

تخمین موقعیت دوربین با استفاده از پایگاه های داده مشترک و تصویر ساختمان واحد
چکیده
شهرها دائما در حال تغییر هستند و مدیران شهری قصد دارند مدل دیجیتالی به روز شهر را برای اداره شهر حفظ کنند. روزانه تصاویر زیادی در پلتفرم های اشتراک گذاری تصویر (به عنوان «فلیکر»، «توئیتر» و غیره) آپلود می شود. این تصاویر دارای محلی سازی خشن و بدون اطلاعات جهت هستند. با این وجود، آنها می توانند به پر کردن یک پایگاه داده مشارکتی فعال از تصاویر خیابانی که برای حفظ یک مدل سه بعدی شهر قابل استفاده است کمک کنند، اما محلی سازی و جهت گیری آنها باید شناخته شود. بر اساس این تصاویر، ما سیستم جمعآوری دادهها را برای تخمین وضعیت تصویر (DGPE) پیشنهاد میکنیم که به یافتن ژست (موقعیت و جهت) دوربین مورد استفاده برای عکاسی با دقت بهتری نسبت به مکانیابی تنها GPS که ممکن است در تصویر تعبیه شده باشد، کمک میکند.

هدر تصویر DGPE از اطلاعات بصری و معنایی استفاده می کند، موجود در یک تصویر واحد پردازش شده توسط یک زنجیره کاملا اتوماتیک متشکل از سه لایه اصلی: لایه بازیابی داده و پیش پردازش، لایه استخراج ویژگی ها، لایه تصمیم گیری. در این مقاله، کل جزئیات سیستم را ارائه می کنیم و نتایج تشخیص آن را با روش پیشرفته مقایسه می کنیم. در نهایت، ما بومیسازی بهدستآمده و اغلب نتایج جهتگیری را نشان میدهیم که پردازش اطلاعات معنایی و بصری را روی 47 تصویر ترکیب میکند. سیستم چندلایه ما در 26 درصد از موارد آزمایشی ما در یافتن محلی سازی و جهت گیری بهتر عکس اصلی موفق شده است. این تنها با استفاده از محتوای تصویر و ابرداده مرتبط به دست می آید. استفاده از اطلاعات معنایی یافت شده در شبکه های اجتماعی مانند نظرات، هش تگ ها و غیره میزان موفقیت را دو برابر کرده و به 59 درصد رسانده است. این منطقه جستجو را کاهش داده و در نتیجه جستجوی بصری را دقیق تر کرده است.
کلید واژه ها
تشخیص ژست ، تشخیص ساختمان ، تک تصویر ، نقشه دوبعدی ، کارتوگرافی مشارکتی ، رسانه های اجتماعی
1. مقدمه
امروزه، مدیران شهری از نمایندگی دیجیتال شهر خود به خوبی استفاده می کنند و بنابراین نیاز شدیدی به به روز نگه داشتن آن دارند. طبق [ 1 ] چنین نمایشی برای مدیریت شهری مانند برنامه ریزی، تجزیه و تحلیل، مالیات، امنیت و بسیاری از اهداف دیگر استفاده می شود . فراتر از این، یک روند داده باز وجود دارد که شامل انتشار اطلاعات شهر برای عموم مردم است. به عنوان مثال، برخی از شهرها، مانند شهر نیویورک، به برخی از داده های جغرافیایی دسترسی دارند که روزانه در [ 2 ] به روز می شوند. دستورالعمل اروپایی Inspire [ 3 ] همچنین چارچوبی برای به اشتراک گذاری داده های جغرافیایی در اروپا ارائه می دهد و شهرهایی مانند لیون در فرانسه از آن پیروی می کنند و از طریق یک پورتال داده باز به داده های جغرافیایی شهری خود دسترسی می دهند [ 4 ].]. به روز رسانی سیستم های اطلاعات جغرافیایی (GIS) به کارکنان و تجهیزات نیاز دارد. برخی از ایالت ها، شهرها یا شرکت های خصوصی از تصاویر هوایی استفاده می کنند و برخی دیگر از زمین اسکن می کنند. هر دو تکنیک نیاز به هزینه و تلاش دارند.
از سوی دیگر، شهروندان اکنون به دستگاههای الکترونیکی مجهز شدهاند که میتوانند عکس، فیلم، مکانهای GPS و سایر دادههای جالبی که میتوانند با افراد دیگر به اشتراک بگذارند، تهیه کنند. در سال 2015، 58 درصد از جمعیت فرانسه تلفن های هوشمند داشتند [ 5 ]، و برخی از آمارهای اخیر مانند [ 6 ] نشان می دهد که این تعداد از 67 درصد در سال 2015 به 77 درصد در اواخر سال 2016 در ایالات متحده افزایش یافته است. شبکه جهانی وب در دهه های گذشته در حال تکامل بوده است. برخی از وبسایتها برای اتصال افراد (مثلا فیسبوک) ایجاد شدند، اما به سرعت معلوم شد که تصاویر، رویدادها و پلتفرم اشتراکگذاری اطلاعات جغرافیایی هستند، طبق [ 7 ]شماره های ] برخی از وب سایت های دیگر برای به اشتراک گذاری تصاویر بین عکاسان یا ایجاد یک نمونه کار دیجیتال ایجاد شده اند. در نهایت، وبسایتهایی مانند Openstreetmap.org بستری برای افزودن یا اصلاح اطلاعات جغرافیایی مانند جادهها، ساختمانها، نام فروشگاهها و حتی نیمکتها و درختان فراهم کردند. این بخشی از رویکردهای نقشه برداری مشارکتی است که از زمان جنبش اطلاعات جغرافیایی داوطلبانه (VGI) به رهبری [ 8 ] به طور فزاینده ای در دسترس هستند . اخیراً، گوگل بستری برای به اشتراک گذاری تصاویر و اطلاعات جغرافیایی و دادن جوایز در ازای تشویق مردم برای مشارکت در غنی سازی پایگاه داده خود فراهم کرده است [ 9 ].
در این مقاله پیشنهاد می کنیم از داده های این منابع فعال برای به روز رسانی اطلاعات شهر استفاده کنید. تصاویر به اشتراک گذاشته شده به صورت عمومی ممکن است منبع اطلاعات جالبی باشند. متأسفانه، محلی سازی آنها به اندازه کافی دقیق نیست: طبق [ 10]، میانگین خطای یک حسگر عمومی GNSS در زیر آسمان 3/5 متر است و این حاشیه خطا در محیط های شهری به دلیل انعکاس سیگنال بر روی سازه های بتنی و فلزی افزایش می یابد. همچنین، این تصاویر شامل هیچ گونه اطلاعات جهتگیری در فراداده خود نمیشوند. هدف DGPE جمع آوری این تصاویر و تلاش برای اصلاح جغرافیایی آنها و یافتن جهت تصویر است. ما از ویژگیهای استخراجشده تصویر و ابردادههای آن برای تلاقی آنها با سایر اطلاعات جغرافیایی برای ارائه یک ژست دوربین دقیق استفاده میکنیم. مدیران GIS شهر، با محلیسازی تصویر متریک و جهتگیری، میتوانند از این اطلاعات برای شروع تحقیق و بهروزرسانی مدل سهبعدی شهر یا پایگاه داده نمای خیابان در صورت مشاهده تغییرات استفاده کنند.
این مقاله به شرح زیر تقسیم شده است. ابتدا آثار مرتبط در زمینه زمینیابی را بر اساس تصاویر واحد ارائه میکنیم. سپس DGPE را ارائه می کنیم و هر لایه را به تفصیل شرح می دهیم. ما روش تشخیص ساختمان را که آن را تشخیص ساختمان مبتنی بر بخشها (SBBD) نامیدهایم توصیف میکنیم و نتایج آن را در بسیاری از چالشهای پردازش تصویر نشان میدهیم. در نهایت، ما برخی از نتایج و مطالعات موردی DGPE را ارائه میکنیم، آماری را برای دو پایگاه داده تصویر نشان میدهیم و نتیجه میگیریم.
2. کارهای مرتبط
مکانیابی تصویر یک فرآیند طولانی و پیچیده است که شامل یافتن مکان دقیق تصویر روی زمین است. این مکان، که توسط عرض جغرافیایی، طول جغرافیایی و ارتفاع تعریف میشود، باید با جهتگیری، زوایای شیب و رول از پارامترهای دوربین گسترش یابد تا بتوان وضعیت دوربین و در نتیجه آن چیزی را که یک تصویر نشان میدهد، تعیین کرد. بنابراین، کارهای تحقیقاتی زمینشناسی تصویر در دو مقیاس اصلی انجام شده است و به این ترتیب: «تصویر جغرافیایی» که یک زمینشناسی گسترده (مثلاً یک کشور، یک شهر یا نوع طبیعتی که تصویر در آن گرفته شده است) را برمیگرداند، مانند [ 11 ] و [ 12 ]، و «تشخیص موقعیت» که جستجو را به یک ناحیه کاهش یافته محدود میکند که در آن میتوانیم از دادههای مرجع دقیقتری برای یافتن مکانیابی دقیق جغرافیایی و جهتگیری دوربین استفاده کنیم، همانطور که برای [ 13 ] [ 13].14 ] [ 15 ] [ 16 ] و [ 17 ].
ما در بخش اول این بخش چند رویکرد جغرافیایی سازی تصویر و همچنین برخی از رویکردهای تشخیص پوس ارائه می دهیم، سپس برخی از روش های تشخیص ساختمان را با استفاده از پردازش تصویر ارائه می کنیم که سپس به ما کمک می کند تا پوز را اصلاح کنیم تا ارتباط بین تصویر و اطلاعات GIS پیدا کنیم.
2.1. ژئولوکیشن تصویر و تشخیص پوس با استفاده از اطلاعات هندسی و معنایی
نویسندگان [ 11 ] سیستمی را ارائه می دهند که 24/7 برای دانلود خودکار تصاویر و استخراج دانش بصری از داده های اینترنتی اجرا می شود. این سیستم اشیاء، صحنه ها و روابط عام را در تصاویر دانلود شده کشف می کند. هدف این سیستم حاشیه نویسی یک تصویر با حداقل تلاش انسان برای برچسب زدن است. این رویکرد در برخی موارد به یافتن موقعیت جغرافیایی خارج از محتوای تصویر کمک می کند، به عنوان مثال، یک برج کج به پیزا در ایتالیا اشاره دارد، یک هرم به مصر و غیره اشاره دارد.
تحقیق دیگری، [ 12 ]، تنها از توصیفگرهای بافت تصویر و یادگیری عمیق برای یافتن موقعیت جغرافیایی آن استفاده می کند. نویسندگان اشاره می کنند که یافتن مکان تصویر تنها با استفاده از اطلاعات بافت ها “بسیار دشوار” به نظر می رسد. با این حال، نویسندگان از محتوای تصویری مانند نقاط دیدنی، الگوهای آب و هوا، پوشش گیاهی، خطکشی جادهها و جزئیات معماری برای انجام این کار استفاده میکنند. فقط 14.9 درصد از تصاویر دارای موقعیت جغرافیایی دقیق در مقیاس یک خیابان شهری (1 کیلومتر)، 20.3 درصد در مقیاس شهر (25 کیلومتر) هستند و بقیه بدتر هستند.
معماریهای حافظه بلندمدت (LSTM) [ 18 ] از چندین تصویر از یک آلبوم عکس استفاده میکنند و نتایج را به 32% از موقعیت جغرافیایی موفق در مقیاس خیابان و 42.1% در مقیاس شهر میرسانند. با این حال، مکانیابی تصویر ارائهشده در بالا برای بهروزرسانیهای GIS و تشخیص تغییرات در یک شهر به اندازه کافی دقیق نیست، زیرا آنها هنوز بهجای تخمین موقعیت دقیق، بهعنوان یک مکانیابی در مقیاس وسیع در نظر گرفته میشوند. دقت جغرافیاییسازی چنین تکنیکهایی برای اهداف تحقیقاتی ما کافی نیست، با این حال هنوز ایدهای در مورد محل عکسبرداری به دست میدهد.
در مقاله [ 13 ] نویسندگان در نظر دارند که ثبت خودکار با جفت کردن یک مدل GIS سه بعدی بافتدار و تصاویر دوبعدی راهی کارآمد برای شناسایی ساختمانها در یک تصویر یا یک جریان ویدیویی است. آنها کار خود را با این فرض شروع می کنند که تصاویر با جهت گیری معتبر و مکان GPS قبلاً در پایگاه داده ثبت شده است. این مقاله استخراج برای هر نمای ساختمان در تصاویر ثبت شده یک توصیف کننده بافت مربوطه را در نظر می گیرد. سپس، برای ثبت یک تصویر جدید، از توصیفگرهای SIFT توسط [ 14 ] استفاده می کند که با توصیفگرهای بافت ثبت شده مطابقت دارد. محدودیت این کار در چرخش افین (30 درجه یا بیشتر) نهفته است و نماهای ساختمان باید بسیار متفاوت از یکدیگر باشند تا از سردرگمی توصیفگرهای SIFT جلوگیری شود.
الگوریتم مورد استفاده در [ 19 ] با کاهش تعداد نامزدهای منطبق و تخصیص اولویتها به آنها، به تخمین پارامتر دوربین مبتنی بر نقطه عطف ویژگی سریع و دقیق دست مییابد. هدف آنها یافتن حالت دوربین با تطبیق تصویر با نشانه های شناخته شده است که قبلاً با دقت با استفاده از حسگر برد لیزری اسکن شده اند. بنابراین، یک پایگاه داده نشانه های مدل سه بعدی با چنین تکنیکی اجتناب ناپذیر است.
نویسندگان [ 20 ] ترکیبی از محلی سازی و نقشه برداری همزمان، به نام SLAM، و یک روش محلی سازی جهانی را پیشنهاد می کنند. نویسندگان یک برنامه AR ساخته شده بر روی دستگاه های هوشمند را در نظر می گیرند که از دو فریم اول برای مقداردهی اولیه ساختار از بازسازی حرکت استفاده می کند. سپس سرور محیط بازسازی شده را با یک ابر جهانی از نقاط مقایسه می کند. در نهایت، مشتری با استفاده از حسگرهای خود و اطلاعات اولیه، وضعیت فعلی را به روز می کند.
از سوی دیگر، Bioret و همکاران. [ 16 ] یک رویکرد محلیسازی در محیطهای شهری را بر اساس تطابق بین GIS دو بعدی و یک عکس خیابانی دو بعدی پیشنهاد میکند. عملا، Bioret از نقاط محو و محدودیت نماها در تصویر دو بعدی برای یافتن زوایای بین نماها و نسبت عرض آنها در ساختمان تصویر استفاده می کند. نویسندگان از این اطلاعات برای پرس و جو از یک GIS و دریافت موضع مربوطه استفاده می کنند. در نهایت، ما توجه می کنیم که الگوریتم منطقه جستجو را به محدوده 100 متر در اطراف یک نقطه اولیه محدود می کند و کاملاً خودکار نیست.
در نهایت، یک رویکرد مشابه [ 17 ] که GIS دوبعدی را با تصاویر دوبعدی تطبیق میدهد از تکنیک تشخیص خودکار ساختمان استفاده میکند. آنها به طور خودکار نقاط ناپدید را تشخیص می دهند، سپس بخش های عمودی را پیدا می کنند که باید گوشه های ساختمان را نشان دهند. سپس از تناظرهای هندسی بین ویژگیهای استخراجشده قبلی و یک نقشه دوبعدی برای یافتن موقعیتی که نزدیکترین حالت به اطلاعات اولیه GPS است، استفاده میکنند.
تصاویر شهری حاوی اطلاعات هندسی هستند که اشکال ساختمان و توصیفگرهای بافت را توصیف می کنند. علاوه بر این، اطلاعات معنایی، مانند ویترین فروشگاه ها، نام خیابان ها، و سایر متن های قابل تشخیص، می توانند اطلاعات محلی سازی را نشان دهند.
در [ 21 ]، نویسندگان سعی می کنند فروشگاه هایی را با استفاده از تصاویر شهر پیدا کنند. این سیستم متن را از تصویر استخراج می کند و با استفاده از لیست هایی مانند [ 22 ] و [ 23 ] با نام فروشگاه های اطراف محلی سازی تصویر مقایسه می کند .
2.2. تشخیص ساختمان و بازسازی صحنه های سه بعدی
در این بخش، برخی از روشهای تشخیص ساختمان را که توسط محققان دیگر توسعه داده شدهاند، ارائه میکنیم، زیرا از ساختمانهای شناساییشده در تصویر و اطلاعات GIS برای پالایش تصویر پوز استفاده میکنیم.
درک محیط شهری یک زمینه تحقیقاتی فعال است که تا حدی بر اساس استفاده از تصاویر خیابان است. چندین تکنیک مانند [ 24 ] [ 25 ] و [ 26 ] از استریوگرافی برای بازسازی محیط های شهری با استفاده از چندین تصویر یا توالی ویدئو استفاده کردند. با این حال، ما به دنبال بازسازی یک محیط شهری یا حداقل درک آن با استفاده از یک تصویر دو بعدی هستیم. بنابراین، روش های قبلی برای مجموعه داده های تصویر ما مناسب نیستند. درک هویم و همکاران [ 27 ] [ 28 ] روشی برای بازسازی محیط های سه بعدی با استفاده از تصاویر دو بعدی پیشنهاد می کند. آنها تصاویر خود را به سوپرپیکسل ها تقسیم می کنند و جهت هر کدام را تخمین می زنند. سوپرپیکسل گروهی از پیکسلها است که به یکدیگر نزدیک هستند و از نظر ویژگیهایشان شباهتهایی دارند. [ 29 ]] برای جزئیات بیشتر. آنها سوپرپیکسلهای تصویر را به سه دسته اصلی حاشیهنویسی میکنند: سطح زمین، میلههای سطح از زمین یا آسمان. سپس دسته دوم به چهار زیرمجموعه تقسیم می شود: سطوح رو به چپ، راست یا رو به دوربین و سطوح غیرمسطح مانند پوشش گیاهی. هدف نویسندگان درک محتوای تصویر نیست، بلکه هدف آن بازیابی جهت آن است. در [ 30 ]، نویسندگان سعی می کنند عمق هر پیکسل را از روی یک تصویر تک چشمی تخمین بزنند. آنها با برچسب گذاری پیکسل ها با استفاده از آنچه که آنها تقسیم معنایی صحنه می نامند، ادامه می دهند. آنها معتقدند که یک پیکسل با برچسب آسمان باید دور باشد، یک برچسب پیکسل دیگر به عنوان زمین افقی است، و غیره. علاوه بر این، [ 31] از الگوریتم های یادگیری آماری برای برچسب گذاری پیکسل ها بر اساس سه دسته عمودی، زمینی و آسمانی استفاده می کند. الگوریتم ها قبلاً با استفاده از سایر تصاویر شهری آموزش داده شده اند. الگوریتم عناصر عمودی یک تصویر، از جمله ساختمان ها را پیدا می کند، اما شکل ساختمان را پیدا نمی کند.
در نهایت، [ 17 ] سعی می کند گوشه های ساختمان را پیدا کند تا آنها را با یک نقشه دو بعدی مقایسه کند. آنها با محاسبه ویژگیهای Tilt-Invariant Corner Edge Position (TICEP) با اعمال متوالی تخمین نقطه ناپدید شدن، شناسایی لبه گوشه و عادیسازی زاویه شیب شروع میکنند. بخش مهمی از تشخیص TICEP، عادی سازی زاویه شیب است. برای این منظور، پارامترهای دوربین مانند چرخش و فاصله کانونی را برای انجام تصحیح نقطه ناپدید شدن عمودی تخمین می زنند. بنابراین، این روش آخر فقط می تواند مرزهای ساختمان را از دو طرف تشخیص دهد. به عبارت دیگر، تنها 3 لبه عمودی ساختمان قابل تشخیص است، حتی اگر تعداد بیشتری در دسترس باشد. لبه های عمودی موجود فقط می توانند به دو نما تبدیل شوند، اگرچه [ 16] ثابت کرد که وقتی نماهای بیشتری در دسترس باشد، تطبیق دو بعدی GIS او بسیار بهتر عمل می کند.
هدف ما اصلاح موقعیت جغرافیایی عکس های منتشر شده آنلاین است. بنابراین، ما فقط یک تصویر تک چشمی و اطلاعات GPS خشن بدون اطلاعات جهتگیری داریم. پس از بررسی تکنیکهای پیشرفته، آنهایی که بیشتر با مجموعه دادههای ما مطابقت دارند باید [ 16 ] یا [ 17 ] باشند. بنابراین ما در بخش 3 سیستم جمعآوری دادهها را برای تخمین موقعیت تصویر (DGPE) پیشنهاد میکنیم که به اصلاح جغرافیایی و جهتیابی تصویر با استفاده از یک تصویر واحد، یک نقشه دو بعدی و تکنیکهای مربوطه مانند [ 16 ] کمک میکند. ما فرآیند خود را با اطلاعات معنایی غنی می کنیم که می تواند از فراداده رسانه های اجتماعی، متن یا تشخیص نقاط عطف در عکس بازیابی شود.
3. سیستم جمعآوری داده برای تخمین وضعیت تصویر (DGPE)
در این بخش، سیستم DGPE را برای مکانیابی جغرافیایی تصویر با استفاده از اطلاعات ساده و گسترده پیشنهاد میکنیم. DGPE تصاویر دوبعدی ورودی را می گیرد، یا از مجموعه داده ای که قبلاً عکس گرفته ایم یا تصاویری که از وب سایت های رسانه های اجتماعی بارگیری شده اند (در مورد ما فلیکر). اطلاعات ورودی دوم نقشه های دو بعدی است که ساختمان های شهر را نشان می دهد.
تمام تصاویری که ارائه خواهیم داد توسط ما با استفاده از دستگاه آیفون 5 با سنسور GNSS گرفته شده است. برای ذخیره محلی سازی مرجع، مکان عکاس بر روی نقشه نمای ماهواره ای سنجاق شد و مختصات مکان پس از آن بازیابی شد. ما فرض می کنیم از منابع اطلاعاتی پویا در DGPE استفاده می کنیم (به طور منظم به روز می شوند)، بنابراین از نقشه های استخراج شده از OpenStreetMap.org استفاده می کنیم. ما همچنین از Nominatim API [ 32 ] استفاده کردیم. این API یک یا چند کلمه کلیدی را وارد می کند. برای هر کلمه کلیدی، فهرستی از محلی سازی های ممکن را برمی گرداند. این به هنگام استفاده از فراداده و اطلاعات معنایی، به دستیابی به نتایج محلی سازی بهتر کمک می کند. نتیجه نهایی DGPE یک مکان GPS و اطلاعات جهت دوربین است.
هنگامی که چندین نتیجه ممکن وجود دارد، DGPE قصد دارد بهترین نتایج بومی سازی را برای مدیران GIS شهر ارائه دهد تا به آنها کمک کند تصمیم بگیرند که آیا اطلاعات جغرافیایی را به روز کنند یا نه.
3.1. معماری سیستم سه لایه
ما یک سیستم سه لایه ایجاد کرده ایم و عملکردهای اصلی آن را در نمودار نشان داده شده در شکل 1 خلاصه کرده ایم.. اولین لایه DGPE “لایه بازیابی داده ها و پیش پردازش” است. این لایه نیازهای کاربر در مورد منطقه ای را که می خواهد تصاویر جدیدی در آن بیابد، به عنوان ورودی می گیرد. DGPE تصاویر را از یک مجموعه داده محلی می خواند یا تصاویر به اشتراک گذاشته شده در وب سایت های رسانه های اجتماعی را دانلود می کند و با نگه داشتن تنها مواردی که نیاز کاربر را تأیید می کنند، آنها را فیلتر می کند. “لایه استخراج ویژگی ها” قسمت دوم DGPE است. وظیفه آن استخراج ویژگی های موجود در بخش بصری تصویر از هر تصویر است. اطلاعات استخراج شده را به دو دسته تقسیم می کنیم: اطلاعات هندسی که نمایانگر شکل ساختمان است (نسبت ها و زوایای بین نماها) و اطلاعات معنایی که اطلاعاتی را در مورد مکان تصویر ارائه می دهد (آرم های فروشگاه، نام خیابان ها، نشانه ها، ابرداده ها و غیره). سپس اطلاعات معنایی و هندسی استخراج شده با سایر اطلاعات جغرافیایی مقایسه می شود که لیستی از موقعیت های دوربین یا اطلاعات محلی سازی را ایجاد می کند. لیست های به دست آمده در لایه بعدی با هم تلاقی داده می شوند تا مرتبط ترین آنها حفظ شود. لایه نهایی DGPE، “تصمیم گیری”،

شکل 1 . نمودار جهانی DGPE
به کاهش تعداد راه حل های لایه قبلی کمک می کند. نتایج حاصل از چندین منبع متقاطع خواهد شد و فقط برخی از آنها حفظ خواهند شد. یک فرآیند نهایی سعی میکند تا با مقایسه آنها با تصاویر خیابانهای جغرافیایی منتشر شده آنلاین، اعتبار این ژستها را تأیید کند.
3.2. لایه بازیابی و پیش پردازش داده ها
اولین لایه DGPE تصاویر را از پایگاه داده های محلی یا آنلاین بازیابی می کند و آنها را با استفاده از نیازهای کاربر فیلتر می کند. کاربر باید حداقل منطقه جستجویی را که می خواهد تصاویر را از آن استخراج کند مشخص کند. او همچنین ممکن است حداقل و حداکثر محدودیت تاریخ را اضافه کند تا از بازیابی تصاویری که قبلاً پردازش شده اند جلوگیری شود. ما DGPE را با استفاده از چندین ماژول طراحی کردهایم تا امکان تغییرات یا جایگزینی ماژولها را در آینده فراهم کنیم. این لایه شامل چهار ماژول است که در این بخش ارائه شده است.
ماژول بازیابی تصویر وظیفه جستجوی تصاویر از پایگاه داده تصویر را بر عهده دارد. دو گزینه برای تصاویر و بازیابی فراداده آنها در دسترس است: از یک مجموعه داده محلی یا یک پایگاه داده آنلاین. هنگام استفاده از ماژول بازیابی تصویر آنلاین، مزایای زیادی وجود دارد. ابتدا، تصاویر بازیابی شده متعلق به یک منطقه جغرافیایی محدود است که از قبل توسط کاربر DGPE تعیین شده است، عکسبرداری یا تاریخ آپلود تصویر نیز در نظر گرفته می شود. بنابراین، در این مورد با فیلتر کردن ابرداده ها شروع می کنیم. مزیت دوم، اطلاعات فراداده ای است که می توانیم از چنین پایگاه داده ای بازیابی کنیم. صرف نظر از مکان GPS، تاریخ عکسبرداری یا آپلود تصویر، تصاویر بازیابی شده از وب سایت های رسانه های اجتماعی نیز دارای برخی فراداده معنایی هستند که می توانند برای پردازش ما مفید باشند. ماژول هشتگ ها را بازیابی می کند، توضیحات و عناوین تصاویر که در قالب متن ساده هستند. از سوی دیگر، تصاویر بازیابی شده از مجموعه داده های محلی یا پایگاه داده هایی که ذخیره و امکان بازیابی EXIF را فراهم می کنند.1 ابرداده به ماژول استخراج کننده متا داده ارسال می شود.
این ماژول ساده اطلاعات جغرافیایی و پارامترهای عکسبرداری دوربین را استخراج می کند تا مراحل بعدی سیستم را اولیه کند. این تصاویر همچنین با استفاده از ماژول فیلتر تصویر با توجه به ابرداده های خود به ویژه اطلاعات مکان فیلتر می شوند تا مطمئن شوید که تصویر به منطقه مشخص شده کاربر تعلق دارد. نتایج هر دو ماژول بازیابی تصویر یک تصویر و اطلاعات موقعیت اولیه در مورد تصویر است. در صورت موجود بودن، فهرستی از کلمات استخراج شده از اطلاعات فراداده نیز برگردانده می شود. در نهایت در شکل 2(ب)، ماژول استخراج نقشه موقعیت GPS تصویر را می گیرد و از نقشه شهر یک منطقه محدود تقریباً 200 متر × 200 متر در اطراف مکان اولیه GPS استخراج می کند. ما فرض می کنیم که یک مربع لبه 200 متری خطای میانگین سنسورهای GNSS گوشی های هوشمند ارائه شده در [ 33 ] را دور می زند.
3.3. ویژگی های لایه استخراج
این لایه از DGPE مرحله مهمی از پردازش است. فراداده تصویر و اطلاعات معنایی استخراج شده در لایه قبلی برای یافتن مکان مفید هستند
 (الف)
(الف) (ب)
(ب)
شکل 2 . (الف) بازیابی تصویر و ابرداده؛ (ب) استخراج منطقه.
از تصویر ما با این حال، یافتن اطلاعات جهت و مکان دقیق دوربین
هدف اصلی DGPE باقی مانده است. تشخیص پوس را می توان با استفاده از ویژگی های هندسی مطابق با نقشه دو بعدی شهر انجام داد. ابتدا قسمت تحلیل معنایی این لایه را توضیح می دهیم و سپس قسمت هندسی را توضیح می دهیم.
3.3.1. تشخیص مکان با استفاده از بازیابی اطلاعات معنایی
شکل 3 ماژولی را نشان می دهد که برچسب های جغرافیایی احتمالی یک تصویر را با استفاده از اطلاعات ورودی متنی پیدا می کند. متن می تواند از فراداده تصویر استخراج شده از یک پایگاه داده آنلاین همانطور که در بالا توضیح داده شد باشد. تصاویر همچنین میتوانند شامل اطلاعات معنایی در بخشهای بصری خود باشند، مانند نشانهها، لوگوهای ویترین فروشگاهها، مبلمان شهری و متن. ما استخراج تشخیص متن را اعمال کرده ایم زیرا به طور خودکار اطلاعات متنی قابل مشاهده در تصویر را برمی گرداند. نشانوارههای فروشگاه و نشانههای شهر نیز ممکن است در چنین تحلیلی مفید باشند، ما مشتاقانه منتظر هستیم که آنها را در پیادهسازیهای بعدی لحاظ کنیم. چندین تکنیک تشخیص متن در کارهای قبلی [ 34 ] [ 35 ] [ 36 ] توسعه یافته است.]. در پیاده سازی خود، از Google Vision API استفاده کرده ایم، اما می توان آن را با هر روش تشخیص متن دیگری در یک تصویر جایگزین کرد.
یکی دیگر از جنبه های معنایی تصاویر ما محتوایی است که آنها نشان می دهند. تصاویر داخل یک منطقه شهری را می توان در خیابان ها گرفت و ساختمان ها را نشان داد، اما برخی دیگر ممکن است نشان دهنده مردم، غذا یا مکان های داخلی باشند. بنابراین از Google Vision API استفاده میکنیم تا مطمئن شویم تصویری که در DGPE استفاده میکنیم حاوی ساختمانها است. API لیستی از کلمات را که صحنه را برای هر تصویر توصیف می کند، برمی گرداند. ما فقط تصاویری را نگه می داریم که در لیست توضیحات آنها کلمات مربوط به ساختمان ها (مانند ساختمان، معماری، ملک، نما، شهر، خانه و غیره) وجود دارد و سایر تصاویر توسط سیستم حذف می شوند. فهرست کلمات بر اساس آماری که با استفاده از پاسخهای بازگرداندهشده از همان API انجام شد، انتخاب شد. کلمات انتخاب شده آنهایی هستند که دارای امتیاز اطمینان بالای 90٪ هستند که توسط API ارائه شده است.
در نهایت، فهرستی از اطلاعات متنی با استفاده از کلمات شناسایی شده از بخش بصری تصویر، و همچنین متن بازیابی شده از ابرداده تصویر موجود در پلت فرم اشتراکگذاری تصویر، ایجاد میشود. سپس لیست به آن منتقل می شود

شکل 3 . دارای لایه استخراج
یک ماژول جدید که برچسب های جغرافیایی را با استفاده از اطلاعات متنی پیدا می کند. همانطور که قبلاً در نمای کلی DGPE ارائه شد، برای این مرحله از Nominatim API استفاده می کنیم. منطقه جستجو محدود به منطقه محدودی است که قبلاً پیکربندی شده است. در لایه بعدی نحوه استفاده از این اطلاعات جغرافیایی را توضیح می دهیم.
3.3.2. تشخیص مکان با استفاده از بازیابی اطلاعات هندسی
ما در این بخش از DGPE فرض می کنیم که یک ساختمان را می توان با استفاده از بخش ها و چند ضلعی های مستطیلی ساده نشان داد. اکنون فرآیند هندسی جهانی را برای مکانیابی جغرافیایی تصویر توضیح میدهیم. ما بعداً ماژول تشخیص ساختمان توسعه یافته در این بخش از DGPE را به تفصیل توضیح خواهیم داد. ما می توانیم در شکل 3 یک ماژول به نام استخراج کننده ویژگی های بصری پیدا کنیم. هدف آن استخراج ویژگی های اساسی از یک تصویر شهری است. بنابراین ما در ماژول استخراج ویژگیها جستجو میکنیم تا تمام بخشهایی را که میتوان از تصویر استخراج کرد، پیدا کرد. برای این کار، ما از LSD [ 37] بخش استخراج کننده. چندین بخش با اندازه های مختلف را برمی گرداند. بخش های کوچک با استفاده از پارامتری نسبت به اندازه تصویر فیلتر می شوند. این بخشها معمولاً در ساختمانهای دور، درختان و سایر مبلمان شهری یافت میشوند که به ساختمان اصلی در تصویر مربوط نیستند. سپس بقیه بخش ها برای تشخیص نقاط ناپدید شدن و طرح کلی ساختمان ها استفاده می شود. سه نقطه ناپدید شدن در تصویر با استفاده از تکنیک [ 38 ] شناسایی می شود. در نهایت، نماهای ساختمان شناسایی شده و نقاط ناپدید شدن به ماژول تطبیق GIS منتقل میشوند که فهرستی از وضعیتهای دوربین را برمیگرداند. این ماژول از تکنیک ارائه شده در [ 16 ] استفاده می کند که زاویه بین نماها و همچنین نسبت طول آنها را مقایسه می کند تا موقعیت های ممکن را در نقشه منطقه محدود که قبلا استخراج شده است پیدا کند.
3.3.3. فرآیند تشخیص ساختمان
اکنون روش تشخیص ساختمان خود را توضیح می دهیم که در DGPE نسبت به روش های پیشرفته بهتر عمل می کند. این روش در طول فرآیند تطبیق GIS ذکر شده در بخش 3.3.2 استفاده خواهد شد.
1) تشخیص ساختمان مبتنی بر بخش ها (SBBD)
در ادامه روش Segments Based Building Detection (SBBD) خود را با استفاده از چندین الگوریتم که یکدیگر را کامل می کنند به منظور تشخیص نماهای ساختمان ارائه می دهیم. SBBD فقط از بخش های یافت شده با الگوریتم LSD [ 37 ] و همچنین نقاط ناپدید شده شناسایی شده استفاده می کند. نتیجه SBBD گروهی از نماها است که هر کدام توسط دو بخش عمودی و یک نقطه ناپدید شدن افقی ارائه می شوند. برای هر تصویر پردازش شده یک نقطه ناپدید عمودی در نظر گرفته می شود.
2) الگوریتم زنجیره بخش
ما اکنون استراتژی مورد استفاده برای گروهبندی مجدد بخشهای کوچک شناساییشده با استفاده از LSD [ 37 ] و فرآیند ساخت بخشهای بزرگتر را ارائه میکنیم که با تشخیص پوشش ساختمان ما مرتبطتر هستند.
تشخیص بخش LSD لیستی از بخشها با اندازههای مختلف را در اختیار ما قرار میدهد ( شکل 4 (الف)). برای جلوگیری از هزینههای محاسباتی بالا، ابتدا تعداد بخشهای کوچک را محدود کردهایم. در واقع، بخشهای کوچک در تصویر خیابان شهری معمولاً در درختان، ابرها و برخی مبلمان شهری یافت میشوند. یک پارامتر نسبت به اندازه تصویر به طور تجربی برای فیلتر کردن آن بخشها انتخاب شد.

شکل 4 . تشخیص کانتور ساختمان
سپس بخش ها را بر اساس ارتفاع از سطح زمین فیلتر می کنیم. فقط بالاترین بخش های تصویر برای SBBD مهم هستند. بنابراین، بخشهایی را که به زمین نزدیکتر هستند دور میاندازیم تا از محاسبات بیشتر جلوگیری کنیم و بخشهای مربوط به خودروها و عابران پیاده را فیلتر کنیم.
هنگامی که فیلتر انجام شد، هر دو بخش را در بین بخشهای باقیمانده مقایسه میکنیم و آنها را تا زمان همگرایی دوباره گروهبندی میکنیم. برای گروه بندی دو بخش، دو پارامتر قبلاً تعریف شده است: زاویه بین زمانی که پسوندهای بخش ها قطع می شوند، و حداقل فاصله ای که بخش ها را از هم جدا می کند. اگر زاویه بین تقاطع دو بخش کوچکتر از زاویه تعریف شده در تنظیمات SBBD باشد ( شکل 5 (ب))، و فاصله جداکننده لبه های دو بخش کوچکتر از حداکثر فاصله مشخص شده در پارامترهای SBBD باشد ( شکل 5 (الف) ، شکل 5 (ب))، بخش ها را می توان گروه بندی کرد. در غیر این صورت، بخش ها جدا باقی می مانند و در مراحل بعدی پردازش می شوند ( شکل 5 (ج)، شکل 5(د)). ما می توانیم دو مورد را هنگام گروه بندی مجدد دو بخش پیدا کنیم. حالت اول زمانی است که نتیجه زنجیره بخش ها با یکی از بخش های ورودی برابر است، بنابراین آن یکی را نگه می داریم و بخش دیگر را از لیست حذف می کنیم ( شکل 5 (ه)). حالت دوم زمانی است که نتیجه زنجیرهبندی بخشها بزرگتر از هر دو بخش است، بنابراین قطعه را به لیست اضافه میکنیم و هر دو بخش اصلی را حذف میکنیم ( شکل 5 (الف)، شکل 5 (ب)). نتیجه نهایی مانند شکل 4 (ب) است.
3) تشخیص بخش های پاکت ساختمان
در ادامه توضیح میدهیم که چگونه بخشها را فیلتر میکنیم تا فقط آنهایی که بخشهای پوشش ساختمان را نشان میدهند حفظ کنیم. بخش ها دو به دو تا همگرایی مقایسه می شوند. هر دو بخش برای آزمایش با هم مقایسه میشوند، و اگر اینطور باشد، ما فقط بالاترین بخش را نگه میداریم.
ابتدا بالاترین نقطه هر بخش را پیدا می کنیم تا بالاترین بخش را تعیین کنیم. سپس فاصله ای را که نقاط انتهایی بخش ها را از هم جدا می کند، مقایسه می کنیم. ما از یک مقدار تلورانس استفاده می کنیم تا از حذف قطعاتی که با تعداد کمی پیکسل با هم تداخل دارند جلوگیری کنیم (به مثال در شکل 6 (ب) مراجعه کنید).
مرحله بعدی شامل یافتن این است که آیا حداقل یک نقطه پایانی s 1 بین دو نقطه انتهایی s 2 قرار دارد یا خیر. این کار با مقایسه طرح افقی x آنها انجام می شود . در آن صورت، بخشها با هم همپوشانی دارند، فاصله همپوشانی بزرگتر از تلورانس است ( شکل 6 (ج) را ببینید)، SBBD فقط بخش بالاتر را نگه میدارد.
در نهایت، زمانی که بخش ها روی هم قرار نمی گیرند ( شکل 6 (الف) را ببینید)، SBBD هر دو بخش را نگه می دارد. نتیجه نهایی در شکل 4 (ج) ارائه شده است.
4) یافتن بخش های پوششی گمشده ساختمان
ما در نهایت الگوریتم مورد استفاده برای افزودن بخش های گمشده به پوشش ساختمان و گوشه های عمودی را در شکل 7 نشان می دهیم . ما با پیدا کردن پسوند هر بخش افقی، تقاطع آن با بخش بعدی شروع می کنیم. اگر نقطه تقاطع بین نقاط انتهایی دو بخش باشد، هر دو بخش را تا نقطه تقاطع آنها گسترش می دهیم، به مثال شکل 7 (الف) مراجعه کنید. اگر نقطه تقاطع متعلق به فاصله بین دو بخش نباشد.

شکل 5 . امکان گروه بندی

شکل 6 . احتمال همپوشانی بخش ها

شکل 7 . موارد بخش های گم شده را اضافه کنید.
نقاط پایانی، یک بخش جدید اضافه می کنیم که نقاط پایانی دو بخش را به هم مرتبط می کند ( شکل 7 (ب)). سپس بخشها را به نقاط منفرد کاهش میدهیم و آنهایی را که خیلی نزدیک هستند حذف میکنیم تا از تشخیص نماهای کوچک جلوگیری کنیم. سپس نقاط به بخش ها تبدیل می شوند و یک لبه عمودی در هر گوشه ساختمان اضافه می شود ( شکل 4 (د)). هر بخش عمودی باید با پایین تصویر قطع شود و از گوشه ساختمان و نقطه ناپدید شدن عمودی عبور کند.
3.4. لایه تصمیم گیری
در این لایه، ما فرآیند فیلتر اعمال شده را توضیح می دهیم تا فقط معقول ترین حالت های دوربین تصویر را حفظ کنیم.
شکل 8 ماژول تشکیل دهنده این لایه را نشان می دهد. این دو لیست از اطلاعات جغرافیایی را با هم مقایسه میکند: 1) مکانهای GPS، که برچسبهای جغرافیایی نیز نامیده میشوند، که از لایه قبلی با استفاده از تجزیه و تحلیل معنایی بهعلاوه موقعیت مکانی GPS اولیه تصویر پیدا شدهاند، و 2) موقعیتهایی که با تطبیق آنها شناسایی شدهاند. شکل ساختمان با GIS دو بعدی که قبلاً در پاراگراف توضیح داده شد تشخیص مکان با استفاده از بازیابی اطلاعات هندسی. این ماژول از برچسبهای جغرافیایی برای فیلتر کردن موقعیتهای یافت شده از تطابق هندسی استفاده میکند. هنگامی که زوایای مشترک ارائه می شود، برای مثال گوشه ساختمان 90 درجه یا ساختمان های پیوسته بدون محدودیت ساختمان ها مسدود می شوند، فرآیند تطبیق GIS تعداد زیادی راه حل را برمی گرداند. ما آن نتایج را با در نظر گرفتن هر برچسب جغرافیایی از لیست، تمام موقعیت های دوربین که در شعاع 20 متری وجود دارد، فیلتر می کنیم. پس از این فرآیند تعداد کمی پوز باقی می ماند.
ما انتخاب کرده ایم که تصویر اولیه را با سایر تصاویر بازیابی شده از GoogleStreetView مقایسه کنیم تا با ویژگی های بصری مطابقت داشته باشیم. برخی از تکنیکها، مانند [ 39 ]، از GoogleStreetView برای تشخیص وضعیت دوربین از تصویر استفاده میکنند. با این حال، تصاویر GoogleStreetView، در صورت وجود، هر پنج تا ده متر در یک خط مستقیم گرفته می شوند. نتایج تکنیک تطبیق GoogleStreetView نمی تواند به اندازه حالت های شناسایی شکل ساختمان مانند [ 16 ] دقیق باشد. امکانات بیشتری در تکنیک های تطبیق GIS موجود است. بنابراین، تصاویر را با استفاده از ژست های باقی مانده از GoogleStreetView دانلود می کنیم. سپس با استفاده از تطبیق توصیفگرهای SIFT آنها را با تصویر اصلی مقایسه می کنیم. این فرآیند به پوزیشنی که با استفاده از فرآیند تطبیق GIS پیدا کردهایم اعتماد میکند. از طرفی این مرحله

شکل 8 . لایه تصمیم گیری
اعتبار پوز را تایید نمی کند و برای یافتن حالت تصویر با مقایسه آن با تصاویر GoogleStreetView استفاده نمی شود. در نهایت، لایه یک یا چند حالت احتمالی دوربین را با امتیاز اطمینان بر اساس تعداد نقاط مطابقت با تصویر GoogleStreetView در صورت موجود بودن، به کاربر برمیگرداند.
4. نتایج
در این بخش، برخی از نتایج تشخیص ساختمان را با استفاده از روش خود ارائه می کنیم. ما روش خود را در شرایط آب و هوایی مختلف مقایسه می کنیم و استحکام آن را در برابر تغییرات آب و هوایی، سایه ها و برخی مشکلات انسداد ثابت می کنیم. سپس روش خود را با روشی که در [ 17 ] شرح داده شده است، با استفاده از مجموعه داده های خود و آنها مقایسه می کنیم. در نهایت، ما یک مطالعه موردی را نشان میدهیم که تکامل زنجیره پردازش ما را توضیح میدهد.
4.1. نتایج SBBD
ما SBBD را با استفاده از شرایط و مجموعه داده های مختلف آزمایش کرده ایم. در شکل 9 ، ما این روش را بر روی تصاویر شهری تحت دو شرایط آب و هوایی مختلف آزمایش کردهایم. در ردیف بالای شکل 9 ، تصاویر در ژانویه 2017 در یک روز آفتابی گرفته شدهاند. درختان کوچکتر و برخی بدون برگ بودند، برخی از ساختمان ها در معرض آفتاب و سایه آن بودند. در ردیف پایین شکل 9، تصاویر در آوریل 2017 در یک روز بارانی گرفته شده است. برگ های درختان شروع به ظاهر شدن کردند و خبر از بهار دادند، چند درخت دیگر روییده بودند و در برخی تصاویر داربست هایی برای بازسازی به ساختمان اضافه شد. با این حال، ما به همان تشخیص ساختمان دست یافته ایم. حتی اگر در برخی موارد تشخیص کامل ساختمان کامل نبود، همان اطلاعات را در مورد نماها و زاویه بین آن به ما می داد.
سپس نتایج SBBD را در نمودار شکل 10 خلاصه کرده ایم . چو و همکاران نتایج تشخیص با رنگ قرمز و نتایج تشخیص روش ما به رنگ آبی ارائه شده است. چو و همکاران مجموعه داده متشکل از 252 تصویر ساختمان است که هر کدام از دیدگاههای متفاوتی گرفته شدهاند تا لبههای هشت ساختمان را نشان دهند . این تصاویر از تصاویر کروی آپلود شده در GoogleStreetView گرفته شده اند. مجموعه داده ما شامل یک تصویر واحد از 19 ساختمان ساده است که از نقطه نظر عابر پیاده گرفته شده است.
ما الگوریتم تشخیص ساختمان را بر روی عکس های موجود با استفاده از هر دو روش اجرا کرده ایم. چو و همکاران هدف روش تشخیص سه لبه عمودی ساختمان است. این لبه ها حدود دو نما از ساختمان مرکزی را در تصویر ترسیم می کنند. بنابراین ما تشخیص را زمانی موفق میدانیم که هر دو نما پیدا شوند، در غیر این صورت تشخیص به عنوان یک شکست در نظر گرفته میشود.
هدف SBBD یافتن نما یا بخشی از نما با یافتن لبه های عمودی هر دو طرف است. از آنجایی که یک نما به اندازه کافی برای یافتن یک ساختمان در GIS مرتبط نیست، هدف ما یافتن حداقل دو نما در تصویر است. بنابراین، زمانی که دو یا چند نما با موفقیت شناسایی شوند، یک تشخیص موفق را در نظر می گیریم. هنگامی که یک نما یا بدون نما تشخیص داده شود، تشخیص اشتباه را در نظر می گیریم.

شکل 9 . تشخیص کانتور ساختمان در هوای خوب و بد.

شکل 10 . نمودار خلاصه تشخیص ساختمان محور منتخب میزان تشخیص خوب ساختمان را نشان می دهد.
با توجه به مجموعه داده چو، ما دریافتیم که روش او 56٪ را به طور کلی به دست می دهد ( شکل 10 ستون خلاصه چو را ببینید). ما همچنین مجموعه داده چو را با استفاده از SBBD آزمایش کردهایم که عملکرد تشخیص کمی پایینتر با نرخ تشخیص 54% ارائه میدهد ( شکل 10 ستون خلاصه چو را ببینید). ما متوجه شده ایم که وقتی روش ما در یک مکان خاص کار می کند، مهم نیست که دوربین چگونه حرکت می کند، روش همچنان می تواند ساختمان را تشخیص دهد. با این حال، هنگامی که لبه سقف شامل جزئیات کوچک زیادی باشد (موقعیت 3 در شکل 11 )، یا زمانی که ساختمان های زیادی در تصویر وجود دارند (موقعیت های 6، 7، و 8 در شکل 11 )، تشخیص با شکست مواجه می شود.
سپس مجموعه داده خود را با هر دو روش تشخیص ساختمان آزمایش کرده ایم. ما دریافتیم که در مجموعه داده ما، SBBD بهتر از چو و همکاران عمل می کند. یکی در واقع، روش چو تنها 15 درصد (به شکل 10 ستون مکانهای ما را ببینید) از ساختمانهای مجموعه داده ما را پیدا کرد. از سوی دیگر، ما از SBBD استفاده کردیم و نرخ تشخیص موفقیت آمیز 89٪ را به دست آوردیم ( شکل 10 ستون مکان های ما را ببینید).
بنابراین ما تعدادی عکس را برای نشان دادن نتایج تشخیص ساختمان هر دو پیاده سازی در شکل 12 و شکل 13 انتخاب کرده ایم . نتایج SBBD خوب بود

شکل 11 . عکس فوری از مجموعه داده های 11 مکان چو که 8 ساختمان مختلف را ارائه می کند.

شکل 12 . مقایسه تشخیص کانتور ساختمان با [ 17 ] در مجموعه دادههای ما.

شکل 13 . مقایسه تشخیص کانتور ساختمان با [ 17 ] در مجموعه دادههای آنها.
تا کنون، ساختمان های پیچیده چالش برانگیز بودند، اما نتایجی که ما پیدا کردیم، دلگرم کننده است. در برخی موارد، نتایج بهتری نسبت به نتایجی که با روش چو و همکاران برگردانده شده است، مییابیم. علاوه بر این، SBBD قادر به تشخیص بیش از دو نما بود که می تواند به تطبیق بهتر یک ساختمان با نقشه دو بعدی کمک کند.
در نهایت، SBBD نیز محدودیت های خود را دارد. سقف های کج شده، دیوارهای شیبدار، معماری های پیچیده، یک دیوار منفرد با چندین نما و مشکلات مهم انسداد باعث عدم شناسایی می شوند. ما همچنین توجه می کنیم که SBBD تنها یک ساختمان را در تصویر تشخیص می دهد، بنابراین چندین ساختمان در یک تصویر به خوبی شناسایی می شوند. برخی از نتایج تشخیص اشتباه در شکل 14 ارائه شده است.
4.2. نتایج DGPE
ما در این بخش دو مطالعه موردی را ارائه می کنیم که مراحل اصلی تشخیص پوس تصویر با DGPE را خلاصه می کند. ما برخی از تشخیص وضعیت تصویر را با استفاده از شکل ساختمان استخراج شده به صورت خودکار و تطبیق GIS دو بعدی و برخی اطلاعات معنایی نشان میدهیم. ما ژست تصویری که با استفاده از DGPE پیدا شده است را با حالت مرجعی که در طول گرفتن تصویر با استفاده از نمای ماهواره ای ذخیره کرده ایم، مقایسه می کنیم.
4.2.1. مطالعه موردی اول
شکل 15 (الف) تصویری را نشان میدهد که میخواهیم حالت آن را پیدا کنیم و محلیسازی نادرست موجود در ابرداده آن را نشان میدهد که با یک پین سیاه نشان داده شده است. هیچ اطلاعات جهتگیری در فراداده تصویر موجود نیست. در شکل 15 (ب)، یک نقشه تقریبی 200 متر × 200 متر با موقعیت های احتمالی یافت شده به تصویر کشیده شده است. این ژستها که در نقاط خاکستری تیره و چند ضلعی ترسیم شدهاند، از تشخیص ساختمان و تطبیق دو بعدی GIS حاصل شدهاند. ساختمان ها به رنگ خاکستری روشن ترسیم شده اند. در شکل 15(ب) ژستها به سختی قابل مشاهده هستند، زیرا تعداد بسیار زیاد آنها دقیقاً 644 است. دایره های سیاه با حروف، مناطق استخراج شده با استفاده از اطلاعات معنایی و ابرداده های موجود را نشان می دهند. ما برای این تصویر چهار مکان پیدا کردهایم که به فیلتر کردن 644 حالتی که قبلاً پیدا شده بود کمک میکند. تمام ژست هایی را که به دایره شعاع 20 متری احاطه کننده ژست معنایی تعلق ندارند فیلتر می کنیم.
در شکل 15 (ج)، وضعیت های باقی مانده را در چهار نقشه کاهش یافته نشان می دهیم. پوزهای معنایی (یعنی پوزیشن های استخراج شده از داده های معنایی) با استفاده از نمایش داده می شوند

شکل 14 . نتایج اشتباه در تشخیص کانتور ساختمان
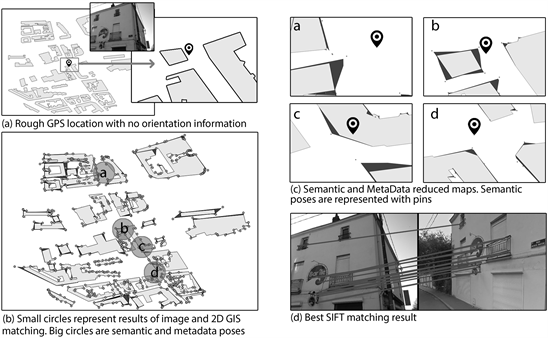
شکل 15 . فرآیند تشخیص ژست تصویر
پین های سیاه، ساختمان ها به رنگ خاکستری روشن و 18 حالت ممکن باقی مانده در خاکستری تیره. همه ژستها برای دانلود یک تصویر GoogleStreetView با مکان و جهت مربوطه استفاده میشوند، سپس با استفاده از توصیفگرهای SIFT با تصویر اولیه مقایسه میشوند. بهترین نتیجه تطبیق SIFT در شکل 15 (د) ارائه شده است. برخی از عناصر معماری و جزئیات تجاری در این تصویر شناسایی شده است. بنابراین، ما پوزی را که دارای بیشترین تعداد ویژگی SIFT منطبق است به عنوان قابل اعتمادترین در نظر می گیریم.
در شکل 16 ، تکامل نتیجه و داده های مرجع را نشان می دهیم. پین سیاه اطلاعات اولیه GPS موجود در فراداده تصویر را نشان می دهد. چند ضلعی بافت سیاه و سفید و مربع بهترین نتیجه را نشان می دهد که توسط DGPE (اطلاعات مکان و جهت گیری) برگردانده شده است. چند ضلعی بافت نقاط سیاه نشان دهنده حالت مرجع تصویر است.
می بینیم که مکان تصویر از فاصله 7.3 متری از محل مرجع به یک خطای مکان 3.98 متری تبدیل شده است. با این حال، مهمترین چیز تشخیص جهت دوربین است که تقریباً با جهت مرجع مطابقت دارد.
4.2.2. مطالعه موردی دوم
شکل 17 (الف) تصویری را نشان میدهد که میخواهیم ژست آن را پیدا کنیم و محلیسازی خشن موجود در ابرداده آن را نشان میدهد که با یک پین سیاه نشان داده شده است. هیچ اطلاعات جهت گیری در فراداده تصویر موجود نیست. در شکل 17 (ب)، یک نقشه تقریبی 200 متر × 200 متر با موقعیت های احتمالی یافت شده به تصویر کشیده شده است. این ژستها که در نقاط خاکستری روشن ترسیم شدهاند و چند ضلعیها ناشی از تشخیص ساختمان و تطبیق دو بعدی GIS هستند، ساختمانها به رنگ خاکستری تیره ترسیم میشوند. در شکل 17 (ب) ژستها دوباره به سختی قابل مشاهده هستند، زیرا عدد مهم آنها دقیقاً 1104 است. دایره سیاه نشان دهنده ناحیه استخراج شده با استفاده از اطلاعات معنایی است. ما برای این تصویر فقط یک مکان پیدا کردهایم که به فیلتر کردن 1104 حالتی که قبلاً پیدا شده بود کمک میکند.
در شکل 17 (ج)، ما 1104 حالت باقیمانده را در یک نقشه کاهش یافته نشان می دهیم. حالت معنایی (یعنی ژست استخراج شده از داده های معنایی) با استفاده از یک پین سیاه، ساختمان ها به رنگ خاکستری تیره، و 69 حالت ممکن باقی مانده در خاکستری روشن نشان داده می شود. به یاد می آوریم که ژست های باقیمانده آنهایی هستند که به یک پرتوی 20 متری در اطراف ژست معنایی تعلق دارند. ما یک تصویر GoogleStreetView را با استفاده از مکان و جهت هر ژست دانلود می کنیم. سپس با استفاده از توصیفگرهای SIFT تصاویر دانلود شده را با تصویر اولیه مقایسه می کنیم. بهترین نتیجه تطبیق SIFT در شکل 17 (د) ارائه شده است. برخی از عناصر معماری و جزئیات تجاری در این تصویر شناسایی شده است. بنابراین، ما پوزی را با تعداد بیشتری از ویژگیهای SIFT منطبق به عنوان قابل اعتمادترین در نظر میگیریم.
در شکل 18 ، تکامل نتیجه و داده های مرجع را نشان می دهیم. پین سیاه اطلاعات اولیه GPS موجود در فراداده تصویر را نشان می دهد. چند ضلعی بافت مربعی سیاه و سفید بهترین نتیجه برگردانده شده توسط DGPE (اطلاعات مکان و جهت) را نشان می دهد. چند ضلعی بافت نقاط سیاه نشان دهنده حالت مرجع تصویر است.

شکل 16 . نتیجه تشخیص ژست تصویر

شکل 17 . فرآیند تشخیص ژست تصویر

شکل 18 . نتیجه تشخیص ژست تصویر
می بینیم که مکان تصویر از فاصله 18.3 متری از محل مرجع به یک خطای مکان 10.8 متری تبدیل شده است. با این حال، مهم ترین اطلاعات یافت شده جهت گیری دوربین است که همان ساختمان را برای جهت گیری مرجع صحیح و یک نمای مشترک برای هر دو مرجع و ژست شناسایی شده نشان می دهد.
4.2.3. اعداد و بحث ها
ما در این بخش نمودارهایی را ارائه می کنیم که نتایج DGPE اعمال شده در دو پایگاه داده تصویری را که ایجاد کرده ایم نشان می دهد. تصویر اول شامل 19 تصویر است که بدون داده های معنایی مرتبط استفاده شده است، نتایج در شکل 19 ارائه شده است. پایگاه داده دوم شامل 28 تصویر است که ما در پلتفرم “فلیکر” آپلود کرده ایم و بنابراین حاوی داده های معنایی اضافی است که به عنوان نظرات، عناوین تصویر و هشتگ ها در دسترس است. ما نتایج این پایگاه داده را هنگام استفاده از داده های معنایی ( شکل 20 ) و زمانی که داده های معنایی نادیده گرفته می شوند ( شکل 21 ) مقایسه می کنیم تا اهمیت این اطلاعات در فرآیند تشخیص پوس را درک کنیم.
در شکل 19 میتوان دریافت که در 32 درصد از تصاویر، بخشی از متن را که ممکن است اطلاعات جغرافیایی را نشان دهد، شناسایی کردهایم. در 21 درصد موارد، تنها متنی را مییابیم که اطلاعات جغرافیایی را نشان میدهد و در 21 درصد از تصاویر، متنی که اطلاعات جغرافیایی را نشان میدهد، با متن بیفایده نیز شناسایی میشود. سپس از این اطلاعات متنی برای یافتن موقعیت جغرافیایی عکس ها استفاده می شود. DGPE در 36% موارد مکان مربوطه را با توجه به اطلاعات معنایی پیدا می کند. همچنین نتایج نشان می دهد که تمامی تصاویر شامل ساختمان هستند.
سپس تشخیص کانتور ساختمان را با استفاده از روش خود ارزیابی می کنیم. نتایج نشان می دهد که در 74 درصد موارد ساختمان شناسایی و در 5 درصد موارد بخشی از ساختمان پیدا می شود. شکل ساختمان، مطابق با لایه ساختمان های GIS دوبعدی، در 26 درصد موارد با برخی راه حل های اضافی اشتباه، موقعیت های صحیح را برمی گرداند.
در نهایت، شکل 19نمودار نشان می دهد که DGPE در 21٪ موارد مکانی را بدون اطلاعات جهت و در 26٪ موارد یک حالت دوربین می یابد که ساختمان صحیح را نشان می دهد. در مجموع، DGPE مکان تصویر را در 47٪ موارد پیدا می کند. سپس از پایگاه داده تصویر آپلود شده در “Flickr” استفاده می کنیم. ما دریافتیم که ماژول تشخیص متن در 32٪ موارد متنی را که اطلاعات جغرافیایی را آشکار می کند، برمی گرداند. در 18 درصد موارد، متن تا حدی شناسایی می شود و در 18 درصد موارد دیگر، متن با متن اضافی شناسایی می شود که هیچ اطلاعات محلی سازی را نشان نمی دهد. هنگام استفاده از اطلاعات معنایی می توان متوجه شد که در 39% موارد ساختمان موجود در تصویر و در 25% موارد ساختمان صحیح با مکان های اضافی یافت می شود. این اطلاعات،شکل 21 . نتایج همچنین نشان میدهد که تمامی تصاویر حاوی ساختمانهایی مطابق با «Google Vision API» هستند.
همچنین می بینیم که در هر دو شکل 20 و شکل 21 ، ساختمان در 32 درصد موارد شناسایی شده و در 29 درصد موارد به طور جزئی شناسایی شده است. سپس متوجه میشویم که نتایج تولید شده با استفاده از تصویر و تطبیق GIS در 11% تا 14% موارد موفق هستند. همچنین در 18 تا 21 درصد موارد می توانیم تشخیص های اشتباه را پیدا کنیم. بقیه موارد تطبیق نتیجه ای ندارند.

شکل 19 . نمودار خلاصه نتایج DGPE با استفاده از پایگاه داده تصویر اول.

شکل 20 . نموداری که نتایج DGPE را با استفاده از پایگاه داده تصویر دوم با داده های معنایی مرتبط آن خلاصه می کند.

شکل 21 . نمودار خلاصه ای از نتایج DGPE با استفاده از پایگاه داده تصویر دوم بدون داده معنایی مرتبط.
مجموع نتایج DGPE نشان می دهد که هنگام استفاده از پایگاه داده تصاویر مشابه، تنها در 11 درصد موارد می توانیم ساختمان صحیح را بدون بومی سازی اطلاعات معنایی پیدا کنیم. از سوی دیگر، هنگام استفاده از اطلاعات معنایی از یک متن شناسایی شده و دادههای دانلود شده مرتبط، میتوانیم در 14 درصد حالتی نزدیکتر به حالت مرجع با جهتی که به ساختمان صحیح اشاره دارد، پیدا کنیم. همچنین میتوانیم در 54 درصد موارد اطلاعات محلیسازی را بدون اطلاعات جهتگیری پیدا کنیم. بنابراین، میتوانیم نتایج بومیسازی را از 11 درصد، زمانی که فقط از تطبیق ساختمان و GIS استفاده میکنیم، به 59 درصد در هنگام استفاده از اطلاعات معنایی و تطبیق شکل ساختمان با لایه ساختمان GIS، ارتقا دهیم.
5. نتیجه گیری
در این مقاله، ما سیستم جمعآوری دادهها را برای تخمین وضعیت تصویر (DGPE) پیشنهاد کردهایم که برای اصلاح مکانیابی تصویر و تخمین جهتگیری دوربین استفاده میشود. ما از دادههای ورودی ساده برای DGPE استفاده کردهایم، زیرا معتقدیم این دادهها بهطور گسترده در دسترس هستند و دائماً در منابع فعال مانند رسانههای اجتماعی و کارتوگرافی مشترک بهروزرسانی میشوند. ما روش جدید تشخیص ساختمان SBBD خود را توضیح دادهایم و استحکام آن را در برابر برخی مشکلات انسداد و تغییرات آب و هوایی ثابت کردهایم. در نهایت، ما دو مطالعه موردی ارائه کردهایم که نتایج کاملاً خودکار DGPE را برای تشخیص وضعیت تصویر نشان میدهد. ما همچنین کل نتایج DGPE را با استفاده از دو پایگاه داده تصویر ارائه کردهایم. برای پایگاه داده اول، فقط تصاویر به عنوان داده ورودی استفاده می شود. بنابراین، تنها 26 درصد از ژستهای تصاویر با استفاده از شکل ساختمان و فرآیند تطبیق دو بعدی GIS یافت میشوند. متن شناسایی شده در تصاویر نیز در موارد معدودی مفید است، اما برای مرتبط تر بودن نیاز به پیش پردازش و فیلتر دارد. برای پایگاه داده دوم، تصاویر در “فلیکر” آپلود شدند، داده های معنایی مانند عناوین تصاویر و تگ های هش اضافه شدند. ما با این پایگاه داده دوم تفاوت در بومی سازی را هنگام استفاده از اطلاعات معنایی مقایسه کردیم. ما دریافتیم که افزودن اطلاعات معنایی به فرآیند، فرآیند بومیسازی را تا 48 درصد بهبود میبخشد، اما اطلاعات جهتگیری را که میتوان با استفاده از شکل ساختمان و تطبیق GIS یافت، اضافه نمیکند. ساختمان تنها در 11 درصد موارد که اطلاعات معنایی در دسترس نبود شناسایی شده است. نتایج همان تصاویر با استفاده از داده های معنایی بهبود یافت و 59 درصد ساختمان ها شناسایی شدند. ما مشتاقانه منتظر افزودن قابلیت های بیشتری به DGPE با ادغام آرم ها و آشکارساز نشانه های شناخته شده هستیم. استفاده از روش هایی مانند مواردی که در [40 ] و [ 41 ] می توانند درک معنایی ما از صحنه را بهبود بخشند. چنین الگوریتم هایی به ما کمک می کنند تا ناحیه مناسب تصویر را انتخاب کنیم تا بتوانیم یک پرس و جوی اطلاعاتی خاص را در میان ماژول های دیگر بسازیم. ما همچنین به بهبود روش تشخیص ساختمان خود برای تشخیص قوس های سقف های کج شده و افزودن توانایی تشخیص چندین ساختمان فکر می کنیم. در نهایت، هندسه های ساختمان شناسایی شده نیز ممکن است با داده های GIS سه بعدی مقایسه شوند. این ممکن است با مقایسه نمای ساختمان های شناسایی شده با داده های GIS سه بعدی، دقت حالت را بهبود بخشد.
اختصارات زیر در این دست نوشته استفاده شده است
API: رابط برنامه نویسی برنامه
AR: واقعیت افزوده
DGPE: سیستم جمع آوری داده برای تخمین وضعیت تصویر
EXIF: فرمت فایل تصویری قابل تعویض
GIS: سیستم های اطلاعات جغرافیایی
GNSS: سیستم ماهواره ای ناوبری جهانی
GPS: سیستم موقعیت یابی جهانی
LOH: فرضیه های جهت گیری مکان
LSD: آشکارساز بخش خط
LSTM: حافظه بلند مدت
SBBD: تشخیص ساختمان مبتنی بر بخش ها
SIFT: تبدیل ویژگی تغییر ناپذیر مقیاس
SLAM: محلی سازی و نقشه برداری همزمان
TICEP: موقعیت لبه گوشه شیبدار ثابت
VGI: اطلاعات جغرافیایی داوطلبانه


بدون دیدگاه