

خلاصه
در این مقاله، ما پیادهسازی یک سیستم مدیریت دادههای تحقیقاتی را ارائه میکنیم که دارای ذخیرهسازی دادههای ساختاریافته برای دادههای تجربی مکانی-زمانی (ادراک محیطی و ناوبری در چارچوب رانندگی مستقل)، از جمله مدیریت ابرداده و رابطهایی برای تجسم و پردازش موازی است. خواسته های محیط تحقیق، طراحی سیستم، سازماندهی ذخیره سازی داده ها، و سخت افزار محاسباتی و همچنین ساختارها و فرآیندهای مربوط به جمع آوری داده ها، آماده سازی، حاشیه نویسی و ذخیره سازی به تفصیل شرح داده شده است. ما مثالهایی برای مدیریت مجموعههای داده ارائه میکنیم، مراحل آمادهسازی دادههای مورد نیاز برای ذخیرهسازی دادهها و همچنین مزایای استفاده از دادهها در زمینه وظایف علمی را توضیح میدهیم.
کلید واژه ها:
زیرساخت داده های مکانی – زمانی ; مدیریت داده ها ؛ پایگاه داده فضایی ; اینترنت GIS ; ابرداده
1. معرفی
آگاهی روزافزونی در جامعه پژوهشی از اهمیت اصول FAIR در مدیریت داده ها وجود دارد [ 1]: داده ها باید رایگان، در دسترس، قابل استفاده و قابل استفاده مجدد باشند. الزامات پروژه های تحقیقاتی پیچیده می تواند از این هم فراتر رود: اغلب، چنین پروژه هایی شامل آزمایش های غنی و جمع آوری داده های گسترده با حسگرهای متنوع و وابسته به هم هستند. بنابراین، آنها به یک زیرساخت پیچیده برای نظارت بر جمع آوری داده ها، ذخیره سازی و ارائه دسترسی ساختاریافته و شهودی به داده ها نیاز دارند. به منظور فراتر رفتن از ذخیره سازی و دسترسی صرف به داده ها، پیوند داده ها در امتداد جزء مکانی و زمانی مفید است. برای این منظور، همه دادهها ارجاع داده میشوند، که از قبل امکان پردازش و تجزیه و تحلیل عمومی را به سمت یکپارچهسازی و ادغام دادهها فراهم میکند. تنها از این طریق، دادههای بهدستآمده با زمان و پول قابلتوجهی میتوانند به روش مورد نظر مورد بهرهبرداری قرار گیرند و امکان استفاده فراتر از هدف اصلی خود را فراهم کنند.
نمونه ای برای چنین پروژه تحقیقاتی پیچیده ای یک گروه آموزشی تحقیقاتی (RTG) است که توسط بنیاد علم آلمان تامین مالی شده است، با عنوان “یکپارچگی و همکاری در شبکه های حسگر پویا” (GRK2159). این RTG مفاهیمی را برای اطمینان از یکپارچگی سیستم های مشترک در شبکه های حسگر پویا در زمینه رانندگی مستقل و ادراک محیطی بررسی می کند [ 2]]. بهرهبرداری از حسگرهای مختلف – همکار – در ارتباط با مفاهیم جدید و پیشرفته توصیف یکپارچگی اندازهگیریها، کلید مهمی در نظر گرفته میشود تا در نهایت امکان تعامل ایمن سیستمهای مستقل و انسانها را فراهم کند. این پروژه بر این فرض تکیه دارد که همکاری سنسورها و سیستمهای حسگر مختلف منجر به بهبود ناوبری و سنجش محیط توسط یک سیستم مستقل میشود. این پروژه بر آزمایشهای مشترک در مقیاس بزرگ متکی است، که در آن طیف وسیعی از دادههای حسگر توسط چندین سیستم چندحسی برای توسعه الگوریتمها و آزمایش کامل آنها در یک محیط واقعی به دست میآید. طیف سنسورهای مورد استفاده در این کمپین های اندازه گیری شامل سیستم های اسکن لیزری سه بعدی (LiDAR) است که ابرهای نقطه متراکم سه بعدی محیط را ضبط می کند. دوربین های استریو برای تصویربرداری و بازسازی سه بعدی فتوگرامتری، و همچنین سیستم های GNSS/IMU برای محلی سازی. به منظور ایجاد یک نمایش واقعی از وضعیت پویا در زمان جمعآوری دادهها، دادهها باید در یک سیستم مدیریت داده جامع ادغام شوند. سپس این سیستم امکان انجام آزمایشهای بدون درز با ترکیبهای حسگر دلخواه را بر اساس دادههای ذخیرهشده فراهم میکند.
با این حال، چنین تنوعی از داده ها و تقاضاها منجر به الزامات سازمانی در مورد ذخیره سازی و مستندسازی داده ها می شود (همچنین به [ 3 ] مراجعه کنید). سوال اصلی تحقیق این مقاله این است که چگونه دادههای وابسته به هم بهدستآمده در طول این آزمایشهای بزرگ مقیاس را ساختار دهیم تا محققان با پیشینههای مختلف بتوانند دادهها را در رابطه با سؤالات پیچیده تحقیقاتی مختلف پیدا، بررسی و تجزیه و تحلیل کنند. در عین حال، طرحواره ذخیره سازی و مستندسازی یکنواخت ایجاد شده باید به راحتی قابل تبدیل به قالب های هدف پلت فرم های انتشار داده ها باشد تا از استفاده مجدد توسط سایر محققان پشتیبانی کند.
در این بخش، ما در مورد تحقق یک سیستم مدیریت داده برای مجموعه دادههای مکانی-زمانی بزرگ و ناهمگن که با نیازهای ما مطابقت دارد، گزارش میدهیم: دادههای حسگر به روشی ساختاریافته، مستند و قابل همکاری ذخیره میشوند. ابرداده های ساختاریافته با هر مجموعه داده مرتبط هستند و از اتوماسیون یافتن و فیلتر کردن وظایف پشتیبانی می کنند. سختافزار ذخیرهسازی دادهها به سختافزار محاسباتی متصل است که از وظایف تحلیل دادههای بزرگ با استفاده از رابطهای دسترسی مناسب به داده پشتیبانی میکند. ساختار پیشنهادی به اندازه کافی کلی است که به عنوان نمونه برای پروژه های مشابه عمل کند.
ساختار باقیمانده مقاله به شرح زیر است: بخش 2 یک نمای کلی از پروژه تحقیقاتی ارائه می دهد و در بخش 3 مروری بر کارهای مرتبط و پیشرفته ترین فناوری های مدیریت داده ها (تحقیق) به طور کلی، به ویژه برای حوزه داده های جغرافیایی- مکانی بخش 4 شامل جزئیات پیاده سازی مفاهیم، و همچنین اجزای Backend و Frontend سیستم ذخیره سازی داده است. در بخش 5 ، گردش کار کامل از دریافت داده تا استفاده از داده با چند مثال شرح داده شده است، قبل از اینکه با خلاصه و ایده هایی برای پیشرفت های آینده در بخش 6 به پایان برسد .
2. مروری بر پروژه تحقیقاتی و الزامات آن در مورد مدیریت داده ها
موضوعات تحقیقاتی شامل بومی سازی مشارکتی برای وسایل نقلیه و همچنین شناسایی و نقشه برداری از اشیاء ایستا و پویا در فضای جاده اطراف، با تمرکز عمده بر یکپارچگی سیستم حاصل، یعنی پتانسیل سیستم برای شناخت محدودیت های خود و هنگامی که از آستانه های کیفیت از پیش تعریف شده تجاوز کرد، به موقع به کاربر هشدار می دهد [ 4 ]. در 30 سال گذشته، الگوریتمهای مختلفی برای نظارت بر یکپارچگی ناوبری مبتنی بر GPS توسعه یافتهاند که از حمل و نقل هوایی شروع شده و مرحله به مرحله به ناوبری خودرو منتقل شده است [5 ] . با این حال، بسیاری از مسائل باز همچنان پابرجا هستند [ 6]، و مفاهیم جدید برای توصیف یکپارچگی باید مورد بهره برداری قرار گیرند، به عنوان مثال، در قالب معیارهای کیفی مانند مرزهای بالای خطاهای اندازه گیری توسط ریاضیات بازه ای [ 7 ، 8 ]، و می توان به عنوان مثال با همکاری بین چند سنسور [7] به دست آورد. 9 ].
بیشتر موضوعات تحقیقاتی حول مشاهدات بسیاری از حسگرهای متصل به چندین وسیله نقلیه که برای بهبود کیفیت کلی سیستم با یکدیگر ادغام شدهاند، متمرکز شدهاند. به عنوان مثال، از ابرهای نقطه ای برای ساختن نقشه های مرجع پویا استفاده می شود که می تواند متعاقباً برای بهبود خود محلی سازی اعمال شود [ 10 ]. اطلاعات سه بعدی از اسکن لیزری و دوربین ها را می توان برای تشخیص اشیاء قوی یکپارچه کرد [ 11 ]. سایر موضوعات تحقیقاتی به همکاری در چندین وسیله نقلیه برای ترکیب مشاهدات متعدد از دیدگاه های مختلف در یک درک مشترک از محیط می پردازند [ 12 ]. مشاهده یک عابر پیاده از چندین وسیله نقلیه به طور همزمان کیفیت طبقه بندی و همچنین محلی سازی و بازسازی سه بعدی آن را بهبود می بخشد.13 ].
RTG میزبان 9 کاندیدای دکترا در یک دوره 3 ساله در یک دوره بودجه حداکثر 9 ساله است که منجر به نزدیک به 30 محقق دکترا می شود که توسط این برنامه تامین مالی می شوند. یکی از ارکان RTG، جمعآوری مداوم دادههای تجربی است که منجر به مجموعهای از مجموعه دادههای مکانی-زمانی میشود که میتوانند به روشهای دلخواه ادغام شوند، به این ترتیب از طیف گستردهای از سؤالات مختلف تحقیقاتی پشتیبانی میکنند. در حالی که موضوعات تحقیقاتی فاز اول بر روی دادههای همتراز زمانی از یک آزمایش واحد تمرکز میکنند، مراحل بعدی تحقیق میتوانند تجزیه و تحلیلهایی را در مجموعه دادههای جمعآوریشده طی چندین سال انجام دهند. در نتیجه، ذخیره سازی صدا و مستندسازی داده ها برای تحقیقات موفق الزامی است. این به محققان این امکان را میدهد تا وابستگیهای پیچیده اشیاء در دادههای ثبتشده را به صورت ماسبق بررسی کنند – شبیه به یک آزمایش بلادرنگ. به این ترتیب، دادههای جمعآوریشده با سیستمها و پلتفرمهای مختلف را میتوان به صورت یکپارچه تجزیه و تحلیل کرد و امکان انجام آزمایشهای مجازی پیچیده بر اساس دادههای واقعی را فراهم میکند، بنابراین، محیط تحقیق را «محل آزمایش مرکزی» مینامند.
2.1. آزمایش ها و داده ها
به منظور جمعآوری دادههایی که از موضوعات پژوهشی ناهمگن پشتیبانی میکنند، آزمایشهای مشترک در مقیاس بزرگ ( شکل 1 را ببینید) در فواصل زمانی منظم انجام می شود و با تجهیز خودروهای واقعی به پلتفرم های چند سنسوری که مقادیر زیادی داده در مورد محیط را جمع آوری می کند، قابلیت های سنسورهای خودرو نسل های آینده خودرو را شبیه سازی می کند. از آنجایی که قابلیت های ارتباطی و پردازش آنلاین در کانون توجه پروژه نیست، یکی از اهداف اصلی ارائه یک محیط واقعی است که در آن شبیه سازی ها با داده های واقعی انجام شود. طیف سنسورهای مورد استفاده در این کمپینهای اندازهگیری شامل سیستمهای LiDAR است که ابرهای نقطهای 3 بعدی متراکم محیط را ضبط میکنند، دوربینهای استریو برای تصویربرداری و بازسازی سهبعدی فتوگرامتری، و همچنین سیستمهای GNSS/IMU برای محلیسازی. علاوه بر این، اطلاعات موجود از نقشه ها و مدل های ساختمانی سه بعدی نیز در سیستم گنجانده شده است.
مانند هر سیستم چند سنسوری، داده های حسگر در چارچوب مختصات هر سنسور به دست می آید. کالیبراسیون تمام موقعیتها و جهتگیریهای نسبی بین حسگرها برای هر آزمایش انجام میشود تا امکان تبدیل همه اندازهگیریها به یک قاب مشترک را فراهم کند. این تبدیل تمام دادههای حسگر را به یک قاب مختصات جهانی ممکن میسازد، با استفاده از اندازهگیری حسگرهای محلیسازی روی برد برای ایجاد رابطه بین اندازهگیریها و اشیاء فضایی با مختصات جهانی شناخته شده یا بین چندین وسیله نقلیه. این ممکن است شامل اندازه گیری وسیله نقلیه به وسیله نقلیه، اندازه گیری وسیله نقلیه به زیرساخت، یا اندازه گیری مطلق مستقیم موقعیت جغرافیایی (مثلاً با GNSS) باشد.
علاوه بر حسگرهای محلی سازی، اطلاعات مربوط به اجسام استاتیک و پویا در محیط به طور پیوسته ثبت می شود: این شامل اشیاء ثابت مانند سطح جاده و ساختمان ها و همچنین اشیاء پویا مانند سایر وسایل نقلیه و عابران پیاده در جاده می شود.
با توجه به تعداد زیاد حسگرهای درگیر و وضوح مکانی و زمانی بالای اندازهگیریها، این آزمایشها حجم زیادی از دادههای خام تولید میکنند. در طول اولین آزمایش در مقیاس بزرگ، سه وسیله نقلیه مجهز به پلتفرمهای چند سنسوری اطلاعات را برای حدود دو ساعت ثبت کردند. در طول این مدت، دادههای جمعآوریشده توسط سه جفت دوربین استریو، دو سیستم اسکنر لیزری و ده سیستم GNSS/IMU به نرخ اکتساب دادهها تا ۱ گیگابایت در ثانیه دادههای خام حسگر رسید. این منجر به یک مجموعه داده حدود 5 ترابایت پس از فشرده سازی و پس پردازش اولیه، قبل از پردازش بیشتر در زمینه پروژه های تحقیقاتی فردی شد.
2.2. چالش ها و اهداف
تنوع و ارتباط متقابل حسگرها، داشتن وضوحهای متفاوت در فضا و زمان با اندازهگیریهای حوزههای مختلف (مشاهدات نقطهای/مشاهدات منطقهای)، مشاهدات عناصر استاتیک و دینامیکی محیط و کیفیت (سنسورهای با دقت بالا و پایین)، منجر به مجموعه داده های بسیار پیچیده آزمایشها تعداد زیادی گزارش داده جداگانه با قالبهای داده خاص حسگر را در چندین پلتفرم حسگر به دست میدهند. دادههای تجربی پردازشنشده، اندازهگیریهای حسگر خام را نشان میدهند، و هنوز هم تراز نیستند تا با مشاهدات دیگر سازگار باشند. این بدان معناست که ارجاع جغرافیایی ممکن است بهینه نباشد و حتی ممکن است به تنهایی یک هدف باشد، زیرا اکثر اندازهگیریهای حسگر نمیتوانند مستقیماً به زمین ارجاع داده شوند. بجای، یک تبدیل بین سیستمهای مختصات چندگانه (بهکارگیری پارامترهای تبدیل بهدستآمده از کالیبراسیون حسگر به حسگر) اعمال میشود که با اندازهگیریها در یک قاب جهانی به سنسورهای موقعیتیابی جهانی ختم میشود. علاوه بر این، اندازهگیریهای حسگر مربوط به نقاط روی سطح اجسام (اشیاء ثابت یا اجسام پویا) است که شناسایی آنها (از طریق تقسیمبندی و طبقهبندی) بخشی از تحقیق است اما بخشی از اندازهگیری نیست.
بنابراین، دادههای حسگر تحت یک فرآیند تبدیل تدریجی از اندازهگیریهای حسگر خام (دادههای اولیه) از طریق نمایشهای مختلف (دادههای پردازششده) با درجه افزایشی از پالایش تا اطلاعات شی معنایی قرار میگیرند (شکل 2 را ببینید ) . برای اشیاء پویا، تخصیص یک مکان در فضا فقط برای لحظه زمانی اندازه گیری قابل استفاده است، بنابراین اطلاعات زمانی نیز باید ذخیره شود. به این ترتیب، دادهها هم دادههای خام و هم دادههای غنیشده را در بر میگیرند، جایی که «غنیشده» به جنبههای مختلف مربوط میشود، به عنوان مثال، تبدیل به یک سیستم مختصات جهانی یا حاشیهنویسی با معنایی (سبک).
حتی اگر مجموعه دادههای ما بیشتر توسط محققان در RTG استفاده میشود، ما با چالشهای مرتبط با مدیریت دادههای تحقیقاتی در مقیاس بزرگتر مواجه هستیم: در حالی که مؤسسات شرکتکننده در حوزههای مرتبط و در یک موضوع کلی مشترک کار میکنند، آنها راههای مختلفی را برای نمایش دادههای خود ایجاد کردهاند. و نتایجی که فوراً با یکدیگر سازگار نیستند. این جوامع مختلف از متخصصان حوزه با هم در چارچوب RTG کار می کنند و باید مبنای مشترکی برای به اشتراک گذاشتن داده ها و نتایج خود بیابند تا از معرفی مراحل اضافی مربوط به درک و تبدیل بازنمایی داده های یکدیگر برای هر تجزیه و تحلیل داده ها اجتناب کنند. وظیفه. علاوه بر این، از آنجایی که RTG در سه گروه متوالی از محققانی که بر روی یک مجموعه داده مشترک کار می کنند، سازماندهی شده است. امکان برقراری ارتباط شخصی در مورد داده ها بین اعضای گروه های مختلف محدود است. در این موارد، مستندسازی خوب داده ها و ویژگی های آن بسیار مهم است.
با این حساب، از اصول داده های FAIR می توان برای تعریف الزامات مدیریت داده های تحقیقات داخلی استفاده کرد. اصول دادههای FAIR ایجاب میکند که دادههای پژوهشی باید قابل یافتن و در دسترس باشند و همچنین قابل استفاده و قابل استفاده مجدد باشند. این امر به ضرورت ذخیره سازی داده های ساختاریافته با مکانیسم های جستجوی خودکار روی ابرداده های غنی (الزامات فراداده F2، R1.2-3، و همچنین نیاز زیرساختی F4 در [ 1 ]) دلالت دارد. برای اینکه مجموعه دادههای پیچیده (شامل همه نسخهها و بازنماییها) قابل یافتن برای محققان باشد، مکانیسمهای جستجو باید ارائه شود که امکان بازرسی دادهها را با استفاده از پرسوجوهای مکانی-زمانی در دادهها و متا دادههای مرتبط، نزدیک به دادههای مفهومی فراهم کند. مکعب [ 14 ]، یا به طور خاص مکعب فضا-زمان [15 ]. از آنجایی که دسترسی به داده ها به محققان RTG در سطح سیستم فایل داده می شود، اصول A1 و A2 در اینجا اعمال نمی شوند. چالشهای باقیماندهای که زیرساخت مدیریت دادههای پژوهشی پیشنهادی سعی در حل آنها دارد، مربوط به اصول دادههای FAIR I1-3 (قابلیت همکاری بازنمایی دادهها) است. در نظر گرفتن این اصول FAIR در حال حاضر در سطح ذخیره سازی داخلی داده ها، انتشارات بعدی بخش هایی از داده ها را آسان تر می کند. از آنجایی که اصول F1، F3 و R1.1 مستقیماً در مورد دادههای استفاده شده داخلی اعمال نمیشوند، باید در طول فرآیند انتشار دادهها در نظر گرفته شوند. این شامل تخصیص شناسههای منحصربهفرد جهانی (مثلاً در قالب DOI) و مجوزهای استفاده از دادههای مناسب است.
هدف پروژه های تحقیقاتی تجزیه و تحلیل و تفسیر بیشتر داده ها است. این فرآیندهای تجزیه و تحلیل باید برای مجموعه داده های بزرگ قابل اجرا باشد. بنابراین، سیستم برای پردازش موازی به سخت افزار محاسباتی متصل می شود. تکنیک های تجزیه و تحلیل به کار گرفته شده در تحقیق ما ارتباط نزدیکی با انواع خاصی از حسگرها دارد. تصاویر با استفاده از الگوریتمهای پردازش تصویر پردازش میشوند، بهعنوان مثال، OpenCV [ 16 ] یا تشخیص شی با استفاده از یادگیری عمیق (به عنوان مثال، TensorFlow [ 17 ])، دادههای LiDAR به الگوریتمهای ابر نقطهای نیاز دارند (به عنوان مثال، Point Cloud Library [ 18]]). داده های GNSS و IMU را می توان برای تعیین مسیر قوی جفت کرد. این تکنیکها، در میان بسیاری دیگر، همراه با مدلسازی ژئودتیکی فرآیند اندازهگیری و همچنین فیلتر کردن اندازهگیریها از چندین حسگر، مجموعه دادههایی با پیچیدگی بالا (دادههای سری زمانی با ابعاد بالا در چندین حسگر) ایجاد میکنند. به عنوان مثال، با استفاده از شبکههای اشغال، نقشههایی ساخته میشوند که هم شامل ویژگیهای ثابت (مثلاً هندسه جادهها و ساختمانها) و هم اطلاعات مکانی-زمانی هستند، به عنوان مثال، در قالب نقشههای حرارتی حاوی اطلاعاتی در مورد احتمال کلاسهای خاص اشیاء پویا که در مکان های خاصی در محیط ظاهر می شوند. برای این منظور، اشیاء منفرد از طریق تقسیم بندی و طبقه بندی تصاویر و همچنین ابرهای نقطه ای شناسایی می شوند. مجموعه داده های مشتق شده که توسط تجزیه و تحلیل این پروژه های تحقیقاتی جداگانه تولید می شوند، علاوه بر داده های حسگر خام ذخیره می شوند. این امکان تحلیل های پیچیده تری را در حوزه موقعیت یابی (زمان واقعی) فراهم می کند و از دانش سطح بالاتر استفاده می کند. نمونههایی برای مجموعه دادههای مشتقشده شامل نسخههای تصحیح شده مجموعه دادهها (مثلاً ابرهای نقطهای تراز شده)، تقسیمبندیهای شی یا مدلهای خودروی سهبعدی است.
در بخش محاسباتی، کمیت و پیچیدگی داده های مورد نیاز برای مراحل تجزیه و تحلیل فردی در یک زمان زیاد است، که منجر به الزامات بالایی در مورد انتقال داده ها و محاسبات از نظر پهنای باند و توان محاسباتی می شود. بنابراین، ضروری است که مجموعه داده های (بزرگ) با سخت افزار و نرم افزار کافی پردازش شوند، بنابراین عناصر موازی سازی نیز در چارچوب گنجانده شده است.
در نهایت، هدف، امکان استفاده مجدد از نرم افزار با توسعه و ارائه عناصر نرم افزاری [ 19 ] است که برای استفاده به عنوان نوعی کیت ساخت و ساز برای یکپارچگی مشترک مناسب هستند. ماژولهای نرمافزاری توسعه خواهند یافت که میتوانند به فرآیندهای تجزیه و تحلیل مرسوم متصل شوند تا قابلیتهای خود را با امکان تعیین کمیت یکپارچگی افزایش دهند. اما این جنبه از حوصله این مقاله خارج است.
3. کارهای مرتبط
افزایش دیجیتالی شدن و توسعه و استقرار حسگرهای جدید منجر به اطلاعات بیشتر در مورد محیط ما می شود و بنابراین به طور بالقوه به بینش های بیشتری در مورد روابط متقابل ناشناخته قبلی منجر می شود. با این حال، مشکلات در مواجهه با مقادیر روزافزون داده ها، ناشی از افزایش تعداد و عملکرد حسگرها، که راه خود را در تمام زمینه های زندگی روزمره پیدا می کنند، به موضوع مهمی در تحقیقات در سال های اخیر تبدیل شده است. حجم وسیعی از مجموعه دادههای موجود برای تحقیق به طور فزایندهای به زیرساختهای فنی برای ذخیرهسازی کافی دادهها نیاز دارد تا بتوان آنها را به راحتی پیدا کرد، به آنها دسترسی پیدا کرد، ادغام کرد و تجزیه و تحلیل کرد.
برای تسهیل عملکرد بهتر انتشار داده های علمی، اصول FAIR مستقل از دامنه و سطح بالا (قابلیت یافتن، دسترسی، قابلیت همکاری، و قابلیت استفاده مجدد) پیشنهاد شد [ 1 ]. این اصول مستلزم – از جمله – این است که ویژگیهای مجموعه دادهها همراه با دادهها به روشی استاندارد شده که برای ماشین قابل درک است ذخیره شود، و خود دادهها در قالبهای دادهای قابل همکاری ذخیره شوند. برای این منظور، استانداردهایی برای حاشیه نویسی مجموعه داده ها با فراداده (“داده در مورد داده ها”) توسعه داده شد. چارچوب توصیف منابع (RDF) که توسط W3C توسعه یافته است [ 20] یک زبان مبتنی بر XML برای رمزگذاری فراداده به روشی ساختاریافته و قابل خواندن توسط ماشین است. از نظر ویژگیهای مفید، پیشنهادهایی مانند مجموعه اقلام فراداده هسته دوبلین برای افزودن جزئیات در مورد محتوا، مالکیت معنوی و نمونهسازی دادهها وجود دارد [ 21 ، 22 ]. علاوه بر این، استانداردهای دامنه خاص در جوامع مختلف تحقیقاتی ایجاد شد، به عنوان مثال [ 23 ، 24 ] برای مجموعه داده های جغرافیایی. مروری بر استانداردهای عمومی و دامنه خاص بیشتر در وب سایت اتحاد تحقیقات داده یا در وب سایت های فهرست فراداده [ 25 ، 26 ] موجود است.
کاربردهای عملی اصول FAIR در حوزههای تحقیقاتی جداگانه با تمرکز بر الزامات خاص دامنه توسعه یافته است. کاربردهای معمولی FAIR در حوزه داده های جغرافیایی ( برای یک نمای کلی به [ 27 ، 28 ] مراجعه کنید) به زیرساخت های داده های جغرافیایی (GDI، نگاه کنید به [ 29) مربوط می شود.]): رمزگذاری داده های جغرافیایی به فرمت های قابل همکاری و استفاده مجدد از ماژول های تبدیل داده های موجود (سرویس های وب) به روشی غیرمتمرکز، که به داده های جغرافیایی از منابع مختلف اجازه می دهد تا در یک چارچوب مرجع فضایی مشترک با استفاده از اطلاعات جغرافیایی معمولی یکپارچه شوند ( GIS) عملیاتی که به طور گسترده برای انواع مختلف داده های مکانی قابل استفاده است. این سرویس های وب می توانند تبدیل داده ها، یکپارچه سازی داده ها، یا وظایف تجزیه و تحلیل داده ها با پیچیدگی های مختلف و همچنین تجسم داده های جغرافیایی را پوشش دهند. سازمانهای استانداردسازی مانند کنسرسیوم فضایی باز (OGC) [ 30 ] استانداردهایی را برای قابلیت همکاری بهتر، از جمله فرمتهای داده و مشخصات رابط، ترویج میکنند. برای دادههای حسگر خام که مستقیماً از طریق وب قابل دسترسی هستند، سرویس مشاهده سنسور OGC [ 31] یک استاندارد سرویس وب است که زبانها را هم برای توصیف خود حسگر (زبان مدل سنسور [ 32 ]) و هم برای رمزگذاری اندازهگیریهای حسگر (مشاهده و اندازهگیری [ 33 ]) تعریف میکند.
با این حال، رایجترین راه برای دسترسی به دادهها در حال حاضر، انتشار مجموعههای داده در مخازن دادههای تحقیقاتی عمومی یا سازمانی است (یک مرور کلی از مخازن دادهها توسط فرامخزنهایی مانند [34] ارائه شده است)، که زیرمجموعههای مختلف دادهها و استانداردهای فراداده را پشتیبانی میکنند . . علاوه بر این، خدمات کاتالوگ داده، به عنوان مثال، [ 35 ] توسط OSGeo [ 36 ]، MIT Geodata Repository [ 37 ]، Pangea [ 38 ] و کتابخانه جغرافیایی هاروارد [ 39 ]، دسترسی مستقیم به مجموعه داده های فردی، معمولاً دامنه خاص را فراهم می کند. به اصطلاح برداشت ابرداده [ 40] برای تبدیل بین استانداردهای مختلف و ادغام تمام استانداردهای مختلف مورد استفاده توسط مخازن و محققان انتشارات استفاده می شود.
4. راه حل پیشنهادی ذخیره سازی داده – مروری بر سیستم
ذخیره سازی داده ها به روشی ساختاریافته و ایمن یکی از جنبه های اصلی مدیریت داده است. سیستم مدیریت داده پیشنهادی به گونه ای طراحی شده است که اندازه و ساختار سازمانی پروژه را منعکس کند. هدف، ذخیره و دسترسی آسان به دادههای خام و همچنین دادههای مشتقشده، علاوه بر مستندسازی دادهها در قالب ابرداده، برای طیف وسیعی از سنسورها و انواع دادهها (از جمله ابرهای نقطه LiDAR، تصاویر، و همچنین GNSS/) بود. داده های سری زمانی IMU). در مورد بازرسی داده ها، روش معمول برای پرس و جو از داده ها از طریق اطلاعات معنایی است (به عنوان مثال، “همه داده های به دست آمده با نوع خاصی از حسگر را به من بدهید”). علاوه بر این، یک راه طبیعی برای بازرسی و پرس و جو از داده های مکانی، دامنه مکانی است، به عنوان مثال، مختصات یا جعبه های مرزی (به عنوان مثال، “همه تصاویر گرفته شده در محل اتصال X را به من نشان دهید”). علاوه بر این،
در این بخش، اجزای کلیدی سیستم ذخیره سازی داده ها توضیح داده شده است. همانطور که در پروژه RTG آزمایشها یک عنصر مرکزی را تشکیل میدهند، ذخیره دادهها در امتداد آزمایشهای انجامشده سازماندهی میشوند که ساختار منطقی آن را میدهد. یک عنصر اصلی یک رابط بصری است که امکان تجسم و بازرسی آسان داده های موجود را فراهم می کند.
مجموعه داده ها به طور مداوم در یک سرور فایل مرکزی ذخیره می شوند (به بخش 4.1 مراجعه کنید ). داده ها به روشی سلسله مراتبی ذخیره می شوند که ساختار آزمایشات در مقیاس بزرگ را منعکس می کند (به بخش 4.2 مراجعه کنید ). یک فایل فراداده منفرد به هر پوشه مجموعه داده اضافه می شود (به بخش 4.3 مراجعه کنید)، که در آن یک مجموعه داده مربوط به مجموعه واحد اندازه گیری مداوم یک حسگر منفرد است (یعنی از ابتدا تا انتهای ضبط). از آنجایی که این ساختار از جستجوی ساختاریافته با معیارهای سفارشی پشتیبانی نمی کند، یک خزنده داده کاملاً خودکار (به بخش 4.4 مراجعه کنید.) برای مرور ساختار فعلی پوشه های داده استفاده می شود و همه مجموعه داده ها را با ابرداده های زمانی، مکانی و دیگر آنها در یک پایگاه داده مکانی نشان می دهد. به این ترتیب، می توان به جدایی بین نمای منطقی داده ها (که به صورت آرایه داده نشان داده می شود) و ذخیره سازی فیزیکی (سلسله مراتبی) دست یافت.
علاوه بر دسترسی مستقیم به فایل های داده های تحقیق، سرور فایل به عنوان میزبان یک رابط وب گرافیکی عمل می کند (به بخش 4.5 مراجعه کنید) که به اعضای پروژه اجازه می دهد به صورت بصری همه مجموعه داده ها را در یک نقشه وب پویا و تعاملی بررسی و مقایسه کنند و از داده ها پشتیبانی کند. پرس و جو در پایگاه داده فراداده مکانی به منظور اجرای محاسبات پرهزینه محاسباتی، RTG یک خوشه Hadoop (چارچوب موازی سازی داده های بزرگ برای مجموعه داده های ساخت یافته بزرگ، نگاه کنید به [ 41 ]) متشکل از شش گره و همچنین یک سرور GPU با هشت GPU، که عمدتاً برای پشتیبانی از آموزش استفاده می شود، اجرا می کند. شبکه ها در زمینه یادگیری عمیق (به بخش 4.6 مراجعه کنید ). شکل 3یک نمای کلی از اجزای سیستم و فعالیت های مرتبط برای تمام مراحل مدیریت داده های تحقیقاتی در RTG ارائه می دهد.
4.1. زیرساخت فناوری اطلاعات
RTG یک سرور فایل مرکزی را با همکاری (مسکن سرور و خدمات مدیریت شبکه) با بخش خدمات فناوری اطلاعات دانشگاه لایبنیتز (LUIS) اجرا می کند. داده ها به صورت فیزیکی بر روی هارد دیسک ها در یک گروه RAID-6 ذخیره می شوند که در حال حاضر ظرفیت خالص کل آن حدود 60 ترابایت است.
سرور فایل به عنوان یک نقطه دسترسی برای چندین سرویس در سطح پروژه عمل می کند: اشتراک فایل برای فراهم کردن دسترسی به تمام مجموعه داده ها برای همه اعضای RTG در سیستم عامل های مختلف کلاینت (عمدتا مبتنی بر Win/Linux) تنظیم شده است. پوشههای خانگی فردی و پوشههای اشتراکگذاری شده برای واحدهای سازمانی به همین ترتیب تحقق مییابند که از نظر مالکیت و حقوق دسترسی برای کاربران و گروههای کاربری مختلف متفاوت است.
سرورهای محاسباتی (خوشه Hadoop و سرور GPU) به طور فیزیکی در کنار سرور فایل قرار دارند. همه سرورها در یک LAN داخلی 10 گیگابیتی (با استفاده از تجمع لینک برای دستیابی به پهنای باند تا 20 گیگابیت) برای پشتیبانی از انتقال سریع فایل بین سرور فایل و سایر گرههای خوشه متصل هستند، در حالی که ارتباط با این خوشه از خارج به 1 محدود است. Gbit (به دلایل زیرساختی). سرور فایل به عنوان دروازه ای برای دسترسی به خوشه های محاسباتی (که در غیر این صورت مستقیماً قابل دسترسی نیستند) برای آپلود و اجرای کد برنامه و همچنین دسترسی به نتایج محاسبات در آن ماشین ها عمل می کند.
مجوز برای همه سرویس ها از طریق یک اکتیو دایرکتوری (AD) مدیریت می شود که در آن کاربران و نقش هایی با حقوق دسترسی متفاوت مدیریت می شوند. تلاشهای ورود به هر یک از رابطهای سرور (کنسول Hadoop Gateway، رابط وب، اشتراکگذاری فایل Samba) به سرور AD تفویض شده و پردازش میشوند. علاوه بر این، قوانین فایروال تنظیم شده اند تا فقط اتصالات از محدوده IP خاص مربوط به واحدهای سازمانی در پروژه را مجاز کنند، که محدود به مجموعه خاصی از پورت های مربوط به خدمات پشتیبانی شده است. ارتباطات در همه موارد به پروتکل های امن/رمزگذاری شده محدود می شود، یعنی SSL/TLS، SSH، HTTPS و LDAPS.
4.2. ذخیره سازی داده های فیزیکی
در سطح سیستم فایل، هر مجموعه داده شامل یک یا چند فایل است که در برخی موارد با ساختار پوشه داخلی، بسته به نوع حسگر و فرمت داده، تشکیل شده است. هر مجموعه داده در یک پوشه جداگانه همراه با فایل فراداده ذخیره می شود (به بخش 4.3 مراجعه کنید ). دانه بندی یک مجموعه داده بسته به ساختار آزمایش مربوطه انتخاب می شود به طوری که تجزیه بیشتر داده ها با توجه به اهداف آزمایش امکان پذیر نیست. برای مثال، یک درایو منفرد با نقاط شروع و پایان مشخص ممکن است یک آزمایش را تشکیل دهد. تمام مجموعههای داده جمعآوریشده در این راه نیز بهعنوان بخشهای جداگانه مربوط به آن درایو وجود خواهند داشت.
در اطراف آن پوشههای مجموعه داده در پایین سلسلهمراتب پوشه، ساختار پوشهای ایجاد شد که برای مرور دستی توسط محققان مناسب است، که عمدتاً توسط ساختار سازمانی آزمایش هدایت میشود. در حال حاضر، بالاترین سطح پوشه مربوط به کمپینهای اندازهگیری مختلف است، سطح بعدی پلتفرمها/وسایل نقلیه موبایل را جدا میکند، سطح سوم حسگرها را جدا میکند و غیره. در سطوح پایین، نمایشهای مختلفی از دادهها ذخیره میشوند، از جمله دادههای خام اصلی (که همیشه برای جلوگیری از از دست رفتن دادهها در طول مراحل تبدیل نگهداری میشوند) و فرمتهای قابل همکاری تبدیل شده برای اهداف مختلف (به بخش 5.1 مراجعه کنید ) .
از طریق استفاده از خزنده ابرداده (به بخش 4.4 مراجعه کنید)، سازماندهی مجدد ساختار پوشه در هر زمان بدون تأثیر بر جستجوی خودکار امکان پذیر است، تا زمانی که پوشه های مجموعه داده در سطح پایین سلسله مراتب پوشه دست نخورده نگه داشته شوند.
4.3. فراداده
اصطلاح فراداده به اطلاعات مربوط به مجموعه داده ها اشاره دارد. این شامل اطلاعاتی می شود که به هیچ وجه نمی توان از داده ها استنباط کرد، به عنوان مثال، اطلاعاتی که باید به طور صریح با مجموعه داده در زمان ذخیره داده مرتبط شوند. علاوه بر این، ابرداده همچنین می تواند برای ذخیره اطلاعاتی که به طور ضمنی در داده ها موجود است و می تواند با مقداری تلاش بازیابی شود، به عنوان مثال برای ایجاد اطلاعات صریح که در غیر این صورت نیاز به محاسبات پرهزینه برای دسترسی دارد، استفاده شود [42 ] . برای مجموعه داده های ما، زیرمجموعه ای از ویژگی های Dublin Core [ 21] علاوه بر برخی فرادادههای خاص دامنه سفارشی که روابط بین دادهها و تنظیمات آزمایشی را منعکس میکنند، به کار گرفته شد. این شامل ویژگیهای اسمی و طبقهای مانند مالکیت/تألیف مجموعههای داده (معادل سازنده/ناشر در Dublin Core) و همچنین جزئیات کدگذاری/فرمت فایل (قالب) میشود. یک فیلد متنی عمومی (توضیح) برای ذخیره توضیحات متنی برای کاربران آینده، حاوی جزئیاتی در مورد زمینه آزمایش یا فرآیند کالیبراسیون استفاده میشود.
علاوه بر این، فیلدهای فراداده مخصوص دامنه برای ذخیره ارتباط بین آزمایشها و پلتفرمهای حسگر یا اطلاعات مربوط به انواع حسگر و شناسههای دستگاه حسگر اضافه شدند. دو فیلد فراداده برای نشان دادن اطلاعات مکانی و زمانی مشتق شده به عنوان مبنایی برای نمایه سازی مکانی-زمانی مجموعه داده ها، با الهام از تاریخ و زمینه های فراداده پوشش هسته دوبلین استفاده می شود. بازه زمانی که مجموعه داده در آن به دست آمده است (با استفاده از مُهرهای زمانی GPS با دقت بالا و همگامسازی شده در سراسر آزمایش) به صراحت ذخیره میشود و اجازه فیلتر کردن موقت مجموعههای داده را میدهد. برای برخی از حسگرها، این مهرهای زمانی به صراحت در دادهها ذخیره میشوند، که یک بار از آنها بازیابی میشوند و سپس به عنوان بخشی از ابرداده ذخیره میشوند. برای حسگرهایی که به صراحت مُهرهای زمانی را ذخیره نمیکنند، فاصله زمانی سنسورهای دیگر در همان پلتفرم که به طور همزمان (در حین ثبت داده ها) ضبط می کردند، استفاده شد. همین اصل برای مکان مشاهدات حسگر اعمال شد: اطلاعات محلیسازی از سیستمهای GNSS/IMU موجود در تمام پلتفرمهای حسگر منتقل شد و با مجموعه دادههای ثبتشده در همان پلت فرم همراه شد، دوباره برای پشتیبانی از فیلتر/جستجوی مجموعههای داده با معیارهای مکانی. برای این منظور، حداقل مستطیلهای مرزی مسیرهای GNNS با هر یک از مجموعه دادهها ذخیره میشوند، زیرا وضوح فضایی دقیقتر (از طریق ارتباط زمانی مشاهدات حسگر با موقعیتهای فردی GNSS) به تجزیه بیشتر مجموعه دادهها به مشاهدات فردی نیاز دارد. هر دوی این فیلدها فقط حاوی مقادیر تقریبی برای پشتیبانی از فیلتر فضایی-زمانی هستند.
در فرآیند ایجاد ساختار پوشه پس از آزمایش، یک الگو برای فایل فراداده، حاوی تمام فیلدهای فراداده اجباری، به هر پوشه مجموعه داده اضافه می شود. این الگو شامل نظراتی است که معنایی و مقادیر مجاز (در صورت لزوم) را برای هر فیلد ابرداده تعریف می کند. سپس این فایل فراداده توسط محققان مسئول هر مجموعه داده پر می شود. بررسی خودکار اعتبار XML (به عنوان مثال، در برابر یک دستور زبان از پیش تعریف شده) هنوز انجام نشده است، اما مطمئناً یک ویژگی است که در آینده باید در نظر گرفته شود.
4.4. پایگاه داده های مکانی
به منظور امکان ذخیره سازی مقیاس پذیر و دسترسی چند کاربره، داده ها به طور خودکار به یک پایگاه داده فضایی وارد می شوند (به طور خاص [ 43]])، که در آن تمام ابرداده های مجموعه داده ها مستقیماً برای پرس و جوهای پیچیده قابل دسترسی هستند. از یک اسکریپت استفاده می کند که به صورت بازگشتی ساختار پوشه کامل را طی می کند و به طور خاص به دنبال وجود یک فایل فراداده است که مجموعه داده ها را نشان می دهد. بر اساس محتویات فایل فراداده، اسکریپت ورودی های پایگاه داده را برای هر مجموعه داده، از جمله مکان ذخیره سازی فعلی هر مجموعه داده در سرور فایل ایجاد می کند. در این فرآیند، خطاهای نحوی در فایل های ابرداده قابل شناسایی است. در طول وارد کردن پایگاه داده، مجموعه دادهها بیشتر تجزیه نمیشوند (مثلاً به اندازهگیریهای فردی)، زیرا این امر باعث ایجاد تعدادی چالش اضافی میشود: مشاهدات به فرآیندهای اندازهگیری خاص مرتبط میشوند، خطاهای اندازهگیری و وابستگیهای متقابل بین حسگرهای متعدد در طول یک آزمایش را معرفی میکنند.
پایگاه داده به پرس و جوهای SQL در مورد خصوصیات داده دلخواه و روابط آنها (به عنوان مثال، پرس و جوهای فضایی) و پرس و جوهای زمانی ساده و همچنین پرس و جوهای مربوط به همه فراداده های اسمی و طبقه ای که در فایل های XML فراداده گنجانده شده اند اجازه می دهد. این رابط جستجو از موارد استفاده مانند بازیابی همه مجموعه دادههای جمعآوریشده در یک زمان خاص (مثلاً در همان آزمایش)، دادههای مشاهده شده در یک مکان (در چندین آزمایش)، یا مجموعه دادههای تولید شده توسط حسگر یکسان (مستقل از زمان و مکان) پشتیبانی میکند. )، شبیه به عملیات تعریف شده در یک مکعب داده [ 14 ].
4.5. رابط وب و WebGIS
سرور فایل میزبان وب سایتی است که امکان بازرسی بصری داده ها را فراهم می کند و قابلیت های فیلتر و تجسم را به کاربران ارائه می دهد. عنصر مرکزی این رابط وب یک نقشه وب است که تجسم های از پیش پردازش شده را برای همه مجموعه داده های فضایی در بالای یک نقشه کلی (مثلاً از OSM یا آژانس های نقشه برداری) نمایش می دهد، که امکان بازرسی، انتخاب و مقایسه داده های احتمالاً مرتبط را فراهم می کند. علاوه بر افزودن صریح لایههای مربوط به مجموعه دادههای خاص به نقشه، مجموعه دادهها را میتوان با افزودن عبارات فیلتر SQL به یک فیلد متنی، از نظر مکانی-زمانی یا معنایی، فیلتر کرد.
بسته به نوع داده های موجود، پیش نمایش مجموعه داده ها به صورت کاشی های شطرنجی و/یا به صورت داده های برداری در دسترس هستند. آنها را می توان به سرعت پردازش و تجسم کرد و حاوی تمام اطلاعات لازم برای انتخاب و تجسم داده ها است ( شکل 4 را ببینید). برای داده های متراکم و توزیع شده به صورت فضایی مانند ابرهای نقطه ای، نمایش های شطرنجی دوبعدی (پیش بینی ها به صفحه xy) با چندین LOD/رزولوشن پیش پردازش می شوند تا از سطوح مختلف زوم نقشه وب پشتیبانی کنند (یعنی سطوح بالاتری از جزئیات در هنگام بزرگنمایی بیشتر آشکار می شوند. بدون اینکه در سطوح زوم کم با کاشیهای بزرگ تا با وضوح بالا دچار مشکل شوید). اسکریپتهایی برای تولید یک هرم تصویر کامل از کاشیها برای سطوح زوم چندگانه در دسترس هستند، که میتوانند ویژگیهای رندر را سفارشی کنند، به عنوان مثال، نگاشت دادهها به رنگهای پیکسل بسته به ویژگیهای داده دلخواه، بسته به تحلیل مورد نیاز (نگاه کنید به شکل 5 ) . به این ترتیب، هر مجموعه داده ممکن است با تجسم های متعدد و متفاوت مرتبط باشد.
برای جلوگیری از اختلاط داده ها و داده های پیش نمایش، فایل های پیش نمایش (به عنوان مثال، مجموعه های کاشی یا فایل های داده برداری) در یک پوشه جداگانه به عنوان بخشی از فایل های رابط وب قرار می گیرند. این پوشه ساختار پوشه داده های اصلی را برای حفظ رابطه با مجموعه داده های مربوطه منعکس می کند. همچنین میتوان پیشنمایشها را بهصورت توزیعشده بهطور مستقیم در خوشه Hadoop با استفاده از نسخه موازیشده اسکریپت تجسم تولید کرد. فایل های پیش نمایش حاصل را می توان مستقیماً از سیستم فایل توزیع شده Hadoop (HDFS) از خوشه Hadoop با استفاده از WebHDFS REST-API به نقشه وب وارد کرد.
علاوه بر تجسم دادهها، رابط وب همچنین امکان بازرسی مجموعه دادههای کامل را از طریق مرورگر فراهم میکند: پوشههای ذخیرهسازی دادهها را میتوان به صورت دستی جستجو کرد و مجموعههای داده را میتوان بازرسی کرد (اگر انواع دادهها مستقیماً توسط مرورگر پشتیبانی میشوند، به عنوان مثال، دادههای تصویر) و با استفاده از پروتکل https دانلود شد. برای راحتی، یک رابط برای مرور محتویات سیستم فایل کلاستر Hadoop (HDFS) نیز وجود دارد. برای ابرهای نقطه، یک نمایشگر ابر نقطه مبتنی بر WebGL یکپارچه شد. علاوه بر این، رابطهایی را برای پایگاه داده ابرداده فراهم میکند تا محتویات پایگاه داده ابرداده را بررسی کرده و پرسوجوهای SQL را روی آن اجرا کند.
4.6. خوشه Hadoop/GPU Cluster
به منظور ارائه ظرفیت محاسباتی برای وظایف محاسباتی کلان داده، یک سرور GPU منفرد شامل هشت پردازنده گرافیکی و یک خوشه Hadoop متشکل از شش سرور (گره)، به صورت فیزیکی درست در کنار سرور فایل میزبانی می شود تا امکان اتصال داده با پهنای باند بالا را فراهم کند. انتقال سریع داده ها سرور فایل به عنوان دروازه ای برای آپلود و اجرای کارها عمل می کند.
خوشه Hadoop آخرین نسخه توزیع Cloudera از جمله Apache Hadoop (CDH [ 41) را اجرا می کند])، با نصب خدمات توزیع شده مرتبط با اکوسیستم هادوپ، از جمله HDFS/YARN، Spark/Spark2، HBase/Hive/Zookeeper. سرور فایل طوری پیکربندی شده است که یک گره لبه از خوشه باشد که به عنوان دروازه برای همه سرویس های پشتیبانی شده (HDFS/YARN/Spark و غیره) پیکربندی شده است، به طوری که داده ها را می توان مستقیماً از سرور فایل به سیستم فایل توزیع شده Hadoop (HDFS) آپلود کرد. ) از خوشه، به عنوان مثال، برای توزیع و اجرای برنامه های کاربردی. به این ترتیب، این رابط های مبتنی بر کنسول از کنسول فایل سرور در دسترس هستند. علاوه بر این، کاربران برای نظارت بر وضعیت خوشه، تخصیص منابع و پیشرفت برنامه، دسترسی فقط خواندنی به رابط مدیریت گرافیکی Cloudera Manager در گره اصلی Hadoop خوشه دارند.
در مورد خوشه GPU، سرور فایل یک ماشین مجازی جداگانه میزبان DC/OS [ 44 ] را اجرا می کند، یک سیستم عملیاتی توزیع شده بر اساس هسته سیستم های توزیع شده Apache Mesos. منابع خوشه GPU را در یک رابط گرافیکی واحد مدیریت می کند و امکان استقرار برنامه های کاربردی توزیع شده، از جمله تخصیص/مدیریت منابع برای چندین کاربر همزمان را فراهم می کند. این رابط گرافیکی برای کاربران کلاستر تحت یک IP و URL جداگانه در یک مرورگر در دسترس است. نتایج محاسبات از هر دو خوشه بلافاصله قابل دسترسی است: خوشه GPU نتایج را مستقیماً به سرور فایل باز می نویسد، در حالی که خوشه Hadoop نتایج را در HDFS ذخیره می کند، که می تواند مانند یک سیستم فایل معمولی از کنسول فایل سرور قابل دسترسی باشد.
5. مدیریت داده ها
این بخش فرآیندهای توسعهیافته برای آمادهسازی دادههای آزمایشی برای ذخیرهسازی دادهها در بخش 5.1 ، به دنبال نمونههایی برای این مراحل پیشپردازش در بخش 5.2 و مثالهایی برای مزایایی که سیستم در هنگام کار با دادههای ذخیرهشده در بخش 5.3 ارائه میدهد، توضیح میدهد .
5.1. آماده سازی و پس پردازش داده ها
در زمینه ذخیرهسازی دادههای فیزیکی، فرآیندهایی برای حفظ سازگاری و یکپارچگی در داخل و در بین تمام مجموعههای داده ایجاد شد. به عنوان حفاظتی در برابر خطاها در هر فرآیند پس از پردازش یا تبدیل، همه مجموعه دادهها به صورت اضافی در قالب اصلی خود ذخیره میشوند. با این حال، بسته به حسگر و فرمتهای دادههای موجود، این ممکن است منجر به فرمتهای داده اختصاصی شود که فقط با استفاده از نرمافزار یا سختافزار خاص حسگر قابل دسترسی هستند و در یک پروژه مقیاس بزرگ در واحدهای تحقیقاتی سازمانی غیرعملی میشوند. علاوه بر این، سیستم های مرجع فضایی داخلی و/یا نمایش اندازه گیری های زمانی ممکن است در حسگرها متفاوت باشد.
بنابراین، تمام مجموعه دادهها به قالبهای باز قابل تعامل با سیستمهای مرجع فضایی یکپارچه (به ویژه ETRS89/UTM منطقه 32N، زیرا این فرمت خروجی سیستمهای حسگر چندگانه مورد استفاده در آزمایشهای ما است) و نمایش زمان (زمان Unix، از زمان ثبت دادهها و زمان) تبدیل میشوند. همگام سازی در آزمایش های ما از سیستم عامل روبات استفاده می کند (ROS [ 45]) در ماشینهای لینوکس) که هم قابلیت همکاری و هم سازگاری اندازهگیریهای مکانی/زمانی بین همه مجموعههای داده را ممکن میسازد. به طور خاص، توالی های تصویر استریو به عنوان دنباله های جداگانه ای از تصاویر PNG برای هر دوربین، با یک جدول ASCII جداگانه شامل نقشه برداری بین شناسه های تصویر و مُهرهای زمانی ذخیره می شوند. فرمت ASCII PLY برای داده های ابر نقطه ای، فرمت RINEX برای داده های GNSS استفاده می شود، اکثر انواع دیگر خروجی حسگر در قالب CSV ذخیره می شوند. تبدیل به آن فرمت ها توسط اسکریپت های توسعه یافته برای هر نوع فرمت خروجی حسگر خام انجام می شود.
پس از تبدیل موفقیت آمیز داده ها، ابرداده ها جمع آوری و/یا محاسبه می شوند و به صورت دستی به سند ابرداده اضافه می شوند (یکی برای هر نسخه از هر مجموعه داده). سپس سند فراداده در پوشه مجموعه داده قرار می گیرد (به بخش 4.3 مراجعه کنید ). ساختار پوشه برای آزمایش به صورت دستی و به دنبال یک ترتیب ثابت از تقسیم بندی ساخته شده است (به بخش 4.2 مراجعه کنید.) سپس تمام پوشه های مجموعه داده در سطح پایین این سلسله مراتب پوشه قرار می گیرند. سطح بالای سلسلهمراتب پوشه برای آزمایش حاوی اسناد مربوط به آزمایش، اسناد برنامهریزی و جزئیات مربوط به سکوهای حسگر (شامل اطلاعات کالیبراسیون: حسگر به حسگر و حسگر به وسیله نقلیه) است. دادههای کالیبراسیون برای حسگرهای جداگانه در پوشههای حسگر مربوطه قرار میگیرند (برخی سطوح بالاتر از سطح مجموعه دادههای فردی).
هنگامی که ساختار پوشه ایجاد شد و تمام فایل های فراداده کامل شد، یک اسکریپت خزنده اجرا می شود که وضعیت فعلی سلسله مراتب پوشه سرور فایل را به پایگاه داده ابرداده منتقل می کند (به بخش 4.4 مراجعه کنید ). پایگاه داده مکان های ذخیره سازی فعلی مجموعه داده های فردی را با ابرداده مربوطه مرتبط می کند، و امکان جستجوی سرور برای مجموعه داده های ثبت شده توسط کلمات کلیدی و مقادیر فیلدهای فراداده را فراهم می کند.
به عنوان آخرین مرحله از آمادهسازی دادهها، نسخههای پیشنمایش برای هر مجموعه داده (به عنوان مثال، کاشیهای شطرنجی برای استفاده بهعنوان پوشش روی نقشه وب یا یک نمایش برداری نمونهبرداری شده پایین) با استفاده از اسکریپتهای سنسور نوع خاص که قبلاً توضیح داده شد، تولید میشوند. فایلهای پیشنمایش در پوشهای قرار میگیرند که توسط رابط وب قابل دسترسی است و از آنجا به طور خودکار در نقشه وب ادغام میشوند (به بخش 4.5 مراجعه کنید ).
5.2. نمونه بلع داده ها
در بخش بعدی، مفاهیم عملی مراحل بخش 5.1 با نگاهی دقیقتر به دادههای تولید شده توسط پیکربندی چند سنسوری یک خودروی مورد استفاده در یکی از آزمایشهای ما نشان داده میشوند و برخی از چالشهای پیشرو در این فرآیند را برجسته میکنند. جزئیات فنی بی ربط در زمینه فرآیند حذف شده است.
این خودرو مجهز به سیستم نقشه برداری موبایل RIEGL VMX-250 (MMS)، شامل دو اسکنر لیزری دوبعدی RIEGL VQ-250، چهار دوربین (مورد استفاده برای رنگ آمیزی ابرهای نقطه ای)، یک GNSS/IMU و یک کامپیوتر با نرم افزار اختصاصی است. اندازه گیری از این سنسورها خروجی سنسور یک پوشه پروژه پیچیده با استفاده از فرمتهای فایل اختصاصی است که به نرمافزار اختصاصی برای استخراج خروجیهای حسگر مختلف، از جمله راهحلهایی برای مسیر GNSS و ابرهای نقطه (رنگی)، چه در مختصات حسگر یا در مختصات جهانی، نیاز دارد. علاوه بر این، یک جفت دوربین استریو به جلوی سقف خودرو و یک سیستم GNSS/IMU جداگانه متصل شده است، زیرا متأسفانه MMS به دادههای خام GNSS دسترسی نمیدهد. داده های دوربین استریو و سیستم GNSS/IMU با استفاده از گره های ROS در یک سیستم لینوکس ثبت می شوند. در این فرآیند، مهرهای زمانی GPS از حسگر GNSS با تصاویر استریو مرتبط است. MMS با استفاده از مهرهای زمانی GPS نیز به رایانه دیگری وارد می شود. با این حال، هر دو سیستم GNSS از سیستم های مرجع فضایی متفاوتی استفاده می کنند.
سنسورهای مختلف روی خودرو فرمتهای داده خام زیر را تولید میکنند: یک پوشه بزرگ با ساختار داخلی پیچیده برای دادههای MMS و به اصطلاح کیسههای ROS ثبتشده توسط ROS، که حاوی پیامهای مهر زمانی (سازماندهی شده در موضوعات به اصطلاح ROS) از ضبط کردن این گزارش های خام (یا اولین) داده ها در سرور فایل ذخیره می شوند. از آنجایی که این فرمتها مستقیماً توسط همه محققین قابل استفاده نیستند، به فرمتهای قابل همکاری تبدیل میشوند (فرمتهای استاندارد باینری بدون ضرر برای دادههای تصویر و قالبهای متنی ASCII به خوبی تعریف شده برای دادههای GNSS و LiDAR). برای پروژه های MMS، از نرم افزار MMS اختصاصی برای استخراج داده های مورد نیاز استفاده می شود (به عنوان مثال، یک نمایش ASCII از مسیر GNSS و ابر نقطه رنگی و با وضوح کامل در مختصات جهانی). برای کیسه های ROS،
علاوه بر این، یک مرحله پس پردازش برای همه نسخههای صادر شده دادهها انجام میشود، که طی آن مُهرهای زمانی و مختصات مکانی همه دادههای حسگر به نمایشهای رایج تبدیل میشوند، با استفاده از اسکریپتهای فرمت خاص برای خودکارسازی تبدیل. این بعداً به محققان ما اجازه میدهد تا با مجموعه دادههای آمادهشده بدون نیاز به پرداختن به تغییرات مختصات و مهر زمان کار کنند. وجود مُهرهای زمانی یکپارچه و سیستمهای مرجع مختصات مکانی، صادرات خودکار دادهها را به فرمتهای دیگر به راحتی ممکن میسازد.
برای هر مجموعه داده، از جمله نسخهها یا قالبهای مختلف همان مجموعه داده، یک فایل XML فراداده به عنوان کپی یک الگوی از پیش تعریفشده XML ایجاد میشود. این شامل زمینههای فرادادهای است که در زمینه تحقیق ما مفید هستند، از جمله سنسور نوع، سنسور نام، فرمت داده، شناسه سنسور، شناسه تجربی، شناسه سنسور، محدوده زمانی، مرزهای فضایی، مالک و همچنین یک قسمت توصیف متن آزاد برای جزئیات/نظرات بدون ساختار بیشتر. برخی از این فیلدها برای عملکردهای خاصی مورد نیاز هستند. به عنوان مثال، این فیلدها در پایگاه داده ابرداده قرار دارند و بنابراین در پرس و جوهای SQL روی ابرداده موجود هستند. هنگام پر کردن ابرداده می توان فیلدهای اضافی دلخواه را تعریف کرد. با این حال، اینها توسط هیچ فرآیند خودکاری استفاده نمی شوند. فایل های فراداده توسط “صاحبان” حسگرهای مربوطه ویرایش می شوند، به عنوان مثال، در بیشتر موارد، محققانی که سخت افزار و نرم افزار حسگر را به پلت فرم حسگر کمک کردند. برای کاهش خطر خطاهای ورودی، لیست های از پیش تعریف شده مقادیر مورد انتظار در قالب XML فراداده برای برخی از فیلدهای فراداده تعریف شده است، به عنوان مثال، قسمت فوق داده sensorType ممکن است فقط دارای مقادیری مانند STEREO_CAMERA، LASER_SCANNER، GNSS و غیره باشد. اسکریپت ها به محاسبه فاصله زمانی و مرزهای مکانی برای همه مجموعه داده ها کمک می کنند، زیرا این مقادیر بخشی جدایی ناپذیر از فراداده هستند، زیرا از پرس و جوهای زمانی- مکانی (تقریبی) در پایگاه داده فراداده پشتیبانی می کنند. برای سنسورهای بدون قابلیت محلی سازی خود (به عنوان مثال، دوربین های استریو)، از مرزهای مکانی داده های یکی از حسگرهای GNSS در همان پلت فرم حسگر استفاده می شود. البته در میان فایل های ابرداده مقداری افزونگی وجود دارد،
هنگامی که تمام مجموعه داده ها به فرمت های نهایی خود تبدیل شدند، یک ساختار پوشه در سرور ایجاد می شود که از جستجوی دستی پشتیبانی می کند. برای این منظور، روابط بین مجموعههای داده حاصل از طراحی آزمایش در سلسله مراتب پوشه منعکس میشود که ساختاری به شرح زیر دارد:
EXPERIMENT_ID > SENSOR_PLATFORM_ID > SENSOR_TYPE > SENSOR_ID > DATA_FORMAT > مجموعه داده ها
برای پلت فرم حسگر خاص از مثال، این منجر به ساختار پوشه نشان داده شده در جدول 1 می شود .
نام پوشه های پررنگ، ساختار پوشه ها را بر اساس دسته ها مشخص می کند. نام پوشههای کج، پوشههای سطح پایینی هستند که شامل مجموعه دادههای واقعی و همچنین فایلهای فراداده فردی هستند. نام پوشه های خط دار دارای داده های کالیبراسیون مورد نیاز برای یکپارچه سازی و تفسیر مجموعه داده های مربوطه هستند. برخی از نامهای پررنگ پوشهها ویژگیهای فراداده را منعکس میکنند و ویژگیهای داده صریح را در سطح سیستم فایل برای پشتیبانی از فرآیندهای جستجوی دستی ایجاد میکنند. نام پوشه ها به صورت دستی اختصاص داده می شوند و نه به شدت اجرا می شوند و نه توسط فرآیندهای جستجوی خودکار استفاده می شوند. در واقع، از آنجایی که فایلهای فراداده بخشی از پوشه مجموعه داده مربوطه هستند، پوشههای بالا در سلسله مراتب را میتوان بدون ایجاد مانع در قابلیتهای جستجوی خودکار، خودسرانه ساختار مجدد داد.
در این مرحله، یک اسکریپت خزنده به صورت دستی اجرا می شود که سلسله مراتب پوشه سرور فایل را طی می کند. هر زمان که با یک فایل XML فراداده مواجه می شوید، محتویات آن (مقادیر فیلدهای از پیش تعریف شده) و همچنین مکان آن (که همیشه یک پوشه مجموعه داده است) در پایگاه داده فضایی ذخیره می شود. برای داده های مثال، پایگاه داده اکنون شامل هفت ورودی است: یکی برای کیسه های ROS خام، یکی برای داده های خام MMS، دو صادرات MMS، مجموعه داده های دوربین استریو و دو مجموعه داده GNSS.
به عنوان آخرین مرحله پس از ذخیره داده ها، نسخه های پیش نمایش برای هر مجموعه داده آماده می شود که می تواند در نقشه وب رابط وب نمایش داده شود. اگر یک مجموعه داده در قالب های متعدد موجود باشد، تنها یک پیش نمایش تولید می شود. برای ابرهای نقطه، تصاویر شطرنجی (کاشیها) با رندر کد با وضوح و تجسم قابل تنظیم ایجاد میشوند. این کاشیها بعداً مستقیماً در بالای نقشه اصلی نقشه وب نمایش داده میشوند ( شکل 4 را ببینید ). برای مسیرهای MMS و GNSS، نمایش های برداری مناسب تر هستند. برای این منظور، نسخههای زیر نمونهای از مسیرهای اصلی تولید میشوند که بعداً به صورت چند خط در بالای نقشه وب نمایش داده میشوند ( شکل 5 را ببینید.، درست). در حال حاضر هیچ عملکرد پیش نمایشی برای تصاویر دوربین استریو وجود ندارد. فایلهای پیشنمایش در یک ساختار پوشه جداگانه نگهداری میشوند و ساختار پوشه داده را منعکس میکنند تا از مخلوط کردن دادهها و نمایش آنها جلوگیری شود، در حالی که رابطه بین دادههای اصلی و دادههای پیشنمایش را واضح میسازد.
5.3. نمونه های استفاده از داده
این بخش به طور خلاصه وظایف یکپارچه سازی داده های واقعی را که از مجموعه داده های متعدد از یک آزمایش واحد با استفاده از تنظیم حسگر شرح داده شده در بخش 4.2 استفاده می کند، توضیح می دهد، و نشان می دهد که چگونه سیستم مدیریت داده از آماده سازی و اجرای مراحل لازم پشتیبانی می کند.
مثال 1:
فرض کنید یک محقق می خواهد علائم راهنمایی و رانندگی را در یک ابر نقطه ای در اطراف یک تقاطع تشخیص دهد. این را می توان به سادگی با بررسی رنگ نقاط سه بعدی و اعمال یک تقسیم بندی معنایی حل کرد. از آنجایی که ابرهای نقطه حاوی مقادیر رنگی نیستند، رنگ نقاط سه بعدی باید ابتدا از داده های تصویر بدست آید که در سیستم نیز موجود است. نمایش نقاط LiDAR سه بعدی به تصاویر دوبعدی برای بازیابی مقادیر رنگی صحیح، مستلزم یک سری تغییرات بین چندین سیستم مختصات سراسری یا حسگر محور بر اساس ابر نقطه LiDAR در مختصات مطلق، پارامترهای ذاتی دوربین (از کالیبراسیون دوربین)، وضعیت مطلق پلت فرم حسگر از سیستم GNSS-IMU و همچنین تبدیل (استاتیک) بین سیستم مختصات GNSS و سیستم مختصات دوربین (از کالیبراسیون حسگر به سنسور). نتیجه این دگرگونی مجموعه ای از مختصات تصویر دو بعدی مربوط به نقاط سه بعدی اندازه گیری شده توسط حسگر LiDAR است که می توان مقادیر رنگ را از آن بازیابی و به نقاط سه بعدی اختصاص داد.
سیستم مدیریت داده ها کار را به طرق مختلف پشتیبانی می کند. رابط کاوش داده ها با استفاده از پایگاه داده ابرداده و/یا نقشه وب به محقق ابزاری می دهد تا داده ها را از قبل بررسی کند. با استفاده از رابط بصری، محقق می تواند بررسی کند که کدام داده های LiDAR و کدام داده های تصویری در آن اتصال وجود دارد. علاوه بر این، مجموعه دادههای موجود در سرور فایل را میتوان برای دادههای مربوط به ماشین، آزمایش و حسگرهای خاص با استفاده از پرسوجوهای SQL فیلتر کرد. علاوه بر این، محدودیت های مکانی و زمانی را می توان برای محدود کردن جستجو اضافه کرد. این همچنین دسترسی مستقیم به ابرداده و مستندات آزمایش را می دهد.
بسته به گردش کار در دست، مجموعه داده های یافت شده را می توان سپس برای پردازش بیشتر در ایستگاه کاری محقق (با استفاده از اشتراک فایل Samba) یا در HDFS خوشه Hadoop (با استفاده از رابط کنسول Hadoop) دانلود کرد. در مورد دوم، کد تبدیل (ویژه Hadoop) باید در HDFS نیز آپلود شود. نتایج تبدیل را می توان با استفاده از رابط های مشابه به سرور فایل کپی کرد.
مثال 2:
مثال دیگر محققی است که می خواهد در سیستم مبتنی بر دید خود برای سایر شرکت کنندگان در ترافیک (خودروها، عابران پیاده) به عنوان “نقاط کنترل زمینی متحرک” استفاده کند. این امر مستلزم آن است که سیستم مدیریت داده دادههایی از جمله تصاویر و ژستهای دیگر خودروها و عابران پیاده را که از تجزیه و تحلیلها در زمینه موضوعات تحقیقاتی ما بهدست میآید، ارائه دهد. برای این منظور، نتایج تجزیه و تحلیل از کار تحقیقاتی فردی به عنوان مجموعه داده های مشتق شده در سرور فایل آپلود می شود. از آنجایی که همه مجموعههای داده در یک سیستم مختصات ثبت میشوند و تمام اطلاعات لازم (موقعیت، جهتگیری، کالیبراسیون دوربین) در دسترس است، این کار به ترتیب به انتخاب اشیایی که در هر تصویر قابل مشاهده هستند کاهش مییابد.
6. خلاصه و کار آینده
در این مقاله، ما پیادهسازی یک سیستم مدیریت دادههای تحقیقاتی را ارائه کردیم که دارای ذخیرهسازی ساختار یافته دادهها برای دادههای تجربی مکانی-زمانی، از جمله مدیریت ابرداده و رابطهایی برای تجسم و پردازش موازی است. ما سازماندهی ذخیره سازی و سخت افزار محاسباتی خود و همچنین ساختارها و فرآیندهای مربوط به جمع آوری، آماده سازی و ذخیره سازی داده ها را به تفصیل شرح دادیم و ارتباط داده ها را با ابرداده ها نشان دادیم که منجر به یک پایگاه داده کاملاً قابل جستجو شد. در نهایت، مثالهای عملی برای مدیریت مجموعه دادههای واقعی، یعنی مراحل آمادهسازی دادههای مورد نیاز برای ذخیرهسازی دادهها و همچنین مزایای استفاده از دادهها در زمینه وظایف علمی واقعی ارائه کردیم.
حوزه تحقیقاتی ما چالش برانگیز است، زیرا مشاهده محیطهای بسیار پویا با استفاده از پلتفرمهای حسگر پویا منجر به وابستگی متقابل بالایی بین کالیبراسیون سنسور، خود محلیسازی، اندازهگیری حسگر و هماهنگسازی زمانی بین سنسورها میشود. رسیدگی به این پیچیدگی با راه حل های ذخیره سازی داده خارج از جعبه دشوار است. با رویکرد ارائه شده می توان بر برخی از مشکلات بازنمایی مرتبط با این چالش ها غلبه کرد. با رعایت اصل FAIR، تمام مجموعه داده ها به صورت فرمت های باز و قابل تعامل ذخیره می شوند. در این زمینه، فرمتهای زمانی و مکانی یکنواخت استفاده میشود که امکان ادغام مستقیم همه مجموعههای داده را فراهم میکند. داده های کالیبراسیون (از کالیبراسیون پلت فرم حسگر و کالیبراسیون حسگر) به طور صریح به شیوه ای منطقی نسبت به مجموعه داده ها ذخیره می شوند.
در حین کار با سیستم مدیریت داده های تحقیق توصیف شده، برخی از بهبودهای احتمالی شناسایی شد که ما قصد داریم در آینده از آنها استفاده کنیم. این شامل بهبودهایی در برخی از گردشهای کاری استاندارد است، مانند ویرایش ابردادهها، که میتواند از یک اپراتور ویرایش انبوه استفاده کند (افزودن همان فیلد/مقادیر فراداده به تعدادی از مجموعههای داده به طور همزمان، کاهش نیاز به کپی دستی و چسباندن). ما همچنین میخواهیم از صادرات خودکار فایلهای ابرداده خود به استانداردهای ابرداده متفاوتی که معمولاً توسط مخازن دادههای تحقیقاتی استفاده میشود (نگاه کنید به [ 25 ، 26 ]) برای پشتیبانی و تسهیل فرآیند انتشار دادهها، پشتیبانی کنیم.
از نظر عملکردهای اضافی، وابستگی متقابل بین مجموعه داده ها می تواند بهتر مدل شود. این شامل ارجاعات متقابل (با استفاده از شناسههای داده منحصربفرد) بین مجموعههای داده از طریق ابرداده است که نسخهسازی مجموعههای داده را درک میکند. سپس هر مجموعه داده به مجموعه داده(هایی) که از آنها ایجاد شده است اشاره می کند، در حالت ایده آل نیز با ارجاع به کدی که با آن ایجاد شده است، یعنی کدگذاری رابطه “مجموعه داده B از مجموعه داده A با استفاده از نرم افزار تبدیل T ایجاد شده است” در ابرداده را رمزگذاری می کند. فایل ها. به همین ترتیب، رابطه بین سنسورها یا پلتفرم های حسگر و داده های کالیبراسیون آنها را می توان به عنوان ابرداده ذخیره کرد.
گام بعدی دیگر تجزیه مجموعه داده های موجود و از نظر دانه بندی داده ها، رفتن از سطح آزمایشات کامل به سطح مشاهدات فردی است. به عنوان مثال، به جای ذخیره مجموعه داده های ابر نقطه ای کامل، مشاهدات نقطه ای منفرد را می توان ذخیره کرد. این به پایگاه داده فضایی اجازه می دهد تا مجموعه داده های پیچیده جدیدی را از پرس و جوهای فضایی ایجاد کند، به عنوان مثال، بازگرداندن تمام نقاط سه بعدی اندازه گیری شده در یک منطقه فضایی تعریف شده در میان ابرهای چند نقطه ای. در سطح پایگاه داده، این نوع تجزیه به هیچ چالش جدیدی منجر نمی شود. با این حال، پیچیدگی چنین راه حلی به شدت افزایش می یابد، زیرا تمام اطلاعات در مورد منشاء (به عنوان مثال، ویژگی ها و وابستگی های متقابل در آزمایش مربوطه / ابر نقطه اصلی،
منابع
- ویلکینسون، MD؛ دومانتیه، ام. آلبرسبرگ، آی جی; اپلتون، جی. آکستون، ام. باک، ا. بلومبرگ، ن. Boiten، J.-W. د سیلوا سانتوس، LB; بورن، PE; و همکاران اصول راهنمای FAIR برای مدیریت داده های علمی و مباشرت. علمی داده 2016 ، 3 ، 1-9. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- شون، اس. برنر، سی. الخطیب، ح. کوئنن، ام. دبوک، اچ. گارسیا-فرناندز، ن. کونتزش، سی. هیپکه، سی. لومان، ک. نویمان، آی. و همکاران یکپارچگی و همکاری در شبکه های حسگر پویا. Sensors 2018 , 18 , 2400. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- اصول مدیریت داده های تحقیق. در دسترس آنلاین: https://www.mpg.de/230783/Principles_Research_Data_2010.pdf (در 18 اوت 2020 قابل دسترسی است).
- کاپلان، ED; Hegarty، CJ Understanding GPS/GNSS: Principles and Applications , 3rd ed.; آرتک هاوس: لندن، بریتانیا، 2017. [ Google Scholar ]
- رید، TG; Houts، SE; کاماراتا، آر. میلز، جی. آگاروال، اس. وورا، ا. Pandey، G. الزامات محلی سازی برای وسایل نقلیه خودران. SAE Int. J. اتصال. خودکار وه 2019 ، 2 ، 173-190. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شون، اس. یکپارچگی – موضوعی برای فتوگرامتری؟ در آرشیو بین المللی فتوگرامتری، سنجش از دور و علوم اطلاعات فضایی XLIII-B1-2020، مجموعه مقالات کنگره XXIV ISPRS، رویداد مجازی، 31 اوت تا 2 سپتامبر 2020 ؛ Copernicus GmbH: گوتینگن، آلمان، 2020؛ صص 565-571. [ Google Scholar ]
- ووگس، آر. Wieghardt، CS; Wagner, B. یافتن انحرافات مهر زمانی برای یک سیستم چند سنسوری با استفاده از مشاهدات حسگر. فتوگرام مهندس Remote Sens. 2018 , 84 , 357–366. [ Google Scholar ] [ CrossRef ]
- دبوک، اچ. شون، اس. قابلیت اطمینان و اندازه گیری یکپارچگی موقعیت یابی GPS از طریق محدودیت های هندسی. در مجموعه مقالات نشست فنی بین المللی 2019 موسسه ناوبری، رستون، ویرجینیا، 28 تا 31 ژانویه 2019؛ صص 730-743. [ Google Scholar ]
- گارسیا فرناندز، ن. Schön, S. بهینه سازی ترکیبات حسگر و پارامترهای پردازش در شبکه های حسگر پویا. در مجموعه مقالات سی و دومین نشست فنی بین المللی بخش ماهواره موسسه ناوبری (ION GNSS+ 2019)، میامی، فلوریدا، ایالات متحده آمریکا، 16 تا 20 سپتامبر 2019؛ صفحات 2048–2062. [ Google Scholar ]
- Schachtschneider، J. Schlichting، A. برنر، سی. ارزیابی رفتار زمانی در ابرهای نقطهای LiDAR از محیطهای شهری. بین المللی قوس. فتوگرام Remote Sens. Spatial Inf. علمی 2017 ، XLII-1/W1 ، 543–550. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پیترز، تی. برنر، سی. شبکههای متخاصم شرطی برای رندر ابری نقطهای چندوجهی. PFG 2020 ، 88 ، 257-269. [ Google Scholar ] [ CrossRef ]
- کوئنن، ام. روتنشتاینر، اف. Heipke, C. بازسازی دقیق وسیله نقلیه برای کاربردهای رانندگی خودمختار. ISPRS Ann. فتوگرام Remote Sens. Spatial Inf. علمی 2019 ، IV-2/W5 ، 21-28. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- نگوین، یو. روتنشتاینر، اف. Heipke, C. ردیابی عابر پیاده آگاه با استفاده از دوربین استریو. ISPRS Ann. فتوگرام Remote Sens. Spatial Inf. علمی 2019 ، IV-2/W5 ، 53–60. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گری، جی. چاودهری، س. بوسورث، آ. لایمن، ا. ریچارت، دی. ونکاترائو، ام. پلو، اف. پیرهش، اچ. در مجموعه مقالات دوازدهمین کنفرانس بین المللی مهندسی داده، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، 26 فوریه تا 1 مارس 1996. صص 152-159. [ Google Scholar ]
- کراک، ام.-جی. مکعب فضا-زمان از دیدگاه ژئوتصویرسازی بازبینی شد. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی کارتوگرافی، دوربان، آفریقای جنوبی، 10-16 اوت 2003. صفحات 1988-1995. [ Google Scholar ]
- OpenCV. در دسترس آنلاین: https://opencv.org/ (در 18 اوت 2020 قابل دسترسی است).
- TensorFlow. در دسترس آنلاین: https://www.tensorflow.org/ (در 18 آگوست 2020 قابل دسترسی است).
- Point Cloud Library. در دسترس آنلاین: https://pointclouds.org/ (در 18 اوت 2020 قابل دسترسی است).
- کنکول، م. کرای، سی. بررسی عمیق شکلهای فضایی-زمانی در تحقیقات بازتولیدپذیر. کارتوگر. Geogr. Inf. علمی 2018 ، 46 ، 412-427. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- میلر، ای. مقدمه ای بر چارچوب توصیف منابع. گاو نر صبح. Soc. Inf. علمی 1998 ، 25 ، 15-19. [ Google Scholar ]
- Weibel, S. The Dublin Core: یک مدل توصیف ساده محتوا برای منابع الکترونیکی. گاو نر صبح. Soc. Inf. علمی تکنولوژی 1997 ، 24 ، 9-11. [ Google Scholar ] [ CrossRef ]
- فراداده هسته دوبلین برای کشف منابع. در دسترس آنلاین: https://tools.ietf.org/html/rfc2413 (در 18 اوت 2020 قابل دسترسی است).
- ISO 19115-1:2014: اطلاعات جغرافیایی – فراداده – قسمت 1: اصول. در دسترس آنلاین: https://www.iso.org/standard/53798.html (در 18 اوت 2020 قابل دسترسی است).
- استانداردها و دستورالعمل های فراداده جغرافیایی. در دسترس آنلاین: https://www.fgdc.gov/metadata/geospatial-metadata-standards/ (در 18 اوت 2020 قابل دسترسی است).
- فهرست فراداده. در دسترس آنلاین: https://rd-alliance.github.io/metadata-directory/standards/ (در 18 اوت 2020 قابل دسترسی است).
- فهرست استانداردهای فراداده در دسترس آنلاین: https://www.dcc.ac.uk/resources/metadata-standards/list/ (در 18 اوت 2020 قابل دسترسی است).
- کوتزی، اس. ایوانووا، آی. میتاسووا، اچ. بروولی، کارشناسی ارشد نرمافزار و دادههای مکانی باز: مروری بر وضعیت فعلی و چشماندازی به آینده. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 90. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- برونیگ، ام. بردلی، PE; جان، م. کوپر، پی. مزروب، ن. روش، ن. الدوری، م. استفناکیس، ای. جدیدی، م. تحقیقات مدیریت داده های جغرافیایی: پیشرفت و جهت گیری های آینده. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 95. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- برنارد، ال. براونر، جی. جرم.؛ Wiemann، S. Geodateninfrastrukturen. در ژئوانفورماتیک ; سستر، ام.، اد. Springer Spektrum: برلین، آلمان، 2019؛ صص 91-122. [ Google Scholar ]
- OGC. در دسترس آنلاین: https://www.ogc.org/ (در 18 اوت 2020 قابل دسترسی است).
- سرویس مشاهده سنسور. در دسترس آنلاین: https://www.opengeospatial.org/standards/sos/ (در 18 اوت 2020 قابل دسترسی است).
- زبان مدل سنسور (SensorML). در دسترس آنلاین: https://www.ogc.org/standards/sensorml/ (در 18 اوت 2020 قابل دسترسی است).
- ISO 19156:2011. در دسترس آنلاین: https://www.iso.org/standard/32574.html (در 18 اوت 2020 قابل دسترسی است).
- ثبت مخازن داده های پژوهشی. در دسترس آنلاین: https://re3data.org/ (در 18 اوت 2020 قابل دسترسی است).
- ژئوشبکه. در دسترس آنلاین: https://www.osgeo.org/projects/geonetwork/ (در 18 اوت 2020 قابل دسترسی است).
- OSGeo. در دسترس آنلاین: https://www.osgeo.org/ (در 18 اوت 2020 قابل دسترسی است).
- مخزن جغرافیایی MIT. در دسترس آنلاین: https://libguides.mit.edu/gis/Geodata/ (در 18 اوت 2020 قابل دسترسی است).
- PANGAEA. در دسترس آنلاین: https://www.pangaea.de/ (در 18 اوت 2020 قابل دسترسی است).
- کتابخانه جغرافیایی هاروارد. در دسترس آنلاین: https://hgl.harvard.edu:8080/opengeoportal/ (در 18 اوت 2020 قابل دسترسی است).
- پروتکل ابتکار بایگانی باز برای برداشت فراداده. در دسترس آنلاین: https://www.openarchives.org/OAI/openarchivesprotocol.html (در 18 اوت 2020 قابل دسترسی است).
- آپاچی هادوپ در دسترس آنلاین: https://hadoop.apache.org/ (در 18 اوت 2020 قابل دسترسی است).
- هاینزله، اف. Anders, KH; Sester, M. شناسایی الگو در شبکه های جاده ای به عنوان مثال تشخیص جاده دایره ای. در مجموعه مقالات چهارمین کنفرانس بین المللی علم اطلاعات جغرافیایی، مونستر، آلمان، 20 تا 23 سپتامبر 2006. Springer: برلین/هایدلبرگ، آلمان، 2006; صص 153-167. [ Google Scholar ]
- PostGIS. در دسترس آنلاین: https://postgis.net/ (در 18 اوت 2020 قابل دسترسی است).
- DC/OS. در دسترس آنلاین: https://dcos.io/ (در 18 آگوست 2020 قابل دسترسی است).
- ROS. در دسترس آنلاین: https://www.ros.org/ (در 18 اوت 2020 قابل دسترسی است).

شکل 1. ( سمت چپ ) عکس یک موقعیت معمولی در طول آزمایشات ما: در اولین سناریوی Meet و Greet، هر سه خودرو در یک تقاطع به هم می رسند. ( سمت راست ) حسگرها به سکوهای حسگر متحرک (وسایل نقلیه) متصل می شوند، به عنوان مثال، مجموعه ای از حسگرها به صورت مکانی به یک قاب مشترک متصل می شوند، که خود در یک قاب جهانی حرکت می کند.
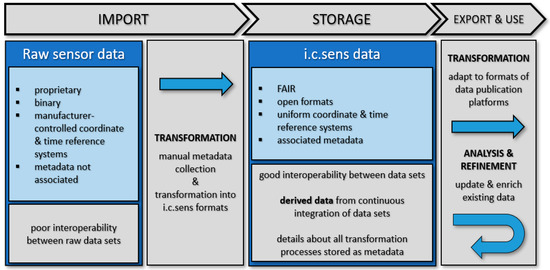
شکل 2. فرآیند تبدیل دادههای حسگر خام به فرمتهای یکنواخت از یکپارچهسازی مداوم دادهها در پروژه تحقیقاتی پشتیبانی میکند و به رابطهای ساده برای بازرسی، تحلیل و تجسم دادهها اجازه میدهد.
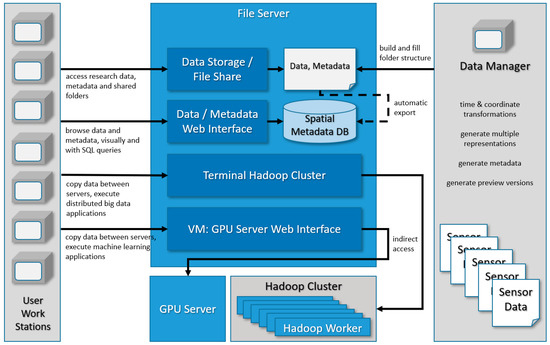
شکل 3. مروری بر اجزای سیستم مدیریت داده های تحقیق، از جمله رابط ها و فرآیندهای مرتبط با نقش های مختلف در گروه آموزشی پژوهشی (RTG). دادههای حسگر خام و بدون ساختار و ابردادههای آن توسط محققین منفرد در سرور آپلود میشوند. تبدیل به فرمتهای داده یکپارچه و وارد کردن دادهها و ابردادهها به ذخیرهسازی دادههای ساختیافته توسط مدیر داده سازماندهی میشود.
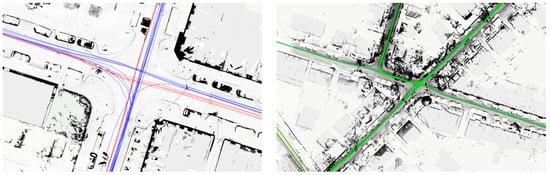
شکل 4. تصاویری از رابط وب: پیش نمایش دو مسیر از وسایل نقلیه مختلف (با رنگ های متفاوت) و یک ابر نقطه در بالای نقشه وب. رندر برای تجسم ابر نقطه برای برجسته کردن ساختارهای عمودی بهینه شده است.
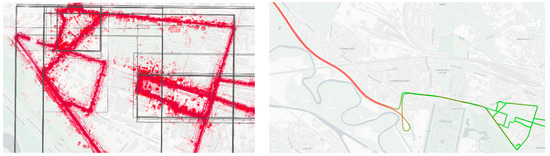
شکل 5. عملکردهای اضافی رابط وب: ( سمت چپ: ) کادرهای محدودکننده (از فراداده مبتنی بر حسگرهای سیستم ماهواره ناوبری جهانی (GNSS) در همان پلت فرم حسگر) که علاوه بر مسیرها / ابرهای نقطه نشان داده شده است. در این مثال، رندر ابر نقطه، تمام نقاط و چگالی نقطه محلی را نشان می دهد. ( سمت راست 🙂 مسیر وسیله نقلیه، رنگ آمیزی شده توسط یک ویژگی واحد (سرعت).


بدون دیدگاه