1. معرفی
جستارهای پیوسته k نزدیکترین همسایه در جریان داده های متنی- فضایی (به اختصار CkQST) حداکثر k نزدیکترین همسایه (به اختصار kNN) را در مکان مشخص شده توسط کاربر که شامل همه کلمات کلیدی مشخص شده توسط کاربر است، بازیابی می کند و به طور مداوم نظارت می کند. به طور گسترده در انواع برنامه های مبتنی بر مکان، مانند هدف گیری مکان یابی تبلیغات، تجزیه و تحلیل میکرو وبلاگ ها، و سرویس های ناوبری تلفن همراه استفاده می شود.
در یک سیستم توصیه کوپن الکترونیکی یا یک سیستم انتشار/اشتراک Weibo، کاربران علایق خود را (مثلاً برند مورد علاقه غذا یا لباس برای اولی و اخبار یا افراد برای دومی) به عنوان درخواست ثبت میکنند. جریانی از اشیاء متنی فضایی (مثلاً کوپن های الکترونیکی یا Weibos) تولید شده به کاربران مربوطه داده می شود. پرس و جوهای مستمر در جریان داده های مکانی-متنی که توسط کار موجود مطالعه شده است [ 1 ، 2 ، 3 ، 4 ، 5 ، 6 ، 7 ، 8 ، 9 ، 10 ، 11 ، 12] در درجه اول از نظر تطابق بولی یا تطبیق تقریبی هستند که تعداد غیرقابل پیش بینی اشیا یا نتایج تقریبی را برمی گرداند. تعداد اشیاء واجد شرایط حاوی تمام کلمات کلیدی مشخص شده توسط کاربر می تواند بسیار بیشتر از آن باشد ک، زیرا اشیاء (به عنوان مثال، توییت ها، اخبار) معمولاً حاوی کلمات کلیدی بسیار بیشتری نسبت به جستجوها هستند. این ما را تشویق میکند تا CkQST را مطالعه کنیم، که حداکثر k شیء نزدیکترین همسایه را که حاوی تمام کلمات کلیدی پرس و جو هستند، برمیگرداند.
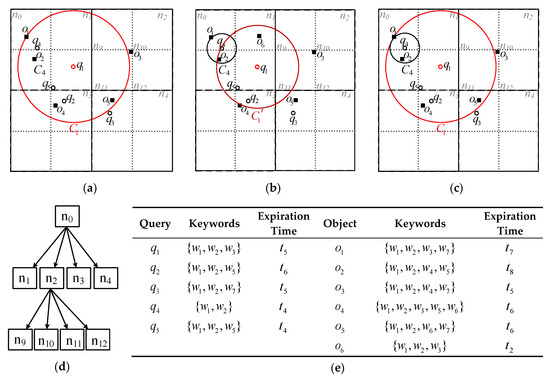
مثال 1. شکل 1 یک مثال در حال اجرا را نشان می دهد که در سراسر این مقاله استفاده شده است. در مهر زمان تی0، پنج 2-NN مشترک وجود دارد (یعنی ک=2) پرس و جو q1،q2،⋯،q5با دایره کوچکی که موقعیت جغرافیایی آنها را نشان می دهد و پنج شی o1،o2،⋯،o5با یک مربع کوچک که موقعیت جغرافیایی آنها را در شکل 1 الف نشان می دهد، در حالی که کلمات کلیدی مربوطه و زمان انقضا در شکل 1 e نشان داده شده است. ناحیه فضایی توسط یک چهاردرخت سه لایه سازماندهی شده است، جایی که گره های فضایی به صورت متوالی شماره گذاری می شوند و گره ریشه n0. گرفتن ارزیابی از q1به عنوان مثال، {o4،o1}برگردانده می شود. برای q1، محدوده جستجوی فضایی و سپس “محدوده جستجو” به عنوان یک دایره حداقل در مرکز موقعیت جغرافیایی تعریف می شود. q1و پوشش {o4،o1}، یعنی سی1. در مهر زمانی تی1، یک شی o6همانطور که در شکل 1 ب نشان داده شده است، با کلمات کلیدی می رسد{w1،w2،w3}و زمان انقضا تی2. o6شامل تمام کلمات کلیدی از q1و q4، اما تنها سی1مورد ضربه قرار می گیرد o6. نتیجه و محدوده جستجو از q1به روز می شوند {o6،o4}و دایره سی1″، به ترتیب، در حالی که نتیجه و محدوده جستجو از q4تحت تاثیر قرار نمی گیرند. در مهر زمان تی2، o6منقضی می شود. برای q1، تعداد اشیاء واجد شرایط در سی1″کمتر از 2 است، بنابراین نتیجه باید دوباره ارزیابی شود. نتیجه و محدوده جستجو از q1به روز می شوند {o4،o1}و دایره سی1، به ترتیب. بنابراین، برای CkQST، محدوده جستجوی فضایی که اشیاء kNN را پوشش میدهد به صورت پویا با ورود و انقضای اشیاء واجد شرایط تغییر میکند.
چالش ها. چارچوب راهحل برای ارزیابی پرسوجوهای پیوسته عمومی بر روی جریانهای دادههای مکانی-متنی شامل انتخاب یک شاخص فضایی مناسب و یک شاخص متنی برای تشکیل یک شاخص فضایی-متن ترکیبی، و بهرهبرداری از آن با استراتژیهای فیلتر فضایی و/یا متنی مناسب برای پردازش اطلاعات ورودی است. اشیاء با توجه به ویژگی های پرس و جوها [ 1 ، 2 ، 3 ، 4 ، 5 ، 6 ، 7 ، 8 ، 9 ، 10 ، 11 ، 12 ]. سه چالش کلیدی در ساخت چنین شاخصی برای CkQST وجود دارد.
اول، با توجه به فیلتر فضایی، ارزیابی CkQST اساساً جستجوهایی را شناسایی می کند که محدوده جستجوی آنها توسط اشیاء ورودی مورد اصابت قرار می گیرد. سازماندهی موثر محدوده جستجوی CkQST بسیار مهم است. بنابراین، نحوه نگاشت محدوده جستجوی CkQST به گرههای فضایی تمرکز دارد. محدوده جستجوی CkQST که اشیاء kNN را پوشش میدهد، به طور مکرر با ورود و انقضای اشیاء واجد شرایط تغییر میکند، که این امر مستلزم آن است که شاخص دارای قابلیت فیلترینگ قوی و هزینه بهروزرسانی کم باشد. برای بیشتر شاخص های فضایی، داشتن قابلیت فیلترینگ قوی و هزینه کم به روز رسانی متناقض است. دو رویکرد برای نگاشت محدوده جستجوی جستجوها به گره های فضایی برای بهبود توانایی فیلتر و کاهش هزینه به روز رسانی ایندکس وجود دارد. (1) کوئری ها به گره های برگ در نمایه فضایی نگاشت می شوند،2 , 5 , 7 , 8 , 9 , 10 , 13 , 14 , 15 ]. (2) پرس و جوها با توجه به توزیع فضایی [ 10 ، 11 ، 12 ]، توزیع کلیدواژه [ 6 ] یا مدل هزینه مربوطه [ 1 ، 3 ، 4 ] به گره های فضایی نگاشت می شوند. این رویکردها در سناریوهایی که محدوده جستجوی پرس و جوها به ندرت تغییر می کند مناسب هستند، اما برای CkQST نامناسب هستند، جایی که به روز رسانی مکرر محدوده جستجوی پرس و جوها منجر به هزینه های بالا می شود.
دوم، با توجه به فیلتر متنی، ارزیابی CkQST اساساً عبارت است از شناسایی پرس و جوهایی که کلمات کلیدی آنها به طور کامل در یک شی معین وجود دارد. یک نمایه معکوس معمولاً برای سازماندهی پرس و جوهای پیوسته استفاده می شود [ 1 ، 2 ، 6 ، 10 ]. تعداد زیاد پرسوجوها، فهرستهای ارسال را بسیار طولانی میکنند، و اشیاء سریعالسیر با لیستهای ارسالی متناظر در چند دور در مدت زمان کوتاهی تأیید میشوند، که به گلوگاه فیلتر کردن متن تبدیل میشود. سه راه برای بهبود قابلیت فیلتر کردن متن وجود دارد. (1) پرس و جوها را با توجه به فراوانی کلمات کلیدی پرس و جو در کوتاه ترین لیست ارسال قرار دهید تا تعداد پرس و جوها در لیست های ارسال، مانند شاخص معکوس کلید رتبه بندی [ 1، 6 ]. لیست های ارسال ممکن است هنوز طولانی باشد. (2) عمق پارتیشن متنی را افزایش دهید، مانند کلمه کلیدی مرتب شده trye [ 3 ، 4 ، 6 ]. ساخت ایندکس زمان زیادی می برد و اگر کوئری ها به روز شوند، گره ها باید بازسازی شوند، که برای سناریوهایی مانند CkQST که در آن کوئری ها اغلب به روز می شوند، مناسب نیست. (3) پرس و جوها را در لیست های ارسال به ترتیب صعودی با توجه به امتیاز رتبه بندی سازماندهی کنید [ 10 ]. با این حال، هیچ مفهوم متناظری در CkQST وجود ندارد. هیچ یک از رویکردهای فوق نمی تواند به طور موثر از فیلتر متنی CkQST پشتیبانی کند.
سوم، ارزیابی مجدد kNN اغلب با انقضای شی آغاز می شود. هنگامی که یک شی منقضی می شود، چندین CkQST باید دوباره از ابتدا ارزیابی شوند، که گران است. چندین تکنیک برای حل مسائل مشابه در پرس و جوی top-k تقریبی پیشنهاد شده است (به عنوان مثال، [ 10 ، 13 ، 16 ، 17 ]). همه آنها طرفدار حفظ بیش از کنتایج برای کاهش شانس برای ارزیابی مجدد. با این حال، آنها یا تمام اشیاء خط آسمان را در کل منطقه حفظ می کنند [ 13 ، 16 ]، یا یک نوار آسمانی k حاوی اشیاء خط افق را حفظ می کنند که امتیاز آنها بزرگتر از یک آستانه است [ 10 ، 17 ]، که برای بازگشت دقیق CkQST طراحی نشده اند. نتایج.
با توجه به چالشها، ما یک چهار درخت با یک شاخص مرتب و معکوس برای سازماندهی CkQST گسترش میدهیم. سه تکنیک کلیدی برای بهره برداری از شاخص فضایی-متن و رسیدگی به سه چالش فوق پیشنهاد شده است. مشارکت های این مقاله در ادامه می آید.
(1) برای پشتیبانی از تغییر مکرر محدوده جستجوی CkQST، یک مدل هزینه مبتنی بر حافظه برای نقشهبرداری محدوده جستجوی CkQST به گرههای چهار درختی پیشنهاد شده است که هزینه تأیید و هزینه بهروزرسانی فهرست را به حداقل میرساند.
(2) برای کاهش تعداد پرس و جوهای تأیید شده و پردازش اشیاء در دسته ها، یک نمایه مرتب و معکوس مبتنی بر بلوک تطبیقی برای سازماندهی کلمات کلیدی پرس و جو در گره های چهاردرخت پیشنهاد شده است، که به چندین اشیاء حاوی متون مشترک اجازه می دهد تا به طور همزمان تأیید شوند. برای این شاخص، یک استراتژی درج برای درج تطبیقی پرسوجوها در نماهای توزیعهای اریب CkQST و اشیاء پیشنهاد شده است.
(3) برای کاهش هزینه ارزیابی مجدد، یک تکنیک k-skyband مبتنی بر هزینه پیشنهاد شده است تا محدوده جستجوی CkQST را با توجه به حجم کاری اشیاء به طور عاقلانه تعیین کند، که هزینه تأیید، هزینه بهروزرسانی و ارزیابی مجدد را به حداقل میرساند. هزینه.
آزمایشها بر روی مجموعه دادههای مصنوعی و دنیای واقعی نشان میدهند که تکنیکهای پیشنهادی میتوانند به طور موثر CkQST را ارزیابی کنند. در مقایسه با تکنیکهای پیشرفته، زمانی که تعداد CkQST به 20 M میرسد، میانگین زمان بهروزرسانی شاخص ناشی از اشیاء ورودی تا 61 درصد کاهش مییابد و میانگین زمان پردازش شی ورودی تا 36 درصد کاهش مییابد. در مقایسه با ارزیابی مجدد از ابتدا، میانگین زمان پردازش برای اشیاء منقضی شده 99.99٪ کاهش می یابد. بقیه این مقاله به شرح زیر سازماندهی شده است. بخش 2 به طور رسمی CkQST را تعریف می کند و چارچوبی را برای ارزیابی CkQST ارائه می دهد. بخش 3 سه تکنیک کلیدی را برای ارزیابی CkQST ارائه می کند. بخش 4 مطالعات تجربی را گزارش می کند. در نهایت، بخش 5این مقاله را به پایان می رساند.
2. چارچوب برای ارزیابی CkQST
در این بخش، ما به طور رسمی CkQST را در بخش 2.1 تعریف می کنیم و چارچوبی برای ارزیابی CkQST در بخش 2.2 ارائه می دهیم .
2.1. تعریف مشکل
یک شی فضایی – متنی به این صورت تعریف می شود o=لoج،ψ،تیه، جایی که o.لoجموقعیت جغرافیایی است، o.ψمجموعه ای از کلمات کلیدی (اصطلاحات) از مجموعه واژگان است V، و o.تیهیک مهر زمانی است که زمان انقضا را نشان می دهد o. تمام اشیاء فضایی-متنی در جریان داده ها به صورت نشان داده می شوند O. یک CkQST به صورت تعریف شده است q=لoج،ψ،ک،تیه، جایی که q.لoج، q.ψ، و q.تیهاز معنای مشابه پیروی کنید o، q.کتعداد اشیاء برگشتی است، یعنی حداکثر q.ک(به اختصار ک) نتایج برای حفظ می شوند q. لیست نتایج q، نشان داده شده است q(O)ک، شامل مجموعه ای از کاشیایی که هر کدام از آنها تمامی کلمات کلیدی را در بر می گیرد q.ψ. q(O)کتوسط یک لیست پیوندی سازماندهی شده است، که در آن اشیاء به ترتیب صعودی بر اساس فواصل تا مرتب شده اند q. به طور رسمی، ∀o∈q(O)ک((∄o”∈O\q(O)ک)(o”.ψ⊇q.ψ∧دمنستی(o”،q)≤دمنستی(o،q)))، جایی که دمنستی(o،q)فاصله اقلیدسی بین است oو q. اجازه دهید q.کدمنستیفاصله بین باشد qو آن کتیساعتنتیجه نزدیکترین همسایه محدوده جستجو برای q، نشان داده شده است q.اسآرک، به عنوان یک دایره در مرکز تعریف می شود q.لoجبا شعاع q.کدمنستی.
اشیاء متنی- فضایی معمولاً تبلیغاتی هستند که توسط بازرگانان یا آخرین اخبار منتشر می شوند و CkQST درخواست جستجوی کاربران است. اگر ابهامی وجود نداشته باشد، از این پس شی فضایی-متن و CkQST به ترتیب به عنوان شی و پرس و جو مخفف می شوند. برای ساده کردن محاسبه، اصطلاحات موجود در واژگان را تنظیم کنید Vبه اعداد صحیح بین 1 و نگاشت می شوند Vبر اساس ترتیب حروف الفبا، جایی که Vتعداد اصطلاحات در است V. ما فرض می کنیم که شرایط در V، و عبارات موجود در پرس و جوها و اشیاء به ترتیب فزاینده مرتب می شوند. به طور خاص، برای ∀q∈س، ما استفاده می کنیم q.ψ[من]برای نشان دادن منتیساعتکلمه کلیدی از q، q.ψ[من:j]برای نشان دادن زیر مجموعه ای از q.ψ، یعنی ∪من≤ل≤jq.ψ[ل]، q.ψ[:من]نشان دادن ∪1≤ل≤منq.ψ[ل]، q.ψ[من:]نشان دادن ∪من≤ل≤q.ψq.ψ[ل]، و q.ψبرای نشان دادن تعداد کلمات کلیدی در q.ψ. اشیا از نمادهای مشابه پیروی می کنند. جدول 1 نمادهای مورد استفاده در این مقاله را خلاصه می کند.
بیان مسأله. با توجه به مجموعه ای از CkQST سو جریان های داده های مکانی – متنی O، برای هر CkQST، اشیاء kNN حاوی تمام کلمات کلیدی پرس و جو را پیدا کنید Oهر زمان که اشیا می رسند یا منقضی می شوند.
2.2. چارچوب برای ارزیابی CkQST
چارچوب برای ارزیابی CkQST نشان داده شده در شکل 2 از دو شاخص و چهار تکنیک کلیدی تشکیل شده است. نمایه شی اشیا را سازماندهی می کند و می تواند با هر شاخص فضایی-متنی موجود پیاده سازی شود، و ما چهار درخت خطی معکوس (IL-quadtree) [ 18 ] را به عنوان مثال در نظر می گیریم. نمایه پرس و جو پرس و جوها را سازماندهی می کند، که اساساً یک چهار درخت ادغام شده با یک نمایه مرتب و معکوس شرح داده شده در بخش 3 است .
رسیدن و انقضای اجسام. هنگامی که چندین شیء به یک دسته میرسند، در فهرست شی وارد میشوند و توسط الگوریتم پردازش دستهای شی با کمک فهرست پرس و جو پردازش میشوند تا تمام پرسوجوهای آسیبدیده را پیدا کرده و نتایج و محدوده جستجوی جستجوهای مربوطه را بهروزرسانی کنند. هنگامی که اشیاء منقضی می شوند، لیست نتایج جستجوهای تحت تأثیر بررسی می شود. آن دسته از پرسوجوهایی که نمیتوانند از طریق فهرست نتایج دوباره پر شوند، مجدداً از ابتدا در برابر شاخص شیء ارزیابی میشوند. برای صرفهجویی در هزینههای محاسباتی، اشیاء منقضی شده با تنبلی از فهرست شی حذف میشوند تا زمانی که دوباره به آنها دسترسی پیدا کنید.
ورود و حذف پرس و جوها. هنگامی که یک پرس و جو جدید ارسال می شود، در ابتدا با استفاده از شاخص شی با چندین استراتژی ارزیابی می شود. یک تکنیک k-skyband مبتنی بر هزینه برای یافتن محدوده جستجوی بهینه برای پرس و جو استفاده می شود تا هزینه به روز رسانی شاخص را با قربانی کردن کمی عملکرد فیلتر کاهش دهد. یک مدل هزینه مبتنی بر حافظه برای بدست آوردن گره های فضایی نگاشت شده مربوطه استفاده می شود. یک استراتژی درج تطبیقی برای دریافت لیست ارسال و بلوک مربوطه برای درج استفاده می شود. این استراتژی ها می توانند عملکرد فیلترینگ شاخص را بیشتر بهبود بخشند و هزینه به روز رسانی شاخص را کاهش دهند. هنگامی که یک پرس و جو حذف می شود یا محدوده جستجوی آن کوچک می شود، یک پرچم در گره های مربوطه تنظیم می شود، جایی که یک جدول پرس و جو نگهداری می شود، و تا زمانی که دوباره به آن دسترسی پیدا کنید، از فهرست پرس و جو حذف نمی شود. که به آن حذف تاخیری می گویند و در یک سیستم به روز رسانی پسند ضروری است. درخواست درج پرس و جو ممکن است موارد علامت گذاری شده را لغو کند، که از حذف مکرر اشیاء جلوگیری می کند. اگر یک پرس و جو حذف شود، لیست نتایج آن نیز حذف می شود.
3. فهرست پرس و جو
با توجه به بحث های بالا، شاخص پرس و جو اساساً یک چهار درخت است که با یک شاخص مرتب و معکوس گسترش یافته است. سه تکنیک برای افزایش توانایی فیلتر کردن و کاهش هزینه به روز رسانی شاخص پیشنهاد شده است. بخش 3.1 انگیزه ها را معرفی می کند. بخش 3.2 فهرست مرتب شده و معکوس را تشریح می کند و به دنبال آن یک الگوریتم درج پرس و جو تطبیقی مفصل در بخش 3.3 ارائه می شود . بخش 3.4 مدل هزینه مبتنی بر حافظه را برای تجزیه و تحلیل کمی چگونگی یافتن گرههای مرتبط بهینه برای CkQST پیشنهاد میکند. الگوریتم پردازش اشیاء در دسته برای بهبود توان عملیاتی در بخش 3.5 ارائه شده است . تکنیک ارزیابی مجدد در بخش 3.6 معرفی شده است.
3.1. انگیزه ها
سازماندهی محدوده جستجوی CkQST. اولین مسئله استفاده از چهار درخت برای سازماندهی محدوده جستجوی CkQST این است که چگونه محدوده جستجو را به گره های چهار درختی نگاشت کنیم. با توجه به اینکه ∀q∈س، q.اسآرکمی توان به هر مجموعه ای از گره های چهار درختی نگاشت ناس={n1،n2،⋯،nمن}، تنها در صورتی که اتحاد ناحیه فضایی مربوط به این گره ها در ناسپوشش می دهد q.اسآرک، که به آن نیز می گویند qدر همکاری است با ناس. ارتباط یک پرس و جو با گره های چهاردرخت چالش برانگیز است زیرا بر دو هزینه محاسباتی تأثیر می گذارد: (1) هزینه تأیید، به عنوان مثال، هزینه تأیید پرس و جو با اشیائی که در گره های مرتبط قرار می گیرند. (2) هزینه به روز رسانی، به عنوان مثال، هزینه درج یا حذف پرس و جو در یا از گره های مرتبط. اگر محدوده جستجو توسط گره هایی با مناطق بزرگ سازماندهی شود، هزینه به روز رسانی فهرست کوچک است و هزینه تأیید بزرگ است. در غیر این صورت، اگر چندین گره با مناطق کوچک استفاده شود، وضعیت برعکس می شود. بنابراین، یک مدل هزینه برای معاوضه با هزینه تأیید و هزینه بهروزرسانی و یافتن گرههای بهینه مرتبط برای CkQST مورد نیاز است.
سازماندهی کلمات کلیدی CkQST. هنگامی که اشیاء جدید وارد می شوند، هزینه تأیید این اشیاء با پرس و جو در گره های فضایی گران است. نحوه کاهش هزینه تأیید، کلید بهبود توانایی فیلتر کردن شاخص است. ما سه جنبه از ساخت یک شاخص معکوس را مورد بحث قرار می دهیم. (1) برای یک نمایه معکوس، پرس و جوها در لیست های ارسال معمولا نامرتب هستند. برای پنج پرس و جو در شکل 1 ، آنها را به لیست پست یک کلمه کلیدی پیوست کردیم. شکل 3 a نمایه معکوس است که در آن پرس و جوها به لیست ارسال مربوط به اولین کلمه کلیدی پرس و جو پیوست می شوند و شکل 3b شاخص معکوس شده با کلید رتبهبندی است که در آن پرسوجوها به فهرست پست مربوط به کمتکرارترین کلمه کلیدی پیوست میشوند. اگر اشیاء ورودی حاوی عبارت مربوطه باشند، همه پرس و جوها در لیست های ارسال تایید می شوند [ 1 ، 2 ] که ناکارآمد است. در این کار از یک شاخص مرتب و معکوس برای حل مشکل فوق استفاده می کنیم. شکل 3 ج نمایه مرتب و معکوس است در صورتی که پرس و جوها به لیست ارسال متناظر با اولین کلمه کلیدی پیوست شده باشند، به عنوان مثال، پرس و جوها در لیست های ارسال به ترتیب صعودی مطابق با کلمات کلیدی سازماندهی شده اند. چه زمانی o6با کلمات کلیدی {w1،w2،w3}می رسد، لیست ارسال مربوط به w1تایید می شود. چه زمانی o6با تایید می شود q2، کلمات کلیدی آن کوچکتر از q2، بنابراین ما می توانیم تأیید را زودتر خاتمه دهیم و پردازش اشیاء را سرعت بخشیم.
(2) در مقایسه با نمایه مرتب و معکوس ساخته شده توسط یک کلمه کلیدی، نمایه مرتب و معکوس ساخته شده توسط چندین کلمه کلیدی مزایای بیشتری دارد. طول کوتاهتر و احتمال تأیید کوچکتر است. همانطور که شکل 3 d نشان می دهد، o6با دو لیست ارسال اول تأیید می شود و شامل تمام کلمات کلیدی جستجوهای موجود در این لیست های ارسال است. با این حال، تعداد لیست های ارسال ممکن است به شدت افزایش یابد. اگر تعداد اصطلاحات موجود در مجموعه واژگان V1 M است و تعداد کلمات کلیدی پرس و جو بیشتر از 5 نیست، در مجموع 10 لیست ارسال 6×5 مورد نیاز است که به دلیل نیاز به حافظه پیوسته زیاد، پیاده سازی توسط جدول هش دشوار است. مانند سایر آثار در [ 1 ، 2 ، 3 ، 4 ، 5 ، 6 ، 7 ، 8 ، 9 ، 10 ، 11 ، 12 ]، این مقاله از کلاس Map در Microsoft Visual Studio [ 19 ] برای ساخت فهرست مرتب و معکوس استفاده می کند. . لم 1 کارایی تأیید را با تعداد کلمات کلیدی برای ساخت شاخص مرتب و معکوس توصیف می کند.بخش 4.2 این لم را از طریق آزمایشات تأیید می کند. بر اساس بحثها، دو کلمه کلیدی را برای ساخت شاخص مرتب و معکوس انتخاب میکنیم.
(3) معمولاً پرس و جوهای زیادی در لیست های ارسال وجود دارد، اما فقط تعداد کمی با اشیاء ورودی مطابقت دارند. بنابراین، مکان یابی سریع پرس و جوهایی که باید در لیست های ارسال تایید شوند، راه دیگری برای بهبود کارایی ارزیابی CkQST است. پرس و جوها در لیست ارسال به بلوک های متعدد تقسیم می شوند به طوری که اشیاء با پرس و جوها در چند بلوک به جای کل لیست ارسال تایید می شوند. تنها مشکل این است که چگونه این پرس و جوها را در لیست های ارسالی پارتیشن بندی کنیم. داشتن پرس و جوهای خیلی زیاد یا خیلی کم در یک بلوک ناکارآمد است. یک استراتژی درج تطبیقی در بخش 3.3 پیشنهاد شده است .
3.2. مرتب شده، شاخص معکوس
تعریف رسمی یک شاخص مرتب و معکوس ساخته شده با استفاده از دو کلمه کلیدی به شرح زیر است. پرس و جوها به لیست ارسال دو کلمه کلیدی اول خود پیوست می شوند و بر اساس کلمات کلیدی آنها به ترتیب صعودی مرتب می شوند.
تعریف 1 (فهرست ارسال مرتب / مرتب شده، فهرست معکوس).
با توجه به مجموعه ای از پرس و جو q1،q2،⋯،qمن در یک گره چهاردرخت درج شود، اگر q1.ψ[1:2]=q2.ψ[1:2]⋯=qمن.ψ[1:2]={wمن1،wمن2} ، و q1.ψ[3:]≤q2.ψ[3:]≤⋯≤qمن.ψ[3:]، لیست ارسال شده توسط دو عبارت تعیین می شود wمن1،wمن2 در گره به عنوان نشان داده شده است پLwمن1wمن2، که این پرس و جوها به صورت متوالی درج می شوند. پLwمن1wمن2لیست ارسال سفارشی نامیده می شود. به طور خاص، اگر این پرس و جوها فقط حاوی یک کلمه کلیدی باشند، لیست پست مربوطه به عنوان نشان داده می شود پLwمن1wمن1. همه لیست های ارسال مرتب شده، فهرست مرتب و معکوس را تشکیل می دهند.
از این به بعد لیست ارسال سفارش شده در صورت عدم وجود ابهام به اختصار لیست ارسال می شود. برای مکان یابی سریع پرس و جوهایی که باید تأیید شوند، فهرست های ارسال به بلوک های متعدد تقسیم می شوند.
تعریف 2 (بلوک).
با توجه به هر لیست ارسال سفارش شده پLwمن1wمن2، wمن1≠wمن2، بr هست rتیساعت بلوک از پLwمن1wمن2. برای هر پرس و جو qکه در بr، q.ψ[3]∈[بr.مترمنnw،بr.مترآایکسw]، جایی که بr.مترمنnw=دقیقهqمن∈بrqمن.ψ[3]، بr.مترآایکسw=حداکثرqمن∈بrqمن.ψ[3]. بr.ψ تمام کلمات کلیدی رضایت بخش را نشان می دهد بr.ψ={w|w∈[بr.مترمنnw،بr.مترآایکسw]}. مخصوصا اگر q فقط شامل یک یا دو کلمه کلیدی است که در بلوک درج می شود ب0 از لیست پست مربوطه
لم 1.
اگر تعداد کلمات کلیدی برای ساخت یک شاخص مرتب، معکوس باشد مترمتر≥1، حداکثر وجود دارد Vمترارسال لیست ها در یک گره برای هر شی oبا بیش از دو کلمه کلیدی، هزینه تایید را می توان با معادله (1) تخمین زد. جایی که ب تعداد بلوک های موجود در یک لیست ارسال است، ب تعداد پرس و جوها در است ب، س شامل پرس و جوهایی است که کلمات کلیدی آنها در آنها وجود دارد o، و تعداد کلمات کلیدی کمتر از متر. اثبات در پیوست A نشان داده شده است .
برای ∀wj∈ب.ψ، احتمال تأیید، به عنوان نشان داده شده است پVw(wj)، حفظ می شود، یعنی احتمال تایید این پرس و جوها در معرض qمن.ψ[3]={wj}که در بr. برای ∀بr، احتمال تأیید، به عنوان نشان داده شده است پVب(بr)، حفظ می شود، یعنی احتمال بلوک بrتایید می شود که می توان آن را با رابطه (2) تخمین زد.
قضایای زیر ادعا می کنند که شی ورودی با پرس و جوهای کمی در لیست های ارسال تایید می شود. برای هر شی ورودی، بلوک هایی که تأیید می شوند را می توان با توجه به فاصله کلمه کلیدی بلوک قرار داد [بr.مترمنnw،بr.مترآایکسw](به قضیه 1 مراجعه کنید). تأیید شیء با یک بلوک یا یک لیست ارسال را می توان در صورتی خاتمه داد که کلمات کلیدی کوچکتر از مواردی باشند که در حال تأیید هستند. (به قضیه 2 مراجعه کنید).
قضیه 1.
داده شده ∀o∈Oو یک لیست ارسال پLwمن1wمن2در حال تایید شدن با o، برای ∀بrکه در پLwمن1wمن2، اگر ∃qکه در بr، oشامل تمام کلمات کلیدی از q، فقط اگر ∃wj∈o.ψ، wj∈[بr.مترمنnw،بr.مترآایکسw].
اثبات
فرض کنید که oشامل تمام کلمات کلیدی از q، اما اصطلاحی در آن وجود ندارد o.ψرضایت بخش wj∈[بr.مترمنnw،بr.مترآایکسw]. بر اساس تعریف 2، q.ψ[3]∈[بr.مترمنnw،بr.مترآایکسw]، oشامل کلمه کلیدی سوم از q، بنابراین oشامل تمام کلمات کلیدی نیست q. با فرضیه مخالف است، بنابراین قضیه ثابت می شود. □
قضیه 2.
داده شده ∀o∈Oو یک لیست ارسال پLwمن1wمن2در حال تایید شدن با o، برای ∀بrکه در پLwمن1wمن2، ما نتایج زیر را داریم. (1) اگر بr.مترمنnw>حداکثرw∈o.ψ، oنتیجه پرسوجوهایی در بلوکهایی نیست که از آن شروع میشوند بr، و پLwمن1wمن2می توان تأیید را خاتمه داد. به طور خاص، برای ∀qمنکه در بr، اگر qمن.ψ[3]>حداکثرw∈o.ψ، پLwمن1wمن2 می توان تأیید را خاتمه داد. (2) اگر بr.مترآایکسw<دقیقهw∈o.ψ|w>wمن2، o نتیجه پرس و جو در نیست بr.
اثبات
(1) اگر بr.مترمنnw=دقیقهqمن∈بrqمن.ψ[3]>حداکثر{w∈o.ψ}، یعنی برای هر qمنکه در بr، oسومین کلمه کلیدی خود را ندارد، oنتیجه نیست qمن. بلوک هم همینطور بr+j، از آنجا که بr+j.مترمنnw>بr.مترمنnw>حداکثر{w∈o.ψ}. به طور مشابه، برای هر qمنکه در بr، qمن+j.ψ[3]>qمن.ψ[3]>حداکثر{w∈o.ψ}، oنتیجه پرس و جوهای بعد نیست qمن.
(2) اگر بr.مترآایکسw=حداکثرqمن∈بrqمن.ψ[3]<دقیقهw∈o.ψ|w>wمن2، oنتیجه پرس و جوهای موجود در آن نیست بr. □
3.3. الگوریتم درج پرس و جو تطبیقی
با توجه به هر لیست ارسال در یک گره، ما دو حالت شدید را در نظر می گیریم: (1) لیست ارسال فقط شامل یک بلوک است که شامل تمام پرس و جوها می شود. (2) لیست ارسال شامل بلوک های زیادی است که هر کدام فقط شامل یک پرس و جو هستند. اولی توانایی فیلترینگ ضعیفی دارد و دومی هزینه به روز رسانی بالایی دارد. آن چیزی که ما انتظار داریم نیست. در دنیای واقعی، مردم به علایق متفاوتی توجه میکنند و اغلب به اخبار فوری یا موضوعات موضوعی توجه زیادی میکنند، بنابراین کلمات کلیدی پرسشها و موضوعات در طول زمان تغییر میکنند. برای هر پرس و جو، ما آن را به صورت تطبیقی با توجه به جستارها و اشیاء تاریخی در لیست های ارسال قرار می دهیم. ما انتظار داریم که افزایش هزینه تأیید و هزینه بهروزرسانی فهرست ارسال پس از درج درخواست حداقل باشد.
با توجه به لیست ارسال پLwمن1wمن2، هزینه به روز رسانی به عنوان نشان داده شده است سیUپL(پLwمن1wمن2)، و هزینه تأیید به عنوان نشان داده می شود سیVپL(پLwمن1wمن2)، که می توان با معادله (3) تخمین زد که در آن سیVب(بr)=پVب(بr)∗(لogب+بr)هزینه تأیید بلوک را نشان می دهد بrکه در پLwمن1wمن2.
قضیه 3.
اجازه دهید qدرخواستی باشد که باید در آن درج شود پLwمن1wمن2، q.ψ[1:3]={wمن1،wمن2،wj}، پLwمن1wمن2دارد ب(ب≥1)بلوک ها ، ΔسیVپLافزایش هزینه تایید است پLwمن1wمن2بعد از qدر حال درج شدن ما نتیجه گیری های زیر را داریم .
مورد 1: اگر ∃بr∈پLwمن1wمن2راضی می کند wj∈بr.مترمنnw،بr.مترآایکسw، q درج می شود بr. ΔسیVپL=پVب(بr).
مورد 2: اگر ∄ب∈پLwمن1wمن2 راضی می کند wj∈[ب.مترمنnw،ب.مترآایکسw]، اما ∃بr∈پLwمن1wمن2 راضی می کند بr.مترآایکسw<wj، q به دم وارد می شود بr. بلوک به روز شده به عنوان نشان داده شده است بr”. ΔسیVپL=(پVب(بr”)-پVب(بr))∗(لogب+بr)+پVب(بr”).
مورد 3: مشابه مورد 2 اگر ∄ب∈پLwمن1wمن2 راضی می کند wj∈[ب.مترمنnw،ب.مترآایکسw]، اما ∃بr∈پLwمن1wمن2 راضی می کند wj<بr.مترمنnw، q در سر وارد می شود بr. ΔسیVپL=(پVب(بr”)-پVب(بr))∗(لogب+بr)+پVب(بr”).
مورد 4: اگر ∄ب∈پLwمن1wمن2 راضی می کند wj∈[ب.مترمنnw،ب.مترآایکسw]، یک بلوک جدید ب ساخته شده است در پLwمن1wمن2، و qدرج می شود ب. ΔسیVپL=ورود به سیستم((ب+1)/ب)∗∑بrپVب(بr)+پVw(wj)∗ورود به سیستم(ب+1).
اثبات
(1) مورد 1: اگر qدرج می شود بr، احتمال تایید پب(بr)از آن زمان تغییر نمی کند wj∈بr.مترمنnw،بr.مترآایکسw، اما تعداد پرس و جوها در بr1 افزایش می یابد.
(3) مشابه مورد 2.
(4) مورد 4: برای هر بمنکه در پLwمن1wمن2، سیVببمن=پVببمن∗ورود به سیستمب+بمن، سیVب”بمن=پVببمن∗ورود به سیستمب+1+بمن
قضیه 3 تمام مواردی را نشان می دهد که در صورت درج درخواست در لیست ارسال، هزینه های تأیید افزایش می یابد. افزایش هزینه های به روز رسانی ΔسیUپLمربوط به چهار مورد فوق می باشد O(بr+1)، O(1)، O(1)، و O(1+لogب)به ترتیب. برای مقایسه هزینه های تأیید و هزینه های به روز رسانی، یک پارامتر عادی سازی را معرفی می کنیم θU(0<θU≤1)برای نشان دادن نسبت عملیات به روز رسانی به عملیات تأیید، به عنوان مثال، اگر یک پرس و جو در یک گره درج شود، وجود خواهد داشت 1/θUاشیاء با آن تأیید می شوند. یک پرس و جو به صورت تطبیقی در لیست ارسال طبق قضیه زیر درج می شود. □
قضیه 4.
اجازه دهید q درخواستی باشد که باید در آن درج شود پLwمن1wمن2، q.ψ[1:3]={wمن1،wمن2،wj}. اگر ∃بrکه در پLwمن1wمن2 راضی می کند wj∈[بr.مترمنnw،بr.مترآایکسw]، qدرج می شود بr. در غیر این صورت، حداقل ΔسیVپL+θUΔسیUپLاز موارد 2-4 گرفته شده است .
| الگوریتم 1: منnسهrتیستوهryپL(q،پLq.ψ[1]q.ψ[2]) |
| 1 اگر ∄پLq.ψ[1]q.ψ[2]سپس |
| 2 بلوک جدید b را بسازیدپLq.ψ[1]q.ψ[2]q را در b وارد کنید . برگشت؛ |
| 3 بr←دقیقه{ب|ب.مترمنnw≥q.ψ[3]}; |
| 4 اگر q.ψ[3]==بr.مترمنnwسپس q در b r وارد می شود . برگشت؛ |
| 5 اگر r>1و q.ψ[3]≤بr-1.maxw سپس |
| 6 q به b r -1 وارد می شود . برگشت؛ |
| 7 اگر ∄بrسپس محاسبه کنید دقیقه{ΔسیVپL+θUΔسیUپL}جآسه2،جآسه4بر بب; |
| 8 اگر r == 1 باشد، محاسبه کنید دقیقه{ΔسیVپL+θUΔسیUپL}مورد3،جآسه4; |
| 9 اگر r > 1 باشد محاسبه کنید دقیقه{ΔسیVپL+θUΔسیUپL}مورد2، مورد 3، مورد4; |
| 10 اگر مورد 2 باشد، q در دم br – 1 قرار می گیرد . |
| 11 اگر مورد 3 باشد، q در سر b r قرار می گیرد . |
| 12 اگر مورد 4 در یک بلوک جدید درج شود. |
داده شده ∀q∈س، اگر qحاوی بیش از دو کلمه کلیدی نیست، مستقیماً در آن درج می شود ب0از لیست پست مربوطه الگوریتم 1 نحوه پرس و جو را نشان می دهد qحاوی بیش از دو کلمه کلیدی به صورت تطبیقی در یک لیست ارسال قرار می گیرد. اگر پLq.ψ[1]q.ψ[2]وجود ندارد، یک بلوک جدید بساخته شده است، و qدرج می شود ب(خطوط 1-2). در غیر این صورت، یک بلوک در پLq.ψ[1]q.ψ[2]یافت می شود برای qبه حداقل رساندن ΔسیVپL+θUΔسیUپL(خطوط 3-12). ابتدا بلوک را پیدا می کنیم که با نشان داده شده است بr، که بr.مترمنnwکوچکترین است – نه کوچکتر از q.ψ[3](خط 3). اگر q.ψ[3]==بr.مترمنnw، qدرج می شود بr(خط 4). اگر q.ψ[3]∈[بr-1.مترمنnw،بr-1.مترآایکسw]( r>1) qدر بلوک درج می شود بr-1(خطوط 5-6). در غیر این صورت محاسبه می کنیم ΔسیVپL+θUΔسیUپLبا توجه به موارد 2-4 در قضیه 3 و حداقل مورد را انتخاب کنید (خطوط 7-12). شایان ذکر است که در مقایسه با اولین بلوک لیست، فقط موارد 3-4 وجود دارد و اگر q.ψ[3]بزرگتر از بr.مترمنnwاز بین تمام بلوک ها، فقط موارد 2 و 4 وجود دارد.
پیچیدگی محاسبات در بدترین حالت، هزینه محاسباتی الگوریتم 1 به صورت لم 1 نشان داده می شود. یعنی در ارسال لیست های ساخته شده توسط دو کلمه کلیدی، پیچیدگی درج یک پرس و جو در یک گره است. O(o.ψ2ورود به سیستمV2+o.ψ3(ورود به سیستمب+ب/بب.ψ)). الگوریتم می تواند به صورت تطبیقی تنظیم شود بو ب.
3.4. مدل هزینه مبتنی بر حافظه
یک مدل هزینه مبتنی بر حافظه، پرس و جوها را با گره های چهار درختی بهینه مرتبط می کند. با توجه به محدوده جستجوی CkQST، مدل چهار درخت را از گره ریشه پیمایش می کند، مجموع هزینه تأیید و هزینه به روز رسانی فهرست را در صورتی که پرس و جو با گره فعلی و گره های فرزند آن مرتبط باشد، مقایسه می کند و کوچکتر را انتخاب می کند. هزینه تأیید حاصل ضرب تعداد اشیاء تأیید شده و انتظار هزینه تأیید است، و هزینه به روز رسانی انتظار هزینه به روز رسانی است اگر پرس و جو در بلوک مربوطه از لیست ارسال درج شود.
تعریف 3 (حداقل گره مرزی).
داده شده ∀q∈س و محدوده جستجو q.اسآرک، اگر ∃ن، q.اسآرک⊆ن.آرو برای هر گره فرزند nمن از ن، q.اسآرک⊈nمن.آر، ن حداقل گره مرزی است q ، جایی که ن.آر، n.آر منطقه ای هستند که در آن ن و n به ترتیب مکان یابی کنید . حداقل گره مرزی از q گره ای است که محدوده جستجوی آن را پوشش می دهد، اما هیچ یک از گره های فرزند آن نمی توانند محدوده جستجو را به طور کامل پوشش دهند .
هزینه تأیید داده شده ∀q∈سو حداقل گره مرزی آن ن، q.ψ[1:3]={wمن1،wمن2،wمن3}، اگر qدر همکاری است با ن، هزینه تأیید در بازه زمانی واحد، به عنوان نشان داده شده است سیVqq،نرا می توان با رابطه (4) تخمین زد. ما فرض می کنیم که پرس و جو و شی بیش از دو کلمه کلیدی دارند و میانگین هزینه تأیید واحد زمان است.
به طور خاص، اگر پرس و جو یا شی شامل یک یا دو کلمه کلیدی باشد، هزینه تأیید با معادله (5) برآورد می شود. این مورد ساده است، بنابراین ما جزئیات را حذف می کنیم.
جایی که نتومترoن(ن)تعداد اجسامی است که در آن سقوط می کنند ندر بازه زمانی واحد پVqq|ناین احتمال است که qدر صورت درج شدن در آن تأیید می شود بrکه در ن، یعنی احتمال اینکه اشیاء دارای اصطلاحات باشند wمن1، wمن2، و wj∈[wمن3،بr.مترآایکسw]، و می توان با معادله (6) تخمین زد.
جایی که بr.ψتعداد کلمات کلیدی موجود در است بr.ψ. EVq|نهزینه تأیید است اگر qدرج می شود بrکه در ن، و می توان با انتظار هزینه تأیید پرس و جوها در آن تخمین زد بr، یعنی معادله (7).
جایی که (نتومترq)≤wjتعداد پرس و جوهایی است که در معرض آن قرار می گیرند qمن.ψ[3]≤wjکه در بr. به طور مشابه، اگر پرس و جو qبا مجموعه ای از گره های غیر همپوشانی همراه است که به عنوان نشان داده می شود ناس، هزینه تأیید به عنوان نشان داده می شود سیVqq،ناسو می توان با رابطه (8) تخمین زد.
برای ∀q∈س، گره های بهینه مرتبط را پیدا می کنیم که از حداقل گره محدود کننده آن شروع می شود و بررسی می کنیم که آیا پرس و جو با گره فعلی مرتبط است یا با گره های فرزند آن مرتبط است. تفاوت دو هزینه تأیید با معادله (9) برآورد می شود.
جایی که منناسنتیجه متوسط را حفظ می کند، n.جساعتمنلدشامل گره های فرزند از nکه با محدوده جستجوی پرس و جو تلاقی می کنند. شایان ذکر است که اگر ΔسیVq≤0، تکرار را خاتمه می دهیم.
هزینه به روز رسانی هنگام درج یا حذف پرسوجوها در گرهها، هزینه بهروزرسانی فهرست متحمل میشود. ما حذف پرسشها را تا زمانی که دوباره به این پرسشها دسترسی پیدا کنند به تأخیر میاندازیم، بنابراین هزینه حذف نادیده گرفته میشود. اگر پرس و جو qبا حداقل گره مرزی آن مرتبط است ن، و در یک بلوک درج می شود بrاز لیست ارسال پLq.ψ[1]q.ψ[2]که در ن، هزینه درج شامل دو بخش است، زمان یافتن بلوک مربوطه و زمان یافتن موقعیت درج. هزینه به روز رسانی، نشان داده شده به عنوان سیUqq،نرا می توان با رابطه (10) تخمین زد.
اگر qبا مجموعه ای از گره های غیر همپوشانی همراه است که به عنوان نشان داده می شود ناس، هزینه به روز رسانی به عنوان نشان داده شده است سیUqq،ناسو می توان با رابطه (11) تخمین زد.
مشابه به ΔسیVq، تفاوت دو هزینه به روز رسانی بین پرس و جو مرتبط با گره و مرتبط با گره های فرزند توسط معادله (12) تخمین زده می شود.
داده شده ∀q∈سو محدوده جستجو q.اسآرک، از حداقل گره مرزی شروع می کنیم و محاسبه می کنیم ΔسیVqو ΔسیUqبین پرس و جو مرتبط با گره و مرتبط با گره های فرزند. اگر ΔسیVq≥θU⋅ΔسیUq، گره های فرزند بهینه هستند. در غیر این صورت گره بهینه است. هزینه محاسبات از دو بخش تشکیل شده است که حداقل گره مرزی را پیدا می کند q، و یافتن یک ارتباط بهینه در گره های نزول گره حداقل محدود. هزینه محاسباتی قسمت اول است O(θساعت)، و قسمت دوم است O((4θساعت-1)/3)به عنوان مثال، در بدترین حالت، گره تا گره برگ، جایی که θساعتارتفاع چهار درخت است.
3.5. پردازش اشیاء به صورت دسته ای
برای این اشیاء که با همان لیست پست تأیید می شوند، یک الگوریتم پردازش شی، که یک تکنیک تطبیق گروهی است که از استراتژی فیلتر کردن و تأیید پیروی می کند، برای پردازش اشیاء به صورت دسته ای پیشنهاد شده است.
یک ساختار داده بمند،w،oسهتیبرای گروه بندی اشیاء در حال تأیید با همان لیست پست، جایی که بمند(بمند>0)شناسه بلوک است، w(w∈[ببمند.مترمنnw،ببمند.مترآایکسw])یک اصطلاح است، oسهتیمجموعه ای از اشیاء است که با بلوک تأیید می شوند ببمندو حاوی w. برای سهولت در توضیحات، wسهتیبمندمجموعه ای از شرایط رضایت بخش است w∈[ببمند.مترمنnw،ببمند.مترآایکسw]، oسهتیبمند،wمجموعه ای از اشیاء است که با پرس و جوهای موجود در بلوک تأیید می شوند ببمندو حاوی w.
الگوریتم 2 نحوه پردازش مجموعه ای از اشیاء ارائه شده توسط را شرح می دهد بمند،w،oسهتی، که با جستجوهای موجود در لیست ارسال تأیید می شوند پLwمن1wمن2. اگر ببمنداست ب0، پرس و جوها در ب0با اشیاء در تأیید می شود oسهتی(خطوط 1-5). در غیر این صورت، برای هر مدت wjکه در wسهتیبمند، طبق قضیه 2، اگر ببمند.مترمنnw>wj، عبارت بعدی را بررسی می کنیم (خط 7)؛ اگر ببمند.مترآایکسw<wj، بلوک بعدی (خط 8) را بررسی می کنیم. در غیر این صورت، برای هر پرس و جو qکه در ببمند، اگر q.ψ[3]>wj، عبارت بعدی را بررسی می کنیم (خط 10)؛ اگر q.ψ[q.ψ]<wjپرس و جو بعدی (خط 11) را بررسی می کنیم. در غیر این صورت، بررسی می کنیم که آیا شیء نتایج حاصل از آن است یا خیر q. اگر بله، q،oبه اضافه می شود سOاس(خطوط 12-13). علاوه بر این، لیست نتایج و محدوده جستجو از qبه روز می شوند.
پیچیدگی محاسبات الگوریتم 2 نحوه پردازش اشیاء به صورت دستهای را در لیست پستهای مرتب شده توضیح میدهد. در بدترین حالت، اشیا به صورت جداگانه پردازش می شوند. همانطور که Lemma 1 نشان می دهد، در ارسال لیست های ساخته شده توسط دو کلمه کلیدی، برای یک شی، پیچیدگی زمانی یافتن پرس و جوهای واجد شرایط در یک گره است. O(o.ψ2ورود به سیستمV2+o.ψ3(ورود به سیستمب+ب/بب.ψ)).
| الگوریتم 2: پردازش شی(پLwمن1wمن2،{بمند،w،oسهتی}). |
 |
3.6. تکنیک k-Skyband مبتنی بر هزینه
برای کاهش هزینه ارزیابی مجدد، یک تکنیک k-skyband مبتنی بر هزینه پیشنهاد شده است تا به طور عاقلانه محدوده جستجوی بهینه برای CkQST را تعیین کند به طوری که هزینه کلی تعریف شده در مدل هزینه را بتوان به حداقل رساند. به طور خاص، برای ∀q∈س، سه پارامتر تعریف شده است: یک محدوده جستجوی گسترده به عنوان نشان داده می شود q.اسآر، جایی که q.اسآر⊇q.اسآرک; یک k-skyband، به عنوان مثال، یک لیست نتایج توسعه یافته، با نشان داده شده است q(O)، جایی که q(O)⊇q(O)ک; تعداد اشیاء حاوی تمام کلمات کلیدی پرس و جو در داخل q.اسآردر مهر زمانی اولیه به عنوان نشان داده شده است q.θک، جایی که q.θک≥q.ک.
تعریف 4 (تطبیق سست).
داده شده ∀o∈O و ∀q∈س، o کم کبریت q فقط اگر q.ψ⊆o.ψ و o.لoج∈q.اسآر. همه اشیایی که به طور ضعیف با هم مطابقت دارند qبه عنوان مشخص می شوند q(O)شام={o∈O|q.ψ⊆o.ψ∧o.لoج∈q.اسآر}.
تعریف 5 (تسلط).
داده شده ∀q∈سو دو شی o1، o2، که به راحتی مطابقت دارند q، o1 مسلط است o2 فقط اگر دمنستی(q،o1)<دمنستی(q،o2) و o1.تیه≥o2.تیه یا دمنستی(q،o1)≤دمنستی(q،o2) و o1.تیه>o2.تیه.
تعریف 6 (k-skyband/لیست نتایج توسعه یافته).
داده شده ∀q∈س، برای هر شی ورودی o”، آن را در نوار آسمانی k قرار می دهیم q(O)فقط اگر: (1) o”کم کبریت q; (2) o” تحت سلطه کمتر از ک اشیاء دیگر برای ∀q∈س، اگر یک شی o” کم کبریت q، و وجود دارد ک اشیاء در q(O) مسلط o”، o”در هر مُهر زمانی نتیجه ای نخواهد داشت. بنابراین، ما این اشیاء را در لیست نتایج درج نمی کنیم .
قضیه 5.
داده شده ∀q∈سو دامنه جستجوی گسترده q.اسآر، ما همیشه نتیجه گیری های زیر را داریم. (1) q(O)ک⊆q(O); (2) q(O)⊆q(O)شام; (3) q(O)<کاگر q(O)شام<ک.
اثبات
(1) در هر مُهر زمانی، برای ∀o∈q(O)ک، ما داریم q.ψ⊆o.ψو o.لoج∈q.اسآرک⊆q.اسآر، یعنی oکم کبریت q، و کمتر از کاشیاء تسلط دارند o. بنابراین o∈q(O). (2) طبق تعریف 4، برای ∀o∈q(O)، oکم کبریت q، بنابراین o∈q(O)شام، q(O)⊆q(O)شام. (3) از آنجا که q(O)⊆q(O)شام، اگر q(O)شام<ک، ما داریم q(O)≤q(O)شام<ک. از سوی دیگر، اگر q(O)<ک، q(O)شام≥ک، یعنی ∃o∈q(O)شامو o∉q(O)، که به معنی oکم کبریت q، ولی oتحت سلطه بیش از کاشیاء دیگر، که با q(O)<ک. قضیه ثابت می شود. □
طبق قضیه 5، لیست نتایج توسعه یافته، مجموعه فوق العاده لیست نتایج دقیق است که می توانیم اشیاء kNN را از آن استخراج کنیم و تعداد اشیاء در لیست نتایج توسعه یافته کمتر از کفقط در صورتی که تعداد اشیاء در q(O)شامکمتر است از ک.
داده شده ∀q∈س، یک محدوده جستجوی گسترده q.اسآر، و لیست نتایج توسعه یافته مربوطه q(O)، سه هزینه در تکنیک k-skyband مبتنی بر هزینه تعریف شده است: هزینه تأیید qدر داخل q.اسآر، هزینه به روز رسانی q(O)، و هزینه ارزیابی مجدد.
هزینه تأیید هزینه تایید از qدر داخل q.اسآر، در بازه زمانی واحد، به عنوان نشان داده شده است سیVآرq|q.اسآر، با معادله (13) تخمین زده می شود، یعنی هزینه تأیید اگر qدر تمام گره های برگ که با آنها تلاقی می کنند وارد می شود q.اسآر.
هزینه به روز رسانی مشابه به q(O)ک، لیست نتایج توسعه یافته q(O)توسط یک لیست پیوندی سازماندهی شده است. برای ∀o∈q(O)، یک شمارنده تسلط برای شمارش تعداد اشیاء غالب تعریف شده است o. اگر یک شی ورودی o”درج می شود q(O)، شمارنده تسلط همه اشیاء در q(O)با دمنستی(q،o”)<دمنستی(q،o)و o”.تیه≥o.تیه، یا دمنستی(q،o”)≤دمنستی(q،o)و o”.تیه>o.تیه1 افزایش می یابد و اشیاء با برتری شمارنده برابر است کاخراج خواهد شد که قابل رسیدگی است O(q(O))زمان. وقتی یک شی در q(O)منقضی می شود، از آن حذف می شود q(O)تا زمانی که دوباره به آن دسترسی پیدا کنید. هزینه ناچیز است. هزینه به روز رسانی q(O)در بازه زمانی واحد، نشان داده شده به عنوان سیUL(q|q(O))، با معادله (14) تخمین زده می شود. جایی که frهqUoتعداد به روز رسانی های شی در بازه زمانی واحد است، پمq(q.اسآر)احتمال تطابق کم اجسام است qدر محدوده جستجو q.اسآر، و توسط تخمین زده می شود پمq(q.اسآر)=q.θک/نتومترoن(n0)، 1/2احتمال ورود یک شی واجد شرایط است، q(O)را می توان تخمین زد q(O)=حداکثر{ک⋅لوگاریتم(θک/ک)،θک}.
هزینه ارزیابی مجدد هزینه ارزیابی مجدد در بازه زمانی واحد به عنوان نشان داده می شود 1/θتیسیمنهq. جایی که θتیدوره ارزیابی مجدد است، یعنی کوتاهترین زمان لازم بین دو ارزیابی مستقل متوالی، و 1/θتیفراوانی ارزیابی مجدد است. سیمنهqهزینه ارزیابی مجدد است و به هزینه تأیید تقریبی می شود q.اسآرک، یعنی سیمنهq=سیVآرq|q.اسآرک=∑n.آر∩q.اسآرک≠∅سیVqq،n.
هزینه کلی در روش k-skyband مبتنی بر هزینه، به عنوان نشان داده شده است سیآرهq، در معادله (15) نشان داده شده است. چه زمانی سیآرهqحداقل است، محدوده جستجو بهینه است.
در ادامه به نحوه بدست آوردن می پردازیم θتی. θتیدوره ارزیابی مجدد است، یعنی کوتاهترین زمانی که q(O)به کاهش می یابد ک-1از آخرین ارزیابی مجدد برای ∀q∈س، روند به روز رسانی تعداد اشیاء در q(O)را می توان به عنوان یک پیاده روی تصادفی ساده، که یک دنباله تصادفی است، مدل کرد اسل، با اس0بودن وضعیت اصلی، تعریف شده توسط اسل=∑من=1لایکسمن، جایی که ایکسمنبه روز رسانی شی است که یک متغیر تصادفی مستقل و به طور یکسان توزیع شده است. که در q(O)، اگر یک شی درج شود، ایکسمن=1; اگر یک شی منقضی شود یا تحت تسلط باشد، ایکسمن=-1; در غیر این صورت ایکسمن=0. تخمین زدن آن دشوار است ایکسمنبه دلیل تخلیه اشیاء توسط رابطه سلطه در q(O). به عنوان مثال، یک شی درج می شود، اما تعداد اشیاء به دلیل بیرون راندن اشیایی با رسیدن شمارنده های غالب کاهش می یابد. ک. طبق قضیه 5، تعداد اجسام در q(O)کمتر است از کفقط در صورتی که تعداد اشیاء در q(O)شامکمتر است از ک، و اشیاء در q(O)شامبر یکدیگر مسلط نباشید بنابراین ما کمترین زمان را تخمین می زنیم q(O)شامبه کاهش می یابد ک-1، نشان داده شده است θتی”، جایی که θتی”=θتی. به روز رسانی شی در q(O)شامدر هر مهر زمانی را می توان به عنوان معادله (16) تخمین زد.
تعداد به روز رسانی های شی مورد نیاز برای کاهش تعداد اشیاء از q.θکبه ک-1که در q(O)، نشان داده شده است ℤ(q)، با معادله (17) تخمین زده می شود. θتیبرآورد می شود θتی=ℤ(q)/frهqUo.
برای ∀q∈س، متغیرهای معادله (15) هستند q.اسآرو q.θک. برای به حداقل رساندن معادله (15)، از الگوریتم تخمین افزایشی برای محاسبه بهینه استفاده می کنیم. q.θکو مربوطه q.اسآر.
برای تطبیق دامنه جستجوی گسترده خود با الگوریتم پردازش اشیاء و الگوریتم ساخت و نگهداری فهرست، ما جایگزین q(O)کبا q(O)و جایگزین کنید q.اسآرکبا q.اسآر.
4. آزمایشات
در این بخش، مجموعهای از آزمایشهای جامع را برای ارزیابی کارایی و مقیاسپذیری تکنیکهای کلیدی انجام میدهیم. بخش 4.1 محیط آزمایشی را معرفی می کند. بخش 4.2 اثر سه پارامتر تنظیم و تکنیک ارزیابی مجدد را ارزیابی می کند. بخش 4.3 کارایی و مقیاس پذیری تکنیک های شاخص ما را ارزیابی می کند.
4.1. تنظیمات آزمایشی
همه آزمایشها در VC++ اجرا میشوند و بر روی یک ماشین Win10 با پردازنده Intel I7-8700K 3.7 گیگاهرتز و حافظه 32 گیگابایتی اجرا میشوند. مطابق با کارهای قبلی (به عنوان مثال، [ 2 ، 3 ، 4 ، 5 ، 6 ، 7 ، 8 ، 9 ، 10 ، 11 ، 12 ])، ما فهرست های پرس و جو را در حافظه اصلی بارگذاری می کنیم تا از پاسخ بلادرنگ پشتیبانی کند.
مجموعه داده ها سه مجموعه داده برای ارزیابی های تجربی جمع آوری شده است. آمار در جدول 2 نشان داده شده است . TWEETS حاوی توییترهایی است که از توییتر جمع آوری شده است [ 8 ]. TWEETS مجموعه داده پیش فرض است. GN از هیئت نامهای جغرافیایی ایالات متحده به دست میآید که در آن هر رکورد حاوی یک مکان جغرافیایی و برخی اصطلاحات است ( https://geonames.usgs.gov/ ). GOWALLA یک مجموعه داده مصنوعی است که در آن هر رکورد حاوی یک مکان جغرافیایی جمعآوری شده از Gowalla ( https://snap.stanford.edu/data/loc-gowalla.html ) و کمتر از 50 عبارت است که به طور تصادفی از 20 گروه خبری اختصاص داده شده است. https://people.csail.mit.edu/jrennie/20Newsgroups ). بر اساس مجموعه داده ها، کوئری ها و اشیاء تولید می کنیم.
حجم کاری پرس و جو برای هر مجموعه داده نمونه، موقعیت جغرافیایی را به عنوان موقعیت جغرافیایی پرس و جو در نظر می گیریم و به طور تصادفی انتخاب می کنیم. jشرایط داده های نمونه به عنوان کلمات کلیدی پرس و جو، که در آن 1≤j≤5. تعداد نتایج kNN برگشتی کروی یک مقدار پیش فرض تنظیم شده است. در هر مهر زمانی، پرس و جوهای منقضی شده به طور تصادفی انتخاب می شوند.
بار کاری شی برای هر مجموعه داده نمونه، همه عبارتها را به عنوان کلیدواژه شی در نظر میگیریم، و مکانهای جغرافیایی را که از موقعیت جغرافیایی اصلی ۰.۰۱٪ تا ۱٪ از حداکثر فاصله در منطقه منحرف میشوند، در نظر میگیریم. در هر مهر زمانی، اشیاء منقضی شده به طور تصادفی انتخاب می شوند.
مجموعه ای از کوئری ها و اشیاء. برای هر مجموعه داده، مگر اینکه در غیر این صورت مشخص شده باشد، ما 5 M شی و پرس و جو را برای ساختن نمایه پرس و جو و نمایه شی در ابتدا انتخاب می کنیم و سه مجموعه آزمایشی را تولید می کنیم که هر کدام شامل 2 M شی و 2 M کوئری است. معیارهای ارزیابی میانگین عملکرد سه مجموعه تست را در نظر می گیرند.
خط مبنا. ما تکنیک های شاخص خود را با IQ-tree [ 1 ]، Ap-tree [ 3 ] و FAST [ 6 ] مقایسه می کنیم. به طور پیش فرض، برای Ap-tree، fanout، آستانه پارتیشن و آستانه KL-Divergence روی 200، 40 و 0.001 تنظیم شده است. برای جایگزینی تعداد ورودی/خروجی در مدل هزینه IQ-tree از تعداد تأییدها استفاده می کنیم. در بخشهای بعدی، از AOIQ-tree برای نشان دادن شاخص ادغام شده چهاردرخت با شاخص مرتب، معکوس و سه تکنیک کلیدی استفاده میکنیم. ما تکنیک k-skyband مبتنی بر هزینه را با Kmax مقایسه می کنیم [ 16 ] مقایسه میکنیم که در درخت AOIQ ادغام شوند.
معیارهای ارزیابی. ما چهار معیار را گزارش میکنیم: (1) زمان ساخت فهرست (یعنی ICT )، یعنی زمان درج درخواستها در فهرست پس از یافتن محدوده جستجوی آنها. (2) میانگین زمان پردازش شی ورودی (یعنی AOPT )، به عنوان مثال، زمان یافتن پرس و جوهای تحت تأثیر و تغییر پارامترهای مربوطه آنها هنگام رسیدن یک شی. (3) میانگین زمان به روز رسانی نمایه ناشی از اشیا (به عنوان مثال، AIUT )، به عنوان مثال، زمان به روز رسانی فهرست پرس و جو پس از پردازش اشیاء. (4) اندازه شاخص، به عنوان مثال، حافظه مورد استفاده برای ساختن فهرست پرس و جو. به طور پیشفرض، تعداد کلمات کلیدی برای ساخت فهرست مرتب و معکوس متر، تعداد نتایج kNN بازگشتی برای CkQST ک، ارتفاع چهاردرخت θساعت، نسبت عملیات به روز رسانی به عملیات تأیید θUو تعداد به روز رسانی های شی در بازه زمانی واحد frهqUoبر روی 2، 20، 10، 0.001 و 20000 تنظیم می شوند.
4.2. تنظیم تجربی
در این بخش، مجموعهای از آزمایشها برای ارزیابی تأثیر پارامترها در تکنیکها بر روی درخت AOIQ انجام میشود.
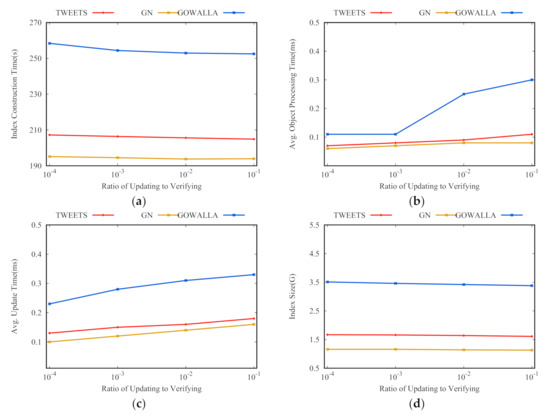
اثر متر. شکل 4 معیارهای ارزیابی درخت AOIQ را نشان می دهد متر1، 2، 3، 4 و 5 می گیرد. با توجه به لم 1، اگر مترکوچک است، تعداد پرسوجوها در فهرستهای ارسال زیاد است، بنابراین تأیید پرسوجوها در فهرستهای ارسالی زمان زیادی طول میکشد. برعکس، اگر متربزرگ است، زمان زیادی طول می کشد تا لیست های ارسال را تأیید کنید. بنابراین، بهینه مترنه خیلی کوچک است و نه خیلی بزرگ همانطور که در شکل 4 نشان داده شده است ، زمانی که متر2 را می گیرد، عملکرد شاخص بهترین است. بزرگتر متراست، اندازه شاخص بزرگتر است. چه زمانی متر>3، هزینه تأیید و هزینه به روز رسانی در یک لیست پست کاهش می یابد، بنابراین مدل هزینه پرس و جوها را به گره هایی با مناطق بزرگ نگاشت می کند، بنابراین اندازه ICT ، AIUT و شاخص کاهش می یابد، در حالی که AOPT افزایش می یابد.
اثر θU. شکل 5 معیارهای ارزیابی درخت AOIQ را نشان می دهد θU0.0001، 0.001، 0.01 و 0.1 را می گیرد. چه زمانی θU0.0001 می گیرد، هزینه تأیید نقش عمده ای در یافتن گره های مرتبط دارد، بنابراین، پرس و جوها با گره های کوچک زیادی مرتبط هستند، بنابراین ICT طولانی است، AOPT و AIUT کوتاه هستند و اندازه شاخص بزرگ است. چه زمانی θUافزایش می یابد، هزینه به روز رسانی شاخص مهم تر است، بنابراین پرس و جوها با گره های بزرگتر کمتری مرتبط می شوند، بنابراین اندازه ICT و شاخص کاهش می یابد، در حالی که AOPT و AIUT افزایش می یابد.
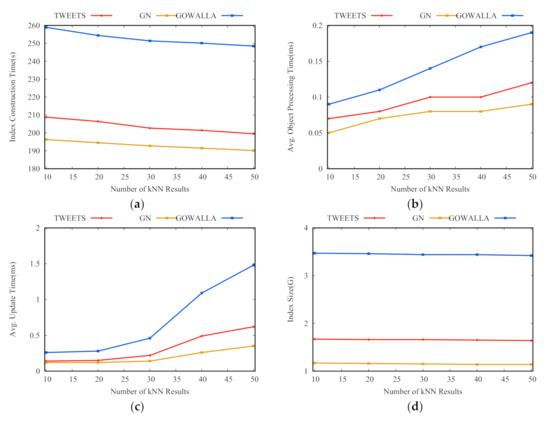
اثر ک. شکل 6 معیارهای ارزیابی درخت AOIQ را نشان می دهد ک10، 20، 30، 40 و 50 را می گیرد ککوچک است، تعداد اشیاء برگشتی برای پرس و جوها کم است، محدوده جستجوی پرس و جوها کوچک است، و پرس و جوها با گره های کوچک زیادی مرتبط هستند، بنابراین ICT طولانی است، AOPT و AIUT کوتاه هستند و اندازه فهرست بزرگ است. برعکس، وقتی کبزرگ است، محدوده جستجوی پرس و جوها بزرگتر می شود، و پرس و جوها با تعداد کمی گره بزرگتر مرتبط می شوند، اندازه ICT و شاخص کاهش می یابد و AOPT و AIUT افزایش می یابد.
تأثیر تکنیک های ارزیابی مجدد ما عملکرد ارزیابی مجدد را در سه مورد ارزیابی میکنیم که بهعنوان AOIQ-tree، AOIQ-tree_Kmax، و AOIQ-tree_Skyband مشخص میشوند. AOIQ-درخت فقط نگه می دارد کاشیاء در لیست نتیجه، AOIQ-tree_Kmax را نگه می دارد کحداکثر=2کاشیاء در لیست نتیجه، و تعداد اشیاء در لیست نتیجه برای AOIQ-tree_Skyband با توجه به تکنیک k-skyband مبتنی بر هزینه محاسبه می شود. شکل 7 ICT ، AOPT و EOPT را در سه مورد با متغیر نشان می دهدک، که در آن EOPT میانگین زمان پردازش برای اشیاء منقضی شده است، به عنوان مثال، میانگین زمان تغییر پارامترهای جستارهای تحت تأثیر یا ارزیابی مجدد جستارها در صورتی که تعداد اشیاء در لیست نتایج آنها کمتر از کزمانی که یک شی منقضی می شود تعداد اشیاء نگهداری شده در AOIQ-tree_Kmax بیشتر از AOIQ-tree_Skyband است که بیشتر از AOIQ-tree است. ICT AOIQ-tree_Kmax کوتاه ترین و AOIQ-tree طولانی ترین است . AOPT AOIQ-tree و AOIQ-tree_Skyband کوتاهتر از AOIQ-tree_Kmax است. EOPT AOIQ-tree_Kmax و AOIQ- tree_Skyband کوتاهتر از AOIQ-tree هستند. این پدیده به تعداد اشیایی که در لیست نتایج نگهداری می شوند مربوط می شود. در مقایسه با AOIQ-tree، EOPT دو تکنیک دیگر بسیار کمتر است، و اگر ک10، 20 طول می کشد، میانگین زمان به روز رسانی نزدیک به 0 است.
4.3. سنجش عملکرد
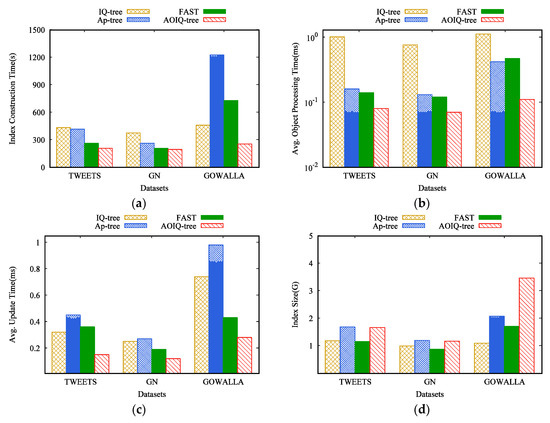
ارزیابی بر روی مجموعه داده های مختلف ما کارایی تکنیک های کلیدی را در برابر سه مجموعه داده در شکل 8 ارزیابی می کنیم . تعداد پرس و جوها 5 M است. همانطور که در نشان داده شده است شکل 8 نشان داده شده استعلاوه بر اندازه شاخص، درخت AOIQ همیشه بهترین است. IQ-tree عملکرد فیلتر فضایی خوبی دارد، اما توانایی فیلتر متنی آن ضعیف است. AP-tree به طور جامع توزیع مکانی و متنی پرس و جوها را در نظر می گیرد، اما هزینه ساخت و به روز رسانی فهرست گران است. FAST عملکرد فیلتر متنی خوبی دارد، اما توانایی فیلتر فضایی آن ضعیف است. مدل هزینه مبتنی بر حافظه در درخت AOIQ میتواند هزینه تأیید و هزینه بهروزرسانی را به حداقل برساند، که باعث میشود تعداد جستجوها در گرههای فضایی نه خیلی زیاد و نه خیلی کم باشد. شاخص مرتب و معکوس در درخت AOIQ با دو کلمه کلیدی ساخته می شود که باعث می شود هزینه تأیید نزدیک به کلمه کلیدی مرتب شده تلاش شود و هزینه به روز رسانی نزدیک به شاخص وارونه کلید رتبه بندی شده باشد. AOIQ-tree بیشترین حافظه را اشغال می کند که با ساختار لیست های ارسال آن مشخص می شود. معیارهای ارزیابی GN کوچکترین هستند و Gowalla بزرگترین هستند، زیرا داده های Gowalla حاوی کلمات کلیدی بسیار بیشتری نسبت به دو مجموعه داده دیگر هستند. برای گووالا،AOPT درخت AP کوتاهتر از FAST است. این به این دلیل است که تعداد زیادی از پرسوجوها در Gowalla فقط حاوی کلمات کلیدی مکرر هستند، در مقایسه با FAST، AP-tree به طور جامع توزیع مکانی و متنی پرسوجوها را در نظر میگیرد، یعنی فیلتر فهرست قدرتمندتر است، بنابراین AOPT کوتاهتر است .
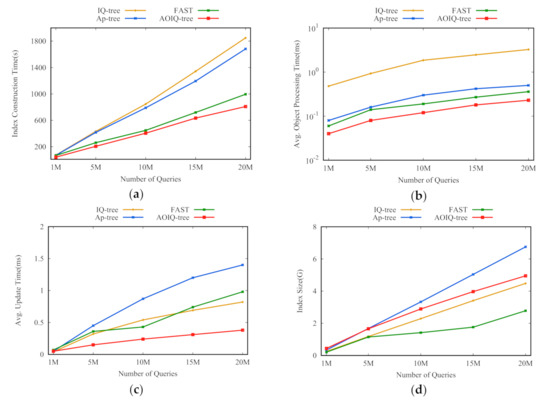
تأثیر تعداد پرس و جوها برای ارزیابی مقیاس پذیری تکنیک های کلیدی بر روی تعداد پرس و جوها و اشیاء، تعداد پرس و جوها و اشیاء را از 1 M به 20 M افزایش می دهیم تا نمایه شی و نمایه پرس و جو را بسازیم. همانطور که شکل 9 نشان می دهد، ICT ، AOPT و AIUT همه شاخص ها با افزایش تعداد پرس و جوها افزایش می یابند، و AOIQ-tree بسیار مقیاس پذیرتر است. برای مثال، زمانی که تعداد پرسوجوها به 20 مگابایت میرسد، پردازش اشیاء ورودی به طور متوسط 0.23 میلیثانیه طول میکشد که 54 درصد سریعتر از Ap-tree و 36 درصد سریعتر از FAST است. این نشان می دهد که تکنیک های ما مقیاس پذیری خوبی دارند. را _درخت AOIQ کوتاه ترین و درخت Ap طولانی ترین است. دلیل آن این است که AOIQ-tree پرس و جوها را با گره های بهینه مرتبط می کند تا با اشیاء موجود در جریان داده ها تطبیق داده شود، و برخی از گره های Ap-tree دوباره ساخته می شوند اگر بسیاری از پرس و جوها در این گره ها به روز شوند. در مقایسه با AP-tree، فقط برخی از پرس و جوها در گره های FAST به روز می شوند، بنابراین AIUT درخت AOIQ کوتاه تر است.
تأثیر تعداد کلمات کلیدی پرس و جو q.ψ. برای ارزیابی مقیاس پذیری تکنیک های کلیدی در q.ψ، افزایش می دهیم q.ψاز 1 تا 5. همانطور که در شکل 10 نشان داده شده است، معیارهای ارزیابی IQ-tree به تعداد کلمات کلیدی حساس نیستند زیرا بر توزیع فضایی پرس و جوها تمرکز دارد. Ap-tree، FAST، و ایندکس ما توزیع کلیدواژهها را در نظر میگیرند، بنابراین معیارهای ارزیابی با q.ψ. مانند q.ψافزایش می یابد، اندازه ICT و شاخص افزایش می یابد و AOPT کاهش می یابد. دلیل آن این است که Ap-tree به طور پیوسته نحوه تقسیم پرس و جوها به گره ها را بر اساس کلمات کلیدی پرس و جو محاسبه می کند و تعداد گره های متنی و ارتفاع درخت را افزایش می دهد. برای FAST، به عنوان q.ψافزایش مییابد، کلمات کلیدی بیشتری که به فهرستهای ارسالی پیوست میشوند، مکرر میشوند، و احتمال بیشتری وجود دارد که پرسوجوها در چندین گره سطح بالاتر درج شوند. برای AOIQ-tree، زمان مرتبسازی پرسوجوها زمانی افزایش مییابد که شاخص مرتب و معکوس ساخته میشود.
5. نتیجه گیری و دیدگاه های آینده تحقیقاتی
چالشی که برای ارزیابی CkQST وجود دارد این است که چگونه بین توانایی فیلتر کردن و هزینه به روز رسانی شاخص فضایی-متن تعادل ایجاد کنیم. برای پرداختن به چالش، از چهار درخت و شاخص معکوس برای سازماندهی میلیونها CkQST با سه تکنیک استفاده میکنیم. یک مدل هزینه مبتنی بر حافظه، محدوده جستجوی CkQST را به گرههای چهار درختی ترسیم میکند تا توانایی فیلتر فضایی شاخصها و هزینه بهروزرسانی شاخصها را متعادل کند. تعادل را می توان با تکنیک k-skyband مبتنی بر هزینه تنظیم کرد، که به طور عاقلانه محدوده جستجوی CkQST را با توجه به حجم کاری اشیا تعیین می کند. یک نمایه مرتب و معکوس مبتنی بر بلوک تطبیقی توانایی فیلتر کردن متن را افزایش می دهد. نتایج تجربی بر روی مجموعه داده های واقعی و مصنوعی نشان می دهد که تکنیک های پیشنهادی موثر و مقیاس پذیر هستند، و می تواند به طور قابل توجهی کارایی ارزیابی CkQST را بهبود بخشد. کار آینده برای ارزیابی پرس و جو مستمر بر روی جریان های داده های مکانی- متنی شامل حل چالش های پرس و جوهای مستمر در تلفن همراه و سایر سناریوهای مربوطه، و کاوش تکنیک های ارزیابی کارآمد با استفاده از فناوری های سخت افزاری مانند واحد پردازش گرافیک و خوشه های توزیع شده و استراتژی مبادله برای دقت و کارایی ارزیابی











بدون دیدگاه