1. معرفی
در دسترس بودن و استفاده گسترده از تصاویر با برچسب جغرافیایی و برچسب زمانی تولید شده توسط کاربر در مقیاس بزرگ، فرصتی منحصر به فرد برای ثبت الگوهای فعالیت انسانی است. به عنوان مثال، فلیکر ( www.flickr.com )، یک پروکسی برای ثبت فعالیت های تفریحی انسان از مقیاس های جغرافیایی محلی تا جهانی فراهم می کند [ 1 ، 2 ، 3 ]. مطالعات قبلی که از عکسهای آنلاین برای استنباط فعالیتهای انسانی مبتنی بر طبیعت استفاده میکردند، تمرکز تحقیقاتی متنوعی داشتند. برخی از مثالها عبارتند از، اما محدود به شناسایی مناظر [ 4 ]، پوشش زمین و کاربری زمین [ 5 ]، تقاضای تفریحی در منابع آب [ 1 ]، رویدادها و نقاط توریستی [ 6],7 ، 8 ، تأثیر گونههای کمیاب در گردشگری [ 9 ]، مسیرهای متداول گردشگری [ 10 ، 11 ]، بازدید تفریحی در پارکهای ملی [ 3 ]، ارزش زیباییشناختی درک شده اکوسیستمها [ 12 ، 13 ] و همچنین رابطه بین خدمات اکوسیستم فرهنگی و ویژگی های چشم انداز [ 14 ، 15 ].
تشخیص فعالیت های انسانی از روی تصاویر رسانه های اجتماعی با برچسب جغرافیایی چالش برانگیز است. متداول ترین روشی که برای استخراج معناشناسی از تصاویر استفاده می شود، جستجوی فراداده تصاویر تولید شده توسط کاربر یا برنامه رسانه های اجتماعی است. با این حال، ابرداده ها اغلب وجود ندارند، یا ممکن است بازنمایی هایی نادرست، ناکافی یا دشوار برای تفسیر بافت تصویر را به تصویر بکشند. یک راه جایگزین برای گرفتن معناشناسی از تصاویر، استفاده از الگوریتم های بینایی کامپیوتری است که اطلاعات را از طریق تجزیه و تحلیل محتوای واقعی تصویر استخراج می کند. پیشرفت های اخیر در محاسبات با کارایی بالا و یادگیری عمیق به طور قابل توجهی کارایی و دقت الگوریتم های بینایی کامپیوتری را در طبقه بندی تصاویر و تشخیص اشیا بهبود بخشیده است. با این حال،5 ، 16 ، 17 ]. یکی دیگر از چالشهای مهم برای ثبت فعالیتهای انسانی از تصاویر برچسبگذاریشده جغرافیایی، فقدان دادههای واقعی برای اعتبارسنجی کاربرد پستهای رسانههای اجتماعی، و شناسایی نمایندگی و سوگیریهایی است که ممکن است ناشی از عوامل مختلفی مانند تاریخ، زمان، مکان باشد. از محتوای پست شده، رفتارهای کاربر، و جمعیت شناسی. به منظور ارزیابی اعتبار و کاربرد منابع رسانههای اجتماعی، مطالعات کمی دادههای رسانههای اجتماعی را با نتایج بررسیهای میدانی سنتی و نتایج مدلسازی مقایسه کردند و همبستگی قوی بین محتوای تولید شده توسط کاربر و الگوهای واقعی فعالیت انسانی پیدا کردند [1 ، 2 ، 3 ] .
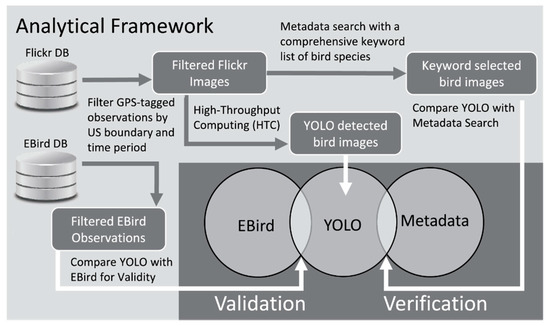
در این مطالعه، ما یک چارچوب تحلیلی برای: (1) ارزیابی کاربرد یک الگوریتم بینایی کامپیوتری، YOLOv3 (شما فقط یک بار نگاه می کنید) [ 18] معرفی می کنیم.]، در گرفتن معناشناسی با تشخیص اشیاء در محتوای تصویر. و (2) شناسایی ردپای مکانی و زمانی فعالیت های انسانی، و درک بهتر سوگیری ها و ویژگی های تصاویر رسانه های اجتماعی و رفتارهای کاربران. به طور خاص، ما از پرنده نگری به عنوان یک مطالعه موردی برای نشان دادن چارچوب تحلیلی استفاده کردیم که شامل سه مرحله است. ما ابتدا از یک الگوریتم بینایی کامپیوتری، YOLOv3 (YOLO) استفاده کردیم که از شبکههای عصبی کانولوشن (CNN) برای شناسایی اشیا، به عنوان مثال، پرندگان، با تجزیه و تحلیل محتوای تصاویر مانند رنگ، شکل، بافت و هر گونه اطلاعات دیگر مرتبط با خود تصویر واقعی سپس روشهای تأیید و اعتبارسنجی را برای ارزیابی دقت و کاربرد چارچوب پیشنهادی برای شناسایی فعالیتهای پرندهنگاری معرفی کردیم. برای تایید، ما ابتدا نتایج الگوریتم بینایی کامپیوتر را با بازیابی تصویر مبتنی بر مفهوم مقایسه کردیم که بر اساس جستجوی کلیدواژه بر روی ابرداده های تصویر مانند توضیحات متنی، برچسب ها و عنوان تصاویر بود. دوم، به منظور ثبت سوگیریهای بالقوه در تصاویر برچسبگذاریشده جغرافیایی، الگوهای فعالیت پرندگان ایجاد شده با استفاده از عکسهای پرنده Flickr را با الگوهای شناسایی شده با استفاده از دادههای eBird مقایسه کردیم.https://eBird.org/content/eBird/ )، مجموعه دادههای رصد آنلاین پرندههای علوم شهروندی، جهانی و آزادانه در دسترس است که توسط آزمایشگاه پرندهشناسی کورنل و انجمن ملی آدوبون جمعآوری و نگهداری میشود [ 19 ]. دادههای پرنده الکترونیکی در طیف گستردهای از مطالعات پرندهشناسی در مقیاسهای وسیع مکانی و زمانی مورد استفاده قرار گرفتهاند. مشاهدات eBird توسط کارشناسان تأیید شده است و بسیار دقیق در نظر گرفته می شود [ 19 ، 20 ]. به این ترتیب، مقایسه ارزیابی ما از فعالیت پرندگان با استفاده از تصاویر Flickr با دادههای eBird برای همان دوره به ما امکان داد تا سوگیریهای هر منبع داده و کاربرد بالقوه Flickr در ثبت رفتار پرندهنگاری را شناسایی کنیم.
در بخشهای فرعی بعدی، ابتدا محدودیتها و سوگیریهای ذاتی در عکسهای شبکههای اجتماعی با برچسب جغرافیایی را مورد بحث قرار میدهیم. دوم، روشهای تشخیص شی تصویر را معرفی میکنیم که امکان گرفتن زمینههای مکانی و موضوعی را از تصاویر دارای برچسب جغرافیایی فراهم میکند. در نهایت، ما پرنده نگری را به عنوان یک فعالیت انسانی مورد بحث قرار می دهیم تا زمینه را برای مطالعه موردی خود فراهم کنیم.
1.1. سوگیری های علم شهروندی و داده های رسانه های اجتماعی
محتوای تولید شده توسط کاربر از برنامه های رسانه های اجتماعی شامل منابع مختلف سوگیری مانند جمعیت شناسی و رفتار کاربر، مکان ها، موضوعات، تاریخ و زمان محتوای تولید شده است [ 21 ، 22 ، 23 ]. افراد مختلف انگیزه ها و ترجیحات متفاوتی برای به اشتراک گذاری اطلاعات دارند، بنابراین داده های به اشتراک گذاشته شده ممکن است نماینده جمعیت بزرگتر یا حتی یک جامعه نباشد. جدای از موضوع بازنمایی جمعیت عمومی جمعیت، سوگیری مشارکت کاربران [ 24 ] و شکاف شهری و روستایی [ 22]] برای نمایش دقیق الگوهای فعالیت انسانی از محتوای تولید شده توسط کاربر چالشهای مهمی ایجاد میکند. سوگیری مشارکت کاربر از این واقعیت ناشی می شود که بخش بزرگی از محتوا تنها توسط چند کاربر بسیار فعال تولید می شود. از سوی دیگر، تأثیر شکاف شهری و روستایی، یا تراکم جمعیت نیز در دادههای رسانههای اجتماعی مانند توییتر، فلیکر و فورسکوئر بسیار مشهود است، زیرا بیشتر محتوا در مناطق شهری تولید میشود [25 ، 26 ] . شکاف شهری و روستایی در استفاده از رسانه های اجتماعی محدودیت بیشتری ایجاد می کند، مشکل مساحت کوچک یا تعداد، که منجر به تنوع کاذب در الگوهای استخراج شده از مناطق با تراکم مشاهدات کم می شود [27] .]. به منظور پرداختن به مشکل چگالی متفاوت، محققان از سطح انتظار با استفاده از آماره کای و تخمین چگالی [ 28 ] استفاده کرده اند. در سطح انتظار، تعداد تعداد عکس های مشاهده شده با مقادیر مورد انتظار حاصل از تراکم جمعیت مقایسه می شود. برای جلوگیری از تسلط بیشتر کاربران بر الگوهای فضایی برانگیخته، مطالعات قبلی تعداد عکسهای هر کاربر را بر اساس آستانه تعیینشده توسط فاصله [4] یا معیارهای تعداد و تراکم کاربر مجزا [ 17 ] نرمال میکردند. سایر شاخصهای مبتنی بر رسانههای اجتماعی که برای نقشهبرداری از فعالیتهای تفریحی استفاده میشوند عبارتند از تعداد عکسهای فلیکر [ 9 ]، تعداد کاربران Panoramio فردی که در فعالیتهای خاص شرکت میکنند. 12] است.]، و Flickr بر اساس تعداد عکسهای گرفته شده توسط کاربران در روزهای منحصر به فرد در یک مکان، روزهای کاربر را تولید کرد [ 1 ، 3 ، 29 ].
1.2. الگوریتم های بینایی کامپیوتر
الگوریتمهای بینایی کامپیوتری برای استخراج معنایی از ویژگیهای تصویر مانند رنگ، شکل، بافت یا هر اطلاعات دیگری که میتوان از خود تصویر استخراج کرد استفاده میشود. الگوریتمهای بینایی رایانه با نمایهسازی تصویر مبتنی بر مفهوم یا توصیف متفاوت هستند [ 30 ، 31 ]، که کلمات کلیدی را در فرادادههای تصویر مانند عنوان، برچسبها و توضیحات برای استنتاج مفاهیم و معناشناسی از تصاویر جستجو میکند. یادگیری عمیق، که امکان استخراج انتزاعات سطح بالا در داده ها را با استفاده از یک معماری سلسله مراتبی فراهم می کند. 32]، به طور گسترده در کاربردهای مختلفی مانند پردازش زبان طبیعی، تجزیه معنایی، یادگیری انتقال و بینایی کامپیوتری استفاده شده است. استخراج معناشناسی از تصاویر به دلیل مشکل شکاف معنایی استخراج مفاهیم معنایی سطح بالا از پیکسل های تصویر سطح پایین گرفته شده توسط الگوریتم های یادگیری عمیق، یک چالش مهم باقی می ماند. با این حال، انواع مختلفی از برنامه های کاربردی موفق CNN برای پرداختن به شکاف معنایی و استخراج زمینه از تصاویر دارای برچسب جغرافیایی وجود داشته است. به عنوان مثال، پورزی و همکاران. [ 33] از یک معماری CNN استفاده کرد تا درک مردم از ایمنی، جذابیت و منحصر به فرد بودن را با استفاده از تصاویر نمای خیابان گوگل به تصویر بکشد. CNN ها همچنین به طور گسترده در مکان یابی جغرافیایی مبتنی بر تصویر و تشخیص صحنه استفاده شده اند. الگوریتمهای مکانیابی جغرافیایی و تشخیص صحنه از محتوای تصویر برای شناسایی مکانی که تصویر گرفته شده است و همچنین ویژگیهای آن مکان استفاده میکنند [ 16 ، 34 ، 35 ]. به طور مشابه، Tracewski و همکاران. [ 5 ] از شبکههای عصبی برای شناسایی پوشش زمین و طبقهبندی کاربری زمین تصاویر بهدستآمده از منابع مختلف رسانههای اجتماعی مانند فلیکر، پانورامیو، جئوگراف و اینستاگرام استفاده کرد. برای بحث عمیق تر در مورد روش های یادگیری عمیق، خوانندگان ممکن است به Guo و همکاران مراجعه کنند. [ 32]، وان و همکاران. [ 36 ] و یانگ و همکاران. [ 37 ].
1.3. تماشای پرندگان
پرنده نگری یک فعالیت تفریحی غیرمصرفی در فضای باز است که در اوایل دهه 1900 بوجود آمد [ 38 ]. پرنده نگری یک فعالیت پرطرفدار است، به طوری که تخمین زده می شود سالانه 7/46 میلیون نفر در ایالات متحده در پرنده گردانی شرکت می کنند [ 39 ]، و بیش از شش میلیون نفر حداقل هر سه هفته یک بار در بریتانیا پرندگان را مشاهده می کنند (CBI 2011). اکثر پرنده داران (88٪) پرندگان را در اطراف خانه های خود مشاهده می کنند، اما بسیاری از آنها (38٪) برای تماشای پرنده در مسافت های طولانی سفر می کنند [ 39 ]. پرنده نگری بر اساس تخصص و انگیزه به چند دسته تقسیم می شود [ 40 ، 41]]. “پرنده داری” توسط افراد سرگرم کننده، حرفه ای یا نیمه حرفه ای متمرکز بر مطالعه و شناسایی پرندگان انجام می شود. پرنده نگری همچنین ممکن است از طریق «فهرست کردن» به عنوان یک ورزش عمل کند، فرآیندی اغلب رقابتی که به موجب آن افراد چک لیست گونه هایی را که مشاهده کرده اند حفظ می کنند. پرندگان ممکن است به دنبال گونهها یا گونههای کمیاب باشند که در خارج از محدوده معمولی خود قرار دارند، وبلاگها را برای گزارشهایی از چنین گونههایی تماشا کنند و مسافتهای زیادی را طی کنند تا چنین پرندگانی را به فهرست خود اضافه کنند. چنین فعالیتهایی معمولاً شامل مستندسازی مشاهدات، اغلب از طریق عکسهای به اشتراکگذاشتهشده از طریق رسانههای اجتماعی، و ممکن است شامل ارسال مشاهدات به برنامههای علمی شهروندی مانند eBird باشد. این فعالیت ها اثرات اقتصادی قابل توجهی را در رابطه با خرید تجهیزات (به عنوان مثال، تلسکوپ، دوربین دوچشمی، دوربین، و لوازم تغذیه پرندگان) ایجاد می کنند.
گونههای پرنده ممکن است مهاجر یا مقیم باشند و در صورت مهاجرت، ممکن است کوتاه (یعنی حرکت در همان منطقه محلی)، متوسط (مثلاً حرکت در میان ایالتهای ایالات متحده) یا مهاجر از راه دور (مثلاً حرکت در عرض یا بین قاره ها). مهاجرت تغییرات فصلی در دسترس بودن منابع و شرایط محیطی را دنبال میکند و شامل جابهجایی بین مکانهای تولید مثل و زمستانگذرانی در فصول پاییز و بهار است [ 42] .]. در طول مهاجرت، پرندگان از مکان های توقف با کیفیت زیستگاه های مختلف برای استراحت و سوخت گیری استفاده می کنند. مکان های توقف با کیفیت زیستگاه بالا ممکن است به گونه های متعددی در تراکم نسبتاً بالا خدمت کنند. این مکانها ممکن است برای تماشاگران پرنده جالب باشند، بهویژه اگر برای مشاهده بسیاری از گونههای گذرا در یک مکان در دسترس عموم قرار گیرند (مثلاً پارکها و پناهگاههای حیات وحش). در نتیجه ماهیت رقابتی فهرستبندی، رسانههای اجتماعی و پستهای علمی شهروندی ممکن است پرندگان کمیابتر و زودگذر را در طول مهاجرت در نقاط توقفگاه برجسته کنند.
2. مواد و روشها
شکل 1چارچوب تحلیلی ارائه شده در این مقاله را نشان می دهد. ما ابتدا تمام فرادادهها و تصاویر تصویر فلیکر در موقعیت جغرافیایی جغرافیایی و مشاهدات eBird را با توجه به تاریخ عکسبرداری و مشاهده، و مرز ایالات متحده در یک دوره سه ساله بین دسامبر 2013 و دسامبر 2016 جمعآوری کردیم. فرادادههای فلیکر شامل ویژگی هایی که عکس را با شناسه، نام و شماره شناسایی کاربر، مکانی که در آن عکس گرفته شده است شناسایی می کند (یعنی مختصات طول و عرض جغرافیایی که به صورت دستی توسط کاربران اضافه می شوند یا توسط دوربین/تلفن های هوشمند تولید می شوند)، زمان و تاریخ در که عکس گرفته شده و آپلود شده است، و حاشیه نویسی متنی ارائه شده توسط کاربران و برنامه، از جمله برچسب ها، توضیحات و عنوان محتوای عکس. از سوی دیگر،https://eBird.org/content/eBird ) [ 19 ]. دادههای eBird شامل نام، شمارش و انواع گونههای مشاهدهشده در طول یک رویداد جستجو، مکان محل جستجو، زمان، تاریخ، و مدت جستجو و همچنین نام ناظر بود.
پس از بارگیری اولیه، هر دو مجموعه داده را فیلتر کردیم تا فقط تصاویر فلیکر با برچسب جغرافیایی و مشاهدات eBird را که در محدوده ایالات متحده بودند شامل شود. در مراحل بعدی، تصاویر پرنده را با استفاده از جستجوی کلمه کلیدی فراداده و کتابخانه یادگیری عمیق YOLO استخراج کردیم. ما ابتدا دقت تشخیص اعتراض توسط YOLO را با جستجوی فراداده و همچنین الگوهای فضایی آنها مقایسه کردیم. دوم، ما الگوهای فضایی فعالیت پرنده نگری را از eBird استخراج کردیم و آنها را با عکس های پرنده Flickr شناسایی شده توسط YOLO مقایسه کردیم تا شباهت ها و تفاوت های بین eBird و Flickr را در ثبت رفتارهای پرنده نگری شناسایی کنیم.
2.1. تو فقط یکبار نگاه میکنی (YOLO)
YOLO یک سیستم تشخیص اعتراض به روز، یکپارچه و در زمان واقعی است [ 18 ، 43 ، 44 ]. بر خلاف سایر رویکردهای تشخیص اشیا مانند مدل قطعات قابل تغییر شکل (DPM) [ 45 ] و R-CNN [ 46 ]، YOLO تشخیص اشیا را به عنوان یک مشکل رگرسیونی قاب می کند. در طول آموزش، مجموع تابع خطای مربع زیر به حداقل رسید [ 44 ]:
جایی که (ایکسمن، yمن)، wمن، ساعتمن، و سیمننشان دهنده مرکز، عرض، ارتفاع و مقدار کلاس، به ترتیب، جعبه مرزی نسبت به سلول شبکه من; پمن(ج)نشان دهنده احتمال وجود شی در سلول شبکه است منمتعلق به کلاس است ج; (ایکس^من، y^من)، w^من، ساعت^من، و سی^مننشان دهنده مرکز، عرض، ارتفاع و مقدار کلاس، به ترتیب، شی آموزشی است که در سلول شبکه قرار می گیرد. من; پ^من(ج)نشان دهنده احتمال افتادن جسم آموزشی در سلول شبکه است منمتعلق به کلاس است ج; منمنjoبjنشان می دهد که آیا شی در سلول ظاهر می شود من; و منمنjnooبjنشان می دهد که jپیشبینیکننده جعبه مرزی در سلول من”مسئول” آن پیش بینی است. λجoorد و λnooبjبه ترتیب وزن خطای محلی سازی و خطای طبقه بندی هستند.
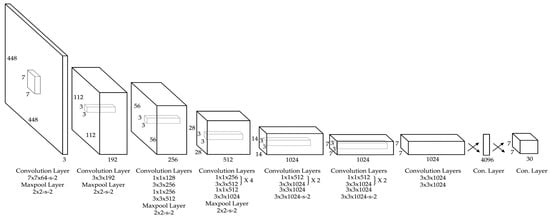
در YOLO، یک شبکه عصبی منفرد برای پیشبینی همزمان جعبههای محدودکننده چند شی و احتمالات کلاس مربوطه به طور مستقیم از پیکسلهای تصویر استفاده میشود ( شکل 2 ). ردمون و همکاران [ 44 ] میانگین میانگین دقت (mAP) و فریم در ثانیه (FPS) YOLO را با سایر الگوریتمهای تشخیص با استفاده از مجموعه دادههای اعتبارسنجی از PASCAL VOC 2007 مقایسه کرد. 47 ]، سریعترین DPM [ 48 ]، R-CNN منهای R [ 49 ]، سریع R-CNN [ 48 ]، سریعتر R-CNN VGG-16 [ 50 ]، سریعتر R-CNN ZF [ 50]، تصمیم گرفتیم از YOLO برای تشخیص پرندگان در تصاویر استفاده کنیم.
24 لایه کانولوشنال اولیه شبکه ویژگی هایی را از تصویر استخراج می کند و دو لایه کاملاً متصل جعبه های مرزی خروجی و احتمالات کلاس را پیش بینی می کنند. خروجی سیستم به عنوان یک تانسور S × S × (B * 5 + C) ذخیره شد. یک معماری شبکه معمولی با S = 7، B = 2، C = 20 در شکل 3 نشان داده شده است [ 44 ].
ما آخرین نسخه YOLO، YOLOv3 را آزمایش کردیم که تقریباً 15 ثانیه در واحد پردازش مرکزی (CPU) طول کشید. تعداد کل تصاویری که باید پردازش شوند 20 میلیون بود. ما محاسبات با توان عملیاتی بالا (HTC) را بر روی سیستم آرگون HPC در دانشگاه آیووا (UI) انجام دادیم. سیستم HPC آرگون از 366 گره محاسباتی با محدوده 40 تا 56 هسته در هر گره تشکیل شده است. با توجه به تعداد قابل توجهی بیشتر و در دسترس بودن واحدهای CPU، ما HTC را روی گرههای CPU انجام دادیم. آرگون از سیستم صف بندی Son of Grid Engine (SGE) برای ارسال شغل استفاده می کند. سیستم آرگون دارای محدودیت 10000 شغل فعال به ازای هر کاربر است که شامل مشاغل در حال اجرا و در حال انتظار در انتظار ارسال می باشد. ما از آرایهها برای ارسال وظایف تشخیص اعتراض YOLO استفاده کردیم. یک کار آرایه شامل وظایف یکسانی است که بر اساس طیف وسیعی از اعداد فهرست مرتب شده اند. حداکثر مقدار وظایفی که یک کار آرایه می تواند انجام دهد 75000 است. با توجه به محدودیتهای کار کاربر و آرایه، ما 267 کار آرایه را برای پردازش 20 میلیون تصویر ارسال کردیم که تقریباً یک هفته طول کشید.
2.2. تخمین چگالی هسته
به منظور مقایسه توزیع فضایی تصاویر شناسایی شده توسط YOLO و جستجوی فراداده، و مشاهدات eBird و YOLO شناسایی شده، ما دو نوع تخمین چگالی هسته (یعنی فاصله ثابت و پهنای باند تطبیقی) را انجام میدهیم که هر دو با استفاده از فرمول انجام شدند. زیر [ 51 ]:
که در آن x 1 ، x 2 ، …، x n∈Oمنمجموعه ای از مکان های مشاهده در پهنای باند (همسایگی) است جیمن; nتعداد کل مشاهدات است. ایکسمحل برآورد است. K تابع هسته است. و h پهنای باند (فاصله) است. توابع کرنل معمولاً مورد استفاده قرار می گیرند: Uniform، Epanechnikov، Triangular و Gaussian. انتخاب تابع هسته اغلب نتیجه تخمین چگالی را تغییر نمی دهد. با این حال، پهنای باند hیک پارامتر کلیدی است که نتیجه تخمین کرنل با فاصله ثابت را تعیین می کند. همین فرمول برای تخمین چگالی هسته با فاصله ثابت و تطبیقی (صاف کردن) اعمال می شود. هموارسازی هسته را می توان بر روی شبکه های منظم یا واحدهای فضایی سطوح مختلف تجمع (به عنوان مثال، شهرستان ها، مناطق سرشماری، و گروه های بلوک) انجام داد. در این مطالعه، ما منطقه مورد مطالعه را به شبکه ای با وضوح 5 مایل (8 کیلومتر) تقسیم کردیم که ایالات متحده را پوشش می داد. ما از این وضوح برای تخمین چگالی هسته ثابت برای مقایسه الگوهای فضایی تشخیص YOLO با جستجوی فراداده، و eBird به مشاهدات شناسایی شده توسط YOLO استفاده کردیم. هموارسازی هسته با فاصله ثابت نیاز به آستانه فاصله برای تعیین پهنای باند دارد. ما پهنای باند را 20 مایل تعیین کردیم که تقریباً معادل همسایگی مرتبه دوم یک سلول شبکه است.
فیلترهای فضایی با فاصله ثابت در تخمین چگالی هسته اغلب منجر به از دست رفتن جزئیات جغرافیایی می شود که چگالی مشاهده بسیار بیشتر است. علاوه بر این، فیلترهای کوچکتر تخمین های غیر قابل اعتمادی را در مناطقی با مشاهدات پراکنده تولید می کنند. متفاوت از تخمین چگالی هسته با فاصله ثابت، تخمین چگالی هسته تطبیقی (صاف کردن) [ 52] یک روش ناپارامتریک است که از اطلاعات محلی در همسایگی های تعریف شده با اندازه های مختلف هسته برای تخمین مقادیر ویژگی های مشخص شده در مکان های معین استفاده می کند. هموارسازی هسته تطبیقی به حداقل تعداد آستانه مشاهده (k-نزدیکترین مشاهدات) برای تعیین پهنای باند و مشاهدات در همسایگی تخمین و همچنین وزن فضایی آنها نیاز دارد. در حالی که هسته فاصله ثابت به ما اجازه میدهد تفاوتهای مطلق بین دو مجموعه داده را با هم مقایسه کنیم، به سوگیری مشارکت کاربر و مشکل منطقه کوچک که تخمینهای غیر قابل اعتمادی را برای مناطق با تراکم مشاهدات پایینتر تولید میکرد، رسیدگی نکرد.
علاوه بر استفاده از تخمین چگالی هسته با فاصله ثابت، ما از یک تخمین چگالی هسته تطبیقی استفاده کردیم تا نرخ هموار مشاهدات Flickr و eBird را بر اساس تعداد کاربران بدست آوریم. با توجه به این واقعیت که تعداد مشاهدات روی هم به یک مجموعه داده بزرگ با 125 میلیون مشاهده eBird و 750000 تصویر پرنده شناسایی شده توسط YOLO می رسد و تعداد قابل توجهی از مشاهدات که مختصات دقیق را به اشتراک می گذاشتند، الگوریتمی را برای محاسبه کارآمد معرفی کردیم. تخمین هسته تطبیقی بر اساس تعداد مکان های کاربر مجزا. تعاریف و مراحل هموارسازی هسته تطبیقی در زیر تعریف شده است. در مرحله 1، منطقه به شبکه ای با وضوح 5 مایل (8 کیلومتر) تقسیم شد که همان وضوح مورد استفاده در هموارسازی هسته با فاصله ثابت بود. تعداد قابل توجهی از مشاهدات با همان مختصات وجود داشت. در مرحله 2، مشاهداتی را که مختصات دقیق را قبل از تعیین k-نزدیکترین کاربران به اشتراک میگذاشتند، در مکانهای مشاهده مجزا به اشتراک گذاشتیم. در نتیجه، فهرستی از مکانهای مشاهده متمایز به دست آوردیم که شامل اطلاعاتی در مورد تعداد کل مشاهدات و فهرست کاربران برای eBird و Flickr بود. ما k را به عنوان حداقل تعداد کاربران برای تعیین محله تعریف می کنیم. با توجه به آستانه اندازه همسایگی مثبت k بر اساس تعداد کاربران، یک همسایگی با اندازه k برای هر شبکه به دست می آید. ما فهرستی از مکانهای مشاهده متمایز را به دست آوردیم که شامل اطلاعاتی در مورد تعداد کل مشاهدات و لیست کاربران برای eBird و Flickr بود. ما k را به عنوان حداقل تعداد کاربران برای تعیین محله تعریف می کنیم. با توجه به آستانه اندازه همسایگی مثبت k بر اساس تعداد کاربران، یک همسایگی با اندازه k برای هر شبکه به دست می آید. ما فهرستی از مکانهای مشاهده متمایز را به دست آوردیم که شامل اطلاعاتی در مورد تعداد کل مشاهدات و لیست کاربران برای eBird و Flickr بود. ما k را به عنوان حداقل تعداد کاربران برای تعیین محله تعریف می کنیم. با توجه به آستانه اندازه همسایگی مثبت k بر اساس تعداد کاربران، یک همسایگی با اندازه k برای هر شبکه به دست می آید.G i ∈ G که کوچکترین k-نزدیکترین همسایه G i است که محدودیت اندازه را برآورده می کند. در مرحله 3، ما از یک الگوریتم Sort-Tile-Recursive Tree برای محاسبه شاخص فضایی k-نزدیک ترین کاربران متمایز و مکان آنها برای هر سلول شبکه استفاده کردیم تا کارایی محاسباتی برای تعیین k-نزدیک ترین کاربران متمایز و آنها را بهبود دهیم. مکان ها ما آستانه k را به صورت ترکیبی از 100 کاربر Flickr و eBird تنظیم کردیم. هنگامی که همسایگی به آستانه تعریفشده k رسید، فهرست مشاهدات، O i ، پهنای باند h ( G i ، k)، و وزن مکانهای مشاهده متمایز را برای هر سلول شبکه در مرحله 3 تعیین کردیم. Kتابع هسته است و h پهنای باند برای هموارسازی است. توابع کرنل وزن هر مشاهده را در هسته تعیین می کنند و انتخاب تابع اغلب تأثیر قابل توجهی بر نتیجه ندارد. متداول ترین توابع کرنل عبارتند از Uniform، Epanechnikov، Triangular و Gaussian. در این مطالعه، ما از هسته یکنواخت برای ساده کردن تفسیر تخمین استفاده کردیم. با توجه به فهرست مشاهدات، وزنهای فضایی و تعداد مشاهدات برای eBird و Flickr، ما یک سطح پیوسته را محاسبه کردیم که تعداد کاربران متمایز در هر هسته تعریف شده در مرحله 5 را در نظر گرفت.
تعاریف:
-
G : Grid: مجموعه کل سلول های شبکه ای که منطقه مورد مطالعه را پوشش می دهد.
-
G i : سلول شبکه i . G i ∈ G .
-
k : آستانه فیلتر تطبیقی (همسایگی) بر اساس تعداد کل کاربران مجزا.
-
U i : فهرست کاربران در همسایگی G i .
-
O i : فهرست مشاهدات در همسایگی G i .
-
h (G i , k): پهنای باند همسایگی k-Size سلول شبکه G i به عنوان کوچکترین KNN تعریف می شود (G i , k) = { جیj∈جی} که تعداد کل کاربران مجزا دارد: ∑کمن≥ک.
-
K: تابع هسته. تابع یکنواخت برای تفسیر ساده نتایج استفاده می شود.
مراحل:
- (1)
-
G، شبکه منطقه مورد مطالعه را با وضوح r محاسبه کنید. در این تحقیق از r=8 کیلومتر استفاده شد.
- (2)
-
آمار مشاهدات را جمع آوری کنید، مانند تعداد مشاهدات، و فهرست (هش) کاربران را برای هر مکان مشاهده مجزا برای Flickr و eBird نگه دارید.
- (3)
-
با توجه به k = 100، یک شاخص فضایی را بر اساس درخت مرتب سازی-کاشی-بازگردانی (STR) برای یافتن k-نزدیک ترین کاربران Flickr و eBird برای هر سلول شبکه محاسبه کنید.
- (4)
-
با استفاده از تخمین هسته تطبیقی، O i ، h (Gi ، k) و وزن مشاهدات را برای هر سلول شبکه تعیین کنید .
- (5)
-
درصد تصاویر Flickr شناسایی شده توسط YOLO را برای مشاهدات eBird برای هر سلول شبکه محاسبه کنید.
3. نتایج و ارزیابی
بین دسامبر 2013 و دسامبر 2016، 19،711،242 تصویر فلیکر دارای برچسب جغرافیایی در داخل ایالات متحده بود. میز 148 شیء برتر شناسایی شده توسط YOLO و تعداد تصاویری که حداقل یکی از این اشیاء را در خود دارند نشان می دهد. از این اشیاء برای استنباط فعالیت های انسانی و همچنین ویژگی های محیطی مکان هایی که عکس ها در آن گرفته شده اند استفاده می شود. به عنوان مثال، وجود دوچرخه ممکن است برای تعیین کمیت رفتار دوچرخه سواری مفید باشد، توپ ورزشی ممکن است فعالیت های ورزشی را نشان دهد و اشیایی مانند مبل، تخت، گلدان و صندلی ممکن است نشان دهنده فعالیت های داخل خانه باشد. در این مقاله، ما فقط بر روی تصاویر پرنده تمرکز کردیم و از فعالیت پرنده نگری به عنوان مطالعه موردی برای نشان دادن سودمندی چارچوب تحلیلی خود استفاده کردیم. شی “پرنده” پنجمین شیء متداول کشف شده در 747 هزار تصویر بود.
ما نتایج و ارزیابی را در دو بخش فرعی سازماندهی کردیم: تأیید و اعتبار. ما ابتدا ارزیابی مقایسه ای خود را از جستجوی فراداده و YOLO برای تأیید صحت هر دو رویکرد ارائه می کنیم. دوم، ما فعالیت پرنده شناسایی شده توسط YOLO را با مشاهدات EBird مقایسه می کنیم تا اعتبار و سوگیری داده های Flickr و eBird را در استنباط فعالیت پرنده نگری ارزیابی کنیم.
3.1. تایید
هدف ما برای تأیید این بود که به سؤالات زیر پاسخ دهیم:
در حالی که ما 747015 (3.8٪) تصویر با پرندگان را با استفاده از YOLO شناسایی کردیم، 534121 (2.7٪) تصویر را شناسایی کردیم که حاوی کلمات کلیدی پرنده با جستجوی مبتنی بر فراداده است. جدول 2نشان دهنده تنوع زمانی در تشخیص پرندگان با جستجوی فراداده و YOLO است. به طور کلی، YOLO امکان افزایش تشخیص پرندگان را بیش از 50 درصد از آنچه جستجوی ابرداده میتوانست شناسایی کند، فراهم کرد و این افزایش در فصول مختلف ثابت بود. در هنگام استفاده از YOLO در مقایسه با تعداد تصاویر ثبت شده توسط جستجوی فراداده، افزایش قابل توجهی بیش از 1٪ در تعداد عکس های شناسایی شده پرنده مشاهده شد. در میان 19.7 میلیون تصویر، جستجوی YOLO و فراداده معمولاً پرندگان را در 409779 (2٪) تصویر شناسایی کردند. از آنجایی که هر دو روش پرندگان را در این تصاویر شناسایی کردند، ما طبقه بندی را دقیق در نظر گرفتیم. به منظور شناسایی عدم تطابق بین دو روش، تصاویری را که فقط توسط YOLO و فقط با جستجوی فراداده شناسایی شده بودند، مقایسه کردیم. YOLO 1.8% تصاویر پرنده اضافی را شناسایی کرد که با جستجوی فراداده شناسایی نشدند.
ما دقت تصاویر شناسایی شده توسط پرندگان را تنها با YOLO و فقط جستجوی فراداده، با استفاده از طبقهبندی انسانی توسط نویسنده اول ارزیابی کردیم. ما وظیفه طبقه بندی انسان را با این سوال تعریف کردیم: “آیا پرنده واقعی در این عکس وجود دارد؟” ما از یک نمونه تصادفی از 1000 عکس پرنده استفاده کردیم که فقط توسط YOLO یا فقط با جستجوی فراداده شناسایی شده بود. طبق آزمایش دقت، تصاویر پرنده که فقط با جستجوی ابرداده طبقهبندی شدهاند اما نه با YOLO، به دقت قابل ملاحظهای کمتر از 26 درصد منجر میشوند، در حالی که تصاویر پرنده که تنها توسط YOLO شناسایی شدهاند، به دقت 89 درصد منجر میشوند. اگرچه حجم نمونه ما برای طبقه بندی انسان در این مرحله کم بود، اما این یافته افزایش دقت تشخیص YOLO را تایید کرد.
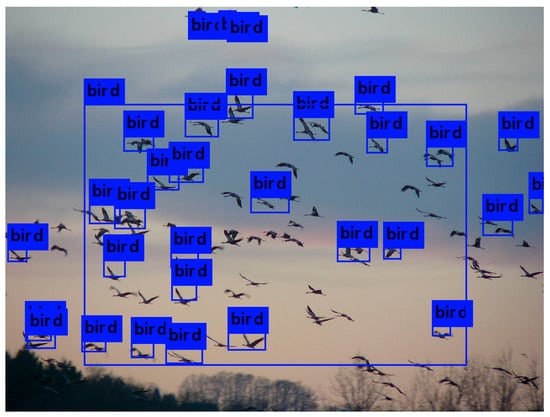
اگرچه تشخیص YOLO دقت 89% در طبقه بندی پرندگان داشت، شکل 4 نمونه های مختلفی از طبقه بندی های دقیق و نادرست YOLO را نشان می دهد. شکل 4 a,b,d طبقه بندی دقیق پرندگان را نشان می دهد. این الگوریتم دو پرنده را در شکل 4 الف با دقت تخمینی 60% و 59% شناسایی کرد، اگرچه آشکارا تعداد پرندگان بیشتری (پنج) در این تصویر وجود داشت. با این حال، از آنجایی که تصویر با کلمات کلیدی پرنده برچسب گذاری نشده بود، توسط جستجوی ابرداده گرفته نشد. این الگوریتم همچنین یک نیمکت را با دقت 60 درصد شناسایی کرد، اگرچه چندین نیمکت در این عکس وجود داشت. هر دو پرنده در شکل 4 ب با دقت 85% و 80% تخمین زده شده و پرنده در شکل 4 با دقت شناسایی شدند.d به دقت با دقت 98 درصد شناسایی شد. اگرچه بقیه تصاویر در شکل 4 c,e,f حاوی پرندگان نیستند، اما YOLO آنها را به اشتباه به عنوان پرنده طبقه بندی کرد. شکل یک پروانه در شکل 4 ج و شکل گل ها شبیه ویژگی های یک پرنده مانند بال ها، گردن و منقار است که احتمالاً منجر به طبقه بندی اشتباه شده است. اما دقت طبقه بندی برای این دو تصویر به ترتیب پایین، 54% و 51% بود. از آنجایی که ما آستانه ای را لحاظ نکردیم، هر طبقه بندی را بدون توجه به مقدار احتمال ارائه شده توسط YOLO گنجانده ایم. در نهایت، شکل 4f شامل یک نقاشی واقع گرایانه از مرغ مگس خوار است که توسط YOLO به عنوان پرنده طبقه بندی شده است. این طبقه بندی موردی را نشان می دهد که در آن طبقه بندی از نظر الگوریتمی دقیق است، اما از نظر معنایی نادرست است زیرا هدف شناسایی پرندگان واقعی است.
شکل 5 تصاویر پرنده را نشان می دهد که فقط توسط ابرداده شناسایی شده اند و نه YOLO. شکل 5 a طبقه بندی دقیق یک دارکوب، یک گونه معمولی پرنده به لطف عنوان این تصویر “دارکوب بلوط” است. الگوریتم YOLO قادر به تشخیص پرنده در این عکس نبود، زیرا پرنده چگونه با شاخه درخت به خوبی ترکیب شده بود، که ویژگی های اصلی پرنده را برای تشخیص اعتراض پنهان می کرد. از سوی دیگر، شکل 5 ب تا د حاوی پرندگان واقعی نیست، اما معمولاً حاوی کلمات کلیدی “پرنده” هستند.
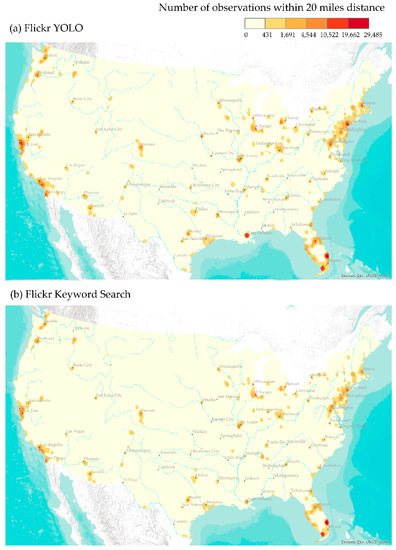
مقایسه چگالی تصاویر پرنده به دست آمده از جستجوی فراداده و YOLO در شکل 6 نشان داده شده است . ما تعداد مشاهدات YOLO و داده های جستجوی کلمه کلیدی را ترکیب کردیم و از طبقه بندی شکست های طبیعی برای تعیین شکست های کلاس در شکل 6 استفاده کردیم.. در حالی که نواحی تصاویر پرنده شناسایی شده توسط YOLO و جستجوی فراداده بطور قابل ملاحظه ای همپوشانی داشتند، YOLO تصاویر پرنده بیشتری را نسبت به جستجوی فراداده برای بیشتر منطقه مورد مطالعه شناسایی کرد. YOLO تعداد بسیار بیشتری از تصاویر پرندگان را در مناطق شهری مانند نیواورلئان، سانفرانسیسکو، نیویورک، واشنگتن دی سی و سیاتل شناسایی کرد. علاوه بر این، نتایج YOLO نشان دهنده تداوم مناطق زیستگاه پرندگان در مناطق ساحلی فلوریدا، شمال شرق، دریاچه میشیگان و کالیفرنیا است. از سوی دیگر، تراکم تصاویر پرنده شناسایی شده توسط جستجوی فراداده، الگوهای فضایی پراکنده تری را در سراسر کشور ایجاد کرد.
3.2. اعتبار سنجی
هدف ما از اعتبارسنجی پاسخ به سوالات زیر بود:
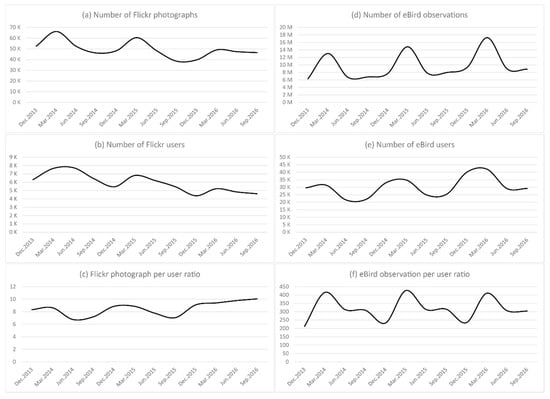
برای پاسخ به این سوالات، آمار تصویر پرنده Flickr شناسایی شده توسط YOLO را با مشاهدات eBird مقایسه کردیم. ما ابتدا همبستگی رتبه اسپیرمن را بر اساس تعداد فاصله ثابت مشاهدات و کاربران مجزا محاسبه کردیم. ما یک همبستگی قوی بین تعداد مشاهدات eBird و تصاویر پرنده Flickr شناسایی شده توسط YOLO با ضریب همبستگی 79٪ پیدا کردیم. علاوه بر این، تعداد کاربران متمایز eBird و کاربران Flickr حتی ضریب بزرگتری 85٪ را ایجاد کرد. این مقادیر همپوشانی قوی بین مشاهدات eBird و تصاویر پرنده Flickr را نشان داد. سپس الگوهای زمانی تصویر فلیکر، کاربر و نسبت تصویر به کاربر را با مشاهده eBird، کاربر و نسبت مشاهده به کاربر مقایسه کردیم ( شکل 7). به طور کلی، فلیکر از سال 2013 تا 2016 هم از نظر تعداد عکس های پرنده و هم از نظر کاربران روندی کاهشی داشته است. این کاهش همچنین با کاهش کلی استفاده از فلیکر مطابقت داشت. در مقابل، مشاهدات و کاربران eBird روند افزایشی را در طول دوره سه ساله نشان دادند. هم عکس های Flickr و eBird و آمار کاربران در ماه های بهار به اوج خود رسید. نسبت عکس به کاربر برای فلیکر روند افزایشی داشت. از سوی دیگر، نسبت مشاهده به کاربر eBird در طول دوره سه ساله بسیار ثابت بود و در ماههای بهار و تابستان به اوج خود رسید.
بین دسامبر 2013 و دسامبر 2016، 125،179،161 مشاهده eBird در جعبه مرزی ایالات متحده همسایه وجود داشت. در میان این مشاهدات، 115،682،223 مشاهدات دقیقاً در محدوده ایالات متحده بود. تنها 1,422,554 مختصات متمایز وجود داشت که مربوط به 1٪ از مشاهدات eBird در ایالات متحده است. این بیشتر به دلیل مشاهدات متعدد انجام شده از یک سایت در طول روز بود. از بین 746998 تصویر پرنده فلیکر، 346549 تصویر دارای مختصات متمایز (46%) بودند، در حالی که بقیه 54% تصاویر دارای مختصاتی بودند که بیش از یک بار تکرار شدند. این نیز نتیجه اشتراکگذاری تصاویر متعدد از یک مختصات توسط یک کاربر، یا حتی در موارد نادر، توسط چندین کاربر بود (به عنوان مثال، برجهای مشاهده زیستگاه).
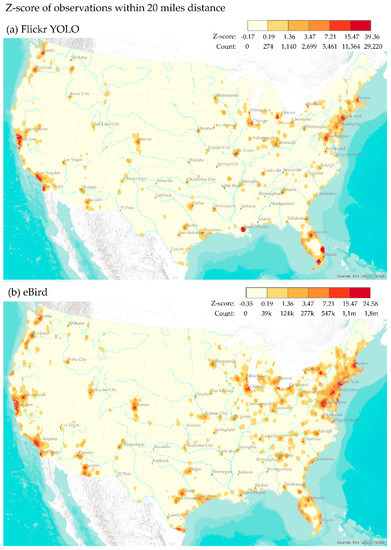
به منظور شناسایی تنوع فضایی بین تصاویر پرنده فلیکر و مشاهدات eBird، ما تخمین های چگالی هسته مشاهدات YOLO و eBird را با آستانه فاصله ثابت 20 مایل مقایسه کردیم (شکل 8) .). ما شاهد افزایش پراکندگی توزیع فضایی مشاهدات eBird بودیم که میتوان آن را به این واقعیت نسبت داد که eBird تقریباً 167 برابر بیشتر از عکسهای پرنده Flickr مشاهدات داشت و تقریباً 3.7 برابر بیشتر از کاربران Flickr که عکسهای پرنده گرفتند. ما امتیاز z را برای مشاهدات YOLO و eBird محاسبه کردیم تا دو توزیع مختلف را که در آن مشاهدات eBird چگالی بسیار بالاتری نسبت به عکسهای Flickr شناسایی شده توسط YOLO داشتند، مقایسه کنیم. ما امتیازهای z دو مجموعه داده را با هم ترکیب کردیم و از طبقه بندی شکست های طبیعی برای تعیین شکست های کلاس برای نقشه های Flickr و YOLO در شکل 8 استفاده کردیم . از شکل 8ما تأیید کردیم که توزیع فضایی مشاهدات eBird و عکسهای فلیکر مشابه یکدیگر بودند، به جز مناطق معدودی که در آنها بزرگی و وسعت فضایی مشاهدات eBird و Flickr تفاوتهای اساسی را نشان داد. هر دو مجموعه داده نشان داد که فعالیت های پرنده نگری در اطراف مناطق ساحلی و مناطق پرجمعیت مجاور مناطق شهری انجام می شود. در حالی که الگوهای فضایی پرنده نگری بین دو مجموعه داده مشابه بود، eBird در مناطق ساحلی شمال شرق، جنوب شرق، غرب، ساحل خلیج فارس و دریاچه های بزرگ نسبتا برجسته تر بود. جنگلهای ملی، زمینهای چمنزار، تالابها و مناطقی که زیرساختهایی برای دسترسی انسان و تماشای پرندگان وجود دارد. در حالی که بزرگی تراکم eBird بسیار بیشتر از Flickr در سراسر کشور بود،
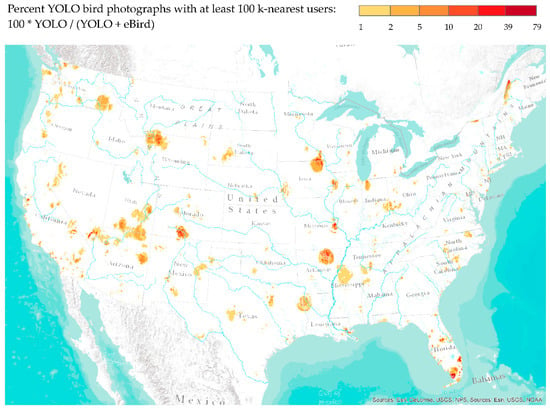
شکل 9 درصد تصاویر پرنده Flickr شناسایی شده توسط YOLO را در بین مشاهدات Flickr و eBird نشان می دهد. این رقم نسبت دوقطبی فلیکر به eBird را نشان میدهد و مناطقی را که عکسهای فلیکر شناسایی شده توسط YOLO بالای 1% هستند، با استفاده از هموارسازی هسته تطبیقی که از 100 نزدیکترین کاربر (هم فلیکر و هم eBird) برای شناسایی محله در پارامتر هموارسازی استفاده میکند، برجسته میکند. . شکل 9مناطق برجسته ای از عکس های پرندگان فلیکر در زمین های طبیعی را برجسته می کند که لانه سازی، توقف و زمستان گذرانی را برای پرندگان فراهم می کند. جالب توجه است که الگوهای فضایی بسیار متمایز و متفاوت از توزیع چگالی با فاصله ثابت بودند و ورودی ارزشمندی را ارائه میکردند که در آن استفاده از فلیکر در مقایسه با eBird نسبتاً بالاتر بود. صرف نظر از تفاوت بین تعداد مشاهدات بین فلیکر و eBird، عکس های پرنده فلیکر (بیش از 10٪) در مناطقی که دسترسی و زیرساخت برای پرنده نگری در سراسر کشور وجود داشت برجسته بودند. مناطق نمونه ای که عکس های پرندگان فلیکر نسبتاً بالاتر بود عبارتند از: رودخانه گرند کنیون و کلرادو پلاتو، پارک ملی سنگ زرد، کلرادو جنوبی، مناطق حفاظت شده ملی و حیات وحش در جنوب فلوریدا، و زمین های تالاب و دشت در غرب میانه.
4. بحث و نتیجه گیری
در این مقاله، ما یک چارچوب تحلیلی را معرفی کردیم که یک الگوریتم بینایی کامپیوتری مبتنی بر شبکههای عصبی کانولوشن (CNN) با تخمین چگالی هسته را برای شناسایی اشیاء و استنتاج الگوهای فعالیت انسانی از عکسهای برچسبگذاری شده جغرافیایی یکپارچه میکند. برای نشان دادن چارچوب خود، فعالیت پرنده نگری را با شناسایی پرندگان از تقریباً 20 میلیون تصویر به اشتراک گذاشته شده عمومی در فلیکر در یک دوره سه ساله از دسامبر 2013 تا دسامبر 2016 استنباط کردیم. مقایسه ما از مشاهدات Flickr و eBird تفاوت های رفتاری را در بین رسانه های اجتماعی و شهروندان برجسته می کند. کاربران علم، که ما بیشتر آن را به پرنده نگری معمولی (Flickr) و پرنده نگری جدی (eBird) نسبت می دهیم.
ما نشان دادهایم که چگونه الگوریتم بینایی کامپیوتر، YOLO، میتواند برای شناسایی اشیا و استخراج معنایی از تصاویر رسانههای اجتماعی دارای برچسب جغرافیایی و مهر زمان استفاده شود. تصاویر پرنده که فقط بر اساس فراداده طبقهبندی میشوند، اما نه با YOLO، منجر به دقت قابل ملاحظهای کمتر از 26% میشوند، در حالی که تصاویر پرنده که تنها توسط YOLO شناسایی میشوند، منجر به دقت 89% میشوند. مطالعه موردی ما در پرنده نگری، و مقایسه الگوهای گرفته شده از فلیکر با الگوهای مشاهدات eBird، سوگیری ها را در رسانه های اجتماعی و مجموعه داده های علوم شهروندی برجسته می کند. در حالی که eBird به شناسایی رفتارهای جدی پرنده نگری که در مناطق خاصی در سراسر ایالات متحده متمرکز است کمک می کند، الگوهای Flickr فعالیت های پرنده نگری معمولی و فضایی متنوع تری را پیشنهاد می کند.
در حالی که دادههای eBird در طیف گستردهای از مطالعات پرندهشناسی در مقیاسهای مکانی و زمانی گسترده استفاده شدهاند [ 19 ، 20 ]، و منبع داده به دلایل مختلفی مانند کاربران، مکانها و دورههای زمانی دارای تعدادی سوگیری مهم است. . به عنوان مثال، در حالی که در دوره های قبلی، دانشمندان شهروند اطلاعاتی را از مجموعه متنوعی از گونه ها جمع آوری می کردند، در سال های اخیر دانشمندان شهروند نسبت به جمع آوری اطلاعات در مورد گونه های در معرض تهدید و مناطق حفاظت شده تعصب داشتند [53] .]. از سوی دیگر، کاربران فلیکر معمولاً عکاسانی هستند که پرنده نگر نیز هستند و نه تنها تصاویر خود را آپلود می کنند، بلکه تصمیم می گیرند که آنها را برچسب جغرافیایی و اشتراک گذاری کنند. نتایج ما که توزیع فضایی دو مجموعه داده را مقایسه میکند، نتایج مشابه و همچنین برخی تغییرات جغرافیایی را برجسته میکند، که میتواند به تعصبات بالقوه در میان برنامههای کاربردی و کاربران علوم شهروندی و رسانههای اجتماعی نسبت داده شود. در حالی که کاربران eBird به احتمال زیاد مسافتهای طولانی را برای مشاهده پرندگان طی میکنند، کاربران Flickr پرندهنگاران معمولی هستند که احتمالاً از پرندهها در اطراف مکانهای فعالیت معمول خود عکس میگیرند. مطالعات آینده در مورد استخراج الگوهای تحرک کاربران eBird و Flickr می تواند به درک بهتر پویایی فعالیت های پرنده نگری کمک کند.
در کار آینده، ما قصد داریم ارزیابی دقت همه تصاویر طبقهبندیشده توسط فراداده و کتابخانه یادگیری عمیق YOLO را تکمیل کنیم. علاوه بر این، ما قصد داریم سایر کتابخانه های تشخیص اشیا را ارزیابی کنیم و نتایج دقت را با YOLO مقایسه کنیم. فراتر از محدوده تمرکز خاص ما بر پرنده نگری، ما قصد داریم ویژگی های مکان ها را بر اساس اشیاء شناسایی شده در یک منطقه در یک دوره زمانی مشخص شناسایی کنیم. به این ترتیب، بررسی میکنیم که آیا تشخیص شی میتواند برای ارتقای درک ما از مکانها، و معناشناسی تعبیهشده در آن مکانها، و شناسایی شباهتهای بین مکانها در سراسر جهان استفاده شود.






بدون دیدگاه