

کلید واژه ها:
استخراج جاده ; اتصال جاده ای ؛ تصویر سنجش از دور ; داده های مکان ؛ افزایش داده ها ؛ پس پردازش داده ها ؛ شبکه عصبی کانولوشنال عمیق
1. مقدمه
- (1)
-
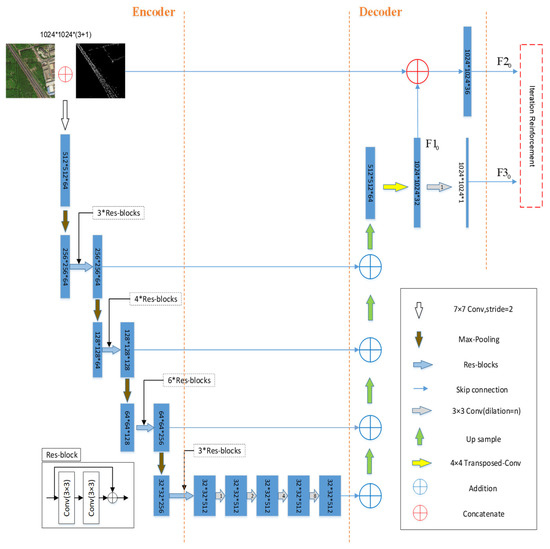
ما یک روش استخراج جاده جدید را بر اساس ادغام داده های مکان پیشنهاد می کنیم و یک شبکه استخراج جاده را بر اساس D-LinkNet، شبکه فیوژن (FuNet) به طور خلاصه طراحی می کنیم. علاوه بر این، روشهای پیشپردازش و پس پردازش دادههای عمومی شبکه پیشنهادی را مطالعه کردیم. ماژول Iteration Reinforcement (IteR) تابع پس پردازش را به ترمینال خروجی شبکه اضافه کردیم تا تمام اطلاعات داده های ورودی اصلی و نتایج خروجی شبکه را به هم متصل، فیوز کرده و دوباره آموزش دهیم.
- (2)
-
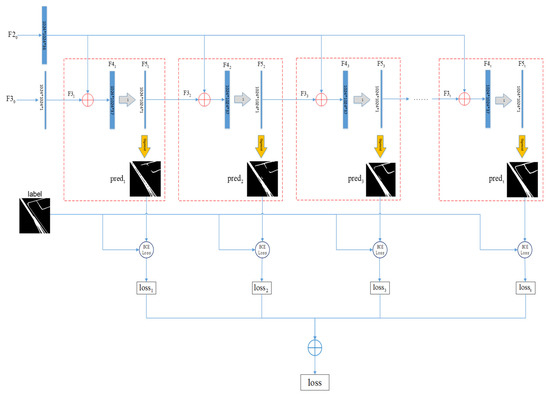
ما یک ماژول IteR برای انجام پس پردازش داده ها طراحی می کنیم. IteR از n بلوک اساسی تشکیل شده است. با معرفی تکنیکهای بهینهسازی تکراری چندگانه، نتایج پیشبینی میتوانند پس از بهینهسازیهای چندگانه به یک نتیجه بهینه و پایدار برسند، و شناسایی اتصال جاده نیز میتواند زمانی که نرخ تشخیص کلی مدل جاده افزایش مییابد بهبود یابد. ساختار بلوک اصلی برای بهبود عملکرد مدل معرفی شده است. ماژول پیشنهادی جهانی است.
- (3)
-
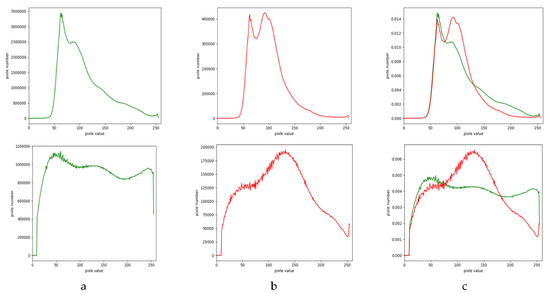
الگوریتم یکسان سازی هیستوگرام برای پیش پردازش داده های تصویر سنجش از راه دور استفاده می شود. داده ها با یکسان سازی هیستوگرام برای بهبود کنتراست تصویر افزایش می یابد. متفاوت از روشهای متداول تقویت دادهها مانند چرخش تصویر، بریدن، و بزرگنمایی و غیره، مجموعه آموزشی محدود ناشی از دشواری در حاشیهنویسی قطعهبندی معنایی تصویر را جبران میکند. روش پیشنهادی جهانی است.
- (4)
-
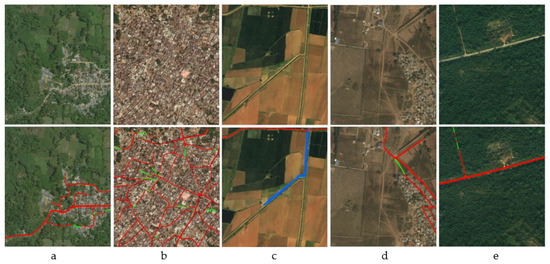
در این مقاله، ما تعدادی از روشهای پیشرفته استخراج جاده را در مجموعه دادههای عمومی BeiJing DataSet [ 1 ] مقایسه و تجزیه و تحلیل میکنیم تا اثربخشی و پیشروی (1)- (3) را تأیید کنیم. ما همچنین تغییرات عملکرد مدل پیشنهادی را تحت شرایط مختلف، از جمله استفاده از یکسان سازی هیستوگرام قبل و بعد از پردازش داده ها، نقش ماژول IteR و تغییرات با تعداد بلوک های اصلی ماژول IteR مورد بحث قرار دادیم. با توجه به نتایج بحث، پیشنهادات عملی برای کاربرد در این مقاله ارائه شد.
2. کارهای مرتبط
3. روش شناسی
3.1. معماری FuNet
3.2. تقویت تکرار
Iteration Reinforcement ( شکل 3 ) به ترمینال خروجی شبکه D-LinkNet متصل می شود تا پردازش پس از خروجی داده ها را افزایش دهد. داده های ورودی D-LinkNet، خروجی دکانولوشن لایه ماقبل آخر و خروجی لایه پیچیدگی بسط لایه آخر به صورت بیان شده است. نوع گره ناشناخته: فونتنوع گره ناشناخته: فونت، نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونت، و نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتUnknown node type: fontUnknown node type: fontUnknown node type: font. خروجی D-LinkNet را می توان به صورت زیر تعریف کرد:
مدل IteR اطلاعات چند بعدی را از طریق یادگیری مکرر بهبود مکرر نتایج اتصال داده های خروجی D-LinkNet و تصاویر اصلی یکپارچه می کند، به طوری که دقت نتایج تحت تأثیر از دست دادن اطلاعات در هنگام پیش بینی مدل قرار نمی گیرد. نتیجه نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتاز اتصال نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتبا تصویر ورودی اصلی در امتداد کانال به صورت زیر تعریف می شود:
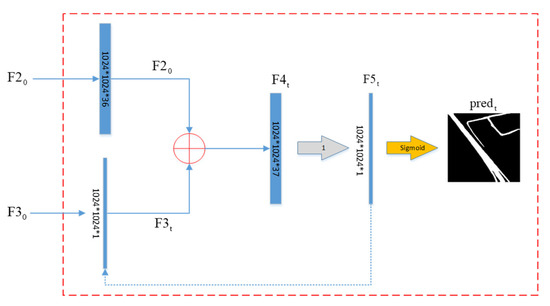
اف3تیاف3تیورودی از است تیتی ساعتتیتیساعتبلوک پایه که به صورت زیر تعریف می شود:
اف4تیاف4تینتیجه اتصال است اف20اف20و اف3تیاف3تیدر امتداد کانال در تیتی ساعتتیتیساعتبلوک پایه که به صورت زیر تعریف می شود:
اف5تیاف5تینقشه ویژگی پیش بینی است که با کانولوشن (اندازه هسته 3، اتساع 1 است) محاسبه می شود اف4تی�4�، که به صورت زیر تعریف می شود:
جایی که n�تعداد بلوک های اصلی است که روی آن تنظیم شده است n = 5�=5( بخش 5.2 ) پس از بحث تجربی. در معادله (1) اف10اف10و اف30اف30به ترتیب خروجی لایه ماقبل آخر و آخرین لایه D-LinkNet هستند. در معادلات (2) و (4)، concat (.) اتصال در امتداد کانال است. در معادله (3) اف5t – 1 اف5تی-1نقشه ویژگی خروجی است t –1تی ساعتتی-1تیساعتبلوک اساسی در معادله (5)، conv(.) عملیات پیچیدگی نقشه ویژگی ورودی است.
پیش بینی شده p r eدتیپ�هدتیهر بلوک اصلی به صورت زیر تعریف می شود:
3.3. عملکرد از دست دادن
در طول فرآیند آموزش FuNet، هر بلوک پایه نتایج پیشبینی را خروجی میدهد و مجموع ضرر در فرآیند آموزش با محاسبه تلفات انباشته n بلوک پایه به دست میآید. با فرض اینکه تیهفتم�thبلوک اصلی نقشه ویژگی پیش بینی را خروجی می دهد اف5تی�5�، نتیجه پیش بینی p r eدتی�����بلوک اصلی فعلی توسط اف5تی�5�از طریق لایه سیگموئید، و من _ _ستی�����از p r eدتی�����و برچسب و کل من s _ _����( شکل 4 ) به شرح زیر محاسبه می شود:
جایی که t = 1 ، … ، nتی=1،…،�شاخص بلوک پایه است و n�تعداد کل بلوک های اساسی است.
4. آزمایش و نتایج
4.1. مجموعه داده ها
4.2. برپایی
4.3. متریک تکامل
نتایج تجربی با میانگین تقاطع روی اتحاد ( من _o Uمترمن��) طبق تعریف زیر:
جایی که تیپمنتیپمنتعداد نمونه های صحیح شناسایی شده به عنوان نمونه مثبت است، افپمن افپمنتعداد نمونه های نادرست شناسایی شده به عنوان نمونه مثبت است، افنمن افنمنتعداد نمونه های نادرست شناسایی شده به عنوان نمونه های منفی است منمنتعداد نمونه ها و n تعداد کل نمونه ها است.
ما برچسب را تبدیل می کنیم y�و خروجی پیش بینی y^�^را به شکل نمودار دریافت کنید G = ( V، ای)جی=(�،�)و جی^= (V^،E^)جی^=(�^،�^). تعریف از A Pال اسآپ�اسبه سادگی به شرح زیر است:
جایی که a ، b ∈ Vآ،ب∈�، آ^،ب^∈V^آ^،ب^∈�^. | V||�|تعداد کل گره ها در نمودار حقیقت زمین است، ننتعداد کل تصاویر است، L ( a , b )�(آ،ب)و L (آ^،ب^)�(آ^،ب^)طول مسیر بین هستند a ⟶ بآ⟶بو آ^⟶ب^آ^⟶ب^، به ترتیب. اسپ⟶ تیاسپ⟶تیمجموع تجمعی کوتاهترین تفاوت مسیر بین تمام جفتهای گره در نمودار بررسی است G = ( V، ای)جی=(�،�)و نمودار جی^= (V^،E^)جی^=(�^،�^). استی⟶ پاستی⟶پبه طور متقارن به محاسبه نهایی معرفی می شود A Pال اسآپ�اسبرای مجازات موارد مثبت کاذب استی⟶ پاستی⟶پمجموع تجمعی کوتاهترین تفاوت مسیر بین تمام جفتهای گره در نمودار بررسی است جی^= (V^،E^)جی^=(�^،�^)و نمودار G = ( V، ای)جی=(�،�).
4.4. نتایج و تجزیه و تحلیل
5. بحث
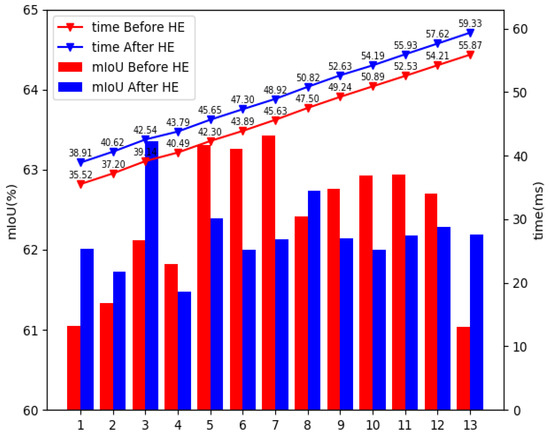
5.1. قبل از برابری پس از هیستوگرام
5.2. بلوک چند پایه
6. نتیجه گیری
مشارکت های نویسنده
منابع مالی
قدردانی
تضاد علاقه
منابع
- سان، تی. دی، ز. چه، پ. لیو، سی. Wang, Y. استفاده از دادههای GPS جمعسپاری شده برای استخراج جاده از تصاویر هوایی. در مجموعه مقالات کنفرانس IEEE/CVF 2019 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 15 تا 20 ژوئن 2019؛ ص 16-20. [ Google Scholar ]
- الشهی، ر. Marpu، بخشبندی مبتنی بر نمودار سلسله مراتبی روابط عمومی برای استخراج شبکههای جادهای از تصاویر ماهوارهای با وضوح بالا. ISPRS J. Photogramm. Remote Sens. 2017 , 126 , 245–260. [ Google Scholar ] [ CrossRef ]
- ژو، ال. ژانگ، سی. Wu, M. D-LinkNet: لینک نت با رمزگذار از پیش آموزش دیده و پیچش گشاد شده برای استخراج جاده تصاویر ماهواره ای با وضوح بالا. در مجموعه مقالات کنفرانس IEEE/CVF 2018 در کارگاه های آموزشی بینایی رایانه و تشخیص الگو (CVPRW)، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ صفحات 192-1924. [ Google Scholar ]
- ژانگ، ز. لیو، کیو. وانگ، Y. استخراج جاده توسط Deep Residual U-Net. IEEE Geosci. سنسور از راه دور Lett. 2018 ، 15 ، 749-753. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شلهامر، ای. لانگ، جی. دارل، تی. شبکه های کاملاً پیچیده برای تقسیم بندی معنایی. arXiv 2016 , arXiv:1411.4038. [ Google Scholar ] [ CrossRef ]
- چن، L.-C.; پاپاندرو، جی. کوکینوس، آی. مورفی، ک. Yuille، AL DeepLab: Semantic Segmentation image with Deep Convolutional Nets، Atrous Convolution، و CRFهای کاملاً متصل. arXiv 2016 , arXiv:1606.00915. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- چن، L.-C.; پاپاندرو، جی. شروف، اف. Adam, H. Rethinking Convolution Atrous for Semantic Image Segmentation. arXiv 2017 , arXiv:1706.05587. [ Google Scholar ]
- چن، L.-C.; زو، ی. پاپاندرو، جی. شروف، اف. آدام، اچ. رمزگذار-رمزگشا با پیچیدگی قابل جداسازی آتروس برای تقسیم بندی تصویر معنایی. arXiv 2018 , arXiv:1802.02611. [ Google Scholar ]
- ژائو، اچ. شی، ج. Qi، X. وانگ، ایکس. شبکه تجزیه صحنه هرمی جیا، جی. arXiv 2016 , arXiv:1612.01105. [ Google Scholar ]
- رونبرگر، او. فیشر، پی. Brox، T. U-Net: شبکه های کانولوشن برای تقسیم بندی تصویر زیست پزشکی. arXiv 2015 ، arXiv:1505.04597. [ Google Scholar ]
- چاوراسیا، ا. Culurciello، E. LinkNet: بهرهبرداری از بازنماییهای رمزگذار برای تقسیمبندی معنایی کارآمد. در مجموعه مقالات IEEE Visual Communications and Image Processing (VCIP) 2017، سن پترزبورگ، FL، ایالات متحده آمریکا، 10–13 دسامبر 2017؛ صص 1-4. [ Google Scholar ]
- واسوانی، ع. Shazeer، N. پارمار، ن. Uszkoreit، J. جونز، ال. گومز، AN; قیصر، ال. Polosukhin، I. توجه تمام چیزی است که شما نیاز دارید. arXiv 2017 , arXiv:1706.03762. [ Google Scholar ]
- جادربرگ، م. سیمونیان، ک. Zisserman، A. شبکه های ترانسفورماتور فضایی. Adv. عصبی Inf. روند. سیستم 2015 ، 28 ، 2017–2025. [ Google Scholar ]
- وانگ، اف. جیانگ، م. کیان، سی. یانگ، اس. لی، سی. ژانگ، اچ. وانگ، ایکس. تانگ، X. شبکه توجه باقیمانده برای طبقه بندی تصویر. arXiv 2017 , arXiv:1704.06904. [ Google Scholar ]
- وانگ، ایکس. گیرشیک، آر. گوپتا، ا. او، K. شبکه های عصبی غیر محلی. در مجموعه مقالات کنفرانس IEEE/CVF 2018 در مورد دید رایانه و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ صفحات 7794-7803. [ Google Scholar ]
- ژائو، اچ. ژانگ، ی. لیو، اس. شی، ج. لوی، سی سی; لین، دی. جیا، J. PSANet: شبکه توجه فضایی نقطهای برای تجزیه صحنه. در کامپیوتر ویژن-ECCV 2018 ؛ فراری، وی.، هبرت، ام.، اسمینچیسسکو، سی.، ویس، ی.، ویرایش. انتشارات بین المللی اسپرینگر: چم، سوئیس، 2018; جلد 11213، ص 270–286. شابک 978-3-030-01239-7. [ Google Scholar ]
- چن، ی. کالانتیدیس، ی. لی، جی. یان، اس. Feng, J. A^2-Nets: Double Attention Networks. در پیشرفت در سیستم های پردازش اطلاعات عصبی 31 ; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds. Curran Associates, Inc.: Red Hook, NY, USA, 2018; صص 352-361. [ Google Scholar ]
- لی، ایکس. ژونگ، ز. وو، جی. یانگ، ی. لین، ز. لیو، اچ. شبکههای توجه بیشینهسازی انتظارات برای تقسیمبندی معنایی. arXiv 2019 ، arXiv:1907.13426. [ Google Scholar ]
- زی، ی. میائو، اف. ژو، ک. پنگ، J. HsgNet: یک شبکه استخراج جاده بر اساس درک جهانی از اطلاعات فضایی با مرتبه بالا. ISPRS Int. J. Geo.-Inf. 2019 ، 8 ، 571. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Kipf، TN; ولینگ، ام. طبقه بندی نیمه نظارت شده با شبکه های کانولوشن گراف. arXiv 2017 , arXiv:1609.02907. [ Google Scholar ]
- بیاجیونی، جی. اریکسون، جی. استنتاج نقشه در مواجهه با نویز و نابرابری. در مجموعه مقالات بیستمین کنفرانس بین المللی پیشرفت در سیستم های اطلاعات جغرافیایی ; انجمن ماشینهای محاسباتی: نیویورک، نیویورک، ایالات متحده آمریکا، 2012. صص 79-88. [ Google Scholar ]
- کاراگیورگو، اس. Pfoser، D.; اسکوتاس، دی. یک رویکرد لایهای برای تولید قویتر نقشههای شبکه جادهای از دادههای ردیابی خودرو. ACM Trans. تف کردن سیستم الگوریتم 2017 . [ Google Scholar ] [ CrossRef ]
- لیو، ایکس. بیاجیونی، جی. اریکسون، جی. وانگ، ی. فورمن، جی. ژو، ی. ردیابی GPS پراکنده در مقیاس بزرگ معدن برای استنتاج نقشه: مقایسه رویکردها. در مجموعه مقالات هجدهمین کنفرانس بین المللی ACM SIGKDD در زمینه کشف دانش و داده کاوی ; انجمن ماشینهای محاسباتی: نیویورک، نیویورک، ایالات متحده آمریکا، 2012. صص 669-677. [ Google Scholar ]
- شان، ز. وو، اچ. سان، دبلیو. Zheng, B. COBWEB: یک سیستم به روز رسانی نقشه قوی با استفاده از مسیرهای GPS. در مجموعه مقالات کنفرانس مشترک بین المللی ACM 2015 در محاسبات فراگیر و فراگیر، اوزاکا، ژاپن، 7 تا 11 سپتامبر 2015. ص 927-937. [ Google Scholar ]
- وانگ، ی. لیو، ایکس. وی، اچ. فورمن، جی. Zhu, Y. CrowdAtlas: نقشههای خودبهروزرسانی برای استفادههای ابری و شخصی. در مجموعه مقالات یازدهمین کنفرانس بین المللی سالانه سیستم های تلفن همراه، برنامه ها و خدمات، تایپه، تایوان، 25-28 ژوئن 2013. صص 469-470. [ Google Scholar ]
- سان، تی. دی، ز. چه، پ. لیو، سی. Wang, Y. استفاده از دادههای GPS جمعسپاری شده برای استخراج جاده از تصاویر هوایی. arXiv 2019 ، arXiv:1905.01447. [ Google Scholar ]
- السامرایی، افزایش کنتراست MF تصاویر جاده ها با صحنه های مه آلود بر اساس همسان سازی هیستوگرام. در مجموعه مقالات دهمین کنفرانس بینالمللی آموزش علوم رایانه (ICCSE) در سال 2015، کمبریج، انگلستان، 22 تا 24 ژوئیه 2015. صص 95-101. [ Google Scholar ]
- Shadeed، WG; ابوالنادی، دی; Mismar، MJ تشخیص علائم ترافیکی جاده در تصاویر رنگی. در مجموعه مقالات دهمین کنفرانس بین المللی IEEE در الکترونیک، مدارها و سیستم ها، شارجه، امارات متحده عربی، 14-17 دسامبر 2003. جلد 2، ص 890–893. [ Google Scholar ]
- فرناندز کابالرو، آ. مالدونادو باسکون، اس. آسودو رودریگز، جی. لافونته آرویو، اس. López Ferreras، F. یک بهینه سازی در شناسایی پیکتوگرام برای کار تشخیص علائم جاده با استفاده از svms. محاسبه کنید. Vis. تصویر زیر. 2010 ، 114 ، 373-383. [ Google Scholar ]
- اونیدینما، ای. Onyenwe، I.; اینییاما، اچ. ارزیابی عملکرد تساوی هیستوگرام و تکنیک های تقویت تصویر فازی در تصاویر با کنتراست کم. بین المللی جی. کامپیوتر. علمی نرم افزار مهندس 2019 ، 8 ، 144-150. [ Google Scholar ]
- گونزالس، آرسی Woods, RE Digital Image Processing ; Addison-Wesley: Boston, MA, USA, 1977. [ Google Scholar ]
- آهنگ، م. Civco، D. استخراج جاده با استفاده از SVM و تقسیم بندی تصویر. فتوگرام مهندس Remote Sens. 2004 ، 70 ، 1365-1371. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- داس، اس. میرنالینی، تی تی; Varghese, K. استفاده از ویژگی های برجسته برای طراحی یک چارچوب چند مرحله ای برای استخراج جاده ها از تصاویر ماهواره ای چندطیفی با وضوح بالا. IEEE Trans. Geosci. Remote Sens. 2011 , 49 , 3906–3931. [ Google Scholar ] [ CrossRef ]
- جنید، م. غفور، م. حسن، ع. خالد، س. طارق، س. احمد، جی. ضیا، تی. شبکه عصبی کانولوشنال کم عمق مبتنی بر نمای چند ویژگی برای تقسیمبندی جاده. دسترسی IEEE 2020 ، 8 ، 36612–36623. [ Google Scholar ] [ CrossRef ]
- سایتو، اس. یاماشیتا، تی. Aoki، Y. استخراج چند شیء از تصاویر هوایی با شبکه های عصبی کانولوشنال. J. Imaging Sci. تکنولوژی 2016 ، 60 ، 104021–104029. [ Google Scholar ] [ CrossRef ]
- باستانی، ف. او هست.؛ آببر، س. علیزاده، م. بالاکریشنان، اچ. چاولا، س. مدن، اس. DeWitt, D. RoadTracer: استخراج خودکار شبکه های جاده ای از تصاویر هوایی. در مجموعه مقالات کنفرانس IEEE/CVF 2018 در مورد دید رایانه و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ صص 4720–4728. [ Google Scholar ]
- شیا، دبلیو. ژانگ، Y.-Z. لیو، جی. لو، ال. یانگ، ک. استخراج جاده از تصویر با وضوح بالا با شبکه پیچیدگی عمیق – مطالعه موردی تصویر GF-2. مجموعه مقالات 2018 ، 2 ، 325. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- سنتیلناث، جی. واریا، ن. دوکانیا، ع. آناند، جی. Benediktsson، JA Deep TEC: Deep Transfer Learning با Ensemble Classifier برای استخراج جاده از تصاویر پهپاد. Remote Sens. 2020 , 12 , 245. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یوان، ی. Wang, J. OCNet: Object Context Network برای تجزیه صحنه. arXiv 2018 , arXiv:1809.00916. [ Google Scholar ]
- هوانگ، ز. وانگ، ایکس. هوانگ، ال. هوانگ، سی. وی، ی. لیو، W. CCNet: توجه متقاطع برای تقسیم بندی معنایی. arXiv 2018 ، arXiv:1811.11721. [ Google Scholar ]
- متعجب.؛ ژانگ، ز. زی، ز. Lin, S. شبکه های ارتباط محلی برای تشخیص تصویر. arXiv 2019 ، arXiv:1904.11491. [ Google Scholar ]
- یو، ک. سان، م. یوان، ی. ژو، اف. دینگ، ای. Xu, F. شبکه غیرمحلی تعمیم یافته فشرده. arXiv 2018 , arXiv:1810.13125. [ Google Scholar ]
- لیانگ، ایکس. استدلال نمودار نمادین با پیچیدگی ها ملاقات می کند. در مجموعه مقالات سی و دومین کنفرانس بین المللی سیستم های پردازش اطلاعات عصبی ; Curran Associates Inc.: Red Hook، نیویورک، ایالات متحده آمریکا، 2018؛ پ. 11. [ Google Scholar ]
- لی، ی. گوپتا، A. فراتر از شبکهها: آموزش بازنمایی نمودار برای تشخیص بصری. در مجموعه مقالات سیستمهای پردازش اطلاعات عصبی (NeurIPS)، مونترال، QC، کانادا، 3 تا 8 دسامبر 2018؛ پ. 11. [ Google Scholar ]
- چن، ی. رورباخ، م. یان، ز. شویچنگ، ی. فنگ، جی. Kalantidis، Y. شبکه های استدلال جهانی مبتنی بر نمودار. arXiv 2018 ، arXiv:1811.12814. [ Google Scholar ]
- ژانگ، اس. یان، اس. او، X. LatentGNN: یادگیری روابط کارآمد غیر محلی برای تشخیص بصری. arXiv 2019 ، arXiv:1905.11634. [ Google Scholar ]
- او، جی. دنگ، ZY; ژو، ال. وانگ، ی. Qiao، Y. شبکه زمینه هرمی تطبیقی برای تقسیم بندی معنایی. در مجموعه مقالات کنفرانس IEEE/CVF 2019 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 15 تا 20 ژوئن 2019؛ صفحات 7511–7520. [ Google Scholar ]
- فو، جی. لیو، جی. تیان، اچ. لی، ی. بائو، ی. نیش، ز. لو، اچ. شبکه توجه دوگانه برای تقسیم بندی صحنه. arXiv 2018 , arXiv:1809.02983. [ Google Scholar ]
- لیو، ام. یین، اچ. شبکه توجه متقاطع برای تقسیم بندی معنایی. arXiv 2019 ، arXiv:1907.10958. [ Google Scholar ]
- زو، س. ژونگ، ی. لیو، ی. ژانگ، ال. لی، دی. چارچوب ترکیبی ویژگی عمیق-محلی-جهانی برای طبقه بندی صحنه تصاویر با وضوح فضایی بالا. Remote Sens. 2018 , 10 , 568. [ Google Scholar ]
- خو، ی. زی، ز. فنگ، ی. Chen, Z. استخراج جاده از تصاویر سنجش از دور با وضوح بالا با استفاده از یادگیری عمیق. Remote Sens. 2018 , 10 , 1461. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لافرتی، جی. مک کالوم، ا. Pereira، F. میدان های تصادفی شرطی: مدل های احتمالی برای قطعه بندی و برچسب گذاری داده های توالی. در مجموعه مقالات هجدهمین کنفرانس بین المللی یادگیری ماشین، ویلیامزتاون، MA، ایالات متحده آمریکا، 28 ژوئن تا 1 ژوئیه 2001. صص 282-289. [ Google Scholar ]
- لائو، ن. میچل، تی. کوهن، WW تصادفی استنتاج و یادگیری در یک پایگاه دانش در مقیاس بزرگ. در مجموعه مقالات کنفرانس 2011 روشهای تجربی در پردازش زبان طبیعی ; انجمن زبانشناسی محاسباتی: ادینبورگ، انگلستان، 2011; صص 529-539. [ Google Scholar ]
- برتاسیوس، جی. ترسانی، ال. یو، اس ایکس; Shi, J. شبکههای پیادهروی تصادفی کانولوشن برای تقسیمبندی تصویر معنایی. arXiv 2017 , arXiv:1605.07681. [ Google Scholar ]
- وانگ، ایکس. گوپتا، A. ویدئوها به عنوان نمودارهای منطقه فضا-زمان. در مجموعه مقالات چشم انداز کامپیوتر-ECCV 2018 ; فراری، وی.، هبرت، ام.، اسمینچیسسکو، سی.، ویس، ی.، ویرایش. انتشارات بین المللی اسپرینگر: چم، سوئیس، 2018; صص 413-431. [ Google Scholar ]
- یانگ، ال. ژوانگ، جی. فو، اچ. ژو، ک. Zheng, Y. SketchGCN: Semantic Sketch Segmentation with Graph Convolutional Networks. arXiv 2020 ، arXiv:2003.00678. [ Google Scholar ]
- ولیچکوویچ، پ. کوکورول، جی. کازانووا، آ. رومرو، آ. لیو، پی. Bengio، Y. گراف شبکه های توجه. arXiv 2018 ، arXiv:1710.10903. [ Google Scholar ]
- Kipf، TN; ولینگ، ام. رمزگذار خودکار گراف متغیر. arXiv 2016 , arXiv:1611.07308. [ Google Scholar ]
- لی، ی. تارلو، دی. بروکشمیت، ام. زمل، R. شبکه های عصبی توالی گراف دردار. arXiv 2017 , arXiv:1511.05493. [ Google Scholar ]
- Wegner، JD; Montoya-Zegarra، JA; شیندلر، کی. یک مدل CRF با مرتبه بالاتر برای استخراج شبکه جاده ای. در مجموعه مقالات کنفرانس IEEE 2013 در مورد بینایی کامپیوتری و تشخیص الگو، پورتلند، OR، ایالات متحده آمریکا، 23 تا 28 ژوئن 2013. صفحات 1698-1705. [ Google Scholar ]
- چای، دی. فورستنر، دبلیو. لافارژ، F. بازیابی شبکه های خط در تصاویر توسط فرآیندهای نقطه اتصال. در مجموعه مقالات کنفرانس IEEE 2013 در مورد بینایی کامپیوتری و تشخیص الگو، پورتلند، OR، ایالات متحده آمریکا، 23 تا 28 ژوئن 2013. صفحات 1894–1901. [ Google Scholar ]
- باترا، ا. سینگ، اس. پانگ، جی. باسو، س. جواهر، CV; Paluri، M. بهبود اتصال جاده با یادگیری مشترک جهت گیری و تقسیم بندی. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 15 تا 21 ژوئن 2019؛ پ. 9. [ Google Scholar ]
- موسینسکا، آ. مارکز-نیلا، پ. کوزینسکی، م. Fua, P. Beyond the Pixel-Wise Loss for Topology-Aware Delineation. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ صص 3136–3145. [ Google Scholar ]
- چن، دبلیو. تقسیم بندی جاده بر اساس یادگیری عمیق با لایه احتمال پس پردازش. در مجموعه مقالات ششمین کنفرانس بین المللی مکاترونیک و مهندسی مکانیک، ووهان، چین، 9 تا 11 نوامبر 2019؛ جلد 719، ص. 012076. [ Google Scholar ]
- Mnih، V. یادگیری ماشین برای برچسب گذاری تصویر هوایی. Ph.D. پایان نامه، دانشگاه تورنتو، تورنتو، ON، کانادا، 2013. [ Google Scholar ]
- ون اتن، ا. لیندنباوم، دی. Bacastow، TM SpaceNet: مجموعه داده سنجش از راه دور و سری چالش. arXiv 2018 , arXiv:1807.01232. [ Google Scholar ]
- Kingma، DP; لی، جی آدام: روشی برای بهینه سازی تصادفی. arXiv 2015 ، arXiv:1412.6980. [ Google Scholar ]
- ابراهیم، ام اس; وحدت، ع. رنجبر، م. تقسیمبندی تصویر معنایی نیمهنظارتشده Macready، WG با شبکههای خود تصحیحکننده. arXiv 2020 ، arXiv:1811.07073. [ Google Scholar ]






بدون دیدگاه