نمونه برداری داده ها
نمونه برداری داده ها-موسسه چشم انداز هزاره سوم ملل-آموزش کاربردی GIS و RS
مقدمه
یکی از چالش های پیش روی بسیاری از مطالعات و پژوهش ها دریافت اطلاعات از مجموعه داده های بزرگ می باشد (فیشر، اوپن شاو و الوندیس). یکی از روشهای انجام این کار، نمونه برداری از داده های بزرگ (جامعه آماری) است. نمونه ای که برداشت می شود باید نماینده جامعه ای باشدکه پژوهشگر قصد بررسی آن را دارد. در این فصل روشهای متداول نمونه برداری با دید مکانی و غیر مکانی مطرح می شود و مشاهده می شود برخی از روش هایی که با دید غیر مکانی برای نمونه برداری استفاده می شوند با قدری تغییرات برای نمونه برداری مکانی کاربرد دارند.

رایج ترین روش های نمونه برداری غیر مکانی
در زیر با برخی از روش های متداول نمونه برداری غیر مکانی آشنا می شوید.
نمونه برداری تصادفی
یکی از روشهای متداول در نمونه برداری که برای جمع آوری اطلاعات به کار می رود، روش تصادفی ساده است. جان بست (1983) نمونـه برداری تصـادف سـاده را به این صورت تعریف می کند که روشـی کـاربردی و پایـه ای بـرای نمونـه برداری اسـت کـه در آن همـۀ واحدهای جامعه ای، احتمال انتخاب برابـر در نمونـه دارنـد. همچنـین هـر ترکیبـی از واحـدهای جامعه ای با تعداد واحدهای یکسان و مشخص، شانس یکسان برای انتخاب شدن در نمونـه را دارند. بنابراين تعميم قوي و قابل دفاع براي جامعه آماري مربوطه وجود دارد. نمونه برداري تصادفي منطبق با تئوري احتمال است و اين موضوع امکان بررسي توزيع مقادير نمونه ها و توزيع احتمال در جامعه آماري را ممکن مي سازد. این نمونه برداری به دو صورت ” با جایگذاری” و “بدون جایگذاری” انجام می شود.
اگر در انتخاب n واحد نمونه، پس از انتخاب هر واحد، به جامعه برگشت داده شود و سپس انتخاب بعدی انجام شود نمونه برداری تصادفی ساده را با جای گذاری می نامند. در این روش، انتخاب هر واحد مستقل از انتخاب واحدهای دیگر است. در نمونه برداری بدون جای گذاری واحد منتخب نمونه به جامعه برگشت داده نمیشود. یک ویژگی مهم نمونه برداری تصادفی ساده بدون جای گذاری اینست که احتمال استخراج هر واحد مشخص از جامعه در هر استخراجی مساوی با احتمال آن واحد مشخص در استخراج اول است (جوی زاده و همکاران، 1398).
نمونه برداری با جای گذاری در بسیاری از نمونه برداری های پیچیده به کار می رود اما دقت این روش کمتر از روش بدون جای گذاری است. لازم به ذکر است که در روش تصادفی ممکن است از برخي مناطق هيچ نمونه اي برداشت نشود.

نمونه برداری سیستماتیک
نمونه برداری سیستماتیک چه به تنهایی و چه در ترکیب با برخی از روشهای دیگر می تواند متداولترین روش نمونه برداری باشد. نمونه برداری سیستماتیک برخلاف بیشتر شیوه های نمونه برداری مستلزم دانستن کل تعداد واحدهای نمونه برداری نیست و به همین دلیل نمونه برداری را میتوان همزمان با ایجاد چارچوب نمونه برداری اجرا کرد.
نمونه برداری سیستماتیک مشتمل بر گزینش نمونه ها به روشی سیستماتیک (منظم) و در نتیجه به صورتی غیر تصادفی است. منظور از این نوع نمونه برداری معمولاً پخش کردن واحدها به طور یکنواخت بر روی چارچوب است. به عبارتی دیگر با فرض اینکه حجم جامعه N باشد و واحدهای جامعه از 1 تا N شماره گذاری شود. انتخاب نمونهای سیستماتیک یک در K، به حجم n از این جامعه به صورت زیر تعریف می شود:
از واحدهای شماره 1 تا K یک واحد انتخاب می شود. برای نمونه واحد شماره r، که به آن واحد اول نمونه گفته می شود. سپس به شماره r به ترتیب مضارب صحیح K را اضافه کرده تا شماره های واحدهای بعدی نمونه مشخص شوند. این عمل را آنقدر ادامه داده می شودکه شمارهای بزرگتر از N به دست آید. K را فاصله نمونه برداری می نامند. اگر صفت مورد نظر جامعه y باشد و واحدهای جامعه به صورت زیر شماره گذاری شوند:
![]()
به عبارتی دیگر وقتی از شماره های 1 تا k عددی به تصادف انتخاب شود و این عدد r باشد اولین واحد نمونه yr است واحد دوم yr+k، واحد سوم، yr+2k و الی آخر است. نمونه حاصل را نمونه سیستماتیک با فاصله نمونه برداری K می نامیم. اگر حجم نمونه برابر با n شود، نمونه به صورت زیر است:
![]()
اگر این نمونه را یک دنباله بگیریم جمله عمومی آن yr+jk است که j از 0 تا n-1 تغییر می کند.
قابل الذکر است فاصله نمونه برداری که با k نشان داده ميشود از تقسيم تعداد نمونه هاي مورد نظر (n) به وسعت (N) به دست مي آيد. نمونه ای از نمونه برداری سیستماتیک در زیر نشان داده شده است.
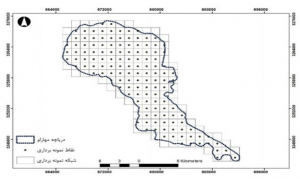
در نمونه برداری سیستماتیک اگر n و K هر دو از قبل تعیین شود نمی توان نمونه برداری را به درستی انجام داد.
نمونه برداری سیستماتیک در عمل استفاده گسترده ای دارد زیرا کاربرد آن آسان است. از طرفی این روش نمونه برداری زمانی کاراست که تعداد جامعه مورد بررسی به نسبت زیاد است. نمونه برداري سیستماتیک، و انواع آن داراي دو نقطه ضعف هستند: (1) بازه نمونه برداري ممکن است با نقاطي که در دوره هاي زماني قبل مطالعه شده اند منطبق باشد و 2) چون فواصل نمونه برداري ها برابر است، برخي از تأثيرات ناشي از فاصله (مانند پراکندگي شيوع و مانند آن) ممکن است ناديده انگاشته شوند.
نمونه برداری طبقه بندی شده
گاهی اوقات می توان چارچوب نمونه برداری را به گروهها یا طبقه هایی افراز و نمونه برداری را جداگانه در داخل هر طبقه اجرا کرد. این طرح نمونه برداری را نمونه برداری طبقه بندی شده می نامند. اگر برای انتخاب نمونه در داخل هر طبقه از نمونه برداری تصادفی ساده استفاده شود طرح نمونه را نمونه برداری تصادفی طبقه بندی شده می نامند.
نمونۀ تصادفی طبقه بندی شده یک برنامۀ نمونه برداری است که در آن جامعۀ به حجم N را ابتدا به زیر جامعه هایی به حجم های NL ،…، N1 تقسیم می کنند. این زیر جامعه ها متداخل نیستند و اجتماع آنها برابر با کل جامعه است، یعنی
![]()
هر زیر جامعه را یک طبقه می نامند. برای بهره گیری عمده از کار طبقه بندی باید مقدارهای h= 1,…,L، Nn را دانست. وقتی طبقات مشخص شدند از هر طبقه نمونه ای انتخاب می شود انتخاب ها در هر طبقه مستقل از طبقۀ دیگر صورت می گیرند. حجم های نمونه های طبقات را به ترتیب با nL،…،n1 نشان داده می شود. در واقع می توان طرح نمونه برداری تصادفی ساده را به صورت نمونۀ تصادفی سادۀ مجزا تصور کرد.
طبقه بندی، تکنیکی بسیار متداول است که به دلایلی زیاد انجام می شود. عمده ترین این دلایل به شرح زیرند:
– اگر برای بعضی از زیرجامعه های یک جامعه، داده ها و اطلاعاتی با دقت معلوم بخواهند، توصیه می شود که هر زیر جامعه، یک طبقه به حساب آید.
– سهولت ادارۀ امور، همیشه بر طبقه بندی تاکید خاص دارد. تشکیلاتی که در یک کشور، مسئول انجام نمونه برداری برای ارائه نتایج به سازمان های ذیربط است در نواحی مختلف کشور واحدهای متبوع مختلفی دارد. کارکنان هر واحد دربارۀ ویژگی های ناحیۀ خود اطلاعاتی دقیق تر از سایرین دارند و لذا اگر نمونه برداری در هر ناحیه به عنوان یک طبقه به صورتی مستقل از نواحی دیگر صورت گیرد با دقت بیشتری همراه است و به علاوه از لحاظ هزینه و سازماندهی کار نمونه برداری تسهیلاتی بیشتر فراهم می شود همگنی تقریبی برخی از صفات تحت نمونه برداری در یک ناحیه نیز به طوری که خوهیم دید به کارآیی نمونه برداری با طبقه بندی کمکی فراوان می کند. مشکلات نمونه برداری به صورتی بارز در بخش های مختلف یک جامعه متفاوت اند. دربارۀ جامعه های انسانی، افرادی که در موسساتی نظیر هتل ها، بیمارستان ها، زندان ها و .. کار و زندگی می کنند در طبقاتی با خصوصیات متفاوت از افراد عادی قرار دارند و لذا نمونه برداری از این طبقات باید مستقل از افراد عادی باشد و در نمونه برداری از واحدهای تجاری و صنعتی ممکن است فهرستی بزرگ در اختیار ما باشد که ضرورت قرار دادن این واحدها را در یک طبقه ایجاب کند.
– با طبقه بندی می توان دقت برآوردهای صفت کل جامعه را کنترل کرد. ممکن است یک جامعه ناهمگن را هم به وسیلۀ طبقه بندی به زیر جامعه ها (طبقات) همگن تقسیم کرد. طبقۀ همگن بدین معناست که اندازه ها از واحدی به واحد دیگر تغییر کمی دارد و می توان در چنین طبقه ای یا نمونه ای به حجم اندک برآورد دقیقی از صفت تحت بررسی تهیه کرد.
به نظر لوین ورابین (1998) مزیت نمونه هاي طبقه بندي شده آن است که اگر به درستی طراحی شوند به صورت دقیق تري مشخصه هاي جامعه اي که از آن بر گرفته شده اند را نسبت به دیگر انواع نمونه ها نشان میدهد (صالح و سعدي ، 1387).
نمونه برداری خوشه اي
متداول ترین روشی است که در زمینه یابی مورد استفاده قرار می گیرد و آن نمونه برداری پیاپی از واحدها ، مجموعه ها و زیر مجموعه هاست. به عبارت دیگر، اين روش براي پديده هاي داراي سازمان سلسله مراتبي به کار ميرود. برای نمونه، انتخاب تعداد معيني شهر، ابتدا به طريق تصادفي چند سازمان بزرگ (استان) انتخاب ميشود. در هر استان به اندازه سهمش چند شهرستان انتخاب ميگردد. در هر شهرستان هم چند شهر انتخاب مي شود با توجه به تقسیم جامعه به خوشه ها میتوان نمونه ای را برای برآورد مورد نظر به یکی از صورت های زیر تهیه کرد:
الف) از N خوشه n خوشه به تصادف انتخاب کرد. سپس کلیۀ واحدهای هر خوشه را اندازه گرفته و بدین ترتیب با همۀ واحدهای n خوشه، نمونه ای را به نام نمونه خوشه ای یک مرحله ای مشخص کرد و آن را استنباط قرار داد. اگر حجم n خوشه برابر باشد، نمونه را نمونۀ خوشه ای با حجم برابر خوشه ها می نامند و در غیر اینصورت، نمونه را نمونه ای خوشه ای با حجم نابرابر خوشه ها می گویند.
ب) ممکن است از N خوشه جامعه در مرحلۀ اول، n خوشه به تصادف انتخاب شود. سپس به جای این که تمام واحدهای خوشه ها را به عنوان واحدهای نمونه اختیار کرد در مرحلۀ دوم از هر خوشه تعدادی را به صورت تصادفی به عنوان واحدهای نمونۀ اصلی برگزینیم. در این صورت از همۀ واحدهایی که در مرحلۀ دوم از n خوشۀ منتخب مرحلۀ اول برگزیده ایم نمونه ای به وجود می آید که آن را نمونۀ خوشه ای دو مرحله ای می نامیم. در این حالت نیز ممکن است حجم خوشه ها برابر و حجم نمونه های تصادفی خوشه ها در مرحلۀ دوم نیز برابر باشند که در این صورت نمونه را نمونه خوشه ای دو مرحلهای با حجم برابر خوشه در جامعه و نمونه می نامیم.
ج) ممکن است جامعه شامل N خوشه بوده و سپس هر خوشه شامل تعدادی زیر خوشه باشد. در این صورت امکان دارد در مرحلۀ اول n خوشه از N خوشه را به تصادف انتخاب کنیم. بدیهی است هر یک از این خوشه منتخب در مرحلۀ اول دارای تعدادی زیر خوشه است. می توانیم در مرحلۀ دوم تعدادی از زیر خوشه های هر خوشه ای را که در مرحلۀ اول انتخاب کرده ایم به تصادف اختیار کنیم. تا این دو مرحله، تعدادی زیر خوشه از n خوشه به دست آمده است. حال اگر در مرحلۀ سوم از هر زیر خوشه تعدادی واحد به تصادف برگزینیم از همۀ واحدهای انتخابی از زیر خوشه های مرحلۀ دوم نمونه ای به دست می آید که آن را نمونۀ خوشه ای سه مرحله ای می نامیم.
می توانید تصور کنید که وقتی زیر خوشه ها نیز از خوشه های کوچکتری تشکیل شده باشند می توانیم با تعمیم این فرآیند به نمونۀ خوشه ای چهار مرحله ای و غیره نیز برسیم.
نمونه برداری خوشه ای، در جامعه هایی اجرا می شود که پراکندگی صفت در درون هر خوشه کم نباشد. چون بررسی روی همۀ واحدها و یا برخی از واحدهای هر خوشه انجام می شود هزینۀ مراجعه و رفت و آمد کاهش می یابد و صرفه جویی در وقت چشم گیر است.
دقت نمونه برداری خوشه ای از نمونه گیري تصادفی کمتر است زیرا در نمونه گیري تصادفی ساده فقط یک اشتباه نمونه گیري وجود دارد در صورتی که در نمونه برداری خوشه اي در هر مرحله یک اشتباه نمونه گیري وجود خواهد داشت.



9 نظرات