

خلاصه
با ورود به عصر حمل و نقل و ارتباطات بسیار توسعه یافته، اطلاعات جغرافیایی علاقه و اهمیت زیادی پیدا می کند. علیرغم گسترش شبکه تلفن همراه و وای فای، در برخی موارد، کاربران هنوز با موانعی برای دسترسی به داده های مکانی روبرو هستند. در این مقاله، ما یک سیستم نمونه اولیه توزیعشده با یک شبکه تحملکننده تاخیر/اختلال (DTN)، به نام Geo-DMP، برای اشتراکگذاری و تبادل مشارکتی و فرصتطلبانه محتویات مکانی نامگذاری شده به روش دستگاه به دستگاه، طراحی و پیادهسازی میکنیم. اول از همه، ما یک ماژول سبک وزن “عامل محتوا” می سازیم تا شکاف بین لایه برنامه و پشته پروتکل DTN زیرین را پر کند. پس از آن، برای نمایه کردن تاریخچه تحرک کاربران در محیط های مکانی عملی، ما یک طرح تقسیم بندی نقشه را بر اساس اطلاعات شبکه جاده و بخش اداری ارائه می دهیم. متعاقبا، ما اطلاعات تاریخچه حرکت منطقه ای را با فرآیند بازیابی محتوا مرتبط می کنیم تا یک طرح مسیریابی DTN سلسله مراتبی و منطقه گرا برای درخواست ها و پاسخ ها ایجاد کنیم. در نهایت، ما آزمایشهای گستردهای را با مسیرهای دنیای واقعی و پیادهسازی کامل بر روی پلتفرم شبیهسازی متشکل از ماشینهای مجازی انجام میدهیم. آزمایشها تأیید میکنند که Geo-DMP توانایی بازیابی موفقیتآمیز محتویات مکانی را برای کاربران در بیشتر مواقع تحت شرایط تلفن همراه با اتصال اپیزودیک دارد. علاوه بر این، حافظه نهان در مسیر میتواند به طور موثر برای تهیه محتوا از منابع متعدد با مصرف کمتر منابع شبکه و تأخیرهای کمتر درکشده توسط کاربر مورد سوء استفاده قرار گیرد. ما اطلاعات تاریخچه حرکت منطقه ای را با فرآیند بازیابی محتوا مرتبط می کنیم تا یک طرح مسیریابی DTN سلسله مراتبی و منطقه گرا برای درخواست ها و پاسخ ها ایجاد کنیم. در نهایت، ما آزمایشهای گستردهای را با مسیرهای دنیای واقعی و پیادهسازی کامل بر روی پلتفرم شبیهسازی متشکل از ماشینهای مجازی انجام میدهیم. آزمایشها تأیید میکنند که Geo-DMP توانایی بازیابی موفقیتآمیز محتویات مکانی را برای کاربران در بیشتر مواقع تحت شرایط تلفن همراه با اتصال اپیزودیک دارد. علاوه بر این، حافظه نهان در مسیر میتواند به طور موثر برای تهیه محتوا از منابع متعدد با مصرف کمتر منابع شبکه و تأخیرهای کمتر درکشده توسط کاربر مورد سوء استفاده قرار گیرد. ما اطلاعات تاریخچه حرکت منطقه ای را با فرآیند بازیابی محتوا مرتبط می کنیم تا یک طرح مسیریابی DTN سلسله مراتبی و منطقه گرا برای درخواست ها و پاسخ ها ایجاد کنیم. در نهایت، ما آزمایشهای گستردهای را با مسیرهای دنیای واقعی و پیادهسازی کامل بر روی پلتفرم شبیهسازی متشکل از ماشینهای مجازی انجام میدهیم. آزمایشها تأیید میکنند که Geo-DMP توانایی بازیابی موفقیتآمیز محتویات مکانی را برای کاربران در بیشتر مواقع تحت شرایط تلفن همراه با اتصال اپیزودیک دارد. علاوه بر این، حافظه نهان در مسیر میتواند به طور موثر برای تهیه محتوا از منابع متعدد با مصرف کمتر منابع شبکه و تأخیرهای کمتر درکشده توسط کاربر مورد سوء استفاده قرار گیرد. ما آزمایشهای گستردهای را با مسیرهای دنیای واقعی و پیادهسازی کامل بر روی پلتفرم شبیهسازی متشکل از ماشینهای مجازی انجام میدهیم. آزمایشها تأیید میکنند که Geo-DMP توانایی بازیابی موفقیتآمیز محتویات مکانی را برای کاربران در بیشتر مواقع تحت شرایط تلفن همراه با اتصال اپیزودیک دارد. علاوه بر این، حافظه نهان در مسیر میتواند به طور موثر برای تهیه محتوا از منابع متعدد با مصرف کمتر منابع شبکه و تأخیرهای کمتر درکشده توسط کاربر مورد سوء استفاده قرار گیرد. ما آزمایشهای گستردهای را با مسیرهای دنیای واقعی و پیادهسازی کامل بر روی پلتفرم شبیهسازی متشکل از ماشینهای مجازی انجام میدهیم. آزمایشها تأیید میکنند که Geo-DMP توانایی بازیابی موفقیتآمیز محتویات مکانی را برای کاربران در بیشتر مواقع تحت شرایط تلفن همراه با اتصال اپیزودیک دارد. علاوه بر این، حافظه نهان در مسیر میتواند به طور موثر برای تهیه محتوا از منابع متعدد با مصرف کمتر منابع شبکه و تأخیرهای کمتر درکشده توسط کاربر مورد سوء استفاده قرار گیرد.
کلید واژه ها:
بازیابی داده های جغرافیایی ; نمونه اولیه موبایل توزیع شده شبکه متحمل تاخیر ; پروتکل مسیریابی مبتنی بر منطقه
1. معرفی
پیشرفت ها و دستاوردهای محاسبات سیار، جامعه معاصر را عمیقاً متحول کرده است. در طول دهه گذشته، دستگاه های قابل حمل کالایی همه کاره و در عین حال مقرون به صرفه، رشد رو به رشدی را در سرتاسر جهان، به ویژه در بازارهای نوظهور، به نمایش گذاشته اند، همانطور که در شکل 1 نشان داده شده است [ 1 ]. با آزاد کردن کاربران از رایانه های رومیزی و اتصالات سیمی، آنها تقریباً همه برنامه ها را به طور فراگیر در دسترس قرار می دهند، بنابراین، جای تعجب نیست، آنها به طور جدایی ناپذیری با فعالیت های روزمره مردم در هم تنیده شده اند [ 2 ].
برای اکثر کاربران تلفن همراه، برنامه هایی که اطلاعات مکانی را ارائه می دهند اغلب در لیست برنامه های ضروری ظاهر می شوند [ 3 ]. چنین تقاضای اساسی تا حد زیادی ناشی از “تحرک موتوری” (یعنی سفر با ماشین، اتوبوس، قطار یا هواپیما) و سیستم حمل و نقل بسیار توسعه یافته [ 4 ] در زندگی مدرن است. مردم فرصتهای بیشتری برای رسیدن به مکانهای دور و عجیب و غریب دارند و با محیطهای پیچیدهای که توسط شهرنشینی سریع شکل گرفته است مواجه میشوند [ 5 ]. تحت این شرایط، اطلاعات مکانی فوری ممکن است کمک بزرگی باشد.
همراه با ارزش و اهمیت بالای اطلاعات مکانی که به طور گسترده درک می شود و ظهور عصر وب 2.0، کاربران نه تنها مصرف کنندگان داده ها هستند، بلکه به طور فعال در سهم محتوای جغرافیایی مشارکت می کنند. چنین پیشرفتی توسط محققان به عنوان «جمع سپاری جغرافیایی» [ 6 ] یا «اطلاعات جغرافیایی داوطلبانه» [ 7 ] مفهوم سازی شده است. در مقایسه با روشهای جمعآوری مرسوم، در این مورد، هزینههای استقرار و نگهداری گرانقیمت ابزارهای حسی را میتوان صرفهجویی کرد، پوشش مکانی-زمانی گستردهتری را میتوان به دست آورد، و دادههای به موقع، دقیقتر و متنوعتر را جمعآوری کرد. همانطور که اتفاق نظر وجود دارد که بخش قابل توجهی از داده های تولید شده در زندگی روزمره انسان با ویژگی های مکانی حاشیه نویسی شده است [ 8 ، 9]، با کمک داوطلبان بیشماری و تعداد زیادی حسگر قابل برنامهریزی تعبیهشده در دستگاههای تلفن همراه، بینشهای بیشتری در مورد محیط اطراف از دیدگاههای بیشتر، از پیشبینی ترافیک جادهای [ 10 ]، حفاظت از میراث فرهنگی [ 11 ]، هواشناسی یا آمار اقلیم شناسی [ 12 ]، و نظارت بر محیط زیست [ 13 ]، به نام چند.
با این حال، در حال حاضر، بیشتر برنامه های کاربردی مرتبط با فضای مکانی به یک زیرساخت شبکه متمرکز وابسته هستند. اگرچه اخیراً شبکه های تلفن همراه (3G/4G) و Wi-Fi تقریباً همه جا وجود دارند، هنوز نمی توان پذیرفت که همیشه برای استفاده در دسترس هستند. اولاً، بلایای طبیعی ممکن است زیرساخت های ارتباطی را ناتوان کرده و باعث قطعی طولانی مدت شود [ 14 ، 15 ]. ثانیاً، در برخی موقعیتهای پرجمعیت، مانند کنسرتهای زنده، مسابقات ورزشی، یا نمایشگاههای بزرگ، انبوه مشتریان تلفن همراه ممکن است شبکه سلولی را بیش از حد بارگذاری کند و عملکرد شبکه را بدتر کند [ 16 ، 17 ]. سوم، بودجه محدود و پرهزینه ترافیک داده، به ویژه در کشورهای توسعه نیافته و در حال توسعه، همانطور که درشکل 2 [ 18 ، 19 ] و استراتژی های قیمت گذاری وابسته به زمان (TDP) [ 20 ] بر نگرش مشترکین نسبت به استفاده از داده تأثیر می گذارد. کاربران احتمالاً ترجیح می دهند سهمیه داده را حفظ کنند یا در لحظه ای که نیاز به دسترسی به اطلاعات مکانی دارند حجم داده کافی باقی نمی ماند. در نهایت، اگرچه نقاط اتصال Wi-Fi همیشه در حال رشد مستقر شده اند [ 21 ]، جستجو برای مواردی که به طور آشکار قابل دسترسی هستند هنوز کار آسانی نیست، حتی در مناطق شهری [ 22 ]]. اکثر نقاط دسترسی قابل کشف با رمز عبور محافظت می شوند و برخی از آنها احراز هویت یا ثبت نام را از طریق پورتال ها اعمال می کنند. حتی اگر یک کاربر در حال حرکت به اندازه کافی خوش شانس باشد که یک AP قابل استفاده رایگان پیدا کند، به دلیل پوشش رادیویی محدودش قادر به ارائه اتصالات دائمی برای او نیست [ 23 ].
با در نظر گرفتن تمام این موارد، کاملاً منطقی است که یک روش جایگزین بدون زیرساخت برای به دست آوردن و تبادل محتوای مکانی ارزش بررسی داشته باشد. در واقع، بسیاری از آثار علمی گذشته دارای شواهد امکانسنجی مستند و ابزارهای عملی برای رسیدن به این هدف هستند. مهمتر از همه، تأیید شده است که کاربران تمایل بیشتری برای تحمل محتوای حساس به زمان نشان می دهند [ 24 ، 25 ]. علاوه بر این، چندین رابط رادیویی با برد کوتاه داخلی، راه جدیدی را برای کاربران تلفن همراه برای انتقال مستقیم محتوا بین دستگاه های خود ارائه می دهد. این دستگاه به دستگاه (D2D) [ 26] پارادایم ارتباطی اتکا به زیرساخت ها را کاهش می دهد. علاوه بر این، مانند سناریوهای بیسیم غیرمتمرکز، به دلیل تحرک ذاتی و محدوده ارتباطی محدود دستگاههای تلفن همراه، فقدان مسیر همزمان از پایان به انتها امری عادی است که با پروتکلهای شبکه کلاسیک در تضاد است. شبکههای تحملپذیر تاخیر/اختلال (DTN) [ 27 ] انعطافپذیری و قابلیت اطمینان انتقالها را در این محیطهای چالشبرانگیز با پارادایم “store-carry-forward” افزایش میدهد. با بهرهگیری از فرصتهای مواجهه زوجی زودگذر، شبکههای فیزیکی زیربنایی ناهمگن و منابع ذخیرهسازی محلی، دادهها میتوانند بهطور ناهمزمان یک شبکه را از طریق رلههای چند هاپ طی کنند.
در نتیجه، می توان تصور کرد که ادغام D2D، DTN و اطلاعات مربوط به فضایی از دو جنبه سودمند خواهد بود: یکی این که بتوان محتوایی را که به ندرت تغییر میکند و نیاز فوری به آن ندارند، از مکانهای دور با کلاسیک دریافت کرد. قابلیتهای DTN، مانند نقشهها یا عکسهای دارای برچسب جغرافیایی [ 28 ]. مورد دیگر این است که، به لطف چنین مکانیزم ارتباطی غیرمتمرکز، برخی از اطلاعات بلادرنگ یا اضطراری می توانند قبل از گزارش به سرپرست، بین همسایگان نزدیک اعلام یا مبادله شوند، بنابراین می توان در اسرع وقت با آن آشنا شد و با آنها برخورد کرد. برخی از نمونهها راهنمایی تخلیه [ 29 ]، هشدار برای پیشگیری از تصادف [ 30 ] و بهروزرسانی وضعیتهای ترافیکی بلادرنگ [ 31 ] است.]، بین دیگران.
در عین حال، باید پذیرفت که تحقیقات در مورد DTN آشکارا مغرضانه است. ادبیات حجیم بر استراتژیها (مسیریابی، ذخیرهسازی، کنترل تراکم، تشویق انگیزه، و غیره) تمرکز دارد، در حالی که تنها بخش کوچکی از کار تحقیقاتی به استقرار و کاربرد واقعی اختصاص دارد. در نتیجه، هنوز راه زیادی برای بهره برداری کامل از پتانسیل DTN در یک محیط واقعی وجود دارد. پر کردن این شکاف بین جنبه های نظری و تجربی DTN یکی از انگیزه های اصلی تحقیق ما است.
در کار قبلی ما [ 32]، ما یک سیستم نمونه اولیه بی سیم به نام GeoTile را برای جمع آوری داده های مکانی از طریق گره های رله چند هاپ متصل پیاده سازی کرده ایم. ما به طور کامل مطالعه کردیم که حافظه پنهان درون شبکه تا چه حد می تواند برای کاربر نهایی و عملکرد کلی مفید باشد. در این مقاله، از طریق ادغام با DTN، اتصالات پایدار بین گره ها را می توان به موارد متناوب گسترش داد. ما همچنین به بررسی مکانیسمهای حمایتی برای ارائه سازگاری بهتر با زمینههای تلفن همراه میپردازیم. هدف اصلی این کار ارائه یک روش تکمیلی برای کاربران تلفن همراه برای به دست آوردن یا تبادل داده های مکانی در موارد استثنایی است، به عنوان مثال، زمانی که شبکه های بی سیم دیگر در حال حاضر در دسترس نیستند یا رویدادهای فوری اتفاق افتاده است. این به طور مشابه برای برنامه های کاربردی جمع سپاری سودآور خواهد بود،
به طور خلاصه، نکات برجسته کار در این مقاله به شرح زیر است. در مرحله اول، ما یک سیستم توزیع شده را با هدف به اشتراک گذاری محتوای جغرافیایی در محیط های فرصت طلب پیشنهاد می کنیم. در مرحله دوم، برای مشخص کردن تحرک کاربران و تجسم آن در یک نمایش مختصر تر، یک طرح پارتیشن نقشه چند لایه ای را معرفی می کنیم که شبکه جاده و اطلاعات اداری را ترکیب می کند. ثالثاً، ما یک پروتکل مسیریابی سلسله مراتبی DTN اکتشافی طراحی می کنیم تا فرآیند ارسال بسته نرم افزاری را با تاریخچه دانش حرکت بر اساس مناطق جغرافیایی واقعی مرتبط کند. در نهایت، برای تایید درستی عملکرد سیستم و ارزیابی عملکرد سیستم، آزمایشهایی را روی یک پلت فرم شبیهسازی مبتنی بر ماشین مجازی (VM) اجرا میکنیم.
طرح کلی باقی مانده مقاله به شرح زیر است. در بخش 2 با مروری بر مطالعات آکادمیک مرتبط شروع می کنیم. در مرحله بعد، هر نقطه از کار اصلی را که در بخش 3 در بالا ذکر شد، به ترتیب ترسیم خواهیم کرد . پس از آن، نتایج ارزیابی سیستم بر روی پلت فرم شبیه سازی در بخش 4 ارائه و تحلیل می شود . ما مقاله را با نتیجه گیری و چشم انداز کار آینده در بخش 5 به پایان می بریم .
2. بررسی ادبیات
در رابطه با فرآیند اکتساب محتوا توسط گرههایی با تحرک پویا و اتصال پراکنده، چند سوال باید در نظر گرفته شود: چگونه میتوانیم کاربران عادی را قادر به انتقال نیازهای خود به گرههای آگاه DTN کنیم؟ با توجه به اینکه آنها می توانند تعامل داشته باشند، چگونه می توانیم به طور صریح محتوای مورد نظر را در منابع ذخیره شده توزیع شده شناسایی و پیدا کنیم؟ وقتی میتوان این محتویات را در جایی کشف کرد، چگونه میتوانیم در سناریوهای دنیای واقعی آنها را به طور موثر به درخواستکنندگان بازیابی کنیم؟ در این بخش به بررسی و بحث پیرامون این سه موضوع تحقیق خواهیم پرداخت.
2.1. پل زدن DTN با خدمات مبتنی بر HTTP
از آغاز فعالیتهای علمی در DTN به بعد، نحوه اعمال این تکنیک نوظهور در سرویسهای موجود در سطح برنامه یکی از مهمترین نگرانیها بوده است [ 33 ]. از آنجا که HTTP به عنوان پایه و اساس تعامل بخش بزرگی از این نوع خدمات [ 34 ] در نظر گرفته می شود، شکستن جداسازی بین HTTP و پروتکل بسته از اهمیت بالایی برخوردار است. برای این منظور، Ref. [ 35] سه روش نامزد را از دیدگاه معماری خلاصه می کند، یعنی end-to-end، proxy-based و gateway-based. مورد اول به این مورد اشاره دارد که هر دو طرف کلاینت و سرور دارای DTN هستند، بنابراین نیازی به مفسر اضافی نیست. مورد دوم، در حالی که، به طور مشابه، هر دو طرف از DTN آگاه هستند، یک گره پروکسی جلوتر از خوشه ای از سرورها قرار می گیرد، که سرورها را برای درخواست کنندگان شفاف می کند و تجمیع محتوا و تعادل بار را تسهیل می کند. در آخرین مورد، برخلاف دو روش فوق، استقرار DTN از گره های مشتری و سرور به گره های دروازه اختصاصی متصل به آنها منتقل می شود.
به عنوان شیوه های این افکار طراحی، Ref. [ 36 ] یک راه حل «پایان به انتها» برای مرور مشتری در قالب برنامه های کاربردی مبتنی بر وب از طریق DTN پیشنهاد می کند. برنامه های وب می توانند به طور خودکار مطابق با محیط اطراف کاربران نصب یا حذف شوند. با این حال، به این ترتیب، بار زیادی بر دستگاه نهایی تحمیل می شود: نه تنها باید پشتیبانی DTN داخلی داخلی باشد، بلکه باید یک وب سرور محلی نیز مستقر شود. مرجع. [ 37 ] از گزینه «مبتنی بر پروکسی» استفاده می کند و گره های هات اسپات برای بازیابی محتویات برای کاربران نهایی از سرورهای راه دور تفویض می شوند. مرجع. [ 38] از ساختار “مبتنی بر دروازه” پیروی می کند تا با استفاده از نقاط دسترسی مشترک به عنوان گره های دروازه، محتویات داخل DTN را برای کاربرانی که از DTN آگاه نیستند در دسترس قرار دهد. روی هم رفته، در این کار، به دلایلی که اولاً، از منظر پیادهسازی کمترین تلاش برای اصلاح عملکردهای موجود کلاینتها و سرورها لازم است، رویکرد «مبتنی بر دروازه» را اتخاذ میکنیم. ثانیا، دانش کمی در مورد DTN برای کاربران لازم است. ثالثاً، جداسازی DTN باعث می شود سیستم همه منظوره تر، توسعه پذیرتر و انعطاف پذیرتر باشد. اگرچه ایده اصلی کار ما شباهت هایی به [ 38 ] دارد]، در طراحی ما، گرههای دروازه، APهای تخصصی نیستند، بلکه دستگاههای معمولی حملشده توسط انسان یا سوار بر وسیله نقلیه هستند. جدای از سه مدل معمولی، با هدف ارائه پشتیبانی از طیف وسیع تری از برنامه ها با لایه پایینی یکپارچه، Ref. [ 39 ، 40 ، 41 ] پلتفرم های میان افزار را تصور می کنند. با این وجود، طرحهای ناهمگن و ناسازگار آنها، تولید مثل و استقرار را پیچیده میکند. توسعه دهندگان باید با مشخصات API داده شده مطابقت داشته باشند تا برنامه ها را بر روی آنها قرار دهند.
2.2. به نام بازیابی محتوا
بدون شک، تحولی در نحوه استفاده از شبکه رخ داده است، زیرا چندین گزارش اخیر [ 42 ، 43 ] نشان میدهد که ترافیک دادهها به طور عمده تحت سلطه محتوای دیجیتالی است. چنین روند جدیدی نشان می دهد که به جای مکالمات “پایان به انتها”، اکنون کاربران بیشتر به دنبال به دست آوردن مطالب مورد نظر به طور موثر هستند.
به طور ناامید کننده ای، پروتکل های مرتبط با اینترنت واقعاً در این جنبه خوب نیستند: مشکل “پوسیدگی پیوند” [ 44 ، 45 ] اغلب باعث عدم دسترسی می شود، و درخواست های میزبان محور هدف منجر به ارسال های مکرر و اتلاف قابل توجهی در پهنای باند می شود [ 46 ]. اگرچه اقدامات اصلاحی مانند شبکه توزیع محتوا (CDN) و پوششهای همتا به همتا (P2P) پیشنهاد شدهاند، این روشهای وصلهسازی بهطور اجتنابناپذیری پیچیدگی و مشکلات غیرمنتظرهای را ایجاد میکنند، زیرا هزینه مالی بالایی برای ناشران محتوا و هزینه نگهداری برای ارائهدهندگان خدمات دارد. در CDN [ 47 ]؛ و مقدار زیادی از ترافیک بین ISP که با سیاست های ISP ها در P2P در تضاد است [ 48 ].
این همان چیزی است که جوامع دانشگاهی را بر آن می دارد تا در طراحی های محتوای محور پاک برای نسل بعدی شبکه های بین المللی تجدید نظر کنند. در میان همه پیشنهادها، شبکه اطلاعات محور (ICN) [ 49 ] راه حلی نماینده است که توجه زیادی را به خود جلب می کند. برخلاف شبکههای مبتنی بر IP مرسوم، ICN به طور بومی به محتواها و نامهای منحصربهفرد آنها امتیاز میدهد تا در خدمت هدف انتشار کارآمد و کاهش بار شبکه باشند.
جالب توجه است، علیرغم برخی تفاوتها در سناریوهای قابل اجرا، DTN اشتراکات زیادی با ICN در رابطه با حافظه پنهان درون شبکه، تکنیک اتصال دیرهنگام، انتقال هاپ به هاپ و مدل تعامل ناهمزمان دارد. بنابراین، قرض گرفتن ایده های اصلی ICN برای مقابله با ناکارآمدی اکتساب محتوا و استفاده از منابع در DTN قابل قبول است. اخیراً، چندین کار تحقیقاتی سعی در گسترش مستقیم رویکردهای ICN به DTN دارند [ 50 ، 51 ، 52 ، 53]. با این حال، چنین مهاجرتی نه بی دردسر است و نه بدون درز. برای یک چیز، مطالعات ICN هنوز در مراحل اولیه خود هستند و بسیاری از مشکلات حل نشده باقی مانده اند. برای دیگری، باید توجه داشت که ICN و DTN تفاوت های معماری اساسی دارند.
برای به دست آوردن هم افزایی با سرمایه گذاری کمتر، گروه تحقیقاتی شبکه با تحمل تاخیر (DTNRG) مکانیسم پرس و جو پروتکل بسته (BPQ) را پیشنهاد می کند [ 54 ]. BPQ نامگذاری محتوا و همچنین تطبیق، ذخیره سازی و مسیریابی مبتنی بر نام را امکان پذیر می کند. مهمتر از آن، سازگاری با استانداردهای DTN پیشین است، به این معنی که تغییرات در چارچوب اصلی را می توان به حداقل رساند و کارهای موجود در DTN هنوز ارزش های خود را دارند. حتی اگر BPQ اغلب در مقالات گذشته ذکر شده است [ 55 ، 56 ، 57 ، 58 ]، به طور کامل در کارهای تحقیقاتی مورد استفاده قرار نمی گیرد. تا آنجا که می دانیم، تنها دو مقاله BPQ را عملی کردند: در [ 59]، BPQ برای ادغام پشته پروتکل DTN و شبکه داده (NDN) نامگذاری شده است [ 60 ]. مرجع. [ 61 ] یک معماری برای بارگذاری محتویاتی ارائه می دهد که حجیم هستند و مهلت تحویل محدودی از شبکه سلولی به شبکه محلی DTN ندارند، که در آن BPQ برای جستجوی محتوا در میان گره های DTN کار می کند. برای بررسی بیشتر امکانات BPQ، در این مقاله، BPQ را برای انتشار دادههای مکانی اعمال میکنیم. علاوه بر این، نشانگرهای موقعیت مکانی در بستههای فعال BPQ گنجانده شدهاند تا اطلاعات بیشتری را برای تصمیمگیریهای مسیریابی تکمیل کنند.
2.3. پارتیشن بندی منطقه مبتنی بر نقشه برای انتشار محتوا
مشخص است که تحرک یکی از ویژگی های غالب شبکه DTN است. توپولوژی شبکه نامشخص و تکه تکه مانع اصلی برای گفتن دقیق نحوه و مکان تماس با یک گره معین در مواقع ضروری در یک محیط توزیع شده است. خوشبختانه در حرکت مردم تناوب و منظم بودن تا حدی، هم در بعد اجتماعی [ 62 ] و هم از جنبه جغرافیایی [ 63 ] به طور ضمنی وجود دارد. به عبارت دیگر، افراد تمایل دارند با گروهی از افراد ملاقات کنند و بیشتر به مجموعه ای از مکان ها بروند.
با انگیزه این یافتهها، علیرغم کمبود دانش جهانی در زمان واقعی از یک شبکه، محققان تلاش کردهاند تا با برونیابی رفتارهای آینده از دانش تاریخی روابط اجتماعی [ 64 ] یا حرکات فضایی، در مؤثرتر و معنادارتر کردن DTN پیشرفت کنند. [ 65 ]. در این مقاله، ما بیشتر به روابط جغرافیایی و نه توپولوژیکی بین گره ها علاقه مندیم. ناگفته نماند که گرفتن دقیق الگوی تحرک گره ها به دقت استراتژی های مسیریابی کمک زیادی می کند.
در همین حال، صرفاً ثبت مقدار زیادی از مختصات GPS خام، مصرف بیش از حد ذخیره سازی و محاسبات فشرده برای یادگیری منظم بودن ردیابی متحرک را به همراه خواهد داشت، که نامطلوب است زیرا گره ها در DTN معمولاً با منابع محدود هستند. یکی از راه حل های عملی روش های منطقه محور است. با تقسیم کل منطقه به یک سری از زیرمنطقهها، موقعیت یک گره را میتوان با زیر ناحیهای که در حال حاضر در آن قرار دارد نشان داد، و همچنین، روند حرکت یک گره را میتوان به عنوان یک دنباله گسسته از زیرمنطقهها ساده کرد. در حالی که راه های مختلفی برای تولید زیرمنطقه ها در آثار موجود ارائه شده است، از جمله شکستن به اشکال منظم [ 66 ، 67 ، 68 ، 69 ]، پارتیشن بندی هندسی [ 70 ،71 ]، و خوشهبندی مصنوعی [ 72 ، 73 ] و غیره، یک کاستی آشکار این است که هیچکدام از آنها با محیطهای واقعی همخوانی ندارند، زیرا از مرزهای طبیعی مانند جادهها، ریلها، رودخانهها، حاشیه بیرونی ساختمانها و غیره غفلت میکنند. . بهویژه برای اکثر روشهای مبتنی بر شبکه استفاده میشود، اگرچه کنترل اندازه منطقه، کدگذاری منطقه و حفظ اطلاعات سلسله مراتبی آسانتر است، برخی از محققان خاطرنشان میکنند که تعیین اندازه، موقعیت و جهتگیری شبکهها دلخواه است [ 74 ]. ]، و واحد اندازه ثابت برای منعکس کردن تراکم کاربران و فعالیت های آنها کافی نیست [ 75 ]. در نتیجه، از نظر ماکروسکوپی، روشها بیش از همه در به تصویر کشیدن «فضای فعالیت» کوتاهی میکنند [ 76 ]]، که به مناطقی اطلاق میشود که با سیر روتینهای روزمره افراد مشخص میشوند و از نظر میکروسکوپی، اقدامات حرکت در آن سوی مرزها کممعنا میشوند، زیرا ممکن است فرد صرفاً با سرگردانی در خانه یا محل کار خود، گذرگاههایی ایجاد کند.
به منظور ایجاد ارتباط محکمتر بین فعالیتهای مکانی-زمانی روزانه ساکنان و تقسیمبندی مناطق فرعی، مرزهای مقیاس کوچک با ویژگیهای اداری، بهعنوان مثال، مناطق سرشماری، مناطق کد پستی، یا حوزههای رأیگیری ظاهراً انتخابهای بهتری هستند. آنها صرفاً تقریبهای معقولی برای ساختارهای جامعهشناختی مانند محلههای مسکونی، بلوکهای خیابانی و جوامع نیستند [ 77 ، 78 ]، بلکه ویژگیهای جمعیتی و اجتماعی-اقتصادی را نیز نشان میدهند [ 79 ، 80 ]. همانطور که محققان بیشتر به مزایای چنین روش هایی پی می برند، سال های اخیر شاهد پذیرش گسترده آنها توسط مطالعات چند رشته ای، مانند جرم شناسی [ 81 ]، بهداشت عمومی [81] بوده است.82 ، 83 ]، برنامه ریزی شهری [ 84 ] و غیره. بسیاری از موارد [ 85 ، 86 ، 87 ] ثابت کرده اند که روش های مبتنی بر منطقه می توانند از روش های مبتنی بر شبکه بهتر عمل کنند.
امیدواریم چنین روش هایی به طور مشابه برای تحقیقات در زمینه محاسبات تلفن همراه مفید باشد. با دستور این ایده، ما سعی می کنیم یک طرح پارتیشن بندی نقشه چند سطحی بر اساس شبکه جاده ها و مرزهای اداری ایجاد کنیم. ما انتظار داریم که پایه ای ملموس برای طراحی پروتکل یا برنامه کاربردی آینده ایجاد کند. به طور خاص، مسیریابی پیشبینیکننده بر اساس تجزیه و تحلیل مسیرهای تاریخی، یا ژئوکستینگ [ 88 ، 89 ] که هدف آن هدایت پیامهای خاص (مانند کمپینهای تبلیغاتی یا اعلانهای اضطراری) به مکانهای هدف است.
تقسیم بندی نقشه بر اساس شبکه جاده های شهرهای بزرگ نیز در [ 90 ، 91 ] به عنوان اساس کار آنها ظاهر شد. مرجع. [ 91 ] نقشه را به صورت بازگشتی به چندین سطح بر اساس سلسله مراتب جاده تقسیم می کند، اما این برای انعکاس ویژگی های اداری کافی نیست. در روش خود، ما تلاش خواهیم کرد تا نتیجه تقسیم بندی را با زیربخش های اداری تراز کنیم. مرجع. [ 90 ] اسکلت جاده را با تکنیکهای پردازش تصویر، با قربانی کردن ابردادههایی که ویژگیهای اشیاء برداری را توصیف میکنند، استخراج میکند. در مقابل، بخشبندی روش ما صرفاً از طریق پردازش بر روی دادههای برداری است و ابردادهها را میتوان برای استفاده در آینده حفظ کرد.
3. سیستم موبایل Geo-DMP
در این بخش، به ترتیب در بخشهای بعدی، هر یک از اجزای کار خود را توضیح خواهیم داد. به طور خاص، ما با معرفی چارچوب Geo-DMP شروع می کنیم. پس از آن، گردش کار و مکانیسم بازیابی محتوای با تحمل تاخیر به تفصیل شرح داده می شود. در مرحله بعد، روش پارتیشن بندی نقشه به مناطق را با در نظر گرفتن مرزهای اداری، همراه با سودمندی مناطق تقسیم شده در طراحی پروتکل مسیریابی ارائه می کنیم.
3.1. چارچوب سیستم
همانطور که در شکل 3 نشان داده شده است، چارچوب Geo-DMP از سه ماژول اصلی تشکیل شده است: عامل محتوا، پشته DTN و آداپتور نقشه. عامل محتوا پیاده سازی خود ما برای تحقق “مدل مبتنی بر دروازه” است. روی گرههای دروازه مستقر میشود و از طرف برنامه با DTN تعامل میکند و در نتیجه DTN را برای کاربر شفاف میکند. قلب عامل محتوا ماژول پروکسی است. با هر پروکسی [ 92]، یک ابزار پروکسی با منبع باز جاوا اسکریپت نوشته شده است. با ویژگی اصلی هر پروکسی، که رهگیری درخواستهای HTTP ورودی و ایجاد پاسخهای HTTP جدید است، ما تبدیل بین پیامهای HTTP و بستههای DTN و همچنین استفاده از حافظه پنهان محلی را توسعه دادیم. محتویات دریافتی قبلی در حافظه پنهان محلی ذخیره میشوند تا فوراً درخواستهای محلی تکرار شونده و پاسخ به درخواستهای سایر گرهها در آینده نزدیک ارائه شوند.
پشته DTN که ما در کار خود استفاده می کنیم DTN2 [ 93 ] است. DTN2 یک پیاده سازی مرجع منبع باز از پشته کامل پروتکل DTN است که با اسناد RFC [ 94 ، 95 ، 96 ] سازگار است و توسط DTNRG در C++ توسعه یافته است.
به عنوان یک پیشنهاد امیدوارکننده، اجرای کد مکانیسم BPQ نیز در آخرین نسخه DTN2 گنجانده شده است. ما از این کار سود می بریم و از آن برای نامگذاری و تطبیق محتوا استفاده می کنیم. دو ساختار داده هسته اصلی تعریف BPQ را تشکیل می دهند: بلوک BPQ و حافظه پنهان BPQ. بلوک BPQ یک بلوک افزودنی در هدر بسته است. عمدتاً نام محتوا را ضبط می کند و نوع بسته را مشخص می کند تا از نامگذاری محتوا و مدل ارتباطی میخانه/فرعی پشتیبانی کند. برای تشخیص بستههای دارای بلوک BPQ از بستههای معمولی، دو نوع بسته متمایز جدید تعریف شدهاند: پرس و جو و پاسخ. همانطور که از نام آنها پیداست، اولی محتوایی را که درخواست کننده می خواهد منتقل می کند، در حالی که دومی محتوا را به درخواست کننده باز می گرداند. از آنجایی که این بلوک اجباری نیست،
BPQ Cache منابع محتوایی را مدیریت می کند که BPQ می تواند از آنها استفاده کند، یعنی شامل تمام اطلاعات بسته های پاسخ است. لازم به ذکر است که اگرچه بسته پرس و جو نیز عضوی از بسته BPQ فعال است، اما در حافظه پنهان BPQ گنجانده نشده است زیرا هیچ داده بارگیری ندارد. علاوه بر این، بسته نرمال از کش BPQ نیز حذف شده است. این به این دلیل است که محموله آن نامی ندارد، بنابراین BPQ نمی تواند از آن استفاده کند.
DTN Daemon محور DTN2 است که به عنوان یک کنترل کننده مرکزی و زمانبندی عمل می کند. مسئولیت رسیدگی به تمام رویدادهای ورودی و ارسال کارها به سایر اجزای اختصاصی را بر عهده دارد. Bundle List مکانی است که همه بستههای محلی، از جمله باندلهای معمولی و بستههای دارای BPQ فعال را نگهداری میکند. به عبارت دیگر، BPQ Cache زیرمجموعه ای از Bundle List است.
“Trace Reader” و “Link Emulator” دو ماژول هستند که شامل شبیه سازی هستند. اولی GPS گره موبایل را شبیه سازی می کند. بنا به درخواست مکان، مختصات GPS را از یک فایل ردیابی از پیش تولید شده گزارش می کند. این ماژول می تواند با یک گیرنده GPS واقعی جایگزین شود که پیاده سازی به دستگاه های واقعی منتقل می شود و سایر قسمت ها در لایه های بالایی بدون تغییر باقی می مانند. دومی ایجاد و قطع شدن پیوندها را کنترل می کند. به صورت دورهای، مکان بلادرنگ از خواننده ردیابی مشتق میشود و در یک بسته بیکن پخش میشود. هنگام دریافت بسته بیکن از گره دیگری، شبیه ساز پیوند فاصله بین آنها تا جدولی به نام “فاصله های همسایه” را ثبت می کند. با این جدول، گره محلی می تواند قضاوت کند که آیا در محدوده ارتباطی از پیش تعیین شده با منبع یک بسته معمولی ورودی قرار دارد یا خیر، و آن را رها کند یا آن را بر این اساس منتقل کند. همانطور که این ماژول روی لایه شبکه در فضای هسته لینوکس کار می کند، فیلتراسیون برای DTN شفاف است.
برای تطبیق بهتر بازیابی محتوای مبتنی بر BPQ با سناریوهای مبتنی بر نقشه واقعی، ماژول آداپتور نقشه را ارائه میکنیم. این شامل یک پایگاه داده محلی از نتایج تقسیم بندی نقشه و یک رابط است. در فواصل زمانی ثابت، DTN با ارسال یک پرس و جو به رابط، اطلاعات منطقه را درخواست می کند. رابط، مختصات GPS فعلی را از ماژول ردیابی یا GPS می خواند، پایگاه داده را با مختصات می پرسد، و مناطقی را که گره در حال حاضر در آن قرار دارد، برمی گرداند. سپس، DTN این اطلاعات منطقهای را در ماژول “Movement History Maintanence” برای استفادههای آتی در تصمیمگیری مسیریابی به صورت محلی و تبادل دانش حرکت در هنگام تماس با سایر گرهها ذخیره میکند. فرآیند ایجاد پایگاه داده تقسیم بندی نقشه در بخش 3.3 ارائه خواهد شد .
3.2. گردش کار Geo-DMP
پس از یک مرور کلی سیستماتیک از چارچوب، با توضیح بیشتر در مورد تبدیل و مدیریت انواع مختلف واحدهای داده که در فرآیند بازیابی محتوا رخ داده اند، مکانیسم کار Geo-DMP را نشان می دهیم.
3.2.1. از دیدگاه تحولات بین پیامهای HTTP و بستههای DTN
در این بخش، ما بر تعاملات روی گرههای دروازه تمرکز میکنیم که گرههای آگاه از DTN را با مشتری و سرور متصل میکنند. همانطور که فرآیند تماس با سمت سرور باید روشن شود، در اینجا ما وضعیت کشف کپی در گره های DTN میانی را در نظر نمی گیریم. کل فرآیند را می توان به چهار مرحله تقسیم کرد، همانطور که در شکل 4 نشان داده شده است.
فاز 1: درخواست HTTP به درخواست DTN (سمت مشتری)
پروکسی در ترمینال گیتوی (از این پس TG) به درخواستهای HTTP گوش میدهد و آنهایی را که در پرتو قوانین از پیش تعریفشده درخواست محتوای جغرافیایی میکنند، رهگیری میکند. سپس نوع و نام دادههای درخواستی را از URL تعیین میکند و بررسی میکند که آیا این محتوا از قبل به صورت محلی در دسترس است یا خیر. اگر بله، بدون استفاده از DTN بلافاصله محتوا را به مشتری برمی گرداند. در غیر این صورت، یک بسته پرس و جو جدید با پارامترهای EID مقصد، مناطق مقصد و نام محتوا ایجاد می شود. پس از آن، پروکسی DTN API را فراخوانی می کند تا این بسته را به شبکه DTN تزریق کند.
فاز 2: درخواست DTN به درخواست HTTP (سمت سرور)
از طریق رله چند جهشی گرههای DTN، هنگامی که بسته پرس و جو به دروازه سرور (از این پس SG) میرسد، DTN نام محتوا را از بلوک BPQ استخراج کرده و به ماژول پروکسی میدهد. سپس پروکسی از سرور بکاند آن محتوا را با یک درخواست HTTP جدید ایجاد شده درخواست میکند.
فاز 3: پاسخ HTTP به پاسخ DTN (سمت سرور)
پس از پردازش در داخل سرور (که در مقاله قبلی ما [ 32 ] توضیح داده شد)، پاسخ HTTP تولید شده و به SG بازگردانده می شود. پراکسی در SG پاسخ HTTP را باز می کند و DTN API را فرا می خواند تا این محتوا را در شبکه DTN منتشر کند. پس از آن، این محتوا برای برآوردن بسته پرس و جو در انتظار و ایجاد بسته پاسخ مربوطه استفاده می شود.
فاز 4: پاسخ DTN به پاسخ HTTP (سمت مشتری)
در نهایت، هنگامی که بسته پاسخ به TG هدایت می شود، DTN نام محتوا را از بلوک BPQ می خواند و به پراکسی اطلاع می دهد که محتوا آماده است. پس از آن، پروکسی به واکشی محتوا میرود، payload را در حافظه پنهان محلی ذخیره میکند، یک پاسخ HTTP جدید ایجاد میکند و با برگرداندن آن به مشتری، فرآیند را به پایان میرساند.
3.2.2. از دیدگاه مدیریت بستههای فعال شده با BPQ ورودی
در مرحله بعد، ما نگاهی دقیقتر به عملیاتهایی که در داخل گرههای DTN میانی انجام میشوند و نحوه عملکرد BPQ برای کشف محتوا در طول رله چند جهشی بستههای دارای BPQ فعال میکنیم. بسته به انواع مختلف بسته ورودی، فرآیند داخلی را می توان در سه موقعیت مورد بحث قرار داد.
1. پس از دریافت پرس و جو ایجاد شده جدید
هنگامی که DTN Daemon یک رویداد را که نشان دهنده ورود یک بسته از صف رویداد است، خارج می کند، اولین قدم تشخیص نوع و منبع بسته است. هنگامی که یک BPQ Block در هدر بسته پیدا شود و مقدار فیلد نوع “پرس و جو” باشد، بسته به عنوان یک بسته پرس و جو شناسایی می شود. اگر EID منبع با گره محلی یکسان باشد، به این معنی است که این بسته به تازگی به صورت محلی تولید شده است. از آنجایی که ایجاد بسته پرس و جو فقط پس از اینکه پروکسی نتواند محتوای درخواستی را در حافظه پنهان محلی پیدا کند اتفاق میافتد، این بسته در حال حاضر نمیتواند راضی شود. بنابراین در لیست بستهای نگه داشته میشود تا منتظر شود تا به گرههای دیگر هدایت شود یا با محتوای ورودی مطابقت داده شود. این فرآیند در شکل 5 نشان داده شده است .
2. پس از دریافت پرس و جو خارجی
هنگامی که یک بسته دریافتی به عنوان یک بسته پرس و جو از گره دیگری شناسایی می شود (یعنی EID منبع آن با بسته محلی متفاوت است)، DTN Daemon پس از قرار دادن آن در لیست بسته، سعی می کند آن را برآورده کند. ابتدا، DTN Daemon نام محتوای مشخص شده در بسته query را به ماژول BPQ می دهد. ثانیا، ماژول BPQ این نام را با موارد موجود در حافظه پنهان BPQ مطابقت می دهد تا ببیند آیا محتوای مورد نظر به صورت محلی ذخیره شده است یا خیر. ثالثاً، در صورت یافتن، بدنه محتوا تکرار شده و با اطلاعات مربوط به هدر بسته به عنوان یک بسته پاسخ جدید جمعآوری میشود، سپس به BPQ Cache و Bundle List منتقل میشود. اینکه آیا این بسته پاسخ به همسایه فعلی ارسال شود یا نه، منوط به تصمیم پروتکل مسیریابی است. از آنجایی که بسته پرس و جو وظیفه خود را برای یافتن محتوا انجام داده است، از لیست بسته حذف خواهد شد.شکل 6 این فرآیند را نشان می دهد که در آن فلش های سبز نشان دهنده مراحل پس از تطبیق موفقیت آمیز هستند.
3. پس از دریافت پاسخ بیرونی
پس از شناسایی، اگر بسته دریافتی یک بسته پاسخ از گره دیگری باشد، ابتدا در فهرست بسته و کش BPQ ذخیره می شود. متعاقباً، ماژول BPQ بررسی میکند که آیا میتوان از این محتوای جدید برای برآوردن درخواستهای منتظر محلی استفاده کرد یا خیر. مطابقتهای موفقیتآمیز بستههای پاسخ جدید مربوطه را ایجاد میکنند. باز هم، این بستههای پاسخ به BPQ Cache و Bundle List منتقل میشوند در حالی که بستههای پرس و جو راضی شده حذف میشوند. سپس پروتکل مسیریابی به طور انتخابی برخی از این بستههای پاسخ را به همسایه در تماس ارسال میکند. این فرآیند را می توان در شکل 7 مشاهده کرد.
3.3. توسعه ماژول آداپتور نقشه
در مرحله بعد، فرآیند تولید یکی دیگر از اجزای کلیدی چارچوب، آداپتور نقشه را ارائه خواهیم کرد. به طور خلاصه، ما نقشه برداری را به سه لایه تودرتو با اندازه منطقه مناسب و همچنین مطابق با گونهشناسی معمول در مطالعات جامعهشناسی [ 97 ] تقسیم میکنیم: بلوکها، جوامع، و بخشهای فرعی. سپس آنها را به یک پایگاه داده فشرده و قابل حمل برای دستگاه های تلفن همراه تبدیل می کنیم. منطقه Haidian، که یکی از توسعه یافته ترین و فعال ترین مکان در مرکز پکن است، به عنوان منطقه مطالعه ما انتخاب شده است. پیشنهاد ما به طور کامل با داده های برداری عمومی و نرم افزارهای غیر تجاری اجرا می شود. داده های برداری خامی که ما استفاده می کنیم مجموعه داده گزیده ای از پکن از OSM [ 98 ] است.
1. شبکه راه
برای شروع، ما اسکلت جاده را به عنوان پایه تقسیم بندی استخراج می کنیم زیرا می تواند معنی دارترین مرزهای شهر را نشان دهد. ما دادههای خام را به پایگاه داده PostgreSQL [ 99 ] با پشتیبانی PostGIS [ 100 ] (یک توسعه جغرافیایی برای PostgreSQL) وارد کردیم و شش دسته جاده اصلی را با برچسبهایشان انتخاب کردیم تا شبکه جاده ناهموار را تشکیل دهیم. آنها به ترتیب بزرگراه ، تنه ، اولیه ، ثانویه ، سوم و مسکونی هستند. سایر انواع جادهها به دلیل جزئیات بیش از حد آنها مستثنی هستند. نتیجه همانطور که در شکل 8 نشان داده شده است.
2. چند ضلعی
چند ضلعی سازی فرآیندی است که در آن ما می توانیم چند ضلعی های منطقه را از خطوط جاده استخراج کنیم. ایده اصلی روشی که در نظر می گیریم [ 101 ] این است که از آنجایی که اشیاء خط ورودی واحدهای ابتدایی برای محاسبه اشیاء چند ضلعی هستند، خطوط کوتاه و کوچک به نفع ساخت چند ضلعی های دقیق تر و دقیق تر خواهند بود. بنابراین، خطوط جاده به کوچکترین قطعات شکسته می شوند (هر قطعه فقط شامل دو نقطه است) به عنوان مواد خام برای تابع چندضلعی ارائه شده توسط Shapely [ 102 ]، یک بسته پایتون برای هندسه محاسباتی. همانطور که از شکل 9 مشاهده می کنیم ، پس از چند ضلعی، همه اشیا به چند ضلعی محصور تبدیل می شوند و خطوطی که نمی توانند چند ضلعی تشکیل دهند حذف می شوند.
3. بلوک
همانطور که از خروجی مرحله قبل مشاهده می شود، به عنوان محصولات جانبی چند ضلعی، تعدادی سلول ریز نامطلوب تولید می شود و برخی از آنها حتی برای قابل تشخیص بودن بسیار کوچک هستند. برای حل این مشکل، مساحت همه اشیاء چند ضلعی را محاسبه کرده و آنهای کوچک را فیلتر میکنیم (کمتر از 0.01 کیلومتر). 2به عنوان معیار کلی). سپس آنها را با چند ضلعی بزرگتر که آنها را در بر می گیرد یا به آنها نزدیک می شود ادغام می کنیم. قوانین اساسی عملیات ادغام عبارتند از: (1) منظم بودن: در فرض عدم آسیب رساندن به خطوط جاده اصلی، اگر یک چند ضلعی کوچک با چند ضلعی بزرگتر برخورد کند، راهی را انتخاب می کنیم که شکل چند ضلعی ادغام شده را منظم و ساده می کند. تا جایی که ممکن است. (2) تقارن: برای برخورد با چند ضلعی های کوچکی که در اطراف جاده ها یا تقاطع های موازی ایجاد می شوند، به خط مرکزی جاده یا محور مرکزی تعامل اشاره می کنیم و آنها را با چند ضلعی های بزرگتر در همان سمت ادغام می کنیم. (3) سازگاری: اگر عملیات ادغام انجام شود، به مرجع بقیه در امتداد همان جاده یا جهت تبدیل می شود تا مرزهای ادغام شده کلی پیوسته و هموار شود. این عملیات در QGIS [ 103]، مجموعه ای رایگان و منبع باز و در عین حال قدرتمند GIS. پس از تکمیل ادغام، نواحی بلوکی به دست میآیند ( شکل 10 )، که مناطقی با بهترین دانهبندی هستند.
4. مناطق فرعی و جوامع
از آنجایی که انتظار داریم روش تقسیمبندی نقشه ما بتواند ویژگیهای اداری را منعکس کند، استفاده از مرزهای اداری موجود انتخاب ایدهآلی خواهد بود. با این حال، مناطق، که مرزهای آنها خارج از قفسه از داده های برداری OSM است، برای گرفتن تحرک کاربران بزرگ هستند. بنابراین تقسیمات اداری در مقیاس کوچکتر مورد نظر است. با این حال، بر خلاف برخی از کشورها، مطابق با قوانین و مقررات چین، مرزهای کوچکتر از مناطق به طور رسمی منتشر نمی شود. برای پرداختن به این موضوع، با اطلاعات مربوط به خیابان ها و نواحی فرعی [ 104 ]، ما تقریباً مرزهای مناطق فرعی را از طریق پیوستن به چند ضلعی های بلوک تعیین می کنیم ( شکل 11 ).
پس از آن، برای تشکیل یک سلسله مراتب، باید سطح دیگری بین لایه بلوک و لایه زیر ناحیه ایجاد کنیم. به همین ترتیب، ما چنین سطحی را از طریق پیوستن به مناطق بلوک تولید می کنیم. به منظور اهمیت عملی بهتر، عملیات اتصال از اصول زیر پیروی می کند: (1) اندازه این مناطق باید در وسط بلوک ها و نواحی فرعی باشد. (2) آنها باید رابطه تابعیت را با مرزهای ناحیه بالایی حفظ کنند. (3) مناطق بلوک به هم پیوسته که دارای پیوندهای اجتماعی تجربی هستند باید به عنوان اولویت به یکدیگر ملحق شوند. نتیجه لایه جدید در شکل 12 نشان داده شده است . مقیاس این لایه می تواند مشابه جوامع باشد. همانطور که از آمار جدول 1 پیداست، این سه لایه از نظر اندازه به خوبی متمایز هستند و سلسله مراتب معقولی را تشکیل می دهند. به طور کلی، هر زیر ناحیه شامل حدود 3-5 انجمن و یک جامعه شامل حدود 3-4 بلوک است که تا حد زیادی با وضعیت واقعی مطابقت دارد. علاوه بر این، از آنجایی که هدف تقسیم بندی نقشه خدمت به بازیابی محتوا است، امیدواریم که از پیشرفت رله چند هاپ نیز پشتیبانی کند. از آنجایی که لایه جامعه در سطح متوسط قرار دارد، باید بتواند تغییر ناپذیری را منعکس کند، به عنوان مثال، جابجایی ها و تبادل داده ها در یک محدوده کوچک اتفاق افتاده است. با توجه به اینکه محدوده ارتباطی معمولی گره ها در VANET می تواند تا 300-500 متر باشد [ 105 ]]، قطر مناطق جامعه مشتق شده تقریباً 2-3 کیلومتر است، بنابراین 4-5 هاپ ارسال حداقل در یک منطقه جامعه امکان پذیر است، که فکر می کنیم مناسب است. تا این مرحله، تولید بخشبندی نقشه سلسله مراتبی به پایان رسیده است.
5. نامگذاری
تنها با یک قرارداد نامگذاری ساده می توان مناطق را به راحتی و به طور منحصر به فرد در استفاده عملی شناسایی کرد. در همین حال، از نظر سلسله مراتبی نیز باید مناسب باشد که این نامگذاری با تقسیم بندی نقشه سه لایه سازگار باشد. ما از کدهای تقسیم اداری برای استفاده آماری [ 106 ] (ADC)، منتشر شده توسط اداره ملی آمار چین، به عنوان پایه نامگذاری استفاده می کنیم. همانطور که در شکل 13نشان می دهد که ADC یک منطقه فرعی یک عدد 12 رقمی است. با پیروی از این الگوی نامگذاری، دو رقم به نامهای زیر ناحیه برای نامهای انجمن و دو رقم دیگر به نام انجمنها برای نام بلوکها اضافه میکنیم. ترتیب کلی کدگذاری از غرب به شرق و شمال به جنوب است. برای دقیق تر، منطقه در گوشه شمال غربی به عنوان شماره یک برچسب گذاری شده است. سپس به ترتیب شماره های سریال را برای مناطق در امتداد جهت افقی تا رسیدن به مرز شرقی تعیین می کنیم. سپس عدد بعدی به منطقه ای داده می شود که در مجاورت منطقه شماره یک در جنوب قرار دارد و غیره. به این ترتیب رابطه سلسله مراتبی به طور ضمنی در نام ها دخیل است. نام یک منطقه در سطح بالا را می توان مستقیماً از نام مناطق کوچکتر آن استنباط کرد.
6. پایگاه داده محلی
برای پشتیبانی از دسترسی پیوسته به اطلاعات منطقهای با مختصات GPS بیدرنگ تحت حالت آفلاین، یک پایگاه داده محلی مبتنی بر SQLite [ 107 ] و Spatialite [ 108 ] (افزودنی برای SQLite با قابلیتهای فضایی پیشرفته) توسعه میدهیم. دیتابیس یک فایل فشرده تنها حدود 5 مگابایت است. صرف نظر از پلتفرم، به محض اینکه یک گره با SQLite و Spatialite پیکربندی شود، فایل را می توان در گره کپی کرد و آماده استفاده است. ما عملکرد دسترسی را بر روی برد Intel Galileo (Intel Quark SoC X1000 400 MHz, 256M DRAM) آزمایش کرده ایم و برای یک پرس و جو فقط 0.25 ثانیه طول می کشد. این پایگاه داده با رابط نقشه به عنوان ماژول آداپتور نقشه ترکیب شده است. تصویر کلی مراحل ذکر شده در بالا در شکل 14 نشان داده شده است.
3.4. طرح مسیریابی بر اساس تقسیم بندی نقشه و تاریخچه حرکت
بر اساس تقسیم بندی نقشه ارائه شده در بخش قبل، ما یک طرح مسیریابی ساده طراحی کردیم، اما برای اهداف اعتبارسنجی و آزمایش کافی است.
این طرح تا حدی از کار قبلی ما به ارث رسیده است [ 109 ]، که از مزایای مناطق مربعی برای به تصویر کشیدن الگوهای حرکتی افراد و استفاده از آنها به عنوان مبنایی برای پیش بینی شانس تماس در آینده نزدیک است. از آنجایی که ما اساساً بر بازیابی محتویات مربوط به فضایی که معمولاً وابسته به مکان هستند تمرکز می کنیم، گره ای که احتمال بیشتری برای عبور از مکان هدف دارد می تواند به عنوان حامل بهتری در نظر گرفته شود، بنابراین در این جهت ادامه خواهیم داد.
در مقایسه با [ 109 ]، با حفظ ایده اصلی، تغییرات عمده ای در سه جنبه ایجاد می کنیم:
-
ما از مناطق اداری واقع گرایانه ناشی از تقسیم بندی نقشه به جای مناطق مربع ساده برای توصیف حرکت گره ها استفاده می کنیم.
-
تأکید بر طراحی مسیریابی از مبتنی بر EID (شناسه گرهها) به منطقه محور منتقل میشود، زیرا ما قصد نداریم با گرههای خاصی تماس بگیریم، اما انتظار داریم محتوای مورد نیاز را در طول مسیر به مکانهای خاص بدست آوریم.
-
علاوه بر بستههای معمولی، ما همچنین از بستههای درخواست و پاسخ با BPQ برای دستیابی به بازیابی محتوای دو جهته، مبتنی بر نام و بر اساس تقاضا پشتیبانی میکنیم.
همراه با حرکت، گره موقعیت GPS فعلی خود را در یک بازه دوره ای 5 ثانیه به دست می آورد. با جستجوی موقعیت آن از طریق رابط نقشه، مناطقی که گره در آن قرار دارد به دست می آید. بنابراین، ما مسیر دقیق را بر روی یک دنباله از مناطق فرعی، که برای مقایسه و نگهداری دوستانه تر است، نشان می دهیم. تاریخچه محلی ثبت شده مناطق عبور داده شده صرفاً برای استفاده شخصی نیست. پس از ایجاد پیوند، دو گره این اطلاعات را در قالب یک بسته نرمال مبادله می کنند. یک گره فقط می تواند مناطق تاریخچه همسایه های مستقیم خود را بیاموزد و چنین دانشی از یک همسایه خاص تنها زمانی به آخرین وضعیت به روز می شود که آن همسایه دوباره با آن روبرو شود.
به همین ترتیب، ما فیلدهای جدیدی را اضافه می کنیم که مناطق مبدا و هدف بسته را در هدر بسته نشان می دهد. همانطور که نقشه را به چندین لایه با دانه بندی های مختلف تقسیم می کنیم، منطقه روی هر لایه که مکان داده شده را در بر می گیرد، ثبت می شود. مناطق مبدأ آنهایی هستند که بسته نرم افزاری از آنها سرچشمه می گیرد. به طور دقیق تر، برای بسته های پرس و جو، آنها جایی هستند که درخواست صادر می شود، در حالی که برای بسته های پاسخ، جایی هستند که تطبیق محتوای موفق انجام می شود. فراتر از استفاده در حمل و نقل، این اطلاعات می تواند توزیع فضایی عرضه و تقاضای محتوا را تا حدی منعکس کند. از طرف دیگر، مناطقی که بسته برای آنها مقصد است، مناطق هدف هستند. نامزدهای بالقوه مناطق هدف شامل، اما محدود به موارد زیر نیستند: مکانهای شناخته شده عمومی واحد کنار جاده (RSU)، مناطق احتمالی که در آن محتویات را میتوان یافت، با بستههای پاسخ دریافتی، یا مکانهایی که به شدت با محتوای درخواستی مرتبط هستند (مثلاً بهروزرسانیهایی در مورد ترافیک یا وضعیت آبوهوا، یا عکسها و ویدیوهای کوتاه از صحنه حادثه) نشان داده شدهاند. با مناطق هدف تعیینشده و تاریخچه حرکت منطقهای جمعآوریشده، استراتژی مسیریابی تلاش میکند تا باندلها را با انتخاب پرشهای بعدی که به مناطق هدف دقیقتر نزدیکتر شدهاند، به تدریج به مقصد نزدیک کنند.
با مسیرهای حرکتی که با دنباله ای از مناطق نشان داده می شود، می توان الگوی تحرک را یاد گرفت. با این حال، چگونگی شناسایی دقیق منظم بودن گره های سیار نیز یک مشکل تحقیقاتی پیچیده است. آثار متعددی وجود دارد که این مسئله را از نظر فراوانی، تازگی و یا بهینه بودن و غیره بررسی میکند. در اینجا ما بر نشان دادن توانایی Geo-DMP در پشتیبانی از استراتژی مسیریابی مبتنی بر منطقه تأکید می کنیم. اگر بتوان الگوی تحرک بهتری را از طریق تجزیه و تحلیل مناطق تاریخی بدست آورد، می توان آن را برای Geo-DMP نیز اعمال کرد. بنابراین ما فرض می کنیم که همه گره های متحرک دارای نظم قوی هستند، به عنوان مثال، آنها در طول مسیرهای از پیش تعریف شده خود مانند اتوبوس یا تراموا به عقب و جلو حرکت می کنند. بر اساس این فرض،
همانطور که قبلا ذکر شد، یکی از ویژگی های برجسته روش تقسیم اداری این است که می تواند فعالیت های روزمره زندگی مردم را احاطه کند، یعنی فرد برای مدت طولانی در یک منطقه بماند یا حرکت کند. بنابراین، منطقی است که فرض کنیم درخواستکننده منطقه جامعه را که در آن بستههای پرس و جو را ارسال میکند، ترک نخواهد کرد. در نتیجه، هنگامی که یک بسته پرس و جو تولید یک بسته پاسخ را آغاز می کند، مناطق هدف این بسته پاسخ را می توان روی مناطق منبع آن بسته پرس و جو تنظیم کرد. با ارجاع به مناطق هدف بسته پرس و جو، از آنجایی که بسته پرس و جو احتمالاً توسط کش های میانی در طول فرآیند ارسال ارضا می شود، آنها برای مکانی که باید به آن تحویل داده شود در نظر گرفته نشدهاند، بلکه فقط به شما پیشنهاد میکنند که محتوای درخواستی بهعنوان آخرین راهحل در کجا میتواند پیدا شود. در اینجا آنها به مکانی که RSU در آن قرار دارد تنظیم می شوند. نحوه تعیین هوشمندانه مناطق هدف مناسب توسط خود DTN یکی دیگر از مشکلات تحقیقاتی جالب ما است.
برای اختصار، در شرح زیر از استراتژی مسیریابی، فرآیند ارسال یک بسته پرس و جو به عنوان مثال در نظر گرفته شده است. همین امر در مورد بسته پاسخ جدید نیز صدق می کند. بسته های پرس و جو به صورت تک کپی ارسال می شوند. ما فرض می کنیم که یک بسته پرس و جو B روی گره ایجاد می شود نآ، که مناطق مقصد آن است r1/r2/r3در نمای بالا به پایین که زیرنویس سطح را نشان می دهد. نآتصمیم خود را در مورد ارسال بسته B به یکی از همسایگان خود طبق الگوریتم 1 می گیرد. برای بیان مختصر الگوریتم، ما نشان می دهیم آر={rمن|من=1،2،3}، و نجبه عنوان بهترین گره کاندید فعلی برای پرش بعدی و حالت اولیه آن بر روی گره محلی تنظیم شده است نآ. سپس هر همسایه نمنبا توجه به ارتباط بین مناطق بازدید شده و مناطق هدف مقایسه شده است. نتیجه مقایسه را می توان به چند مورد دسته بندی کرد:
مورد اول : هیچکدام نجنه نمناز هر منطقه ای در R بازدید کرده است (خطوط 9-16)
ما متوجه شدهایم که در مدت زمانی پس از ایجاد بستهها، گره منبع به ندرت میتواند به پرش بعدی واجد شرایط دسترسی پیدا کند، به دلیل فاصله زیاد از مناطق هدف یا به دلیل اینکه بیشتر گرهها دانش کافی در مورد الگوی حرکت خود جمعآوری نکردهاند. در مرحله اولیه آزمایش برای کاهش تأثیر این مشکل شروع سرد، اولین کار این است که بستهها در اسرع وقت به سمت راست حرکت کنند. بنابراین در این مورد، فاصله بین مناطقی را که آنها در آن بوده اند اندازه گیری می کنیم ( Vجو Vمن) و کوچکترین منطقه هدف r3. فاصله بین دو ناحیه به عنوان فاصله خط مستقیم بین دو مرکز آنها تعریف می شود. از آنجایی که هدف از این اندازهگیریها این است که تقریباً مشخص شود کدام یک در جهت درست حرکت میکند، تعداد کمی محاسبات ساده کافی است. اگر یک گره قبلاً در بسیاری از مناطق سفر کرده باشد، محاسبات را می توان به مناطق تاریخ در یک لایه محدود کرد. با توجه به طول شناسه منطقه به راحتی می توان چنین کشسانی را به دست آورد. را نمنجدید خواهد شد نجاگر حداقل فاصله را داشته باشد.
مورد دوم : هر دو نجیا نمناز منطقه(های) در R بازدید کرده است (خطوط 17-20)
در این مورد، یک طرف شواهدی دارد که نشان می دهد حداقل در یک منطقه در R بوده است در حالی که طرف دیگر ندارد. بنابراین، بدیهی است که کسی که مسیر شناخته شده اش از مناطق هدف می گذرد، باید به عنوان نگهدارنده بسته انتخاب شود، زیرا احتمال بیشتری وجود دارد که باندل را به آنجا بیاورد.
مورد سوم : هر دو نجو نمناز منطقه(های) R بازدید کرده اند (خطوط 21-29)
برای اینکه تصمیم بگیریم که کدام گره بر دیگری برتری دارد، وقتی هر دو اعلام کنند که در منطقه(های) R بوده اند، از این اصل پیروی می کنیم که به طور شهودی، گرهی که به منطقه هدف در سطح عمیق تری رسیده است، می تواند باشد. انتظار می رود به محتوا نزدیکتر شود. با توجه به نتیجه تقاطع از Vجو Vمنبا R ، اگر VمنR را به عمقی بیشتر از Vج، نمنبه عنوان بهترین نامزد بعدی واجد شرایط است. به این ترتیب، بسته نرم افزاری به تدریج به مقصد نزدیک می شود.
| الگوریتم 1 طرح مسیریابی بر اساس تقسیم بندی نقشه و تاریخچه حرکت |
|
4. اعتبار سنجی و ارزیابی تجربی
4.1. پلتفرم شبیه سازی
آزمایشهای مرتبط با DTN یک کار چالشبرانگیز طولانی مدت بوده است، عمدتاً به دلیل این واقعیت است که شرایطی مانند تماسهای کوتاه مدت و انتقال چند جهشی برای ارائه در محیطهای آزمایشگاهی بسیار پرهزینه است. به عنوان یک رویکرد ترکیبی بین شبیهسازی مجازی و بستر آزمایش فیزیکی، شبیهسازیها برای فضاهای داخلی قابل اجرا هستند و پشتیبانی آن از کدهای واقعی میتواند نتایج قانعکنندهتری به همراه داشته باشد. یک روند نوظهور در شبیهسازی این است که گرههای مجازی توجه فزایندهای را به خود جلب میکنند و برای مقیاسپذیری و استقرار بهتر خود مورد پذیرش گستردهای قرار میگیرند. در این مقاله، ما یک پلتفرم شبیهسازی غیرمتمرکز و سبک بر اساس ماشینهای مجازی (VM) پیشنهاد میکنیم، زیرا VM با یک هسته مستقل و پشته پروتکل شبکه، توانایی بررسی کامل پیادهسازی و درجه بالاتری از وفاداری را ارائه میدهد.110 ] در مقایسه با ظروف مبتنی بر هسته.
برخلاف اکثر کارهای شبیهسازی که یک کنترلکننده مرکزی اختصاصی را برای کنترل تکامل توپولوژی شبکه اختصاص میدهند [ 111 ، 112 ، 113 ]، با الهام از چندین کار در شبکههای ad-hoc [ 114 ]، ما از ماژول “Link Emulator” استفاده میکنیم. کاری کنید که هر گره به طور خودکار پیوندهای خود را مدیریت کند و از این رو به یک موجودیت مستقل در پیشرفت آزمایش تبدیل می شود. فقط یک سند ساده که موقعیتها را ثبت میکند، لازم است تا یک گره عملاً مطابق آن حرکت کند.
هر گره به عنوان یک VM که توزیع اوبونتو را اجرا می کند، نمونه سازی می شود. همه گره ها از طریق LAN به هم متصل می شوند. برای حل مشکل همگام سازی زمان، یک گره “Starting Pistol” تنظیم می شود تا اسکریپت اولیه سازی و تنظیم زمان را با یک سرور NTP روی هر گره DTN تقریباً همزمان با ابزار “SSH موازی” [ 115 ] راه اندازی کند. پس از آن، این گره در فرآیند آزمایشی دخالت نخواهد کرد و سایر گره های DTN به طور مستقل رفتار خواهند کرد.
4.2. اعتبار سنجی در سناریوهای ساده
ما ابتدا چندین آزمایش را در سناریوهای ساده ارائه میکنیم تا امکانسنجی و کاربردپذیری پیادهسازی را تأیید کنیم. حرکت گره ها برای ایجاد فرصت های تماس برنامه ریزی شده هماهنگ شده است. محتویات درخواستی کاشی های نقشه برداری هستند و در آینده از انواع بیشتری از داده های جغرافیایی آموزنده که می توانند روی نقشه ها قرار بگیرند پشتیبانی خواهیم کرد.
4.2.1. اعتبار سنجی بازیابی محتوای چند هاپ با تحمل تاخیر
شکل 15 سناریوی آزمایشات در این قسمت را نشان می دهد. ما بخشی از مسیر اتوبوس را در شمال غربی جاده کمربندی سوم پکن از مجموعه داده های OSM (osmid: 2094880) به عنوان مسیر انتخاب کردیم. چهار گره در این آزمایش ها شرکت می کنند: دو گره متحرک به اضافه دو گره ثابت. الگوی تحرک این گره ها در جدول 2 آمده است. 30 ثانیه در همان ابتدا برای مقداردهی اولیه گره ها و ایجاد بسته های پرس و جو در نظر گرفته شده است. گره 1 به عنوان درخواست کننده عمل می کند و گره 4 RSU است. آنها به ترتیب در نقطه A و E بدون حرکت می مانند. نقطه C نقطه ملاقات گره های 2 و 3 است. گره 2 بین نقاط B و C حرکت می کند، در حالی که گره 3 بین نقاط C و D حرکت می کند. محدوده ارتباطی 300 متر تنظیم شده است. سپس، آزمایشهایی را در سه موقعیت با توزیعهای مختلف محتوای درخواستی انجام میدهیم.
1. بدون محتوای حافظه پنهان متوسط
در این آزمایش، هیچ محتوای کش در گرههای 2 و 3 وجود ندارد. همه محتویات باید از گره 4 بازیابی شوند. توالی زمانی رویدادهای انتقال در شکل 16 نشان داده شده است . توضیحات فرآیند به شرح زیر است:
-
قبل از 30 ثانیه: در ابتدا، گره 1 مجموعه ای از بسته های پرس و جو را تولید می کند که مناطق منبع آن مناطقی است که در آن قرار دارد، یعنی آر1، آر2، و آر3، و مناطق هدف مناطقی هستند که نود 4 در آنها قرار دارد، یعنی تی1، تی2، و تی3.
-
حدود 200 ثانیه: اندکی بعد، زمانی که Node 2 از کنار Node 1 عبور می کند، طبق استراتژی مسیریابی، زیرا Node 2 از تی1در حالی که گره 1 خارج از تمام مناطق هدف قرار می گیرد، این کوئری ها به گره 2 منتقل می شوند.
-
حدود 400 ثانیه: سپس گره 2 به نقطه C می رود و در آنجا با گره 3 ملاقات می کند. همانطور که Node 3 بوده است تی3که منطقه هدف در سطح عمیق تر از تی1، تنها منطقه هدف بازدید شده توسط Node 2، بنابراین Node 3 جانشین Node 2 می شود تا حامل کوئری ها شود.
-
حدود 600 ثانیه: نود 3 به حمل کوئری ها تا رسیدن به آن ادامه می دهد تی3و آنها را به گره 4 تحویل می دهد. هنگامی که بسته های پاسخ مربوطه در گره 4 تولید می شوند، زیرا هیچ یک از نود 3 و نود 4 هیچ یک از مناطق هدف خود را بازدید نکرده اند، به عنوان مثال، آر1، آر2، و آر3، حداقل فاصله بین مناطق تاریخ خود را مقایسه می کنند و آر3. همانطور که از شکل 15 مشاهده می شود ، برای گره 3 این مقدار فاصله بین است م3و آر3. کوتاهتر از Node 4 است که فاصله بین آن است تی1و آر3. در نتیجه، نود 3 تمام محتویات گره 4 را دریافت می کند و به نقطه C می چرخد.
-
حدود 800 ثانیه: هنگامی که نود 3 دوباره در نقطه C با گره 2 در تماس است، زیرا گره 2 به سمت دیگر حرکت کرده است. آر3در حالی که Node 3 هیچ شانسی برای هیچ یک از مناطق هدف بسته های پاسخ ندارد، محتوا به Node 2 ارسال می شود.
-
حدود 1000 ثانیه: در نهایت، در مسیر گره 2 که به B باز می گردد، پاسخ ها با موفقیت به گره 1 تحویل داده می شوند.
این آزمایش ثابت می کند که سیستم به درستی بر روی بازیابی منظم و فرصت طلبانه محتوای چند هاپ از منبع داده کار می کند. در دو موقعیت زیر، دلایلی که چرا حمل و نقل میتواند تحت دستورالعملهای طرح مسیریابی اتفاق بیفتد، به طور مکرر توضیح داده نخواهد شد، زیرا الگوی تحرک یکسانی دارند.
2. محتویات ذخیره شده کامل متوسط
در این آزمایش، هدف ما این است که مشخص کنیم آیا حافظه پنهان در یک مکان نزدیک می تواند مورد استفاده قرار گیرد یا خیر. تمامی محتویات درخواست شده توسط نود 1 از قبل در نود 3 ذخیره می شوند. با توجه به نتایج زمانی در شکل 17 ، پس از اولین دور حرکت گره 2 بین نقطه B و C (حدود 400 ثانیه)، همه پرس و جوها می توانند در گره 3 برآورده شوند. در نتیجه، پاسخ ها در زمان کمتری به درخواست کننده تحویل داده می شوند و پرش کمتر (حدود 600 ثانیه)، که با انتظارات ما مطابقت دارد.
3. محتوای ذخیره شده جزئی میانی
این آزمایش ترکیبی از دو وضعیت بالا است: محتویات جزئی در گره 3 ذخیره می شوند، در حالی که باقیمانده ها فقط در گره 4 یافت می شوند. با مراجعه به شکل 18 ، تعاملات بین گره ها را به صورت زیر توصیف می کنیم:
-
حدود 200 ثانیه: اولاً، Node 2 تمام بسته های پرس و جو را از Node 1 می گیرد.
-
حدود 400 ثانیه: گره 2 و نود 3 در نقطه C گرد هم می آیند. گره 3 برخی از پرس و جوهای گره 2 را با محتویات کش محلی خود مطابقت می دهد و پاسخ ها را به گره 2 برمی گرداند، سپس پرس و جوهای تکمیل نشده را به سمت RSU می برد. گره 2 با آن دسته های پاسخ به نقطه B برمی گردد.
-
حدود 600 ثانیه: Node 2 اولین دسته از پاسخ ها را به Node 1 برمی گرداند. تقریباً در همان زمان، Node 3 بقیه محتویات درخواستی را از Node 4 دریافت می کند.
-
حدود 800 ثانیه: نود 2 و نود 3 دوباره در نقطه C به هم می رسند. در این زمان بقیه پاسخ ها از نود 3 به گره 2 تخلیه می شوند.
-
حدود 1000 ثانیه: در نهایت، دسته دوم پاسخ ها به گره 1 تحویل داده می شود.
این آزمایش تأیید میکند که تعدادی از درخواستهای صادر شده در یک زمان میتوانند توسط منابع محتوای مختلف برآورده شوند، و پاسخها برای بازگرداندن جداگانه به درخواستکننده پشتیبانی میشوند.
4.2.2. اعتبار سنجی تجسم مشتری با تحمل تاخیر
همانطور که در قسمت قبل تأیید شد، مطالب می توانند از چندین منبع در زمان های مختلف بازگردند. سوال بعدی از دیدگاه کاربر این است که آیا می توان آنها را به طور جمعی و به درستی در مرورگر در مدت زمان طولانی تجسم کرد. به یاد بیاورید که به عنوان یکی از مزیت های پیاده سازی مبتنی بر دروازه، ترمینال نیازی به آگاهی از DTN ندارد و فقط کمی تنظیم برای هدف ما کافی است. در پیاده سازی ما، از طریق تنظیم پارامتر زمان پاسخ مرورگر، پاسخ هایی که در زمان بعدی برگردانده می شوند حذف نمی شوند.
در این آزمایش، تصور می کنیم که کاربر بدون دسترسی به شبکه به نقشه ای از محیط اطراف خود نیاز دارد. داده های نقشه از چندین گره دیگر به شکل کاشی های برداری که واحدهای داده ای هستند که در کار قبلی خود پیشنهاد می کنیم، بازیابی می شوند [ 32 ]. هفت گره در آن شرکت می کنند و تماس های آنها از قبل تنظیم شده است. گره 1 درخواست کننده را عمل می کند و نود 7 به عنوان RSU است. برای دستیابی به اثری که پرس و جوها توسط منابع متعدد برآورده می شوند، یک سوم مطالب درخواستی را از قبل در نود 2 و یک سوم را در نود 3 قرار می دهیم، با این فرض که آنها این مطالب را از قبل دریافت کرده اند. یک سوم باقیمانده باید از گره 7 واکشی شود. مبادلات باندل در شکل 19 نشان داده شده است.. برای واضح تر شدن نتیجه، جزئیات هر دسته از محتویات برگشتی در جدول 3 خلاصه شده است. همانطور که از اسکرین شات های مرورگر در شکل 20 می بینیم ، نقشه برداری به صورت تدریجی کامل می شود. این تأیید می کند که سمت مشتری می تواند از بازیابی و تجسم محتوای با تحمل تاخیر پشتیبانی کند.
4.3. آزمایش در سناریوهای جامع
در این بخش، آزمایشهای گسترده روی Geo-DMP را در سناریوی واقعیتر و جامعتر مورد بحث قرار میدهیم. مساحت تقریبی مربع 3 کیلومتر 2در نزدیکی Zhongguancun، منطقه Haidian به عنوان محدوده حرکت گره ها انتخاب شده است. ده گره در آزمایشها شرکت میکنند که ردپای آنها از T-drive [ 116 ] استخراج میشود، مجموعه دادهای که شامل مسیرهای تاکسیها در دنیای واقعی است. گره ها در مسیر خود به طور مکرر برای دو دور در هر اجرای آزمایش حرکت می کنند و تماس های آنها از قبل برنامه ریزی نشده است. زمان سفر یک طرفه بین 20 تا 40 دقیقه است. ما شرایط متفاوتی را برای هر گروه از آزمایشها با جایگزین کردن همه ردپای گرهها ایجاد میکنیم. محدوده حرکت و یک مجموعه نمونه از ردیابی ها در شکل 21 آورده شده است.
اول، ما عملکرد Geo-DMP را زمانی که تنها یک منبع محتوا در دسترس است ارزیابی می کنیم. گره 1 به عنوان کاربر عمل می کند و گره 10 RSU است، در حالی که سایرین گره های رله هستند. با توجه به تنوع دامنه ارتباط و اینکه آیا گره ها از قبل از حرکات خود آگاهی دارند یا خیر، چهار مورد در یک گروه از آزمایش ها در جدول 4 آورده شده است. ما در مجموع 10 گروه آزمایش انجام دادیم.
4.3.1. بدون محتوای حافظه پنهان متوسط
همانطور که از شکل 22 مشاهده می شود، به جز مورد B، در اکثر موقعیت ها (به طور متوسط بیش از 80٪) می توانیم تحویل دو طرفه را انجام دهیم. از آنجایی که هیچ محتوایی در گرههای میانی ذخیره نمیشود، پرسوجوها تنها پس از اینکه به کوچکترین منطقه هدف خود آورده میشوند توسط RSU برآورده میشوند. به همین ترتیب، تنها زمانی که پاسخها به درخواستکننده بازگردانده میشوند، میتوانند تحویل موفقیتآمیز باشند. از این رو، نسبت تحویل بالا نشان می دهد که مناطق چند لایه تقسیم شده می توانند به طور مناسب حرکت گره ها را مشخص کنند. در طول فرآیند نزدیک شدن باندل ها به مناطق هدف خود، آنها می توانند به عنوان یک مرجع ارزشمند برای انتخاب هاپ بعدی مناسب تحت سناریوهای واقع بینانه عمل کنند. علاوه بر این، در توافق با شهود، بزرگتر شدن محدوده ارتباطی به ارائههای موفقتر با ظهور بسیاری از فرصتهای تماس جدید کمک میکند. در مجموع،
در مرحله بعد، تحلیلی از کاهش نسبت تحویل زمانی که گرهها از قبل از حرکات آگاهی دارند، ارائه میکنیم. به نظر ما این کاهش را می توان به عدم استفاده از تاریخ جنبش تا کنون نسبت داد. با توجه به بررسی ما در مورد برخی از شکستهای تحویل، اگر هر دو گره گزارش دهند که از کوچکترین منطقه هدف بازدید کردهاند، پروتکل مسیریابی فعلی نمیتواند قضاوت کند که کدام یک برتر است. نتیجه این است که بستهها برای اولین بار نمایش داده میشوند. اما گاهی اوقات آن گره میانی پس از ورود به کوچکترین منطقه هدف، نمی تواند با گره مقصد در تماس باشد. دو دلیل ممکن است این پدیده را توجیه کند. مورد اول به دلیل محدودیت شرایط آزمایشی، تعداد گرهها و مجموعههای آزمایشی اجرا شده برای کاهش تأثیر ویژگیهای مسیرهای انتخابشده کافی نبود. مورد دوم این است که از آنجایی که محدوده ارتباطی یک متغیر است، به احتمال زیاد بین اندازه منطقه و محدوده ارتباطی عدم تطابق وجود دارد. وقتی برد ارتباطی کوچکتر شود، این مشکل شدیدتر می شود. به همین دلیل است که این مشکل برای مورد B نسبت به مورد D آشکارتر به نظر می رسد. ما تشخیص می دهیم که دو گره که به بهترین منطقه هدف می رسند و دو گره قادر به تماس با یکدیگر هستند مطلقاً معادل نیستند. مشابه مسئله کلاسیک “آخرین مایل”، اگرچه مناطق هدف می توانند جهت های ارسال صحیح را نشان دهند، استراتژی های اضافی باید برای مشکل “آخرین پرش” تصور شود. از آنجایی که محدوده ارتباطی یک متغیر است، به احتمال زیاد بین اندازه منطقه و محدوده ارتباطی عدم تطابق وجود دارد. وقتی برد ارتباطی کوچکتر شود، این مشکل شدیدتر می شود. به همین دلیل است که این مشکل برای مورد B نسبت به مورد D آشکارتر به نظر می رسد. ما تشخیص می دهیم که دو گره که به بهترین منطقه هدف می رسند و دو گره قادر به تماس با یکدیگر هستند مطلقاً معادل نیستند. مشابه مسئله کلاسیک “آخرین مایل”، اگرچه مناطق هدف می توانند جهت های ارسال صحیح را نشان دهند، استراتژی های اضافی باید برای مشکل “آخرین پرش” تصور شود. از آنجایی که محدوده ارتباطی یک متغیر است، به احتمال زیاد بین اندازه منطقه و محدوده ارتباطی عدم تطابق وجود دارد. وقتی برد ارتباطی کوچکتر شود، این مشکل شدیدتر می شود. به همین دلیل است که این مشکل برای مورد B نسبت به مورد D آشکارتر به نظر می رسد. ما تشخیص می دهیم که دو گره که به بهترین منطقه هدف می رسند و دو گره قادر به تماس با یکدیگر هستند مطلقاً معادل نیستند. مشابه مسئله کلاسیک “آخرین مایل”، اگرچه مناطق هدف می توانند جهت های ارسال صحیح را نشان دهند، استراتژی های اضافی باید برای مشکل “آخرین پرش” تصور شود. به همین دلیل است که این مشکل برای مورد B نسبت به مورد D آشکارتر به نظر می رسد. ما تشخیص می دهیم که دو گره که به بهترین منطقه هدف می رسند و دو گره قادر به تماس با یکدیگر هستند مطلقاً معادل نیستند. مشابه مسئله کلاسیک “آخرین مایل”، اگرچه مناطق هدف می توانند جهت های ارسال صحیح را نشان دهند، استراتژی های اضافی باید برای مشکل “آخرین پرش” تصور شود. به همین دلیل است که این مشکل برای مورد B نسبت به مورد D آشکارتر به نظر می رسد. ما تشخیص می دهیم که دو گره که به بهترین منطقه هدف می رسند و دو گره قادر به تماس با یکدیگر هستند مطلقاً معادل نیستند. مشابه مسئله کلاسیک “آخرین مایل”، اگرچه مناطق هدف می توانند جهت های ارسال صحیح را نشان دهند، استراتژی های اضافی باید برای مشکل “آخرین پرش” تصور شود.
همانطور که از شکل 23 و شکل 24 می بینیم، با توجه به تعداد پرش و میانگین تاخیر، مورد A با محدوده ارتباطی کوچکتر و بدون دانش حرکت اولیه، طولانی ترین زمان تاخیر و بالاترین جهش ارسال را برای بازیابی محتویات از RSU می گیرد. در مورد C، با محدوده ارتباطی بزرگتر، گرهها میتوانند به راحتی یک جهش بعدی واجد شرایط را پیدا کنند، که منجر به کاهش تعداد تاخیر و پرش میشود. دانش حرکت مزیت خود را در مورد B و D نشان می دهد. میانگین تاخیر مورد B به حدود 50% در مورد A کاهش می یابد، در حالی که میانگین تاخیر مورد D حدود 70% در مورد C است. دلیل قابل توجهی است. صرفه جویی در مصرف زمان را می توان با دانش حرکت اولیه توضیح داد که نیاز به جمع آوری مناطق بازدید شده را از ابتدا حذف می کند. آگاهی از مکانهای موجود در مسیر، گرهها را قادر میسازد تا راحتتر و سریعتر یک هاپ بهتر، حتی بهترین، را پیدا کنند. در ضمن به همین دلیل
4.3.2. با محتوای حافظه پنهان متوسط
در این قسمت به بررسی تاثیر کش های میانی در فرآیند اکتساب محتوا می پردازیم. ما شش مجموعه از مسیرها را انتخاب می کنیم که در آزمایش های قبلی می توان مطالب را با موفقیت ارائه کرد. برای هر مجموعه از مسیرها، آزمایش جدید را بر اساس نتایج آزمایش قبلی آغاز می کنیم. به بیان واضح تر، آزمایش بدون حافظه پنهان میانی قبل از آزمایش جدید اجرا می شود تا محتوا را به برخی از گره ها در حال آماده سازی برساند. به جز گره 1، گره 10 و گره هایی که دارای محتوای کش هستند، سایر گره ها به نوبه خود نقش درخواست کننده را در اجرای جداگانه ایفا می کنند.
از آنجا که در آزمایشهای قبلی، محتویات عمدتاً در دو یا سه جهش به درخواستکننده بازگردانده میشوند، تعداد زیادی از گرهها دارای محتوای کش نیستند. با این حال، ما فکر میکنیم که در واقعیت بسیار رایج است که محتوای درخواستی در مناطق اطراف پراکنده شود. عوامل زیادی می تواند دلیل این امر باشد: محبوبیت کمتر محتوا، عدم تمایل برخی از کاربران به افشای حافظه پنهان خود در معرض عموم یا پشتیبانی محدود از مکانیسم BPQ در بین گره های DTN.
ما نتایج را بر اساس جایی که محتویات از آنها در شکل 25 بازیابی شده است، دسته بندی می کنیم . همانطور که مشاهده می شود، زمانی که محدوده ارتباطی 300 متر است، به دلیل محتوای کش شده تنها در چند گره میانی، سایر گره ها شانس نسبتاً محدودی برای کشف آنها دارند، بنابراین بخش بزرگی از درخواست ها هنوز توسط RSU انجام می شود. با وجود این، گرههای کش میتوانند تقریباً نیمی از بازیابیهای موفق را انجام دهند، که به این معنی است که Geo-DMP میتواند به طور مؤثر از مقدار متوسطی از محتویات کش استفاده کند تا بازیابی ناموفق را به میزان قابل توجهی کاهش دهد و در مقایسه با آزمایشهای بدون حافظه پنهان، بازیابی محتوا را از مکانهای نزدیکتر ارتقا دهد. شکل 22. با محدوده ارتباطی تا 600 متر، مشاهده میکنیم که تعداد درخواستهای انجامشده توسط حافظههای پنهان در عوض کمی کاهش مییابد. دلیل این امر این است که همانطور که قبلاً گفته شد، محدوده ارتباطی بزرگتر فرصت های تماس بیشتری را ایجاد می کند و از این رو گره های میانی می توانند راحت تر با هاپ های بعدی بهتر، حتی RSU تماس بگیرند. بنابراین این تمایل وجود دارد که فورواردها به جهت RSU ترجیح داده می شوند و نقش کش های میانی به طور اجتناب ناپذیری کاهش می یابد.
برای بستن این بخش، آزمایشهای گستردهای را که در بالا ارائه شد به طور خلاصه خلاصه میکنیم. اولاً، ما ثابت میکنیم که چارچوب Geo-DMP به درستی و به درستی بر روی بازیابی محتوای تحملپذیر تاخیر در یک سناریوی ساده با توزیعهای کش مختلف کار میکند. ثانیاً، با یک سناریوی واقعیتر و مسیر گرهها، نشان میدهیم که توانایی تحویل Geo-DMP برای اکثر موارد قابل قبول است و اطلاعات تاریخچه حرکت میتواند به انتخاب پرشهای بعدی مناسب و همچنین کاهش میانگین پرش و تاخیر کمک کند. ثالثاً، دلیل برخی از شکستهای تحویل را برای بهبود بالقوه استراتژی مسیریابی مبتنی بر منطقه مورد بحث قرار میدهیم. در نهایت، ما تأیید میکنیم که Geo-DMP میتواند مقدار کمی از حافظههای پنهان میانی را برای تأثیر مثبت قابلتوجهی بر کارایی کلی به کار گیرد.
5. نتیجه گیری و چشم انداز
در این مقاله، ما Geo-DMP، یک سیستم نمونه اولیه تلفن همراه را ارائه میکنیم که از اشتراکگذاری و تبادل محتویات مکانی به روشی فرصتطلبانه، توزیعشده و مشارکتی پشتیبانی میکند. چارچوب Geo-DMP از یک پشته پروتکل کامل DTN، یک ماژول «نماینده محتوا» و یک ماژول «آداپتور نقشه» تشکیل شده است. DTN و مکانیسم BPQ آن بهعنوان پایهای برای قابلیتهای شناسایی، تطبیق، و ارسال با تحمل تاخیر چند جهشی محتویات نامگذاری شده به کار گرفته میشوند. سپس ما از الگوی ارتباطی “مبتنی بر دروازه” پیروی می کنیم تا ماژول “عامل محتوا” را توسعه دهیم تا جداسازی بین گره های غیر DTN و گره های آگاه از DTN را بشکنیم. برای استخراج الگوی تحرک مختصر کاربران از حرکات آنها به منظور مسیریابی، ماژول “آداپتور نقشه” را ارائه می دهیم. که اطلاعات منطقه ای بلادرنگ را بر اساس محصول طرح تقسیم بندی نقشه چند مقیاسی پیشنهادی ما ارائه می دهد. در مرحله بعد، برای انجام یک فرآیند بازیابی کامل محتوا با چارچوب Geo-DMP، ما طراحی یک طرح مسیریابی DTN منطقه محور خالص را بررسی می کنیم که برای محیط های فضایی واقعی طراحی شده است. پیاده سازی کامل به طور کامل بر روی پلت فرم شبیه سازی متشکل از ماشین های مجازی تایید شده است. از طریق آزمایشهای روی مسیرهای دنیای واقعی در سناریوهای واقعی، میتوان نتیجه گرفت که با Geo-DMP، درخواستهای محتوای فضایی نامگذاری شده را میتوان از طریق اتصالات گذرا و همکاری گرههای DTN به منابع محتوایی دوردست هدایت کرد و انجام داد و درخواستکننده میتواند از آن استفاده کند. پاسخ هایی که در یک دوره زمانی طولانی به عقب برمی گردند.
با وجود دستاوردها، ما همچنین آگاه هستیم که هنوز جای پیشرفت زیادی وجود دارد. جهتهای بالقوه عبارتند از: آزمایشهای مقیاس بزرگ با دستگاههای جاسازی شده فیزیکی در محیطهای واقعی. بهبود طراحی پروتکل مسیریابی با بهره برداری بهتر از دانش حرکات تاریخی و تعیین هوشمند مناطق هدف. و کاوش یک روش برنامهریزیشده برای خودکارسازی پردازش یا کالیبره کردن شبکه جادهها و مسیرهای گرهها.
علاوه بر پیشرفت های خود سیستم، ما همچنین به دنبال گسترش دامنه کاربردی Geo-DMP خواهیم بود. دو راه ممکن میتواند پیشنهاد شود: اول، پشتیبانی از بازیابی بیشتر به موقع یا سفارشیشده محتویات جغرافیایی مانند هشدارهای رویدادهای اضطراری، احتیاطهای ایمنی (مانند ناهنجاریهای سطح جاده یا بخشهای مستعد تصادف)، بهروزرسانیهای آب و هوا، یا POI -interest) توصیه ها؛ و دوم، ادغام بهتر با خدمات جمعسپاری برای کمک به برداشت کارآمد و به اشتراکگذاری اطلاعات بهروز و همچنین اطلاعات ارزشمند درباره موقعیت مکانی اطراف ما.
منابع
- آمار و ارقام ICT 2017، اتحادیه بین المللی مخابرات. در دسترس آنلاین: https://www.itu.int/en/ITU-D/Statistics/Pages/facts/default.aspx (در 15 مه 2019 قابل دسترسی است).
- لاین، تی. جین، جی. لیون، جی. نقش فناوری اطلاعات و ارتباطات در زندگی روزمره تلفن همراه. J. Transp. Geogr. 2011 ، 19 ، 1490-1499. [ Google Scholar ] [ CrossRef ]
- هوانگ، اچ. گارتنر، جی. کریسپ، جی.ام. راوبال، م. de Weghe، NV خدمات مبتنی بر مکان: دستور کار تکامل و تحقیق در حال انجام. J. Locat. سرویس مبتنی بر 2018 ، 12 ، 63-93. [ Google Scholar ] [ CrossRef ]
- پوچر، جی. پنگ، ZR؛ میتال، ن. زو، ی. Korattyswaroopam، N. روندها و سیاست های حمل و نقل شهری در چین و هند: تأثیرات رشد سریع اقتصادی. ترانسپ Rev. 2007 , 27 , 379-410. [ Google Scholar ] [ CrossRef ]
- وانگ، اچ. او، س. لیو، ایکس. ژوانگ، ی. هنگ، اس. تحقیقات شهرنشینی جهانی از 1991 تا 2009: مروری بر تحقیقات سیستماتیک. Landsc. طرح شهری. 2012 ، 104 ، 299-309. [ Google Scholar ] [ CrossRef ]
- ببینید، L. مونی، پی. فودی، جی. باستین، ال. کامبر، ا. استیما، ج. فریتز، اس. کرل، ن. جیانگ، بی. لااکسو، م. و همکاران جمع سپاری، علم شهروندی یا اطلاعات جغرافیایی داوطلبانه؟ وضعیت فعلی اطلاعات جغرافیایی جمعسپاری شده ISPRS Int. J. Geo-Inf. 2016 ، 5 ، 55. [ Google Scholar ] [ CrossRef ]
- ویلسون، ام. گراهام، ام. نئوجئوگرافی و اطلاعات جغرافیایی داوطلبانه: گفتگو با مایکل گودچایلد و اندرو ترنر. محیط زیست طرح. یک اقتصاد. فضا 2013 ، 45 ، 10-18. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هامن، اس. Burghardt, D. چه مقدار اطلاعات از نظر جغرافیایی ارجاع داده شده است؟ شبکه ها و شناخت بین المللی جی. جئوگر. Inf. علمی 2013 ، 27 ، 1171-1189. [ Google Scholar ] [ CrossRef ]
- Arribas-Bel، D. تصادفی، باز و همه جا: منابع داده در حال ظهور برای درک شهرها. Appl. Geogr. 2014 ، 49 ، 45-53. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، ز. جیانگ، اس. ژو، پی. لی، ام. سیستم نظارت بر ترافیک شهری مشارکتی: قدرت سواران اتوبوس. IEEE Trans. هوشمند ترانسپ سیستم 2017 ، 18 ، 2851-2864. [ Google Scholar ] [ CrossRef ]
- ترنر، ام. داولند، اس. مازل، ع. Giesen, M. Rock art CARE: یک برنامه تلفن همراه بین پلتفرمی برای جمعسپاری دادههای حفاظت از میراث برای حفاظت از هنر صخرهای در فضای باز. J. Cult. میراث. مدیریت حفظ کنید. توسعه دهنده 2018 ، 8 ، 420-433. [ Google Scholar ] [ CrossRef ]
- مولر، سی. چپمن، ال. جانستون، اس. کید، سی. ایلینگورث، اس. فودی، جی. Overeem، A.; Leigh, R. جمع سپاری برای علوم آب و هوا و جو: وضعیت فعلی و پتانسیل آینده. بین المللی جی.کلیماتول. 2015 ، 35 ، 3185-3203. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رادیچی، ا. هنکل، دی. Memmel, M. Citizens به عنوان حسگرهای هوشمند و فعال برای یک شهر آرام و درست. مورد رویکرد “مناظر صوتی منبع باز” برای شناسایی، ارزیابی و برنامه ریزی “مناطق آرام روزمره” در شهرها. نقشه نویز. 2018 ، 5 ، 1-20. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دیویس، جی ال. رابین، الف. اثربخشی واکنش به بلایای شبکه: مورد فناوری اطلاعات و ارتباطات و طوفان کاترینا. جی. هومل. امن ظهور. مدیریت 2015 ، 12 ، 437-467. [ Google Scholar ] [ CrossRef ]
- یامامورا، اچ. کاندا، ک. Mizobata، Y. مشکلات ارتباطی پس از زلزله بزرگ ژاپن شرقی در سال 2011. فاجعه پزشکی. آمادگی بهداشت عمومی 2014 ، 8 ، 293-296. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کاستانو، پی. مانکوزو، وی. سرنو، ام. Marsan، MA چرا گوشی هوشمند شما در محیط های شلوغ کار نمی کند؟ در مجموعه مقالات 2017 IEEE هجدهمین سمپوزیوم بین المللی دنیایی از شبکه های بی سیم، موبایل و چند رسانه ای (WoWMoM)، ماکائو، چین، 12 تا 15 ژوئن 2017؛ صفحات 1-9. [ Google Scholar ]
- شفیق، م.ز. جی، ال. لیو، تبر; پانگ، جی. ونکاتارامان، اس. Wang, J. اولین نگاه به عملکرد شبکه سلولی در طول رویدادهای شلوغ. در مجموعه مقالات ACM SIGMETRICS/کنفرانس بینالمللی اندازهگیری و مدلسازی سیستمهای کامپیوتری (SIGMETRICS ’13)، پیتسبورگ، PA، ایالات متحده آمریکا، 17-21 ژوئن 2013. ص 17-28. [ Google Scholar ]
- درآمد ماهانه CEIC. در دسترس آنلاین: https://www.ceicdata.com/en/indicator/monthly-earnings (در 15 مه 2019 قابل دسترسی است).
- قیمت گذاری داده موبایل در سراسر جهان: هزینه 1 گیگابایت داده تلفن همراه در 230 کشور. در دسترس آنلاین: https://www.cable.co.uk/mobiles/worldwide-data-pricing/ (در 15 مه 2019 قابل دسترسی است).
- دینگ، جی. لی، ی. ژانگ، پی. جین، دی. قیمت گذاری وابسته به زمان برای شبکه های موبایل در مقیاس بزرگ محیط شهری: امکان سنجی و سازگاری. IEEE Trans. خدمت محاسبه کنید. 2017 . [ Google Scholar ] [ CrossRef ]
- ماهادوان، ل. Kaleta, JP Wi-Fi رایگان: خرید یا نخریدن. جی. کامپیوتر. Inf. سیستم 2018 . [ Google Scholar ] [ CrossRef ]
- ژانگ، ال. ژائو، ال. وانگ، ز. لیو، جی. شبکه های وای فای در کلانشهرها: از نقطه دسترسی و دیدگاه کاربر. IEEE Commun. Mag. 2017 ، 55 ، 42-48. [ Google Scholar ] [ CrossRef ]
- برزین، من; روسو، اف. Duda، A. دسترسی به اینترنت سیار در سطح شهر با استفاده از پوشش متراکم وای فای شهری. در مجموعه مقالات اولین کارگاه در مورد شبکه های شهری (UrbaNe ’12)، نیس، فرانسه، 10 دسامبر 2012; صص 31-36. [ Google Scholar ]
- ها، س. سن، اس. جو وانگ، سی. من، ی. Chiang، M. TUBE: قیمت گذاری وابسته به زمان برای داده های تلفن همراه. در مجموعه مقالات کنفرانس ACM SIGCOMM 2012 در مورد کاربردها، فناوریها، معماریها و پروتکلها برای ارتباطات کامپیوتری (SIGCOMM ’12)، هلسینکی، فنلاند، 13 تا 17 اوت 2012. ص 247-258. [ Google Scholar ]
- مهمتی، ف. اسپیروپولوس، تی. مدلسازی عملکرد، تجزیه و تحلیل و بهینه سازی بارگذاری تاخیری داده های موبایل برای کاربران موبایل. IEEE/ACM Trans. شبکه 2017 ، 25 ، 550-564. [ Google Scholar ] [ CrossRef ]
- گاندوترا، پ. Jha، RK; جین، اس. نظرسنجی در مورد ارتباط دستگاه به دستگاه (D2D): مسائل معماری و امنیتی. J. Netw. محاسبه کنید. Appl. 2017 ، 78 ، 9-29. [ Google Scholar ] [ CrossRef ]
- خباز، م.ج. Assi، CM; فواز، شبکههای متحمل به اختلال WF: بررسی جامع در مورد تحولات اخیر و چالشهای پایدار. IEEE Commun. Surv. معلم خصوصی 2012 ، 14 ، 607-640. [ Google Scholar ] [ CrossRef ]
- رست، م. کرامر، اچ. Holmquist، LE Mobile کاوش عکس های دارای برچسب جغرافیایی. پارس محاسبات همه جا حاضر. 2012 ، 16 ، 665-676. [ Google Scholar ] [ CrossRef ]
- Gorbil, G. بدون راه حل: تخلیه اضطراری بدون دسترسی به اینترنت. در مجموعه مقالات کنفرانس بین المللی IEEE 2015 در کارگاه های آموزشی فراگیر محاسبات و ارتباطات (کارگاه های PerCom)، سنت لوئیس، MO، ایالات متحده آمریکا، 23-27 مارس 2015. ص 505-511. [ Google Scholar ]
- گوکولاکریشنان، پ. Ganeshkumar، P. پیشگیری از تصادفات جاده ای با انتشار پیام هشدار فوری اضطراری در شبکه Ad-Hoc وسایل نقلیه. PLoS ONE 2015 , 10 , e0143383. [ Google Scholar ]
- مارتوسلی، جی. بوکرچه، ا. فوشینی، ال. پروتکلهای Bellavista، P. V2V برای کشف تراکم ترافیک در مسیرهای مورد علاقه در VANET: یک مطالعه کمی. سیم. اشتراک. اوباش محاسبه کنید. 2016 ، 16 ، 2907-2923. [ Google Scholar ] [ CrossRef ]
- لی، سی. لو، اچ. شیانگ، ی. لیو، ز. یانگ، دبلیو. لیو، آر. نزدیکتر کردن دادههای مکانی به کاربران موبایل: رویکرد ذخیرهسازی مبتنی بر کاشیهای برداری برای سناریوهای چند هاپ بیسیم. اوباش Inf. سیستم 2018 , 2018 , 5186495. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Kärkkäinen، T. پیتکنن، ام. Ott, J. کاربردها در شبکه های تحمل تاخیر و فرصت طلب. In Mobile Ad Hoc Networking: Cutting Edge Directions , 2nd ed.; Basagni, S., Conti, M., Giordano, S., Stojmenovic, I., Eds. جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2013. صص 315-359. [ Google Scholar ]
- پوپا، ال. قدسی، ع. Stoica، I. HTTP به عنوان کمر باریک اینترنت آینده. در مجموعه مقالات نهمین کارگاه ACM SIGCOMM در مورد موضوعات داغ در شبکه ها، مونتری، کالیفرنیا، ایالات متحده آمریکا، 20 تا 21 اکتبر 2010. [ Google Scholar ]
- اوت، جی. Kutscher, D. Bundling the Web: HTTP over DTN. در مجموعه مقالات کارگاه شبکه سازی در حمل و نقل عمومی (WNEPT) در ارتباط با QShine 2006، واترلو، ON، کانادا، 7 تا 9 اوت 2006. [ Google Scholar ]
- سنکران، ک. چان، ام سی; په، چارچوب پویا LS برای ساخت برنامههای DTN وب تلفن همراه بسیار محلیسازی شده. محاسبه کنید. اشتراک. 2016 ، 73 ، 56-65. [ Google Scholar ] [ CrossRef ]
- پیتکنن، ام. Kärkkäinen، T. Ott, J. دسترسی فرصت طلبانه به وب از طریق نقاط مهم WLAN. در مجموعه مقالات کنفرانس بین المللی IEEE در سال 2010 در محاسبات و ارتباطات فراگیر (PerCom)، مانهایم، آلمان، 29 مارس تا 2 آوریل 2010. ص 20-30. [ Google Scholar ]
- نگی، م. Kärkkäinen، T. Ott, J. تقویت شبکه های فرصت طلب با گره های قدیمی. در مجموعه مقالات نهمین کارگاه ACM MobiCom در مورد شبکه های چالش برانگیز (CHANTS ’14)، مائوئی، HI، ایالات متحده آمریکا، 7 سپتامبر 2014. صص 1-6. [ Google Scholar ]
- هلگاسون، Ó. کویومجیوا، ST; پاژویچ، ال. یاووز، EA; کارلسون، جی. یک میان افزار برای توزیع محتوای فرصت طلب. محاسبه کنید. شبکه 2016 ، 107 ، 178-193. [ Google Scholar ] [ CrossRef ]
- ژوانگ، اچ. Ntareme، H. او، ز. Pehrson, B. A Midware Adaptation Service for Delay Tolerant Network بر اساس سرویس صف ساده HTTP. در مجموعه مقالات ششمین کارگاه USENIX/ACM در مورد سیستم های شبکه ای برای مناطق در حال توسعه (NSDR ’12)، بوستون، MA، ایالات متحده آمریکا، 15 ژوئن 2012. [ Google Scholar ]
- سرینیواسان، وی. Julien, C. MadApp: میانافزاری برای داده های فرصت طلب در برنامه های کاربردی وب موبایل. در مجموعه مقالات پانزدهمین کنفرانس بین المللی IEEE در سال 2014 در مدیریت داده های تلفن همراه، بریزبن، QLD، استرالیا، 14 تا 18 ژوئیه 2014. صص 172-177. [ Google Scholar ]
- دسترسی سریع به اینترنت پرسرعت، دستگاههای بیشتر و محتوای بیشتر ترکیب میشوند تا مصرف رسانه را افزایش دهند. پرایس واترهاوس کوپرز. 2016. در دسترس آنلاین: https://www.pwc.com/gx/en/entertainment-media/publications/assets/internet-access-outlook-article-december-2016.pdf (در 31 مارس 2019 قابل دسترسی است).
- گزارش تحرک اریکسون اریکسون 2018. در دسترس آنلاین: https://www.ericsson.com/assets/local/mobility-report/documents/2018/ericsson-mobility-report-june-2018.pdf (دسترسی در 31 مارس 2019).
- اوغوز، اف. کولر، دبلیو. تحلیل URL در سال 20: یک یادداشت تحقیقاتی. J. Assoc. Inf. علمی تکنولوژی 2016 ، 67 ، 477-479. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- جونز، اس ام. de Sompel، HV; شانکار، اچ. کلاین، ام. توبین، آر. Grover, C. Scholarly Context Adrift: سه مورد از چهار مرجع URI منجر به تغییر محتوا می شود. PLoS ONE 2016 , 11 , e167475. [ Google Scholar ] [ CrossRef ]
- ژانگ، ی. انصاری، ن. در مورد حذف افزونگی داده های مستقل از پروتکل. IEEE Commun. Surv. معلم خصوصی 2014 ، 16 ، 455-472. [ Google Scholar ] [ CrossRef ]
- Agyapong، PK؛ Sirbu، M. انگیزه های اقتصادی در شبکه اطلاعات محور: مفاهیم برای طراحی پروتکل و خط مشی عمومی. IEEE Commun. Mag. 2012 ، 50 ، 18-26. [ Google Scholar ] [ CrossRef ]
- Choffnes، DR. Bustamante، FE رام کردن تورنت: رویکردی عملی برای کاهش ترافیک متقاطع isp در سیستمهای همتا به همتا. در مجموعه مقالات کنفرانس ACM SIGCOMM 2008 در مورد ارتباطات داده (SIGCOMM ’08)، سیاتل، WA، ایالات متحده آمریکا، 17-22 اوت 2008. صص 363-374. [ Google Scholar ]
- مورلی، ا. تورتونزی، م. استفانلی، سی. سوری، N. شبکه اطلاعات محور در سناریوهای ارتباطی نسل بعدی. J. Netw. محاسبه کنید. Appl. 2017 ، 80 ، 232-250. [ Google Scholar ] [ CrossRef ]
- ساروس، کالیفرنیا؛ دیامانتوپولوس، اس. رنه، اس. پساراس، آی. Lertsinsrubtavee، A.; مولینا-خیمنز، سی. مندز، پی. صوفیه، آر. ساتیاسلان، ع. پاولو، جی. و همکاران اتصال لبه ها: معماری ارتباطات جهانی، موبایل محور و فرصت طلب. IEEE Commun. Mag. 2018 ، 56 ، 136-143. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آناستازیادس، سی. اشمید، تی. وبر، جی. براون، تی. بازیابی محتوای اطلاعات محور برای شبکه های تحمل تاخیر. محاسبه کنید. شبکه 2016 ، 107 ، 194-207. [ Google Scholar ] [ CrossRef ]
- اسلام، HMA; چاتزوپولوس، دی. لاگوتین، دی. هوی، پی. Ylä-Jääski, A. تقویت عملکرد شبکه های محتوا محور با استفاده از مکانیسم های شبکه تحمل تاخیر. دسترسی IEEE 2017 ، 5 ، 23858–23870. [ Google Scholar ] [ CrossRef ]
- تروسن، دی. ساتیاسلان، ع. Ott, J. به سوی معماری شبکه اطلاعات محور برای دسترسی جهانی به اینترنت. محاسبات ACM SIGCOMM. اشتراک. Rev. 2016 , 46 , 44-49. [ Google Scholar ] [ CrossRef ]
- فارل، اس. لیندگرن، ا. لینچ، ا. Kutscher، D. Bundle Query Block Extension Protocol. 2012. در دسترس آنلاین: https://tools.ietf.org/pdf/draft-irtf-dtnrg-bpq-00.pdf (دسترسی در 20 ژوئن 2019).
- پنتیکوسیس، ک. اوهلمن، بی. کورجو، دی. بوگیا، جی. تایسون، جی. دیویس، ای. مولینارو، ا. Eum, S. شبکه اطلاعات محور: سناریوهای پایه. 2015. در دسترس آنلاین: https://tools.ietf.org/pdf/rfc7476.pdf (دسترسی در 20 ژوئن 2019).
- کورنیکوف، آ. Kärkkäinen، T. Ott, J. داده ها به مردم. در مجموعه مقالات هشتمین کارگاه ACM MobiCom در مورد شبکه های چالش برانگیز (CHANTS ’13)، میامی، فلوریدا، ایالات متحده آمریکا، 30 سپتامبر 2013. صص 49-50. [ Google Scholar ]
- تایسون، جی. بیگام، ج. Bodanese, E. Towards a Towards a Delay-Tolerant Information-centric Network. در مجموعه مقالات کنفرانس IEEE 2013 در کارگاه های آموزشی ارتباطات کامپیوتری (INFOCOM WKSHPS)، تورین، ایتالیا، 14-19 آوریل 2013. صص 387-392. [ Google Scholar ]
- پرز-سانچز، اس. Cabero, JM; Urteaga، I. مسیریابی DTN بهینه شده توسط روتین های انسانی: پروتکل HURry. در مجموعه مقالات سیزدهمین کنفرانس بین المللی (WWIC 2015) در مورد ارتباطات اینترنتی بی سیم/بی سیم، مالاگا، اسپانیا، 25 تا 27 مه 2015؛ صص 299-312. [ Google Scholar ]
- اسلام، HM; لوکیاننکو، آ. تارکوما، اس. Yla-Jaaski, A. Towards disruption tolerant ICN. در مجموعه مقالات سمپوزیوم IEEE 2015 در زمینه کامپیوتر و ارتباطات (ISCC)، لارناکا، قبرس، 6 تا 9 ژوئیه 2015؛ صص 212-219. [ Google Scholar ]
- ژانگ، ال. آفاناسیف، آ. بورک، جی. جاکوبسون، وی. کراولی، پی. پاپادوپولوس، سی. وانگ، ال. Zhang، B. به نام شبکه داده. محاسبات ACM SIGCOMM. اشتراک. Rev. 2014 , 44 , 66-73. [ Google Scholar ] [ CrossRef ]
- پتز، آ. لیندگرن، ا. هوی، پی. Julien, C. MADServer: A Server Architecture for Mobile Advanced Delivery. در مجموعه مقالات هفتمین کارگاه بین المللی ACM در مورد شبکه های به چالش کشیده (CHANTS ’12)، استانبول، ترکیه، 22 تا 26 اوت 2012; صص 17-22. [ Google Scholar ]
- Toole، JL; هررا-یاکو، سی. اشنایدر، سی ام. گونزالس، MC کوپلینگ تحرک انسانی و روابط اجتماعی. JR Soc. رابط 2015 ، 12 ، 1-9. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اولیویرا، EMR؛ ویانا، AC؛ ساراوت، سی. بری، جی. آلوارز-هاملین، I. در مورد نظم حرکت انسان. اوباش فراگیر. محاسبه کنید. 2016 ، 33 ، 73-90. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وی، ک. لیانگ، ایکس. Xu, K. بررسی پروتکلهای مسیریابی آگاه اجتماعی در شبکههای متحمل تاخیر: برنامهها، طبقهبندی و مسائل مرتبط با طراحی. IEEE Commun. Surv. معلم خصوصی 2014 ، 16 ، 556-578. [ Google Scholar ]
- وانگ، تی. کائو، ی. ژو، ی. لی، پی. بررسی پروتکلهای مسیریابی جغرافیایی در شبکههای متحمل تاخیر/اختلال. بین المللی J. Distrib. Sens. Netw. 2016 ، 12 ، 1-12. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ون، اچ. رن، اف. لیو، جی. لین، سی. لی، پی. Fang, Y. A Storage-Friendly Routing Scheme در شبکه موبایل متصل به طور متناوب. IEEE Trans. وه تکنولوژی 2011 ، 60 ، 1138-1149. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یامادا، ا. ایشیهارا، اس. استراتژی های تبادل داده برای تجمیع توزیع جغرافیایی تقاضاها برای اطلاعات وابسته به مکان با استفاده از طرح های حالت نرم در VANET. در مجموعه مقالات سی و یکمین کنفرانس بین المللی IEEE 2017 در مورد شبکه های اطلاعاتی پیشرفته و برنامه های کاربردی (AINA)، تایپه، تایوان، 27 تا 29 مارس 2017؛ صص 728-736. [ Google Scholar ]
- او، X. یانگ، جی. Zhang، H. DRANS: تجزیه و تحلیل روتین روزانه برای جستجوی گره در شبکه های تحمل تاخیر. بین المللی J. Distrib. Sens. Netw. 2017 ، 13 ، 1-15. [ Google Scholar ] [ CrossRef ]
- فوروتانی، تی. کاواموتو، ی. نیشیاما، اچ. Kato, N. پیشنهاد و ارزیابی عملکرد تکنیک انتشار اطلاعات با Wi-Fi مستقیم مبتنی بر سلول مجازی جدید. IEEE Trans. ظهور. بالا. محاسبه کنید. 2019 . [ Google Scholar ] [ CrossRef ]
- چن، ک. Shen, H. Greedyflow: مسیریابی بسته حریصانه توزیع شده بین نشانهها در DTN. Ad Hoc Netw. 2019 ، 83 ، 168-181. [ Google Scholar ] [ CrossRef ]
- چوی، CS; باچلی، اف. د وسیانا، جی. تحرک اهرمی تراکم: معماری اینترنت اشیاء مبتنی بر شبکه شبکه و وسایل نقلیه. در مجموعه مقالات هجدهمین سمپوزیوم بین المللی ACM در مورد شبکه و محاسبات موقتی موبایل (Mobihoc ’18)، لس آنجلس، کالیفرنیا، ایالات متحده آمریکا، 26 تا 29 ژوئن 2018؛ صص 71-80. [ Google Scholar ]
- ژانگ، ال. یو، بی. Pan, J. GeoMobCon: یک طرح انتقال جغرافیایی آگاه از تحرک برای VANET های شهری. IEEE Trans. وه تکنولوژی 2016 ، 65 ، 6715-6730. [ Google Scholar ] [ CrossRef ]
- انور، ت. لیو، سی. Vu، HL؛ Leckie, C. پارتیشن بندی شبکه های جاده با استفاده از نمودارهای اوج تراکم: کارایی در مقابل دقت. Inf. سیستم 2017 ، 64 ، 22-40. [ Google Scholar ] [ CrossRef ]
- لیو، ایکس. آی، تی. لیو، Y. تجزیه و تحلیل تراکم جاده بر اساس پارتیشن بندی اسکلت برای تعمیم جاده. ژئو اسپات. Inf. علمی 2009 ، 12 ، 110-116. [ Google Scholar ] [ CrossRef ]
- لای، سی. وانگ، ال. چن، جی. منگ، ایکس. زیتونی، ک. جستارهای چگالی موثر برای اجسام متحرک در شبکه های جاده ای. در مجموعه مقالات نهمین کنفرانس مشترک وب آسیا و اقیانوسیه (APWeb 2007) و هشتمین کنفرانس بین المللی، در مورد مدیریت اطلاعات عصر وب (WAIM 2007)، هوانگ شان، چین، 16-18 ژوئن 2007. ص 200-211. [ Google Scholar ]
- لی، آر. تانگ، دی. ساخت فضاهای فعالیت انسانی: رویکرد جدیدی که شامل فعالیتهای شهری پیچیده است. J. Transp. Geogr. 2016 ، 56 ، 23-35. [ Google Scholar ] [ CrossRef ]
- مارکو، AD; مارکو، MD مفهوم سازی و اندازه گیری محله در محیط های روستایی: مروری نظام مند از ادبیات. J. روانی جامعه. 2010 ، 38 ، 99-114. [ Google Scholar ] [ CrossRef ]
- هیپ، جی آر؛ فارس، RW; Boessen، A. اندازه گیری “همسایگی”: ساخت محله های شبکه. Soc. شبکه 2012 ، 34 ، 128-140. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Weden, MM; پترسون، CE; Miles, JN; Shih، RA ارزیابی تخمینهای میانسرانهای درونیابی خطی ویژگیهای جمعیتشناختی و اجتماعی-اقتصادی بخشهای ایالات متحده و سرشماری 2001-2009. مردمی Res. Policy Rev. 2015 , 34 , 541-559. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- الناکات، ع. گومز، جی دی. Booth، N. مطالعه کد پستی تأثیر جنسیتی اجتماعی، اقتصادی، جمعیتی و خانوار بر بخش انرژی مسکونی. انرژی ، 2016 ، 2 ، 21-27. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تامپسون، ال. جانسون، اس. اشبی، م. پرکینز، سی. Edwards, P. UK داده های جرم منبع باز: دقت و امکانات برای تحقیق. کارتوگر. Geogr. Inf. علمی 2015 ، 42 ، 97-111. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کریگر، ن. چن، جی تی. Waterman، PD; سوبادر، ام جی; سوبرامانیان، SV; کارسون، آر. ژئوکدینگ و نظارت بر نابرابری های اجتماعی-اقتصادی ایالات متحده در مرگ و میر و بروز سرطان: آیا انتخاب اندازه گیری مبتنی بر منطقه و سطح جغرافیایی اهمیت دارد؟: پروژه ژئوکدگذاری نابرابری های بهداشت عمومی. صبح. J. Epidemiol. 2002 ، 156 ، 471-482. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- توماس، ای جی; ابرلی، LE; اسمیت، جی دی. Neaton، JD مبتنی بر کد پستی در مقابل معیارهای درآمد مبتنی بر تراکت به عنوان پیشبینیکنندههای مرگومیر تنظیمشده با ریسک بلندمدت. صبح. J. Epidemiol. 2006 ، 164 ، 586-590. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- یانگ، ز. آهنگ، تی. Chahine، T. بازنمایی های فضایی و پیامدهای سیاستی هم تراکم های صنعتی، مطالعه موردی پکن. Habitat Int. 2016 ، 55 ، 32-45. [ Google Scholar ] [ CrossRef ]
- وانگ، ایکس. ژو، ز. ژائو، ی. ژانگ، ایکس. زینگ، ک. شیائو، اف. یانگ، ز. لیو، ی. بهبود پیشبینی جریان جمعیت شهری در پارتیشن منطقه انعطافپذیر. IEEE Trans. اوباش محاسبه کنید. 2019 . [ Google Scholar ] [ CrossRef ]
- رن، ی. چنگ، تی. Zhang، Y. شبکههای عصبی باقیمانده فضایی-زمانی عمیق برای مدلسازی دادههای مبتنی بر شبکه جادهای. بین المللی جی. جئوگر. Inf. علمی 2019 ، 33 ، 1894–1912. [ Google Scholar ] [ CrossRef ]
- راسر، جی. دیویس، تی. Bowers، KJ; جانسون، SD; چنگ، تی. نقشه برداری جنایت پیش بینی کننده: شبکه های خودسرانه یا شبکه های خیابانی؟ جی. کوانت. Criminol. 2017 ، 33 ، 569-594. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رجایی، ع. چالمرز، دی. ویکمن، آی. Parisis, G. Geocasting کارآمد در شبکه های فرصت طلب. محاسبه کنید. اشتراک. 2018 ، 127 ، 105-121. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لو، اس. Liu, Y. Geoopp: Geocasting برای شبکه های فرصت طلب. در مجموعه مقالات کنفرانس ارتباطات و شبکه بی سیم IEEE 2014 (WCNC)، استانبول، ترکیه، 6 تا 9 آوریل 2014. صص 2582-2587. [ Google Scholar ]
- یوان، نیوجرسی؛ ژنگ، ی. Xie، X. وانگ، ی. ژنگ، ک. Xiong، H. کشف مناطق عملکردی شهری با استفاده از مسیرهای فعالیت پنهان. IEEE Trans. بدانید. مهندسی داده 2015 ، 27 ، 712-725. [ Google Scholar ] [ CrossRef ]
- گونزالس، اچ. هان، جی. لی، ایکس. میسلینسکا، ام. سونداگ، محاسبه سریعترین مسیر تطبیقی JP در شبکه جاده: رویکرد استخراج ترافیک. در مجموعه مقالات سی و سومین کنفرانس بین المللی پایگاه های داده بسیار بزرگ (VLDB ’07)، وین، اتریش، 23 تا 27 سپتامبر 2007. صص 794-805. [ Google Scholar ]
- Anyproxy—یک پروکسی http/https کاملاً قابل تنظیم در NodeJS. در دسترس آنلاین: https://github.com/alibaba/anyproxy (در 15 سپتامبر 2018 قابل دسترسی است).
- DTN2— پیاده سازی مرجع DTN. در دسترس آنلاین: https://github.com/delay-tolerant-networking (در 15 سپتامبر 2018 قابل دسترسی است).
- سرف، وی. بورلی، اس. دورست، آر. پاییز، ک. هوک، ا. اسکات، ک. تورگرسون، ال. ویس، اچ. معماری شبکه های متحمل تاخیر. 2007. در دسترس آنلاین: https://tools.ietf.org/html/rfc4838 (در 6 مه 2019 قابل دسترسی است).
- اسکات، ک. مشخصات پروتکل Burleigh، S. Bundle. 2007. در دسترس آنلاین: https://tools.ietf.org/html/rfc5050 (در 6 مه 2019 قابل دسترسی است).
- راماداس، م. بورلی، اس. Farrell, S. Licklider Transmission Protocol—مشخصات. 2008. در دسترس آنلاین: https://tools.ietf.org/html/rfc5326 (در 6 مه 2019 قابل دسترسی است).
- کوزنباخ، M. سلسله مراتب جوامع شهری: مشاهدات در مورد شخصیت تو در تو مکان. جامعه شهر 2008 ، 7 ، 225-249. [ Google Scholar ] [ CrossRef ]
- استخراج داده های OpenStreetMap در دسترس آنلاین: https://download.geofabrik.de/ (دسترسی در 15 سپتامبر 2018).
- PostgreSQL-پیشرفته ترین پایگاه داده ارتباطی منبع باز جهان. در دسترس آنلاین: https://www.postgresql.org/ (دسترسی در 15 سپتامبر 2018).
- PostGIS – اشیاء مکانی و جغرافیایی برای PostgreSQL. در دسترس آنلاین: https://postgis.net/ (دسترسی در 15 سپتامبر 2018).
- بلوک های شهر OpenStreetMap به عنوان چند ضلعی GeoJSON. در دسترس آنلاین: https://peteris.rocks/blog/openstreetmap-city-blocks-as-geojson-polygons/ (دسترسی در 17 مه 2018).
- شکلپذیر – دستکاری و تحلیل اجسام هندسی در صفحه دکارتی. در دسترس آنلاین: https://github.com/Toblerity/Shapely (در 6 مه 2019 قابل دسترسی است).
- QGIS – یک سیستم اطلاعات جغرافیایی رایگان و منبع باز. در دسترس آنلاین: https://qgis.org/en/site/ (دسترسی در 15 سپتامبر 2018).
- روزنامه حیدیان. در دسترس آنلاین: https://www.xzqh.org/html/list/397.html (در 2 نوامبر 2018 قابل دسترسی است). (به زبان چینی).
- وو، جی. لو، اچ. Xiang، Y. اندازهگیری و مقایسه Sub-1GHz و IEEE 802.11p در شبکههای خودرو. در مجموعه مقالات سمپوزیوم IEEE 2017 در زمینه کامپیوتر و ارتباطات (ISCC)، هراکلیون، یونان، 3 تا 6 ژوئیه 2017؛ صص 1063-1066. [ Google Scholar ]
- کدهای بخش اداری برای استفاده آماری، منطقه هایدیان، پکن. در دسترس آنلاین: https://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/11/01/110108.html (در 2 نوامبر 2018 قابل دسترسی است). (به زبان چینی)
- SQLite. در دسترس آنلاین: https://www.sqlite.org/index.html (دسترسی در 15 سپتامبر 2018).
- SpatiaLite. در دسترس آنلاین: https://www.gaia-gis.it/fossil/libspatialite/index (در 15 سپتامبر 2018 قابل دسترسی است).
- وانگ، دبلیو. لو، اچ. شیانگ، ی. کای، بی. وو، جی. Gao, R. AAaS: نزدیک شدن به منطقه و طرح مسیریابی اسپری و انتظار برای DTN در Android. در مجموعه مقالات 2016 هجدهمین کنفرانس بین المللی فناوری ارتباطات پیشرفته (ICACT)، پیونگ چانگ، کره، 31 ژانویه تا 3 فوریه 2016؛ صص 510-516. [ Google Scholar ]
- سو، ک. ژائو، ی. چن، دبلیو. رائو، جی. تجزیه و تحلیل و مطالعه تجربی شبکه های کانتینری. در مجموعه مقالات IEEE INFOCOM 2018 — کنفرانس IEEE در زمینه ارتباطات کامپیوتری، هونولولو، HI، ایالات متحده آمریکا، 15-19 آوریل 2018؛ ص 189-197. [ Google Scholar ]
- سیبی، اس. گالاتی، ع. بورچاس، تی. اولیوارس، ام. ناخالص، TR; Mangold, S. MethoD: چارچوبی برای شبیه سازی سناریوی شبکه متحمل تاخیر برای توزیع محتوای رسانه ای در مناطقی که کمتر خدمات رسانی می شود. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی ارتباطات و شبکه های کامپیوتری (ICCCN) 2015، لاس وگاس، NV، ایالات متحده، 3 تا 6 اوت 2015؛ صفحات 1-9. [ Google Scholar ]
- لی، ی. هوی، پی. جین، دی. چن، اس. تست و ارزیابی پروتکل شبکه با تحمل تاخیر. IEEE Commun. Mag. 2015 ، 53 ، 258-266. [ Google Scholar ] [ CrossRef ]
- سانچز-کارمونا، آ. گایدک، اف. Launay، P. ماهئو، ی. Robles, S. پر کردن حلقه مفقوده بین شبیه سازی و کاربرد در شبکه های فرصت طلب. جی. سیست. نرم افزار 2018 ، 142 ، 57-72. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کیس، دبلیو. Mauve, M. نظرسنجی در مورد پیاده سازی دنیای واقعی شبکه های ad-hoc موبایل. Ad Hoc Netw. 2007 ، 5 ، 324-339. [ Google Scholar ] [ CrossRef ]
- ParallelSSH. در دسترس آنلاین: https://parallel-ssh.org/ (دسترسی در 19 نوامبر 2018).
- یوان، جی. ژنگ، ی. Xie، X. Sun, G. رانندگی با دانش از دنیای فیزیکی. در مجموعه مقالات هفدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی (KDD ’11)، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 21 تا 24 اوت 2011. صص 316-324. [ Google Scholar ]
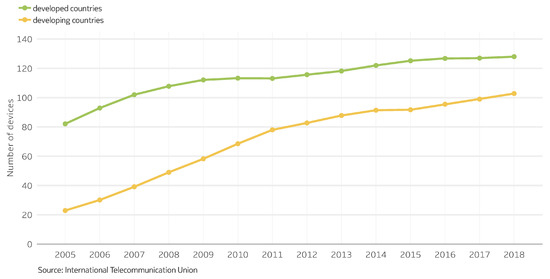
شکل 1. تعداد اشتراک جهانی تلفن همراه به ازای هر 100 نفر جمعیت.

شکل 2. میانگین قیمت 1 گیگابایت ترافیک موبایل و نسبت آن در درآمد سرانه روزانه بر اساس کشور.

شکل 3. چارچوب Geo-DMP.

شکل 4. تبدیل بین پیام های HTTP و بسته های شبکه تحمل کننده تاخیر/اختلال (DTN) در طول فرآیند بازیابی محتوا.

شکل 5. رسیدگی به پرس و جوی جدید ایجاد شده.

شکل 6. رسیدگی به یک پرس و جو بیرونی.

شکل 7. مدیریت پاسخ بیرونی.

شکل 8. شبکه جاده ناهموار استخراج شده از مجموعه داده های برداری OSM (جزئی).

شکل 9. اثر پس از چند ضلعی (جزئی).

شکل 10. نتیجه تقسیم بندی مناطق بلوک.

شکل 11. نتیجه تقسیم بندی مناطق فرعی.

شکل 12. نتیجه تقسیم بندی مناطق جامعه.

شکل 13. نمونه ای از نامگذاری منطقه.
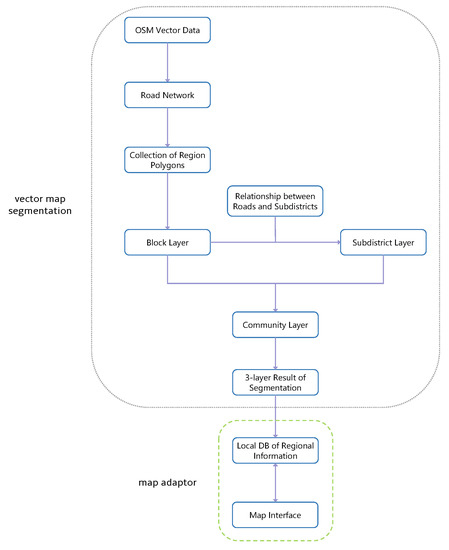
شکل 14. روش تولید ماژول آداپتور نقشه.

شکل 15. سناریو و مکان های کلیدی برای آزمایش ها در بخش 4.2.1 .

شکل 16. جدول زمانی تعاملات-مورد عدم وجود حافظه پنهان میانی.

شکل 17. جدول زمانی تعاملات – مورد حافظه پنهان کامل میانی.

شکل 18. جدول زمانی تعاملات-مورد کش های میانی جزئی.

شکل 19. جدول زمانی تعاملات – در آزمایش روی تجسم مشتری.

شکل 20. اسکرین شات های مرورگر در اعتبار سنجی تجسم مشتری با تحمل تاخیر.

شکل 21. محدوده حرکت سناریوی جامع و یک مجموعه از آثار به عنوان مثال.

شکل 22. نسبت تحویل آزمایشات بدون حافظه پنهان میانی.

شکل 23. میانگین تأخیر تحویل در آزمایشات بدون حافظه پنهان میانی.

شکل 24. میانگین جهش تحویل در آزمایشات بدون حافظه پنهان میانی.

شکل 25. منابع بازیابی محتوا با گره های کش.


بدون دیدگاه