

پیشبینی خطر جرم و جنایت شهری با استفاده از دادههای نقطهنظر
خلاصه
سیستمهای اطلاعات جغرافیایی کاربردهای موفقی برای پیشبینی و تصمیمگیری در چندین حوزه از اهمیت حیاتی برای جامعه معاصر یافتهاند. این مقاله نشان میدهد که چگونه میتوان آنها را با الگوریتمهای یادگیری ماشین برای ایجاد مدلهای پیشبینی جرم برای مناطق شهری ترکیب کرد. لایه های انتخاب شده نقطه مورد علاقه (POI) از OpenStreetMapبرای استخراج ویژگیهایی استفاده میشوند که مناطق خرد را توصیف میکنند، که طبق سوابق جرم پلیس، طبقات خطر جرم اختصاص داده میشوند.

سپس ویژگیهای POI به عنوان ویژگیهای ورودی برای یادگیری مدلهای پیشبینی خطر جرم با الگوریتمهای یادگیری طبقهبندی عمل میکنند. نتایج تجربی بهدستآمده برای چهار منطقه شهری بریتانیا نشان میدهد که ویژگیهای POI کاربرد پیشبینی بالایی دارند. مدلهای طبقهبندی که از این ویژگیها استفاده میکنند، بدون هیچ شکلی از شناسایی مکان، عملکرد پیشبینیکننده خوبی را در زمانی که برای نواحی کوچک جدید و قبلاً دیده نشده اعمال میشوند، نشان میدهند. این باعث میشود که آنها بتوانند خطر جرم و جنایت را برای محلههای تازه توسعهیافته یا در حال تغییر پویا پیشبینی کنند. ابعاد بالای فضای ورودی مدل را می توان بدون از دست دادن عملکرد پیش بینی شده با انتخاب ویژگی یا تجزیه و تحلیل مولفه اصلی به طور قابل توجهی کاهش داد.
کلید واژه ها:
پیش بینی جرم ; نقطه مورد علاقه یادگیری ماشینی ؛ طبقه بندی
1. معرفی
دو دهه اخیر افزایش عظیمی در دامنه و پیچیدگی کاربردهای روشها و ابزارهای محاسباتی توسعهیافته در حوزه علم اطلاعات جغرافیایی ایجاد کرده است [ 1 ، 2 ، 3 ]. آنها به اجزای اساسی زیرساخت اطلاعاتی جوامع معاصر و نهادهای آنها تبدیل شده اند. یکی از امکانهای افزایش کاربرد سیستمهای اطلاعات جغرافیایی، ترکیب آنها با روشهای هوش مصنوعی برای استنتاج، تصمیمگیری، بهینهسازی و پیشبینی است. این جهت کاری برای مدت طولانی فعال بوده است [ 4 , 5 , 6 , 7]، اما افزایش قدرت محاسباتی موجود و شروع الگوریتمهای دقیقتر و مؤثرتر، آن را امیدوارکنندهتر از همیشه میکند [ 8 ]. به طور خاص، الگوریتم های یادگیری ماشین ممکن است برای کشف و تعمیم روابط غیر پیش پا افتاده بین اطلاعات جغرافیایی و سایر عوامل یا کمیت ها مورد استفاده قرار گیرند و آنها را به مدل های پیش بینی قابل استفاده مجدد تبدیل کنند.
یکی از حوزههای کاربردی مهم که در آن علم اطلاعات جغرافیایی با یادگیری ماشین ملاقات میکند، پلیس پیشبینی است [ 9 ]. توانایی پیشبینی اینکه کدام مناطق دارای ریسک بالایی از انواع خاص رویدادهای جنایی هستند ممکن است به تخصیص مؤثر منابع اجرای قانون در جایی که بیشتر مورد نیاز است کمک کند. بنابراین، پیشبینی جرم با استفاده از الگوریتمهای تحلیلی از یادگیری ماشین و آمار، به یک حوزه محبوب تحقیقاتی و کاربردهای عملی تبدیل شده است [ 10 ، 11 ، 12 ، 13 ، 14 ، 15 .]. سهم بالقوه دستاوردها در این راستا به امنیت عمومی انگیزه بالایی را برای به کارگیری روشهای مختلف برای انواع مختلف دادههای بالقوه مفید فراهم میکند. علاوه بر سوابق جرم پلیس، این موارد ممکن است شامل آمارهای اجتماعی و اقتصادی، پست های رسانه های اجتماعی یا داده های سیستم های اطلاعات جغرافیایی باشد. یک نوع به طور گسترده در دسترس و اغلب به روز شده از دومی، مکان های نقطه مورد علاقه (POI) هستند که ممکن است ویژگی مفیدی از مناطق شهری ارائه دهند.
1.1. مشارکت ها
این کار نشان میدهد که چگونه الگوریتمهای یادگیری ماشینی میتوانند برای دادههای سیستمهای اطلاعات جغرافیایی برای ایجاد مدلهای پیشبینی جرم اعمال شوند. این پتانسیل سودمندی بالای اطلاعات جغرافیایی را از یک سو تأیید میکند و از سوی دیگر دستورالعملهای عملی در مورد استفاده از الگوریتمهای یادگیری ماشین با دادههای جغرافیایی ارائه میکند. دومی شامل فرآیند آمادهسازی دادهها با تجمیع جغرافیایی در ریز ناحیههای شبکه، تخصیص برچسبهای کلاس، استخراج ویژگیهای جغرافیایی، مدیریت عدم تعادل کلاس، کاهش ابعاد و استفاده مجدد از مدل در مناطق مختلف است.
پیشبینی جرم برای مناطق شهری را میتوان یک کار طبقهبندی در نظر گرفت که در آن مدلی ایجاد میشود که خطر انواع خاصی از رویدادهای جنایی را بر اساس ویژگیهایی که ویژگیهای مناطق خرد خاص را مشخص میکند، پیشبینی میکند. ایجاد چنین مدلی مستلزم تهیه یک مجموعه داده ترکیبی است که هم ویژگیهای جغرافیایی مناطق خرد مشتقشده از مکانهای POI و هم برچسبهای خطر جرم ناشی از سوابق جرم را شامل میشود. الگوریتمهای طبقهبندی این امکان را فراهم میکنند که روابط بین اولی و دومی را به تصویر بکشیم و تعمیم دهیم. مدلهای بهدستآمده را میتوان برای پیشبینی سطح خطر جرم برای مناطق خرد دلخواه جدید که ویژگیهای جغرافیایی در دسترس هستند، به کار برد.
سناریوی ایجاد و پیشبینی مدل فرضی را میتوان به صورت زیر خلاصه کرد:
-
تجمیع جغرافیایی: منطقه مورد علاقه شهری را به مناطق خرد و کل سوابق جرم و جنایت و تعداد POI در سطح مناطق خرد تقسیم کنید.
-
اشتقاق ویژگی جغرافیایی: مناطق خرد را با ویژگیهای جغرافیایی توصیف میکند که از مکانهای POI جمعآوری شده است.
-
شناسایی نقاط داغ: با توجه به تعداد مجموع رویدادهای جرم تاریخی، مناطق خرد را به عنوان پرخطر/کم برچسب گذاری کنید.
-
مدلسازی نقطههای مهم: ایجاد مدلهایی برای پیشبینی برچسبهای ریسک بالا/کم بر اساس ویژگیهای جغرافیایی با استفاده از الگوریتمهای طبقهبندی،
-
پیشبینی نقطههای مهم: مدلهای ایجاد شده را برای پیشبینی برچسبهای پرخطر/کم خطر برای مناطق خرد بر اساس ویژگیهای جغرافیایی اعمال کنید.
این سناریو از داده های تاریخی برای ایجاد مدل هایی استفاده می کند که قادر به پیش بینی خطر جرم در آینده هستند. قابل توجه است که ریز نواحی با شناسه ها یا مختصات نشان داده نمی شوند، بلکه منحصراً با ویژگی های مشتق شده از مکان های POI جمع آوری شده جغرافیایی توصیف می شوند. این امکان ثبت روابط عمومی تر و قابل استفاده مجدد را، مستقل از توپوگرافی شهر خاص، فراهم می کند.
روش آزمایشی مورد استفاده برای تأیید سودمندی رویکرد پیشنهادی شامل عملیات اضافی زیر است:
-
ارزیابی قدرت پیشبینی: کیفیت پیشبینیهای جرم بهدستآمده را با استفاده از روش اعتبارسنجی متقاطع k -fold و تحلیل ROC ارزیابی کنید.
-
ارزیابی سودمندی پیشبینی کننده ویژگی: ویژگیهای جغرافیایی را با توجه به کاربرد آنها برای پیشبینی خطر جرم با استفاده از معیار اهمیت متغیر تصادفی جنگل رتبهبندی میکند.
-
کاهش ابعاد: بررسی امکان کاهش ابعاد داده ها بدون تنزل کیفیت مدل با انتخاب ویژگی و تجزیه و تحلیل مؤلفه اصلی،
-
انتقال مدل: امکان استفاده از مدلی آموزش دیده بر روی داده های یک منطقه شهری برای پیش بینی خطر جرم در یک منطقه شهری دیگر را تأیید می کند.

1.2. کار مرتبط
بررسی کاربرد منابع دادههای مختلف موجود برای توصیف مناطق جغرافیایی و ایجاد مدلهای پیشبینی کانون جرم بر اساس این ویژگیها به جهتهای پیشرو در تحقیقات پیشبینی جرم تعلق دارد. ادبیات شامل چندین مطالعه است که تا حدی با این کار مرتبط است. خلاصهای از آنهایی که اهداف یا روشها برای آنها بیشتر شبیه به اهداف یا روشهای اتخاذ شده در این مقاله است، در جدول 1 ارائه شده است .
هر یک از این مطالعات مرتبط، سوابق جرم و جنایت را برای یک منطقه شهری واحد با برخی از دادههای فضایی اضافی ترکیب میکند و تجمیع جغرافیایی را در مناطق خرد با اندازههای مختلف انجام میدهد. سپس الگوریتمهای طبقهبندی یا رگرسیون را برای پیشبینی سطح خطر جرم (پس از نوعی شناسایی نقطه داغ) یا تعداد رویدادهای جرم اعمال میکنند. دو استثنای جزئی از این الگوی رایج که مدلهای پیشبینی جرم را ایجاد نمیکنند، آثار Traunmueller و همکاران هستند. [ 16 ] و مالسون و آندرسن [ 17]. اولی همبستگی بین تعداد جرم و مشخصات اجتماعی جمعیت شناختی افرادی را که از مناطق خرد خاص بازدید می کنند، بر اساس تعداد قدم ها و ویژگی های مشتری به دست آمده از یک ارائه دهنده تلفن همراه تجزیه و تحلیل می کند. دومی ها به دنبال الگوهای ارتباطی بین ویژگی های جمعیت و منطقه از یک سو و کانون های جرم و جنایت از سوی دیگر هستند.
از ویژگی های بارز این اثر می توان به موارد زیر اشاره کرد:
-
با استفاده از داده های چهار منطقه شهری مختلف، بدون توجه به تحقیقات قبلی، به جای یک شهر واحد،
-
پیشبینی خطر به طور جداگانه برای چندین نوع جرم مختلف، با فراوانی وقوع متفاوت،
-
ریزدانه 300 × 300300×300-مناطق خرد متر که برای تجمع جغرافیایی، برچسبگذاری نقاط کانونی و پیشبینی استفاده میشوند، بهجای مناطق بسیار بزرگتر LSOA، جامعه یا انتشار آمار عمومی،
-
مجموعه گسترده ای از دسته بندی های POI که برای توصیف ریز نواحی استفاده می شوند،
-
مدیریت عدم تعادل کلاس با راه اندازی الگوریتم مناسب،
-
مقایسه سیستماتیک کیفیت پیشبینی با استفاده از تحلیل ROC،
-
بررسی اثر کاهش ابعاد با انتخاب ویژگی و تحلیل مولفه اصلی،
-
بررسی امکان انتقال مدلهای پیشبینی جرم در مناطق مختلف شهری.
قابل توجه است که چندین مطالعه قبلی فهرست شده در جدول 1 هر دو بعد مکانی و زمانی جرم را تجزیه و تحلیل می کند [ 18 , 19 , 20 , 21 , 22 , 23]. این امر یا با اعمال همبستگی و تجزیه و تحلیل خودرگرسیون سری های زمانی رویداد جرم یا با افزودن ویژگی های ساعت و تقویم (مانند فاصله ساعت یا ساعت، روز هفته و ماه) به ورودی های مدل به دست می آید. بسیاری از آنها همچنین دو یا چند منبع داده مکانی را برای به دست آوردن یک مشخصه ریز ناحیه کاملتر و مفیدتر ترکیب می کنند. بنابراین، ممکن است به نظر محدودیت این کار باشد که دادههای جرم را تنها با یک منبع دادههای مکانی ترکیب میکند و هیچ عامل زمانی را شامل نمیشود. در حالی که ترکیب منابع بیشتر اطلاعات مکانی و زمانی برای مدلسازی ریسک جرم یک جهت ادامه طبیعی و امیدوارکننده است، این تحقیق عمداً فقط بر مکانهای POI متمرکز شده است.

جدول 1. کارهای مرتبط.
1.3. بررسی اجمالی کاغذ
بخش 2 مجموعه دادههای مورد استفاده برای این کار، روش آمادهسازی دادههای اعمال شده برای دادههای جرم و POI، الگوریتمهای مورد استفاده برای ایجاد مدلهای پیشبینی خطر جرم، و روش تجربی را ارائه میکند. نتایج آزمایش ها در بخش 3 ارائه شده است. یافته های اصلی و جهت گیری های کاری آینده در بخش 4 مورد بحث قرار گرفته است.
2. مواد و روشها
2.1. داده ها
مطالعه تجربی ارائه شده در این مقاله از دو منبع دادههای در دسترس عموم استفاده میکند: سوابق جرم پلیس بریتانیا و مکانهای مورد علاقه OpenStreetMap .
2.1.1. داده های جرم و جنایت
سوابق جرم پلیس انگلستان از وب سایت data.police.uk در دسترس است. برای این کار، سوابق جرم برای نیروهای پلیس منطقه زیر بازیابی شد:
-
پلیس بزرگ منچستر،
-
پلیس مرسی ساید،
-
پلیس دورست،
-
پلیس یورکشایر غربی،
دربرگیرنده بازه زمانی بین اکتبر 2016 و سپتامبر 2019. برای هر رویداد جرم، موقعیت جغرافیایی و اطلاعات نوع جرم در دسترس است.
چهار مجموعه داده جرم فیلتر شدند تا فقط بزرگترین مناطق شهری مربوطه را شامل شوند، به عنوان مثال، به ترتیب، مناطق زیر بریتانیا:
-
منطقه منچستر (که پس از آن منچستر نامیده می شود)،
-
ناحیه لیورپول (پس از آن لیورپول نامیده می شود)،
-
بورنموث، کرایست چرچ و ناحیه پول (که پس از آن بورنموث نامیده می شود)،
-
ناحیه ویکفیلد (پس از آن ویکفیلد نامیده می شود).
فیلترینگ با استفاده از مرزهای اداری بریتانیا در دسترس از وب سایت ordnancesurvey.co.uk انجام شد.
از 14 نوع جرم اولیه شامل زیر مجموعه زیر برای آزمایش ها استفاده می شود:
-
رفتار ضد اجتماعی (که پس از آن ضد اجتماعی نامیده می شود)،
-
خشونت و جرایم جنسی (که پس از آن خشونت نامیده می شود)،
-
دزدی (که پس از آن دزدی نامیده می شود)،
-
دزدی از فروشگاه (که پس از آن دزدی مغازه نامیده می شود)،
-
سرقت های دیگر (پس از آن دزدی نامیده می شود)،
-
دزدی (که بعداً به آن ROBBERY گفته می شود).
شکل 1 نمودارهای شمارش جرم را برای این انواع جرم در هر یک از مناطق شهری مورد علاقه نشان می دهد. شکل 2 مکان های جرم را بر روی نقشه های مرزی مناطق مربوطه نشان می دهد. توزیع انواع جرم برای هر منطقه شهری مشابه است و نوع ضد اجتماعی و خشونت بیشترین فراوانی را دارند، انواع دزدی، دزدی از مغازه و دزدی دارای فراوانی متوسط و نوع سرقت کمترین فراوانی را دارند. فراوانی و تراکم فضایی جنایات برای منچستر بیشترین و برای ویکفیلد کمترین است.

2.1.2. داده های POI
داده های نقطه مورد علاقه به صورت فایل های شکل با عصاره های لایه OpenStreetMap انتخاب شده، در دسترس از Geofabrik.de [ 26 ] به دست آمد. بارگذاری و پیش پردازش شکل فایل POI با استفاده از بسته های rgdal [ 27 ] و sp [ 28 ] R انجام شد. از لایه های زیر استفاده شد:
- pois :
-
اشیاء POI که به صورت نقاط نمایش داده می شوند،
- pois_a :
-
اشیاء POI که به صورت چند ضلعی نمایش داده می شوند،
- حمل و نقل :
-
اشیاء حمل و نقل که به صورت نقاط نمایش داده می شوند،
- transport_a :
-
انتقال اشیاء به صورت چند ضلعی نمایش داده می شود.
هر شی POI با مختصات جغرافیایی و یک دسته توصیف می شود. تعداد دسته بندی های واقعی در مناطق مختلف متفاوت است و از 107 برای لیورپول تا 122 برای بورنموث متغیر است. 97 مقوله مشترک در هر یک از چهار منطقه شهری وجود دارد که تنها از این دسته ها در مطالعه تجربی استفاده می شود.
شکل 3 بار پلات های شمارش POI را برای 30 دسته بندی متداول در هر یک از مناطق شهری مورد علاقه نشان می دهد. شکل 4 مکان های POI را بر روی نقشه های مرزی مناطق مربوطه نشان می دهد. متداول ترین دسته های POI عمدتاً برای همه مناطق شهری یکسان هستند. تفاوت اصلی این است که رده اتوبوس_ایستگاه ، که همیشه پرتکرارترین است، مطلقاً بر سایر دستهها برای منچستر، لیورپول و ویکفیلد غالب است، در حالی که برای بورنموث کمی بالاتر از دسته بعدی است.
2.1.3. تجمیع جغرافیایی
برای شناسایی ساده هات اسپات، هر منطقه شهری به یک شبکه مربعی با ابعاد تقسیم شد. 300 × 300300×300m، همانطور که در شکل 5 نشان داده شده است. داده های POI با استفاده از همان تجمیع شدند 300 × 300300×300توری. POI در داخل حساب می شود 300 × 300300×300سلول های شبکه برای هر یک از دسته های POI رایج به عنوان ویژگی های ورودی برای پیش بینی خدمت می کنند.
رزولوشن شبکه اعمال شده ممکن است یک مبادله معقول بین ارائه پیشبینیهای کانون جرم در سطح ریز مناطق کوچک برای حداکثر سودمندی از یک سو و استفاده از ریز ناحیههای بزرگتر برای قابلیت اطمینان بیشتر پیشبینی از سوی دیگر در نظر گرفته شود. یک شبکه ریز دانه، پیشبینیهای مدل را برای سازمانهای مجری قانون مفیدتر میکند، و تخصیص دقیقتر منابع پیشگیری را ممکن میسازد، اما تعداد اشیاء POI در سلولهای شبکه ممکن است برای امکان کشف الگوهای قابل تعمیم با ارزش پیشبینی بسیار کم باشد. یک شبکه درشت دانه تضمین می کند که نقاط داده کافی در سلول های شبکه وجود دارد، اما پیش بینی های حاصل از کاربرد عملی مشکوک خواهند بود. را 300 × 300300×300سلولهای شبکهای بسیار کوچکتر از موارد مورد استفاده در بسیاری از مطالعات قبلی ذکر شده در بخش 1.2 هستند، اما هنوز به اندازه کافی بزرگ هستند که معمولاً چندین شی POI را شامل میشوند.
2.1.4. شناسایی هات اسپات
شمارش جرم برای انواع جرایم خاص در سلولهای شبکه با استفاده از چارک سوم به عنوان نقطه برش به برچسبهای باینری با خطر بالا / کم تبدیل شد ( در صورتی که تعداد رویداد بالاتر از ربع سوم باشد، در غیر این صورت خطر کم ). شاخصهای ریسک باینری بهعنوان ویژگیهای هدف برای پیشبینی عمل میکنند. مناطق خرد پرخطر را می توان کانون جرم و جنایت [ 29 ] در نظر گرفت.
روش بکار گرفته شده برای شناسایی هات اسپات ساده و کارآمد است، اما به وضوح ناقص است. مرزهای شبکه مربعی دلخواه و وضوح ثابت، غیر حساس به تفاوت در ساختمان و تراکم جمعیت و همچنین الگوهای ترافیک، کاستی های آشکار آن است. این رویکرد برای این کار، علیرغم محدودیتهایش، برای تمرکز بر کاربرد دادههای POI و سطح کیفیت پیشبینی ممکن برای دستیابی به پایهایترین محیط، و به تعویق انداختن بررسی روشهای دقیقتر با وضوح متغیر به کار آینده اتخاذ شده است.
یک جایگزین ممکن برای یک شبکه با وضوح ثابت معمولی می تواند تقسیم منطقه شهری در امتداد مرزهای خیابان [ 30 ] باشد. از آنجایی که ترافیک، ساختمانهای مسکونی، ادارات، مغازهها و غیره در امتداد خیابانها متمرکز میشوند، تعیین مرزها بر اساس چیدمان و اتصالات آنها ممکن است مناطق کوچک تری را با توجه به خطر و نوع رویدادهای مجرمانه شناسایی کند. آنها همچنین می توانند برای برنامه ریزی فعالیت های پیشگیری از جرم مفیدتر باشند.
تجمیع جغرافیایی رویدادهای جرم و جنایت در مناطق خرد، حتی با وضوح متغیر، حاکی از مرزهای ثابت و تغییرات پله ای بین ریزمناطق مجاور است. حتی مکانهای بسیار نزدیک متعلق به دو ریز ناحیه مختلف میتوانند سطوح ریسک قابل ملاحظهای متفاوتی را در نظر بگیرند. یک نمایش مناسب تر از ریسک واقعی می تواند یک سطح ریسک هموار باشد که به تدریج با فاصله تغییر می کند. این را می توان با استفاده از تخمین چگالی هسته (KDE) [ 31]. در این رویکرد، مکان های رویداد برای تخمین تابع چگالی احتمال با هموارسازی، کنترل شده توسط پارامتر پهنای باند استفاده می شود. این یک نگاشت پیوسته از نقاط از یک منطقه تجزیه و تحلیل شده به یک چگالی احتمال رویداد تولید می کند. ریز نواحی با بیشترین تراکم احتمال، که نقاط داغ در نظر گرفته می شوند، مرزهای خودسرانه از پیش تعریف شده ندارند، اما بر اساس توزیع رویداد شناسایی می شوند [ 32 ، 33 ، 34 ، 35 ]. ترکیب مدلسازی ریسک جرم و پیشبینی بر اساس ویژگیهای POI با روش شناسایی کانون مبتنی بر KDE میتواند یک جهت کاری جالب در آینده باشد.
ایده کانونهای جرم و جنایت را میتوان به گونهای گسترش داد که علاوه بر تراکم سرزمینی، تغییرات فراوانی جرم در زمان را نیز در بر گیرد. چنین نقاط کانونی مکانی-زمانی ترکیبی از مناطق خرد و پنجره های زمانی با خطر بالای فعالیت مجرمانه را نشان می دهد [ 14 ، 36 ]. این مطالعه بعد زمانی را در تجزیه و تحلیل گنجانده است، هرچند، به طور کامل بر روی ابزار پیش بینی داده های POI تمرکز می کند.
2.1.5. داده های ترکیبی
پیوستن به داده های جرم و POI جمع آوری شده جغرافیایی توسط سلول های شبکه، مجموعه داده های ترکیبی را برای هر منطقه شهری به دست می دهد که برای ایجاد و ارزیابی مدل استفاده می شود. ردیفهای این مجموعه دادهها با سلولهای شبکه و ستونها با شاخصهای ریسک و ویژگیهای POI مطابقت دارند. هر یک از این مجموعه دادهها به سلولهای شبکهای محدود میشوند که در محدوده شهری مربوطه قرار میگیرند یا با آن تلاقی میکنند، طبق مرزهای منطقه بریتانیا. جدول 2 اندازه هر مجموعه داده و درصد کانون را برای انواع جرم خاص نشان می دهد. برای انواع جرایم کمتکرار، این درصد به میزان قابلتوجهی کمتر از سطح مورد انتظار ۲۵ درصد است. این زمانی اتفاق میافتد که کمتر از 25 درصد سلولهای شبکه با شمارش رویداد غیر صفر برای نوع جرم مربوطه وجود داشته باشد.
2.2. الگوریتم ها
یک الگوریتم طبقهبندی دلخواه میتواند برای پیشبینی برچسبهای ریسک بالا/پایین بر اساس ویژگیهای POI استفاده شود. مجموعهای از مفیدترین الگوریتمهای شناخته شده از ادبیات در این کار اعمال میشود: رگرسیون لجستیک، ماشینهای بردار پشتیبان، درختهای تصمیمگیری، و جنگلهای تصادفی [ 37 ].
2.2.1. رگرسیون لجستیک
رگرسیون لجستیک نمونهای از مدلهای خطی تعمیمیافته است که یک تابع نمایش مدل ترکیبی را با یک مدل خطی داخلی و یک تبدیل لاجیت بیرونی اتخاذ میکند [ 38 ]. آموزش یک مدل رگرسیون لجستیک شامل یافتن پارامترهای مدل است که احتمال ورود به سیستم کلاس های مجموعه آموزشی را به حداکثر می رساند.
با توجه به تابع هدف احتمالی مورد استفاده برای تخمین پارامتر، رگرسیون لجستیک میتواند پیشبینیهای احتمال خوب کالیبرهشده را ایجاد کند و اغلب الگوریتم طبقهبندی انتخابی است که در آن مورد نیاز است. استفاده از آن آسان است و بیش از حد مستعد بیش از حد برازش نیست مگر اینکه برای داده های با ابعاد بالا استفاده شود. در آزمایشهای ما، رگرسیون لجستیک بهعنوان یک پایه مقایسه طبیعی برای الگوریتم ماشینهای بردار پشتیبان اصلاحشدهتر عمل میکند که طبقهبندی خطی را گسترش میدهد، به مقاومت بیش از حد برازش بهتری دست مییابد و اجازه روابط غیرخطی را میدهد.
2.2.2. ماشین های بردار پشتیبانی
ماشینهای بردار پشتیبان (SVM)، که اغلب به مؤثرترین الگوریتمهای طبقهبندی همه منظوره تعلق دارند، میتوانند بهعنوان نسخهای تقویتشده قابل توجهی از طبقهبندیکننده آستانه خطی پایه با پیشرفتهای زیر مشاهده شوند [ 39 ، 40 ، 41 ]:
-
حداکثر سازی حاشیه: محل مرز تصمیم گیری (هیپرصفحه جداکننده) با توجه به حاشیه طبقه بندی بهینه شده است.
-
حاشیه نرم: نمونه هایی که به طور نادرست جدا شده اند مجاز هستند،
-
ترفند هسته: روابط غیرخطی پیچیده را می توان با تبدیل نمایش با استفاده از توابع هسته نشان داد.
الگوریتم SVM یک سناریوی طبقه بندی باینری با دو کلاس را فرض می کند. پیشبینیهای کلاس با استفاده از یک قانون آستانه خطی استاندارد تولید میشوند. پارامترهای مدل با حل یک مسئله برنامهریزی درجه دوم تعریف شده برای دستیابی به حداکثر کردن حاشیه طبقهبندی، یعنی قرار دادن مرز تصمیم به گونهای که فاصله را از نزدیکترین نمونههای جدا شده به درستی به حداکثر میرساند، با جریمه برای نقض محدودیتها که توسط پارامتر هزینه کنترل میشود، پیدا میشوند.
تبدیل این مشکل به شکل دوگانه با استفاده از ضرب کننده های لاگرانژ مزایای قابل توجهی را فراهم می کند [ 42 ، 43 ]. یکی از ویژگیهای مهم فرم دوگانه این است که فقط از بردارهای ارزش ویژگی در محصولات نقطهای استفاده میکند، هم در طول ایجاد مدل و هم در حین پیشبینی. این امکان اعمال ترفند هسته – یک تبدیل نمایش ضمنی را فراهم می کند. به جای محصولات نقطه ای بردارهای ارزش ویژگی اصلی، از مقادیر تابع هسته استفاده می شود که نشان دهنده محصولات نقطه ای بردارهای ارزش ویژگی افزایش یافته است. این به اثر تبدیل مقادیر مشخصه بردارها بدون اعمال واقعی تبدیل میشود.
به جای پیشبینیهای SVM آستانه خطی باینری، ممکن است اغلب استفاده از پیشبینیهای احتمالی راحتتر باشد. این با اعمال یک تبدیل لجستیک به فاصله علامتدار نمونههای طبقهبندیشده از مرز تصمیم، با پارامترهای تنظیمشده برای حداکثر احتمال امکانپذیر است [ 44 ].
یکی از ویژگیهای قابل توجه SVM عدم حساسیت کیفیت مدل به ابعاد داده است که – بر خلاف بسیاری از الگوریتمهای دیگر – خطر تطبیق بیش از حد را افزایش نمیدهد زیرا پیچیدگی مدل به تعداد موارد نزدیک به مرز تصمیمگیری مرتبط است نه به تعداد. از صفات
2.2.3. درختان تصمیم
درخت تصمیم [ 45 ، 46 ] یک ساختار سلسله مراتبی است که یک مدل طبقه بندی را نشان می دهد. گرههای درختی داخلی، تقسیمهایی را نشان میدهند که برای تجزیه دامنه به مناطق اعمال میشوند، و گرههای پایانی برچسبها یا احتمالات کلاس را به مناطقی که تصور میشود به اندازه کافی کوچک یا به اندازه کافی یکنواخت هستند، اختصاص میدهند.
درختهای تصمیم در بسیاری از کاربردها به دلیل توانایی آنها در ترکیب دقت پیشبینی نسبتاً خوب با خوانایی مدلها توسط انسان، محبوب هستند. آنها ممکن است به معیارهای توقف یا هرس مناسب نیاز داشته باشند تا از برازش بیش از حد جلوگیری شود. در آزمایشهای ما، درختهای تصمیم بهعنوان یک پایه مقایسه طبیعی برای الگوریتم جنگلهای تصادفی تصفیهشدهتر عمل میکنند که چندین درخت را برای دستیابی به کیفیت پیشبینی بهتر و مقاومت بیش از حد ترکیب میکند.
2.2.4. جنگل تصادفی
جنگلهای تصادفی به محبوبترین الگوریتمهای مدلسازی گروه تعلق دارند [ 47 ]، که با ترکیب چندین مدل متنوع برای یک حوزه، عملکرد پیشبینی بهبود یافته را به دست میآورند. یک جنگل تصادفی [ 48 ] یک مدل مجموعه ای است که توسط مجموعه ای از درختان تصمیم هرس نشده نشان داده شده است، که بر اساس نمونه های راه انداز متعددی که با جایگزینی از مجموعه آموزشی ترسیم شده اند، با انتخاب تقسیم تصادفی رشد می کنند. میتوان آن را یک شکل بهبودیافته از کیسهبندی [ 49 ] در نظر گرفت که بهعلاوه با تصادفیسازی الگوریتم رشد درخت تصمیم که برای ایجاد آنها استفاده میشود، تنوع مدلهای فردی را در مجموعه تحریک میکند.
رشد تصادفی جنگل شامل رشد درخت های تصمیم گیری چندگانه است که هر کدام بر اساس یک نمونه راه انداز از مجموعه آموزشی (معمولاً هم اندازه مجموعه آموزشی اصلی) است، با استفاده از یک الگوریتم رشد درخت تصمیم اساساً استاندارد [ 45 ، 46 ]. از آنجایی که بهبود مورد انتظار مجموعه مدل حاصل از یک مدل واحد منوط به تنوع کافی از مدلهای فردی در مجموعه است [ 47 ، 49 ]، اصلاحات زیر برای تحریک تنوع درختهای تصمیمگیری اعمال میشوند که قرار است یک تصادفی را تشکیل دهند. جنگل:
-
درختان بزرگ با حداکثر تناسب رشد می کنند (با شکافتن تا رسیدن به یک کلاس یکنواخت ادامه می یابد، مجموعه ای از نمونه ها خسته می شود، یا مجموعه ای از تقسیم های احتمالی خسته می شود)
-
هر زمان که باید یک تقسیم برای یک گره درختی انتخاب شود، زیر مجموعه کوچکی از ویژگی های موجود به طور تصادفی انتخاب می شود و تنها آن ویژگی ها برای تقسیم های نامزد در نظر گرفته می شوند.
پیشبینی تصادفی جنگل با رأیگیری بدون وزن ساده درختان منفرد از مدل به دست میآید. توزیع رای همچنین می تواند برای به دست آوردن پیش بینی های احتمال کلاس استفاده شود. با تعداد کافی درختان متنوع (معمولاً صدها) این مکانیسم رای گیری ساده معمولاً جنگل های تصادفی را بسیار دقیق و در برابر بیش از حد مقاوم می کند. در واقع، در بسیاری از موارد، آنها متعلق به دقیق ترین مدل های طبقه بندی هستند که می توان به آنها دست یافت.
2.3. کاهش ابعاد
تعداد زیادی از ویژگیها ممکن است برخی از الگوریتمهای مدلسازی، بهویژه آنهایی که مستعد بیش از حد برازش هستند، از دستیابی به مدلهای با کیفیت بالا جلوگیری کند. زیرا ایجاد مدل یک فرآیند جستجو در فضای نمایش مدل است که پیچیدگی آن معمولاً مستقیماً به ابعاد داده بستگی دارد [ 50 ]. این خطر مدل های بیش از حد برازش شده با قابلیت تعمیم ناکافی را افزایش می دهد. برخی از ویژگی های موجود ممکن است ارزش پیش بینی واقعی نداشته باشند و فقط به صورت تصادفی با برچسب های کلاس ارتباط برقرار کنند.
مجموعه داده های تهیه شده برای تجزیه و تحلیل همانطور که در بخش 2.1 توضیح داده شده است دارای 97 ویژگی ورودی است که مربوط به دسته های POI مشترک برای هر چهار منطقه شهری است. این را می توان ابعاد نسبتاً بالایی در نظر گرفت، به ویژه با توجه به اندازه متوسط مجموعه داده ها (بین 1500 تا 4000)، که در آن نمونه ها با سلول های شبکه مطابقت دارند. بنابراین ممکن است جالب باشد که ببینیم آیا تکنیکهای کاهش ابعاد میتوانند به بهبود کیفیت پیشبینی منجر شوند یا خیر.
دو نوع کاهش ابعاد در نظر گرفته خواهد شد:
-
انتخاب ویژگی، که زیرمجموعه کوچکی از مجموعه ویژگی های اصلی را حفظ می کند،
-
تبدیل بازنمایی، که ویژگی های اصلی را با یک زیر مجموعه کوچک از ویژگی های جدید جایگزین می کند.
2.3.1. انتخاب صفت
هدف از انتخاب ویژگی محدود کردن مجموعه کامل ویژگیهای موجود به زیرمجموعه احتمالاً کوچک آن با بالاترین کاربرد پیشبینی است [ 51 ]. روشهای انتخاب ویژگی شامل رویکردهای فیلتری است که از برخی معیارهای سودمندی پیشبینی ویژگیها و زیرمجموعه ویژگیها بدون فرض الگوریتم مدلسازی هدف خاص استفاده میکنند، و رویکردهای پوششی که در آن یک الگوریتم هدف از پیش تعیینشده برای ایجاد مدلهایی بر روی زیرمجموعه ویژگیها برای ارزیابی سودمندی آنها استفاده میشود. [ 52 ]. مورد دوم ممکن است در مواقعی که مفیدترین ویژگی برای یک الگوریتم مورد نیاز باشد، دارای مزایایی باشد، اما حالت اولی هنگام آزمایش با چندین الگوریتم راحتتر است، مانند این کار.
یکی از انواع فیلترهای انتخاب ویژگی که محبوبیت بالایی به دست آورده است بر اساس معیارهای سودمند ویژگی است که می تواند به عنوان یک “عوارض جانبی” الگوریتم جنگل تصادفی [ 48 ] محاسبه شود، که اغلب به عنوان اهمیت متغیر جنگل تصادفی شناخته می شود. یکی از این معیارها که به نام دقت کاهش میانگین (MDA) نامیده می شود و قابل اطمینان ترین در نظر گرفته می شود، کاهش تخمینی دقت پیش بینی به دلیل جایگشت مقدار مشخصه تصادفی است [ 53 ]. هرچه کاهش بیشتر باشد، ویژگی مفیدتر به نظر می رسد. برخلاف معیارهای ساده رابطه آماری، این نوع اهمیت متغیر به زمینه ارائه شده توسط سایر ویژگی های موجود حساس است.
دو مشکل مرتبط با اعمال مستقیم اهمیت متغیر جنگل تصادفی برای انتخاب ویژگی وجود دارد. یکی ناپایداری است که ناشی از تصادفی بودن الگوریتم است و دیگری فقدان مکانیزم انتخاب خودکار زیرمجموعه است که تعیین می کند چه تعداد از مفیدترین ویژگی ها باید استفاده شوند. بوروتا [ 54 ] بر این ناراحتی ها غلبه می کند] الگوریتم، که به طور مکرر جنگل تصادفی را اعمال می کند تا تصمیم بگیرد کدام ویژگی ها باید حفظ شوند و کدام یک از زیر مجموعه حذف شوند. اگرچه این هزینه محاسباتی قابل توجهی دارد. برای آزمایشهای ارائهشده در این مقاله، اهمیت متغیر MDA بهطور مستقیم استفاده میشود، اما ثبات با میانگینگیری مقادیر اهمیت از همه مدلهای ایجاد شده در یک روش اعتبارسنجی متقابل افزایش مییابد. سپس از این مقادیر اهمیت متوسط برای انتخاب زیرمجموعههای ویژگیهای برتر از چند اندازه از پیش تعیینشده استفاده میشود.
2.3.2. تبدیل PCA
یک رویکرد جایگزین برای کاهش ابعاد شامل تبدیل دادهها به نمایش دیگری با اعمال برخی تبدیلهای جبری است. مجموعهای کوچکتر از ویژگیها تولید میکند که هر کدام از نظر عملکردی به برخی یا همه ویژگیهای اصلی وابسته هستند. رایج ترین نوع چنین تبدیلی، تحلیل مؤلفه اصلی (PCA) است [ 55 ، 56 ].
تبدیل PCA با شناسایی ویژگی های جدید به عنوان اجزای اصلی انجام می شود – ترکیبات خطی نامرتبط از ویژگی های اصلی. هر مؤلفه اصلی بعدی قرار است واریانس را به حداکثر برساند و در عین حال متعامد بودن را نسبت به موارد قبلی حفظ کند. این را می توان با تعیین بردارهای ویژه و مقادیر ویژه ماتریس همبستگی صفت یا کوواریانس یا با اعمال تجزیه مقدار منفرد [ 57 ] به ماتریس کوواریانس به دست آورد.
برای کاهش ابعاد اصلی n باید انتخاب شود k < nک<�اولین اجزای اصلی هنگام استفاده از مجموعه داده کاهش ابعاد برای ایجاد مدلهای پیشبینی، لازم است دادههای جدید در مرحله پیشبینی به همان نمایشی که بر اساس دادههای آموزشی تعیین میشود، با ضرب در ماتریس پیشبینی مربوطه تبدیل شود.
2.4. ارزیابی عملکرد پیش بینی کننده
متداولترین معیارهای کیفیت طبقهبندی مانند خطای طبقهبندی اشتباه یا دقت طبقهبندی زمانی که کلاسها نامتعادل هستند یا احتمالاً قابلیت پیشبینی متفاوتی دارند، بسیار مفید نیستند. آنها همچنین به اندازه کافی قدرت پیشبینی مدلهای احتمالی را که میتوانند در نقاط عملیاتی مختلف، مربوط به مقادیر قطع احتمال مختلف، استفاده کنند، دریافت نمیکنند. به همین دلیل است که در آزمایشهای گزارششده در این مقاله، کیفیت طبقهبندی با استفاده از منحنیهای ROC تجسم میشود و نقاط مبادله احتمالی بین نرخ مثبت واقعی و نرخ مثبت کاذب را ارائه میدهد [ 58 , 59]. اولی نسبت تعداد تمام نقاط جرم و جنایت است که به درستی توسط مدل پیشبینی شده است به تعداد همه کانونهای جرم واقعی، و دومی نسبت تعداد سلولهای شبکه غیرهتاسپات است که مدل بهطور اشتباه پیشبینی کرده است بهعنوان کانون به تعداد سلولهای شبکه غیرهتاسپت. نقاط عملیاتی مدل که توسط منحنیهای ROC تجسم میشوند با استفاده از ناحیه زیر منحنی ROC (AUC) خلاصه میشوند. این به عنوان یک معیار کلی برای قدرت پیش بینی عمل می کند و می تواند به عنوان احتمال دستیابی سلول شبکه هات اسپات به پیش بینی خطر جرم بالاتر نسبت به سلول شبکه غیر هات اسپات تفسیر شود. متناسب با مقدار آماره Mann-Whitney U برای آزمایش این فرضیه است که نقاط داغ، پیشبینیهای ریسک بالاتری نسبت به نقاط غیر کانونی دریافت میکنند.
برای دستیابی به تخمینهای عملکرد پیشبینیکننده قابل اعتماد، کم سوگیری و کم واریانس، روش اعتبارسنجی متقاطع 10 برابری که 10 بار تکرار شده است، اعمال میشود [ 60 ]. از داده های موجود برای ایجاد و ارزیابی با تقسیم تصادفی آن به 10 زیرمجموعه با اندازه مساوی که هر کدام به عنوان یک مجموعه آزمایشی برای ارزیابی مدل ایجاد شده بر روی زیر مجموعه های ترکیبی باقی مانده عمل می کند و این فرآیند را 10 بار تکرار می کند، از داده های موجود برای ایجاد و ارزیابی استفاده موثر می کند. واریانس را بیشتر کاهش دهد. برچسبها و پیشبینیهای کلاس واقعی برای همه 10 × 1010×10سپس تکرارها برای تعیین منحنی های ROC و مقادیر AUC ترکیب می شوند.
2.5. پیاده سازی و راه اندازی الگوریتم
از پیاده سازی الگوریتم های زیر در آزمایش ها استفاده می شود:
-
رگرسیون لجستیک: پیاده سازی ارائه شده توسط تابع استاندارد glm R [ 61 ]،
-
SVM: پیاده سازی ارائه شده توسط بسته e1071 R [ 62 ]،
-
درختان تصمیم: پیاده سازی ارائه شده توسط بسته rpart R [ 63 ].
-
جنگل تصادفی: پیاده سازی ارائه شده توسط بسته randomForest R [ 64 ].
برای رگرسیون لجستیک و الگوریتم های SVM پارامترهای کنترل کننده فرآیند بهینه سازی اساسی در مقادیر پیش فرض باقی مانده اند. پارامترهای SVM که مسئله بهینهسازی را مشخص میکنند به صورت زیر تنظیم شدند:
-
هزینه نقض محدودیت ( هزینه ): 1،
-
نوع هسته ( هسته ): شعاعی ،
-
پارامتر هسته ( گاما ): معکوس تعداد صفات (بعد ورودی)،
-
وزن کلاس در جریمه نقض محدودیت ( Class.weights ): 3 برای کلاس پرخطر ، 1 برای کلاس کم خطر.
برای الگوریتم درخت تصمیم، معیارهای توقف پیشفرض استفاده شد، از جمله minsplit (حداقل تعداد نمونههای مورد نیاز برای تقسیم) روی 20 و cp (پارامتر پیچیدگی) تنظیم شده بر روی 0.010.01. قرار است از این کار جلوگیری شود و بررسی شود که آیا روابط بین خطر جرم و ویژگیهای POI به اندازه کافی ساده هستند تا بتوانند پیشبینی موفق با درختان نسبتاً کوچک را فراهم کنند. احتمالات قبلی یکنواخت برای دو کلاس از طریق پارامتر قبلی تنظیم شد.
برای الگوریتم جنگل تصادفی، از تنظیمات زیر استفاده شد:
-
تعداد درخت ( ntree ): 500،
-
تعداد مشخصهها برای انتخاب تقسیم در هر گره ( mtry ): جذر تعداد کل ویژگیهای موجود،
-
اندازه نمونه راهانداز طبقهای ( sampsize ): تعداد نمونههای کلاس پرخطر (طبقه اقلیت).
شایان ذکر است که تنظیمات پارامتر برای SVM، درخت تصمیم، و الگوریتم جنگل تصادفی شامل تنظیماتی هستند که مسئول مدیریت صحیح کلاسهای نامتعادل هستند (تضمین حساسیت کافی به کلاس اقلیت). این امر با تعیین وزن کلاس برای SVM (تخصیص وزن بالاتر به کلاس اقلیت هنگام محاسبه مجازات نقض محدودیت در هدف بهینهسازی)، تنظیم اولویتهای کلاس یکنواخت برای درختهای تصمیم، و تعیین اندازه نمونه راهانداز طبقهای برای الگوریتم جنگل تصادفی به دست میآید. (رسم حداکثر تعداد ممکن نمونه های کلاس اقلیت و همان تعداد نمونه های کلاس اکثریت). این تنظیمات برای بهبود کیفیت مدل در واقع تأیید شد. هیچ شکلی از تعادل مجدد کلاس برای الگوریتم رگرسیون لجستیک لازم نیست، از آنجایی که هر وزن یا پیشین کلاس فقط نقطه برش احتمال پیش فرض کلاس را که برای تخصیص برچسب کلاس پیش بینی شده استفاده می شود، تغییر می دهد. با توجه به این واقعیت که تحلیل ROC که برای ارزیابی عملکرد پیشبینیکننده استفاده میشود، بههرحال به جای برچسبهای کلاس، بر اساس احتمالات کلاس پیشبینیشده است، هیچ هدف مفیدی نخواهد داشت.
3. نتایج
ارزیابی تجربی کاربرد دادههای POI برای پیشبینی خطر جرم بر اساس ارزیابی کیفیت مدلهای طبقهبندی است که شاخصهای خطر را برای انواع جرم انتخابشده بر اساس ویژگیهای POI پیشبینی میکنند. آزمایش ها در سه مطالعه زیر سازماندهی شده اند:
-
کیفیت پیشبینی: ارزیابی سطح کیفیت پیشبینی خطر جرم به دست آمده توسط الگوریتمهای خاص با استفاده از تمام ویژگیهای POI،
-
ابزار پیش بینی ویژگی: ارزیابی کاربرد پیش بینی ویژگی های خاص POI،
-
کاهش ابعاد: بررسی اثرات کاهش ابعاد با انتخاب ویژگی و تجزیه و تحلیل مولفه اصلی،
-
انتقال مدل: تأیید امکان به کارگیری مدل آموزش دیده بر روی داده های یک منطقه شهری برای پیش بینی خطر جرم در منطقه شهری دیگر.
3.1. کیفیت پیش بینی
منحنی های ROC که کیفیت پیش بینی را برای مدل های رگرسیون لجستیک (LR)، SVM، درخت تصمیم (DT) و جنگل تصادفی (RF) تجسم می کنند در شکل 6 ، شکل 7 ، شکل 8 و شکل 9 ارائه شده است. مساحت زیر مقادیر منحنی در افسانه های نمودار ارائه شده است. خط مورب چین دار خاکستری عملکرد حدس تصادفی را با AUC نشان می دهد 0.50.5.
مشاهدات زیر را می توان انجام داد:
-
پیشبینی خطر با کیفیت خوب برای هر یک از شش نوع جرم انتخاب شده با استفاده از ویژگیهای POI، با نزدیک یا بیشتر شدن مقادیر AUC امکانپذیر است. 0.80.8برای اکثر مناطق شهری و انواع جرم،
-
نقاط عملیاتی معقول با نرخ مثبت واقعی در حدود 0.80.8و نرخ مثبت کاذب حداکثر 0.20.2معمولاً قابل دستیابی هستند (و می توان آنها را شناسایی کرد، به عنوان مثال، با انتخاب مقادیر برش احتمال کلاس که حداکثر نرخ مثبت واقعی را به دست می دهد و نرخ مثبت کاذب از آن تجاوز نمی کند. 0.20.2)
-
الگوریتم جنگل تصادفی بدون در نظر گرفتن منطقه شهری و نوع جرم، بهترین عملکرد پیش بینی را به دست می آورد.
-
الگوریتم SVM در اکثر موارد به طور مشابه موفق است،
-
رگرسیون لجستیک و مدلهای درخت تصمیم کیفیت پیشبینی به وضوح پایینتری ارائه میدهند، که نشان میدهد رابطه بین خطر جرم و ویژگیهای POI ممکن است به اندازه کافی ساده نباشد که به اندازه کافی توسط یک تابع خطی یا یک درخت کوچک نمایش داده شود.
-
به نظر می رسد قابلیت پیش بینی جرم و جنایت برای ویکفیلد بهتر از سایر مناطق شهری است، با مقادیر AUC نزدیک یا فراتر از آن 0.90.9،
-
به نظر می رسد دزدی از مغازه بهترین نوع جرم قابل پیش بینی بر اساس ویژگی های POI باشد، که با توجه به ارتباط آشکار آن با مکان های فروشگاه، تعجب آور نیست.
برای بررسی اینکه آیا تفاوتهای مشاهدهشده در عملکرد الگوریتم از نظر آماری معنیدار هستند، از آزمون ناپارامتری DeLong [ 65 ] برای مقایسه AUC استفاده شد. برای هر یک از چهار منطقه شهری و شش نوع جرم و برای هر جفت الگوریتم، p-value برای فرضیه جایگزین تعیین شد که مقدار AUC به دست آمده توسط الگوریتم اول بیشتر از مقدار بدست آمده توسط الگوریتم دیگر است. جدول 3 نتایج آزمون به دست آمده را با ارائه هر جفت الگوریتم خلاصه می کند a l g1،a l g2alg1،alg2، جایی که a l g1alg1یک برچسب ردیف جدول است و a l g2alg2یک برچسب ستون جدول است که تعداد دفعات آن (یعنی جفت منطقه شهری-جنایت) برای آن است a l g1alg1عملکرد قابل توجهی داشت a l g2alg2در 0.010.01سطح اهمیت
بلافاصله می توان مشاهده کرد که جنگل تصادفی بهتر از هر دو رگرسیون لجستیک و درخت تصمیم در تمام 24 مورد و بهتر از SVM در 14 مورد از 24 مورد بود. دومی همیشه بهتر از رگرسیون لجستیک و تقریباً همیشه بهتر از درخت تصمیم بود. رگرسیون لجستیک عمدتاً بهعنوان درختهای تصمیم مشابه عمل میکند، که در 10 مورد از 24 مورد به طور قابلتوجهی بهتر و در 4 مورد از 24 مورد بدتر بود. الگوریتم درخت تصمیم بدترین عملکرد کلی را نشان می دهد.
3.2. ابزار پیش بینی ویژگی
برای بررسی کاربرد پیشبینی ویژگیهای POI برای انواع جرم خاص، از معیار اهمیت متغیر دقت میانگین کاهش تصادفی جنگل استفاده شد. مقادیر MDA مربوطه از مدلهای جنگل تصادفی که قبلاً برای ارزیابی کیفیت پیشبینی ایجاد شده بودند، در تمام تکرارهای اعتبارسنجی متقاطع و انواع جرم به طور میانگین محاسبه شدند. نتایج در شکل 10 ارائه شده است. در هر طرح، 30 ویژگی برتر ارائه شده است که از مفیدترین تا کم سودمندترین آنها رتبه بندی شده اند.
رتبه بندی ابزارهای پیش بینی کننده در مناطق شهری تفاوت چندانی ندارد. موارد زیر از جمله مفیدترین دسته بندی های پیش بینی کننده اشیاء POI هستند: bus_stop ، سوپرمارکت ، صندوق پستی ، میخانه ، مدرسه ، کافه ، راحتی ، فست فود ، رستوران ، تلفن . در حالی که bus_stop ، post_box ، میخانه ، کافه و فست فود به متداولترین دستههای POI تعلق دارند (همانطور که میتوان در آن مشاهده کرد شکل 3 مشاهده می شود)، این کاملاً صادق نیست. سوپرمارکت ، راحتی ، یا تلفن. بنابراین نمی توان اهمیت دسته های POI را فقط به فراوانی وقوع آنها نسبت داد.
3.3. کاهش ابعاد
برای بررسی اثر کاهش ابعاد، آزمایشهای حاصل از مطالعه کیفیت پیشبینی در دو نوع اصلاحشده زیر تکرار شد:
-
با انتخاب ویژگی: با استفاده از 5، 10 و 25 ویژگی برتر با توجه به رتبه بندی اهمیت متغیر جنگل تصادفی،
-
با PCA: با استفاده از 5، 10 و 25 جزء اصلی اولیه.
برای صرفه جویی در فضا، تنها مقادیر AUC، به طور میانگین در همه انواع جرم، برای این مطالعه کاهش ابعاد ارائه شده است: در جدول 4 برای انتخاب ویژگی و در جدول 5 برای PCA. برای مقایسه آسانتر با نتایج بهدستآمده با استفاده از ابعاد اصلی، برای هر الگوریتم یک ردیف اضافی مربوط به اندازه زیرمجموعه ویژگی یا تعداد مؤلفههای اصلی برابر با 97 وجود دارد، یعنی تعداد تمام ویژگیهای POI مورد استفاده در آزمایشهای ارائهشده قبلی.
مشاهدات زیر را می توان انجام داد:
-
کاهش ابعاد به الگوریتمهای رگرسیون لجستیک و درخت تصمیم کمک میکند تا کیفیت پیشبینی بهتری را به دست آورند (فقط PCA باعث بهبود دومی میشود)،
-
کیفیت SVM و پیشبینیهای تصادفی جنگل به دلیل کاهش ابعاد بهبود نمییابد،
-
کاهش ابعاد توسط PCA موثرتر از انتخاب ویژگی است (این مورد بهبود کمتری را برای رگرسیون لجستیک و بدون بهبود برای درختان تصمیمگیری میکند).
-
25 ویژگی برتر معمولاً برای دستیابی به بهترین سطح ممکن از کیفیت پیشبینی کافی هستند،
-
پنج جزء اصلی اول معمولاً برای دستیابی به بهترین سطح ممکن از کیفیت پیشبینی کافی هستند.
3.4. انتقال مدل
در آزمایشهای انتقال مدل، تمام جفتهای مناطق مختلف شهری در نظر گرفته شد. برای هر جفت، مجموعه داده برای یک منطقه شهری برای ایجاد مدلهای پیشبینی برای همه انواع جرم استفاده شد. سپس مدلهای بهدستآمده برای ایجاد پیشبینی خطر جرم برای سایر مناطق شهری اعمال شد. کیفیت این پیش بینی ها مانند قبل با استفاده از ناحیه زیر منحنی ROC مورد ارزیابی قرار گرفت. توجه داشته باشید که برخلاف دو مطالعه قبلی، 10 × 1010×10روش اعتبار سنجی متقاطع برابر استفاده نشد. این به این دلیل است که مجموعه داده ها برای ایجاد مدل و ارزیابی مدل به طور طبیعی از هم جدا هستند، زیرا از دو منطقه شهری متفاوت می آیند.
از آنجایی که ویژگیهای ورودی مورد استفاده توسط مدلهای پیشبینی، تعداد POI در سلولهای شبکه با وضوح یکنواخت ثابت هستند، در واقع چگالیها را نشان میدهند و بنابراین برای فعال کردن انتقال مدل نیازی به نرمالسازی بر اساس ناحیه ندارند. سایر اشکال عادی سازی – به عنوان مثال، بر اساس جمعیت یا تعداد کلی اشیاء POI در یک منطقه شهری معین – ممکن است برای جبران تفاوت بین مناطق شهری با توسعه متراکم و کم توسعه یافته مفید باشد، اما بررسی تأثیر چنین تکنیک هایی بر مدل عملکرد انتقال برای کارهای آینده به تعویق افتاده است.
مقادیر AUC به دست آمده در مطالعه انتقال مدل در جدول 6 ارائه شده است. بخش جداگانه ای از این جدول مربوط به هر نوع جرم است و شامل ردیف ها و ستون های مربوط به چهار منطقه شهری است. ردیف ها مربوط به مناطق شهری مورد استفاده برای ایجاد مدل (آموزش) و ستون ها مربوط به مناطق شهری مورد استفاده برای کاربرد مدل (پیش بینی) است. با این حال، مقادیر مورب با آموزش و ارزیابی روی یک مجموعه داده به دست نمیآیند. اینها AUC متقاطع به دست آمده در مطالعه کیفیت پیش بینی هستند ( شکل 6 ، شکل 7 ، شکل 8 و شکل 9). این امکان مقایسه کیفیت پیشبینی مدلهای منتقلشده به یک منطقه شهری متفاوت و مدلهای مورد استفاده در همان منطقه شهری که در آن آموزش دیدهاند (اگرچه بر اساس دادههای دیده نشده قبلی) امکانپذیر است.
مشاهدات را می توان به صورت زیر خلاصه کرد:
-
انتقال مدل به طور کلی می تواند موفقیت آمیز در نظر گرفته شود، با تفاوت مقادیر AUC بین مدل های “خارجی” و “بومی” بیش از این نیست. 0.050.05– 0.10.1در بیشتر موارد،
-
مدل های آموزش دیده بر روی داده های منچستر و لیورپول عملکرد انتقال بهتری نسبت به مدل های آموزش دیده بر روی داده های بورنموث و ویکفیلد دارند،
-
وقتی برای پیشبینی در بورنموث و ویکفیلد اعمال میشود، مدلهای «خارجی» به خوبی مدلهای «بومی» هستند.
4. بحث
این مقاله به طور تجربی کاربرد داده های نقطه مورد علاقه را برای پیش بینی خطر جرم بررسی می کند. این مطالعه با استفاده از سوابق جرم پلیس برای لایههای POI OpenStreetMap منتخب مناطق شهری بریتانیا انجام شد. یک روش جمعبندی شبکهای ساده برای ترکیب رویدادهای جرم دارای برچسب جغرافیایی با مکانهای نقطهنظر استفاده شد. نتایج نشان میدهد که ویژگیهای POI برای پیشبینی جرم بسیار مفید هستند و تشخیص دقیق بین مناطق پرخطر و کم خطر را ممکن میسازند. مدلهای با کیفیت بالا برای پیشبینی کانون جرم بر اساس ویژگیهای POI ممکن است به اجزای اساسی سیستمهای پلیس پیشبینی تبدیل شوند و به سازمانهای مجری قانون اجازه میدهند تا با استفاده از منابع محدود به طور مؤثرتری از جرم جلوگیری کنند [ 9 ].
شایان ذکر است که پیشبینی خطر جرم با استفاده از شمارش POI هر دسته به عنوان تنها نوع توصیف منطقه، بدون هیچ شناسه یا مختصات منطقه انجام میشود. مدلهای ایجاد شده روابط بین خطر جرم و تراکم POI مشاهده شده در دادههای تاریخی را ثبت میکنند و از آنها برای پیشبینی خطر جرم در آینده استفاده میکنند، بدون اینکه به توپوگرافی شهر خاصی گره بخورند.
الگوهای رابطه بین ریسک جرم و ویژگیهای POI بیاهمیت نیستند، زیرا رگرسیون لجستیک و درختهای تصمیم توسط SVM و مدلهای جنگل تصادفی با حاشیه قابلتوجهی بهتر عمل میکنند. برتری دو الگوریتم اخیر که از نظر آماری معنی دار هستند، با توجه به این واقعیت که آنها به موفق ترین الگوریتم های طبقه بندی تعلق دارند، غیرمنتظره نیست. به طور خاص، هر دو نسبتاً در برابر بیش از حد مقاوم هستند، که به نظر می رسد یک مزیت قابل توجه در این برنامه است، با نزدیک به صد ویژگی POI و بیش از چند هزار سلول شبکه برای یادگیری. این همچنین با این مشاهدات مطابقت دارد که عملکرد آنها پس از اعمال کاهش ابعاد بهبود نیافته است.
کیفیت طبقه بندی به دست آمده توسط هر دو درخت تصمیم و رگرسیون لجستیک به دلیل کاهش ابعاد توسط PCA بهبود یافته است. مؤثرتر از انتخاب ویژگی بود: هیچ زیرمجموعه کوچکی از دستههای POI برای پیشبینی جرم با کیفیت بالا کافی نبود، اما فرافکنی در فضایی از تنها چند مؤلفه اصلی امکان دستیابی به عملکرد پیشبینیکننده تقریباً مشابه مجموعه کامل ویژگیها را فراهم کرد. این تأیید می کند که روابط بین خطر جرم و ویژگی های POI نمی تواند به اندازه کافی توسط فرمول ها یا شرایط ویژگی-ارزش بر اساس تعداد کمی از رایج ترین یا مشخص ترین دسته های POI بدست آید.
کار بیشتری برای تأیید سودمندی ویژگیهای POI برای پیشبینی جرم برای شهرهای مختلف مورد نیاز است. همچنین بررسی تأثیر وضوح شبکه بر کیفیت پیشبینی و کاربرد روشهای تصفیهشدهتر تجمع فضایی و شناسایی نقطههای مهم، از جمله شبکههای با وضوح متغیر و تخمین چگالی هسته، جالب خواهد بود. با مقایسه سوابق جرم و پیشبینیهای بهدستآمده با استفاده از دادههای POI برچسبگذاریشده با زمان (مثلاً از عصارههای نقشه جمعآوریشده در یک دوره چند ماهه یا چند ساله)، ممکن است بتوان مشاهده کرد که چگونه توسعه ناحیه شهری جدید با تغییر تعداد POI مربوط به ظهور جدید منعکس میشود. مناطق خطر آزمایشات انتقال مدل گسترده تر، غنی شده توسط تجزیه و تحلیل تفاوت های منطقه شهری با توجه به ویژگی های جمعیت و سطح توسعه و تکنیک های عادی سازی جبران کننده این تفاوت ها، می تواند به شناسایی شرایطی کمک کند که تحت آن انتقال مدل موفق امکان پذیر است. همچنین ممکن است جالب و مفید باشد که روابط شناسایی شده بین دسته های خاص POI و انواع جرم توسط کارشناسان جرم شناسی بررسی شود.
نتایج امیدوارکننده بهدستآمده با مدلهای طبقهبندی، تشویقی برای در نظر گرفتن انواع دیگر مدلسازی با استفاده از سوابق جرم و ویژگیهای POI، مانند رگرسیون برای پیشبینی تعداد جرم یا خوشهبندی برای شناسایی الگوهای شباهت بین مناطق خرد با توجه به POI و وقوع جرم است. همچنین بررسی سودمندی سایر منابع داده ای که می توان از آنها ویژگی های توصیف کننده مناطق شهر استخراج کرد، مانند داده های رسانه های اجتماعی دارای برچسب جغرافیایی و داده های شبکه تلفن همراه، ارزشمند است.
در حالی که این تحقیق فقط رابطه خطر جرم و جنایت را با ویژگیهای منطقه در نظر میگیرد، یک گسترش طبیعی میتواند علاوه بر در نظر گرفتن ویژگیهای توصیف کننده زمان باشد. اینها می توانند به طور خاص شامل ساعت، روز هفته، ماه سال، و شاخص تعطیلات و همچنین ویژگی هایی باشند که شرایط آب و هوایی واقعی یا پیش بینی شده را توصیف می کنند. این جهت کار را می توان با اتخاذ برخی روش های شناسایی نقطه کانونی مکانی-زمانی [ 14 ، 36 ] و روش های ارزیابی پیش بینی مکانی- زمانی مناسب [ 66 ] گسترش داد.
منابع
- Goodchild، MF سیستم های اطلاعات جغرافیایی و علم: امروز و فردا. ان GIS 2009 ، 15 ، 3-9. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لانگلی، پی. Goodchild، MF; مگوایر، دی جی; Rhind، DW سیستم های اطلاعات جغرافیایی و علوم ، ویرایش 4. Wiley: نیویورک، نیویورک، ایالات متحده آمریکا، 2015. [ Google Scholar ]
- فیض، س. محمودی ، ک . IGI Global: Hershey، PA، ایالات متحده آمریکا، 2017. [ Google Scholar ]
- اسمیت، TR هوش مصنوعی و کاربرد آن در حل مسائل جغرافیایی. پروفسور Geogr. 1984 ، 36 ، 147-158. [ Google Scholar ] [ CrossRef ]
- لئونگ، ی. Leung، KS یک پوسته سیستم خبره هوشمند برای سیستم های اطلاعات جغرافیایی مبتنی بر دانش: 1. ابزارها. بین المللی جی. جئوگر. Inf. سیستم 1993 ، 7 ، 189-199. [ Google Scholar ] [ CrossRef ]
- لئونگ، ی. Leung, KS یک پوسته سیستم خبره هوشمند برای سیستم های اطلاعات جغرافیایی مبتنی بر دانش: 2. برخی کاربردها. بین المللی جی. جئوگر. Inf. سیستم 1993 ، 7 ، 201-213. [ Google Scholar ] [ CrossRef ]
- هاگناور، جی. Helbich، M. استخراج الگوهای کاربری زمین شهری از اطلاعات جغرافیایی داوطلبانه با استفاده از الگوریتمهای ژنتیک و شبکههای عصبی مصنوعی. بین المللی جی. جئوگر. Inf. علمی 2012 ، 26 ، 963-982. [ Google Scholar ] [ CrossRef ]
- یانوویچ، ک. گائو، اس. مک کنزی، جی. هو، ی. Bhaduri، B. GeoAI: تکنیکهای هوش مصنوعی صریح فضایی برای کشف دانش جغرافیایی و فراتر از آن. بین المللی جی. جئوگر. Inf. علمی 2019 . [ Google Scholar ] [ CrossRef ]
- پری، WL; مک اینیس، بی. قیمت، سی سی; اسمیت، اس. هالیوود، JS نقش پیشبینی جرم در عملیات اجرای قانون ؛ گزارش فنی RR-233-NJ; RAND Corporation: سانتا مونیکا، کالیفرنیا، ایالات متحده آمریکا، 2013. [ Google Scholar ]
- چن، اچ. چانگ، دبلیو. خو، جی جی. وانگ، جی. Qin، Y. Chau, M. Crime Data Mining: A Framework General and Some Examps. کامپیوتر 2004 ، 37 ، 50-56. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- برناسکو، دبلیو. Nieuwbeerta, P. چگونه سارقان مسکونی مناطق هدف را انتخاب می کنند؟ رویکردی جدید برای تحلیل انتخاب مکان مجرمانه.برادر J. Criminol. 2005 ، 45 ، 296-315. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Bowers، KJ; جانسون، SD; Pease, K. Hot-Spoting: آینده نقشه برداری جنایت؟ برادر J. Criminol. 2004 ، 44 ، 641-658. [ Google Scholar ] [ CrossRef ]
- کوتاه، مگابایت؛ D’Orsogna، MR; برانتینگهام، پی جی. Tita، GE Measuring and Modeling Repeat and Near-Repeat Burglarry Effects. جی. کوانت. Criminol. 2009 ، 25 ، 325-339. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مولر، برو؛ کوتاه، مگابایت؛ برانتینگهام، پی جی. شوئنبرگ، FP; تیتا، مدلسازی جرم و جنایت در فرآیند نقطه هیجان انگیز جنرال الکتریک. مربا. آمار دانشیار 2011 ، 106 ، 100-108. [ Google Scholar ] [ CrossRef ]
- مالسون، ن. هپنستال، ا. ببینید، L. Evans, A. استفاده از یک شبیهسازی جنایت مبتنی بر عامل برای پیشبینی اثرات بازآفرینی شهری بر خطر سرقت خانگی فردی. محیط زیست طرح. طرح. دس 2013 ، 40 ، 405-426. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تراونمولر، ام. کواترون، جی. کاپرا، ال. دادههای تلفن همراه ماینینگ برای بررسی نظریههای جرم شهری در مقیاس. در مجموعه مقالات ششمین کنفرانس بین المللی انفورماتیک اجتماعی، بارسلون، اسپانیا، 10 تا 13 نوامبر 2014. [ Google Scholar ]
- مالسون، ن. اندرسن، MA در حال بررسی تأثیر اقدامات جمعیتی محیطی بر کانونهای جرم و جنایت لندن. جی. جنایت. عدالت 2016 ، 46 ، 52-63. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بوگومولوف، آ. لپری، بی. استایانو، جی. الیور، ن. پیانسی، اف. Pentland، A. Once Upon a Crime: Towards Crime Prediction from Demographics and Mobile Data. در مجموعه مقالات شانزدهمین کنفرانس بین المللی تعامل چندوجهی، استانبول، ترکیه، 12-16 نوامبر 2014. [ Google Scholar ]
- بوگومولوف، آ. لپری، بی. استایانو، جی. لتوزه، ای. الیور، ن. پیانسی، اف. Pentland, A. Moves on the Street: Classifying Crime Hotspots با استفاده از دادههای ناشناس انبوه در پویایی افراد. کلان داده 2015 ، 3 ، 148-158. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Lin، YL; ین، MF; Yu, LC پیشبینی جرم مبتنی بر شبکه با استفاده از ویژگیهای جغرافیایی. ISPRS Int. J. Geo Inf. 2018 ، 7 ، 298. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- داش، SK; سافرو، آی. Srinivasamurthy، RS پیشبینی فضایی-زمانی جرایم با استفاده از رویکرد تحلیلی شبکه. arXiv 2018 , arXiv:1808.06241. [ Google Scholar ]
- یی، اف. یو، ز. ژوانگ، اف. ژانگ، ایکس. Xiong, H. یک مدل یکپارچه برای پیش بینی جرم با استفاده از عوامل زمانی و مکانی. در مجموعه مقالات هجدهمین کنفرانس بین المللی IEEE در مورد داده کاوی، سنگاپور، 17 تا 20 نوامبر 2018. [ Google Scholar ]
- باپی، FK; پتری، LM; سوآرس، آ. متوین، اس. تجزیه و تحلیل تأثیر داده های چهار ضلعی و روشنایی خیابان با جمعیت شناسی انسانی بر پیش بینی جنایت در آینده. arXiv 2020 ، arXiv:2006.07516. [ Google Scholar ]
- وانگ، اچ. کیفر، دی. گرایف، سی. لی، زی. استنتاج نرخ جرم با داده های بزرگ. در مجموعه مقالات بیست و دومین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 13 تا 17 اوت 2016. [ Google Scholar ]
- یانگ، دی. هینی، تی. تونن، ا. وانگ، ال. Cudré-Mauroux، P. Crime Telescope: Crime Hotspot Prediction بر اساس ادغام داده های شهری و رسانه های اجتماعی. شبکه جهانی وب 2017 ، 21 ، 1323-1347. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Ramm, F. OpenStreetMap داده ها در قالب لایه ای GIS. در دسترس آنلاین: https://www.geofabrik.de/data/geofabrik-osm-gis-standard-0.6.pdf (در تاریخ 22 مه 2018 قابل دسترسی است).
- بیوند، ر. کیت، تی. Rowlingson, B. rgdal: Bindings for the ‘Geospatial’ Data Abstraction Library. بسته R نسخه 1.3-4. 2018. در دسترس آنلاین: https://cran.r-project.org/web/packages/rgdal/index.html (در 26 ژوئن 2020 قابل دسترسی است).
- Pebesma، EJ; بیوند، کلاسها و روشهای RS برای دادههای فضایی در R: بسته sp. R News 2005 ، 5 ، 9-13. [ Google Scholar ]
- اک، ج. چینی، اس. کامرون، جی جی. لایتنر ویلسون، RE Mapping Crime: Understanding Hot Spots ; گزارش ویژه موسسه ملی دادگستری; ویژه موسسه ملی دادگستری: راکویل، MD، ایالات متحده آمریکا، 2005.
- راسر، تی. Bowers، KJ; جانسون، SD; چنگ، تی. نقشه برداری جنایت پیش بینی کننده: شبکه های خودسرانه یا شبکه های خیابانی؟ جی. کوانت. Criminol. 2017 ، 33 ، 569-594. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- عصا، نماینده مجلس؛ جونز، MC صاف کردن هسته ; چپمن و هال: لندن، بریتانیا، 1995. [ Google Scholar ]
- هیرشفیلد، ا. Bowers, K. (Eds.) Mapping and Analysing Crime Data: Lessons from Research and Practice ; CRC Press: لندن، انگلستان، 2001. [ Google Scholar ]
- Chainey، SP; Ratcliffe، JH GIS و Crime Mapping ; جان وایلی و پسران: چیچستر، بریتانیا، 2005. [ Google Scholar ]
- چینی، اس. تامپسون، ال. Uhlig, S. Utility of Hotspot Mapping برای پیش بینی الگوهای فضایی جرم. امن J. 2008 , 21 , 4-28. [ Google Scholar ] [ CrossRef ]
- گربر، ام اس پیش بینی جرم با استفاده از توئیتر و تخمین تراکم هسته. تصمیم می گیرد. سیستم پشتیبانی 2014 ، 61 ، 115-125. [ Google Scholar ] [ CrossRef ]
- شیود، اس. Shiode، N. مبتنی بر شبکه مبتنی بر فضا-زمان جستجوی-پنجره تکنیک برای تشخیص نقطه کانونی حوادث جرم در سطح خیابان.بین المللی جی. جئوگر. Inf. علمی 2013 ، 27 ، 866-882. [ Google Scholar ] [ CrossRef ]
- Cichosz, P. الگوریتم های داده کاوی: توضیح داده شده با استفاده از R ; Wiley: Chichester، UK، 2015. [ Google Scholar ]
- مدل های رگرسیون لجستیک هیلب، JM ; چپمن و هال: لندن، انگلستان، 2009. [ Google Scholar ]
- کورتس، سی. Vapnik، شبکه های پشتیبان VN-Vector. ماخ فرا گرفتن. 1995 ، 20 ، 273-297. [ Google Scholar ] [ CrossRef ]
- Platt, JC Fast Training Machines Vector Support with Sequential Minimal Optimization. در پیشرفت در روشهای هسته: آموزش بردار پشتیبانی ؛ Schölkopf, B., Burges, CJC, Smola, AJ, Eds. انتشارات MIT: کمبریج، MA، ایالات متحده آمریکا، 1998. [ Google Scholar ]
- همل، کشف دانش LH با ماشینهای بردار پشتیبانی ؛ وایلی: نیویورک، نیویورک، ایالات متحده آمریکا، 2009. [ Google Scholar ]
- کریستیانینی، ن. Shawe-Taylor, J. مقدمهای بر پشتیبانی از ماشینهای برداری و سایر روشهای یادگیری مبتنی بر هسته . انتشارات دانشگاه کمبریج: کمبریج، انگلستان، 2000. [ Google Scholar ]
- شولکوپف، بی. Smola، AJ یادگیری با هسته ; مطبوعات MIT: کمبریج، MA، ایالات متحده آمریکا، 2001. [ Google Scholar ]
- خروجی های احتمالی پلات، JC برای ماشین های بردار پشتیبان و مقایسه با روش های درستنمایی منظم. در پیشرفت در طبقه بندی کننده های حاشیه بزرگ ; اسمولا، ای جی، بارلت، پی.، شولکوپف، بی.، شورمنز، دی.، ویرایش. مطبوعات MIT: کمبریج، MA، ایالات متحده آمریکا، 2000. [ Google Scholar ]
- بریمن، ال. فریدمن، جی اچ. اولشن، RA; سنگ، CJ طبقه بندی و رگرسیون درختان ; چپمن و هال: لندن، بریتانیا، 1984. [ Google Scholar ]
- Quinlan، JR القای درختان تصمیم. ماخ فرا گرفتن. 1986 ، 1 ، 81-106. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دیتریش، روشهای گروه TG در یادگیری ماشینی. در مجموعه مقالات اولین کارگاه بین المللی در مورد سیستم های طبقه بندی کننده چندگانه، کالیاری، ایتالیا، 21 تا 23 ژوئن 2000. [ Google Scholar ]
- بریمن، ال. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بریمن، ال. پیش بینی کننده های بگینگ. ماخ فرا گرفتن. 1996 ، 24 ، 123-140. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- میچل، تی. یادگیری ماشینی ; McGraw-Hill: نیویورک، نیویورک، ایالات متحده آمریکا، 1997. [ Google Scholar ]
- لیو، اچ. Motoda, H. انتخاب ویژگی برای کشف دانش و داده کاوی . Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 1998. [ Google Scholar ]
- کهوی، ر. جان، GH Wrappers برای انتخاب زیر مجموعه ویژگی. آرتیف. هوشمند 1997 ، 97 ، 273-324. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- استروبل، سی. Boulesteix، AL; زیلیس، ع. Hothorn، T. Bias in Random Forest Variable Importance Measures: Illustrations, Sources and a Solution. BMC Bioinform. 2007 ، 8 ، 25. [ Google Scholar ] [ CrossRef ] نسخه سبز ] ]
- Kursa، MB انتخاب ویژگی با بسته Boruta. J. Stat. نرم افزار 2010 ، 36 ، 1-13. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Jolliffe ، IT Pricipal Component Analysis ; Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2002. [ Google Scholar ]
- عبدی، ح. ویلیامز، LJ تجزیه و تحلیل مؤلفه اصلی. WIREs Comput. آمار 2010 ، 2 ، 433-459. [ Google Scholar ] [ CrossRef ]
- Trefethen، LN; باو، دی.، III. جبر خطی عددی ; SIAM: Philadelphia, PA, USA, 1997. [ Google Scholar ]
- ایگان، نظریه تشخیص سیگنال JP و تجزیه و تحلیل ROC و تجزیه و تحلیل ROC . انتشارات آکادمیک: نیویورک، نیویورک، ایالات متحده آمریکا، 1975. [ Google Scholar ]
- Fawcett, T. مقدمه ای بر تجزیه و تحلیل ROC. تشخیص الگو Lett. 2006 ، 27 ، 861-874. [ Google Scholar ] [ CrossRef ]
- آرلوت، اس. سلیس، الف. بررسی رویههای اعتبارسنجی متقابل برای انتخاب مدل. آمار Surv. 2010 ، 4 ، 40-79. [ Google Scholar ] [ CrossRef ]
- تیم اصلی توسعه R. R: زبان و محیطی برای محاسبات آماری . بنیاد R برای محاسبات آماری: وین، اتریش، 2018. [ Google Scholar ]
- مایر، دی. دیمیتریادو، ای. هورنیک، ک. وینگسل، آ. Leisch, F. e1071: توابع متفرقه وزارت آمار ; بسته R نسخه 1.7-0; گروه نظریه احتمال (قبلاً: E1071)، TU Wien: وین، اتریش، 2018. [ Google Scholar ]
- ترنو، تی. اتکینسون، بی. Ripley, B. rpart: Recursive Partitioning and Regression Trees. بسته R نسخه 2017 ، 4 ، 1-9. [ Google Scholar ]
- لیاو، ا. وینر، ام. طبقه بندی و رگرسیون توسط جنگل تصادفی.R News 2002 , 2 , 18-22. [ Google Scholar ]
- دلانگ، ای آر. DeLong، DM; Clarke-Pearson، DL مقایسه نواحی زیر دو یا چند منحنی مشخصه عملکرد گیرنده همبسته: یک رویکرد ناپارامتریک. بیومتریک 1988 ، 44 ، 837-845. [ Google Scholar ] [ CrossRef ]
- ادپژو، م. راسر، جی. چنگ، تی. معیارهای ارزیابی رمان برای پیشبینیهای نقطه کانونی فرآیند پراکنده مکانی-زمانی – مطالعه موردی جرم.بین المللی جی. جئوگر. Inf. علمی 2016 ، 30 ، 2133-2154. [ Google Scholar ] [ CrossRef ]
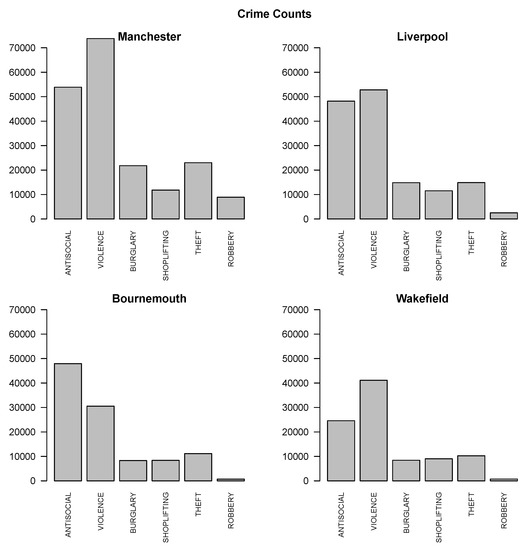
شکل 1. شمارش جرم برای هر نوع جرم در هر منطقه شهری.
شکل 2. محل وقوع جرم در هر منطقه شهری.
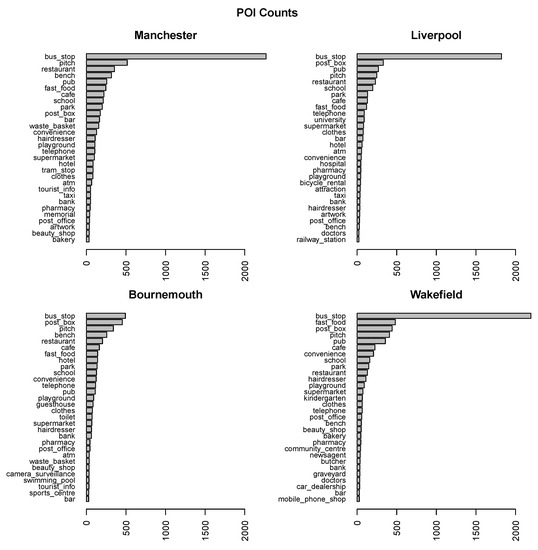
شکل 3. POI متداول ترین 30 دسته در هر منطقه شهری را شامل می شود.
شکل 4. مکان های نقطه مورد علاقه (POI) در هر منطقه شهری.

شکل 5 300 ×300300×300شبکه متر برای تجمع جغرافیایی.
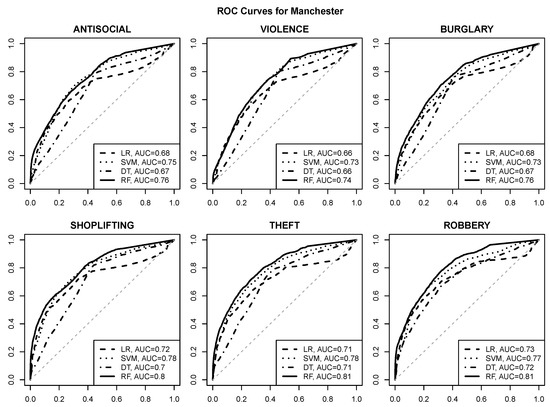
شکل 6. منحنی های ROC برای پیش بینی خطر جرم در منچستر.
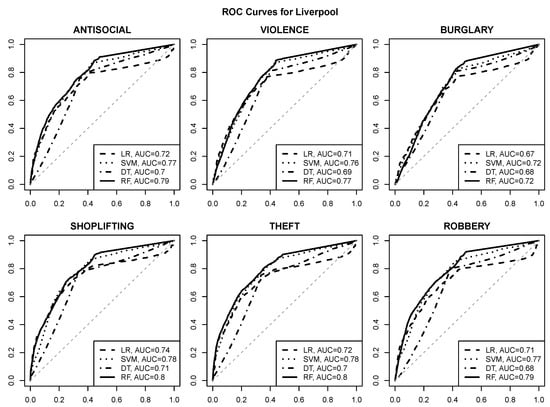
شکل 7. منحنی های ROC برای پیش بینی خطر جرم در لیورپول.
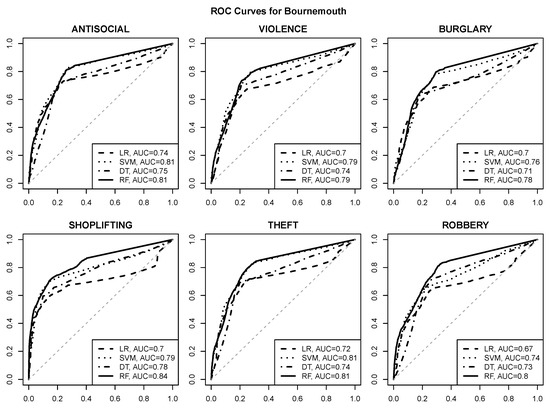
شکل 8. منحنی های ROC برای پیش بینی خطر جرم در بورنموث.
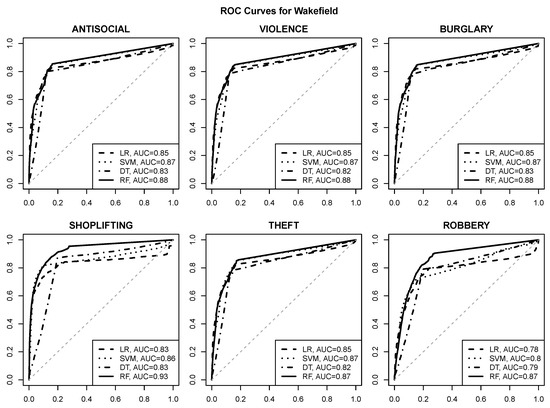
شکل 9. منحنی های ROC برای پیش بینی خطر جرم در Wakefield.
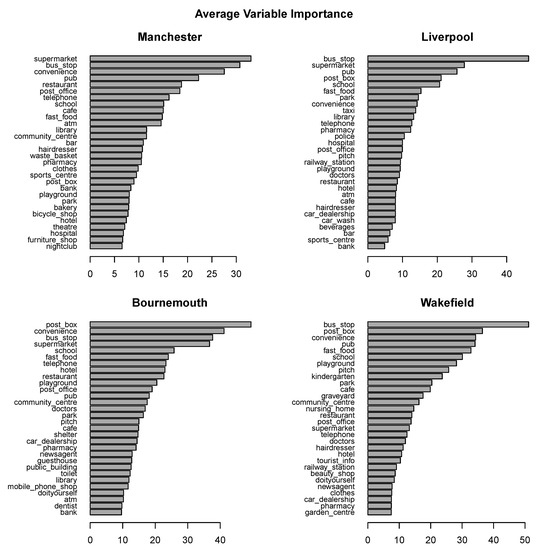
شکل 10. نمودارهای میانگین اهمیت متغیر برای پیش بینی خطر جرم.


بدون دیدگاه