

خلاصه
:
فراداده مکانی بخش مهمی از هر زیرساخت داده مکانی است که سازماندهی، اشتراک گذاری، کشف و استفاده از داده های مکانی را امکان پذیر می کند. این مقاله یک شکاف دانش در قابلیت استفاده از سیستم های ابرداده برای کاربران نهایی را برجسته می کند. سپس این شکاف را با استفاده از رویکرد طراحی کاربر محور برای بررسی قابلیت استفاده رکوردهای ابرداده برطرف می کند. این تحقیق با کاربران نهایی در مورد کارایی و اثربخشی سیستم های ابرداده و رضایت و انتظارات کاربران نهایی درگیر است. نتایج حاکی از شکاف های قابل توجه با اثربخشی و کارایی سیستم های ابرداده برای کشف و انتخاب داده های مکانی است. ناهماهنگی و اطلاعات نامربوط در رکوردهای فراداده در عنوان، کلمات کلیدی، چکیده ها، کیفیت داده ها و سایر عناصر فراداده یافت شد. علاوه بر این، بهبودهای اساسی برای رابط های کاربری شناسایی شد. ارائه دلسرد کننده ابرداده یک مشکل برجسته است که در رابط سیستم های ابرداده یافت می شود.
کلید واژه ها:
زیرساخت داده های مکانی ; فراداده مکانی ; ژئوپورتال ; طراحی کاربر محور ؛ قابلیت استفاده ؛ استرالیا
1. معرفی
ابرداده های مکانی نقش مهمی در ترویج اشتراک گذاری داده های مکانی و استفاده مجدد و حمایت از طرح های توسعه محلی و جهانی ایفا می کند که به داده های مکانی برای مدیریت، نظارت و اندازه گیری توسعه نیاز دارد. این شامل اطلاعاتی درباره توصیفات داده های جغرافیایی یا مکانی است، به عنوان مثال، محتوا، ساختار، کیفیت و سیستم مرجع که به کاربران داده های مکانی کمک می کند تا از طریق سیستم های فهرست داده های مکانی شبکه ای، به عنوان مثال، داده های مکانی، مناسب بودن داده ها را برای اهداف خود کشف و تعیین کنند. زیرساخت (SDI) و ژئوپورتال.
با این حال، قابلیت استفاده از ابرداده های مکانی برای کاربران داده مورد تردید قرار می گیرد، زیرا ابرداده بر اساس استانداردهایی ایجاد می شود که در ابتدا برای تولیدکنندگان داده های مکانی برای اهداف موجودی داده ها طراحی شده بود. علاوه بر این، با کاربردهای بی حد و حصر ممکن فراداده، حداقل باید بدانیم که ابرداده برای کاربران داده های مکانی برای کشف و انتخاب داده های مکانی مناسب چقدر قابل استفاده است. با افزایش روزافزون کاربران داده های مکانی خارج از حوزه فضایی با دانش خاص، الزامات و انتظارات کاربران داده های مکانی باید در نظر گرفته شود.
قابلیت استفاده از ابرداده فضایی ترکیبی از قابلیت استفاده سوابق ابرداده و قابلیت استفاده رابط کاربری است. وضعیت تحقیق در فراداده های مکانی به چند حوزه وسیع محدود می شود. برخی از تحقیقات به ایجاد رکوردهای فراداده کامل و سازگار اختصاص داده شده است [ 1 ، 2 ، 3 ، 4 ، 5 ، 6 ، 7 ، 8 ، 9]. این مقالات نشان میدهند که بیشتر چالشها برای ایجاد و بهروزرسانی خودکار فراداده به نوع اطلاعات موجود در ویژگیهای دادههای مکانی مربوط میشود. فقط تعداد کمی از اطلاعات در مورد داده های مکانی را می توان به طور خودکار استخراج و در ابرداده ذخیره کرد، به عنوان مثال، سیستم مرجع، پیش بینی، تاریخ آخرین به روز رسانی، و بیانیه اصل و نسب. تمام اطلاعات دیگر (به عنوان مثال، چکیده ها و توضیحات کیفیت داده ها) هنوز به ورودی دستی توسط انسان متکی هستند. همچنین تلاش هایی برای تأکید بر مشارکت کاربران در ایجاد ابرداده وجود دارد. همچنین تعداد زیادی از مطالعات وجود دارد که کشف داده های مکانی را با استفاده از معناشناسی و هستی شناسی بهبود می بخشد [ 10 ، 11 ، 12 ، 13 ، 14 ، 15 ،16 ، 17 ، 18 ، 19 ، 20 ، 21 ، 22 ]. مقالات نشان میدهد که تلاشهایی برای مشارکت دادن کاربران در ایجاد ابردادهها، چه مستقیم و چه غیرمستقیم، صورت گرفته است. برای مثال، مشارکت مستقیم با درگیر کردن مستقیم کاربران برای ارائه اطلاعات برای ایجاد ابرداده انجام شده است. از سوی دیگر، مشارکت غیرمستقیم یا ضمنی کاربر با جمعآوری و تجزیه و تحلیل کلمات جستجوی کاربران و تخصیص نتایج به عنوان برچسب برای دادههای مکانی انجام میشود.
برای پرداختن به شکافهای دانش فعلی در قابلیت استفاده فراداده مکانی، این مقاله نتایج آزمایشی را برای بررسی قابلیت استفاده فراداده مکانی با استفاده از دو روش طراحی کاربر محور، یعنی تست قابلیت استفاده پروتکل Think-Aloud (TAP) و مصاحبههای نیمه ساختاریافته گزارش میکند. TAP بیان شفاهی افکار شرکت کنندگان را در طول فرآیند تکمیل کار و یادداشت های محقق در حین مشاهده فرآیند ثبت می کند. مصاحبههای نیمه ساختاریافته برای آشکار کردن اطلاعات دقیق از تجربیات شرکتکنندگان با تشویق آنها به یادآوری رویدادهای خاص در طول انجام کار استفاده میشود. هر دو داده های گرفته شده توسط TAP و مصاحبه های نیمه ساختاریافته سپس برای تعیین قابلیت استفاده ابرداده های مکانی، شناسایی مشکلات قابلیت استفاده، تجزیه و تحلیل و استخراج می شوند.
بخش 2 با توضیح روش تجزیه و تحلیل داده ها و سپس طراحی آزمایش، استدلال برای مواد و انتخاب شرکت کنندگان آغاز می شود. بخش 3 مقاله خلاصه ای از نتایج را ارائه می دهد. بخش 4 و بخش 5 نتایج کشف داده و وظیفه انتخاب داده توسط شرکت کنندگان را تجزیه و تحلیل می کند. بخش 6 بینش هایی را از نظرات شرکت کنندگان در طول آزمایش جمع آوری می کند. بخش 7 بحثی را در مورد یافته های مقاله ارائه می دهد و بخش 8 تحقیق را به پایان می رساند.
2. روش
2.1. روش های تجزیه و تحلیل داده ها
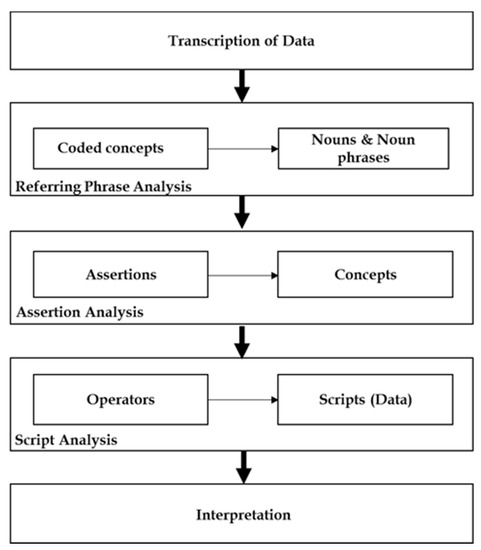
روش مورد استفاده در فرآیند تحلیل از تجزیه و تحلیل پروتکل (PA) و تحلیل محتوا اقتباس شده است. PA قادر به تولید تجزیه و تحلیل عمیق و دقیق از داده های TAP است، زیرا این روش ها ماهیت کیفی دارند و برای به دست آوردن داده های غنی و عمیق از مقادیر کمی از نمونه ها طراحی شده اند [ 10 ، 11 ، 12 ]. همانطور که در شکل 1 نشان داده شده است PA از چندین مرحله پیشرونده تشکیل شده است .
فرآیند تحلیل با رونویسی داده ها (ToD) آغاز می شود، جایی که ضبط ها و یادداشت های محقق در طول آزمایش به رونوشت های متنی تبدیل می شوند. مرحله بعدی، تحلیل عبارت ارجاع (RPA) است. این کار با برجسته کردن تمام اسم ها و عبارات اسمی شناسایی شده در داده های کلامی هر شرکت کننده و پیوست کردن کدهایی به آن عبارات مطابق با ارجاعات کد در فعالیت های جستجوی داده های مکانی انجام می شود. بر اساس نتایج کدگذاری موقت RPA، محقق سپس هر کد را بر اساس هر اقدام مرتبط در طول کشف و انتخاب دادههای مکانی گروهبندی میکند. مرحله بعدی تحلیل ادعاها است که در آن محقق مجموعه ای از ادعاهای مطرح شده توسط آزمودنی ها را شناسایی می کند تا تعیین کند که چگونه روابط بین مفاهیم در طول حل مسئله شکل می گیرد. به عنوان بخشی از تجزیه و تحلیل، اهداف اظهارات آزمودنی ها مشخص می شود. آخرین مرحله تجزیه و تحلیل اسکریپت برای شناسایی و ارائه یک توصیف کلی از فرآیند استدلال در طول حل مسئله است و به محقق اجازه می دهد تا مشکلات شناسایی شده توسط آزمودنی ها را در طول فرآیند حل مسئله نشان دهد.
2.2. طراحی آزمایش
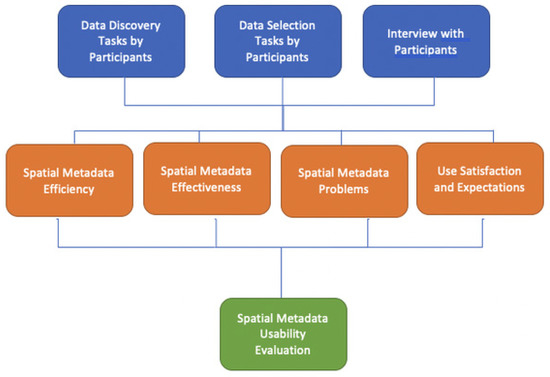
هدف این آزمایش جمع آوری و تجزیه و تحلیل داده ها برای پاسخ به سؤالات تحقیق بر اساس روش ارزیابی قابلیت استفاده انتخابی است که در شکل 2 نشان داده شده است. این آزمایش بر اساس چارچوب ارزیابی قابلیت استفاده، TAP طراحی شده است. روش جمعآوری دادههای TAP از مصاحبههای نیمه ساختاریافته و پرسشنامههای پس از آن استفاده میکند و قابلیت استفاده ابردادههای مکانی با استفاده از سه معیار: سودمندی، اثربخشی و رضایت کاربر (بلوکهای میانی در شکل 2 ) ارزیابی میشود. این طراحی بر اساس یک فعالیت وظیفهمحور بود که در آن به شرکتکنندگان مجموعهای از وظایف مربوط به ابردادههای مکانی، به دنبال سناریویی برای دستیابی به اهداف مشخص (بلوکهای برتر در شکل 2) داده شد.). در طول انجام تکالیف، از آنها خواسته شد که به طور فعال و مستمر افکار و نظرات خود را به صورت شفاهی بیان کنند و همچنین به سؤالات داده شده توسط محقق پاسخ دهند (بلوک های برتر در شکل 2 ). در پایان آزمایش، شرکتکنندگان در مصاحبههای نیمهساختیافته به چند سؤال پاسخ دادند تا اطلاعات دقیقتر و عمیقتری در رابطه با وظایف داده شده و بر اساس تجربیات خود در طول TAP در اختیار محقق قرار دهند (بلوکهای برتر در شکل 2 ).
2.3. شركت كنندگان
برای این مطالعه، پنج کاربر دادههای مکانی با پیشینههای آموزشی مختلف انتخاب شدند. مهندسی عمران، علوم فضایی و علوم کامپیوتر. آنها روی مدیریت بلایا کار می کردند. این عدد برای روش تست قابلیت استفاده با استفاده از پروتکل TA بهینه است، زیرا قادر است بیشترین مشکلات قابلیت استفاده را با نسبت سود به هزینه بهینه شناسایی کند [ 12 ]. علاوه بر آن، این مطالعه ماهیت کیفی و اکتشافی دارد و بر استخراج بینش کاربر در مورد ابرداده های مکانی تمرکز دارد. این نوع مطالعه معمولاً به تعداد کمی از شرکتکنندگان با مدت زمان طولانی تعامل شرکتکننده و محقق نیاز دارد، برخلاف مطالعه کمی که بر آمار متمرکز است، از تعداد زیادی شرکتکننده استفاده میکند و تعامل شرکتکننده-محقق کم است [ 10 ].].
2.4. مواد
رکوردهای ابرداده مکانی از دو فهرست یا پورتال داده انتخاب شدند: فهرست راهنمای داده های ویکتوریا (VDD) و فهرست راهنمای داده های فضایی استرالیا (FIND). پورتال ها بر اساس معیارهای زیر انتخاب شدند. ابرداده (1) مطابق با استانداردهای بین المللی ابرداده (ISO 19115) ایجاد شده است. (2) در دسترس عموم و قابل دسترس از طریق اینترنت؛ (3) VDD نشان دهنده پلت فرم داده باز و VDD نشان دهنده کاتالوگ داده های مکانی است. VDD یک پورتال در سطح ایالتی است که مخازن ابرداده های مکانی را با مؤسسات رسمی در ایالت ویکتوریا به اشتراک می گذارد، در حالی که FIND یک پورتال در سطح ملی است که از گره های ابرداده موسسات ملی مانند Geoscience استرالیا و اداره هواشناسی تشکیل شده است.
مطالب دیگر مجموعه ای از سؤالات بود که به عنوان سؤالات راهنما برای مصاحبه های نیمه ساختاریافته و دستورالعمل های کتبی برای شرکت کنندگان شامل سناریوها، وظایف و اهداف طراحی شده بود. یکی دیگر از تکنیک های مهم برای این مطالعه استفاده از ضبط صوتی برای جمع آوری عبارات کلامی و نظرات شرکت کنندگان در طول اتمام آزمون بود.
2.5. سناریو
برای این آزمایش، سناریو تهیه نقشه تخلیه برای ملبورن بزرگ و ساحل شرقی استرالیا (کوئینزلند و نیو ساوت ولز) بود. مجموعه داده های مکانی مورد نیاز برای این فعالیت به شرح زیر است:
-
مجموعه داده ارتفاعی با حداقل مقیاس 1:25000
-
مجموعه داده های هیدروگرافی (مانند رودخانه ها، سدها، برکه ها و غیره) با حداقل مقیاس 1:25000
-
مجموعه داده های هواشناسی از اطلاعات (به عنوان مثال، بارندگی)
-
مجموعه داده های شبکه راه یا شبکه حمل و نقل با حداقل مقیاس 1:10000 برای مناطق شهری و 1:100000 برای مناطق روستایی
-
نقشه های نوع خاک با حداقل مقیاس 1:100000
برای به دست آوردن داده های مناسب، شرکت کنندگان وب سایت های راهنمای داده های ویکتوریا (VDD) و فهرست راهنمای داده های مکانی استرالیا (FIND) را جستجو کردند.
وظایف – بر اساس سناریوی داده شده، سه وظیفه اصلی به شرکت کنندگان اختصاص داده شد:
-
داده های مکانی مورد نیاز را از سیستم های کشف (VDD و FIND) پیدا کنید.
-
تعیین مناسب بودن داده های مکانی برای سناریوی داده شده؛ و
-
تعیین چگونگی به دست آوردن و استفاده مناسب از داده های مکانی.
اولین کار برای بررسی قابلیت استفاده ابرداده ها و همچنین سیستم های کشف در کمک به کاربران برای یافتن و مکان یابی داده های مکانی مورد نیاز طراحی شد. دوم این بود که شرکت کنندگان از اطلاعات سوابق فراداده برای ارزیابی مناسب بودن داده های مکانی برای هدف معین استفاده کنند. سوال سوم کاربرد داده های مکانی برای برنامه داده شده را هدف قرار می دهد. از آنها خواسته شد تا به صورت شفاهی افکار خود را در مورد وظایف و ابرداده های مکانی با جزئیات بیان کنند.
2.6. روش
تست قابلیت استفاده در یک محیط آزمایشگاهی آماده با استفاده از روش های زیر انجام شد:
-
جلسه جهت یابی – هر شرکت کننده قبل از انجام کارهای کشف و انتخاب داده ها در جهت گیری شرکت کرد. در طی جهت گیری، به شرکت کنندگان در مورد هدف مطالعه، محدوده و انتظارات از آزمایش و وظایفی که قرار است انجام شود، توضیح داده شد. دستورات کتبی نیز داده شد. در این جلسه شرکت کنندگان مجاز به طرح سوالات مرتبط با مطالعه و تکالیف بودند و در پایان از شرکت کنندگان خواسته شد تا فرم رضایت نامه را امضا کنند. این جلسه 5 دقیقه به طول انجامید.
-
عملکرد وظیفه – هر شرکت کننده سه وظیفه را همانطور که در بخش وظیفه توضیح داده شده است انجام داده و تکمیل کرد.
-
اولین کار جستجو و مکان یابی فراداده مکانی مورد نیاز برای سناریوی داده شده از دایرکتوری داده های مکانی بود. به شرکتکنندگان 30 دقیقه فرصت داده شد تا دادههای مکانی مورد نیاز را از سیستمهای کشف پیدا کنند. از آنها خواسته شد که پس از اتمام زمان، کار را متوقف کنند. در آن مرحله میزان موفقیت مشاهده شد.
-
وظیفه دوم تصمیم گیری در مورد مناسب بودن یا نبودن داده ها برای پروژه داده شده بود، با بررسی سوابق فراداده مکانی به دست آمده از کار اول یا، اگر شرکت کننده قادر به یافتن سوابق مربوطه نبود، سوابق فراداده از پیش انتخاب شده تهیه شده توسط محقق
-
-
مصاحبه ها – پس از تکمیل تکالیف، از شرکت کنندگان خواسته شد تا پرسشنامه ای را پر کنند و پاسخ های خود را برای محقق توضیح دهند. سوالات برای دریافت نظرات شرکت کنندگان در مورد تجربیات آنها در کار با ابرداده های مکانی در طول فرآیند کشف و انتخاب داده ها طراحی شده است.
در طول آزمایش، شرکت کنندگان توسط نماینده ای از تیم تحقیقاتی همراه بودند. نقش نماینده ارائه دستورالعمل ها و توضیحات در مورد آزمون در جلسه توجیهی، پاسخ به سوالات مطرح شده توسط شرکت کنندگان در حین انجام وظایف و اطمینان از تمرکز شرکت کنندگان بر روی اهداف بود. نماینده همچنین از شرکت کنندگان سؤالات آماده شده را در زمانی که مصاحبه متوقف شد یا برای به دست آوردن بینش های دقیق تر از شرکت کنندگان در مورد فراداده، پرسید.
3. نتایج
دو منبع داده از آزمایش جمعآوری شد: ضبطهای صوتی و مصاحبههای نیمه ساختاریافته بر اساس مجموعهای از سؤالات. به عنوان یک مطالعه اکتشافی، روش های تحلیل مورد استفاده عمدتاً کیفی بودند. برای تجزیه و تحلیل داده های TAP از آنالیز TAP استفاده شد. داده های مصاحبه با استفاده از تحلیل محتوا مورد تجزیه و تحلیل قرار گرفت.
پروتکل Think-Aloud (TAP)
در طی فرآیند کشف و انتخاب داده های مکانی، عبارات کلامی شرکت کنندگان ثبت شد. سپس هر رکورد با استفاده از تجزیه و تحلیل پروتکل به طور جداگانه رونویسی و تجزیه و تحلیل شد. رونویسی ها با شناسایی عبارات ارجاع دهنده (RPA) تجزیه و تحلیل شدند و به هر عبارت کدهایی بر اساس کدهای مرجع فهرست شده در جدول 1 داده شد. نمونههایی از عبارات و کدهای حاصل از این فرآیند، در جدول 2 ارائه شدهاند .
از جدول 2 ، عبارات و مفاهیم مربوطه (کدها) حاصل از عبارات کلامی شرکت کنندگان در طول کشف و انتخاب داده های مکانی را می بینیم. این عبارات و کدها همه واژگان و مفاهیمی را که شرکت کنندگان در طول فرآیند بر روی آنها متمرکز شده اند، مشخص می کند.
سپس عبارات و کدها بیشتر مورد تجزیه و تحلیل قرار گرفتند تا ادعاهای هر عبارت مشخص شود. سپس از این ادعاها برای درک چگونگی شکل گیری روابط در طول کشف و انتخاب داده های مکانی استفاده شد. جدول 3 عبارات و ادعاهای مربوط به آنها را نشان می دهد.
مرحله نهایی فرآیند تجزیه و تحلیل با پیاده سازی تجزیه و تحلیل اسکریپت انجام شد که مجموعه ای از عملگرها را به عبارات اختصاص می دهد تا فرآیند استدلال در هنگام کشف و انتخاب داده های مکانی را شناسایی کنند. از سه عملگر پیشنهاد، مطالعه و نتیجه گیری استفاده شد. این عملگرها نشان دهنده تعاملات در فرآیند استدلال کشف و انتخاب داده های مکانی هستند. جدول 4 توضیحی در مورد عملگرها ارائه می دهد.
از جداول ارائه شده در بالا، میتوانیم فعالیتها، اهداف و انتظارات شرکتکنندگان و همچنین روابط بین آنها و استدلال آنها را در هنگام تلاش برای کشف و انتخاب دادههای مکانی با استفاده از ابرداده از طریق رابطهای کاربری شناسایی کنیم.
سپس نتایج تحلیل اسکریپت به عنوان مبنایی برای شناسایی اثربخشی، کارایی و رضایت کاربر و همچنین شناسایی مشکلات قابلیت استفاده و انتظارات کاربر برای کشف دادههای مکانی و انتخاب دادههای مکانی مورد استفاده قرار گرفت.
4. تجزیه و تحلیل نتایج وظایف کشف داده های مکانی
در كشف دادههاي مكاني، كاربران از رابط كاربر براي تعامل با ابرداده استفاده ميكنند تا براساس سناريو، دادهها را براي هدف معين كشف كنند. سپس با تفسیر نتایج، اثربخشی، کارایی، رضایت کاربر، مشکلات و انتظارات کاربر شناسایی شد.
4.1. اثربخشی
اثربخشی ابرداده مکانی ترکیبی بین سیستمهای کشف یا ابزارهای جستجو و سوابق فراداده است. برای این منظور، اثربخشی با موفقیت شرکت کنندگان در یافتن و کشف داده های فضایی بالقوه برای سناریوی داده شده از دو سیستم کشف سنجیده شد: VDD و FIND. از نتایج تجزیه و تحلیل اسکریپت، میتوانیم نرخ موفقیتآمیز کشف را با نگاه کردن به عملگر نتیجهگیری که به اهمیت، ارزش یا نتایج یک عمل مرتبط است، شناسایی کنیم.
برای به دست آوردن یک نتیجه جامع، عبارات نتیجه گیری بر اساس لحن عبارات بررسی و گروه بندی شدند. تن های مثبت، خنثی و منفی. مثبت زمانی است که یک عبارت نشان دهنده نتیجه موفقیت آمیز باشد و منفی اگر خلاف آن را نشان دهد. خنثی لحنی است که در آن یک عبارت نه مثبت است و نه منفی.
“من نتایجی را می بینم” – نتیجه گیری مثبت
“من نمی توانم اطلاعات دقیقی برای ملبورن پیدا کنم” – نتیجه منفی
“آیا می توانیم فرض کنیم که در کشف نقشه شکست می خوریم؟” – نتیجه گیری خنثی
تنها با تجزیه و تحلیل عبارات نتیجه گیری در سراسر سند تجزیه و تحلیل، ارائه یک بیانیه واضح در مورد اثربخشی ابرداده های مکانی برای کشف داده ها دشوار است. با این وجود، نتیجه گیری ها نشانه هایی از ناکارآمدی ارائه می دهد. این مثال نتیجه میگیرد که عباراتی که در بالا آورده شده است، بیانهای یک شرکتکننده در طول فرآیند کشف نقشه توپوگرافی ملبورن است. داده های هواشناسی نمونه های دیگری از عبارات نتیجه گیری را ارائه می دهد:
“بنابراین، هواشناسی آنقدر پاسخ نداد”
“اگر به دنبال باران باشید، فقط یک نتیجه می گیرید”
اکثر عبارات نتیجه گیری، نشانه روشنی از اینکه فرآیند کشف داده ها می تواند با موفقیت تکمیل شود یا خیر، ارائه نمی دهند. در مثالهای بالا، شرکتکننده سعی کرد با یک تصمیم مشکوک جستجو را به پایان برساند. جالب است که بررسی کنیم چرا این شرکت کننده به این تصمیم رسیده است. برای پی بردن به این موضوع، به عبارات دیگری نگاه می کنیم، مطالعه و پیشنهاد می کنیم که به همراه نتیجه گیری، کل فرآیند استدلال را تشکیل می دهند، همانطور که در جدول 5 نشان داده شده است.
با نگاهی به کل فرآیند استدلال، شرکت کنندگان به دلیل اینکه نتوانستند مقیاس را در عنوان پیدا کنند، نتیجه گیری منفی دارند. یک شرکتکننده با 37 نتیجه اولیه، 1300 نتیجه پس از کلیک کردن بر مرتبطترین نتایج و 2000 نتیجه پس از کلیک روی جدیدترین نتایج روبرو شد. این شرکتکننده دریافت که نتایج، نشاندادهشده در فهرستی از عناوین، باید شامل یک مقیاس باشد. یک مقیاس به آنها کمک زیادی می کرد تا داده های مکانی مورد نیاز را پیدا کنند، زیرا شرکت کننده نمی خواست زمان زیادی را صرف جستجوی عناوین با کلیک کردن روی آنها یک به یک کند.
یکی دیگر از شرکتکنندگان در مواجهه با وضعیت مشابه، نگرش متفاوتی نشان داد، زیرا آنها فقط روی عنوانی کلیک کردند که فکر میکردند بیشترین ارتباط را با دادههای مورد نیاز دارد.
«مشکلاتی در این زمینه وجود دارد. elevation را تایپ می کنم، و این یکی از همه مرتبط تر است، اما اول نمی شود.
“من فکر می کنم دقت کافی است، فکر می کنم اگر این را داشته باشیم، دقت کافی خواهد بود.”
“پس، آیا می توانم دنبال یکی دیگر بگردم؟”
شرکتکننده در نهایت زمان زیادی را صرف کرد، بیشتر از زمانی که برای انجام جستجو در نظر گرفته شده بود، با کلیک کردن و باز کردن هر عنوان در لیست نتایج برای یافتن دادههای مربوطه برای سناریوی داده شده.
گروههای تکرارشوندهای از عبارات مثبت، منفی و خنثی از دادهها در طول فرآیند کشف دادههای مکانی وجود داشت که نشان میدهد اثربخشی ابرداده مکانی منوط به کیفیت فراداده است. کیفیت فراداده با موارد زیر تعیین می شود: کامل بودن، سازگاری و مرتبط بودن اطلاعات ارائه شده به کاربران. شهودی بودن رابط کاربری در برابر نیازهای کاربر؛ معیارهای دقیق برای فیلترهای جستجوی داده؛ و تمایل کاربران به انجام جستجوی دقیق بیشتر در نتایج.
نتایج نشان میدهد که ابردادههای مکانی، همراه با ابزار جستجو، میتوانند برای یافتن و کشف دادههای مکانی استفاده شوند، اما کاربران موانعی را پیدا کردند که مانع از انجام کارها به طور کارآمد، همانطور که در بخش بعدی توضیح داده شد، شدند. این موانع ممکن است کاربران را از رسیدن به هدف کار بازدارد، زیرا وقتی متوجه شدند که جستجو آنطور که انتظار داشتند پیش نمی رود، تمایل داشتند بلافاصله جستجو را متوقف کنند. آنها راههای دیگری را برای یافتن دادهها امتحان میکنند، مانند یافتن اطلاعات مربوط به دادهها از یک موتور جستجوی اینترنتی و تماس مستقیم با تولیدکننده.
4.2. بهره وری
کاربران داده های مکانی می توانند داده های بالقوه مورد نیاز را از وب سایت ها جستجو کنند، اما برای یافتن و کشف داده ها مقداری تلاش و زمان لازم بود. نتیجهگیریهای زیر نشان میدهد که کشف دادهها فرآیند سادهای نبوده و شرکتکنندگان نمیتوانند نتایج مورد انتظار را در زمان معین به دست آورند:
“ما می توانیم زمان زیادی را صرف جستجوی هر داده کنیم”
“و شاید بعد از نیم ساعت یا بیشتر، ما بتوانیم موردی را که به دنبالش هستید پیدا کنیم”
اما کارایی ابزارهای جستجو و پایگاه داده باید بالاتر از این باشد.
“من باید بتوانم داده های (بالقوه) را در یک دقیقه پیدا کنم، در غیر این صورت، می توانم زمان زیادی را صرف کنم.”
در طول این فرآیند، نتیجهگیریهای مشابه تا حدی تکرار میشد که اکثر کاربران نمیخواستند به جستجوی دادههای فعلی خود ادامه دهند و از آنها خواستند به جستجوی دیگری بروند.
“اگر نتوانم آن را در عرض یک دقیقه پیدا کنم، به این معنی است که باید به جستجوی بعدی بروم.”
یادداشت های محقق در طول فرآیند این کار نیز نشان می دهد که هیچ یک از شرکت کنندگان نتوانسته اند تمام داده های مورد نیاز را در زمان معین کشف کنند.
این نتایج نشان میدهد که ابردادههای مکانی میتوانند به کاربران کمک کنند تا دادههای مکانی را از وبسایتها کشف کنند، اما تلاشهایی برای افزایش کارایی فرآیند وجود دارد. آنچه که برای افزایش کارایی باید انجام شود، ممکن است با آشکارسازی مشکلات و انتظارات کاربر، همانطور که در بخشهای بعدی توضیح داده شد، و رفع مشکلات با ارتقای متادیتا و رابط کاربری به طور همزمان مشخص شود.
4.3. مشکلات قابلیت استفاده
شرکت کنندگان در تلاش برای کشف داده های مکانی مورد نیاز با استفاده از وب سایت ها با مشکلات متعددی مواجه شدند. مشکلات هم به وب سایت (رابط کاربری) و هم به ابرداده (محتوا) مربوط می شود. این مشکلات را می توان با بررسی نتایج در مثال های زیر شناسایی کرد. شکل 3 برخی از مشکلات شناسایی شده در حین کشف داده های مکانی را که توسط شرکت کنندگان ذکر شد، نشان می دهد، به عنوان مثال، کلمات کلیدی و نتایج بی همتا، برچسب ها/فیلترهایی که به راحتی قابل تشخیص نیستند و برای نیازهای شرکت کنندگان کافی نیستند.
“هیچ ابزاری برای انتخاب مقیاس وجود ندارد”
«برخی از عناوین دارای مقیاس هستند و برخی ندارند».
“چرا نمی توانیم آن را بر اساس مرتبط ترین موارد کوتاه کنیم”
“عنوان به مقیاس اشاره ای ندارد”
“(با اعمال) مرتبط ترین، 1300 به من می دهد. سعی کردم جدیدترین را برگردانم و 2000 نتیجه به من می دهد.”
“و وقتی سعی کردم با استفاده از منطقه (به عنوان کلمه کلیدی) جستجو کنم، نمی توانم اطلاعات دقیقی برای ملبورن پیدا کنم.”
“سیستم هیچ جستجوی اولیه ای ارائه نمی دهد”
“من فکر می کنم فیلترها (برای جستجو) کافی نیستند و داده ها به خوبی برچسب گذاری نشده اند.”
“بخش جالب این است که عناوین خیلی دقیق نیستند، من فکر می کنم از عنوان پایگاه داده یا مجموعه داده ها آمده اند.”
“این برچسب مفید است، در غیر این صورت می بینید که عنوان ممکن است مرتبط نباشد”
“شما باید نوعی مقیاس داشته باشید تا بتوانید فیلتر کنید.”
“یکی (کاری که) من می توانم انجام دهم این است که این یکی را باز کنم تا مقیاس را پیدا کنم زیرا در اینجا ذکر نشده است. ببینید چقدر داده باید باز کنید تا مقیاس را ببینید.»
“اگر از این سیستم استفاده می کنید پس از مدتی متوجه می شوید که برچسب ها مفید نیستند”
«این VIF 2015 چیست؟ نمیدونم باید بازش کنم من باید داده ها را ببینم تا VIF را بفهمم و زمان می برد.”
“به همین دلیل مهم است که نام را بگذاریم، نه اختصارات.”
“عنوان در مورد ارتفاع است، اما در اینجا جستجو زمین است.”
“وقتی کلمات کلیدی را تایپ کردم و همان ها بیرون آمدند، کاملاً با آنچه انتظار داشتم متفاوت است”
انواع مشابهی از نتیجه گیری در نتایج یافت می شود. از لیست ها، مشکلات شناسایی شده را می توان به دو نوع گروه بندی کرد. مشکلات رابط کاربری و مشکلات ثبت ابرداده. جدول 6 مشکلاتی را که می توان برای افزایش قابلیت استفاده ابرداده های مکانی برای کشف داده های مکانی حل کرد، خلاصه می کند.
4.4. رضایت و انتظارات کاربر
رضایت کاربر یک ویژگی قابل استفاده نیست که بتوان آن را به راحتی ارزیابی کرد، زیرا با احساسات، احساسات و تجربیات شرکت کنندگان در طول انجام کار مرتبط است. با این حال، می توان آن را با مشاهده دقیق داده ها (عبارات) همراه با یادداشت های محقق در حین مشاهده آزمایش ها تشخیص داد. در فرآیند شناسایی رضایت کاربر، انتظارات کاربر در هر دو سوابق فراداده مکانی و رابط کاربری به طور همزمان مشاهده می شود، زیرا رضایت با شکاف بین انتظارات و واقعیت تعیین می شود. در زیر برخی از عباراتی که می توان برای تشخیص رضایت و انتظارات کاربر در طول کشف داده های مکانی استفاده کرد، آورده شده است.
“فکر می کنم، نمی توانم ترازو را پیدا کنم، احتمالا باید یکی یکی باز کنم تا ببینم مقیاس چیست”
“مردم باید برخی نیازهای اساسی را تعریف کنند و باید با این نوع جستجو روبرو شوند.”
عبارات مشابهی در طول فرآیند کشف داده های مکانی تکرار می شد که می تواند برای تشخیص رضایت کاربر و همچنین شناسایی انتظارات استفاده شود. از عبارات بالا، یک نتیجه رضایت بخش را می توان تشخیص داد زیرا شرکت کننده نتوانست مقیاس فیلتر را برای محدود کردن نتایج پیدا کند. آنها انتظار داشتند که ابزار جستجو مجموعه ای از معیارهای اساسی را برای محدود کردن جستجوی آنها در اختیارشان بگذارد.
یادداشتهای محقق همچنین نشان میدهد که شرکتکنندگان هنگام باز کردن وبسایت VDD مشتاق نبودند، زیرا این وبسایت تنها با ارسال کلمات کلیدی، جستجوی سادهای را فراهم میکند. آنها متوجه برچسب های ارائه شده در پنجره ناوبری در سمت چپ صفحه وب نشدند. حتی زمانی که آنها از برچسب ها مطلع شدند، خوشحال نبودند، زیرا زمانی که آنها سعی کردند از آنها استفاده کنند، نتایج بیش از آنچه انتظار داشتند بی ربط بود. هنگام باز کردن وبسایت FIND واکنشهای متفاوتی از سوی شرکتکنندگان نشان داده شد. شرکت کنندگان وقتی جستجوی پیشرفته را در وب سایت پیدا کردند مشتاق بودند. با این حال، وقتی نتایج را دریافت کردند، شروع به شکایت از وب سایت کردند، به خصوص به این دلیل که نتوانستند راهی برای محدود کردن جستجوی خود با استفاده از مقیاس پیدا کنند. جدول 7انتظارات کاربر برای کشف داده های مکانی را خلاصه می کند.
5. تجزیه و تحلیل نتایج وظایف انتخاب داده های مکانی
انتخاب دادههای مکانی فرآیندی است که در آن شرکتکنندگان سعی میکنند ویژگیهای دادههای مکانی را با خواندن و تفسیر اطلاعات ارائهشده در فرادادههای مکانی درک کنند تا تصمیم بگیرند که آیا دادههای مکانی برای سناریوی دادهشده مناسب یا مناسب هستند یا خیر. در تلاش برای خواندن و تفسیر اطلاعات، شرکت کنندگان از دانش و تجربیات خود استفاده می کنند که بین آنها متفاوت است.
اثربخشی، کارایی، مشکلات قابلیت استفاده، رضایت کاربر و انتظارات برای انتخاب داده های مکانی را می توان از نتایج تجزیه و تحلیل پروتکل شناسایی کرد.
5.1. اثربخشی
عبارات نتیجه گیری مربوط به این فرآیند برای شناسایی نتیجه تلاش شرکت کنندگان برای انتخاب داده ها مشاهده شد.
بنابراین، تصمیم گیری سریع چندان آسان نیست.
“بعد از اینکه آنها نمونه ای به شما دادند، شاید مجبور شوید با آنها تماس بگیرید و از آنها بپرسید که این داده ها در مورد چیست”
“در حال حاضر از این ابرداده، در مورد داده ها مطمئن نیستید”
“من از این مطمئن نیستم. فکر میکنم، میتوانم بگویم که در وسط هستم.»
“من مطمئن هستم، اما به زمان بیشتری برای خواندن نیاز دارم، احتمالاً به تجربه بیشتری نیاز دارم”
“شما باید زمان بیشتری را صرف کنید و اعتماد به نفس بیشتری خواهید داشت”
“فکر می کنم برای من کافی است که تصمیم بگیرم آیا این چیزی است که من نیاز دارم یا نه”
“من فکر می کنم، اگر بتوانم به خود داده ها نگاهی بیندازم، ممکن است مطمئن باشم.”
دوباره، عبارات مشابه در طول آزمایش به عنوان افکار شرکت کنندگان تکرار شد. همانطور که در کشف فضایی، نمی توان به وضوح گفت که ابرداده های مکانی برای انتخاب داده های مکانی موثر یا بی اثر هستند، زیرا شرکت کنندگان نتایج مثبت، منفی و خنثی ارائه کردند. با این وجود، عبارات به ما اجازه می دهند درجه ای از ناکارآمدی را احساس کنیم. برای مثال، بیانهای یک شرکتکننده در طول فرآیند متزلزل شد. در برخی موارد، شرکتکننده به تصمیمهای خود مطمئن میشود، اما بعداً زمانی که تجربه متفاوتی با ابرداده داشتند، قانع نمیشوند.
بر اساس یادداشتهای نویسندگان در طول فرآیند، در ابتدا، شرکتکنندگان به صفحه ابرداده بهعنوان یک کل نگاه کردند تا اطلاعاتی را پیدا کنند که ممکن است برای تصمیمگیریهایشان حیاتی باشد، از جمله چکیده، تاریخ تولید، بهروزرسانی، تولیدکننده و دقت، و سپس احساس اطمینان کردند که می تواند تصمیم بگیرد با این حال، پس از بررسی دقیق هر عنصر، آنها شروع به تردید کردند. به عنوان مثال، هنگامی که آنها به دقت داده ها نگاه می کردند، بسیار انتقادی بودند و اطلاعات دقیقی را می خواستند. آنها از مقادیر نامشخص دقت شکایت کردند، به عنوان مثال، 1-10 متر، و درخواست فرآیند ارزیابی دقت را داشتند. شرکت کنندگان تجربیات مشابهی با ابرداده از هر دو وب سایت VDD و FIND داشتند. علاوه بر این، همه شرکتکنندگان به اطلاعات بیشتری نیاز داشتند که در فراداده ارائه نشده بود،
5.2. بهره وری
مشابه اکتشاف فضایی، شرکت کنندگان فقط قادر به خواندن و ارزیابی نیمی یا کمتر از ابرداده از وظایف داده شده بودند. آنها بیشتر وقت خود را صرف یافتن اطلاعات حیاتی در فراداده کردند تا مناسب بودن داده ها را ارزیابی کنند، به عنوان مثال، صحت، تا بفهمند آیا اطلاعات مفید هستند یا نه. آنها زمان بیشتری را صرف تفسیر اطلاعاتی کردند که همیشه با دانش آنها مرتبط نبود. عبارات زیر نمونه هایی از آنچه شرکت کنندگان باید با آن دست و پنجه نرم می کردند و چه هزینه ای برای آنها برای مکان یابی و تفسیر اطلاعات در فراداده هزینه داشت است.
“توضیحات چندان واضح نیست و برای منبع داده خیلی زیاد است”
“فقط لیستی از ارائه دهندگان داشته باشید”
“چرا این را در منبع داده قرار دهید؟ کلاس نباید در منابع داده باشد.
“من فکر می کنم آنها اطلاعات (در این بخش از ابرداده) را به هم ریخته اند (به هم ریخته اند)”
بر این اساس، کارایی ابرداده ها باید افزایش یابد. علاوه بر این، شرکت کنندگان برای به دست آوردن اطلاعات اضافی از منابع مختلف، از جمله تولیدکنندگان و کارشناسان داده، به زمان بیشتری نیاز دارند تا به آنها کمک کند تا تصمیمات روشنی در مورد داده ها بگیرند.
5.3. مشکلات قابلیت استفاده
نتایج تجزیه و تحلیل دادهها مشکلات مختلفی را که شرکتکنندگان در فرآیند انتخاب دادههای مکانی با آنها مواجه هستند، در اختیار ما قرار میدهد. این مشکلات آنها را از تصمیم گیری واضح در مورد مناسب بودن داده ها برای سناریوی معین و همچنین مانع از شرکت کنندگان در انتخاب در مدت زمان معین جلوگیری می کند. از دست دادن محتوای مهم، مانند تاریخ نگهداری یا آخرین بهروزرسانی، ارائه ناامیدکننده کیفیت دادهها و چکیدهها نیز مسائلی بودند. با این حال، مشکل اصلی، که همه شرکتکنندگان آن را شناسایی کردند، نامرتبط و ناهماهنگی اطلاعات برگشتدادهشده در چکیدهها و دقت بود. شکل 4 مشکل موجود در یک چکیده را نشان می دهد.
شرکت کنندگان توافق کردند که چکیده نقش مهمی در انتخاب داده های مکانی ایفا می کند، زیرا آنها فرآیند و استدلال را با آن آغاز می کنند. یک چکیده مختصر، واضح، آسان برای درک و مرتبط، با اصطلاحاتی که آنها میدانند، ضروری است تا به آنها کمک کند تا بفهمند دادهها در مورد چیست و چگونه دادهها با اهدافشان مطابقت دارند. یک چکیده با کیفیت خوب، با توجه به ادراک کاربران، آنها را تشویق و راهنمایی می کند تا اطلاعات دیگری در مورد داده های درون ابرداده پیدا کنند. برعکس، یک چکیده درهم و برهم باعث سردرگمی و منصرف شدن آنها از دریافت اطلاعات بیشتر از ابرداده می شود. جدول 8 مشکلات قابلیت استفاده شناسایی شده از آزمایش را خلاصه می کند.
علاوه بر مشکلات قابلیت استفاده فهرست شده در بالا، داده ها یک متا-مسئله را در اختیار ما قرار می دهند، یعنی مشکلی فراتر از یک مشکل قابلیت استفاده یافت شده توسط شرکت کنندگان در سوابق فراداده و رابط های کاربر. این متا مشکل از عبارات زیر شناسایی شد.
“من فکر می کنم این ارائه دهنده است، زیرا ما باید بدانیم که آیا می توانیم به داده ها اعتماد کنیم یا نه.”
“برای توصیف واضح داده ها، اما من فکر می کنم بهترین راه داشتن یک نمونه است”
“یا آنها یک نمونه به شما می دهند و پس از آن شاید مجبور شوید با آنها تماس بگیرید”
“اگر می توانید بروید و یک نمونه را جستجو کنید، نه بیش از حد، بلکه ببینید چه نوع داده هایی دارند تا مطمئن شوید.”
“شما می توانید بخوانید و بگویید – قطعاً من به این نیاز دارم – اما وقتی دانلود می کنید یا پایین می آیید، متوجه می شوید که این اطلاعات من نیست.”
مشکل مربوط به اعتماد بود، جایی که شرکت کنندگان احساس می کردند که اطلاعات ارائه شده در فراداده تنها برای بررسی اطلاعات موجود در فراداده مفید است. اینطور نیست که آنها به ابرداده ها اعتماد نداشتند، بلکه فکر می کردند که نمی توانند تصمیمات خود را بر اساس مناسب بودن داده های مکانی صرفاً بر اساس اطلاعات ارائه شده در ابرداده ها قرار دهند. برای تصمیم گیری، آنها به اطلاعات بیشتری نیاز داشتند که به آن متا اطلاعات گفته می شود، از جمله شهرت تولیدکنندگان، تجربیات آنها با داده ها یا سیستم ابرداده، که فقط از طریق تعامل مستقیم یا مستقیم با داده ها به دست می آمد. استدلال مشابهی ممکن است در تجارت فروش خودرو یافت شود، جایی که مشتریان بروشور یا تبلیغات را نگاه می کنند و می خوانند تا خودروهای بالقوه ای را که با معیارهای آنها مطابقت دارند شناسایی کنند. با این حال، تصمیم گیری برای خرید یا نخریدن خودرو داستان متفاوتی است و نیاز به اطلاعات متفاوتی دارد که توسط بروشورها یا تبلیغات قابل ارائه نیست، یعنی تجربه زنده با خود خودرو. از این رو، تست رانندگی. نیازها و انتظارات این فرااطلاعات در بخش بعدی توضیح داده شده است.
5.4. رضایت و انتظارات کاربر
در طول فرآیند انتخاب داده های مکانی، شرکت کنندگان اطلاعات خاصی را در سوابق فراداده شناسایی می کنند که می تواند برای ارزیابی مناسب بودن داده ها برای پروژه داده شده مفید باشد. در انجام این کار، شرکت کنندگان با خواندن چکیده ها شروع می کنند تا قبل از ادامه روند، درک مختصری در مورد داده ها بدست آورند. با این حال، شرکت کنندگان دریافتند که بیشتر چکیده ها مشکل ساز هستند و آنها را از خواندن و صرف زمان بیشتر برای درک اطلاعات منصرف می کنند. این باعث شد که آنها بر اساس دانش موجود خود به سراغ سایر رکوردهای ابرداده بروند تا اطلاعات مهمی را که ممکن است برای ارزیابی مناسب بودن برای آنها مفید باشد، شناسایی کنند. بیشتر آنها به دنبال اطلاعات دقیق رفتند و دریافتند که اطلاعات ارائه شده لزوماً واضح و قابل درک نیست. شرکت کنندگان از جمله موارد دیگر، اطلاعاتی مانند تاریخ تولید (تاریخ ایجاد) و مرز (پوشش جغرافیایی). در طول این فرآیند، آنها افکار خود را که عمدتاً منفی بود، در مورد فراداده ها به صورت شفاهی بیان کردند، زیرا دریافتند که ابرداده ها انتظارات آنها را برآورده نمی کند.جدول 9 .
6. تجزیه و تحلیل مصاحبه ها
پس از تکمیل وظایف داده شده، به شرکت کنندگان مجموعه ای از سوالات در مورد کشف و انتخاب داده های مکانی داده شد. نویسندگان از این سوالات برای بررسی نظرات و تجربیات شرکت کنندگان در مورد کار با ابرداده های مکانی استفاده کردند. آنها تشویق شدند تا هر گونه حادثه مهم را در طول فرآیند یادآوری کنند و توضیحات خود را در مورد حوادث ارائه دهند.
سوال 1: تا چه حد موافقید که بتوانید داده های مکانی مورد نیاز را پیدا کنید؟
شرکت کنندگان به دلیل داشتن تجربیات و مشکلات مختلف به این سوال پاسخ های مختلفی دادند. همانطور که در جدول 10 مشاهده می شود ، برای هر دو سیستم کشف داده های مکانی، نظرات شرکت کنندگان متفاوت است، بدون هیچ نشانه قوی مبنی بر اینکه آنها با موفقیت داده های مکانی مورد نیاز را پیدا کرده اند.
شرکت کنندگان فقدان معیارها را به عنوان فیلترهایی برای محدود کردن جستجوی خود از همان مرحله اولیه ذکر کردند. آنها به یاد آوردند که چقدر آزاردهنده بود وقتی مجبور بودند به تعداد زیادی عناوین فهرست شده نگاه کنند و عناوین را یکی یکی بخوانند و بررسی کنند تا متوجه شوند که عناوین ناسازگاری ارائه شده است. هنگامی که به آنها در مورد برچسب هایی در وب سایت VDD یادآوری شد که می توان از آنها برای فیلتر کردن داده ها استفاده کرد، اکثر آنها هنوز خوشحال نبودند، زیرا برچسب ها به راحتی تشخیص داده نمی شدند و معیارهای مورد انتظار مانند مقیاس نقشه و منطقه (جغرافیایی) را ارائه نمی کردند. پوشش). آنها نمیخواستند زمان زیادی را صرف جستجوی دادههایی کنند که وجود نداشت. از این رو، نیاز آنها به فیلترهای کامل و دارای برچسب مناسب برای معیارهای جستجو برای به دست آوردن نتایج فوری یا بدون نتیجه است.
سوال 2: تا چه حد موافقید که ابرداده های مکانی (و رابط کاربری) انتظارات شما را برآورده می کند؟
همانطور که در جدول 11 مشاهده می شود ، پاسخ شرکت کنندگان به سوالات بیشتر منفی بود، همانطور که پاسخ آنها به سوال قبلی بود. آنها در طول فرآیند کشف مشکل جدی پیدا کردند، به عنوان مثال، ناسازگاری بین کلمات کلیدی ارسال شده با عناوین ارائه شده در نتیجه. شرکتکنندهای که تجربهای با وبسایتهای اکتشافی داشت، در مورد چگونگی بهبود سیستم، به عنوان مثال، ارائه برچسبهایی از کاربران قبلی برای کمک به او در شناسایی دادههای مناسب، به دلیل اینکه ممکن است اصطلاحات متفاوتی برای همان دادهها داشته باشند و آن را با سایر کاربران به اشتراک بگذارد، اشاره کرد.
یکی دیگر از شرکتکنندگان به تلاش بیشتر برای کامل، واضح و سازگار کردن سوابق فراداده، هم در یک رکورد و هم بین سوابق فراداده اشاره کرد. آنها تجربه خاصی را به یاد آوردند که در آن با عنوانی با اختصارات در آن مواجه شده بودند که هیچ توضیحی در چکیده یا بقیه رکوردها ندارد و مجبور شدند ابرداده را باز کنند زیرا عنوان در بالای مرتبط ترین نتیجه ظاهر می شود.
سوال 3: تا چه حد موافقید که بتوانید تناسب داده های مکانی را برای استفاده تعیین کنید تا تصمیم بگیرید که آیا از داده ها استفاده خواهید کرد یا خیر؟
شرکتکنندگانی که پیشزمینه اطلاعات مکانی داشتند، هنگامی که اطلاعاتی درباره محتوا/ویژگیها، سن دادهها (آخرین بهروزرسانی) و پوشش جغرافیایی (منطقه تحت پوشش دادهها) داشتند، صفحه ابرداده را ترک میکردند. آنها به دنبال فرصتهایی برای دانلود و دریافت دادهها میگردند و ارزیابی خود را بر روی دادهها یا نمونه دادههای واقعی انجام میدهند تا دریابند که آیا دادهها برای هدفشان مناسب است یا خیر. یا، آنها ترجیح میدهند بهجای خواندن فرادادهها و استناد به تصمیمگیریهای خود بر اساس فراداده، مستقیماً با تولیدکننده داده تماس بگیرند تا اطلاعات مورد نیاز برای تصمیمگیری درباره دادهها را دریافت کنند. کسانی که دارای پیشینه غیرمکانی هستند، مانند مهندس عمران، ترجیح می دهند به تولیدکننده داده نگاه کنند و اطلاعاتی در مورد شهرت تولیدکنندگان به دست آورند تا از داده ها مطمئن شوند.بنابراین جدول 12 عمدتاً منفی بود.
یکی دیگر از شرکت کنندگان که به دانش فضایی خود بسیار مطمئن بود، ترجیح داد که گزارش پردازش داده های مکانی را مطالعه کند تا اطلاعاتی در مورد روش جمع آوری داده ها و استانداردهای اعتبارسنجی کیفیت پیدا کند.
سوال 4: تا چه حد موافق هستید که ابرداده های مکانی انتظارات شما را برای ارزیابی مناسب بودن داده های مکانی برآورده می کند؟
همانطور که از پاسخ های شرکت کنندگان در جدول 13 مشاهده می شودکفایت ابرداده برای ارزیابی مناسب بودن دادههای مکانی برای یک هدف خاص، منوط به تجربه آنها با دادهها و سوابق حرفهای آنها است. اکثر شرکتکنندگان پاسخهای منفی دادند، زیرا ابردادهها به سختی انتظارات آنها را برآورده میکنند. در عوض، آنها به اطلاعات اضافی نیاز داشتند که بخشی از ابرداده نبود. سوال بعدی این است که تا چه حد می توان ابرداده ها را برای برآورده کردن انتظارات آنها بهبود بخشید؟ پاسخهای شرکتکنندگان نامشخص بود، زیرا نمیتوانستند آنچه را که از فراداده انتظار داشتند بیان کنند. برخی از آنها مجدداً خواستار دسترسی به داده های نمونه شدند. برخی از کاربران قبلی مانند گزارشها یا بررسیها، استفادههای قبلی را درخواست کردند. برخی از شرکت کنندگان گفتند که در مورد مناسب بودن داده ها بر اساس فراداده تصمیم نخواهند گرفت.
سوال 5: تا چه حد موافقید که در آینده از ابرداده های مکانی مجدد برای کشف و انتخاب داده های مکانی استفاده کنید؟
این آخرین سوالی بود که به شرکت کنندگان داده شد. به عنوان جدول 14نشان می دهد، پاسخ ها، دوباره، عمدتا منفی هستند. با این حال، توضیحات آنها چندان منفی نبود. اکثر شرکتکنندگان همچنان از ابردادهها و سیستمهای کشف دادهها برای جستجوی ابردادههای مکانی بالقوه برای اهداف آیندهشان استفاده میکنند و به آنها تکیه میکنند. آنها مایلند ابرداده ها و رابط کاربری را با پرداختن به مشکلات شناسایی شده و الزامات آنها از این آزمایش بهبود ببخشند. آنها هنوز فکر می کردند که ابرداده مهم است، اما باید بهبودهایی صورت گیرد تا ابرداده برای آنها قابل استفاده تر و مفیدتر شود. یکی از شرکتکنندگان مایل است ابردادهها را در سبکها و ارائههای مختلف بر اساس سطح تخصص کاربران، عمومی، متوسط و متخصص، با استفاده از اصطلاحات مختلف مطابق با سطح تخصص، ببیند. کاربران می توانستند سیستم کشف و ارائه مناسب برای خود را انتخاب و استفاده کنند.
7. بحث
نتایج و یافتههای ارزیابی قابلیت استفاده ابردادههای مکانی ایجاد شده نشان میدهد که ابرداده و رابط کاربری برای کاربران دادههای مکانی برای کشف و انتخاب دادههای مکانی مشکلساز باقی میمانند. مشکلاتی مانند اطلاعات ناسازگار در اکثر عناصر در سوابق فراداده، کاربران دادههای مکانی را از کشف و انتخاب موثر و کارآمد دادههای مکانی ممانعت میکرد. مشکل دیگری که می توان برجسته کرد، بی ربط بودن اطلاعات ارائه شده در ابرداده با دانش کاربران است. مشکلاتی که در رابط کاربری یافت می شود، مشکل دیگری را به فرآیند کشف و انتخاب اضافه می کند. فقدان معیارهای جستجو، نتایج نامربوط از جستجوی ارسالی، و ارائه متنی دلسرد کننده که خیلی کوتاه یا طولانی است، فرآیند کشف و انتخاب را دشوارتر می کند.
این واقعیت که این سوابق فراداده با پیروی از همان استاندارد فراداده ISO 19115 ایجاد شده اند، مانع از بروز مشکلات نمی شود. بیشتر مشکلات ناشی از نوع متن آزاد عناصر در استانداردهای ابرداده مکانی مانند عنوان، چکیده، کلمات کلیدی، کیفیت داده و منشأ داده است. اطلاعات عمدتاً از درک نویسندگان فراداده در مورد داده ها می آید. این نشان میدهد که استاندارد قابلیت برای حفظ سازگاری اطلاعات ارائه شده در ابرداده و ارتباط اطلاعات با دانش کاربران دادههای مکانی، کم است.
یافته دیگری در انتخاب دادههای مکانی نشان میدهد که کاربران دادههای مکانی برای اینکه بتوانند دادهها را برای اهداف خود انتخاب کنند، بیش از اطلاعات صرفاً از ابردادهها نیاز دارند. دسترسی به داده های مکانی واقعی یا یک نمونه برای آنها مهم است تا بتوانند مناسب بودن داده ها را خودشان ارزیابی کنند. آنها همچنین فکر می کنند که تجربیات سایر کاربرانی که با داده ها کار کرده اند برای فرآیند انتخاب مفید است. این شاخص دیگری است که استانداردهای دستورالعمل اصلی ایجاد ابرداده مکانی باید بهبود یابد.
آخرین نسخه استاندارد ISO برای ابردادههای مکانی، ISO 19115–1:2014، اطلاعات جغرافیایی — فراداده، قسمت 1: مبانی است. طبق استاندارد، یک رکورد فراداده کامل، مجموع 12 کلاس فراداده است. اطلاعاتی وجود دارد که می تواند به کاربران کمک کند که استاندارد در حال حاضر عناصری برای تطبیق آنها ندارد. به عنوان مثال، رتبه بندی داده های کاربر و تعداد بارگیری ها. تحقیقات آینده باید به گونه ای طراحی شود که به مشکلات و انتظارات کاربران از ابرداده مکانی بپردازد تا قابلیت استفاده فراداده مکانی را بهبود بخشد و توصیه کند که چگونه استاندارد فراداده مکانی ISO 19115 را می توان برای ارائه راه حلی برای استفاده بهتر ابرداده گسترش داد.
8. نتیجه گیری
این مقاله نتایج یک آزمایش ارزیابی قابلیت استفاده فراداده فضایی را تشریح کرد. نتایج نشان میدهد که ابرداده فضایی برای کشف و انتخاب دادههای مکانی نه مؤثر است و نه کارآمد، و بهبودهایی هم برای سوابق فراداده و هم در رابط کاربر مورد نیاز است. این آزمایش همچنین برخی مشکلات قابلیت استفاده را در سوابق ابرداده و رابط های کاربر (وب سایت ها) نشان داد. ناهماهنگی و اطلاعات نامربوط در رکوردهای فراداده در عنوان، کلمات کلیدی، چکیده ها، کیفیت داده ها و سایر عناصر فراداده یافت شد. فقدان معیارهای جستجو، نتایج نامربوط از جستجوی ارسالی، و ارائه دلسرد کننده ابرداده برخی از مشکلات برجسته ای هستند که در رابط کاربری یافت می شوند. این مشکلات کاربران دادههای مکانی را از کشف و انتخاب موثر و کارآمد دادههای مکانی ممانعت میکرد. علاوه بر این، نتایج همچنین نشان داد که اطلاعات ارائه شده در رکوردهای فراداده، نیازهای کاربران داده های مکانی را برای انتخاب داده های مکانی کافی نمی کند. بررسیها و تجربیات قبلی کاربران و دسترسی به دادهها یا نمونه واقعی نیز برای انتخاب کاربران مورد نیاز است.
بر این اساس، کاربران دادههای مکانی راضی نبودند و انتظار داشتند که وبسایتها ابزارهای جستجوی بهتر و نتایج بهتری را از نظر سازگاری مرتبط بودن اطلاعات در مورد دادههای مکانی در اختیار آنها قرار دهد.
نتایج و یافتههای این ارزیابی به عنوان مبنایی برای بهبود قابلیت استفاده و برای جمعآوری نیازها و انتظارات کاربران دادههای مکانی از جامعه گستردهتر، به عنوان یک جهت آینده، استفاده خواهد شد.
9. ثبت اختراع
این بخش اجباری نیست، اما در صورت وجود اختراعات حاصل از کار گزارش شده در این نسخه، ممکن است اضافه شود.
مشارکت های نویسنده
مفهومسازی، محسن کلانتری و سیاهالدین سیاهالدین; روش شناسی، سیاح الدین سیاهرودین; نرم افزار، Hardi Subagyo; اعتبارسنجی، سیاهالدین سیاهالدین، محسن کلانتری و عباس رجبیفرد. تحلیل صوری، سیاحرودین سیاحرودین; تحقیق، سیاهرودین سیاحرودین; منابع، محسن کلانتری; Data Curation, Syahrudin Syahrudin; Writing—Original Draft Preparation, Syahrudin Syahrudin; نگارش- نقد و ویرایش، محسن کلانتری; تجسم، محسن کلانتری; سرپرستی، محسن کلانتری، عباس رجبی فرد; مدیریت پروژه، HH; تامین مالی، محسن کلانتری، عباس رجبی فرد. همه نویسندگان نسخه منتشر شده نسخه خطی را خوانده و با آن موافقت کرده اند.
منابع مالی
این تحقیق توسط بورسیه های جوایز استرالیا و کمک هزینه شورای تحقیقات استرالیا به شماره DP170100153 تامین شده است.
قدردانی ها
نویسندگان همچنین از همه اعضای مرکز زیرساختهای دادههای مکانی و مدیریت زمین (CSDILA) و مرکز مدیریت بلایای دانشگاه ملبورن برای همه بحثها و لذتها تشکر میکنند.
تضاد علاقه
تامین کنندگان مالی هیچ نقشی در طراحی مطالعه نداشتند. در جمع آوری، تجزیه و تحلیل یا تفسیر داده ها؛ در نوشتن دستنوشته یا تصمیم به انتشار نتایج.
منابع
- هان، اچ. Giles، CL; ماناوغلو، ای. ژا، اچ. ژانگ، ز. Fox، EA استخراج خودکار فراداده سند با استفاده از ماشینهای بردار پشتیبانی. در مجموعه مقالات کنفرانس مشترک IEEE 2003 در کتابخانه های دیجیتال، هیوستون، تگزاس، ایالات متحده، 27-31 می 2003. صص 37-48. [ Google Scholar ]
- کلانتری، م. رجبی فرد، ع. اولفت، اچ. اتوماسیون ابرداده فضایی: رویکردی جدید. در مجموعه مقالات SSC2009، کنفرانس علوم فضایی، آدلاید، استرالیا، 28 سپتامبر تا 2 اکتبر 2009. صص 629-635. [ Google Scholar ]
- کلانتری، م. رجبی فرد، ع. الفت، ح. پتیت، سی. کشتیراست، الف. سیستمهای فراداده مکانی خودکار – مورد شبکه زیرساخت تحقیقات شهری استرالیا. کارتوگر. Geogr. Inf. علمی 2017 ، 44 ، 327-337. [ Google Scholar ] [ CrossRef ]
- کلانتری، م. رجبی فرد، ع. الفت، ح. Williamson, I. Metadata Geospatial 2.0-رویکردی برای اطلاعات جغرافیایی داوطلبانه. محاسبه کنید. محیط زیست سیستم شهری 2014 ، 48 ، 35-48. [ Google Scholar ] [ CrossRef ]
- Norlund، P. روش های خودکار و نیمه خودکار برای ایجاد و نگهداری فراداده: اجرای طولانی مدت دستورالعمل INSPIRE، (اوت). 2010. موجود به صورت آنلاین: https://www.diva–portal.org/smash/record.jsf?pid=diva2:383048 (در 10 اکتبر 2019 قابل دسترسی است).
- اولفت، اچ. به روز رسانی و غنی سازی خودکار فراداده فضایی. پایان نامه دکتری، دانشگاه ملبورن، ملبورن، استرالیا، 2013. موجود به صورت آنلاین: https://www.csdila.unimelb.edu.au/publication/theses/ (دسترسی در 10 اکتبر 2019).
- الفت، ح. کلانتری، م. رجبی فرد، ع. سنوت، اچ. ویلیامسون، اول. اتوماسیون فراداده فضایی: کلیدی برای بسترسازی فضایی. بین المللی جی. اسپات. زیرساخت. Res. 2012 ، 7 ، 173-195. [ Google Scholar ] [ CrossRef ]
- الفت، ح. کلانتری، م. رجبی فرد، ع. سنوت، اچ. ویلیامسون، IP یک رویکرد مبتنی بر GML برای خودکارسازی بهروزرسانی ابردادههای مکانی. بین المللی جی. جئوگر. Inf. علمی 2013 ، 27 ، 231-250. [ Google Scholar ] [ CrossRef ]
- الفت، ح. کلانتری، م. رجبی فرد، ع. ویلیامسون، IP; پتیت، سی. ویلیامز، اس. کاوش در زمینه های کلیدی تحقیقات اتوماسیون فراداده فضایی در استرالیا. 2010. در دسترس آنلاین: https://ezp.lib.unimelb.edu.au/login?url=https://search.ebscohost.com/login.aspx?direct=true&db=ir00004a&AN=irunimelb.265613&site=eds–live&scope =site%5Cnhttps://repository.unimelb.edu.au/10187/9210 (دسترسی در 10 اکتبر 2019).
- Ahonen-rainio، P. تجسم فراداده های مکانی برای انتخاب مجموعه داده های جغرافیایی . دانشگاه فناوری هلسینکی: اسپو، فنلاند، 2005. [ Google Scholar ]
- آهونن – راینیو، پی. Kraak، MJ تصمیم گیری در مورد تناسب برای استفاده: ارزیابی کاربرد نقشه های نمونه به عنوان عنصری از ابرداده های مکانی. کارتوگر. Geogr. Inf. علمی 2005 ، 32 ، 101-112. [ Google Scholar ] [ CrossRef ]
- آرناس، اچ. هاربلوت، بی. کروز، سی. یک رویکرد وب معنایی برای کشف دادههای جغرافیایی. در مجموعه مقالات بیست و یکمین کنفرانس سالانه IFIP WG 11.3 در مورد امنیت داده ها و برنامه های کاربردی، DBSEC، ردوندو بیچ، کالیفرنیا، ایالات متحده آمریکا، 8 تا 11 ژوئیه 2007. یادداشتهای سخنرانی در علوم کامپیوتر (شامل یادداشتهای سخنرانی در هوش مصنوعی و یادداشتهای سخنرانی در بیوانفورماتیک). جلد 8697، ص 117–126. [ Google Scholar ]
- آتاناسیو، اس. جورجومانولیس، ن. پاترومپاس، ک. الکساکیس، م. Stratiotis, T. TripleGeo–CSW: میانافزاری برای افشای خدمات کاتالوگ جغرافیایی در وب معنایی. CEUR Workshop Proc. 2015 ، 1330 ، 229-236. [ Google Scholar ]
- بوئین، ا. هانتر، جی. چه چیزی کیفیت را به مصرف کننده داده های مکانی ارتباط می دهد؟ کیفیت Asp. تف کردن حداقل داده 2008 ، 34 ، 285-296. [ Google Scholar ] [ CrossRef ]
- Devillers Rodolphe Gervais، M. Bédard، Y.; Jeansoulin, R. Spatial Data Quality: From Metadata to Quality Indicators and Contextual End-User Manual. OEEPE/ISPRS Jt. کارگاه اسپات. کیفیت داده مدیریت 2002 ، 45-55. [ Google Scholar ]
- دیویلر، آر. Bédard، Y.; ژانسولین، آر. Moulin، B. ابزارهای تحلیل اطلاعات کیفیت دادههای مکانی برای کارشناسانی که تناسب استفاده از دادههای مکانی را ارزیابی میکنند. بین المللی جی. جئوگر. Inf. علمی 2007 ، 21 ، 261-282. [ Google Scholar ] [ CrossRef ]
- فوگازا، سی. پپه، م. اوجیونی، ا. تاگلیولاتو، پ. کاررارا، ص. سادهسازی ابردادههای مکانی در وب معنایی. در مجموعه مقالات مجموعه کنفرانس IOP: زمین و علوم محیطی، هالیفاکس، NS، کانادا، 5 تا 9 اکتبر 2015. انتشارات IOP: بریستول، انگلستان، 2016; جلد 34. [ Google Scholar ] [ CrossRef ]
- وانوا، آی. مورالس، جی. de By, RA; بشه، تی اس; Gebresilassie، MA جستجوی منابع داده های مکانی بر اساس تناسب برای استفاده. جی. اسپات. علمی 2013 ، 58 ، 15-28. [ Google Scholar ] [ CrossRef ]
- لیمباخ، تی. ریترر، اچ. کلاین، پی. Müller, F. تجسم ابرداده: LevelTable در مقابل GranularityTable در چارچوب SuperTable/Scatterplot. هوم محاسبه کنید. تعامل داشتن. عمل تئوری. (بخش دوم) 2003 ، 2 ، 1106-1110. [ Google Scholar ]
- لاکاستا، جی. Nogueras–Iso، J.; بیجار، ر. Muro-Medrano، روابط عمومی; Zarazaga-Soria، FJ یک سرویس هستی شناسی وب برای تسهیل قابلیت همکاری در زیرساخت داده های مکانی: کاربرد برای کشف. دانستن داده ها مهندس 2007 ، 63 ، 947-971. [ Google Scholar ] [ CrossRef ]
- پاترومپاس، ک. جورجومانولیس، ن. استراتیوتیس، تی. الکساکیس، م. آتاناسیو، اس. افشای INSPIRE در وب معنایی. J. وب سمنت. 2015 ، 35 ، 53-62. [ Google Scholar ] [ CrossRef ]
- پاترومپاس کوستاس الکساکیس، م. جیانوپولوس، جی. Athanasiou، S. TripleGeo: یک ابزار ETL برای تبدیل داده های مکانی به سه گانه RDF. CEUR Workshop Proc. 2014 ، 1133 ، 275-278. [ Google Scholar ]
شکل 2. نمای نموداری طرح آزمایش.
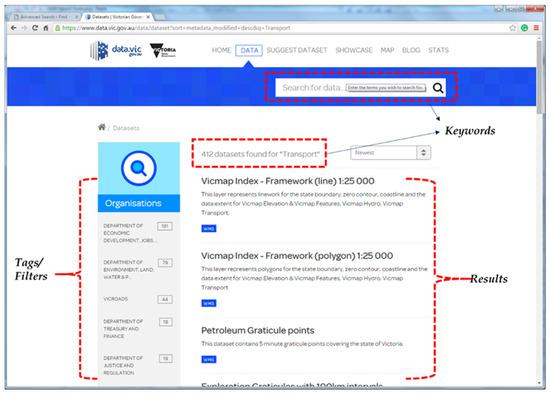
شکل 3. مشکلات شناسایی شده با سیستم های دایرکتوری داده ویکتوریا (VDD) در کشف داده های مکانی.
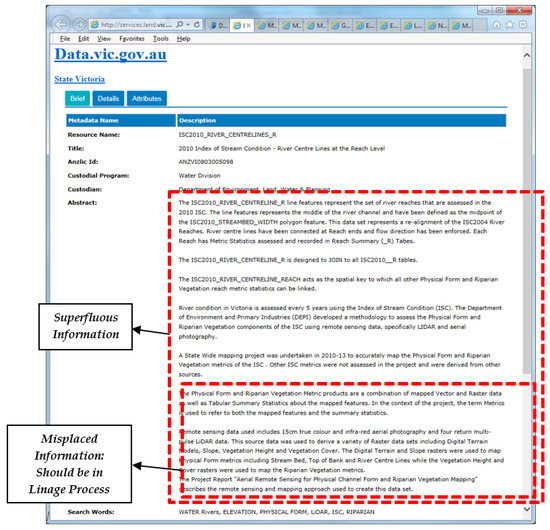
شکل 4. اطلاعات اضافی در یک چکیده.


بدون دیدگاه