


داده و ماهیت آن :آنچه که باید درباره داده ها بدانید
داده و ماهیت آن :آنچه که باید درباره داده ها بدانید عنوان پستی است که من قصد دارم درباره آن صحبت کنم .امیدوارم این پست که از فصل دوم کتاب جغرافیای محاسباتی من انتخاب شده است لذت ببرید .ممنون میشم که نظرات خودتان را در این باره با من به اشتراک بگذارید.
نویسنده:
دکتر سعید جوی زاده
2-1 مقدمه
به طور کلی داده، نمودی از وقایع، معلومات، رخدادها، پدیده ها و مفاهیم می باشد. در علم جغرافیا با دو دیدگاه به داده نگاه می شود.
الف)دیدگاه غیر مکانی (توصیفی)؛
ب) دیدگاه مکانی.
در آمار کلاسیک از داده های غیر مکانی (توصیفی) و در آمار فضایی از داده های مکانی استفاده می شود. داده های غیر مکانی، شامل اطلاعات ثبت شده برای توصیف پدیده هاست و داده های مکانی به داده هایی اطلاق می شود که مختصات زمینی عوارض و موقعیت مکانی پدیده ها را نشان می دهد. این ویژگی ها در بخش های این فصل توضیح داده می شود.

-2 تفاوت داده و اطلاعات
داده شامل مواد خام آماری است که از واقعیتها و ارقامی تشکیل میشود و تشریح کمی-کیفی مشخصههای پدیده و یا واحدهای مورد نظر را بر عهده دارد. دادهها شامل اعداد، گزارشها، نقشهها، جداول و نمودارهایی است که از منابع مختلف جمعآوری و بدون هیچ گونه پردازشی به صورت خام ارائه میشود.

اطلاعات، دادههایی است که پس از پردازش برای دستیابی به مقاصد مختلف مورد توجه قرار میگیرند. در واقع اطلاعات عبارت است از نتایج فرآیندهای انجام شده بر روی دادهها برای دستیابی به واقعیتها، روابط و نمایش ساختارهای پیچیده.

به طور کلی دادههای جغرافیایی را میتوان به دو دستۀ دادههای مکانی و غیر مکانی (توصیفی) تقسیم کرد. دادههای مکانی به دادههایی اطلاق میشود که مختصات زمینی عوارض و موقعیت مکانی پدیدهها را نشان میدهد. این دادهها در دو شکل رستری و برداری قابل نمایش و استفاده است. دادههای غیر مکانی (توصیفی) شامل اطلاعات ثبت شده برای توصیف پدیدههاست.
دادههای جغرافیایی به دو شکل پیوسته و ناپیوسته هستند. دادههای پیوسته دادههایی هستند که در همه جای سطح زمین وجود دارند مانند ارتفاع از سطح دریا، دما، و باران. دادههای ناپیوسته در همه جا یافت نمیشوند. مانند معدن آهن، جنگل، رودخانه، روستا، خانه، دریاچه، چاه آب و غیره. دادههای ناپیوسته در حقیقت عارضههای جغرافیایی را تشکیل میدهند. عارضههای جغرافیایی میتوانند به صورت نقطه، خط و سطح دیده شوند. در بخش بعدی راجع به این نوع عارضهها بحث میشود. معمولاً دادههای ناپیوسته شمارش میشوند. فراوانی عارضهها یا در داخل واحدهای طبیعی یا مصنوعی شمرده میشوند.
دادههای پیوسته در نقاط معینی از سطح زمین اندازه گیری میشوند. اندازه دما یا نم نسبی در ایستگاههای هواشناسی تعیین میشود. برای استفاده از این دادهها در نقاط فاقد داده از فرآیند درونیابی استفاده میشود. برای درونیابی دادههای پیوسته سطح زمین به واحدهای کوچکی بنام پیکسل تقسیم میشود. در فصلهای بعدی راجع به درونیابی بحث میشود.
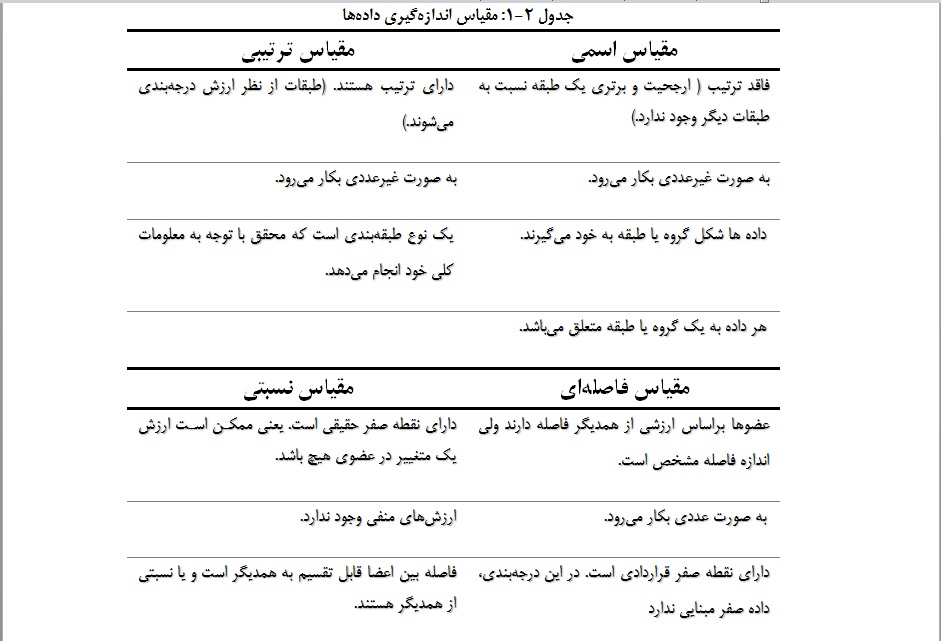
دادههای جغرافیایی در مقیاسهای اسمی، رتبهای، فاصلهای و یا نسبتی تعریف میشوند.
مقياس اسمي: در اين مقياس دادهها شكل گروه يا طبقه به خود ميگيرند. طبقۀ مونث در قبال مذكر، حاضر يا غايب، موفق يا ناموفق، زير ميانگين يا بالاي ميانگين، انگليسي يا آمريكايي، آلماني، ايراني، فرانسوي. انواع پوششها و کاربریهای زمین. انواع ناحیههای جغرافیایی. به عبارت كليتر در اين نوع مقياس فقط تعلق يا عضويت يك داده به يك گروه يا طبقه مشخص ميشود. بر روی زمین معمولاً طبقات اسمی مانند گروههای مختلف پوشش زمین و یا ناحیههای مختلف حرارتی ایران در کنار هم قرار دارند و با همدیگر همسایه هستند. از این جهت به این طبقات دادهها، واحدهای همجوار هم گویند. در هر طبقه کاربری زمین، نوع استفاده از زمین در همه جای آن یکسان است. در یک منطقه جنگلی همه جا جنگل است. اما در ناحیههای حرارتی همه جا دما یکسان نیست بلکه متوسط دما در آن ناحیه با متوسط دمای ناحیه مجاور فرق دارد. به عبارت دیگر در ناحیههای جغرافیایی معمولاً ارزش نقاط مختلف داخل ناحیه معدلگیری و ساده شده است.
مقياس ترتيبي: عارضهها و سطح زمین از نظر داشتن یک ارزش و صفت ویژه درجهبندي ميشوند. مثلاً شهرها به شهرهاي پرجمعيت، متوسط، كم جمعيت. هتلها به چهار ستاره، سه ستاره، دو ستاره، تك ستاره، وضع سطح بهداشت يك شهر به عالي، بسيار خوب، خوب، متوسط، ضعيف، بسيار ضعيف، بد درجهبندی میشوند. در اين نوع مقياسبندي، فاصله بين درجه يا رتبهها معلوم نيست و يا اينكه دقيق نيست. در هر موردي ميتواند يك معيار خاصي را به خود بگيرد. مثلاً شهر درجه 1 شهري باشد كه بهترين هتل و دبيرستان و دانشگاه دارد، شهر درجه دو شهري كه مثلاً دانشگاه ندارد. باد درجه 1 يا غالب با باد درجه 2 از نظر دفعات وزش فرق دارد ولي چقدر معلوم نيست. فقط كمتر از آن باشد كافي است. البته مقياس درجهاي يا ترتيبي يك نوع طبقهبندي است كه محقق با توجه به معلومات كلي خود انجام ميدهد.
مقياس فاصلهاي: در اين حالت نيز همانند مقياسهاي قبلي عضوها براساس ارزشي از همديگر فاصله دارند ولي اندازه فاصله مشخص است. مثلاً تهران در مقياس دما از يزد 4 درجه فاصله دارد. فاصله بين دو عضو متوالي ميتواند به صورت عدد صحيح يا اعشاري باشد. در اين درجهبندي، دادهها صفر مبنايي ندارند. مثلاً نمي توان گفت كه يك شهر دما ندارد. مثلاً دماي صفر درجه مبنا نيست و اندازهها ميتوانند تا بينهايت ادامه يابند. اگرچه فاصله بين اعضاي متوالي مشخص است ولي اندازه فاصلهها نميتوانند نسبتي از همديگر باشند. براي مثال نمي توان گفت كه دماي 20 درجه دو برابر دماي 10 درجه ارزش دارد.
مقياس نسبتي: اين مقياس همانند مقياس فاصلهاي است با دو تفاوت. اولاً مبناي صفر مطلق دارد يعني ممكن است ارزش يك متغيير در عضوي هيچ باشد. یعنی اینکه ارزش متغيير اندازههاي منفي نميپذيرد. مثلاً بارش در مقابل دما. بارش مقياس نسبتي دارد ولي دما مقياس فاصلهاي. ثانياً ارزشهاي اعضا قابل تقسيم به همديگر هستند. يعني ميتوان گفت 200 ميليمتر بارش دو برابر 100 ميليمتر بارش ارزش دارد.
به سخن كوتاه، در مقياس اسمي عضو به يك طبقه یا ناحیه تعلق پيدا ميكند و تفاوت طبقات از همديگر براساس يك مقياس يا درجه مشخص نيست، بلكه كيفي است. اما در مقياس ترتيبي تفاوت بين طبقات بر اساس درجهبندي يك ارزش معيني انجام شده است ولي فاصله بين طبقات مساوي نيست و قابل اندازهگيري هم نيست. فقط ميدانيم كه طبقه يا رده اول بهتر از رده دوم است. ولي نميدانيم چند برابر بزرگ است. در مقياس فاصلهاي، فاصله بين اعضا قابل اندازهگيري ولي قابل تقسيم به همديگر نيست. در مقياس نسبتي فاصله بين اعضا قابل تقسيم به همديگر است و يا نسبتي از همديگر هستند.در مقياس نسبتي ارزشهاي منفي وجود ندارد. مقياسهاي اسمي و ترتيبي قابل پردازش با روشهاي آماري متداول نيستند و به تعبير ديگر ميتوان آنها را اطلاعات كيفي نامگذاري كرد. اما مقياسهاي فاصلهاي و نسبتي قابل پردازش هستند و به آنها دادههاي پارامتري يا كمّي گويند. مقياسهاي اسمي و ترتيبي دادههاي ناپارامتري یا کیفی ناميده ميشوند. جدول 2-1 خلاصهای از مقیاس اندازهگیری دادهها را نشان میدهد.
-3 الف) فرم دادههای غیر مکانی (توصیفی)
دادههاي توصيفي كه تشريحي و موضوعي نيز ناميده ميشوند، ارائه دهندۀ تمامي اجزاي غير مکانی نظير: نام (مالك، شهر) شماره (پارسل، خانه) اندازههاي كمي و كيفي (شوري خاك، حجم، تعداد و كيفيت درختان جنگل) نوع (سنگ مادر و خاك) و خلاصه هر نوع مشخصه مرتبط با فرم مکانی ميباشد.
2-3-1 جداول توصیفی
جداول توصیفی، نمودارها و برخی از شاخصهای آماری از جمله روشهایی هستند که برای توصیف دادهها به کار میروند. دادههای توصیفی معمولاً به صورت جداول توصیفی نشان داده میشوند. ساختار جداول توصیفی مشتمل بر سطرها و ستونهایی است. سطرها با عنوان رکورد و ستونهای جدول توصیفی، با عنوان فیلد معرفی میشوند. نمونهای از جداول توصیفی در جدول 2-2 و 2-3 نشان داده شده است. برخي از آماردانان معتقدند كه نمايش تصويري به درک ساختار دروني دادهها كمك مؤثرتري میکند. راجع به نمودارهای کاربردی در جغرافیا و شاخصهای توصیفی در فصلهای بعدی توضیح داده میشود.

2-4 ساختارهای دادههای غیر مکانی (توصیفی)
تنوع زيادي در ساختار دادههاي توصيفي وجود دارد كه عمدتاً از تكامل يكديگر حاصل شـده انـد مهمترين این ساختارها عبارتست از:
الف) ساختار داده تخت
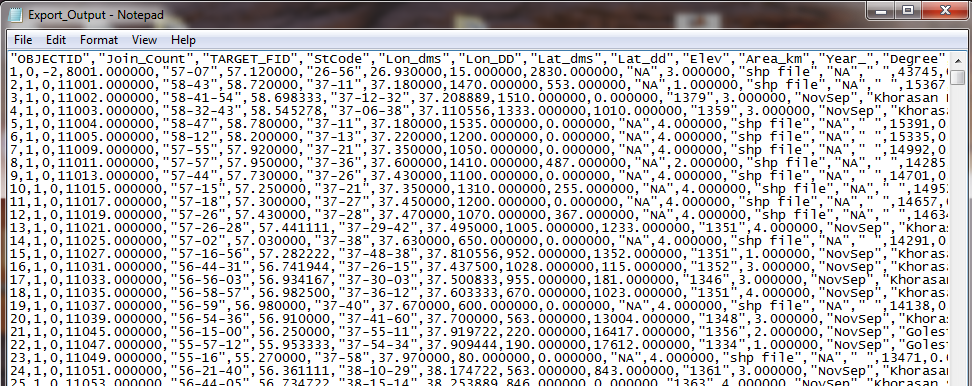
در سادهترين حالت، ساختار دادههاي تخت را ميتوان در يک فايل متني ارائه کرد. در اين حالت معمولاً عنوان هر توصيف در يک ” ” قرار گرفته و مقادير هر توصيف با جداکنندهها (معمولاً کاما) از يکديگر متمايز ميشوند (يوجي، 2012). براي نمونه ساختار دادههاي تخت مربوط به ويژگيهاي برخي از ايستگاههاي هیدرومتري ايران در شکل 2-1 نشان داده شده است.
ب) ساختار سلسله مراتبي
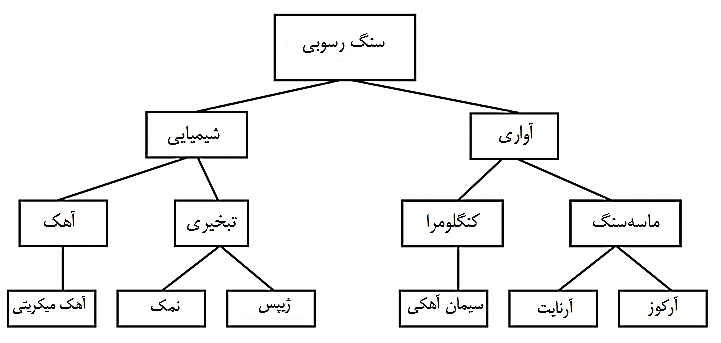
در این نوع از بانکهای اطلاعاتی، اطلاعات به صورت درختی در اختیار کاربران قرار میگیرد. دادهها در بخشهایی به نام قطعه ذخیره میشوند. قطعه بالای هرم ریشه نامیده میشود. ریشه به صورت رابطه پدر – فرزندی به قطعات زیرین وصل میشود. قطعه پدر میتواند چندین فرزند داشته باشد، ولی هر فرزند فقط یک پدر دارد.این نوع پایگاه داده دو اشکال عمده داشت. اول اینکه به دلیل نوع ساختار خود از جامعیت خوبی برخوردار نبود چون به دلیل افزونگی داده باعث ناسازگاری در بانک اطلاعاتی میشد و دوم اینکه اشکال ساختاری داشت یعنی با حذف و اضافه کردن رکوردها کل ساختار پایگاه داده باید تغییر میکرد (توني و فلورنس 2016). براي نمونه در شکل 2-2 ساختار سلسله مراتبي در بانک اطلاعاتي مربوط به سنگهاي رسوبي نشان داده شده است.
ج) ساختار شبکه اي
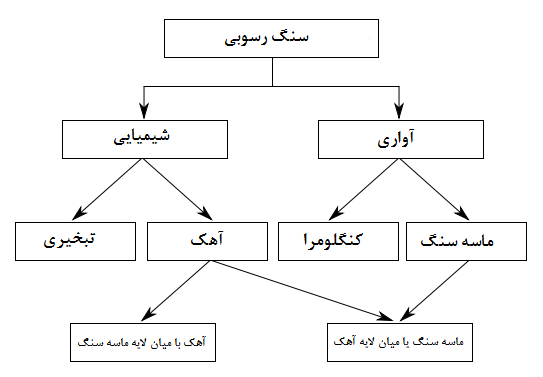
در واقع حالت تغییر یافته مدل بانک اطلاعاتی سلسله مراتبي است. این دو مدل به سادگی قابل تبدیل به یکدیگر هستند. در مدل سلسله مراتبي میتوان یک عامل را به چندین عامل پیوند داد ولی در مدل شبکهای میتوان چندین عامل را به چندین عامل پیوند داد. اگر چه با اجازه دادن ایجاد سیکل اشکال اول مدل سلسله مراتبي (عدم جامعیت) برطرف میشود اما مشکل ساختاری همچنان پابرجا بود (تورستن و مولوني 2014). در شکل 2-3 ساختار شبکهای دادههاي مربوط به سنگهاي رسوبي نشان داده شده است.
د) ساختار رابطه ای
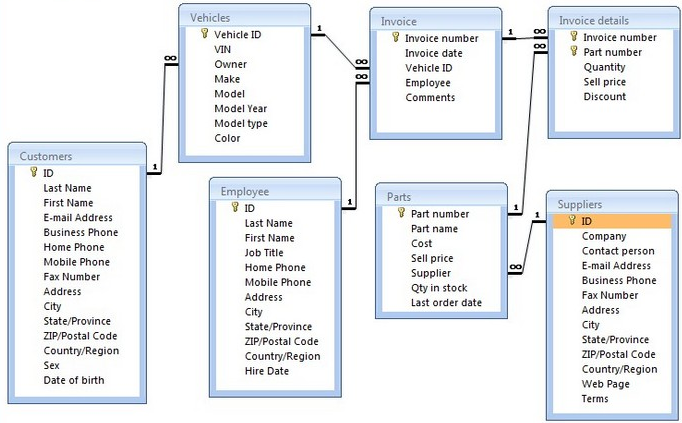
در این مدل، دادهها به صورت مجموعهای از جداول دو بعدی ذخیره میشوند که توسط فیلدهای کلیدی (فیلدهای مشترک) به هم وصلمیشوند. در واقع یک کلاس عارضه توسط یک جدول با فیلدهای مشترک ارائه میشود. جدول به نامهای رابطه یا چندتایی نیز نامیده میشود. مزایاي اين ساختار عبارتند از: 1) انعطاف پذیری بالا و عدم محدودیت در پرسشدهی یا به عبارت دیگر امکان انجام جستجو در هر جدول و بر اساس هر فیلد توصیفی؛ 2) عدم نیاز به ذخیرهسازی جدول الحاقیو جلوگیری از تولید افزونگی؛ 3) نرمال بودن جداول که باعث ایجاد انسجام و حداقل افزونگی میشود؛ 4) افزونگی کمتر نسبت به مدلهای سلسله مراتبی و شبکهای؛ 5) دارای پایه تئوری دقیق و ریاضی؛ 6) سادگی ساختار؛ 7) سادگی ایجاد تغییرات و 8) رایجترین مدل در نرمافزارهای تجاری و کاربردهای به علت انعطاف پذیری بالا. همچنين از معايب اين ساختار ميتوان به مواردي چون: 1) سخت بودن پیاده سازی و اجرا؛ 2) کارآیی کمتر و کند بودن سیستم به دليل عدم وجود اتصالات فیزیکی یا اشارهگرها 3) مناسب نبودن برای کار با اشیاء پیچیده و 4) میزان بالای بروز اشتباهات منطقی به علت انعطاف پذیری بالای مدل (نوئل، 1991). در شکل 2-4 نمونهاي از ساختار رابطهاي نشان داده شده است.
-5 ب) فرم دادههای مکانی
مدلهای فرم مکانی ساختار و توزیع عوارض را در مکان جغرافیایی ارائه میکند. مدل فرم مکانی پاسخگوی دو سوال است: 1) چه چیز؟ و 2) کجاست؟ در مدل فرم مکانی، جهان واقعی (کره زمین) به صورت یک مدل شبیهسازی (نقطه، خط و سطح) تبدیل میشود. برای نمونه تعدادی چندضلعی که بر روی یک صفحه یا نقشه مختصاتدار ترسیم شده است. نشاندهنده فرم دادههای مکانی است چرا که بیانگر شکل پدیده (در این جا چندضلعی) و همچنین محل قرارگیری آن میباشند (توبلر 1989). مدل فرم مکانی به دو دسته مدل برداریو رستری تقسیم میشود:
2-5-1 مدلهای برداری
در مدل برداري اشيا يا پدیدهها در جهان واقعي به وسيله عناصر هندسـي نمـايش داده ميشوند. بدين معنا كه موقعيت هر شي به وسيله مختصات آن و توسط نقاط، خطـوط و سطوح مشخص
ميشود. در اين مدل موقعيت هر نقطه بهطور دقيق بـا يـك جفـت مختصات در يك سيستم مختصات معين ارائه ميگردد كه روابـط همـسايگي را نيز ميتوان به آن افزود، بدين معنا كه نقاط آغاز و پايان يك خـط و همچنـين سـطوح مجاور آنها را تعيين نمود . اين ساختار در ارائه موقعيت پديدههـا دقـت بـالايي دارد و بنابراين براي تشريح موقعيت مکاني پدیدههاي نقطهاي، خطي و سطحي بسيار مناسب ميباشد.
الف) نقاط
هر نقطه نشاندهنده یک موقعیت منحصر به فرد در فضا میباشد، برای نمونه یک مسجد و یا مدرسه، که با استفاده از علائم کارتوگرافی در نقشههای شهری قابل نمایش هستند. معمولاً از نقاط برای نمایش عوارضی استفاده میشود که نتوان آنها را با خطوط و سطوح نمایش داد (مانند چاهها و دکلهای برق. از نقاط برای نمایش عوارضی میتوان استفاده کرد که دارای امتداد و مساحت نیستند). در شکل تعدادی پدیده نقطهای نشان داده شده است.

ب) خطوط
خطوط نشاندهنده نقاط با ویژگیهای یکسان هستند. برای نمونه، جادهها و یا مسیرهای لولهگذاری، نمایش دهنده عوارض خیلی باریک و بسیار کم عرضی هستند که دارای طول میباشد اما فاقد سطح هستند. منحنی میزان در روی نقشه توپوگرافی نیز پدیدههایی خطی محسوب میشوند. در روی نقشه توپوگرافی هر منحنی میزان نو8434.وئوظک92232عی خط هم ارزش است که ارزش عددی آن در تمام نقاط یکسان میباشد. از خطوط هم ارزش میتوان برای نمایش پدیدههای مختلف مانند میزان بارندگی، تراکم آلودگی آلایندههای هوا در محیطهای شهری و یا سطح ایستابی سفرههای آب زیرزمینی استفاده کرد. در شکل تعدادی پدیده نقطهای نشان داده شده است.

ج) سطوح
نشاندهنده یک محدوده فضایی همگونی در داخل یک چندضلعی میباشند. برای نمونه محدوده جنگلی و یا تمامیت یک کشور به خصوص در محدودههای سیاسی خود که توسط چندضلعیهای بسته نشان داده شده است. در شکل تعدادی پدیده از نوع محدودهای نشان داده شده است.


2-5-2 ساختار مدل رستری
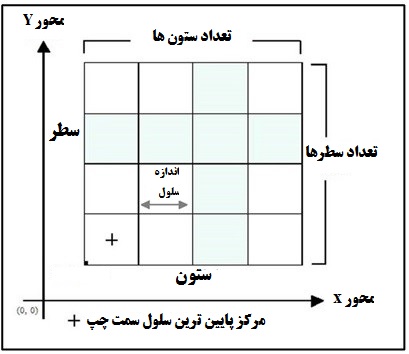
رستر شامل مجموعه اي از نقاط يا سلولهايي است كه عوارض زمين را در يـك شـبكه منظم ميپوشاند و به كمك شمارههاي رديف و ستون آنهـا، آدرسدهـي مـيشـود. كوچكترين عنصر تشكيل دهنده رستر، پیکسل يا سلول ناميده مـيشـود كه ارزش هـر يك از آنها، نمايانگر اطلاعات طیفی یا توصيفي عارضه زميني است. بين سـلولهـاي يك داده رستري هيچ رابطه منطقي وجود ندارد و هر سلول تنها داراي يك ارزش است كه نمايانگر يك ويژگي مانند جمعيت، كاربري، نوع خاك و . . . خواهد بود. تصاویر ماهوارهای، عکسهای هوایی، نقشههای کاغذی اسکن شده، مدلهای رقومی ارتفاعی دارای ساختار رستری میباشند (جویزاده و همکاران، 1396). در شکل اجزای یک لایه رستری نشان داده شده است.
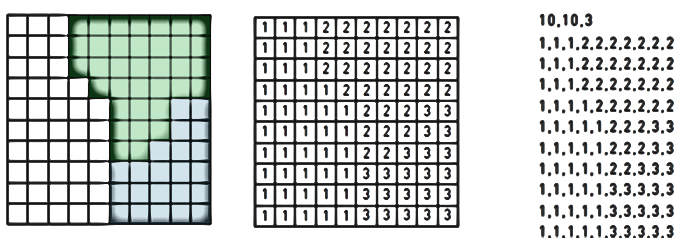
در مدل رستري به هر سلول يك كد يا مقدار ارزش اختصاص داده ميشود كه در واقع معرف نوع عارضه است. همچنین هر سلول نمايشگر مساحتي از سطح زمين است كه اين مقدار مساحت به ضريب تفكيك پـذيري مـدل بـستگي دارد. در شکل 2-9 چگونگی کدگذاری به سلولها در لایههای رستری نشان داده شده است.
در مدل رستری عوارض نقطهای با یک سلول منفرد، عوارض خطی با رشتهای از پیکسلهای ممتد و سطوح با پهنه یا مجموعهای از پیکسلهای متصل به هم نمایش داده میشود. به واسطه همین نوع نمایش، عوارض این مدل نسبت به مدل برداری دارای قابلیت تحلیلی بسیار بالاتری است. دادههای رستری به نسبت دادههای برداری از تنوع بیشتری برخوردار هستند (جویزاده و همکاران، 1396). در شکل 2-10 چگونگی نشان دادن پدیدههای سطح زمین با مدلهای برداری و رستری نشان داده شده است.

دادهها را با روشهای متعددی میتوان وارد مدل رستری نمود. برای نمونه با اسکن کردن و تبدیل دادهها به تصویر، تبدیل دادههای برداری به دادههای رستری با انواع نرم افزارها و یا دریافت دادهها به صورت رقومی از دیگر ورودیها مانند تصاویر ماهوارهای میتوان به دادههای رستری دست یافت.
لایههای رستری را به دو صورت اعداد صحیح و اعشاری میتوان ارزشگذاری کرد. ارزش گذاری با اعداد صحیح در رابطه با دادههایی است که دارای رتبهبندی یا طبقهبندی هستند، برای نمونه دادههای مربوط به نقشه تراکم پوشش گیاهی یک منطقه که تراکم زیاد را با عدد 1، تراکم متوسط با عدد 2، و تراکم کم با عدد 3 ارزش گذاری شدهاند. از مزایای این روش ارزشگذاری استفاده از آنها در جدول اطلاعاتی لایه رستری است.
ارزش گذاری با اعداد اعشاری در رابطه با عوارضی به کار میرود که دارای دادههای پیوسته هستند، برای نمونه مقدار ارتفاع، مقدار بارندگی یا درجه حرارت و… یک لایه رستری اعشاری، میتواند شامل اعدادی مانند 26/ 1002 ، 90/ 1500 و …. باشد. فرمت اعشاری حجم بیشتری را نسبت به فرمت اعداد صحیح به خود اختصاص میدهد.
ابعاد و اندازه پیکسلها در مدل رستری نشان دهنده درجه وضوح و قدرت تفکیک آن میباشد هر چه ابعاد لایه رستری کوچکتر باشد، لایه رستری از وضوح بیشتری برخوردار است و برای نمایش دقیقتر عوارض مناسبتر میباشد. البته به همان میزان که ابعاد پیکسلها کوچکتر
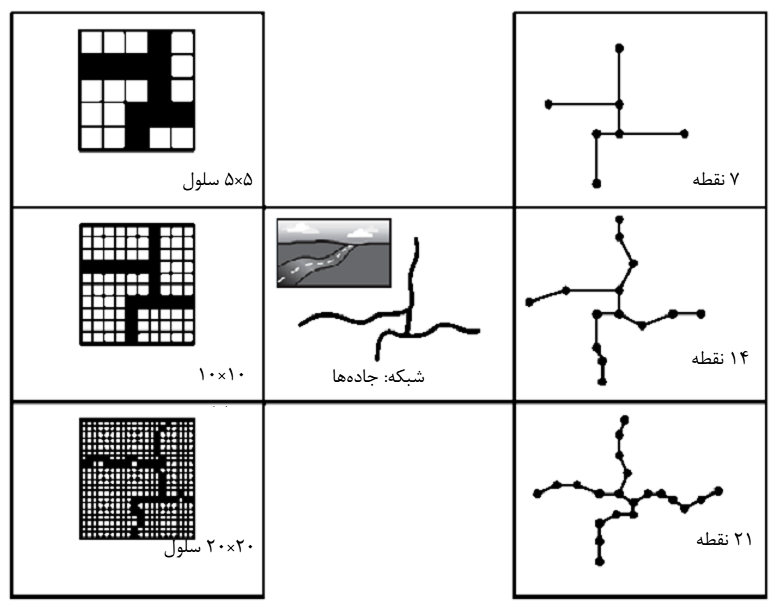
میشود حجم ذخیرهسازی آن نیز بیشتر میشود. هر دو مدل برداری و رستری قابلیت تبدیل به یکدیگر را دارند ولی در هر رفت و برگشت تعدادی از ارزش دادهها دچار تغییراتی میشوند، اعمال دقت بیشتر و استفاده از روشهای مناسبتر میتواند از بروز این مشکل جلوگیری کند و یا آن را به حداقل برساند .در شکل 2-11 تأثیر قدرت تفکیک بر وضوح دادههای رستری و برداری نشان داده شده است.
2-5-3 پیچیدگیهای جهان واقعی و مدلسازی
مشکلات متعددی در رابطه با سادهسازی پیچیدگیهای جهان واقعی با مدلهای برداری و رستری وجود دارد. که از میان آنها میتوان به ماهیت پویایی جهان واقعی، تعیین عوارض گسسته و پیوسته و مقیاس کار اشاره کرد. جهان واقعی ساکن نیست برای نمونه در یک ناحیه جنگلی درختان روییده و قطع میشوند، رودها طغیان میکنند و شهرها گسترش مییابند. ماهیت پویایی جهان باعث دشوار شدن تعریف عارضه در پروژههای مرتبط با سیستم اطلاعات جغرافیایی میشود (لاورینی، 2000). این دشواریها را میتوان مشتمل بر موارد زیر دانست:
الف) نماد سازی عوارض
معمولاً انتخاب نوع و نماد عارضه در مدل سازی دشوار میباشد. برای نمونه تصمیمگیری در مورد این که بهترین شیوه برای نشان دادن جنگل استفاده از مجموعهای از نقاط است (نشان دادن موقعیت درختان به صورت جدا از هم) یا استفاده از یک ناحیه (چندضلعی) دشوار است.
ب) نمایش تغییرات
چگونگی ارائه تغییرات زمانی پدیدهها نیز دشوار است. برای نمونه ممکن است جنگلی که با یک ناحیه نشان داده شده است با گذشت زمان آنچنان فرسوده شود که گروه پراکندهای از درختان را شامل شده و در آن صورت با استفاده از نقاط بهتر بتوان آن را نشان داد.
ج) نگرش متفاوت
گر چه ممکن است ماهیت فیزیکی عوارض ثابت باشد اما درک ما از ساختار جغرافیایی آنها میتواند با توجه به هدف کار متفاوت باشد. بازدید کننده از یک درّه جنگلی ممکن است به نقشه شبکه راههای منطقه به عنوان عوارض خطی بنگرد در حالی که برای مهندسین راهسازی که باید سطح جاده را بعد از فصل زمستان تعمیر کنند، جادهها نوعی عوارض سطحی محسوب میشوند.
گاهی اوقات تعیین مرز عوارض دشوار میباشد. برای نمونه در یک ناحیه جنگلی مرز مشخصی بین واحدهای مختلف گونههای گیاهی وجود ندارد زیرا معمولاً در یک منطقه گذر، درختان با گیاهان ناحیه مجاور در هم میآمیزند. در این مورد، چنانچه بخواهیم جنگل را به وسیله یک چندضلعی نشان دهیم، نمیتوان مرز دقیقی را تعیین نمود به نظر یک بومشناس، پوشش گیاهی میتواند عارضهای پیوسته باشد که با یک عارضه نشان داده میشود در حالی که برای یک جنگلبان بهتر است گیاهان به صورت مجموعهای از عوارض ناحیهی منفصل نشان داده شوند. بنابراین تعیین نوع عارضهای که در مدلسازی جهان واقعی به کار میرود در برخی موارد کار سادهای نیست.
خلاصه :
– فرم دادههای مکانی به مکان پدیده مرتبط میشود. فرم توصیفی دادهها در مورد چیستی فرم مکانی دادهها بحث میکند.
– مدل فرم مکانی به دو دسته مدل برداری و رستری تقسیم میشود.
– در مدلبرداري اشيا يا پدیدهها در جهان واقعي به وسيله عناصر هندسـي نمـايش داده ميشوند. بدين معنا كه موقعيت هر شي به وسيله مختصات آن و توسط نقاط، خطـوط و سطوح مشخص ميشود.
– نقطه در مدل برداری نشاندهنده یک موقعیت منحصر به فرد در فضا میباشد، برای نمونه یک مسجد و یا مدرسه
– خطوط در مدل برداری نشاندهنده نقاط با ویژگیهای یکسان هستند. برای نمونه، جادهها و یا مسیرهای لولهگذاری، نمایش دهنده عوارض خیلی باریک و بسیار کم عرضی هستند که دارای طول میباشد اما فاقد سطح هستند.
– سطوح در مدل برداری نشاندهنده یک محدوده فضایی همگونی در داخل یک چندضلعی
میباشند. برای نمونه محدوده جنگلی
– رستر شامل مجموعه اي از نقاط يا سلولهايي است كه عوارض زمين را در يـك شـبكه منظم ميپوشاند و به كمك شمارههاي رديف و ستون آنهـا، آدرسدهـي مـيشـود.
– كوچكترين عنصر تشكيل دهنده رستر، پیکسل يا سلول ناميده مـيشـود.
– ابعاد و اندازه پیکسلها در مدل رستری نشان دهنده درجه وضوح و قدرت تفکیک آن میباشد هر چه ابعاد لایه رستری کوچکتر باشد، لایه رستری از وضوح بیشتری برخوردار است و برای نمایش دقیقتر عوارض مناسبتر میباشد.
– هر دو مدل برداری و رستری قابلیت تبدیل به یکدیگر را دارند ولی در هر رفت و برگشت تعدادی از ارزش دادهها دچار تغیراتی میشوند، اعمال دقت بیشتر و استفاده از روشهای مناسبتر میتواند از بروز این مشکل جلوگیری کند و یا آن را به حداقل برساند .
– تنوع زيادي در ساختار دادههاي توصيفي وجود دارد كه عمدتاً از تكامل يكديگر حاصل شـده انـد. ساختار داده تخت، ساختار سلسله مراتبی، ساختار شبکهای و مدل رابطهای از مهمترين ساختارها هستند.
– در سادهترين حالت، ساختار دادههاي تخت را ميتوان در يک فايل متني ارائه کرد. در اين حالت معمولاً عنوان هر توصيف در يک ” ” قرار گرفته و مقادير هر توصيف با جداکنندهها (معمولاً کاما) از يکديگر متمايز ميشوند.
– در ساختار سلسله مراتبی، اطلاعات به صورت درختی در اختیار کاربران قرار میگیرد. دادهها در بخشهایی به نام قطعه ذخیره میشوند.
– قطعه بالای هرم در ساختار سلسله مراتبی ریشه نامیده میشود.
– ساختار شبکهای در واقع حالت تغییر یافته مدل بانک اطلاعاتی سلسله مراتبي است. در مدل سلسله مراتبي میتوان یک عامل را به چندین عامل پیوند داد ولی در مدل شبکهای میتوان چندین عامل را به چندین عامل پیوند داد.
– در مدل رابطهای، در واقع یک کلاس عارضه توسط یک جدول با فیلدهای مشترک ارائه میشود.
[1].Anselin, L., Syabri, I. and Kho, Y., (2006), GeoDa: An Introduction to Spatial Data Analysis. Geographical Analysis 38, 5–22.
[2].Bivand, R. S., Pebesma, E. J. and Gomez-Rubio, V., (2008). Applied Spatial Data Analysis with R . Springer. 378p.Chambers, J.M., (2009). Software for Data Analysis: Programming with R .Springer. 498p.
[3].Couclelis, H., (1992), People manipulate objects (but cultivate fields): Beyond the rastervector debate in gis. in frank, a., u., campari, i. and formentini, u. (eds.). Theories and Methods of Spatio-Temporal Reasoning in Geographic Space, 639:65–77.
[4].Grandchamp, E. (2010), Raster-vector cooperation algorithm for GIS GeoProcessing.
[5].Heywood, I., Cornelius, S. and Carver, S., (2006), Introduction to Geographical Information Systems. Pearson Prentice Hall, New York. Lo, C. P. and A. K. W. Yeung. (2007). Concepts and Techniques of Geographic Information Systems. Pearson Education Inc. 532 pp.
[6].Schneider, M. (1999), Uncertainty management for spatial data in databases: fuzzy spatial data types, in: Advances in Spatial Databases, Lecture Notes in Computer Science, vol. 1651, Springer, Berlin, pp. 330–351.
[7].Wiegand, N., et al., (2007), “A Task-Based Ontology Approach to Automate Geospatial Data Retrieval”, In Transactions in GIS, vol. 11, issue 3, pp. 355–376.
[8].Zandbergen, P.A. (2008), Positional Accuracy of Spatial Data: Non-Normal Distributions and a Critique of the National standard for Spatial Data Accuracy, In Transactions in GIS, vol. 12, issue 1, pp. 103–130.



4 نظرات