با بهبود وضوح فضایی تصاویر سنجش از دور، تعداد فزاینده ای از محققان تشخیص اشیا را در تصاویر سنجش از دور مطالعه کرده اند [ 4 ، 5 ، 6 ، 7 ، 8 ، 9 ، 10]. در حال حاضر، این رویکرد عمدتاً به سه دسته روش تقسیم می شود: تجزیه و تحلیل تصویر مبتنی بر شی، ادغام اطلاعات مکانی و
یادگیری ماشین. الگوریتم های اصلی تشخیص اشیا عمدتاً مبتنی بر
مدل های یادگیری عمیق هستند که می توان آنها را به دو دسته تقسیم کرد. اول، الگوریتمهای تشخیص دو مرحلهای میتوانند پیشنهادهای منطقهای را تولید کنند، بر اساس امتیازات طبقهبندی این پیشنهادها از سرکوب غیر حداکثری (NMS) برای حذف پیشنهاد اضافی، پس از غربالگری NMS برای به دست آوردن اشیاء شناساییشده استفاده میکند. الگوریتمهای نماینده شامل الگوریتمهای سری R-CNN بر اساس پیشنهادات منطقهای هستند، مانند R-CNN [ 6 ]، Fast R-CNN [ 11 ] و Faster R-CNN [ 12] .]. دوم، الگوریتمهای تشخیص یک مرحلهای که نیازی به فاز پیشنهادی منطقه ندارند، مستقیماً مختصات احتمال و موقعیت اشیاء را تولید میکنند. نمونه های معمولی YOLO [ 13 ] و SSD [ 14 ] هستند.
اگرچه سریعتر R-CNN، YOLO و SSD برای تشخیص اشیایی مانند گربهها، ماشینها، کشتیها یا انسانها در تصاویر مبتنی بر طبیعت موفق هستند، اما بهطور ویژه برای تشخیص اجسام پوششی کوچک منهول در تصاویر سنجش از راه دور طراحی نشدهاند. چندین چالش کاربرد آنها را به این روش محدود می کند. پوشش های منهول نسبتا کوچک هستند و در گروه های پراکنده ظاهر می شوند. حتی در یک تصویر سنجش از دور اپتیکال با وضوح بالا با وضوح 0.1 متر × 0.1 متر، پوشش منهول تنها 5 تا 8 پیکسل عرض دارد. R-CNN، YOLO و SSD سریعتر با اشیاء کوچک مبارزه میکنند زیرا ویژگیهای CNN مورد استفاده برای تشخیص اشیا از بالاترین نقشه ویژگی کانولوشن با وضوح پایینتر جمعآوری شدهاند. پس از چند بار پایین آوردن نمونه، اندازه جسم پوشش منهول در بالاترین نقشه ویژگی کانولوشن، 1/16 یا 1/32 اندازه اصلی در تصاویر ورودی از راه دور است. این کاهش وضوح ممکن است منجر به از بین رفتن ویژگی های مهم شود و در نتیجه منجر به عملکرد تشخیص ضعیف شود.
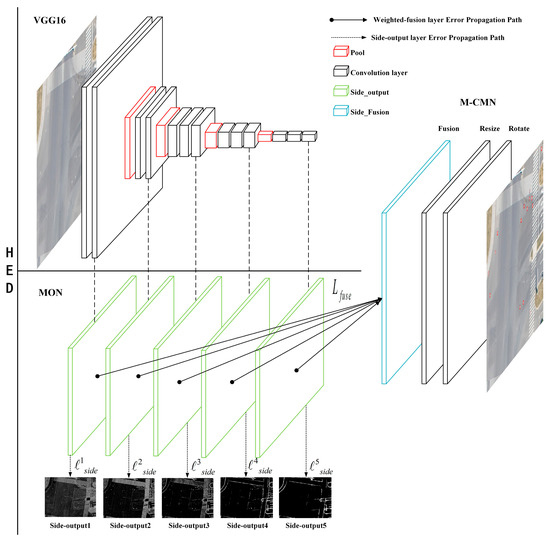
برای پرداختن به این مسائل، در این مقاله، ما روشی را برای بهبود شبکه HED نشان میدهیم [ 15 ] و یک رویکرد عمیق مبتنی بر CNN برای شناسایی پوششهای منهول کوچک در تصاویر سنجش از راه دور پیشنهاد میکنیم. مشابه سریعتر R-CNN، روش ما شامل دو مرحله است: یک شبکه خروجی چند مقیاسی (MON) و یک شبکه تطبیق پیچیدگی چند سطحی (M-CMN). ابتدا، معماری استخراج کننده ویژگی را با استفاده از روش گروه هندسه بصری (VGG) طراحی مجدد می کنیم [ 16 ]، که می تواند تنوع اندازه میدان های پذیرنده را افزایش دهد. برای شناسایی اجسام پوششی منهول کوچک، MON چندین خروجی جانبی لایههای میانی را برای افزایش وضوح نقشههای ویژگی ترکیب میکند. در نتیجه، اجسام پوششی منهول کوچک و متراکم را قادر میسازد تا مناطق بزرگتری از پاسخهای قوی ایجاد کنند. طرحهای شی از نقشههای ویژگی میانی مختلف با هم ترکیب میشوند تا خروجیهای MON را تشکیل دهند. سپس، این طرح های پیشنهادی برای تشخیص دقیق شی به M-CMN ارسال می شود.
سهم اصلی این مقاله به شرح زیر است:
1. ما معماری CNN را با استفاده از ماژول قدرتمند HED برای افزایش تنوع اندازههای میدان پذیرایی که میتوان برای گرفتن اشیاء پوششی منهول کوچک بهطور مؤثرتری مورد استفاده قرار داد، دوباره طراحی کرد. اگرچه HED برای طبقه بندی صحنه و تشخیص لبه آزمایش شده است، طبق دانش ما این اولین باری است که برای تأیید کارایی وظایف تشخیص اشیای کوچک در تصاویر سنجش از راه دور استفاده می شود.
2. ما چندین نقشه ویژگی میانی را ترکیب کردیم تا بتوان چندین سطح از جزئیات را به طور همزمان در نظر گرفت، بنابراین وضوح و دقت تشخیص اشیاء پوشش منهول کوچک و متراکم را بهبود می بخشد.
بقیه این مقاله به شرح زیر سازماندهی شده است. بخش 2 چارچوب تشخیص اشیا را پوشش می دهد. بخش 3 نتایج تجربی مقایسه ای را برای تشخیص اشیا پوشش منهول ارائه می دهد. بخش 4 شامل بحثی درباره این نتایج است و نتیجه گیری در بخش 5 ارائه شده است .
2. CNN چند مقیاسی برای تشخیص اشیاء پوشش منهول
ابتدا ساختار شبکه HED را دوباره طراحی کردیم. شکل 1 معماری دقیق روش پیشنهادی ما را نشان می دهد که از یک VGG16 و یک شبکه خروجی چند مقیاسی (MON) تشکیل شده است که منجر به یک شبکه تطبیق کانولوشن چند سطحی (M-CMN) می شود. VGG16 به عنوان یک استخراج کننده ویژگی استفاده می شود در حالی که هدف MON تولید خروجی های جانبی چند مقیاسی با میدان های مختلف دریافت فیلتر با استفاده از یک سری لایه های میانی است. پس از الحاق مقدار خروجی دکانولوشن خروجی های جانبی و انجام محاسبات کانولوشن برای به دست آوردن لایه همجوشی، این خروجی های جانبی متعدد و لایه همجوشی آنها برای تشخیص دقیق به M-CMN ارسال می شوند. با اشاره به نظارت عمیق [ 15 ]، پارامترهای شبکه ℓسمندهو Lfتوسهبه طور خودکار با استفاده از یک الگوریتم انتشار برگشتی برای تکمیل آموزش شبکه به روز می شوند.
2.1. جزئیات در مورد VGG16 Architecture
استخراج کننده کانولوشن ویژگی یک تصویر سنجش از راه دور با هر اندازه ای را به عنوان ورودی می گیرد و نقشه های ویژگی چند سطحی را خروجی می کند. طراحی این عنصر از آنجایی که انواع لایه ها و تعداد پارامترها به طور مستقیم بر کارایی، دقت و عملکرد آن تأثیر می گذارد، از اهمیت بسیار بالایی برخوردار است. مطالعات [ 17] نشان داده اند که استفاده از یک مدل کانولوشن عمیق تر با عمق چند صد لایه می تواند به طور قابل توجهی عملکرد بسیاری از وظایف تشخیص بصری، مانند تشخیص اشیا، طبقه بندی تصویر و تقسیم بندی معنایی را بهبود بخشد. با این حال، استفاده مستقیم از مدل تشخیص اشیاء بسیار عمیق در تشخیص تصویر سنجش از دور دشوار است زیرا این مدلهای بسیار عمیق میتوانند هزینههای محاسباتی بالایی را متحمل شوند، زیرا تصاویر سنجش از راه دور بزرگ هستند (معمولاً چند صد مگاپیکسل). علاوه بر این، یک مدل محاسباتی بسیار عمیق به تعداد زیادی نمونه آموزشی نیاز دارد، اما کمبود نسبی تصاویر سنجش از راه دور برچسبگذاری شده که میتوانند به عنوان دادههای آموزشی مورد استفاده قرار گیرند، وجود دارد. به منظور برآورده کردن این الزامات، ما VGG16 را به عنوان شبکه ستون فقرات انتخاب کردیم که به دلیل عملکرد تعمیم خوب آن به طور گسترده در استخراج کننده های ویژگی استفاده شده است.18 ، 19 ].
از آنجایی که وظیفه تشخیص در این مطالعه شامل اشیاء بسیار کوچک است، ما تکنیکهای برش دنباله، هسته پیچشی کوچک و “حفظ اندازه ورودی” را برای شبکه VGG16 برای افزایش عمق شبکه اتخاذ کردیم. این تضمین می کند که اندازه ورودی هر لایه با افزایش عمق به شدت کاهش نمی یابد و برای تشخیص اجسام کوچک بهتر سازگار است. به همین دلیل، شبکه فقط از پنج گروه اول VGG16 استفاده می کند. لایه های کاملا متصل و لایه های Soft-Max بریده شده اند. پس از برش دم، ساختار شبکه نشان داده شده در شکل 2 با پیکربندی شبکه ارائه شده در جدول 1 به دست می آید . شبکه اصلاح شده یک ساختار شبکه یادگیری چند مقیاسی و چند ترکیبی است که همانطور که در شکل 1 نشان داده شده است.، خروجی آخرین لایه کانولوشن را در هر مجموعه VGG16 استخراج می کند زیرا اندازه هر مجموعه تصویر متفاوت است. بنابراین، برای گسترش تصویر از هر گروه، که در واقع، به ترتیب معادل 2 تا 16 برابر اندازه گروه دوم تا پنجم تصاویر است، استفاده از کانولوشن/جلوگیری انتقالی نیز ضروری است. به این ترتیب، تصویر در هر مقیاس (هر مجموعه از VGG16 یک مقیاس است) یک اندازه است و سپس این تصاویر با هم ترکیب می شوند.
فرآیند فوق سه مزیت دارد.
1. برش لایه های کاملا متصل و لایه های Soft-Max می تواند به طور قابل توجهی هزینه حافظه و زمان را در طول آموزش و آزمایش کاهش دهد. علاوه بر این، به دلیل اینکه هیچ محدودیتی برای لایههای کاملاً متصل و لایههای Soft-Max وجود ندارد، تصاویر سنجش از راه دور با هر اندازهای میتوانند برای آموزش و تشخیص اشیا وارد شوند.
2. استفاده از هسته های کانولوشن 1×1 می تواند به کاهش پارامترهای پیچیدگی کمک کند. علاوه بر این، ظرفیت شبکه و پیچیدگی مدل را می توان به طور موثر افزایش داد، که تشخیص اشیاء پوشش منهول کوچک را بهبود می بخشد.
3. کانولوشن/جلوگیری جابجا شده اجازه می دهد تا هر گروه از تصاویر بسط داده شوند، که می تواند خروجی ویژگی را “حفظ اندازه ورودی” کند و بهتر آن را با تشخیص پوشش منهول کوچک تطبیق دهد.

2.2. شبکه خروجی چند مقیاسی (MON)
HED یک الگوریتم یادگیری ویژگی چند مقیاسی و چند سطحی است که با استفاده از تشخیص لبه برای دستیابی به پیشبینی انتها به انتها با یک مدل یادگیری عمیق مبتنی بر شبکههای عصبی کاملاً کانولوشن و شبکههای تحت نظارت عمیق است. HED به طور خودکار عبارات سلسله مراتبی غنی را یاد می گیرد و برای حل ابهام چالش برانگیز در تشخیص لبه و تشخیص مرز شی بسیار مهم است. به منظور رسیدگی به اندازه بسیار کوچک درپوش های منهول، ما مدل HED را برای انجام بهتر استخراج مرز و ایجاد مناطق لبه از طریق چندین لایه میانی با میدان های دریافتی مختلف بهبود دادیم. جدول 2) بهبود دادیم.) با الهام از SSD. این شبکه خروجی چند مقیاسی (MON) نام دارد. به طور خاص، فیلترهایی با اندازه کوچکتر (1 × 1) اضافه کردیم تا اشیاء پوشش منهول متراکم را در تصاویر سنجش از دور ثبت کنیم.
همانطور که در شکل 1 و 2 نشان داده شده است، لایه خروجی جانبی خود را به آخرین لایه کانولوشن در هر گروه (conv1_2، conv2_2، conv3_3، conv4_3 و conv5_3) متصل می کنیم. اندازه میدان پذیرنده هر یک از این لایه های کانولوشن با لایه خروجی جانبی مربوطه یکسان است. ما آخرین گروه VGG16 شامل لایه پنجم و تمام لایههای کاملاً متصل را برش میدهیم، زیرا لایه با گام 32 یک پوشش منهول خروجی ایجاد میکند که بسیار کوچک است، در نتیجه نقشه پیشبینی درونیابی شده برای استفاده بیش از حد مبهم خواهد بود. .
در طول آموزش، بیش از 90 درصد از پیکسل ها در زمینه حقیقت غیر لبه هستند، که بسیار مغرضانه است. در پاسخ به این نمونه گیری مغرضانه، هوانگ و لیو [ 8 ] یک تابع زیان حساس به هزینه را معرفی کردند و پارامترهای مبادله اضافی را شامل شدند. MON از همان روش HED برای جلوگیری از از دست دادن تعادل بین نمونههای مثبت و منفی استفاده میکند، که عبارت است از معرفی سطح پیکسلی وزن متعادل کلاس β . تابع تلفات متقابل آنتروپی متعادل کلاس به صورت زیر تعریف می شود:
جایی که W به پارامترهای لایه شبکه استاندارد اشاره دارد، w = ( w (1)، …، w ( m )) به وزن های مربوط به هر لایه خروجی جانبی اشاره دارد، m شبکه ای است که m لایه خروجی جانبی دارد و β = | Y _|/| Y | و 1 – β = | Y +|/| Y | و | Y _| و | Y +| به ترتیب مجموعه برچسب حقیقت زمین لبه و غیر لبه هستند.
برای استفاده از نتایج پیشبینی خروجی جانبی، تابع تلفات به نام فیوز L ( W , w , h ) برای افزودن یک لایه همجوشی وزنی است:
که در آن h = ( h 1 ، …، h m ) وزن همجوشی و Dist (…) فاصله بین پیش بینی های ذوب شده و نقشه برچسب حقیقت زمین است. با کنار هم قرار دادن هر تابع ضرر، MON تابع هدف زیر را از طریق انتشار گرادیان نزولی تصادفی (SGD) به حداقل می رساند:
که در آن پارامترهای بهینه W توسط SGD [ 20 ] بهینه شده است. برای جلوگیری از برازش بیش از حد، ما مدل HED از پیش آموزشدیده [ 15 ] را برای بخشبندی PASCAL VOC-2012 اتخاذ کردیم تا لایههای کانولوشنال را مقداردهی کنیم. هنگامی که آموزش MON به پایان رسید، نتایج پیش بینی شده را از لایه خروجی جانبی و لایه همجوشی وزنی به طور همزمان بدست می آوریم و آنها را با هم ادغام می کنیم تا تصویر بهتری بدست آوریم.
روشهای سنتی تشخیص شیء، تصویر سنجش از راه دور ورودی را چندین بار تغییر مقیاس میدهند ( شکل 3 الف) یا چندین فیلتر را روی یک تصویر ورودی اعمال میکنند ( شکل 3 ب) تا با تمام اشیاء هدف ممکن مطابقت داشته باشد. این امر استفاده از چندین لایه نقشه ویژگی را برای این روش ها دشوار می کند. به منظور افزایش دقت تشخیص، روش جدیدی به نام M-CMN برای به دست آوردن تشخیص پوشش منهول از طریق پنج لایه خروجی جانبی و چند لایه همجوشی با اندازههای مختلف فیلتر پیشنهاد میکنیم (شکل 3) .ج). M-CMN یک تصویر سنجش از راه دور با لبههای پیشبینیشدهاش (تولید شده توسط MON) به عنوان ورودی میگیرد و تشخیص پوشش منهول تصفیه شده را خروجی میکند. M-CMN با الهام از موفقیت ترکیب نمایش چند سطحی در SSD، لایههای چند سطحی را با وضوحهای مختلف ترکیب میکند تا به نقشههای ویژگی آموزندهتر برای تشخیص دقیق پوشش منهول دست یابد ( شکل 3) .ج). از آنجایی که اشیاء پوشش منهول در تصاویر سنجش از راه دور در مقیاس بزرگ اندازه نسبتاً کوچکی دارند و در گروههای توزیع متراکم ظاهر میشوند، ما به طور خاص لایه conv1_2 را به عنوان لایه مرجع انتخاب کردیم و لایههای conv2_2 و conv3_3 و لایههای conv4_3 و conv5_3 را با مقیاسبندی بالا به هم متصل کردیم. (با استفاده از کانولوشن انتقال/پیچیدگی انتقالی). این به این دلیل است که لایه conv1_2 با وضوح بالاتر برای تشخیص اجسام کوچک و متراکم پوشش منهول مناسب تر است. همانطور که در آزمایشهای ما نشان داده شده است، از آنجایی که لایههای کمعمقتر برای مرجع مناسبتر هستند و لایههای عمیقتر برای تطبیق مناسبتر هستند، نقشههای ویژگی به هم پیوسته برای تشخیص پوشش منهول در اندازه کوچک مکمل هستند.
3. نتایج تجربی
در این بخش، روش خود را برای تشخیص پوشش منهول کوچک از تصاویر سنجش از دور ارزیابی میکنیم. آزمایشها بر اساس چارچوب یادگیری عمیق ما پیادهسازی شده و بر روی سروری با E5-2697V4 * 2 CPU، NVIDIA K80*20 GPU، حافظه 256 گیگابایتی و Ubuntu 16.04 به عنوان سیستم عامل سرور اجرا میشوند.
3.1. مجموعه داده
عکسهای هوایی با وضوح فضایی 0.05 متر از شهر ژنجیانگ، استان جیانگ سو، که در سال 2017 گرفته شدهاند، در این مطالعه استفاده شد. یک سند نتیجه بررسی (نقاط برداری) برای پوشش های منهول در این منطقه وجود دارد که به راحتی می توان با دسته حقیقت زمین در تصویر برچسب گذاری کرد. داده های حقیقت زمینی برچسب گذاری شده را می توان در آن مشاهده کرد شکل 4 مشاهده کرد. با در نظر گرفتن حافظه GPU و سرعت پردازش، هر تصویر هوایی اصلی به چندین بلوک تصویر مجاور با وضوح 512 × 512 پیکسل برش داده می شود، که افزایش آن ها را آسان تر می کند و حافظه GPU کمتری مصرف می کند، که می تواند کارایی آموزش را بهبود بخشد. با توجه به اندازه کوچک درپوش های منهول، نسبت همپوشانی بلوک تصویر مجاور را 0.05 تنظیم کردیم و حاشیه نویسی اهدافی را که از مرزهای بلوک تصویر عبور می کنند حذف کردیم. سپس، بلوک های تصویری بدون اهداف پوشش منهول دور ریخته می شوند. از 2382 تصویر (23252 شی پوشش منهول) پس از پردازش دسته ای، 1500 به عنوان مجموعه داده های آموزشی، 500 به عنوان مجموعه داده های اعتبار سنجی و 382 به عنوان مجموعه داده های آزمایشی استفاده می شود.
3.2. مدل و پارامترها
روش ما به هک مهندسی نسبتا کمی نیاز دارد زیرا چارچوب ما با استفاده از کتابخانه Caffe و TensorFlow در دسترس عموم پیادهسازی میشود و شبکه از مدل VGG16 و مدل HED از پیش آموزشدیده تنظیم شده است.
با پیروی از استراتژیهای مشخص شده در Dollár و Zitnick [ 21 ]، ما تغییرات مختلف شبکه و همچنین آموزش پارامترهای فوقالعاده را در مجموعه اعتبارسنجی ارزیابی میکنیم. از طریق آزمایش، ما فوق پارامترهای زیر را انتخاب کردیم: اندازه کوچک دسته ای (12)، نرخ یادگیری (1e-6)، کاهش وزن αm برای هر لایه خروجی جانبی (1)، تکانه (0.9)، وزن های اولیه فیلتر تو در تو. (0)، وزن اولیه لایه همجوشی (1/5)، کاهش وزن (0.0002) و تکرار تمرین (10000؛ تقسیم نرخ یادگیری بر 10 بعد از 5000).
3.3. نتایج
به منظور استفاده بهتر از شبکههای کانولوشن برای شناسایی اشیاء پوشش منهول، ما تشخیص پیچیدگی را در چندین لایه خروجی MON انجام میدهیم. همانطور که در شکل 5 نشان داده شده است، اطلاعات مربوط به تصاویر سنجش از راه دور شناسایی شده توسط شش لایه خروجی شبکه MON نشان می دهد که جزئیات لایه های خروجی جانبی 1-5 تمایل به کاهش دارد، در حالی که لبه لایه همجوشی آشکار است و برخی جزئیات نیز مشخص است. حفظ شد. این به این دلیل است که شبکه MON خود یک شبکه همجوشی چند مقیاسی است. همانطور که میدان های پذیرنده لایه خروجی جانبی بزرگتر می شوند، جزئیات محلی به تدریج تخریب می شوند، در حالی که لایه همجوشی با به دست آوردن اطلاعات چند مقیاسی، جزئیات محلی را حفظ می کند.
ما سه شاخص پرکاربرد را برای ارزیابی عملکرد تشخیص پوشش منهول اتخاذ می کنیم. یعنی دقت، یادآوری و امتیاز F1. دقت اندازه گیری کسر تشخیص هایی است که مثبت واقعی هستند و یادآوری اندازه گیری کسری از موارد مثبت است که به درستی شناسایی شده اند. امتیاز F1 معیارهای ترکیبی دقت و یادآوری در یک معیار واحد برای ارزیابی جامع کیفیت یک روش تشخیص شی است [ 4 ].
جدول 3 نتایج مقایسه کمی 9 روش مختلف را نشان می دهد که با دقت، یادآوری و امتیاز F1 اندازه گیری شده اند. بهترین اجراها به صورت ایتالیک و زیر خط کشیده شده اند. مشاهدات زیر ذکر شد: (1) در مقایسه با سریعتر R-CNN، YOLOv3 به عملکرد تشخیص مشابه اندازهگیری شده در Precision و YOLOv3 دستاوردهای عملکردی در Recall و F1-score به دست میآورد. SSD بالاترین Recall را دارد اما دقت کمی پایینتر است. در بین سه روش مقایسه، YOLOv3 بهترین عملکرد را با توجه به نرخ فراخوان و دقت دارد و سرعت پردازش آن نیز سریعترین است. (2) در مقایسه با SSD، الگوریتم DSSD [ 22 ] امتیاز FI را به 0.8108 افزایش میدهد. با این حال، از آنجایی که DSSD از resnet-101 به عنوان یک شبکه اصلی استفاده می کند، سرعت آموزش بسیار کمتر است. FSSD [ 23] از FPN درس می گیرد و از یک هسته پیچشی کوچک استفاده می کند، بنابراین دقت الگوریتم به وضوح بهبود می یابد و سرعت آموزش کاهش نمی یابد. در تست پوشش منهول کوچک، عملکرد FSSD کمی بهتر است و امتیاز FI به 0.8266 می رسد. (3) روش های همجوشی ما به مقادیر بهینه یا کمتر از حد بهینه دقت، یادآوری و امتیاز F1 برای اجسام پوشش منهول دست می یابند. در مقایسه با هر نه روش، Ours-fusion 4 بهترین عملکرد را از نظر دقت و Ours-fusion 2 بهترین عملکرد را از نظر Recall به دست آورد، که نشان می دهد جسم پوشش منهول که 4 بار ظاهر می شود می تواند به طور موثر دقت تشخیص اشیا را بهبود بخشد اما تأثیر زیادی در یادآوری. شیء پوشش منهول که دو بار ظاهر می شود می تواند به طور موثر Recall تشخیص شی را افزایش دهد، اما تأثیر زیادی بر دقت تشخیص اشیا دارد. نتیجه ادغام سه بار اجسام پوشش منهول از نظر دقت مناسب، یادآوری و امتیاز F1 بهترین است. این به این دلیل است که اکثر اجسام پوششی منهول سه بار در پنج لایه خروجی جانبی و یک لایه همجوشی ظاهر می شوند.شکل 5).
شکل 6 تعدادی از نتایج تشخیص جسم پوشش چاه را با رویکرد پیشنهادی نشان می دهد. نقاط قرمز نشان دهنده اشیاء پوشش منهول شناسایی شده است. برخی از اشیاء دارای قله های متراکم و کوچک با زمینه های پیچیده هستند. این نشان می دهد که روش ما می تواند با موفقیت اکثر اجسام پوشش چاه را شناسایی کند.
4. بحث
4.1. آیا افزایش عمق شبکه ستون فقرات می تواند عملکرد تشخیص اشیای کوچک را بهبود بخشد؟
در این مطالعه، YOLOv3 از Darknet-53 به عنوان یک شبکه ستون فقرات و DSSD از Resnet-101 به عنوان یک شبکه ستون فقرات استفاده کردند. با این حال، مثبت واقعی تشخیص شی YOLOv3 و DSSD به طور قابل توجهی بهبود نیافته است ( جدول 4 ). Darknet-53 و Resnet-101 عمیق تر از VGG16 هستند و ویژگی های استخراج شده دارای اطلاعات معنایی بالاتری هستند، بنابراین اثر تشخیص Darknet-53 و Resnet-101 باید بیشتر از VGG16 باشد. برخی از مطالعات نشان می دهد که جایگزینی VGG16 با Resnet-101 به طور مستقیم در زیر تصویر ورودی 300 × 300 منجر به کاهش به جای افزایش دقت می شود [ 22 ].
بلوک های تصویر با وضوح 512 × 512 پیکسل مورد استفاده در این مقاله از طریق افزایش عمق شبکه ستون فقرات بدون پیشرفت قابل توجه در عملکرد تشخیص پوشش منهول کوچک ( جدول 3 و جدول 4 ) عبور داده شد. این به این دلیل است که پوششهای منهول در تصاویر سنجش از راه دور نسبتا کوچک هستند و در گروههای پراکنده ظاهر میشوند، در حالی که شبکههای پیچش عمیق مانند Darknet-53 و Resnet-101 که برای تشخیص اشیا استفاده میشوند، از بالاترین نقشه ویژگی کانولوشن با وضوح پایینتر ترکیب شدهاند. پس از چند بار نمونه برداری، درپوش های منهول کوچک در بالاترین نقشه ویژگی کانولوشن ناپدید می شوند. خروجی جانبی 5 در شکل 5نشان می دهد که تنها پس از پنج بار نمونه برداری پایین، ویژگی های پوشش منهول ناپدید می شوند، که منجر به بهبود محدود اثر تشخیص با استفاده از شبکه عمیق Darknet-53 و Resnet-101 می شود. به دلایل بالا، ما VGG16 را به عنوان شبکههای ستون فقرات انتخاب کردیم، پردازش tail-cutting و corenel convolution کوچک را پذیرفتیم و میدان دریافتی بزرگ را رها کردیم. بنابراین، نتیجه تشخیص برای اندازه کوچک، ساختار منفرد و ظاهر متراکم اجسام پوشش منهول بهتر بود.
4.2. آیا فیچر فیوژن چند مقیاسی و چند سطحی می تواند عملکرد تشخیص اشیای کوچک را بهبود بخشد؟
SSD از نقشههای ویژگی چند مقیاسی برای پیشبینی اهداف استفاده میکند، از ویژگیهای سطح بالا با میدان پذیرنده بزرگتر برای پیشبینی اشیاء بزرگ و از ویژگیهای سطح پایین با میدان پذیرنده کوچکتر برای پیشبینی اهداف کوچک استفاده میکند. این یک سوال را ایجاد می کند: هنگام استفاده از ویژگی های یک شبکه سطح پایین برای پیش بینی اهداف کوچک، نتایج طبقه بندی SSD برای اشیاء کوچک به دلیل فقدان ویژگی های معنایی سطح بالا ضعیف است. نکته استفاده از DSSD برای حل این مشکل، ترکیب اطلاعات معنایی سطح بالا و سطح پایین، غنیسازی جعبههای مرزی رگرسیون پیشبینی و نقشههای ویژگی چند مقیاسی ورودی کار طبقهبندی است تا اثر تشخیص را بهبود بخشد. با این حال، به دلیل پیچیدگی مدل، سرعت آن بسیار کمتر است. FSSD از FPN برای مرجع استفاده میکند و مجموعهای از نقشههای ویژگی هرمی را بازسازی میکند تا به وضوح کارایی تشخیص مدل را با سرعت برتر (یعنی نه به آهستگی) بهبود بخشد. به طور کلی، DSSD و FSSD عملکرد تشخیص را با ترکیب نقشه ویژگی زمینه سطح بالا با نقشه ویژگی سطح پایین بهبود می بخشند.جدول 3 ).
نتایج جدول 3 نشان می دهد که اثرات تشخیص DSSD و FSSD به طور قابل توجهی بالاتر از SSD است و امتیازات F1 می تواند به ترتیب به 0.8108، 0.8266 و 0.7454 برسد. با این حال، همانطور که در جدول 4 نشان داده شده است، مثبت واقعی آنها زیاد نیست. DSSD حتی کمتر از SSD است (به ترتیب 3551 و 3641). DSSD و FSSD میتوانند به چنین امتیاز F-1 بالایی برسند، زیرا نرخهای اشتباه محاسباتی منفی و مثبت کاذب به طور موثر با ترکیب ویژگیهای چند مقیاسی و چند سطحی کاهش مییابد. یعنی احتمال قضاوت نادرست دیگر اجسام به عنوان پوشش منهول از طریق همجوشی ویژگی های چند مقیاسی و چند سطحی بسیار کاهش یافته است. مدل ما همچنین ثابت میکند که اثر تشخیص درپوشهای منهول کوچک را میتوان با همجوشی ویژگیهای چند مقیاسی و چند سطحی، به ویژه مثبت واقعی Ours-fusion3 (4035) بهبود بخشید، در حالی که منفی کاذب و مثبت کاذب را میتوان به 317 کاهش داد. و 635 به ترتیب.
5. نتیجه گیری ها
در این مقاله، ما یک رویکرد موثر مبتنی بر DCNN برای تشخیص اجسام پوششی کوچک منهول در تصاویر سنجش از راه دور پیشنهاد میکنیم. تشخیص با استفاده از یک استخراجکننده ویژگی DCNN بازطراحیشده انجام میشود و توسط دو زیرشبکه دنبال میشود: یک MON برای تولید لبه جسم پوششی منهول از چندین لایه میانی، که میدانهای گیرنده آن با مقیاسهای مختلف جسم پوشش منهول مطابقت دارند و میتوانند چند مقیاس و چند مقیاس تولید کنند. پاسخها و خروجیهای ویژگی سطح و M-CMN برای تشخیص اشیاء پوشش منهول بر اساس نقشههای ویژگی ذوب شده. در مقایسه با سریعتر R-CNN، YOLOv3، SSD، DSSD و FSSD، مدل شبکه DCNN ما میتواند به طور موثری دقت و نرخ فراخوان را در تشخیص اشیاء پوشش منهول کوچک بهبود بخشد. در مطالعات آینده، ما قصد داریم بر روی یادگیری ویژگیهای عمقی ثابت چرخش برای انواع بیشتری از تشخیص اشیا تمرکز کنیم.24 ، 25 ، 26 ]. علاوه بر این، ما محاسبات خوشهای چند GPU را برای کاهش بیشتر زمان محاسبه مدل شبکه عمیق در نظر خواهیم گرفت.








بدون دیدگاه