
پایگاه داده مکانی فضایی :راه ها جدید کشف اطلاعات : پایگاههای داده آرایهای دستهای از پایگاههای داده No-SQL هستند که دادههایی را که ساختار طبیعی آنها آرایه هستند، ذخیره، مدیریت و تجزیه و تحلیل میکنند. با رشد حجم زیادی از داده های مکانی (به عنوان مثال، تصاویر ماهواره ای) نیاز مبرمی به وجود راه های جدید برای ذخیره و دستکاری داده های آرایه وجود دارد. در حال حاضر، چندین پایگاه داده و پلتفرم وجود دارد که معماری اولیه خود را برای پشتیبانی از آرایه های چند بعدی گسترش داده اند. با این حال، در مقایسه با پایگاههای داده آرایه که در ذخیرهسازی، بازیابی و پردازش دادههای n بعدی تخصص دارند، گسترش یک پلتفرم برای پشتیبانی از آرایههای چند بعدی هزینههای عملکردی دارد.
- نمای کلی پایگاه داده آرایه
- عملیات پایگاه داده آرایه
- تجزیه و تحلیل فضایی برای پایگاه های داده آرایه
- دستورالعمل های آینده
پایگاههای داده آرایهای دستهای از پایگاههای اطلاعاتی هستند که دادههایی را که ساختار طبیعی آنها آرایه هستند، ذخیره، مدیریت و تجزیه و تحلیل میکنند. در حال حاضر، چند سیستم از جمله SciDB، RasDaMan، MonetDB و Google Earth Engine وجود دارد که پایگاه دادههای آرایهای هستند (Baumann et al., 2018). اولین پایگاه داده آرایه ای، RasDaMan، در سال 1999 برای ذخیره مجموعه داده های در حال رشد تولید شده از اکتشافات علمی و مشاهدات حسگر که معمولاً به صورت آرایه ها ساخته می شوند، توسعه یافت (Widmann & Baumann, 1999).
سایر پلتفرم ها و پایگاه های داده برای پشتیبانی از آرایه ها توسعه یافته اند. پایگاه داده های رابطه ای، مانند PostgreSQL با PostGIS، از سال 2012 از نوع داده آرایه پشتیبانی می کنند. Oracle GeoRaster یک پروژه مرتبط است و از مدل مشابهی استفاده می کند. با این حال، شبیه سازی ساختارهای آرایه در یک پایگاه داده رابطه ای منجر به هزینه عملکرد می شود. هزینه عملکرد مربوط به اندازه آرایه است که بزرگتر از اندازه صفحه خوانده شده در یک پایگاه داده سنتی است (Stonebraker, Brown, Poliakov, & Raman, 2011).
نیاز به ذخیره و دستکاری دادههای آرایه باعث شده است که بسیاری از پایگاههای داده و پلتفرمها معماری اولیه خود را برای پشتیبانی از آرایههای چند بعدی و عملیات لازم برای پرسوجو در آنها گسترش دهند. با این حال، گسترش یک پلتفرم برای پشتیبانی از یک آرایه چند بعدی هزینه عملکرد دارد و مانند یک پایگاه داده آرایه ای نیست که ساختار داده اولیه آن یک آرایه است.
به عنوان مثال، MonetDB معماری پایگاه داده فروشگاه ستونی خود را برای پشتیبانی از آرایه های چند بعدی گسترش داد. همچنین، آنها یک زبان ثانویه به نام SciQL را برای پشتیبانی از عملیات آرایه توسعه دادند (Kersten, Zhang, Ivanova, & Nes, 2011). برای سیستمهای Hadoop برنامههای افزودنی مانند SciHadoop و SciMate وجود دارد که Hadoop را برای انجام عملیات روی آرایهها گسترش دادهاند، و درایورهایی برای خواندن آرایههای چند بعدی و همچنین عملیات پردازش آرایهها در Map-Reduce ارائه میکنند (Buck et al., 2011; Wang, جیانگ و آگراوال، 2012). در نهایت، همانطور که Hadoop از خواندن مبتنی بر دیسک به خواندن حافظه با Spark منتقل شده است، پسوندهایی مانند SciArray و GeoTrellis وجود دارد (Kini & Emanuele، 2014؛ وانگ و همکاران، 2016). موضوع رایج این است که همه این پلتفرمها پلتفرمهای اولیه و ساختار داده خود را برای ترکیب آرایههای چند بعدی گسترش دادهاند. عملکرد آرایه و عملگرهای موجود برای پردازش آرایه ها بر این اساس متفاوت است. پایگاه داده های آرایه با ساختن آرایه به ساختار داده اولیه و استفاده از طرحواره های پارتیشن بندی فرمت شده برای آرایه ها این مشکل را برطرف می کنند.
دو محبوب ترین پایگاه داده آرایه منبع باز برای تجزیه و تحلیل جغرافیایی RasDaMan و SciDB هستند. RasDaMan، توسعه یافته توسط دکتر پیتر باومن، به صراحت برای جامعه مکانی توسعه یافته است (Baumann, 2016؛ Baumann, Dehmel, Furtado, Ritsch, & Widmann, 1998). در مقایسه، SciDB که توسط دکتر مایکل استون بریکر توسعه یافته است، یک پایگاه داده آرایه ای کلی است که در ژنومیک، مالی و تجزیه و تحلیل جغرافیایی به کار گرفته شده است (Planthaber، Stonebraker، & Frew، 2012؛ Stonebraker و همکاران، 2011). MonetDB در سال 2007 شروع به پشتیبانی از فروشگاه های آرایه با SciSQL کرد اما دیگر یک پروژه فعال در حال حاضر نیست (Kersten et al., 2011).
در حالی که تفاوت های عملیاتی بین سیستم ها وجود دارد، معماری زیربنایی آنها مشابه باقی می ماند. همه سیستمها از رویکرد ذخیره ستونی برای ساختاردهی و ذخیره دادههای آرایه استفاده میکنند. پایگاههای اطلاعاتی فروشگاه ستونی از طریق نحوه ذخیره و دسترسی به دادهها با پایگاههای داده سنتی (مبتنی بر ردیف) متفاوت است. پایگاه های داده ردیف-store داده ها را در مجموعه هایی از تاپل ها ذخیره می کنند، که در آن هر فیلد/ستون یک رکورد خاص با کل رکورد ذخیره می شود (شکل 1A). پایگاههای اطلاعاتی ستونها، دادهها را بر اساس ستونها/فیلدها مرتب و ذخیره میکنند (شکل 1B). سیستمهای آرایهای از رویکردی مشابه با سیستمهای ذخیره ستونی استفاده میکنند، بهطوریکه هر متغیر یا باند، برای مثال، در تصاویر ماهوارهای بهطور مستقل بهعنوان یک فیلد ذخیرهشده در ستون ذخیره میشود.

شکل 1. پایگاه داده Row-store در مقابل Column-store
روشهای فروشگاه ستونی به ذخیره ردیفی ترجیح داده میشوند زیرا دسترسی خواندن و نوشتن برای دادههای بزرگ را با هممکانی و ذخیره دادههایی که مربوط به مکانهای مشابه است، بهبود میبخشند. آرایهها از این تکنیک استفاده میکنند و اجازه میدهند آرایهها بر اساس ابعادشان ساختار یافته و ذخیره شوند. به عنوان مثال، هر پیکسل در یک مجموعه داده شطرنجی به مکان های x و y خاصی گره خورده است. پایگاه داده آرایه از ابعاد به عنوان فرصتی برای پارتیشن بندی داده ها استفاده می کند، در نتیجه همه پیکسل هایی که مختصات مشابهی دارند، با هم قرار می گیرند. این رویکرد مشابه کاشی کاری مکانی است که برای ذخیره و فشرده سازی داده های فضایی شطرنجی استفاده می شود. پارتیشن بندی داده ها، شکستن یک جدول یا آرایه بزرگ به عناصر کوچکتر، باعث افزایش عملکرد جداول پایگاه داده بزرگ می شود (Pavlo, Curino, & Zdonik, 2012). هنگامی که داده ها پارتیشن بندی می شوند و کوئری های حاصل اجرا می شوند، پایگاه داده تنها به کسری از کل مجموعه داده دسترسی دارد. با یک پایگاه داده آرایه ای که داده های مکانی را ذخیره می کند، پارتیشن بندی داده ها به پایگاه داده آرایه-ذخیره اجازه می دهد تا تنها کاشی هایی را که برای هر عملیاتی ضروری هستند واکشی کند. یکی دیگر از مزایای استفاده از این تکنیک ها این است که نیاز به ایجاد شاخص های سفارشی که دست و پا گیر هستند و با تغییر مجموعه داده قدیمی می شوند را کاهش می دهد (آبادی، بونکز و هاریزوپولوس، 2009).
آخرین پیشرفت مهم معماری معرفی شده در فروشگاههای آرایه، ادغام معماریهای اشتراکگذاری شده است که از استقرار در محیط محاسبات ابری یا شبکهای پشتیبانی میکنند. یک معماری اشتراکگذاری شده برای یک پایگاه داده، به این معنی است که دو یا چند نمونه از یک پایگاه داده مستقر شدهاند، که هر کدام در گره خود دارای بخشی از دادهها هستند. اشتراکگذاری هیچ به این معنی است که حافظه یا ذخیرهسازی داده مشترک نیست (Stonebraker, 1986). پیادهسازی این معماری به سیستم اجازه میدهد تا بر روی 10 تا 100 گره با هر نمونه پایگاه داده/گره شامل کسری از کل مجموعه داده مقیاس شود. با هماهنگی و توزیع مجموعه داده در سراسر شبکه ای از گره ها، سیستم از تکنیک های پردازش انبوه موازی (MPP) بهره می برد.
پایگاههای داده آرایهای بهعنوان پایگاههای داده «NoSQL» طبقهبندی میشوند، زیرا دادهها را در یک ساختار ردیفی ذخیره میکنند و از زبان پرس و جو ساختیافته (SQL) استفاده نمیکنند. بر این اساس، آنها یک یا چند زبان پرس و جو را برای پشتیبانی از تعامل با پایگاه های داده پیاده سازی کرده اند. RasDaMan و SciDB دارای یک زبان اصلی هستند که اغلب به آن زبان تابعی میگویند که حاوی اصول اولیه برای ایجاد، تبدیل و اصلاح آرایهها است. عملگر یا توابع نوشته شده به زبان اصلی به گونه ای موازی شرم آور طراحی شده اند تا سیستم بتواند از قابلیت های MPP خود استفاده کند. RasDaMan و SciDB همچنین از دومین زبان سطح بالاتر پشتیبانی می کنند که مشابه زبان پرس و جو ساخت یافته (SQL) است. RASQL RasDaMan و Array Query Language SciDB گویشهای SQL نیستند، بلکه شامل زیرمجموعهای از بندهای SQL خاص هستند که میتوانند به زبانهای تابعی زیربنایی ترجمه شوند. ارائه زبانهای مشابه SQL از مخاطبان گستردهتری برای هر پلتفرم پشتیبانی میکند.
آرایه ها در یک پایگاه داده آرایه معادل جداول در یک پایگاه داده رابطه ای هستند و زبان های تعریف داده خاصی دارند. برای RasDaMan آرایه ها را می توان به عنوان یک مجموعه تعریف کرد که یک یا چند آرایه n بعدی است یا به عنوان یک آرایه خاص که یک آرایه n بعدی است (شکل 2). برای تعریف یک آرایه، کاربر نوع داده، کران های بالا و پایین برای هر بعد و همچنین نام آرایه را مشخص می کند (شکل 2). تعریف مجموعه در RasDaMan به مجموعه ای از آرایه ها اجازه می دهد تا به صورت منطقی گروه بندی شوند به طوری که وقتی عملیات بر روی یک مجموعه اعمال می شود، آنها بر روی تمام آرایه های مرتبط اعمال می شوند. تعریف آرایه SciDB مشابه تعریف نوع آرایه RasDaMan است که پارامترهای مورد نیاز برای ایجاد یک آرایه عبارتند از نام آرایه، نوع داده و کران های بالا و پایین برای همه ابعاد (شکل 3).

شکل 2. تعریف آرایه ها با RasDaMan، RASQL

شکل 3. آرایه را با SciDB، AFL تعریف کنید
2.1 تعریف آرایه
هر دو SciDB و RasDaMan از آرایه های n بعدی پشتیبانی می کنند و هر آرایه می تواند بیش از یک ویژگی داشته باشد. کران ابعاد را می توان با اعداد صحیح 64 بیتی مشخص کرد. همچنین امکان ارائه مرزهای بدون بعد وجود دارد. مرزهای نامشخص ممکن است معیارهای عملکرد غیرمنتظره ای داشته باشند. تعریف آرایه RasDaMan فقط به دو پارامتر نوع آرایه و ابعاد آرایه نیاز دارد، در حالی که، با SciDB، تعریف آرایه به ویژگی های اضافی مانند اندازه پارتیشن و طول همپوشانی آرایه نیاز دارد (شکل 3). SciDB اجازه می دهد تا مشخصات این پارامترهای اضافی را مشخص کند زیرا یک پایگاه داده ذخیره آرایه عمومی است. اندازه پارتیشن، که به آن اندازه تکه می گویند، باید یک عدد صحیح مثبت باشد و در هر بعد مشخص کند که آرایه چگونه باید پارتیشن بندی شود. در اصطلاح GIS، این اندازه کاشی است که می تواند مربع یا مستطیل باشد. پارامتر همپوشانی فقط در SciDB موجود است و برای هر پارتیشن داده (کاشی) تعداد سطرها و ستون های کپی شده از کاشی های مجاور را مشخص می کند. مزیت همپوشانی این است که اگر عملیات از دادههای کاشیهای مجاور استفاده کند، این دادهها از قبل در دسترس هستند و عملیات میتواند بدون توزیع مجدد دادهها ادامه یابد. اطلاعات اضافی در مورد مشخصات آرایه های SciDB در مستندات موجود است (Stonebraker et al., 2011).
در حالی که SciDB فرصت هایی را برای ساختارهای پارتیشن بندی منظم فراهم می کند، RasDaMan گزینه های پارتیشن بندی اضافی را ارائه می دهد. RasDaMan به آرایه ها اجازه می دهد تا از طرح های پارتیشن بندی استفاده کنند که ممکن است منظم، نامنظم، تراز، جهت دار یا غیر تراز باشند (Marques, 1998). توانایی ارائه طرحهای پارتیشن بندی قابل تنظیم برای مجموعههای داده با گستره فضایی زیاد که در آن بسیاری از این دادهها مورد بررسی قرار نمیگیرند، سودمند است. به عنوان مثال، اگر کاربری یک تصویر ماهوارهای از جهان را بارگذاری کرده باشد، اما فقط بخواهد روی سازندهای زمین تجزیه و تحلیل کند، دو سوم دادهها استفاده نمیشوند. ایجاد یک طرح پارتیشن بندی سفارشی اجازه می دهد تا بخشی از داده های مورد علاقه به طور مساوی در بین گره ها توزیع شود و می تواند عملکرد پرس و جو را افزایش دهد.
2.2 عملیات آرایه
زبان های تابعی ارائه شده توسط RasDaMan و SciDB می توانند برای کار بر روی آرایه n بعدی استفاده شوند. صدها عملگر وجود دارد، اما مرتبط ترین آنها برای عملیات جغرافیایی، زیرمجموعه، فیلتر کردن، تجمیع و پیوستن است. این یک لیست جامع نیست و باید مشخصات هر اپراتور را با اسناد هر پلت فرم مقایسه کرد.
2.2.1 زیر مجموعه
زیرمجموعه استخراج بخش مشخصی از اطلاعات از یک آرایه است. این عملیات را می توان بر روی آرایه های دو بعدی، سه بعدی و n بعدی انجام داد. شکل 4 نمونه ای از عملیات زیرمجموعه ممکن را ارائه می دهد. تنها شرط لازم این است که برای هر بعد مرزهای شروع و پایان ارائه شود
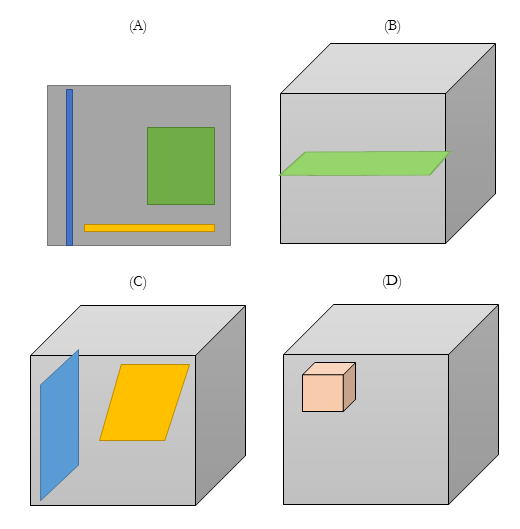
شکل 4. زیر مجموعه آرایه های چند بعدی
شکل 4A نمونه ای از برخی از استخراج های ممکن از یک تصویر 2 بعدی است. امکان انتخاب یک پیکسل، یک بخش تعریف شده، یا یک سطر کامل (زرد) یا ستون (آبی) از آرایه بزرگتر وجود دارد. برای کاربردهای جغرافیایی، عملیات زیرمجموعه احتمالاً شامل انتخاب منطقه از یک تصویر بزرگتر است (به عنوان مثال، کلرادو از کل مجموعه داده پوشش ملی ایالات متحده) (شکل 4A سبز). زیرمجموعه در بعد بالاتر نیز امکان پذیر است (شکل 4B و 4C). صفحه ای از داده ها در هر محوری را می توان از یک آرایه سه بعدی زیر مجموعه کرد. برای کاربردهای جغرافیایی، با استفاده از پارادایم جغرافیای زمانی هاگستراند، این معمولاً به عنوان مکعب های فضا-زمان در نظر گرفته می شود و زیر مجموعه های مسطح مختص مکان و زمان هستند (هدلی، 1999؛ میلر، 1991). علاوه بر این، مکعب های فضا-زمان کوچکتر نیز می توانند از مکعب های فضا-زمان بزرگتر تولید شوند (شکل 4D).
2.2.2 فیلتر کردن
عملیات فیلتر یک ویژگی به شدت مورد استفاده در سیستم های مدیریت پایگاه داده (DBMS) است. یک عملیات فیلتر فقط مقادیر مورد علاقه یک آرایه خاص را حفظ می کند. عملیات فیلتر مشابه عبارت WHERE در پایگاه داده رابطه ای است.
2.2.3 تجمع
عملیات تجمیع یکی دیگر از ویژگی های موجود در RDMB است که در پایگاه داده های آرایه وجود دارد. تجمیع در RDBM اجازه می دهد تا اطلاعات را به صورت ستونی بر روی جداول خلاصه کنید. پایگاههای داده آرایه با خلاصه کردن مقادیر/ستونها و ابعاد، این مفهوم را بیشتر گسترش میدهند. برای فضای جغرافیایی، انجام تجمعات بر اساس ابعاد ممکن است فوراً مفید یا شهودی نباشد. با این حال، خلاصه کردن اطلاعات توسط یک بعد جغرافیایی، بینشی را در مورد چگونگی تغییر مقادیر در یک بعد از فضا فراهم می کند.
2.2.4 پیوستن
یکی دیگر از ویژگیهای پیادهسازی شده در پایگاههای داده آرایه، join است. اتصالات در پایگاه های داده رابطه ای به دو جدول نیاز دارند تا فیلد/ستون هایی با مقادیر یکسان داشته باشند. پیوستن به دو جدول مرتبط اجازه می دهد تا اطلاعات به یکدیگر مرتبط شوند و پایگاه های داده رابطه ای به دلیل انعطاف پذیری اتصالات آنها (یعنی داخلی، راست، چپ، کامل) و توانایی آنها برای پیوستن به چندین جدول و پیوستن به مجموعه داده های بزرگ شناخته شده است (Mishra & Eich, 1992). . پایگاه داده های آرایه از مجموعه محدودی از اتصالات (به عنوان مثال، اتصال متقاطع، اتصال داخلی) پشتیبانی می کنند. اتصال در یک پایگاه داده آرایه بر روی ویژگی ها انجام نمی شود، بلکه بر روی ابعاد آرایه انجام می شود. به عنوان مثال، شکل 5 اتصال بین دو آرایه 2 بعدی را نشان می دهد. بنابراین مقدار پیکسل 5 در (0,0) در آرایه1 اکنون با مقدار پیکسل 80 در (0,0) در آرایه2 تراز خواهد شد. نتیجه هر عملیات اتصال یک آرایه جدید با دو فیلد/ستون است.
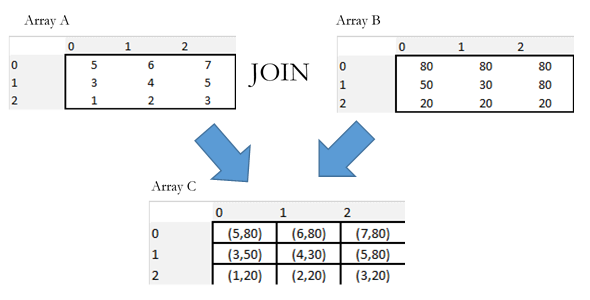
شکل 5. پیوستن آرایه به آرایه
3. تجزیه و تحلیل فضایی برای پایگاه های داده آرایه
توانایی اعمال عملیات شطرنجی (محلی، کانونی و منطقه ای) در یک پایگاه داده آرایه، انگیزه اصلی برای قرار دادن داده های مکانی در یک پایگاه داده آرایه-ذخیره است. توانایی اعمال تمام عملیات شطرنجی در این محیط ها یک حوزه فعال تحقیقاتی است.
3.1 اپراتورهای محلی
عملیات شطرنجی محلی دسته ای از عملیات هستند که با انجام عملیات بر روی هر سلول به صورت جداگانه بدون اشاره به سلول های اطراف مشخص می شوند. بسیاری از عملیات محلی جغرافیایی بر روی این سکوها اجرا شده است، مانند طبقه بندی مجدد، هیستوگرام، و جبر نقشه، اگرچه احتمالاً از نام های دیگری در هر پلت فرم استفاده می شود. مزیت انجام این عملیات در این پلتفرم ها این است که داده ها قبلاً پارتیشن بندی شده اند و بنابراین می توان با عملیات موازی مستقل روی آنها عمل کرد. کامارا و همکاران (2016) مستندات خاصی را در مورد عملیات جغرافیایی برای SciDB ارائه می دهند.
3.2 اپراتورهای کانونی
عملگرهای کانونی با عملگرهای محلی تفاوت دارند زیرا مقادیر خروجی تحت تأثیر سلول های اطراف قرار می گیرند. RasDaMan و SciDB هر دو اجازه می دهند که یک هسته یا پنجره با هر اندازه دلخواه و در ابعاد چندگانه تعریف شود. مقدار یک سلول خاص با عملیات انبوه مورد استفاده در هسته تعیین می شود.
3.3 اپراتورهای منطقه ای
عملیات منطقه ای آنالیزهای پیچیده ای برای پایگاه داده های آرایه ای هستند، زیرا معمولاً شامل مجموعه داده های شطرنجی و برداری هستند. انواع داده های برداری به صورت بومی در فروشگاه های آرایه پشتیبانی نمی شوند. بنابراین، برای انجام یک تجزیه و تحلیل منطقه ای، مجموعه داده برداری باید شطرنجی شده و برای تجزیه و تحلیل در پایگاه داده آرایه بارگذاری شود. حتی پس از بارگذاری دادهها، پیچیدگی آنها کاهش نمییابد، زیرا عملیات ناحیهای بهطور ضعیف و همزمان هستند (Ding & Densham, 1996). بنابراین، هنگامی که یک محاسبه برای یک منطقه خاص اعمال می شود، کل مجموعه داده تحت تأثیر قرار نمی گیرد. عملگرهای منطقه ای مانند خلاصه های چند ضلعی در پایگاه داده آرایه امکان پذیر هستند، اما به عملگرهای پیوستن و تجمیع نیاز دارند (Haynes, Manson, & Shook, 2017).
پایگاه های داده آرایه یک ابزار نوآورانه اصلی در جعبه ابزار GIScience هستند. توانایی دستکاری، ویرایش و تجزیه و تحلیل داده های فضایی بزرگ در مقیاس یک مزیت فوق العاده برای هر محققی است که از داده های شطرنجی چند بعدی استفاده می کند. مزیت استفاده از پایگاه داده آرایه ای این است که محقق دیگر نیازی به ساخت یک محیط موازی که عملیات روی داده ها را انجام می دهد (مثلا انتقال داده ها به محاسبات) نیست. در عوض، داده ها و چارچوب پردازش موازی در یک مکان قرار دارند (به عنوان مثال، انتقال محاسبات به داده ها). این اجازه می دهد تا هر الگوریتمی که با استفاده از چارچوب محاسباتی توسعه یافته است، به طور موازی و بدون تخصص اضافی پیاده سازی شود.
مانع عمده ای که برای پایگاه داده های آرایه ای وجود دارد، چالش بارگذاری داده ها در سیستم است. در حال حاضر، فقط RasDaMan و Google Earth Engine (GEE) به طور بومی از خواندن تصاویر ماهوارهای جغرافیایی پشتیبانی میکنند. GEE اولین پلت فرمی است که به صورت بومی از خواندن همه مجموعه دادههای پشتیبانی شده توسط کتابخانه انتزاعی دادههای جغرافیایی (GDAL) پشتیبانی میکند، در حالی که RasDaMan در حال حاضر تنها از چهار فرمت تصویر (به عنوان مثال، فرمت فایل تصویر برچسبگذاری شده، گرافیک شبکه قابل حمل، گروه مشترک متخصصان عکاسی و دیجیتال پشتیبانی میکند). مدل ارتفاعی). جامعه SciDB یک برنامه افزودنی برای GDAL ایجاد کرده است که هر مجموعه داده خوانده شده GDAL را به فرمت SciDB تبدیل می کند (Appel، 2017). یک حوزه فعال تحقیقات در حال انجام، توسعه ابزارهایی برای خواندن و صادرات داده های مکانی به پایگاه داده است (Kovanen, Makinen, & Sarjakoski, 2018).
افزایش ناگهانی در تولید و در دسترس بودن داده های بزرگ شطرنجی فرصتی فوق العاده برای جامعه GIScience ارائه می کند. دادههای جغرافیایی همیشه بزرگ بودهاند، اما اکنون در یک زمان بحرانی هستیم که در آن دادههای مکانی در دانهبندی مکانی و زمانی برای پاسخ به سؤالات مهم در مورد محیط زیست و تعامل انسانی در دسترس هستند. توسعه زیرساختهای فضایی برای حمایت از این تولید دانش جدید و همچنین تسهیلاتی که از اتکا به ظرفیت محاسباتی ایستگاههای کاری خود به محیطهای محاسباتی ابری یا شبکهای دور میشوند، ضروری است. توسعه دادههای فضایی ترکیبی و زیرساختهای محاسباتی بزرگ مانند پایگاههای داده آرایهای آیندهای هستند که در آن تحلیلها روی دادههای بزرگ به صورت موازی انجام میشوند و منتشر میشوند.
Abadi, DJ, Boncz, PA, & Harizopoulos, S. (2009). سیستم های پایگاه داده ستون گرا. Proceedings of the VLDB Endowment, 2 (2), 1664-1665. DOI: 10.14778/1687553.1687625
Appel, M. (2017). SciDB4GDAL [Github]. بازیابی شده در 1 مارس 2019، از وب سایت SciDB4GDAL: https://github.com/appelmar/scidb4gdal
باومن، پی (2016). سفری از طریق ابعاد: نوآوری های اخیر در پوشش های جغرافیایی 2016 IEEE بین المللی زمین شناسی و سمپوزیوم سنجش از دور (IGARSS) ، 3599-3601. DOI: 10.1109/IGARSS.2016.7729932
Baumann, P., Dehmel, A., Furtado, P., Ritsch, R., & Widmann, N. (1998). سیستم پایگاه داده چند بعدی RasDaMan. Acm Sigmod Record, 27 (2), 575-577.
باومن، پی.، میسف، دی.، مرتیکاریو، وی.، هوو، بی پی، بل، بی.، و کو، ک.-اس. (2018). پایگاه های داده آرایه: مفاهیم، استانداردها، پیاده سازی ها (ص 73) . اتحاد داده های پژوهشی.
باک، جی بی، واتکینز، ن.، لوفور، جی.، یوانیدو، ک.، مالتزاهن، سی.، پولیزوتیس، ن.، و برانت، اس. (2011). SciHadoop: پردازش پرس و جو مبتنی بر آرایه در Hadoop. مجموعه مقالات کنفرانس بین المللی 2011 برای محاسبات با عملکرد بالا، شبکه، ذخیره سازی و تجزیه و تحلیل در – SC ’11 , 1. DOI: 10.1145/2063384.2063473
کامارا، جی.، اسیس، الاف، ریبیرو، جی.، فریرا، KR، لاپا، ای.، و وینهاس، ال. (2016). تجزیه و تحلیل داده های رصد زمین بزرگ: تطبیق الزامات با معماری سیستم مجموعه مقالات پنجمین کارگاه بین المللی ACM SIGSPATIAL در تجزیه و تحلیل برای داده های بزرگ جغرافیایی – BigSpatial ’16 ، 1-6. DOI: 10.1145/3006386.3006393
Ding, Y., & Densham, PJ (1996). استراتژیهای فضایی برای مدلسازی فضایی موازی مجله بین المللی سیستم های اطلاعات جغرافیایی، 10 (6)، 669-698.
هاینز، دی، منسون، اس.، و شوک، ای. (2017). معماری Terra Populus برای خدمات یکپارچه بزرگ زمین فضایی. معاملات در GIS، 21(3)، 546-559. DOI: 10.1111/tgis.12286
هدلی، NR (1999). هاگرستراند بازبینی کرد: تجسم فضا-زمان تعاملی دادههای مکانی پیچیده. انفورماتیکا، 23 (2)، 155-168.
Kersten, M., Zhang, Y., Ivanova, M., & Nes, N. (2011). SciQL، یک زبان پرس و جو برای کاربردهای علمی. مجموعه مقالات کارگاه آموزشی EDBT/ICDT 2011 در مورد پایگاه های داده آرایه – AD ’11 ، 1-12. DOI: 10.1145/1966895.1966896
Kini، A.، & Emanuele، R. (2014). Geotrellis: Adding Geospatial Capabilities to Spark، 2014.
Kovanen، J.، Makinen، V.، & Sarjakoski، T. (2018). رویکردی برای ارزیابی آرایه های DBMS برای داده های شطرنجی مکانی. GEOProcessing، کنفرانس بین المللی سیستم های پیشرفته اطلاعات جغرافیایی، برنامه ها و خدمات ، 6.
مارکز، PJP (1998). کاشیکاری دلخواه مکعبهای داده گسسته چند بعدی در سیستم RasDaMan (مرکز تحقیقات باواریا برای سیستمهای مبتنی بر دانش).
میلر، اچ جی (1991). مدلسازی دسترسی با استفاده از مفاهیم منشور فضا-زمان در سیستمهای اطلاعات جغرافیایی مجله بین المللی سیستم های اطلاعات جغرافیایی، 5 (3)، 287-301. DOI: 10.1080/02693799108927856
Mishra, P., & Eich, MH (1992). به پردازش در پایگاه داده های رابطه ای بپیوندید. ACM Computing Surveys (CSUR)، 24 (1)، 63-113.
Pavlo, A., Curino, C., & Zdonik, S. (2012). پارتیشن بندی خودکار پایگاه داده آگاهانه در سیستم های OLTP موازی و غیر مشترک. مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 2012 در مدیریت داده ها ، 61-72. DOI: 10.1145/2213836.2213844
Planthaber، G.، Stonebraker، M.، & Frew، J. (2012). EarthDB: تجزیه و تحلیل مقیاس پذیر داده های MODIS با استفاده از SciDB. مجموعه مقالات اولین کارگاه بین المللی ACM SIGSPATIAL در تجزیه و تحلیل داده های بزرگ جغرافیایی ، 11-19. DOI: 10.1145/2447481.2447483
Stonebraker, M., Brown, P., Poliakov, A., & Raman, S. (2011). معماری SciDB در کنفرانس بین المللی مدیریت پایگاه های علمی و آماری (ص 1-16) . اسپرینگر.
استون بریکر، مایکل. (1986). مورد برای هیچ چیز مشترک. مهندس پایگاه داده IEEE بول.، 9 (1)، 4-9.
Wang, W., Liu, T., Tang, D., Liu, H., Li, W., & Lee, R. (2016). SparkArray: یک سیستم مدیریت داده علمی مبتنی بر آرایه که بر روی اسپارک آپاچی ساخته شده است. 2016 کنفرانس بین المللی IEEE در زمینه شبکه، معماری و ذخیره سازی (NAS) ، 1-10. DOI: 10.1109/NAS.2016.7549422
Wang, Y., Jiang, W., & Agrawal, G. (2012). SciMATE: چارچوبی شبیه به نقشه کاهش برای چندین قالب داده علمی. 2012 دوازدهمین سمپوزیوم بین المللی IEEE/ACM در مورد محاسبات خوشه ای، ابری و شبکه ای (Ccgrid 2012) ، 443-450. DOI: 10.1109/CCGrid.2012.32
Widmann, N., & Baumann, P. (1999). ارزیابی عملکرد تکنیک های ذخیره سازی آرایه چند بعدی در پایگاه های داده اقدامات. IDEAS’99. سمپوزیوم بین المللی مهندسی پایگاه داده و برنامه های کاربردی (Cat. No.PR00265) , 385-389. DOI: 10.1109/IDEAS.1999.787289
- روش مورد استفاده برای ذخیره سازی و ساختاردهی داده ها در پایگاه داده های آرایه ای را توضیح دهید.
- بین پایگاه داده های آرایه-فروشگاه، ستون-فروشگاه و فروشگاه ردیفی تفاوت قائل شوید.
- مقایسه و مقایسه تفاوت های مفهومی بین ذخیره پایگاه داده آرایه و پایگاه داده رابطه ای.
- پلتفرم های مرتبط (مانند SQL، Hadoop، Apache Spark) را که مدل های داده آرایه را پیاده سازی می کنند، شرح دهید.
- مدل چند بعدی و عملیات اساسی موجود برای ذخیرهسازی دادههای آرایه را شرح دهید.
- عملیات فضایی اساسی انبارهای آرایه را شرح دهید.
- پایگاه داده فروشگاه آرایه چیست؟
- فروشگاه های آرایه چه تفاوتی با پایگاه های داده ستونی دارند؟
- چه عملیاتی را می توان برای پشتیبانی از عملیات فضایی اجرا کرد.
- چرا یک معماری پردازش انبوه موازی انتخاب خوبی برای ذخیره، دسترسی و پردازش داده های فضایی بزرگ است؟
6 نظرات