

کلید واژه ها:
متن کاوی ; استخراج رویداد ; آموزش عمیق دشمنی
1. مقدمه
-
در ابتدا، این مقاله استخراج رویداد را با چهار کار فرعی به عنوان یک کار دو مرحلهای بر اساس اهداف وظایف فرعی ساده میکند و سپس یک مدل مشترک عمیق ناهمگن را برای تحقق استخراج رویداد اضطراری چینی انتها به انتها توسعه میدهد. شناسایی آرگومان از مدل کلاسیک BiLSTM-CRF (حافظه کوتاهمدت-فیلدهای تصادفی شرطی) کلاسیک استفاده میکند و طبقهبندی نقش آرگومان به عنوان یک کار انتخاب چند سر تحقق مییابد. در مقایسه با مدلهای مشترک استخراج رویداد حرفهای موجود، این مدل یک مدل سبک وزن است که به ابزارهای تحلیل نحوی خارجی وابسته نیست و دارای ساختار شبکهای سادهتر برای تسریع همگرایی مدل در مجموعه دادههای آموزشی کوچک است.
-
ثانیا، این مقاله آموزش خصمانه را بر اساس آموزش خصمانه رایگان (FreeAT) [ 15 ] در مدل مشترک استخراج رویداد ادغام می کند. با افزودن اغتشاشات کوچک و مداوم به ورودی مدل مشترک، برازش بیش از حد مدل ناشی از مجموعه داده های آموزشی کوچک و ساختار شبکه ساده می تواند برای بهبود استحکام و تعمیم مدل کاهش یابد.
-
ثالثاً، متفاوت از مطالعات متنکاوی موجود بر اساس مجموعه دادههای عمومی CEC، برچسبهای قالب XML از مجموعه دادههای استاندارد CEC حذف شدند تا با سناریوی کاربردی واقعی مطابقت داشته باشند. آزمایشها روی این مجموعه داده CEC بازیابی شده انجام شد. نتایج تجربی نشان میدهد که مدل پیشنهادی میتواند رویدادهای اضطراری را از متون اخبار آنلاین به طور مؤثرتر و جامعتر در مقایسه با مدلهای استخراج رویداد موجود استخراج کند.
2. کارهای مرتبط
2.1. متن کاوی اطلاعات اضطراری
2.2. استخراج رویداد
3. روش ها
3.1. تعریف رویداد اضطراری
می توان آن را به صورت پنج تایی تعریف کرد:
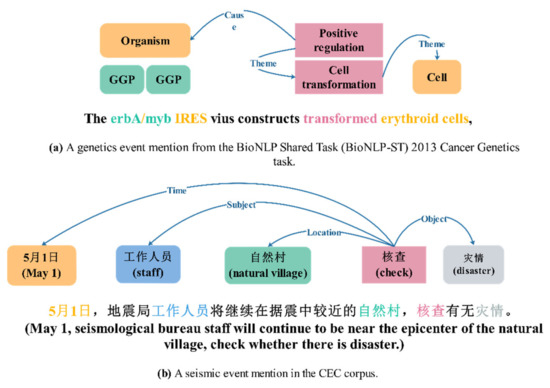
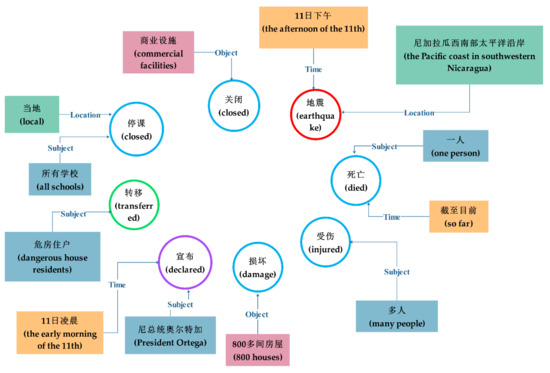
که در آن موضوع و شی هر دو به شرکت کنندگان رویدادها اشاره می کنند، زمان به زمان یا دوره ای که یک رویداد رخ می دهد، مکان اشاره به مکانی دارد که رویداد رخ داده است، و Trigger به یک عمل کلیدی اشاره دارد که می تواند تغییرات و ویژگی های خاصی را در رویداد نشان دهد. فرآیند وقوع رویداد شکل 2 نمونه ای از یک رویداد اضطراری را نشان می دهد. استخراج رویداد اضطراری شامل یافتن رویداد، شناسایی نوع رویداد و استخراج جامع محتوای رویداد پنجگانه فوق از متون اضطراری بدون ساختار است.
3.2. داده ها و پیش پردازش
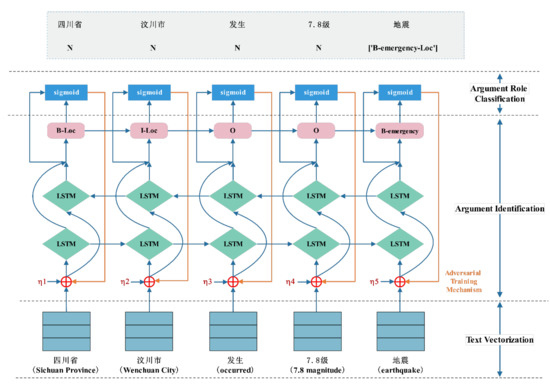
3.3. EmergEventMine
3.3.1. لایه برداری متن
لایه برداری متن، متون اضطراری ورودی را به عنوان بردار جمله رمزگذاری می کند. به منظور توسعه یک مدل کامل از پایان به انتها و اجتناب از وابستگی به ابزارهای تحلیل نحوی خارجی، این مقاله تنها از جاسازی کلمه بر اساس word2vec [ 40 ] برای ساخت بردارهای جمله استفاده می کند. برای یک جمله داده شده اس=w1، w2، …، wتی،…،wn، بردار جمله آن به صورت زیر است:
جایی که vتینشان دهنده کلمه برداری است wتی.
3.3.2. لایه شناسایی آرگومان
همانطور که در بالا گفته شد، مدلهای مشترک پیشرفته موجود برای استخراج رویدادهای حرفهای عمدتاً بر توسعه شبکههای پیچیده برای ثبت ویژگیهای عمیق در متون متمرکز شدهاند که منجر به افزایش تقاضا برای مجموعههای برچسبدار در مقیاس بزرگ میشود. با این حال، متون اضطراری چینی به دلیل ساختار نحوی نسبتاً واضح و توزیع پارامترهای متمرکز، و همچنین پیکرههای برچسبگذاری شده در مقیاس کوچک، به یک مدل سبک وزن نیاز دارند. بنابراین، این مقاله فقط BiLSTM را برای ثبت ویژگیهای جهانی برچسبهای کلمه اتخاذ میکند. فرآیند را می توان به صورت زیر تعریف کرد:
جایی که vتیبردار ترکیبی کلمه است wتی، Lاستیم→vتیخروجی لایه پنهان رو به جلو است، Lاستیم←vتیخروجی لایه پنهان به عقب است و ساعتتییک نمایش کلمه ای از بردار ترکیبی است Lاستیم→vتیو Lاستیم←vتی.
بر اساس خروجی BiLSTM، CRF برای انجام وظیفه برچسبگذاری دنباله برای پیشبینی عناصر رویداد استفاده میشود. در لایه CRF، با در نظر گرفتن رابطه بین تگ های مجاور، می توان راه حل بهینه جهانی را به دست آورد. امتیاز هر کلمه را محاسبه می کنیم wتیبرای هر تگ عنصر رویداد:
جایی که f·یک تابع فعال سازی است، V∈ℝپ×ل، U∈ℝ2د×ل، پتعداد مجموعه تگ عنصر رویداد است، لعرض لایه LSTM است و داندازه پنهان لایه LSTM است. بنابراین، با توجه به ترتیب بردارهای امتیاز اس1، اس2، …، اسnو بردار پیش بینی برچسب ها y1، y2، …، yn، امتیاز CRF زنجیره خطی را می توان به صورت زیر محاسبه کرد:
جایی که yتیبرچسب از است wتی، ستی،yتیامتیاز پیش بینی شده است wتیبرچسب داده شده است yتی، و تیماتریس انتقال است. سپس، احتمال توالی تگ داده شده را بر روی تمام دنباله های برچسب ممکن در جمله ورودی محاسبه کنید. سبه شرح زیر است:
در فرآیند آموزش، لایه BiLSTM-CRF تلفات ورودی متقاطع را به حداقل می رساند LنEآر:
جایی که θمجموعه ای از پارامترها است.
3.3.3. لایه طبقه بندی نقش استدلال
لایه طبقهبندی نقش آرگومان، نقشهای آرگومانها، یعنی روابط بین ماشه و آرگومانها را بر اساس عناصر رویداد پیشبینیشده تشخیص میدهد. ماشه در رویدادها معمولاً با چندین آرگومان مطابقت دارد که یک رابطه یک به چند است. بنابراین، این مقاله وظیفه طبقه بندی نقش آرگومان را به عنوان یک مسئله انتخاب چند سر مدل می کند [ 42 ]. برای یک برچسب نقش مشخص rک، امتیاز پیش بینی بین wتیو wjرا می توان به صورت زیر محاسبه کرد:
جایی که f·یک تابع فعال سازی است، ساعتمنخروجی حالت پنهان LSTM مربوط به است wمن، ایکس∈ℝل، لاندازه پنهان LSTM است م∈ℝل∗2د، دبلیو∈ℝل∗2د، و داندازه پنهان لایه LSTM است. سپس، احتمال wjبه عنوان رئیس انتخاب شود wتیبا برچسب نقش rکبین آنها را می توان به صورت زیر محاسبه کرد:
جایی که σ·تابع سیگموئید است.
در فرآیند آموزش، این مقاله ضرر ورودی متقاطع را به حداقل می رساند Lrهل:
جایی که yتیبردار حقیقت زمینی است، yتی⊆سو rک⊆ آرو متر( متر< n) تعداد سرهای مرتبط است wتی. در طول رمزگشایی، محتمل ترین سرها و نقش ها با استفاده از پیش بینی مبتنی بر آستانه انتخاب می شوند.
در نهایت، برای کار استخراج رویداد مشترک، مدل مشترک هدف نهایی را در فرآیند آموزش به حداقل می رساند:
3.3.4. مکانیسم آموزش خصمانه
ساختار شبکه سادهتر مدل مشترک، همگرایی مدل را در مجموعه دادههای آموزشی کوچک تسریع میکند، اما همچنین میتواند به راحتی منجر به برازش بیش از حد شود. آموزش خصمانه برای به روز رسانی پارامترهای مدل در طول آموزش مدل، اغتشاش را به ورودی های مدل فعلی اضافه می کند. اگرچه توزیع خروجی مدل اساساً با توزیع اصلی سازگار است، تعمیم و استحکام مدل افزایش یافته است [ 38 ]. بنابراین، این مقاله آموزش خصمانه مبتنی بر FreeAT [ 15 ] را در مدل مشترک استخراج رویداد ادغام می کند. اغتشاش زیر در بدترین حالت به تعبیه اصلی اضافه می شود تا تابع ضرر را به حداکثر برساند:
جایی که radvبدترین حالت آشفتگی است، مترتعداد تکرارهای درونی است، θ^یک کپی از پارامتر مدل فعلی است و ϵ=αDیک فراپارامتر اغتشاش است، که در آن αعامل و Dبعد تعبیه ها است ایکسمن.
در نهایت، با ترکیب ورودی های اصلی و ورودی های رویارویی تولید شده توسط آموزش خصمانه مدل، از دست دادن نهایی مدل مشترک به شرح زیر است:
جایی که θ^مقدار فعلی پارامتر مدل است.
3.4. ارزیابی
میزان دقت پ، نرخ فراخوان آر، و اف1مقدار [ 43 ] برای ارزیابی نتایج استخراج رویداد اضطراری اتخاذ شد. آنها را می توان به صورت زیر محاسبه کرد:
که در آن TP تعداد رویدادهایی را نشان می دهد که همه آرگومان ها و نقش های آنها به درستی شناسایی شده اند، |TP + FP| تعداد رویدادهای شناسایی شده را نشان می دهد، به عنوان مثال، جملاتی که در آن آرگومان رویداد شناسایی می شود، و |TP + FN| تعداد رویدادها در مجموعه داده را نشان می دهد.
4. آزمایش ها و نتایج
4.1. تنظیمات آزمایشی
4.2. نتیجه
4.2.1. روش های پایه
-
DMCNN [ 28 ]: این یک مدل استخراج رویداد مبتنی بر خط لوله با وظایف دو مرحله ای، از جمله تشخیص ماشه و تشخیص آرگومان است.
-
JRNN [ 32 ]: این یک مدل استخراج رویداد مشترک مبتنی بر RNNS است که با گرفتن وابستگی بین محرک ها و پارامترها، بازنمایی جملات را غنی می کند.
-
dbRNN [ 33 ]: این یک مدل استخراج رویداد مشترک است که بازنمایی جملات را با گرفتن پلهای وابستگی بین کلمات و تعاملات بالقوه بین آرگومانها غنی میکند.
-
BERT-BLMCC [ 33 ]: این یک مدل استخراج رویداد مشترک با شبکه پیچیده است که در آن چند CNN و BiLSTM برای استخراج ویژگیهای عمقی زبانهای تخصصی یکپارچه شدهاند. این مدل یک بردار ویژگی مشترک متشکل از خروجی مدل BERT، ویژگی POS و ویژگی نهاد، و خروجی لایه کدگذاری معنایی را اتخاذ میکند.
-
PLMEE [ 37 ]: به طور خودکار نمونه های رویداد برچسب گذاری شده را با ویرایش نمونه های اولیه و غربالگری نمونه های تولید شده با رتبه بندی کیفیت تولید می کند تا مشکل داده های آموزشی ناکافی را حل کند.
4.2.2. تجزیه و تحلیل نتایج
4.3. بحث
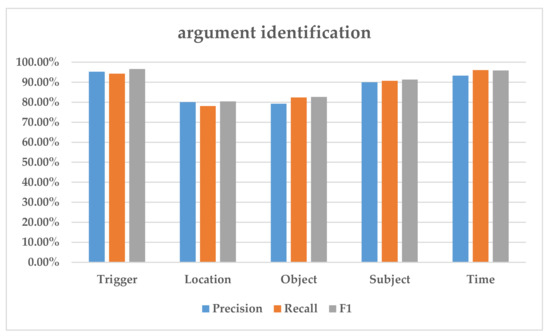
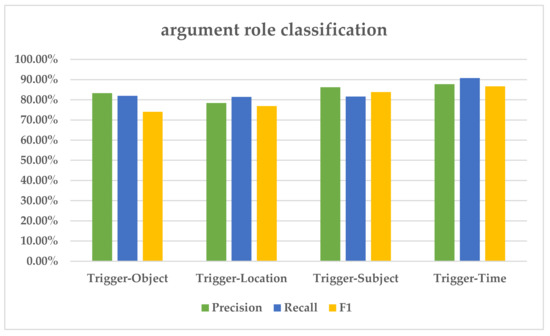
4.3.1. تجزیه و تحلیل عملکرد وظایف فرعی
4.3.2. تحلیل اثربخشی استخراج رویدادهای اضطراری
5. نتیجه گیری ها
منابع
- شن، اچ. شی، ج. Zhang، Y. CrowdEIM: جمع سپاری وظایف مدیریت اطلاعات اضطراری برای کاربران رسانه های اجتماعی موبایل. بین المللی J. کاهش خطر بلایا. 2021 ، 54 ، 102024. [ Google Scholar ] [ CrossRef ]
- Yan, X. تحقیق در مورد شناسایی رویدادهای ناگهانی در وب بر اساس ترکیب قوانین و روش آماری. داده آنال. بدانید. کشف کنید. 2011 ، 26 ، 65-69. [ Google Scholar ]
- هان، ایکس. وانگ، جی. استخراج و مقایسه اطلاعات زلزله از منابع مختلف بر اساس متن وب. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 252. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- بای، اچ. یو، اچ. یو، جی. Huang, X. یک رویکرد یادگیری ماشینی جدید آگاهی از وضعیت اضطراری برای ارزیابی خطر بلایای سیل بر اساس Weibo چینی. محاسبات عصبی اعمال کنید. 2022 ، 34 ، 8431-8446. [ Google Scholar ] [ CrossRef ]
- یین، اچ. کائو، جی. کائو، ال. وانگ، جی. تشخیص رویداد اضطراری چینی با استفاده از مدل Conv-RDBiGRU. محاسبه کنید. هوشمند نوروسک. 2020 ، 2020 ، 7090918. [ Google Scholar ] [ CrossRef ]
- شیل، م. کالینز، جی. کاما، م. ناند، دی. فکتافون، دی. ساموئلا، جی. بیاکولا، وی. هاسکیو، سی. فلینت، جی. روپر، ک. و همکاران ارزیابی سیستم هشدار اولیه، هشدار و پاسخ پس از طوفان وینستون، فیجی، 2016. بول. ارگان بهداشت جهانی. 2019 ، 97 ، 178-189C. [ Google Scholar ] [ CrossRef ]
- شویاما، ک. کوی، کیو. هاناشیما، م. سانو، اچ. Usuda، Y. تشخیص سیل اضطراری با استفاده از منابع اطلاعاتی متعدد: تجزیه و تحلیل یکپارچه نظارت بر مخاطرات طبیعی و داده های رسانه های اجتماعی. علمی کل محیط. 2021 , 767 , 144371. [ Google Scholar ] [ CrossRef ]
- لی، دی. هوانگ، ال. هنگ، جی. Han, J. استخراج رویدادهای زیست پزشکی بر اساس Tree-LSTM دانش محور. در مجموعه مقالات کنفرانس 2019 بخش آمریکای شمالی انجمن زبانشناسی محاسباتی: فناوریهای زبان انسانی، مینیاپولیس، MN، ایالات متحده آمریکا، 2 تا 7 ژوئن 2019؛ ص 1421-1430. [ Google Scholar ]
- Yu, F. LSLSD: وابستگی معنایی سطح کوتاه بلند مدت EMR چینی برای استخراج رویداد. Appl. علمی 2021 ، 11 ، 7237. [ Google Scholar ]
- ژنگ، اس. کائو، دبلیو. خو، دبلیو. Bian, J. Doc2EDAG: چارچوبی در سطح سند سرتاسر برای استخراج رویدادهای مالی چینی. در مجموعه مقالات کنفرانس 2019 روش های تجربی در پردازش زبان طبیعی و نهمین کنفرانس مشترک بین المللی در مورد پردازش زبان طبیعی (EMNLP-IJCNLP)، هنگ کنگ، چین، 3 تا 7 نوامبر 2019؛ صص 337-346. [ Google Scholar ]
- وانگ، پی. دنگ، ز. Cui, R. TDJEE: یک مدل مشترک در سطح سند برای استخراج رویدادهای مالی. Electronics 2021 , 10 , 824. [ Google Scholar ] [ CrossRef ]
- لیو، ز. خو، اچ. ژو، دی. چی، جی. سان، دبلیو. شن، اس. ژائو، جی. مدل رویداد سلسله مراتبی مبتنی بر توجه به خود وابسته به ساختار برای استخراج رویدادهای مالی چینی. در نمودار دانش و محاسبات معنایی: نمودار دانش ساخت زیرساخت جدید را تقویت می کند . Qin, B., Jin, Z., Wang, H., Pan, J., Liu, Y., An, B., Eds. CCKS 2021; ارتباطات در علوم کامپیوتر و اطلاعات؛ اسپرینگر: سنگاپور، 2021؛ جلد 1466. [ Google Scholar ]
- کونمن، اف. Van Den Bosch، A. استخراج دامنه باز رویدادهای آینده از توییتر. نات لنگ مهندس 2016 ، 22 ، 655-686. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، ایکس. هوانگ، اچ. Zhang، Y. استخراج رویداد دامنه باز با استفاده از مدل های متغیر نهفته عصبی. arXiv 2019 ، arXiv:1906.06947. [ Google Scholar ]
- شفاهی، ع. نجیبی، م. غیاثی، ع. خو، ز. دیکرسون، جی. استودر، سی. داوین، LS; تیلور، جی. آموزش Goldstein, T. Adversarial به صورت رایگان! arXiv 2019 ، arXiv:1904.12843. [ Google Scholar ]
- وانگ، ی. وانگ، تی. بله، X. ژو، جی. لی، جی. استفاده از رسانه های اجتماعی برای واکنش اضطراری و پایداری شهری: مطالعه موردی طوفان باران پکن در سال 2012. پایداری 2016 ، 8 ، 25. [ Google Scholar ] [ CrossRef ]
- هان، ایکس. وانگ، جی. استفاده از رسانه های اجتماعی برای استخراج و تجزیه و تحلیل احساسات عمومی در طول یک فاجعه: مطالعه موردی سیل 2018 شهر شوگوانگ در چین. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 185. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- یو، م. هوانگ، Q. کین، اچ. شیل، سی. یانگ، سی. یادگیری عمیق برای طبقهبندی متن رسانههای اجتماعی در زمان واقعی برای آگاهی از موقعیت با استفاده از طوفانهای سندی، هاروی و ایرما به عنوان مطالعات موردی. بین المللی جی دیجیت. زمین 2019 ، 12 ، 1230-1247. [ Google Scholar ] [ CrossRef ]
- کومار، ا. سینگ، جی پی؛ Dwivedi، YK; Rana, NP یک شبکه عصبی چندوجهی عمیق برای طبقه بندی محتوای آموزنده توییتر در مواقع اضطراری. ان اپراتور Res. 2020 ، 1–32. [ Google Scholar ] [ CrossRef ]
- ژانگ، ی. لیو، ز. Zhou، W. تشخیص رویداد بر اساس یادگیری عمیق در متون چینی. PLoS ONE 2016 , 11 , e0160147. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، اچ. یو، ال. تیان، اس. تورگن، آی. ژائو، جی. تشخیص اضطراری اویغور بر اساس مدل DCNNS-LSTM. جی. چین. Inf. علمی تکنولوژی 2018 ، 6 ، 52-61. [ Google Scholar ]
- آنام، م. شفیق، ب. شمایل، س. چون، SA; Adam, N. کشف رویدادها از رسانه های اجتماعی برای برنامه ریزی اضطراری. در مجموعه مقالات بیستمین کنفرانس بین المللی سالانه تحقیقات دولت دیجیتال، دبی، امارات متحده عربی، 18 تا 20 ژوئن 2019؛ صص 109-116. [ Google Scholar ]
- وانگ، ز. وانگ، ایکس. هان، ایکس. لین، ی. هو، ال. لیو، ز. لی، پی. لی، جی. ژو، جی. کلیو: پیش آموزش متضاد برای استخراج رویداد. در مجموعه مقالات پنجاه و نهمین نشست سالانه انجمن زبانشناسی محاسباتی و یازدهمین کنفرانس مشترک بین المللی پردازش زبان طبیعی، آنلاین. 1–6 اوت 2021؛ صص 6283-6297. [ Google Scholar ]
- فنگ، آر. یوان، جی. ژانگ، سی. مدلهای درک مطلب کاوش و تنظیم دقیق برای استخراج رویداد چند شات. arXiv 2020 ، arXiv:abs/2010.11325. [ Google Scholar ]
- یو، دبلیو. یی، م. هوانگ، ایکس. یی، ایکس. یوان، Q. آن را مستقیماً بسازید: استخراج رویداد بر اساس Tree-LSTM و Bi-GRU. دسترسی IEEE 2020 ، 8 ، 14344–14354. [ Google Scholar ] [ CrossRef ]
- ژانگ، ی. خو، جی. وانگ، ی. لین، دی. Huang, T. چارچوبی مبتنی بر پاسخ به سؤال برای استخراج آرگومان رویداد یک مرحله ای. دسترسی IEEE 2020 ، 8 ، 65420–65431. [ Google Scholar ] [ CrossRef ]
- شیانگ، دبلیو. وانگ، بی. بررسی استخراج رویداد از متن. دسترسی IEEE 2019 ، 7 ، 173111–173137. [ Google Scholar ] [ CrossRef ]
- چن، ی. خو، ال. لیو، ک. زنگ، دی. ژائو، جی. استخراج رویداد از طریق شبکههای عصبی کانولوشنال چند ادغامی پویا. در مجموعه مقالات پنجاه و سومین نشست سالانه انجمن زبانشناسی محاسباتی و هفتمین کنفرانس مشترک بینالمللی پردازش زبان طبیعی، پکن، چین، 26 تا 31 ژوئیه 2015. صص 167-176. [ Google Scholar ]
- لی، کیو. جی، اچ. Huang, L. استخراج رویداد مشترک از طریق پیشبینی ساختاریافته با ویژگیهای جهانی. در مجموعه مقالات پنجاه و یکمین نشست سالانه انجمن زبانشناسی محاسباتی، صوفیه، بلغارستان، 4 تا 9 اوت 2013. صص 73-82. [ Google Scholar ]
- نگوین، TM; نگوین، TH One for All: مدلسازی مشترک عصبی موجودیتها و رویدادها. arXiv 2018 , arXiv:1812.00195. [ Google Scholar ] [ CrossRef ]
- نگوین، تی. چو، ک. Grishman, R. استخراج رویداد مشترک از طریق شبکه های عصبی بازگشتی. در مجموعه مقالات کنفرانس 2016 بخش آمریکای شمالی انجمن زبانشناسی محاسباتی: فناوریهای زبان انسانی، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 12 تا 17 ژوئن 2016. صص 300-309. [ Google Scholar ]
- شا، ال. کیان، ف. چانگ، بی. Sui، Z. استخراج مشترک محرکها و آرگومانهای رویداد توسط RNN پل وابستگی و تعامل آرگومان مبتنی بر تانسور. در مجموعه مقالات سی و دومین کنفرانس AAAI در مورد هوش مصنوعی (AAAI-18)، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، 2 تا 7 فوریه 2018؛ صص 5916-5923. [ Google Scholar ]
- وانگ، اس. رائو، ی. فن، X. Qi، J. مدل استخراج رویداد مشترک بر اساس همجوشی چند ویژگی. Procedia Comput. علمی 2020 ، 174 ، 115-122. [ Google Scholar ]
- ژائو، دبلیو. ژانگ، جی. یانگ، جی. او، تی. Li، Z. یک چارچوب جدید استخراج رویداد زیست پزشکی مشترک از طریق مدلسازی دو سطحی اسناد. Inf. علمی 2021 ، 550 ، 27-40. [ Google Scholar ] [ CrossRef ]
- فرگوسن، جی. لاکارد، سی. جوش، DS; حاجی شیرزی، ح. استخراج رویداد نیمه نظارتی با خوشه های پارافراسی. در مجموعه مقالات کنفرانس 2018 بخش آمریکای شمالی انجمن زبانشناسی محاسباتی: فناوریهای زبان انسانی، نیواورلئان، لسآنجلس، ایالات متحده آمریکا، 1 تا 6 ژوئن 2018؛ صص 359-364. [ Google Scholar ]
- چن، ی. لیو، اس. ژانگ، ایکس. لیو، ک. ژائو، جی. تولید داده با برچسب خودکار برای استخراج رویداد در مقیاس بزرگ. در مجموعه مقالات پنجاه و پنجمین نشست سالانه انجمن زبانشناسی محاسباتی (جلد 1: مقالات طولانی)، ونکوور، BC، کانادا، 30 ژوئیه تا 4 اوت 2017؛ صص 409-419. [ Google Scholar ]
- یانگ، اس. فنگ، دی. کیائو، ال. کان، ز. لی، دی. کاوش مدل های زبانی از پیش آموزش دیده برای استخراج و تولید رویداد. در مجموعه مقالات پنجاه و هفتمین کنفرانس انجمن زبانشناسی محاسباتی، فلورانس، ایتالیا، 28 ژوئیه تا 2 اوت 2019؛ صص 5284-5294. [ Google Scholar ]
- زنگ، ی. فنگ، ی. ما، ر. وانگ، ز. یان، آر. شی، سی. ژائو، دی. یادگیری استخراج رویداد را از طریق تولید خودکار داده های آموزشی افزایش دهید. در مجموعه مقالات سی و دومین کنفرانس AAAI در مورد هوش مصنوعی، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، 2 تا 7 فوریه 2018. [ Google Scholar ]
- سانگ، ای اف. Veenstra، J. نشان دهنده تکه های متن. arXiv 1999 ، arXiv:cs/9907006. [ Google Scholar ]
- میکولوف، تی. چن، ک. کورادو، جی. Dean, J. برآورد کارآمد نمایش کلمات در فضای برداری. arXiv 2013 , arXiv:1301.3781. [ Google Scholar ]
- لی، ایکس. ون، کیو. لین، اچ. جیائو، ز. ژانگ، جی. بررسی اجمالی وظیفه 3 CCKS 2020: شناسایی موجودیت نامگذاری شده و استخراج رویداد در سوابق پزشکی الکترونیکی چین. هوش داده 2021 ، 3 ، 376-388. [ Google Scholar ] [ CrossRef ]
- جیانیس، بی. یوهانس، دی. توماس، دی. کریس، دی. شناسایی موجودیت مشترک و استخراج رابطه به عنوان یک مشکل انتخاب چند سر. سیستم خبره Appl. 2018 ، 114 ، 34-45. [ Google Scholar ]
- گوت، سی. Gaussier, E. یک تفسیر احتمالی از دقت، یادآوری و امتیاز F، با مفهومی برای ارزیابی. در مجموعه مقالات پیشرفت در بازیابی اطلاعات، مجموعه مقالات کنفرانس اروپایی در مورد بازیابی اطلاعات، سانتیاگو د کامپوستلا، اسپانیا، 21-23 مارس 2005. صص 345-359. [ Google Scholar ]
- زینگ، ز. سو، ایکس. لیو، جی. سو، دبلیو. Zhang، X. تجزیه و تحلیل تغییر مکانی و زمانی اطلاعات اضطراری زلزله بر اساس داده های میکروبلاگ: مطالعه موردی زمین لرزه جیوژایگو “8.8”. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 359. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]





بدون دیدگاه