پایگاه داده توپوگرافی
پایگاه داده توپوگرافی مجموعه داده ای است که زمین تمام فنلاند را به تصویر می کشد. اشیاء کلیدی در پایگاه داده توپوگرافی عبارتند از: شبکه راه ها، ساختمان ها و ساختمان ها، مرزهای اداری، نام های جغرافیایی، کاربری زمین، آبراه ها و ارتفاعات.
عکس های هوایی، داده های اسکن و داده های ارائه شده توسط سایر ارائه دهندگان داده در به روز رسانی پایگاه داده توپوگرافی استفاده می شود. به روز رسانی با همکاری نزدیک شهرداری ها انجام می شود. بررسی های میدانی در زمین نیز تا حدی مورد نیاز است، بیشتر در مورد طبقه بندی ویژگی ها.
پایگاه داده توپوگرافی در تولید سایر محصولات نقشه و در کارهای مختلف بهینه سازی استفاده می شود.
این محصول متعلق به داده های باز نقشه برداری ملی فنلاند است.
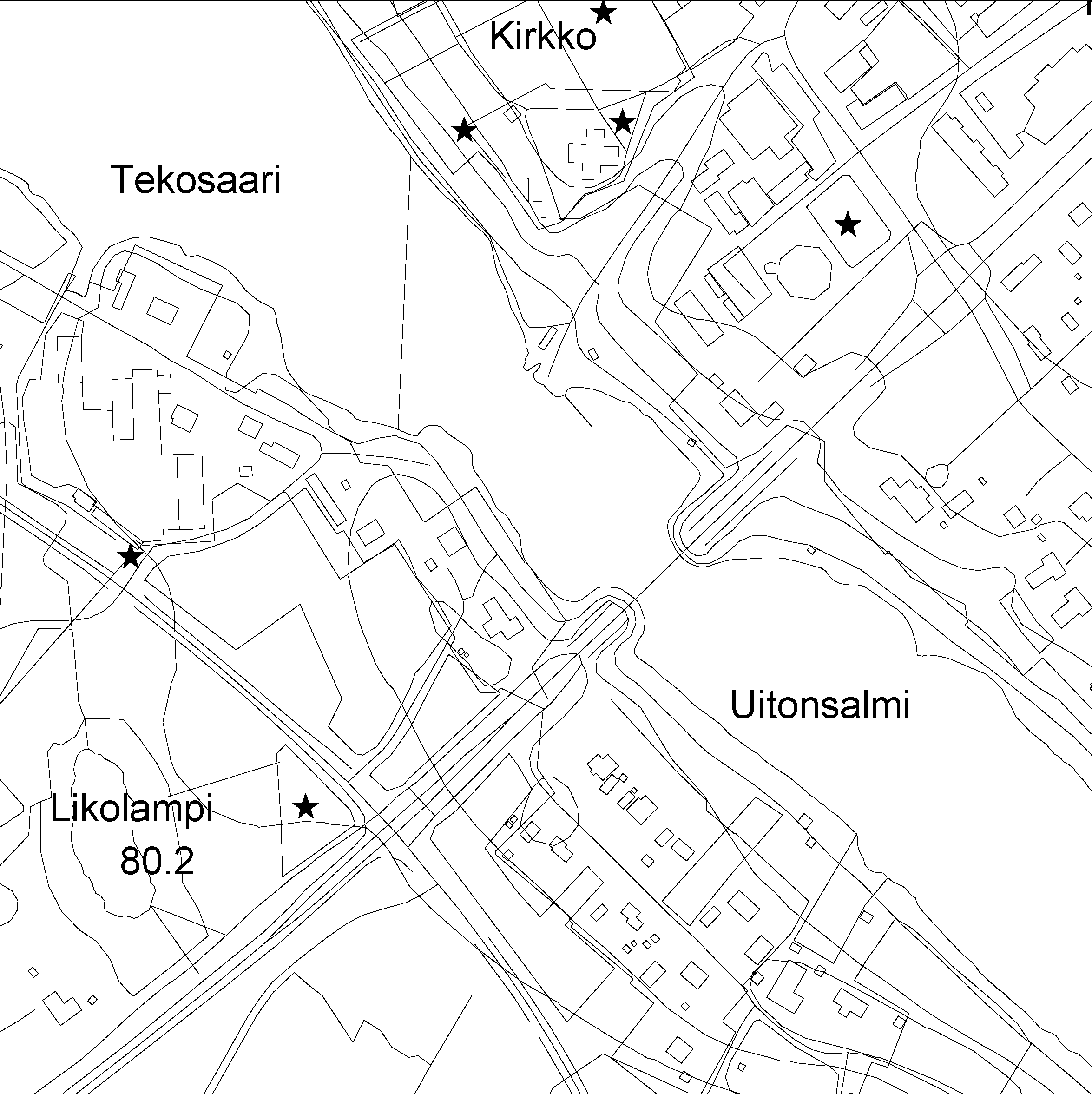
پایگاه داده توپوگرافی در قالب برداری می تواند به عنوان داده منبع برای محصولات مختلف نقشه استفاده شود. پایگاه داده توپوگرافی برای استفاده به عنوان نقشه پایه برای برنامه ریزی کاربری اراضی و برای انجام وظایف و تحلیل های مختلف بهینه سازی مناسب است. پایگاه داده توپوگرافی همچنین برای استفاده به عنوان مثال در برنامه های مختلف برای موقعیت یابی، جستجوی مسیر، نگهداری و جمع آوری داده هایی که از موقعیت یابی GPS استفاده می کنند، مناسب است.a/Maastotietojarjestelma/MTK/202203/Koodistot/
پایگاه داده توپوگرافی
تعریف
پایگاه داده توپوگرافی (pl. Baza Danych Obiektów Topographicznych ) یک پایگاه داده برداری (شیء) است که شامل موقعیت مکانی اشیاء توپوگرافی با ویژگی های آنها برای لهستان است. محتوا و جزئیات پایگاه با نقشه توپوگرافی در مقیاس 1:10000 مطابقت دارد. دامنه موضوعی شامل اطلاعات مربوط به شبکه آب، شبکه ارتباطی، پوشش زمین، ساختمان ها و سازه های فنی، زیرساخت های تاسیساتی، کاربری زمین، مناطق حفاظت شده، واحدهای تقسیم سرزمینی و سایر اشیاء است. پایگاه داده در قالب زبان نشانه گذاری جغرافیایی (GML) موجود است. منبع داده های آن از:
- سایر پایگاههای اطلاعاتی فضایی که توسط دفتر مرکزی ژئودزی و کارتوگرافی لهستان نگهداری میشود (مانند ثبت شهرها، خیابانها و آدرسها ، ثبت زمین و ساختمانها ، ثبت دولتی مرزها )،
- پایگاه های داده ای که توسط سایر وزارتخانه ها یا مؤسسات نگهداری می شود (به عنوان مثال، وزارت زیرساخت، مدیریت آب دولتی، اداره کل حفاظت از محیط زیست)،
- کارهای میدانی
هدف
هدف از این وینیت انجام عملیات فضایی بر روی داده های برداری از پایگاه داده توپوگرافی است. ما روی چهار حالت تمرکز می کنیم، با در نظر گرفتن انواع مختلف هندسه، یعنی نقطه، خط، و چندضلعی و ویژگی های آنها. همچنین، ما نشان می دهیم که چگونه می توان آنها را تجسم کرد.
تحلیل و بررسی
# attach packages
library(sf)
library(rgugik)منطقه تجزیه و تحلیل ما، شهرستان bieszczadzki است که در ناحیه ساب کارپات ( podkarpackie ) voivodeship واقع شده است. این دورترین منطقه جنوبی در لهستان است که کمترین تراکم جمعیت را نیز دارد (19 نفر در کیلومتر مربع ).
پایگاه داده
ما با جستجو در پایگاه داده توپوگرافی برای شهرستان خود با استفاده از topodb_download()تابع شروع می کنیم.
# 22.4 MB
topodb_download("bieszczadzki", outdir = "./data")اگر در دانلود با مشکلی مواجه شدید، به یاد داشته باشید که می توانید روش دانلود دیگری را به download.file()عنوان آرگومان تابع ارسال کنید.
topodb_download(req_df, outdir = "./data", method = "wget")پایگاه داده دانلود شده از فایل های زیادی با فرمت GML تشکیل شده است . تمام داده های لازم برای تجزیه و تحلیل را می توان در data/PL.PZGiK.332.1801/BDOT10k/مکان یافت.
ابتدا، اجازه دهید فایل را با واحدهای مدیریتی (“PL.PZGiK.332.1801__OT_ADJA_A.xml”) با استفاده از بسته sf و read_sf()عملکرد آن بارگذاری کنیم.
territory = read_sf("data/PL.PZGiK.332.1801/BDOT10k/PL.PZGiK.332.1801__OT_ADJA_A.xml")فایل شامل واحدهای اداری در سطوح مختلف است، بیایید پایین ترین سطح یعنی مشترکات را انتخاب کنیم. سه نوع جامعه در این مجموعه داده وجود دارد که در rodzajستون مشخص شدهاند: شهری ( GM )، روستایی ( GW ) و شهری-روستایی ( Gmw ). بیایید آنها را انتخاب کنیم.
communes = territory[territory$rodzaj %in% c("GM", "GW", "Gmw"), "rodzaj"]
table(communes$rodzaj)##
## Gmw GW
## 1 2می بینیم که شهرستان bieszczadzki از دو کمون روستایی و یک کمون شهری- روستایی تشکیل شده است. بیایید آن را تجسم کنیم.
plot(communes, axes = TRUE, main = "Bieszczadzki county")
طول و دسته بندی جاده ها
در کار اول، طول جاده ها را با در نظر گرفتن دسته بندی آنها محاسبه می کنیم. داده های جاده را می توان در فایل “PL.PZGiK.332.1801__OT_SKDR_L.xml” یافت.
roads = read_sf("data/PL.PZGiK.332.1801/BDOT10k/PL.PZGiK.332.1801__OT_SKDR_L.xml")بیایید آنها را طرح کنیم. ما plot()دوباره از تابع استفاده می کنیم، اما این بار دو لایه را در یک تصویر ترکیب می کنیم. لایه اول (در پس زمینه) شامل جاده ها است و برای اضافه کردن یک لایه دیگر، باید آرگومان را resetروی "FALSE". سپس با قرار دادن آرگومان addروی "TRUE".
plot(roads["katZarzadzania"], main = "Road category", reset = FALSE)
plot(st_geometry(territory), add = TRUE)
ما شش دسته راه مرتبط با نهاد مدیریت داریم. آنها عبارتند از: جادههای ملی (K)، شهرستانی (W)، شهرستانی (P)، عمومی (G)، نهادی (Z)، و سایر جادههای (I).
st_length()از تابع برای یافتن طول هر جسم در جدول استفاده می کنیم . در مرحله بعد، ما یک چارچوب داده متشکل از دسته جاده و طول آن ایجاد می کنیم. سپس این قاب داده را جمع می کنیم و مجموع طول های هر دسته را محاسبه می کنیم.
length_roads = st_length(roads)
length_roads = data.frame(length = length_roads,
class = as.factor(roads$katZarzadzania))
length_roads = aggregate(length ~ class, data = length_roads, FUN = sum)نتایج بر حسب متر داده شده است – بیایید آنها را به کیلومتر تبدیل کنیم.
# convert to [km]
length_roads$length = units::set_units(length_roads$length, "km")بیایید نام دسته ها را نیز تغییر دهیم.
road_class = c("communal", "other", "national", "county", "voivodeship",
"institutional")
levels(length_roads$class) = road_classحالا می توانیم نتایج را ببینیم. نوع otherراهها غالب است که عمدتاً از راههای غیر عمومی تشکیل شده است.
length_roads## class length
## 1 communal 186.17329 [km]
## 2 other 2819.55806 [km]
## 3 national 19.24996 [km]
## 4 county 187.17870 [km]
## 5 voivodeship 105.67567 [km]
## 6 institutional 10.44893 [km]همچنین می توانیم طول کل جاده های این منطقه را محاسبه کنیم.
sum(length_roads$length)## 3328.285 [km]نتیجه حدود 3328.285 کیلومتر است. جنبه دیگری از داده هایی که می توانیم بررسی کنیم، تراکم شبکه راه است. ابتدا باید مساحت کل را محاسبه کنیم و سپس طول کل جاده را بر مساحت کل تقسیم کنیم.
communes_area = sum(st_area(communes))
communes_area = units::set_units(communes_area, "km2")
density = sum(length_roads$length)/communes_area
density = units::set_units(density, "km/km2")
density## 2.921031 [km/km2]تراکم جاده حدود 2.92 کیلومتر در کیلومتر مربع است .
جاده ها از طریق رودخانه ها
مجموعه داده دیگری که در پایگاه داده توپوگرافی گنجانده شده است شامل رودخانه هایی برای این منطقه است (“PL.PZGiK.332.1801__OT_SWRS_L.xml”).
rivers = read_sf("data/PL.PZGiK.332.1801/BDOT10k/PL.PZGiK.332.1801__OT_SWRS_L.xml")
rivers = rivers[rivers$rodzaj == "Rz", ] # select only riversرودخانه ها به بخش های کوچکتر با پارامترهای مختلف مانند عرض رودخانه یا منبع داده تقسیم می شوند. idMPHPبیایید بخشهایی از همان رودخانهها را در یک ویژگی واحد (هندسه) ادغام کنیم – برای این منظور میتوانیم از ویژگی با شناسه ( ) استفاده کنیم . همچنین میتوانیم با ایجاد یک دنباله از 1 تا n با استفاده از seq_lenتابع، به هر رودخانه یک عدد دسته بدهیم.
rivers = aggregate(rivers[, c("geometry", "idMPHP")],
list(rivers$idMPHP),
sum)
rivers$idMPHP = seq_len(length(unique(rivers$idMPHP)))
rivers$idMPHP = as.factor(rivers$idMPHP)بیایید مسیرهای رودخانه ها را تجسم کنیم.
plot(rivers["idMPHP"], main = "Rivers", reset = FALSE)
plot(st_geometry(territory), add = TRUE)
با رودخانهها و جادهها، میتوانیم نقاط تقاطع را مشخص کنیم که نماد پلها و گذرگاهها هستند. st_intersection()برای این کار می توانیم از تابع استفاده کنیم .
bridges = st_geometry(st_intersection(rivers, roads))
length(bridges)## [1] 81ما 81 امتیاز از این دست گرفتیم. بیایید آنها را طرح کنیم.
# use 'dev.off()' to reset previous plot
plot(st_geometry(rivers), main = "Bridges and crossings", col = "blue")
plot(st_geometry(territory), add = TRUE)
plot(bridges, add = TRUE, pch = 20)
پوشش زمین
پوشش زمین مواد فیزیکی سطح زمین مانند چمن، درختان، زمین برهنه، آب و غیره است. بیایید داده های پوشش زمین را برای شهرستان خود بررسی کنیم – در فایل هایی با PTپیشوند ذخیره می شود. ما از list.files()تابع برای لیست کردن آنها استفاده می کنیم. آرگومان patternدر اینجا مهم است زیرا تعیین می کند چه فایل هایی باید انتخاب شوند. ما patternباید به این شکل باشد: PT+.+A\\.xml$– فقط فایل های حاوی داده های منطقه ای (A) پوشش زمین (PT) فهرست می شوند.
files = list.files("data/PL.PZGiK.332.1801/BDOT10k",
pattern = "PT+.+A\\.xml$",
full.names = TRUE)
# print filenames
basename(files)## [1] "PL.PZGiK.332.1801__OT_PTGN_A.xml"
## [2] "PL.PZGiK.332.1801__OT_PTKM_A.xml"
## [3] "PL.PZGiK.332.1801__OT_PTLZ_A.xml"
## [4] "PL.PZGiK.332.1801__OT_PTNZ_A.xml"
## [5] "PL.PZGiK.332.1801__OT_PTPL_A.xml"
## [6] "PL.PZGiK.332.1801__OT_PTRK_A.xml"
## [7] "PL.PZGiK.332.1801__OT_PTSO_A.xml"
## [8] "PL.PZGiK.332.1801__OT_PTTR_A.xml"
## [9] "PL.PZGiK.332.1801__OT_PTUT_A.xml"
## [10] "PL.PZGiK.332.1801__OT_PTWP_A.xml"
## [11] "PL.PZGiK.332.1801__OT_PTWZ_A.xml"
## [12] "PL.PZGiK.332.1801__OT_PTZB_A.xml"همچنین میتوانیم فایل “PL.PZGiK.332.1801__OT_PTSO_A.xml” را از لیست حذف کنیم، زیرا این فایل حاوی هیچ شی (ویژگی) است.
# drop "OT_PTSO_A.xml"
files = files[-7]بیایید نام اشیایی را که داده ها در آنها بارگذاری می شوند آماده کنیم. نامهای زیر، نام توسعهیافته اختصارات ذخیرهشده در نام فایلها هستند.
layer_names = c("fallowlands", "communication", "forest", "undeveloped",
"squares", "shrublands", "crops", "grassland",
"water", "heaps", "buildings")اکنون هر فایل GML را بارگذاری می کنیم و آن را از لیست بالا نامگذاری می کنیم. به جای استفاده از یک حلقه، میتوانیم از lapply()تابعی استفاده کنیم که عمل خاصی را برای هر عنصر بردار انجام میدهد. عمل در مورد ما بارگذاری فایل های GML با استفاده از read_sf().
layers = lapply(files, read_sf)
names(layers) = layer_namesقبلا st_length()طول خط را محاسبه می کردیم، حالا از st_area()تابع مربوطه برای محاسبه مساحت استفاده می کنیم. در اینجا ما از lapply()تابع به طور مشابه استفاده می کنیم، که برای هر آیتم در لیست کار می کند. تابع مشابهی است sapply()که به جای لیست، یک بردار را برمی گرداند.
# calculate areas in each layer
area_landcover = lapply(layers, st_area)
# sum areas for each layer
area_landcover = sapply(area_landcover, sum)
# convert units
area_landcover = units::set_units(area_landcover, "m^2")
area_landcover = units::set_units(area_landcover, "km^2")
names(area_landcover) = layer_namesبیایید نتایج را (به کیلومتر) ببینیم.
area_landcover## Units: [km^2]
## fallowlands communication forest undeveloped squares
## 0.07561383 1.97014481 860.17248134 0.27817715 0.29038385
## shrublands crops grassland water heaps
## 1.57266555 255.13528884 0.63447491 8.81181550 0.09220115
## buildings
## 10.38781092بیایید مطمئن شویم که کل پوشش زمین برابر با مساحت شهرستان ما باشد. برخی از تفاوت های دقت کوچک ممکن است، بنابراین ما باید تحمل تفاوت را تنظیم کنیم. این با استفاده از all.equal()تابع امکان پذیر است.
all.equal(sum(area_landcover), communes_area, tolerance = 0.001)## [1] TRUEهمه چیز درست است. بیایید نتایج را به صورت درصدی از مساحت ارائه کنیم و آنها را به ترتیب نزولی مرتب کنیم.
landcover_percentage = area_landcover / sum(area_landcover) * 100
units(landcover_percentage) = NULL # drop units
landcover_percentage = sort(landcover_percentage, decreasing = TRUE)
landcover_percentage = round(landcover_percentage, 2)
landcover_percentage## forest crops buildings water communication
## 75.49 22.39 0.91 0.77 0.17
## shrublands grassland squares undeveloped heaps
## 0.14 0.06 0.03 0.02 0.01
## fallowlands
## 0.01بیش از 75 درصد از مساحت شهرستان توسط جنگل ها و تنها کمتر از 1 درصد توسط ساختمان ها پوشیده شده است.
بافر
در آخرین تجزیه و تحلیل در این تصویر، ما می خواهیم بررسی کنیم که چند ساختمان در یک فاصله معین ایستگاه اتوبوس دارند. برای حل این سوال می توانیم از بافرهای فضایی استفاده کنیم. اطلاعات مربوط به ایستگاه های اتوبوس در فایل “PL.PZGiK.332.1801__OT_OIKM_P.xml” است، جایی که آنها با مقدار OIKM04x_kod مشخصه نشان داده می شوند.
bus_stop = read_sf("data/PL.PZGiK.332.1801/BDOT10k/PL.PZGiK.332.1801__OT_OIKM_P.xml")
bus_stop = bus_stop[bus_stop$x_kod == "OIKM04", ]بیایید تجسمی تهیه کنیم که در آن ایستگاه های اتوبوس با نقاط آبی مشخص شده و ساختمان ها به صورت چند ضلعی قرمز ارائه می شوند.
buildings = layers$buildings
plot(st_geometry(communes), main = "Bus stops")
plot(st_geometry(layers$buildings), add = TRUE, border = "red")
plot(st_geometry(bus_stop), add = TRUE, pch = 20, cex = 0.7, col = "blue")
بیایید برای هر ایستگاه اتوبوس با برد 1 کیلومتر بافر ایجاد کنیم st_buffer().
bus_buffer = st_buffer(bus_stop, 1000)اکنون، ما می توانیم همه آن را ترسیم کنیم.
plot(st_geometry(communes), main = "Bus stops buffers")
plot(st_geometry(buildings), add = TRUE, border = "red")
plot(st_geometry(bus_buffer), add = TRUE)
برای برگرداندن ساختمان ها در محدوده بافر، می توانیم st_within()عملیات را انجام دهیم.
buildings_buffer = st_within(buildings, bus_buffer)نتیجه یک لیست تودرتو است که از 2828 ساختمان و بافرهای مرتبط با آنها تشکیل شده است. بیایید با استفاده sapply()از مثالهای قبلی، شمارش کنیم که چند ساختمان در هیچ بافری قرار ندارند.
buildings_ex = sapply(buildings_buffer, length)
buildings_ex = sum(buildings_ex == 0)
buildings_ex = round(buildings_ex / nrow(buildings) * 100)
buildings_ex## [1] 14پاسخ آخرین سوال ما: 14 درصد ساختمان های این شهرستان به ایستگاه اتوبوس در شعاع 1 کیلومتری دسترسی ندارند.
مروری بر طراحی پایگاه داده جغرافیایی
- مروری بر طراحی پایگاه داده جغرافیایی
- نمایندگی
- تم های داده
- مجموعه داده های GIS مجموعه ای از نمایش های یک موضوع داده است
- مجموعه داده های GIS منفرد اغلب در هماهنگی با سایر لایه های داده جمع آوری می شوند
مروری بر طراحی پایگاه داده جغرافیایی
طراحی پایگاه ژئودیتابیس بر اساس مجموعه ای مشترک از مراحل طراحی اساسی GIS است، بنابراین داشتن درک اساسی از این اهداف و روش های طراحی GIS مهم است. این بخش یک نمای کلی ارائه می دهد.
طراحی GIS شامل سازماندهی اطلاعات جغرافیایی در یک سری از مضامین داده است – لایه هایی که می توانند با استفاده از موقعیت جغرافیایی یکپارچه شوند. بنابراین منطقی است که طراحی پایگاه جغرافیایی با شناسایی مضامین دادهای که قرار است استفاده شود، شروع میشود، سپس محتویات و نمایشهای هر لایه موضوعی را مشخص میکند.
این شامل تعریف است
- نحوه نمایش ویژگی های جغرافیایی برای هر موضوع (مثلاً به عنوان نقاط، خطوط، چندضلعی ها یا شطرنجی ها) همراه با ویژگی های جدولی آنها
- نحوه سازماندهی داده ها در مجموعه داده ها، مانند کلاس های ویژگی، ویژگی ها، مجموعه داده های شطرنجی و غیره
- چه عناصر فضایی و پایگاه داده اضافی برای قوانین یکپارچگی، برای پیاده سازی رفتار غنی GIS (مانند توپولوژی ها، شبکه ها و کاتالوگ های شطرنجی)، و تعریف روابط فضایی و ویژگی بین مجموعه داده ها مورد نیاز است.
نمایندگی
هر طراحی پایگاه داده GIS با تصمیم گیری در مورد اینکه نمایش های جغرافیایی برای هر مجموعه داده چه خواهد بود آغاز می شود. واحدهای جغرافیایی منفرد را می توان به عنوان نشان داد
- کلاس های ویژگی (مجموعه نقاط، خطوط و چندضلعی ها)
- تصویرسازی و شطرنجی
- سطوح پیوسته ای که می توان با استفاده از ویژگی ها (مانند خطوط)، شطرنجی (مدل های ارتفاعی دیجیتال [DEM])، یا شبکه های نامنظم مثلثی (TIN) با استفاده از مجموعه داده های زمینی نمایش داد.
- جداول مشخصه برای داده های توصیفی
تم های داده
بازنمایی های جغرافیایی در یک سری از مضامین داده سازماندهی می شوند (گاهی اوقات به عنوان لایه های موضوعی شناخته می شوند ). یک مفهوم کلیدی در GIS یکی از لایه های داده یا مضامین است. موضوع داده مجموعه ای از عناصر جغرافیایی رایج مانند شبکه جاده، مجموعه ای از مرزهای بسته، انواع خاک، سطح ارتفاع، تصاویر ماهواره ای برای یک تاریخ معین، مکان چاه ها و غیره است.
مفهوم لایه موضوعی یکی از مفاهیم اولیه در GIS بود. تمرینکنندگان به این فکر کردند که چگونه اطلاعات جغرافیایی موجود در نقشهها را میتوان به لایههای اطلاعات منطقی تقسیم کرد – به عنوان چیزی بیش از مجموعهای تصادفی از اشیاء منفرد (مانند یک جاده، یک پل، یک تپه، یک خانه، یک شبه جزیره). این کاربران اولیه GIS اطلاعات را در لایه های موضوعی سازماندهی کردند که توزیع یک پدیده و نحوه نمایش آن را در یک گستره جغرافیایی توصیف می کرد. این لایهها همچنین یک پروتکل (قوانین ضبط) برای جمعآوری نمایشها (به عنوان مجموعه ویژگیها، لایههای شطرنجی، جداول ویژگیها و غیره) ارائه کردند.
در GIS، لایه های موضوعی یکی از اصول سازماندهی اصلی برای طراحی پایگاه داده GIS هستند.

هر GIS شامل چندین موضوع برای یک منطقه جغرافیایی مشترک خواهد بود. مجموعه تم ها به عنوان لایه های یک پشته عمل می کنند. هر موضوع را می توان به عنوان یک مجموعه اطلاعات مستقل از موضوعات دیگر مدیریت کرد. هر کدام نمایش های مخصوص به خود را دارند (نقاط، خطوط، چندضلعی ها، سطوح، شطرنجی ها و غیره). از آنجایی که مضامین مختلف مستقل به صورت مکانی ارجاع داده می شوند، روی یکدیگر قرار می گیرند و می توانند در یک نمایش نقشه مشترک ترکیب شوند. بعلاوه، عملیات تجزیه و تحلیل GIS، مانند همپوشانی، می تواند اطلاعات را بین موضوعات ترکیب کند.
مجموعه داده های GIS مجموعه ای از نمایش های یک موضوع داده است
مجموعه داده های جغرافیایی را می توان به عنوان کلاس های ویژگی و مجموعه داده های مبتنی بر شطرنجی در یک پایگاه داده GIS نشان داد.
بسیاری از مضامین با یک مجموعه واحد از ویژگی های همگن مانند یک کلاس ویژگی از چند ضلعی های نوع خاک و یک کلاس ویژگی نقطه ای از مکان های چاه نشان داده می شوند. موضوعات دیگر، مانند چارچوب حمل و نقل، با مجموعه دادههای متعدد (مانند مجموعهای از کلاسهای ویژگی مرتبط با فضایی برای خیابانها، تقاطعها، پلها، رمپهای بزرگراه و غیره) نشان داده میشوند.
مجموعه داده های شطرنجی برای نمایش سطوح پیوسته، مانند ارتفاع، شیب، و جنبه، و همچنین برای نگهداری تصاویر ماهواره ای، عکس های هوایی، و سایر مجموعه داده های شبکه ای (مانند پوشش زمین و انواع پوشش گیاهی) استفاده می شود.
هم استفاده مورد نظر و هم منابع داده موجود بر نمایش های فضایی در یک GIS تأثیر می گذارند. هنگام طراحی پایگاه داده GIS، کاربران مجموعه ای از برنامه ها را در ذهن دارند. آنها می دانند که چه سوالاتی از GIS پرسیده می شود. تعریف این کاربردها به تعیین مشخصات محتوا برای هر موضوع و نحوه نمایش جغرافیایی هر یک کمک می کند. به عنوان مثال، جایگزین های متعددی برای نشان دادن ارتفاع سطح وجود دارد: به عنوان خطوط کانتور و مکان های ارتفاع نقطه (مانند تپه ها، قله ها)، به عنوان یک سطح زمین پیوسته (یک TIN)، یا به عنوان برجسته سایه دار. هر یک یا همه اینها ممکن است برای هر طراحی پایگاه داده GIS خاص مرتبط باشد. استفاده های مورد نظر از داده ها به تعیین اینکه کدام یک از این نمایش ها مورد نیاز است کمک می کند.
اغلب، بازنمایی های جغرافیایی تا حدی توسط منابع داده موجود برای موضوع از پیش تعیین می شود. اگر یک منبع داده از قبل موجود در مقیاس و نمایش خاصی جمعآوری شده باشد، اغلب لازم است طرح خود را برای استفاده از آن تطبیق دهید.
مجموعه داده های GIS منفرد اغلب در هماهنگی با سایر لایه های داده جمع آوری می شوند
در حالی که هر مجموعه داده GIS می تواند مستقل از سایر داده های GIS مورد استفاده قرار گیرد، اغلب بسیار مهم است که مجموعه داده ها را در هماهنگی با سایر لایه های اطلاعاتی جمع آوری کنیم تا رفتار فضایی و روابط مکانی اساسی بین لایه های داده GIS مرتبط حفظ و سازگار باشد. در اینجا چند مثال وجود دارد که به توضیح این مفهوم کمک می کند:
- اطلاعات هیدرولوژیکی در مورد حوضه های آبخیز و حوضه های زهکشی باید به صورت هماهنگ با شبکه زهکشی جمع آوری شود. خطوط زهکشی باید در داخل حوضه ها قرار گیرند. همه این لایهها باید در نمای سطح زمین قرار بگیرند.
- لایههای دادههای مختلف در یک پارچه پاکت باید در هماهنگی با سایر لایههای کاداستر و با اطلاعات نقشهبرداری زیربنایی جمعآوری شوند تا ویژگیهای بسته در چارچوب کنترل نقشهبرداری قرار بگیرند. مجموعههای متعددی از ویژگیهای دیگر، مانند کلاسهای حق تقدم، حق ارتفاق و منطقهبندی، جمعآوری شدهاند تا بر روی پارچه بسته قرار گیرند.
- روابط فضایی بین ارتفاع، شکل زمین، نوع خاک، شیب، پوشش گیاهی، زمین شناسی سطحی، و سایر ویژگی های زمین معمولاً به صورت هماهنگ برای مشخص کردن واحدهای منابع محیطی جمع آوری می شوند. درک علم پشت این روابط فضایی به ایجاد یک پایگاه داده منسجم و منطقی کمک می کند که در آن ویژگی های هر لایه داده با یکدیگر سازگار باشند.
- اطلاعات نقشه پایه توپوگرافی به صورت یکپارچه گردآوری شده است. هیدروگرافی، حمل و نقل، سازه ها، مرزهای اداری و دیگر لایه های نقشه توپوگرافی به صورت هماهنگ جمع آوری می شوند. این نمایش های نقشه برداری در نمایش نقشه به شیوه ای یکپارچه برای ارتباط واضح و دقیق و جلب توجه به مکان های کلیدی نقشه ساخته شده اند.
در هر یک از این موارد، یک مدل داده مجموعهای از مضامین داده مرتبط را تعریف میکند که در یک چارچوب اطلاعاتی کلی قرار میگیرند. هر فریم ورک اساساً مجموعهای از مضامین دادههای مرتبط است که به بهترین وجه در هماهنگی با یکدیگر جمعآوری میشوند. دستورالعملهای جمعآوری دادهها از اصول علمی صحیح در مورد رفتار و روابط فضایی آنها پیروی میکند. هر موضوع نقش مهمی در توصیف کلی یک منظره خاص دارد. مثلا:
- منظره زمین. نقشه های توپوگرافی، ارتفاع، شبکه زهکشی، شبکه حمل و نقل، ویژگی های نقشه، حرکت برون کشوری و غیره
- منظر شهری. ساختمان ها، زیرساخت های حیاتی و غیره
- منظره تصویری دارایی های ماهواره ای و هوایی، محلی، منطقه ای و ملی و غیره
- منظره انسانی جمعیت شناسی (ویژگی های جمعیتی)، مراکز فرهنگی، شهروندان، مناطق اداری و مناطق و غیره
- چشم انداز نیروی کار ردیابی نیروی کار سیار، مراکز خدمات، شرایط ترافیکی، انبارها و غیره
- منظره سنسور. مکان های دوربین، دستگاه ها، و غیره
- چشم انداز عملیات و طرح ها. مناطق کنترل، حرکات برنامه ریزی شده، پاسخ، و غیره
این مفهوم از جمع آوری مضامین داده های یکپارچه به صورت هماهنگ یکی از اصول طراحی کلیدی است که در هر یک از مدل های داده ArcGIS استفاده می شود .
ایجاد پایگاه ژئودیتابیس متقابل (تولید توپوگرافی)
خلاصه
یک پایگاه جغرافیایی ارجاع متقابل ایجاد می کند که ابزار Load Data از آن برای نگاشت داده های منبع برای داده های هدف در هنگام بارگیری داده های دسته ای استفاده می کند.
استفاده
-
مقدار پارامتر پایگاه داده خروجی را می توان به عنوان پایگاه جغرافیایی مرجع متقابل ورودی در ابزار Load Data استفاده کرد .
-
مقدار پارامتر Source Workspace می تواند یک geodatabase یا shapefile باشد.
-
مقدار پارامتر Target Database باید یک geodatabase باشد.
-
این ابزار یک فایل پایگاه داده جغرافیایی حاوی جداول و سوابق مورد نیاز برای تبدیل و بارگذاری پارامتر مقدار Source Workspace به مقدار پارامتر Target Database ایجاد می کند.
-
زمانی که شمای مقادیر پارامتر Source Workspace و Target Database با یکدیگر مطابقت ندارند، می توان از فایل نگاشت برای تعیین نحوه نگاشت ویژگی ها استفاده کرد.
-
صفحه گسترده Mapping File Excel به فرمت خاصی نیاز دارد. این الگو برای استفاده در هنگام تعریف فایل نقشه برداری سفارشی در فایل های محصول نقشه برداری تولید گنجانده شده است.
-
اگر مقدار پارامتر Mapping File مشخص نشده باشد، پایگاه جغرافیایی مرجع متقابل شامل نگاشت بین تمام کلاسهای ویژگی و فیلدهایی است که نام یکسانی دارند.
-
- یک کلاس شی (کلاس ویژگی، شکل فایل یا جدول) در منبع را نمی توان به یک کلاس شی در هدف نگاشت.
- یک فیلد در یک کلاس شی منبع را نمی توان به یک فیلد در کلاس شی هدف نگاشت.
- یک کلاس شی در هدف، کلاس شی منبعی ندارد که به آن نگاشت شده باشد.
- یک فیلد در کلاس شیء هدف وجود دارد اما هیچ فیلدی در کلاس شی مبدأ وجود ندارد که به آن نگاشت شده باشد.
- یک کلاس شی در مقدار پارامتر Mapping File فهرست شده است که در مقادیر پارامتر Source Workspace یا Target Database وجود ندارد .
- فیلدی در مقدار پارامتر Mapping File فهرست شده است که در کلاس شی منبع یا هدف وجود ندارد.
- نوع فیلد یک فیلد منبع با نوع فیلد یک فیلد هدف مطابقت ندارد و هیچ نگاشت مقداری ارائه نشده است.
این ابزار هشدارهایی را در مواقعی که نمیتوان در پایگاه جغرافیایی مرجع متقابل برای سناریوهای زیر ایجاد کرد، هشدار میدهد:
مولفه
| برچسب | توضیح | نوع داده |
|
منبع فضای کاری
|
فضای کاری، یا یک پایگاه داده جغرافیایی یا دایرکتوری shapefile، که شامل طرحی از داده هایی است که به فضای کاری هدف نگاشت می شود. |
Shapefile; فضای کار |
|
پایگاه داده هدف
|
پایگاه جغرافیایی که شامل طرح واره پایگاه داده ای است که منبع به آن نگاشت می شود. |
فضای کار |
|
پایگاه داده خروجی
|
پایگاه داده جغرافیایی فایلی که ایجاد خواهد شد حاوی نگاشت از مقدار پارامتر Source Workspace تا پارامتر مقدار Target Database است . |
فضای کار |
|
فایل نقشه برداری
(اختیاری)
|
یک صفحه گسترده اکسل که حاوی اطلاعاتی درباره نحوه نگاشت ویژگی های منبع، فیلدها و مقدار ویژگی به مقدار پارامتر پایگاه داده هدف است . |
فایل |
محیط ها
اطلاعات مجوز
- پایه: خیر
- استاندارد: نیاز به نقشه برداری تولید دارد
- پیشرفته: نیاز به نقشه برداری تولید دارد
پایگاه داده های توپوگرافی ملی (NTDB)
شرح
پایگاه داده های توپوگرافی ملی (NTDB) که از طریق GeoGratis در دسترس است ، شامل مجموعه داده های برداری دیجیتالی است که کل خشکی کانادا را پوشش می دهد. Geomatics کانادا هزاران نقشه توپوگرافی را دیجیتالی و ساختار داده است و محصولی کامل و یکنواخت ایجاد کرده است که می تواند در طیف وسیعی از صنایع بسیار مفید باشد.
واحد سازمانی NTDB، سیستم توپوگرافی ملی (NTS) است که بر اساس داده آمریکای شمالی (NAD) 83 است. هر فایل (مجموعه داده ها) از یک واحد NTS در مقیاس 1:50000 یا 1:250000 تشکیل شده است. علاوه بر این، دادهها اکنون بر اساس مضامین درون یک فایل در دسترس هستند. داده های زمینی از طریق نقاط، خطوط و مناطق به تصویر کشیده می شوند.
پوشش ها در یکی از 13 موضوع زیر سازماندهی می شوند: هیدروگرافی، هیپسوگرافی (کانتورها)، پوشش گیاهی، شبکه جاده ها، جاده ها، شبکه ریلی، شبکه برق، مناطق تعیین شده، شکل زمین و تسکین، خاک های اشباع از آب، توپونیوم و ویژگی های دست ساز. .
بسیاری از پوشش ها یا مجموعه داده های فردی در لیست زیر فهرست شده اند.
- کابل های هوایی
- خراب کننده های خودرو
- موانع / دروازه ها
- موج شکن ها
- پل ها
- ساختمان ها
- مناطق ساخته شده
- گورستان ها
- دودکش ها
- خطوط (10 متر برای مقیاس 1:50000، 50 متر برای مقیاس 1:250000 متر)
- نوار نقاله
- جرثقیل ها
- مناطق/خطوط را برش دهید
- جریان های ناپدید شدن
- نقاط ارتفاعی
- کشتی ها
- مسیرهای کشتی
- پل های عابر پیاده
- استحکامات
- زمین های گلف
- خطرات برای پیمایش
- مکان های تاریخی / نقاط دیدنی
- خروجی بزرگراه
- مایعات: انبارها / انبارها
- جاده های با کاربری محدود
- مارینا
- مناطق معدنی
- وسایل کمک ناوبری
- محدودیت های سیستم ملی توپوگرافی (NTS)
- پارک ها
- سایت های پیک نیک
- برکه ها
- راه آهن
- جاده ها
- باند
- منطقه شنی
- دیوارهای دریایی
- سیلوها
- مسیرهای ورزشی / مسیرهای مسابقه
- استادیوم ها
- تانک ها
- نام های محلی
- برج ها
- مسیرها
- خطوط انتقال
- تونل ها
- مخازن زیرزمینی
- زندگی گیاهی
- دیوارها / نرده ها
- اختلال آب (سریع، تخلیه و غیره)
- بدنه های آبی
- جریان های آب
- تالاب ها
- اسکله ها
- باغ وحش ها
مرجع مکانی و نوع داده
این مجموعه داده ها به صورت جغرافیایی (لات/طول) و مختصات موجود هستند. داده افقی NAD 83 است. این داده ها در قالب Esri Shapefile موجود هستند.
دستکاری و ذخیره سازی داده ها
ایستگاه های کاری عمومی در مرکز جغرافیایی وجود دارد که دسترسی به برنامه های نرم افزاری ArcGIS، برنامه های افزودنی و ابزارهای دستکاری داده ها را فراهم می کند. کاربران ممکن است از سیستم اطلاعات جغرافیایی (GIS) و نرم افزار پردازش تصویر در کتابخانه برای مشاهده و دستکاری داده ها استفاده کنند. اساتید، دانشجویان و کارکنان UWaterloo ممکن است این داده ها را در رسانه های دیگر (به عنوان مثال: CD، DVD یا دیسک Zip) برای استفاده در جاهای دیگر کپی کنند.
خروجی داده
این تصاویر ممکن است از ArcGIS در قالبهای انتخابی بیت مپ (همچنین به عنوان گرافیک شطرنجی شناخته میشوند) از جمله JPG، TIFF، GIF، و BMP یا در قالبهای گرافیکی انتخابی از جمله Adobe Illustrator (AI)، Encapsulated Postscript (EPS)، صادر شوند. و گرافیک برداری مقیاس پذیر (SVG). گزینه دیگر PDF است. کاربر وضوح خروجی را تعریف می کند.
نقل قول
پایگاه ملی داده های توپوگرافی (ویرایش سوم) [فایل کامپیوتری]. مرکز اطلاعات توپوگرافی وزارت منابع طبیعی کانادا (1998).
نمای نمونه از داده ها
بدون دیدگاه