

خلاصه
اخیراً حجم فزایندهای دادههای چندمنبعی جغرافیایی (دادههای تصادفی ماهوارهها و دادههای متنی ایستگاههای هواشناسی) تولید شده است که میتواند نقش مشارکتی و مهمی در بسیاری از کارهای تحقیقاتی داشته باشد. ذخیره سازی، سازماندهی و مدیریت کارآمد این داده ها برای کاربرد بعدی آنها ضروری است. HBase، به عنوان یک پایگاه داده ذخیره سازی توزیع شده، به طور فزاینده ای برای ذخیره سازی داده های بدون ساختار محبوب است. طراحی کلید ردیف HBase برای بهبود کارایی آن بسیار مهم است، اما تعداد زیادی از محققان در منطقه جغرافیایی تحقیقات زیادی در مورد این موضوع انجام نمی دهند. طبق راهنمای مرجع رسمی HBase، کلیدهای ردیف باید تا حد معقول کوتاه نگه داشته شوند و در عین حال برای دسترسی به داده های مورد نیاز مفید باشند. در این صفحه، ما یک روش رمزگذاری کلید ردیف جدید به جای کلیشه های معمولی پیشنهاد می کنیم. ما یک چارچوب شبکه مکانی-زمانی سلسله مراتبی موجود را به عنوان کلید ردیف HBase برای مدیریت این دادههای مکانی اتخاذ کردیم، با این تفاوت که از کد استاندارد مبهم اما کوتاه آمریکایی برای تبادل اطلاعات (ASCII) برای دستیابی به ساختار شبکه استفاده کردیم. نسبت به کد شبکه اصلی که به راحتی توسط انسان قابل درک است اما بسیار طولانی است. به منظور نشان دادن مزیت روش پیشنهادی، ما داده های هواشناسی روزانه 831 ایستگاه هواشناسی در چین را از سال 1985 تا 2019 در HBase ذخیره کردیم. نتایج تجربی نشان داد که روش پیشنهادی نه تنها میتواند سرعت جستجوی معادل را حفظ کند، بلکه میتواند کلید ردیف را کوتاه کرده و منابع ذخیرهسازی را تا 20.69 درصد در مقایسه با کدهای شبکه اصلی ذخیره کند. در همین حال، ما همچنین از تصاویر GF-1 برای آزمایش اینکه آیا این کلیدهای ردیف بهبود یافته می توانند از ذخیره سازی و جستجوی داده های شطرنجی پشتیبانی کنند یا خیر استفاده کردیم. ما بخشی از تصاویر GF-1 را در استان هنان چین از سال 2017 تا 2018 دانلود و ذخیره کردیم. حجم کل داده ها به حدود 500 گیگابایت رسید. سپس در مدت زمان 54 دقیقه موفق به محاسبه مقدار شاخص تفاوت نرمال شده گیاهی روزانه (NDVI) در استان هنان از سال 2017 تا 2018 شدیم. بنابراین، آزمایش نشان داد که کلیدهای ردیف بهبود یافته همچنین می توانند برای ذخیره داده های شطرنجی هنگام استفاده از HBase اعمال شوند. ما موفق به محاسبه مقدار شاخص گیاهی تفاوت نرمال شده روزانه (NDVI) در استان هنان از سال 2017 تا 2018 در مدت 54 دقیقه شدیم. بنابراین، آزمایش نشان داد که کلیدهای ردیف بهبود یافته همچنین می توانند برای ذخیره داده های شطرنجی هنگام استفاده از HBase اعمال شوند. ما موفق به محاسبه مقدار شاخص گیاهی تفاوت نرمال شده روزانه (NDVI) در استان هنان از سال 2017 تا 2018 در مدت 54 دقیقه شدیم. بنابراین، آزمایش نشان داد که کلیدهای ردیف بهبود یافته همچنین می توانند برای ذخیره داده های شطرنجی هنگام استفاده از HBase اعمال شوند.
کلید واژه ها:
داده های بزرگ جغرافیایی ؛ HBase _ کلیدهای ردیف ؛ مقیاس بزرگ ؛ ذخیره سازی ؛ تصاویر GF-1
1. معرفی
حجم داده های چندمنبعی جغرافیایی از سیستم های رصد زمین، مانند ماهواره ها، ایستگاه های هواشناسی و غیره، در حال حاضر به سرعت در سراسر جهان در حال افزایش است. سیستم های رصد زمین مقادیر زیادی داده تولید کرده اند که می تواند به محدوده پتابایت برسد. در آینده، حجم احتمالاً به سطح اگزابایت یا حتی بیشتر از آن خواهد رسید [ 1]. داده ها دارای مقادیر بالقوه متعددی هستند، اما ما معمولاً تنها می توانیم از بخش کوچکی از آنها در یک حوزه تحقیقاتی پس از فیلتر کردن تعداد زیادی مجموعه داده استفاده کنیم. بنابراین، لازم است همه دادههای مشاهدهشده ذخیره شوند، زیرا نمیتوانیم پیشبینی کنیم که کدام دادهها را میتوانیم در یک تحقیق قبل از فیلتر کردن استفاده کنیم. به این معنی که برای ذخیره سازی داده های چندمنبعی جغرافیایی که در فواصل زمانی کوتاه تولید می شوند، به منابع ذخیره سازی زیادی نیاز است. بنابراین، صرفه جویی در منابع ذخیره سازی یک موضوع مهم در سطح جهانی است. این داده ها نه تنها از نظر حجم زیاد هستند، بلکه دارای فرمت های مختلفی هستند، مانند داده های شطرنجی [ 2 ]، داده های متنی [ 3 ]، داده های برداری [ 4] .]، و غیره.؛ بنابراین، ذخیره و سازماندهی این داده ها به طور موثر برای کاربردهای بعدی داده های چندمنبعی جغرافیایی، مانند ترکیب داده ها [ 5 ، 6 ، 7 ]، جذب داده ها [ 8 ، 9 ، 10 ] و غیره ضروری است.
تا به امروز، تعداد زیادی کار تحقیقاتی انجام شده است که بر استفاده از انواع استراتژی ها یا مقررات برای مدیریت و سازماندهی این داده های مکانی متمرکز شده است. به نظر می رسد که اکثر محققان تا حدی در مورد استفاده از شبکه های مکانی به اتفاق نظر رسیده اند [ 11 ، 12 ، 13 ، 14 ]. از لحاظ نظری، با توجه به مقیاسهای تحقیقاتی مختلف، یک شبکه را میتوان به دو دسته تقسیم کرد: یک دسته شبکه جهانی گسسته، و دیگری شبکه مبتنی بر طرح ریزی مسطح محلی [15 ] . شبکه جهانی گسسته شامل یک سیستم شبکه منظم مبتنی بر چند وجهی است [ 16 ، 17 ، 18 ، 19]، یک سیستم شبکه مبتنی بر VORONOI کره ای [ 20 ، 21 ] و یک سیستم شبکه مبتنی بر خط طول و عرض جغرافیایی [ 22 ، 23 ، 24 ]. این نوع شبکه می تواند کل کره زمین را پوشش دهد و دارای ویژگی های سلسله مراتبی و بازگشتی است، اما به طور کلی دارای یک فرآیند محاسباتی بسیار پیچیده است [ 25 ، 26 ]. یک شبکه مبتنی بر طرح ریزی مسطح محلی به طور کلی از یک شبکه کیلومتر مربعی سلسله مراتبی برای مدیریت داده های مکانی استفاده می کند [ 13]]. اگرچه این نوع شبکه پس از پرتاب شدن به صفحه از یک کره دارای اعوجاج هایی است، اما می تواند فرآیند محاسبات را ساده کند. علاوه بر این، اگر فرآیند فرافکنی با تقسیم کل کره زمین به مناطق (مثلاً تقسیم بر طول جغرافیایی) از قبل و سپس پرتاب کردن هر منطقه به صفحه تکمیل شود، می تواند این اعوجاج را کاهش دهد. به همین دلیل است که پیش بینی جهانی عرضی مرکاتور (UTM) از 3 تشکیل شده است ∘UTM و 6 ∘UTM. در این کار، ما نوعی شبکه مبتنی بر طرح ریزی مسطح را برای دستیابی به مدیریت منطقی داده های مکانی انتخاب کردیم که در بخش 2.1 نشان داده خواهد شد .
همچنین تعداد زیادی از محققین وجود دارند که به راه حل های مربوط به ذخیره سازی چنین داده های عظیمی توجه دارند. در این میان، یک سیستم فایل توزیع شده، مانند سیستم فایل توزیع شده هادوپ (HDFS)، یک گزینه ممکن است [ 27 ، 28 ، 29 ، 30 ، 31 ]. HDFS یک برنامه زیر هسته ای از برنامه Hadoop از بنیاد نرم افزار آپاچی است که یک سازمان غیرانتفاعی است که هدف آن پشتیبانی از برنامه های نرم افزار منبع باز است. با این حال، HDFS برای مجموعه دادههای بزرگ طراحی شده است و اگر فایلهای کوچک عظیم را ذخیره کنیم، فشارهای زیادی را برای گره اصلی متحمل میشود، زیرا گره اصلی نیاز به ذخیره ابرداده برای هر فایل کوچک ذخیره شده در گره برده دارد [32] .]. به منظور حل این مشکل، HBase، که یک پایگاه داده مبتنی بر HDFS است، توسعه یافت [ 33 ]. پایگاه داده به دلیل انعطاف پذیری خود برای ذخیره مقادیر زیادی از داده های بدون ساختار و توانایی گسترش به ستون ها و ردیف های نامحدود معروف است که می تواند مشکل ذخیره فایل های کوچک عظیم را حل کند [34 ]]. در این کار، همانطور که در بالا ذکر شد، ما یک استراتژی شبکه ای را برای سازماندهی داده ها انتخاب کردیم، به این معنی که داده های مکانی ما که باید ذخیره شوند به صورت تعداد زیادی فایل کوچک ارائه می شوند. بنابراین، تصمیم گرفتیم از HBase برای ذخیره دادههای مکانی خود مانند برخی دیگر از محققان استفاده کنیم. با توجه به استفاده کارآمد از HBase، طراحی کلیدهای ردیف یکی از موارد ضروری است. HBase داده ها را به عنوان الگویی از مقادیر کلید ذخیره می کند، به این معنی که همیشه یک کلید ردیفی وجود دارد که باید همراه با مقداری که می خواهیم ذخیره کنیم [ 35]]. بنابراین، کلیدهای ردیف قرار است تا حد معقول کوتاه نگه داشته شوند و در عین حال برای دسترسی به داده های مورد نیاز مفید باشند، که می تواند مقادیر زیادی از منابع ذخیره سازی را ذخیره کرده و کارایی را بهبود بخشد، اما اکثر محققان به این مشکل توجه نمی کنند. شایان ذکر است که یک کلید کوتاه که برای دسترسی به داده ها بی فایده است بهتر از یک کلید طولانی تر با ویژگی های دریافت/اسکن بهتر نیست. ما باید در هنگام طراحی کلیدهای ردیف انتظار معاوضه داشته باشیم [ 36 ]. در واقع، اکثر محققان صرفاً علاقه مند هستند که کلیدهای ردیف خود را طوری طراحی کنند که اطلاعاتی را که فکر می کنند به آن نیاز دارند، در بر گیرند و به ندرت متوجه مشکل طول بیش از حد کلیدهای ردیف می شوند [14 ، 37 ، 38 ، 39 ، 40 ] .
در این کار روشی برای حل این مشکل پیشنهاد کردیم. ما از کدهای ASCII برای جایگزینی کدهای مکانی اصلی استفاده کردیم، که می تواند طول کلیدهای ردیف HBase را کوتاه کند. ما همچنین آزمایشهایی را برای آزمایش تأثیر صرفهجویی در منابع ذخیرهسازی و مقایسه زمان مصرف پرسوجوها طراحی کردیم. روش پیشنهادی میتواند مفهوم جدیدی را برای طراحی کلیدهای ردیفی برای همه محققینی که قصد دارند از HBase برای ذخیره دادههای خود استفاده کنند، ارائه دهد.
این مقاله به شرح زیر سازماندهی شده است. بخش 2 استراتژی شبکه فضایی را که انتخاب کردیم، کلید ردیف اصلی که توسط استراتژی شبکه فضایی به دست آمده و روش بهبود یافته ما برای کوتاه کردن کلید ردیف اصلی معرفی می کند. بخش 3 اثر روش پیشنهادی را نشان می دهد. در نهایت، بخش 4 و بخش 5 نتایج تجربی را مورد بحث قرار می دهند و کارهای آینده را فهرست می کنند.
2. روش شناسی
بر اساس تحقیقات و دانش قبلی خود، تصمیم گرفتیم که مجموعه دادههای Raster Clean and Reconstitution Multi-Grid (RDCRMG) [ 13 ] [13 ] را به عنوان شبکه شاخص فضایی برای برش، ذخیره و سازماندهی دادههای چند منبعی خود انتخاب و استفاده کنیم . در این بخش، به منظور سهولت درک خوانندگان از طراحی کلیدهای ردیف بعد در مقاله، استراتژی پارتیشن و کدگذاری RDCRMG ارائه شده است. با توجه به ساختار RDCRMG، طراحی مکانی-زمانی اصلی جدول در HBase توضیح داده شده است. سپس، یک ساختار جدول کاربردی تر برای رفع کاستی های جدول اصلی توضیح داده شده است. در همین حال، روش طراحی مکانی-زمانی بهبود یافته کلیدهای ردیف بر اساس کدهای ASCII نیز پیشنهاد شده است.
2.1. چندشبکه ای شاخص فضایی
2.1.1. مرجع فضایی
مرجع فضایی RDCRMG سیستم ژئودتیک جهانی 1984 (WGS 84) مبتنی بر Universal Transverse Mecator (UTM) 6 است. ∘سیستم مختصات طرح تقسیم نوار، که دارای ویژگی های زیر است: اولا، به دلیل پایه ریاضی صریح فضایی، قانون تقسیم بندی و الگوریتم تبدیل برای کد شبکه و مختصات فضایی، قابلیت قابل توجهی برای بهبود کارایی مدیریت وجود دارد. ثانیاً، سیستم میتواند هنگام تقسیم دادههای مکانی به شبکههای وسعت، سازگاری داشته باشد و غیرممکن است که دادهها به یک شبکه و شبکههای دیگر تعلق داشته باشند. ثالثاً، در مقایسه با سایر پیشبینیها (به عنوان مثال، برآمدگی مخروطی یا ازیموتال، برآمدگی گاوس-کروگر)، دقت بالاتری را میتوان حفظ کرد و اعوجاج کمتری را در مرز منطقه طرحریزی حفظ کرد. در نهایت، سیستم هنگام انجام محاسبات فشرده داده مفید است،
2.1.2. پارتیشن بندی و کدنویسی
RDCRMG کل منطقه جغرافیایی (به عنوان مثال، چین) را به چندین منطقه با 6 تقسیم می کند ∘طول جغرافیایی. در هر منطقه، RDCRMG شامل یک استراتژی شبکه سلسله مراتبی است که از شبکه های 100 کیلومتری و شبکه های 10 کیلومتری تشکیل شده است (لایه دیگری در RDCRMG وجود دارد – شبکه 1 کیلومتری – اما به منظور برجسته کردن تحقیقات در این مقاله، ما نادیده گرفته شدیم. شبکه 1 کیلومتری برای ساده تر کردن ساختار). همانطور که در شکل 1 نشان داده شده است، این دو سطح از شبکه های مربعی با روابط تودرتوی دقیق ایجاد می شوند. شبکه های هم سطح دارای اندازه، شکل و جهت یکنواخت هستند و هیچ درزی بین دو شبکه مجاور وجود ندارد. بنابراین، هنگام ذخیره دادههای جغرافیایی، دادهها باید با توجه به مرز شبکههایی که با این دادهها همپوشانی دارند، به بلوکهای کوچک تقسیم یا برش داده شوند. علاوه بر این، RDCRMG ساختار سطر-ستون را به جای ساختار چهار درختی اتخاذ می کند، زیرا RDCRMG بر کارایی استخراج داده ها، پیچیدگی الگوریتم پرس و جو کمتر و سازگاری الگوی سازمانی بالاتر تمرکز دارد.
از نظر کدگذاری شبکه، کد شبکه 100 کیلومتری از چهار رقم تشکیل شده است: دو رقم اول به مختصات y راس جنوب غربی شبکه (واحد: کیلومتر) و دو رقم آخر نشان دهنده مختصات x است. هنگام استفاده از کد برای محاسبه مختصات یک شبکه 100 کیلومتری، فقط باید دو قسمت را در 100 کیلومتر ضرب کنیم. به عنوان مثال، مانند شکل 1b نشان می دهد که مختصات y و مختصات x راس جنوب غربی شبکه 100 کیلومتری (A) به ترتیب 4400 (km) و 300 (km) هستند. بنابراین کد شبکه 4403 است. با توجه به محدودیت اعوجاج و مقیاس فضایی، حداکثر دو رقم اول شبکه 100 کیلومتر 59 و برد دو رقم آخر شبکه 100 کیلومتر از 00 تا 09 است. با توجه به شبکه 10 کیلومتری، دو رقم اضافی برای نشان دادن موقعیت استفاده می شود. جهت افزایشی دو رقم با منحنی az از جنوب غربی به شمال شرقی در یک شبکه 100 کیلومتری (از 00 تا 99) مطابقت دارد. همانطور که در شکل 1c نشان داده شده است، مختصات y و مختصات x راس جنوب غربی (B) به ترتیب 4460 (km) و 430 (km) و کد شبکه 10 کیلومتری مربوطه (مربع قرمز در شکل) 440363 است.
علاوه بر این، RDCRMG داده ها را با نام دایرکتوری و نام فایل ذخیره می کند تا یک مسیر ذخیره سازی منطقی از هر بلوک داده بدون هیچ ابرداده ای، همانطور که در شکل 2 نشان داده شده است، ایجاد کند . دایرکتوری های ریشه از نام سیستم مختصات فضایی WKID (شناسه شناخته شده سیستم مرجع فضایی) نامگذاری شده اند و با نوارهای طرح ریزی UTM مختلف مطابقت دارند. سپس زیر شاخه های دیگر با کد 100 کیلومتر، کد 10 کیلومتر و سال نامگذاری می شوند. در نهایت، بلوک های فایل در دایرکتوری ها در سال ذخیره می شوند. همانطور که در شکل 3 نشان داده شده است، بلوک فایل نیز دارای کدهای نام خاص خود است. کدهای نوع داده برای تمایز داده های مختلف مانند GF1WFV (001)، Sentinel 2 (002) و طبقه بندی محصول (005) استفاده می شود. یک کد تصادفی برای جلوگیری از حذف فایل هایی با نام مشابه به شکل حروف یا شکل استفاده می شود.
2.2. جدول HBase فضایی-زمانی بر اساس RDCRMG
2.2.1. ساختار یک جدول HBase
قبل از معرفی جدول HBase فضایی-زمانی خود، ساختار یک جدول HBase عمومی را از منظر منطقی و دیدگاه فیزیکی ارائه میکنیم. ساختار منطقی در جدول 1 نشان داده شده است . این شامل کلید ردیف، خانواده ستون، ستون، مهر زمانی و مقدار است. علاوه بر این، مُهرهای زمانی (t1، t2، t3، t4) برای رتبهبندی مقادیر داده استفاده میشوند. اگر مجموعه پیش فرض را حفظ کنیم، این زمان دقیقی است که در آن داده ها را ذخیره می کنیم.
ساختار فیزیکی در شکل 4 نشان داده شده است . برای یک HTable، هر سرور HRegion تعدادی HRegion را مدیریت می کند. HRegion حاوی HStore است و تعداد HStore به تعداد خانواده ستون بستگی دارد. سپس، هر HStore از MemStore و StoreFile تشکیل شده است. با افزایش حجم داده، یک HRegion بزرگ باید به دو HRegion کوچک تقسیم شود تا محدودیتهای حجم داده برای هر HStore برآورده شود.
2.2.2. طراحی کلید ردیف
طراحی کلید ردیف برای ساختار جدول HBase بسیار مهم است. شاخص سطح اول HBase کلید ردیف آن است، به این معنی که با توجه به داده های مکانی-زمانی، بهتر است اطلاعات مکانی-زمانی در کلید ردیف به جای خانواده ستون یا ستون ها ذخیره شود. در غیر این صورت، زمان بیشتری برای HBase طول می کشد تا داده ها را با شرایط مکانی-زمانی وارد شده جستجو کند [ 36 ]. بنابراین، ما عمداً اطلاعات مکانی-زمانی مربوط به داده ها را در کلیدهای ردیف قرار می دهیم. همانطور که در بالا ذکر شد، RDCRMG دارای سه لایه مقیاس است: 100 کیلومتر، 10 کیلومتر و 1 کیلومتر. در این مقاله، ما فقط طراحی HBase را برای شبکههای مکانی-زمانی 10 کیلومتری مورد بحث قرار میدهیم. به طور مشابه، میتوانیم جدول HBase را برای شبکههای مقیاس دیگر با همان استراتژی به دست آوریم.
از شکل 2 و شکل 3 ، می توانیم اطلاعات مورد نیاز برای طراحی کلیدهای ردیف را جمع آوری کنیم. اطلاعات مکان کد WKID، کد 100 کیلومتر و کد 10 کیلومتر و اطلاعات زمان تاریخ ضبط است. با توجه به اینکه برنامه ما به احتمال زیاد داده های سری زمانی را پرس و جو می کند، تصمیم گرفتیم آن اطلاعات را با هم ترکیب کنیم، همانطور که در شکل 5 نشان داده شده است .
ترکیبی از WKID، کد 100 کیلومتری و کد 10 کیلومتری قادر است فضایی منحصر به فرد را تضمین کند. در همین حال، تاریخ ضبط تنها زمان را محدود می کند. بنابراین، یک کلید ردیف نشان دهنده یک زمان و مکان منحصر به فرد است. علاوه بر این، اطلاعات مکان در مقابل اطلاعات زمانی قرار دارد که تضمین میکند دادههای سری زمانی یک شبکه جغرافیایی در یک بلوک فیزیکی یا بلوکهای مجاور ذخیره میشوند. به این ترتیب، سرورهای منطقه به سادگی می توانند داده های مکانی-زمانی مرتبط یک شبکه 10 کیلومتری را پیدا کنند. برای سهولت بیشتر استناد در بخشهای بعدی، از این نوع کلید ردیف به عنوان کلید ردیف اصلی یاد میکنیم و به این روش، روش رمزگذاری کلید ردیف اصلی میگویند.
2.2.3. طراحی خانواده ستون
از نظر تئوری، یک جدول HBase می تواند شامل بیش از یک خانواده ستون باشد و هر خانواده ستون می تواند تعداد زیادی ستون داشته باشد. با این حال، HBase یک HStore برای هر خانواده ستون ایجاد می کند. یعنی اگر چند خانواده ستون بسازیم، زمانی که HBase باید عملیات تقسیم را برای کاهش حجم برخی از مناطق داده انجام دهد، تمام HStore ها نیز باید تقسیم شوند. در یک برنامه واقعی، ما نمیتوانستیم حجم دادهها را برای هر خانواده ستون کنترل کنیم، به این معنی که برخی از HStoreها به سرعت افزایش مییابند و باعث میشوند HBase مناطق را تقسیم کند، اما برخی HStoreها که کوچک بودند نیز به HStoreهای جدید متعدد تقسیم میشوند، و بنابراین سرور HRegion باید HStore های بیشتری را مدیریت کند. علاوه بر عملیات تقسیم، عملیات شستشو از MemStore همچنین به دلیل افزایش تعداد خانواده های ستون، منجر به مصرف بیشتر I/O می شود.
2.3. مدل مکانی-زمانی بهبود یافته
ایده اصلی مدل بهبود یافته مکانی-زمانی استفاده از کد ASCII برای جایگزینی کد اصلی است.
طبق دستورالعمل رسمی HBase [ 36 ]، بهتر است طول کلیدهای ردیف و سایر واجد شرایط را به همراه نام خانواده ستون ها، ستون ها و غیره کوتاه کنید. بنابراین، اگر بتوانیم طول این برچسبها را کوتاه کنیم، ممکن است منابع ذخیرهسازی بیشتری ذخیره کنیم و بازیابی دادهها را تسریع کنیم. جدول کد ASCII در جدول 2 نشان داده شده است . در واقع، در رویکرد ما، ما از همه کدهای ASCII استفاده نمی کنیم، زیرا چاپ دستی برخی از کاراکترها با صفحه کلید سخت است. بنابراین، ما فقط از کاراکترهای ” ” (فضا) تا “” استفاده می کنیم. اعشار مربوطه از 32 تا 126 است.
2.3.1. کلید ردیف بر اساس کد اسکی
ساختار کلید ردیف پیشنهادی در شکل 6 نشان داده شده است . در این بخش، خواننده را برای توضیح تغییر کد اصلی و کد اسکی به بخش 2.1.2 و شکل 5 ارجاع می دهیم.
نماد اول نشان دهنده WKID است. پروجکشن Universal Transverse Mercator (UTM) هر 6 کد گذاری می شود ∘از غرب به شرق؛ اولین شماره منطقه 32601 و آخرین شماره منطقه 32660 است و بنابراین ما از کد اسکی برای نمایش این مناطق به جای پنج عدد استفاده می کنیم. روش مورد استفاده برای تبدیل استفاده از دو عدد آخر هر منطقه و جمع کردن 32 است. سپس کد اسکی مربوطه به دست می آید. برای منطقه 32601، از 01 + 32 برای بدست آوردن 33 استفاده می کنیم و سپس عدد را به کد اسکی “!” تبدیل می کنیم. بنابراین، می توانیم از نماد (“!”) برای جایگزینی 32601 استفاده کنیم. علاوه بر این، دلیل اضافه کردن 32 این است که چاپ 32 نماد اول کد ASCII به طور مستقیم دشوار است – به خصوص که گاهی اوقات نیاز داریم تا داده ها را به صورت دستی کار کنیم – و بنابراین تصمیم گرفتیم 32 علامت اضافه کنیم تا چاپ نماد آسان تر شود. .
نماد دوم نشان دهنده دو رقم اول شبکه 100 کیلومتری (شبکه 100 کیلومتری y) است و نماد سوم دو رقم آخر شبکه 100 کیلومتری (شبکه 100 کیلومتری x) است. برای 100 کیلومتر شبکه y، کد اصلی 00 تا 59 است، یعنی از استوا تا 60 ∘N، و بنابراین ما اعداد و 32 را جمع می کنیم تا یک کد اسکی با محدوده ای از ” ” (فضا) تا “[” به دست آوریم. در مورد شبکه 100 کیلومتری x، به جای کد اصلی که از 01 تا 08 است، از “1” تا “8” استفاده می کنیم.
نماد چهارم و پنجم کد 10 کیلومتری است. محدوده هر نماد از “0” تا “9” است. هیچ تغییری نسبت به کد اصلی وجود ندارد.
همانطور که نمادهای ششم و هفتم نشان می دهند، اطلاعات مربوط به سال را به Year1 (سه رقم اول سال) و Year2 (آخرین رقم سال) تقسیم می کنیم. محدوده مقدار Year2 بدیهی است که از 0 تا 9 است، و بنابراین ما فقط باید از همان کاراکتر ASCII (از “0” تا “9”) برای ارائه آن استفاده کنیم. در مورد Year1، ما با مشکل مواجه می شویم زیرا همیشه بیش از 190 است و آشکارا از محدوده جدول کد ASCII فراتر می رود. بنابراین تصمیم می گیریم از روش جدیدی برای جایگزینی این مقدار استفاده کنیم. به عنوان مثال، 190 به 19 و 0 تقسیم می شود و سپس 19 منهای 15 برای به دست آوردن 4 انجام می شود. در مرحله بعد، 4 را با 0 ترکیب می کنیم تا 40 به دست آید و کاراکتر ASCII مربوطه “() است. اساساً این روش جنبه های مثبت و منفی خود را دارد؛ مزیت این است که تعداد ارقام را با موفقیت از 3 به 2 کاهش می دهیم. به این معنی که کد را می توان در جدول کد ASCII یافت. محدودیت این است که ما فقط میتوانیم از این روش برای برخورد با اعداد از 182 تا 276 استفاده کنیم، به این معنی که فقط میتوانیم دادههای تولید شده از 1820 تا 2769 را ذخیره کنیم. در مورد ماه و روز، آنها را اضافه کرده و به ترتیب 31 را اضافه میکنیم. کد اسکی
2.3.2. ستون ها بر اساس کد اسکی
تغییر طول کلید ردیف تنها راه برای کوتاه کردن طول جفتهای کلید-مقدار نیست. از شکل 7 ، می بینیم که جفت های کلید-مقدار از سه بخش تشکیل شده اند: اطلاعات طول، کلید و مقدار. در بخش اطلاعات طول، هر دو KeyLength و ValueLength ثابت هستند. آنها به ترتیب 4 بایت را اشغال می کنند. در قسمت های کلید و مقدار، طول برخی از اطلاعات متغیر است، به این معنی که اگر بخواهیم طول جفت های کلید-مقدار را کوتاه کنیم، کاهش طول این پارامترها ضروری است. کلید ردیف ذکر شده در بالا یکی از این پارامترها است، اما تنها یکی نیست. همچنین باید به طول خانواده و تعیین کننده (نام ستون) توجه کنیم. ما در مورد این واقعیت بحث کرده ایم که ما فقط از یک خانواده ستون در بخش 2.2.3 استفاده می کنیم; بنابراین، ما از یک کاراکتر ASCII “T” برای نامگذاری خانواده ستون خود استفاده می کنیم. “T” مخفف کلمه “type” است – به این معنی که ما انواع مختلفی از داده ها را در این خانواده ستون ذخیره می کنیم.
با توجه به نام گذاری ستون ها، تفاوت هایی بین داده های ایستگاه هواشناسی و تصاویر سنجش از دور وجود دارد. برای دادههای ایستگاه هواشناسی، میتوانیم ستونی به نام «M» ایجاد کنیم تا شناسه ایستگاه، طول جغرافیایی و عرض جغرافیایی یا سایر اطلاعات مربوط به این ایستگاه ذخیره شود. ما میتوانیم ۱۲ شاخص هواشناسی روزانه را از ایستگاهها به دست آوریم که شامل میانگین فشار اتمسفر، میانگین دما، بارندگی و ۲۱ شاخص دیگر میشود. بنابراین، با توجه به محدوده مفید کد ASCII که در بالا ذکر شد، تصمیم میگیریم “M” و یک کاراکتر دیگر را برای نامگذاری ستون هر نشانگر ترکیب کنیم. این شخصیت از “!” به “8” در جدول کد ASCII. یعنی نام ستونی که برای ذخیره فشار متوسط اتمسفر استفاده می شود “M!” است.
برای تصاویر سنجش از دور، تصمیم گرفتیم از چهار کاراکتر (ABCD) برای ذخیره ابرداده و سه کاراکتر (EFG) برای ذخیره تصاویر استفاده کنیم. در مورد “ABCD”، کاراکتر “a” را در وهله اول (A) قرار می دهیم، به این معنی که این ستون برای ابرداده است. کاراکتر در وهله دوم (B) از “”” شروع می شود – به این معنی که تصاویر از کجا آمده اند. برای مثال، ” ” نشان دهنده GF1WFV، “!” نشان دهنده Sentinel2، “”” نشان دهنده Landsat8 و غیره است. مکان سوم (C) برای درصد ابر هر تصویر برش خورده طراحی شده است، و محدوده از “0” تا “9” است؛ برای مثال، “0” به معنای درصد ابر [0٪، 10٪) است، “1” نشان می دهد که درصد ابر [10٪، 20٪) و غیره است. آخرین مکان (D) دارای دو مقدار است: “A” و “B.” “A” به این معنی است که نام این تصویر برش خورده ذخیره شده است، در حالی که “B” به این معنی است که تصویر اصلی که این تصویر برش خورده از آن گرفته شده است، ثبت شده است. در مورد “EFG”، کاراکتر در وهله اول (E) “b” است – به این معنی که این ستون برای داده های تصویر است. معانی F و G به ترتیب همان B و C است. به عنوان مثال، اگر یک تصویر اصلی GF1WFV را برش دهیم (به عنوان مثال، نام GF1_WFV1_E78.2_N39.6_20180816_L1A0003394802) به تعداد زیادی از تصاویر کوچک و برش خورده، یکی از این تصاویر کوچک برش خورده شده، 83106% است و 831206% آن 4408% است. وقتی این تصویر برش خورده کوچک را ذخیره می کنیم، “GF1_WFV1_E78.2_N39.6_20180816_L1A0003394802” در ستونی با نام “a 2B” ذخیره می شود. “44036320180816016001000” در ستونی با نام “a 2A” ذخیره می شود. و تصویر واقعی با نام 44036320180816016001000.tif در ستونی با نام “b 2” ذخیره می شود. به عنوان مثال، اگر دادههای هواشناسی جدید و دادههای سنجش از دور GF1WFV شبکه مکانی-زمانی A را بدست آوریم (شبکه مکانی 32650440363، تاریخ 20180816 است)، این دادهها همانطور که در نشان داده شده است در HBase ذخیره میشوند.شکل 8 .
3. نتایج
3.1. طراحی آزمایش
در این مقاله، ما سه آزمایش را طراحی کردیم تا نشان دهیم که روش رمزگذاری کلید ردیف پیشنهادی برای دادههای متنی ایستگاه هواشناسی و تصاویر سنجش از دور کارآمد است. آزمایش اول مقایسه ای بین روش رمزگذاری کلید ردیف اصلی و روش رمزگذاری کلید ردیف پیشنهادی انجام داد تا نشان دهد آیا روش پیشنهادی می تواند منابع ذخیره سازی را ذخیره کند یا خیر. آزمایش دوم کارایی پرس و جو داده این دو روش را مقایسه کرد. آخرین آزمایش شامل یک برنامه کاربردی ساده بود که لایه NDVI هر تصویر GF-1 را در استان هنان چین از سال 2017 تا 2018 تولید کرد. این آزمایش می تواند به طور مقدماتی نشان دهد که روش رمزگذاری کلید ردیف پیشنهادی می تواند برای محاسبات مکانی-زمانی بعدی استفاده شود.
3.2. راندمان فشرده سازی کلید ردیف
به منظور بررسی مزایا و معایب روش پیشنهادی رمزگذاری کلید ردیف در فشردهسازی، از دو نوع مختلف داده استفاده کردیم: دادههای متنی ایستگاه هواشناسی و تصاویر سنجش از دور.
برای داده های هواشناسی، ما شاخص های هواشناسی روزانه 831 ایستگاه هواشناسی در چین را از سال 1985 تا 2019 ذخیره کردیم. سپس، چهار الگو را برای مقایسه اتخاذ کردیم، از جمله حجم کلید-مقدار بر اساس روش رمزگذاری کلید ردیف اصلی، کلید-مقدار. حجم بر اساس روش رمزگذاری کلید ردیف پیشنهادی، حجم کلید بر اساس روش رمزگذاری کلید ردیف اصلی و حجم کلید بر اساس روش رمزگذاری کلید ردیف پیشنهادی. نتیجه در شکل 9 نشان داده شده است. بدیهی است که چهار خط در شکل تقریباً با افزایش ردیف ها به صورت خطی افزایش می یابد. در همین حال، روش رمزگذاری کلید ردیف پیشنهادی میتواند مصرف منابع را صرف نظر از حجم کلید یا حجم کلید-مقدار در مقایسه با روش اصلی کاهش دهد. برای کل دادههای هواشناسی (7946627 ردیف) ذخیره شده در HBase، میتوانیم 1874 مگابایت از منابع ذخیرهسازی را ذخیره کنیم و درصد فشردهسازی کلید 29.41٪ بود، در حالی که درصد فشردهسازی کلید ردیف 52.63٪ بود. درصد فشردهسازی کلید و کلید ردیف نسبتاً پایدار بود، اما درصد فشردهسازی جفتهای کلید-مقدار رابطه قوی با حجم دادههای ذخیرهشده در هر ستون از جدول HBase داشت. برای این آزمایش، درصد فشردهسازی جفتهای کلید-مقدار 20.69% بود.
همانطور که در شکل 10 نشان داده شده است، برای تصاویر سنجش از دور، حجم مقدار و کلید ردیف سطرهای مختلف را محاسبه کردیم .
میتوانیم ببینیم که روش پیشنهادی به سختی بر حجم جفتهای کلید-مقدار تأثیر میگذارد، زیرا حجم تصاویر سنجش از راه دور بسیار بیشتر از حجم کلید یا کلید ردیف است (واحد حجم کلید کیلوبایت است (KB) واحد حجم مقدار مگابایت (MB) است. در واقع روش پیشنهادی بر طول کلید ردیف یا کلید تاثیر می گذارد و در نتیجه بر تمام جفت های کلید-مقدار تاثیر می گذارد، بنابراین اگر اختلاف حجم زیادی بین مقدار و کلید وجود داشته باشد، این روش از نظر میزان کارایی رضایت بخشی نخواهد داشت. فشرده سازی حجم جفت های کلید-مقدار. با این حال، برای درصد فشرده سازی کلید، میانگین 28.57٪ است، به این معنی که، اگر ردیف ها و ستون های متعددی وجود داشته باشد، مقدار زیادی از منابع ذخیره سازی را نیز ذخیره می کند. البته، این محدود به مقایسه منابع ذخیرهسازی است که تصاویر سنجش از راه دور باید اشغال کنند. علاوه بر این، سرعت تغییر حجم با افزایش ردیف ها تا حدودی با سرعت تغییر حجم متفاوت استشکل 10 اما تقریباً مشابه شکل 9 است . به این دلیل که مقدار داده متنی ایستگاه هواشناسی که باید هر روز برای هر ایستگاه هواشناسی ذخیره شود ثابت است، بنابراین جدول HBase افزایش ثابتی از سطرها و ستون ها خواهد داشت. با این حال، مقدار تصاویر سنجش از دور که باید ذخیره شود برای هر ردیف متغیر است. بنابراین، جدول HBase یک افزایش پایدار برای سطرها و افزایش ناپایدار برای ستون ها خواهد داشت. برای تصاویر سنجش از دور در این آزمایش، محدوده ستونها برای هر ردیف از سه تا نه است.
3.3. کارایی پرس و جو داده ها
در این آزمایش، ما کارایی پرس و جو روش رمزگذاری کلید ردیف پیشنهادی و روش اصلی را با دو نوع پرس و جو بررسی می کنیم: یکی یک پرس و جو تصادفی و دیگری یک پرس و جو منطقه ای است. داده های آزمایشی داده های متنی ایستگاه هواشناسی روزانه از 831 ایستگاه هواشناسی در چین از سال 1985 تا 2019 است.
3.3.1. پرس و جو تصادفی
در همان خوشه کامپیوتری، ما به طور تصادفی 562 ردیف داده و 1126 ردیف داده را انتخاب کردیم و سپس بر اساس این دو روش مختلف رمزگذاری کلید ردیف، مصرف زمان پرسوجوها را برای ردیفهای مختلف داده محاسبه کردیم. نتیجه در جدول 3 نشان داده شده است . از نتیجه می بینیم که مصرف زمان پرس و جوهای تصادفی برای این دو روش تقریباً معادل است. با این حال، مصرف زمان آنها بسیار بیشتر از کارایی پرس و جو در برخی پایگاه های داده رابطه ای است. به عنوان مثال، MySql. بنابراین این نوع شاخص مکانی-زمانی انتخاب خوبی برای یک پرس و جو تصادفی نیست.
3.3.2. پرس و جو منطقه
با توجه به طراحی کلید ردیف، داده های زمانی شبکه 10 کیلومتری قرار است در همان منطقه داده یا برخی از مناطق داده مجاور ذخیره شوند. بنابراین، برای روشهای مختلف رمزگذاری کلید ردیف، یک شبکه 10 کیلومتری را بهطور تصادفی انتخاب کردیم تا زمان مصرف درخواست را با طولهای زمانی مختلف محاسبه کنیم. نتیجه در شکل 11 نشان داده شده است. ما همچنین زمان مصرف رمزگشایی را برای روش رمزگذاری کلید ردیف پیشنهادی در نتیجه در نظر گرفتیم. از طریق خطوط مربوط به میانگین زمان در شکل، می بینیم که، اگرچه هنگام استفاده از روش پیشنهادی، کلید ردیف باید کد اسکی مبهم را رمزگشایی کند، روش پیشنهادی هنوز در مقایسه با روش اصلی به زمان کمتری برای پرس و جو نیاز دارد. . اگر تاریخ طولانی تری را پرس و جو کنیم، می توانیم با استفاده از روش پیشنهادی در زمان بیشتری صرفه جویی کنیم، اما برای هر پرس و جو، تغییراتی از نظر زمان مصرف وجود دارد، همانطور که با مستطیل های آبی و قرمز در شکل نشان داده شده است. هنگامی که مصرف زمانی پرس و جو منطقه و پرس و جو تصادفی را تجزیه و تحلیل می کنیم، می بینیم که این نوع شاخص مکانی-زمانی برای یک پرس و جو تصادفی کارآمد نیست اما برای یک پرس و جو منطقه مفید است. آخرین دوره داده، 19850101–20130418،
با توجه به طراحی RDCRMG، کد شبکه فضایی قبل از کد سری زمانی است، به این معنی که ما انتخاب میکنیم که دادههای سری زمانی یک شبکه را بهجای شبکه مجاور ذخیره کنیم. بنابراین، این نوع پرسوجو منطقه کارآمد روی سریهای زمانی کار میکند اما نه شبکههای همسایه در بعد فضایی. اگر بخواهیم بهترین کارایی را برای جستجوی فضایی یک شبکه همسایه به دست آوریم، باید ترتیب کد سری فضا و زمانی را معکوس کنیم، که می تواند شبکه همسایه یک تاریخ معین را به همان منطقه بیاورد.
3.4. کاربرد در محاسبات مکانی-زمانی
در این آزمایش، ما برخی از تصاویر GF-1 را در استان هنان، چین از سال 2017 تا 2018 در HBase با روش رمزگذاری کلید ردیف پیشنهادی ذخیره کردیم. ما برخی از پارامترها را تنظیم کردیم، از جمله محدوده مکانی (استان هنان)، دوره زمانی (از 2017 تا 2018)، نوع داده (تصاویر GF-1)، مدل محاسبه (NDVI) و درصد ابر تصاویر (ما استفاده کردیم). دو نسبت ابر: filter1: 0-100٪ و filter2: 0-50٪. سپس، ما حالت محاسبه موازی Map-Reduce را برای تعیین لایههای NDVI در سریهای زمانی در استان هنان با شرایط درصد ابر متفاوت اتخاذ کردیم. نتیجه در شکل 12 نشان داده شده است. علاوه بر این، وقتی فیلتر درصد ابری را تنظیم میکنیم – برای مثال 0 تا 50٪ – به این معنی است که HBase سعی میکند تصاویر را با کمترین درصد ابر در 0٪ تا 50٪ در روز و در هر شبکه 10 کیلومتری فضایی ارائه دهد. هدف از این طراحی ارائه تصاویر با آلودگی کمتر ابری برای مقادیر زیادی از محاسبات مکانی-زمانی بعدی تا آنجا که ممکن است است. همانطور که در بخش 2.3.2 ذکر شد، به همین دلیل است که نام ستون ها برای تصاویر سنجش از دور طراحی شده است.. HBase ستون های یک ردیف را از چپ به راست اسکن می کند. بنابراین، برای مثال، ستونی به نام “b 2” (که در آن درصد ابر (20٪، 30٪) بود) قبل از ستون “b 4” (که در آن درصد ابر (40٪، 50٪) بود، مرتب می شود. ). بنابراین، HBase قادر است ستونی به نام “b 2” را سریعتر از ستونی به نام “b 4” پیدا کند – که دقیقاً نتیجه مطلوب است. البته اگر ابرها موضوع تحقیق هستند، این طرح باید معکوس شود. از شکل 12، میتوانیم ببینیم که، حتی اگر هیچ محدودیتی برای درصد ابر تعیین نکردهایم، تنها 67 روز وجود داشت که دارای لایههای NDVI بود. این به این دلیل است که دوره بازدید از ماهواره سنجش از دور GF-1 چهار روز است و ما اکثر تصاویر را دانلود کردیم اما نه همه آنها را. علاوه بر این، می بینیم که اگر درصد ابر را روی کمتر از 50 درصد قرار دهیم، روزهای بیشتری با کمبود لایه NDVI مربوطه وجود دارد که منطقی است. زمان مورد نیاز برای هر دوی این محاسبات حدود 54 دقیقه است. این آزمایش می تواند به طور مقدماتی نشان دهد که شاخص مکانی-زمانی طراحی شده برای محاسبه مکانی-زمانی بعدی موثر است.
4. بحث
روش رمزگذاری کلید ردیف پیشنهادی میتواند طول کلید ردیف را کوتاه کند، که برای ذخیره منابع ذخیرهسازی بیشتر برای HBase، که نیاز به ذخیره مکرر کلید ردیف برای هر ستون دارد، حیاتی است. هرچه تعداد ستون های هر ردیف بیشتر باشد، منابع ذخیره سازی بیشتری ذخیره می شود. در این مقاله، دادههای ما دادههای مکانی-زمانی در مقیاس بزرگ هستند، به این معنی که وقتی دادهها را در یک برنامه کاربردی واقعی قرار میدهیم، جدول باید دارای تعداد زیادی ستون باشد زیرا مقادیر زیادی دادههای مکانی-زمانی چند منبعی وجود دارد. . بنابراین، این روش کاربرد آینده نگر خود را خواهد داشت. با این حال، کارایی آن بستگی به این دارد که کلید ردیف اصلی چقدر اطلاعات دارد و طول کلید ردیف اصلی چقدر است.
از نتایج، مشاهده شد که کارایی پرس و جو تصادفی رضایت بخش نبود، اما کارایی پرس و جو منطقه قابل قبول بود. این ربطی به روش رمزگذاری کلید ردیف پیشنهادی ندارد، بلکه مربوط به شاخص مکانی-زمانی اصلی است. هیچ طرحی وجود ندارد که بتواند برای هر برنامه ای مناسب باشد. برای برنامههای بعدی ما باید دادههای مکانی-زمانی را برای سریهای زمانی طولانی واکشی کنیم، و بنابراین کارایی پرسوجو منطقه برای ما مهمتر بود. اگر بخواهیم کارایی پرس و جو تصادفی بهبود یابد، باید از یک تابع هش با افزودن “نمک” برای شاخص اصلی استفاده شود، که داده ها را به هر گره داده به شیوه ای نامنظم تخصیص می دهد. با این حال،
ما همچنین به طور مختصر روشهای دیگری را بررسی کردیم تا ببینیم آیا آنها منابع ذخیرهسازی بیشتری را ذخیره میکنند یا کارایی پرس و جو را بهبود میبخشند. یکی از متدهای معمولی “prefixtree” است که نوعی روش رمزگذاری کلید است. درخت پیشوند به عنوان Trie نیز شناخته می شود. برای بهینه سازی پیچیدگی های جستجو استفاده می شود. ما چهار گروه آزمایش را اجرا کردیم: روش رمزگذاری کلید ردیف اصلی و درخت غیر پیشوندی، روش رمزگذاری کلید ردیف پیشنهادی و درخت غیرپیشوندی، روش رمزگذاری کلید ردیف اصلی و درخت پیشوند و روش رمزگذاری کلید ردیف و پیشوند پیشنهادی. ما دریافتیم که روش درخت پیشوند در مقایسه با روش رمزگذاری کلید ردیف پیشنهادی، کارایی ظاهری بیشتری برای دادههای تجربی مورد استفاده در این مقاله دارد. با این حال، آزمون نشان داد که نتیجه ترکیب این دو روش از نظر کارایی ذخیره سازی و کارایی پرس و جو بهترین بود. دلیل این امر این است که این دو روش متضاد نیستند; آنها کلید HBase را در ابعاد مختلف بهینه می کنند. روش “snappy” همچنین می تواند منابع ذخیره سازی را ذخیره کند، اما این روش همیشه بر روی مقدار جدول HBase (مخصوصاً زمانی که مقادیر بزرگ هستند و از پیش فشرده نشده اند) به جای کلید ردیف یا کلید عمل می کند و بنابراین این روش از محدوده فراتر می رود. تحقیق در این مقاله در آینده، قصد داریم به نحوه فشرده سازی مقدار ذخیره شده در ستون های HBase توجه کنیم. آنها کلید HBase را در ابعاد مختلف بهینه می کنند. روش “snappy” همچنین می تواند منابع ذخیره سازی را ذخیره کند، اما این روش همیشه بر روی مقدار جدول HBase (مخصوصاً زمانی که مقادیر بزرگ هستند و از پیش فشرده نشده اند) به جای کلید ردیف یا کلید عمل می کند و بنابراین این روش از محدوده فراتر می رود. تحقیق در این مقاله در آینده، قصد داریم به نحوه فشرده سازی مقدار ذخیره شده در ستون های HBase توجه کنیم. آنها کلید HBase را در ابعاد مختلف بهینه می کنند. روش “snappy” همچنین می تواند منابع ذخیره سازی را ذخیره کند، اما این روش همیشه بر روی مقدار جدول HBase (مخصوصاً زمانی که مقادیر بزرگ هستند و از پیش فشرده نشده اند) به جای کلید ردیف یا کلید عمل می کند و بنابراین این روش از محدوده فراتر می رود. تحقیق در این مقاله در آینده، قصد داریم به نحوه فشرده سازی مقدار ذخیره شده در ستون های HBase توجه کنیم.
موضوع دیگری در مورد شاخص مکانی-زمانی استفاده شده در مقاله وجود دارد. ما سعی کردیم داده های مجاور را از نظر مکان و زمان در همان منطقه داده یا منطقه داده مجاور ذخیره کنیم، که برای یک پرس و جو منطقه مفید است، اما همچنین باعث ایجاد مشکل نقطه اتصال برای ذخیره سازی و پرس و جو شد. ما همچنین سعی کردیم از خط مشی presplit و خط مشی تقسیم خودکار برای حل مشکل هات اسپات برای ذخیره سازی استفاده کنیم که به نظر می رسید در ابتدا موثر بود. ما می خواهیم در آینده به این مشکل رسیدگی کنیم.
5. نتیجه گیری ها
به منظور صرفه جویی در منابع ذخیره سازی بیشتر و بهبود سرعت پرس و جو برای HBase، ما روشی با کاراکترهای ASCII کوتاهتر برای کوتاه کردن طول کلید ردیف اصلی ایجاد شده توسط Raster Dataset Clean and Reconstitution Multi-Grid (RDCRMG) پیشنهاد کردیم. نتایج نشان میدهد که روش ما نهتنها میتواند منابع ذخیرهسازی را در مورد کلید HBase (با نسبت فشردهسازی 29.41%) ذخیره کند، بلکه میتواند در مقایسه با کلید ردیف اصلی کارایی بسیار خوبی برای یک جستجوی منطقه داشته باشد. این روش تفکر مرسوم پشت طراحی خط مشی کلید ردیف را تغییر می دهد. برای کاربردهای دیگر، محققان همچنین میتوانند از کاراکترهای ASCII کوتاهتر برای جایگزینی اطلاعات طولانیتر مطابق روش پیشنهادی در این مقاله استفاده کنند. علاوه بر این، هنگامی که از کلیدهای طولانی (در مقایسه با مقادیر) یا ستون های زیادی استفاده می شود، میتوانیم به طور همزمان از روش درخت پیشوند و روش پیشنهادی برای کاهش حجم دادههای کلید و بهبود سرعت جستجوی منطقه استفاده کنیم. ما همچنین از حالت محاسبه موازی کاهش نقشه برای واکشی دادههای مکانی-زمانی از HBase استفاده کردیم و محاسبه NDVI را برای استان هنان از سال 2018 تا 2019 انجام دادیم. بنابراین، میتوانیم در ابتدا نشان دهیم که مدل ذخیرهسازی مکانی-زمانی طراحیشده ما برای موارد بعدی مؤثر است. کاربرد مکانی – زمانی بر این اساس، ما قادر خواهیم بود مدلهای محاسباتی مکانی-زمانی بیشتری را در تحقیقات خود ادغام کنیم. ما همچنین از حالت محاسبه موازی کاهش نقشه برای واکشی دادههای مکانی-زمانی از HBase استفاده کردیم و محاسبه NDVI را برای استان هنان از سال 2018 تا 2019 انجام دادیم. بنابراین، میتوانیم در ابتدا نشان دهیم که مدل ذخیرهسازی مکانی-زمانی طراحیشده ما برای موارد بعدی مؤثر است. کاربرد مکانی – زمانی بر این اساس، ما قادر خواهیم بود مدلهای محاسباتی مکانی-زمانی بیشتری را در تحقیقات خود ادغام کنیم. ما همچنین از حالت محاسبه موازی کاهش نقشه برای واکشی دادههای مکانی-زمانی از HBase استفاده کردیم و محاسبه NDVI را برای استان هنان از سال 2018 تا 2019 انجام دادیم. بنابراین، میتوانیم در ابتدا نشان دهیم که مدل ذخیرهسازی مکانی-زمانی طراحیشده ما برای موارد بعدی مؤثر است. کاربرد مکانی – زمانی بر این اساس، ما قادر خواهیم بود مدلهای محاسباتی مکانی-زمانی بیشتری را در تحقیقات خود ادغام کنیم.
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| ASCII | کد استاندارد آمریکایی برای تبادل اطلاعات |
| GF-1 | GaoFen شماره 1 |
| NDVI | شاخص گیاهی تفاوت عادی شده |
| UTM | مرکاتور عرضی جهانی |
| HDFS | سیستم فایل توزیع شده Hadoop |
| RDCRMG | Raster Dataset Clean and Reconstitution Multi-Grid |
| WGS 84 | سیستم ژئودتیک جهانی 1984 |
| WKID | شناسه شناخته شده سیستم مرجع فضایی |
منابع
- ناتیوی، س. مازتی، پی. سانتورو، ام. پاپسچی، ف. کراگلیا، ام. Ochiai, O. چالشهای کلان داده در ساخت سیستمهای جهانی رصد زمین. محیط زیست مدل. نرم افزار 2015 ، 68 ، 1-26. [ Google Scholar ] [ CrossRef ]
- زو، ایکس. کای، اف. تیان، جی. ویلیامز، تی. ادغام فضایی و زمانی دادههای سنجش از راه دور چند منبعی: بررسی ادبیات، طبقهبندی، اصول، کاربردها و جهتگیریهای آینده. Remote Sens. 2018 , 10 , 527. [ Google Scholar ]
- وی، ایکس. دوان، ی. لیو، ی. جین، اس. Sun، C. ارزیابی منابع انرژی بادی خشکی-دریایی بر اساس استفاده هم افزایی از داده های ماهواره ای متعدد و ایستگاه های هواشناسی در استان جیانگ سو، چین. جلو. علوم زمین 2019 ، 13 ، 132-150. [ Google Scholar ] [ CrossRef ]
- یائو، ایکس. لی، جی. مدیریت داده های برداری فضایی بزرگ: یک بررسی. داده های بزرگ زمین 2018 ، 2 ، 108-129. [ Google Scholar ] [ CrossRef ]
- او، دبلیو. Yokoya، N. چند زمانی Sentinel-1 and-2 Data Fusion برای شبیه سازی تصویر نوری. ISPRS Int. J. Geo-Inf. 2018 ، 7 ، 389. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- تان، ز. یو، پی. دی، ال. تانگ، جی. استخراج تصاویر سنجش از دور فضایی و زمانی بالا با استفاده از شبکه کانولوشن عمیق. Remote Sens. 2018 , 10 , 1066. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- غمیسی، پ. راستی، ب. یوکویا، ن. وانگ، کیو. هوفل، بی. بروزون، ال. بوولو، اف. چی، م. اندرس، ک. گلوگوئن، آر. و همکاران ادغام داده های چندمنبعی و چندزمانی در سنجش از دور: بررسی جامع وضعیت هنر IEEE Geosci. سنسور از راه دور Mag. 2019 ، 7 ، 6-39. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژو، دبلیو. هوانگ، جی. لی، ال. ژانگ، ایکس. ما، اچ. گائو، ایکس. هوانگ، اچ. خو، بی. Xiao, X. جذب رطوبت خاک بازیابی شده از داده های Sentinel-1 و Sentinel-2 در مدل WOFOST برای بهبود تخمین عملکرد گندم زمستانه. Remote Sens. 2019 ، 11 ، 1618. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- هوانگ، جی. سدانو، اف. هوانگ، ی. ما، اچ. لی، ایکس. لیانگ، اس. تیان، ال. ژانگ، ایکس. فن، جی. Wu, W. جذب یک سری شاخص سطح برگ فیلتر کالمن مصنوعی در مدل WOFOST برای بهبود برآورد عملکرد منطقهای گندم زمستانه. کشاورزی برای. هواشناسی 2016 ، 216 ، 188-202. [ Google Scholar ] [ CrossRef ]
- هوانگ، جی. تیان، ال. لیانگ، اس. ما، اچ. بکر رشف، آی. هوانگ، ی. سو، دبلیو. ژانگ، ایکس. زو، دی. Wu, W. بهبود برآورد عملکرد گندم زمستانه با جذب شاخص سطح برگ از دادههای Landsat TM و MODIS در مدل WOFOST. کشاورزی برای. هواشناسی 2015 ، 204 ، 106-121. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لوئیس، ا. الیور، اس. لیمبرنر، ال. ایوانز، بی. وایبورن، ال. مولر، ن. رایوکسی، جی. هوک، جی. وودکاک، آر. سیکس اسمیت، جی. و همکاران مکعب داده های علوم زمین استرالیا – مبانی و درس های آموخته شده سنسور از راه دور محیط. 2017 ، 202 ، 276-292. [ Google Scholar ] [ CrossRef ]
- یائو، ایکس. لی، جی. شیا، جی. بن، جی. کائو، کیو. ژائو، ال. ممکن است.؛ ژانگ، ال. زو، دی. فعال کردن دادههای رصد بزرگ زمین از طریق محاسبات ابری و DGGS: فرصتها و چالشها. Remote Sens. 2020 , 12 , 62. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آره.؛ لیو، دی. یائو، ایکس. تانگ، اچ. Xiong، Q. ژو، دبلیو. دو، ز. هوانگ، جی. سو، دبلیو. شن، اس. و همکاران RDCRMG: یک معماری چندشبکه ای تمیز و بازسازی مجموعه داده شطرنجی برای نظارت از دور خشکی پوشش گیاهی. Remote Sens. 2018 ، 10 ، 1376. [ Google Scholar ]
- هان، دی. Stroulia, E. Hgrid: یک مدل داده برای مجموعه داده های جغرافیایی بزرگ در hbase. در مجموعه مقالات ششمین کنفرانس بین المللی IEEE در سال 2013 در محاسبات ابری، سانتا کلارا، کالیفرنیا، ایالات متحده آمریکا، 28 ژوئن تا 3 ژوئیه 2013. ص 910-917. [ Google Scholar ]
- Ye, S. تحقیق در مورد کاربرد سنجش از دور نظارت Tupu-Take از بلایای هواشناسی به عنوان مثال. Ph.D. پایان نامه، دانشگاه کشاورزی چین، پکن، چین، 2016. [ Google Scholar ]
- ژو، ام. چن، جی. Gong, J. یک سیستم شبکه جهانی گسسته قطب گرا: مش چهارگوش چهارتایی. محاسبه کنید. Geosci. 2013 ، 61 ، 133-143. [ Google Scholar ] [ CrossRef ]
- داتون، جی. تبادل جهانی داده های مکانی از طریق مختصات سلسله مراتبی جهانی. در مجموعه مقالات کنفرانس بین المللی شبکه های جهانی گسسته، سانتا باربارا، کالیفرنیا، ایالات متحده آمریکا، 26-28 مارس 2000. جلد 3، ص 1-15. [ Google Scholar ]
- Goodchild، MF; گوا، اچ. آنونی، ا. بیان، ال. دی بی، ک. کمبل، اف. کراگلیا، ام. اهلرز، ام. ون جندرن، جی. جکسون، دی. و همکاران نسل بعدی زمین دیجیتال Proc. Natl. آکادمی علمی ایالات متحده آمریکا 2012 ، 109 ، 11088-11094. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چنگ، سی. آهنگ، X. ژو، سی. هیستوگرام سطل حلقوی تجمعی عمومی برای تخمین گزینش پذیری فضایی سیستم مدیریت پایگاه داده فضایی. بین المللی جی. جئوگر. Inf. علمی 2013 ، 27 ، 339-362. [ Google Scholar ] [ CrossRef ]
- لوکاتلا، اچ. هیپارخوس. ساختار داده: نقاط، خطوط و مناطق در شبکه کروی Voronoi. مجموعه مقالات Auto-Carto. 1989 ، 9 ، 164-170. [ Google Scholar ]
- وانگ، ال. ژائو، ایکس. ژائو، ال. یین، N. الگوریتم چند سطحی مبتنی بر QTM برای تولید نمودار Voronoi کروی. Geomat. Inf. علمی دانشگاه ووهان 2015 ، 40 ، 1111-1115. [ Google Scholar ]
- لی، دی. Shao, Z. چندشبکه اطلاعات فضایی و عملکردهای آن. ژئوسپات. Inf. 2005 ، 3 ، 1-5. [ Google Scholar ]
- لی، DR; شیائو، ZF؛ زو، XY; Gong, JY تحقیق در مورد تقسیم شبکه و رمزگذاری شبکه های چندشبکه ای اطلاعات مکانی. Acta Geod. کارتوگر. گناه 2006 ، 1 ، 52-56. [ Google Scholar ]
- لی، دی. شائو، ز. زو، ایکس. Zhu, Y. از نقشه دیجیتال تا چندشبکه اطلاعات مکانی. در مجموعه مقالات سمپوزیوم بین المللی زمین شناسی و سنجش از دور IEEE 2004 (IGARSS 2004)، انکوریج، AK، ایالات متحده آمریکا، 20-24 سپتامبر 2004. جلد 5، ص 2933–2936. [ Google Scholar ]
- Bjørke، JT; گریتن، جی کی. هاگر، ام. Nilsen, S. یک مدل شبکه جهانی بر اساس چهارضلعی های “مساحت ثابت”. ScanGIS Citeseer 2003 ، 3 ، 238-250. [ Google Scholar ]
- Bjørke، JT; نیلسن، اس. بررسی یک شبکه چهار ضلعی با مساحت ثابت در نمایش مدلهای ارتفاع دیجیتال جهانی. بین المللی جی. جئوگر. Inf. علمی 2004 ، 18 ، 653-664. [ Google Scholar ] [ CrossRef ]
- قماوت، س. گوبیوف، اچ. Leung, ST سیستم فایل گوگل. در مجموعه مقالات نوزدهمین سمپوزیوم ACM در مورد اصول سیستم عامل، بولتون لندینگ، نیویورک، ایالات متحده آمریکا، 19 تا 22 اکتبر 2003. [ Google Scholar ]
- Palankar، MR; ایامنیچی، ا. ریپیانو، ام. Garfinkel، S. Amazon S3 برای شبکه های علمی: یک راه حل قابل اجرا؟ در مجموعه مقالات کارگاه بین المللی 2008 در مورد محاسبات توزیع شده آگاه از داده، بوستون، MA، ایالات متحده آمریکا، 25 ژوئن 2008. صص 55-64. [ Google Scholar ]
- الدوی، ا. Mokbel، MF Spatialhadoop: یک چارچوب کاهش نقشه برای داده های مکانی. در مجموعه مقالات سی و یکمین کنفرانس بین المللی IEEE 2015 در زمینه مهندسی داده، سئول، کره، 13 تا 17 آوریل 2015؛ صص 1352–1363. [ Google Scholar ]
- اعرابی، ل. موکبل، MF; Musleh, M. St-hadoop: یک چارچوب کاهش نقشه برای داده های مکانی-زمانی. GeoInformatica 2018 ، 22 ، 785-813. [ Google Scholar ] [ CrossRef ]
- Borthakur, D. سیستم فایل توزیع شده هادوپ: معماری و طراحی. Hadoop Proj. وب سایت 2007 ، 11 ، 21. [ Google Scholar ]
- لیو، ایکس. هان، جی. ژونگ، ی. هان، سی. او، X. پیادهسازی WebGIS در Hadoop: مطالعه موردی بهبود عملکرد ورودی/خروجی فایلهای کوچک در HDFS. در مجموعه مقالات کنفرانس بین المللی IEEE 2009 در مورد محاسبات خوشه ای و کارگاه ها، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، 31 اوت تا 4 سپتامبر 2009. صص 1-8. [ Google Scholar ]
- ختراپل، ا. Ganesh, V. HBase and Hypertable for Large Scale Distributed Storage Systems ; گروه علوم کامپیوتر، دانشگاه پردو: وست لافایت، IN، ایالات متحده آمریکا، 2006; جلد 10. [ Google Scholar ]
- آپاچی اچ بیس. بنیاد نرم افزار آپاچی 2012. در دسترس آنلاین: https://hadoop.apache.org (در 8 اوت 2020 قابل دسترسی است).
- کاپلانیس، ا. کندیا، م. سیوتاس، س. مکریس، سی. Tzimas، G. HB+ tree: از hadoop و HBase استفاده کنید حتی داده های شما آنقدر بزرگ نیست. در مجموعه مقالات سی امین سمپوزیوم سالانه ACM در محاسبات کاربردی، سالامانکا، اسپانیا، 13 تا 17 آوریل 2015. ص 973-980. [ Google Scholar ]
- Team, AH Apache Hbase Reference Guide , Apache, Version; 2016، جلد 2. در دسترس آنلاین: https://hbase.apache.org/book.html (در 8 اوت 2020 قابل دسترسی است).
- لیو، ی. چن، بی. او، دبلیو. Fang, Y. مدیریت داده های تصویر عظیم با استفاده از HBase و MapReduce. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی ژئوانفورماتیک 2013، کایفنگ، چین، 20 تا 22 ژوئن 2013. صص 1-5. [ Google Scholar ]
- وانگ، ال. چنگ، سی. وو، اس. وو، اف. Teng, W. مدیریت داده های تصویر سنجش از راه دور عظیم بر اساس HBase و GeoSOT. در مجموعه مقالات سمپوزیوم بین المللی علوم زمین و سنجش از دور IEEE 2015 (IGARSS)، میلان، ایتالیا، 26 تا 31 ژوئیه 2015. ص 4558-4561. [ Google Scholar ]
- نیشیمورا، اس. داس، اس. آگراوال، دی. El Abbadi، A. Md-hbase: یک زیرساخت داده چند بعدی مقیاس پذیر برای خدمات آگاه از موقعیت مکانی. در مجموعه مقالات دوازدهمین کنفرانس بین المللی IEEE در سال 2011 در مورد مدیریت داده های تلفن همراه، Lulea، سوئد، 6-9 ژوئن 2011. جلد 1، ص 7-16. [ Google Scholar ]
- وانگ، ال. چن، بی. Liu, Y. ذخیره سازی توزیع شده و شاخص داده های مکانی برداری بر اساس HBase. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی ژئوانفورماتیک 2013، کایفنگ، چین، 20 تا 22 ژوئن 2013. صص 1-5. [ Google Scholar ]
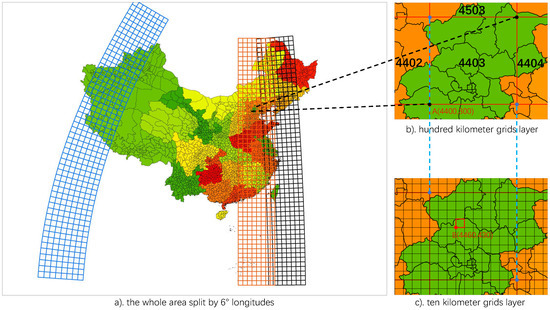
شکل 1. پارتیشن شبکه چندشبکه ای (RDCRMG) پاکسازی و بازسازی مجموعه داده Raster. ( الف ) کل منطقه به 6 تقسیم می شود ∘طول جغرافیایی ( ب ) لایه شبکه 100 کیلومتری. ( ج ) لایه شبکه 10 کیلومتری.
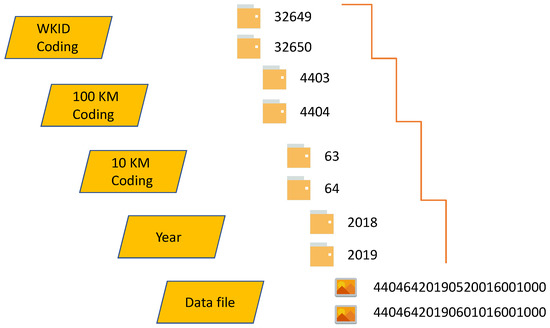
شکل 2. مسیر ذخیره سازی بلوک فایل مبتنی بر RDCRMG.

شکل 3. ساختار کد نام بلوک فایل مبتنی بر RDCRMG.
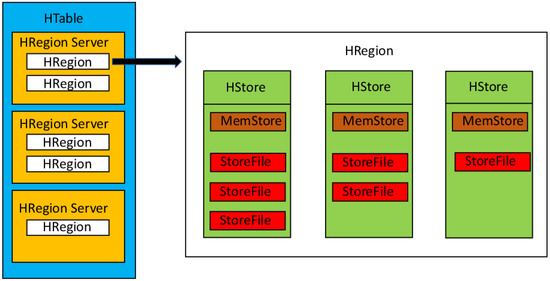
شکل 4. ساختار فیزیکی جدول HBase.

شکل 5. ساختار کلید ردیف اصلی.
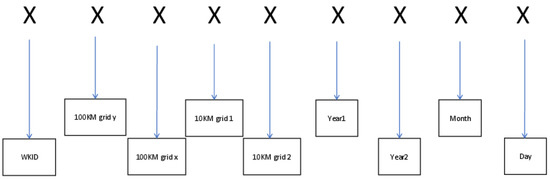
شکل 6. ساختار کلید ردیف پیشنهادی.

شکل 7. ساختار جفت های کلید-مقدار.
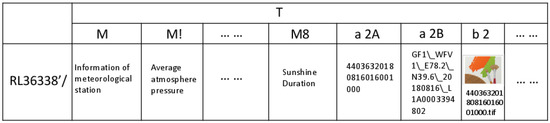
شکل 8. چگونه داده های کد 3265044036320180816 در جدول HBase ذخیره می شود.
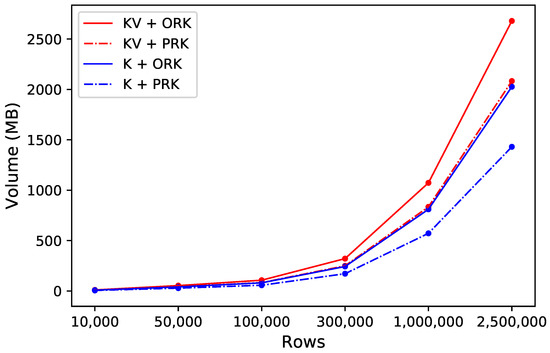
شکل 9. راندمان فشرده سازی با داده های متنی ایستگاه هواشناسی (KV: کلید-مقدار؛ K: کلید؛ ORK: کلید ردیف اصلی؛ PRK: کلید ردیف پیشنهادی).
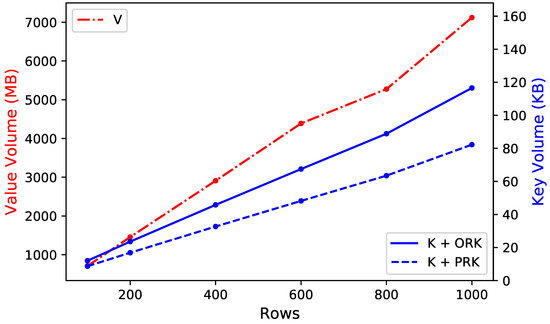
شکل 10. راندمان فشرده سازی با تصاویر سنجش از راه دور (V: مقدار؛ K: کلید؛ ORK: کلید ردیف اصلی؛ PRK: کلید ردیف پیشنهادی).
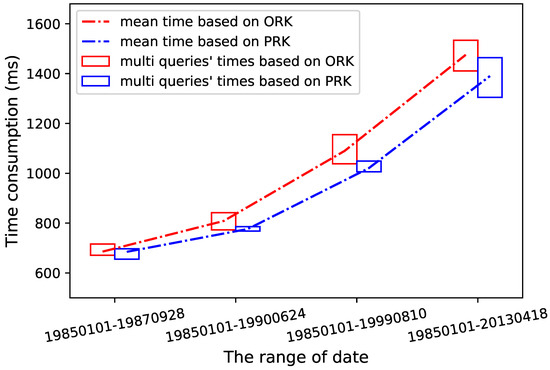
شکل 11. کارایی پرس و جو منطقه با روش های مختلف (ORK: کلید ردیف اصلی؛ PRK: کلید ردیف پیشنهادی).
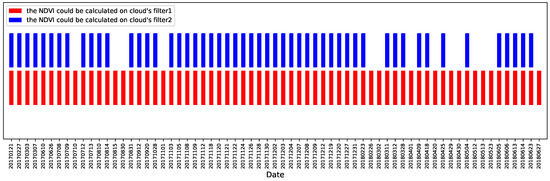
شکل 12. توزیع زمانی شاخص گیاهی تفاوت نرمال شده (NDVI) بر اساس فیلترهای مختلف درصد ابر (فیلتر1: درصد ابر بین 0 تا 100 درصد است؛ فیلتر2: درصد ابر بین 0 تا 50 درصد است).


بدون دیدگاه