1. مقدمه
استنباط حالت های حمل و نقل یکی از اجزای حیاتی سیستم های حمل و نقل هوشمند است. حالت حمل و نقل انتخاب شده توسط مسافر یک ویژگی رفتاری اساسی است. استنباط توزیع حالت حمل و نقل می تواند به آژانس های مدیریت شهری کمک کند تا رفتار ساکنان [ 1 ] را درک کنند و سیستم حمل و نقل شهری را کنترل کنند [ 2 ، 3 ، 4 ]. علاوه بر این، اطلاعات حالت حمل و نقل نقش حیاتی در ساخت یک مدل کاربر مبتنی بر فعالیت [ 5 ] و ارائه پشتیبانی های وظیفه محور [ 6 ] ایفا می کند. به عنوان مثال، شناسایی حالت حمل و نقل به سفارشی کردن خدمات تلفن همراه [ 7 ] و با توصیه های تبلیغاتی کمک می کند.8 ]. در سال های اخیر، تعداد فزاینده ای از شهرها شروع به استقرار Mobility as a Service (MaaS) کرده اند. این سرویس حمل و نقل جدید مبتنی بر تقاضا، رفتارهای سفر ساکنان شهری را تغییر خواهد داد. برای پیش بینی و رفع نیازهای سفر ساکنان شهری به صورت معقول، باید مشکل اساسی شناسایی نحوه حمل و نقل ساکنان حل شود.
در چند دهه گذشته، استفاده از دستگاههای GPS که توسط تلفنهای هوشمند نشان داده میشوند، گسترده شده است و حجم عظیمی از دادههای ساکنین را با اطلاعات مکانی-زمانی تولید کرده است که فرصتی عالی برای تحلیل حالتهای حملونقل شهری با هزینه کم و با کارایی بالا ارائه میدهد. با این حال، استنباط حالت های حمل و نقل از مسیر خام آسان نیست، و هنوز با چالش های متعددی روبرو است.
برای شروع، سوابق خام جیپیاس فقط حاوی مُهرهای زمانی و اطلاعات مکان هستند که مستقیماً ویژگیهای مسیر را منعکس نمیکنند. متفاوت از داده های تصویری، استفاده از مدل های یادگیری عمیق برای استخراج مستقیم و خودکار ویژگی ها از مسیرهای GPS خام دشوار است. بنابراین، اولین مشکل در شناسایی حالت حمل و نقل، چگونگی ساخت یک نمایش موثر از مسیرهای خام است که می تواند توسط مدل نیز استفاده شود. روش اصلی تحقیق موجود استخراج یک سری ویژگی های حرکتی است. با این حال، در سناریوهای زندگی واقعی، مسیرهای GPS کاربران تحت تأثیر اطلاعات جغرافیایی پیچیده است [ 9 ]]. مطالعات قبلی قابلیتهای عالی پیشبینی ترافیک را با بهرهبرداری از رابطه توپولوژیکی فضایی در شبکههای جادهای برای یادگیری وابستگی مکانی-زمانی جریانهای ترافیک نشان دادهاند [ 10 ، 11 ]. علاوه بر این، بافت جغرافیایی اطلاعات ارزشمندی را برای پیشبینیها تکمیل میکند و با استفاده از دادههای حسگر محدود [ 12 ، 13 ] و رفتار متحرک بر اساس دادههای مسیر [ 14 ] ، سهم تعیینکنندهای در پیشبینیها و پیشبینیهای کیفیت هوا داشته است.
در سال های اخیر، مطالعات نشان می دهد که رابطه بین خوانش های GPS و اطلاعات جغرافیایی به شناسایی حالت حمل و نقل کمک می کند. برای مثال، ویژگیهای حرکتی برای یک نوع وسیله نقلیه ممکن است متفاوت باشد، زیرا آنها باید از محدودیتهای سرعت متفاوت در جادههای مختلف شهر تبعیت کنند [ 15 ]. همانطور که در شکل 1 نشان داده شده است، از 1 و 0 برای نشان دادن وجود ایستگاه اتوبوس در 100 متری خوانش GPS استفاده می کنیم. ویژگی های سرعت این مسیر به طور قابل توجهی در هنگام عبور از ایستگاه اتوبوس تحت تأثیر قرار می گیرد. مشاهده می شود که ویژگی های حرکتی مسیرها در شهر تحت تأثیر امکانات اطراف است. مطلوب است که نمایش مسیرها با ویژگی های خود و بافت جغرافیایی اطراف ساخته شود [ 9 ، 16 ، 17 ]. بنابراین، ما اطلاعات جغرافیایی (به عنوان مثال، سطح شبکه جادهها، توزیع ایستگاههای عمومی) را رمزگذاری میکنیم و آن را با ویژگیهای حرکتی هر قرائت GPS از مسیرها برای ایجاد جاسازی مسیر ترکیب میکنیم.
دوم، مسیرهای جیپیاس خام جمعآوریشده از دستگاههای هوشمند مجهز به GPS مستقیماً حاوی برچسبهای دقیق حالت حمل و نقل نیستند. بنابراین، برای ساختن نمونه برای آموزش مدل یادگیری نظارت شده، کاربران یا محققان اغلب برچسبهای حالت حمل و نقل را به صورت دستی به مسیرها اختصاص میدهند، که باعث میشود مطالعات مبتنی بر مدل یادگیری نظارتشده با محدودیتهای مشابه تحقیقات سنتی پیمایش سفر مواجه شوند. برخلاف تصاویر و متون زبان طبیعی، درک مسیر متشکل از خوانشهای GPS برای محققان دشوار است، و باعث میشود که حاشیهنویسی برچسبها کاری بسیار وقتگیر باشد. علاوه بر این، اغلب برای تعداد زیادی از کاربران حاشیه نویسی مسیرهای خود پرهزینه است. به عنوان مثال، همانطور که استوفر و گریوز معرفی کردند [ 18]، 750 دلار آمریکا برای جمع آوری داده های یک هفته ای کاربر هزینه دارد. در مقایسه با حاشیه نویسی برچسب پر هزینه، تعداد زیادی از مسیرهای GPS بدون برچسب به راحتی به دست می آیند. بنابراین، لازم است مدلی طراحی شود که بتواند به ما کمک کند تا به طور خودکار اطلاعاتی را که برای شناسایی حالت حمل و نقل مفید است از داده های بدون برچسب به راحتی به دست آوریم، استخراج کنیم.
بر اساس مطالعات قبلی [ 15 ، 17 ، 18 ]، دو سوال تحقیقاتی برای شناسایی حالت حمل و نقل در مسیرهای GPS وجود دارد، به عنوان مثال: 1. چگونه می توان ویژگی های ناهمگن، مانند ویژگی های حرکت و اطلاعات جغرافیایی، را برای نمایش یک مسیر ادغام کرد؟ 2. چگونه می توان یک مدل شناسایی حالت حمل و نقل نیمه نظارت شده تنها با مقدار کمی از مسیرهای برچسب دار و تعداد زیادی مسیر بدون برچسب ساخته شد؟
به منظور حل مشکلات فوق، ما یک چارچوب شناسایی حالت حمل و نقل جدید به نام GeoSDVA پیشنهاد می کنیم که در آن ابتدا جاسازی مسیر را با ترکیب ویژگی های حرکت و اطلاعات جغرافیایی هر خواندن GPS از یک مسیر خام تولید می کنیم و سپس یک مدل شناسایی حالت حمل و نقل نیمه نظارت شده بر اساس رمزگذار خودکار متغیر دیریکله بسازید. بر این اساس، مشارکت های اصلی مطالعه به شرح زیر خلاصه می شود:
-
ما یک روش طراحی نمونه جدید برای ترکیب ویژگیهای ناهمگن با هم، از جمله اطلاعات جغرافیایی و ویژگیهای حرکت از مسیرهای خام، پیشنهاد میکنیم. این روش ویژگیهای حرکت و زمینههای جغرافیایی را که مسیر GPS به آنها مرتبط است، از جمله ایستگاههای اتوبوس، تقاطعهای جادهای، و سطح شبکه جادهای، ادغام میکند تا یک نمایش جاسازی شده از مسیر خام را تشکیل دهد.
-
ما یک رمزگذار خودکار متغیر نیمه نظارت شده دیریکله (DirVAE) مبتنی بر مدل شناسایی حالت حمل و نقل، به نام GeoSDVA، میسازیم که از سه ماژول تشکیل شده است: یک ماژول رمزگذاری برای رمزگذاری مسیرها در بردارهای پنهان، یک ماژول طبقهبندی کننده با پیچش چند مقیاسی برای استخراج چند ماژول. مقیاس ویژگی ها و پیش بینی حالت های حمل و نقل مسیرها، و یک ماژول رمزگشایی که مسیرهای ورودی را بازسازی می کند.
-
ما آزمایشهای گستردهای را روی سه مجموعه داده دنیای واقعی انجام میدهیم، یعنی Geolife v1.3، MTL Trajet 2017، و MTL Trajet 2016. نتایج تجربی نشان میدهد که GeoSDVA از سایر چارچوبهای پیشرفته برتری دارد. علاوه بر این، ما معیارهای شناسایی GeoSDVA را تحت مقادیر مختلف مسیرهای نشاندار ارزیابی میکنیم. نتایج ارزیابی نشان میدهد که GeoSDVA برای شناسایی حالت حمل و نقل مسیرها عملی است، به خصوص زمانی که تعداد کمی از مسیرهای برچسبگذاری شده در مجموعه دادههای آموزشی گنجانده شده باشد.
2. کارهای مرتبط
اکثر کارهای قبلی شناسایی حالت حمل و نقل بر اساس مسیرهای GPS را به عنوان یک مشکل شناسایی چند طبقه [ 19 ] تعریف کرده اند که شامل دو مشکل فرعی است، یعنی طراحی ویژگی یا نمونه و طراحی مدل شناسایی.
2.1. ویژگی یا طراحی نمونه
طراحی ویژگی یک گام اساسی در شناسایی حالت حمل و نقل است. در مطالعات پیشگام [ 19 ، 20 ، 21 ، 22 ]، ویژگی های آماری استخراج شده از مسیرهای خام به طور گسترده ای برای شناسایی حالت های حمل و نقل استفاده می شود. در کار ژنگ و همکاران. [ 19 ]، ویژگی های آماری مانند طول مسیر، سرعت، شتاب، نرخ تغییر سمت (HCR)، نرخ توقف (SR)، یا سرعت تغییر سرعت (VCR) استفاده شد. سان و همکاران از نسبت قرائت های GPS با آمار شتاب بیشتر از آستانه در مسیر به عنوان ویژگی برای تمایز بین کامیون ها و اتوبوس ها استفاده کرد [ 20 ]]. در مطالعه دیگری، Nitsche و همکاران. ویژگی های آماری انتخاب شده مانند صدک 5 و 50 سرعت، شتاب، کاهش سرعت و پیشروی برای طبقه بندی حالت های حمل و نقل [ 21 ]. در مقایسه با مطالعات فوق الذکر، زو و همکاران. ویژگی های آماری مانند نوع برش زمانی (TS)، نرخ تغییر شتاب (ACR)، سرعت 85 و شتاب [ 22 ] را اتخاذ کردند. با این حال، بسیاری از روش های انتخاب ویژگی ذهنی و زمان بر هستند.
خوانش های GPS جمع آوری شده از ساکنان منعکس کننده محیط های پیچیده شهری و شرایط ترافیکی [ 19 ] است. بنابراین، برای بهبود دقت شناسایی حالت حمل و نقل، یک زمینه GIS خارجی، مانند شبکه ترافیک جادهای، زیرساخت عمومی یا توزیع POI، به تدریج در برخی مطالعات معرفی شده است. سمنجسکی و همکاران اشاره کرد که توزیع فضایی نشان دهنده حالت های مختلف ترافیک در شهرها است [ 17 ]. استنث و همکاران ویژگیهای آماری ویژگیهای GIS شهری، مانند فاصله بین ایستگاههای اتوبوس و مکانهای ساکنان را استخراج کرد [ 9 ]. کاساهارا و همکاران از ویژگی های GIS شهری مانند خطوط اتوبوس، خطوط مترو، بزرگراه ها و مناطق عابر پیاده استفاده می شود [ 16 ]]. با این حال، این مطالعات بر استخراج ویژگی های مصنوعی از اطلاعات جغرافیایی تکیه می کنند که منجر به استفاده ناکافی از آنها می شود.
تعداد فزاینده ای از مطالعات در ادبیات، مدل یادگیری عمیق شبکه های عصبی را به عاریت گرفته اند تا به طور خودکار ویژگی های بالقوه را از مسیرهای خام بیاموزند [ 23 ، 24 ]. با این حال، هنوز هم لازم است که پیش پردازش داده های مناسب روی مسیر خام برای تولید نمونه ها قبل از اینکه مسیر خام به مدل یادگیری عمیق تغذیه شود، انجام شود.
برخی از مطالعات مسیر را به نمونه های تصویر تبدیل می کنند. انود و همکاران یک روش طراحی نمونه برای تطبیق مسیرهای خام با تصاویر شبکه پیشنهاد کرد [ 23 ]. ژانگ و همکاران همین روش را اتخاذ کرد و مسیرها را به تصاویر چند نمای تبدیل کرد [ 25]. با این حال، با استفاده از این روش، تنها اطلاعات فضایی خط سیر خام، بدون هیچ ویژگی حرکتی قابل استخراج است. علاوه بر این، فرآیند ساخت تصاویر مسیر بر بسیاری از پارامترهای فوق متکی است، مانند گستره جغرافیایی، اندازه شبکه، و نرخ نمونه گیری ثابت. این نوع روش شکل مسیر را حفظ می کند، اما نمی تواند به طور موثر ویژگی حرکت مسیر را حفظ کند. دبیری و همکاران مسیرهای خام را بهعنوان بخشهایی با قرائتهای ثابت GPS پردازش کرد، و سپس چهار ویژگی حرکت کلاسیک، سرعت، شتاب، حرکت ناگهانی و نرخ تغییر مسیر را در هر بخش ادغام کرد [ 24 ، 26 ]. نواز و همکاران از بردار ویژگی حرکت و اطلاعات اجتماعی استفاده کرد [ 27]. جیمز و همکاران بردارهای ویژگی حرکت و ویژگی های تبدیل موجک را برای شناسایی حالت های انتقال ادغام کرد [ 28 ]. با این حال، آن روش ها اطلاعات جغرافیایی مربوط به مسیر خام را در نظر نمی گیرند.
در حال حاضر، مدلهای یادگیری عمیق در چند مطالعه برای ترکیب ویژگیهای حرکت مسیرهای خام با اطلاعات جغرافیایی برای کارهای شناسایی استفاده شدهاند. به عنوان مثال، شیائو و همکاران. ترکیبی از نوع کاربری زمین، حالتهای حمل و نقل و اطلاعات شخصی برای شناسایی هدف سفر کاربر از طریق شبکه عصبی مصنوعی [ 29 ]. سرویزی و همکاران مسیر GPS خام را با نوع کاربری زمین و امکانات عمومی برای شناسایی نقاط توقف از طریق یک مدل یادگیری عمیق [ 30 ] ترکیب کرد. بنابراین، استفاده از مدلهای یادگیری عمیق برای استخراج خودکار و ترکیب ویژگیهای بالقوه از اطلاعات جغرافیایی و مسیرهای GPS برای شناسایی حالت حملونقل، یک رویکرد امیدوارکننده است.
2.2. طراحی مدل شناسایی
مدل شناسایی یکی دیگر از مؤلفه های حیاتی در شناسایی شیوه حمل و نقل شهری است. کارهای قبلی عمدتاً در یادگیری ماشین سنتی و مدلهای یادگیری عمیق بودند.
مدلهای یادگیری ماشین سنتی عمدتاً مبتنی بر ویژگیهای آماری برای شناسایی حالت حمل و نقل هستند، مانند روش اکتشافی مبتنی بر احتمال قبلی [ 19 ]، مدل مجموعه مبتنی بر درخت [ 31 ]، شبکههای بیزی [ 32 ]، و طبقهبندی کننده LightGBM [ 19]. 33 ]. این روش ها به نتایج شناسایی خوبی بر اساس داده های GPS در برخی از برنامه ها دست یافتند. با این حال، آنها به شدت به ویژگی های استخراج شده در فرآیند قبلی، که ذهنی و زمان بر هستند، وابسته هستند.
مدل های یادگیری عمیق نظارت شده به طور گسترده در شناسایی حالت حمل و نقل در سال های اخیر به کار گرفته شده است. مطالعات قبلی نشان داد که مدلهای یادگیری عمیق، یادگیری ویژگیهای بالقوه از نمونهها، معمولاً از تصاویر مسیر یا بردارهای ویژگی حرکتی را ممکن میسازد. برای مثال، اندو و همکاران. ویژگی های عمیق را از تصاویر مسیر با استفاده از یک شبکه عصبی عمیق کاملا متصل [ 23 ] استخراج کرد. ژانگ و همکاران یک شبکه عصبی پیچیده چند مقیاسی را برای استخراج ویژگیهای عمیق مقیاسهای زمانی و مکانی مختلف از تصاویر مسیر چندگانه معرفی کرد [ 25 ]]. با این حال، ویژگیهای حرکتی مسیرها را نمیتوان با آن مدلها استخراج کرد و در نتیجه دقت شناسایی ضعیفی دارد. یزدی زاده و همکاران یک مجموعه بزرگ کتابخانه متشکل از مجموعهای از مدلهای CNN (شبکه عصبی کانولوشنال) با مقادیر فراپارامتر و معماریهای مختلف برای شناسایی حالتهای حملونقل طراحی کرد [ 22 ]. جیمز و همکاران ویژگی های عمیق را از ویژگی های حرکت توسط یک شبکه LSTM انباشته، همراه با ویژگی های تبدیل موجک، برای استنتاج حالت سفر آموخته است [ 28 ]. محدودیت مطالعات آنها این است که از ویژگی های فضایی نهفته به طور کامل استفاده نکردند. نواز و همکاران یک روش مبتنی بر LSTM کانولوشن برای شناسایی حالت های حمل و نقل با بردار ویژگی حرکت و اطلاعات اجتماعی پیشنهاد کرد [ 27 ]]. با این حال، همه آنها روشهای یادگیری تحت نظارت هستند که پردازش مجموعه دادهها با مسیرهای GPS کمتر برچسبگذاریشده برایشان دشوار است.
برای غلبه بر کاستی های فوق، چند مطالعه کاربرد مدل های نیمه نظارت شده را در شناسایی حالت حمل و نقل بررسی کرده اند. در این میان دبیری و همکاران. یک مدل نیمه نظارت شده مبتنی بر رمزگذار خودکار کانولوشن برای شناسایی حالت های حمل و نقل [ 26 ] ساخته شد. با این حال، در مدل آنها، خروجی طبقهبندی کننده در فرآیند بازسازی رمزگشا شرکت نمیکند. لی و همکاران نمونه های مسیر برچسب گذاری شده را با استفاده از شبکه های متخاصم ایجاد شده گسترش داد [ 34]. پس از آن، آنها مجموعه داده توسعه یافته را برای آموزش مدل شناسایی حالت حمل و نقل مبتنی بر CNN اتخاذ کردند. به این ترتیب، لی و همکاران، با در نظر گرفتن مسئله شناسایی حالت حمل و نقل به عنوان یک وظیفه طبقهبندی متراکم، یک شباهت شباهت مبتنی بر آنتروپی شبهنظارتشده رمزگذار-رمزگشا [ 35 ] ایجاد کردند. به طور کلی، یادگیری نیمه نظارت شده از شناسایی حالت حمل و نقل یک موضوع مورد مطالعه باقی مانده است.
2.3. رمزگذار خودکار متغیر نیمه نظارت شده
رمزگذار خودکار متغیر نیمه نظارت شده (نیمه VAE) ابتدا توسط Kingma و همکاران به طبقه بندی تصویر معرفی شد. [ 36 ]. علاوه بر بینایی کامپیوتری، VAE نیمه نظارت شده نیز به طور گسترده در پردازش زبان طبیعی استفاده می شود. مدل یادگیری عمیق نیمه نظارت شده سنتی مبتنی بر شبکه رمزگذار-رمزگشا به طور کلی باعث میشود رمزگذار و طبقهبندی کننده وزنهایی را به اشتراک بگذارند تا از ویژگیهای بالقوه مجموعه دادههای بدون برچسب استفاده کنند [ 26 ]]. آنچه با مدل سنتی ذکر شده در بالا متفاوت است این است که در مدل VAE نیمه نظارت شده، برچسب کلاس واقعی یا برچسب پیشبینیشده طبقهبندی کننده به ورودی مربوطه ماژول رمزگذار و به ورودی ماژول رمزگشا اضافه میشود. به طوری که مدل می تواند از داده های برچسب دار و بدون برچسب یاد بگیرد. در سال های اخیر، برخی از مطالعات بر پتانسیل مدل VAE برای داده کاوی مکانی-زمانی تأکید کرده اند [ 37 ، 38 ]. با توجه به توانایی تولید و توانایی استنتاج VAE ها، مشکل کمبود نمونه یا برچسب داده های مکانی – زمانی قابل حل است. VAE کلاسیک فرض می کند که توزیع قبلی یک توزیع گاوسی است، که از آن مقدار تقریبی را یاد می گیرد. [ خطای پردازش ریاضی ]�(متوسط) و [ خطای پردازش ریاضی ]�(انحراف معیار) [ 36 ]. در مقایسه با توزیع گاوسی، توزیع دیریکله می تواند توزیع چند مدل را بهتر شبیه سازی کند. به منظور استفاده از مزایای توزیع دیریکله، DirVAE [ 39مدل ] با جایگزینی توزیع قبلی VAE های کلاسیک با توزیع دیریکله به دست می آید. با الهام از کارهایی که تاکنون در دسترس بوده است، یک چارچوب جدید مبتنی بر DirVAE نیمه نظارتی به نام GeoSDVA طراحی کردیم تا حالت حمل و نقل در مجموعه داده را با مقدار زیادی از مسیرهای بدون برچسب و مقدار کمی از مسیرهای برچسب دار شناسایی کنیم. در یک کلام، این مقاله یک چارچوب جدید به نام GeoSDVA برای بستن شکاف تحقیقاتی در شناسایی حالت حمل و نقل پیشنهاد میکند. GeoSDVA عمدتاً از دو مرحله زیر تشکیل شده است: اول، استخراج ویژگیهای حرکتی از مسیرهای GPS خام قبل از ادغام آنها با اطلاعات جغرافیایی نزدیک. دوم، آموزش یک مدل DirVAE نیمه نظارت شده که بر روی ویژگی های مسیر چندگانه طراحی شده است.
3. روش شناسی
همانطور که در شکل 2 نشان داده شده استچارچوب کلی GeoSDVA از دو جزء اصلی تشکیل شده است: تعبیه مسیر و مدل نیمه نظارت شده DirVAE. در بخش اول، ویژگیهای حرکت معمولی، مانند سرعت، شتاب و نرخ حرکت هر GPS از مسیر GPS خام محاسبه میشود. سپس، اطلاعات جغرافیایی نزدیک مسیر خام کدگذاری شده و با توالی ویژگی های حرکت ترکیب می شود. در بخش دوم، ما یک مدل DirVAE نیمه نظارتی میسازیم که برای ویژگیهای مسیر، از جمله ماژولهای رمزگذاری، رمزگشایی و طبقهبندیکننده طراحی شده است. در حالی که ماژول رمزگذار ویژگی های زمانی بالقوه را از توالی ویژگی های مسیر پیوسته از طریق یک GRU استخراج می کند، ماژول رمزگشا یک شبکه متراکم را برای بازسازی توالی ویژگی مسیر اتخاذ می کند. ماژول طبقهبندیکننده یک پیچیدگی یکبعدی چند مقیاسی را برای استخراج ویژگیهای بالقوه چند مقیاسی دنباله ویژگی مسیر برای طبقهبندی بهتر اتخاذ میکند. قبل از معرفی دقیق GeoSDVA، ابتدا نمادهای مهم ریاضی و توضیحات مربوطه را درجدول 1 .
3.1. تعبیه مسیر
تعریف 1.
مسیر GPS: یک مسیر GPS دنباله ای است که از n قرائت GPS تشکیل شده است. [ خطای پردازش ریاضی ]تی=پ1،پ2،پ3…پ�. هر قرائت یک سه گانه متشکل از طول جغرافیایی، طول جغرافیایی و مهرهای زمانی است. [ خطای پردازش ریاضی ]پمن=لآتیمن،ل��من،تیمنمترهستیآمترپمننشان دهنده i-امین خواندن GPS از یک مسیر GPS است.
خوانشهای GPS اغلب در حین جمعآوری تحت تأثیر محیط قرار میگیرند، مانند درههای شهری یا وقفههای انسانی، و در نتیجه خوانشهای حرکتی از دست میرود. برای شناسایی حالت حمل و نقل مسیرها، باید یک سری ویژگی از خوانش های GPS استخراج کنیم. اگر فاصله زمانی بین دو قرائت GPS خیلی طولانی باشد، ویژگیهای غیرعادی استخراج میشوند. به منظور اطمینان از تداوم مسیر GPS، از یک آستانه بازه زمانی برای تقسیمبندی مسیر GPS استفاده میکنیم. بنابراین، در پیش پردازش دادهها، ما مسیر خام را به مسیرهای فرعی به نام سفرها تقسیم میکنیم که فاصله زمانی بین دو قرائت GPS مجاور بیشتر از آستانه باشد، همانطور که در مطالعات ذکر شده در [ 19 ، 24 ] به عنوان 20 دقیقه تعیین شده است.
تعریف 2.
سفر: سفر یک مسیر فرعی است که از m خوانش GPS متوالی تشکیل شده است. برای هر دو قرائت GPS مجاور در سفر، فاصله زمانی بین آنها کمتر از یک آستانه زمانی معین است.
برای سفرهایی که قبلاً در مجموعه دادهها برچسبگذاری شدهاند، هر یک از آنها را بر اساس حالت حمل و نقل به بخشهایی تقسیم میکنیم. پس از آن، هر بخش به عنوان یک حالت حمل و نقل مشخص می شود. برای سفرهای بدون برچسب، از یک الگوریتم اکتشافی [ 19 ] برای تقسیمبندی آنها استفاده میکنیم. سپس، بخش های از پیش پردازش شده را با استفاده از یک پنجره با طول ثابت تقسیم می کنیم. پس از آن، هر بخش برای تولید یک بردار ویژگی از دو بخش استفاده می شود: ویژگی حرکت و ویژگی جغرافیایی. ویژگی حرکت شامل ویژگی های حرکت بخش است و ویژگی جغرافیایی اطلاعات جغرافیایی در مجاورت یک قطعه را تشکیل می دهد. طراحی دو قسمت به طور جداگانه در فرآیند زیر توضیح داده خواهد شد.
3.1.1. ویژگی حرکت
تعریف 3.
دنباله ویژگی حرکت: برای قطعه ای که حاوی m خوانش است، ویژگی حرکت به صورت نشان داده می شود [ خطای پردازش ریاضی ]م�تیمن��= { [ خطای پردازش ریاضی ]متر�تیمن��1، [ خطای پردازش ریاضی ]متر�تیمن��2… [ خطای پردازش ریاضی ]متر�تیمن���}، جایی که [ خطای پردازش ریاضی ]متر�تیمن��مننشان دهنده ویژگی های حرکت بخش از خواندن GPS است [ خطای پردازش ریاضی ]پمن.
این مقاله سه ویژگی فیزیکی معمولی، یعنی سرعت، شتاب، و نرخ تغییر سرفصل را استخراج میکند که ویژگیهای حرکت بخشها را نشان میدهد، با ادبیات قبلی [ 24 ، 27 ، 28 ] برای مرجع. بردار ویژگی حرکت [ خطای پردازش ریاضی ]متر�تیمن��مناز خواندن GPS شامل سرعت است [ خطای پردازش ریاضی ]�من, شتاب / کاهش سرعت [ خطای پردازش ریاضی ]آمن، و نرخ باربری [ خطای پردازش ریاضی ]بمن.
برای بدست آوردن مقدار سرعت [ خطای پردازش ریاضی ]�من، فاصله جغرافیایی بین دو قرائت GPS را با فرمول وینسنتی [ 40 ] محاسبه می کنیم. سپس، سرعت [ خطای پردازش ریاضی ]�مندر خواندن GPS [ خطای پردازش ریاضی ]پمنرا می توان با فاصله و فاصله زمانی بین آنها تعیین کرد [ خطای پردازش ریاضی ]پمنو خواندن GPS بعدی [ خطای پردازش ریاضی ]پمن+1همانطور که در رابطه ( 1 ) نشان داده شده است. علاوه بر این، شتاب / کاهش سرعت خواندن GPS [ خطای پردازش ریاضی ]پمنرا می توان با توجه به رابطه ( 2 ) محاسبه کرد. نرخ تغییر عنوان [ خطای پردازش ریاضی ]بمنتغییر زاویه بین جهت مسیر رو به جلو و جهت شمال است که با معادلات ( 3 )-( 5 ) محاسبه می شود.
3.1.2. ویژگی های جغرافیایی
همانطور که قبلاً بحث شد، شیوه های حمل و نقل در مناطق شهری نیز توسط محیط جغرافیایی تا حدودی تعیین می شود. بنابراین، ما ویژگیهای جغرافیایی را به عنوان اطلاعات زمینهای حیاتی معرفی میکنیم تا محیط جغرافیایی مرتبط با مسیر GPS و جاسازی مسیر را نشان دهیم.
تعریف 4.
دنباله ویژگی های جغرافیایی: برای قطعه ای که حاوی m خوانش است، دنباله ویژگی های جغرافیایی به صورت Geo = نشان داده می شود. [ خطای پردازش ریاضی ]�ه�1، [ خطای پردازش ریاضی ]�ه�2، … [ خطای پردازش ریاضی ]�ه��، جایی که [ خطای پردازش ریاضی ]�ه�منیک بردار ویژگی مربوط به اطلاعات جغرافیایی خواندن GPS است [ خطای پردازش ریاضی ]پمن.
در این مطالعه اطلاعات جغرافیایی یک GPS قرائت می شود [ خطای پردازش ریاضی ]پمنبه عنوان مشخص می شود [ خطای پردازش ریاضی ]�ه�من= [ [ خطای پردازش ریاضی ]آرمن، [ خطای پردازش ریاضی ]سیمن، [ خطای پردازش ریاضی ]اسمن]. این ویژگیها از سطح جاده، تقاطعهای جادهها و ایستگاههای اتوبوس در نزدیکی خوانشهای GPS مشتق شدهاند.
در میان آنها، سطح جاده به عنوان یک ویژگی مفید برای طبقه بندی وسایل نقلیه در جاده در نظر گرفته می شود [ 15 ]. به طور مشابه، بسیاری از مسیرهای دوچرخه و پیاده روی در جاده های سطح پایین ظاهر می شوند، در حالی که اتومبیل ها و حمل و نقل عمومی عمدتاً و عمدتاً در جاده های سطح بالا توزیع می شوند. بنابراین، ما استفاده می کنیم [ خطای پردازش ریاضی ]آرمنبرای نشان دادن سطح جاده که در آن GPS خواندن [ خطای پردازش ریاضی ]پمنواقع شده است.
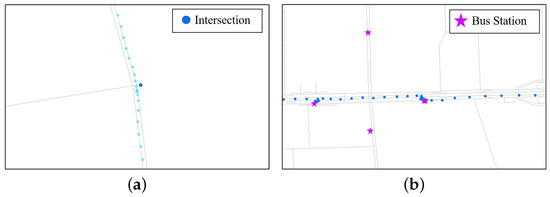
ساختار شبکه جاده ها بر حرکت وسایل نقلیه و عابران پیاده تأثیر می گذارد. به عنوان مثال، وسیله نقلیه ای که از یک تقاطع جاده عبور می کند، می تواند توسط یک علامت راهنمایی و رانندگی کنترل شود، یا ممکن است نیاز به تسلیم شدن داشته باشد، که ویژگی های حرکتی آن را تغییر می دهد. مطابق شکل 3 الف، مسیر حرکت خودرو هنگام عبور از یک تقاطع کاهش می یابد. بنابراین از متغیر باینری استفاده می کنیم [ خطای پردازش ریاضی ]سیمنبرای نشان دادن وجود تقاطع های جاده ای در 100 متری خواندن GPS [ خطای پردازش ریاضی ]پمن.
ایستگاه های اتوبوس در شبکه جاده ها می توانند به تمایز بین خودروها و حمل و نقل عمومی کمک کنند. ویژگی های حرکتی خودروها و اتوبوس ها مشابه است، اما تفاوت قابل توجه این است که اتوبوس ها معمولاً به صورت دوره ای در ایستگاه ها توقف می کنند. به عنوان مثال، مسیر اتوبوس نشان داده شده در شکل 3 ب در نزدیکی ایستگاه های اتوبوس کاهش می یابد. بنابراین از متغیر باینری استفاده می کنیم [ خطای پردازش ریاضی ]اسمنبرای نشان دادن وجود ایستگاه های اتوبوس در 100 متری خواندن GPS [ خطای پردازش ریاضی ]پمن.
با ترکیب ویژگی حرکت با ویژگی جغرافیایی، هر GPS را می خواند [ خطای پردازش ریاضی ]پمناز بخش به عنوان یک بردار ویژگی بیان می شود [ خطای پردازش ریاضی ]همن= [ [ خطای پردازش ریاضی ]�من، [ خطای پردازش ریاضی ]آمن، [ خطای پردازش ریاضی ]بمن، [ خطای پردازش ریاضی ]آرمن، [ خطای پردازش ریاضی ]سیمن، [ خطای پردازش ریاضی ]اسمن]. هر بخش با یک برچسب حالت حمل و نقل به صورت یک نشان داده می شود [ خطای پردازش ریاضی ]6×ندنباله جاسازی [ خطای پردازش ریاضی ]�مترب=همترب1،همترب2،همترب3…همترب�، که در آن L تعداد قرائت های GPS است.
3.2. مدل DirVAE نیمه نظارت شده
بر اساس مدل VAE نیمه نظارت شده ارائه شده در [ 36 ] و بر اساس مدل DirVAE ارائه شده در [ 41 ]، ما یک مدل جدید DirVAE نیمه نظارت شده طراحی می کنیم که عمدتاً ویژگی های مسیر مانند کدگذاری، طبقه بندی و رمزگشایی ماژول را هدف قرار می دهد. شناسایی مدل حمل و نقل؛ هر ماژول در قسمت بعدی به تفصیل معرفی خواهد شد.
3.2.1. ماژول رمزگذاری
ماژول رمزگذاری دارای دو لایه است. لایه اول یک GRU رمزگذاری (واحد بازگشتی دروازه) است که به طور موثر اطلاعات زمانی بالقوه را ضبط کرده است و به طور گسترده در استخراج مسیر استفاده می شود. دنباله جاسازی یک بخش مسیر را می گیرد [ خطای پردازش ریاضی ]�مترب=همترب1،همترب2،همترب3…همترب�به عنوان ورودی، و حالت پنهان کدگذاری شده را خروجی می کند [ خطای پردازش ریاضی ]ساعتمناز هر مرحله زمانی [ خطای پردازش ریاضی ]اچ=ساعت1،ساعت2،ساعت3…ساعت�توسط یک مجموعه نشان داده شده است. فرآیند استخراج GRU ویژگی های زمانی بالقوه در معادلات ( 6 ) – ( 9 ) نشان داده شده است. لایه دوم یک شبکه متراکم است که H و برچسب حالت حمل و نقل y را به عنوان ورودی می گیرد و بردارهای پنهان کدگذاری شده این بخش مسیر را خروجی می دهد.
3.2.2. ماژول طبقه بندی
ماژول طبقه بندی کننده برای شناسایی حالت حمل و نقل یک قطعه مسیر y در ابعاد چندگانه استفاده می شود و می تواند توزیع را پارامتر کند. [ خطای پردازش ریاضی ]��(�∣ایکس). از چهار قسمت تشکیل شده است. بخش اول یک لایه کانولوشن تک بعدی چند مقیاسی است که از چندین شبکه کانولوشن یک بعدی موازی با میدان های گیرنده هسته مختلف تشکیل شده است. این برای استخراج ویژگی های چند مقیاسی بخش های مسیر در بلند مدت و کوتاه مدت طراحی شده است. فرآیند پیچش یک بعدی در معادله ( 10 ) نشان داده شده است:
که در آن l عدد مرتبه لایه پیچشی یک بعدی است، p نشان دهنده اندازه هسته پذیرنده، u تعداد مرتبه واحدهای لایه، و W پارامتر وزن قابل آموزش است. ما از تابع فعال سازی ReLU در این لایه استفاده می کنیم. یک لایه max-pooling برای حفظ ویژگی های اساسی در نقشه ویژگی پس از هر پیچیدگی یک بعدی اعمال می شود. به طور خاص، ما از چهار شبکه کانولوشنیک یک بعدی با اندازههای میدان گیرنده هسته مختلف برای استخراج ویژگیها در مقیاسهای مختلف استفاده میکنیم.
قسمت دوم یک لایه همجوشی است. برای ادغام چندین نقشه ویژگی پتانسیل با مقیاس های مختلف، که از لایه قبلی خروجی شده اند، استفاده می شود. همانطور که در معادله ( 11 ) نشان داده شده است، تمام نقشه های ویژگی چند مقیاسی را در بعد کانال با استفاده از یک تابع فعال سازی ReLU به هم متصل می کند :
که در آن F خروجی این لایه و [ خطای پردازش ریاضی ]�منخروجی یک شبکه کانولوشن را نشان می دهد.
بخش سوم یک لایه GRU است. GRU می تواند بیشتر ویژگی های زمانی بالقوه را از F برای شناسایی حالت حمل و نقل استخراج کند. حالت پنهان [ خطای پردازش ریاضی ]ساعتتیآخرین مرحله زمانی GRU به عنوان نمایانگر ویژگی های زمانی بالقوه F در نظر گرفته می شود .
قسمت آخر یک شبکه متراکم است. این احتمال را ایجاد می کند که بخش فعلی به هر حالت حمل و نقل y از آن تعلق دارد[ خطای پردازش ریاضی ]ساعتتیبا استفاده از تابع softmax
3.2.3. ماژول رمزگشایی
ماژول رمزگشایی برای بازسازی بخش مسیر ورودی استفاده می شود. ماژول شامل سه بخش است. بخش اول یک شبکه متراکم با هدف یادگیری بردار است [ خطای پردازش ریاضی ]�– پارامترهای توزیع دیریکله – با در نظر گرفتن خروجی های کدگذاری و ماژول طبقه بندی کننده به عنوان ورودی. با توجه به [ 41 ]، ما همچنین از یک توزیع گوسی softmax برای تقریب توزیع دیریکله استفاده می کنیم. پارامترها [ خطای پردازش ریاضی ]�و [ خطای پردازش ریاضی ]�توزیع گاوسی را می توان با پارامترها محاسبه کرد [ خطای پردازش ریاضی ]�توزیع دیریکله با استفاده از معادلات ( 12 ) و ( 13 ) زیر:
که در آن K بعد تانسور پارامتر است، i شاخص پارامتر است، [ خطای پردازش ریاضی ]�و [ خطای پردازش ریاضی ]�میانگین و انحراف معیار توزیع گاوسی هستند و [ خطای پردازش ریاضی ]�پارامتر توزیع دیریکله است.
بخش دوم یک لایه نمونه برداری است که برای تولید متغیرهای پنهان z با نمونه برداری از توزیع دیریکله استفاده می شود. به طور تقریبی، z را از توزیع گاوسی نرمافزار از طریق یک ترفند پارامترسازی مجدد نمونهبرداری میکنیم. این فرآیند در معادله ( 14 ) نشان داده شده است:
که در آن z بردار پنهان استخراج شده توسط رمزگذار متغیر و [ خطای پردازش ریاضی ]�تانسور خطای تصادفی تابع توزیع نرمال استاندارد است.
بخش سوم یک شبکه رمزگشایی متراکم است که برای بازسازی بخش مسیر ورودی و پارامترسازی توزیع زیر استفاده می شود که می تواند به صورت معادله ( 15 ) فرموله شود:
جایی که [ خطای پردازش ریاضی ]�(.)نشان دهنده توزیع بخش های مسیر ورودی و [ خطای پردازش ریاضی ]�د(.)عملکرد شبکه رمزگشایی متراکم را نشان می دهد.
3.2.4. هدف مدل
شناسایی حالت حمل و نقل یک مشکل چند طبقه بندی معمولی است. برای بخشهای مسیر نشاندار، [ خطای پردازش ریاضی ]��(�∣ایکس)ماژول طبقهبندیکننده را میتوان با از دست دادن آنتروپی متقاطع، که به عنوان معادله ( 16 ) تعریف میشود، بهینه کرد:
که در آن M تعداد برچسب ها و [ خطای پردازش ریاضی ]پمنج0نشان دهنده این احتمال است که نمونه i به برچسب c تعلق دارد .
تابع هدف مدل ما از آنچه توسط [ 36 ] اشاره شده است، مشتق شده است. برای بخش های مسیر با برچسب های حالت حمل و نقل در مجموعه داده، تابع هدف به صورت معادله ( 17 ) تعریف می شود:
جایی که [ خطای پردازش ریاضی ]��نشان دهنده شبکه رمزگذار و [ خطای پردازش ریاضی ]پ�نشان دهنده شبکه رمزگشا است.
در مقایسه با تابع فوق الذکر، تابع هدف برای بخش های مسیر بدون برچسب حالت حمل و نقل در مجموعه داده به صورت معادله ( 18 ) تعریف می شود:
جایی که [ خطای پردازش ریاضی ]پ�و [ خطای پردازش ریاضی ]��هنوز هم به ترتیب نشان دهنده شبکه های رمزگشا و رمزگذار هستند.
در نهایت، تابع هدف مدل از ترکیب توابع هدف مربوط به سه بخش به دست میآید که به صورت معادله ( 19 ) تعریف میشود:
جایی که [ خطای پردازش ریاضی ]�فراپارامتری است که برای کنترل اهمیت نسبی از دست دادن طبقهبندیکننده و از بین رفتن رمزگذار خودکار استفاده میشود.
4. نتایج آزمایش
در این بخش، نتایج GeoSDVA را از طریق یک سری آزمایش توضیح داده و مورد بحث قرار میدهیم. همه آزمایشها روی یک رایانه شخصی با پردازنده Core i7 3.20 گیگاهرتز و حافظه 32.0 گیگابایتی انجام میشوند. همه مدلها و آزمایشها از طریق TensorFlow v1.8 و Scikit-learn پیادهسازی میشوند.
4.1. داده های GPS
در این مقاله از سه مجموعه داده واقعی Geolife V1.3، MTL Trajet 2017 و MTL Trajet 2016 برای ارزیابی رویکرد پیشنهادی استفاده شده است. یک نمای کلی از این سه مجموعه داده در جدول 2 نشان داده شده است .
مجموعه داده Geolife v1.3 داده های GPS به ارزش پنج سال را از 182 کاربر بین آوریل 2007 تا اوت 2012 جمع آوری کرد. در میان این کاربران، 73 نفر از آنها حالت های حمل و نقل خود را مشخص کرده اند. برچسبهای حالت حمل و نقل مسیرها در مجموعه داده Geolife عمدتاً شامل پیادهروی، دوچرخه، اتوبوس، ماشین، تاکسی، قطار، مترو، هواپیما، قایق، دویدن و غیره است.
مجموعه داده MTL Trajet 2017 داده های GPS 4425 کاربر را از 18 سپتامبر تا 15 اکتبر 2017 جمع آوری کرد. در مجموعه داده MTL Trajet 2017، حالت های حمل و نقل با برچسب کاربر شامل حمل و نقل عمومی، پیاده روی، ماشین/موتور سیکلت، دوچرخه، اشتراک خودرو، تاکسی و غیره است. .
مجموعه داده MTL Trajet 2016 داده های GPS را از سپتامبر تا نوامبر 2016 جمع آوری کرد. در این مجموعه داده، حالت های حمل و نقل با برچسب کاربر شامل حمل و نقل عمومی، پیاده روی، اتومبیل، دوچرخه و غیره است.
سه دلیل اصلی برای استفاده از این مجموعه دادهها برای بررسی عملکرد مدل GeoSDVA وجود دارد. ابتدا، بیشتر مسیرهای این مجموعه داده ها در یک محیط شهری جمع آوری می شوند، بنابراین می توانیم داده های GIS مربوطه را از طریق منابع داده باز به دست آوریم. دوم، بیش از سه حالت حمل و نقل در این مجموعه داده ها وجود دارد که ما را قادر می سازد تا عملکرد شناسایی حالت حمل و نقل GeoSDVA را تأیید کنیم. سوم و آخر، مجموعه دادهها از برخی مسیرهای برچسبگذاریشده و برخی مسیرهای بدون برچسب تشکیل شدهاند، که ما را قادر میسازد تا توانایی یادگیری نیمهنظارتشده GeoSDVA را کشف کنیم.
به منظور اطمینان از اینکه مسیرهای GPS می توانند با داده های GIS مرتبط شوند، داده ها را بر اساس مناطق جغرافیایی فیلتر کردیم. برای مجموعه داده Geolife، خوانش های GPS را در پکن انتخاب کردیم (116.15 درجه شرقی، 39.75 درجه شمالی تا 116.6 درجه شرقی، 40.1 درجه شمالی)، که حدود 70٪ از کل مجموعه داده را تشکیل می دهد. برای مجموعه دادههای MTL Trajet 2017 و MTL Trajet 2016، خوانشهای GPS را در مونترال انتخاب کردیم (73.942 درجه غربی، 45.415 درجه شمالی تا 73.479 درجه غربی، 45.701 درجه شمالی)، که حدود 90٪ از هر مجموعه داده را شامل میشود.
ما فقط حالت های حمل و نقل زمینی را برای آزمایش انتخاب کردیم. در مجموعه داده Geolife، مسیرهایی که با عنوان تاکسی، ماشین، اتوبوس، پیادهروی و دوچرخه مشخص شدهاند، اشیاء انتخابی هستند که خودرو و تاکسی در یک دسته قرار میگیرند و بهویژه با عنوان «ماشین» برچسبگذاری میشوند. در نهایت، مجموعه داده تجربی چهار حالت حمل و نقل را پوشش می دهد: دوچرخه، حمل و نقل عمومی (اتوبوس)، ماشین و پیاده روی. مسیرهای با برچسب های دیگر یا بدون برچسب، مسیرهای بدون برچسب در نظر گرفته می شوند. در مجموعه داده MTL Trajet 2017، ما مسیرهایی را با عنوان حمل و نقل عمومی، تاکسی، اشتراک خودرو، ماشین/موتور سیکلت، دوچرخه، و پیاده روی برای آزمایش انتخاب کردیم. دادههایی که بهعنوان اشتراکگذاری خودرو، تاکسی، و خودرو/موتور سیکلت برچسبگذاری شدهاند، با عنوان «ماشین» ترکیب میشوند. در نهایت، مجموعه داده شامل چهار برچسب است: پیاده روی، حمل و نقل عمومی، ماشین و دوچرخه. مسیرهای با برچسب های متعدد، با برچسب های دیگر، و بدون برچسب به عنوان مسیرهای بدون برچسب در نظر گرفته می شوند. در مجموعه داده MTL Trajet 2016، ما مسیرهایی را انتخاب می کنیم که به عنوان پیاده روی، دوچرخه، حمل و نقل عمومی و خودرو برچسب گذاری شده اند. داده هایی که به عنوان خودرو برچسب گذاری شده اند، دوباره به عنوان “ماشین” برچسب گذاری می شوند. در نهایت، مجموعه داده شامل پیاده روی، دوچرخه، حمل و نقل عمومی و دوچرخه است. توزیع مسیرهای برچسب مختلف در هر مجموعه داده نشان داده شده استجدول 2 .
4.2. داده های GIS
دادههای GIS که ما استفاده میکنیم عمدتاً از دادههای شبکه جاده OSMNX [ 42 ] میآیند. شبکه جاده های پکن و مونترال در شکل 4 نشان داده شده است. داده های شبکه راه ها شامل گره های شبکه راه ها و لبه های شبکه راه است. با در نظر گرفتن داده های شبکه جاده پکن به عنوان مثال، جدول 3 داده های جزئی لبه شبکه جاده را نشان می دهد و جدول 4داده های جزئی گره شبکه راه را نشان می دهد. برای لبههای شبکه راه، سطح شبکه راه را بر اساس مقدار مشخصه بزرگراه تعیین میکنیم که عمدتاً شامل «بزرگراه»، «تنه»، «اولیه»، «ثانویه»، «ثالثیه»، «طبقهبندی نشده» است. و “مسکونی”. برای گرههای شبکه جاده، گرهها را با مقادیر ویژگی بزرگراه «تقاطع»، «سیگنال_ترافیکی» و «اتصال_موتور راه» فیلتر میکنیم. برای داده های ایستگاه اتوبوس، از یک منبع داده عمومی برای استخراج مختصات آنها استفاده می کنیم. داده های ایستگاه های اتوبوس در پکن از فایل های عمومی SHP می آید. داده های ایستگاه های اتوبوس در مونترال از Google Transit API می آید.
4.3. تنظیم آزمایش
در این آزمایش، چندین معیار ارزیابی معمولی، مانند دقت، دقت، یادآوری، و امتیاز F1 کلان، برای ارزیابی عملکرد مدل پیشنهادی استفاده میشوند. روش های محاسبه در این مقاله در معادلات ( 17 )-( 21 ) نشان داده شده است). در ماتریس سردرگمی شناسایی چند طبقه، وقتی این معیارهای ارزیابی برای هر دسته محاسبه می شود، نمونه هایی که به این دسته تعلق دارند مثبت در نظر گرفته می شوند. نمونه هایی که به این دسته تعلق ندارند منفی هستند. دقت برای ارزیابی شناسایی کلی مدل در مجموعه تست استفاده می شود. از آنجایی که حالت حمل و نقل در مجموعه داده ها نامتعادل است، از امتیاز F1 کلان برای ارزیابی عملکرد کلی مدل در شناسایی هر حالت حمل و نقل در مجموعه آزمایشی استفاده می شود.
در تمام آزمایشات، L روی 100 تنظیم شده است. اگر تعداد قرائت های GPS در یک قطعه کمتر از 100 باشد، از درون یابی خطی برای آن استفاده می کنیم. در ابتدای آموزش مدل، از دست دادن رمزگذار بسیار بیشتر از از بین رفتن طبقهبندیکننده است که منجر به نادیدهانگاری بهینهساز از دست دادن طبقهبندیکننده میشود. به منظور رفع این مشکل، تنظیم کردیم [ خطای پردازش ریاضی ]�در تابع از دست دادن به 0.1 به وزن اهمیت نسبی بین از دست دادن طبقه بندی و از دست دادن رمزگذار.
در زیر بخش زیر، عملکرد GeoSDVA را در شناسایی حالت حمل و نقل نیمه نظارت شده ارزیابی کردیم. در مرحله اول، GeoSDVA پیشنهادی با سایر روشهای پایه توسط آزمایش مقایسه شد تا توانایی GeoSDVA برای استفاده از اطلاعات مسیرهای بدون برچسب تحت هدایت تعداد مختلف مسیرهای برچسبدار بهدستآمده از تنظیم نسبتهای آنها را بررسی کند. در مرحله دوم، ما تجزیه و تحلیل کردیم که چگونه دانش آموخته شده توسط DirVAE از مسیرهای بدون برچسب به وظیفه شناسایی حالت حمل و نقل کمک می کند. در نهایت، نحوه حمل و نقل مسیرهای بدون برچسب در مناطق خاص با استفاده از GeoSDVA آموزش دیده شناسایی شد و نتایج آن مورد تجزیه و تحلیل قرار گرفت.
4.4. معیارها
برای نشان دادن مزایای GeoSDVA، مدل پیشنهادی را با چندین روش پایه که در زیر فهرست شدهاند، مقایسه میکنیم:
-
DT: این روش که توسط ژنگ و همکاران توسعه یافته است. [ 19 ]، برخی از ویژگی های آماری را از بخش مسیر GPS استخراج می کند و حالت حمل و نقل را از طریق درخت تصمیم C4.5 شناسایی می کند.
-
RF: این روش که توسط Xiao و همکاران توسعه یافته است. [ 31 ]، از مدلهای مجموعهای مبتنی بر درخت، مانند جنگلهای تصادفی، برای استنتاج حالتهای حمل و نقل استفاده میکند.
-
SVM: این روش که توسط Bolbol و همکاران توسعه یافته است. [ 43 ]، از ویژگی های آماری در سطح بخش و یک SVM برای شناسایی حالت های حمل و نقل استفاده می کند.
-
DNN: این روش توسط اندو و همکاران توسعه یافته است. [ 23 ]، از یک شبکه متراکم برای استخراج ویژگی ها از تصاویر متشکل از مسیرهای مشبک و شناسایی حالت های حمل و نقل استفاده می کند.
-
CNN-GAN: این روش توسط لی و همکاران توسعه یافته است. [ 34 ]، از شبکههای متخاصم مولد برای گسترش مجموعه داده مسیر برچسبگذاری شده استفاده میکند و مجموعه دادههای پیشرفته را برای آموزش یک شبکه CNN شش لایه برای شناسایی حالت حملونقل اتخاذ میکند.
-
SECA: این مدل توسط دبیری و همکاران توسعه یافته است. [ 44 ]، از چارچوب رمزگذار خودکار برای یادگیری نیمه نظارت شده پیروی می کند و از یک شبکه CNN شش لایه به عنوان رمزگذار و طبقه بندی کننده برای تقسیم وزن بین مسیرهای برچسب دار و بدون برچسب استفاده می کند.
-
برچسب شبه: این مدل توسط دبیری و همکاران توسعه یافته است. [ 44 ]، از یک استراتژی خودآموزی برای یادگیری نیمه نظارتی استفاده می کند.
-
دو مرحله ای: این مدل توسط دبیری و همکاران توسعه یافته است. [ 44 ]، دارای یک مدل آموزشی دو مرحله ای است که ابتدا شبکه رمزگذار-رمزگشا را آموزش می دهد و سپس طبقه بندی کننده را بر اساس بردار نهفته رمزگذار آموزش می دهد.
لازم به ذکر است که فرم های نمونه مورد نیاز این روش ها متفاوت است. برای انصاف تجربی، همه نمونهها از همان مجموعه دادهای که از بخشهای مسیر GPS خام تشکیل شده است، تولید میشوند. در طول آزمایش، مسیرهای نشاندار به مجموعه دادههای قطار و مجموعه دادههای آزمایشی، با توجه به نسبت 8:2 تقسیم میشوند و همه مسیرهای بدون برچسب در آموزش شرکت میکنند. با تغییر تعداد مسیرهای برچسب گذاری شده، به طور تصادفی از مجموعه داده آموزشی با توجه به نسبت برچسب نمونه برداری می کنیم. در همین حال، مجموعه داده بدون برچسب بدون تغییر باقی می ماند.
4.5. عملکرد شناسایی
در مرحله اول، ما مزیت حالت GeoSDVA پیشنهادی خود را نسبت به همتایان آن تأیید می کنیم. ما GeoSDVA و سایر روشهای پایه را به طور جداگانه با مقادیر متفاوت مسیرهای برچسبگذاری شده میسازیم و سپس آنها را بر روی همان مجموعه داده آزمایشی ارزیابی میکنیم. نتایج ارزیابی شده بین GeoSDVA و سایر روشهای پایه در سه مجموعه داده واقعی در جدول 5 ، جدول 6 و جدول 7 ، با بهترین عملکردها به صورت پررنگ نشان داده شده است. درصد در ردیف اول جداول نشان دهنده نرخ نمونه برداری از مجموعه داده آموزشی برچسب گذاری شده است. به عنوان مثال، 10٪ به این معنی است که فقط 10٪ از مسیرهای برچسب گذاری شده در آموزش شرکت کردند.
طبق جدول 5 ، جدول 6 و جدول 7 ، GeoSDVA در شناسایی حالت های حمل و نقل بهتر از روش پایه تحت هر نرخ نمونه برداری از مسیرهای برچسب دار عمل می کند. آزمایشهای SVM، DT و DNN، که از دو مجموعه داده استفاده میکنند و مبتنی بر یادگیری نظارتشده هستند، به طور کلی در مقایسه با روشهای دیگر مضراتی را نشان میدهند. هنگامی که نرخ نمونه برداری از داده های برچسب گذاری شده در مقایسه با سایر روش های یادگیری تحت نظارت کم است، RF مزایایی را نشان می دهد. با این حال، زمانی که نرخ نمونه برداری از داده های برچسب دار قابل توجه باشد، عملکرد شناسایی آن به اندازه کافی خوب نیست. علاوه بر این، شایان ذکر است که مدل دو مرحله ای در هر دو مجموعه داده، به ویژه در Geolife، همانطور که از جدول 5 مشاهده می شود، عملکرد ضعیفی دارد.. در مدل دو مرحله ای، طبقه بندی کننده در اولین مرحله آموزشی شرکت نمی کند، که ممکن است منجر به شکست رمزگذار در یادگیری اطلاعاتی شود که برای شناسایی حالت حمل و نقل مفید است. در مقایسه با SECA، شبه برچسب و CNN-GAN، امتیاز F1 ماکرو GeoSDVA از 4٪ به 7٪ در مجموعه داده Geolife، از 0.4٪ به 3٪ در مجموعه داده MTL Trajet 2017 و بیش از 0.8 بهبود می یابد. ٪ در مجموعه داده MTL Trajet 2016 زمانی که نرخ نمونه برداری 10٪ است. SECA از یک رمزگذار خودکار و طبقهبندیکننده با وزنهای مشترک برای یادگیری نیمهنظارتی استفاده میکند. به دلیل فقدان محدودیت در بردار نهفته که توسط رمزگذار خودکار یاد می شود، SECA نمی تواند به طور موثر از مسیر بدون برچسب زمانی که داده های برچسب گذاری شده کمتری وجود دارد استفاده کند. روش شبه برچسب، مسیرهای بدون برچسب را در فرآیند آموزش به طور مداوم برچسب گذاری می کند. اما برچسب شبه مسیرهای بدون برچسب ممکن است اشتباه باشد. روش CNN-GAN از مسیرهای برچسبگذاری شده برای گسترش مجموعه داده از طریق شبکه GAN به جای استفاده از مسیرهای بدون برچسب برای یادگیری استفاده میکند. هنگامی که تمام داده های برچسب گذاری شده برای آموزش مدل استفاده می شود، GeoSDVA همچنان می تواند بهترین عملکرد را داشته باشد. در مقایسه با سایر روشها، امتیاز F1 ماکرو آن در مجموعه داده Geolife حدود 2%، در مجموعه داده MTL Trajet 2017 از 0.6% به 1.6% و در مجموعه داده MTL Trajet 2016 تا حداقل 2% بهبود مییابد. این به این دلیل است که GeoSDVA از ویژگیهای GIS استفاده میکند که توسط مدلهای دیگر استفاده نمیشود، که تشخیص حالتهای حمل و نقل را آسانتر میکند. هنگامی که تمام داده های برچسب گذاری شده برای آموزش مدل استفاده می شود، GeoSDVA همچنان می تواند بهترین عملکرد را داشته باشد. در مقایسه با سایر روشها، امتیاز F1 ماکرو آن در مجموعه داده Geolife حدود 2%، در مجموعه داده MTL Trajet 2017 از 0.6% به 1.6% و در مجموعه داده MTL Trajet 2016 تا حداقل 2% بهبود مییابد. این به این دلیل است که GeoSDVA از ویژگیهای GIS استفاده میکند که توسط مدلهای دیگر استفاده نمیشود، که تشخیص حالتهای حمل و نقل را آسانتر میکند. هنگامی که تمام داده های برچسب گذاری شده برای آموزش مدل استفاده می شود، GeoSDVA همچنان می تواند بهترین عملکرد را داشته باشد. در مقایسه با سایر روشها، امتیاز F1 ماکرو آن در مجموعه داده Geolife حدود 2%، در مجموعه داده MTL Trajet 2017 از 0.6% به 1.6% و در مجموعه داده MTL Trajet 2016 تا حداقل 2% بهبود مییابد. این به این دلیل است که GeoSDVA از ویژگیهای GIS استفاده میکند که توسط مدلهای دیگر استفاده نمیشود، که تشخیص حالتهای حمل و نقل را آسانتر میکند.
به طور کلی، دو دلیل اصلی وجود دارد که چرا GeoSDVA نسبت به مدل پایه برتری دارد. اول، GeoSDVA اطلاعات جغرافیایی در اطراف مسیرها را ترکیب می کند، که تشخیص بین حالت های مختلف حمل و نقل را آسان تر می کند و در نتیجه امتیاز F1 ماکرو بالاتری ایجاد می کند. دوم، در مقایسه با مدلهای نیمهنظارتشده مبتنی بر یادگیری عمیق، مانند روشهای SECA، دو مرحلهای، و CNN-GAN، نیمه DirVAE در GeoSDVA بهتر میتواند ویژگیها را از مسیرهای بدون برچسب استخراج کند و عملکرد بهتری را در زمانی که مسیرهای برچسب کمی وجود دارد. نقش این دو عامل را در بخش های فرعی زیر تحلیل خواهیم کرد.
4.6. مزیت DirVAE نیمه نظارت شده
در این بخش، مزیت DirVAE نیمه نظارت شده در مدل را تحلیل میکنیم. اولاً، با مقادیر متفاوت مسیرهای برچسبگذاری شده، GeoSDVA و GeoSDVA نظارتشده را بهطور جداگانه میسازیم، که یک مدل متغیر است که فقط ماژول طبقهبندیکننده را حفظ میکند. ما دو مدل را بر روی مجموعه دادههای آزمایشی یکسانی آزمایش میکنیم و تأثیر DirVAE نیمهنظارتشده بر شناسایی حالت حملونقل را تحلیل میکنیم. جدول 8مقایسه بین GeoSDVA و نظارت شده-GeoSDVA را نشان می دهد. نتایج مقایسه نشان میدهد که GeoSDVA بهطور قابلتوجهی بهتر از GeoSDVA نظارتشده عمل میکند، بهویژه در مورد مجموعه دادههای مسیر برچسبگذاریشده کمتر. بدیهی است که می توان مشاهده کرد که امتیاز F1 ماکرو GeoSDVA از 7% به 8% بهبود می یابد زمانی که 10% از مسیرهای برچسب گذاری شده در حال تمرین هستند. در حالی که تمام مسیرهای برچسبگذاریشده در آموزش دخیل هستند، امتیاز F1 ماکرو GeoSDVA حدود ۲ تا ۶ درصد بیشتر از امتیاز GeoSDVA تحت نظارت است. نتایج آزمایش نشان میدهد که مهم نیست که چقدر مسیرهای برچسبگذاری شده در آموزش شرکت میکنند، عملکرد شناسایی حالت حملونقل مدل با افزودن DirVAE بهبود مییابد. هنگامی که نسبت مسیرهای برچسب گذاری شده نسبتاً کم است، بهبودی که DirVAE به ارمغان می آورد بسیار آشکار است، به ویژه از نظر امتیاز F1 ماکرو.شکل 5 a,b ماتریس های سردرگمی GeoSDVA و نظارت شده-GeoSDVA را نشان می دهد. به دلیل تعداد کم مسیرهای برچسبگذاری شده، GeoSDVA نظارت شده تعداد زیادی از مسیرها را بهعنوان خودرو و حملونقل عمومی به اشتباه شناسایی میکند. به عنوان مقایسه، نتیجه شناسایی GeoSDVA این مشکل را ندارد. این ثابت میکند که افزودن DirVAE میتواند باعث شود که مدل نتایج شناسایی بهتری را در زمانی که مسیرهای برچسبدار کمتری وجود دارد، به دست آورد.
برای تجزیه و تحلیل بیشتر اینکه DirVAE نیمه نظارت شده چگونه از داده های بدون برچسب برای کمک به شناسایی حالت حمل و نقل استفاده می کند، بردار پنهان ماژول رمزگذار DirVAE را از GeoSDVA از پیش آموزش دیده استخراج می کنیم. برای سه مجموعه داده، یک نمونه تصادفی از 20000 بخش مسیر به ترتیب از مجموعه داده های مسیر برچسب دار و بدون برچسب گرفته شده است. سپس، این مسیرها به GeoSDVA از پیش آموزش دیده وارد می شوند تا بردارهای نهفته خود را به دست آورند. شکل 6 توزیع بردارهای پنهان را پس از کاهش ابعاد T-SNE نشان می دهد.
به طور کلی، بردارهای پنهان مسیرهای مختلف حالت حمل و نقل استخراج شده توسط DirVAE دارای مرزهای واضح هستند. از تجسم بردار نهفته Geolife، مشخص شد که بردارهای پنهان خودرو (پراکنده سبز) و حمل و نقل عمومی (پراکنده صورتی) دارای مرزهای واضح هستند، اما بردارهای نهفته دوچرخه (پراکنده آبی) و راه رفتن ( پراکنده های زرد) برچسب ها در برخی فضاها در هم تنیده شده اند. این به این دلیل است که برخی از مسیرهای پیاده روی و دوچرخه در مجموعه داده Geolife در یک محیط جغرافیایی مشابه هستند و ویژگی های حرکتی مشابهی دارند. علاوه بر این، یک مرز واضح بین برچسب راه رفتن (پراکندههای آبی) و سایر مسیرها در تجسم بردار پنهان مجموعه داده MTL Trajet 2017 ظاهر میشود. در مقایسه، مرز بین بردارهای پنهان حمل و نقل عمومی (پراکندگی صورتی)، برچسب دوچرخه (پراکنده آبی) و ماشین (پراکنده سبز) خیلی واضح نیست. در مجموعه داده MTL Trajet 2016، ما همچنین مشاهده کردیم که اتومبیل ها (پراکنده های سبز) و حمل و نقل عمومی (پراکنده های صورتی) در هم تنیده شده اند. دو دلیل برای این نتیجه وجود دارد. در مجموعه داده MTL Trajet 2017، مسیرهای خودرو بسیار رایج تر از مسیرهای دیگر حالت حمل و نقل است. در مجموعه داده MTL Trajet 2016، مسیرهای خودرو بیش از 60٪ از کل را تشکیل می دهند. دوم، برخی از مسیرهایی که در مجموعه دادههای MTL Trajet 2017 و MTL Trajet 2016 بهعنوان حملونقل عمومی برچسبگذاری شدهاند، در حین حرکت به طور دورهای در نزدیکی ایستگاههای اتوبوس متوقف نمیشوند. این مسیرها ممکن است در حالت اتوبوس یا راه آهن ثبت نشوند، که تشخیص این مسیرها از مسیرهای ماشین را دشوار می کند. در مجموعه داده MTL Trajet 2016، ما همچنین مشاهده کردیم که اتومبیل ها (پراکنده های سبز) و حمل و نقل عمومی (پراکنده های صورتی) در هم تنیده شده اند. دو دلیل برای این نتیجه وجود دارد. در مجموعه داده MTL Trajet 2017، مسیرهای خودرو بسیار رایج تر از مسیرهای دیگر حالت حمل و نقل است. در مجموعه داده MTL Trajet 2016، مسیرهای خودرو بیش از 60٪ از کل را تشکیل می دهند. دوم، برخی از مسیرهایی که در مجموعه دادههای MTL Trajet 2017 و MTL Trajet 2016 بهعنوان حملونقل عمومی برچسبگذاری شدهاند، در حین حرکت به طور دورهای در نزدیکی ایستگاههای اتوبوس متوقف نمیشوند. این مسیرها ممکن است در حالت اتوبوس یا راه آهن ثبت نشوند، که تشخیص این مسیرها از مسیرهای ماشین را دشوار می کند. در مجموعه داده MTL Trajet 2016، ما همچنین مشاهده کردیم که اتومبیل ها (پراکنده های سبز) و حمل و نقل عمومی (پراکنده های صورتی) در هم تنیده شده اند. دو دلیل برای این نتیجه وجود دارد. در مجموعه داده MTL Trajet 2017، مسیرهای خودرو بسیار رایج تر از مسیرهای دیگر حالت حمل و نقل است. در مجموعه داده MTL Trajet 2016، مسیرهای خودرو بیش از 60٪ از کل را تشکیل می دهند. دوم، برخی از مسیرهایی که در مجموعه دادههای MTL Trajet 2017 و MTL Trajet 2016 بهعنوان حملونقل عمومی برچسبگذاری شدهاند، در حین حرکت به طور دورهای در نزدیکی ایستگاههای اتوبوس متوقف نمیشوند. این مسیرها ممکن است در حالت اتوبوس یا راه آهن ثبت نشوند، که تشخیص این مسیرها از مسیرهای ماشین را دشوار می کند. در مجموعه داده MTL Trajet 2017، مسیرهای خودرو بسیار رایج تر از مسیرهای دیگر حالت حمل و نقل است. در مجموعه داده MTL Trajet 2016، مسیرهای خودرو بیش از 60٪ از کل را تشکیل می دهند. دوم، برخی از مسیرهایی که در مجموعه دادههای MTL Trajet 2017 و MTL Trajet 2016 بهعنوان حملونقل عمومی برچسبگذاری شدهاند، در حین حرکت به طور دورهای در نزدیکی ایستگاههای اتوبوس متوقف نمیشوند. این مسیرها ممکن است در حالت اتوبوس یا راه آهن ثبت نشوند، که تشخیص این مسیرها از مسیرهای ماشین را دشوار می کند. در مجموعه داده MTL Trajet 2017، مسیرهای خودرو بسیار رایج تر از مسیرهای دیگر حالت حمل و نقل است. در مجموعه داده MTL Trajet 2016، مسیرهای خودرو بیش از 60٪ از کل را تشکیل می دهند. دوم، برخی از مسیرهایی که در مجموعه دادههای MTL Trajet 2017 و MTL Trajet 2016 بهعنوان حملونقل عمومی برچسبگذاری شدهاند، در حین حرکت به طور دورهای در نزدیکی ایستگاههای اتوبوس متوقف نمیشوند. این مسیرها ممکن است در حالت اتوبوس یا راه آهن ثبت نشوند، که تشخیص این مسیرها از مسیرهای ماشین را دشوار می کند. برخی از مسیرهایی که در مجموعه دادههای MTL Trajet 2017 و MTL Trajet 2016 بهعنوان حملونقل عمومی برچسبگذاری شدهاند، در حین حرکت به طور دورهای در نزدیکی ایستگاههای اتوبوس متوقف نمیشوند. این مسیرها ممکن است در حالت اتوبوس یا راه آهن ثبت نشوند، که تشخیص این مسیرها از مسیرهای ماشین را دشوار می کند. برخی از مسیرهایی که در مجموعه دادههای MTL Trajet 2017 و MTL Trajet 2016 بهعنوان حملونقل عمومی برچسبگذاری شدهاند، در حین حرکت به طور دورهای در نزدیکی ایستگاههای اتوبوس متوقف نمیشوند. این مسیرها ممکن است در حالت اتوبوس یا راه آهن ثبت نشوند، که تشخیص این مسیرها از مسیرهای ماشین را دشوار می کند.
4.7. تأثیر اطلاعات جغرافیایی
در این بخش به تحلیل نقش اطلاعات جغرافیایی در شناسایی حالت حمل و نقل می پردازیم. ما حدس می زنیم که در مناطق شهری، اطلاعات جغرافیایی اطراف مسیر برای تشخیص حالت های حمل و نقل مفید است. ما سه ویژگی مربوط به اطلاعات جغرافیایی را در جاسازی مسیر حذف میکنیم و سپس مدل GeoSDVA را به ترتیب روی دو مجموعه داده آموزش میدهیم. در جدول 9 ، ما از «Motion+GIS» و «Motion» برای تمایز بین مدلهایی با ویژگیهای مختلف استفاده میکنیم.
با توجه به نتایج تجربی، در مجموعه داده Geolife، امتیاز F1 حمل و نقل عمومی، ماشین و پیاده روی با اطلاعات جغرافیایی تکمیلی بهبود یافته است. در میان آنها، امتیاز F1 مسیرهای اتومبیل به طور قابل توجهی افزایش یافت و به 6٪ رسید. در همان زمان، امتیاز F1 مسیرهای دوچرخه حدود 0.5٪ کاهش یافت. به طور مقایسه ای، در مجموعه داده MTL Trajet 2017، مکمل اطلاعات جغرافیایی امتیازات F1 را در تمام حالت های حمل و نقل بهبود بخشیده است، همانطور که در جدول بالا نشان داده شده است، به ترتیب با افزایش حمل و نقل عمومی، دوچرخه، ماشین و پیاده روی توسط 0.6٪، 0.4٪، 0.1٪ و 1٪. در مجموعه داده MTL Trajet 2016، مکمل اطلاعات جغرافیایی امتیاز F1 حمل و نقل عمومی، دوچرخه، ماشین و پیاده روی را به ترتیب 6٪، 0.6٪، 1.2٪ و 4.8٪ بهبود بخشیده است. از دیدگاه کلان،
همانطور که در شکل 7 ، شکل 8 و شکل 9 نشان داده شده است، ماتریس های سردرگمی سه مجموعه داده با ویژگی های مختلف را تجسم کردیم .. در مجموعه داده Geolife، طبقهبندی اشتباه معمولی بین دوچرخه و پیادهروی و همچنین بین حملونقل عمومی و ماشین رخ میدهد. افزودن ویژگی های GIS دقت شناسایی حمل و نقل عمومی، دوچرخه و ماشین را بهبود می بخشد، اما دقت شناسایی پیاده روی را کاهش می دهد. طبق ماتریس سردرگمی، طبقه بندی اشتباه حمل و نقل عمومی به عنوان خودرو 0.8٪ کاهش می یابد، و خودرو به عنوان حمل و نقل عمومی حدود 1.4٪ کاهش می یابد. به طور مشابه، طبقه بندی اشتباه دوچرخه به عنوان پیاده روی حدود 1.2٪ کاهش می یابد، در حالی که طبقه بندی اشتباه پیاده روی به عنوان دوچرخه 0.6٪ بهبود یافته است. دلیل کاهش ممکن است این باشد که پیاده روی و دوچرخه دارای ویژگی های GIS مشابه هستند. در مجموعه داده MTL Trajet 2017، شناسایی صحیح مسیرهای حمل و نقل عمومی، که به اشتباه به عنوان ماشین و پیاده روی شناسایی می شوند، دشوار است. افزودن ویژگیهای GIS، دقت شناسایی همه حالتهای حمل و نقل را بهبود میبخشد. با این حال، افزودن ویژگی های GIS نمی تواند به طور موثر حمل و نقل عمومی را از خودرو متمایز کند. نسبت طبقه بندی اشتباه حمل و نقل عمومی به عنوان خودرو به سختی تغییر کرده است. بهبود حمل و نقل عمومی عمدتاً به دلیل طبقه بندی اشتباه کمتر به عنوان پیاده روی و دوچرخه است. مسیر حملونقل عمومی در این مجموعه داده ممکن است شامل حالتهای دیگری باشد، مانند ماشینهای کشتی، که در ایستگاههای اتوبوس توقف نمیکنند، که تشخیص بین حملونقل عمومی و ماشین را دشوار میکند. در مجموعه داده MTL Trajet 2016، نتایج مشاهده شده مشابه نتایج در مجموعه داده MTL Trajet 2017 است. ویژگی های GIS دقت شناسایی همه حالت های حمل و نقل را بهبود می بخشد. افزودن ویژگیهای GIS نسبت مسیرهای حملونقل عمومی را که به اشتباه به عنوان مسیرهای خودرو طبقهبندی شدهاند، افزایش نمیدهد، اما نسبت مسیرهای حملونقل عمومی را که به عنوان مسیرهای پیادهروی به اشتباه طبقهبندی شدهاند، بهطور قابلتوجهی کاهش میدهد. علاوه بر این، نسبت دوچرخه هایی که به اشتباه به عنوان خودرو شناسایی شده اند، 2٪ کاهش می یابد، و تعداد خودروهایی که به اشتباه به عنوان حمل و نقل عمومی شناخته می شوند، 2.3٪ کاهش می یابد. شناسایی پیاده روی به طور قابل توجهی بهبود نیافته است. به طور کلی، افزودن ویژگی های GIS دقت شناسایی حمل و نقل در هر مجموعه داده را بهبود می بخشد. شناسایی پیاده روی به طور قابل توجهی بهبود نیافته است. به طور کلی، افزودن ویژگی های GIS دقت شناسایی حمل و نقل در هر مجموعه داده را بهبود می بخشد. شناسایی پیاده روی به طور قابل توجهی بهبود نیافته است. به طور کلی، افزودن ویژگی های GIS دقت شناسایی حمل و نقل در هر مجموعه داده را بهبود می بخشد.
4.8. مطالعه موردی
در این بخش فرعی، از GeoSDVA برای تجزیه و تحلیل توزیع حالتهای حملونقل در یک منطقه خاص از پکن، واقع بین (116.300831° E, 39.971985° شمالی) و (116.333889° E, 40.026152° N) استفاده میکنیم، همانطور که در شکل 10 نشان داده شده است. در این منطقه یک محوطه دانشگاهی وجود دارد که در اطراف آن جاده هایی وجود دارد. به منظور توضیح بهتر نتایج، ما سطح جاده و ایستگاه های اتوبوس را در این منطقه به تصویر کشیدیم، همانطور که در شکل 10 نشان داده شده است.ب مشاهده می شود که محوطه دانشگاه توسط جاده های سطح «اصلی» و «ثانویه» احاطه شده است، در حالی که سطح جاده در داخل محوطه دانشگاه «غیر طبقه بندی» و «مسکونی» است. علاوه بر این، نمادهای الماس فیروزه ای نشان دهنده مکان ایستگاه های اتوبوس است. در این منطقه، ایستگاههای اتوبوس عمدتاً در جادههای درجه بالا، مانند جادههای سطح «اولیه» و «ثانویه» توزیع میشوند. بدیهی است که در داخل محوطه دانشگاه هیچ ایستگاه اتوبوسی وجود ندارد. ما تمام مسیرهای واقع در این منطقه را که توسط کاربر علامتگذاری نشدهاند از مجموعه داده Geolife انتخاب کردهایم و از مدل GeoSDVA از پیش آموزشدیدهشده برای شناسایی حالتهای حمل و نقل این مسیرها استفاده کردهایم. از آنجایی که مدل GeoSDVA به ورودی با طول ثابت نیاز دارد، از پنجره کشویی و حداکثر رای برای تعیین حالت انتقال یک مسیر استفاده میکنیم.
شکل 11 چهار مسیر حالت حمل و نقل شناسایی شده توسط GeoSDVA را به ترتیب در این منطقه نشان می دهد. نتایج شناسایی نشان می دهد که تعداد زیادی مسیر پیاده روی و دوچرخه در داخل محوطه دانشگاه وجود دارد، در حالی که مسیرهای حمل و نقل عمومی و اتومبیل به ندرت در آنجا ظاهر می شوند. در داخل محوطه دانشگاه، مردم تمایل به پیاده روی و استفاده از دوچرخه دارند، در حالی که استفاده از ماشین در این منطقه ممکن است محدود باشد. برای توضیح بهتر، همانطور که در شکل 12 نشان داده شده است، آماری را از نسبت حالت های حمل و نقل مختلف در داخل و خارج از محوطه دانشگاه ارائه می کنیم .. در این منطقه حدود 14.3 درصد از مسیرها مسیرهای پیاده روی و 42.8 درصد مسیرهای دوچرخه در داخل محوطه دانشگاه هستند. در مقابل، تنها 2 درصد از مسیرهای موجود در داخل پردیس دانشگاه، مسیرهای حمل و نقل عمومی و 3 درصد از آنها مسیرهای خودرو هستند. در بخش شمال شرقی منطقه، جاده همسطح «بزرگراه» وجود دارد. مسیر پیاده روی و دوچرخه در این جاده مشخص نیست، زیرا این دو حالت مجاز به استفاده از آن نیستند. ما مسیرهای حمل و نقل عمومی کمتری را نسبت به مسیرهای خودرو در داخل محوطه دانشگاه شناسایی کردیم. این به این دلیل است که در داخل محوطه دانشگاه ایستگاه اتوبوس وجود ندارد، بنابراین ایستگاه اتوبوس به یک تکیه گاه قوی برای تمایز بین مسیر حرکت خودروها و حمل و نقل عمومی در این منطقه تبدیل شده است. علاوه بر این، ما همچنین مشاهده کردیم که در مقایسه با مسیرهای خودرو، مسیر حمل و نقل عمومی در جادههایی با سطح جاده بالاتر ظاهر میشود، که با موقعیت ایستگاههای اتوبوس نیز تعیین میشود. به طور کلی، نتایج شناسایی GeoSDVA با عقل سلیم در واقعیت سازگار است و نتایج آن دارای ارزش مرجع است.
5. بحث و نتیجه گیری
این مقاله یک مدل نیمه نظارتی جدید به نام GeoSDVA برای شناسایی حالتهای حمل و نقل ساکنان پیشنهاد میکند. اول، ورودی GeoSDVA برای خوانش های GPS طراحی شده است که ویژگی های حرکتی را با اطلاعات جغرافیایی ترکیب می کند. دوم، یک مدل نیمه نظارت شده بر اساس DirVAE برای یادگیری ویژگی هایی ساخته شده است که برای شناسایی حالت حمل و نقل از مسیرهای بدون برچسب مفید هستند. سپس، با ارزیابی GeoSDVA بر روی دو مجموعه داده مسیر واقعی GPS، ثابت شد که GeoSDVA توانایی یادگیری نیمه نظارتی را دارد که تنها چند مسیر برچسب گذاری شده باشند و عملکرد آن در شناسایی حالت حمل و نقل بهتر از روش های پایه است. پس از آن، ما تجزیه و تحلیل می کنیم که چگونه ماژول DirVAE اطلاعات مفیدی را از مسیرهای بدون برچسب برای شناسایی حالت حمل و نقل به دست می آورد. علاوه بر این، ما تأثیر اطلاعات جغرافیایی را بر شناسایی حالتهای حملونقل خاص تجزیه و تحلیل میکنیم. در نهایت، ما از یک GeoSDVA از پیش آموزشدیده برای برچسبگذاری و تجزیه و تحلیل مسیرهای بدون برچسب در یک منطقه استفاده میکنیم که نشان میدهد نتایج شناسایی شده دارای اهمیت عملی هستند.
GeoSDVA با توجه به مزایای زیر می تواند برای تصمیم گیری عملی توسط بخش های مدیریت شهری و شرکت های حمل و نقل استفاده شود. اولاً، جمع آوری تعداد زیادی از مسیرهای GPS بدون برچسب آسان است، در حالی که GeoSDVA فقط به چند خط سیر برچسب دار گران قیمت در آموزش نیاز دارد که مزیت هزینه را به همراه دارد. دوم، سفرهای کم کربن در حال حاضر به یک نقطه داغ در حوزه های تحقیقاتی حمل و نقل تبدیل شده است. تفاوت های قابل توجهی در انتشار کربن در روش های مختلف حمل و نقل وجود دارد. GeoSDVA می تواند برای شناسایی انتشار کربن از مسافران فردی استفاده شود تا به دولت کمک کند سیاست های مربوطه را برای تشویق سفرهای سبز تدوین کند. سوم، شناسایی حالت حمل و نقل مسیرهای GPS در شهر توسط GeoSDVA می تواند به تدوین سایر طرح های برنامه ریزی شهری کمک کند. مثلا،
علاوه بر این، GeoSDVA دارای مزایای زیر نسبت به مدل های شناسایی حالت حمل و نقل موجود است. در مقایسه با مدلی که فقط از ویژگیهای حرکتی برای شناسایی حالت حملونقل استفاده میکند، GeoSDVA تأثیر اطلاعات GIS بر مسیر را در نظر میگیرد و از شبکههای عمیق برای استخراج ویژگیهای مرتبط استفاده میکند. در مقایسه با حالت حمل و نقل مبتنی بر یادگیری ماشین سنتی، مدل GeoSDVA نیازی به طراحی دستی ویژگی های آماری ندارد و می تواند به طور خودکار ویژگی ها را از مسیرهای خام استخراج کند. در مقایسه با مدل شناسایی حمل و نقل مبتنی بر یادگیری نظارت شده، GeoSDVA می تواند از مسیرهای بدون برچسب برای یادگیری استفاده کند، و می تواند از تعداد کمی از مسیرهای دارای برچسب برای شناسایی دقیق حالت حمل و نقل استفاده کند. که مشکل هزینه بالای مرتبط با مسیرهای برچسب گذاری را حل می کند. در مقایسه با حالت شناسایی حمل و نقل نیمه نظارت شده بر اساس رمزگذار خودکار، GeoSDVA از ساختار رمزگذار متغیر برای ایجاد فضای پنهان محدودتر و بهبود توانایی یادگیری نیمه نظارت شده استفاده می کند.
در آینده از سه نقطه زیر کار خود را بهبود و ارتقا خواهیم داد. اولاً، ممکن است برخی از حالتهای حمل و نقل در مجموعه داده بدون برچسب وجود داشته باشد که در مجموعه داده برچسبگذاری شده ظاهر نشود. مسیرهای این حالتهای حملونقل ناشناخته ممکن است باعث ایجاد نویز در مدل یادگیری نیمهنظارت شوند. ثانیا، حفاظت از حریم خصوصی در خدمات مبتنی بر مکان به طور فزاینده ای به یک کانون تحقیقاتی تبدیل شده است. شناسایی حالت حمل و نقل در سناریوی حفاظت از حریم خصوصی مشکلی است که ارزش مطالعه دارد. در نهایت، معرفی ویژگی های GIS بیشتر برای شناسایی حالت حمل و نقل بسیار جذاب است. ویژگی های GIS مانند انواع زمین شهری ممکن است برای تمایز بین مسیرها مفید باشد.















بدون دیدگاه