1. معرفی
مقاصد در سراسر جهان حدود 1.5 میلیارد گردشگر بین المللی را در سال 2019 ثبت کردند که نسبت به سال قبل 3.8 درصد افزایش داشت [ 1 ]. بنابراین، مدیران گردشگر علاقه مند به پیش بینی رفتار حرکت گردشگران آینده بخش های مختلف از بازار گردشگری هستند [ 2 ]. بخش توریستی گروهی است که ممکن است به تجربیات جداگانه یا ترکیب خدمات بازاریابی توریستی نیاز داشته باشد [ 3 ]. استفاده از دادههای جمعسپاری GNSS (سیستم ناوبری ماهوارهای جهانی) امکان دستیابی به بینشهایی را از رفتار گردشگران به منظور پاسخگویی به سؤالات پیچیده بدون توجه به اینکه محیط شهری یا روستایی است [4، 5] فراهم کرده است .]. برخی از این پرسشها پیامدهای اقتصادی مستقیمی برای مناطق مقصد گردشگری دارند، مانند جستجوی نقاط مهمی که فعالیتهای گردشگری در آن انجام میشود و ارتباط آنها با بخشهای بازار گردشگری.
تجزیه و تحلیل بازار گردشگری به دلیل گروه متنوعی از گردشگران فعال درگیر، یک کار پیچیده است. یک استراتژی مدیریتی مورد استفاده، بخشبندی بازار است، که در آن دادههای توریستی توسط مدیران خدمات برای شناسایی بخشهای گردشگری بهدنبال پیشبینی رفتار گردشگران آینده استفاده میشود [ 2 ]. طبق ادبیات، تقسیمبندی بازار گردشگری بر اساس رویکردهایی مانند مزایای توریستی [ 6 ]، معیارهای انتخاب صنایع دستی و مشارکت خرید [ 7 ] و فصلی [ 8 ] انجام شده است. در کار قبلی [ 9 ]، تقسیمبندی بازار گردشگری در استان زیلند در هلند بر اساس الگوهای زمان اقامت انجام شد که سه بخش گردشگری را شناسایی میکرد:خارجی 24 ، گردشگرانی که کمتر از 24 ساعت را در منطقه زیلند صرف کرده اند تنها در یک موقعیت. خارجی طولانی ، کسانی که بیش از 24 ساعت را در منطقه Zeeland تنها در یک موقعیت سپری کردند. و خارجی مکرر ، کسانی که برای آنها سفرهای متعدد در داخل و خارج از منطقه Zeeland مشاهده شد.
به طور سنتی، آمار گردشگری با استفاده از نظرسنجی های کاغذی جمع آوری می شود که قادر به ثبت رفتار طولی یک گردشگر نیست. امروزه، کمپینهای گردشگری دادههای توریستی را با استفاده از برنامههای کاربردی تلفنهای هوشمند جمعسپاری، مانند Bucketfood [ 10 ] و Zeeland App [ 11 ] جمعآوری میکنند، که زمانی که دانش درباره گردشگر در تمام مراحل سفر ضروری است، مزایایی دارند. استفاده از گوشیهای هوشمند بهعنوان حسگر به ما این امکان را میدهد که دادهها را در مناطق بزرگ جغرافیایی (روستایی)، در مناطق (حتی) کمتر بازدیدکننده و به طور مداوم در هر زمانی از روز جمعآوری کنیم. بنابراین، دقت داده های مکانی-زمانی بالاتر از آمار گردشگری معمولی است [ 12]. کمپینهای گردشگری جمعسپاری برای به دست آوردن بینشهای مختلف مانند جریانهای تحرک گردشگران، استفاده از انواع مختلف حالتهای حملونقل، تعداد بازدیدکنندگان و الگوهای تحرک آنها، درک پروفایلهای تحرک بازدیدکنندگان، و مشوقهای بالقوهای که ممکن است برای تأثیرگذاری بر تحرک کاربران استفاده شوند، راهاندازی میشوند. رفتار – اخلاق. با این حال، تجزیه و تحلیل داده های بزرگ مکانی-زمانی برای تبدیل داده های جمع آوری شده به بینش های ارزشمند و معنادار مورد نیاز است.
در ادبیات، تجزیه و تحلیل دادههای بزرگ مکانی-زمانی، کمکهایی مانند الگوریتمها، روشها، چارچوبها، رویکردها و راهحلهای جدید برای پرداختن به چالشهای حوزه خاص [13] برای استخراج اطلاعات به منظور درک پدیدهها به عنوان تحرک انسان از دادههای GNSS جمعسپاری شده توسعه داده است. [ 14 ، 15 ، 16 ]. در حوزه گردشگری، تحلیل مسیر [ 17 ] به نام داده کاوی مسیر در زمینه های خاصی مانند گردشگری برای کشف الگوهای حرکت گردشگری شهری یا روستایی استفاده شده است [ 4 ، 5 ، 8] .] یکی از اهداف آن برای استخراج نقاط مورد علاقه است. برای شناسایی خوشهها (به عنوان مثال، نقاط مهم)، ویژگیهای مکانی-زمانی به عنوان بخشی از دادههای ورودی زنجیرههای پردازشی استفاده شدهاند که شامل فرآیندهای فرعی دادهکاوی برای تبدیل دادهها به دانش است [18 ] . در [ 19 ]، یادگیری قانون تداعی برای الگوبرداری در بازدید از جاذبههای توریستی برای نشان دادن پتانسیل شبکههای سنجش موقت در اندازهگیری غیر مشارکتی حرکات در مقیاس کوچک اعمال میشود. در [ 20]، نویسندگان رویکردهای مختلف خوشه بندی را برای شناسایی افراد و نقاط داغ جمعی در نظر می گیرند. یافتههای آنها ثابت کرد که OPTICS قویترین الگوریتم در برابر پارامترهای اولیه است، اما تنظیم پارامتر و بازنمایی دادهها مورد ارزیابی قرار نگرفت. با این وجود، این نتایج مبتنی بر داده باید اعتبار سنجی شوند. در ادبیات، منابع داده خارجی مانند اطلاعات جغرافیایی معنایی [ 21 ]، دستهبندیهای Google [ 22 ] و OpenStreetMaps [ 20 ] برای انجام این کار استفاده شدهاند.
در این تحقیق، روشی برای شناسایی نقاط داغ از دادههای جمعسپاری شده که تفسیری مبتنی بر داده را به آنها میدهد پیشنهاد شده است. یک مجموعه داده جمعسپاری که از بیش از 1500 شرکتکننده، طی یک دوره پنج ماهه، در استان توریستی زیلند، هلند جمعآوری شده است، استفاده میشود. فقط سفرهایی که توسط گردشگر انجام می شود که متعلق به بخش های توریستی خارجی طولانی و دوره ای خارجی است [ 9] در نظر گرفته شده اند. مشارکتهای پژوهشی بنیادی این کار به سؤال تحقیقاتی زیر مربوط میشود: (1) چگونه میتوان دادههای جمعسپاری و خوشههای حاصل از این نوع منبع داده را تأیید کرد؟ (ii) بینشهای اضافهای که دادههای جمعسپاری میتوانند در بالای آمارهای موجود به ارمغان بیاورند، چیست؟ (iii) آیا بین بخش های توریستی در الگوهای فعالیت آنها تفاوت وجود دارد؟
بقیه این مقاله به شرح زیر سازماندهی شده است: بخش 2 یک نمای کلی از منطقه مطالعاتی جغرافیایی و توضیحات مجموعه داده می دهد. روش دقیقی که برای کشف خوشههایی که نقاط داغ را نشان میدهند نیز در این بخش گنجانده شده است. در بخش 3 ، نتایج به همراه برخی از بینشها در مورد کانون گردشگری و کمپین جمعسپاری گردشگری ارائه شده است. بحث در مورد یافته ها در بخش 4 صورت می گیرد و نتایج این تحقیق را می توان در بخش 5 یافت .
2. مواد و روشها
2.1. منطقه مطالعاتی جغرافیایی
در هلند، استان زیلند ( شکل 1 ) یکی از استان های پربازدید از نظر گردشگران خارجی است، اما کم جمعیت ترین استان کشور است [ 23] .]. گردشگران برای فعالیت های قابل توسعه (جدول 3) از استان بازدید می کنند. از نظر جغرافیایی، زیلند در جنوب غربی هلند واقع شده است و حدود 2930 کیلومتر مربع مساحت دارد که از سواحل و جزایر تشکیل شده است. استان زیلند دارای 13 شهرداری است. بر اساس آمار هلند، یک موسسه دولتی هلند، که در هلندی به عنوان Centraal Bureau voor de Statistiek (CBS) شناخته می شود، این استان در سال 2017 بیش از 10 میلیون اقامت شبانه را ثبت کرده است و برای اولین بار تعداد شب اقامت گردشگران خارجی ثبت شده است. (غیر هلندی) از تعداد شب اقامت هلندی ها (غیر مقیم) بیشتر شد [ 24]. این تحقیق در این استان انجام شد که از نظر تعداد شب در هلند رتبه 6 و از نظر گردشگران خارجی رتبه 3 را دارد.
2.2. مجموعه داده
در این تحقیق از مجموعه داده های زیر استفاده شده است:
-
مجموعه داده گردشگری جمع سپاری شده دادهها توسط اپلیکیشن جمعسپاری تلفن همراه ارائهشده توسط آژانس رسمی اطلاعات توریستی منطقهای VVV Zeeland (استان زیلند، هلند) جمعآوری شد. کاربران هدف گردشگرانی بودند که از ماه می تا سپتامبر 2017 از استان بازدید کردند. در این مدت، در مجموع 10597 کاربر این اپلیکیشن را دانلود کردند که از این تعداد 1505 کاربر داده های خود را ارائه کردند. کاربران فعال 124725 سفر (مسیر پیموده شده از مبدأ سفر تا محل مقصد سفر) و 151612 بخش سفر (قسمتهایی از سفر که با حالت حملونقل تکی انجام میشود) مشارکت کردند. در مجموعه داده، هر رکورد یک بخش سفر را نشان می دهد. شرح مفصلی از ویژگی های جمع آوری شده برای هر بخش سفر در جدول 1 آورده شده است .
-
مجموعه داده CBS . این مجموعه داده شامل آمار منتشر شده توسط CBS در مورد گردشگران در اقامتگاه های استان زیلند [ 24 ] است. دوره زمانی در نظر گرفته شده در مقایسه، از ژوئیه تا سپتامبر 2017 است. این منبع داده خارجی برای اندازه گیری نمایندگی داده های جمع سپاری استفاده می شود.
-
کاربری اراضی هلند این مجموعه داده شامل فایل کاربری زمین از هلند است که توسط CBS [ 25 ] منتشر شده است. این شامل هندسه دیجیتالی استفاده از زمین مانند مناطق ترافیکی، ساختمان ها و مناطق تفریحی است. این منبع داده خارجی برای تکمیل مجموعه داده استفاده می شود تا بتواند تفسیری مبتنی بر داده را به نتایج ارائه دهد. جدول 2 فیلدهای مجموعه داده را نشان می دهد.
-
مجموعه داده اعتبار سنجی NBTC-NIPO Research یک شرکت تحقیقاتی است که در تحقیقات تعطیلات، اوقات فراغت و سفرهای کاری تخصص دارد. یکی از پروژه های تحقیقاتی آنها، تحقیقات مداوم تعطیلات است که در هلندی به عنوان ContinuVakantieOnderzoek (CVO) شناخته می شود. این پروژه یک نظرسنجی در مقیاس بزرگ مصرف کنندگان در مورد رفتار تعطیلات در هلند است. در CVO 2015، که از 1 اکتبر 2014 تا 30 سپتامبر 2015 انجام شد، از افرادی که تعطیلات توریستی را در زلند گذرانده بودند، پرسیده شد که آیا در طول تعطیلات خود فعالیت های خاصی انجام داده اند یا خیر. 10 مورد برتر از فعالیت های گردشگران هلندی شبانه در زیلند در جدول 3 نشان داده شده است . در این تحقیق از این منبع داده خارجی برای اعتبار سنجی تفسیر نتایج استفاده شده است.
2.3. روش شناسی
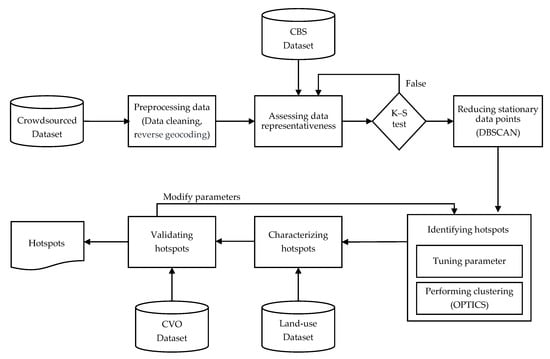
در این بخش روش پیشنهادی توضیح داده شده است. شکل 2 زنجیره پردازش را نشان می دهد زیرا داده های جمع سپاری به عنوان ورودی ارائه می شوند تا زمانی که هات پات های معنی دار به عنوان یک نتیجه ارائه شوند. در ادامه مراحل مختلف با جزئیات بیشتر مورد بحث قرار خواهد گرفت.
2.3.1. پیش پردازش مجموعه داده
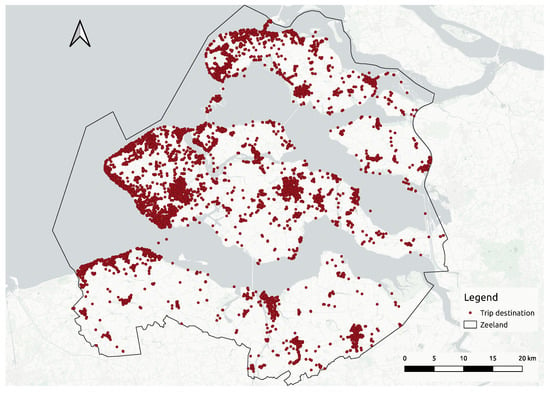
در مرحله پیش پردازش، پاکسازی داده ها انجام می شود تا بخش های سفر با داده های از دست رفته یا فیلدهای خالی حذف شوند. سفرها با استفاده از بخش های سفر معتبر به منظور استخراج ویژگی هایی مانند مکان مقصد سفر بازسازی می شوند. سفرهایی که مکان مقصد خارج از منطقه مورد مطالعه است فیلتر می شوند. سپس، تبدیل داده ها برای استخراج برخی از ویژگی ها انجام می شود. ابتدا ژئوکدینگ معکوس در مبدا و مقصد اعمال می شود تا در صورتی که نقاط مکان در داخل محدوده مورد مطالعه باشد، نام مبدا و مقصد شهرداری به دست آید، در غیر این صورت خالی خواهند بود. دوم، برای هر سفر، زمان اقامت به عنوان اختلاف زمانی بین زمان رسیدن به مقصد سفر فعلی و زمان عزیمت سفر بعدی محاسبه میشود. سرانجام، ویژگی مکان مقصد از درجه اعشار به سیستم مختصات Mercator عرضی جهانی (UTM) تبدیل می شود تا بتواند از متر به عنوان واحد اندازه گیری فاصله در طی مراحل روش شناسی زیر استفاده کند. علاوه بر این، با استفاده از تقسیمبندی بازار گردشگری انجام شده در [9 ]، بخش توریستی که کاربر به آن تعلق دارد به هر سفر اضافه می شود تا سفرهایی را که توسط بخش های توریستی طولانی مدت و خارجی انجام نشده است فیلتر کند. شکل 3 مکان های جغرافیایی مقصد سفر مجموعه داده را با نشان دادن منطقه مورد مطالعه نشان می دهد.
در این مجموعه داده، 25613 نقطه داده وجود دارد. هر کدام نشان دهنده مکان مقصد سفر است. شرح مفصلی از ویژگی های جمع آوری شده برای هر مکان مقصد سفر در جدول 4 آورده شده است .
2.3.2. نمایندگی مجموعه داده
این مطالعه بر روی تشخیص نقاط داغ برای بهبود درک رفتار بازدیدکنندگان Zeeland تمرکز دارد. هدف آن ایجاد یک مدل خوشهبندی مبتنی بر چگالی است. با این حال، این نوع مدل معمولاً با داده های تاریخی آموزش داده می شود، با این فرض که متغیرهای مورد استفاده مدل در آینده نزدیک همان رفتار را حفظ خواهند کرد. بنابراین، ارزیابی میشود که آیا مجموعه داده جمعسپاری یک مجموعه داده نماینده است یا خیر. از این رو، مقایسه توزیع دادهها بین تعداد گردشگران در اقامتگاههای توریستی توسط هر شهرداری استان زلاند ثبتشده در مجموعه داده آمار هلند، و تعداد سفرهای ورودی توسط هر شهرداری استان زیلند ثبتشده در مجموعه دادههای جمعسپاری شده است. انجام شد.
قبل از انجام مقایسه، هر دو نمونه استاندارد شدند تا آنها را در یک مقیاس قرار دهند و میانگین را روی 0 با انحراف استاندارد 1 متمرکز کنیم. روش استانداردسازی را می توان به صورت زیر بیان کرد:
جایی که μایکسو σایکسمیانگین و انحراف معیار صفت را نشان می دهد.
سپس، آزمون دو نمونه ای کولموگروف-اسمیرنوف ( آزمون K-S ) (معادله ( 2 ))، که یک آزمون ناپارامتریک برای برابری پیوسته یا ناپیوسته است، برای ارزیابی اینکه آیا هر دو نمونه از یک جمعیت با توزیع یکسان این آزمون فاصله KS را کمی می کند که به عنوان حداکثر فاصله عمودی بین توابع توزیع تجربی دو نمونه تعریف می شود. این به صورت زیر تعریف می شود:
جایی که اف(ایکس)تابع توزیع تجمعی مشاهده شده اولین نمونه است که دارای اندازه n و است جی(ایکس)تابع توزیع تجمعی مشاهده شده نمونه دوم است که اندازه m است . اگر فاصله K-S کوچک یا مقدار p زیاد باشد، هر دو نمونه از جمعیتی با توزیع یکسان می آیند (فرضیه صفر).
2.3.3. تجزیه و تحلیل خوشه بندی
در این مطالعه، هدف شناسایی نقاط داغ بازدید شده توسط گردشگران زیلند با استفاده از خوشه بندی، یک تکنیک یادگیری بدون نظارت برای کشف ساختارهای داده به منظور استخراج اطلاعات معنادار است. یک الگوریتم خوشه بندی مبتنی بر چگالی از مفهوم چگالی استفاده می کند که می تواند به عنوان تعداد نقاط داده در واحد حجم فضای ویژگی تعریف شود [ 27 ]. یک نقطه داده از متغیرهای نشان داده شده در جدول 5 ساخته شده است . یک منطقه از فضای ویژگی به عنوان یک منطقه با چگالی بالا یا کم تراکم با توجه به وقوع نقاط داده ای که نزدیک به هم بسته بندی شده اند شناسایی می شود. سپس، خوشه ها با تقسیم بندی و الگوهای یادگیری از مناطق با تراکم بالا شناسایی می شوند.
در این مرحله، اولین هدف کاهش تعداد نقاط داده تولید شده توسط یک گردشگر منفرد است تا سپس به دنبال خوشه هایی با تراکم ناهمگن بگردند. به طور کلی، الگوریتمهای خوشهبندی مالکیت نقاط داده را در نظر نمیگیرند، بنابراین یک نقطه میتواند به اشتباه بهعنوان یک نقطه مهم طبقهبندی شود، فقط به دلیل تعداد بالای بازدیدهای ثبتشده توسط یک کاربر. برای رسیدگی به این مشکل، الگوریتم خوشهبندی فضایی مبتنی بر چگالی برنامههای کاربردی با نویز (DBSCAN) [ 28 ] انتخاب میشود زیرا مکانهایی را که گردشگران بازدید کردهاند، بدون توجه به تعداد دفعاتی که از آنها بازدید کردهاند، پیدا میکند، به عنوان مثال، خوشههایی با هر شکلی بدون توجه به چگالی آنها. و به دلیل توانایی DBSCAN برای پردازش مجموعه داده های بسیار بزرگ [ 29]. برای رسیدگی به مسئله چگالی خوشه ناهمگن، از الگوریتم Ordering Points To Identify the Clustering Structure (OPTICS) [ 30 ] استفاده می شود. مزیت اصلی OPTICS این است که می تواند خوشه هایی با چگالی متفاوت پیدا کند. تا جایی که میدانیم، الگوریتمهای مبتنی بر چگالی که هم خوشهها را با نقاط داده کاربران مختلف و هم شرایط چگالی خوشهای ناهمگن را پیدا میکنند، وجود ندارند. برای مثال، Reverse Nearest Neighbor-DBSCAN [ 31 ] که یک الگوریتم مبتنی بر DBSCAN است، فقط جستجوی خوشههایی با چگالی ناهمگن را انجام میدهد. Photo-DBSCAN [ 32 ] خوشه هایی را پیدا می کند که حاوی نقاط داده کاربران مختلف است، اما تضمین نمی کند که بتواند خوشه هایی با چگالی های مختلف را شناسایی کند.
DBSCAN دارای دو پارامتر است: حداقل تعداد نقاط داده برای تشکیل یک ناحیه متراکم ( minPts ) و ε ( epsilon ) که نشان دهنده حداکثر فاصله، بیان شده بر حسب واحد فضای ویژگی، بین دو نقطه داده برای یک نقطه داده است که باید در نظر گرفته شود. همسایگی دیگری با توجه به ادبیات، تعداد ابعاد ( کم ) یک مجموعه داده را می توان برای تعیین مقدار minPts هایپرپارامتر استفاده کرد . در بسیاری از موارد یک مجموعه داده دو بعدی، می توان آن را در مقدار پیش فرض minPts = 4 [ 28 ] نگه داشت، در حالی که در موارد مجموعه داده های بزرگ و با ابعاد بالا، می توان minPts = 2* dim [ 33] را تنظیم کرد.]. در برخی از مطالعات، یک مقدار مطلق منفرد مناسب نیست، بنابراین آنها آن را بر اساس درصدی از مالکیت نقطه داده [ 34 ]، با استفاده از یک رویکرد اکتشافی بر اساس اندازه مجموعه داده [ 35 ] تنظیم کرده اند یا تخمین مقدار آن را انجام می دهند. با استفاده از یک تابع هدف [ 36 ]. به طور کلی، مقادیر بیشتری از minPtsنسبت به نویز قوی تر هستند و خوشه های مهم تری تولید می کنند. با این حال، سعی بر این است که بازدیدهای متعددی را که یک کاربر از یک مکان انجام می دهد با یک نقطه داده منفرد نشان دهد در حالی که مکان هایی که فقط یک بار بازدید شده اند باید نگه داشته شوند، بنابراین نقاط غیر داده باید به عنوان نویز طبقه بندی شوند. فراپارامتر ε که حداکثر فاصله شعاع جستجو را نشان می دهد باید با کمترین مقدار ممکن تنظیم شود. این فراپارامتر همچنین در بسیاری از مطالعات با استفاده از فاصله k-NN (یعنی 25 تا 550 متر) یا با در نظر گرفتن دامنه کاربردی و دانش منطقه مورد مطالعه تنظیم شده است [33 ، 36 ، 37 ] .
الگوریتم با انتخاب یک نقطه داده تصادفی p از مجموعه داده D شروع می شود . سپس به دنبال نقاط داده در همسایگی ε p می گردد . اگر حداقل نقاط داده minPts (از جمله آن) وجود داشته باشد، p به عنوان یک نقطه اصلی نشان دهنده شروع یک خوشه علامت گذاری می شود و تمام نقاط داده در همسایگی ε آن به خوشه آن اضافه می شود. در غیر این صورت، نقطه داده p به عنوان نویز مشخص می شود. با این حال، p ممکن است بعداً بخشی از همسایگی ε نقطه اصلی دیگری باشد و از این رو بخشی از یک خوشه شود. سپس الگوریتم از هر نقطه داده خوشه جدید بازدید می کند تا همان کار را انجام دهد. اگر یک نقطه qاز ε-همسایگی p یک نقطه هسته است ، گفته می شود که این نقاط داده به طور مستقیم با چگالی متصل و قابل دسترسی از یکدیگر هستند. شبکه ساخته شده توسط این نقاط داده متصل به چگالی یک خوشه در نظر گرفته می شود. الگوریتم به صورت بازگشتی از طریق اتصالات چگالی از نقاط اصلی جستجو می کند . هنگامی که یک نقطه داده از یک نقطه اصلی قابل دسترسی باشد، متوقف می شود، اما یک نقطه اصلی نیست . این نقطه داده یک نقطه مرزی در نظر گرفته می شود . سپس، الگوریتم با انتخاب یک نقطه داده بازدید نشده برای تکرار فرآیند ادامه مییابد.
در DBSCAN، متریک فاصله پیشفرض مورد استفاده برای محاسبات همسایگی، فاصله اقلیدسی بین دو نقطه داده است (معادله ( 3 )). این به صورت زیر تعریف می شود:
جایی که من = ( ایکسمن1، ایکسمن2، …، x در ) و j = ( ایکسj1، ایکسj2, …, x jn ) نشان دهنده دو نقطه داده توصیف شده توسط n ویژگی عددی است. هنگامی که DBSCAN با نقاط داده یک گردشگر ارزیابی شد، برای هر خوشه به دست آمده، مرکزی ترین نقطه داده آن استخراج می شود و ویژگی “زمان اقامت” با میانگین “زمان اقامت” از نقاط داده در خوشه به روز می شود. این ویژگی در مرحله توصیف مبتنی بر داده استفاده خواهد شد. این رویه برای هر گردشگر (غیر فیلتر شده) در مجموعه داده اعمال می شود تا مجموعه داده جدیدی ساخته شده از مرکزترین نقاط استخراج شده ایجاد شود.
سپس، Ordering Points To Identify the Clustering Structure (OPTICS) [ 30 ] برای تخصیص عضویت خوشه بر روی مجموعه داده کاهش یافته استفاده می شود. OPTICS به دلیل توانایی آن برای یافتن خوشه هایی با چگالی متفاوت انتخاب شد. این الگوریتم از پارامترهای مشابه DBSCAN استفاده می کند. با این حال، تنها فراپارامتر اجباری minPts است . شعاع جستجو (ε) در اطراف یک نقطه داده اختیاری است. ثابت نیست و افزایش می یابد در حالی که حداقل minPts وجود نداردنقاط داده ای که در آنها به OPTICS اجازه می دهد تا مناطق با چگالی متفاوت را شناسایی کند. مناطق با چگالی بالا یک ε کوچک دارند در حالی که مناطق با چگالی کم یک ε بزرگ دارند. بنابراین، ε برای محدود کردن تعداد نقاط داده در نظر گرفته شده در جستجوی همسایگی برای کاهش پیچیدگی محاسباتی استفاده میشود.
کوچکترین فاصله دور از یک نقطه داده که شامل minPts سایر نقاط داده است، فاصله هسته نامیده می شود (معادله ( 5 )). فاصله بین یک نقطه هسته p و یک نقطه هسته q در داخل ε آن، که نمی تواند کمتر از فاصله هسته باشد، فاصله قابل استفاده مجدد است (معادله ( 5 )). فاصله مرکزی و فاصله دسترسی در OPTICS [ 30 ] به صورت زیر تعریف شد :
که در آن minPts-dist ( p ) فاصله تا minPts نزدیکترین همسایه p است ، سیآrد(نϵ(پ))اصلی بودن زیرمجموعه ای از مجموعه داده D موجود در همسایگی ε نقطه داده p است . نϵ(q)ε-همسایگی یک نقطه داده q است و dist ( q , p ) فاصله اقلیدسی بین p و q است .
الگوریتم شروع به بازدید از هر نقطه داده از مجموعه داده برای شناسایی و علامت گذاری نقاط اصلی می کند. برای هر نقطه، محاسباتی انجام می شود. ابتدا فاصله هسته و فاصله دسترسی محاسبه می شود. دوم، امتیاز دسترسیکه به عنوان بزرگتر فاصله هسته یا کوچکترین فاصله دسترسی آن محاسبه می شود. در نهایت، توالی نقاط داده ای که الگوریتم قرار است بعداً از آنها بازدید کند، بر اساس فاصله دسترسی تا نقطه داده فعلی به روز می شود. این بدان معنی است که نقطه مرکزی بعدی برای بازدید، نقطه ای است که کمترین فاصله دسترسی را نسبت به نقطه فعلی دارد. هنگامی که الگوریتم تمام نقاط را بازدید کرد، هم ترتیب بازدید از هر نقطه داده و هم امتیاز دسترسی هر مورد را برمیگرداند.
فرآیند استخراج خوشهبندی با استفاده از نمودار Reachability انجام میشود. دو روش برای انجام تشخیص خوشه بندی وجود دارد. روش اول شامل انتخاب مقداری امتیاز دسترسی برای رسم یک خط افقی در سراسر نمودار دسترسی است. هنگامی که نمودار به زیر خط افقی فرو می رود، نقطه شروع یک خوشه مشخص می شود، در حالی که، اگر نمودار به بالای خط برگردد، انتهای خوشه مشخص می شود. سپس، هر مورد بالاتر از خط افقی را می توان به عنوان نویز طبقه بندی کرد. دوم روش ξ( xi ) است که از شیب استفاده می کندمفهوم به صورت 1 – ξ تعریف شده است. در اینجا، شروع و پایان یک خوشه در نمودار Reachability زمانی اتفاق میافتد که دسترسی به دو نقطه داده متوالی با ضریب 1 – ξ تغییر کند. یک شیب رو به پایین با حداقل مقدار شیب انتخاب شده شروع یک خوشه را ایجاد می کند در حالی که یک شیب رو به بالا با حداقل مقدار شیب انتخاب شده پایان آن را نشان می دهد. در این تحقیق از این روش به دلیل قابلیت یافتن خوشه هایی با تراکم متفاوت و همچنین سلسله مراتبی در بین آنها استفاده شده است. با این حال، یک الگوریتم خوشهبندی فقط خوشهها را در نقاط داده شناسایی میکند، اما مشخص نمیکند که چقدر خوب یا بد هستند.
یک الگوریتم خوشهبندی که با پیکربندی فراپارامترهای مختلف محاسبه میشود، ممکن است نتیجه خوشهبندی متفاوتی تولید کند. بنابراین، از یک ارزیابی متریک خوشهبندی استفاده میشود تا بتوان محاسبات الگوریتم OPTICS را با مقادیر فراپارامتر مختلف به منظور تعیین مقادیر بهینه که در آن متریک بهترین است، مقایسه کرد. در این تحقیق از ضریب Silhouette [ 38 ] به عنوان معیاری برای ارزیابی کیفیت خوشه بندی استفاده شده است. این متریک زمانی استفاده می شود که برچسب های حقیقت زمینی شناخته نشده باشند. یک نتیجه خوشهبندی را میتوان با چهار معیار ارزیابی کرد: فشردگی، جداسازی، تناسب کلی، و ابعاد ذاتی [ 39]. ارزیابی فشردگی و جداسازی خوشهبندی با این متریک برای هر مدل تولید شده توسط ترکیب هر ابرپارامتر انجام میشود. ضریب silhouette به صورت زیر تعریف می شود:
جایی که آ(من)فشردگی خوشه را نشان می دهد که به عنوان فاصله متوسط بین یک نمونه محاسبه می شود ایکس(من)و تمام نقاط داده دیگر در همان خوشه، و ب(من)جداسازی خوشه ای را نشان می دهد که به عنوان میانگین فاصله بین نمونه محاسبه می شود ایکس(من)و تمام نمونه ها در نزدیکترین خوشه. ضریب Silhouette بین -1 برای خوشهبندی نادرست و +1 برای خوشهبندی بسیار متراکم محدود میشود. نمرات حدود صفر نشان دهنده همپوشانی خوشه ها است. آزمایشها برای تنظیم فراپارامترهای OPTICS minPts و ξ در بخش 3.2 توضیح داده شدهاند .
2.3.4. خصوصیات و اعتبارسنجی داده محور
پس از انتخاب مقادیر فراپارامتر بهینه، یعنی ترکیب مقادیری که میانگین امتیاز ضریب سیلوئت در میان خوشههای بهدستآمده بالاترین است، OPTICS با استفاده از آنها برای تولید یک مدل خوشهبندی با خوشههای متراکمتر و به خوبی جداشدهتر انجام میشود. سپس، یک خصوصیات مبتنی بر داده از هر خوشه (هات اسپات) انجام می شود. در این مرحله، از مجموعه داده کاربری زمین و ویژگی زمان ماندن نقاط داده خوشه استفاده می شود. کاربری زمین هر نقطه داده با توجه به ویژگی مکان مقصد تعیین می شود، به عنوان مثال، یک خوشه ممکن است نقاط داده با کاربری های مختلف داشته باشد. سپس، کاربری اصلی یک خوشه با بیشترین استفاده از زمین در میان نقاط داده آنها مشخص می شود. علاوه بر این،
در مرحله آخر، با توجه به اینکه کاربری اراضی با فعالیت های انسانی توسعه یافته در یک ملک مرتبط است، تعداد نسبی کانون ها بر اساس کاربری با فعالیت گردشگران شبانه منطقه مورد مطالعه که در اعتبار سنجی شرح داده شده است، مقایسه می شود. مجموعه داده محاسبه می شود. در صورت عدم تطابق بین این منابع داده، باید دوباره با یک مقدار فراپارامتر دیگر، خوشه بندی انجام شود. در غیر این صورت، خوشه ها (نقاط داغ) به عنوان یک نتیجه از این زنجیره پردازش ارائه می شود.
3. نتایج
این بخش نتایج تجزیه و تحلیل را برای کشف نقاط داغی که گردشگران در آن زمان در منطقه مورد مطالعه سپری می کنند ارائه می کند.
3.1. تجزیه و تحلیل سفرهای ورودی برای نمایندگی
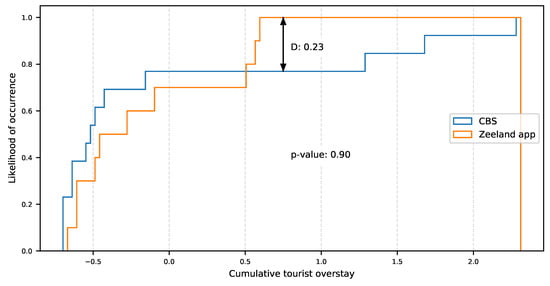
نمایندگی مجموعه داده جمعسپاری براساس مقایسه آن با آمار گردشگران در دادههای اقامتگاههای توریستی از آمار هلند ارزیابی شد. نمودار نشان داده شده در شکل 4 توابع توزیع تجمعی مجموعه داده جمع سپاری و آمار رسمی را نشان می دهد. فاصله KS برای تعیین اینکه آیا هر دو نمونه از جمعیتی با توزیع یکسان آمده اند یا نه، D = 0.23 و p -value = 0.90 است.
فاصله K–S برای جدول مقدار بحرانی با α = 0.05، n = 12 و m = 12 ، D-crit = 0.84 است . از آنجایی که D = 0.23 < 0.84، تفاوت معنیداری بین توزیعهای نمونهها وجود ندارد، به این معنی که هر دو نمونه از جمعیتی با توزیع یکسان هستند که نشان میدهد مجموعه دادههای جمعسپاری نماینده این مطالعه است.
3.2. آزمایش کنید
تجزیه و تحلیل خوشهبندی مبتنی بر چگالی در دو مرحله بر روی مجموعه دادههای ساخته شده از 25613 نقطه داده انجام میشود. مرحله اول با هدف کاهش تعداد نقاط داده تولید شده توسط هر کاربر به منظور جلوگیری از شناسایی خوشه های ساخته شده توسط نقاط داده تنها از یک کاربر است. این روش با استخراج n زیر مجموعه نقطه داده، یکی برای هر کاربر، شروع می شود تا سپس DBSCAN برای هر زیر مجموعه اعمال شود.
در ادبیات، محدوده بافر فضایی از 20 تا 1000 متر در مطالعات مختلف برای تجزیه و تحلیل رفتار ساکن کاربر استفاده شده است [ 40 ، 41 ، 42 ]. بنابراین، مقدار فراپارامتر ε روی 50 متر ثابت شد. سپس، تلاش میشود بازدیدهای متعددی را که یک کاربر از یک مکان انجام میدهد با یک نقطه داده منفرد نشان دهد، در حالی که مکانهایی که فقط یک بار بازدید شدهاند باید حفظ شوند. بر اساس این دو فرض، minPts= 1 انتخاب شده است. با این مقدار هایپرپارامتر، نقاط غیر داده به عنوان نویز توسط DBSCAN طبقه بندی می شوند. سپس، DBSCAN را روی هر زیر مجموعه اعمال می کنیم تا فشرده سازی داده ها توسط کاربر انجام شود. در مواردی که یک خوشه از بیش از یک نقطه داده تشکیل شده است، مرکز بیشترین نقطه داده برای نمایش خوشه در نظر گرفته می شود. مجموعه داده حاصل شامل 12337 نقطه داده است که 48.17 درصد از مجموعه داده اصلی است. شکل 5 مقایسه بین داده های اصلی و داده های فشرده یک کاربر را نشان می دهد.
مرحله بعدی شامل استفاده از OPTICS برای کشف خوشهها در مجموعه دادههای فشرده شده است. در آزمایش، مقدار فراپارامتر ε برای کاهش پیچیدگی محاسباتی تنظیم شده است. یک مقدار مناسب با رسم فاصله k-NN نقاط ( شکل 6 ) به منظور افزایش به دنبال یک زانو در نمودار انتخاب شد. سپس، k = 3 بر اساس تعداد ویژگی های مجموعه داده به اضافه یک استفاده می شود. فاصله ε = 300 متر به عنوان حداکثر شعاع جستجو در اطراف یک نقطه داده انتخاب شد. به عبارت دیگر، جستجوی الگوریتم در یک نقطه داده زمانی متوقف خواهد شد که فاصله هسته به 300 متر برسد.
بخش مقدار Hyperparameter را نمی توان از داده ها انجام داد. فراپارامترهای minPts و xi به دنبال ترکیب مقادیر بهینه برای اجرای الگوریتم OPTICS با مجموعه داده و برای انجام انتخاب خوشهبندی بر اساس چگالیهای مختلف تنظیم شدهاند . ابتدا فضای جستجوی فراپارامتر تعریف می شود. هایپرپارامتر minPts بین 5 تا 15 برای حداقل و حداکثر تعداد نقاطی که یک نقطه داده باید در همسایگی خود داشته باشد تا خوشه باشد محدود می شود. در مراحل یک نقطه داده افزایش می یابد. xi _هایپرپارامتر در مراحل 0.01 بین 0 و 1 محدود می شود. دوم، با استفاده از رویکرد بوت استرپینگ، 10 نمونه از 70 درصد مجموعه داده، طبقه بندی شده توسط شهرداری و بخش گردشگری تولید می شود. سپس برای هر نمونه بوت استرپ، الگوریتم OPTICS محاسبه می شود مترمنnپتیسمنو با استفاده از هر کدام ایکسمنjبرای استخراج خوشه ها میانگین ضریب Silhouette (معادله ( 6 )) برای اندازه گیری خوب بودن نتیجه خوشه بندی با استفاده از مترمنnپتیسمندر ایکسمنj. در نهایت، میانگین معیار کیفیت در بین نمونههای بوت استرپ برای هر ترکیبی از مقادیر فراپارامترها انجام میشود. شکل 7 نشان می دهد که چگونه ضریب Silhouette برای هر ترکیبی از minPts و xi تغییر می کند . در اینجا، هر منحنی نشان دهنده میانگین ضریب Silhouette در بین 10 نمونه بوت استرپ است.
در نهایت، مقادیر minPts و xi در جایی انتخاب می شوند که میانگین امتیاز ضریب Silhouette بالاترین باشد. این در شکل 7 در 0.83 قابل مشاهده است. بنابراین، مدلی با خوشه های متراکم تر و به خوبی از هم جدا شده، مدلی با minPts = 5 و xi = 0.38 است. سپس، الگوریتم OPTICS بر روی مجموعه داده کامل با استفاده از minPts = 5 اعمال می شود. مقدار شیب xi = 0.38 برای استخراج خوشه هایی با چگالی های مختلف استفاده می شود. نمودار دسترسی برای این مدل خوشه بندی در شکل 8 نشان داده شده است .
مدل خوشه بندی محاسبه شده با مقادیر انتخاب شده، 288 خوشه را در مجموعه داده شناسایی می کند. محل این خوشه ها در شکل 9 الف نشان داده شده است. ضریب Silhouette برای هر یک از خوشه های به دست آمده برای بررسی کیفیت هر خوشه محاسبه شد. شکل 9 ب نشان می دهد که 11 خوشه دارای ضریب سیلوئت منفی هستند در حالی که بقیه دارای امتیاز بیشتر از 0 هستند که نشان دهنده یک نتیجه خوشه ای خوب است. میانگین ضریب Silhouette از 288 خوشه 0.79 است.
3.3. بینش های مبتنی بر داده هات های توریستی
در این کار، هیچ دادهای وجود ندارد که صریحاً مشخص کند که آیا خوشههای حاصل با آمار رفتار گردشگران مطابقت دارند یا خیر. با این حال، مجموعه داده استفاده از زمین از هلند برای ارائه یک تفسیر مبتنی بر داده برای توصیف خوشهها (نقاط داغ) شناسایی شده استفاده میشود. کاربری زمین برای هر نقطه داده از مجموعه داده تخصیص داده می شود، بنابراین یک هات اسپات ممکن است بیش از یک کاربری داشته باشد. سپس، کاربری اصلی هر کانون بر اساس بیشترین استفاده از زمین در بین نقاط داده آنها تعیین شد. جدول 6 تعداد کانون های شناسایی شده را بر اساس کاربری اراضی نشان می دهد.
بر اساس مجموعه داده های CVO 2015، گردشگران عمدتاً برای تفریح در فضای باز مانند بازدید از ساحل از این منطقه بازدید می کنند. این با نتایج بخش 3.2 مطابقت دارد . مشخص شده است که 42/35 درصد از کانونها مربوط به فعالیتهای تفریحی، 40/18 درصد آنها کاربری تفریحی و 01/17 درصد مابقی در مناطق خشک طبیعی شامل سواحل هستند. نتایج نشان میدهد که دومین گروه اصلی از کانونها (9.03%) در مناطق خردهفروشی و پذیرایی قرار دارند ، که با دومین فعالیت انجام شده در طول تعطیلات ثبتشده در CVO 2015 مطابقت دارد. در نهایت، سومین کاربری رایج زمین در مجموعه داده (7.99٪). ) محل کسب و کار است .
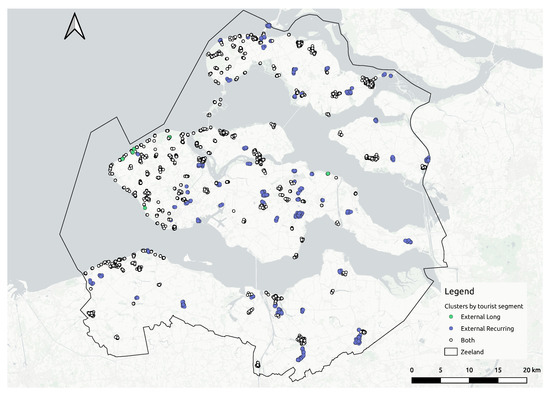
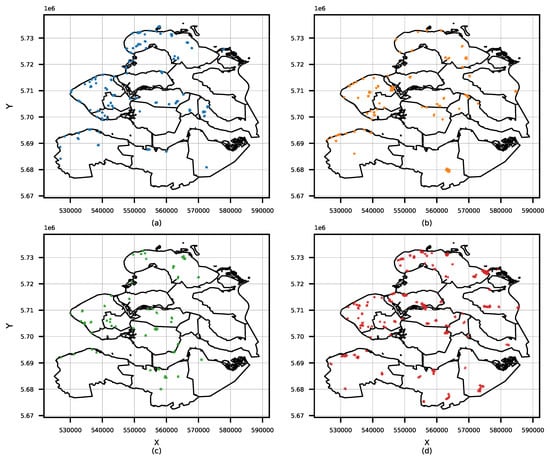
در این مطالعه، رفتار دو بخش توریستی بازار گردشگری از استان زیلند مورد تجزیه و تحلیل قرار گرفته است. شکل 10 نقاط حساس شناسایی شده را بر اساس بخش گردشگری نشان می دهد. نتایج نشان میدهد که هر دو بخش توریستی در اکثر نقاط داغ حضور دارند. با این حال، مشاهده می شود که بازدیدکنندگان مکرر مکان های دور از خط ساحلی را نیز کشف می کنند.
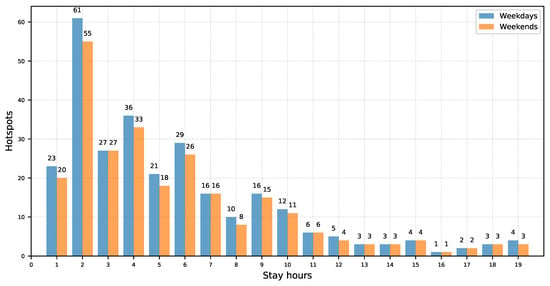
به منظور به دست آوردن بینشی در مورد رفتار زمانبندی گردشگران در هاتاسپات، برای هر نقطه، میانگین زمان اقامت با استفاده از نقاط دادهای که ساخته میشوند محاسبه شد. شکل 11 توزیع هات اسپات را بر اساس زمان اقامت گردشگر نشان می دهد. نتایج نشان میدهد که 51 درصد از کانونها مربوط به مکانهایی است که گردشگر کمتر از 4 ساعت در آنها میماند.
رفتار زمانبندی گردشگران بر اساس مکان کانون در شکل 12 نشان داده شده است . نتایج نشان میدهد که وقوع نقاط داغ، که در آن گردشگران بیش از 4 ساعت میمانند، بیشتر در سرزمین اصلی است تا در ساحل.
3.4. بینش کمپین توریستی Crowdsourced
کمپینهای جمعسپاری گردشگری به ما این امکان را میدهند که رفتار بازدیدکنندگان را درک کنیم، بدانیم از کجا آمدهاند و زمانهای ترجیحی ورود آنها به منطقه مورد مطالعه را بدانیم. این بینش ها برای ایجاد سیاست هایی برای موقعیت یابی مقاصد جذاب مختلف، فعالیت های گردشگری پایدار و بهبود تجارب بازدیدکنندگان مهم هستند [ 1 ].
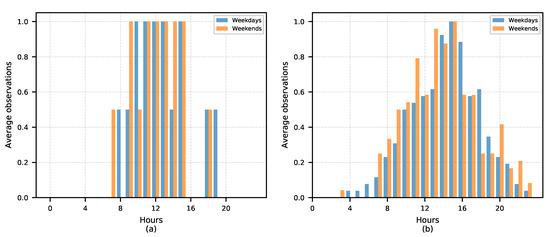
شکل 13 توزیع ساعات ورود گردشگران به منطقه مورد مطالعه را نشان می دهد. مشاهده می شود که بخش توریستی طولانی خارجی دارای زمان ورود در حوالی ظهر است که در روزهای هفته و آخر هفته همین الگو را ارائه می دهد. این رقم همچنین نشان می دهد که زمان ورود بخش توریستی مکرر خارجی در کل روز توزیع شده و در حدود ساعت 2 بعد از ظهر متمرکز است که با ورود به اکثر مکان های اقامتی مطابقت دارد.
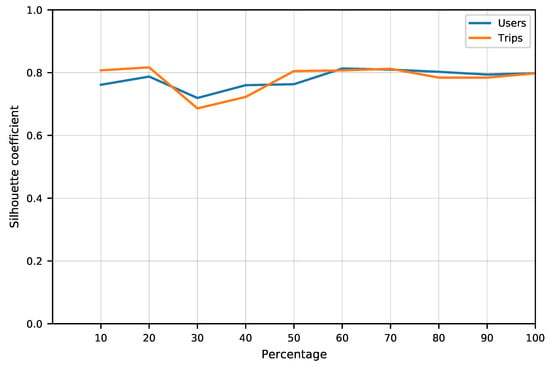
به منظور دستیابی به بینش بهتری در مورد تعداد گردشگران در یک کمپین جمعسپاری گردشگری در برابر کیفیت خوشهبندی حاصل، تحلیل عمیقتری در مورد چگونگی تغییر میانگین ضریب Silhouette با توجه به تعداد گردشگران موجود انجام شد. الگوریتم OPTICS با استفاده از مقادیر فراپارامتر انتخاب شده بر روی زیرمجموعه هایی محاسبه شد که تعداد گردشگران را در 10٪ تغییر می دهد. شکل 14 نشان می دهد که چگونه این معیار کیفیت برای هر مورد متفاوت است. ضریب Silhouette پس از استفاده از نقاط داده تولید شده توسط 60٪ (430 کاربر) گردشگر موجود از مجموعه داده، به دلیل افزایش تراکم نقاط داده در نقاط حساس کشف شده، پایدارتر می شود.
4. بحث
استفاده از داده های جمع سپاری گردشگری برای حمایت از مدیران گردشگر مستلزم استفاده از زنجیره ای از فرآیندها برای تبدیل داده های خام به دانش به عنوان روش پیشنهادی است. قبل از انجام هر تجزیه و تحلیل، دادههای crowdsourced باید پاک شوند تا مسائل مربوط به کیفیت دادهها مانند دادههای از دست رفته، نویز، و خطاها مانند هر فرآیند کشف دانش رسیدگی شود [ 18 ]. با این حال، حل مسائل مربوط به کیفیت داده ها صحت، عینیت و نمایندگی داده های جمع سپاری را تضمین نمی کند [ 43 ، 44 ].
این مطالعه به دانش در مورد ارزیابی بازنمایی داده ها از منابع اطلاعات جغرافیایی داوطلبانه گردشگری کمک می کند تا بینشی برای مدیران گردشگری فراهم کند. روشهای مختلفی برای ارزیابی بازنمایی دادهها برای اطمینان از سودمندی نتایج از دیدگاه سیاست عمومی استفاده شده است [ 45 ]. در [ 46 ]، هدف آنها استخراج محتوای تولید شده توسط کاربر و جمعسپاری از شرکتکنندگان بود، بنابراین یک نظرسنجی را برای اطمینان از اینکه شرکتکنندگان نماینده کل جمعیت اینترنتی ایالات متحده هستند، اعمال کردند. برای ارزیابی جنبه های مختلف نمایندگی داده های تحرک جمعی، در [ 44]، یک فرآیند اعتبارسنجی با معیارهایی مانند پوشش جغرافیایی، تطابق مبدا-مقصد، تطابق جمعیتی، توزیع فاصله-مدت، و تطابق مسیر پیشنهاد شده است. در این مطالعه، ارزیابی بازنمایی دادههای جمعسپاری گردشگری از دو بخش از گردشگر علامتگذاری شده با استفاده از یک منبع داده خارجی مانند آمار رسمی گردشگری همانطور که در بخش 3.1 نشان داده شده است، انجام میشود . ثابت شد که هر دو مجموعه داده از جمعیتی با توزیع یکسان می آیند که نشان می دهد مجموعه داده جمع سپاری نماینده این مطالعه است. با این حال، تضمین نمیکند که مجموعه داده جمعسپاری به دلیل روش جمعآوری مغرضانه نباشد [ 47]]. این یک محدودیت روش به دلیل فقدان توصیفکنندههای اجتماعی-اقتصادی و روانشناختی است، اما این مجموعه داده به دلیل سطح جزئیات موجود همچنان منبع اطلاعاتی ارزشمندی است.
سپس، تجزیه و تحلیل دادههای گردشگری با ترکیب رویکردهای خوشهبندی مبتنی بر تراکم برای به دست آوردن نتایج مطلوب در جستجوی نقاطی که در آن فعالیتهای گردشگری از بخش خاصی از یک بازار توریستی انجام میشود، انجام شد. در این مقاله از داده های جمع آوری شده از 1505 کاربر اپلیکیشن که 124725 سفر و 151612 قسمت سفر را ثبت کرده بودند استفاده شد. علاوه بر این، 12337 نقطه داده ثابت شناسایی شد. چنین دادههایی بهعنوان ورودی برای تجزیه و تحلیل جغرافیایی-فضایی با استفاده از تکنیکهای خوشهبندی برای شناسایی نقاط داغ که در آن فعالیتهای گردشگری خارجی طولانی و خارجی تکراری هستند، استفاده میشود.بخش های گردشگری انجام می شود. همچنین 288 خوشه (هات اسپات) شناسایی شد. بر اساس تجزیه و تحلیل کاربری اصلی نقاط داغ مرتبط با هدف سفر، سه گروه بزرگ متمایز می شوند. با 35.42 درصد از کل کانون ها، بیشترین گروه مربوط به مکان های تفریحی است. این منطقه از 102 نقطه تشکیل شده است که 53 مورد از آنها دارای کاربری تفریحی و 49 مورد دارای کاربری “زمین طبیعی خشک” هستند که سواحل به آن تعلق دارند. گروه دوم 03/9 درصد، 26 درصد از کل کانونها را تشکیل میدهد و با «خردهفروشی و پذیرایی» بهعنوان کاربری اصلی مرتبط است. در نهایت، نقاط داغ مرتبط با “محل تجاری” 7.99٪ را نشان می دهد.
تجزیه و تحلیل کاربری زمین هات اسپات شباهت زیادی را بین متداول ترین هدف سفر مستند شده توسط آمار رسمی استان زلند با این نقاط داغ کشف شده جمع آوری شده سیار نشان می دهد. هدف اصلی سفر برای بازدید از منطقه، تفریح است [ 48 ]. مناطقی که استفاده از زمین «تفریحی» یا «زمین طبیعی خشک» است، تنها 2.35 درصد از استان زلند را تشکیل میدهند. بزرگترین گروه نقاط شناسایی شده دارای کاربری زمینی است که در آن فعالیتهای تفریحی توسعه مییابد که نشان میدهد دادههای تلفن هوشمند پتانسیل نشان دادن موفقیتآمیز نقاط گردشگری در یک منطقه معین و همچنین ارائه بینش طولی بیشتری در مورد رفتار فعالیتهای مرتبط با گردشگری را دارند.
به منظور کشف رفتار توریستی، بینش دقیقی در مورد نقاط داغ ارائه شده است. ابتدا، خوشهها بر اساس بخشهای گردشگری موجود بر روی آنها مشخص شدند. نتایج نشان می دهد که 65 خوشه فقط از گردشگران خارجی بازگشتی تشکیل شده است، در حالی که شش خوشه فقط از گردشگران خارجی طولانی تشکیل شده اند. بنابراین، هر دو بخش گردشگری در بیشتر خوشه ها حضور دارند. با این حال، مشاهده شد که بازدیدکنندگان مکرر بیشتر در نقاط دور از خط ساحلی حضور دارند. سپس، خوشهها بر اساس میانگین زمان اقامت گردشگر در یک کانون مشخص شدند. نتایج نشان می دهد که یک گردشگر بین 1 تا 4 ساعت در 51 درصد از نقاط شناسایی شده باقی می ماند.
فقدان دادههای مربوط به فعالیت حقیقت زمینی بازدیدکننده میتواند به عنوان یک محدودیت بالقوه در روش پیشنهادی دیده شود. این ممکن است با اجرای یک عملکرد 2 کاناله برای ارائه بازخورد در مورد فعالیت اصلی که گردشگر در هنگام تشخیص زمان ثابت انجام می دهد، حل شود. یکی دیگر از محدودیتهای احتمالی مربوط به کیفیت دادههای حسشده گوشی هوشمند است. روش پیشنهادی مشخص میکند که 8.33 درصد از خوشهها دارای “بزرگراه” به عنوان کاربری زمین هستند. با توجه به نویز موجود در این نوع دادهها، وزنهای مبتنی بر دقت موقعیت جغرافیایی و کاربری اراضی نقاط داده هنگام تخصیص کاربری اصلی یک خوشه ممکن است در نظر گرفته شود. با این حال، دقت موقعیت جغرافیایی در مجموعه دادههای حسشده موبایل در دسترس نیست.
به دنبال این، خطوط آینده تحقیقات بر تعریف یک معیار ارزیابی خوشهبندی متمرکز خواهد شد که اطلاعات زمینهای مانند کاربری زمین را در طول تحلیل ارزیابی نیز در نظر میگیرد.
5. نتیجه گیری ها
این تحقیق روشی را توصیف می کند که به دانش در مورد ارزیابی بازنمایی داده ها از منابع اطلاعات جغرافیایی داوطلبانه گردشگری کمک می کند. همچنین از تکنیکهای خوشهبندی مبتنی بر چگالی برای کشف نقاط حساس بالقوه از دادههای حسشده گوشیهای هوشمند استفاده میکند. با استفاده از دادههای جمعسپاری جمعآوریشده توسط یک برنامه گردشگری مانند Zeeland App، کاربردی بودن روش برای حمایت از مدیران گردشگری با بینشهایی که این نوع دادهها میتوانند در بالای آمار موجود به ارمغان بیاورند و توصیف رفتار توریستی بخشهایی از بازار گردشگری است. نشان داده شده. طراحی، تنظیم پارامتر، اجرا، و نتایج اجرای روش نیز ارائه شده است. 288 خوشه (نقطه داغ) شناسایی شد. با توجه به کاربری، سه گروه اصلی شناسایی می شوند: 102 کانون (35. 42٪ با کاربری تفریحی، 26 نقطه (9.03٪) با کاربری زمین “خرده فروشی و پذیرایی”، و 23 نقطه (7.99٪) مرتبط با “محل تجاری” مرتبط بودند. نتایج بهدستآمده نشاندهنده استفاده بالقوه از دادههای حسشده گوشیهای هوشمند بهعنوان روشی مکمل برای نظرسنجیهای گردشگری سنتی است، زمانی که بینشهای رفتاری مرتبط با فعالیت از یک منطقه جغرافیایی بزرگ مورد نیاز است. با این حال، مدیران گردشگر هنوز باید مراقب مشکلات معمول مبتنی بر دادهها مانند نمایش صحیح جمعیت باشند. نتایج بهدستآمده نشاندهنده استفاده بالقوه از دادههای حسشده گوشیهای هوشمند بهعنوان روشی مکمل برای نظرسنجیهای گردشگری سنتی است، زمانی که بینشهای رفتاری مرتبط با فعالیت از یک منطقه جغرافیایی بزرگ مورد نیاز است. با این حال، مدیران گردشگر هنوز باید مراقب مشکلات معمول مبتنی بر دادهها مانند نمایش صحیح جمعیت باشند. نتایج بهدستآمده نشاندهنده استفاده بالقوه از دادههای حسشده گوشیهای هوشمند بهعنوان روشی مکمل برای نظرسنجیهای گردشگری سنتی است، زمانی که بینشهای رفتاری مرتبط با فعالیت از یک منطقه جغرافیایی بزرگ مورد نیاز است. با این حال، مدیران گردشگر هنوز باید مراقب مشکلات معمول مبتنی بر دادهها مانند نمایش صحیح جمعیت باشند.49 ] و نتایجی که به دقت موقعیتی/زمانی و خطاهای معرفی شده توسط پردازش بستگی دارد [ 50 ]. بنابراین، سؤالات متعددی هنوز برای تحقیقات آینده باقی مانده است و این سؤالات عمدتاً بر ادغام منابع داده و بینش های مختلف به منظور نتیجه گیری قابل اعتماد برای حمایت از سیاست ها متمرکز هستند.










بدون دیدگاه