکندگی لیزری نشان دهنده وضعیت هنر برای ذرات در محدوده اندازه 0.3-10 میکرومتر است. اما به دلیل هزینه و حجیم بودن این ابزارها برای استقرار گسترده در محیط مناسب نیستند.
با توجه به ارتباط آلودگی هوا برای سلامت انسان و نیاز به تفکیک مکانی-زمانی بهتر در نقشه برداری از پدیده های پیچیده مانند تولید گرد و غبار، غلظت و حمل و نقل، در دهه گذشته تلاش های زیادی برای توسعه دستگاه های فشرده و مقرون به صرفه برای اندازه گیری PM انجام شده است. به روشی فراگیر و توزیع شده اجرای اخیر شبکههای حسگر بیسیم در مقیاس شهر امکانسنجی این پارادایم را نشان داده است [ 75 ، 76 ، 77 ، 78 ، 79 ، 80 ]، و فناوریهای خاصی برای پرداختن به چندین چالش، بهویژه برای حفظ محیط زیست و انسان، به کار گرفته شدهاند. سلامت، از پایش هوا، آب [ 81] و محیط اطراف برای کنترل بلایای طبیعی و حفظ منابع چشم انداز [ 82 ].
استفاده از دستگاه های مینیاتوری با ویژگی های مختلف گسترش یافته است که عمدتاً به دو دسته تقسیم می شوند. حسگرهای مبتنی بر سیلیکون ریز ماشینکاری شده، درجه نهایی کوچک سازی را نشان می دهند و از قابلیت های میکروساخت برای افزایش حساسیت تشخیص بهره می برند [ 83 ]. دو رویکرد اصلی برای تشخیص حالت جامد پیشنهاد شده است: استفاده از رزونانس مکانیکی در مقیاسهای نوسانی میکرو و نانو وزن و اندازهگیری ظرفیت با وضوح بالا امپدانس تک ذره روی تراشه [ 84 ].]. علیرغم نتایج اولیه بسیار امیدوارکننده و پتانسیل برای تشخیص نانوذرات و ادغام همه جا در دستگاه های دستی، مانند گوشی های هوشمند، به لطف اندازه میلی متری آنها، آنها هنوز از بلوغ تجاری فاصله دارند. یک جنبه مهم، علاوه بر گرفتگی، تمیز کردن، طول عمر و اتلاف انرژی، هنگام کوچک شدن اندازه سنسور، سیالات فعال لازم برای جذب و جمع آوری ذرات گرد و غبار در تراشه باقی می ماند.
یکی دیگر از دستهبندیشدهتر حسگرهای PM، سنسورهای نوری کمهزینه است که شمارشگر ذرات نوری (OPC) نامیده میشود. آنها نشان دهنده تکامل آشکارسازهای دود هستند که در آن یک ردیاب نوری میزان نور پراکنده شده از گرد و غبار را هنگام روشن شدن توسط یک LED اندازه گیری می کند. چندین سنسور از این کلاس از شرکت هایی مانند Alphasense، Honeywell، Plantower، Sharp و Shinei در بازار موجود است. دومی بسیار فشرده (به اندازه کارت اعتباری، شکل 19 a,b) و یکپارچه هستند و سناریوهای همه کاره جدیدی را در نظارت فراگیر غلظت گرد و غبار امکان پذیر می کنند و همچنین قادر به مقابله با موقعیت های اضطراری مانند مراحل حاد بیماری های همه گیر هستند. .
کارهای مختلف عملکرد خود را با ابزار دقیق مرجع مقایسه کرده اند، چه در آزمایشگاه [ 85 ، 86 ] و چه در زمینه [ 87 ] و توافق خوبی پیدا کرده اند. در اکثر شرایط، آنها می توانند غلظت ذرات با محدوده اندازه مشابه با پراکندگی لیزر را با مقیاس کامل حدود 1000 میکروگرم بر سانتی متر تعیین کنند. 33و حساسیت چند ده میکروگرم بر سانتی متر است 33، به خوبی با محدودیت تنظیمی 50 میکروگرم بر سانتی متر مطابقت دارد 33. علاوه بر این، زمان پاسخگویی به ترتیب ثانیه، به اندازه کافی سریع است تا پویایی حمل و نقل انسانی و هوایی را به تصویر بکشد. بنابراین، آنها برای هدف این پروژه مناسب هستند و امکان استقرار هزاران گره حسگر را دارند که قادر به تشخیص سریع بیش از حد غلظت PM10 و PM2.5 هستند. در واقع، هوش مصنوعی می تواند از سطح بالای افزونگی و همپوشانی در نقشه برداری فضایی برای جبران محدودیت های ذاتی این دسته از دستگاه ها استفاده کند.
5.3. همبستگی بین تحرک و داده های COVID-19
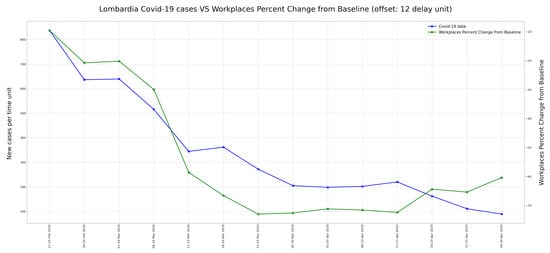
در نهایت آزمایش دیگری انجام شد. در این مورد، هدف جستجو برای ارتباط احتمالی بین روند مثبتهای جدید COVID-19 و دادههای تحرک بود. همانطور که در بخش 3.1 بحث شد ، داده های تحرک با پردازش گزارش تحرک Google [ 21 ] به دست آمد. این مجموعه داده حاوی گزارش تحرک جهانی از زمان شیوع COVID-19 است. هر گزارش شامل یک سری زمانی از شش متغیر است که تحرک را نشان می دهد. آنها عبارتند از: خرده فروشی و تفریح، خواربار فروشی و داروخانه، پارک ها، ایستگاه های حمل و نقل، محل کار و مسکونی. هر متغیر به صورت درصد تغییر نسبت به خط پایه محاسبه شده در سال های قبل بیان می شود.
در شکل 20 ، روند داده های تحرک برای شش متغیر بالا مشخص شده برای منطقه لمباردی، در مدت مشابه در شکل 5 نشان داده شده است.
با پیروی از همان اصل بخش 5.1 ، در این مورد یک نمودار پراکندگی با تحلیل تاخیر محاسبه شد. در این مطالعه موردی حداکثر همبستگی پس از 12 واحد تاخیر (60 روز) به دست آمد که در جدول 2 مشاهده می شود . نمودار مربوط به حداکثر همبستگی بین داده های تحرک و داده های COVID-19 در شکل 21 نشان داده شده است .
6. بحث
برخی ملاحظات اضافی در این بخش آورده شده است، اگرچه بسیاری از نکات مرتبط قبلاً در بخش قبلی که نتایج اولیه ارائه شده است برجسته شده است.
همانطور که با جزئیات تجزیه و تحلیل شد، رویکرد پیشنهادی با هدف توسعه یک مدل جدید برای ادغام مشترک دادههای بسیار ناهمگن، هم از نظر ماهیت و منبع (دادههای اپیدمیولوژیک، دادههای محیطی و دادههای مربوط به فعالیتهای انسانی)، و هم از نظر فضایی است. نمونه برداری (کیلومتر تا متر) و زمانی (روز تا ثانیه)، برای به تصویر کشیدن پویایی بسیار پیچیده، شناسایی با سایر ابزارهای روش شناسی سنتی دشوار است. در حالی که ما میتوانیم نمونههایی از کارهای مشابه با هدف تحقق یک DSS به نفع تصمیمگیرندگان پیدا کنیم، هیچکدام از آنها مبتنی بر الگوریتمهای هوش مصنوعی نیستند که قادر به کار بر روی حجم عظیمی از دادهها و استفاده از جزئیات لازم بر اساس واحد زمان 24 ساعت یا کمتر هستند. . در واقع الگوریتم های هوش مصنوعی قادر به استخراج ویژگی های مربوط به همبستگی های پنهان بین چندین عنصر و داده های مختلف هستند. مانند غلظت ذرات اتمسفر، روندهای هواشناسی و شیوع ویروس، برای تخمین سطح خطر. علاوه بر این، بسیاری از ماهوارههای جدیدی که اخیراً به فضا پرتاب شدهاند، با ارائه پاسخهای سریع از نظر دادههای موجود و اطلاعات لازم برای استخراج، زمان بازدید مجدد بسیار پایینی دارند.
علاوه بر آن، توضیح داده شده است که انتظار می رود مدل طراحی شده در دو سطح تحلیل عمل کند:
بنابراین، خروجی نهایی مدل، یک سری زمانی از نقشههای ریسک خواهد بود، با وضوحی که میتواند از وضوح پایین در نظر گرفته شده به عنوان خطر برای یک کشور تا وضوح بالا در نظر گرفته شده به عنوان خطر برای یک شهر یا یک منطقه کوچکتر متفاوت باشد. رزولوشن نهایی به سنسوری با بدترین وضوح مرتبط خواهد شد. سپس داده ها برای مطابقت با وضوح پردازش می شوند. برای به دست آوردن یک تصویر کلی، چه در سطح ملی و چه در سطح جهانی، پیش بینی های فردی انجام شده در این قطعنامه می تواند واسطه شود. بدیهی است که از آنجایی که این یک مقاله مفهومی است، این راه حل باید بیشتر مورد بررسی قرار گیرد و ممکن است نیاز به آموزش مدل های مختلف در وضوح های مختلف باشد.
در واقع، دو مطالعه موردی ارائه شده در بخش بالا که به ترتیب به مناطق لومباردی و هوبی اشاره میکنند، با هدف مقایسه برخی اقدامات قرنطینه و تأثیرات بر کاهش COVID-19 انجام شده است. با این حال، شایان ذکر است که ایده در ابتدا توسعه این ابزار با توجه ویژه به بحرانی ترین مناطق ایتالیا بود، اما بعداً زمانی که شبکه عصبی به درستی در موارد مختلف آموزش داده شد، می توان از آن در نقاط مختلف جهان نیز استفاده کرد. شرایط و پارامتر آن به درستی تنظیم شده است.
مرحله نهایی این کار، همانطور که در چکیده پیش بینی شده است، پیاده سازی یک سیستم مبتنی بر ابر خواهد بود. این سیستم به کاربر امکان ورود به فضای کاری شخصی و انجام تحلیل را می دهد. این پلتفرم دارای یک رابط کاربری گرافیکی (رابط کاربری گرافیکی) کاربردی و آسان برای استفاده است که به کاربران در انجام تجزیه و تحلیل کمک می کند. هسته سیستم مدل شبکه عصبی است، اما رابط کاربری گرافیکی به کاربر کمک می کند تا با انتخاب و تنظیم ورودی های خاص به ساده ترین روش، با آن تعامل داشته باشد.
7. نتیجه گیری
در این مقاله، پروژه بین رشتهای AIRSENSE-TO-ACT را با هدف ایجاد یک سیستم پشتیبانی تصمیم برای فعالسازی به موقع و مؤثر اقدامات متقابل هدفمند در طول همهگیریهای ویروسی، مانند COVID-19، بر اساس یک مدل ارائه کردهایم. ادغام داده ها از منابع بسیار ناهمگن، از جمله شبکه های بی سیم زمینی مانیتورهای گرد و غبار کم هزینه، و داده های ماهواره ای، از داده های هواشناسی و آلودگی تا سنجش جمعیت. ارتباط بین انتشار ویروس و غلظت NO 22تجزیه و تحلیل شده است، و تجزیه و تحلیل بیشتر همبستگی بین انتشار ویروس و PM در هوا تمرکز اصلی تحقیقات آینده خواهد بود. با این حال، مدل پیشنهادی فراتر از آن است، زیرا هدف آن جمعآوری اطلاعات ورودی مانند تحرک، شرایط آب و هوایی، کیفیت هوا، اعداد آلودگی و غیره است تا بتواند تمام تعاملات ممکن را به تصویر بکشد و سطح ریسک را به عنوان خروجی پیشنهاد کند. ، بر اساس یک تحلیل خرد و کلان برای اقدامات هدفمند. «موج دوم» که در حال حاضر در اروپا در حال گسترش است، نیاز مبرم به ابزاری مانند آنچه در این مقاله پیشنهاد شده است، به منظور محدود کردن آسیب های اقتصادی ناشی از قرنطینه ها و محدودیت های عمومی، و مهمتر از همه برای جلوگیری از تعداد زیادی از افراد کشته شده را نشان می دهد.













بدون دیدگاه