1. معرفی
تحقیق بر روی تشخیص شکل زمین، نقشهبرداری از مسیر تاریخی، وضعیت فعلی و گرایش آینده اشیاء زمین در مقیاسهای مختلف را امکانپذیر میسازد. مدل ارتفاعی دیجیتال با وضوح بالا (DEM) و مشتقات آن (به عنوان مثال، انحنا، شیب، جنبه) امکان نمایش جزئیات سطح زمین را در فضای سه بعدی ارائه می دهد که می تواند از برنامه های مختلف از جمله برآورد آسیب پذیری بلایای طبیعی پشتیبانی کند [1 ] ]، منظر شهری [ 2 ]، برنامه ریزی شهری [ 3 ]، پایداری اکولوژیکی [ 4در دهههای اخیر، تعدادی از سیستمهای طبقهبندی لندفرم برای تسهیل خصوصیات لندفرم پیشنهاد شدهاند، از جمله طبقهبندی متغیرهای ژئومورفولوژیکی و توصیفهای صریح مربوط به آنها [ 5 ، 6 ، 7 ، 8 ، 9 ، 10 ]. اگرچه تحقیقات تحقیقاتی قبلی در مورد خصوصیات لندفرم اهمیت متغیر ژئومورفولوژیکی را در به تصویر کشیدن ساختار اصلی سطوح زمین تصدیق کرد، متغیرهای ژئومورفولوژی نقطهای یا خطی به تنهایی نمیتوانند دقیقاً ساختار یک لندفرم منطقهای (مانند دهانه، دایره و غیره) را مشخص کنند.
اولین چالش از ناهمگونی بین پارامترهای ژئومورفولوژیکی نقطه ای و خطی ناشی از مجموعه داده DEM و کل ساختار یک شی زمین شکل [ 11 ] سرچشمه می گیرد. به عبارت دیگر، پارامترهای ژئومورفولوژیکی در اشکال مختلف برای نشان دادن شکل زمین که عموماً توسط قطعات متعدد در یک سازمان معنادار ترکیب شده است، کافی نیستند. تاکنون، مطالعات اندکی رویکردی را گزارش کرده اند که از معناشناسی شکل زمین برای تسهیل تشخیص اشیاء شکل زمین از DEM های با وضوح بالا استفاده می کند.
علاوه بر این، محدودیت های متغیرهای ژئومورفولوژیکی در خصوصیات لندفرم منجر به ظهور تعدادی از ویژگی های ژئومورفولوژیکی مبتنی بر منطقه مانند شکل، بافت، بافت و غیره می شود [12 ، 13 ، 14 ، 15 ، 16 ، 17 ، 18 ] . اگر چه راه حل های زیادی پیشنهاد شده است [ 12 ، 13 ، 14 ، 15 ، 16 ، 17]، چالشهای متعددی در میان رویکردهای مشخصهسازی لندفرم حل نشده باقی میمانند. اول، حقیقت زمین در مقیاس بزرگ یا مجموعه داده DEM با وضوح بالا در مورد اشیاء شکل زمین، در جامعه ژئومورفولوژی و تجزیه و تحلیل زمین در دسترس نیست. فقدان یک مجموعه داده آموزشی به خوبی آماده شده یک مانع حیاتی برای پیاده سازی الگوریتم های یادگیری ماشینی پیشرفته در تشخیص اشیاء شکل زمین است [ 19 ].
مهمتر از همه، تشخیص اشیاء لندفرم از DEM های با وضوح بالا با دو چالش مواجه است: (1) ناهمگونی بین پارامترهای ژئومورفولوژی نقطه ای و خطی و کل ساختار یک شی زمین شکل، و (2) در دسترس بودن محدود مجموعه داده DEM مناسب در مورد اشیاء شکل زمین. . بنابراین، این مقاله یک مدل یکپارچه به نام کیسه کلمات ژئومورفولوژیکی (BoGW) را گزارش میکند که تشخیص خودکار لندفرم را از طریق ادغام نقطه و متغیرهای ژئومورفولوژی خطی، ویژگیهای مبتنی بر منطقه (به عنوان مثال، شکل، بافت)، و توصیفات شکل زمین در سطح بالا امکانپذیر میسازد. باقیمانده این نسخه به شرح زیر تنظیم شده است. بخش 2 کارهای مربوط به تمرکز این مقاله را گزارش می کند. بخش 3معماری و جزئیات BoGW پیشنهادی را به ترتیب شامل تولید ویژگی، تولید کتاب کد و طبقهبندی ارائه میکند. بخش 4 نتیجه تشخیص دهانه و دایره را از طریق BoGW ارائه می کند. بخش 5 نتیجه گیری و دیدگاه مربوط به تلاش ما در مورد تشخیص شی ژئومورفولوژیکی از DEM های با وضوح بالا را ارائه می دهد.
2. آثار مرتبط
2.1. از متغیرهای ژئومورفولوژیکی تا جسم شکل زمین
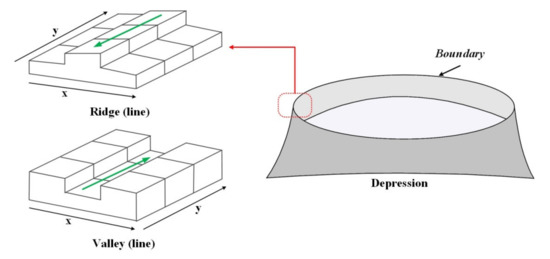
همانطور که در بالا ذکر شد، متغیرهای ژئومورفولوژیکی به تنهایی نمی توانند به طور موثر با نمایش جسم شکل زمین مقابله کنند. به عنوان مثال، برآمدگی و فرورفتگی نشان داده شده در قسمت سمت چپ نمی تواند ویژگی های یک دهانه را نشان دهد. در شکل 1 ، دهانه از چندین متغیر ژئومورفولوژیکی شامل خطوط برآمدگی و یک فرورفتگی تشکیل شده است. علاوه بر این، خطوط برآمدگی و فرورفتگی نزدیک به دایره هستند که به پارامترهای سطح منطقه اشاره دارد. بنابراین، تشخیص در این شی دهانه نه تنها خطوط برآمدگی و فرورفتگی را از DEM های با وضوح بالا تشخیص می دهد، بلکه تعیین می کند که آیا شکل آنها به دایره نزدیک است یا خیر.
برای ترسیم شکاف بین پارامترهای ژئومورفولوژیکی و شی زمین شکل، BoGW را بر اساس رابطه بین متغیرهای ژئومورفولوژیکی و کل شیء شکل زمین طراحی کردیم. به طور مفصل، بخش اول BoGW انواع متغیرهای ژئومورفولوژیکی را استخراج می کند، و بخش دوم BoGW روشی را که متغیرهای ژئومورفولوژیکی به صورت معنایی یک شی زمین شکل را تشکیل می دهند، کشف می کند.
2.2. مدل کیسه ای کلمات در تحلیل متن و تصویر
کیسه کلمات (BoW) مدلی برای کشف موضوع اطلاعات متنی با تکنیک های یادگیری ماشینی [ 20 ] است که به طور گسترده در پردازش زبان طبیعی و بازیابی اطلاعات استفاده می شود. کیف در این مدل به سندی اشاره دارد که شامل چند کلمه است. بدون در نظر گرفتن ترتیب کلمات در یک جمله، فراوانی هر کلمه در یک کیف به عنوان ویژگی برای تعیین موضوع این کیف (سند) استفاده می شود. BoW به طور کلی شامل دو مرحله است: طراحی یک لیست واژگان از اسناد و سپس ایجاد یک بردار ویژگی (یا ماتریس معنایی) برای نمایش سند. علاوه بر این، عملیات دیگری برای مدیریت واژگان انجام شد، مانند هش کردن کلمه، n-gram، stopwords، و فرکانس اصطلاح-فرکانس معکوس سند (TF-IDF).
فکر BoW توجه مطالعات پردازش تصویر و تجزیه و تحلیل الگو را به خود جلب می کند. صحنه و شیء تصویر همیشه حاوی چندین عنصر معنادار هستند. بنابراین، بر اساس دامنه BoW، مدلی به نام کیسه کلمات بصری (BoVW) پیشنهاد شد تا ساختار صحنه و شیء تصویر را از طریق ویژگیهای بصری محلی نشان دهد [ 21] .]. کیسه در BoVW به تصاویر اشاره دارد و کلمات بصری به ویژگیهای محلی گروهبندی شده معنایی (مثلاً تبدیل ویژگی تغییر ناپذیر مقیاس-SIFT) اشاره دارد. BoVW به طور کلی شامل سه مرحله است: تشخیص ویژگی ها از طریق توصیفگرهای ویژگی قوی، تولید یک کتاب کد برای سازماندهی ویژگی های شناسایی شده، و طبقه بندی یک تصویر با کتاب کد توسط یک مدل یادگیری تولیدی یا یک مدل یادگیری متمایز. “کد” در این کتاب کد به نتایج به دست آمده توسط توصیفگرهای ویژگی اشاره دارد که مشابه کلمه در یک سند است).
اگرچه BoW و BoVW در بسیاری از کاربردها در سالهای اخیر به کار گرفته شدهاند، تفکر BoW و BoVW هنوز در تحلیل زمین به کار گرفته نشده بود. فکر BoW و BoVW که یک شی را به قطعات متعدد تجزیه میکند و به راحتی قابل تشخیص است، ما را به طراحی مدلی تشویق میکند که همچنین امکان استفاده از مزایای BoVW را در تشخیص شکل زمین بر اساس DEMهای با وضوح بالا فراهم میکند. جزئیات BoGW پیشنهادی ما در بخش 3 ارائه شده است .
3. کلمات ژئومورفومتریک کیسه ای (BoGW) برای تشخیص شکل زمین
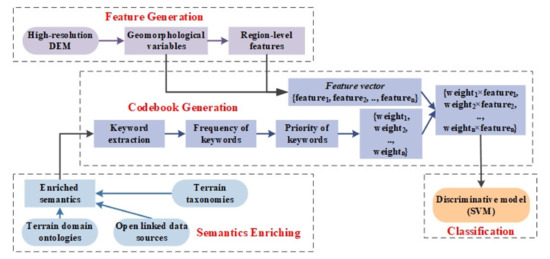
با اشاره به گردش کار BoW و BoVW، شکل 2معماری کلمات ژئومورفومتری کیسهای (BoGW) را نشان میدهد که از سه بخش تشکیل شده است: (1) غنیسازی معنایی: غنیسازی معنایی شکلهای زمین از منابع داده پیوندی باز. (2) تولید ویژگی: ایجاد یک بردار ویژگی شامل متغیرهای ژئومورفولوژیکی و ویژگیهای سطح منطقه. (3) تولید کتاب کد: ایجاد یک کتاب کد برای ترکیب متغیرهای ژئومورفولوژیکی و ویژگیهای سطح منطقه (پارامترهای کمی) و معنایی شکلهای زمین (وزنهای کیفی). (4) طبقه بندی: طبقه بندی هر شی به یک کلاس از پیش تعریف شده بر اساس خروجی کتاب کد. در BoGW واژههای ژئومورفولوژیکی به متغیرهای ژئومورفولوژیکی و ویژگیهای منطقهمحور از جمله شکل، بافت و غیره اشاره دارند. Bag به مجموعه متغیرهای ژئومورفولوژیکی و ویژگیهای منطقهمحور اشاره دارد.
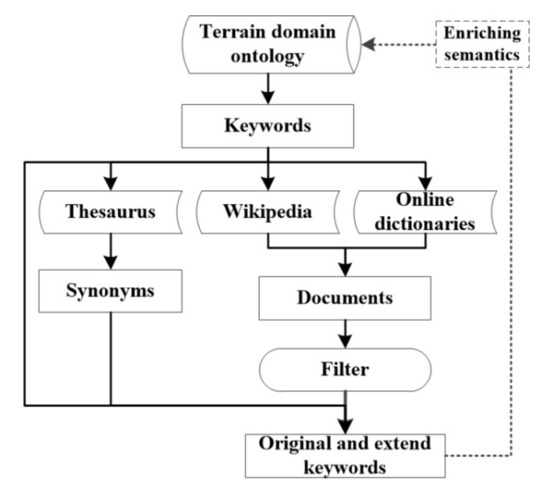
غنیسازی معنایی اطلاعات به دست آمده از هستیشناسیهای حوزه زمین، طبقهبندی زمین و منابع دادهای باز (مانند اطلاعات جغرافیایی داوطلبانه، ویکیپدیا، و غیره) را یکپارچه میکند. هستی شناسی ها و طبقه بندی های زمین موجود ممکن است حاوی اطلاعات معنایی محدودی باشد. بنابراین، ما این مرحله را برای غنی سازی محتوای معناشناسی طراحی می کنیم.
نمایش ویژگی یک بردار ویژگی ایجاد می کند که شامل متغیرهای ژئومورفولوژیکی و ویژگی های مبتنی بر منطقه مربوط به تغییرات ارتفاع، گرادیان ارتفاع، جهت شیب و غیره است: {ویژگی 1 ، ویژگی 2 ، …، ویژگی n }، که در آن n تعداد ویژگی ها است. جزئیات متغیرهای ژئومورفولوژیکی و ویژگی های منطقه در جدول 1 زیربخش بعدی فهرست شده است.
هدف تولید کتاب کد استخراج معنای هر طبقه زمین از طبقه بندی موجود و غنی سازی معناشناسی با منابع داده باز خارجی، مانند ویکی پدیا و فرهنگ لغت آنلاین است. سپس، ما کلمه کلیدی را که برای توصیف صریح کلاسهای زمین پشتیبانی میکند، از معناشناسی غنی شده استخراج میکنیم. علاوه بر این، از آنجایی که اهمیت هر کلمه کلیدی در مشخص کردن کلاس لندفرم متفاوت است، ما اولویت هر کلمه کلیدی را از طریق یک بردار وزنی-{weight 1 , weight 2 , …, weight n }- ایجاد شده توسط تحلیل معنایی پنهان (LSA) به صورت کمی وزن می کنیم. در نهایت، بردار ویژگی و بردار وزنی را در یک بردار ویژگی وزندار جدید ترکیب میکنیم—{weight 1 × feature 1 , weight 2× ویژگی 2 ، …، وزن n × ویژگی n }. سپس بردار ویژگی وزنی به عنوان ویژگی ورودی برای طبقه بندی مبتنی بر SVM استفاده می شود.
3.1. نسل ویژگی
3.1.1. استخراج متغیر ژئومورفولوژیکی
ما از یک رویکرد فضایی-زمینی [ 14 ] برای شناسایی متغیرهای ژئومورفولوژیکی بر اساس جنبه و انحنا استفاده می کنیم. این رویکرد به دلیل توانایی آن در تشخیص متغیرهای ژئومورفولوژیکی از DEM با وضوح بالا و پایین به خوبی مورد استفاده قرار می گیرد.
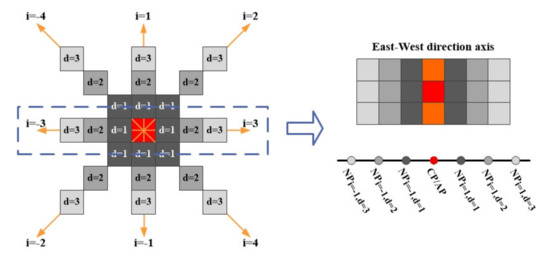
شکل 3 اصل این روش را نشان می دهد. در شکل 3 ، سلول قرمز یک پیکسل (CP) در یک DEM است، تا مشخص شود که آیا به یک متغیر ژئومورفولوژیکی تعلق دارد یا خیر. سلول های نارنجی پیکسل های مجاور آن (AP) و سلول های خاکستری پیکسل های مجاور آن (NP) در فواصل متعدد هستند. د و منبه ترتیب فاصله و شاخص جهت را نشان می دهند. این رویکرد فضایی-مکانی، تفاوت ابعاد و اختلاف ارتفاع بین پیکسل قرمز (CP) و پیکسل همسایه آن (NP) را در هر محور جهت در فواصل متعدد، و تفاوت ابعاد و اختلاف ارتفاع بین یکی از پیکسلهای مجاور آن (AP) را اندازهگیری میکند. و پیکسل همسایه این AP (NP) در هر محور جهت در فواصل متعدد. مجموعه جهت شامل محور جهت شرق – غرب، محور جهت شمال – جنوب، محور جهت شمال شرق – جنوب غرب و محور جهت شمال غرب – جنوب شرق است. سپس، نتایج تفاوت ابعاد و اختلاف ارتفاع برای تعیین اینکه آیا این پیکسل قرمز به یک متغیر ژئومورفولوژیکی از پیش تعریف شده تعلق دارد یا خیر، ترکیب میشوند.
3.1.2. تشخیص ویژگی مبتنی بر منطقه
رویکرد استخراج ویژگی مبتنی بر منطقه به شرح زیر خلاصه می شود:
- (1)
-
لحظه تغییرات ارتفاع را اندازه گیری می کند و شامل اولین گشتاور خام (میانگین)، دومین لحظه مرکزی (واریانس یا انحراف معیار)، سومین ممان مرکزی (چرخش) و چهارمین ممان مرکزی (کورتوزیس) است. عبارات این چهار لحظه در معادله زیر نشان داده شده است:
جایی که [ خطای پردازش ریاضی ]�نشان دهنده ارتفاع یک پیکسل در DEM است، [ خطای پردازش ریاضی ]نبه تعداد پیکسل ها در کل DEM یا منطقه محلی DEM اشاره دارد.
- (2)
-
شیب نشان دهنده شیب سطح زمین در ابعاد عمودی و افقی است. انحنا نشان دهنده “شیب” شیب است. در جزئیات، انحنای پروفیل محدب و مقعر یک شیب بر روی بعد عمودی را توصیف می کند، و انحنای پلت فرم محدب و مقعر یک شیب بر روی بعد افقی را توصیف می کند.
- (3)
-
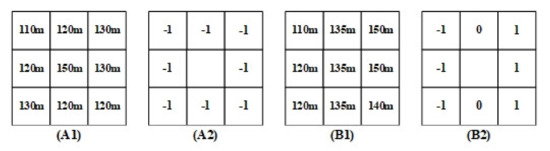
الگوی باینری محلی (LBP) [ 22 ] جهت هر پیکسل را بر اساس هیستوگرام گرادیان (HOG) محاسبه می کند. برخلاف LBP در بینایی کامپیوتر که گرادیان شدت را اندازه میگیرد، این مقاله LBP را بر اساس گرادیان ارتفاع محاسبه میکند [ 14 ]. با فرض اینکه جهت یک پیکسل با یک بردار نشان داده شده است—[d1, d2, d3, d4, d5, d6, d7, d8] که d1–d8 به ترتیب به تفاوت بین پیکسل مرکزی و پیکسل همسایه آن در 8 اشاره دارد. جهت ها. اگر پیکسل مرکزی کمتر، مشابه یا بالاتر از پیکسل همسایه خود باشد، مقدار d* به ترتیب به 1-، 0 و 1 اختصاص داده می شود.
یک کار قبلی تصدیق کرد که الگوی تولید شده توسط LBP می تواند جزئیات بیشتری را ارائه دهد [ 15 ]. در شکل 4 ، اگر دو پیکسل به ترتیب به قله و صخره تعلق داشته باشند. ابعاد این دو پیکسل برابر است – 315 درجه، به این معنی که این جنبه به تنهایی نمی تواند تفاوت آنها را تشخیص دهد. در همین حال، الگوی LBP این دو پیکسل ( شکل 4 (A2,B2)) متفاوت است: [-1,0,1,1,1,0,-1,-1] و [-1,-1,- 1،-1،-1،-1،-1،-1]، به ترتیب.
رویکردهای تشخیص ویژگیهای مبتنی بر منطقه زیر بر اساس نتایج استخراج متغیر ژئومورفولوژیکی است.
- (4)
-
تبدیل دایره Hough بر تعیین اینکه آیا یک دایره در نتیجه استخراج متغیر ژئومورفولوژیکی وجود دارد یا خیر تمرکز دارد. این ویژگی برای تشخیص شکلهای دایرهای مانند دهانه، آتشفشان و غیره مفید است. از طریق تعریف حداقل و حداکثر شعاع، تبدیل دایره Hough برای شناسایی همه دایرههای ممکن پشتیبانی میکند.
- (5)
-
هدف تقریب کانتور تشخیص شکل مستطیل از نتیجه استخراج متغیر ژئومورفولوژیکی است. شکل مستطیل را می توان در سطح زمین که در اثر کنده کاری و رسوب تشکیل شده است، مانند دره، کارست و غیره مشاهده کرد.
مهمتر از همه، ساختار بردار ویژگی ها به صورت زیر نشان داده شده است:
جایی که [ خطای پردازش ریاضی ]�شاخص طبقه بندی زمین است. [ خطای پردازش ریاضی ]��متر�متربه ویژگی لحظه ای اشاره دارد که دارای چهار نوع لحظه است: [ خطای پردازش ریاضی ]دمنمتر��متر�متر=4. [ خطای پردازش ریاضی ]افلبپبه نقشه الگوی LBP اشاره دارد که شامل LBP هر پیکسل در هشت جهت است: [ خطای پردازش ریاضی ]دمنمتر��لبپ=1. [ خطای پردازش ریاضی ]��سساعتپبه نتیجه باینری تبدیل هاف و تقریب کانتور اشاره دارد. اگر شکل دایره یا مستطیل قابل تشخیص باشد، [ خطای پردازش ریاضی ]��سساعتپ1 است، در غیر این صورت 0 است. [ خطای پردازش ریاضی ]��سلپو [ خطای پردازش ریاضی ]��جتو��به ترتیب به نتیجه شیب و میانگین انحنا اشاره دارد.
3.2. نسل کتاب کد
در عمل، همه موارد موجود در بردار ویژگی معادله (1) برای تشخیص کلاس های لندفرم خاص مفید نیستند. کارهای قبلی ثابت کردند که عملکرد یادگیری ماشین در طبقهبندی به شدت به ویژگیهای پراکندهای که برای نمایش دادهها مفید هستند متکی است [ 23 ]. بنابراین، هدف تولید کتاب کد انتخاب ویژگیهای پراکنده مناسب برای نمایش هر کلاس لندفرم است. شکل 5 گردش کار تولید کتاب کد را نشان می دهد که از چهار مرحله تشکیل شده است: انتخاب کلمات کلیدی از هستی شناسی ها و منابع داده خارجی باز، فیلتر کردن کلمات کلیدی نامربوط، جمع آوری کلمات کلیدی با تجزیه و تحلیل معنایی پنهان، و اختصاص اولویت به هر کلمه کلیدی.
3.2.1. انتخاب کلمه کلیدی توسط هستی شناسی و منابع داده باز
افراد لندفرم ها را بر اساس توصیف های صریح سطح بالا، به جای ویژگی های سطح پیکسل یا ویژگی های خطی مشتق شده از DEM ها، تعریف و دسته بندی می کنند. مفهوم حوزه ای که ویژگی های لندفرم ها را تعریف می کند در هستی شناسی ها، سیستم طبقه بندی و منابع پیوندی باز، مانند هستی شناسی شکل زمین [ 24 ، 25 ]، هستی شناسی زمین شناسی [ 26 ]، هستی شناسی هیدروژئولوژی [ 27 ]، و هستی شناسی توپوگرافی [ 28] ارائه شده است. ].
با این حال، تعاریف رسمی برای اشیاء، ویژگیها، رویدادها و پدیدهها در هستیشناسیها و سیستمهای طبقهبندی همیشه به پیشینه خاصی در یک دوره معین محدود میشوند. بنابراین، علاوه بر اطلاعات معنایی در هستی شناسی های حوزه زمین، ما سعی می کنیم دامنه و مقدار اطلاعات معنایی را از سه منبع پیوند باز خارجی گسترش دهیم: فرهنگ لغت آنلاین (Dictionary و Webster Merriam)، ویکی پدیا، و اصطلاحنامه. ویکی پدیا یک دایره المعارف آنلاین رایگان است که توسط داوطلبان در سراسر جهان ایجاد و ویرایش شده و توسط بنیاد ویکی مدیا میزبانی می شود. اطلاعات ویکیپدیا در بسیاری از زمینهها استفاده شده است [ 29 , 30 , 31]. در مقایسه با اطلاعات سایر منابع، منشأ تعاریف و مقدمهها در ویکیپدیا برچسبگذاری شدهاند. علاوه بر این، این منشأها از مواد آموزشی، ادبیات داوری شده و کتابها است. اینها اطلاعات ذخیره شده در ویکی پدیا را نسبت به اطلاعات سایر منابع داوطلبانه قابل اعتماد می کند.
ابتدا، ما کلمات کلیدی (کلمات و عبارات) را از حاشیه نویسی و تعریف هر کلاس لندفرم در هستی شناسی ها و طبقه بندی های دامنه استخراج می کنیم. نمونه ای از استخراج کلمه کلیدی در جدول 1 نشان داده شده است . نام کلاس و حاشیه نویسی کلاس از USTopographic [ 28 ] است. دو جمله “ناشی از برخورد شهاب سنگ” و “ناشی از انفجار” به عنوان کلمه کلیدی انتخاب نمی شوند، زیرا آنها یک عمل پویا را همراه با تغییرات زمان بیان می کنند که تشخیص آن از DEM غیرممکن است. به طور خاص، حروف اضافه، حرف های معین، حرف های نامشخص همه در اینجا حذف می شوند. جزئیات عملیات حذف کلمات کلیدی نامربوط در بخش 3.2.3 معرفی شده است .
سپس، کلمات کلیدی مشتق شده از هستی شناسی ها و طبقه بندی های دامنه نشان داده شده در جدول 1 برای جمع آوری تمام جملاتی که حاوی این کلمات کلیدی هستند از فرهنگ لغت آنلاین و ویکی پدیا استفاده می شوند. جدول 2 نمونه ای از گسترش کلمات کلیدی مربوط به دهانه را از فرهنگ لغت آنلاین (فرهنگ لغت) نشان می دهد. تمام کلمات کلیدی مشتق شده از USTopographic در جدول 1 به عنوان متن سیاه و سفید علامت گذاری شده اند. علاوه بر این، انواع مختلفی از کلمات کلیدی استخراج شده از جملات جمعآوریشده از دیکشنری را با رنگهای مختلف برچسبگذاری میکنیم تا به وضوح منشأ هر یک از کلمات کلیدی را نشان دهیم.
منبع دیگری که برای غنی سازی کلمات کلیدی پشتیبانی می کند، مترادف هر کلمه کلیدی است که توسط Thesaurus ارائه شده است. مترادف اصطلاحنامه در موارد قبلی مانند پرسش اطلاعات [ 32 ، 33 ] و بازیابی اطلاعات [ 34 ] استفاده شده است. در این مقاله، ما کلمات کلیدی مشتق شده را از نظر ارتباط رتبه بندی می کنیم و مترادفی را که اولویت کمتری در نتیجه رتبه بندی دارد حذف می کنیم.
3.2.2. پس پردازش و فیلتر کردن متن مبتنی بر کلمات کلیدی
کلمه کلیدی استخراج شده از هستی شناسی ها، دیکشنری ها و ویکی پدیا ممکن است دارای پسوند و پیشوند باشد، مانند چند-، نیمه-، -پایه، -شکل، -driven، -like و غیره. ما n-gram را به عنوان کلمه ای که پیشوند یا پسوند تعریف می کنیم. با. به عنوان مثال، کاسه شکل به عنوان یک کلمه کلیدی تعریف می شود: کاسه . علاوه بر این، برای n-gram های دیگر که حاوی چندین کلمه بدون پیشوند و پسوند هستند، این نوع n-gram ها را به دو کلمه تقسیم می کنیم. به عنوان مثال، اثرات شوک دگرگونی به عنوان دو کلمه کلیدی تعریف می شود: اثرات شوک و اثرات دگرگونی.
علاوه بر پسوند، پیشوند و n-gram، محتوای موجود در برخی از کلمات کلیدی ممکن است برای تشخیص لندفرم مبتنی بر LiDAR بی معنی باشد. جدول 3 فهرستی از این کلمات کلیدی را که باید با چندین دسته حذف شوند، خلاصه می کند.
3.2.3. وزن بردار ویژگی
ما آمار فراوانی هر کلمه کلیدی را بر روی نتایجی که توسط پس پردازش و فیلتر متن به آنها دسترسی دارند، انجام می دهیم. فراوانی کلمات کلیدی به صورت یک بردار وزنی سازماندهی شده است که در معادله زیر نشان داده شده است:
جایی که [ خطای پردازش ریاضی ]��متر�متر، [ خطای پردازش ریاضی ]��لبپ، [ خطای پردازش ریاضی ]��سساعتپ، [ خطای پردازش ریاضی ]��سلپو [ خطای پردازش ریاضی ]��جتو��وزن را برای [ خطای پردازش ریاضی ]�متر�متر، [ خطای پردازش ریاضی ]�لبپ، [ خطای پردازش ریاضی ]�سساعتپ، [ خطای پردازش ریاضی ]�سلپو [ خطای پردازش ریاضی ]�جتو��، به ترتیب در معادله (2). سپس، بردار ویژگی وزنی نشان داده شده در شکل 1 به صورت زیر بیان می شود:
3.3. نگاشت بین تولید ویژگی و چکیده سطح بالا
جدول 4 جزئیات متغیرهای ژئومورفولوژیکی و ویژگی های منطقه محور را فهرست می کند. ستونی با عنوان ویژگی Data داده هایی را فهرست می کند که از تشخیص ویژگی پشتیبانی می کند. ستونی با عنوان چکیده سطح بالا شامل کلمه کلیدی برای توصیف شکل زمین است که متغیرهای ژئومورفولوژیکی و ویژگیهای مبتنی بر منطقه ممکن است نشان دهند.
3.4. طبقه بندی
بخش طبقه بندی با هدف یادگیری ویژگی های وزنی کلاس های لندفرم و پیش بینی اینکه آیا یک منطقه شناسایی شده متعلق به یک کلاس لندفرم است یا خیر. ویژگی های ورودی برای آموزش و متن از ساختار بردار ویژگی وزنی نشان داده شده در معادله (4) پیروی می کند. جدول زیر گردش کار طبقه بندی را خلاصه می کند:
| بخش آموزشی: |
| مرحله A1. برچسب گذاری جعبه مرزی حداقل (MBB) چندین شی متعلق به یک کلاس لندفرم از پیش تعریف شده بر اساس DEM های با وضوح بالا. |
| مرحله A2. محاسبه فراوانی کلمات کلیدی برای این کلاس لندفرم از پیش تعریف شده، و ایجاد یک بردار وزن مرجع. |
| مرحله A3. ایجاد یک بردار ویژگی مرجع بر اساس MBB های این کلاس لندفرم از پیش تعریف شده. |
| مرحله A4. ایجاد یک بردار ویژگی وزنی مرجع از طریق ترکیب بردار وزن مرجع و بردار ویژگی مرجع. ساختار بردار ویژگی وزنی مرجع در رابطه (4) نشان داده شده است. |
| بخش تست: |
| مرحله T1. تشخیص متغیرهای ژئومورفولوژیکی با رویکرد فضایی متنی گزارش شده در [ 14 ]. |
| مرحله T2. تولید چندین MBB بر اساس نتیجه تشخیص متغیر ژئومورفولوژیکی. |
| مرحله T3. ایجاد بردار ویژگی برای هر مگابایت دریافتی توسط مرحله T2 . |
| مرحله T4. ایجاد یک بردار ویژگی وزنی مرجع برای هر مگابایت دریافتی توسط مرحله T2 ، از طریق ترکیب بردار وزن ارجاع شده به دست آمده توسط مرحله A2 و بردار ویژگی ایجاد شده توسط مرحله T3 . |
| بخش پیش بینی: |
| انجام طبقهبندی از طریق طبقهبندی کننده SVM: دادههای آموزشی بردار ویژگی وزنی است که در مرحله A4 به دست میآید و دادههای آزمون بردار ویژگی وزنی است که توسط مرحله T4 به دست میآید. |
4. تجزیه و تحلیل تجربی
بر اساس DEM های با وضوح بالا، دهانه، دایره و صخره را به عنوان کلاس لندفرم انتخاب کردیم تا در بخش تجربی شناسایی شوند. کار قبلی ما [ 14 ] نشان داد که برخی از رویکردهای رایج برای DEM با وضوح فضایی متوسط نمی توانند در DEM با وضوح بالا عملکرد خوبی داشته باشند. نتایج نشان داده شده در مرجع [ 14 ] ثابت کرد که الگوریتم های سنتی برای تشخیص دهانه بدون پردازش اضافی نمی توانند کل ساختار دهانه ها را استخراج کنند. در آزمایش خود، ما همچنین متوجه شدیم که ساختار دهانه و سیرک در DEM با وضوح بالا مورد استفاده در آزمایش موجود نیست. بنابراین، این مقاله فقط عملکرد روش ما را گزارش کرد.
هستی شناسی و طبقه بندی دامنه USTopographic است و منبع داده با پیوند باز شامل Dictionary، Merriam Webster و Wikipedia است. در بخش اول آزمایش، ما تمام اطلاعات مربوط به دهانه، دایره و صخره را از منابع داده های USTopographic و پیوند باز استخراج کردیم و سپس به صورت معنایی اطلاعات را برای غنی سازی معناشناسی در USTopographic سازماندهی کردیم. در قسمت دوم، نتایج تشخیص دهانه، سیرک و صخره را از طریق BoGW ارائه کردیم.
4.1. غنی سازی معناشناسی
ما نتیجهی معناشناسی را غنیسازی ساختمان نشان دادیم که یک دهانه را به عنوان مثال در نظر گرفتیم. گردش کار شامل سه مرحله معرفی شده در بخش 4 است: استخراج کلمات کلیدی از USTopographic، جملات و اسناد مشتق شده از منابع داده با پیوند باز (Dictionary، Merriam Webster و Wikipedia) بر اساس کلمات کلیدی استخراج شده، و جملات و اسناد مفید انتخاب شده.
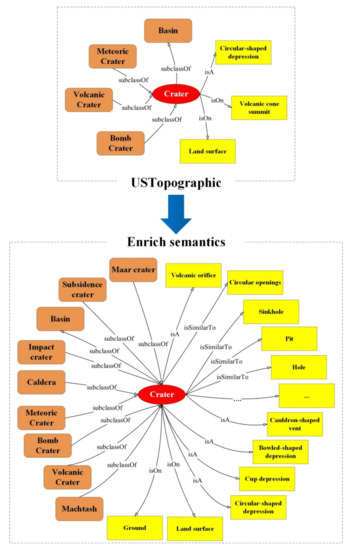
جدول 5 فراوانی کلمات کلیدی را فهرست می کند. کلمات کلیدی به ترتیب از USTopographic ( جدول 1 ) و Dictionary، Merriam-Webster و Wikipedia ( جدول 2 ) استخراج شدند. کلمات کلیدی نامربوط نشان داده شده در جدول 3 فیلتر شدند و کلمات کلیدی باقی مانده با ویژگی ها مطابقت داده شدند ( جدول 4 ). جزئیات نگاشت بین کلمات کلیدی و ویژگی ها در جدول 5 فهرست شده است . به طور خاص، اصطلاح “داخل دهانه” به شدت با “حوضه” و “افسردگی” با توجه به USTopographic، Dictionary، Merriam-Webster و Wikipedia مرتبط بود. بنابراین، ما حوضه و فرورفتگی را به عنوان دو کلیدواژه برای نمایش دهانه در نظر گرفتیم.
محتوای موجود در جدول 5برخی از پدیده ها را آشکار کرد. اول، سه کلمه کلیدی موجود در USTopographic – فرورفتگی دایرهای شکل، قله مخروط آتشفشانی و سطح زمین – در کلیدواژه اولیه، ثانویه و چهارم قرار گرفتند. این بدان معنی است که هستی شناسی و طبقه بندی دامنه می تواند اصطلاحات حرفه ای و معمولی را برای توصیف رسمی یک کلاس لندفرم ارائه دهد. علاوه بر این، برخی از کلیدواژههای نامربوط، مانند سنگ، حاوی top، flack volcano و غیره، و کلمات کلیدی با رتبه برتر (به عنوان مثال، سوراخ / گودال / فروچاله / دهانههای دایرهای، بالا بردن لبه / تشکیل حلقه) معمولاً در دامنه مشاهده میشوند. هستی شناسی و طبقه بندی و منابع داده با پیوند باز. این نشان میدهد که ویژگیهای یک کلاس لندفرم عموماً با توصیفهای مشابه از منابع متفرقه تعریف میشوند. این پدیده همچنین ثابت کرد که اطلاعات از هستیشناسیها و طبقهبندیهای حرفهای و مجموعه دادههای داوطلبانه برای پشتیبانی از تشخیص و طبقهبندی شکل زمین مفید بودند. علاوه بر این،جدول 5 متغیرهای ژئومورفولوژیکی مرتبط با کلمات کلیدی و ویژگی های مورد استفاده برای دهانه و دایره، و الگوریتم های مربوطه برای تشخیص آن متغیرها و ویژگی ها را فهرست کرده است. بنابراین، با توجه به نتایج فهرست شده در جدول 5 ، WF دهانه و سیرک به صورت زیر نشان داده شده است:
جایی که [ خطای پردازش ریاضی ]�سساعتپ1و [ خطای پردازش ریاضی ]�سساعتپ2به ترتیب نشان دهنده شکل دایره ای و شکل دایره ای بسته است. [ خطای پردازش ریاضی ]�سلپ1و [ خطای پردازش ریاضی ]�سلپ2به ترتیب شیب و صخره را نشان می دهد.
علاوه بر این، ما کلمات کلیدی استخراج شده از دهانه را از طریق ایجاد فروشگاه های سه گانه به عنوان معناشناسی سازماندهی کردیم [ 35 ]. شکل 6 سلسله مراتب مفهومی را از هستی شناسی موجود و معناشناسی غنی مقایسه کرد. فروشگاه سه گانه محصور شده توسط مستطیل های گرد نارنجی نشان دهنده کلمه کلیدی است که رابطه بین دهانه و سایر کلاس های شکل زمین را تعریف می کند، و ذخیره سه گانه محصور شده توسط مستطیل های زرد نشان دهنده کلمه کلیدی است که کلاس دهانه را مشخص می کند. اطلاعات به دست آمده با کشف اسناد مربوطه از منابع داده با پیوند باز می تواند به طور موثر معنای یک کلاس لندفرم را غنی کند و ویژگی های بیشتری را برای این خصوصیات لندفرم فراهم کند.
4.2. تشخیص دهانه و سیرک
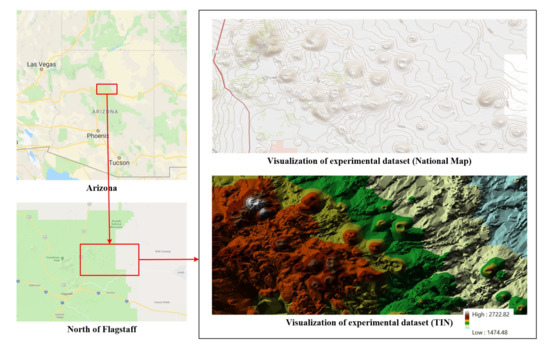
برای تأیید سهم معناشناسی غنیسازی و عملکرد BoGW در تشخیص اشیاء شکل زمین از DEM، ما نتایج تشخیص را در تشخیص دهانه و دایره بر اساس یک مجموعه داده DEM در مقیاس بزرگ که از برنامه ارتفاع سهبعدی ایجاد شده توسط سازمان زمینشناسی ایالات متحده [36] قابل دسترسی است، نشان دادیم . ]. مجموعه داده تجربی عمدتاً بنای یادبود ملی آتشفشان غروب غروب را پوشش می دهد که در شمال فلگستاف در ایالت آریزونا ایالات متحده واقع شده است. بنای یادبود ملی آتشفشان دهانه غروب خورشید مکان مهمی است که در آن امکان مشاهده و مطالعه دهانه ها و سیرک های آتشفشانی جوان را فراهم می کند. شکل 7مکان و تجسم مجموعه داده آزمایش را نشان می دهد. تعدادی از دهانه ها به وضوح در نقشه ملی و داده های TIN قابل مشاهده هستند. وسعت DEM یک ناحیه مستطیل شکل است که دارای مختصات بالا سمت چپ (35.430462963، −111.573981482) و مختصات پایین سمت راست (35.2937037037، −111.248425926) است. ما میتوانیم از DEM برای شناسایی دقیقتر سیستم مختصات 1 crameri و DEM استفاده کنیم. با وضوح فضایی 1 متر، ابعاد 3516 × 1477.
همانطور که در جدول 4 نشان داده شده است ، خط الراس به یک عنصر اساسی دهانه و سیرک اشاره دارد. بنابراین، ما خطوط برآمدگی را با رویکرد فضایی – زمینهای شناسایی کردیم. در اینجا 0.46 را به عنوان آستانه اختلاف ارتفاع در روش انتخاب کردیم. شکل 8A نتیجه تشخیص خط الراس را نشان می دهد. خطوط برآمدگی شناسایی شده به عنوان خطوط قرمز برچسب گذاری شدند و پس زمینه یک نقشه انحنا بود. اکثر خطوط برآمدگی متعلق به لبه دهانه ها و سیرک ها قابل تشخیص هستند. با توجه به سطح زمینی ناهموار که DEM با وضوح بالا همیشه نشان دهنده آن است، برخی از خطوط برآمدگی خطی و گسترده نبودند. با این حال، اصلاح بیشتری برای این خطوط برآمدگی قطع شده داده نشد. ما دریافتیم که بسیاری از خطوط برآمدگی به عنوان یک ویژگی خطی نشان داده نمیشوند، که با نمایش مشاهده شده در یک DEM با وضوح پایین متفاوت است.
سپس، MBB را محاسبه کردیم که نتیجه تشخیص متغیر ژئومورفولوژیکی (خط پشته) را در بر می گیرد. علاوه بر این، با توجه به اینکه لبه های یک دهانه ممکن است به عنوان رشته های مختلف خط الراس شناسایی شوند، ما هر MBB مشابه را در مقیاس های متعدد ایجاد کردیم. شکل 8 B نتیجه MBB چند مقیاسی را نشان می دهد. خطوط سیاه به خط الراس شناسایی شده اشاره دارد. جعبه های قرمز، جعبه های نارنجی و جعبه های آبی به ترتیب نشان دهنده MBB ساخته شده با مقیاس کوچک، متوسط و بزرگ هستند.
در جدول 3 ، دهانه و سیرک کلمات کلیدی مشابهی را به اشتراک گذاشتند، مانند فرورفتگی، کاسه شکل، نیمه محصور، و غیره . بیضی قرمز لبه های ایده آل دهانه را نشان می داد و خط فیروزه ای خط الراس نامرئی از تصویر ماهواره ای بود. شکل 9 A دهانه ای را نشان می دهد که دارای یک مرز صاف در قسمت جنوب شرقی آن است که به عنوان منحنی فیروزه ای نشان داده شده است. چنین کیتری که شکافی در لبه اطراف داشت، در مجموعه دادههای آزمایشی نیز دیده میشود. جسم موجود در شکل 9 B به نظر می رسید که تقریباً به جای دهانه یک توخالی باشد، زیرا دارای یک ناحیه کف پهن و صاف بود. شکل 9C دهانه ای را نشان داد که ویژگی های مشابهی با جسم نشان داده شده در شکل 9 B داشت، دارای شکاف در لبه اطراف، فرورفتگی مبهم و کف صاف بود. ویژگی های فهرست شده در جدول 4 و اشیاء نشان داده شده در شکل 9 نشان می دهد که تشخیص دهانه و سیرک ممکن است در مورد برخی از اشیاء شناسایی شده دشوار باشد. بنابراین، ما مدل BoGW پیشنهادی را برای تشخیص شکل زمین بدون تشخیص دهانه و سیرک ارزیابی کردیم.
سپس، بردار ویژگی وزنی را بر اساس مساحت محصور شده توسط هر MBB محاسبه کردیم. سپس از یک طبقهبندی کننده SVM برای طبقهبندی دستهبندی هر MBB استفاده کردیم. به طور خاص، اگر MBB هایی که به دهانه یا حلقه طبقه بندی شده بودند با یکدیگر همپوشانی داشته باشند، MBB هایی را که کوچکترین اندازه را داشتند به عنوان نتیجه تشخیص نهایی انتخاب کردیم.
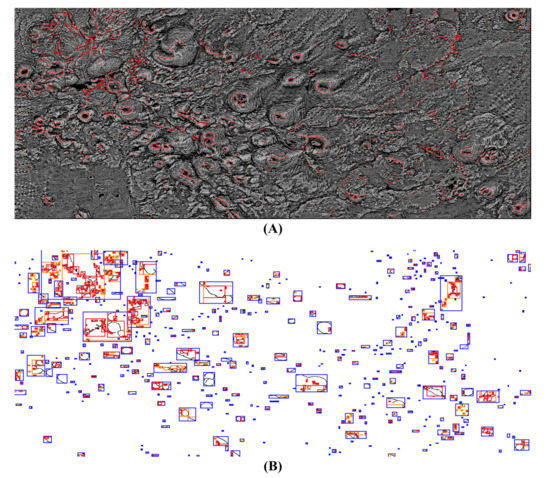
شکل 10 نتیجه تشخیص دهانه و سیرک را نشان می دهد. جعبه های قرمز، جعبه های زرد و جعبه های فیروزه ای به ترتیب تشخیص مثبت واقعی، تشخیص منفی کاذب و تشخیص مثبت کاذب بودند. برای نشان دادن واضح تر نتایج تشخیص، نتایج تشخیص را به ترتیب بر روی یک تصویر ماهواره ای و یک نقشه انحنا قرار دادیم. دقت کاربر و صحت تولید کننده به ترتیب 84% و 93% بود. ارزیابی بصری و دقت نشان داد که BoGW پیشنهادی میتواند از تشخیص اشیاء شکل زمین از DEMهای با وضوح بالا پشتیبانی کند. علاوه بر این، ما همچنین دریافتیم که BoGW پیشنهادی عموماً یادآوری بسیار بالاتری نسبت به دقت در تشخیص دهانه و سیرک ایجاد میکند.
دلیل محاسبه این پدیده ها ممکن است شامل سه بخش باشد. اول، کارهای قبلی گزارش کردند که الگوریتم برای تشخیص شکل دایره ای متغیرهای ژئومورفولوژیکی می تواند به طور موثر اکثر اجسامی را که شبیه دهانه و دایره هستند استخراج کند. این بدان معنی است که تعداد کمی از اشیاء نامربوط پاک شده اند که منجر به دقت تولید کننده یا فراخوانی بالا می شود. علاوه بر این، ما معتقد بودیم که این نتیجه اهمیت شکل را در تشخیص شکل زمین نشان میدهد. دوم، رویکرد موجود برای تشخیص اشکال، مانند تبدیل Hough و کانتور تقریبی، ممکن است با چالش تشخیص شکل دقیق متغیرهای ژئومورفولوژیکی از DEM های با وضوح بالا مواجه شود. به عنوان مثال، تشخیص منفی کاذب زیادی به دلیل دشواری تشخیص ویژگیهای خطی خمشی و ویژگیهای منحنی رخ داده است. سرانجام، دقت تشخیص متغیر ژئومورفولوژیکی از DEM با وضوح بالا نقش کلیدی در تشخیص اشیاء شکل زمین ایفا کرد. این منجر به این واقعیت شد که دقت کاربر بسیار کمتر از دقت سازنده بود.جدول 6 به طور کمی نتایج تشخیص را ارزیابی می کند.
5. نتیجه گیری ها
انواع سیستمهای طبقهبندی بر روی متغیرهای ژئومورفولوژیکی پارامتر اساسی برای مشخصهسازی شکل زمین بوده است. با این حال، متغیرهای ژئومورفولوژیکی نمی توانند به طور موثر از نمایش یک شی زمین شکل، که همیشه با یک ویژگی منطقه ای به جای نقطه یا خطی نشان داده می شود، پشتیبانی کنند. تلاشهای قبلی برای تشخیص شکل زمین با ویژگیهای منطقهای، مانند روشهای مبتنی بر الگو، تقسیمبندی مبتنی بر شی، الگوریتمهای یادگیری ماشین، چالشهای متعددی برای پر کردن شکاف بین ویژگیهای به دست آمده از یک DEM و توضیحات روی شکل زمین دارد. این مقاله با استفاده از تفکر BoVW برای تشخیص بصری، الگوریتم جدیدی به نام BoGW را پیشنهاد میکند که هدف آن نمایش شی زمین شکل از طریق ویژگیهای مشتق از DEM و توصیفهایی است که به صورت معنایی توسط انسان تعریف شدهاند.
در مقایسه با تشخیص شیء از تصاویر ماهوارهای، تشخیص شیء زمین از DEM فاقد مجموعه دادههای عظیم حقیقت زمینی است که ویژگیهای کلاسهای شکل زمین را نشان میدهد. علاوه بر این، نقش معناشناسی همیشه در تشخیص شکل زمین از داده های سنجش از دور نادیده گرفته شده است. این مقاله تجزیه و تحلیلی از چگونگی تأثیر معناشناسی و تسهیل تشخیص اشیاء لندفرم از DEM های با وضوح بالا و ادغام متغیرهای ژئومورفولوژیکی و توصیفات معنایی برای تسهیل تشخیص شی زمین شکل انجام داد.
در آینده، ایجاد مجموعه دادههای معیار در مورد DEMهای با وضوح بالا، برای بهرهگیری کامل از مزایای تکنیکهای یادگیری عمیق در پردازش DEM، فشار میآورد. علاوه بر این، ادغام شبکههای عصبی کانولوشنال (یا شبکههای عصبی مکرر) و قوانین برنامهریزی شده صریح (مثلاً نمودار دانش) که هدف آنها بهرهبرداری از ویژگیهای داده سطح بالا و دانش است، شایسته توجه بیشتر است.






بدون دیدگاه