
هوش مصنوعی و GIS : ابزارها و بسترهای فوق العاده
هوش مصنوعی مطالعه عوامل هوشی است که توسط ماشین ها نشان داده شده است. این یک زمینه بین رشته ای است که شامل علوم کامپیوتر و همچنین انواع مختلف مهندسی و علوم است، به عنوان مثال، رباتیک، مهندسی زیست پزشکی، که اتوماسیون اعمال انسان و هوش از طریق ماشین ها را برجسته می کند. هوش مصنوعی نشاندهنده استفاده پیشرفته از ماشینها برای ایجاد محاسبات الگوریتمی و درک وظایفی است که شامل یادگیری، حل مسئله، نقشهبرداری، ادراک و استدلال میشود. با توجه به داده ها و شرح خصوصیات آن و روابط بین اشیاء مورد علاقه، روش های هوش مصنوعی می توانند وظایف فوق را انجام دهند. قابلیتهای هوش مصنوعی بهطور گسترده، به عنوان مثال یادگیری، اکنون در مقیاس بزرگ از طریق یادگیری ماشینی (ML)، حجم زیادی از دادهها و ماشینهای محاسباتی تخصصی قابل دستیابی هستند. ML یادگیری بدون هیچ نوع نظارت (یادگیری بدون نظارت) و یادگیری با نظارت کامل (یادگیری تحت نظارت) را در بر می گیرد. تکنیکهای یادگیری با نظارت گسترده شامل یادگیری عمیق و سایر روشهای یادگیری ماشینی است که به دادههای کمتری نسبت به یادگیری عمیق نیاز دارند، بهعنوان مثال ماشینهای بردار پشتیبان، جنگلهای تصادفی. نمونه های یادگیری بدون نظارت شامل یادگیری فرهنگ لغت، تجزیه و تحلیل اجزای مستقل و رمزگذارهای خودکار است. برای کارهای کاربردی با دادههای برچسبگذاری شده کمتر، هم تکنیکهای نظارت شده و هم بدون نظارت میتوانند به شیوهای نیمه نظارتی برای تولید مدلهای دقیق و افزایش اندازه دادههای آموزشی برچسبگذاریشده تطبیق داده شوند. تکنیکهای یادگیری با نظارت گسترده شامل یادگیری عمیق و سایر روشهای یادگیری ماشینی است که به دادههای کمتری نسبت به یادگیری عمیق نیاز دارند، بهعنوان مثال ماشینهای بردار پشتیبان، جنگلهای تصادفی. نمونه های یادگیری بدون نظارت شامل یادگیری فرهنگ لغت، تجزیه و تحلیل اجزای مستقل و رمزگذارهای خودکار است. برای کارهای کاربردی با دادههای برچسبگذاری شده کمتر، هم تکنیکهای نظارت شده و هم بدون نظارت میتوانند به شیوهای نیمه نظارتی برای تولید مدلهای دقیق و افزایش اندازه دادههای آموزشی برچسبگذاریشده تطبیق داده شوند. تکنیکهای یادگیری با نظارت گسترده شامل یادگیری عمیق و سایر روشهای یادگیری ماشینی است که به دادههای کمتری نسبت به یادگیری عمیق نیاز دارند، بهعنوان مثال ماشینهای بردار پشتیبان، جنگلهای تصادفی. نمونه های یادگیری بدون نظارت شامل یادگیری فرهنگ لغت، تجزیه و تحلیل اجزای مستقل و رمزگذارهای خودکار است. برای کارهای کاربردی با دادههای برچسبگذاری شده کمتر، هم تکنیکهای نظارت شده و هم بدون نظارت میتوانند به شیوهای نیمه نظارتی برای تولید مدلهای دقیق و افزایش اندازه دادههای آموزشی برچسبگذاریشده تطبیق داده شوند.
- تعاریف
- مقدمه ای بر هوش مصنوعی
- داده کاوی
- فراگیری ماشین
- شبکه های عصبی مصنوعی
- یادگیری عمیق
- یادگیری تقویتی
- فضای فرضیه
- آموزش انتقالی
- یادگیری ماشین در توابع تخصصی جغرافیایی
حوضه جاذبه مجموعه ای از حالت های شروع را تعریف می کند که در نهایت منجر به یافتن یک بهینه محلی می شود.
داده کاوی (همچنین به عنوان کشف دانش در داده ها شناخته می شود) فرآیند کشف و استخراج الگوهای قابل استفاده از مجموعه داده های بزرگ است.
یادگیری عمیق (DL) زیر شاخه ای از یادگیری ماشین است که از شبکه های عصبی مصنوعی برای تقریب یک تابع نگاشت بین مقادیر ورودی و خروجی الهام گرفته شده است. این الگوریتم ها را در لایه ها ساختار می دهد تا یک ساختار سلسله مراتبی از تبدیل های غیرخطی ایجاد کند که یادگیری بهترین تقریب تابع را امکان پذیر می کند.
یک راه حل عملی به عنوان مجموعه ای از مقادیر برای متغیرهای تصمیم تعریف می شود که تمام محدودیت ها را در یک مسئله بهینه سازی برآورده می کند.
یک راه حل بهینه جهانی ، یک راه حل عملی با مقدار هدف است که از همه راه حل های امکان پذیر دیگر برای مدل بهتر است.
فضای فرضی در مسائل یادگیری، حوضه ای از جاذبه را تعریف می کند که شامل مجموعه ای از حالت های شروع می شود که در نهایت منجر به یافتن یک بهینه محلی برای مدل های برآورد شده می شود. با ویژگی هایی از جمله ابعاد، ظرفیت بازنمایی و همچنین بهینه محلی و حوضه جاذبه مشخص می شود.
یادگیری به عنوان فرآیندی تعریف میشود که طی آن یک ماشین الگوهای خاص وظایف کاربردی را از دادهها پیدا میکند. این فرآیند را می توان به عنوان یک کار تحت نظارت، نیمه نظارت یا بدون نظارت به دست آورد.
بهینه محلی راه حلی است که برای آن هیچ راه حل عملی بهتری در همسایگی راه حل داده شده یافت نمی شود.
یادگیری ماشینی به مجموعه ای از مراحل محاسباتی یا الگوریتمی اشاره دارد که یک فرمول ریاضی را مشخص می کند تا امکان یادگیری از داده ها را فراهم کند.
یک مسئله بهینه سازی به عنوان یافتن بهترین راه حل از بین همه راه حل های امکان پذیر تعریف می شود.
یادگیری تقویتی (RL) شاخه ای از هوش مصنوعی است که مستقل است و چارچوب خودآموزی را – که هم سیستماتیک و هم پویا – است – از طریق مفهوم یادگیری از طریق اعمال تطبیق می دهد.
آموزش فرآیندی است که طی آن یک ماشین یاد می گیرد تا همبستگی بین ورودی ها و خروجی های مورد انتظار را بیابد.
حجم دادههای مکانی به میزان فوقالعادهای در حال رشد است و در عین حال بر پیشرفتهای جدید در فناوریهای سختافزاری و نرمافزاری که شامل هوش مصنوعی و تأثیر آن بر مشکلات اجتماعی است، تأثیر مثبت میگذارد. دادههای بزرگ جغرافیایی و پیشرفتهای اخیر در منابع محاسباتی سختافزار مقرونبهصرفه، هر دو پشت سر جهش یادگیری ماشین، یادگیری عمیق، و یادگیری تقویتی هستند – همه زیرشاخههای هوش مصنوعی. در این یادداشت کوتاه، ما یک مرور کلی از روشهای هوش مصنوعی انتخابی مانند یادگیری ماشینی، یادگیری عمیق، یادگیری تقویتی و روشهای یادگیری انتقال ارائه میکنیم. ما نمونه فضاهای فرضیه یادگیری را توصیف می کنیم که شامل جستجوی راه حل های بهینه است، و ابزارهای هوش مصنوعی فعلی را شناسایی می کنیم که ممکن است برای علوم و فناوری اطلاعات جغرافیایی (GIS&T) مفید باشند. تلاشهای تحقیق و توسعه نشان میدهد که یکپارچهسازی دادههای استخراجشده از سیستمهای اطلاعات جغرافیایی با هوش مصنوعی پتانسیلی برای ارتقای درک جامعه از جهان اطراف دارد. چند مثال که در آن هوش مصنوعی در حال گسترش عملکرد توابع تحلیل مکانی تخصصی است نیز ارائه شده است.
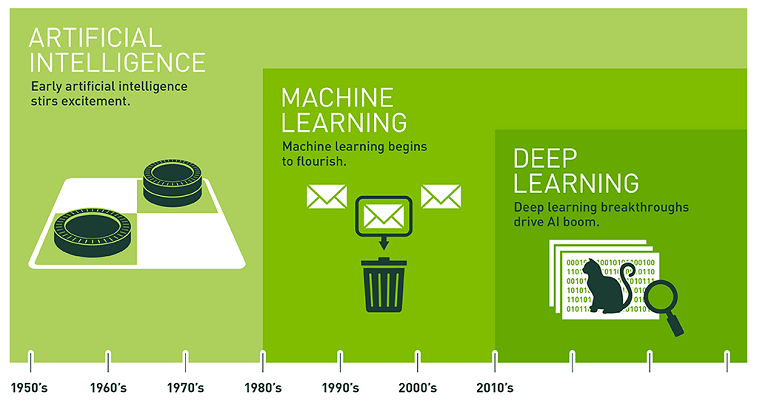
شکل 1. جدول زمانی برای هوش مصنوعی. منبع: NVIDIA
هوش مصنوعی (AI) یک زمینه بین رشتهای است که شامل علوم کامپیوتر و همچنین انواع مختلف مهندسی و علوم، به عنوان مثال رباتیک، مهندسی پزشکی زیستی است که اتوماسیون اعمال انسان و هوش از طریق ماشینها را برجسته میکند. برای بیش از دو دهه، موفقیتهای هوش مصنوعی در برنامههایی پدیدار شد که نیاز به همپوشانی بین عملکردهای شناختی سطح پایین و بالا داشت که در تکنیکهای مختلف از جمله یادگیری تقویتی، و یادگیری ماشین به تصویر کشیده شد (Duch and Mandziuk 2007؛ Russell and Norvig 2010. شکل 1 جدول زمانی را نشان میدهد. تکامل هوش مصنوعی از اواسط دهه 1950. در آن زمان، هوش مصنوعی بر حل مسئله و روشهای نمادین متمرکز بود. وظایف استدلال ادراکی در دهه 1960 زمانی که آژانس پروژههای تحقیقاتی پیشرفته دفاعی (دارپا) به هوش مصنوعی علاقهمند شد، ظاهر شد. در دهههای 1970 و 1980 دارپا در ادامه به استفاده از هوش مصنوعی در مسئله تشخیص کاراکترهای نوری با استفاده از طرحهای معماری اولیه شبکههای عصبی پرداخت (Le Cun et al. 1990). اواسط دهه 1990 شاهد ظهور روشهای یادگیری ماشینی بودیم، اما عملکرد و مقیاسپذیری آنها به دلیل سختافزار و کمبود دادههای بزرگ محدود شد. از اواخر دهه 2000 تا به امروز، پیشرفتها در فناوریهای سختافزار محاسباتی (مثلاً معرفی واحدهای پردازش گرافیکی به محاسبات) و در دسترس بودن حجم زیادی از دادهها، بسیاری از پیشرفتهای یادگیری ماشینی امروزی را ممکن ساخته است (کریژفسکی، سوتسکور و هینتون 2012). . ما همچنان شاهد این هستیم که الگوریتمهای هوش مصنوعی به رایانهها این امکان را میدهند تا با پردازش مکرر حجم زیادی از دادهها، تطبیق با تغییرات ورودیها و تشخیص الگوهای مورد علاقه، از تجربه یاد بگیرند. برای مقایسه موج کنونی موفقیت با کارهای اولیه که هوش مصنوعی را برای حل مشکلات و درک دانش نمادین ترغیب می کرد (راسل و نورویگ 2010)، یافته های تحقیقات دهه گذشته نشان می دهد که وظایف پیچیده ای که معمولاً با توانایی های شناختی مرتبط هستند، می توانند به یک معقول تبدیل شوند. درجه، با برازش توابع به داده ها گرفته و بازتولید شود (دارویچی 2018). تناسب توابع پیچیده به داده ها اخیراً به دلیل در دسترس بودن حجم زیادی از داده ها، دستاوردهای تکنولوژیکی اخیر در محاسبات سخت افزاری و پیشرفت مداوم در روش های آماری بهبود یافته است. جامعه جغرافیایی به همان اندازه شاهد تعداد فزاینده ای از برنامه های کاربردی عملی است که با توابعی مطابقت دارند که به اندازه کافی ساده هستند تا الگوریتم های یادگیری جدیدی را فعال کنند که می توانند به طور کارآمد ارزیابی شوند. این شامل روش های بسیار مقیاس پذیر برای تشخیص الگوهای شی از مجموعه داده های تصویری است. موفقیت خیرهکننده در مشکل کاربرد زمینفضایی شامل پیشبینی الگوهای آبوهوای شدید شناساییشده در مقیاس بزرگ (Kurth et al. 2018) برای فعال کردن ماشینهای خودران فریدمن و همکاران است. (2018). بخش زیر به طور خلاصه چند شاخه از هوش مصنوعی را توضیح می دهد که همچنان چنین عملکرد باورنکردنی را برای تکمیل و تقویت توانایی های شناختی فعال می کنند.
داده کاوی که به عنوان کشف دانش در داده نیز شناخته می شود، فرآیند کشف و استخراج الگوهای قابل استفاده از مجموعه داده های بزرگ است (تان و همکاران 2018). دادهها بهصورت دستهای با استفاده از تکنیکهای مختلف یادگیری ماشین از جمله الگوریتمهای توصیه، تداعی، خوشهبندی، و پیشبینیهای عددی و غیره پردازش میشوند. در عمل، دادهکاوی برنامههای کاربردی سنتی را تقویت میکند که پایگاه داده را برای جمعآوری، خلاصهسازی و تجزیه و تحلیل محتویات آن با القای الگوریتمهای ریاضی پیچیده تقویت میکند. از هوش مصنوعی و یادگیری ماشین، برای یافتن همبستگیهای ناشناخته یا کشف نشده قبلی در میان مجموعه دادههای مختلف و بزرگ (Tan et al. 2018) . ویژگیهای کلیدی داده کاوی شامل پیشبینی الگوهای خودکار مبتنی بر تحلیل روند و رفتار، نگاشت بین ورودی و خروجی بر اساس نتایج احتمالی، ایجاد اطلاعات تصمیممحور، استخراج اطلاعات از مجموعه دادهها و پایگاههای داده بزرگ برای تجزیه و تحلیل، و خوشهبندی بر اساس یافته است. و گروههایی از حقایق که قبلاً شناخته نشدهاند بهصورت بصری مستند شدهاند. در برنامههای GIS، عملکردهای مشابه در دادهکاوی تطبیق داده میشود، با این حال، روی دادههای مکانی با هدف کشف و استخراج همبستگیها در دادهها و در عین حال ترکیب جغرافیا – از این رو به نام دادهکاوی مکانی اعتبار داده میشود (Li، Wang و Li 2016). .
یادگیری ماشینی (ML) به مجموعه ای از مراحل محاسباتی یا الگوریتمی اشاره دارد که یک فرمول ریاضی را مشخص می کند تا امکان یادگیری از داده ها را فراهم کند (Goodfellow، Bengio و Courville 2016؛ Skymind 2018؛ Pang-Ning و همکاران 2018). “گفته می شود که یک برنامه کامپیوتری از تجربه E با توجه به دسته ای از وظایف T و معیار عملکرد P یاد می گیرد، اگر عملکرد آن در وظایف در T، همانطور که توسط P اندازه گیری می شود، با تجربه E بهبود یابد” (میچل 1997). همانطور که در شکل 2 نشان داده شده است، تکنیک های ML معمولاً به دو دسته کلی تقسیم می شوند: روش های یادگیری تحت نظارت و بدون نظارت (Goodfellow، Bengio و Courville 2016؛ Castrounis 2016؛ Mitchell 1997).
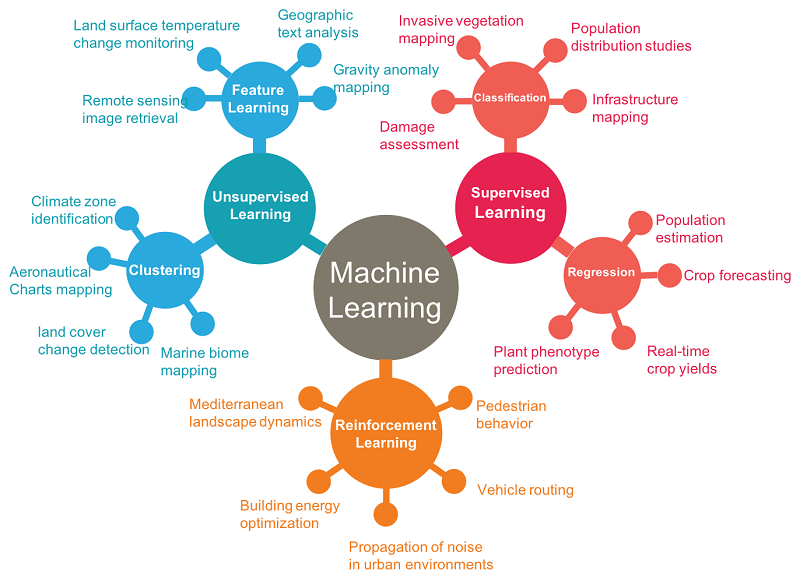
شکل 2. نمونه برنامه های GIS و فرمول بندی بالقوه آنها برای یادگیری خودکار به عنوان یک مسئله ML. منبع: نویسنده
4.1 یادگیری تحت نظارتالگوریتمها یک مجموعه داده حاوی ویژگیها را تجربه میکنند، اما هر نمونه ورودی نیز با یک برچسب یا خروجی هدف مرتبط است. روشها معمولاً از سه دیدگاه (1) پارامتری، (2) ناپارامتریک و (3) روشهایی که بین تکنیکهای پارامتری و ناپارامتریک هستند تعریف میشوند. روشهای پارامتری برازش دادهها را به یک تابع پیچیده تعریفشده برای استفاده در وظایف پیشبینی فرض میکنند، در حالی که روشهای غیر پارامتری اینطور نیستند. یادگیری تحت نظارت رایجترین و مورد مطالعهترین نوع مقوله یادگیری است، زیرا آموزش ماشین برای یادگیری با دادههای برچسبدار آسانتر از دادههای بدون برچسب است. بسته به کار کاربردی، یادگیری نظارت شده می تواند برای حل مشکلات رگرسیون یا طبقه بندی استفاده شود. تصاویر ماهواره ای یک نمونه مجموعه داده از جامعه مکانی را ارائه می دهد که می تواند برای نشان دادن وظایف رگرسیون یا طبقه بندی استفاده شود. برای کارهایی که نیاز به پیشبینی مقادیر گسسته دارند، مانند شناسایی و طبقهبندی مجموعهای از اشیاء از تصاویر ماهوارهای به کلاسهای مختلف، وظایف به عنوان یک مشکل طبقهبندی حل میشوند. برای پیش بینی مقادیر پیوسته، مانند تعداد اشیاء در یک تصویر، مشکل به عنوان یک کار رگرسیون حل می شود.
4.2 الگوریتم های یادگیری بدون نظارت ، مجموعه داده ای حاوی ویژگی های بسیاری را تجربه می کنند، سپس ویژگی های مفید ساختار این مجموعه داده را یاد می گیرند. این روشها به دلیل نیاز به کشف الگوهای طبیعی از دادهها بدون آگاهی از اطلاعات برچسبگذاری اساسی هدایت میشوند. هیچ پاسخ صحیحی به ماشین در حین یادگیری داده نمیشود، الگوهای طبیعی در دادهها امیدواریم ماشین را به یادگیری تشخیص الگوهای کلیدی و گروهبندی دادهها بر اساس چنین الگوهایی راهنمایی کند، یعنی یادگیری بدون نظارت، ماشینهایی هستند که سعی میکنند «به تنهایی» و بدون کمک یاد بگیرند. از داده های برچسب گذاری شده وظایف یادگیری بدون نظارت را می توان بسته به برنامه به صورت مشکلات خوشه بندی یا تداعی حل کرد. به عنوان یک مشکل خوشه بندی ، یادگیری بدون نظارت را می توان با مجموعه ای از تکنیک های یادگیری ماشینی انجام داد که یاد می گیرد ساختارها را در داده ها کشف کند و حل مسئله را با جستجوی شباهت ها با استفاده از الگوهای طبیعی از داده ها بیاموزد. اگر یک خوشه یا گروه مشترک وجود داشته باشد، الگوریتم آنها را به شکل خاصی دسته بندی می کند. نمونه ای از این می تواند به دنبال گروه بندی تصاویر با محتوای مشابه برای فعال کردن بازیابی مبتنی بر محتوا از پایگاه های داده بزرگ باشد. به عنوان یک مشکل تداعی، یادگیری بدون نظارت سعی می کند این مشکل را با تلاش برای کشف ویژگی های مهم و در عین حال درک قوانین و معنای پشت گروه های مختلف حل کند. یافتن رابطه بین خرید مشتری در یک جغرافیای خاص یا جمعیتی یک مثال رایج از مشکل ارتباط در پلتفرم های توصیه خرده فروشی آنلاین است.
در حالی که خلاصهای جامع از یادگیری ماشینی فراتر از محدوده این مدخل است، برخی زمینههای اساسی هنوز برای درک ظهور بلوکهای سازنده حیاتی در چند تکنیک مدرن یادگیری ماشین بسیار مهم است. به طور خاص، شبکههای عصبی مصنوعی به دهههای 1940 تا 1960 برمیگردد، جایی که به عنوان سایبرنتیک شناخته میشد، در دهههای 1980-1990 به عنوان پیوندگرایی شناخته میشد. و جدیدترین تجدید حیات آن تحت نام یادگیری عمیق در سال 2006 (Goodfellow, Bengio, and Courville 2016). به عنوان یک مدل محاسباتی برای گرفتن یادگیری بیولوژیکی، شبکه عصبی مصنوعی (ANNs) به تعریف بلوکهای ساختمان اصلی فعلی برای یادگیری عمیق مدرن آمد. مدلهای ANN به عنوان سیستمهای مهندسی شده الهامگرفته از مغز بیولوژیکی در نظر گرفته میشوند تا آنچه را میتوان بهعنوان مدرکی برای اینکه هوش را میتوان آموخت، ارائه کرد. در دهه 1940، شبکه های عصبی مصنوعی به دلیل مدل های خطی ساده ای بودند که مجموعه ای از مقادیر ورودی را می گرفتند و آنها را با یک مقدار خروجی مرتبط می کردند. مدل با یادگیری مجموعهای از وزنها تعریف میشود و مدل خطی برای تشخیص دستههای مختلف استفاده میشود، به عنوان مثال تشخیص دو دسته مختلف با بررسی اینکه آیا تابع خطی است یا خیر.مثبت است یا منفی برای اینکه مدل بتواند پیش بینی های درستی داشته باشد، وزن ها باید به صورت دستی تنظیم شوند. در دهه 1950، پرسپترون (روزنبلات 1958) اولین الگوریتمی بود که میتوانست وزنهای مدل را یاد بگیرد که ورودیها را به کلاسهای مربوطه نگاشت میکرد. الگوریتم آموزشی مورد استفاده برای انطباق وزن مدل، مورد خاصی از نزول گرادیان تصادفی بود . بیشتر بلوکهای ساختمان شبکههای عصبی که امروزه از روشهای یادگیری عمیق استفاده میشود، مبتنی بر نورون مدلی به نام واحد خط اصلاحشده با استفاده از علوم اعصاب بهعنوان الهام هستند (Goodfellow، Bengio و Courville 2016).
یادگیری عمیق (DL) یک فناوری مبتنی بر شبکه عصبی مصنوعی اخیر است که به طور گسترده در وظایف یادگیری نظارت شده و بدون نظارت برای تعریف الگوریتمهای یادگیری ماشینی که مستقل هستند و از ساختار و عملکرد خودآموز شبکههای عصبی مصنوعی الهام گرفتهاند، استفاده میشود. مفهوم DL اغلب به عنوان شبکه های عصبی عمیق شناخته می شود که به لایه های زیادی از تبدیل داده ها اشاره دارد. در حالی که یک شبکه عصبی ممکن است با یک لایه برای تبدیل داده طراحی شود (میچل 1997؛ کولوبرت و بنژیو 2004؛ راسل و نورویگ 2010)، یک شبکه عصبی عمیق اغلب بیش از دو لایه دارد. لایه ها در یک سلسله مراتب سازماندهی شده اند و هر لایه به طور غیرخطی سیگنال های اطلاعاتی را به سمت نمایش انتزاعی تر نگاشت می کند (گودفلو و همکاران 2016). فرآیند آموزش اغلب مستلزم استفاده از میلیونها رکورد از دادههای موجود برای آموزش الگوریتمها برای یافتن الگوهایی با پیشبینیهای دادههای جدید ساختهشده با استفاده از مدلهای برآورد شده است. در چندین کاربرد نشان داده شده است که با دادهها و محاسبات بیشتر، عملکرد پیشبینیکننده روشهای DL با نرخهایی که از روشهای یادگیری ماشین قبلی پیشی میگیرد، مقیاسپذیر است (مثلاً روشهای یادگیری مبتنی بر سطحی از جمله ماشینهای بردار پشتیبان – به شکل 3 مراجعه کنید.) (Coates 2018؛ Collobert). و Bengio 2004). به عنوان مثال، یک الگوریتم DL را برای تشخیص ساختمان ها از روی یک تصویر ماهواره ای آموزش می دهد. این امر با ارائه نمونههای بسیاری از تصاویر به دست میآید که پیکسلهای آنها برای نشان دادن داشتن یا نداشتن ساختمان برچسبگذاری شدهاند. یادگیری به عنوان یک جستجوی بهینهسازی برای وزنها (یا پارامترهای) مدل بهینه به دست میآید که به تمایز الگوها با تمایز ویژگیهای تصویر (به عنوان مثال لبهها، اشکال، رنگها، زمینه فضایی) کمک میکند. ویژگی های آموخته شده در مرحله استنتاج مدل مورد استفاده قرار می گیرند تا پیکسل های تصویر را بر اساس اینکه آیا دارای ساختمان هستند یا نه طبقه بندی می شوند.
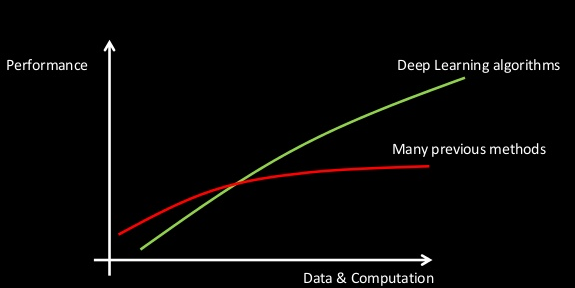
شکل 3. مقیاس پذیری الگوریتم های یادگیری عمیق. منبع: After Coates (2018).
اگرچه هنوز به طور گسترده در بسیاری از کاربردهای مکانی اقتباس نشده است، یادگیری تقویتی (RL) یک شاخه در حال رشد از هوش مصنوعی است که مستقل است و یک چارچوب خودآموزی مبتنی بر یادگیری از طریق اقدامات را تطبیق می دهد. RL اقداماتی را در یک محیط انجام می دهد تا تابع پاداش را در یک بعد خاص به حداکثر برساند و در نتیجه یادگیری را از طریق آزمون و خطا از طریق الگوریتم های هدف گرا آغاز کند. با استفاده از مفاهیم عامل ها، محیط ها، حالت ها، اقدامات و پاداش ها، روش های RL با سایر تکنیک های یادگیری ماشینی متفاوت است به این معنا که یادگیری افزایشی است و هیچ داده آموزشی ثابتی قبل از یادگیری جمع آوری نمی شود. در عوض، عوامل RL با محیطها تعامل میکنند، دادهها را تولید میکنند یا منفعلانه منتظر دادههای جدید میمانند و تصمیم میگیرند که چگونه برای انجام یک وظیفه معین عمل کنند. به خاطر همین، الگوریتم ها به عنوان یادگیری پویا از محیط ها شناخته می شوند. RL شامل سطحی از یادگیری عمومی تر از رویکردهای نظارت شده یا بدون نظارت است. انتظار میرود الگوریتمهای RL با یادگیری از تجربه، بهجای دادههای آموزشی، در محیطهای مبهمتر و واقعیتر از روشهای دیگر بهتر عمل کنند، در حالی که از بین تعداد دلخواه اقدامات ممکن انتخاب میشوند (Sharma 2018).
با توجه به مجموعهای از مشاهدات ورودی (مثلاً پیکسلهای تصویر)، یک الگوریتم ML ممکن است به دنبال یادگیری تابعی باشد که قادر به پیشبینی یک مقدار خروجی باشد (مثلاً دسته کلاس). سپس مشکل یادگیری مدل مربوطه به جستجوی یک فرضیه بهینه کاهش می یابد که رابطه بین ورودی ها و مقادیر خروجی مورد انتظار را توضیح می دهد. فضای فرضیه را می توان با ویژگی هایی از جمله ابعاد، ظرفیت بازنمایی و همچنین بهینه محلی مشخص کرد (دولک 2013). پیچیدگی های یادگیری از طریق نفرین ابعاد معرفی می شوند زیرا اندازه مؤثر فرضیه به طور تصاعدی با تعداد ابعاد افزایش می یابد (بلمن 2003؛ بلومر و همکاران 1989).
قدرت بیانی، غنا یا انعطاف پذیری فضایی از توابع که می توان توسط یک الگوریتم یاد گرفت، ظرفیت بازنمایی فضای فرضیه را مشخص می کند. جستجو در تمام فرضیه های ممکن از هر دو فضای پیوسته و گسسته می تواند غیر ممکن باشد. در عوض، روشهای یادگیری از روشهای اکتشافی برای عبور از فضای جستجوی اقلیدسی محلی خود استفاده میکنند (میچل 1997). همانطور که در شکل 4 نشان داده شده است، روش های یادگیری مبتنی بر نزول گرادیان از یک فرضیه اولیه اولیه می شوند و فضای آن را برای راه حل بهتر طی می کنند تا زمانی که هیچ پیشرفتی پیدا نشود (میچل 1982، 1997). فرض رایج این است که بهترین فرضیه در فاصله ای اپسیلونی یا همسایگی سایر فرضیه های خوب است. مفهوم بهینه محلی فرضیه هایی را معرفی می کند که خوب هستند اما ممکن است نزدیک به بهترین راه حل جهانی نباشند. همانطور که در شکل 4 نشان داده شده است، معمول است که روشهای نزولی مبتنی بر گرادیان در بهینه محلی به دام میافتند، هیچ راهحل بهتری در این نزدیکی پیدا نمیکنند و آن را به عنوان پاسخ برمیگردانند، حتی اگر بهینه جهانی در جای دیگری وجود داشته باشد. اینکه کدام بهینه محلی پیدا می شود به نقطه اولیه و تنظیمات فراپارامتر الگوریتم یادگیری بستگی دارد.
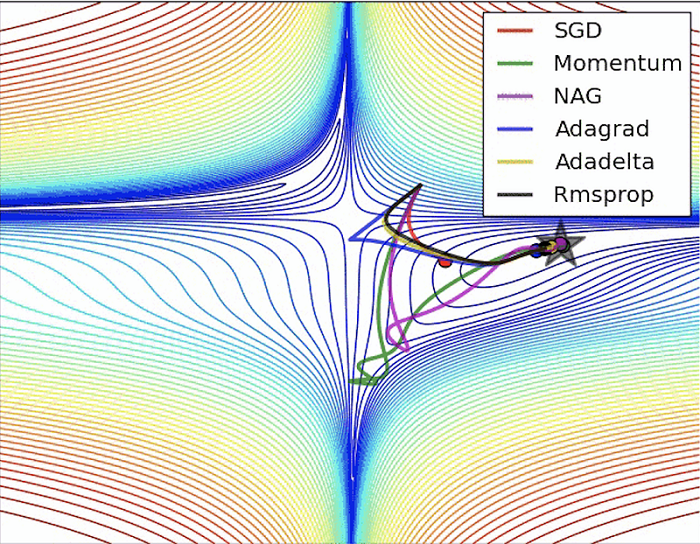
شکل 4. نشان دادن جستجو برای مقادیر بهینه یک تابع معین با استفاده از الگوریتم های مختلف بهینه سازی مبتنی بر شیب نزولی. نمودارها نزول گرادیان تصادفی (SGD)، تکانه، گرادیان شتاب دار نیستروف (NAG) را نشان می دهد. در ابتدا مقادیر گرادیان بزرگ هستند و باعث میشوند تکنیکهای جستجوی مبتنی بر سرعت شلیک میکنند و به اطراف پرتاب میشوند – adagrad تقریباً ناپایدار میشود. تابعی که باید بهینه شود دارای مقادیر آن با خطوط در خطوط مختلف از قرمز (بالاترین خطوط) تا آبی (مناطق با کمترین مقادیر) است. GIF: http://ruder.io/optimizing-gradient-descent/ . منبع: Ruder 2016.
برای ارائه یک فرضیه مثال، کار (Darwiche 2018) تمایز زیادی در دو رویکرد برای حل فرضیه بهینه در مسائل هوش مصنوعی ایجاد میکند. بسیاری از مشکلات در GIS را می توان به هر دو رویکرد یعنی رویکرد مبتنی بر عملکرد و رویکرد مبتنی بر مدل ترسیم کرد. اگر وظیفه تشخیص اشیا را با تصاویر ماهواره ای در نظر بگیریم، فضای فرضیه از منظر مبتنی بر عملکرد مستلزم فرمول بندی کار به عنوان یک مسئله متناسب با عملکرد است، با پیکسل های تصویری به عنوان ورودی تابع و خروجی های تابع مربوط به تشخیص انتزاعی شی مورد نظر استفاده می شود. شکل عملکردی می تواند از نظر پیچیدگی دلخواه باشد اما ارزیابی آن آسان است. سپس میتوان الگوریتمهای بهینهسازی مختلفی را در فضای توابع اعمال کرد تا مقادیر بهینه را جستجو کند که تابعی را برای استفاده در پیشبینی اینکه چه شیئی در تصاویر آزمایشی جدید وجود دارد، به دست میدهد. با استفاده از رویکرد مبتنی بر مدل، وظایف تشخیص را می توان از طریق نمایش اشیاء با استفاده از یک هستی شناسی حل کرد. استدلال از طریق منطق و احتمال به ابزاری برای استخراج دانش برای استنتاج و پیش بینی در نمونه های آزمایشی تبدیل می شود (راسل و نورویگ 2010).
یادگیری انتقالی (TL)، یک الگوریتم نیست و نه شاخه ای از مطالعه است، بلکه یک روش طراحی، در یادگیری ماشین، برای تطبیق و اعمال نفوذ مدل هایی است که از یک کار برای استفاده در یک کار متفاوت تخمین زده می شوند. اغلب یادگیری ویژگی تعمیم یافته را می توان از یک دامنه منبع حاوی مقادیر زیادی از داده های برچسب گذاری شده بدست آورد و در حالی که دامنه هدف برنامه ممکن است حاوی نمونه های دارای برچسب کمتر باشد. همانطور که در شکل 5 نشان داده شده است، از طریق فرآیند مدلهای تنظیم دقیق، دانش استخراج ویژگی میتواند مجدداً برای بهبود تعمیم در حوزه هدف مورد استفاده قرار گیرد. این روش طراحی معمولاً در روشهای یادگیری عمیق برای انتقال دانش وظیفه A (با مجموعه داده A) که توسط وزن مدل به کار B (مجموعه داده هدف مشخص شده است) منتقل میشود (Gerrand و همکاران 2017).
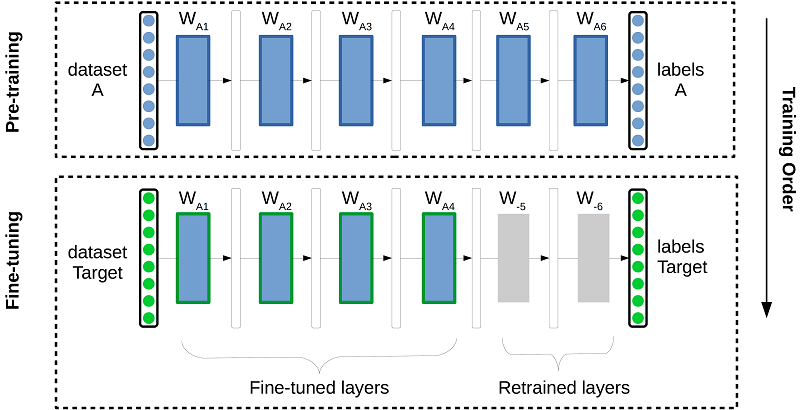
شکل 5. تصویری از انتقال یادگیری به یک مجموعه داده هدف جدید با یک مدل از پیش آموزش داده شده بر روی مجموعه داده A. در بالا نشان داده شده است، یادگیری انتقال از طریق تنظیم دقیق انجام می شود (مدل هدف آموزش در چند تکرار با لایه های انتخابی اولیه شده از مدل آموزش داده شده بر روی مجموعه داده A به عنوان مثال. W_A1،…،W_A4) در حالی که لایه های W_-5 و W-_6 از مقداردهی اولیه تصادفی آموزش داده شده اند. این فرآیند دانش را از وظیفه A به وظیفه B منتقل می کند، در نتیجه وظیفه هدف را قادر می سازد تا مجموعه داده هدف کوچک برچسب گذاری شده را جستجو کند و در عین حال از دانش به دست آمده از مجموعه داده A بهره مند شود. منبع: نویسنده، پس از جراند و همکاران. (2017).
10. یادگیری ماشینی در توابع تخصصی جغرافیایی
همانطور که در شکل 2 نشان داده شده است، تکنیک های یادگیری ماشین طیفی از کاربردها از جمله تشخیص اشیاء مبتنی بر دید، رانندگی خودکار، کشاورزی، امنیت غذایی، نظارت بر زیرساخت و مدیریت بلایا را تغییر می دهند. به عنوان مثال، در نقشه برداری جمعیت، نیاز به درک مکان زندگی مردم برای درک اینکه مردم چه کاری انجام می دهند و نیازهای اجتماعی آنها در رابطه با امنیت انرژی چیست، اساسی است. سیاست و توسعه شهری؛ تاب آوری؛ واکنش در بلایا و اضطراری؛ و حمایت انسان دوستانه، و همچنین درک پویایی های اجتماعی رفتاری. با حجم زیادی از تصاویر ماهوارهای موجود و سختافزار محاسباتی گرافیکی شتابیافته، شاهد افزایش انطباق یادگیری ماشین و هوش مصنوعی برای راهحلهای نقشهبرداری در مقیاس جهانی هستیم، بهعنوان مثال، تشخیص سکونت انسان از تصاویر ماهوارهای با وضوح بالا (Lunga et al. 2018). چندین مورد استفاده از جمله پشتیبانی از پاسخ به فاجعه FEMA در غرب ایالات متحده برای رفع نیازهای خاص جامعه اطلاعاتی (یانگ و همکاران 2018) موارد استفاده نمونه ای هستند که از به کارگیری فناوری های هوش مصنوعی سود می برند. با بسط دادن مثالهای کاربردی، کار (وانگ و همکاران 2017) نشان میدهد که چگونه مشکل تعمیم نقشه، کاهش مقیاس، و نمادسازی ویژگی از طریق الگوریتمهای ژنتیک طراحیشده برای ترکیب محدودیتهای نقشهبرداری بهبود مییابد.
بیشتر وظایف مکانی به صورت دستی انجام شده است که به تعداد زیادی نیروی انسانی نیاز دارد. فقدان اتوماسیون در کارهای بزرگ به طور قابل توجهی گران است، مستعد بروز رسانی های نادر و خطاهای انسانی است. برای مثال، جمعآوری آدرسهای خیابان یک تلاش انسانی است که اکنون میتواند با روشهای هوش مصنوعی سادهسازی شود. اخیراً هوش مصنوعی پتانسیل ایجاد خودکار آدرس خیابان ها از تصاویر ماهواره ای را با یادگیری و برچسب گذاری جاده ها، مناطق و سلول های آدرس نشان داده است (Demir et al. 2018). در مثالی دیگر، نقشهبرداری پلانیمتری خدمات اغلب توسط ارزیابهای مالیاتی دولت محلی برای ایجاد پایگاههای اطلاعاتی ارزیابی مالیات مورد نیاز است. به عنوان نماینده، استخرهای شنا به سوابق ارزیابی اضافه می شوند زیرا ارزش ملک را افزایش می دهند. از این رو، یافتن استخرهایی که در فهرست اموال به روز شده نیستند، برای ارزیاب اهمیت زیادی دارد. بدون اتوماسیون این کار دلهره آور است. با این حال، استفاده از ابزارهای GIS و هوش مصنوعی کاهش نیروی انسانی پرهزینه مربوط به به روز رسانی سوابق را از طریق بازدید میدانی از هر ملک نشان داده است (Singh 2018). در حالی که استخرها می توانند ارزش یک ملک را افزایش دهند، می توانند باعث نگرانی در مورد شیوع بیماری در دوران رکود و بهبود آهسته برای بخش های اقتصادی املاک و مستغلات شوند. بسیاری از خانه های مسکونی را می توان با استخرهای بی توجهی که اغلب محل پرورش پشه ها هستند، رها کرد. در کنفرانس اخیر کاربران، دانشمندان در Esri، ادغام نرمافزار ArcGIS را با آخرین نوآوریهای هوش مصنوعی برای انجام تشخیص استخرها با استفاده از تصاویر هوایی نشان دادند. دانشمندان تجزیه و تحلیل های بیشتری را برای شناسایی استخرهایی که در حالت غفلت قرار دارند توسعه دادند، که از آن زمان به بازرسان سلامت برای کمک به جلوگیری از گسترش بیماری های منتقله از طریق ناقل کمک می کند (Jha and Singh 2018؛ Rodriguez-Cuenca and Alonso 2014). در اپیدمیولوژی محیطی، مدلسازی مواجهه یک رویکرد رایج برای انجام ارزیابی مواجهه برای تعیین توزیع مواجهه در جمعیتهای مورد مطالعه است. هوش مصنوعی همراه با فناوریهای GIS مزایای مهمی را برای مدلسازی مواجهه در اپیدمیولوژی محیطی فراهم میکند، از جمله توانایی ترکیب مقادیر زیادی از دادههای مکانی و زمانی بزرگ در قالبهای مختلف. کارایی محاسباتی؛ انعطاف پذیری در الگوریتم ها و گردش کار برای تطبیق ویژگی های مربوط به فرآیندهای فضایی (محیط زیستی) از جمله غیر ایستایی فضایی. و مقیاسپذیری برای مدلسازی سایر مواجهههای محیطی در مناطق مختلف جغرافیایی (VoPham et al. 2018). در سایر حوزههای تخصصی، موجی از روشهای هوش مصنوعی جدید با ترکیب مقدار زیادی از اطلاعات جمعآوریشده توسط دوربینهای ترافیکی و حسگرها برای نقشهبرداری جاده، به جذب وسایل نقلیه خودران و سیستم حملونقل هوشمند کمک میکنند (آگاچای و هانگ 2018). علاوه بر این، فناوری هوش مصنوعی بر کشف دانش جغرافیایی در داده های متنی بدون ساختار در زبان های مختلف تأثیر می گذارد (اشمیت و همکاران 2013). همچنین کاربردهای بسیاری دیگر از تکنیکهای هوش مصنوعی در تحقیقات زمینفضایی، مانند پیشبینی انتشار فضایی در اپیدمیولوژی، تجزیه و تحلیل گسترش شهری، و تجزیه و تحلیل تصویر فراطیفی وجود دارد (Abdelkader et al. 2017؛ GIS Resources 2018; Peter 2016).
عبدالقادر، EG، دیوید، JM، Said، EG، و جوزف، K. (2017). تجزیه و تحلیل رشد شهری و پراکندگی از داده های سنجش از دور: مورد فاس، مراکش. مجله بین المللی محیط زیست پایدار ، 6 (1)، 160-169.
آگاچای، اس.، و هونگ، WH (2018). هوشمندتر و متصل تر: سیستم حمل و نقل هوشمند آینده. تحقیقات IATSS، 42 (2)، 67-71.
بلمن، RE (2003). برنامه نویسی پویا انتشارات پیک دوور.
Beni, G., & Wang, J. (1989). هوش ازدحام در سیستم های رباتیک سلولی در مجموعه مقالات کارگاه پیشرفته ناتو در مورد روبات ها و سیستم های بیولوژیکی.
بلومر، ا.، ارنفوشت، ا.، هاسلر، دی.، و وارموث، MK (1989). یادگیری پذیری و بعد vapnik-chervonenkis. مجله انجمن ماشین های محاسباتی ، 36، 929-965.
Castrounis A. (2016). یادگیری ماشینی: مروری کامل و تفصیلی برگرفته از https://www.kdnuggets.com/2016/10/machine-learning-complete-detailed-overview.html .
کوتس، A. (2018). هوش مصنوعی برای 100 میلیون نفر با یادگیری عمیق. برگرفته از https://www.slideshare.net/AIFrontiers/adam-coatesai-for-100-million-people-with-deep-learning/7 .
Collobert, R. & Bengio, S. (2004). پیوندهای بین پرسپترون ها، MLP ها و SVM ها. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی یادگیری ماشین (ICML ’04). ACM، نیویورک، نیویورک، ایالات متحده آمریکا، 23-. DOI: 10.1145/1015330.1015415
دارویچه، ا. (2018). هوش در سطح انسان یا توانایی های حیوانی؟ اشتراک. ACM ، 61.
دمیر، [U+FFFD]، هیوز، اف.، راج، ا.، دهروو، ک.، مودالا، اس ام، گارگ، اس.، . . . راسکار، ر. (2018). آدرسهای خیابانهای تولیدی از تصاویر ماهوارهای. ISPRS International Journal of Geo-Information, 7(3). برگرفته از http://www.mdpi.com/2220-9964/7/3/84
دوچ، دبلیو (2007). هوش محاسباتی چیست و چه چیزی می تواند باشد؟ اسپرینگر.
Duch, W., & Mandziuk, J. (2007). چالش های هوش محاسباتی اسپرینگر. دولک، آر (2013). ویژگی های فضای فرضیه و تأثیر آنها بر یادگیری ماشین. پایان نامه 2013، مخزن دانشگاه اوترخت.
Fridman، L.، Brown، DE، Glazer، M.، Angell، W.، Dodd، S.، Jenik، B.، . . . ریمر، بی. (اکتبر 2018). مطالعه فناوری خودروی خودمختار Mit: تجزیه و تحلیل مبتنی بر یادگیری عمیق در مقیاس بزرگ از رفتار راننده و تعامل با اتوماسیون Arxiv.
جراند، جی.، ویلیامز، کیو، لونگا، دی.، پانتانوویتز، آ.، مدی، SA، و محمود، ن. (2017). غربالگری رادیوگرافی قفسه سینه پیشانی کودکان با شبکه های عصبی کانولوشنال تنظیم شده دقیق در Miua.
منابع GIS (2018). مبانی سنجش از دور فراطیفی، منابع GIS. برگرفته از http://www.gisresources.com/fundamemtals-ofhyperspectral-remote-sensing-2/ .
Goodfellow I.، Bengio Y.، & Courville A. (2016). یادگیری عمیق . مطبوعات MIT.
Jha، D.، و Singh، R. (2018). تشخیص و طبقه بندی استخر با استفاده از یادگیری عمیق برگرفته از https://medium.com/geoai/swimming-pool-detectionand-classification-using-deep-learning-aaf4a3a5e652 .
Karpathy، A. (2015). دانشگاه استنفورد cs231n: شبکه های عصبی کانولوشن برای تشخیص بصری.
Khandelwal, R. (2019). مروری بر بهینه سازهای مختلف برای شبکه های عصبی برگرفته از https://medium.com/datadriveninvestor/overview-of-different-optimizers-for-neural-networks-e0ed119440c3 .
Krizhevsky، A.، Sutskever، I.، و Hinton، GE (2012). طبقهبندی شبکههای تصویری با شبکههای عصبی کانولوشنال عمیق در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی سیستم های پردازش اطلاعات عصبی – جلد 1 (ص 1097–1105). ایالات متحده آمریکا: Curran Associates Inc.
Kurth، T.، Treichler، S.، Romero، J.، Mudigonda، M.، Luehr، N.، Phillips، E.، . . . هیوستون، ام. (2018، اکتبر). یادگیری عمیق Exascale برای تجزیه و تحلیل آب و هوا. Arxiv.
Le Cun, YL, Boser, B., Denker, JS, Howard, RE, Habbard, W., Jackel, LD, & Henderson, D. (1990). تشخیص رقم دستنویس با یک شبکه انتشار برگشتی، در پیشرفتها در سیستمهای پردازش اطلاعات عصبی 2 : 396-404.
لی، دی، وانگ اس. و لی، دی (2016). داده کاوی فضایی: نظریه و کاربرد (ویرایش اول). شرکت انتشارات Springer، ثبت شده است
Lunga، D.، Yang، HL، Reith، A.، Weaver، J.، J. and Yuan، & Bhaduri، B. (2018). شبکههای کانولوشنال سازگار با دامنه برای طبقهبندی تصاویر ماهوارهای: یک گردش کار یادگیری تعاملی در مقیاس بزرگ مجله IEEE از موضوعات منتخب در مشاهدات کاربردی زمین و سنجش از دور، 11 (3)، 962-977.
میچل، تی ام (1982). تعمیم به عنوان جستجو هوش مصنوعی ، 18، 203-226.
میچل، تی ام (1997). فراگیری ماشین. McGraw-Hill, Inc.
پیتر، سی (2016). چارچوب های فضایی و زمانی برای انتشار بیماری های عفونی و اپیدمیولوژی Int J Environ Res Health عمومی ، 13(12).
Pang-Ning، T. Steinbach, M., Karpatne, A. and Kumar, V.. (2018). مقدمه ای بر داده کاوی (ویرایش دوم) (ویرایش دوم). پیرسون.
رودریگز-کوئنکا، بی، و آلونسو، ام سی (2014). تشخیص نیمه خودکار استخرهای شنا از تصاویر هوایی با وضوح بالا و داده های لیدار. سنجش از دور 6(4): 2628-2646. DOI: 10.3390/rs6042628 .
روزنبلات (1958). پرسپترون: مدل احتمالی برای ذخیره و سازماندهی اطلاعات در مغز، بررسی روانشناختی، 65–386
رودر، اس (2016). مروری بر الگوریتمهای بهینهسازی گرادیان نزول. برگرفته از http://ruder.io/optimizing-gradient-descent/
راسل، اس جی، و نورویگ، پی (2010). هوش مصنوعی: یک رویکرد مدرن (ویرایش سوم). نیوجرسی: پرنتیس هال.
اشمیت، اس.، مانشیتز، اس.، رنسینگ، سی.، و اشتاینمتز، آر. (2013). استخراج داده های آدرس از متن بدون ساختار با استفاده از منابع دانش رایگان. مجموعه مقالات سیزدهمین کنفرانس بین المللی مدیریت دانش و فناوری های دانش. شارما، وی (2018). یادگیری تقویتی – پاداش برای یادگیری. برگرفته از https://vinodsblog.com/2018/04/16/reinforcementlearning-reward-for-learning/ .
صدیق، ن.، و عادلی، ح. (2013). هوش محاسباتی: هم افزایی منطق فازی، شبکه های عصبی و محاسبات تکاملی . جان وایلی و پسران
سینگ، آر (2018). چگونه این کار را انجام دادیم: یکپارچه سازی arcgis و یادگیری عمیق در UC 2018. برگرفته از https://www.esri.com/arcgisblog/products/api-python/analytics/how-we-did-itintegrating-arcgis-and-machine- Learn-at-uc-2018/ .
Skymind. (2018). الگوریتم های یادگیری ماشینی برگرفته از https://skymind.ai/wiki/machine-learning-algorithms .
VoPham، T.، Hart، JE، Laden، F.، و Chiang، Y.-Y. (2018، 17 آوریل). روندهای نوظهور در هوش مصنوعی زمین فضایی (geoai): کاربردهای بالقوه برای اپیدمیولوژی محیطی بهداشت محیط، 17(1)، 40.
وانگ، ال.، گو، کیو، لیو، ی.، سان، ی.، و وی، زی (2017). انتخاب ساختمان متنی بر اساس الگوریتم ژنتیک در تعمیم نقشه ISPRS International Journal of Geo-Information , 6(9). برگرفته از http://www.mdpi.com/2220-9964/6/9/271
یانگ، اچ ال، یوان، جی.، لونگا، دی.، لاوردیر، ام.، رز، ا.، و بهادوری، بی. (2018). استخراج ساختمان در مقیاس با استفاده از شبکه عصبی کانولوشنال: نقشه برداری از ایالات متحده مجله IEEE موضوعات منتخب در مشاهدات کاربردی زمین و سنجش از دور .
- روش های هوش محاسباتی را که ممکن است در GIS&T اعمال شود، توضیح دهید
- نمونهای از پتانسیل یادگیری ماشینی برای گسترش عملکرد توابع تحلیل مکانی تخصصی
- یک فضای فرضی را توصیف کنید که شامل جستجو برای بهینه بودن راه حل ها در آن فضا می شود
- روش های هوش مصنوعی را که ممکن است در GIS&T اعمال شود، توضیح دهید
- ابزارهای هوش مصنوعی که ممکن است برای GIS&T مفید باشند را شناسایی کنید
- یادگیری عمیق چیست؟
- یادگیری ماشینی را توضیح دهید.
- هوش مصنوعی چه تفاوتی با یادگیری ماشینی دارد؟
- یادگیری تقویتی چیست؟
- یادگیری انتقالی چیست؟
- فضای فرضیه برای مشکلات یادگیری ماشین چیست؟
- نمونه ای از استفاده تخصصی از یادگیری ماشین در کاربردهای مکانی را شرح دهید.
منابع یادگیری برای هوش مصنوعی
- Coursera – یادگیری ماشین و علوم داده
- داده کاوی فضایی
- Coursera – شبکه های عصبی برای یادگیری ماشین
- دوره های تخصصی علوم داده
- Udacity – مقدمه ای بر یادگیری ماشین
- Udacity – یادگیری ماشین و داده کاوی
- Udacity – یادگیری عمیق
- فراگیری ماشین
- یادگیری عمیق عملی برای کدنویسان
- Stanford CS231n — شبکه های عصبی کانولوشن برای تشخیص بصری (زمستان 2016) ( لینک کلاس )
- Stanford CS224n — پردازش زبان طبیعی با یادگیری عمیق (زمستان 2017) ( لینک کلاس )
- Oxford Deep NLP 2017
- یادگیری تقویتی
- آموزش عملی یادگیری ماشین با پایتون
ابزارهای هوش مصنوعی
- Microsoft and Esri – GeoAI Data Science Virtual Machine به عنوان بخشی از خانواده محصولات ماشین مجازی Data Science/Deep Learning Virtual Machine در Azure منتشر شده است. این نتیجه همکاری بین دو شرکت است و هوش مصنوعی، فناوری ابری و زیرساخت، تجزیه و تحلیل جغرافیایی و تجسم را برای کمک به ایجاد برنامههای کاربردی قویتر و هوشمندانهتر به هم میآورد.
- TensorFlow یک کتابخانه نرم افزار منبع باز برای محاسبات عددی با استفاده از نمودارهای جریان داده است. گره ها در نمودار عملیات ریاضی را نشان می دهند، در حالی که لبه های نمودار نشان دهنده آرایه های داده چند بعدی (تانسورها) هستند که بین آنها جریان دارد. این معماری انعطاف پذیر به شما امکان می دهد محاسبات را در یک یا چند CPU یا GPU در دسکتاپ، سرور یا دستگاه تلفن همراه بدون بازنویسی کد مستقر کنید.
- Keras یک API شبکه های عصبی سطح بالا است که به زبان پایتون نوشته شده است و می تواند در بالای TensorFlow ، CNTK یا Theano اجرا شود. این با تمرکز بر امکان آزمایش سریع توسعه داده شد. اینکه بتوانید از ایده ای به نتیجه دیگر با کمترین تاخیر ممکن بروید، کلید انجام یک تحقیق خوب است.
- PyTorch یک بسته پایتون است که دو ویژگی سطح بالا را ارائه می دهد: محاسبات تانسور (مانند numpy) با شتاب قوی GPU و شبکه های عصبی عمیق ساخته شده بر روی یک سیستم autograd مبتنی بر نوار.
- Caffe یک چارچوب یادگیری عمیق است که با بیان، سرعت و مدولار بودن در ذهن ساخته شده است. این توسط تحقیقات هوش مصنوعی برکلی و توسط مشارکت کنندگان جامعه توسعه یافته است. معماری رسا آن کاربرد و نوآوری را تشویق می کند، در حالی که کد توسعه پذیر آن توسعه فعال را تقویت می کند.
- مجموعه ابزار شناختی مایکروسافت ، که قبلاً به عنوان CNTK شناخته می شد، یک جعبه ابزار یادگیری عمیق یکپارچه است که شبکه های عصبی را به عنوان مجموعه ای از مراحل محاسباتی از طریق یک گراف جهت دار توصیف می کند. در این گراف جهت دار، گره های برگ مقادیر ورودی یا پارامترهای شبکه را نشان می دهند، در حالی که سایر گره ها عملیات ماتریس را بر روی ورودی های خود نشان می دهند.
- Chainer یک چارچوب یادگیری عمیق مبتنی بر پایتون است که هدف آن انعطافپذیری است. این APIهای تمایز خودکار را بر اساس رویکرد تعریف با اجرا، که به عنوان نمودارهای محاسباتی پویا نیز شناخته می شود، و همچنین APIهای سطح بالا شی گرا برای ساخت و آموزش شبکه های عصبی ارائه می دهد. از CUDA و cuDNN با استفاده از CuPy برای آموزش و استنتاج با کارایی بالا پشتیبانی می کند.
- MXNet یک چارچوب یادگیری عمیق است که هم برای کارایی و هم برای انعطافپذیری طراحی شده است. این به شما امکان می دهد طعم برنامه نویسی نمادین و برنامه نویسی ضروری را برای به حداکثر رساندن کارایی و بهره وری ترکیب کنید. در هسته آن یک زمانبندی وابستگی پویا وجود دارد که به طور خودکار هر دو عملیات نمادین و ضروری را در پرواز موازی می کند. یک لایه بهینه سازی گراف در بالای آن اجرای نمادین را سریع و کارآمد می کند. این کتابخانه قابل حمل و سبک است و برای چندین GPU و چندین ماشین مقیاس بندی می شود.
- انویدیا به توسعه دهندگان، محققان و دانشمندان داده دسترسی آسان به کانتینرهای چارچوب یادگیری عمیق بهینه سازی شده را فراهم می کند، که عملکردی برای پردازنده های گرافیکی NVIDIA تنظیم و آزمایش شده است. این امر نیاز به مدیریت بسته ها و وابستگی ها یا ساخت چارچوب های یادگیری عمیق از منبع را از بین می برد. برای کسب اطلاعات بیشتر از NVIDIA GPU Cloud دیدن کنید .
9 نظرات