
GEOBIA در مقیاس تراپیکسل: به سمت نقشه برداری کارآمد از ویژگی های چوبی کوچک از صحنه های ناهمگن VHR
خلاصه
نقشه برداری پوشش زمین از معرفی پارادایم تحلیل تصویر مبتنی بر شی جغرافیایی (GEOBIA) سود زیادی برده است، که اجازه می دهد از تجزیه و تحلیل پیکسلی به پردازش عناصر با محتوای معنایی غنی تر، یعنی اشیا یا مناطق، حرکت کنیم. با این حال، این پارادایم مستلزم تعریف یک مقیاس مناسب است، که می تواند در یک مطالعه بزرگ که در آن طیف وسیعی از مناظر قابل مشاهده است چالش برانگیز باشد.

ما در اینجا پیشنهاد میکنیم که تجزیه و تحلیل چند مقیاسی را بر اساس نمایشهای سلسله مراتبی انجام دهیم، که از آن ویژگیهای شناخته شده به عنوان پروفایل ویژگیهای دیفرانسیل بر روی هر پیکسل منفرد مشتق میشوند. الگوریتمهای کارآمد و مقیاسپذیر برای ساخت و تحلیل چنین نمایشهایی، همراه با استفاده بهینه از طبقهبندیکننده جنگل تصادفی، یک چارچوب نیمه نظارت شده به ما ارائه می دهد که در آن کاربر می تواند نقشه برداری از عناصری مانند ویژگی های چوبی کوچک را در یک منطقه بسیار بزرگ هدایت کند. در واقع، روش منبع باز پیشنهادی با موفقیت برای استخراج بخشی از محصول لایههای وضوح بالا (HRL) از سرویس نظارت بر زمین کوپرنیک استفاده شده است، بنابراین نشان میدهد که چگونه چارچوب GEOBIA میتواند در یک سناریوی کلان دادههای ساخته شده از بیش از 38000 تصویر ماهواره ای با وضوح بسیار بالا (VHR) که بیش از 120 ترابایت داده را نشان می دهد.
کلید واژه ها:
کلان داده ؛ مقیاس پذیری ؛ تجزیه و تحلیل چند مقیاسی ; نقشه برداری پوشش زمین ; نقشه برداری ویژگی های چوبی ; پروفایل های ویژگی دیفرانسیل ; جنگل تصادفی ; متن باز
1. معرفی
در حالی که پارادایم GEOBIA به لطف پردازش اشیاء (یعنی مناطق) به جای پیکسل ها [1] منجر به پیشرفت های قابل توجهی در تجزیه و تحلیل و درک تصاویر سنجش از دور با وضوح بالا شده است، اما همچنان نیاز به شناسایی اشیاء (یا قطعه بندی تصویر) دارد . به مناطق) قبل از اعمال مجموعه ای از قوانین برای طبقه بندی اشیاء استخراج شده. این مرحله تقسیمبندی ساده نیست و اغلب به تخصص کاربر یا تنظیم تجربی برای تطبیق با هر صحنه جدیدی که باید پردازش شود، متکی است، حتی اگر برخی از رویکردهای خودکار وجود داشته باشد [ 2 ، 3]]. بنابراین، نمیتوان از آن برای دادههای جغرافیایی بزرگ استفاده کرد که در آن تحلیلهای منطقه بزرگ به روشهایی نیاز دارند که هم بسیار کارآمد و هم قوی (قابل استفاده در زمینههای مختلف) برای طیف گستردهای از صحنههای قابل مشاهده هستند.
ما در اینجا با تکیه بر چارچوب نمایش تصویر چند مقیاسی به این مسائل متعدد می پردازیم. این چارچوب، اشیاء مختلف (تودرتو) را در ساختاری به نام درخت مورفولوژیکی، بدون نیاز به تنظیم پارامتر، جاسازی میکند. محاسبه چنین پشتهای از بخشبندیها از برخی پیادهسازیهای مقیاسپذیر اخیر سود میبرد که استخراج بسیار سریع آنها را از مجموعه دادههای تصویری که مناطق وسیعی را پوشش میدهند (بیش از 1 میلیون کیلومتر مربع ) واقع بینانه میسازد [ 4 ، 5]]. به منظور جلوگیری از سردرگمی در اصطلاح “درخت” در این سند. ما از SWF (ویژگی های چوبی کوچک) برای پوشش گیاهی، درختان تصمیم برای جنگل تصادفی و درختان برای نمایش سلسله مراتبی (یا ساختار درختی) استفاده خواهیم کرد. هنگامی که ساختار درختی استخراج شد، تجزیه و تحلیل تصویر بیشتر با هزینه محاسباتی بسیار کم، با تکیه بر پیادهسازی کارآمد پروفایلهای مشخصه دیفرانسیل (DAP)، که ویژگیهای مهندسی شده پیشرفتهای برای نقشهبرداری پوشش زمین هستند، انجام میشود [ 6 ] . ما از کارایی مراحل مختلف (ساخت درخت، استخراج ویژگی، آموزش، پیشبینی) برای پیشنهاد یک استراتژی نیمه نظارت بهره میبریم. 7]] که در آن ما مدل را برای هر نوع منظره بازآموزی میکنیم، بنابراین اجازه میدهیم تا با تنوع زیاد ظاهر اشیاء در یک منطقه بسیار بزرگ (یعنی تصاویر VHR در مقیاس پاناروپایی) مقابله کنیم. با توجه به هزینه محاسباتی کم (به عنوان مثال، چند دقیقه برای یک صحنه Pleiades یا WorldView-2/3)، کاربر می تواند به طور تعاملی طبقه بندی را با به روز رسانی نمونه های مرجع مورد استفاده برای آموزش مدل بهبود بخشد. راهحل مقیاسپذیر پیشنهادی کاملاً بر مؤلفههای منبع باز متکی است (Orfeo ToolBox ( https://www.orfeo-toolbox.org ) [ 8 ]، Boost ( https://www.boost.org ) [ 9 ]، GDAL ( https: //www.gdal.org ) [ 10 ]، کوسه ( https://image.diku.dk/shark/ ) [ 11]، Triskele ( https://sourcesup.renater.fr/triskele ) ماژول راه دور OTB) و بنابراین می توان در هر برنامه GEOBIA استفاده کرد.
برای نشان دادن روششناسی خود، ما در اینجا نقشهبرداری از ویژگیهای چوبی کوچک (SWF) را در نظر میگیریم، که قرار است به عنوان بخشی از یک لایه جدید با وضوح بالا (HRL ( https://land.copernicus.eu/pan-european/high ) گنجانده شود. لایه های رزولوشن )) که کل اروپا را از ایسلند تا ترکیه در بخش پان-اروپایی کوپرنیک خدمات نظارت بر زمین پوشش می دهد. ویژگیهای چوبی کوچک (SWF) برخی از پایدارترین ویژگیهای خطی و کوچک مناظر با پوشش گیاهی را نشان میدهد که عملکردهای زیستمحیطی و اجتماعی-فرهنگی متعددی را در رابطه با حفاظت از خاک و آب، حفاظت و سازگاری آب و هوا، تنوع زیستی و هویت فرهنگی ارائه میکند [12 ، 13 ، 14 ]]. اگرچه یک ویژگی خطی به تنهایی نمی تواند همه این عملکردها را تضمین کند، SWF از نظر اکولوژیکی عناصر چشم انداز ساختاری مهمی هستند که به عنوان بردارهای مهم تنوع زیستی عمل می کنند و زیستگاه های حیاتی و خدمات اکوسیستم را ارائه می دهند. پرچین ها و گروه های درختی با غنای چشم انداز و تکه تکه شدن زیستگاه ها با پتانسیل مستقیم برای بازسازی مرتبط هستند و در عین حال به حفاظت از خطرات و زیرساخت های سبز، از جمله، کمک می کنند. اهمیت اکولوژیکی خاص SWF نیاز به اطلاعات مکانی دقیق و قابل اعتماد در مورد وقوع و توزیع ویژگی های خطی چشم انداز را نشان می دهد. SWF بخش ابتدایی زیرساخت سبز چشم انداز است و بنابراین از طریق طیف وسیعی از سیاست ها و دستورالعمل ها مانند استراتژی تنوع زیستی 2020 اتحادیه اروپا [ 15] مورد توجه قرار می گیرد.] و به طور خاص هدف 2 آن با توجه به نگهداری اکوسیستم، احیا و ایجاد زیرساخت سبز، به وضوح نیاز به نظارت سیستماتیک چنین ویژگی هایی را بیان می کند که برای وضعیت اکوسیستم و ارائه خدمات اکوسیستم بسیار مهم است.
استخراج این اشیاء در چنین منطقه وسیعی (تقریباً 6 میلیون کیلومتر مربع ) از تصاویر VHR چالش های متعددی را به همراه دارد: حجم زیاد داده (بیش از 120 ترابایت)، تعداد زیادی صحنه های تصویری فردی (بیش از 38000)، تنوع مناظر اروپایی. ، و نیاز به پردازش به موقع این داده ها و در عین حال اطمینان از درجه رضایت بخشی از دقت دارد. ابزارهای موجود برای نقشهبرداری خودکار SWF تا حدی بر چالشهای فوق غلبه میکنند، اما توانایی مقابله با Big GeoData را ندارند. مشابه روش پیشنهادی ما، روشهای موجود علاوه بر ویژگیهای طیفی بر ویژگیهای فضایی به ماهیت متنوع مدل SWF متکی هستند، اما روش ما ویژگیهای فضایی را به شیوهای متفاوت و کارآمدتر مدلسازی میکند. به عنوان مثال، در [ 16استراتژیهای مبتنی بر نمونهگیری متقاطع خطی برای تشخیص ویژگیهای خطی استفاده شد، در [ 17 ] ویژگی خطی بر اساس گرادیان تصویر، و ویژگیهای مبتنی بر همزمانی استخراج شدند، در [ 18 ، 19 ] ویژگیهای مبتنی بر شی از طریق تقسیمبندی تصویر با پارامترهای مختلف استخراج شدند. ، در [ 20 ] ویژگی های گابور و گرانولومتری استخراج شد و سپس از عملگرهای مورفولوژیکی استفاده شد و در نهایت در [ 21 ، 22]ویژگی های مورفولوژیکی جهت دار با عناصر ساختاری مختلف استخراج شد. به خوبی شناخته شده است که این ویژگی ها تعمیم نمی یابند و نمی توان آنها را به طور موثر محاسبه کرد در حالی که چنین الزاماتی برای EO در مقیاس بزرگ مورد نیاز است. از سوی دیگر، روش پیشنهادی ما بر اساس پروفایل های ویژگی، ویژگی های بهتری را استخراج می کند و همچنین می تواند الزامات Big GeoData را برآورده کند. علاوه بر این، روشهای موجود به نمونههای مرجع پیشزمینه و پسزمینه برای آموزش طبقهبندیکننده نظارتشده نیاز دارند، اما در سناریوهای عملی، ما اغلب اشیاء پیشزمینه را فقط از طریق نقشههای کمکی در اختیار داریم. برای رسیدگی به این وضعیت که در آن نمونههای آموزشی تنها از یک کلاس در دسترس است، میتوانیم یک طبقهبندیکننده تک کلاسی را در نظر بگیریم. با این حال، نشان داده شد که چنین رویکردی عمدتا قابل اعتماد نیست [ 23] در برنامه های نقشه برداری. بنابراین، در روش پیشنهادی ما، یک استراتژی نیمه نظارت شده ساده ابداع کردیم که به طور خودکار اشیاء پسزمینه متنوع را در رابطه با اشیاء پیشزمینه انتخاب میکند، و همچنین نمونههای مرجع شی پیشزمینه را از طریق تعامل کاربر گسترش میدهد. روش معرفی شده در اینجا مزایای عمده ای نسبت به روش های موجود برای پردازش منطقه بزرگ دارد.
این مقاله به شرح زیر سازماندهی شده است. ما روش شناسی پیشنهادی را در بخش 2 بررسی می کنیم . کاربرد موضوعی در نقشه برداری SWF در بخش 3 مورد بررسی قرار گرفته است ، جایی که نتایج کمی و همچنین بحث نیز ارائه شده است. در نهایت مقاله را در بخش 4 به پایان می رسانیم .
2. روش
در این بخش، روش پیشنهادی را با تمرکز بر معماری کلی ارائه میکنیم، قبل از اینکه دو جزء اصلی را که استخراج ویژگی بر اساس پروفایلهای ویژگی و طبقهبندی نیمه نظارت شده بر اساس جنگل تصادفی هستند، با جزئیات بیشتر شرح دهیم.
2.1. معماری کلی
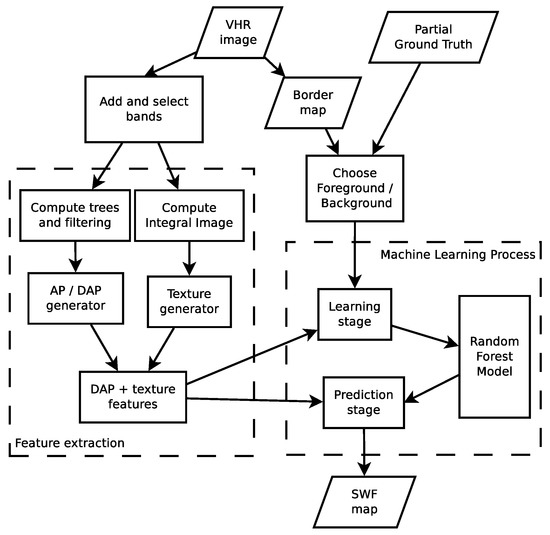
برای تطابق پارادایم GEOBIA با تجزیه و تحلیل منطقه بسیار بزرگ، ما در اینجا پیشنهاد می کنیم که به جای کاربرد استاندارد مجموعه قوانین GEOBIA بر روی اشیاء از پیش استخراج شده، تجزیه و تحلیل پیکسلی ویژگی های مبتنی بر شی را در یک چارچوب طبقه بندی نیمه نظارت شده انجام دهیم. روش شناسی کلی در شکل 1 آورده شده است .
در مرحله اول، تصویر VHR ورودی با محاسبه برخی از شاخص های از پیش تعریف شده برای استخراج کانال های تصویر جدید غنی می شود. در میان معیارهای در نظر گرفته شده، ما به NDVI معروف و کمهزینه (شاخص گیاهی تفاوت عادی) و همچنین گرادیان Sobel برای توصیف بافت (مرحله «افزودن و انتخاب باندها») تکیه میکنیم. در واقع، در حالی که ویژگی های Haralick برای توصیف بافت محبوب هستند، و اخیراً با چارچوب مشخصات ویژگی [ 24] همراه شده اند.] برای بهبود خصوصیات تصاویر بافت ماهواره ای، آنها بر یک ماتریس همزمانی سطح خاکستری تکیه می کنند که باید برای فواصل و جهت گیری های متعدد محاسبه شود (مرحله “مولد توصیفگر”). اطلاعات بافت از هر باند طیفی تصویر چند طیفی اصلی و همچنین از تصویر NDVI استخراج میشود، بنابراین منجر به تولید چندین تصویر سوبل میشود. علاوه بر این، ما ویژگیهای بافتی تک مقیاس را با الگوریتمهای کارآمد بر اساس نمایشهای تصویر یکپارچه [ 25 ]، مانند ویژگیهای Haar مانند و آمار محلی (میانگین، انحراف استاندارد، آنتروپی) محاسبه میکنیم.
این مرحله اول همچنین امکان استخراج یک ماسک باینری (“نقشه مرزی”) را فراهم می کند که برای کنار گذاشتن پیکسل های علامت گذاری شده به عنوان بدون داده در مراحل پردازش بعدی مفید خواهد بود. چنین مقادیری به پیکسل های غیر قابل توجه پس از مراحل استاندارد پیش پردازش مانند تصحیح ارتو و پوشش ابری داده می شود. در مورد ما، مقدار صفر در تمام باندها به آنها اختصاص داده شده است.
همه باندها برای تعیین مناطق بدون داده استفاده می شوند، زیرا همانطور که قبلاً گفته شد، پیکسل های بدون داده به عنوان پیکسل هایی که دارای مقادیر تهی در همه باندها هستند، شناسایی می شوند. اما ما برای پیش بینی طبقه بندی به همه باندها نیاز نداشتیم. به عنوان مثال، می توان تنها از NDVI برای تجزیه و تحلیل ویژگی های چوبی استفاده کرد. با توجه به هر تحلیل، برخی از باندها انتخاب می شوند.
از مجموعه باندهای انتخاب شده، سپس از طریق مدل درختان مورفولوژیکی که ویژگیهای چند مقیاسی نامیده میشوند (مرحله «مولد AP/DAP») از آنها، نمایشهای چند مقیاسی ایجاد میکنیم. چنین درختانی را می توان به عنوان پشته ای از تقسیم بندی های تو در تو و در نتیجه به عنوان تعمیم مفهوم لایه تقسیم بندی تک مقیاس در ابزار GEOBIA مشاهده کرد. برای هر نمایش سلسله مراتبی، ما برخی از ویژگی ها (به عنوان مثال، مساحت، وزن، …) را برای همه اجزا، به عنوان مثال، اشیایی که در مقیاس های مختلف برای یک پیکسل مشخص ظاهر می شوند، اندازه گیری می کنیم. بنابراین این ویژگی ها به هر پیکسل اختصاص داده می شود. محاسبه درختان و نمایه های ویژگی با جزئیات بیشتر در بخش 2.2 توضیح داده شده است .
مرحله بعدی استفاده از طبقهبندیکننده جنگل تصادفی در یک چارچوب نیمه نظارت شده (مرحله یادگیری و پیشبینی) است. مزیت استفاده از طبقهبندیکننده نظارتشده نسبت به مجموعه قوانین از پیش تعریفشده، توانایی انطباق با طیف وسیعی از مناظر بدون تعریف صریح از ویژگیهای اشیاء نقشهبرداری شده است. با این حال، همچنین به نمونههای برچسبگذاریشدهای نیاز دارد که کلاس جستجو و پسزمینه را توصیف کنند. از آنجایی که برچسب زدن یک تصویر کامل با وضوح بسیار بالا فوق العاده است، ما ترجیح می دهیم یک استراتژی نیمه نظارتی را معرفی کنیم که در آن نمونه های آموزشی با گسترش مجموعه های اولیه ارائه شده توسط کاربر تولید می شوند. با توجه به زمان کم محاسباتی فرآیند طبقهبندی بر روی نمونههای برچسبگذاری شده، کاربر میتواند به راحتی کیفیت مجموعه آموزشی را با ارائه نمونههای جدید (پیشزمینه و پسزمینه) بهبود بخشد. زمانی که مدل دقت کافی داشت، پیش بینی نهایی انجام می شود. جزئیات بیشتر در آورده شده استبخش 2.3 .
فرآیند کلی به دلیل سطح بالای موازی در مراحل مختلف بسیار کارآمد است. خواننده علاقه مند به جزئیات الگوریتمی و بهینه سازی خط لوله کلی به مقاله اختصاصی ارجاع داده می شود [ 7 ].
2.2. استخراج ویژگی
پارادایم GEOBIA معمولاً بر اساس برخی از ویژگی هایی است که از هر شی یا منطقه منفرد در یک نقشه تقسیم بندی استخراج می شود. چنین ویژگیهایی شی مانند شکل، طیف، محتوای بافتی و غیره آن را توصیف میکنند .]. تفاوت اصلی با گردش کار استاندارد GEOBIA در این واقعیت است که پروفایل های ویژگی روی هر پیکسل اندازه گیری می شوند. می توان تعجب کرد که چگونه چنین تحلیل پیکسلی می تواند با پارادایم مبتنی بر شی سازگار باشد. در واقع، در حالی که بر روی هر پیکسل محاسبه میشود، این ویژگیها از ویژگیهای اشیایی که پیکسلها در بخشهای مختلف به آنها تعلق دارند، ساخته میشوند. بنابراین استخراج ویژگی با نمایه های ویژگی می تواند به عنوان یک استراتژی برای استخراج ویژگی های مبتنی بر شی در هر پیکسل دیده شود. این یک چارچوب عمومی ارائه می دهد که به ویژگی های قوی اجازه می دهد تا به روشی بسیار کارآمد از تصاویر ورودی از طریق مدل سازی آنها به نمایش های مبتنی بر درخت استخراج شوند.
مدلهای درختی مورفولوژیکی مختلفی وجود دارد، و ما در اینجا بر روی درختهای گنجاننده، یعنی درخت کوچک، درخت حداکثر، و درخت اشکال تمرکز میکنیم. این مدلها مجموعههای سطح یک تصویر ورودی را توصیف میکنند، و تقسیمبندیهای تودرتو جزئی هستند (یعنی برای یک مقیاس معین ممکن است قسمتهایی از یک تصویر وجود داشته باشد که با هیچ منطقه تقسیمبندی شده مطابقت نداشته باشد). یک min-tree حداقل های محلی را که با برگ های درخت مطابقت دارد برجسته می کند. برعکس، درخت حداکثر بر ماکزیمم محلی در برگ های خود تأکید می کند. این نمایشهای دوگانه را میتوان با یک مدل خود دوگانه به نام درخت شکلها جایگزین کرد که در برگهایش گزافهایی دارد. در همه موارد، ریشه درخت از کل تصویر ساخته شده است. در حالی که میتوانستیم درختهای پارتیشن را نیز در نظر بگیریم (که شامل تقسیمبندی استاندارد چند وضوح مورد استفاده در چارچوب GEOBIA میشود)،28 ]. یک بررسی جامع اخیر در مورد بازنمایی های مختلف مبتنی بر درخت در [ 29 ] ارائه شده است.
برای توضیح انتخاب خود، در زیر مقایسه ای از رویکردهای مختلف موجود برای تجزیه و تحلیل یک تصویر ارائه می کنیم ( شکل 2 را ببینید ).
- رویکرد پیکسلی تنها پیکسل ها را تنها در نظر می گیرد. قبل از گروه بندی پیکسل های همان کلاس برای تعریف مناطق، مستقیماً از مقدار پیکسل برای طبقه بندی استفاده می کند.
- رویکرد شی ابتدا روابط بین پیکسل های همسایه را برای تعیین یک طبقه بندی در نظر می گیرد. کلاس اختصاص داده شده به یک پیکسل به مقدار همسایگی آن نیز بستگی دارد. این مرحله مجموعهای از پیکسلهای متصل را نشان میدهد که به عنوان اشیا در نظر گرفته میشوند. اجسام مجاور با هم ادغام می شوند تا مناطق همگن تولید کنند.
- رویکرد چند مقیاسی با استفاده از ساختار درختی، رویکرد قبلی را افزایش داد. این فرآیند توسط:
- –
- ساخت سلسله مراتب همانطور که در رویکرد شیء، پیکسل ها با همسایگان خود در نظر گرفته می شوند. همین فرآیند برای اتصال اشیاء و تشکیل اجسام بزرگتر اعمال می شود. پس از چند بار تکرار همه اشیا به یکدیگر متصل می شوند و کل تصویر را ارجاع می دهند.
- –
- طرح هرس این مرحله گره ها را با توجه به برخی از آستانه ها انتخاب کرد (به زیر مراجعه کنید). استفاده از آستانه های مختلف منجر به برش های مختلف درخت و در نتیجه پارتیشن های مختلف تصویر می شود.
- –
- محاسبات بردار ویژگی در این مرحله، تمام پیکسل ها توسط یک بردار ویژگی ساخته شده از مقادیری که پس از برش های مختلف به آنها اختصاص داده شده اند، توصیف می شوند.
سپس یک طبقهبندیکننده نظارتشده (در اینجا Random Forest) روی هر بردار ویژگی برای طبقهبندی همه پیکسلها استفاده میشود. نتایج برای به دست آوردن تقسیم بندی معنایی نهایی یا طبقه بندی پیکسلی جمع آوری می شوند.
پیچیدگی ظاهری این روش آخر واقعاً بر زمان محاسبه تأثیر نمی گذارد. در واقع، الگوریتم های کارآمد را می توان برای ارائه نتایج با کیفیت قابل توجه به کار گرفت.
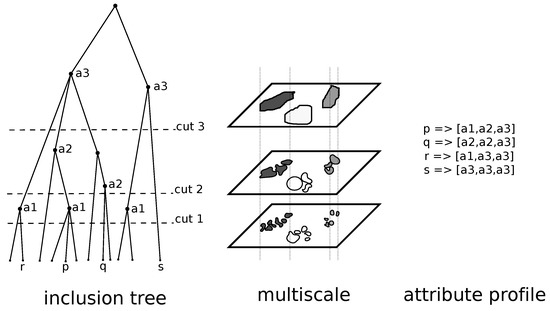
شکل 3 جزئیات بیشتری از رویکرد چند مقیاسی و پیوند بین نمایش سلسله مراتبی و محاسبه پروفایل های ویژگی را نشان می دهد. سمت چپ اشیاء مرتبط با گره ها در درخت گنجاندن را نشان می دهد. اجسام دارای یک سطح (اندازه) و یک نشانگر پوشش گیاهی (NDVI) هستند. ما برای هر گره ویژگی ها را محاسبه می کنیم (اندازه، میانگین، محلی سازی، …). خطوط چین نشان دهنده جایی است که درخت باید طبق برخی از آستانه ها هرس شود ( تی1، تی2، تی3) مربوط به یک نوع ویژگی (مثلاً اندازه). این مرحله هرس منجر به برآمدگی های نشان داده شده در وسط شکل می شود. در ریشه درخت، طرح ریزی با کل تصویر مطابقت دارد. با کاهش آستانه، پیشبینی میشود که در آن بخشها تقسیم میشوند. برای هر یک از پیکسل های نمونه ( p , q , r , s)، ما لیستی از مقادیر گره را در درخت گنجاندن مرتبط می کنیم. این مقادیر به بخش هایی بستگی دارد که گره ها در مسیر برگ تا ریشه درخت به آن تعلق دارند. می توان فرض کرد که آستانه اندازه می تواند به ترتیب با اندازه معمول گیاه، SWF و چوب مطابقت داشته باشد. فهرست [پوشش گیاهی، دیگر، دیگر] مربوط به گیاه است. لیست [پوشش گیاهی، پوشش گیاهی، سایر] نشان دهنده SWF است. فهرست [پوشش گیاهی، پوشش گیاهی، پوشش گیاهی] به عنوان چوب در نظر گرفته می شود.
بنابراین به طور رسمی تر، هنگامی که یک درخت ساخته می شود، محاسبه پروفایل های ویژگی [ 6] به شرح زیر است. ابتدا برخی از ویژگی ها در هر گره اندازه گیری می شوند. این ویژگی ها شکل، ناهمگونی یا هر خاصیت دیگر اشیاء زیرین را توصیف می کنند. آنها می توانند افزایش یابند (مانند مساحت یا اندازه منطقه) از برگ ها تا ریشه یا غیر افزایشی (مانند انحراف استاندارد مقادیر پیکسل یا ممان اینرسی که شکل ناحیه را مشخص می کند). سپس مجموعهای از آستانهها برای فیلتر کردن درخت و حفظ گرههای انتخابی که دارای مقادیر مشخصههای مربوط به آستانه هستند، تعریف میشود. این مرحله که فیلتر نامیده می شود، با هدف هرس درخت اولیه و حفظ زیرمجموعه بسیار کوچکی از گره ها است. هر پیکسل به تعدادی از آنها (در واقع حداکثر تعداد آستانه ها) تعلق دارد و می توان آن را با ویژگی های آنها مشخص کرد.
در چارچوب مشخصات ویژگی استاندارد، این مشخصه به سادگی با در نظر گرفتن مقادیر خاکستری گره ها انجام می شود، با فرض اینکه هر باند طیفی تصویر چند طیفی اصلی به طور مستقل در نظر گرفته شود. در حالی که اخیراً برنامههای افزودنی برای مقابله با تصاویر چند طیفی [ 30 ]، یا استخراج ویژگیهای غنیتر [ 31 ، 32 ] وجود داشته است ، ما در اینجا بر چارچوب اصلی که با هزینه محاسباتی کمتری همراه است، تمرکز میکنیم. از آنجایی که فیلتر ممکن است به تصاویر مشابه بین دو آستانه متوالی منجر شود، اغلب مرتبط است که به جای پروفایل های ویژگی استاندارد، به پروفایل های ویژگی های تفاضلی تکیه کنیم. نمایش دیفرانسیل با محاسبه تفاوت بین دو مقدار متوالی در درخت فیلتر شده ساخته می شود.
در سناریوی ما، و به منظور محدود کردن هزینه محاسباتی، ما به برخی از پیادهسازیهای کارآمد ساخت درخت و مراحل محاسبه ویژگیها تکیه میکنیم. چنین الگوریتم هایی در [ 7 ] شرح داده شده اند و به عنوان یک کتابخانه منبع باز به نام Triskele ( https://sourcesup.renater.fr/triskele ) در دسترس قرار گرفته اند که می تواند به عنوان یک ماژول راه دور در OTB استفاده شود. علاوه بر این، در طول یک مرحله تنظیم، میتوانیم از امتیازدهی تصادفی جنگل برای تعیین ویژگیهایی که واقعاً به فرآیند پیشبینی کمک میکنند، استفاده کنیم. در آن صورت، ما محاسبه ویژگیهای کامل را به زیرمجموعهای از پیکسلهای مربوط به مرحله یادگیری محدود میکنیم. و ویژگی های ویژگی های مورد نیاز را برای همه پیکسل ها محاسبه کنید.
2.3. طبقه بندی نیمه نظارتی
برعکس متدولوژی استاندارد GEOBIA که از مجموعه قوانین از پیش تعریف شده برای اعمال بر روی اشیاء استخراج شده از یک بخش بندی قبلی استفاده می کند، ما در اینجا بیشتر بر یک طبقه بندی کننده نظارت شده تکیه می کنیم. انگیزه این انتخاب این است که با توجه به زمینه یک مطالعه منطقه بسیار بزرگ که در آن ظاهر اشیا ممکن است از یک منظره به چشم انداز دیگر متفاوت باشد، تعیین یک مجموعه قوانین مناسب برای اشیاء مورد نظر آسان نیست.
در میان طبقهبندیکنندههای مختلف تحت نظارت موجود، ما تصمیم گرفتهایم به جنگل تصادفی تکیه کنیم که موفقیت بزرگی در سنجش از دور نشان داده است [ 33 ]. جنگل تصادفی یک روش مجموعه ای است [ 34 ] که چندین درخت تصمیم را برای افزایش استحکام فرآیند طبقه بندی کلی ترکیب می کند. هر درخت تصمیم بر روی زیرمجموعهای از نمونههای آموزشی با زیرمجموعهای از ویژگیهای موجود عمل میکند و میتواند برای استخراج یک پیشبینی از یک نمونه ورودی استفاده شود. سپس مجموعه پیشبینیهای فردی از طریق رویه رای اکثریت جمعآوری میشوند.
طبقهبندیکننده جنگل تصادفی به راحتی تنظیم میشود و تنها با چند پارامتر تنظیم میشود، یعنی تعداد درختان در جنگل و تعداد متغیرهای تصادفی مورد استفاده در هر درخت (معمولاً به عنوان جذر طول بردار ویژگی تنظیم میشود). تعداد درختها معمولاً به تعداد کلاسها، پیچیدگی فضای ویژگی و نیازهای احتمالی حافظه/محاسبات بستگی دارد. به منظور سرعت بخشیدن به فرآیند، تعداد کمتری از درختان را انتخاب می کنیم، به عنوان مثال، 100. علاوه بر این، جنگل تصادفی با پیاده سازی های موازی، مقیاس پذیر و منبع باز مانند کتابخانه Shark (https://image.diku) همراه است . dk/کوسه ). ما در اینجا از این کتابخانه استفاده می کنیم که اخیراً در چارچوب OTB ( https://www.orfeo-toolbox.org ) نیز تعبیه شده است.
یکی دیگر از مزایای طبقهبندیکننده تصادفی جنگل، توانایی آن در اندازهگیری اهمیت ویژگیهای مختلف است. در واقع، می توان نقش هر یک از ویژگی های فردی را در روش مجموعه ارزیابی کرد (به عبارت دیگر، چند بار از آن برای استخراج پیش بینی استفاده شده است). بنابراین به کاربر این امکان را میدهیم که هنگام تطبیق پویا مجموعه آموزشی خود، ویژگیهای مناسب را انتخاب کند. با تعداد کمتری از ویژگیهای متمایزتر، انتظار داریم هم به دقت بالاتر و هم هزینه محاسباتی کمتری دست یابیم.
همانطور که قبلاً اشاره شد، ما در اینجا طبقهبندیکننده جنگل تصادفی را در یک چارچوب نیمه نظارتی در نظر میگیریم. همانطور که قبلاً برای نقشه برداری SWF ذکر شد، ما فقط به نمونه های برچسب گذاری شده ارائه شده توسط کاربر برای مشخص کردن پیش زمینه (کلاس مورد علاقه، به عنوان مثال، SWF) دسترسی داریم و هیچ نمونه مرجعی برای پس زمینه (کلاس های دیگر) موجود نیست. برای انجام این کار، از نمونههای برچسبگذاریشده پیشزمینه و نمونههای انتخابی تصادفی برای پسزمینه (که ممکن است شامل کلاسهای پیشزمینه نیز باشد)، استراتژی خودکار برای انتخاب نمونههای متنوع برای کلاسهای پسزمینه طراحی شده است. انتخاب پسزمینه بر اساس تابع فاصله تا میانگین کلاس پیشزمینه است و نمونههایی که به میانگین پیشزمینه نزدیکتر هستند از مجموعه پسزمینه اصلی حذف میشوند. بدین ترتیب، اکنون نمونه های مرجع پیش زمینه و پس زمینه اولیه برای آموزش طبقه بندی کننده جنگل تصادفی داریم. در اینجا، ما فقط یک زیر مجموعه تصادفی (تعریف شده توسط fg_rآتیهو بg_rآتیهپارامترها) نمونه های آموزشی برای محدود کردن زمان محاسبه.
به منظور کاهش اثر منفی ناشی از اشتباهات در مجموعه آموزشی (که نمی توان آنها را کامل در نظر گرفت)، ما همچنین اجازه می دهیم نمونه های مثبتی را که منجر به نمره اطمینان پایین می شود دور بیندازیم. علاوه بر این، مجموعه پسزمینه باید ناهمگن باشد تا بهاندازه کافی همه طبقات را در صحنه نمایش دهد، اما طبقات مورد نظر را نشان دهد. در حالی که کاربر می تواند چنین نمونه هایی را ارائه دهد، به سختی با تمام کلاس های پس زمینه مطابقت دارد. بنابراین، ما به پالایش خودکار پیکسلهای پسزمینه در میان پیکسلهایی که طبقهبندیکننده جنگل تصادفی با اطمینان بسیار کم به کلاس مورد نظر اختصاص میدهد، اجازه میدهیم. اجازه دهید توجه داشته باشیم که این استراتژی فقط از بخشی از مجموعه داده مرجع درگیر در آموزش استفاده میکند و ارزیابی دقت نهایی بر روی مجموعه اعتبار سنجی تکمیلی در بخش 3.2 انجام خواهد شد .
به لطف زمان کم محاسباتی مرحله یادگیری تصادفی جنگل، این امکان برای کاربر وجود دارد که کیفیت پیشبینی را بر روی مجموعه آموزشی قضاوت کند و در صورت لزوم محتوای مجموعه را تطبیق دهد. هنگامی که مدل پیشبینی رضایتبخش بود، میتوان آن را روی کل تصویر اعمال کرد تا نقشه نهایی به دست آید.
3. کاربرد
3.1. متن نوشته
در سالهای گذشته، سنجش از دور به طور فزایندهای پذیرفته شده است که رویکردهای عینی و مقرون به صرفه را برای نقشهبرداری از عناصر کوچک چشمانداز ارائه میکند، با این حال، هنوز موجودی ثابتی از SWF در سراسر اروپا وجود ندارد. از طریق ابتکاراتی مانند هماهنگی اطلاعات در مورد محیط زیست (CORINE) پوشش زمین، و حتی بیشتر از زمان شروع کوپرنیک و عملیات اولیه آن با لایه های وضوح بالا (HRL) و اطلس شهری، اروپا به طور قابل توجهی پایگاه دانش خود را در خشکی بهبود بخشیده است. پوشش/استفاده و الگوهای پوشش گیاهی بر اساس دادههای EO. در حالی که ناهمگونی کلی چشم انداز با آرایش فضایی تکه های پوشش زمین همگن تعریف می شود، همانطور که توسط مؤلفه نظارت بر زمین قاره ای کوپرنیک اندازه گیری می شود.35 ]. هم آرایش فضایی پوشش زمین و هم وجود ساختارهای خطی، دو عنصر مرتبط هستند که ساختارهای منظر را مشخص می کنند [ 36 ]. اطلاعات جغرافیایی در مورد SWF هنوز وجود ندارد و فقط در قالب تحقیقات ملی محدود عمدتاً با تمرکز بر ویژگیهای زمین کشاورزی [ 37 ] یا دیگر فهرستهای چشمانداز در مقیاس کوچک متمرکز بر موضوع، به عنوان مثال، مطالعات تکه تکهسازی مانند [ 38 ] در دسترس است.
تنها اطلاعات کمی در سطح پان-اروپایی از طریق مشاهدات زمینی از پایگاه داده LUCAS (بررسی آماری چارچوب استفاده از زمین/منطقه پوششی) [ 39 ] در دسترس است. مطالعات اخیر مانند [ 13 ] نقشههای چگالی توزیع فضایی عناصر خطی چشمانداز را برای اروپا بر اساس درونیابی فضایی دادههای LUCAS به دست آوردهاند، اما وضوح چنین اطلاعاتی (1 کیلومتر) برای ارزیابیهای دقیق بسیار درشت است و واقعی را ارائه نمیکند. اطلاعات کمی در مورد مکان و وسعت آنها.
به عنوان بخشی از خدمات پایش زمین پاناروپایی کوپرنیک، لایههای با وضوح بالا (HRLs) نقشههایی از ویژگیهای پوشش زمین چند زمانی را برای 5 منطقه موضوعی از جمله SWF به روشی ثابت برای 39 کشور اروپایی (EEA39 با بیش از 6 میلیون کیلومتر) ارائه میکنند. 2 ). نقشه پان-اروپایی SWF یک محصول کاملاً جدید به عنوان بخشی از HRL ها برای سال مرجع 2015 است که بر اساس تخصص نشان داده شده گسترده در تولید HRL ها در سطح پاناروپایی [40] و با کار اکتشافی اختصاصی به طور خاص بر روی SWF است. 41]. نقشه برداری SWF از داده های با وضوح بسیار بالا (VHR) به عنوان ورودی اولیه با پوشش پاناروپایی و همچنین داده های درجا استفاده می کند. مجموعه داده VHR_IMAGE_2015 موجود در ESA Copernicus Data Warehouse (DWH) منبع داده اصلی برای تشخیص ویژگیهای چوبی کوچک قابل شناسایی در وضوح تصویر داده شده (≤1 متر پانکروماتیک، 2 تا 4 متر چند طیفی) است. این مجموعه داده شامل بیش از 38000 تصویر VHR است که با بیش از 120 ترابایت داده مطابقت دارد.
مشکل اصلی هنگام برخورد با تصاویر VHR ناشی از تنوع داخلی اطلاعات برای یک کاربری واحد است. به عنوان مثال، عناصر چوبی با تعداد بالایی از مقادیر پیکسل ناهمگن نشان داده می شوند که مانع از تکنیک های معمول مبتنی بر پیکسل می شود. با این وجود، اگرچه به نظر می رسد تحلیل تصویر مبتنی بر شی (OBIA) مناسب ترین رویکرد برای ترسیم SWF با تصاویر VHR باشد، به طور بالقوه می تواند برخی از اشکالات جدی مربوط به اندازه و شکل ناهمگون اشیاء SWF و دشواری تعیین تقسیم بندی مناسب را نشان دهد. پارامترهای [ 22]. علاوه بر این، برای اشیاء بسیار کوچک نزدیک به وضوح تصویر، تقسیم بندی می تواند منجر به ادغام اشیاء SWF یا غیر SWF جداگانه به دلیل مقادیر پیکسلی مخلوط شود. این باعث می شود که تعریف یک مقیاس تقسیم بندی مناسب در مناظر مختلف به ویژه اگر برای منطقه EEA39 اعمال شود، بسیار چالش برانگیز است. بنابراین، یک رویکرد چند مقیاسی که هم در سطح پیکسل و هم در سطح شی انجام میشود برای اطمینان از شناسایی صحیح SWF شکل کوچک و نامنظم (مبتنی بر پیکسل) و SWF بزرگتر (OBIA) مانند تکههای کوچک درختان یا درختان یا پرچینهای بزرگتر پیشنهاد میشود.
3.2. آزمایش
یک زنجیره پردازش اختصاصی به منظور پردازش مجموعه داده های بزرگ از تصاویر VHR (بیش از 38000 صحنه) برای تولید لایه SWF توسعه و پیاده سازی شده است. زمان محاسبات با توجه به زیرساخت سرور اختصاصی با قابلیت های محاسباتی بالا (Bi-CPU Xeon، 24 هسته) اندازه گیری شده است. گردش کار به طور خلاصه به شرح زیر توضیح داده می شود: (1) پیش پردازش تصویر VHR (تصحیحات رادیومتری و هندسی، پوشش ابری، شفاف سازی)، (2) آماده سازی پایگاه داده مرجع (استخراج مرجع SWF از مجموعه داده های مرجع قبلی و تأیید خودکار)، (3) ) طبقه بندی خودکار نظارت شده، (4) پس پردازش (هموارسازی برداری و تمایز بین چند ضلعی ها و تکه های خطی). به عنوان بخشی از تولید نقشه SWF،
خاطرنشان می شود که فقط به منظور کامل بودن گردش کار تولید SWF، مرحله پس پردازش را گنجانده ایم، اما از این مرحله در تولید نقشه های طبقه بندی و ارزیابی دقت در بقیه مقاله استفاده نکرده ایم.
ما ( بخش 2.2 ) امکان تعیین پویا ویژگی های کارآمد را برای پیش بینی تصادفی جنگل ارائه کرده ایم . چنین تحلیلی مجموعهای از ویژگیها را کاهش میدهد (مجموعه کاملی از ویژگیها را که در ابتدا در فرآیند در دسترس هستند را بنویسید). از آنجایی که ما با تصاویر VHR با وضوح فضایی زیرمتری سروکار داریم، هنگام محاسبه نمایه منطقه از مجموعه آستانه های زیر استفاده می کنیم: 1000، 2500، 5000، 7500 پیکسل.
این مقاله بر مرحله طبقهبندی خودکار تمرکز دارد، که از هر تصویر VHR نقشهای از پوشش گیاهی چوبی و غیر چوبی را میسازد. روش کلی برای تولید چنین نقشه ای در بخش 2 ارائه شده است .
3.2.1. داده ها
در حالی که استراتژی پیشنهادی در مقیاس پان-اروپایی بیش از 38000 صحنه VHR اعمال شده است، ما ارزیابی را تنها بر روی یک زیرمجموعه کوچک انجام میدهیم که دادههای مرجع حقیقت زمینی برای آنها در دسترس است. به طور دقیق تر، ما یک مجموعه داده ارزیابی را در نظر می گیریم که دو سایت مطالعه را پوشش می دهد، یکی در رومانی (منطقه بزرگ 9-LR09) و دیگری در آلمان (LR61). مجموعه داده ارزیابی شامل 37 تصویر VHR در مجموع است که به ترتیب حدود 7000 و 10200 کیلومتر مربع را پوشش می دهد . این تصاویر توسط ماهواره های مختلف، Pleiades ( https://www.satimagingcorp.com/satellite-sensors/pleiades-1/ ) و WorldView ( https://www.satimagingcorp.com/satellite-sensors/worldview-2/ ) به دست آمده است.) اما همه صحنه ها شامل 4 باند طیفی (آبی، سبز، قرمز و مادون قرمز نزدیک) هستند و دارای وضوح فضایی 2 متری هستند. مساحت تحت پوشش تصاویر از 192 تا 1223 کیلومتر مربع (حدود 48 تا 306 مگاپیکسل) متغیر است.
همانطور که قبلاً معرفی شد، مجموعه داده مرجع به طور خودکار از استخراج و اعتبار سنجی عناصر SWF در مجموعه داده های مرجع قبلی ساخته می شود: لایه تراکم پوشش درختی Copernicus HRL (TCD)، مجموعه داده رودخانه Riparian و Natura 2000 از مؤلفه های محلی Copernicus و پایگاه داده LUCAS. سپس طبقهبندی خودکار با استفاده از 70 درصد از مجموعه دادههای نمونه مرجع برای آموزش اعمال میشود و 30 درصد باقیمانده برای ارزیابی دقت به منظور استخراج معیارهای ارزیابی کمی استفاده میشود.
3.2.2. مقایسه با سایر روش های طبقه بندی
ابتدا، ما مقایسه ای از نتایج روش طبقه بندی را در یک سایت در رومانی ارائه می کنیم (id c55a). برای این مقایسه، ما از روشهای طبقهبندی پیشرفته با پیادهسازی از جعبه ابزار Orfeo ( https://www.orfeo-toolbox.org/CookBook/Applications/app_TrainImagesClassifier.html ) برای روشهای پیکسلی و راهحل eCognition استفاده کردیم. ( https://www.ecognition.com/) برای رویکرد مبتنی بر شی. برای هر روش از تنظیم خودکار و پایه استفاده می شود. ما این نتایج را با روش خود با استفاده از زمان محاسبات (با مراحل آموزش و پیشبینی برای رویکرد پیکسلی و تقسیمبندی/ساخت درخت برای روش GEOBIA) و دقت طبقهبندی برای کلاس SWF مقایسه میکنیم. همه این طبقه بندی ها با 4 باند طیفی و محصول مصنوعی NDVI به عنوان ورودی ساخته شده اند. برای راه حل eCognition، ابتدا یک بخش بندی قبل از انجام یک طبقه بندی جنگل تصادفی محاسبه می شود. رویکرد ما در شکل 1 خلاصه شده است .
نتایج در جدول 1 ارائه شده است . رویکرد ما از همه روشهای مبتنی بر پیکسل دقیقتر است و دقت تولیدکننده بهتری نسبت به راهحل E-cognition© دارد. از نظر زمان محاسبه، رویکرد ما سریعتر از روش مبتنی بر شی دیگر است.
3.2.3. نتایج تولید
جدول 2 و جدول 3 نتایج طبقه بندی را برای هر تصویر VHR تجزیه و تحلیل شده از نظر زمان پردازش و دقت طبقه بندی نشان می دهد. در حالی که زمان پردازش برای طبقه بندی یک تصویر Pleiades (استخراج ویژگی، آموزش + طبقه بندی) در سایت رومانیایی حدود 5 دقیقه است، این زمان برای تصاویر Worldview در سایت آلمانی دو برابر است که حدود دو برابر منطقه Pleaides (481 در مقابل 867 کیلومتر) را پوشش می دهد. 2 ). با توجه به چنین زمانهای پردازش معقولی، یک منطقه بزرگ با مساحت 40000 کیلومتر مربع را میتوان در عرض یک روز با در نظر گرفتن همپوشانی تصویر حدود 50 درصد پردازش کرد. چنین زمان پردازش کم اجازه می دهد تا این روش در یک حالت تولید در مقیاس پان اروپایی اعمال شود.
کیفیت طبقهبندی با دقت تولیدکننده (PA، مربوط به خطاهای حذف) و دقت کاربر (UA، مربوط به خطاهای کمیسیون) اندازهگیری میشود. تعداد پیکسلهای مرجع نشاندهنده اطمینان رقم دقت است (عدد مرجع کم به معنای اطمینان کمتر است).
در سایت رومانیایی ( جدول 2 )، PA از 77 تا 99 درصد متغیر است در حالی که UA از 83 تا 100 درصد است. میانگین PA و UA به ترتیب 89.4٪ و 95.7٪ است. در سایت آلمانی ( جدول 3 )، PA از 84 تا 95 درصد متغیر است در حالی که UA از 75 تا 99 درصد است. میانگین PA و UA به ترتیب 89.9٪ و 91.4٪ است. برای هر دو سایت، دقت طبقه بندی بالا است (بیش از 80%) حتی اگر ارقام دقت برای سایت رومانیایی کمی بالاتر باشد. این را می توان با خطاهای کمیسیون بالاتر به دلیل مزارع کشاورزی با پوشش گیاهی بالا در سایت آلمان توضیح داد. نتایج بصری در شکل 4 قرار دارد و در شکل 5 و شکل 6 در رومانی و آلمان ارائه شده است.به ترتیب. این نتایج فقط منعکس کننده خروجی های طبقه بندی است. سپس پردازش خودکار پست برای بدست آوردن نقشه SWF قابل تحویل اعمال می شود.
3.3. بحث
رویکرد ما برای تولید نقشه پان-اروپایی HRL Small Woody Features با 38000 صحنه VHR استفاده می شود. در حال تولید در سطح وسیع تری در اروپا (نزدیک به 800000 کیلومتر). ).با 6000 صحنه) نتایج قابل قبولی با دقت تولید کننده 1.51 ± 82.8 درصد و دقت کاربر 0.86 ± 86.3 درصد می دهد. رویکرد ما انعطافپذیر و قوی است زیرا دقت طبقهبندی تقریباً ثابتی را در اروپا ارائه میدهد. اگرچه ما دقت طبقه بندی قابل قبولی را تولید کرده ایم، اما می توان آن را بیشتر بهبود بخشید. برای انجام این کار، یکی از عوامل محدود کننده دسترسی به نمونه های مرجع پیش زمینه با برچسب گذاری دقیق است. با این حال، در عمل ما به آنها دسترسی نداریم، زیرا برای استخراج نمونه های مرجع برچسب گذاری شده، به پایگاه های داده قبلی و نقشه های کمکی موجود تکیه می کنیم. مشخص است که این می تواند نویز برچسب یا نمونه های دارای برچسب اشتباه را در مجموعه آموزشی به دلیل عوامل متعددی مانند ثبت نام اشتباه، نقشه ها و پایگاه های داده قدیمی و غیره معرفی کند. بنابراین، در کار آینده ما می خواهیم روش های طبقه بندی قوی نویز برچسب را در نظر بگیریم [42 ، 43 ] برای بهبود عملکرد طبقهبندی، و همچنین ترکیب اطلاعات ارزشمندتر و تکنیکهای کارآمد برای کاهش بیشتر زمان محاسبات و در عین حال افزایش دقت طبقهبندی.
4. نتیجه گیری
در این مقاله، ما یک مورد استفاده ارائه کردهایم که در آن روش GEOBIA در مقیاس بسیار بزرگ، یعنی بیش از 38000 صحنه و 120 ترابایت انجام شده است. برای پرداختن به طیف گسترده ای از مناظر در مقیاس پان-اروپایی، ما پیشنهاد می کنیم که بر بازنمایی تصاویر چند مقیاسی معروف به درختان مورفولوژیکی مانند درخت کوچک، درخت حداکثر یا درخت اشکال تکیه کنیم. پس از ساخته شدن، چنین نمایشهایی به ما اجازه میدهند تا برخی از ویژگیهای تصویر را که به یک طبقهبندیکننده تصادفی جنگل وارد میشوند، بهطور مؤثر استخراج کنیم. با تشکر از هزینه محاسباتی پایین تمام مراحل جداگانه فرآیند کلی (ساخت درخت، استخراج ویژگی، یادگیری نظارت شده و پیشبینی)، این امکان برای کاربر وجود دارد که ورودی خود (نمونه های آموزشی) را با ارزیابی سریع نتایج و به روز رسانی مدل طبقه بندی در صورت لزوم، بهینه سازی کند و دقت طبقه بندی را به حداکثر برساند. روش ارائه شده از طریق ارزیابی دقت کمی در دو سایت مطالعه در رومانی و آلمان تأیید شده است و در یک مورد استفاده از منطقه بسیار بزرگ، یعنی نقشهبرداری ویژگیهای چوبی کوچک برای محصول لایههای با وضوح بالا از سرویس نظارت بر زمین کوپرنیک استفاده شده است. . کار ما نشان میدهد که مفاهیم GEOBIA را میتوان در یک منطقه بسیار بزرگ به کار برد، در صورتی که از ابزارهای کارآمد کافی و مدلهای نمایش استفاده شود. یعنی نقشهبرداری از ویژگیهای چوبی کوچک برای محصول لایههای با وضوح بالا از سرویس نظارت بر زمین کوپرنیک. کار ما نشان میدهد که مفاهیم GEOBIA را میتوان در یک منطقه بسیار بزرگ به کار برد، در صورتی که از ابزارهای کارآمد کافی و مدلهای نمایش استفاده شود. یعنی نقشهبرداری از ویژگیهای چوبی کوچک برای محصول لایههای با وضوح بالا از سرویس نظارت بر زمین کوپرنیک. کار ما نشان میدهد که مفاهیم GEOBIA را میتوان در یک منطقه بسیار بزرگ به کار برد، در صورتی که از ابزارهای کارآمد کافی و مدلهای نمایش استفاده شود.
ما اکنون در نظر داریم که بر اساس این کار ایجاد کنیم و ویژگیهای پیشرفتهتری مانند نمایههای ویژگی محلی [ 31 ] یا نمایههای ویژگی [ 32 ] را شامل کنیم. در واقع، چارچوب نمایههای ویژگی از بسیاری از پیشرفتهای اخیر بهره برده است [ 27 ] که هنوز باید در آزمایشهای منطقه بزرگ تأیید شوند.
منابع
- Blaschke, T. تجزیه و تحلیل تصویر مبتنی بر شی برای سنجش از راه دور. ISPRS J. Photogramm. Remote Sens. 2010 , 65 , 2-16. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دراگوت، ال. سیلیک، او. آیسانک، سی. Tiede، D. پارامترسازی خودکار برای تقسیم بندی تصویر در مقیاس چندگانه در چندین لایه. ISPRS J. Photogramm. Remote Sens. 2014 ، 88 ، 119-127. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مینگ، دی. لی، جی. وانگ، جی. Zhang، M. انتخاب پارامتر مقیاس توسط آمار فضایی برای GeOBIA: استفاده از تقسیم بندی چند مقیاسی مبتنی بر میانگین تغییر به عنوان مثال. ISPRS J. Photogramm. Remote Sens. 2015 ، 106 ، 28-41. [ Google Scholar ] [ CrossRef ]
- هاول، جی. مرسیول، اف. Lefèvre، S. ساخت درخت کارآمد برای نمایش و پردازش تصویر چند مقیاسی. J. فرآیند تصویر در زمان واقعی. 2016 ، 1-18. [ Google Scholar ] [ CrossRef ]
- کارلینت، ای. Géraud, T. بررسی مقایسه ای الگوریتم های محاسبه درخت جزء. IEEE Trans. فرآیند تصویر 2014 ، 23 ، 3885-3895. [ Google Scholar ] [ CrossRef ]
- دالا مورا، م. بندیکتسون، جی. واسکه، بی. Bruzzone، L. مشخصات صفات مورفولوژیکی برای تجزیه و تحلیل تصاویر با وضوح بسیار بالا. IEEE Trans. Geosci. Remote Sens. 2010 , 48 , 3747–3762. [ Google Scholar ] [ CrossRef ]
- مرسیول، اف. بالم، تی. Lefèvre, S. طبقه بندی پوشش زمین کارآمد و مقیاس بزرگ با استفاده از تجزیه و تحلیل تصویر چند مقیاسی. در مجموعه مقالات کنفرانس ESA در مورد داده های بزرگ از فضا (BiDS)، تولوز، فرانسه، 28 تا 30 نوامبر 2017. [ Google Scholar ]
- گریزوننت، ام. میشل، جی. پوون، وی. اینگلادا، جی. ساوینو، ام. Cresson, R. Orfeo ToolBox: پردازش منبع باز تصاویر سنجش از راه دور. Geospat را باز کنید. نرم افزار داده ایستادن. 2017 ، 2 ، 15. [ Google Scholar ] [ CrossRef ]
- Karlsson, B. Beyond the C++ Standard Library: An Introduction to Boost ; Addison-Wesley: Boston, MA, USA, 2005. [ Google Scholar ]
- مشارکت کنندگان GDAL/OGR. کتابخانه نرم افزار انتزاع داده های جغرافیایی GDAL/OGR. بنیاد زمین فضایی منبع باز. 2018. در دسترس آنلاین: https://github.com/OSGeo/gdal/blob/master/CITATION (در 17 ژانویه 2019 قابل دسترسی است).
- ایگل، سی. هایدریش مایسنر، وی. گلاسماچرز، تی کوسه. جی. ماخ. فرا گرفتن. Res. 2008 ، 9 ، 993-996. [ Google Scholar ]
- فورمن، آر. گادرون، ام. تکهها و اجزای ساختاری برای بومشناسی منظر. BioScience 1981 ، 31 ، 733-740. [ Google Scholar ]
- وان درزندن، ای. وربورگ، پی. Mücher, C. مدل سازی توزیع فضایی عناصر خطی چشم انداز در اروپا. Ecol. اندیک. 2013 ، 27 ، 125-136. [ Google Scholar ] [ CrossRef ]
- Jongman, R. پیوندهای چشم انداز و تنوع زیستی در مناظر اروپایی. در ابعاد جدید چشم انداز اروپا ; جونگمن، آر.، اد. Springer: Dordrecht، هلند، 2004; صص 179-189. [ Google Scholar ]
- کمیسیون اروپا Direction Générale de la Recherche. جهت I، محیط زیست. Unité 5, Ccere استراتژی تنوع زیستی اتحادیه اروپا تا سال 2020 ؛ دفتر انتشارات اتحادیه اروپا: لوکزامبورگ، 2011; شابک 978-92-79-20762-4. [ Google Scholar ] [ CrossRef ]
- پاشر، ج. مک گاورن، ام. پوتینسکی، وی. اندازهگیری و پایش ویژگیهای چوبی خطی در مناظر کشاورزی از طریق دادههای مشاهده زمین به عنوان شاخصی از در دسترس بودن زیستگاه. بین المللی J. Appl. زمین Obs. Geoinf. 2016 ، 44 ، 113-123. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لنون، ام. Mouchot, MC; مرسیه، جی. Hubert-Moy, L. تقسیم بندی پرچین ها بر روی تصاویر فراطیفی CASI با ترکیب داده ها از تحلیل بافت، طیفی و شکل. در مجموعه مقالات سمپوزیوم بین المللی علوم زمین و سنجش از دور IEEE 2000. گرفتن نبض سیاره: نقش سنجش از دور در مدیریت محیط (Cat. No.00CH37120)، هونولولو، HI، ایالات متحده آمریکا، 24-28 ژوئیه 2000; جلد 2، ص 825–827. [ Google Scholar ]
- Tansey، K. چمبرز، آی. آنستی، ا. دنیس، آ. بره، الف. طبقه بندی شی گرا از تصاویر هوابرد با وضوح بسیار بالا برای استخراج پرچین ها و پوشش حاشیه مزرعه در مناطق کشاورزی. Appl. Geogr. 2009 ، 29 ، 145-157. [ Google Scholar ] [ CrossRef ]
- وانیر، سی. هوبرت-موی، ال. تشخیص پرچین های چوبی در تصاویر ماهواره ای با وضوح بالا با استفاده از روش شی گرا. در مجموعه مقالات IGARSS 2008-2008 IEEE بین المللی زمین شناسی و سمپوزیوم سنجش از دور، بوستون، MA، ایالات متحده آمریکا، 7 تا 11 ژوئیه 2008. جلد 4، ص IV-731–IV-734. [ Google Scholar ]
- آکسوی، اس. Akcay، HG; Wassenaar, T. نقشه برداری خودکار ویژگی های خطی پوشش گیاهی چوبی در مناظر کشاورزی با استفاده از تصاویر با وضوح بسیار بالا. IEEE Trans. Geosci. Remote Sens. 2010 , 48 , 511-522. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فاوول، م. شیرن، دی. چانوسوت، جی. Benediktsson، JA Hedges تشخیص با استفاده از ویژگیهای جهتدار محلی و پشتیبانی از توصیف دادههای برداری. در مجموعه مقالات سمپوزیوم بین المللی زمین شناسی و سنجش از دور IEEE 2012، مونیخ، آلمان، 22 تا 27 ژوئیه 2012. صص 2320–2323. [ Google Scholar ]
- فاوول، م. آربلوت، بی. بندیکتسون، جی. شیرن، دی. Chanussot، J. تشخیص پرچین ها در منظر روستایی با استفاده از ویژگی جهت گیری محلی: از باز شدن خطی تا باز شدن مسیر. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2013 ، 6 ، 15-26. [ Google Scholar ] [ CrossRef ]
- مک، بی. روزچر، آر. Waske، B. آیا می توانم به طبقه بندی تک کلاسی خود اعتماد کنم؟ Remote Sens. 2014 , 6 , 8779–8802. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فام، م. لفور، اس. Merciol, F. مشخصات ویژگیهای بافتی مشتقشده برای طبقهبندی تصاویر نوری با بافت بالا. IEEE Geosci. سنسور از راه دور Lett. 2018 ، 15 ، 1125-1129. [ Google Scholar ] [ CrossRef ]
- ویولا، پ. Jones, M. Rapid Object Detection با استفاده از یک آبشار تقویت شده از ویژگی های ساده. در مجموعه مقالات کنفرانس IEEE Computer Society در سال 2001 در مورد دید رایانه و تشخیص الگو، Kauai، HI، ایالات متحده آمریکا، 8-14 دسامبر 2001. [ Google Scholar ]
- غمیسی، پ. مورا، دکتر Benediktsson، J. بررسی تکنیک های طبقه بندی طیفی فضایی بر اساس پروفایل های ویژگی. IEEE Trans. Geosci. Remote Sens. 2015 , 53 , 2335–2353. [ Google Scholar ] [ CrossRef ]
- فام، م. آپتولا، ای. لفور، اس. Bruzzone, L. تحولات اخیر از نمایه های ویژگی برای طبقه بندی تصویر سنجش از دور. در مجموعه مقالات کنفرانس بین المللی تشخیص الگو و هوش مصنوعی، مونترال، QC، کانادا، 14 تا 17 مه 2018. [ Google Scholar ]
- بوسیلج، پ. داموداران، ب. آپتولا، ای. مورا، دکتر Lefèvre, S. مشخصات ویژگی از درختان تقسیم. در مورفولوژی ریاضی و کاربردهای آن در پردازش سیگنال و تصویر . Springer: Cham، سوئیس، 2017. [ Google Scholar ]
- بوسیلج، پ. کیجک، ای. Lefèvre, S. تقسیم و گنجاندن سلسله مراتب تصاویر: یک بررسی جامع. J. Imaging 2018 , 4 , 33. [ Google Scholar ] [ CrossRef ]
- آپتولا، ای. مورا، دکتر لفور، اس. Aptoula، E. پروفایل های ویژگی برداری برای طبقه بندی تصاویر ابرطیفی. IEEE Trans. Geosci. Remote Sens. 2016 , 54 , 3208–3220. [ Google Scholar ] [ CrossRef ]
- فام، م. لفور، اس. Aptoula، E. نمایههای ویژگی مبتنی بر ویژگی محلی برای طبقهبندی تصویر سنجش از دور نوری. IEEE Trans. Geosci. Remote Sens. 2018 , 56 , 1199–1212. [ Google Scholar ] [ CrossRef ]
- فام، م. لفور، اس. Aptoula, E. نمایه ویژگی از فیلتر ویژگی برای طبقه بندی تصاویر سنجش از دور. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2018 , 11 , 249–256. [ Google Scholar ] [ CrossRef ]
- بلژیک، م. Drăguţ، L. جنگل تصادفی در سنجش از دور: بررسی برنامهها و جهتهای آینده. ISPRS J. Photogramm. Remote Sens. 2016 ، 114 ، 24–31. [ Google Scholar ] [ CrossRef ]
- بریمن، ال. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ترنر، ام. بوم شناسی چشم انداز: تأثیر الگو بر فرآیند. آنو. کشیش اکول. سیستم 1989 ، 20 ، 171-197. [ Google Scholar ] [ CrossRef ]
- شاخص های ساختار چشم انداز از LUCAS – آمار توضیح داده شده است. در دسترس آنلاین: https://ec.europa.eu/eurostat/statistics-explained/index.php?title=Landscape_structure_indicators_from_LUCAS&oldid=327105 (در 9 ژانویه 2019 قابل دسترسی است).
- جونگمن، آر. Bunce, R. مزرعه ویژگی ها در اتحادیه اروپا. شرح و فهرست آزمایشی توزیع آنها. Alterra Report 1936 ; Alterra: Wageningen، هلند، 2009. [ Google Scholar ]
- جیگر، جی. برتیلر، آر. شویک، سی. مولر، ک. اشتاین مایر، سی. ایوالد، ک. Ghazoul, J. پیاده سازی تکه تکه شدن چشم انداز به عنوان یک شاخص در سیستم نظارت سوئیس توسعه پایدار (MONET). جی. محیط زیست. مدیریت 2008 ، 88 ، 737-751. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- یورواستات اجرای عمومی پوشش زمین و استفاده مدیریت آب عکس های ترانسکت خاک: دستورالعمل برای نقشه برداران ; سند مرجع فنی c-1; کمیسیون اروپا: لوکزامبورگ، 2009. [ Google Scholar ]
- لوفور، ا. بوژاندر، ن. پنک، ای. سانییر، سی. Corpetti, T. استفاده از ترکیب داده ها برای به روز رسانی مناطق ساخته شده از نفوذناپذیری لایه با وضوح بالا اروپا در سال 2012. در مجموعه مقالات سی و سومین سمپوزیوم EARseL، ماترا، ایتالیا، 3 تا 8 ژوئن 2013. [ Google Scholar ]
- Lefebvre, A. مطالعه امکان سنجی در مورد نقشه برداری و نظارت بر ویژگی های خطی سبز بر اساس تصاویر ماهواره ای VHR . گزارش نهایی EEA/MDI/14/006. آژانس محیط زیست اروپا: København، دانمارک، 2014. [ Google Scholar ]
- داموداران، بی بی; فلماری، ر. Seguy، V. کورتی، ن. تلفات انتقال بهینه آنتروپیک برای یادگیری شبکه های عصبی عمیق تحت نویز برچسب در تصاویر سنجش از دور. arXiv , 2018; arXiv:1810.01163. [ Google Scholar ]
- ماس، ا. روتنشتاینر، اف. Heipke, C. استفاده از رگرسیون لجستیک قوی نویز برچسب برای بهروزرسانی خودکار پایگاههای دادههای مکانی توپوگرافی. در مجموعه مقالات ISPRS Annals of the Photogrammetry، سنجش از دور و علوم اطلاعات فضایی، پراگ، جمهوری چک، 12-19 ژوئیه 2016. جلد III-7. [ Google Scholar ]
شکل 1. نمودار جریان کلی رویکرد پیشنهادی.

شکل 2. رویکرد چند مقیاسی.
شکل 3. ویژگی های مشخصات مشخصات استخراج شده از گنجاندن درخت.
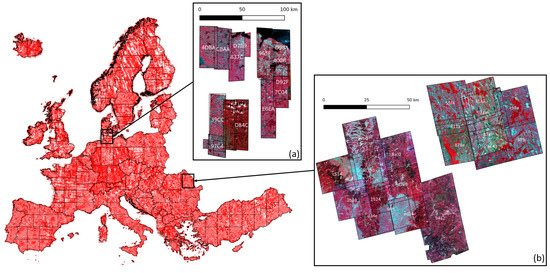
شکل 4. نقشه پان-اروپایی از 38000 ردپای صحنه (جعبه های قرمز) مورد استفاده برای تولید ویژگی های چوبی Swall Layer با وضوح بالا (HRL) کوپرنیک. از دو مجموعه داده برای آزمایشها استفاده میشود: ( الف ) 17 صحنه جهان بینی بر روی سایت مطالعه LR61 (آلمان، 10200 کیلومتر مربع ) و ( ب ) 20 صحنه Pleiades بر روی سایت مطالعه LR09 (رومانی، 7000 کیلومتر مربع ). تصاویر صحنه در ترکیب رنگ کاذب ارائه می شوند: (نزدیک به مادون قرمز، قرمز، سبز) به عنوان RGB.

شکل 5. تصویری از نتایج طبقهبندی: ( الف ) ترکیب رنگ کاذب صحنه Pleiades #c55a بر روی سایت مطالعه LR09 در رومانی و ( ب ) ترکیب رنگ کاذب مشابه با روی هم قرار دادن خروجی طبقهبندی لایههای Small Woody Features (سبز).

شکل 6. تصویری از نتایج طبقهبندی: ( الف ) ترکیب رنگ نادرست صحنه Worldview #400B بر روی سایت مطالعه LR61 در آلمان و ( ب ) ترکیب رنگ کاذب یکسان با روی هم قرار دادن خروجی طبقهبندی لایههای Small Woody Features (سبز).

بدون دیدگاه