1. معرفی
برچسبگذاری معنایی مناطق شهری یک کار ضروری اما چالش برانگیز برای طیف گستردهای از کاربردها مانند نقشهبرداری شهر، ناوبری در فضای باز و نظارت بر ترافیک است. پیشرفت سریع سیستمهای تشخیص و محدوده نور (LiDAR) به حل این کار کمک کرده است و با استفاده از ابرهای نقطه سهبعدی به مرحلهای در دسترس، مقرونبهصرفه، دقیق و قابل اجرا منجر شده است. در میان انواع سیستمهای LiDAR که از پلتفرمهای مختلف استفاده میکنند، سیستم هوابرد (یعنی اسکن لیزری هوابرد (ALS) قبلاً ثابت شده است که یک تکنیک همه کاره برای جمعآوری دادههای توپوگرافی در مقیاس بزرگ، با وضوح بالا و بسیار دقیق است که مستقیماً ارائه میکند. اندازه گیری ارتفاع زمین [ 1]. اگرچه محققان و مهندسان از پتانسیل دادههای اسکن لیزری هوابرد (ALS) آگاه بودهاند و سعی کردهاند از آن در کارهای مختلف استفاده کنند، قبل از هر کاربرد با استفاده از دادههای ALS چالشی وجود دارد: ما باید اطلاعات معنایی صحنههای مشاهدهشده ارائهشده را تفسیر کنیم. توسط ابرهای نقطه سه بعدی ALS. هدف اصلی تفسیر معنایی ابرهای نقطه ALS اختصاص دادن هر نقطه سه بعدی با یک برچسب معنایی منحصر به فرد است که کلاس اشیاء خاص در صحنه را مطابق با اطلاعات هندسی یا رادیومتری ارائه شده توسط خود نقطه و نقاط همسایه آن نشان می دهد. .
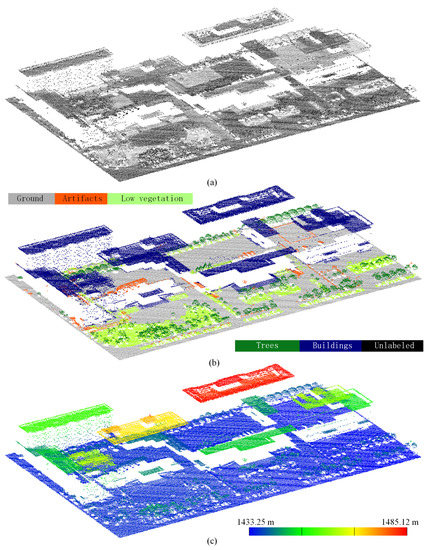
برای دستیابی به برچسب گذاری معنایی نقاط، تعداد زیادی الگوریتم و روش برای حل معماهای پنهان در ابرهای نقطه سه بعدی اندازه گیری شده توسعه داده شده است. برای بسیاری از کاربردها و مطالعات، عملکرد الگوریتم یا روش توسعهیافته باید از طریق مجموعه دادههای معیار استاندارد عمومی ارزیابی شود، که به طور قابلتوجهی به توسعه، ارزیابی و مقایسه الگوریتم کمک میکند [ 2 ].]. برای برچسبگذاری معنایی ابرهای نقطه ALS، طبیعتاً به چارچوبهای استاندارد برای انجام فرآیند ارزیابی نیز نیاز داریم که باید توسط مجموعه دادههای معیار کمک شود. با این حال، ایجاد مجموعه دادههای مشروح در مقیاس بزرگ در دسترس عموم، که برای ارزیابی عملکرد الگوریتمها و روشهای توسعهیافته حیاتی هستند، هنوز در سنین پایین است. برای این منظور، در این مقاله، یک مجموعه داده ابر نقطهای هوایی در مقیاس بزرگ ارائه شده است که در یک منطقه شهری بسیار متراکم به دست آمده است. این مجموعه داده یک منطقه شهری با ساختمانهای بسیار متراکم تقریباً 1 کیلومتر مربع را پوشش میدهد و شامل بیش از 3 میلیون نقطه با پنج کلاس از اشیاء برچسبگذاری شده است. نمونه ای از یک منطقه کوچک از مجموعه داده ارائه شده در شکل 1 نشان داده شده است .
هدف این مقاله معرفی یک مجموعه داده ALS مشروح جدید است که به عنوان معیاری برای ارزیابی روشها و الگوریتمهای برچسبگذاری معنایی ابر نقطه عمل میکند. علاوه بر این، با انجام آزمایشها با استفاده از چندین روش مرجع، هدف ما تعیین تأثیر بالقوه استفاده از استراتژیهای سلسله مراتبی و چند مقیاسی در روشهای مبتنی بر یادگیری عمیق است. بنابراین، سهم اصلی این مقاله دو جنبه است: یکی ارائه یک مجموعه داده ابر نقطه ای ALS در مقیاس بزرگ با برچسب های نقطه ای برای برچسب گذاری معنایی است. دادهها در یک منطقه شهری بسیار متراکم و چالش برانگیز، با انواع مختلف ساختمانهای پیچیده، زیرساختها و پوشش گیاهی اندازهگیری و حاشیهنویسی به دست آمد. با ویژگی های مشابه اما سناریوهای چالش برانگیزتر و اندازه بزرگتر، این مجموعه داده به طور قابل توجهی برای مجموعه داده های برچسب گذاری معنایی ISPRS 3D که معمولاً استفاده می شود مکمل است. سهم دیگر این مقاله ارزیابی و تحلیل عملکرد برچسبگذاری معنایی روی مجموعه داده پیشنهادی با استفاده از چندین روش مبتنی بر یادگیری عمیق با در نظر گرفتن استراتژیهای مقیاس مختلف است. از نتایج ارزیابی، ما تأیید کردیم که عوامل مقیاس تأثیر قابلتوجهی بر عملکرد شبکه عصبی عمیق برای برچسبگذاری معنایی ابر نقطهای در سناریویی که در آن اشیا دارای اندازههای هندسی مختلف هستند، دارند.
2. مجموعه داده ها را از LiDAR Point Clouds محک بزنید
در دهه گذشته، طیف گسترده ای از مجموعه داده های معیار برای وظایف مختلف پردازش ابری نقطه ای ارائه شده است. به عنوان مثال، مجموعه دادههای معیار نابودکننده برای ثبت ابر نقطهای مانند مجموعه دادههای اسکنهای دنیای واقعی با همپوشانی کوچک (RESSO) [ 3 ] و مجموعه دادههای معیار ثبت ابر نقطهای اسکن زمینی LiDAR (TLS) در مقیاس بزرگ (WHU-TLS) وجود دارد. [ 4 ، 5 ]. با توجه به بخشبندی معنایی و برچسبگذاری معنایی، مجموعه دادههای معیار فراوانی وجود دارد که ارائه شدهاند، مانند مجموعه دادههای اسکن LiDAR تلفن همراه در فضای باز اوکلند (MLS) [ 6 ]، معیار برچسبگذاری معنایی ISPRS [ 7 ]، مجموعه داده Semantic3D.net TLS. Semantic3D) [ 8]، مجموعه داده های MLS1-TUM City Campus (2016) [ 9 ]، مجموعه داده های پاریس–لیل-3D MLS [ 10 ]، مجموعه داده های TorontoCity [ 11 ]، و مجموعه داده های Toronto-3D MLS [ 12 ]]. به طور خاص، مجموعه داده TorontoCity شامل دادههایی از منابع تصاویر RGB هوایی، پانورامای نمای خیابان، LIDAR نمای خیابان، و LIDAR هوابرد است که کل منطقه بزرگتر تورنتو را پوشش میدهد. به جای برچسبهای حاشیهنویسی دستی، از نقشههای مختلف با دقت بالا برای ایجاد حقیقت زمینی استفاده شد، که این مجموعه داده را به ابزاری قدرتمند برای ارزیابی روشهای توسعهیافته در طیف گستردهای از کاربردها تبدیل کرد. با این حال، برای هر یک از مجموعه دادههای ابر نقاط معیار، همیشه یک مرزبندی برای پلتفرم مورد استفاده برای اندازهگیری نقاط سهبعدی وجود دارد. این به این دلیل است که ویژگی ها، دقت، چگالی و کیفیت انواع مختلف ابرهای نقطه ای به دلیل پلت فرم های مختلف مورد استفاده در اندازه گیری، به طور قابل توجهی متفاوت است [ 13 ].]. بنابراین، برای ارزیابی الگوریتمها و روشهای طراحیشده برای کاربردهای مختلف، باید انواع مختلف ابرهای نقطهای (یعنی ابرهای نقطهای که از انواع مختلف پلتفرمها به دست میآیند) برای تولید مجموعه دادههای معیار مورد استفاده قرار گیرند. علاوه بر این، هزینه ها و مشکلات تولید این مجموعه داده های معیار نیز کاملاً متفاوت است. در بخشهای فرعی بعدی، به بررسی مختصری از تفاوتهای ویژگیهای بین ابرهای نقطه LiDAR بهدستآمده با پلتفرمهای مختلف و معرفی مجموعههای داده ابر نقطهای ALS برای برچسبگذاری معنایی سه بعدی خواهیم پرداخت.
ادامه این مقاله به شرح زیر سازماندهی شده است. در بخش 2 ، بررسی مختصری از مجموعه دادههای معیار ALS خروجی برای برچسبگذاری معنایی ارائه شده است. در بخش 3 ، اطلاعات اساسی و ویژگیها، و همچنین چالشهای مجموعه داده LASDU ارائه شده توضیح داده شده است. بخش 4 آزمایش های انجام شده را با استفاده از مجموعه داده ارائه شده معرفی می کند. بخش 5 نتایج تجربی را گزارش میکند و بحث و تحلیل دقیقی از عملکرد ارائه میدهد. در نهایت، بخش 6 مقاله را به پایان می رساند و کارهای آینده را ارائه می دهد.
2.1. تفاوت بین ابرهای نقطه ای LiDAR که با پلتفرم های مختلف به دست آمده اند
همانطور که در بالا ذکر شد، با سیستمها و پلتفرمهای مختلف LiDAR، مجموعه دادههای معیار تولید شده با ابرهای نقطهای مختلف، ویژگیهای مختلفی را نشان میدهند. به عنوان مثال، چگالی نقطه می تواند از کمتر از 10 نقطه در متر مربع ( pts/m2 ) تا 5000 pts/m2 [2 ] متفاوت باشد . به طور کلی، با توجه به پلتفرمهای مورد استفاده در کمپین اندازهگیری، ابرهای نقطهای که با سیستمهای LiDAR به دست میآیند به انواع عمده طبقهبندی میشوند: ابرهای نقطهای TLS، ابرهای نقطهای MLS، و ابرهای نقطهای ALS.
TLS با یک پلت فرم ثابت کار می کند که معمولاً روی سه پایه با موقعیت های اسکنر دقیق و پایدار نصب می شود. TLS میتواند اندازهگیریهای میانی و نزدیک را ارائه دهد، و چگالی نقطهای همراه با فواصل اندازهگیری متفاوت است [ 14 ]. بنابراین، TLS را می توان برای به دست آوردن ابرهای نقطه ای با دقت بالا در کاربردهایی مانند نقشه برداری داخلی [ 15 ]، باستان شناسی [ 16 ] و نظارت [ 17 ] ساختمان ها و زیرساخت های دست ساز اعمال کرد. با این حال، به دلیل پلت فرم کار ثابت، میدان دید برای TLS همیشه به دلیل انسداد محدود است. این یک مشکل به خصوص در اندازه گیری سناریوهای شهری با ساختمان های شلوغ و مرتفع است.
MLS معمولاً روی یک پلت فرم موبایل (مثلاً اتومبیل یا قایق) کار می کند. در مقایسه با TLS، اسکن لیزری از MLS یک نمای جانبی از نماهای ساختمان و خیابان ها یا سواحل رودخانه ها را ارائه می دهد، که آن را به ابزاری مفید برای کارهایی مانند نقشه برداری سه بعدی شهر [ 18 ] و رانندگی مستقل [ 6 ] تبدیل می کند. علاوه بر این، ابرهای نقطهای از MLS با بهرهمندی از یک پلتفرم انعطافپذیر و متحرک، میتوانند تا حدی از پدیدههای انسدادی که در دادههای بهدستآمده از طریق TLS رخ میدهند، جلوگیری کنند. ALS روی هواپیما یا پهپاد کار می کند و اسکن در طول پرواز انجام می شود. اندازه گیری با ALS می تواند یک منطقه بزرگ را پوشش دهد، اما چگالی نقطه به فرکانس اسکن و ارتفاع پرواز بستگی دارد. بر اساس این ویژگی، ALS اغلب در نقشه برداری شهری استفاده می شود [ 7]، تحقیقات کشاورزی، و نقشه برداری جنگلداری [ 19 ]. با این حال، در مراحل اولیه توسعه، ALS تنها میتواند ابرهای نقطهای 2.5 بعدی را ارائه دهد که ویژگیهای آن به DEM یا دادههای تصویر عمق نزدیکتر است. اسکن لیزری انجام شده از طریق یک پلت فرم پهپاد را نیز می توان در ALS دسته بندی کرد. به لطف اندازه کوچکتر و وزن سبک تر پلت فرم خود، ALS مبتنی بر پهپاد می تواند انعطاف پذیری عملیاتی بالایی را ارائه دهد [ 2 ]، که حتی می تواند در یک سناریوی داخلی استفاده شود [ 20 ]. یکی از معایب اصلی ALS ناپایداری پلت فرم کار است، به این معنی که ابرهای نقطه ای که توسط ALS به دست می آیند معمولاً دقت موقعیت جغرافیایی نسبتاً پایینی دارند. در برخی شرایط، جبران حرکت نیز برای پردازش داده مورد نیاز است.
2.2. نماینده مجموعه داده های ابر نقطه ای ALS برای برچسب گذاری معنایی سه بعدی
سکوی متحرک و اندازه گیری از راه دور باعث می شود که ابرهای نقطه ALS در مقایسه با ابرهای TLS و MLS پراکنده و نادرست باشند. عدم دقت سیستم جهانی ناوبری ماهواره ای (GNSS) و واحد اندازه گیری اینرسی (IMU) نیز کیفیت ابرهای نقطه ای ALS اندازه گیری شده را کاهش می دهد. علاوه بر این، اندازهگیری ALS در جهت نمای بالا انجام میشود، که منجر به این میشود که نقاط بهدستآمده بیشتر شبیه یک طرح ریزی از اجسام سه بعدی هستند. به عنوان مثال، تنها سقف و بخش کوچکی از ساختمان در طول اندازهگیری اسکن میشوند ( شکل 1 را ببینید.). همه این اشکالات تولید مجموعه داده های معیار از ابرهای نقطه ای ALS را پیچیده و زمان بر می کند. در برخی شرایط، حاشیه نویسی نکات باید توسط متخصصان آموزش دیده انجام شود. بنابراین، تنها چند معیار برچسبگذاری معنایی قابل دسترسی از ابرهای نقطهای ALS وجود دارد، و نمونههای معرف شامل مجموعه دادههای پردیس شهری و آبنبرگ TUM (TUM-ALS) [ 21 ]، مجموعه دادههای معیار ISPRS در برچسبگذاری معنایی سه بعدی (Vaihingen) است [ 22 ، 23 ]، مجموعه داده هلندی Actueel Hoogtebestand (AHN3) [ 24 ، 25 ]، مجموعه داده ابر نقطه LiDAR مشروح DublinCity (DublinCity) [ 26 ، 27 ]، مجموعه داده مسابقه ادغام داده IEEE GRSS (DFC) [ 28]، مجموعه داده اسکن زمین LiDAR مشروح دیتون (DALES) [ 29 ].
2.2.1. TUM City Campus و Abenberg ALS Dataset
مجموعه داده TUM-ALS ( https://www.iosb.fraunhofer.de/servlet/is/54965/) یک معیار مشارکتی است که توسط Photogrammetry و Remote Sensing، دانشگاه فنی مونیخ، و Fraunhofer-IOSB، Ettlingen، آلمان به دست آمده و ایجاد شده است. این مجموعه داده در پردیس شهری TUM و آبنبرگ به ترتیب در آوریل 2008 و اوت 2009 به دست آمد. این دو محل آزمایش اسکن شده و توسط چهار نوار در یک الگوی متقاطع با تعداد انباشته امتیاز 5.4 میلیون پوشانده شدند. این مجموعه داده در دو دوره اما در مکان های مشابه به دست آمد، که امکان تجزیه و تحلیل بیشتر، مانند تشخیص تغییر را فراهم می کند. در این مجموعه داده، هر نقطه شامل مختصات سه بعدی، موقعیت سنسور، جهتهای نرمال محلی، شدت پالس-اکوی و برچسبهای طبقهبندی اولیه است. به طور خاص، نقاط این مجموعه داده به چهار کلاس زیر از اشیاء مختلف حاشیه نویسی شده است: سطح زمین، پوشش گیاهی، سطوح دیگر، و اشکال مسطح میانگین چگالی نقطه ای در حدود 16 pts/m است2 . مهمترین جنبه این مجموعه داده این است که از چهار اسکن تقریباً همپوشانی برای یک منطقه مشاهده شده تشکیل شده است، که امکان استفاده برای ارزیابی تشخیص تغییر با اطلاعات معنایی را فراهم می کند. با این حال، منطقه مشاهده شده نسبتا کوچک است و سناریو فقط شامل مناطق مسکونی است.
2.2.2. مجموعه داده های معیار ISPRS در برچسب گذاری معنایی سه بعدی
مجموعه داده Vaihingen ابر نقطه ALS است که به طور رسمی توسط ISPRS منتشر شده است، که برای مسابقه برچسبگذاری معنایی سه بعدی ( https://www2.isprs.org/commissions/comm3/wg4/3d-semantic-labeling.html ) نیز ارائه شده است. به عنوان طبقه بندی شهری و بازسازی سه بعدی. این مجموعه داده در آگوست 2008 توسط یک سیستم Leica ALS50 به دست آمد. میانگین ارتفاع پرواز حدود 500 متر بود 45∘میدان دید در این مجموعه داده، هر نقطه حاوی x -، y -، z است– مختصات در فضای اقلیدسی، مقادیر شدت و تعداد بازگشتها. نقاط این مجموعه داده به صورت دستی به 9 کلاس زیر از اشیاء مختلف حاشیه نویسی شده است: خط برق، پوشش گیاهی کم، سطوح غیر قابل نفوذ، اتومبیل ها، حصارها/پرچین ها، سقف ها، نماها، درختچه ها و درختان. کل مجموعه داده به بخش های تست و آموزش تقسیم می شود. بخش آزمایش در مرکز شهر واقع شده است، جایی که ساختمان ها به صورت متراکم و پیچیده با مساحت 389 متر × 419 متر با تقریباً 412000 نقطه وجود دارند. بخش آموزشی عمدتاً شامل خانههای مسکونی و ساختمانهای بلند است که مساحتی معادل 399 متر × 421 متر را پوشش میدهد و تقریباً 753000 امتیاز دارد. میانگین چگالی نقطه تقریباً 4 pts/m2 است. مجموعه داده Vaihingen یکی از متداول ترین مجموعه داده های معیار برای برچسب گذاری معنایی در فضای باز است و حاشیه نویسی بسیار دقیقی از اشیاء شهری ارائه می دهد. با این حال، محدود به اندازه مجموعه داده، برخی از دستههای اشیاء دارای امتیاز بسیار کمی هستند، به این معنی که در برخی از روشهای مبتنی بر یادگیری تحت نظارت، فرآیند آموزش ممکن است با مشکلاتی مانند کمبود نمونههای آموزشی یا داشتن نمونههای آموزشی نامتعادل مواجه شود. علاوه بر این، سناریوی ساختمانهایی که به طور مساوی توزیع شدهاند نیز برای تجزیه آسانتر است.
2.2.3. مجموعه داده Actueel Hoogtebestand Nederland
مجموعه داده AHN3 ابر نقطه ALS است که به عنوان بخشی از فایل ارتفاع واقعی هلند (AHN) ( https://downloads.pdok.nl/ahn3-downloadpage/ ) به دست آمده است، که داده های ارتفاعی با وضوح بالا و دقیق را برای کل منطقه ارائه می کند. هلند. چندین نسخه از مجموعه داده های AHN وجود دارد و جدیدترین و دقیق ترین آنها AHN3 است. مجموعه داده با رویکرد اسکن لیزری FLI-MAP در آوریل 2010 به دست آمد. در این مجموعه داده، هر نقطه دارای x -، y – و z است.– مختصات در فضای اقلیدسی، مقادیر شدت، تعداد بازگشت و زمان GPS. نقاط به صورت دستی به پنج کلاس مختلف اشیاء زیر مشروح شده اند: سطح زمین، آب، ساختمان ها، اشیاء مصنوعی، و طبقه بندی نشده (از جمله پوشش گیاهی). کل مجموعه داده به طور خاص به بخش های آزمایشی و آموزشی تقسیم نمی شود و معمولاً تنها بخشی از مجموعه داده AHN3 برای آزمایش ها استفاده می شود. میانگین چگالی نقطه ای از حدود 8-60 pts/m2 متغیر است. مجموعه داده AHN مجموعه داده بسیار بزرگی را ارائه می دهد و نه تنها مناطق شهری، بلکه مناظر طبیعی و سطوح آب را نیز پوشش می دهد، که زمینه های کاربردی آن را گسترش می دهد. با این حال، تعداد دستههای مشروح اشیاء پتانسیل آن را در برخی از وظایف نقشهبرداری دقیق محدود کرده است. علاوه بر این، برای استفاده به عنوان یک مجموعه داده معیار، مجموعه آموزشی و مجموعه تست در AHN3 مشخص نشده است، که استفاده از این مجموعه داده را در مقایسه با سایرین محدود می کند.
2.2.4. مجموعه دادههای ابر نقطهای LiDAR مشروحشده DublinCity
مجموعه داده DublinCity اولین ابر نقطه ALS بسیار متراکم در مقیاس شهر است و بخشی از داده های ALS مرکز شهر دوبلین است که توسط پروژه بررسی لیزر هوایی و فتوگرامتری مجموعه شهر دوبلین در سال 2015 به دست آمده است. ( https://archive.nyu.edu/handle/2451/38684?mode=full). این مجموعه داده توسط یک سیستم LiDAR در یک هلیکوپتر در سال 2015 با پرواز حدود 300 متر بدست آمد. همه نقاط به صورت دستی با برچسب هایی از 13 کلاس (به عنوان مثال، ساختمان ها، درختان، نماها، پنجره ها، و خیابان ها) در سه سطح سلسله مراتبی حاشیه نویسی شده اند. در سطح اول، امتیازات با برچسب گذاری درشت چهار طبقه اختصاص داده می شود: ساختمان ها، زمین، پوشش گیاهی و تعریف نشده. در سطح دوم، سه دسته اول سطح اول به طبقات بیشتری از جمله سقف، نما، درختان، بوته ها، خیابان ها، پیاده روها و چمن اصلاح می شوند. در سطح سوم، درها و پنجره های سقف و نما بیشتر از هم جدا شده اند. داده های مشروح شامل بیش از 260 میلیون نقطه است که مساحتی در حدود 2 کیلومتر مربع را پوشش می دهد . میانگین چگالی نقطه 348.43 pts/m2 است. جذاب ترین ویژگی مجموعه داده DublinCity، چگالی بالای آن است که امکان بازسازی سه بعدی دقیق مدل های ساختمان را با سطح بالایی از جزئیات فراهم می کند. علاوه بر این، سیستم حاشیه نویسی سلسله مراتبی این مجموعه داده نیز هنگامی که برای کارهایی با سطوح مختلف دقت مورد نیاز اعمال می شود، ارزش زیادی دارد. با این حال، اکثر برنامههای کاربردی در فضای باز، و همچنین الگوریتمها و روشهای مرتبط، همچنان از چگالی نقطه نسبتاً پایینی در نقشهبرداری در مقیاس بزرگ برای مبادله بین هزینهها و دقت استفاده میکنند. بنابراین، برای چنین کاربردها و روشهایی، یک معیار با چگالی نقطه نسبتاً کم که شرایط رایج را برآورده میکند، مناسبتر خواهد بود. علاوه بر این، چگالی نقطه بالا نیز نیازمند کارایی محاسباتی الگوریتمها است.
2.2.5. مجموعه داده مسابقه فیوژن داده IEEE GRSS (DFC)
مجموعه داده DFC یک مجموعه داده معیار مرتبط با طبقه بندی است که در مسابقه ادغام داده های IEEE GRSS در سال 2018 استفاده شد [ 28 ] ( https://www.grss-ieee.org/community/technical-committees/data-fusion/2018 -ieee-grss-data-fusion-contest/). مجموعه داده توسط مرکز ملی نقشه برداری لیزری هوابرد (NCALM) با استفاده از Optech Titan MW (14SEN/CON340) با دوربین یکپارچه به دست آمد. تمام نکات به صورت دستی به 20 دسته کاربری و پوشش زمین حاشیه نویسی شده است. این مجموعه داده در قالب یک DEM با شطرنجی در فاصله نمونه برداری از زمین 0.5 متر (GSD) ارائه شده است. همراه با DEM، تصاویر چند طیفی از همان منطقه نیز ارائه شده است. مجموعه داده DFC بیشترین تعداد دسته بندی اشیاء مشروح را دارد و منطقه نسبتاً زیادی را پوشش می دهد. علاوه بر این، اطلاعات طیفی نیز ارائه می شود که ویژگی های داده ها را برای کاربردهای بیشتر غنی می کند. به عنوان مثال، اطلاعات چند طیفی ارائه شده توسط مجموعه داده DFC میتواند تنوع ویژگیهایی را که میتوان برای توسعه الگوریتمها و روشها مورد استفاده قرار داد، بسیار افزایش داد. برخی از داده های LiDAR شکل موج کامل نیز می توانند برای برنامه های جنگلداری مفید باشند. با این حال، مجموعه داده در DEM ساختار یافته است که مقدار مشخصی از اطلاعات سه بعدی را از دست می دهد. بنابراین، این مجموعه داده نیز به عنوان نوعی مجموعه داده تصویری با اطلاعات عمق در نظر گرفته می شود. علاوه بر این، چگالی نقطه پراکنده آن نیز کاربردهای بالقوه آن را محدود می کند.
2.2.6. مجموعه داده اسکن زمین LiDAR مشروح دیتون
مجموعه داده DALES [ 29 ] جدیدترین مجموعه داده هوایی LiDAR در مقیاس بزرگ است که توسط دانشگاه دیتون با استفاده از سیستم دو کاناله Riegl Q1560 که در یک Piper PA31 Panther Navajo ( https://udayton.edu/engineering/research/centers ) به دست آمده است. /vision_lab/research/was_data_analysis_and_processing/dale.php ). ارتفاع پرواز 1300 متر بود که حداقل 400% همپوشانی اسکن ها را تضمین می کرد. کل ابر نقطهای هوایی LiDAR 330 کیلومتر مربع بر فراز شهر سوری در بریتیش کلمبیا، کانادا اندازهگیری شده است و شامل بیش از نیم میلیارد نقطه با برچسب دستی است که 10 کیلومتر مربع را پوشش میدهد .از منطقه و شامل هشت کلاس از اشیاء. DALES دادههای حاشیهنویسی را بهطور تصادفی به کاشیهای آموزشی و آزمایشی با نسبت تقریباً ۷۰ تا ۳۰ درصد کج کرده است. یکی از مهم ترین ویژگی های DALES اندازه بزرگ آن است که در واقع به طور ویژه برای ارزیابی الگوریتم های یادگیری عمیق سه بعدی طراحی شده است.
2.2.7. محدودیتهای مجموعه دادههای معیار فعلی ابرهای نقطهای ALS
برای به دست آوردن تصور بهتر از مجموعه داده های معیار فعلی ابرهای نقطه ALS، در جدول 1 ، مقایسه ای از شاخص های جامع مجموعه داده های ذکر شده در بالا ارائه می دهیم.
با ترکیب اطلاعات جدول 1 و نقاط قوت و ضعفی که در مقدمه مجموعه داده های موجود ذکر کردیم، می توانیم چندین محدودیت را در مجموعه داده های معیار ALS فعلی پیدا کنیم و نکاتی را ارائه کنیم.
اولین نکته اندازه محدود مناطق تحت پوشش است. ابر نقطه ALS به ویژه برای نقشه برداری سه بعدی در مقیاس بزرگ مناسب است. بنابراین، برای الگوریتمها و روشهای توسعهیافته، کارایی مقابله با دادههای مقیاس بزرگ باید به عنوان یک عامل حیاتی در نظر گرفته شود. این بدان معناست که در مرحله ارزیابی، باید معیاری در مقیاس بزرگ ارائه کنیم. با این حال، برای بسیاری از مجموعههای داده، اندازه ابرهای نقطه مشروح شده توسط هزینه و مشکلات در جمعآوری داده و حاشیهنویسی محدود میشود. اگرچه مجموعه داده AHN3 یک منطقه پوششی بسیار بزرگ را فراهم می کند، مجموعه داده های آموزشی و آزمایشی به طور پیش فرض اختصاص داده نمی شوند، که ممکن است منجر به مقایسه ناعادلانه نتایج ارزیابی با انتخاب عمدی مناطق تحقیق شود. مجموعه داده DALES این مشکل را حل کرده است، که منطقه بزرگی را در بر می گرفت و مجموعه داده های آموزشی و آزمایشی را با کاشی کاری تصادفی ثابت می کرد. با این حال، این مجموعه از مجموعه داده های آموزشی و آزمایشی کاملاً متفاوت از روشی است که در متداول ترین مجموعه داده Vaihingen استفاده می شود، که نمی تواند مستقیماً به عنوان مکمل برای آن عمل کند. نکته دوم ناشی از چگالی نقطه و فیلدهای ویژگی است. از نظر تئوری، هر چه چگالی نقطه بالاتر باشد، جزئیات بیشتری از جسم زمین قابل اندازه گیری و نمایش است. با این حال، محدود به ارتفاع پرواز و عملکرد دستگاه های LiDAR، اکثر مجموعه داده های معیار ALS می توانند تنها ابرهای نقطه پراکنده را ارائه دهند. استثنا مجموعه داده DublinCity است که بالاترین تراکم نقطه را در بین تمام مجموعه داده های معیار محبوب ALS ارائه می دهد. با این حال، همانطور که در مقدمه این مجموعه داده اشاره کردیم، اکثر الگوریتمها و روشهای طراحیشده برای کاربردهای فضای باز در مقیاس بزرگ برای مجموعههای داده با تراکم نقطه نسبتاً کم توسعه داده شدهاند که به یک معیار مناسب نیاز دارد. علاوه بر این، تراکم نقطه بالا چالش های خاص خود را در مورد هزینه ها و حاشیه نویسی به همراه دارد. فیلدهای ویژگی غنی می توانند اطلاعات بیشتری را در برنامه های کاربردی بالقوه ارائه دهند و گنجاندن اطلاعات طیفی می تواند به طور قابل توجهی عملکرد روش های طبقه بندی را افزایش دهد. با این حال، به عنوان یک مجموعه داده معیار برای برچسبگذاری معنایی، کمک کمتری به الگوریتمها و روشهای مبتنی بر هندسه خالص میکند. آخرین اظهار نظر ما مربوط به سناریوی بررسی مناطق تحت پوشش مجموعه داده است. سبکها، تراکم و توزیع ساختمانها، پوشش گیاهی و زیرساختها، منظرههای شهری متفاوتی را تشکیل میدهند. نشان دادن ویژگی های متنوع ابرهای نقطه به دست آمده. برای مجموعه داده های معیار، زمانی که از مناطقی با سناریوهای مختلف به دست می آیند، ویژگی های متفاوتی خواهند داشت. الگوریتم ها و روش های مختلف معمولاً از عملکرد ناسازگار در مجموعه داده های مختلف رنج می برند. بنابراین، الگوریتمها یا روشهای طراحیشده برای وظایف خاص (مثلاً استخراج ساختمان) باید توسط مجموعه دادههای معیار مربوطه ارزیابی شوند. در غیر این صورت، ارزیابی مغرضانه خواهد بود. برای این منظور، مجموعه دادههای معیاری که انواع سناریوهای چالش برانگیز را پوشش میدهند (به عنوان مثال، منطقه مسکونی، منطقه حومهای، مناظر طبیعی) مورد نیاز است تا به کاربردهایی با اهداف مختلف خدمت کند. الگوریتم ها و روش های مختلف معمولاً از عملکرد ناسازگار در مجموعه داده های مختلف رنج می برند. بنابراین، الگوریتمها یا روشهای طراحیشده برای وظایف خاص (مثلاً استخراج ساختمان) باید توسط مجموعه دادههای معیار مربوطه ارزیابی شوند. در غیر این صورت، ارزیابی مغرضانه خواهد بود. برای این منظور، مجموعه دادههای معیاری که انواع سناریوهای چالش برانگیز را پوشش میدهند (به عنوان مثال، منطقه مسکونی، منطقه حومهای، مناظر طبیعی) مورد نیاز است تا به کاربردهایی با اهداف مختلف خدمت کند. الگوریتم ها و روش های مختلف معمولاً از عملکرد ناسازگار در مجموعه داده های مختلف رنج می برند. بنابراین، الگوریتمها یا روشهای طراحیشده برای وظایف خاص (مثلاً استخراج ساختمان) باید توسط مجموعه دادههای معیار مربوطه ارزیابی شوند. در غیر این صورت، ارزیابی مغرضانه خواهد بود. برای این منظور، مجموعه دادههای معیاری که انواع سناریوهای چالش برانگیز را پوشش میدهند (به عنوان مثال، منطقه مسکونی، منطقه حومهای، مناظر طبیعی) مورد نیاز است تا به کاربردهایی با اهداف مختلف خدمت کند.
3. LASDU: ابرهای نقطه ای هوایی LiDAR در مقیاس بزرگ از مناطق شهری بسیار متراکم
بر اساس تجزیه و تحلیل محدودیتها و مشکلات موجود در مجموعه دادههای معیار فعلی ابرهای نقطهای ALS، یک مجموعه داده هوایی جدید LiDAR با نام LASDU (دادههای ALS در مقیاس بزرگ برای برچسبگذاری معنایی در مناطق متراکم شهری) ارائه میکنیم که برای برچسبگذاری معنایی ابرهای نقطهای ALS در مناطق شهری بسیار متراکم
3.1. اکتساب داده ها
این مجموعه داده بخشی از دادههای بهدستآمده در کمپینهای پروژه HiWATER (تحقیق تجربی تله متری متحد حوضه Heihe) [ 30 ] بود. منطقه مورد مطالعه در دره کنار رودخانه هیهه در شمال غربی چین است. توپوگرافی منطقه مورد مطالعه تقریباً مسطح و با میانگین ارتفاع 1550 متر است. ابرهای نقطه ای ALS در ابتدا در جولای 2012 با استفاده از سیستم ALS70 لایکا در هواپیمای با ارتفاع پرواز حدود 1200 متر به دست آمدند. کیفیت هندسی این مجموعه داده در انتشار قبلی [ 31 ] ارائه شده است، که نشان می دهد میانگین چگالی نقطه تقریباً 3-4 pts/m2 و دقت عمودی بین 5-30 سانتی متر بوده است. مجموعه داده مشروح یک منطقه شهری حدود 1 کیلومتر را پوشش می دهد2 ، با ساختمان های مسکونی و صنعتی بسیار متراکم. در شکل 2 ، نقشه ارتفاع مجموعه داده نشان داده شده است، با ارتفاع منطقه مورد مطالعه نشان داده شده است. از شکل 2 می بینیم که منطقه مشروح تقریباً مسطح است و حداکثر اختلاف ارتفاع تنها حدود 70 متر است که به دلیل ارتفاعات مختلف ساختمان ها ایجاد می شود.
3.2. توضیحات داده ها
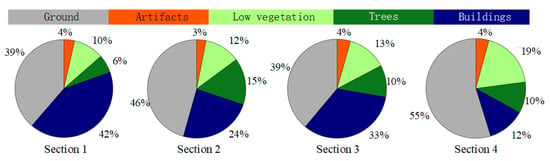
تعداد کل نکات مشروح تقریباً 3.12 میلیون است. کل ابر نقطه برچسب گذاری شده منطقه مورد بررسی به چهار بخش تقسیم شده است و تعداد نقاط این چهار بخش به ترتیب حدود 0.77 میلیون، 0.59 میلیون، 1.13 میلیون و 0.62 میلیون است. در شکل 3 ب، تفکیک منطقه مورد مطالعه نشان داده شده است.
نقاط همان بخش به طور جداگانه در فایل های .las جداگانه ذخیره شدند. جداسازی و حاشیه نویسی نقاط به صورت دستی با استفاده از CloudCompare 2.10 ( https://www.danielgm.net/cc/ ) با دقت نقطه ای انجام شد. در فایل las، هر نقطه با هفت ویژگی زیر تخصیص داده شد:
-
موقعیت ها: ثبت مختصات سه بعدی هر نقطه، با واحد متر در طرح UTM.
-
Intensity: ثبت شدت بازتاب هر نقطه، با محدوده بین 0 تا 255.
-
لبه خط پرواز: مقدار 1 را فقط زمانی نشان می دهد که نقطه در پایان اسکن باشد.
-
جهت اسکن: نشان دهنده جهت آینه اسکنر هنگام ارسال یک پالس.
-
تعداد بازگشت: ثبت تعداد برگشت های متعدد در هر پالس ارسالی.
-
زاویه اسکن: ضبط زاویه اسکن هر نقطه بر حسب درجه.
-
برچسبها: کلاسهای شیء نمایهسازی هر نقطه، با شاخص عدد صحیح از 0 تا 5.
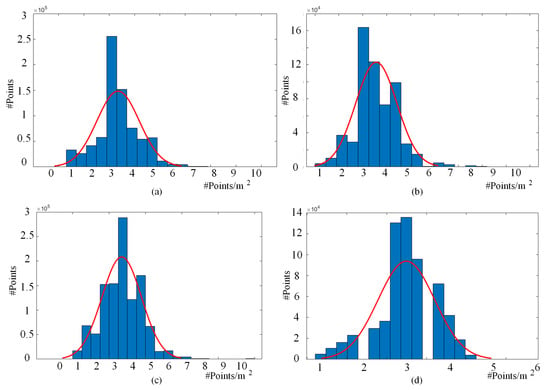
برای به دست آوردن برداشت بیشتر از کیفیت داده ها، تراکم نقاط و در بخش های مختلف به روش آماری تجزیه و تحلیل می شود. برای محاسبه چگالی نقاط، چگالی نقطه محلی (LPD) [ 32 ] ابر نقطه محاسبه می شود:
که در آن k تعداد همسایگان درگیر و دکبه ترتیب مخفف فاصله از نقطه مرکزی تا دورترین همسایه آن است.
در شکل 4 ، توزیع تراکم نقاط نشان داده شده توسط LPD در بخش های مختلف آورده شده است. در این شکل، محور افقی نشاندهنده LPDهای مختلف نقاط است و محور عمودی نشاندهنده تعداد نقاط با تراکم نقطه محلی مشخص است. همانطور که از شکل 4 مشاهده می شود ، چگالی نقطه ای این چهار بخش عموماً در مقدار LPD در حدود 3 pts/m2 متمرکز می شود . چگالی ابر نقطه بخش 3 بزرگتر از بخش های 1 و 2 است و به حدود 3.5 pts/m2 می رسد .. این عمدتا به دلیل ساختمانهای مرتفع و درختان است که ساختار شی بسیار پیچیدهای را با نقاط بیشتری اسکن میکنند. در مقابل، چگالی نقطه ای بخش 4 در مقدار LPD تنها در حدود 2.7 pts/m2 متمرکز می شود که توزیع نقطه پراکنده ناشی از یک سناریوی ساده در این بخش را نشان می دهد. به طور کلی، ما فرض میکنیم که چگالی نقاط در این مجموعه داده ثابت است، زیرا فاصلههای اندازهگیری تقریباً ثابت ALS منجر به چگالی نقاط مشابه میشود.
در مورد حاشیه نویسی نقاط، ما به صورت دستی این منطقه را با پنج کلاس مختلف از اشیا و یک کلاس از نقاط طبقه بندی نشده برچسب گذاری کرده ایم و نقاط برچسب های مختلف با رنگ های مختلف ارائه می شوند:
-
برچسب 1: زمین (کدهای رنگی: #AFAFAF): زمین مصنوعی، جاده، زمین بایر.
-
برچسب 2: ساختمان ها (کدهای رنگی: #00007F): ساختمان ها.
-
برچسب 3: درختان (کدهای رنگی: #09781A): درختان بلند و کم ارتفاع.
-
برچسب 4: پوشش گیاهی کم (کدهای رنگی: #AAFF7F): بوته ها، چمن، تخت گل.
-
برچسب 5: مصنوعات (کدهای رنگی: #FF5500): دیوارها، نرده ها، تیرهای چراغ برق، وسایل نقلیه، سایر اشیاء مصنوعی.
-
برچسب 0: طبقه بندی نشده (کدهای رنگی: #000000): نویز، نقاط پرت، و نقاط بدون برچسب.
در شکل 5، آمار درصد نقاط برچسب گذاری شده در بخش های مختلف آورده شده است. از آمار، میتوان دریافت که برای هر چهار بخش، درصد اشیاء مختلف گرایش مشابهی را نشان میدهند، اما به صورت نامتعادل. نقاط زمین بیشترین درصد را در حدود 40٪ تا 55٪ اشغال می کنند، در حالی که درصد نقاط ساختمانی با ارزش حدود 30٪ در رتبه دوم قرار دارد، به جز قسمت 4. نقاط آثار تنها به حدود 4٪ در بین تمام موارد می رسد. نکات مشروح هنگام تلاش برای استفاده از آنها به عنوان مجموعه داده های آموزشی و آزمایشی، توزیع نامتعادل درصد نقاط برچسب گذاری شده در هر بخش باید در نظر گرفته شود. توصیه می شود از بخش های 2 و 3 به عنوان داده های آموزشی و از بخش های 1 و 4 به عنوان داده های آزمایشی برای کار برچسب گذاری معنایی استفاده شود.
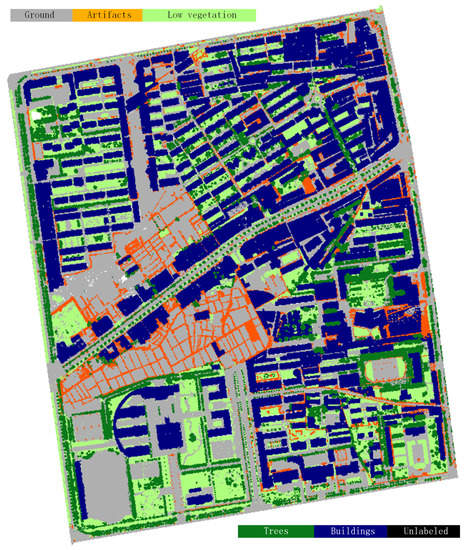
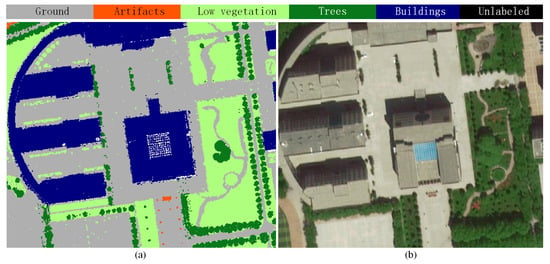
در شکل 6 ، نمونه هایی از نقاط حاشیه نویسی اشیاء مختلف در مقایسه با اشیاء در تصاویر ماهواره ای آورده شده است. همانطور که از شکل 6 مشاهده می شود ، به وضوح می توانیم ببینیم که ساختمان های بلند متراکم مستقیماً با یکدیگر همسایه هستند و همیشه با پوشش گیاهی کم مانند بوته ها و تخت های گل احاطه شده اند که جداسازی آنها را دشوار می کند. علاوه بر این، درختان معمولاً توسط بوته ها احاطه شده اند یا روی چمن هستند. چالش برانگیزترین بخش، مصنوعات است که نه تنها وسایل نقلیه بلکه دیوارهای کوتاه موقت در محل ساختمانهای تخریب شده و پرچینها در زمینهای لخت را نیز شامل میشود. این اجسام کوچک دارای اشکال نامنظم و دارای ویژگی های هندسی مشابه بوته ها هستند. در شکل 6ج، ما حتی می توانیم تفاوت های ظاهری بین ابر نقطه اندازه گیری شده و تصویر ماهواره ای را به دلیل تغییرات دینامیکی در این ناحیه مشاهده کنیم.
در شکل 7 ، نقشه برچسب گذاری شده ابر نقطه ALS در کل منطقه آزمایشی با اشیاء مختلف با رنگ های مختلف ارائه شده است. تمام ساختمان های بسیار متراکم، درختان شلوغ، و مصنوعات با شکل نامنظم را می توان به وضوح مشاهده کرد، که نشان دهنده وظیفه چالش برانگیز برچسب زدن معنایی تمام نقاط در این سناریو است.
3.3. ویژگی های مجموعه داده LASDU
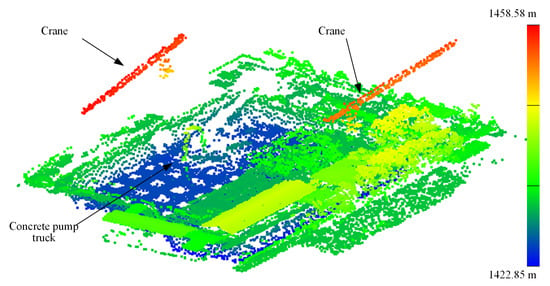
برای این مجموعه داده، بلوک های شهر مشاهده شده هم منطقه بدون تغییر و هم منطقه تغییر یافته را پوشش می دهند. ناحیه بدون تغییر، ناحیه ای است که در آن اشیاء پایدار (به عنوان مثال، جاده، ساختمان ها، درخت) در طول سال ها هنگام مقایسه ابر نقطه ای و تصویر ماهواره ای تغییر نکرده اند. اشیاء دینامیکی مانند وسایل نقلیه متحرک شامل نمی شوند. در شکل 8 ، مثالی از ناحیه بدون تغییر ارائه می دهیم. توجه داشته باشید که ابر نقطه در سال 2012 به دست آمد، در حالی که تصویر ماهواره ای در سال 2014 گرفته شده است. منطقه تغییر در این داده ها عمدتا به سایت های ساخت و ساز اشاره دارد. در طول به دست آوردن ابر نقطه ALS، چندین پروژه ساخت و ساز در حال انجام (برای یک ساختمان یا برای یک منطقه کامل) وجود داشت. در شکل 9، نمونه ای از منطقه تغییر با ساختمانی را که در بازه زمانی بین دستیابی به ابر نقطه و تصویر ماهواره ای به پایان رسیده است، ارائه می دهیم. موقعیت این سایت ساخت و ساز با یک کادر سفید رنگ در شکل مشخص شده است.
علاوه بر این، در شکل 10 ، نمای دقیقی از ابر نقطه محل ساخت و ساز فوق الذکر ارائه می دهیم. نقاط با مقادیر شدت خود ارائه می شوند. وضعیت این محل ساخت در مرحله ساخت سازه از گودال پی بود. همانطور که از شکل 10 مشاهده می شود ، می توانیم نقاط جرثقیل و بیل مکانیکی را تعیین کنیم. قالب ها و سازه های بتنی فولادی در این گودال پی نیز قابل مشاهده است. این امر برای مطالعات تشخیص اشیاء در سایت ساخت و ساز از مجموعه داده های ALS جالب خواهد بود.
علاوه بر این، این سایت های ساخت و ساز همچنین نشان می دهد که منطقه مورد بررسی با تغییرات زیادی در ساختمان ها و جاده ها توسعه قابل توجهی را تجربه کرده است. یک مجموعه داده با ساختمان های تغییر یافته برای تحقیقات تشخیص تغییر جالب تر خواهد بود. این نیز دلیلی است که ما به طور ویژه منطقه سایت های ساخت و ساز را در مجموعه داده انتخاب و ذکر کردیم. با توجه به شرایطی که مجموعه داده ارائه شده ما هیچ اندازه گیری چند زمانی ندارد، بنابراین انجام مقایسه بین ابرهای نقطه برای چنین تحقیقات تشخیص تغییر غیرممکن است. با این حال، انجام تشخیص تغییرات بین مجموعه داده های ALS ارائه شده ما و جدیدترین تصاویر ماهواره ای از Google Maps همچنان ارزشمند است، زیرا چشم انداز به شدت تغییر کرده است.
3.4. اهمیت مجموعه داده LASDU
در مقایسه با مجموعه داده های ALS موجود، اهمیت عمده مجموعه داده LASDU دو مورد است: اول، مجموعه داده های مقیاس بزرگ قابل مقایسه در مقایسه با مجموعه های موجود، به ویژه برای متداول ترین مجموعه داده Vaihingen ارائه می دهد. دوم، سناریوی بسیار پیچیده ای را پوشش می دهد که برچسب زدن آن چالش برانگیز است.
3.4.1. اندازه داده در مقیاس بزرگ قابل مقایسه
با توجه به اندازه مجموعه داده، با مقایسه با مجموعه داده معروف Vaihingen، مجموعه داده LASDU از یک صحنه در فضای باز شهری است که توسط یک سیستم هوایی LiDAR با حسگر ALS جمع آوری شده است. با این حال، LASDU. با مساحت کل تقریباً 1 کیلومتر مربع ، تقریباً چهار برابر بزرگتر از مجموعه داده Vaihingen است که حدود 0.4 کیلومتر مربع را پوشش می دهد .و شامل چهار برابر تعداد امتیاز است. اگرچه اندازه منطقه تحت پوشش در LASDU کوچکتر از DFC، DALES و AHN3 است، اما هنوز با اندازه DublinCity قابل مقایسه است و بهتر از مجموعه داده قبلی TUM-ALS ما است، که صرفاً منطقه اطراف پردیس شهری TUM را پوشش می داد. از یک طرف، اندازه مجموعه داده بزرگ، نیاز آموزش الگوریتمها و روشهای مبتنی بر یادگیری عمیق را برآورده میکند. از سوی دیگر، یک مجموعه داده بزرگ چالش کارایی را افزایش می دهد و این به وضعیت واقعی برای نقشه برداری شهری در مقیاس بزرگ نزدیک تر است.
با توجه به تعداد کلاسهای برچسبگذاریشده، مجموعه دادههای LASDU و Vaihingen هر دو با تعداد مشابهی از کلاسها برای برچسبگذاری معنایی برچسبگذاری شدهاند، که جزئیات بیشتری نسبت به TUM-ALS و AHN3 دارد اما از حاشیهنویسی DublinCity و DFC پایینتر است. با این حال، انواع اصلی اشیاء (به عنوان مثال، ساختمان ها و پوشش گیاهی) در نظر گرفته شده در وظایف نقشه برداری شهری در LASDU گنجانده شده است. یک حاشیه نویسی دقیق، تفسیر معنایی صحنه شهری را تسهیل می کند، اما افزایش هزینه غیرقابل قبول و اجرای برچسب گذاری دستی غیرممکن خواهد بود [ 11 ]]. با توجه به تراکم نقاط، مجموعه داده DublinCity چگالی نقطه ای بسیار بالاتری نسبت به ما دارد و تراکم نقطه بالاتر وظایفی مانند بازسازی سه بعدی در سناریوهای شهری را بهبود می بخشد. با این حال، ابرهای نقطهای اندازهگیری شده با چنین چگالی بالایی معمولاً منابع دادهای در دسترس برای نقشهبرداری شهری در مقیاس بزرگ، به ویژه برای برنامههای کاربردی در کشورهای در حال توسعه نیستند. علاوه بر این، تراکم بالای نقاط اندازهگیری شده، هزینه نقشهبرداری و مشکلات حاشیهنویسی را افزایش میدهد. بنابراین، مجموعه داده LASDU ارائه شده دارای یک اندازه داده در مقیاس بزرگ است در حالی که دارای تعداد معقولی از کلاس های برچسب گذاری شده و چگالی نقطه است.
3.4.2. سناریوهای چالش برانگیز و پیچیده
در مقایسه با سایر مجموعههای داده، مجموعه داده LASDU با سناریوی چالش برانگیز و پیچیدهاش مشخص میشود که چالشهای بیشتری را برای انجام برچسبگذاری معنایی کافی نقاط به همراه دارد. این همچنین ارزیابی انتقادی تری از روش ها و الگوریتم های توسعه یافته ارائه می دهد. مجموعه داده LASDU منطقه ای پر از ساختمان های بسیار متراکم را پوشش می دهد. بر خلاف توزیع یکنواخت ساختمان ها در مجموعه داده Vaihingen، مجموعه داده LASDU دارای تغییرات اساسی تر در تراکم ساختمان است. به عنوان مثال، در برخی از مناطق، تراکم بسیار بالایی از ساختمان ها وجود دارد، در حالی که مکان های دیگر فقط دارای زیرساخت های کم هستند، اما درختان و بوته های انبوه دارند. علاوه بر این، در مقایسه با مناطق مسکونی ثبت شده در مجموعه دادههای TUM-ALS، DublinCity و DFC، مجموعه داده LASDU یک منطقه ترکیبی را اسکن کرد. انواع ساختمانهای شامل مجموعه دادههای LASDU از ساختمانهای مسکونی گرفته تا ساختمانهای صنعتی متفاوت است و مجموعه دادهها حتی مکانهای ساخت و ساز را با تغییرات پویا ثبت میکند. همه اینها چالش های توسعه روش های برچسب گذاری معنایی قوی و موثر را افزایش می دهد. مهمتر از همه، همه ساختمان ها به صورت فشرده قرار گرفته اند و میانگین فاصله بین ساختمان های مجاور فقط حدود 5 است.m ، که بسیار کوچکتر از وضعیت TUM-ALS و AHN3 است. حتی با مقایسه جدیدترین مجموعه داده DALES، تراکم ساختمانهای بلند در مجموعه داده LASDU ما هنوز بسیار بیشتر است. ساختمان ها در LASDU در کنار هم قرار دارند. فاصله کوتاه بین ساختمان ها به طور مستقیم دشواری برچسب گذاری و جداسازی را افزایش می دهد. در شکل 11، ما توزیع ساختمان دو بخش را از مجموعه داده های Vaihingen و LASDU مقایسه می کنیم و از مقایسه، می توانیم به وضوح ساختمان های بسیار متراکم در مجموعه داده LASDU را مشاهده کنیم. این ساختمان های متراکم با اشکال مستطیلی کوچک و باریک، دشواری برچسب گذاری را بسیار افزایش می دهند. علاوه بر این، در سناریوی ثبتشده، نه تنها ساختمانهای مجاور چالشهایی را ایجاد میکنند، بلکه پوشش گیاهی کم و وسایل نقلیه، بهویژه در مناطقی که با قطبها و درختان همپوشانی دارند و نزدیک به ساختمانها هستند، نیز چالشهایی را ایجاد میکنند. علاوه بر این، برجستگی های کوتاه در زمین برهنه و دیوارهای پنهان در ساختارهای عمودی مختلف دیوار مانند نیز برای شناسایی چالش برانگیز هستند. در واقع، مجموعه داده LASDU همچنین وسایل نقلیه پارکینگ را در کلاس مصنوعات علامت گذاری کرده است، که می تواند بیشتر در کارهایی مانند تشخیص وسیله نقلیه مورد استفاده قرار گیرد. با این حال،
3.4.3. استفاده بالقوه برای برنامه های کاربردی مرتبط با ترافیک
از آنجایی که مجموعه داده LASDU در اصل برای کاربردهایی مانند نقشهبرداری شهری و بازسازی سهبعدی ساختمانها طراحی شده است، بنابراین هنگام طراحی دستهبندیهای اشیایی که نیاز به حاشیهنویسی دارند، بیشتر بر روی پوششهای گیاهی و ساختمانهایی که در ابرهای نقطهای اسکن میشوند، تمرکز کردیم. با این حال، برنامههای مرتبط با ترافیک هنگام اعمال ابرهای نقطهای در سناریوی شهری توجه فزایندهای را به خود جلب کردهاند. این بدان معنی است که جاده ها و وسایل نقلیه نیز دسته های جالبی از اشیاء هستند که ممکن است در کاربردهای مرتبط اهمیت خود را نشان دهند.
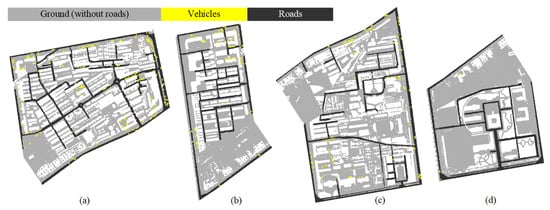
برای این منظور، برای بررسی بیشتر پتانسیل استفاده در برنامه های مرتبط با ترافیک، ما همچنین یک دسته بندی دقیق از حاشیه نویسی ابر نقطه ای بر اساس پنج دسته موجود ارائه می دهیم، اگرچه مجموعه داده ALS منبع داده کافی برای برنامه های کاربردی مرتبط با ترافیک نیست. به دلیل تراکم نقطه پراکنده و گرفتگی های ناشی از ساختمان های مرتفع و درختان در مشاهده نادر. به طور خاص، ما نقاط “جاده” را از نقاط زمین جدا کردیم و نقاط وسایل نقلیه را از نقاط مصنوع استخراج کردیم. این نقاط با برچسب های منحصر به فرد حاشیه نویسی می شوند و گزینه ای برای استفاده از این برچسب ها در کارهایی مانند تشخیص جاده یا استخراج وسیله نقلیه است. در کار برچسبگذاری معنایی، آنها همچنان به ترتیب به عنوان بخشی از زمین یا مصنوعات در نظر گرفته میشوند. در شکل 12، ما نکات مشروح این دو دسته جدید از اشیاء را نشان می دهیم. حاشیه نویسی جاده ها توسط نقشه های گوگل و بازرسی های بصری به صورت دستی هدایت می شود.
4. ارزیابی تجربی
برای ارزیابی مختصری از مجموعه داده پیشنهادی، ما این مجموعه داده را در طبقه بندی نظارت شده اعمال کردیم تا نقاط را با پنج کلاس اشیاء فوق الذکر در صحنه برچسب گذاری کنیم.
4.1. آزمایش های برچسب گذاری معنایی
بر خلاف کاربردهای معمول داخلی در زمینه بینایی رایانه، برچسبگذاری معنایی در مناطق شهری با مقیاس بزرگ باید تغییرات مقیاس اشیاء را در نظر بگیرد. در سناریوی فضای باز، برای اشیاء با ابعاد مختلف، ویژگی های رمزگذاری شده به میزان زیادی با اندازه محله های محلی [ 18 ] یا مقیاس نمونه گیری [ 13 ] متفاوت خواهد بود.]. بهویژه برای مناطق شهری متراکم، ساختمانهای فشرده باعث تعیین نادرست مقیاس در برخی روشهای تطبیقی میشوند. مجموعه داده پیشنهادی ما موردی با مقیاس بزرگ و مناطق بسیار متراکم با ساختمان های نزدیک است. بنابراین، در آزمایشهای ارزیابی، سه روش برچسبگذاری معنایی مبتنی بر نقطه انتخاب شده و بر روی مجموعه داده پیشنهادی به عنوان خطوط پایه آزمایش میشوند. همه این سه روش مبتنی بر یادگیری عمیق هستند، اما از استراتژیهای مختلفی برای مقابله با مشکلات مقیاس استفاده میکنند که مستقیماً به سناریوهای شهری بسیار متراکم مرتبط است.
-
PointNet [ 33 ]: PointNet یک شبکه عصبی است که مستقیماً با ابرهای نقطه ای کار می کند و به عدم تغییر جایگشت نقاط در چاه ورودی احترام می گذارد. این یک معماری یکپارچه برای برنامه های کاربردی از طبقه بندی اشیا تا تقسیم بندی معنایی ارائه می دهد.
-
PointNet++ [ 34 ]: PointNet ابتدا ویژگی های جهانی را با MLP با ابرهای نقطه خام یاد می گیرد. PointNet++ PointNet را در محله های محلی هر نقطه اعمال می کند تا ویژگی های محلی را به تصویر بکشد، و یک رویکرد سلسله مراتبی برای گرفتن ویژگی ها با زمینه محلی چند مقیاسی اتخاذ شده است.
-
Hierarchical Data Augmented PointNet++ (HDA-PointNet++): این یک روش بهبود یافته مبتنی بر PointNet++ اصلی است که در کار قبلی [ 13 ] به عنوان ویژگی های عمیق چند مقیاسی (MDF) در زمینه یادگیری ویژگی های عمیق سلسله مراتبی پیشنهاد شد. HDL) روش. این بر اساس یک استراتژی افزایش سلسله مراتبی داده توسعه داده شد، که در آن مجموعه دادههای ابر نقاط شهری قابل توجهی به مجموعههای چند مقیاسی تقسیم میشوند و توانایی مقابله با تغییرات مقیاس را افزایش میدهند. این استراتژی نمونهگیری سلسله مراتبی یک راهحل مبادلهای برای یکپارچگی شی و جزئیات دقیق است.
برای روش HDA-PointNet++، در شکل 13 ، تصویری برای گردش کار HDA-PointNet++ ارائه می دهیم. در کار قبلی [ 13 ]، در روش HDL نیز به عنوان MDF نامیده میشود، که در مرحله آموزش، ابر نقطه ورودی، تقسیمبندیهای سهگانه با مقیاسهای مختلف را به طور مکرر تجربه میکند. سپس تمام زیرمجموعههای نقاط نمونهبرداری میشوند و برای آموزش به شبکه PointNet++ داده میشوند و از توانایی تعمیم قویتر هنگام برخورد با مقیاسهای بسیار متنوع از اشیاء مختلف اطمینان حاصل میکنند. با این حال، اشاره شده است که ابرهای نقطه برای آزمایش مستقیماً بدون تقسیم و نمونه برداری به شبکه تغذیه می شوند که با مرحله HDL در [ 13 ] متفاوت است.
در آزمایشها، از بخشهای 2 و 3 به عنوان دادههای آموزشی و از بخشهای 1 و 4 به عنوان دادههای آزمایش استفاده میکنیم. از آنجایی که نقاط موجود در مجموعه داده ما نه تنها به مختصات سه بعدی بلکه به ویژگی های دیگری مانند شدت مجهز هستند، ما دو گروه آزمایش را انجام دادیم. گروه اول فقط از مختصات سه بعدی نقاط با هر سه روش استفاده می کند که برای ارزیابی عملکرد هندسی سه بعدی نقاط در مجموعه داده طراحی شده است. در گروه دوم، مقادیر شدت نقاط در مجموعه داده در آزمایشها با استفاده از دو روش (یعنی PointNet++ و HDA-PointNet++)، با هدف بررسی تأثیر اطلاعات رادیومتری در برچسبگذاری معنایی، درگیر میشوند. علاوه بر این، تأثیر مسائل مقیاس فوق برای هر سه روش مورد تجزیه و تحلیل و بحث قرار خواهد گرفت.
4.2. معیارهای ارزیابی
معیارهای ارزیابی شامل دقت ( پrه، یادآوری ( آرهج، اندازه گیری F1 ( اف1)، دقت کلی ( Oآ) و میانگین گرفت اف1معیارهای ( میانگیناف1) که از مجموعه داده های معیار ISPRS از برچسب گذاری معنایی سه بعدی پیروی می کنند [ 7 ]. دقت ( پrه.) و یادآوری ( آرهج.) مقادیر نیز برای ارزیابی عملکرد، بر اساس محاسبه شده، داده می شود تیپ، افپ، و افن. تیپبه مثبت واقعی برای نتیجه برچسبگذاری شده یک کلاس اشاره دارد، که تعداد نقاطی است که به درستی به عنوان آن کلاس برچسبگذاری شدهاند، یعنی نقاطی که دارای علامت مناسب هستند. افپنشان دهنده مثبت کاذب، نشان دهنده تعداد نقاط با علامت اشتباه است. افنمنفی کاذب است، که تعداد نقاطی است که باید به عنوان کلاس های دیگر علامت گذاری شوند اما اشتباه علامت گذاری شده اند. معیار ارزیابی برای کلاس i به صورت تعریف شده است
اندازه گیری ارزیابی برای کل نتیجه طبقه بندی است میانگیناف1، که میانگین جمع آوری است اف1منبرای هر کلاس i .
در نهایت، دقت کلی ( Oآ) نیز محاسبه می شود.
5. نتایج و بحث
5.1. پیش پردازش و آموزش
به عنوان آماده سازی برای آموزش شبکه های عصبی عمیق برای همه روش ها، تعداد ثابتی از نقاط به عنوان زیر مجموعه های قالب بندی شده به عنوان ورودی نمونه برداری شد. در نتیجه، ابرهای نقطه ای از مجموعه داده های آموزشی و آزمایشی به زیرمجموعه هایی بدون همپوشانی تقسیم شدند.
برای آزمایش با استفاده از مختصات سه بعدی، هر نقطه در یک زیرمجموعه با یک بردار سه بعدی با مختصات x -، y -، z – نشان داده شد ، در حالی که برای آزمایش با استفاده از شدت های اضافی، هر نقطه در زیر مجموعه به عنوان یک بردار 4 بعدی با x -، y -، z – مختصات و شدت. تعداد نقاط نمونه برداری شده در هر زیرمجموعه برابر با [ 13 ] تنظیم شد]. یعنی در روشهای PointNet و PointNet++ 8192 نقطه بدون جایگزینی از هر زیر مجموعه نقاط انتخاب شد، در حالی که هنگام اجرای استراتژی چند مقیاسی در روش HDA-PointNet++، زیر مجموعههایی از نقاط با مقیاسهای مختلف تولید کردیم. آموزش شبکه ها با این زیرمجموعه نقاط با مقیاس های مختلف نیز به صورت انفرادی انجام شد. بنابراین، ما توانستیم ویژگیهای رمزگذاریشدهای را که سطوح مختلف اطلاعات زمینهای را از نقاط محصور میکند، بدست آوریم. با در نظر گرفتن مقیاس واقعی اشیاء (به عنوان مثال، ساختمان ها، درختان، پوشش گیاهی کم)، اندازه زیرمجموعه نقاط به طور تجربی برای مقیاس های مختلف به ترتیب 10000، 20000 و 30000 تنظیم شد، زیرا آنها عملکرد رضایت بخشی را در آزمایش ها نشان دادند.
برای اعتبارسنجی و نظارت بر فرآیند آموزش، 10 درصد از نمونه های آموزشی از مجموعه داده های آموزشی به طور مستقیم برای اعتبار سنجی انتخاب شدند. در فرآیند آموزش، از بهینه ساز Adam با نرخ یادگیری اولیه 0.001، مقدار حرکت 0.9 و اندازه دسته ای 16 استفاده شد. نرخ یادگیری به طور مکرر بر اساس دوره فعلی با ضریب 0.7 کاهش یافت. روند آموزش در مجموع 500 دوره به طول انجامید، به این معنی که شرایط پایان دوره آموزشی با 500 دوره تعیین شد. اگر کاهش تمرین ظاهراً کاهش یابد، وزنهها ذخیره میشوند. علاوه بر این، مدلها بر اساس بالاترین OA در مجموعه اعتبارسنجی انتخاب شدند. با توجه به سخت افزار مورد استفاده در آزمایشات،
5.2. نتایج طبقهبندی مجموعه داده LASDU با استفاده از موقعیتهای نقطه
اولین گروه از آزمایش ها با مختصات سه بعدی نقاط بدون استفاده از ویژگی های دیگر انجام شد که صرفاً بر اساس ویژگی های هندسی نقاط بود. ما در نهایت به OA 83.11% برای برچسب زدن پنج کلاس با روش HDA-PointNet++ در مجموعه داده LASDU خود دست یافتیم. علاوه بر این، ما مقایسه ای با دو روش دیگر ارائه کردیم که نشان داد، با در نظر گرفتن استراتژی چند مقیاسی، روش HDA-PointNet++ توانست از دو خط پایه دیگر بهتر عمل کند. جدول 2نتایج طبقه بندی هر سه روش را فهرست می کند. با توجه به دقت کلی، میتوانیم مشاهده کنیم که HDA-PointNet++ با استفاده از ویژگیهای عمیق چند مقیاسی میتواند در درجه اول عملکرد طبقهبندی را با افزایش OA تا حدود 17 درصد در مقایسه با PointNet++ بهبود بخشد. این به این دلیل است که برای شبکه عصبی عمیق مبتنی بر نقطه، تقسیم بندی و نمونه برداری از ابرهای نقطه ای در صحنه های بزرگ شهری موضوع مهمی است که مستقیماً بر نتایج طبقه بندی تأثیر می گذارد. PointNet که از ویژگی های عمیق تک مقیاسی استفاده می کند، در مدیریت اشیاء شهری با مقیاس های مختلف مشکل دارد. به عنوان یک پیشرفت، PointNet++ نمونه گیری و گروه بندی را با مقیاس های مختلف معرفی کرد که می تواند نتایج طبقه بندی را بهبود بخشد. از آنجایی که مجموعههای نقطهای تقسیمشده مبنایی برای ارائه اطلاعات متنی از خوشهبندی نقاط بودند، مقیاس های هر مجموعه امتیاز باید آزمایش و بررسی شود. به جای جستجوی اندازه مقیاس بهینه برای مجموعه نقاط تقسیم شده، از یک استراتژی سازش استفاده کردیم. در اینجا، روش HDA-PointNet++ ویژگی های عمیق استخراج شده را با استفاده از یک استراتژی تقسیم سلسله مراتبی با ویژگی های استخراج شده مستقیم از شبکه مقایسه کرد. با استفاده از استراتژی تقسیم سلسله مراتبی، می توان برخی از حوزه های طبقه بندی اشتباه را اصلاح کرد. در مقایسه با روشهای تک مقیاسی، ویژگیهای چند مقیاسی هم از نظر آمار دقت و هم از نظر تجسم در نقشه طبقهبندی، عملکرد بهتری در نتایج طبقهبندی داشتند. روش HDA-PointNet++ ویژگی های عمیق استخراج شده را با استفاده از یک استراتژی تقسیم سلسله مراتبی با ویژگی های استخراج شده مستقیم از شبکه مقایسه کرد. با استفاده از استراتژی تقسیم سلسله مراتبی، می توان برخی از حوزه های طبقه بندی اشتباه را اصلاح کرد. در مقایسه با روشهای تک مقیاسی، ویژگیهای چند مقیاسی هم از نظر آمار دقت و هم از نظر تجسم در نقشه طبقهبندی، عملکرد بهتری در نتایج طبقهبندی داشتند. روش HDA-PointNet++ ویژگی های عمیق استخراج شده را با استفاده از یک استراتژی تقسیم سلسله مراتبی با ویژگی های استخراج شده مستقیم از شبکه مقایسه کرد. با استفاده از استراتژی تقسیم سلسله مراتبی، می توان برخی از حوزه های طبقه بندی اشتباه را اصلاح کرد. در مقایسه با روشهای تک مقیاسی، ویژگیهای چند مقیاسی هم از نظر آمار دقت و هم از نظر تجسم در نقشه طبقهبندی، عملکرد بهتری در نتایج طبقهبندی داشتند.
نتایج طبقه بندی بصری در شکل 14 نشان داده شده است. مشاهده می شود که نتیجه PointNet++ عملکرد خوبی را نشان داد که نشان دهنده کارایی شبکه عصبی عمیق در ارائه ویژگی های تولیدی است. همچنین می توان مشاهده کرد که روش های مختلف خروجی های کاملاً متنوعی را نشان می دهند. به طور خاص، برای دستهای از مصنوعات با اشیاء بسیار پیچیده، PointNet به سختی نتیجه درستی برای برجستگیهای روی زمین برهنه به دست میآورد. در مقابل، PointNet++ با معرفی استراتژی نمونهبرداری و گروهبندی، به اشیا در مقیاس کوچک و بزرگ حساس میشود و بنابراین میتوان چنین مصنوعات کوچک و پیچیدهای را به درستی برچسبگذاری کرد. با این حال، برای پوشش گیاهی کم و درختان در میان ساختمانهای بسیار متراکم، PointNet++ نتوانست با این موارد مقابله کند. در مقابل، روش HDA-PointNet++ با ساختار سلسله مراتبی میتواند این موضوع را به روشی قویتر و سازگارتر مدیریت کند. بنابراین، میتوان نتیجه گرفت که ویژگیهای عمیق چند مقیاسی، توصیف بالاتری را ارائه میدهند. از سوی دیگر، از جنبه مجموعه داده، ما همچنین می توانیم اظهار کنیم که مجموعه داده LASDU ما چالش برانگیزتر از مجموعه داده معیار کلاسیک ISPRS است، اگرچه دارای دسته های بیشتری از اشیاء است. با این حال، چنین سناریوهای پیچیده شهری موارد مکرر زمانی هستند که ما نقشه برداری سه بعدی در مقیاس بزرگ را در مناطق مسکونی انجام می دهیم.
5.3. نتایج طبقه بندی مجموعه داده LASDU با استفاده از شدت نقطه اضافی
از آنجایی که شدت نقطه اطلاعات قابل اعتمادی است و به طور مکرر در بسیاری از برنامه های کاربردی داده LiDAR استفاده می شود، گروه دوم آزمایش ها با مختصات سه بعدی نقاط با شدت انجام شد که نتایج آن بر اساس ویژگی های هندسی و ویژگی های رادیومتری نقاط بود. در این آزمایش نتایج روشهای PointNet++ و HDA-PointNet++ را مقایسه کردیم. در نهایت، برای برچسب گذاری پنج کلاس از اشیاء در مجموعه داده LASDU، به مقادیر OA 82.84٪ و 84.37٪ رسیدیم. جدول 3نتایج طبقه بندی دقیق این دو روش را فهرست می کند. همانطور که از جدول مشاهده می شود، می توان افزایش قابل توجهی در دقت طبقه بندی PointNet++ با افزایش OA بیش از 15٪ مشاهده کرد. این عمدتا به دلیل افزایش دقت در مورد پوشش گیاهی کم است. با معرفی شدت، از آنجایی که اشیاء با پوشش گیاهی کم همیشه در مقایسه با مصنوعات دست ساز دارای شدت های متفاوتی هستند، نقاط این دو طبقه راحت تر از هم جدا می شوند. نتایج HDA-PointNet++ نشان می دهد که افزایش اندکی OA در حدود 1٪ را تجربه کرده است که به ویژه قابل توجه نیست. این به دلیل این واقعیت است که نمونهبرداری سلسله مراتبی داده و تقویت در HDA-PointNet++ پتانسیل این روش را به طور کامل بررسی کرده است، به این معنی که شدتها به سختی کمک بیشتری به بهبود دقت میکنند.
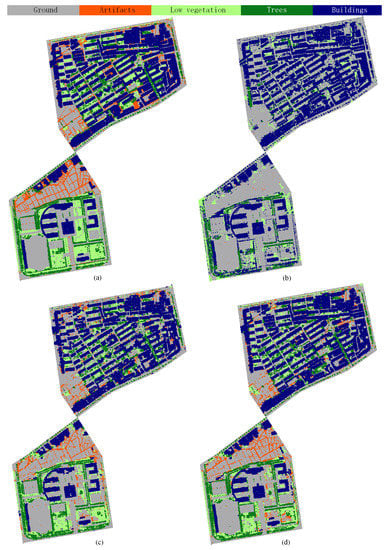
علاوه بر این، نتایج طبقهبندی بصری در شکل 15 آورده شده است. همانطور که مشاهده می شود، عملکرد PointNet++ به طور قابل توجهی بهبود یافته است که نشان دهنده سهم استفاده از شدت است. نقاط علف و برآمدگی هایی که به درستی برچسب گذاری شده اند در زمین برهنه به وضوح قابل مشاهده هستند. علاوه بر این، درختان و بوته های شلوغ توسط ساختمان های فشرده بسته را می توان جدا کرد و همچنین برچسب گذاری کرد. به طور مشابه، روش HDA-PointNet++ با ساختار سلسله مراتبی کیفیت مشابهی از نتایج را نشان می دهد. بنابراین، به عنوان یک نتیجه، میتوانیم اظهار کنیم که برای برچسبگذاری معنایی روی مجموعه داده LASDU ما که در یک منطقه ساختمانی بسیار پیچیده به دست آمده است، نه تنها ویژگیهای هندسی نقش حیاتی دارند، بلکه ویژگیهایی مانند شدتها نیز میتوانند در تمایز نقاط اشیاء مختلف نقش داشته باشند. این همچنین شاخصی از استفاده از مجموعه داده ما در ارزیابی روش پیشنهادی جدید ارائه می دهد. در شکل 16ما همچنین دو منطقه نمونه از بخشهای 1 و 3 (یعنی دادههای آزمایشی) را برای نشان دادن جزئیات در مناطق ساختمانی متراکم پر از درختان و پوشش گیاهی کم انتخاب کردیم. واضح است که وقتی مقادیر شدت به داده های ورودی اضافه می شود، هر دو روش می توانند به نتایج طبقه بندی رضایت بخشی برای ساختمان ها، زمین ها و درختان دست یابند. با این حال، برای نتایج بهدستآمده از PointNet++ اصلی، نقاط بیشتری با برچسب نادرست عایقبندیشده برای پوشش گیاهی و مصنوعات کم وجود دارد، در حالی که برای ساختمانهای مستقل، آنها به اشتباه بهعنوان ساختمانهای متصل شناخته میشوند (ساختمانهای مجاور را در جعبه خط تیره سفید شکل 16 ببینید.آ). برای روش HDA-PointNet++ با در نظر گرفتن ضریب مقیاس، نقاط برچسبگذاری شده احتمالاً میتوانند یک مرز واضح و صاف را برای اشیاء جداگانه نگه دارند، به عنوان مثال، مرز بین ساختمانها و درختان و مرزهای بین درختان و پوشش گیاهی کم. علاوه بر این، از آنجایی که مقیاس درختان و ساختمانها به طور قابلتوجهی متفاوت است، نتیجه HDA-PointNet++ میتواند از خطاهای بزرگ و ادامه دار هنگام برچسبگذاری نقاط ساختمانها جلوگیری کند (منطقه را در کادر خط تیره سفید شکل 16 ج ببینید). این امر به ویژه هنگام ترسیم سناریوی شهری از دادههای ALS بسیار ارزشمند است.
5.4. بحث در مورد استراتژی سلسله مراتبی/چند مقیاسی برای برچسب گذاری معنایی شهری در مقیاس بزرگ
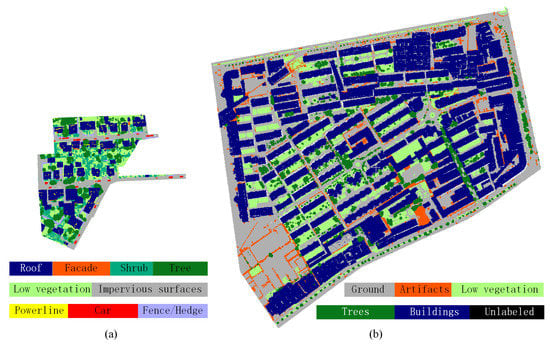
با توجه به دو گروه آزمایش بالا، میتوانیم ببینیم که روش HDA-PointNet++ با یک استراتژی افزایش سلسله مراتبی دادهها نشاندهنده پیشرفت قابلتوجهی نسبت به روش اصلی PointNet++ است، اگرچه ساختار شبکه اصلی یکسانی دارند. همانطور که قبلا ذکر کردیم، مقیاس در هر دو توصیف هندسی و رادیومتری شی نقش دارد. مقیاس نامناسب نمونهبرداری فقط میتواند تا حدی شی را نشان دهد، که منجر به توصیف ویژگی ناقص یا بیش از حد پوشانده میشود، افزایش چند مقیاسی دادههای ورودی، عمومیت شبکه عصبی آموزشدیده را افزایش داده است، که باعث میشود ویژگیهای کدگذاری شده با مقیاس سازگار شوند. از شی سناریوی پیچیده با ساختمانهای متراکم و شلوغ در مجموعه داده ما، دشواری را افزایش میدهد و سهم استراتژی چند مقیاسی را برجسته میکند. با این حال، در سایر مجموعههای داده معیار کلاسیک – به عنوان مثال، مجموعه داده Vaihingen – روشهایی که از یک استراتژی سلسله مراتبی یا چند مقیاسی استفاده میکنند نیز عملکرد امیدوارکنندهای را نشان میدهند. ما نتایج روش های طبقه بندی از جمله LUH را جمع آوری و مقایسه کرده ایم.35 ]، PointNet++ [ 34 ]، شبکه عصبی کانولوشنال چند مقیاسی (MCNN) [ 36 ]، شبکه عصبی واحدهای خطی اصلاح شده (ReLu-NN) [ 37 ]، PointNet در مقیاس های چندگانه (PointNet-MS) [ 38 ] تعبیه نقطه عمیق (DPE) [ 13 ]، شبکه هندسی توجه (GA-Conv) [ 39 ]، و شبکههای مبتنی بر نمایش وکسل و پیکسل (VPNet) [ 40]، و میتوانیم ببینیم که برای روشهایی که مستقیماً روی نقاط سهبعدی کار میکنند، آنهایی (مانند LUH، DPE، و GA-Conv) که از یک استراتژی سلسله مراتبی یا چند مقیاسی استفاده میکنند، عملکرد قابلتوجهی نشان میدهند. به عنوان مثال، روش GA-Conv یک معماری سلسله مراتبی متراکم و ماژول ارتفاع-توجه را پیشنهاد کرد و به یک نتیجه امیدوارکننده دست یافت. علاوه بر این، روش VPNet که هم پیکسل ها و هم وکسل ها را جمع آوری می کند، نمایش مقیاس های مختلف را نیز در نظر می گیرد و نقاط مجزا جدا شده را به هم متصل می کند و عملکرد عالی با میانگین امتیاز F1 73.9٪ به دست می آورد. همه این نتایج نشان می دهد که عامل مقیاس در نظر گرفته شده از طریق یک استراتژی چند مقیاسی یا سلسله مراتبی به برچسب گذاری معنایی در فضای باز کمک می کند، به ویژه برای صحنه های شهری متراکم و پیچیده، که کمی با موارد داخلی متفاوت است. بدین ترتیب،18 ]، بلکه روشهای مبتنی بر یادگیری عمیق نیز باید مقیاسها را در ورودی داده یا مستقیماً در طراحی شبکه عصبی در نظر بگیرند.
6. نتیجه گیری
در این مقاله، ما یک مجموعه داده ابر نقطه LiDAR هوایی را در مقیاس بزرگ ارائه میکنیم که در یک منطقه شهری بسیار متراکم برای ارزیابی روشهای برچسبگذاری معنایی به دست آمده است. این مجموعه داده یک منطقه شهری با ساختمان های بسیار متراکم تقریباً 1 کیلومتر مربع را پوشش می دهدو بیش از 3 میلیون امتیاز را شامل می شود. این مجموعه داده به صورت دستی در پنج دسته از اشیاء حاشیه نویسی شد: زمین، ساختمان ها، درختان، پوشش گیاهی کم، و مصنوعات. با ویژگیهای مشابه و طبقهبندی نقاط حاشیهنویسی، اما سناریوهای چالش برانگیزتر و اندازه بزرگتر، این مجموعه داده مکمل قابل توجهی برای مجموعه دادههای برچسبگذاری معنایی ISPRS 3D است که معمولاً استفاده میشود. آزمایشها با نتایج چندین روش پایه انجام شد. به عنوان یک نتیجه، میتوان گفت که مجموعه داده پیشنهادی LASDU امکانسنجی و قابلیت آن را نشان میدهد که به عنوان معیاری برای ارزیابی روشهای برچسبگذاری معنایی عمل میکند. علاوه بر این، آزمایشهای انجامشده ارزیابی روشهای مبتنی بر یادگیری عمیق را با در نظر گرفتن استراتژیهای مقیاس مختلف ارائه میدهند. به این معنی که تأثیر عوامل مقیاس در شبکه عصبی عمیق برای برچسبگذاری معنایی ابر نقطه در سناریویی که در آن اجسام دارای اندازههای هندسی متفاوتی هستند، تحلیل میشود. مجموعه داده LASDU یک مجموعه داده معیار ALS جدید را در یک صحنه شهری بسیار پیچیده با ساختمان های بسیار متراکم ارائه می دهد. هدف از ارائه این مجموعه داده ابر نقطه ای جدید تشویق توسعه روش های برچسب گذاری معنایی عملی و نوآورانه برای کاربردهای شهری است. در آینده، مجموعه داده برای دسترسی جامعه منتشر میشود و دستهها و برچسبهای این مجموعه داده جدید میتوانند با بازخورد آزمایشها و ارزیابیهای بیشتر بهبود و به روز شوند. مجموعه داده LASDU یک مجموعه داده معیار ALS جدید را در یک صحنه شهری بسیار پیچیده با ساختمان های بسیار متراکم ارائه می دهد. هدف از ارائه این مجموعه داده ابر نقطه ای جدید تشویق توسعه روش های برچسب گذاری معنایی عملی و نوآورانه برای کاربردهای شهری است. در آینده، مجموعه داده برای دسترسی جامعه منتشر میشود و دستهها و برچسبهای این مجموعه داده جدید میتوانند با بازخورد آزمایشها و ارزیابیهای بیشتر بهبود و به روز شوند. مجموعه داده LASDU یک مجموعه داده معیار ALS جدید را در یک صحنه شهری بسیار پیچیده با ساختمان های بسیار متراکم ارائه می دهد. هدف از ارائه این مجموعه داده ابر نقطه ای جدید تشویق توسعه روش های برچسب گذاری معنایی عملی و نوآورانه برای کاربردهای شهری است. در آینده، مجموعه داده برای دسترسی جامعه منتشر میشود و دستهها و برچسبهای این مجموعه داده جدید میتوانند با بازخورد آزمایشها و ارزیابیهای بیشتر بهبود و به روز شوند.











بدون دیدگاه