

کلید واژه ها:
توصیه POI بعدی ؛ همبستگی فاصله زمانی نابرابر فضایی ; توجه به خود ؛ رگرسیون خطی
1. مقدمه
2. کارهای مرتبط
2.1. توصیه POI بعدی متوالی
2.2. توصیه POI بعدی بر اساس زمینه مکانی-زمانی
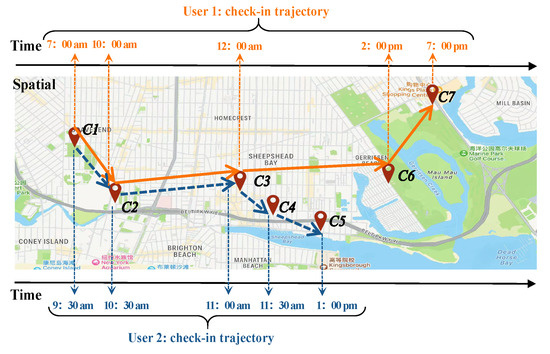
3. مقدمات و تجزیه و تحلیل داده ها
3.1. مقدماتی
تعریف 1.
تعریف 2.
تعریف 3.
تعریف 4.
تعریف 5.
تعریف 6.
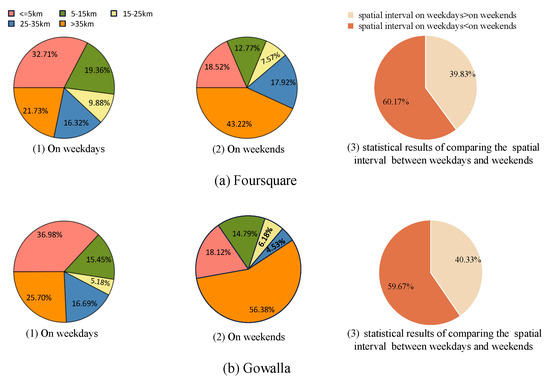
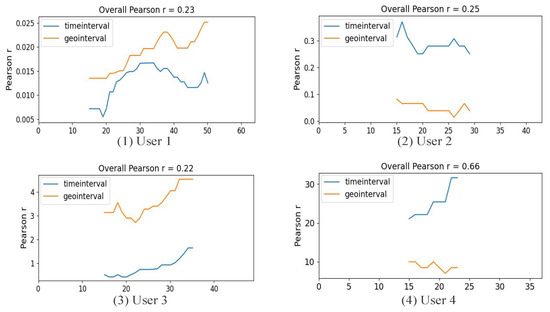
3.2. تجزیه و تحلیل اولیه
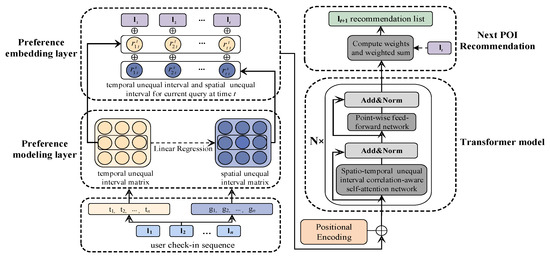
4. روش پیشنهادی
4.1. لایه مدلسازی اولویت همبستگی فاصله زمانی نابرابر فضایی-زمانی شخصی شده توسط کاربر
4.1.1. ساخت ماتریس های بازه نابرابر زمانی شخصی سازی شده توسط کاربران
به طور خاص، ما دنباله زمانی مربوطه را تولید می کنیم تی (تومن) = {تی1،تی2, … ,تیn}�(��)=�1,�2,…,��با توجه به کاربر تومن��ترتیب ورود، و سپس محاسبه فاصله زمانی بین هر دو POI، که با نشان داده شده است rتیتومنمن ج= ∥تیمن–تیj∥������=��−��، و rتیتومنمن ج∈آرتیتومن������∈����، جایی که آرتیتومن����مجموعه ای از فواصل زمانی در ترتیب ورود کاربر را نشان می دهد تومن��، و rتیتومنm i n= ممن n (آرتیتومن)�������=���(����)حداقل فاصله زمانی کاربر را نشان می دهد تومن��. سپس، هر عنصر در مجموعه آرتیتومن����با فرمول (1) به نسبت مساوی کوچک می شود.
بنابراین، ماتریس فاصله زمانی نابرابر شخصی شده است Δتیتومن∈نn × nΔ���∈N�×�کاربر تومن��به صورت بیان می شود
4.1.2. ساخت ماتریس های بازه نابرابر فضایی شخصی سازی شده توسط کاربران
به طور خاص، دنباله فضایی مربوطه را به دست می آوریم g(تومن) = {g1،g2, … ,gn}�(��)=�1,�2,…,��تولید شده از کاربر تومن��ترتیب ورود، و سپس محاسبه فاصله مکانی بین هر دو POI، که با نشان داده شده است rستومنمن ج= اچa v e r s i n e ( G Pاسمن، جی پیاسj)������=���������(����,����)، و rستومنمن ج∈آرستومن������∈����، جایی که آرستومن����مجموعه ای از فواصل مکانی در ترتیب ورود کاربر را نشان می دهد تومن��. بنابراین، ماتریس فاصله نابرابر فضایی شخصی شده است Δستومن∈نn × nΔ���∈N�×�کاربر تومن��به صورت بیان می شود
در مرحله بعد، کاربران را بر اساس میانگین فاصله زمانی بین POIها از هر ترتیب ورود کاربر و میانگین فاصله زمانی بین POIها از توالی های ورود همه کاربران طبقه بندی می کنیم. در میان آنها، میانگین فاصله زمانی هر کاربر با نشان داده می شود rتیتومنm e a n= مe a n (آرتیتومن)��������=����(����)، و میانگین فاصله زمانی همه کاربران با نشان داده می شود rتیm e a n= مe a n (∑Ui = 1آرتیتومن)������=����(∑�=1�����). سپس، میانگین فاصله زمانی کاربر را با هم مقایسه می کنیم تومن��با میانگین فاصله زمانی همه کاربران برای طبقه بندی کاربران. علاوه بر این، تعداد کاربران را در زمان شمارش می کنیم rتیتومنm e a n>rتیm e a n��������>������، rتیتومنm e a n=rتیm e a n��������=������، rتیتومنm e a n<rتیm e a n��������<������به ترتیب، و متوجه شوید که تقریباً هیچ کاربری با آن وجود ندارد rتیتومنm e a n=rتیm e a n��������=������از دو مجموعه داده بنابراین، با توجه به نتایج مقایسه مربوطه، کاربران به دو دسته تقسیم می شوند که در فرمول (4) نشان داده شده است.
جایی که استیs m a l l�������و اسسs m a l l�������نشان دهنده مجموعه های بازه زمانی و فاصله زمانی کاربران با rتیتومنm e a n<rتیm e a n��������<������، به ترتیب. متقابلا، استیl a r gه�������و اسسl a r gه�������مجموعه ای از بازه زمانی و فاصله زمانی کاربران را با rتیتومنm e a n>rتیm e a n��������>������، به ترتیب.
بر اساس طبقه بندی فوق از کاربران، ما از روش رگرسیون خطی [ 35 ] برای به دست آوردن همبستگی بازه زمانی مکانی بین هر دو POI از توالی های ورود مربوط به دو نوع کاربر استفاده می کنیم و از فرمول (5) برای بهینه سازی استفاده می کنیم. هدف اصلی
که در آن j تعداد عناصر مجموعه را نشان می دهد استی��یا اسس��. استیمن∈استی���∈��یک عنصر در مجموعه بازه زمانی یک دسته از کاربران را نشان می دهد. به همین ترتیب، اسسمن∈اسس���∈��عنصری را در مجموعه بازه های مکانی دسته ای از کاربران نشان می دهد. w و b به ترتیب نشان دهنده شیب و قطع در معادله رگرسیون خطی هستند. همانطور که در فرمول های (6) و (7) نشان داده شده است، برای حل مدل از خطای میانگین مربعات کوچک سازی استفاده می کنیم.
جایی که St¯¯¯¯��¯نشان دهنده میانگین فواصل زمانی در مجموعه است St��.
برای هر نوع کاربر، مقادیر مربوط به w , b را به دست می آوریم که با نشان داده شده است wsmall������، bsmall������، wlarge������، blarge������، به ترتیب. با در نظر گرفتن تفاوت ترجیحات بازه زمانی کاربران برای بازدید از POI، ما بیشتر حداکثر فاصله زمانی مربوط به هر کاربر را با توجه به حداکثر فاصله زمانی هر کاربر، همانطور که در فرمول (8) نشان داده شده است، به روشی دقیق تر محاسبه می کنیم.
جایی که Reg(⋅)���(·)عملیات رگرسیون خطی را نشان می دهد، kssmall�������حداکثر فاصله مکانی ماتریس را نشان می دهد ΔsuiΔ���از هر کاربر با rtuimean<rtmean��������<������; kslarge�������حداکثر فاصله مکانی ماتریس را نشان می دهد ΔsuiΔ���از هر کاربر با rtuimean>rtmean��������>������; و rtuimax=Max(Rtui)�������=���(����)نشان دهنده حداکثر فاصله زمانی بین هر دو POI از ترتیب ورود کاربر است ui��. پس از آن، هر عنصر در ماتریس ΔsuiΔ���به عنوان مشخص می شود rsuiij=Min(ks,rsuiij)������=���(��,������). بنابراین، ماتریس بازه نابرابر فضایی شخصی شده کاربر ui��بیشتر به عنوان نشان داده شده است Δsuiclipped=clip(Δsui)Δ����������=����(Δ���).
4.2. ترجیح همبستگی بازه نابرابر فضایی-زمانی ذوب لایه جاسازی
لایه جاسازی برای رمزگذاری اطلاعات POI، اطلاعات همبستگی فاصله زمانی مکانی بین POI و اطلاعات موقعیتی مطلق POIهای متناظر در هر دنباله ورود کاربر به عنوان نمایش های پنهان استفاده می شود. ابتدا یک ماتریس تعبیه شده ایجاد می کنیم ML∈R|L|×d��∈��×�برای POI، که در آن |L|�تعداد POI و d نشان دهنده بعد پنهان است. سپس، برای سیر تاریخی ورود کاربر ui��، ما از یک بردار صفر ثابت به عنوان جاسازی برای اقلام بالشتک استفاده می کنیم و مسیر ورود کاربر را به اولین n فعالیت ثبت نام قطع می کنیم یا آن را تکمیل می کنیم. در مورد POI از اولین n فعالیت ورود، عملیات جستجوی embedding n جاسازی POI قبلی را بازیابی می کند و آنها را روی هم می چیند تا یک ماتریس جاسازی ایجاد کند. EL∈Rn×d��∈��×�همانطور که در فرمول (9) نشان داده شده است.
جایی که Ii∈Rd��∈��نشان دهنده نمایش تعبیه شده POI بازدید شده در فعالیت ورود i-امین از ترتیب ورود کاربر است.
از آنجایی که مکانیسم توجه به خود نمی تواند مستقیماً موقعیت POI را از ترتیب ورود کاربر به دست آورد، ما از دو ماتریس جاسازی موقعیتی قابل یادگیری مختلف استفاده می کنیم. MPK∈Rn×d���∈��×�و MPV∈Rn×d���∈��×�که به ترتیب کلیدها و مقادیر را در مکانیسم توجه به خود نشان می دهند. این روش برای مکانیسم توجه به خود بدون نیاز به تبدیل های خطی اضافی مناسب تر است [ 7 ]. پس از عملیات بازیابی، ماتریس های تعبیه موقعیتی مطلق را به دست می آوریم EPK∈Rn×d���∈��×�، EPV∈Rn×d���∈��×�از ترتیب ورود کاربر، همانطور که در فرمول (10) نشان داده شده است.
مشابه تعبیه موقعیت مطلق، ما همان عملیات را برای تعبیه فاصله زمانی و تعبیه فاصله زمانی انجام می دهیم. به طور خاص، ما از فناوری جاسازی کلمه برای رمزگذاری فواصل زمانی و ایجاد دو ماتریس تعبیه بازه زمانی استفاده می کنیم. MTK∈Rkt×d���∈���×�، MTV∈Rkt×d���∈���×�. به طور مشابه، ماتریس های تعبیه فاصله فضایی را به دست می آوریم MSK∈Rks×d���∈���×�، MSV∈Rks×d���∈���×�. سپس، پس از بازیابی ماتریس بازه زمانی بریده شده ΔtuiclippedΔ����������و ماتریس فاصله مکانی ΔsuiclippedΔ����������، ماتریس های تعبیه بازه زمانی متناظر را به دست می آوریم ETK∈Rn×n×d���∈��×�×�، ETV∈Rn×n×d���∈��×�×�و همچنین ماتریس های تعبیه فاصله فضایی ESK∈Rn×n×d���∈��×�×�، ESV∈Rn×n×d���∈��×�×�از ترتیب ورود کاربر، همانطور که در فرمول های (11) و (12) نشان داده شده است.
4.3. مدل ترانسفورماتور همبستگی آگاه فضایی-زمانی نابرابر
4.3.1. همبستگی فضایی-زمانی نابرابر شبکه خودآگاهی
به طور خاص، با توجه به ماتریس جاسازی POI EL=(I1,I2,…,In)��=(�1,�2,…,��)، جایی که Ii∈Rd��∈��، پس از شبکه توجه به خود، یک دنباله جدید را خروجی می دهد NS=(ns1,ns2,…,nsn)NS=(��1,��2,…,���)، جایی که nسمن∈آرد���∈��، برای اطمینان از اینکه هر عنصر در دنباله جدید نه تنها حاوی اطلاعات خاص خود است، بلکه تأثیر سایر POIهای ترتیب ورود کاربر بر مرحله فعلی را نیز در نظر می گیرد. مورد من _ nسمن���توالی خروجی به عنوان مجموع وزنی از جاسازی POIهای تبدیل شده خطی، تعبیه فاصله زمانی، و جاسازی فاصله زمانی بین POIها، و همچنین جاسازی موقعیتی مطلق POIهای متناظر در دنباله ورود کاربر همانطور که در فرمول نشان داده شده است، محاسبه می شود. 13).
که در آن n حداکثر طول دنباله وارد شده را نشان می دهد، منj��نشان دهنده تعبیه شدن است POمنjPOI�، دبلیوV��نشان دهنده ماتریس طرح ریزی مقادیر مربوطه در ماتریس تعبیه شده POI است. rتیVمن ج�����و rسVمن ج�����به ترتیب تعبیه فاصله زمانی و تعبیه فاصله زمانی بین POI ها را نشان می دهد و پVj���نشان دهنده جاسازی موقعیتی مطلق POIهای متناظر در ترتیب ورود کاربر است. آمن ج���نشان دهنده ضریب وزنی است که با تابع soft-max نشان داده شده در فرمول (14) محاسبه می شود.
جایی که همن ج���نشان دهنده امتیاز توجه است که با در نظر گرفتن جامع اطلاعات POI، اطلاعات بازه زمانی مکانی بین POIها و اطلاعات موقعیتی مطلق POIهای متناظر در ترتیب ورود کاربر در فرمول (15) محاسبه می شود.
جایی که دبلیوس∈آرد× د��∈��×�و دبلیوک∈آرد× د��∈��×�ماتریسهای طرحبندی پرسوجوها و کلیدهای مربوطه را به ترتیب در ماتریسهای تعبیهکننده POI دنباله ورود کاربر نشان میدهد. عامل مقیاس 1د√1�برای جلوگیری از زیاد بودن مقدار محصول داخلی است، که ممکن است باعث ناپدید شدن گرادیان پس از تابع soft-max شود.
4.3.2. شبکه فید فوروارد Point-Wise
همانطور که در بخش 4.3.1 توضیح داده شد ، شبکه خودتوجهی آگاه از همبستگی فاصله زمانی نابرابر از یک روش مبتنی بر ترکیب خطی برای ترکیب اطلاعات POI، اطلاعات بازه زمانی و اطلاعات بازه مکانی بین POIها و همچنین موقعیت مطلق استفاده می کند. اطلاعات POI مربوطه در ترتیب ورود کاربر. با الهام از ایده در [ 14 ]، ما دو تبدیل خطی را با ReLU به عنوان تابع فعالسازی پس از هر شبکهی خودتوجهی آگاه از همبستگی فضایی-زمانی نابرابر اعمال میکنیم، در نتیجه مدل خود را غیرخطی میکنیم.
جایی که دبلیو1،دبلیو2∈آرد× د�1,�2∈��×�ماتریس های وزنی هستند و ب1،ب2∈آرد�1,�2∈��اصطلاحات جانبداری هستند
پس از انباشته شدن شبکه های توجه به خود و شبکه های پیشخور، ممکن است مشکلاتی مانند برازش بیش از حد مدل، ناپدید شدن شیب ها و زمان آموزش بیش از حد رخ دهد. بنابراین، با الهام از مرجع [ 36 ]، ما نرمال سازی لایه، منظم سازی حذف و اتصالات باقیمانده را برای حل این مشکلات همانطور که در فرمول (17) نشان داده شده است، اتخاذ می کنیم.
جایی که L N( نسمن)��(���)با فرمول (18) محاسبه می شود.
که در آن ⊙ نشان دهنده محصول از نظر عنصر است. α�و β�به ترتیب ضریب مقیاس و اصطلاح سوگیری را نشان می دهند. μ�و σ�نشان دهنده میانگین و واریانس nسمن���، به ترتیب، در حالی که ε�هنگامی که واریانس 0 است از محاسبات نامعتبر جلوگیری می کند.
4.4. توصیه POI بعدی
این بخش امتیازهای ترجیحی را محاسبه میکند که POIهای بعدی ممکن است بر اساس نمایشهای ترجیحی مربوطه بازدیدکننده از POI که توسط مدل ترانسفورماتور همبستگی آگاه با فاصله زمانی نابرابر فضایی-زمانی به دست آمده است، بازدید شوند. پس از انباشتن N بلوک های خودتوجهی، نمایش ترکیبی اطلاعات POI، اطلاعات فاصله زمانی مکانی بین POI و اطلاعات موقعیت مطلق POI مربوطه را در هر دنباله ورود کاربر به دست می آوریم. به منظور توصیه POI بعدی به یک کاربر، از فرمول (19) برای محاسبه امتیاز ترجیحی کاربر برای POI استفاده می کنیم. لمن��، POIهای نامزد را بر اساس امتیازهای ترجیحی مربوطه مرتب کنید، سپس لیستی از POIها را با امتیازهای ترجیحی بالاتر به کاربر توصیه کنید.
جایی که ناستی���نمایش ترکیبی از جاسازی POI بازدید شده در اولین بار t در ترتیب ورود کاربر، جاسازی فاصله زمانی- مکانی بین POI های ذکر شده در بالا و POI های بازدید شده در زمان t +1، و همچنین جاسازی موقعیتی مطلق مربوطه را نشان می دهد. ترتیب ورود مLلمن����تعبیه POI است لمن��.
4.5. بهینه سازی مدل
هدف از این بخش بهینه سازی مدل پیشنهادی ما است. با توجه به تاریخچه مسیر ورود کاربر تی آر ( _تومن) = {r1،r2, … ,rمتر}���(��)=�1,�2,…,��، ما یک دنباله چک در طول ثابت ایجاد می کنیم s e q(تومن) = {r1،r2, … ,rn}���(��)=�1,�2,…,��، و بیشتر دنباله زمانی مربوطه را تولید کنید تی (تومن) = {تی1،تی2, … ,تیn}�(��)=�1,�2,…,��و همچنین توالی فضایی g(تومن) = {g1،g2, … ,gn}�(��)=�1,�2,…,��، و تعریف کنید l = {ل1،ل2, … ,لک}�=�1,�2,…,��به عنوان خروجی مورد انتظار از مدل. از آنجایی که اطلاعات تعامل بین کاربران و POI ها داده های ضمنی است، ما نمی توانیم به طور مستقیم امتیازات ترجیحی POI های نامزد را بهینه کنیم. علاوه بر این، خروجی مدل ما لیستی از POI های رتبه بندی شده است. بنابراین، ما یک روش نمونه گیری منفی را برای بهینه سازی رتبه بندی POI های نامزد اتخاذ می کنیم. به طور خاص، برای هر خروجی مثبت مورد انتظار لمن��، یک نمونه منفی ل“من∉ s e q(تومن)��′∉���(��)به طور تصادفی انتخاب شده و برای ایجاد یک جفت اولویت گرفته می شود تیاس= { ( s e q(تومن),t(ui),g(ui),li,l′i)}��=(���(��),�(��),�(��),��,��′). ما کسر خروجی مدل را از طریق تابع soft-max نرمال می کنیم و از آنتروپی متقاطع باینری به عنوان تابع ضرر در فرمول (20) استفاده می کنیم.
جایی که Θ={ML,MPK,MPV,MTK,MTV,MSK,MSV}Θ=��,���,���,���,���,���,���مجموعه ای از ماتریس های تعبیه شده است، ∥⋅∥F·�نشان دهنده هنجار فروبنیوس است وλ�پارامتر منظم سازی است.
5. آزمایشات
5.1. راه اندازی آزمایشی
5.1.1. جمع آوری و پیش پردازش داده ها
5.1.2. معیارهای ارزیابی
به منظور ارزیابی عملکرد توصیه، دو معیار ارزیابی رایج مورد استفاده [ 25 ، 39 ] را اتخاذ می کنیم: NDCG@k و Recall@k ، که در آن k تعداد POI های توصیه شده است. NDCG@k موقعیت POIهای واقعی را در نظر می گیرد و وزن های بیشتری را به POI در موقعیت های بالاتر اختصاص می دهد. Recall@k برای محاسبه نسبت نمونه های مثبت واقعی از POI های توصیه شده در بین تمام نمونه های مثبت استفاده می شود. در مدل ما، NDCG@k نشان میدهد که آیا POIهایی که کاربران واقعاً به آنها مراجعه میکنند، در بالای لیستهای توصیه مربوطه قرار میگیرند یا خیر. Recall@kنشان می دهد که آیا POI هایی وجود دارد که کاربران واقعاً در میان POI های توصیه شده برتر از آنها بازدید می کنند. این معیارها به صورت زیر محاسبه می شوند:
جایی که ri��ارتباط درجه بندی شده POI در موقعیت i است. ما از ارتباط باینری ساده برای کار خود استفاده می کنیم، یعنی، ri=1��=1اگر POI در لیست POI های توصیه شده واقعاً توسط کاربر بازدید شده باشد و در غیر این صورت 0. IDCGu@k�����@�حداکثر را نشان می دهد DCGu@k����@�در یک رتبه بندی ایده آل
جایی که |Vu|��تعداد POI های مثبت در لیست توصیه شده به کاربر u را نشان می دهد. اینجا، |Vu|=1��=1.
5.1.3. رویکردهای پایه
5.1.4. پیکربندی
5.2. نتایج و بحث
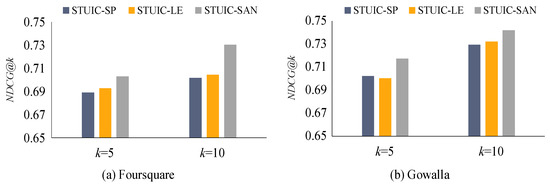
5.2.1. مقایسه عملکرد توصیه
5.2.2. اثربخشی اجزای مختلف
STUIC-TE: مدل فقط تأثیر بازه زمانی نابرابر را در نظر می گیرد. بنابراین، فرمول های (13) و (15) را به صورت زیر بازتعریف می کنیم:
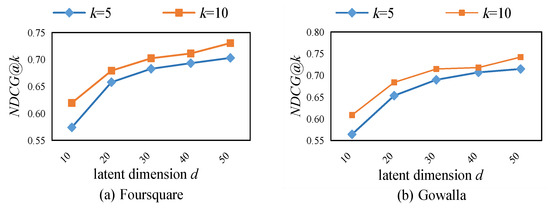
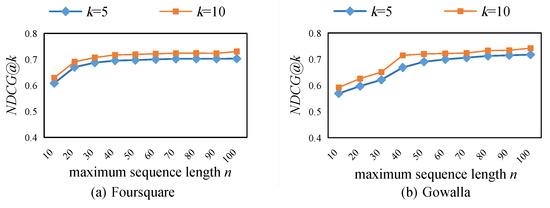
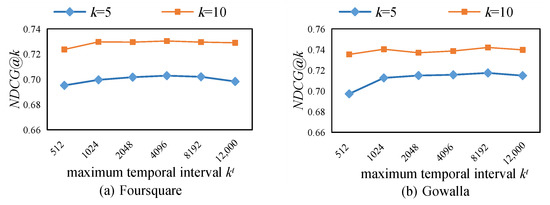
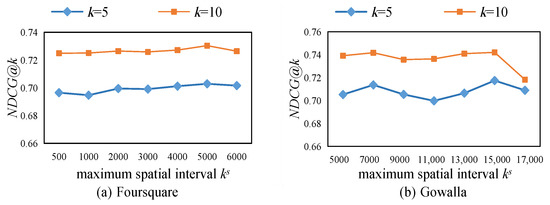
5.3. تجزیه و تحلیل حساس پارامترها
5.3.1. اثر بعد پنهان
5.3.2. اثر حداکثر طول دنباله
5.3.3. اثر حداکثر فاصله زمانی
5.3.4. اثر حداکثر فاصله مکانی
5.4. اثر پردازش همبستگی بازه زمانی مختلف مکانی-زمانی
5.5. تهدید به اعتبار
6. نتیجه گیری و کار آینده
منابع
- گائو، اچ. تانگ، جی. هو، ایکس. لیو، اچ. بررسی اثرات زمانی برای توصیه مکان در شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات هفتمین کنفرانس ACM در مورد سیستم های توصیه کننده، هنگ کنگ، چین، 12 تا 16 اکتبر 2013. صص 93-100. [ Google Scholar ]
- چن، ک. یانگ، اچ. لیو، ام. King, I. جایی که دوست دارید بروید بعدی: توصیه های پی در پی نقطه ای از علاقه. در مجموعه مقالات بیست و سومین کنفرانس بین المللی مشترک هوش مصنوعی، پکن، چین، 5 تا 9 اوت 2013. صص 2605-2611. [ Google Scholar ]
- او، جی. لی، ایکس. لیائو، ال. Song، D. استنباط یک مدل پیشنهادی شخصی شده بعدی با الگوهای رفتار پنهان. در مجموعه مقالات سی امین کنفرانس Aaai در مورد هوش مصنوعی، فینیکس، AZ، ایالات متحده آمریکا، 12 تا 17 فوریه 2016; صص 137-143. [ Google Scholar ]
- شیا، بی. لی، ی. لی، کیو. Li, T. شبکه عصبی بازگشتی مبتنی بر توجه برای توصیه مکان. در مجموعه مقالات دوازدهمین کنفرانس بین المللی سیستم های هوشمند و مهندسی دانش، نانجینگ، چین، 24 تا 26 نوامبر 2017؛ صص 1-6. [ Google Scholar ]
- وو، ی. لی، ک. ژائو، جی. یادگیری ترجیحی بلند مدت و کوتاه مدت برای توصیه POI بعدی. در مجموعه مقالات بیست و هشتمین کنفرانس بین المللی ACM در مدیریت اطلاعات و دانش، پکن، چین، 3 تا 7 نوامبر 2021؛ صص 2301–2304. [ Google Scholar ]
- لیو، ی. پی، ا. وانگ، اف. یانگ، ی. ژانگ، ایکس. وانگ، اچ. دای، اچ. چی، ال. Ma, R. یک مدل GRU مبتنی بر طبقه بندی آگاه برای توصیه POI بعدی. بین المللی جی. اینتل. سیستم 2021 ، 36 ، 3174-3189. [ Google Scholar ] [ CrossRef ]
- وانگ، سی. McAuley، J. توصیه متوالی خود توجه. در مجموعه مقالات کنفرانس بین المللی IEEE 2018 در مورد داده کاوی (ICDM)، سنگاپور، 17 تا 20 نوامبر 2018؛ ص 197-206. [ Google Scholar ]
- وانگ، ایکس. لیو، ی. ژو، ایکس. لنگ، ز. Wang, X. مدلسازی اولویتهای بلندمدت و کوتاهمدت بر اساس توجه چند سطحی برای توصیههای POI بعدی. ISPRS Int. J. Geo-Inf. 2022 ، 11 ، 323. [ Google Scholar ] [ CrossRef ]
- علی، م. راف، دی. ACres، F. یک مدل رتبهبندی مشترک منظم دو مرحلهای حساس به زمان برای توصیههای نقطهنظر. IEEE Trans. بدانید. مهندسی داده 2019 ، 32 ، 1050-1063. [ Google Scholar ]
- ژانگ، ی. لیو، جی. لیو، ا. ژانگ، ی. لی، ز. ژانگ، ایکس. لی، کیو. مدلسازی تأثیر جغرافیایی شخصی برای توصیه POI. IEEE Intell. سیستم 2020 ، 35 ، 18-27. [ Google Scholar ] [ CrossRef ]
- زو، ز. او، X. Zhu، AX یک روش حاشیه نویسی خودکار برای کشف اطلاعات معنایی مکان های جغرافیایی از شبکه های اجتماعی مبتنی بر مکان. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 487. [ Google Scholar ] [ CrossRef ]
- ژائو، ک. ژانگ، ی. یین، اچ. وانگ، جی. ژنگ، ک. ژو، ایکس. زینگ، سی. کشف الگوهای بعدی برای توصیه POI بعدی. در مجموعه مقالات بیست و نهمین کنفرانس مشترک بین المللی هوش مصنوعی، یوکوهاما، ژاپن، 7 تا 15 ژانویه 2020؛ صص 3216–3222. [ Google Scholar ]
- لو، ی. Huang, J. GLR: یک مدل نمایش نهفته مبتنی بر نمودار برای توصیه های پی در پی POI. ژنرال آینده. محاسبه کنید. سیستم 2020 ، 102 ، 230-244. [ Google Scholar ] [ CrossRef ]
- کوی، کیو. ژانگ، ی. Wang, J. CANS-Net: شبکه مدلسازی غیر متوالی آگاه از زمینه برای توصیههای بعدی. arXiv 2021 ، arXiv:abs/2104.02262. [ Google Scholar ]
- لی، جی. وانگ، ی. McAuley، J. توجه به خود آگاه از فاصله زمانی برای توصیه های متوالی. در مجموعه مقالات سیزدهمین کنفرانس بین المللی جستجوی وب و داده کاوی، هیوستون، TX، ایالات متحده، 3 تا 7 فوریه 2020؛ صص 322-330. [ Google Scholar ]
- یانگ، جی. کای، ی. KReddy، C. پیشبینی زمان ورود مکانی-زمانی با تحلیل بقا مبتنی بر شبکه عصبی مکرر. در مجموعه مقالات بیست و هفتمین کنفرانس مشترک بین المللی هوش مصنوعی، استکهلم، سوئد، 9 تا 19 ژوئیه 2018؛ صفحات 2976-2983. [ Google Scholar ]
- ژائو، پی. لو، ا. لیو، ی. خو، جی. لی، ز. ژوانگ، اف. شنگ، VS; ژو، ایکس. بعد کجا برویم: یک شبکه فضایی-زمانی برای توصیه POI بعدی. IEEE Trans. بدانید. مهندسی داده 2022 ، 34 ، 2512-2524. [ Google Scholar ] [ CrossRef ]
- لو، ی. لیو، کیو. Liu, Z. STAN: شبکه توجه مکانی-زمانی برای توصیه مکان بعدی. در مجموعه مقالات WWW ’21: مجموعه مقالات کنفرانس وب 2021، لیوبلیانا، اسلوونی، 19 تا 23 آوریل 2021. صص 2177–2185. [ Google Scholar ]
- او، س. جیانگ، دی. لیائو، ز. هوی، SCH; چانگ، ک. لیم، EP; لی، اچ. توصیه پرس و جو وب از طریق پیش بینی پرس و جو متوالی. در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی مهندسی داده IEEE 2009، شانگهای، چین، 29 مارس تا 2 آوریل 2009. ص 1443-1454. [ Google Scholar ]
- فنگ، اس. لی، ایکس. زنگ، ی. کنگ، جی. Chee, YM; یوان، Q. تعبیه متریک رتبه بندی شخصی برای توصیه POI جدید بعدی. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی هوش مصنوعی، جزیره پوکت، تایلند، 26-27 ژوئیه 2015; ص 2069–2075. [ Google Scholar ]
- او، ر. نیش، سی. وانگ، ز. مکآولی، جی ویستا: یک مدل آگاهانه بصری، اجتماعی و زمانی برای توصیه هنری. در مجموعه مقالات دهمین کنفرانس ACM در مورد سیستمهای توصیهکننده، بوستون، MA، ایالات متحده آمریکا، 15 تا 19 سپتامبر 2016. صص 309-316. [ Google Scholar ]
- لو، ی. شی، دبلیو. گائو، اچ. چانگ، ک. هوانگ، جی. در توصیه های پی در پی نقطه ای از علاقه. شبکه جهانی وب 2018 ، 22 ، 1151–1173. [ Google Scholar ] [ CrossRef ]
- لی، آر. شن، ی. Zhu, Y. توصیه نقطه مورد علاقه بعدی با توجه به زمینه زمانی و چند سطحی. در مجموعه مقالات کنفرانس بین المللی IEEE 2018 در مورد داده کاوی (ICDM)، سنگاپور، 17 تا 20 نوامبر 2018؛ صص 1110–1115. [ Google Scholar ]
- لیو، ی. Wu, A. روش توصیه POI با استفاده از یادگیری عمیق در شبکه های اجتماعی مبتنی بر مکان. سیم. اشتراک. اوباش محاسبه کنید. 2021 ، 2021 ، 9120864. [ Google Scholar ] [ CrossRef ]
- هوانگ، ال. ممکن است.؛ لیو، ی. او، K. DAN-SNR. ACM Trans. فناوری اینترنت (TOIT) 2021 ، 21 ، 1-27. [ Google Scholar ] [ CrossRef ]
- لیم، ن. هوی، بی. Ng، SK; وانگ، ایکس. گوه، ی.ال. ونگ، آر. Varadarajan, J. STP-UDGAT: شبکه توجه نمودار بعدی کاربر فضایی-زمانی- ترجیحی برای توصیه POI بعدی. در مجموعه مقالات بیست و نهمین کنفرانس بین المللی ACM در مدیریت اطلاعات و دانش، مجازی، 19 تا 23 اکتبر 2020؛ صص 845-854. [ Google Scholar ]
- دینگ، آر. چن، ز. Li, X. جاسازی متریک فاصله زمانی-مکانی برای توصیه POI خاص زمان. IEEE Access 2018 ، 6 ، 67035–67045. [ Google Scholar ] [ CrossRef ]
- Doan، KD; یانگ، جی. KReddy، C. یک مدل عصبی مکانی-زمانی توجه برای توصیههای پی در پی نقطهی علاقه. در مجموعه مقالات کنفرانس اقیانوس آرام-آسیا در مورد کشف دانش و داده کاوی، ماکائو، چین، 14 تا 17 آوریل 2019؛ جلد 11441. [ Google Scholar ]
- پنگ پنگ، ز. هایفنگ، ز. یانچی، ال. جیاجی، ایکس. Xiaofang، Z. کجا برویم بعدی: یک شبکه فضایی-زمانی برای توصیه POI بعدی. در مجموعه مقالات کنفرانس AAAI در مورد هوش مصنوعی، هونولولو، HI، ایالات متحده، 27 ژانویه تا 1 فوریه 2019؛ صص 5877–5884. [ Google Scholar ]
- هوانگ، ال. ممکن است.؛ وانگ، اس. Liu, Y. یک شبکه LSTM فضایی-زمانی مبتنی بر توجه برای توصیه POI بعدی. IEEE Trans. خدمت محاسبه کنید. 2021 ، 14 ، 1585-1597. [ Google Scholar ] [ CrossRef ]
- دوطلب، م. Alesheikh, AA یک رویکرد توصیه POI که اطلاعات مکانی-زمانی اجتماعی را در فاکتورسازی ماتریس احتمالی ادغام می کند. بدانید. Inf. سیستم 2021 ، 63 ، 65-85. [ Google Scholar ] [ CrossRef ]
- دای، اس. یو، ی. فن، اچ. دونگ، جی. یادگیری بازنمایی فضایی-زمانی با پیوند اجتماعی برای توصیه POI شخصی شده. اطلاعات علمی مهندس 2022 ، 7 ، 1-13. [ Google Scholar ] [ CrossRef ]
- شی، دی. ژوانگ، اف. لیو، ی. گو، ج. شیونگ، اچ. او، Q. مدلسازی وابستگی مکانی-زمانی دو جهته و ترجیحات پویای کاربران برای شناسایی ورود POI گمشده. در مجموعه مقالات کنفرانس ملی هوش مصنوعی، هونولولو، HI، ایالات متحده آمریکا، 27 ژانویه تا 1 فوریه 2019؛ صص 5458–5465. [ Google Scholar ]
- ممکن است.؛ گان، ام. کاوش چندین اطلاعات مکانی-زمانی برای توصیه نقطه مورد علاقه. محاسبات نرم. 2020 ، 24 ، 18733-18747. [ Google Scholar ] [ CrossRef ]
- جین، جی. میشرا، ن. Sharma، SK CRLRM: توصیه مبتنی بر دسته با استفاده از مدل رگرسیون خطی. در مجموعه مقالات سومین کنفرانس بین المللی پیشرفت در محاسبات و ارتباطات، کوچین، هند، 29 تا 31 اوت 2013. ص 17-20. [ Google Scholar ]
- واسوانی، ع. Shazeer، NM; پارمار، ن. Uszkoreit، J. جونز، ال. گومز، AN; قیصر، ال. Polosukhin، I. توجه تمام چیزی است که شما نیاز دارید. در مجموعه مقالات سی و یکمین کنفرانس بین المللی سیستم های پردازش اطلاعات عصبی، لس آنجلس، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 دسامبر 2017؛ صفحات 6000–6010. [ Google Scholar ]
- Kingma، DP; با، جی. آدام: روشی برای بهینه سازی تصادفی. در مجموعه مقالات سومین کنفرانس بین المللی برای بازنمایی های یادگیری، اسکاتسدیل، AZ، ایالات متحده آمریکا، 2 تا 4 مه 2015. [ Google Scholar ]
- سو، ی. لی، ایکس. لیو، بی. ژا، دی. شیانگ، جی. تانگ، دبلیو. گائو، N. FGCRec: مدلسازی ویژگیهای جغرافیایی با دانهریزی برای توصیه نقطهنظر. در مجموعه مقالات کنفرانس بین المللی ارتباطات IEEE 2020 (ICC)، دوبلین، ایرلند، 7 تا 11 ژوئن 2020؛ صص 1-6. [ Google Scholar ]
- او، X. لیائو، ال. ژانگ، اچ. نی، ال. هو، ایکس. Chua، TS Neural Collaborative Filtering. در مجموعه مقالات بیست و ششمین کنفرانس بین المللی وب جهانی، پرت، استرالیا، 3 تا 7 آوریل 2017؛ صص 173-182. [ Google Scholar ]
- سرور، بی.ام. کاریپیس، جی. آکنستان، ج. ریدل، جی. الگوریتمهای توصیه فیلتر مشارکتی مبتنی بر آیتم. در مجموعه مقالات دهمین کنفرانس بین المللی وب جهانی، هنگ کنگ، چین، 1 تا 5 مه 2001. ص 285-295. [ Google Scholar ]
- رندل، اس. فرودنتالر، سی. Schmidt-Thieme، L. فاکتورسازی زنجیره های مارکوف شخصی شده برای توصیه سبد بعدی. در مجموعه مقالات نوزدهمین کنفرانس بین المللی وب جهانی، رالی، NC، ایالات متحده، 26-30 آوریل 2010; صص 811-820. [ Google Scholar ]
- لیو، کیو. وو، اس. وانگ، ال. Tan, T. پیشبینی مکان بعدی: مدلی تکرارشونده با زمینههای مکانی و زمانی. در مجموعه مقالات سی امین کنفرانس AAAI در زمینه هوش مصنوعی، فینیکس، AZ، ایالات متحده آمریکا، 12 تا 17 فوریه 2016; صص 194–200. [ Google Scholar ]
- گوا، کیو. سان، ز. ژانگ، جی. سپس، YL یک شبکه عصبی عودکننده توجه برای توصیه مکان بعدی شخصی شده. در مجموعه مقالات کنفرانس AAAI-20 در مورد هوش مصنوعی، نیویورک، نیویورک، ایالات متحده آمریکا، 7 تا 12 فوریه 2020؛ صص 83-90. [ Google Scholar ]
- سان، ک. کیان، تی. چن، تی. لیانگ، ی. نگوین، QVH؛ یین، اچ. کجا برویم بعدی: مدلسازی اولویتهای کاربر بلندمدت و کوتاهمدت برای توصیههای نقطهنظر. در مجموعه مقالات کنفرانس AAAI-20 در مورد هوش مصنوعی، نیویورک، نیویورک، ایالات متحده آمریکا، 7 تا 12 فوریه 2020؛ صص 214-221. [ Google Scholar ]
- تکلر، زد. کم، آر. گونای، بی. اندرسن، RK; Blessing، L. یک رویکرد مقیاس پذیر بلوتوث کم انرژی برای شناسایی الگوهای اشغال و نمایه ها در فضاهای اداری. ساختن. محیط زیست 2020 ، 171 ، 106681–106693. [ Google Scholar ] [ CrossRef ]
- کم، آر. تکلر، زد. Cheah, L. چارچوب ترکیبی نقطه مورد علاقه (POI). ISPRS Int. J. Geo-Inf. 2021 ، 10 ، 779. [ Google Scholar ] [ CrossRef ]
- جئون، جی. کانگ، اس. جو، م. چو، اس. پارک، ن. کیم، اس. Song, C. LightMove: توصیه ای سبک وزن بعدی-POI برای تبلیغات روی پشت بام تاکسی. در مجموعه مقالات سی امین کنفرانس بین المللی ACM در مدیریت اطلاعات و دانش، مجازی، 1 تا 5 نوامبر 2021؛ صص 3857–3866. [ Google Scholar ]


بدون دیدگاه