1. معرفی
با محبوبیت دستگاه های تلفن همراه و توسعه زیرساخت های شبکه، رسانه های اجتماعی به سرعت در زندگی مردم ادغام شده اند. مردم به راحتی می توانند آنچه را که می بینند و می شنوند و حتی آنچه را که احساس می کنند و فکر می کنند با رسانه های اجتماعی به اشتراک بگذارند. آنها مانند “حسگرهای تلفن همراه” هستند [ 1] برای جمع آوری اطلاعات پیرامون آنها به طور مداوم. این یک راه جدید برای به دست آوردن داده های مربوط به فاجعه فراهم می کند. در مقایسه با روشهای سنتی جمعآوری اطلاعات بلایا، رسانههای اجتماعی دارای ویژگیهای ارائه اطلاعات در زمان واقعی و هزینه کم هستند. علاوه بر این، این داده ها حاوی اطلاعات جغرافیایی زیادی (مانند مکان، زمان و سایر اطلاعات ویژگی) هستند که برای کاهش بلایا بسیار مهم است. بنابراین، بسیاری از محققان به اهمیت رسانه های اجتماعی در کاهش بلایا پی برده اند. آنها بلایا را از منظر استخراج رویداد [ 2 ، 3 ]، قوانین مسیر کاربر [ 4 ] و ترکیب داده ها [ 5] مطالعه کرده اند.] و غیره و نتایج خوبی به دست آورد. با این حال، تعداد کمی از محققین اطلاعات عاطفی عمومی موجود در رسانه های اجتماعی (به ویژه احساسات ظریف) را به عنوان ویژگی اطلاعات جغرافیایی مرتبط با فاجعه برای کمک به کاهش فاجعه در نظر گرفته اند. هنگامی که بلایا رخ می دهد، احساسات عمومی اغلب بیانگر نگرش مردم نسبت به بلایا، نیازهای هنگام وقوع فاجعه، و بازخورد در مورد امداد رسانی در بلایا و غیره است. این موارد برای درک سریع پیشرفت فاجعه و بهبود موثر کارایی نجات بسیار مفید است. با این حال، هنوز یک چارچوب موثر برای جمع آوری، پردازش و استفاده سریع از این اطلاعات احساسی وجود ندارد. سه مشکل وجود دارد: (1) چگونه می توان دسته بندی های عاطفی عمومی را در طول فاجعه تقسیم کرد؟ (2) رسانه های اجتماعی پایگاه کاربر بزرگی دارند. ما از میکرو وبلاگ سینا استفاده می کنیم، یک رسانه اجتماعی چینی، به عنوان مثال. طبق آمار، تا سه ماهه سوم 2018، پلتفرم رسانه اجتماعی چینی میکرو بلاگ سینا بیش از 431 میلیون کاربر فعال ماهانه داشته است.6 ]. هنگامی که فاجعه رخ می دهد، داده های مربوط به فاجعه زیادی تولید می کند. به این ترتیب، چگونه می توان اطلاعات عاطفی ریز موجود در این داده ها را با دقت بیشتری استخراج کرد؟ (3) هنگامی که این احساسات ریز استخراج می شوند، چگونه می توان آنها را به عنوان یک ویژگی اطلاعات جغرافیایی مرتبط با فاجعه برای کمک به کاهش فاجعه در نظر گرفت؟ در این مقاله، ما از یک ریزوبلاگ سینا استفاده کردیم و یک فاجعه زلزله را به عنوان مثال در نظر گرفتیم تا توضیح دهیم که چگونه چارچوبی که ساختهایم احساسات عمومی ریزدانه را استخراج کرده و از آنها برای کاهش بلایا استفاده میکند.
بر خلاف اکثر مطالعات تحلیل هیجان (آنها معمولاً احساسات را به سه دسته تقسیم می کنند: مثبت، خنثی و منفی)، ما احساسات عمومی در طول فاجعه را به ابعاد بیشتری تقسیم می کنیم، زیرا استفاده از ابعاد چندگانه احساسات در زمینه فاجعه می تواند جزئیات بیشتری را ارائه دهد. از فاجعه ای که باید توصیف شود. علاوه بر این، مطالعات اهمیت اطلاعات هیجانی چند بعدی را در بلایا نشان دادهاند. اکمن و همکاران [ 7 ] تفاوتهای بین خشم، انزجار، ترس و غم را از نظر رویدادهای پیشین و پاسخهای رفتاری احتمالی نشان دادند. الیور گروبنر و همکاران [ 8] چگونگی اعمال ابعاد متعدد احساسات منفی (از جمله خشم، ترس، غم، تعجب، سردرگمی، انزجار) را برای بررسی سلامت روانی ناشی از فاجعه تجزیه و تحلیل کرد. مطالعات روانشناختی موجود [ 9 ، 10 ، 11 ] همچنین به تقسیم دقیق احساسات در یک فاجعه اشاره میکنند. بنابراین، بر اساس این مطالعات قبلی و مجموعه مورد استفاده در این مقاله، ما احساسات منفی را به خشم، اضطراب، ترس و غم تقسیم میکنیم.
روشهای رایج برای طبقهبندی احساسات شامل الگوریتمهای مبتنی بر قانون و مدلهای یادگیری ماشین سنتی [ 12 ] است. الگوریتمهای مبتنی بر قانون عمدتاً از واژگان عاطفی و قواعد گرامری متناظر برای محاسبه شدت احساسی متن استفاده میکنند [ 13 ، 14 ]. این روش متکی بر تعداد زیادی عملیات دستی است، مانند توسعه دستی قوانین جستجو و واژگان عاطفی در مقیاس بزرگ [ 15]] که دقت روش را مشخص می کند. علاوه بر این، این روش در برخورد با کلمات توقف و کلمات جدید ضعیف است. همچنین افزودن برخی واژههای عامیانه و اینترنتی به فرهنگ عاطفی به موقع دشوار است، مانند «喜大普奔» (رضایت عالی)، «狂顶» (بسیار حمایتکننده) و غیره، که اغلب در رسانههای اجتماعی ظاهر میشوند. مدلهای یادگیری ماشین سنتی، مانند بیز ساده [ 16 ]، حداکثر آنتروپی و ماشین بردار پشتیبان [ 17]] به واژگان عاطفی یا قوانین جستجو تکیه نکنید. آنها فقط باید به صورت دستی مجموعه آموزشی را حاشیه نویسی کنند. با این حال، روش سنتی یادگیری ماشین مبتنی بر مدل کیسه کلمات است که روابط معنایی در متن را نادیده میگیرد. به عبارت دیگر ترتیب کلمات را در یک جمله در نظر نمی گیرد که به راحتی می تواند باعث طبقه بندی اشتباه احساسات شود. مثلاً جملات «هرچند زلزله وحشتناک است، اما ما سالم و سلامت هستیم» و «اگرچه ما سالم و سلامت هستیم، زلزله وحشتناک است» حاوی کلمات مشابهی هستند و احساسات متفاوتی را بیان می کنند. علاوه بر این، برای مدلهای یادگیری ماشین سنتی، ورودی کلمات ویژگی است که پس از تقسیمبندی از متن استخراج میشود. تعریف کلمات ویژگی تاثیر قابل توجهی بر کارایی مدل دارد [ 15]. ما روش یادگیری عمیق را برای استخراج احساسات عمومی از رسانه های اجتماعی انتخاب کردیم. در مقایسه با روش مبتنی بر قانون، یادگیری عمیق به هیچ واژگان عاطفی بستگی ندارد. بنابراین تحت تأثیر کلمات جدید و ناشناخته قرار نمی گیرد. برخلاف یادگیری ماشینی سنتی، یادگیری عمیق از مدل های برداری کلمه برای جایگزینی مدل کیسه کلمات استفاده می کند که می تواند از اطلاعات معنایی در جملات به خوبی استفاده کند. تحقیقات زیادی نشان داده است که عملکرد یادگیری عمیق [ 18 ، 19 ] در وظایف پردازش زبان طبیعی (NLP) بهتر از یادگیری ماشین سنتی است.
علاوه بر این، ما از احساسات عمومی استخراجشده استفاده کردیم و آنها را با دادههای اطلاعات جغرافیایی سنتی (دادههای توزیع تراکم جمعیت، دادههای نقطهنظر (POI) و غیره) و توابع تحلیل فضایی قدرتمند یک GIS (سیستم اطلاعات جغرافیایی) ترکیب کردیم. برای کمک به امدادرسانی در بلایای طبیعی ترکیب اطلاعات عاطفی عمومی می تواند مزایای زیر را ایجاد کند: (1) می تواند دقت و کارایی ارزیابی فاجعه را بهبود بخشد. به عنوان مثال، با کمک توابع قدرتمند تجزیه و تحلیل مکانی یک GIS، داده های اطلاعات جغرافیایی سنتی (مانند توزیع جمعیت، توزیع ترافیک و غیره) و داده های توزیع عاطفی را می توان برای ارزیابی جمعیت آسیب دیده در زمان واقعی ترکیب کرد. عموماً افرادی که احساسات منفی را ابراز می کنند بیشتر تحت تأثیر بلایا قرار می گیرند. (2) می تواند به کاهش خسارات ناشی از بلایا کمک کند. به عنوان مثال، بلایا، به ویژه بلایای ناگهانی (مانند زلزله، فوران های آتشفشانی، و غیره)، می توانند به راحتی باعث ایجاد مشکلات روانی مرتبط با فاجعه، مانند اختلال استرس پس از سانحه (PTSD) و افسردگی شوند.20 ، 21 ، 22 ]. نظارت سنتی در به دست آوردن اطلاعات در مورد احساسات مردم در منطقه فاجعه مشکل دارد (علی رغم وجود پرسشنامه، عملکرد آن در زمان واقعی ضعیف است). اگر اطلاعاتی در مورد احساسات عمومی و توزیع مکانی-زمانی مربوطه مشخص باشد، بخش کاهش بلایا میتواند اقدامات نجات روانی مربوطه را برای کاهش وقوع مشکلات سلامت روانی مرتبط با فاجعه انجام دهد. علاوه بر این، بلایای شدید دارای ویژگی های اجتناب ناپذیر و غیرقابل پیش بینی است [ 23 ]. افراد در مراحل مختلف احساسات متفاوتی را ابراز می کنند [ 24 ] و پاسخ های متفاوتی برای غلبه بر آنها دارند [ 9]]. برای مثال، افراد مضطرب نسبت به جنبه های منفی اطلاعات مربوط به رویداد حساس تر هستند و به راحتی می توانند تحت تأثیر شایعات قرار گیرند [ 25] .]. بنابراین، از طریق درک توزیع افراد مضطرب، میتوانیم اطلاعات صحیح بلایای طبیعی را در زمانهای مناسب منتشر کنیم تا از سرزده شایعات برای افراد مضطرب جلوگیری کنیم. (3) یادگیری بیشتر در مورد علل احساسات می تواند به ما در بهینه سازی تصمیمات اضطراری کمک کند. با استفاده از دستههای مختلف هیجانی، میتوانیم علل عاطفی مختلف را بررسی کنیم، از جمله اینکه چرا احساسات خشمگین در یک منطقه خاص و احساسات اضطرابآور در حوزههای دیگر غالب هستند و چرا دستههای هیجانی در برخی مکانها در طول زمان تغییر میکنند. با درک علل احساسات، بخش های کاهش بلایا می توانند اقدامات متقابل هدفمند را انجام دهند. در تحلیل مکانی-زمانی اطلاعات احساسات عمومی، چارچوب در این مقاله شامل ارزیابی جمعیت آسیبدیده در زمان واقعی، کاوش در قانون حرکت عاطفی،
ساختار این مقاله به شرح زیر است: بخش 2 روش جمعآوری، تجزیه، پردازش و طبقهبندی احساسات مورد استفاده در این مقاله را شرح میدهد. بخش 3 نقش احساسات عمومی را در کمک به کاهش بلایا با مطالعه موردی ارائه میکند. بخش 4 ارزیابی شاخص های تجربی را نشان می دهد. بخش 5 مقاله را به پایان می رساند.
2. چارچوبی برای تجزیه و تحلیل احساسات عمومی از داده های بزرگ رسانه های اجتماعی
چارچوبی برای تجزیه و تحلیل نقش احساسات عمومی در کاهش فاجعه پیشنهاد شده در این مقاله شامل پنج مرحله اصلی است: جمعآوری و پردازش دادهها، ساخت یک فهرست برداری کلمه، آموزش مدل، طبقهبندی احساسات، و تحلیل مکانی-زمانی احساسات عمومی (به عنوان مثال). در شکل 1 نشان داده شده است ).
2.1. جمع آوری و تجزیه داده های رسانه های اجتماعی
ما از زلزلهای که در یاآن، سیچوان، چین، در ساعت 08:02 ساعت 20 آوریل 2013 رخ داد، به عنوان مطالعه موردی استفاده کردیم. بر اساس گزارش شبکه لرزه نگاری چین ( https://news.ceic.ac.cn/CC20130420080246.html )، بزرگی این زمین لرزه 7.0 ریشتر و عمق کانونی آن 13 کیلومتر بوده است. کانون این زمین لرزه در 30.30 درجه شمالی، 103.00 درجه شرقی بود که باعث شد حدود 1.52 میلیون نفر در منطقه ای به وسعت 12500 کیلومتر مربع آسیب ببینند.
در این مقاله، دادههای شبکههای اجتماعی از میکرو بلاگ سینا از منطقه اطراف کانون زمین لرزه به شعاع 200 کیلومتر که زلزله به شدت آسیب دیده بود، جمعآوری شد. شهرهای آسیب دیده عبارتند از یاآن، میشان، گانزی، لشان، زیانگ، دیانگ، چنگدو، آبا، زیگونگ، میانیانگ و نیجیانگ، همانطور که در شکل 2 نشان داده شده است.. بازه زمانی داده های رسانه های اجتماعی از 20 آوریل تا 26 آوریل 2017 بود. پلت فرم های رسانه های اجتماعی معمولاً یک رابط یا API (رابط برنامه نویسی برنامه) ارائه می دهند که به توسعه دهندگان اجازه می دهد داده های رسانه های اجتماعی را بازیابی کنند. با این حال، بازیابی داده ها از این طریق محدودیت های زیادی دارد. به عنوان مثال، شما نمی توانید بازه زمانی و موضوعات و غیره را تنظیم کنید. بنابراین، در این مقاله از قابلیت جستجوی پیشرفته میکرو بلاگ سینا برای دریافت داده ها با استفاده از بازه زمانی، نام شهرها و کلمات کلیدی مرتبط با رویداد استفاده کردیم.
قالب داده در ابتدا زبان نشانه گذاری فرامتن (HTML) بود. ما داده ها را در قالب داده های ساختاریافته شامل فیلدهایی مانند “زمان”، “مکان”، “متن” و غیره تجزیه کردیم. در این میان، مکان با آدرس نشان داده می شد و دقت آنها متفاوت بود. ما چنگدو را به عنوان مثال در نظر می گیریم. برخی از آدرسها با جزئیات بیشتری شرح داده شدند، مانند «دروازه شرقی دانشگاه سیچوان»، «خیابان شمالی Sishengci»، و غیره. متن هایی هم بود که اطلاعات آدرسی نداشت. دلیل این امر این است که افراد عادات استفاده متفاوتی دارند (برخی افراد نمی خواهند اطلاعات مکان خود را به اشتراک بگذارند). ما از API ارائه شده توسط بایدو استفاده کردیم ( https://lbsyun.baidu.com/index.php?title=webapi/guide/webservice-geocoding) برای تبدیل این آدرس ها به طول و عرض جغرافیایی. در میان آنها، برای داده های خط، مانند «خیابان شمالی سیشنگجی»، مختصات نقطه میانی آن را برای نشان دادن آن در نظر گرفتیم. برای داده های سطحی، مانند “پردیس Wangjiang دانشگاه سیچوان” و حتی “Funan New District”، مختصات نقطه مرکزی را به ترتیب برای نشان دادن آنها استخراج کردیم. ما مختصاتی را به آن متون که اطلاعات آدرس نداشتند، از جمله متنهایی که آدرسهای نادرست داشتند، اختصاص ندادیم. آنها فقط برچسب “چنگدو” داشتند.
2.2. پردازش داده های رسانه های اجتماعی
در مراحل بعدی پردازش، عمدتاً با داده های متنی سروکار داشتیم. مراحل اصلی پردازش متن شامل تبدیل کاراکترهای تمام عرض به نویسههای نیمهعرض و از چینی سنتی به چینی ساده شده و همچنین تشخیص کاراکترها و نمادهای خاص بود. هدف دو مرحله اول عمدتاً بهبود کارایی محاسباتی مدل بود. مرحله سوم با هدف شناسایی کاراکترها و نمادهای خاص مانند “(>_<)”، “

“، که توسط بسیاری از ابزارهای رایج پردازش زبان طبیعی (NLP) حذف و نادیده گرفته می شوند. با این حال، برای تجزیه و تحلیل عاطفی، این کاراکترها و نمادهای خاص معنای عاطفی دارند، به عنوان مثال، “(>_<)” و “(>_<)>” می توانند احساسات آشفته را بیان کنند. بنابراین، در این مقاله، ما آنها را به متنی تفسیر کردیم که می تواند توسط NLP پردازش شود. برخی از کاراکترها و نمادهای خاص می توانند توسط پلت فرم میکرو بلاگ به متن ترجمه شوند. به عنوان مثال، می تواند به “اشک” (泪) ترجمه شود. با این حال، موارد دیگری که توسط پلتفرم میکرو بلاگ قابل رمزگشایی نبودند، مانند (>_<) و , بر اساس «فهرست شکلکهای» وب تفسیر شدند، که شامل پیامدهای احساسی انواع شکلکها از طریق مقدار زیادی است. از ادبیات منتشر شده به عنوان مثال، (>_<
را می توان به “غمگین” (伤心) ترجمه کرد.
در نهایت، پس از حذف موارد تکراری، 39341 رکورد داده در پایگاه داده ما ذخیره شد.
2.3. ساخت فهرست برداری کلمات
در این مقاله ابتدا هر کلمه از متون پردازش شده قبلی را به یک بردار چند بعدی تبدیل کردیم. این فرآیند شامل دو مرحله بود: تقسیمبندی کلمات و حذف کلمات توقف، و ساخت فهرست برداری کلمه.
2.3.1. تقسیم بندی کلمات و حذف کلمات توقف
بر خلاف زبان انگلیسی، هیچ فاصله ای بین کلمات چینی وجود ندارد. بنابراین، ما باید متن چینی را بخش بندی کنیم تا کلمات جداگانه به دست آوریم. علاوه بر این، میکرو وبلاگ چینی بیشتر محاوره ای است، که چالش های بزرگی را برای تقسیم بندی کلمات به همراه دارد. ما بسیاری از ابزارهای مختلف تقسیمبندی کلمات چینی، مانند «Stanford NLP»، «ANSJ»، «NLPIR (پلتفرم اشتراکگذاری پردازش زبان طبیعی و بازیابی اطلاعات)» و غیره را مقایسه کردیم. ما دریافتیم که “NLPIR” بهترین عملکرد را از نظر دقت و سرعت تقسیم بندی کلمات دارد.
بسیاری از کلمات بی معنی در متن پس از تقسیم کلمه وجود دارد. به این کلمات توقف می گویند، مانند “在 (روشن)، “是 (است)، “一会 (یک لحظه)” و غیره. این کلمات می توانند بر دقت مدل تأثیر بگذارند و بنابراین باید حذف شوند. در این مقاله، ما از واژگان کلمات توقف توسعه یافته توسط موسسه فناوری هاربین – مرکز تحقیقات محاسبات اجتماعی و بازیابی اطلاعات برای حذف کلمات توقف استفاده کردیم. از آنجایی که تمرکز این مقاله بر تحلیل احساسی بود، واژگان کلمات توقف را با حذف کلمات احساسی، مانند “愤然 (خشمگین”)، “幸亏 (خوشبختانه)، “嘻 (هی)” و غیره بهینه کردیم.
2.3.2. ساخت فهرست برداری کلمه
ورودی مورد استفاده برای مدل طبقه بندی احساسات، یک ماتریس برداری کلمه بود. ما نیاز داشتیم که هر کلمه در متن میکروبلاگ را به یک بردار چند بعدی تبدیل کنیم و سپس کل جمله را به یک ماتریس برداری کلمه تبدیل کنیم. در این مقاله، تمام متون پردازش شده قبلی را به یک لیست برداری کلمه تبدیل کردیم. متن آموزشی و متن جدیدی که قرار است دسته بندی شوند با تطبیق آنها با فهرست برداری کلمه به ماتریس برداری کلمه تبدیل شدند. روشی که ما برای این کار استفاده کردیم word2vec [ 26 ] بود که هر کلمه در هر جمله را به یک فضای برداری با ابعاد مشخص نمایش می داد.
دو مدل متداول در word2vec وجود دارد که عبارتند از skip-gram [ 27 ، 28 ] و CBOW (Continuous Bag-of-Words) [ 27 ، 28 ]. تعداد زیادی آزمایش برای مقایسه این دو مدل از نظر عملکرد و دقت [ 29 ] انجام شده است و نتایج نشان میدهد که میزان دقت معنایی مدل پرش گرم بهتر از مدل CBOW است. بنابراین، ما در آزمایش خود از مدل Skip-gram برای ساخت بردار ویژگی متن استفاده کردیم.
مدل پرش گرم می تواند همبستگی بین کلمات را برای آموزش پیکره تعیین کند. این همبستگی ها با بردارهای ویژگی چند بعدی هر کلمه نشان داده می شوند. علاوه بر این، این بردارهای ویژگی چند بعدی با در نظر گرفتن کامل زمینه اطلاعات معنایی محاسبه می شوند. از فرمول زیر، با توجه به یک کلمه فعلی، wمناین مدل سعی می کند کلماتی را بیابد که با کلمه فعلی رابطه معنایی متنی داشته باشند. هدف این مدل به حداکثر رساندن تابع هدف است، G :
در این فرمول، wمنبیانگر کلمه جاری و سیپنجره زمینه را نشان می دهد. پ(سیonتیهایکستی(wمن)|wمن)نشان دهنده احتمال اطلاعات زمینه در کلمه فعلی است.
هنگامی که آموزش همگرا می شود، کلمات با معانی معنایی مشابه در فضای برداری بعدی مشخص شده نزدیکتر می شوند. ما بردار ویژگی متن هر کلمه را در مجموعه آموزشی برای ایجاد جاسازی کلمه صادر کردیم. ساختار بردارهای ویژگی متن به صورت شکل 3 نشان داده شده است .
2.4. آموزش مدل
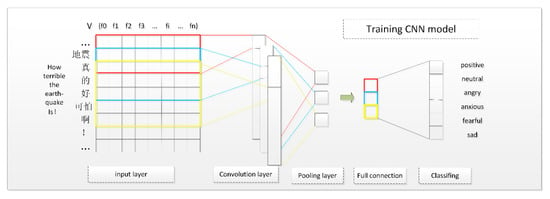
مدل تمایل عمیق انتخاب شده در این مقاله، شبکه عصبی کانولوشن بود. ما ادبیات مرتبط زیادی را خواندیم و دریافتیم که روشهای یادگیری عمیق مختلف را میتوان برای طبقهبندی احساسات انتخاب کرد، مانند شبکه عصبی کانولوشن (CNN)، شبکه عصبی تکراری (RNN)، شبکه توجه سلسله مراتبی (HAN)، و غیره. این مدلها [ 30 , 31 ، 32 ] همگی ویژگی ها و سناریوهای استفاده خاص خود را دارند. با توجه به ادبیات [ 33 ]، CNN طبقه بندی احساسات را به خوبی انجام می دهد، به خصوص در جملات کوتاه تر. RNN طبقه بندی احساسات در سطح سند را به خوبی انجام می دهد [ 34 ]. مطالعه قبلی [ 35] عملکرد CNN، RNN و HAN را در طبقه بندی احساسات ارائه کرد. نتایج نشان داد که وقتی پیکره آموزشی به اندازه کافی بزرگ باشد، HAN بالاترین دقت را دارد، اما CNN بهترین عملکرد را زمانی دارد که پیکره آموزشی خیلی بزرگ نباشد. حاشیه نویسی یک مجموعه آموزشی بزرگ به نیروی انسانی و زمان زیادی نیاز دارد. علاوه بر این، آموزش مدل های HAN و RNN بیشتر از مدل CNN طول می کشد. در این مقاله، مجموعه آموزشی مورد استفاده، متون ریزوبلاگ بوده که عمدتاً متون کوتاه هستند. علاوه بر این، مقدار داده های پیکره آموزشی برچسب گذاری شده دستی برای مدل CNN مناسب تر بود. بنابراین، ما CNN را به عنوان روشی برای استخراج احساسات عمومی موجود در رسانه های اجتماعی انتخاب کردیم. روند آموزش مدل در زیر نشان داده شده است.
2.4.1. تقسیم بندی کلمات، حذف کلمات توقف، و ساخت ماتریس ویژگی
ابتدا متون آموزشی را برای به دست آوردن کلمات جداگانه تقسیم بندی کردیم. سپس، از واژگانی از کلمات توقف استفاده کردیم تا کلمات بی معنی موجود در آن کلمات جداگانه را حذف کنیم. در نهایت، کلمات باقیمانده از طریق تطبیق با فهرست بردار واژهای که قبلاً ایجاد شده بود، به بردارهای کلمه تبدیل شدند. در نهایت، هر جمله به یک ماتریس ویژگی تبدیل شد.
2.4.2. آموزش مدل شبکه عصبی کانولوشنال
شبکه عصبی کانولوشنال (CNN) گونه ای از شبکه عصبی است. برای اولین بار با موفقیت برای تشخیص تصاویر و فیلم ها استفاده شد. بعدها، برخی از محققان آن را وارد حوزه پردازش زبان طبیعی [ 36 ] کردند و دریافتند که تأثیر خوبی دارد. مدل CNN مورد استفاده در این مقاله شامل یک لایه ورودی، یک لایه کانولوشن، یک لایه ادغام، یک لایه کاملا متصل و طبقهبندی بود. ساختار CNN در شکل 4 نشان داده شده است .
در روند آموزش مدل CNN، نورونهای موجود در آن معمولاً به سه بعد عمق، عرض و ارتفاع تنظیم میشوند. اندازه هر لایه عمق × عرض × ارتفاع [ 37 ] است. به عنوان مثال، اگر جمله ای با 140 کلمه وجود دارد و هر کلمه 200 بعد تنظیم شده است، اندازه لایه ورودی 1 × 140 × 200 است.
در ادامه، لایه های شبکه عصبی کانولوشن را معرفی می کنیم.
لایه ورودی : لایه ورودی CNN ماتریسی است که از بردارهای ویژگی متن تشکیل شده است. این ماتریس با استفاده از مدل skip-gram که در بخش 2.2 توضیح داده شد، محاسبه میشود . سطرها و ستونها (بعد) در این ماتریس قبل از اینکه ماتریس را در مدل شبکه عصبی قرار دهیم تنظیم شدند. به عنوان مثال از متن میکرو بلاگ سینا، تعداد کاراکترهای هر جمله کمتر از 140 بود. بنابراین، ردیف های ماتریس را 140 قرار می دهیم. اگر تعداد کلمات یک جمله کمتر از 140 کاراکتر بود، از کاراکتر خالی “space” برای تکمیل کاراکترهای از دست رفته استفاده کرد. بنابراین، هر جمله به صورت زیر بیان می شود:
در این فرمول، S یک کاراکتر یا “pad” را نشان می دهد و ⊕ عملگر الحاق است.
لایه کانولوشن : لایه پیچیدگی عمدتاً برای استخراج ویژگی ها استفاده می شود. برخی از عناصر تکه تکه شده را به ویژگی هایی انتزاع می کند که می توان از آنها برای تشخیص دسته های مختلف استفاده کرد. با کانولوشن، بسیاری از ویژگی های سطح پایین را می توان به ویژگی های سطح بالاتر انتزاع کرد. به عنوان مثال، تنها کلمه “打” یا “تماس” معنای احساسی ندارد. با این حال، ویژگی سطح بالاتر “打تماس (ستایش)” می تواند یک ویژگی احساسی را بیان کند. ویژگی های عاطفی این کلمات را می توان توسط مدل از طریق تعداد زیادی از مجموعه آموزشی به دست آورد.
با توجه به ماتریس u که از لایه ورودی برای عملیات کانولوشن است، فرمول به شرح زیر است:
برای ماتریس تو∈ℝD×LD نشان دهنده ابعاد تعبیه شده و L نشان دهنده طول جمله است . پارامتر ک∈ℝD×سنشان دهنده j- امین هسته کانولوشن است که به پنجره ای از کلمات s اعمال می شود . پارامتر بj∈ℝبیانگر یک اصطلاح جانبداری است. f(تو∗کj+بj)یک تابع فعال سازی غیر خطی است.
لایه ادغام : پس از عملیات پیچیدگی، می توانیم از ویژگی های خروجی برای طبقه بندی مستقیم احساسات استفاده کنیم. با این حال، در انجام این کار، ما نه تنها با چالش پیچیدگی محاسباتی مواجه خواهیم شد، بلکه با مشکل برازش بیش از حد نیز مواجه خواهیم بود که بر دقت طبقه بندی تأثیر می گذارد. عملیات ادغام می تواند این مشکلات را به خوبی حل کند. علاوه بر این، عملیات ادغام همچنین می تواند به عنوان یک انتخابگر ویژگی عمل کند که می تواند به شناسایی مهم ترین ویژگی ها برای بهبود عملکرد طبقه بندی کمک کند.
دو روش وجود دارد که می توان انتخاب کرد، یعنی جمع حداکثری و جمع آوری متوسط. ما با روش max pooling به نتایج بهتری دست یافتیم. این روش ویژگیهای معنایی جهانی را انتخاب میکند و تلاش میکند تا مهمترین ویژگی را با بالاترین مقدار برای هر نقشه مشخصه به تصویر بکشد [ 37 ]. خروجی از عملیات پیچیدگی جjبه عنوان ورودی عملیات ادغام استفاده می شود. فرمول به شرح زیر است:
لایه کاملاً متصل : نورون های این لایه با تمام نورون های لایه قبلی ارتباط کامل دارند. در همین حال، مقدار لایه متصل کامل را می توان از طریق نورون های لایه قبلی محاسبه کرد. در فرآیند محاسبات، معمولاً از روش تنظیم انصراف برای جلوگیری از برازش بیش از حد استفاده می شود.
طبقهبندی : میتوانیم برچسبهای احساسی متن اصلی را از طریق تابع softmax بدست آوریم. به عبارت دیگر، این نتایج محاسبه شده نشان دهنده توزیع احتمال برچسب های احساسی است.
بر اساس مجموعه آموزشی، میتوانیم بهترین پارامترها را برای مدل CNN شناسایی کنیم. سپس می توان از این مدل آموزش دیده برای محاسبه مقوله های احساسی متون جدید استفاده کرد.
2.5. طبقه بندی احساسات
ما از مدل آموزش دیده CNN برای تجزیه و تحلیل متون جدید استفاده کردیم. عواطف موجود در این متون به شش دسته تقسیم می شدند: مثبت، خنثی، عصبانی، مضطرب، ترسناک و غمگین. در میان آنها، عواطف مثبت عمدتاً شامل رضایت عمومی از امدادرسانی در بلایا، آرزوهای عمومی برای منطقه فاجعهزده و لذت زنده ماندن بود. عواطف خنثی عمدتاً شامل توصیفات عینی از فاجعه بود. در فرآیند طبقه بندی، متون جدید ابتدا با استفاده از تقسیم بندی کلمات و حذف کلمات توقف پردازش شدند. سپس، از فهرست بردار کلمه آموزش داده شده قبلی برای ترجمه هر کلمه به یک کلمه برداری استفاده شد. علاوه بر این، هر متن جدید به یک ماتریس برداری کلمه تبدیل شد. در نهایت، کلمه ماتریس برداری به مدل آموزش دیده CNN وارد شد. از طریق محاسبه مدل، هر متن جدید در دسته بندی های احساسی مختلف برچسب گذاری شد. ما تمام 39344 قطعه متن را بر اساس این فرآیند طبقه بندی در شش دسته احساسی طبقه بندی کردیم.
2.6. تحلیل فضایی- زمانی عواطف عمومی
چارچوب در این مقاله با استفاده از اطلاعات عاطفی عمومی موجود در رسانه های اجتماعی، کمک به کاهش فاجعه است. در این فرآیند، اطلاعات عاطفی به عنوان ویژگی اطلاعات جغرافیایی در نظر گرفته شد. قابلیت تجزیه و تحلیل فضایی قدرتمند یک GIS برای ترکیب اطلاعات احساسی با سایر دادههای جغرافیایی برای کشف دانش مفیدتر مورد استفاده قرار گرفت. به عنوان مثال، داده های توزیع تراکم جمعیت را می توان برای انجام یک ارزیابی مکانی-زمانی جمعیت آسیب دیده اضافه کرد. داده های POI (مانند یک پناهگاه) را می توان برای کشف قانون مسیر مکانی-زمانی افراد در بلایای ناگهانی در نظر گرفت. علاوه بر این، اطلاعات احساسی همچنین میتواند به بخشهای کاهش بلایا کمک کند تا خواستههای عمومی فوری را از حجم وسیعی از اطلاعات بررسی کنند. مطالبات عمومی که حاوی اطلاعات احساسی هستند نیز بازخورد مؤثری برای کار کاهش بلایا هستند. آنها می توانند به بهینه سازی تصمیم گیری برای بهبود کارایی نجات کمک کنند.
3. تحلیل مکانی- زمانی اطلاعات عاطفی عمومی
3.1. ارزیابی مکانی- زمانی جمعیت آسیب دیده
دانستن توزیع جمعیت آسیب دیده در زمان وقوع زلزله بسیار مهم است. این می تواند به اطمینان از ارزیابی مؤثر وضعیت فاجعه و استقرار منطقی منابع نجات کمک کند. در این بخش، دادههای توزیع تراکم جمعیت مربوط به منطقه مورد مطالعه را با اطلاعات مکانی-زمانی موجود در رسانههای اجتماعی برای کمک به تجزیه و تحلیل ترکیب کردیم. در میان آنها، داده های توزیع تراکم جمعیت از GHSL (لایه سکونت انسانی جهانی) ( https://cidportal.jrc.ec.europa.eu/ftp/jrc-opendata/GHSL/GHS_POP_GPW4_GLOBE_R2015A/ ) گرفته شده است.). معرفی اطلاعات عاطفی عمومی می تواند دقت ارزیابی را بهبود بخشد. عموماً اعتقاد بر این است که احساسات منفی نشان می دهد که زلزله تأثیر بیشتری بر مردم دارد. علاوه بر این، طبق قوانین تقسیم دوره زمانی از بخش امداد و نجات، ما شش دوره زمانی را تنظیم کردیم که عبارت بودند از: 0-4 ساعت، 4-12 ساعت، 12-24 ساعت، 24-48 ساعت، 48-72 ساعت، و 0 تا 72 ساعت پس از زلزله. سپس از تحلیل همپوشانی نرم افزار GIS برای پردازش این داده ها در هر دوره زمانی استفاده کردیم. نتایج تجزیه و تحلیل داده های مرتبط در شکل 5 نشان داده شده است .
ما می دانیم که: (1) حجم داده های میکروبلاگ در مکان هایی با تراکم جمعیت بالا پس از زلزله و احساسات منفی غالب بود. (2) در عرض چهار ساعت پس از زلزله، همانطور که در شکل 5 الف نشان داده شده است، تقریباً هیچ احساس مثبتی در مناطق نزدیک به مرکز زمین لرزه وجود نداشت. مناطق دورتر از کانون زلزله، مانند لشان (دایره قرمز 3) و چنگدو (دایره قرمز 2)، احساسات مثبت کمتری داشتند. (3) از 4 ساعت تا 12 ساعت پس از زلزله همانطور که در شکل 5 نشان داده شده استب، در مقایسه با توزیع قبلی اطلاعات عاطفی، برخی از احساسات منفی جدید در نزدیکی مرکز زمین لرزه پدیدار شدند، مانند دایره آبی 1. این نشان می دهد که با گذشت زمان، ممکن است آسیب فاجعه جدیدی در این منطقه رخ داده باشد. ما متن مربوطه را بررسی کردیم و متوجه شدیم که این نقاط احساسی جدید بیشتر اضطراب است. دلیل ابراز نگرانی مردم مسدود شدن «جاده فن مین» توسط تخته سنگ بود و مردم نگران بودند که خودروهای امدادی که این اطلاعات را نمی دانستند به دلیل حادثه با تاخیر مواجه شوند. احساسات در حوزه های دیگر این چهره نیز تغییر کرده بود. به عنوان مثال، در مقایسه با دایره قرمز 2 و دایره قرمز 3 در شکل 5 a، احساسات در این مناطق از شکل 5b به طور قابل توجهی افزایش یافت. این نشان می دهد که توجه مردم به زلزله در این بازه زمانی افزایش یافته است. (4) ما منطقه ای با تراکم جمعیت بالا در نزدیکی کانون زمین لرزه را انتخاب کردیم تا چگونگی تغییر احساسات در طول زمان را با جزئیات تجزیه و تحلیل کنیم. منطقه انتخاب شده در منطقه Yucheng در Ya’an واقع شده است و با دایره قرمز 1 در شکل 5 a–e مشخص شده است. شکل 6تغییرات حجم داده ها را در مقوله های احساسی در این حوزه برای دوره های زمانی مختلف نشان می دهد. ما دریافتیم که احساسات مثبت در دوره دوم ظاهر شد و سپس افزایش یافت. دلیلش هم این بود که با شروع عملیات امداد و نجات، قدردانی مردم از امدادگران بیشتر شد. تعداد احساسات منفی در دوره سوم بیشترین افزایش را داشت و سپس به تدریج کاهش یافت. اگرچه این دوره زمانی تنها 12 ساعت به طول انجامید، اما تعداد احساسات منفی در بین تمام دوره ها بالاترین بود. از آنجایی که این بازه زمانی شب اول پس از زلزله بود، اکثر مردم به وسایل امدادی مانند چادر، لباس و … نیاز مبرم داشتند، بنابراین اضطراب غالب بود. تعداد احساسات خنثی ابراز شده تغییر چندانی نداشت. آنها عمدتاً پیشرفت زمین لرزه ها را توصیف می کردند. (5) شکل 5f وضعیت کلی را 72 ساعت پس از زلزله به تصویر می کشد. ما دریافتیم که تراکم جمعیت در Ya’an زیاد نیست و توزیع جمعیت یکنواخت نیست. با این حال، تعداد احساسات ابراز شده در این شهر زیاد بود و توزیع آنها به ویژه در مورد احساسات منفی نسبتاً یکسان بود. این نشان می دهد که تأثیر زلزله بر یاان شدیدترین بوده است. علاوه بر این، چنگدو مرکز استان سیچوان است و بیشترین تراکم جمعیت را دارد. در جریان این زلزله احساسات منفی زیادی در این شهر بروز کرد. اگرچه توزیع این احساسات یکنواخت نبود، اما باید در اینجا توجه بیشتری شود تا از حوادث غیرمنتظره مانند آسیب دیدن مردم به دلیل احساسات اضطراب آور توسط شایعات جلوگیری شود. همین رویکرد را می توان برای سایر شهرهای آسیب دیده نیز اعمال کرد.
در این بخش، ما یک تحلیل پوششی حاوی اطلاعات عاطفی عمومی و توزیع تراکم جمعیت برای ارزیابی جمعیت آسیب دیده انجام دادیم. ویژگی های توزیع مکانی-زمانی اطلاعات عاطفی عمومی می تواند دقت ارزیابی را بهبود بخشد و اطلاعات ارزشمندتری را در اختیار ما قرار دهد. اگرچه این اطلاعات عاطفی به طور نابرابر توزیع شده بود و حتی برخی از مناطق با تراکم جمعیت بالا تنها دارای مقدار کمی از احساسات منفی بودند، مانند ناحیه ای که در دایره آبی 1 در شکل 5 ب وجود دارد، ما همچنان باید به آنها توجه کنیم زیرا احساسات بیان شده توسط کاربران رسانه های اجتماعی همچنین ممکن است احساسات همسایگان یا جوامع اطراف خود را منعکس کنند، حتی اگر این همسایگان یا جوامع از رسانه های اجتماعی استفاده نکنند [ 8]].
3.2. استخراج مسیر عاطفی فضایی-زمانی
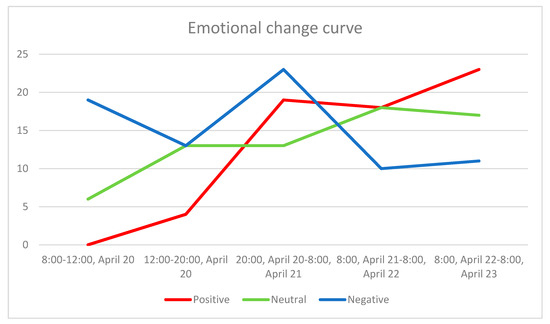
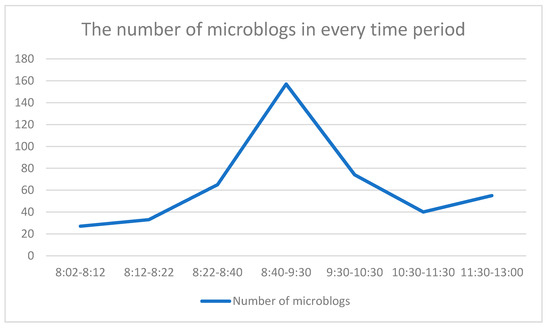
زمین لرزه به عنوان یک فاجعه ناگهانی در مدت زمان کوتاهی خسارات عظیمی به بار می آورد و به ویژه برای زندگی انسان ها خطرناک است. از این رو در اکثر شهرها پناهگاه های زیادی برای دوری از این بلایا برای مردم وجود دارد. در این بخش، چگونگی تغییر مسیرهای مکانی-زمانی انسان ها در هنگام وقوع بلایای ناگهانی و اینکه آیا این تغییرات به مکان پناهگاه ها مربوط می شود را بررسی می کنیم. علاوه بر این، در این فرآیند تغییر، بررسی میکنیم که کدام دستههای هیجانی توسط انسان نشان داده میشوند و چگونه این دستههای هیجانی تغییر میکنند. ما از چنگدو به عنوان مثال استفاده کردیم و مکان پناهگاه ها در این شهر را از “وب سایت رسمی دولت مردمی شهرداری چنگدو ( https://cdtf.gov.cn/chengdu/smfw/csyjbn.shtml تعیین کردیم.)” سپس از طریق API Baidu ( https://api.map.baidu.com/lbsapi/getpoint/index.html ) این پناهگاه ها را به مختصات تبدیل کرده و نقشه این منطقه را برداریم. با توجه به وقوع ناگهانی زمین لرزه ها، هفت بازه زمانی کوچک تعیین کردیم که از ساعت 08:02 تا 08:12 ساعت، 08:12 تا 08:22 ساعت، 8:22 ساعت تا 08:40 ساعت، 08:40 بود. به ترتیب از ساعت 09:30، 09:30 تا 10:30، 10:30 تا 11:30 و 11:30 تا 13:00 (زمین لرزه در ساعت 08:02 رخ داده است) برای تجزیه و تحلیل تغییرات جمعیت در این دوره های زمانی دقیق. شکل 7 تغییرات تعداد افراد را در طول زمان نشان می دهد. ما می توانیم ببینیم که جمعیت در ساعت 08:40 تا 09:30 ساعت سریعترین رشد را داشته است. این ممکن است نشان دهنده این باشد که تعداد زیادی از مردم در این دوره زمانی به پناهگاه های مجاور رسیده بودند.
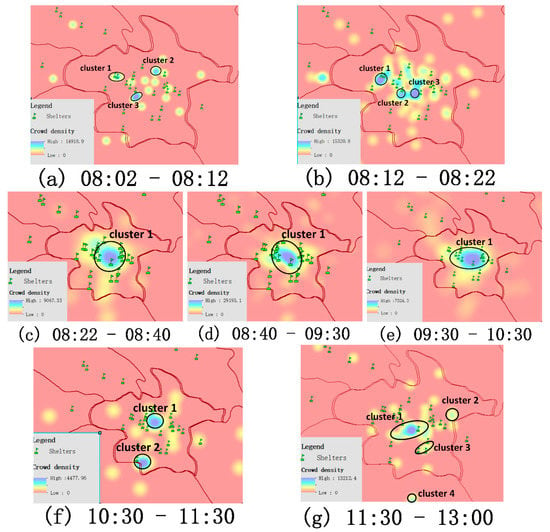
ما از الگوریتم تراکم هسته [ 38 ] برای اعتبارسنجی تغییر تجمع جمعیت در طول زمان و کشف روابط بین مراکز تراکم جمعیت و مکانهای پناهگاه استفاده کردیم، همانطور که در شکل 8 نشان داده شده است . در شکل 8الف، در 10 دقیقه اول پس از زلزله سه خوشه تشکیل شد و آنها را به ترتیب به عنوان خوشه 1، خوشه 2 و خوشه 3 علامت گذاری کردیم. اگرچه چگالی خوشه 1 کم است، اما می توان دید که هسته آن در محل پناهگاه بوده است. این نشان می دهد که در فاصله 10 دقیقه از زلزله، تعداد کمی از مردم در پناهگاه های اطراف جمع شده اند. خوشه 2 و خوشه 3، به ویژه خوشه 3، تراکم بیشتری نسبت به خوشه 1 داشتند. اما مردم این مناطق هنوز در پناهگاه جمع نشده بودند. ده دقیقه بعد، بین ساعت 08:12 تا 08:22، تعداد افراد افزایش یافت، زیرا آنها بیشتر به پناهگاه ها نزدیک شدند. ما متوجه شدیم که برخی از پناهگاه ها افراد زیادی مانند خوشه 1 و خوشه 3 را جمع آوری کرده اند، همانطور که در شکل 8 نشان داده شده است.ب همانطور که در شکل 8 c-e نشان داده شده است، با گذشت زمان، تعداد زیادی از خوشه های گسسته و کوچک در یک خوشه بزرگتر ترکیب شدند . این نشان می دهد که در این دوره ها تعداد زیادی از مردم به پناهگاه ها رسیده بودند. در میان آنها، همانطور که در شکل 8 d نشان داده شده است، تعداد افراد بین ساعت 08:40 تا 09:30 بیشترین تعداد بود . سپس تعداد افرادی که در پناهگاه ها جمع شده بودند رو به کاهش گذاشت. اما جمعیت در این زمان پراکنده نشده بودند، همانطور که در شکل 8 e نشان داده شده است. ما می توانیم این تغییرات را از طریق مقدار مربوط به تراکم جمعیت درک کنیم. در شکل 8f,g، می بینیم که خوشه بزرگ شروع به متلاشی شدن کرد و از خوشه های کوچک تجزیه شد. سپس، این خوشه های کوچک به تدریج از پناهگاه ها دور می شدند. شاید این بدان معناست که احساسات مردم در این زمان دیگر آنقدر متشنج نبود.
علاوه بر این، میخواستیم بدانیم مردم در این دورهها چه دستههایی از احساسات را ابراز میکنند و چگونه این احساسات تغییر کرده است زیرا جابجاییهای گسترده جمعیت در مدت زمان کوتاه ممکن است منجر به حوادث غیرضروری مانند ازدحام احتمالی ناشی از وحشت شود. بنابراین، اگر بتوان احساسات عمومی را در این فرآیند رصد کرد، به ما کمک میکند تا اقدامات سریع و مؤثری را برای بهبود کارایی تخلیه و جلوگیری از حوادث انجام دهیم. جدول 1 ویژگی های عاطفی را در هر دوره زمانی در شکل 8 نشان می دهد . شاخصهای این جدول شامل خوشههای تشکیلشده توسط خوشهبندی چگالی هسته، دستههای احساسات و دستهبندی احساسات اصلی موجود در هر خوشه و غیره است.
از جدول 1 ، می توان دید که احساسات ترسناک در 150 دقیقه اول (ساعت 8:02 تا 10:30 ساعت) پس از زلزله و به دنبال آن اضطراب غالب شد. در این بازه زمانی مردم برای زلزله غیرمنتظره آمادگی نداشتند و می ترسیدند در این زلزله جان خود را از دست بدهند. در میان آنها، در اولین دوره زمانی (8:02 ساعت تا 8:12 ساعت)، افراد در خوشه 1 اضطراب خود را ابراز کردند، همانطور که در شکل 8 نشان داده شده است.آ. از طریق محتوای متنی مربوطه متوجه شدیم که آنها در حال حاضر از جزئیات زمین لرزه (مانند مرکز زمین لرزه، مقیاس بزرگی و غیره) اطلاعی نداشتند، بنابراین نگران امنیت بستگان، دوستان خود بودند. و حتی دیگرانی که آنها را نمی شناختند. احساسات خشمگین، خنثی و مثبت در دوره دوم (ساعت 8:12 تا 8:22 ساعت) شروع به ظهور کردند. با این حال، تعداد احساسات مثبت و خنثی نسبتا کم بود، به طوری که یک قطعه مثبت و دو قطعه خنثی بود. عواطف خشمگین در این دوره زمانی عمدتاً نشان دهنده بیزاری مردم از زلزله بود. احساسات غم انگیز در دوره زمانی سوم (08:22 ساعت تا 08:00) شروع به ظهور کردند. 40 ساعت) افرادی که احساسات غم انگیز را ابراز می کردند عمدتاً به این دلیل بود که این زلزله آنها را به یاد فاجعه هولناکی می انداخت که در سال 2008 در سیچوان رخ داد (زلزله ای که در ونچوان، استان سیچوان، در 12 می 2008 رخ داد، خسارت زیادی ایجاد کرد). با در دسترس قرار گرفتن اطلاعات بیشتر و دقیق تر در مورد زلزله، افراد دسته های بیشتری از احساسات را ابراز می کردند و دلایل این احساسات نیز تغییر کرده بود. به عنوان مثال، در دوره چهارم و پنجم، مردم به دلیل نگرانی از وقوع پس لرزه هایی در آینده نزدیک، احساسات ترسناک و مضطرب را ابراز می کردند. این همچنین نشان می دهد که برای مدت طولانی مردم همچنان در نزدیکی پناهگاه جمع می شدند، همانطور که در نشان داده شده است افراد دسته های بیشتری از احساسات را ابراز می کردند و دلایل این احساسات نیز تغییر کرده بود. به عنوان مثال، در دوره چهارم و پنجم، مردم به دلیل نگرانی از وقوع پس لرزه هایی در آینده نزدیک، احساسات ترسناک و مضطرب را ابراز می کردند. این همچنین نشان می دهد که برای مدت طولانی مردم همچنان در نزدیکی پناهگاه جمع می شدند، همانطور که در نشان داده شده است افراد دسته های بیشتری از احساسات را ابراز می کردند و دلایل این احساسات نیز تغییر کرده بود. به عنوان مثال، در دوره چهارم و پنجم، مردم به دلیل نگرانی از وقوع پس لرزه هایی در آینده نزدیک، احساسات ترسناک و مضطرب را ابراز می کردند. این همچنین نشان می دهد که برای مدت طولانی مردم همچنان در نزدیکی پناهگاه جمع می شدند، همانطور که در نشان داده شده استشکل 8 ج-ه. ما می توانیم ببینیم که بسیاری از مردم در شکل 8 f. با ترکیب با احساساتی که افراد در این دوره ابراز می کردند، متوجه شدیم که احساسات ترسناک دیگر غالب نیستند. مردم در دوره ششم زمانی در خوشه 2 احساسات غم انگیزی را به دلیل غم و اندوه برای قربانیان در مناطقی که بدترین آسیب دیده بودند ابراز کردند. در دوره زمانی هفتم، دسته بندی اصلی احساسات در هر خوشه متفاوت بود. شاید مردم در این زمان آرام شده باشند. حتی احساس اصلی خوشه 2 در شکل 8 g مثبت بود. مردم برای مناطق حادثه دیده دعای خیر کردند.
تجزیه و تحلیل احساسات دقیق نه تنها توضیح بیشتر برای استخراج مسیر مکانی-زمانی انسان بود، بلکه جزئیات بیشتری از فاجعه را برای بخش های کاهش بلایا ارائه می دهد. از یک طرف، درک درستی از قانون آگاهی و حرکت اضطراری عمومی در منطقه مورد مطالعه را فراهم می کند. از سوی دیگر، بر اساس ویژگیهای مسیر عاطفی فضایی-زمانی، بخشهای کاهش بلایا میتوانند مدیریت و راهنمایی به موقع برای «گرههای کلیدی» در این فرآیند ارائه دهند تا از حوادث غیرمنتظره جلوگیری شود. به عنوان مثال، ما می توانیم راهنمایی موثری برای مناطقی که احساسات منفی شدید هستند، به عنوان مثال، در شکل 8 a,b ارائه کنیم تا از ازدحام احتمالی ناشی از وحشت جلوگیری شود.
3.3. تحلیل تغییر عاطفی پس از فاجعه
فاجعه ناگهانی تأثیر طولانی مدت بر مردم دارد. با نظارت و تجزیه و تحلیل اطلاعات عاطفی دقیق عمومی، میتوانیم بسیاری از اطلاعات مهم را از دادههای عظیم مرتبط با فاجعه استخراج کنیم. این اطلاعات می تواند به ما کمک کند تا نیازها و بازخوردهای عمومی را به سرعت درک کنیم، حتی برای برخی از مشکلات غیرقابل یافتن، مانند سلامت روان. این برای ما برای بهبود کارایی واکنش اضطراری و نجات در بلایا بسیار مهم است. در این بخش، Ya’an را به عنوان مثال در نظر گرفتیم و از روزها به عنوان فواصل زمانی برای نظارت بر احساسات عمومی برای مدت طولانی از دیدگاه کلان استفاده کردیم. در همین حال، ما علل تغییر احساسات عمومی را با استفاده از استخراج کلمه داغ تحلیل کردیم. این می تواند به ما کمک کند تا به سرعت نگرانی های عمومی را از اطلاعات عاطفی انبوه درک کنیم.https://www.picdata.cn/ ).
در مورد احساسات مثبت، همانطور که در شکل 9 نشان داده شده است، در روز دوم (21 آوریل) پس از فاجعه، کلمات داغ “感动 (حرکت کرد)” و 感激 (قدردان)” را در متن مربوطه آوردیم. ما متوجه شدیم که مردم عمدتاً از امدادگران حرفه ای مانند ارتش قدردانی می کنند. در این زمان تعداد داوطلبان کمتری بود. با این حال، داوطلبان بیشتری به طور خودجوش در طول زمان، به ویژه در روزهای سوم و چهارم، به عملیات نجات پیوستند. زیرا در این زمان، “志愿者(داوطلب)” بیشتر ظاهر می شود. امداد غیرنظامی از حدود چهارمین روز (23 آوریل) پس از فاجعه به تدریج به منطقه فاجعه رسید. کلمات داغ “爱心 (عشق)” و “物资 (تجهیزات امدادی)” نشان می دهد که مردم در مناطق آسیب دیده از مواد امدادی خودجوش غیردولتی سپاسگزار هستند. بر اساس تغییرات در احساسات مثبت عمومی،
در رابطه با اضطراب، همانطور که در شکل 10 نشان داده شده استبا گذشت زمان، به تدریج از نگرانی مردم کاسته شد. روز دوم بعد از زلزله، اضطراب بیشتر بود. دلیل این امر این بود که: (1) راهها قطع شده و برخی مناطق منزوی شده بودند. ما از کلمات داغ “中断 (وقفه)” و “救援 (نجات)” در متون اصلی میکروبلاگ برای دریافت اطلاعات دقیق استفاده کردیم. ما دریافتیم که “上里镇 (شهر شانگلی)، “中里镇 (شهر ژونگلی)، “下里镇 (شهر Xiali)” و “碧峰峡 (شهر Bifengxia)” از دنیای خارج جدا شده و مورد نیاز است. امداد و نجات فوری پس از زلزله (2) برخی از مناطق نیاز فوری به تجهیزات امدادی داشتند و این مناطق از آب و هوای بد رنج می بردند. به عنوان مثال، از طریق کلمات داغ، متوجه شدیم که برخی از متون میکرو وبلاگی وجود دارد که میگفتند «روستای Wangjia در شهر Longmen کمبود آب، غذا، دارو و چادر دارد». (3) برخی از مردم به دلیل عدم تماس با بستگان و دوستان خود پس از زلزله ابراز نگرانی کردند. از 21 آوریل تا 26 آوریل، متوجه شدیم که نگرانی مردم عمدتاً به دلیل کمبود تجهیزات و آب و هوای بد است. علاوه بر این، با گذشت زمان، تقاضای مردم برای تجهیزات امدادی عمدتاً مربوط به چادرها بود، به ویژه در 26 آوریل. ترکیبی از محتوای میکروبلاگ و اطلاعات مکان میتوانست امکان اجرای طرح نجات دقیقتری را فراهم کند.
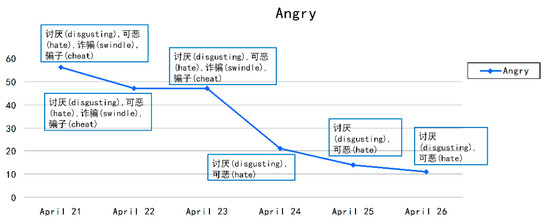
همانطور که در شکل 11 نشان داده شده است، از 21 آوریل تا 23 آوریل، عموم مردم عمدتاً به دلیل بیزاری خود از زلزله و به دلیل برخی کلاهبرداری های اینترنتی ابراز خشم کردند. با ترکیب محتوای میکروبلاگ مربوطه، متوجه شدیم که برخی از کلاهبرداری های اینترنتی توسط کاربران میکرو وبلاگ افشا شده است، مانند «این وحشتناک است. برخی تبهکاران زیر پوشش زلزله کلاهبرداری کردند. لطفا به این شماره تلفن دقت کنید: xxx. این پیامهای خشمگین برای کمک به مردم برای محافظت در برابر شایعات (به ویژه برای افراد مضطرب) استفاده میشد. پس از 23 آوریل، خشم عمومی عمدتاً به دلیل بیزاری از فاجعه بود.
همانطور که در شکل 12 نشان داده شده است، از 21 آوریل تا 25 آوریل، غم و اندوه ناشی از تخریب خانه ها و مرگ اقوام یا دوستان بود. نمونه هایی از متون مربوط به میکرو وبلاگ عبارتند از: «خانه کجاست؟ کلاس درس کجاست؟ دیروز؟ دیروز یتیم نبودم» و «صحنه ویرانی کامل است و کی می توانیم وطن خود را از نو بسازیم؟» در روز ششم فروردین ماه عزاداری های زیادی توسط نهادهای رسمی و غیردولتی انجام شد که همین موضوع باعث ابراز ناراحتی مردم شد. در طول فرآیند نجات زلزله، سازمانهای امدادی میتوانند کمکهای روانی را به مکانهایی ارسال کنند که غم و اندوه در آنها شدید بود، همانطور که توسط مکانهای اطلاعات میکروبلاگ مربوطه تعیین میشود.
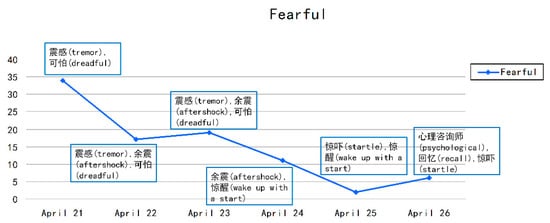
از نظر ترس، همانطور که در شکل 13 نشان داده شده است، از 22 آوریل تا 24 آوریل، پس لرزه های متعددی در Ya’an رخ داد که تأثیر زیادی بر زندگی مردم گذاشت. بسیاری از کلمات داغ مشاهده شد، مانند “余震 (پس لرزه)” و “可怕 (وحشتناک)”. با این حال، بین 24 آوریل و 26 آوریل، به ویژه در 26 آوریل، ترس ناگهانی افزایش یافت و کلمات داغ عمدتاً شامل “心理咨询师 (مشاوران روانشناسی)، “回忆 (یادآوری)” و “惊吓 (بهت زدگی) بود. )” ما از این کلمات داغ برای به دست آوردن میکرو بلاگ اصلی استفاده کردیم و دیدیم که برخی می گویند: «یک معلم در شهر ژونگلی گزارش داد که دختری از صدای بلند می ترسید و به خوردن ادامه می داد. او گفت اگر غذا نخورد می ترسد. بنابراین این معلم امیدوار بود که بخش کاهش بلایا بتواند یک مشاور روانشناسی برای کمک به آن دختر بفرستد» و «برادرم گفت تا زمانی که رعد و برق در یاان بود، خیلی می ترسید! کمک بخواهید!
میتوانیم به همین ترتیب به کاوش در سایر زمینهها ادامه دهیم. این می تواند به ما در درک دقیق واکنش های مردم به پیشرفت کاهش بلایا کمک کند. علاوه بر این، نتایج تجزیه و تحلیل می تواند به بخش امداد کمک کند تا استراتژی های نجات را بهینه کند و کارایی امداد و نجات را بهبود بخشد.
4. ارزیابی شاخص های تجربی
4.1. ارزیابی دقت طبقه بندی احساسات
4.1.1. مجموعه تجربی
در آزمایش طبقهبندی احساسات، ما ابتدا به صورت دستی یک پیکره را بر اساس شش دستههای هیجانی حاشیهنویسی کردیم. در این مجموعه هر دسته عاطفی شامل 1000 نمونه متن بود. از این میان 800 نمونه متن به عنوان پیکره آموزشی و 200 نمونه به عنوان پیکره آزمون از هر دسته هیجان انتخاب شدند.
4.1.2. محیط تجربی
به منظور بهبود دقت طبقه بندی احساسی، کاراکترها و نمادهای خاص در متن را به کلمات چینی ترجمه کردیم. ما چارچوب word2vec (از Google [ 39 ]) و NLPIR-ICTCLAS ( https://ictclas.nlpir.org ) را در چارچوب الگوریتمی خود ادغام کردیم تا به پردازش این متن کمک کنیم. در نهایت، شبکههای عصبی کانولوشنال را بر اساس جریان تانسور [ 40 ] ساختیم و پارامترهای مدل را برای دستیابی به بهترین نتایج بهینهسازی کردیم. در این فرآیند، ابعاد کلمه بردار را 200، تعداد هسته های کانولوشن 3 و اندازه آنها 3، 4 و 5 بود. قدم 1 بود.
4.1.3. نتایج تجربی و مقایسه دقت
ما دقت الگوریتم را بر اساس شاخصهای دقت (P)، فراخوان (R) و ارزیابی جامع ( F-1 ) تأیید کردیم. فرمول ها در زیر نشان داده شده است:
ن_سیorrهجتینشان دهنده تعداد متن هایی است که به درستی در یک دسته طبقه بندی شده اند، ن_افآلسهنشان دهنده تعداد متن هایی است که به اشتباه در این دسته طبقه بندی شده اند، و ن_سیآتیهgoryتعداد متون متعلق به این دسته را در مجموعه تست نشان می دهد.
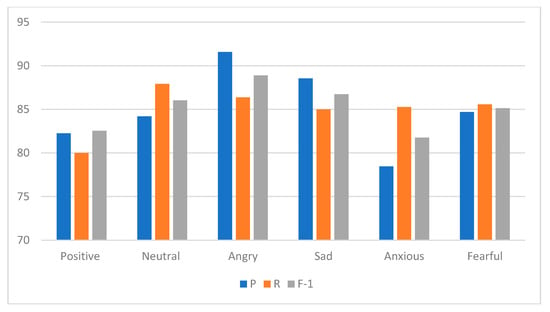
جدول 2 و شکل 14 دقت مدل CNN را در طبقه بندی احساسات ریزدانه نشان می دهد. نمرات شاخص ارزیابی جامع برای هر دسته همگی بالای 81 درصد بود که الزامات تجربی را برآورده می کرد. علاوه بر این، در این مقاله استفاده از عامیانه، کلمات رایج اینترنتی و کاراکترها و نمادهای خاص را نیز برای بهبود عملکرد مدل در نظر گرفتیم.
4.2. ارزیابی آزمایش های تحلیل مکانی- زمانی
4.2.1. شرح داده ها با اطلاعات آدرس
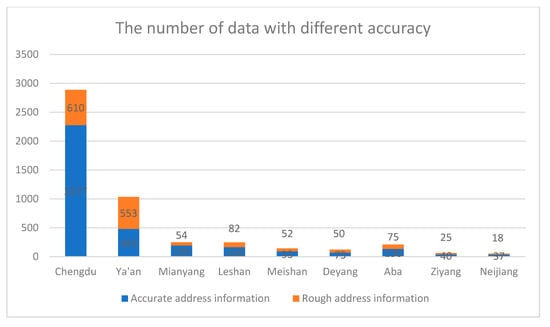
تعداد متون در مجموعه داده های این مقاله 39341 بود. با این حال، همه متون حاوی اطلاعات آدرس نیستند. ما این اطلاعات آدرس را بر اساس روش توضیح داده شده در بخش 2.2 پردازش کردیم . تمام اطلاعات آدرس را می توان در این مقاله به دو دسته تقسیم کرد، از جمله اطلاعات آدرس تقریبی و اطلاعات آدرس دقیق. در این میان، اطلاعات آدرس تقریبی فقط میتواند نشاندهنده روستاها و شهرها، حتی بخشها و شهرستانها باشد، مانند «شهرستان لوشان، شهر یاان» و «منطقه ووهو، شهر چنگدو» و غیره. اطلاعات آدرس دقیق میتواند نشاندهنده خیابانها و نهادهای جغرافیایی باشد. مانند «خیابان شمالی Sishengci»، «پردیس Wangjiang دانشگاه سیچوان»، و غیره. جدول 3 و شکل 15نسبت و تعداد داده ها را با دقت متفاوت در شهرهای مختلف به تصویر می کشد. در میان آنها، فرمول محاسبه نسبت به شرح زیر است:
4.2.2. ارزیابی فرآیند آزمایشی و نتایج
در بخش 3.1 ، ما از داده های توزیع تراکم جمعیت ارائه شده توسط GHSL (لایه سکونت انسانی جهانی) برای کمک به ارزیابی جمعیت آسیب دیده استفاده کردیم. مقیاس نقشه هایی که ما استفاده کردیم نسبتاً کوچک بود. بنابراین، ما در نظر گرفتیم که تمام داده ها با اطلاعات آدرس دقیق و اطلاعات آدرس تقریبی قابل استفاده هستند. از این میان، دادههای آبا و یاان وضعیت واقعی بیانشده توسط رسانههای اجتماعی در منطقه را بهتر منعکس میکنند، زیرا اگرچه حجم دادههای رسانههای اجتماعی در این دو شهر کم است، دادههای حاوی اطلاعات آدرس نسبت بیشتری را به خود اختصاص میدهند. آنها به ترتیب به 34.8 درصد و 26.09 درصد رسیدند. با در نظر گرفتن تراکم جمعیت و محل کانون (مرکز زلزله در یاان رخ داده است)، در بخش 3.1، ما عمدتاً روی وضعیت فاجعه در یاآن و چندین شهر نزدیک به یاان تمرکز کردیم.
در بخش 3.2 ، چگونگی تغییر مسیرهای مکانی-زمانی انسانها در هنگام وقوع بلایای ناگهانی را بررسی کردیم و از دادههای جغرافیایی (پناهگاهها) با اطلاعات مکان دقیق استفاده کردیم. بنابراین، ما در نظر گرفتیم که داده های رسانه های اجتماعی با اطلاعات آدرس دقیق می توانند برای تجزیه و تحلیل استفاده شوند. علاوه بر این، زمین لرزه ها بلایای ناگهانی هستند و در مدت زمان کوتاهی خسارات عظیمی به بار می آورند. بنابراین، در این مقاله، ما هفت دوره زمانی کوچک را برای بررسی جنبش عمومی پس از فاجعه تنظیم کردیم و آن را با احساسات عمومی ترکیب کردیم تا جزئیات بیشتری در مورد فاجعه استخراج کنیم. این به داده های بیشتری با اطلاعات آدرس دقیق نیاز داشت. از شکل 15 میتوانیم ببینیم که چنگدو بیشترین نیازها را برآورده میکندو این نتایج تجزیه و تحلیل رضایت بخشی را در بخش 3.2 ایجاد کرد . البته می توان از همین روش برای تحلیل فاجعه در یان نیز استفاده کرد; با این حال، دانه بندی زمانی درشت خواهد بود.
در بخش 3.3 ، ما عمدتاً اطلاعات احساسی را در هر شهر برای مدت طولانی زیر نظر داشتیم. بنابراین، ما فقط باید بدانیم که داده های رسانه های اجتماعی متعلق به کدام شهر است. اگرچه بسیاری از داده های رسانه های اجتماعی هیچ اطلاعات مکانی نداشتند، اما همه آنها برچسب های خاص خود را داشتند. این در بخش 2.1 توضیح داده شد . با توجه به اینکه Ya’an بیشترین ضربه را از زلزله زده بود، Ya’an را به عنوان هدف تحقیق انتخاب کردیم.
5. نتیجه گیری ها
هنگامی که یک فاجعه رخ می دهد، رسانه های اجتماعی می توانند مقدار زیادی از اطلاعات جغرافیایی مهم مرتبط با بلایا را در زمان واقعی در اختیار بخش های کاهش بلایا قرار دهند. در این مقاله، ما اطلاعات عاطفی عمومی ریز استخراج شده از رسانه های اجتماعی را به عنوان ویژگی اطلاعات جغرافیایی برای کمک به کاهش فاجعه در نظر گرفتیم. در فرآیند استخراج اطلاعات احساسی، ویژگیهای رسانههای اجتماعی چینی را به طور کامل تجزیه و تحلیل کردیم و الگوریتم مناسب (مدل شبکه عصبی پیچشی) را انتخاب کردیم. در همین حال، تعداد زیادی از شخصیت ها و نمادهای خاص با ویژگی های عاطفی موجود در رسانه های اجتماعی نیز برای بهبود دقت طبقه بندی در نظر گرفته شد. روش های موجود در این مقاله به نتایج رضایت بخشی دست یافتند.
به منظور بررسی اثربخشی روش در این مقاله در کاهش بلایا، ما از زلزله 7.0 که در 20 آوریل 2013، در شهر Ya’an، استان سیچوان، چین رخ داد، به عنوان مطالعه موردی استفاده کردیم. ما متون رسانههای اجتماعی مرتبط با مناطق آسیبدیده از زلزله را در شش دسته مختلف احساسی طبقهبندی کردیم. سپس با کمک نرمافزار GIS و سایر دادههای اطلاعات جغرافیایی سنتی (دادههای توزیع تراکم جمعیت و دادههای پناهگاه)، نقش اطلاعات عاطفی عمومی را که برای کاهش بلایا مفید است بررسی کردیم. نتایج نشان داد که احساسات عمومی ریزدانه میتواند پشتیبانی دادههای قدرتمندتری را برای بخشهای کاهش بلایا برای بهینهسازی استراتژیهای نجات و بهبود کارایی نجات فراهم کند.
اگرچه رسانه های اجتماعی نقش مهمی در کمک به کاهش بلایا دارند، اما محدودیت هایی نیز دارند. (1) داده های رسانه های اجتماعی به طور نابرابر توزیع شده است. مناطقی که از نظر اقتصادی توسعه یافته و پرجمعیت هستند، کاربران بیشتری از میکرو بلاگ سینا دارند. در منطقه تحقیقاتی این مقاله، چنگدو بیشترین دادههای میکرو بلاگ سینا را داشت و این دادهها بیشتر در منطقه شهری متمرکز بودند، اما بدترین شهر آسیب دیده نبود. بنابراین، در تحقیقات آینده، دادههای فراوانتری که شامل منابع دیگر نیز میشود، برای تکمیل دادههای رسانههای اجتماعی، مانند دادههای تصویر، دادههای GPS حملونقل خودرو، و غیره مورد نیاز است. (2) همه کاربران رسانههای اجتماعی مایل نیستند اطلاعات موقعیت مکانی خود را به اشتراک بگذارند. . در مجموعه داده مورد استفاده در این مقاله، نسبت متن با اطلاعات مکان بسیار کم بود. این امر استفاده از برخی روش های تحلیل مکانی-زمانی را محدود می کند. با این حال، ما متوجه شدیم که بسیاری از موجودات با نام جغرافیایی در متون وجود دارد و بسیاری از آنها می توانند به موقعیت مکانی کاربر احترام بگذارند. بنابراین، یک روش موثر برای استخراج خودکار این موجودات با نام جغرافیایی برای تکمیل کمبود اطلاعات موقعیت جغرافیایی در رسانه های اجتماعی مورد نیاز است.
علاوه بر این، استفاده از رسانه های اجتماعی برای کاهش بلایا کافی نیست. با توسعه فناوری داده کاوی، می توان اطلاعات مرتبط با بلایای بیشتری را که در رسانه های اجتماعی موجود است استخراج کرد، مانند دسته های مختلف اطلاعات تلفات بلایا و غیره. نقش بیشتری ایفا کند.


 “، که توسط بسیاری از ابزارهای رایج پردازش زبان طبیعی (NLP) حذف و نادیده گرفته می شوند. با این حال، برای تجزیه و تحلیل عاطفی، این کاراکترها و نمادهای خاص معنای عاطفی دارند، به عنوان مثال، “(>_<)” و “(>_<)>” می توانند احساسات آشفته را بیان کنند. بنابراین، در این مقاله، ما آنها را به متنی تفسیر کردیم که می تواند توسط NLP پردازش شود. برخی از کاراکترها و نمادهای خاص می توانند توسط پلت فرم میکرو بلاگ به متن ترجمه شوند. به عنوان مثال، می تواند به “اشک” (泪) ترجمه شود. با این حال، موارد دیگری که توسط پلتفرم میکرو بلاگ قابل رمزگشایی نبودند، مانند (>_<) و , بر اساس «فهرست شکلکهای» وب تفسیر شدند، که شامل پیامدهای احساسی انواع شکلکها از طریق مقدار زیادی است. از ادبیات منتشر شده به عنوان مثال، (>_<
“، که توسط بسیاری از ابزارهای رایج پردازش زبان طبیعی (NLP) حذف و نادیده گرفته می شوند. با این حال، برای تجزیه و تحلیل عاطفی، این کاراکترها و نمادهای خاص معنای عاطفی دارند، به عنوان مثال، “(>_<)” و “(>_<)>” می توانند احساسات آشفته را بیان کنند. بنابراین، در این مقاله، ما آنها را به متنی تفسیر کردیم که می تواند توسط NLP پردازش شود. برخی از کاراکترها و نمادهای خاص می توانند توسط پلت فرم میکرو بلاگ به متن ترجمه شوند. به عنوان مثال، می تواند به “اشک” (泪) ترجمه شود. با این حال، موارد دیگری که توسط پلتفرم میکرو بلاگ قابل رمزگشایی نبودند، مانند (>_<) و , بر اساس «فهرست شکلکهای» وب تفسیر شدند، که شامل پیامدهای احساسی انواع شکلکها از طریق مقدار زیادی است. از ادبیات منتشر شده به عنوان مثال، (>_< 

 را می توان به “غمگین” (伤心) ترجمه کرد.
را می توان به “غمگین” (伤心) ترجمه کرد.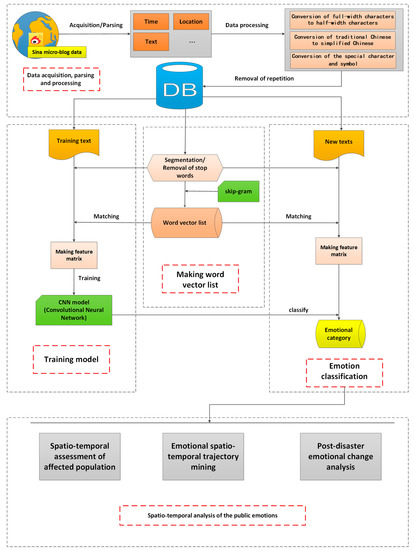








بدون دیدگاه