

خلاصه
کلید واژه ها:
تطبیق ساختمان ; برچسب زدن آرامش ; ترکیبات الگوی ؛ مقیاس های چندگانه ؛ ترکیب نقشه
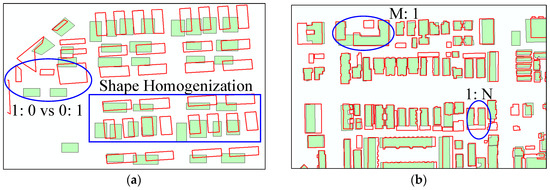
1. معرفی
2. بررسی ادبیات
3. روش شناسی
- ●
-
اشیاء ساختمانی مطابق با نامزد را بر اساس تجزیه و تحلیل بافر شناسایی کنید، اشیاء همسایه را در ترکیبات الگو جمع آوری کنید، و شباهت های جغرافیایی بین اشیاء منطبق با نامزد و ترکیبات الگو را برای مقداردهی اولیه ماتریس تطبیق محاسبه کنید.
- ●
-
سازگاری های متنی بین جفت های تطبیق همسایه را محاسبه کنید تا به طور مکرر ماتریس تطبیق اولیه را به روز کنید، جفت های تطبیق را بر اساس ماتریس تطبیق همگرا انتخاب کنید و آنها را از طریق تشخیص تضاد منطبق اصلاح کنید.
3.1. مقدمهسازی احتمال تطبیق در در نظر گرفتن ترکیبهای الگوی چند مقیاسی
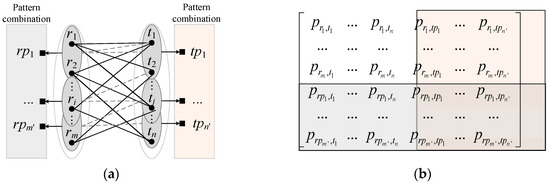
3.1.1. تشخیص اشیاء تطبیق نامزد و ترکیب الگوها
- ●
-
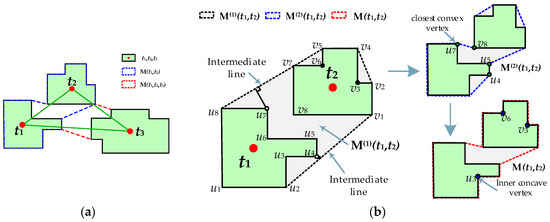
مرحله 1: بدنه محدب دو شیء ساختمانی را به عنوان چند ضلعی ادغام شده اولیه کنید.
- ●
-
مرحله 2: به طور مکرر نقاط محدب نزدیک به خطوط میانی را اضافه کنید تا چند ضلعی ادغام شده را اصلاح کنید.
- ●
-
مرحله 3: برای اصلاح بیشتر چند ضلعی ادغام شده، نقاط مقعر داخلی را در اشیاء t 1 و t 2 وارد کنید.
3.1.2. محاسبه شباهت های جغرافیایی و احتمالات تطبیق اولیه
برای هر جفت تطبیق نامزد ( ri , tj ) در جدول تطبیق نامزد c_Table ، چهار شباهت هندسی، یعنی شباهت موقعیت sim p ، شباهت جهت sim o ، شباهت ناحیه sim a ، و شباهت شکل sim محاسبه شد. ماتریس تطبیق نامزد را مقداردهی اولیه کنید. فرمول ها به شرح زیر فهرست شده اند.
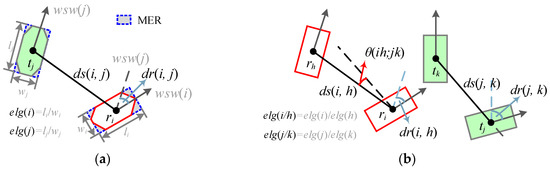
همانطور که در شکل 5 نشان داده شده است، ds ( i ، j ) به معنای فاصله مرکز بین دو جسم r i و t j است ، dr ( i ، j ) جهت گیری وزنی آماری دیوار آنها را نشان می دهد [ 44 ] تفاوت، elg (*) نسبت محور اصلی به فرعی حداقل مستطیل محصور (MER) را نشان می دهد و مساحت (*) مساحت چند ضلعی را اندازه می گیرد. پس از آن، احتمال تطابق اولیه به صورت زیر محاسبه می شود:
که در آن t k ∈ CR i ∪ CRP i , sim ( i , j ) مجموع شباهت جغرافیایی ( r i , t j ) است و sim ( i , k ) نیز همینطور است. sim p ، sim o ، sim a و sim s شباهت های موقعیت، جهت، مساحت و شکل هستند که با فرمول (1) محاسبه می شوند.
3.2. تطابق احتمال آرامش بر اساس اطلاعات متنی چند مقیاسی
3.2.1. تعریف رابطه همسایگی و ضریب سازگاری
بر اساس تعریف روابط همسایه، اطلاعات زمینهای جفتهای همسایه کاندید-تطبیق به عنوان یک ضریب سازگاری با توجه به فرمول (3) [40] که هر دو موقعیت نسبی و مطلق، جهتگیری، شکل و روابط منطقه را ترکیب میکند، کمیتسازی شد.
در جایی که C ( ij ; hk ) نشان دهنده ضریب سازگاری بین دو جفت همجوار ( ri , tj ) و ( rh , tk ) است، sim ( i , j ) شباهت جغرافیایی مطلق محاسبه شده توسط فرمول ( 2)، و rel u ( ij ؛ hk ) ( u = 1…4) چهار رابطه هندسی نسبی بین آنها را نشان می دهد که به ترتیب به عنوان فرمول (4) – (7) محاسبه می شوند.
3.2.2. آرامش ماتریس تطبیق و انتخاب جفت های تطبیق نهایی
- ●
-
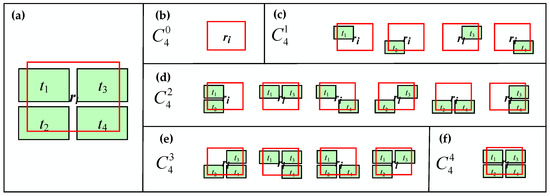
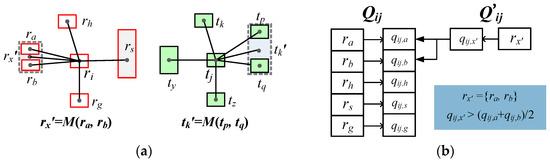
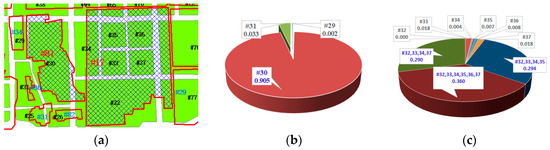
شاخصهای پشتیبانی فرعی همه اشیاء مجزا و ترکیبهای الگوی مجاور را طبق فرمول (8) محاسبه کنید، که به دو صف جداگانه Q ij و Q ‘ ij تقسیم میشوند . Q ij اندیس های پشتیبانی فرعی اشیاء مجاور همسایه و Q ‘ ij شاخص های پشتیبانی فرعی ترکیب های الگوی همسایه را ذخیره می کند. برای جفت منطبق با نامزد ( ri , tj ) در شکل 6 a ، دو صف شاخص پشتیبانی فرعی Q ij و Q ij ‘ در فهرست شده اند .شکل 6 ب.
qمنj،ساعت=حداکثرسک∈سیآرساعت∪سیآرپساعت{سی(منj;ساعتک)پ(ساعت،ک)}،rساعت∈نمن یا نپمن - ●
-
Q ij ‘ را به ترتیب صعودی از تعداد شیء موجود در ترکیب الگوی همسایه عبور دهید و قضاوت کنید که آیا شاخص پشتیبانی فرعی آن بزرگتر از میانگین شاخص پشتیبانی اشیاء شامل آن است یا خیر . اگر بله، شاخص پشتیبانی فرعی آن ترکیب الگو جایگزین شاخصهای پشتیبانی فرعی مربوط به اشیاء موجود در Q ij میشود . همانطور که در شکل 6 ب توضیح داده شده است، شاخص پشتیبانی فرعی q ij , x ‘ از r x ‘ = { r a , r b } بزرگتر از میانگین q ij , a استو q ij , b , بنابراین q ij , x ‘ جایگزین مقادیر q ij , a و q ij , b در Q ij می شود .
- ●
-
هنگامی که تمام عناصر Q ij ‘ پیموده می شوند و با مراحل بالا قضاوت می شوند، میانگین شاخص های پشتیبانی فرعی در Q ij به عنوان شاخص کل پشتیبانی q ij از ( r i , t j ) محاسبه می شود.
هنگامی که کل شاخصهای پشتیبانی همه جفتهای تطبیق نامزد مشخص شد، تکرار ماتریس تطبیق جغرافیایی مشابه طبق فرمول (9) [ 24 ] اجرا شد. فرآیند برچسبگذاری آرامش تا زمانی ادامه مییابد که اختلاف احتمال بین دو تکرار کمتر از آستانه از پیش تعریفشده δ باشد .
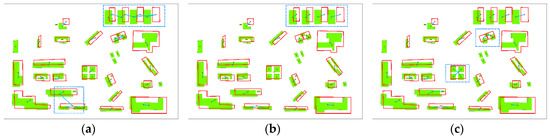
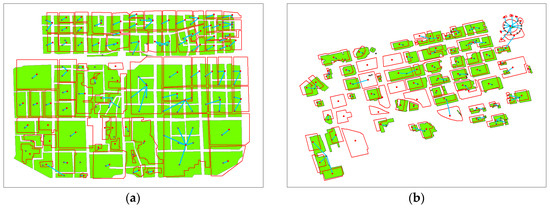
4. آزمایش و تجزیه و تحلیل
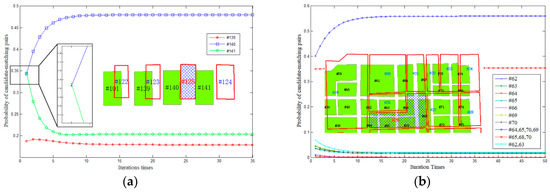
با مقایسه نتایج تطبیق با تطبیق دستی، سه شاخص دقت – دقت P ، Recall R و مقدار F – طبق فرمول (10) محاسبه شد. tp نشاندهنده جفتهای تطبیق واقعی است که توسط روش ما شناسایی شدهاند، fp نشاندهنده جفتهای تطبیق نادرست است که توسط روش ما شناسایی شدهاند، و fn به معنای جفتهای تطبیق واقعی است که توسط روش ما حذف شدهاند. از جدول 2 می توان دریافت که هم میزان دقت و هم نرخ فراخوان بالاتر از 90٪ است و دقت های آشکار بالاتری با روش ما نسبت به روش برچسب زدن آرامش در سطح شی به دست آمده است.
5. نتیجه گیری ها
منابع
- جیانگ، بی. اطلاعات جغرافیایی داوطلبانه و جغرافیای محاسباتی: دیدگاه های جدید. در جمع سپاری دانش جغرافیایی ; Sui, D., Elwood, S., Goodchild, M., Eds. Springer: Dordrecht، هلند، 2013; صص 125-138. [ Google Scholar ]
- Goetz, M. به سمت تولید مدلهای بسیار دقیق 3D CityGML از OpenStreetMap. بین المللی جی. جئوگر. Inf. علمی 2013 ، 27 ، 845-865. [ Google Scholar ] [ CrossRef ]
- برگمن، سی. Oksanen, J. Conflation of OpenStreetMap و داده های ردیابی ورزشی موبایل برای مسیریابی خودکار دوچرخه. ترانس. GIS 2016 ، 20 ، 848-868. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یانگ، دبلیو. آی، تی. Lu, W. روشی برای استخراج اطلاعات مرزهای جاده از مسیرهای GPS وسایل نقلیه جمع سپاری. Sensors 2018 , 18 , 1261. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- هچت، ر. کونز، سی. Hahmann, S. اندازه گیری کامل بودن ردپای ساختمان در OpenStreetMap در مکان و زمان. ISPRS Int. J. Geo-Inf. 2013 ، 2 ، 1066-1091. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رویز، جی جی؛ آریزا، FJ; Ureña، MA; Blázquez، EB تلفیق نقشه دیجیتال: بررسی فرآیند و پیشنهادی برای طبقه بندی. بین المللی جی. جئوگر. Inf. علمی 2011 ، 25 ، 1439-1466. [ Google Scholar ] [ CrossRef ]
- دالیوت، اس. داهیندن، تی. شولز، ام جی; بولجن، ج. سستر، ام. یکپارچه سازی ساختارهای شبکه نمایش های مختلف هندسی. EMP Surv. Rev. 2013 , 45 , 428-440. [ Google Scholar ] [ CrossRef ]
- سستر، ام. ارسنجانی، ج. کلامر، آر. بورگاردت، دی. Haunert، JH یکپارچه سازی و تعمیم اطلاعات جغرافیایی داوطلبانه. در چکیده اطلاعات جغرافیایی در جهان غنی از داده ; Burghardt, D., Duchêne, C., Mackaness, W., Eds.; انتشارات بین المللی Springer: چم، سوئیس، 2014; صص 119-155. [ Google Scholar ]
- تویا، جی. براندو اسکوبار، سی. تشخیص تناقضات سطح جزئیات در مجموعه دادههای اطلاعات جغرافیایی داوطلبانه. کارتوگر. بین المللی جی. جئوگر. Inf. جئوویس. 2013 ، 48 ، 134-143. [ Google Scholar ] [ CrossRef ]
- بارون، سی. نیس، پ. Zipf، A. چارچوبی جامع برای تحلیل کیفی نقشه خیابان باز ذاتی. ترانس. GIS 2014 ، 18 ، 877-895. [ Google Scholar ] [ CrossRef ]
- خو، جی. وو، اف. کیان، اچ. Ma, F. الگوریتم تطبیق حل و فصل با استفاده از روابط شباهت فضایی به عنوان محدودیت. Geomat. Inf. علمی دانشگاه ووهان 2013 ، 38 ، 484-488. [ Google Scholar ]
- Saalfeld, A. Conflation: Automated map Compilation. بین المللی جی. جئوگر. Inf. علمی 1988 ، 2 ، 217-228. [ Google Scholar ] [ CrossRef ]
- کیلر، بی. هوانگ، دبلیو. هاونرت، جی. جیانگ، جی. تطبیق مجموعه دادههای رودخانه در مقیاسهای مختلف. در یادداشت های سخنرانی در اطلاعات جغرافیایی و نقشه برداری ; Sester, M., Bernard, L., Paelke, V., Eds. Springer: برلین/هایدلبرگ، آلمان، 2009; صص 135-154. [ Google Scholar ]
- پورعبدالله، ع. مورلی، جی. فلدمن، اس. جکسون، ام. به سوی نقشه خیابان باز معتبر: تلفیق شبکه جاده ای نقشه های ملی OSM و سیستم عامل OpenData. ISPRS Int. J. Geo-Inf. 2013 ، 2 ، 704-728. [ Google Scholar ] [ CrossRef ]
- چن، سی.-سی. Knoblock، C. شهابی، سی. تلفیق خودکار دادههای بردار جاده با تصوير قاعده. GeoInformatica 2006 ، 10 ، 495-530. [ Google Scholar ] [ CrossRef ]
- ژانگ، جی. یک مدل ترکیبی متجانس برای ترکیب تصاویر ماهواره ای و پایگاه داده جاده. Ph.D. پایان نامه، دانشگاه فنی مونیخ، مونیخ، آلمان، 2013. [ Google Scholar ]
- مک کنزی، جی. یانوویچ، ک. Adams, B. یک روش وزنی چند ویژگی برای تطبیق نقاط مورد علاقه ایجاد شده توسط کاربر. کارتوگر. Geogr. Inf. علمی 2014 ، 41 ، 125-137. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شفلر، تی. شیرو، آر. Lehmann, P. تطبیق نقاط مورد علاقه از سایت های مختلف شبکه های اجتماعی. در KI 2012: Advances in Artificial Intelligence ; Goebel, R., Tanaka, Y., Wahlster, W., Siekmann, J., Eds. Springer: برلین/هایدلبرگ، آلمان، 2012; ص 45-248. [ Google Scholar ]
- شیونگ، دی. Sperling، J. تطبیق نیمه خودکار برای یکپارچه سازی پایگاه داده شبکه. ISPRS J. Photogramm. Remote Sens. 2004 ، 59 ، 35-46. [ Google Scholar ] [ CrossRef ]
- ژانگ، ام. منگ، ال. یک رویکرد تطبیق جاده ای تکراری برای ادغام داده های پستی. محاسبه کنید. محیط زیست سیستم شهری 2007 ، 31 ، 598-616. [ Google Scholar ] [ CrossRef ]
- موستیر، اس. Devogele, T. تطبیق شبکه ها با سطوح مختلف جزئیات. GeoInformatica 2008 ، 12 ، 435-453. [ Google Scholar ] [ CrossRef ]
- فن، اچ. یانگ، بی. Zipf، A.; Rousell, A. رویکردی مبتنی بر چند ضلعی برای تطبیق شبکههای جادهای OpenStreetMap با دادههای معتبر. بین المللی جی. جئوگر. Inf. علمی 2016 ، 30 ، 748-764. [ Google Scholar ] [ CrossRef ]
- صفرا، ای. کانزا، ی. ساگیو، ی. Doytsher, Y. تطبیق موقت شبکه های جاده ای بردار. بین المللی جی. جئوگر. Inf. علمی 2013 ، 27 ، 114-153. [ Google Scholar ] [ CrossRef ]
- یانگ، بی. ژانگ، ی. Luan، X. یک رویکرد آرامش احتمالی برای تطبیق شبکه های جاده ای. بین المللی جی. جئوگر. Inf. علمی 2013 ، 27 ، 319-338. [ Google Scholar ] [ CrossRef ]
- تانگ، ایکس. لیانگ، دی. Jin, Y. روش تطبیق شی جاده خطی برای ادغام بر اساس بهینه سازی و رگرسیون لجستیک. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 824-846. [ Google Scholar ] [ CrossRef ]
- چهرقان، ع. عباسپور، RA یک رویکرد مبتنی بر هندسی برای تطبیق جاده در مجموعه دادههای چند مقیاسی با استفاده از الگوریتم ژنتیک. کارتوگر. Geogr. Inf. علمی 2018 ، 45 ، 255-269. [ Google Scholar ] [ CrossRef ]
- دو، اچ. آناند، اس. آلچینا، ن. مورلی، جی. هارت، جی. لیبوویچی، دی. جکسون، ام. Ware, M. ادغام اطلاعات مکانی برای داده های برداری جاده معتبر و منبع جمعیت. ترانس. GIS 2012 ، 16 ، 455-476. [ Google Scholar ] [ CrossRef ]
- لیو، سی. شیونگ، ال. هو، ایکس. Shan, J. یک روش بافر پیشرونده برای به روز رسانی نقشه راه با استفاده از داده های نقشه خیابان باز. ISPRS Int. J. Geo-Inf. 2015 ، 4 ، 1246-1264. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یانگ، بی. ژانگ، ی. Lu, F. رویکرد مبتنی بر هندسی برای ادغام POI های VGI و شبکه های جاده ای. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 126-147. [ Google Scholar ] [ CrossRef ]
- یانگ، بی. Zhang، Y. روش استخراج الگو برای ترکیب شبکههای جادهای جمعسپاری با POI. بین المللی جی. جئوگر. Inf. علمی 2015 ، 29 ، 786-805. [ Google Scholar ] [ CrossRef ]
- آی، تی. یانگ، م. ژانگ، ایکس. Tian, J. تشخیص و تصحیح ناسازگاری بین شبکه های رودخانه و داده های کانتور توسط دانش محدودیت فضایی. کارتوگر. بین المللی جی. جئوگر. Inf. Geov. 2015 ، 42 ، 79-93. [ Google Scholar ] [ CrossRef ]
- فن، اچ. Zipf، A.; فو، س. Neis, P. ارزیابی کیفیت برای ایجاد داده های ردپایی در OpenStreetMap. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 700-719. [ Google Scholar ] [ CrossRef ]
- گوسلن، جی. سستر، ام. ادغام مجموعه داده های علم زمین و نقشه دیجیتال آلمانی با استفاده از رویکرد تطبیق. در مجموعه مقالات بیستمین انجمن بین المللی فتوگرامتری و کنگره سنجش از دور، استانبول، ترکیه، 12 تا 23 ژوئیه 2004. صص 1249-1254. [ Google Scholar ]
- ها، ی. یو، ک. Heo, J. تشخیص جفت نقطه مزدوج برای تراز نقشه بین دو مجموعه داده چند ضلعی. محاسبه کنید. محیط زیست سیستم شهری 2011 ، 35 ، 250-262. [ Google Scholar ] [ CrossRef ]
- آی، تی. چنگ، ایکس. لیو، پی. یانگ، ام. تحلیل شکل و تطبیق الگوی ویژگیهای ساختمان با روش تبدیل فوریه. محاسبه کنید. محیط زیست سیستم شهری 2013 ، 41 ، 219-233. [ Google Scholar ] [ CrossRef ]
- وانگ، ی. چن، دی. ژائو، ز. رن، اف. Du, Q. یک رویکرد مبتنی بر شبکه عصبی پس انتشار برای تطبیق ویژگی های چندگانه در انتشار به روز رسانی. ترانس. GIS 2015 ، 19 ، 964-993. [ Google Scholar ] [ CrossRef ]
- دو، اچ. آلچینا، ن. جکسون، ام. هارت، جی. روشی برای تطبیق داده های جغرافیایی معتبر و منبع جمعیت. ترانس. GIS 2016 . [ Google Scholar ] [ CrossRef ]
- سمال، ع. ست، اس. Cueto، K. یک رویکرد مبتنی بر ویژگی برای ترکیب منابع جغرافیایی. بین المللی جی. جئوگر. Inf. علمی 2004 ، 18 ، 459-489. [ Google Scholar ] [ CrossRef ]
- کیم، جو. یو، ک. هیو، جی. Lee, WH یک روش جدید برای تطبیق اشیاء در دو مجموعه داده جغرافیایی مختلف بر اساس زمینه جغرافیایی. محاسبه کنید. Geosci. 2010 ، 36 ، 1115-1122. [ Google Scholar ] [ CrossRef ]
- ژانگ، ایکس. آی، تی. استوتر، جی. ژائو، ایکس. تطبیق دادههای چند ضلعیهای ساختمانی در مقیاسهای چندگانه نقشه با اطلاعات متنی و آرامش بهبود یافته است. ISPRS J. Photogramm. Remote Sens. 2014 ، 92 ، 147-163. [ Google Scholar ] [ CrossRef ]
- ها، ی. کیم، جی. لی، جی. یو، ک. Shi, W. شناسایی جفتهای مجموعه شی متناظر چند مقیاسی بین دو مجموعه داده چندضلعی با همخوشهبندی سلسله مراتبی. ISPRS J. Photogramm. Remote Sens. 2014 ، 88 ، 60-68. [ Google Scholar ] [ CrossRef ]
- ژانگ، ی. هوانگ، جی. دنگ، م. نیش، ایکس. Hu, J. تطبیق برچسبگذاری آرامش برای مجموعه دادههای مسکونی چند مقیاسی بر اساس الگوهای همسایه. Geomat. Inf. علمی دانشگاه ووهان 2018 ، 43 ، 1098-1105. [ Google Scholar ]
- دنگ، م. لیو، کیو. چنگ، تی. Shi, Y. یک الگوریتم خوشهبندی فضایی تطبیقی مبتنی بر مثلثسازی دلونی. محاسبه کنید. محیط زیست سیستم شهری 2011 ، 35 ، 320-332. [ Google Scholar ] [ CrossRef ]
- دوچن، سی. بارد، اس. باریلو، ایکس. رواس، ع. ترویسان، جی. Holzapfel, F. توصیف کمی و کیفی جهت گیری ساختمان. در مجموعه مقالات پنجمین کارگاه آموزشی در مورد پیشرفت در تعمیم خودکار نقشه، پاریس، فرانسه، 28-30 آوریل 2003. ICA، کمیسیون تعمیم نقشه: بارسلون، اسپانیا، 2003. [ Google Scholar ]


بدون دیدگاه