

هدف یادگیری
- هدف از این بخش بررسی رایجترین معیارهای توزیع، تمایل مرکزی و پراکندگی است.
هیچ بحثی در مورد تجزیه و تحلیل جغرافیایی بدون مروری کوتاه بر مفاهیم اولیه آماری کامل نخواهد بود. آمارهای اساسی که در اینجا مشخص شده اند، نقطه شروعی برای هر تلاشی برای توصیف، خلاصه و تجزیه و تحلیل مجموعه داده های جغرافیایی هستند. نمونهای از تلاشهای آماری مشترک زمینفضایی، تجزیه و تحلیل دادههای نقطهای بهدستآمده توسط مجموعهای از گیجسنجهای بارندگی است که در سراسر یک منطقه خاص الگوبرداری شدهاند. با توجه به این بارانسنجها، میتوان مقدار معمولی و تغییرپذیری بارندگی در هر ایستگاه و همچنین بارش معمولی در کل منطقه را تعیین کرد. علاوه بر این، می توانید میزان بارندگی را بین هر ایستگاه یا مکانی که بیشترین (یا کمترین) بارندگی در آن اتفاق می افتد، درون یابی کنید. علاوه بر این، شما می توانید مقدار مورد انتظار بارندگی را در آینده در هر ایستگاه، بین هر ایستگاه پیش بینی کنید.
افزایش قدرت محاسباتی در چند دهه گذشته باعث ایجاد مجموعه داده های گسترده ای شده است که نمی توان به راحتی آنها را خلاصه کرد. آمار توصیفی توصیفات عددی ساده ای از این مجموعه داده های بزرگ ارائه می دهد. آمار توصیفی تمایل به تجزیه و تحلیل تک متغیره دارد، به این معنی که آنها یک متغیر را در یک زمان بررسی می کنند. سه خانواده آمار توصیفی وجود دارد که در اینجا به آنها خواهیم پرداخت: معیارهای توزیع، معیارهای گرایش مرکزی و معیارهای پراکندگی. با این حال، قبل از اینکه عمیقاً در تکنیکهای آماری مختلف کاوش کنیم، ابتدا باید چند اصطلاح را تعریف کنیم.
- متغیر : نمادی که برای نشان دادن هر مقدار یا مجموعه ای از مقادیر استفاده می شود
- مقدار : مشاهده فردی یک متغیر (در سیستم اطلاعات جغرافیایی [GIS] به آن رکورد نیز می گویند)
- جمعیت : جهان همه مقادیر ممکن برای یک متغیر
- نمونه : زیر مجموعه ای از جمعیت
- n : تعداد مشاهدات یک متغیر
- آرایه : دنباله ای از معیارهای مشاهده شده (در GIS به آن فیلد نیز گفته می شود و در جدول ویژگی ها به صورت ستون نشان داده می شود)
- آرایه مرتب شده: یک آرایه مرتب و کمی
اقدامات توزیع
اندازه گیری توزیع یک متغیر صرفاً خلاصه ای از فراوانی مقادیر در محدوده مجموعه داده است (از این رو اغلب به آن توزیع فرکانس می گویند). به طور معمول، مقادیر متغیر داده شده در یک سری از کلاس های از پیش تعیین شده (که فواصل، بن ها یا دسته ها نیز نامیده می شوند) گروه بندی می شوند و تعداد مقادیر داده ای که در هر کلاس قرار می گیرند خلاصه می شود. نموداری که تعداد مقادیر داده را در محدوده هر کلاس نشان می دهد، هیستوگرام نامیده می شود . به عنوان مثال، درصد نمرات دریافت شده توسط یک کلاس در یک امتحان ممکن است به آرایه زیر منجر شود ( n = 30):
آرایه نمرات امتحان: {87، 76، 89، 90، 64، 67، 59، 79، 88، 74، 72، 99، 81، 77، 75، 86، 94، 66، 75، 74، 83، 10 92، 75، 73، 70، 60، 80، 85، 57}
هنگام قرار دادن این آرایه در یک توزیع فرکانس، دستورالعمل های کلی زیر باید رعایت شود. اول، بین پنج تا پانزده کلاس مختلف باید به کار گرفته شود، اگرچه تعداد دقیق کلاس ها به تعداد مشاهدات بستگی دارد. دوم، هر مشاهده به یک و تنها یک کلاس می رود. سوم، در صورت امکان، از کلاس هایی استفاده کنید که محدوده مساوی از مقادیر را پوشش می دهند (فروند و پرلز 2006). فروند، جی، و بی پرلز. 1385. آمار ابتدایی مدرن . Englewood Cliffs، NJ: Prentice Hall. با در نظر گرفتن این رهنمودها، آرایه نمرات امتحانی که قبلا نشان داده شده است را می توان با هیستوگرام زیر تجسم کرد ( شکل 6.1 “هیستوگرام نشان دهنده توزیع فراوانی نمرات امتحان” ).
شکل 6.1 هیستوگرام توزیع فراوانی نمرات امتحان را نشان می دهد
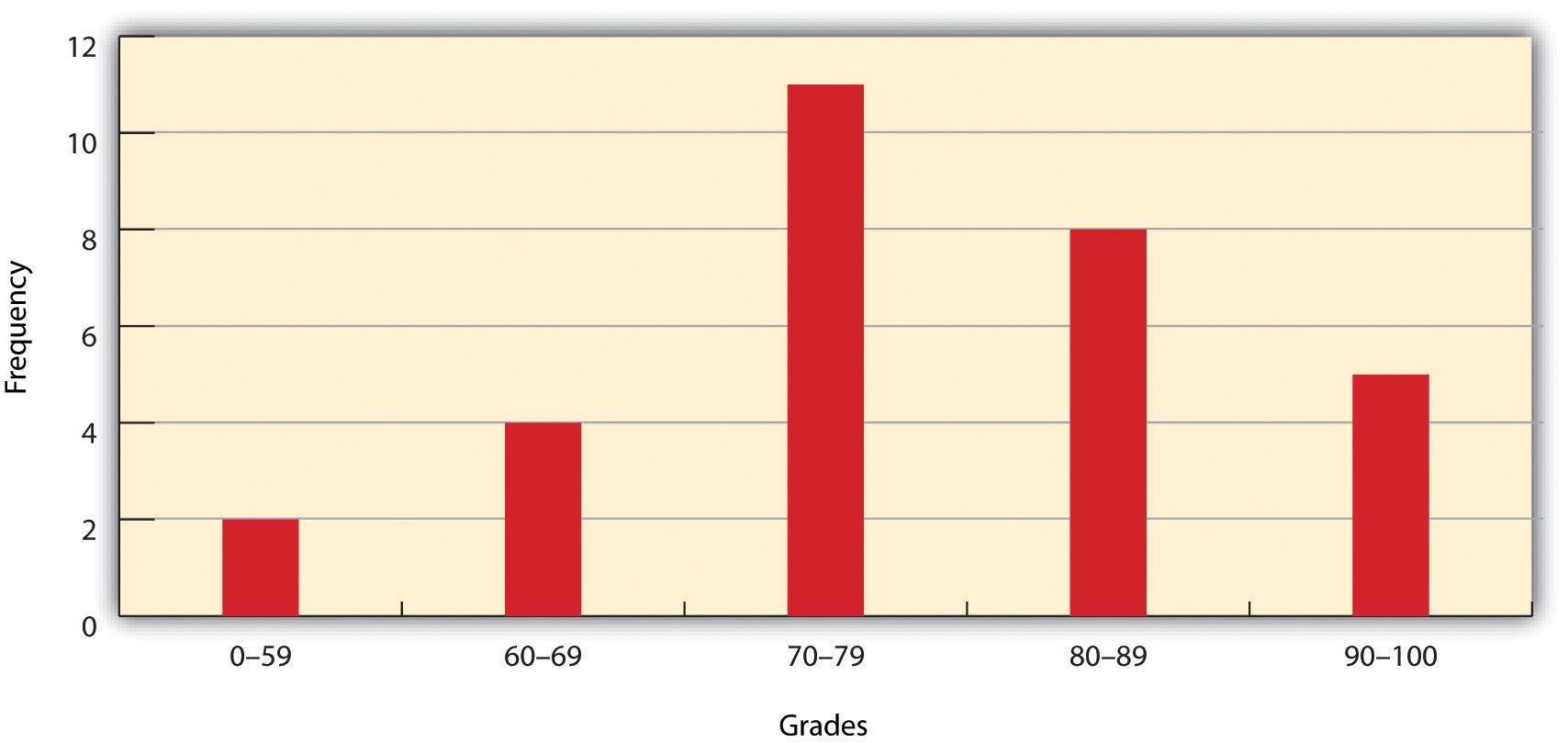
همانطور که از هیستوگرام می بینید، مشاهدات توصیفی خاصی را می توان به آسانی انجام داد. اکثر دانش آموزان در امتحان C دریافت کردند (70-79). دو دانش آموز در امتحان مردود شدند (50-59). پنج دانش آموز A (90-99) دریافت کردند. توجه داشته باشید که این هیستوگرام سومین قانون اساسی را که هر کلاس محدوده مساوی را پوشش می دهد، نقض می کند، زیرا درجه F بین 0 تا 59 متغیر است، در حالی که درجه های دیگر محدوده هایی با اندازه مساوی دارند. صرف نظر از این، در این مورد، ما بیشترین نگرانی را با توصیف توزیع نمرات دریافت شده در طول امتحان داریم. بنابراین، ایجاد محدودههای کلاسی که به بهترین وجه با نیازهای فردی ما مطابقت دارد، کاملاً منطقی است.
اقدامات گرایش مرکزی
ما می توانیم آرایه نمرات امتحان را با اعمال معیارهای گرایش مرکزی بیشتر بررسی کنیم . سه معیار اصلی برای گرایش مرکزی وجود دارد: میانگین، حالت و میانه. میانگین ، که بیشتر به عنوان میانگین نامیده می شود، بیشترین استفاده را برای سنجش گرایش مرکزی دارد. برای محاسبه میانگین، کافی است تمام مقادیر موجود در آرایه را جمع کرده و آن مجموع را بر تعداد مشاهدات تقسیم کنید. برای بازگشت به مثال نمره امتحان قبلی، مجموع آن آرایه 2340 است و 30 مشاهده وجود دارد ( n = 30). بنابراین، میانگین 2340 / 30 = 78 است.
حالت معیار گرایش مرکزی است که بیشترین مقدار را در آرایه نشان می دهد. در مورد نمرات امتحان، حالت آرایه 75 است زیرا بیشترین تعداد دانش آموزان (در مجموع سه نفر) دریافت کردند. در نهایت، میانه مشاهده ای است که وقتی آرایه از پایین ترین به بالاترین مرتب می شود، دقیقاً در مرکز آرایه مرتب شده قرار می گیرد. به طور خاص، میانه مقداری است که در وسط آرایه مرتب شده زمانی که تعداد فرد مشاهدات وجود دارد. از طرف دیگر، هنگامی که تعداد مشاهدات زوج وجود دارد، میانه با یافتن میانگین دو مقدار مرکزی محاسبه می شود. اگر آرایه نمرات امتحان به یک آرایه مرتب شده مجدداً ترتیب داده شود، نمرات به این ترتیب فهرست می شوند:
آرایه مرتب شده از نمرات امتحان: {57، 59، 60، 64، 66، 67، 70، 72، 73، 74، 74، 75، 75، 75، 76، 77، 79، 80، 81، 83، 85، 8 ، 87، 88، 89، 90، 92، 93، 94، 99}
از آنجایی که در این مثال n =30 است، تعداد مشاهدات زوجی وجود دارد. بنابراین، میانگین دو مقدار مرکزی (15 th = 76 و 16 th = 77) برای محاسبه میانه همانطور که قبلا توضیح داده شد استفاده می شود، که در نتیجه (76 + 77) / 2 = 76.5 است. در مجموع، میانگین، حالت و میانه، ابتداییترین راهها برای بررسی روندها در یک مجموعه داده را نشان میدهند.
اقدامات پراکندگی
سومین نوع آمار توصیفی، معیارهای پراکندگی است (که به آن معیارهای تغییرپذیری نیز گفته می شود). این معیارها پراکندگی داده ها در اطراف میانگین را توصیف می کنند. ساده ترین معیار پراکندگی محدوده است. محدوده برابر با بزرگترین مقدار منهای در مجموعه داده کوچکترین است. در مورد ما، محدوده 99-57 = 42 است.
محدوده بین چارکی نشان دهنده اندازه گیری کمی پیچیده تر از پراکندگی است. این روش داده ها را به چارک تقسیم می کند. برای انجام این کار، از میانه برای تقسیم آرایه مرتب شده به دو نیمه استفاده می شود. این نیمه ها دوباره با میانه خود به دو نیم تقسیم می شوند. چارک اول (Q1) میانه نیمه پایینی آرایه مرتب شده است و به عنوان چارک پایین نیز شناخته می شود. Q2 نشان دهنده میانه است. Q3 میانه نیمه بالایی آرایه مرتب شده است و به عنوان چارک بالایی شناخته می شود. تفاوت بین چارک بالا و پایین در محدوده بین چارکی است. در مثال نمره امتحان، Q1 = 72.25 و Q3 = 86.75. بنابراین، محدوده بین چارکی برای این مجموعه داده 86.75 – 72.25 = 14.50 است.
سومین معیار پراکندگی، واریانس ( s2 ) است. برای محاسبه واریانس، مقدار خام هر نمره امتحان را از میانگین نمرات امتحان کم کنید. همانطور که ممکن است حدس بزنید، برخی از تفاوت ها مثبت و برخی منفی خواهند بود که در نتیجه مجموع تفاوت ها برابر با صفر می شود. از آنجایی که ما بیشتر به بزرگی تفاوت ها (یا انحرافات) از میانگین علاقه مندیم، یک روش برای غلبه بر این ویژگی “صفر کردن” مربع کردن هر انحراف است، بنابراین مقادیر منفی را از خروجی حذف می کنیم ( شکل 6.2 ). این منجر به موارد زیر می شود:
شکل 6.2
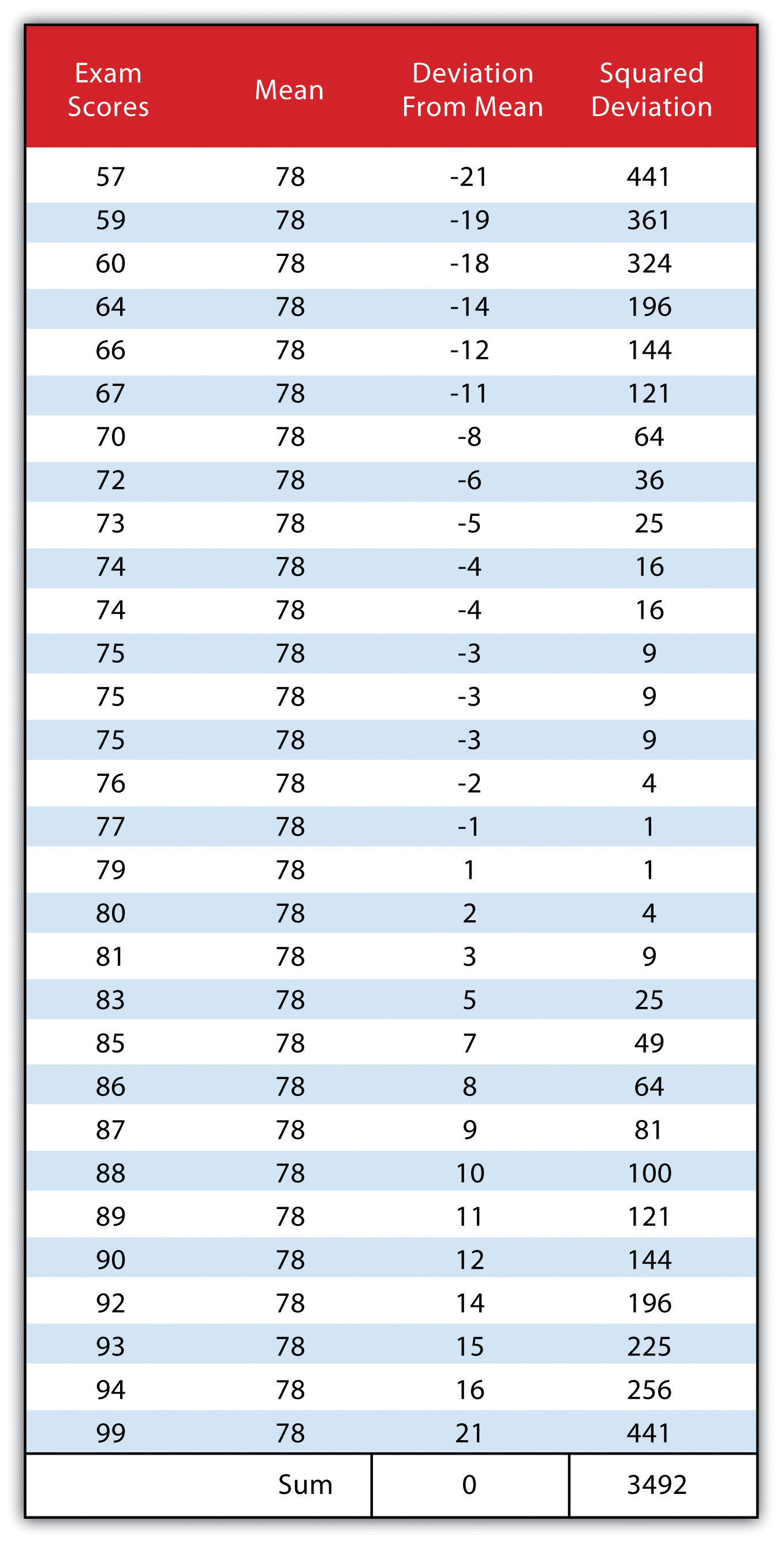
سپس مجموع مربع ها را بر n – 1 (در مورد کار با نمونه) یا n (در مورد کار با جمعیت) تقسیم می کنیم. از آنجایی که نمرات امتحان داده شده در اینجا کل جمعیت کلاس را نشان می دهد، از شکل 6.3 “واریانس” استفاده می کنیم که منجر به واریانس s 2 = 116.4 می شود. اگر بخواهیم از این نمرات امتحانی برای برون یابی اطلاعات در مورد تعداد دانش آموزان بزرگتر استفاده کنیم، با نمونه ای از جامعه کار می کنیم. در آن صورت مجموع مربع ها را بر n -1 تقسیم می کنیم.
شکل 6.3 واریانس
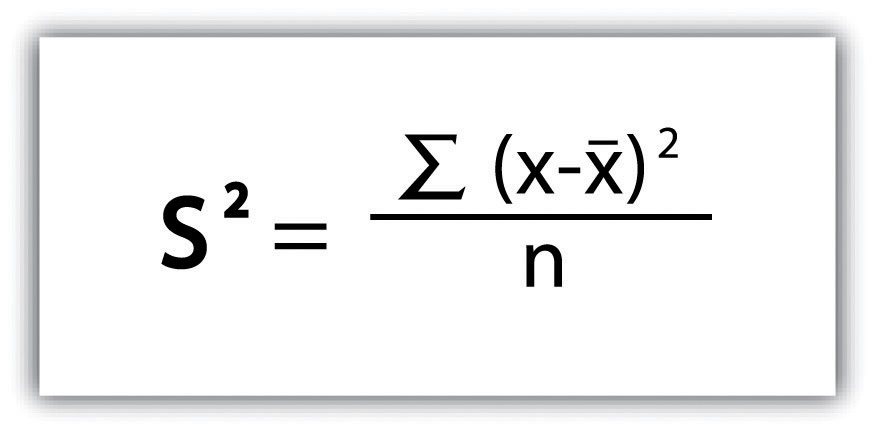
انحراف استاندارد ، اندازه گیری نهایی پراکندگی که در اینجا مورد بحث قرار می گیرد، رایج ترین اندازه گیری پراکندگی است. برای جبران مجذور شدن هر تفاوت از میانگین انجام شده در طول محاسبه واریانس، انحراف استاندارد جذر واریانس را می گیرد. همانطور که در شکل 6.4 “انحراف استاندارد” مشخص شد، مثال نمره امتحان ما منجر به انحراف استاندارد s = SQRT(116.4) = 10.8 می شود.
شکل 6.4 انحراف معیار
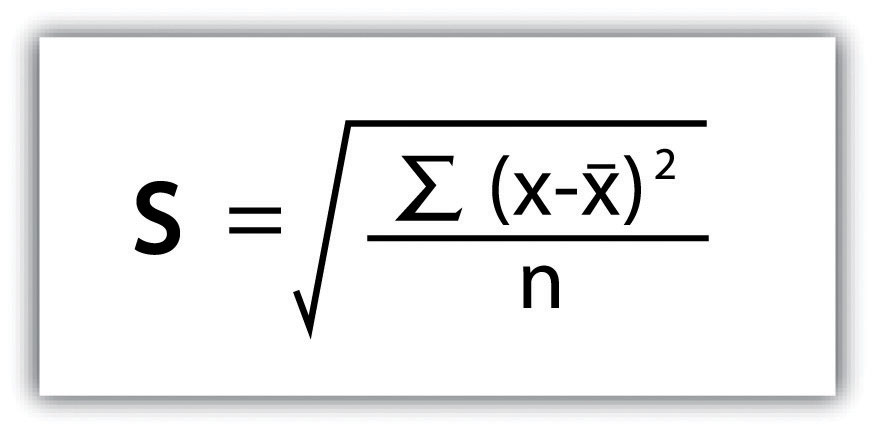
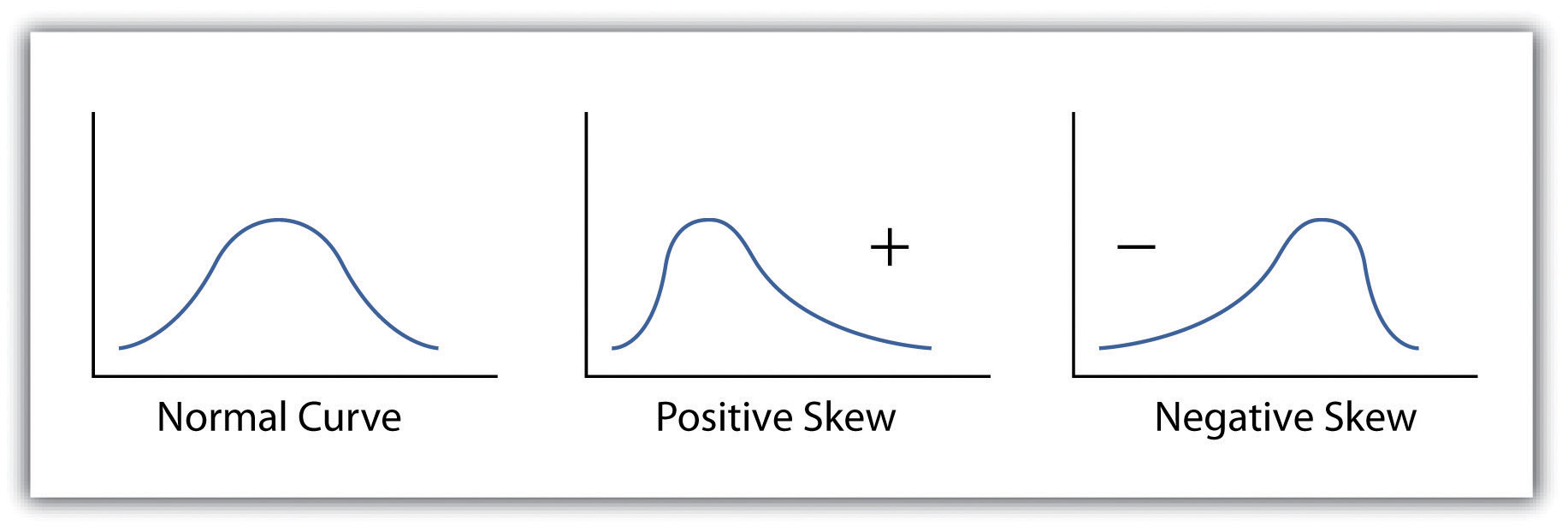
محاسبه انحراف استاندارد به ما امکان می دهد تا استنباط های قابل توجهی در مورد پراکندگی مجموعه داده خود داشته باشیم. یک انحراف استاندارد کوچک نشان می دهد که مقادیر در مجموعه داده حول میانگین جمع شده اند، در حالی که یک انحراف استاندارد بزرگ نشان می دهد که مقادیر به طور گسترده در اطراف میانگین پراکنده شده اند. در صورتی که مجموعه داده با توزیع نرمال مطابقت داشته باشد، ممکن است استنباط های بیشتری در مورد انحراف استاندارد انجام شود. توزیع نرمال به این معنی است که داده ها، هنگامی که در یک توزیع فرکانس (هیستوگرام) قرار می گیرند، متقارن یا “زنگ شکل” به نظر می رسند. هنگامی که “عادی” نیست، توزیع فرکانس مجموعه داده به طور مثبت یا منفی “ارواح” گفته می شود ( شکل 6.5 “هیستوگرام مجموعه داده های منحنی، دارای انحراف مثبت، و منحنی منفی”). داده های اریب آنهایی هستند که مقادیری را حفظ می کنند که در اطراف میانگین متقارن نیستند. صرف نظر از این، دادههای توزیع شده معمولی این ویژگی را حفظ میکنند که تقریباً 68 درصد از مقادیر دادهها در انحراف استاندارد 1± از میانگین قرار میگیرند و 95 درصد از مقدار دادهها در انحراف استاندارد 2± از میانگین قرار میگیرند. در مثال ما، میانگین 78 و انحراف معیار 10.8 است. بنابراین می توان بیان کرد که 68 درصد از نمرات بین 67.2 و 88.8 (یعنی 78 ± 10.8) قرار می گیرند، در حالی که 95 درصد از نمرات بین 56.4 و 99.6 قرار می گیرند (یعنی 78 ± [10.8 * 2]). برای مجموعه داده هایی که با منحنی نرمال مطابقت ندارند، می توان فرض کرد که 75 درصد از مقادیر داده ها در 2± انحراف استاندارد از میانگین قرار می گیرند.
شکل 6.5 هیستوگرام مجموعه داده های منحنی معمولی، دارای انحراف مثبت و منحنی منفی
خوراکی های کلیدی
- اندازه گیری توزیع برای یک متغیر معین خلاصه ای از فراوانی مقادیر در محدوده مجموعه داده است و معمولاً با استفاده از یک هیستوگرام نشان داده می شود.
- اندازهگیریهای گرایش مرکزی تلاش میکنند تا بینشهایی را درباره ارزش «معمولی» برای یک مجموعه داده ارائه دهند.
- معیارهای پراکندگی (یا تغییرپذیری) پراکندگی داده ها در اطراف میانگین یا میانه را توصیف می کند.
تمرینات
- یک جدول حاوی حداقل سی مقدار داده ایجاد کنید.
- برای جدولی که ایجاد کردید، میانگین، حالت، میانه، محدوده، محدوده بین چارکی، واریانس و انحراف معیار را محاسبه کنید.



7 نظرات